NVPC: A Transparent NVM Page Cache
Abstract.
Towards a compatible utilization of NVM, NVM-specialized kernel file systems and NVM-based disk file system accelerators have been proposed. However, these studies only focus on one or several characteristics of NVM, while failing to exploit its best practice by putting NVM in the proper position of the whole storage stack. In this paper, we present NVPC, a transparent acceleration to existing kernel file systems with an NVM-enhanced page cache. The acceleration lies in two aspects, respectively matching the desperate needs of existing disk file systems: sync writes and cache-missed operations. Besides, the fast DRAM page cache is preserved for cache-hit operations. For sync writes, a high-performance log-based sync absorbing area is provided to redirect data destination from the slow disk to the fast NVM. Meanwhile, the byte-addressable feature of NVM is used to prevent write amplification. For cache-missed operations, NVPC makes use of the idle space on NVM to extend the DRAM page cache, so that more and larger workloads can fit into the cache. NVPC is entirely implemented as a page cache, thus can provide efficient speed-up to disk file systems with full transparency to users and full compatibility to lower file systems.
In Filebench macro-benchmarks, NVPC achieves at most 3.55x, 2.84x, and 2.64x faster than NOVA, Ext-4, and SPFS. In RocksDB workloads with working set larger than DRAM, NVPC achieves 1.12x, 2.59x, and 2.11x faster than NOVA, Ext-4, and SPFS. Meanwhile, NVPC gains positive revenue from NOVA, Ext-4, and SPFS in 62.5% of the tested cases in our read/write/sync mixed evaluation, demonstrating that NVPC is more balanced and adaptive to complex real-world workloads. Experimental results also show that NVPC is the only method that accelerates Ext-4 in particular cases for up to 15.19x, with no slow-down to any other use cases.
1. Introduction
As a persistent and byte-addressable memory technology, non-volatile memory (NVM) is considered as a new hierarchy in the memory system, and is expected to speed up lower storage devices while providing consistency guarantees. Specifically, software utilizing NVM can benefit from (1) lower price and higher capacity compared to DRAM (ruanPersistentMemoryDisaggregation2023, ); (2) higher speed than SSD (suzukiNonvolatileMemoryTechnology2015, ; xiangCharacterizingPerformanceIntel2022, ); (3) persistence that will keep data after a power fail; (4) byte-addressable granularity like DRAM, which is much smaller than other persistent block devices. Such benefits bring both opportunities and challenges to software design.
To make use of NVM, various NVM file systems are proposed. NVM-specialized kernel file systems (DAX, ; dulloorSystemSoftwarePersistent2014, ; xuNOVALogstructuredFile2016, ) become the most popular type due to their compatibility with the current kernel software stack. Existing applications can transfer to NVM file systems with minimum cost. Different from traditional block-based file systems, these file systems take the byte-addressable and persistent character as the first principle thinking and achieve higher performance than conventional ones on NVM. However, the much lower capacity of NVM compared with block storage devices hinders NVM-specialized file systems from wide usage. What’s more, most famous and widely accepted NVM file systems, like NOVA, adopt direct access (DAX) to reduce copy from DRAM to NVM, but the relatively slow speed of NVM makes them inferior to page cache in many cases. There are also cross-media file systems (kwonStrataCrossMedia2017, ; zhengZigguratTieredFile2019, ) that attempt to exploit the heterogeneity of performance and capacity from both storage tiers, usually including DRAM, NVM, and block storage. However, because of the complex design, they are usually less mature and robust than those widely used and time-tested file systems like Ext-4. Meanwhile, the redesigned architecture on each media tier makes them incompatible with current file systems used by online systems, thus bringing large data migration costs for prospective customers.
The new trend to utilize NVM is to accelerate existing block device file systems. SPFS (wooStackingPersistentMemory2023, ) and P2CACHE (linP2CACHEExploringTiered2023, ) are two NVM file systems stacked on traditional disk file systems, aiming to empower disk file systems to utilize NVM. Tacitly, these kinds of work use NVM to accelerate the slow persisting progress of disk. However, the speed-up often comes with some side effects. E.g. SPFS introduces a second indexing overhead for its overlay design, and suffers from a low re-access speed once data is absorbed by its NVM part. P2CACHE uses NVM to absorb not only sync writes, but also async ones, to provide strong consistency, which meaninglessly slows down the async writes. The defects of these studies come from their stacked multi-tier design, in which NVM is not put into its optimum place.
It seems like a quite complex problem: how to fully utilize the attractive characteristics of NVM, while maintaining the advantage of traditional software stack and keeping compatible and transparent to current user programs, so that applications can take advantage of NVM with no performance degradation and migration cost? To answer this, we propose NVPC, a transparent NVM-enhanced page cache, to accelerate the performance of current disk file systems. Like SPFS and P2CACHE, NVPC seeks to transparently optimize the performance of existing mature disk file systems with NVM. The unique contribution of NVPC lies in three aspects: (1) NVPC preserves the advantage of the DRAM page cache so that utilizing NVM will not cause performance downgrade to any use case; (2) NVPC extends the usage of NVM to make use of all its large and cheap space; (3) NVPC is implemented as a page cache but not a file system, thus is more efficient and compatible compared with previous work.
However, the heterogeneity of DRAM, NVM, and disks (wuRethinkingComputerArchitectures2016, ) brings great challenges to us. First, these heterogeneous devices have different access granularity, speed, capacity, and price. Only by utilizing the advantages and avoiding the disadvantages of each of the devices can we achieve optimal performance in all use cases, which has been proven to be tricky by previous work (linP2CACHEExploringTiered2023, ; wooStackingPersistentMemory2023, ). Second, to exploit the performance of NVM, elaborate design and implementation are needed so that the software stack won’t become the major bottleneck (leeEmpiricalStudyNVMbased2018, ). Finally, ensuring consistency under the heterogeneity can be difficult, especially when writes are performed on different devices with different timing and granularity.
We observe that with the help of the DRAM page cache, well-heated workloads on a traditional disk file system (Ext-4) perform better than on an NVM-specialized file system (NOVA). We argue that the weaknesses of disk file systems, in comparison with NVM file systems, are sync writes and cache-missed operations, which lead to direct disk I/O, memory allocation, or index rebuilding. Unlike previous NVM utilization, NVPC recognizes the advantage of the DRAM page cache, thus simplifying the problem into accelerating the slow cache-absent path with NVM, while leaving normal r/w operations to DRAM. For sync writes, NVPC persists them to the NVM with a performance-first log structure that makes use of the byte-addressable access pattern, and the DRAM cache is reserved for the speed of later operations. To ensure the eventual consistency on the disk file system, the sequence of NVM sync and disk write-back is strictly defined. Moreover, NVPC optimizes the semantics of sync operation to avoid write amplification on scattered small writes. On the other hand, to reduce cache misses, NVPC uses the free space on NVM as a cheaper and larger second-tier page cache to expand the one on DRAM, like previous work on tiered CXL-memory page placement (marufTPPTransparentPage2023, ). To maximum the performance in this tiered cache, NVPC uses the LRU algorithm to place hot pages on DRAM and the cold ones on NVM, meanwhile introducing an access counter to avoid thrashing. NVPC is implemented into the memory management system of the Linux kernel, thus is fully compatible with the current storage software stack, and is transparent to any user application.
We evaluate NVPC with micro-benchmarks and macro-benchmarks. Experimental results show that NVPC is the only NVM-enabled accelerator/FS with performance not lower than traditional disk file systems in all situations, meanwhile achieving up to 15.19x faster than Ext-4 under sync writes. Under small sync writes, NVPC outperforms NOVA by up to 4.23x, due to our fine-grained log design. For large workloads, NVPC with 1/3 DRAM and 2/3 NVM provides a 1.49x per-$ performance than the same capacity DRAM-only configuration, while achieving 97.07% of its performance.
2. Background
2.1. Non-volatile Memory
Non-volatile memory (NVM) is a type of byte-addressable memory that can persist data. According to the specification from JEDEC (JEDEC, ), NVM can be categorized into three types: NVDIMM-F that uses flash storage on a DIMM; NVDIMM-N which has flash and DRAM on the same module, usually with a backup power source; NVDIMM-P that is naturally persistent as the computer main memory, including technologies like PCM, RRAM and STT-RAM (hosomiNovelNonvolatileMemory2005, ; IntelOptanePersistent, ; leeArchitectingPhaseChange2009, ; wongMetalOxideRRAM2012, ). Intel Optane (IntelOptanePersistent, ) has been the most popular NVM (NVDIMM-P) technology in the past few years. Though Intel has abandoned Optane, we observe that some alternative technologies have already appeared on the market (ComputeExpressLink2023, ; MSSSDSamsungMemory, ), and we believe that there will be various substitutes in the future. In our work, NVM mainly refers to NVDIMM-P, which is the most widely used technology, but the work can also be applied to NVDIMM-N modules.
Typically, NVM has an intermediate performance, capacity, and price between DRAM and SSD (dulloorSystemSoftwarePersistent2014, ; izraelevitzBasicPerformanceMeasurements2019, ; xiangCharacterizingPerformanceIntel2022, ; wuRethinkingComputerArchitectures2016, ), which brings both opportunities and challenges for interested software (wuRethinkingComputerArchitectures2016, ; zhangDesignApplicationNew2023a, ). The main efforts in utilizing NVM can be categorized into three types. The most efficient method is to expose NVM directly to user space programs, so that they can manipulate NVM with minimum software stack latency (cuiSwapKVHotnessAware2023, ; volosAerieFlexibleFilesystem2014, ; wangPacmanEfficientCompaction2022, ; zhongMadFSPerFileVirtualization2023, ; maAsymNVMEfficientFramework2020, ; ruanPersistentMemoryDisaggregation2023, ; chenScalablePersistentMemory2021, ; dongPerformanceProtectionZoFS2019, ; jiFalconFastOLTP2023, ). This can be the best way for new programs that wish to take full advantage of NVM. However, for existing programs, especially those heavyweight ones, migrating to new hardware with new access pattern requires a huge amount of work, which can sometimes be unrealistic. The second way is quite simple in concept, which is, to use NVM as a slow second-tier memory that stores relatively cold data (MigratePagesLieu, ; weinerTMOTransparentMemory2022, ; marufTPPTransparentPage2023, ). Such method adopts the price and capacity advantage of NVM, but not the persistence character. A more balanced method between performance and compatibility is to provide NVM file systems inside the kernel. Since applications usually utilize persistent storage devices via kernel file systems, NVM file systems can be easily applied to current applications.
2.2. File Systems for NVM
Various file systems have been proposed to exploit the performance of NVM devices. Previous work can be mainly categorized into two types: the NVM-specialized file system and the Cross-media file system.
NVM-specialized file system: Different from traditional file systems that orient towards slow block storage devices like SSD and HDD, NVM-specialized file systems are designed to support the specific characteristics of NVM. Direct access (DAX) (DAX, ) is an early attempt that removes the DRAM page cache from the access path of traditional file systems. With DAX, block file systems can be used on NVM without extra copies on DRAM. DAX can be applied to many block file systems, such as Ext-4 and XFS. As DAX is a patch on block file systems, it fails to explore the byte-addressable access pattern of NVM. Meanwhile, it remains to have the unnecessary software overhead for block devices, and fails to provide a proper consistency. However, the idea of DAX has been adopted by later work. NOVA (xuNOVALogstructuredFile2016, ) is proposed as a dedicated file system for NVM that takes full advantage of its fast and persistent characteristics. NOVA introduces a specially designed log structure on NVM to provide a strong consistency guarantee with high performance. However, according to our evaluation shown in Figure 1, due to the relatively lower speed of NVM, NOVA sometimes performs worse than traditional file systems with DRAM page cache. Meanwhile, its copy-on-write (CoW) design also fails to thoroughly exploit NVM’s byte-addressable access pattern. High-performance user space (or user-kernel hybrid) file systems (volosAerieFlexibleFilesystem2014, ; zhongMadFSPerFileVirtualization2023, ; chenScalablePersistentMemory2021, ; dongPerformanceProtectionZoFS2019, ; liuOptimizingFileSystems2024, ) are also proposed to reduce the latency brought by the kernel trap, but are not widely used because they are not compatible with current applications. These NVM-specialized file systems focus on persisting data on NVM, but fail to notice the limited speed and capacity of NVM that are intermediate among DRAM and SSD, thus constraining their usage scenarios.
Cross-media file system: Cross-media file systems introduce monolithic file systems with a holistic view over multiple heterogeneous storage tiers. The file system is usually deployed across DRAM, NVM, SSD, and HDD. Strata (kwonStrataCrossMedia2017, ) uses a user space LibFS with per-process update logs to accelerate single-process access, data are then digested to the shared area protected by the kernel and placed into different media with a strategy. Ziggurat (zhengZigguratTieredFile2019, ) aims to accelerate slower disk storage with NVM, providing a file system that has a speed close to NVM but the size of larger disks. By predicting the write operations from the user, Ziggurat dynamically directs operations to the proper storage tier. These cross-media file systems provide an overall solution to utilize both DRAM, NVM, and disk, for a balancing between speed, capacity, and price. However, the monolithic design makes them hard to tailor and deploy, leading to extra migration costs for current online systems. Meanwhile, considering their complexity, it may require a long time to verify and modify before they become mature.
2.3. Enhancing Disk File Systems with NVM
A novel method to utilize NVM is to enhance existing disk file systems. Such method can provide transparency and compatibility to the current software system, with no migration cost on data and code. These work usually focus on optimizing the sync write operations of disk file systems, which are inherently slow due to their immediate persisting semantics and the slow disk I/O speed. Although they appear less frequently than normal r/w, sync writes often become the main bottleneck of disk file systems, especially under workloads with strict correctness requirements, such as databases.
SPFS (wooStackingPersistentMemory2023, ) is a stackable file system that lies on a traditional disk file system. Small sync write operations are directed to the overlaid NVM layer to remove I/O costs on slower disks, while other writes are left to the lower file system. Since the page cache is reserved in the lower layer, read and write operations without sync can still be performed with the speed of DRAM. SPFS takes into account the different performance characteristics of DRAM and NVM very well. However, SPFS depends on a prediction to absorb sync writes according to the access pattern of many previous sync writes. Before a successful prediction, the system still suffers from the low performance of sync I/O. This is an obvious problem when sync happens with no regular pattern. Meanwhile, once the data is directed to the upper NVM layer, further read operations also have to be performed on NVM, leading to unnecessary high latency. Besides, the two-layer design of SPFS comes with a double-indexing overhead, which may lower the overall performance of the system.
P2CACHE (linP2CACHEExploringTiered2023, ) is yet another stacked file system atop disk file systems. There are two differences between P2CACHE and SPFS. First, P2CACHE moves the DRAM cache upper to the NVM layer. Any data is written to NVM and DRAM simultaneously so that P2CACHE can serve subsequent read operations with faster DRAM. Second, P2CACHE absorbs not only synchronous but also normal write operations to its NVM to provide strong consistency. P2CACHE outperforms the underlying disk file system on sync writes, and can achieve a comparable performance on reads. However, the strong consistency and double write lead to a weaker performance on workloads with normal writes without sync. What’s more, P2CACHE reserves a large amount of DRAM and NVM resources for its lightweight design, meaning that applications on the whole system cannot use those memory resources via the memory management service of the kernel anymore. It is questionable whether the availability of the entire system should be sacrificed for performance. Moreover, the current implementation of P2CACHE lacks some essential parts, such as the write-back from NVM to its lower file system, and the garbage collection mechanism.
On the whole, these accelerators fail to put NVM into the proper position of the memory hierarchy and exploit its best practice, thus leading to limited acceleration or even worse performance than legacy disk file systems under specific use cases. Besides, both SPFS and P2CACHE ignore to make use of the free NVM space to further accelerate the system.
3. Motivation

Previous research has attempted to find a proper position for NVM in the current memory system. However, balancing the factor of speed, capacity, and price between DRAM, NVM, and disks, while keeping compatible with the current system as much as possible, can be a tricky problem, and previous works only focus on one or several of them. The goal of this work is to use NVM to accelerate the current storage system efficiently and transparently, without any performance downgrade and migration cost.
Normally, storage devices are manipulated by file systems in current operating systems. We evaluate the basic (sequential/random, read/write) performance of a traditional disk file system (Ext-4), with and without pre-heated page cache, and compare it with file systems on NVM (NOVA, Ext-4, and Ext4-DAX). Figure 1 shows that operations performed on the DRAM page cache can always achieve a higher performance than on NVM. The shortage of current disk file systems only falls in sync writes and cache-missed operations. Our analysis shows that the slow-down of these cache-absent operations is attributed to synchronous I/O and extra software stack overheads. For cache-missed reads and sync writes, intuitively, the direct I/O requirement is the main contribution (over 90%) of the slow-down. For cache-missed writes, though data can be written to the DRAM cache without I/O, the memory allocation and the index building for the absent pages become the main factors (70%) of performance degradation. We will refer to operations on the DRAM page cache as the fast path, and the ones that cache doesn’t take effect as the slow path. We notice that all the causes of the slow path could have been eliminated if the cached page existed and functioned.
For sync writes, operations must be written to disk due to the persistence requirements of the sync semantics, which is much slower than writing to the page cache. It should be noted that though sync writes happen not as much as normal r/w operations, they may still constitute of the main bottleneck of disk file systems, because writes on disk are usually orders of magnitude slower than on DRAM cache. For cache-missed operations in the slow path, typical workloads can generally avoid them after running for a while as long as the page cache is big enough to hold the hot spot. Extending the size of the page cache will help to reduce cache misses by accommodating larger workloads. However, the maximum DRAM size on each DIMM slot is limited, which restricts the upper bound of the page cache on a system. The high expense of DRAM also makes it costly to expand the memory size. These limitations on the slow path of traditional disk file systems perfectly match the price, capacity, and speed characteristics of NVM. Therefore, we believe that it can be an effective and practical application for NVM to accelerate the slow path with NVM, while leaving the fast path to DRAM.
According to our observation, we introduce NVPC, an NVM-enhanced page cache that runs above disk file systems below user space, aiming to accelerate the performance of traditional disk file systems on its slow path, while keeping transparency to user applications and compatibility with system storage software stack. In NVPC, sync writes that may cause disk I/O are directed to NVM instead of the lower disk, so that any disk file system can leverage a much higher write speed. Meanwhile, considering the larger capacity and the lower cost compared to DRAM, NVPC uses NVM as an extension to the current DRAM page cache for storing cold data, and thus reduces cache-missed access for large workloads. Different from early efforts (linP2CACHEExploringTiered2023, ; wooStackingPersistentMemory2023, ), NVPC accelerates disk file systems with no consistency semantic change and performance downgrade in any case, which better meets the needs of existing file system users.
To respond to the challenges and achieve the goals, NVPC is designed and implemented with four principles:
Principle 1: Transparency to both upper applications and lower file systems. NVPC should be a transparent file system accelerator. Applications shouldn’t be changed in any way to leverage the acceleration. Meanwhile, NVPC should require no modification to the lower file systems, thus all time-tested disk file systems can be accelerated at no cost. The downward transparency also signifies that expensive data migration is not required for users.
Principle 2: No consistency change to current I/O stack. NVPC should not promote or demote the current consistency model at any level. A higher consistency level means a higher cost, but hardly means anything to existing applications. A lower consistency level means the semantics of current file systems can be broken. NVPC believes that the current consistency level is the best practice for existing applications.
Principle 3: No performance downgrade to current file systems. The goal of NVPC is to optimize the shortage of disk file systems, not to provide a biased performance like previous work (dulloorSystemSoftwarePersistent2014, ; xuNOVALogstructuredFile2016, ; linP2CACHEExploringTiered2023, ; wooStackingPersistentMemory2023, ). Hence, NVPC should not slow down current file systems in any case.
Principle 4: Performance-first, price-aware, exploit NVM as much as possible. As long as previous principles are not violated, NVPC aims to provide a maximal acceleration. Meanwhile, unused NVM space should be revitalized in NVPC, considering its low price and large capacity.
4. NVPC Design

NVPC needs a separate design to absorb sync writes and to extend the DRAM cache, because they have different persistence demands. As shown in Figure 2, NVPC contains two main components: a sync absorbing area, and an NVM-extended page cache. Though implemented with different mechanisms, the capacity of NVM space is dynamically shared between the two parts. The sync absorbing area is also referred to as the persistent domain, and the NVM-extended page cache, including the original DRAM page cache and the volatile NVM page cache extension, is called the non-persistent domain. In this section, we will dive into the details of these two parts.
4.1. Sync Absorbing Area
Sync writes has been a drag for many applications that require a high consistency level. To reduce disk I/O caused by sync writes, NVPC introduces the sync absorbing area to persist the data and the metadata that the user requires to persist immediately.
In NVPC, all writes are performed on the non-persistent page cache first (principle 3). Then if a write is required to be sync, it will be persisted by the sync absorbing area on NVM. Note that the write-back of data, sync or not, is handled by the non-persistent page cache, because in this case there’s a great chance that the source of the write-back lies on faster DRAM instead of NVM. There is no data transfer between the NVM persistent domain and the lower disk in NVPC.
Based on principle 2, NVPC needs to provide sync semantics that are no lower than the original one. This means that NVPC should persist sync writes with the strictest consistency level of current disk file systems, e.g. Ext-4 data journal mode. To persist data properly, we need to make sure that the data itself, the index (metadata) of the data, and the write order of the data, are both persisted properly. Further, to keep the atomicity of a write, transactional technologies should be adopted. It can be costly for the system to guarantee these consistency requirements, thus an appropriate design is vital for the performance.
The sync absorbing area uses both logging and shadow-paging mechanisms to ensure the consistency of sync writes on NVM. To maintain consistency between NVM and disk, we further bring up an order-preserving logging mechanism on heterogeneous storage devices. Besides, an active sync policy is proposed to alleviate write amplification introduced by traditional sync operations. Finally, we discuss the crash recovery process.
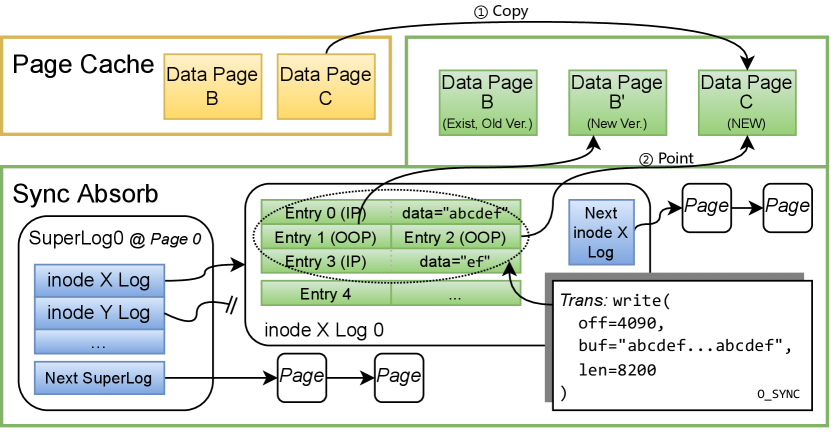

4.1.1. Log Structure
Depicted in Figure 3, the fundamental design of the sync absorbing area is a series of logs on NVM. The main task of the log is to persist the index of the data, so that we can still retrieve the data after a power outage. For each log series, the 64B log entries are first sequentially organized in a 4KB page. When the log exceeds the current page, another page is allocated. The page is then attached to the previous page by a linked list. Page allocation is served by the free page manager of NVPC, which will be introduced in Section 4.3. The traversal operation on the log is accelerated by prefetching.
There are two types of logs in the sync absorbing area. The first one is called a super log that contains pointers that link to the log heads of all the inodes managed by NVPC. There is only one global super log in NVPC, and its first log page (log head) is the physical 0 address of the NVM device, in order that NVPC can find it again directly after power failure. The super log is the root of all logs, from which all the persistent-domain data can be found and replayed. Another type is called an inode log. Each NVPC-managed file has an inode log, and all sync writes and metadata updates on it are recorded by such inode log.
Each entry in the super log describes an inode log. Specifically, there are four fields for each entry: an s_dev field and an i_ino field to find a specific file, a head_log_page pointer that points to the first log page of this inode log, and a committed_log_tail field to indicate the inode’s current log tail. Whenever a new inode is delegated to NVPC, a new super log entry pointing to a new inode log is created. Then when this file is accessed again, NVPC will find the super log entry to retrieve its inode log.
An inode log describes all the sync-relevant update operations on a file, and the most important operation on this log is sync writes. NVPC manages NVM in pages, so the write is naturally separated into parts no larger than a page, and we may need to record them times if a write crosses page boundaries. For inode logs, each entry represents a write part. Two log entry types are designed to persist data. The first one is the out-of-place log entry (OOP entry), meaning that the data it refers to is in a stand-alone persistent domain page. The OOP entry contains a page_index field that points to the address of the whole-page data in NVM. NVPC uses OOP entries for large page-aligned shadow-paging writes, which offers convenience for data page allocating and reclaiming. The new OOP data page is filled with new data, so the old data doesn’t need to be copied to the new page at all. The second type is the in-place log entry (IP entry), meaning that the data is included inside the log zone just next to the entry. IP entry suits for small unaligned write parts with arbitrary sizes, in this case NVPC can take the advantage of NVM’s byte-addressable characteristic (principle 4). Besides these differences, both the OOP entry and the IP entry have the following fields: a file_offset field to indicate the position in the file that the current entry is writing to; a data_len field to indicate the length of the current write entry; a last_write field to find the previous write on the same position for backtracking (Section 4.1.5); a tid field to mark a transaction; and a flag field to mark the state of an entry. Apart from two kinds of write entries, there is also a metadata update entry to record the change of the inode’s metadata, and a write-back record entry that will be discussed in Section 4.1.3.
4.1.2. Sync Write Steps
With the log structure defined, it is time to give a glimpse of the process of sync write. When a sync write is performed (O_SYNC write or stand-alone sync), the data is always written to the non-persistent page cache first (no matter to DRAM or NVM). Then the data is written to the persistent domain again. We are not reusing pages between the non-persistent domain and the persistent domain (yellow and green data pages in Figure 3), even if the cached page is in NVM, because further writes on the non-persistent domain may introduce partial writes to the persistent domain, which violates the transactional consistency on the sync absorbing area (principle 2). Now we focus on the write process of the persistent domain:
Each sync write operation is regarded as a transaction in NVPC. The write transaction is broken into parts according to the page boundaries it crosses. For each part of the write, a log entry will be appended to the end of the inode log of the current file. Aligned whole-page parts are recorded by OOP entries, with the data copied from the non-persistent domain to a newly allocated persistent domain data page (① in Figure 3). Note that even if there is a previous persistent domain data page found for the same offset (Data Page B in Figure 3), we cannot reuse it, otherwise, we may lose the data of the previous transaction if a crash happens in this transaction (principle 2). Unaligned parts are recorded by IP entries, and the data is copied to the entry’s data zone. A simple case is the stand-alone sync operation (e.g. fsync), for which we just need to persist all dirty pages with OOP entries. The transaction division and the entry type selection policies are also depicted in Figure 4
The entries are filled as follows: For OOP entries, the page_index field of the entry points to the data page, as ② in Figure 3 shows. The file_offset and data_len fields are set as is. The tid field is set to an auto-increment id that increases on each transaction. For a write operation, all entries that describe its parts have the same tid. To ensure the integrity of a write transaction, the committed_log_tail of the inode log is only atomically updated after all the parts in a transaction finish.
To further ensure principle 2, several techniques are applied. First, due to the existence of CPU caches, writes to NVM may return before they are eventually persisted to the NVM device. To solve the inconsistency risk, NVPC uses cache line write-back (e.g. Intel’s clwb) to explicitly instruct the CPU to flush data back to NVM. Note that with the help of eADR (EADRNewOpportunities, ), the cache line write-back process can be omitted, in which case NVPC can achieve a better performance. Further, memory barriers (sfence) are performed to maintain the ordering of store operations before and after consistency-critical points. There are only two barriers used in the sync absorbing area. The first one is put after all transaction parts are logged and before the committed_log_tail is updated, to make sure that a transaction is complete before we can see it. Then another barrier is put after the commit before the start of the next transaction to maintain the order between transactions.
4.1.3. Consistency between NVM and Disk
We now have two separate write paths to NVM and disk. Writes with sync indications are persisted directly to the persistent domain of NVM, and may have bytes less than a page. On the other hand, any kind of write, sync or not, dirties some pages in the non-persistent domain page cache, leading to asynchronous write-backs from the non-persistent domain to disk. Put simply, let’s assume that the block size of the disk is equal to the page size. Pages on the underlying disk of NVPC always persist the absolutely right data with absolutely right intra-page write sequences. This is because that a disk page is written as a checkpoint of the non-persistent cached page, and the cached page is always guaranteed to be right by the file system. However, since we have changed all sync writes to async on disk, the page on disk may persist an older data version if a power failure happens before a synchronized dirty page is written back to the disk. Fortunately, NVPC guarantees that we have a fresher version data persisted on NVM. But since we only persist the necessary bytes of sync writes, but not all page bytes of all dirty pages, we may face inconsistency problems here, which violate principle 2.

Figure 5 illustrates a typical scenario of the inconsistency between the data on disk and NVM. At the point of , the page cache, disk, and NVM reach a synchronous status of . At the point of , the disk maintains the latest version , but the NVM has the previous version , which can be rebuilt from and . The lag of the data version on NVM is because is not a sync write, and we have no reason to persist it to NVM. So the first problem is that if we crash at , the recovery process will rebuild from the NVM and overwrite the on the disk, meaning that we encounter an unexpected data rollback. This is an annoying problem but does not violate the sync semantics, because didn’t require itself to be synced. Even if we can bear this problem, we may also face a problem at . At this point, a new sync write was performed and completed with itself successfully recorded by NVM, and the new data is not written back to the disk yet. However, if we have a crash here, we can only rebuild abcxyz from the NVM, which is not any version we expect. The data has been messed up on NVM at this point, and the disk only has the previous version instead of the latest sync version . The key to these frustrating problems is that we don’t have the exact time sequence of disk writes and NVM writes. Now we persist the disk write-back events on NVM (the yellow bubble on the NVM timeline in Figure 5) to maintain a global clock. Whenever a disk write-back happens, if there is a valid previous entry, a write-back entry is appended to the inode log, implying that the previous writes on this page are expired. Then when we rebuild the page after crash, we only replay unexpired operations to the page version on the disk. E.g. at we replay (NVM) to (disk) and get a31xyz, which is exactly what we want (the lost ). By this mechanism NVPC ensures that it will always rebuild the latest data without rollback or mistake.
4.1.4. Sync Semantic Optimization
There are three types of file operations that cause direct I/O on a disk file system: the O_SYNC flag that indicates that a file or a mount point should always be synchronously written; the O_DIRECT flag that attempts to minimize cache effects of I/O on a file which also causes sync writes; the explicit sync operation (e.g. fsync) that claims an immediate data persistence. Both the O_SYNC and the O_DIRECT flags are prior instructions, meaning that we can immediately persist the written data once that write operation is performed. Differently, the sync operation is a posterior instruction after the data of previous write operations is written to the non-persistent page cache, which means that we may need to reposition previous writes to the persistent domain. However, when a sync operation is performed individually, we have lost the data position and length information of all the previous writes. In such case, if we have multiple small writes across many pages before a sync, the sync operation will write all the dirtied full-pages to the persistent-domain NVM, causing severe write amplification. E.g. in Figure 4, the pink fragments will cause all contents of the red dirty pages written to NVM.
To solve the write amplification problem, we introduce active sync (principle 4). The idea is to predict how many following write operations on a file are going to be synchronized. The prediction is made by the previous write-sync pattern. If there are small scattered writes, we actively mark that file as O_SYNC, thereby the following writes will be synchronized immediately inside the write system call, at which time we still have the data position and length information. Vice versa, if the writes are predicted better to be absorbed by the DRAM page cache, we clear the O_SYNC flag. This procedure is described by Algorithm 1. We need the record of written bytes and dirtied pages since the last sync to calculate whether it is better to persist every write directly to the NVM or to wait for a whole page. The is used to tune the algorithm on different workloads to prevent thrashing, and is empirically set to 2 to suit most workloads.
4.1.5. Crash Recovery
To recover the data on NVPC to the disk after a power failure, a crash replay procedure is introduced. The procedure walks multiple times through each inode log to recover the file. First, it walks along the whole inode log. In this pass, log entries on the same data page offset are linked together in sequence through the field of each entry, and the latest write entry is also picked out for each data page. Then for each page, the rebuilder walks from its latest entry towards the earliest via the field. Once a write-back entry or an OOP entry is found, the walk halts, because the previous data are either expired or overwritten. The data of the traversed entries are then replayed to the data page on the disk.
4.2. NVM-extended Page Cache
A larger page cache is helpful to reduce cache misses for applications using big files. However, the density limitation and high price of DRAM are hindering the page cache from becoming larger. As Figure 2 shows, NVPC uses the free space on NVM as an extension to the original DRAM page cache. Due to the lower price and higher capacity of NVM, NVPC can provide a large page cache to workloads with a lower per-byte cost and a higher per-$ performance (principle 4) compared with a DRAM-only page cache.
To maintain compatibility with the memory management system of the current kernel, all the designs on the current DRAM page cache are preserved in our NVM-extended page cache, like the clean/dirty/write-back page state and relevant functions. Take special note that the sync writes that have been persisted by the sync absorbing area are still marked as dirty, and the final write-back to the disk is done by this page cache part.
To keep the advantage of the current DRAM page cache, hot pages should be stored in faster DRAM, and the cold ones should be stored in slower memory tiers (e.g. CXL memory in (marufTPPTransparentPage2023, )), and the slower one is the NVM in our work. NVPC adopts the LRU (clock) algorithm to judge the temperature of pages. Pages on DRAM are still managed by the LRU list of the current memory management system. When a page reaches the end of the DRAM LRU, it is demoted to NVM (MigratePagesLieu, ) and then managed by the NVM-side LRU we introduce. The NVM-side LRU doesn’t use the multi-level design as the DRAM-side one. Instead, each page is assigned an access counter. For each page access, the counter of the page is added by 1. We use such counter to conduct the promotion (back to DRAM) and the eviction (to disk) of pages. Concretely, pages with counter values greater than a promote threshold will be moved back to DRAM. The promote threshold can be set statically, or dynamically according to the access frequency of DRAM pages. In this work, we statically set the promote threshold to 4 to prevent thrashing between DRAM and NVM, and the dynamic strategy is left for future work. On the other hand, when the NVM is short in capacity, an evict thread will start to scan from the end of the LRU. Each scanned page will be evicted from NVM if its counter is zero, or its counter will be decreased by 1 and it will be put back to the front of the LRU if its counter is non-zero.
4.3. Utilities
Free Page Manager: There is a free NVM page manager in NVPC to handle the allocating and freeing of NVM pages. The free page manager serves both the sync absorbing area and the NVM-extended page cache. We implement this manager to isolate NVM pages from the memory management of the kernel, thereby improving the allocation speed and ensuring the security of data in the persistent domain. Free NVM pages are managed with a global linked list. Further, each CPU has a free pool. Pages are allocated from and freed to the per-CPU pool to avoid lock contention on the global list. Once the pages in a pool are less than a low watermark, the pool obtains pages from the global list. Otherwise, if the pages in a pool are more than a high watermark, the pool returns pages to the global list.
Garbage Collector: To reclaim the unused NVM space, a garbage collector is provided as a kernel thread. Different from the page eviction thread of the NVM-extended page cache, the garbage collector periodically runs in the background to walk through the log pages and check if there are any log pages or data pages that would not be used anymore. A log entry becomes useless when it is expired because of a later write-back, or it is overwritten by a later OOP entry. A data page is useless if its log entry is useless. A useless data page is reclaimed once it is found, and a log page is reclaimed once all the entries inside are useless. The walk stops before the latest log pages of inodes, because the latest page is obviously in use. The scanning doesn’t require any lock so there’s no influence to the foreground work.
5. Implementation
NVPC is implemented on Linux kernel 5.15 (LTS) with 7.3K lines of kernel codes and no more than 1K LOC for auxiliary tools. The changes to the kernel code are limited to the VFS (0.3K LOC), the memory management system (6.2K LOC), and the drivers (0.8K LOC). The VFS code is modified carefully with no semantic change to the current API, thus maintaining full compatibility and transparency to current applications and file systems (principle 1). The major work is implemented inside the memory management system, including all functions of NVPC discussed in Section 4 and the necessary collaboration between NVPC and the original kernel memory management. The drivers take charge of the initialization of DAX NVM devices and the configurations of NVPC from users. Besides, two user space utility tools are provided: the nvpcctl tool to configure and monitor NVPC, and the modified daxctl tool to initialize PMEM to NVPC device. The prototype is open source and can be found at https://anonymous.4open.science/r/NVPC/.
6. Evaluation
NVPC can be applied to any disk file system. Here we choose the widely used Ext-4 as the lower file system for our case study. We perform the experiments on a system with Intel Xeon 5218R (1 node used), 128GB DRAM, 256GB Intel Optane PMEM (128GB x2, interleaved), Samsung PM9A3 1.92TB NVMe SSD, and Ubuntu 20.04, unless otherwise specified. We compare NVPC to multiple representative file systems and accelerators, including: Ext-4 as a baseline, NOVA (CoW), SPFS (with Ext-4), and P2CACHE. Note that the published implementation of P2CACHE fails to run on our testbed, due to its rigid memory arrangement and lack of key functions. We use NVPC with sync for each write to simulate the performance of P2CACHE, and the result will be marked as P2CACHE (sim). Besides, the SSD we are using in the evaluation has a high speed, and the bandwidth of NVM is limited because only two modules are installed. For a system with lower speed storage (e.g. SATA SSDs or HDDs) and higher bandwidth NVM (e.g. more PMEM modules installed), the performance improvement ratio of NVPC will be much higher than the numbers reported in this section.
6.1. Microbenchmarks
The fundamental fast-path performance of disk file systems is not the aim of NVPC, and has been discussed in Figure 1. Due to the length limitation of the paper, we will focus on the performance of slow-path accelerations in this section.





6.1.1. Superiority of the Sync-absorbing Design
To comprehensively illustrate the performance superiority of NVPC’s sync-absorbing strategy, we first deploy 4KB random r/w tests with different r/w ratios (0/10, 3/7, 5/5, 7/3) and various sync write percentages (0% to 100% step by 20%). The experimental result is shown in Figure 6. Due to our DRAM-NVM cooperative design, NVPC outperforms NVM file systems, disk file systems, and NVM-based FS accelerators in the majority of cases. In non-sync workloads, NVPC performs the same as a heated Ext-4, which is up to 3.72x, 2.93x, and 1.24x faster than NOVA, P2CACHE, and SPFS. For all-sync workloads, NVPC performs the same as P2CACHE, which is up to 1.70x, 4.44x, and 5.59x faster than NOVA, Ext-4, and SPFS. Meanwhile, in moderate sync level, NVPC outperforms both Ext-4 and P2CACHE. The results indicate that NVPC can always have a good trade-off between DRAM and NVM access over different sync levels.
The blue shadow in Figure 6 is the performance NVPC gains from Ext-4, and the red shadow indicates that any data point within it means a performance degradation to Ext-4. It is obvious that NVPC accelerates Ext-4 efficiently while causing no slowdown at all, which meets our principle 3. For other candidates, however, there are always varying degrees of performance degradation. NOVA and P2CACHE both suffer from slow NVM writes under low sync level, due to their strong consistency. NOVA is also hindered by slow NVM reads when the read proportion rises. SPFS only shows its advantage to Ext-4 in write-only and high sync level scenarios, and falls behind NVPC in all cases, because of its two-tier design and read-after-sync slowdown.
To demonstrate the sync performance of NVPC on different data sizes, we then perform sync append, sequential overwrite, and random overwrite tests with multiple write lengths. Except for NVPC-fsync, tests are performed on an O_SYNC-enabled file. As shown in Figure 7, NVPC accelerates Ext-4 in all cases for up to 15.19x due to the fast NVM sync write path. Note that NVPC can even achieve a higher speedup ratio on slower block storage devices like SATA SSDs and HDDs. NVPC also outperforms SPFS in all cases due to our concise monolayer design. Compared to NOVA, NVPC has a better performance in small sync writes (100B and 1KB), since NVPC adopts a free-length log design that introduces no write amplification, while NOVA manages data by pages and needs copy-on-write to ensure crash consistency for small writes. For larger sync workloads, NOVA performs better than NVPC, because 1) NVPC cannot eliminate the software overhead of lower file systems and page cache, and 2) NVPC has to write to both DRAM and NVM, while NOVA only writes to NVM. However, these overheads are necessary, since our goal is to 1) transparently accelerate current disk file systems, while still utilizing their large capacity and requiring no data migration (principle 1), and to 2) maintain the advantage of DRAM fast path access and refuse slowdown to any use cases (principle 3). Sync writes only account for a small proportion of real-world workloads, and will not be the major bottleneck anymore if they reach the performance of the same order of magnitude as normal r/w. Hence, our moderate but not aggressive acceleration here can bring more benefits to a vast range of mixed scenarios, which has been proven by our previous mixed test. Note that P2CACHE is omitted in this evaluation, because it has the same behavior with NVPC under full-sync workloads. The reason for the absence of P2CACHE in the following evaluations will be the same.
We also evaluate NVPC’s performance with fsync operations instead of O_SYNC flags. The performance is shown as NVPC-fsync and NVPC-fsync +Optm in Figure 7, for vanilla NVPC and NVPC with active sync semantic optimization (Section 4.1.4) respectively. The result shows that the optimization increases the performance of vanilla NVPC by up to 59%, because of the elimination of write amplification. With the optimization, fsync operations in NVPC outperform Ext-4, NOVA, and SPFS under O_SYNC in all tested cases below 4KB.
6.1.2. Crash Consistency
We notice that crash consistency checkers for file systems (leblancChipmunkInvestigatingCrashConsistency2023, ; martinezCrashMonkeyFrameworkAutomatically2017, ) have been proposed. However, these checkers either only intercept writes from the block layer for disk file systems, or raise the persistent semantics to each single write only for strong consistency PM file systems. None of these checkers is suitable under NVPC’s heterogeneous, loose-consistency work conditions. To prove that NVPC provides a proper consistency guarantee, we manually trial the system with crashes injected to the critical points of the code. For log transactions, crashes are added between the memory barriers described in Section 4.1.2. These tests demonstrate whether the log of NVPC is updated with atomicity and isolation. For NVM-disk page consistency presented in Section 4.1.3, crashes are added around the write-back event. These tests demonstrate whether NVPC can provide sync acceleration with eventual correctness. No FS semantics violation is found during our limited test.
6.1.3. NVM-extended Page Cache
To illustrate the effectiveness of our NVM-extended page cache design, we shrink the capacity of DRAM to 16GB and limit the size of NVM to 32GB. We perform a random read test with uniform distribution under 32GB file size and 160GB total I/O size, to demonstrate the performance of the page cache under some certain workloads with uniform access patterns. We also deploy a test with Zipfian distribution under 160GB file size and 1000GB total I/O size to study the performance under daily workloads with hot-spotted working sets and long access terms. We then compare NVPC’s throughput and cost-effectiveness to Ext-4 with 16GB and 48GB DRAM page cache. Since Intel stopped to offer Optane PM modules anymore, we choose the price recorded by previous work (ruanPersistentMemoryDisaggregation2023, ), i.e. $419.0 for 128GB PM and $877.0 for 128GB DDR4 DRAM, to calculate the cost-effectiveness.
Figure 8 shows the results. In the uniform test, NVPC’s DRAM-NVM combined page cache achieves 3.34x faster than 16GB DRAM page cache, and reaches 97.07% of 48GB all DRAM page cache. In the Zipfian test, NVPC performs 2.69x faster than 16GB DRAM and reaches 82.04% of 48GB DRAM. For DRAM-only settings, the per-byte cost is $6.85, while the tested 16GB-DRAM plus 32GB-NVM configuration for NVPC only costs $4.47 for each byte. Meanwhile, our approach achieves the highest cost-effectiveness in all tests, i.e. 48.92% and 25.85% higher than 48GB DRAM-only setting in uniform and Zipfian tests respectively.




6.1.4. Scalability
To measure the scalability of NVPC, we perform a 4KB random r/w test with multiple threads accessing different files, and the thread number varies from 1 to 16. The read-write ratio is set to 1:1, and the writes are all synchronous, to demonstrate the scalability of NVPC’s DRAM-NVM cooperative design. Before the test, a pre-read of each file is performed to heat up the cache and minimize the influence of the lower file system and storage device. The result in Figure 9 shows that with the increment of threads, NVPC scales well and outperforms all competitors. NVPC has a performance up to 1.94x, 3.11x, and 8.87x compared with NOVA, Ext-4, and SPFS. The advantage of NVPC lies in its ability to fully utilize DRAM and NVM to separately serve read and write requests with high efficiency. In comparison, reads on NOVA are served with slower NVM. For SPFS, its second index and read-after-sync slowdown make it inferior to Ext-4 under 2 or more threads. The performance degradation from 8 threads to 16 is caused by the saturation of NVM write bandwidth (since our testbed only has 2 PM modules interleaved) and the contention between threads.
6.2. Macrobenchmarks
In this section, we evaluate NVPC and other file systems/ accelerators using real-world workloads to demonstrate the balanced performance and wide applicability of NVPC. We choose Filebench and RocksDB to cover different application scenarios.
6.2.1. Filebench
Filebench (Filebench, ) provides 3 representative macrobenchmark scripts to simulate server workloads: file- server is a non-sync write intensive workload with 1:2 r/w ratio; webserver is a read intensive workload with 10:1 r/w ratio; varmail is a balanced read/sync-write 1:1 test with small I/O size. The detailed settings of these workloads are listed in Table 1.
| Workload | File size (avg) | I/O size (r/w) | Threads | R/W ratio | # of files |
| Fileserver | 128KB | 1MB/16KB | 16 | 1:2 | 10000 |
| Webserver | 64KB | 1MB/16KB | 16 | 10:1 | 1000 |
| Varmail | 16KB | 1MB/16KB | 16 | 1:1 | 10000 |
The result of the test is shown in Figure 10. In fileserver and webserver workloads, NVPC, SPFS, and Ext-4 show similar performance, significantly leading NOVA, due to the utilization of fast DRAM page cache. E.g. NVPC shows 3.55x and 2.10x performance as NOVA in fileserver and webserver respectively. NVPC is also 2.32x faster than P2CACHE in fileserver, because P2CACHE forces all writes to be persisted by NVM, while NVPC doesn’t. In varmail workload, NVPC is 2.84x and 2.65x faster than Ext-4 and SPFS, while 25.98% slower than NOVA. SPFS fails to effectively accelerate Ext-4 in varmail because it demands a prediction period before absorbing sync writes to NVM. However, varmail synchronously writes to scattered files for only twice on each file, making SPFS fail to predict and absorb most of these scattered sync writes. The relatively lower speed of NVPC compared to NOVA in varmail is attributed to the double-write to DRAM and NVM. Again, we believe the retention of DRAM cache helps to provide a more balanced performance in daily workloads, in which sync operations only account for a small portion.

6.2.2. RocksDB
RocksDB is an LSM-tree-based key-value database. Data written to RocksDB are first recorded by a write-ahead log (WAL). Then the logged data are asynchronously written to the LSM tree (SST files). Reading data from RocksDB will cause reads on the SST file. RocksDB provides db_bench as its test suite. We choose sequential write (fillseq), sequential read (readseq), and multi-thread r/w mixed (readrandomwriterandom) tests to demonstrate the performance of NVPC under different cases. The read- randomwriterandom benchmark is also separately performed with a small and a large working set. The small test runs on the original testbed with 4GB working set size that can fit into the DRAM cache. The large test runs with the DRAM size limited to 16GB while the working set size set to 32GB, in which the working set cannot fit into the DRAM, to illustrate the united speed-up from NVPC’s sync absorbing area and NVM-extended page cache. We pre-deploy a fillseq to create the database and then switch on sync mode for each test, and the database is removed after each test. Note that SPFS encounters several crashes when we try to clean up the existing database. It also fails to run under RocksDB’s O_DIRECT mode. Figure 11 shows the performance of RocksDB.
For fillseq, SPFS, NOVA, and NVPC achieves 5.83x, 4.33x, and 5.23x faster than Ext-4. The reason for the low performance of Ext-4 is that its WAL sync write suffers from the low speed of the disk. NOVA has a lower speed than SPFS and NVPC due to its write amplification for small metadata writes, which is caused by its copy-on-write design.
For readseq, Ext-4 and NVPC perform similarly and both outperform NOVA, because in NVPC and Ext-4, read operations are served by the fast-path DRAM, while NOVA can only perform reads on NVM. Meanwhile, SPFS also provides the same high speed, because SPFS avoids its read-after-write slowdown in RocksDB. Specifically, RocksDB reads from SST files, which are previously written to disk with large-bulk (tens or hundreds of MB) sync. However, SPFS doesn’t absorb sync writes with more than 4MB data, thus it can still serve RocksDB reads with the lower DRAM page cache instead of the slow NVM.
For small readrandomwriterandom, NVPC performs 1.38x and 1.24x faster than Ext-4 and NOVA. The advantage of NVPC comes from its DRAM-NVM cooperative design. SPFS achieves similar performance as NVPC, again, due to its skip of large bulk sync. On the whole, NVPC and SPFS both achieve a balanced performance on RocksDB in small working sets, with a higher speed than Ext-4 on writes and an equal speed on reads, while NOVA provides higher write speed but lower read speed.
For large readrandomwriterandom, NVPC outperforms both Ext-4, SPFS, and NOVA. Note that under this test the workload is larger than the DRAM size, meaning that part of the workload cannot be served with the DRAM page cache. Compared with Ext-4 and SPFS, NVPC can utilize more NVM as the extra page cache, thus relieving the slow reads from the disk. Compared with NOVA, NVPC can serve some of the reads with the limited DRAM at a higher speed.

7. Conclusion
In this paper, we discuss the fast path and the slow path of conventional disk file systems, then propose NVPC as a transparent NVM-enhanced page cache to accelerate current file systems on their slow path. We provide a detailed design of NVPC, including the non-persistent page cache and the persistent sync absorbing area, and relevant methods to improve performance and ensure consistency. We implement a prototype of NVPC on Linux. The evaluation of the prototype shows that NVPC is the only approach that effectively improves the slow-path performance of disk file systems while introducing no slow-down to any use cases.
Acknowledgements.
This work is supported by the talent project of Department of Science and Technology of Jilin Province of China [Grant No. 20240602106RC], and by the Central University Basic Scientific Research Fund [Grant No. 2023-JCXK-04], and by the Key scientific and technological R&D Plan of Jilin Province of China [Grant No. 20230201066GX].References
- [1] DAX. https://www.kernel.org/doc/Documentation/filesystems/dax.txt.
- [2] eADR: New Opportunities for Persistent Memory Applications. https://www.intel.com/content/www/us/en/developer/articles/technical/eadr-new-opportunities-for-persistent-memory-applications.html.
- [3] Filebench. https://github.com/filebench/filebench.
- [4] Intel® Optane™ Persistent Memory. https://www.intel.com/content/www/us/en/products/docs/memory-storage/optane-persistent-memory/overview.html.
- [5] JEDEC. https://www.jedec.org/.
- [6] Migrate Pages in lieu of discard. https://lwn.net/Articles/860215/.
- [7] MS-SSD – Samsung – Memory Solutions Lab. https://samsungmsl.com/cmmh/.
- [8] Compute Express Link. https://computeexpresslink.org/, September 2023.
- [9] Youmin Chen, Youyou Lu, Bohong Zhu, Andrea C. Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, and Jiwu Shu. Scalable Persistent Memory File System with Kernel-Userspace Collaboration. In 19th USENIX Conference on File and Storage Technologies (FAST 21), pages 81–95, 2021.
- [10] Lixiao Cui, Kewen He, Yusen Li, Peng Li, Jiachen Zhang, Gang Wang, and Xiaoguang Liu. SwapKV: A Hotness Aware In-Memory Key-Value Store for Hybrid Memory Systems. IEEE Transactions on Knowledge and Data Engineering, 35(1):917–930, January 2023.
- [11] Mingkai Dong, Heng Bu, Jifei Yi, Benchao Dong, and Haibo Chen. Performance and protection in the ZoFS user-space NVM file system. In Proceedings of the 27th ACM Symposium on Operating Systems Principles, pages 478–493, Huntsville Ontario Canada, October 2019. ACM.
- [12] Subramanya R. Dulloor, Sanjay Kumar, Anil Keshavamurthy, Philip Lantz, Dheeraj Reddy, Rajesh Sankaran, and Jeff Jackson. System software for persistent memory. In Proceedings of the Ninth European Conference on Computer Systems - EuroSys ’14, pages 1–15, Amsterdam, The Netherlands, 2014. ACM Press.
- [13] M. Hosomi, H. Yamagishi, T. Yamamoto, K. Bessho, Y. Higo, K. Yamane, H. Yamada, M. Shoji, H. Hachino, C. Fukumoto, H. Nagao, and H. Kano. A novel nonvolatile memory with spin torque transfer magnetization switching: Spin-ram. In IEEE InternationalElectron Devices Meeting, 2005. IEDM Technical Digest., pages 459–462, Tempe, Arizon, USA, 2005. IEEE.
- [14] Joseph Izraelevitz, Jian Yang, Lu Zhang, Juno Kim, Xiao Liu, Amirsaman Memaripour, Yun Joon Soh, Zixuan Wang, Yi Xu, Subramanya R. Dulloor, Jishen Zhao, and Steven Swanson. Basic Performance Measurements of the Intel Optane DC Persistent Memory Module, August 2019.
- [15] Zhicheng Ji, Kang Chen, Leping Wang, Mingxing Zhang, and Yongwei Wu. Falcon: Fast OLTP Engine for Persistent Cache and Non-Volatile Memory. In Proceedings of the 29th Symposium on Operating Systems Principles, SOSP ’23, pages 531–544, New York, NY, USA, October 2023. Association for Computing Machinery.
- [16] Youngjin Kwon, Henrique Fingler, Tyler Hunt, Simon Peter, Emmett Witchel, and Thomas Anderson. Strata: A Cross Media File System. In Proceedings of the 26th Symposium on Operating Systems Principles, SOSP ’17, pages 460–477, New York, NY, USA, October 2017. Association for Computing Machinery.
- [17] Hayley LeBlanc, Shankara Pailoor, Om Saran K R E, Isil Dillig, James Bornholt, and Vijay Chidambaram. Chipmunk: Investigating Crash-Consistency in Persistent-Memory File Systems. In Proceedings of the Eighteenth European Conference on Computer Systems, EuroSys ’23, pages 718–733, New York, NY, USA, May 2023. Association for Computing Machinery.
- [18] Benjamin C. Lee, Engin Ipek, Onur Mutlu, and Doug Burger. Architecting phase change memory as a scalable dram alternative. In Proceedings of the 36th Annual International Symposium on Computer Architecture, ISCA ’09, pages 2–13, New York, NY, USA, June 2009. Association for Computing Machinery.
- [19] Geonhee Lee, Hyeon Gyu Lee, Juwon Lee, Bryan S. Kim, and Sang Lyul Min. An Empirical Study on NVM-based Block I/O Caches. In Proceedings of the 9th Asia-Pacific Workshop on Systems, APSys ’18, pages 1–8, New York, NY, USA, August 2018. Association for Computing Machinery.
- [20] Zhen Lin, Lingfeng Xiang, Jia Rao, and Hui Lu. P2CACHE: Exploring Tiered Memory for In-Kernel File Systems Caching. In 2023 USENIX Annual Technical Conference (USENIX ATC 23), pages 801–815, 2023.
- [21] Yubo Liu, Yuxin Ren, Mingrui Liu, Hongbo Li, Hanjun Guo, Xie Miao, Xinwei Hu, and Haibo Chen. Optimizing File Systems on Heterogeneous Memory by Integrating DRAM Cache with Virtual Memory Management. In 22nd USENIX Conference on File and Storage Technologies (FAST 24), pages 71–87, 2024.
- [22] Teng Ma, Mingxing Zhang, Kang Chen, Zhuo Song, Yongwei Wu, and Xuehai Qian. AsymNVM: An Efficient Framework for Implementing Persistent Data Structures on Asymmetric NVM Architecture. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS ’20, pages 757–773, New York, NY, USA, March 2020. Association for Computing Machinery.
- [23] Ashlie Martinez and Vijay Chidambaram. CrashMonkey: A Framework to Automatically Test File-System Crash Consistency. In 9th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 17), 2017.
- [24] Hasan Al Maruf, Hao Wang, Abhishek Dhanotia, Johannes Weiner, Niket Agarwal, Pallab Bhattacharya, Chris Petersen, Mosharaf Chowdhury, Shobhit Kanaujia, and Prakash Chauhan. TPP: Transparent Page Placement for CXL-Enabled Tiered-Memory. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ASPLOS 2023, pages 742–755, New York, NY, USA, March 2023. Association for Computing Machinery.
- [25] Chaoyi Ruan, Yingqiang Zhang, Chao Bi, Xiaosong Ma, Hao Chen, Feifei Li, Xinjun Yang, Cheng Li, Ashraf Aboulnaga, and Yinlong Xu. Persistent Memory Disaggregation for Cloud-Native Relational Databases. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ASPLOS 2023, pages 498–512, New York, NY, USA, March 2023. Association for Computing Machinery.
- [26] Kosuke Suzuki and Steven Swanson. The non-volatile memory technology database (NVMDB). Technical Report CS2015-1011, Department of Computer Science & Engineering, University of California, San Diego, May 2015.
- [27] Haris Volos, Sanketh Nalli, Sankarlingam Panneerselvam, Venkatanathan Varadarajan, Prashant Saxena, and Michael M. Swift. Aerie: flexible file-system interfaces to storage-class memory. In Proceedings of the Ninth European Conference on Computer Systems, EuroSys ’14, pages 1–14, New York, NY, USA, April 2014. Association for Computing Machinery.
- [28] Jing Wang, Youyou Lu, Qing Wang, Minhui Xie, Keji Huang, and Jiwu Shu. Pacman: An Efficient Compaction Approach for Log-Structured Key-Value Store on Persistent Memory. In 2022 USENIX Annual Technical Conference (USENIX ATC 22), pages 773–788, 2022.
- [29] Johannes Weiner, Niket Agarwal, Dan Schatzberg, Leon Yang, Hao Wang, Blaise Sanouillet, Bikash Sharma, Tejun Heo, Mayank Jain, Chunqiang Tang, and Dimitrios Skarlatos. TMO: transparent memory offloading in datacenters. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, ASPLOS ’22, pages 609–621, New York, NY, USA, February 2022. Association for Computing Machinery.
- [30] H.-S. Philip Wong, Heng-Yuan Lee, Shimeng Yu, Yu-Sheng Chen, Yi Wu, Pang-Shiu Chen, Byoungil Lee, Frederick T. Chen, and Ming-Jinn Tsai. Metal–Oxide RRAM. Proceedings of the IEEE, 100(6):1951–1970, June 2012.
- [31] Hobin Woo, Daegyu Han, Seungjoon Ha, Sam H. Noh, and Beomseok Nam. On Stacking a Persistent Memory File System on Legacy File Systems. In 21st USENIX Conference on File and Storage Technologies (FAST 23), pages 281–296, 2023.
- [32] Chengwen Wu, Guangyan Zhang, and Keqin Li. Rethinking Computer Architectures and Software Systems for Phase-Change Memory. ACM Journal on Emerging Technologies in Computing Systems, 12(4):33:1–33:40, May 2016.
- [33] Lingfeng Xiang, Xingsheng Zhao, Jia Rao, Song Jiang, and Hong Jiang. Characterizing the performance of intel optane persistent memory: a close look at its on-DIMM buffering. In Proceedings of the Seventeenth European Conference on Computer Systems, pages 488–505, Rennes France, March 2022. ACM.
- [34] Jian Xu and Steven Swanson. NOVA: a log-structured file system for hybrid volatile/non-volatile main memories. In Proceedings of the 14th Usenix Conference on File and Storage Technologies, FAST’16, pages 323–338, USA, February 2016. USENIX Association.
- [35] Guangyan Zhang, Dan Feng, Keqin Li, Zili Shao, Nong Xiao, Jin Xiong, and Weimin Zheng. Design and application of new storage systems. Frontiers of Information Technology & Electronic Engineering, 24(5):633–636, May 2023.
- [36] Shengan Zheng, Morteza Hoseinzadeh, and Steven Swanson. Ziggurat: A Tiered File System for Non-Volatile Main Memories and Disks. In 17th USENIX Conference on File and Storage Technologies (FAST 19), pages 207–219, 2019.
- [37] Shawn Zhong, Chenhao Ye, Guanzhou Hu, Suyan Qu, Andrea Arpaci-Dusseau, Remzi Arpaci-Dusseau, and Michael Swift. MadFS: Per-File Virtualization for Userspace Persistent Memory Filesystems. In 21st USENIX Conference on File and Storage Technologies (FAST 23), pages 265–280, 2023.