Numerical Method for Parameter Inference of Nonlinear ODEs with Partial Observations
Abstract
Parameter inference of dynamical systems is a challenging task faced by many researchers and practitioners across various fields. In many applications, it is common that only limited variables are observable. In this paper, we propose a method for parameter inference of a system of nonlinear coupled ODEs with partial observations. Our method combines fast Gaussian process based gradient matching (FGPGM) and deterministic optimization algorithms. By using initial values obtained by Bayesian steps with low sampling numbers, our deterministic optimization algorithm is both accurate and efficient.
Key words: Gaussian Process, Parameter inference, Nonlinear ODEs, Partial observations
1 Introduction
Many problems in science and engineering can be modelled by systems of Ordinary differential equations (ODEs). It is often difficult or impossible to measure some parameters of the systems directly. Therefore, various methods have been developed to estimate parameters based on available data. Mathematically, such problems are classified as inverse problems which have been widely studied [1, 2, 21, 13]. They can be also treated as parameter inference in statistics [19, 11].
For nonlinear ODEs, standard statistical inference is time consuming as numerical integration is needed after each update of the parameters [5, 14]. Recently, gradient matching techniques have been proposed to circumvent the high computational cost of numerical integration [19, 6, 16, 9]. These techniques are based on minimizing the difference between the values obtained by two different approaches. This usually involves a process consisting of two steps: data interpolation and parameter adaptation. Among them, nonparametric Bayesian modelling with Gaussian processes is one of the promising approaches. Calderhead et al. [5] proposed an adaptive gradient matching method based on a product-of-experts approach and a marginalization over the derivatives of the state variables, which was proposed by Calderhead et al. [5] and extended by Dondelinger et al. [6]. Barber & Wang [3] proposed a GPODE method in which the state variables are marginalized. Macdonald et al. [14] provided an interpretation of the above paradigms. Wenk et al. [23] proposed a fast Gaussian process based gradient matching (FGPGM) algrithm with theoretical framework in systems of nonlinear ODEs. our new approach is more accurate, robust and efficient.
For many practical problems, the variables are only partially observable, or not at all times. As a consequence, parameter inference is more challenging, even for a coupled system where the parameters are uniquely determined by data of partially observed data under certain initial conditions. It is not clear whether the gradient matching techniques can be applied to the case when there are latent variables. The Markov Chain Monte Carlo algorithm has the ability to side-step the issue of parameter identifiability in many cases, but convergence remains a serious issue [19]. Therefore, we need to pay attention to the feasibility, accuracy, robustness and computational cost of numerical computations for such problems.
In this work, we focus on the case of parameter inference with partially observable data. The main idea is to treat the observable and nonobservale variables differently. For observable variables, we use the same approach as proposed by Wenk et al. [23]. For non-observable variablies, they are obtained only by using ODEs. To circumvent the high computational cost of sampling in Bayesian approaches, we also combine FGPGM with least square optimization method. The remaining part of the paper is organized as follows. In Section 2 we give the numerical method to deal with parameter identification problems with partial observation. Numerical examples are presented in Section3. Some concluding remarks are given in Section 4.
2 Algorithm
The main strategy of FGPGM is to minimize the mismatch between the data and the ODE solutions in a maximum likelihood sense, making use of the property that Gaussian process is closed under differentiation.
In this work, we would like to estimate the time-independent parameters of the following dynamical system described by
| (1) |
is the vector of time derivative of the state and can be an nonlinear vector valued function. We assume only parts of the variables are measurable and denote them as . They are observed on discrete time points as with noise such that . We assume that the noise is Gaussian , then
| (2) |
where and are the realizations of and respectively. The latent/unmeasurable variables are denoted as , with . The idea of Gaussian process based gradient matching is as follows. Firstly, we put a Gaussian process prior on ,
| (3) |
Then according to Lemma A.8 the conditional distribution of the th state derivatives is
| (4) |
where
| (5) |
| (6) |
Here we have denoted as the covariance matrix. Its components are given by with respect to a kernel function parameterized by the hyperparameter . For more details we refer to Appendix A. There is also a Gaussian noise with standard deviation introduced to represent the model uncertainty
| (7) |
We set up the following graphical probabilistic model to show the relationship between the variables (Fig. 1 ). Then the joint density can be represented by the following theorem.

Theorem 2.1.
Given the modeling assumptions summarized in the graphical probabilistic model in Fig. 1,
| (8) |
where involved in is the solution determined by and .
The proof can be found in Appendix B. In our computation, can be obtained by integrating the ODE system numerically with proposed and initial values of and . Then, the target is to maximize the likelihood function .
The present algorithm is a combination of a Gaussian process based gradient matching and a least square optimization. In the GP gradient matching step, the Gaussian process model is first fitted by inferring the hyperparameter . Secondly, the states and parameters are inferred using a one chain MCMC scheme on the density as in [23]. Finally, the parameters estimated above is set as initial guess in the least square optimization. The algorithm can be summarized as follows.
| Algorithm | |
| Input: | |
| Step 1. Fit GP model to data | |
| Step 2. Infer , and using MCMC | |
| for do | |
| for each state do | |
| Propose a new state value using a Gaussian distribution with standard | |
| deviation | |
| Accept proposed value based on the density (Eq. 8) | |
| Add current value to | |
| end for | |
| for each parameter do | |
| Propose a new parameter value using a Gaussian distribution with standard | |
| deviation | |
| Integrate with initial values and proposed parameters of ODEs. | |
| Accept proposed value based on the density (Eq. 8) | |
| Add current value to | |
| end for | |
| end for | |
| Discard the first samples of | |
| Return | |
| Step 3. Optimization using from Step 2 as initial guess. |
In Step 1, the Gaussian process model is fitted to data by maximizing the of marginal likelihood of the observations at times
| (9) |
with respect to hyperparameters and . is the standard deviation of the observation noise and is the amount of observations. The numerical integrals of in Step 2 are calculated only after each update of . Step 3 is to solve the following minimization problem,
| (10) |
In the optimization process, gradient descent method is adopted where numerical gradient is used in each searching step. One advantage of doing optimization is its ability to obtain a more accurate result with less computational cost. In fact, with increased data the Gaussian noise can be balanced in the cost functional. But it requires proper initial guess of the parameters so as to avoid falling in local minima, whereas FGPGM has relatively less restrictions on the initial guess. However, for FGPGM a large amount of MCMC samplings are necessary to ensure the expectations of random variables make sense and it is hard to estimate the accuracy of the reconstructed solution. Therefore, if we combine these two methods, it is possible to use less MCMC sampling number to obtain a rough approximation of the parameters first and then adopt them as initial guess to obtain a least square optimization result.
3 Experiments
For the Gaussian regression step for observable variables, the code published alongside Wenk et al. (2019)[23] was used. The MCMC sampling part should then be adapted to the partial observation case according to the diagram provided above. In the following we refer FGPGM to the adapted FGPGM method for partial observation (Step 1 and Step 2 in the present algorithm).
3.1 Lotka Volterra
The Lotka Volterra system was originally proposed in Lotka (1978)[12]. It was introduced to model the prey-predator interaction system whose dynamics are given by
| (11) | ||||
| (12) |
where . In the present work, the system was observed with one variable and the initial value of the other variable. The other setup is the same as Gorbach et al.(2017)[9] and Wenk et al. (2019)[23]. The observed series are located in the time interval at 20 uniformly distributed observation times. The initial values of the variables are . The history of the observable variable is generated with numerical integration of the system with true parameters , added by Gaussian noise with standard deviation 0.1. The RBF kernel was used for the Gaussian process. For the model noise we set . The results with being observed is shown in Fig. 2. Those with observation of are given in Fig. 3. In the later case, we can see that the optimization process can improve the results from FGPGM, with the identified parameters being closer to the true values.
The sensitivities of the variables to the parameters are listed in Tab. 1. The sensitivity indexes at the true parameter set are defined as
| (13) |
which are normalized. It is approximated by numerical difference. It is shown that near the true parameter set, and are relatively less sensitive to the variables than other parameters. This explains that and are less accurate in the numerical test (see Fig. 2(c) and Fig. 3(c)).
| 0.20 | 0.61 | |
| 0.52 | 1.13 | |
| 0.40 | 0.33 | |
| 1.27 | 0.98 |
The cases with larger noise level (std=0.5) are shown in Fig. 4 and Fig. 5, corresponding to and observations respectively. It can be seen that the prediction of the unknown variable can deviate far from the ground truth if we use FGPGM method only. The inferring of states and parameters can be improved after further applying the deterministic optimization.












3.2 Spiky Dynamics
This example is a system proposed by FitzHugh (1961) and Nagumo et al. (1962) for modeling the spike potentials in the giant squid neurons, which is abbreviated as FHN system. This system involves two ODEs with three parameters. The FHN system has notoriously fast changing dynamics due to its highly nonlinear terms. In the following numerical tests, the Matern 52 kernel was used and was set to , the same as that in Wenk et al. (2019)[23]. We assume one of the two variables is observable, which was generated with , , and added by Gaussian noise with average signal-to-noise ratio . There were 100 data points uniformly spaced in .
| (14) | |||
| (15) |
| 2.33 | 1.24 | |
| 0.44 | 0.31 | |
| 1.01 | 0.55 |
In this case, if we merely use FGPGM step, the reconstructed solution corresponding to the identified parameters may deviate significantly from the true time series (see Fig. 6, where data of are observable). It was pointed out [23] that all GP based gradient matching algorithms lead to smoother trajectories than the ground truth. This becomes more severe with sparse observation. Thus a least square optimization after doing FGPGM may well reduce this effect (see Fig. 7).

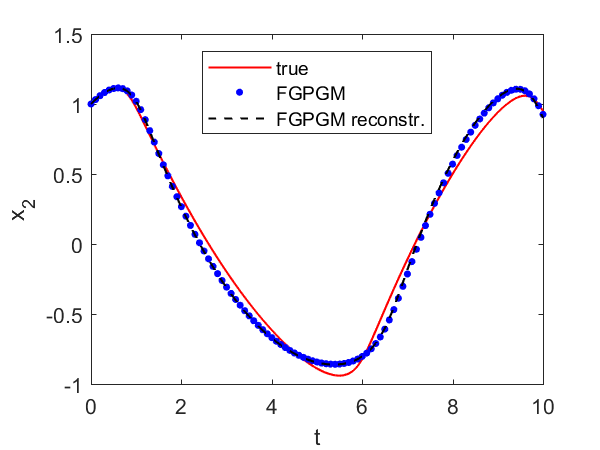
Fig. 7 and Fig. 8 present the results with single and observations respectively. In both cases the identified parameters are more accurate than using FGPGM only. From the sensitivity check in Tab. 2, it is expected that is most accurate because it is most sensitive among these three parameters, whereas is most insensitive and would be harder to be identified. The numerical results agree with that. It is worth mention that in the FGPGM step, only 3500 samplings were taken and the time for optimization step was much less than FGPGM step. This means the time needed for the whole process can be greatly saved compared with that in Wenk et al. 2019 [23], where 100,000 MCMC samplings were implemented.





In this example, we also notice that if we merely use least square optimization method, the local minimum effect would lead to reconstruction being far from the ground truth, which is even less robust than FGPGM method. For example, if we choose initial guess of the parameters near then the costfunctional will fall into the local minimum during gradient based search (see Fig. 9). The existence of many local minima in the full observation case has been pointed out in e.g., [7][19]. These results clearly illustrate the performance of the combination of FGPGM and least square optimization.


3.3 Protein Transduction
Finally the Protein Transduction system proposed in Vyshemisky and Girolami (2008) [22] was adopted to illustrate the performance of the method in ODEs with more equations. As mentioned in Dondelinger et al., 2013 [6], it is notoriously difficult to fit with unidentifiable parameters. The system is described by
| (16) | |||
| (17) | |||
| (18) | |||
| (19) | |||
| (20) |
The in this system is unidentifiable. We adopted the same experimental setup of Dondelinger et al. 2013 and Wenk et al. 2019 as follows. in FGPGM step. The observation were made at discrete times . The initial condition was and the data were generated by numerical integrating the system under , added by Gaussian noise with standard deviation 0.01. A sigmoid kernel was used to deal with the logarithmically spaced observation times and the typically spiky form of the dynamics as in the previous papers.
| 2.86 | 9.78 | 1.73 | 1.77 | 3.33 | |
| 0.70 | 0.98 | 0.22 | 0.59 | 0.41 | |
| 1.35 | 2.11 | 0.47 | 0.92 | 0.90 | |
| 0.26 | 0.43 | 0.03 | 2.64 | 0.62 | |
| 1.53 | 2.58 | 24.48 | 0.90 | 49.38 | |
| 0.04 | 0.07 | 0.60 | 0.02 | 1.21 |






Fig. 10 gives the result with () being unobserved. In fact, the situations with one of other variables being unknown have better results than the case illustrated here, which will not be presented here. We can see that was not well fitted by merely using FGPGM step, whereas the combination of FGPGM and optimization generated satisfactory result, with the parameters and being significantly improved. The sensitivity check is summarized in Tab. 3, from which we can see that is less sensitive and thereby harder to infer accurately. The error of may be affected by the value of the unidentifiable parameter .
It would also be of interest to see the performance of the method for the cases with more latent variables. In this model, although is not involved in equations for other variables, the data of helps infer . We also notice that . If and are both missing, it is impossible to identify . Therefore, in the following test we choose data of , and as observations. The data has a Gaussian noise with standard deviation 0.01, the same as the previous case with one latent variable. It can be seen from Fig. 11 that the result from FGPGM step is worse than the case with only one latent variable, but the final reconstruction of latent variables and parameter identification is not significantly different from the case with one latent variable.






4 Discussion
In the work, we proposed an effective method for parameter inference of coupled ODE systems with partially observable data. Our method is based on previous work known as FGPGM [23], which avoids product of experts heuristics. In order to improve the accuracy and efficiency of the method, we also use Least Square optimization in our computation. Due to the existence of latent variables, numerical integration is necessary for computation of the likelihood function in FGPGM method, which increases computational cost. The Least Square optimization allows us to greatly reduce the sampling number. In our numerical tests, we show that the sampling number in the FGPGM step is only 10% of that suggested in literature. It is worth noting that conventional least square optimization method requires good initial guess, which is not the case in our approach. Our numerical examples illustrated here demonstrate the feasibility of the proposed method for parameter inference with partial observations.
Acknowledgments
This work was supported in part by National Science Foundation of China (NSFC: No. 11971121), Nature Science and Research Council (NSERC) of Canada and the Fields Institute for Research in Mathematical Sciences. The authors also express the gratitude to Prof. Xin Gao, Nathan Gold and other members of the Fileds CQAM Lab on Health Analytics and Modelling for very beneficial discussions.
References
- [1] G. Anger. Inverse Problems in Differential Equations. Berlin: Kluwer, 1990.
- [2] R. C. Aster, B. Borchers and C. H. Thurber. Parameter Estimation and Inverse Problems. Boston: Elsevier, 2005.
- [3] D. Barber, Y. Wang. Gaussian processes for Bayesian estimation in ordinary differential equations. International Conference on Machine Learning. 2014.
- [4] H. G. Bock. Recent advances in parameter identification techniques for ODE. In Numerical Treatment of Inverse Problems in Differential and Integral Equations (eds P. Deuflhard and E. Harrier), 95-121. Basel:Birkhäuser, 1983.
- [5] Ben Calderhead, Mark Girolami and Neil D. Lawrence. Accelerating bayesian inference over nonlinear differential equations with gaussian processes. Neural Information Processing Systems (NIPS), 2008.
- [6] Frank Dondelinger, Maurizio Filippone, Simon Rogers and Dirk Husmeier. Ode parameter inference using adaptive gradient matching with gaussian processes. International Conference on Artificial Intelligence and Statistics (AISTATS), 2013.
- [7] W. R. Esposito and C. Floudas. Deterministic global optimization in nonlinear optimal control problems. J. Glob. Optimizn, 17, 97-126., 2000.
- [8] J. P. Gauthier and I. A. K. Kupka. Observability and Observers for Nonlinear Systems. SIAM J. Control Optim., 32(4), 975-994, 1994.
- [9] Nico S Gorbach, Stefan Bauer, and Joachim M. Buhmann. Scalable variational inference for dynamical systems. Neural Information Processing Systems (NIPS), 2017.
- [10] A. Isidori. Nonlinear Control Systems (3rd Edition). Springer-Verlag, 1995.
- [11] Jari Kaipio and Erkki Somersalo. Statistical and computational inverse problems. Springer Science, 2006.
- [12] Alfred J Lotka. The growth of mixed populations: two species competing for a common food supply. In The Golden Age of Theoretical Ecology: 1923-1940, pages 274-286. Springer, 1978.
- [13] Z. Li, M. Osborne and T. Prvan. Parameter estimation in ordinary differential equations. IMA J. Numer. Anal., 25, 264-285, 2005.
- [14] Benn Macdonald, Catherine Higham and Dirk Husmeier. Controversy in mechanistic modelling with Gaussian processes. Proceedings of the 32 nd International Conference on Machine Learning, Lille, France, 2015. JMLR: W&CP volume 37.
- [15] J. Nocedal and S. Wright. Numerical Optimization, 2nd edn. New York: Springer, 2006.
- [16] Mu Niu, Simon Rogers, Maurizio Filippone, and Dirk Husmeier. Fast inference in nonlinear dynamical systems using gradient matching. International Conference on Machine Learning (ICML), 2016.
- [17] H.Pohjanpalo. System identifiability based on the power series expansion of the solution. Mathematical biosciences, (41)21-33, 1978.
- [18] A. Papoulis, Su Pillai. Probability, Random Variables, and Stochastic Processes, 2002.
- [19] Jim O Ramsay, Giles Hooker, David Campbell, and Jiguo Cao. Parameter estimation for differential equations: a generalized smoothing approach. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 69(5):741-796, 2007.
- [20] Carl Edward Rasmussen. ”Gaussian processes in machine learning.” Summer School on Machine Learning. Springer, Berlin, Heidelberg, 2003.
- [21] A. Tarantola. Inverse Problem Theory. Philadelphia: Society for Industrial and Applied Mathematics, 2005.
- [22] Vladislav Vyshemirsky and Mark A Girolami. Bayesian ranking of biochemical system models. Bioinformatics, 24(6):833-839, 2008.
- [23] P. Wenk, A. Gotovos, S. Bauer, N. Gorbach, A. Krause, J. M. Buhmann, Fast Gaussian process based gradient matching for parameter identification in systems of nonlinear ODEs. Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics (AISTATS) 2019, Naha, Okinawa, Japan. PMLR: Volume 89, 2019.
Appendix A Preliminaries
In the following we list some preliminaries on derivatives of a Gaussian process that are used in this work, the proofs can be find in, e.g., [18][20][23]. Denote a random process , its realization and its time derivative .
Definition A.1.
([18]) The random variable converges to in the first-mean sense (limit in mean) if for some ,
| (21) |
Definition A.2.
The stochastic process is first-mean differentiable if for some
| (22) |
Definition A.3.
For given random variable , the moment generating function (MGF) is defined by
| (23) |
Proposition A.4.
If is the MGF, then
-
1.
where is the moment of .
-
2.
Let and be two random variables. X and Y have the same distribution if and only if they have the same MGFs.
-
3.
we say if and only if .
-
4.
If and are two random variable, then the MGF
By the above propositions, one has
Lemma A.5.
If are two independent Gaussian random variables with means and covariances , then is a Gaussian random variable with mean and covariance .
Definition A.6.
([20]) A real-valued stochastic process , where is an index set, is a Gaussian process if all the finite-dimensional distributions are a multivariate normal distribution. That is, for any choice of distinct values , the random vector has a multivariate normal distribution with joint Gaussian probability density function given by
| (24) |
where the mean vector is defined as
| (25) |
and covariance matrix .
The Gaussian processes only depend on the mean and covariance functions. Usual covariance functions could be Squared exponential , where is a hyperparameter and represents the nonlocal interaction length scale.
Let , and be a Gaussian Process with constant mean and kernel function , assumed to be first-mean differentiable. Then and are jointed Gaussian distributed
| (26) |
with density function
| (27) |
where
| (28) |
If we define linear transformation
| (31) |
then we have
| (32) |
i.e.
| (33) |
where
| (36) |
The above derivation shows that and are jointly Gaussian distributed. Using the definition of differential and the fact that convergence implies convergence in distribution, it is clear that and are jointly Gaussian
| (37) |
In general, and are jointly Gaussian
| (38) |
Here is the covariance between between and , and predefined kernel matrix of Gaussian process. By linearity of the covariance operator and the predefined kernel function , we have
| (39) | |||
| (40) | |||
| (41) |
Lemma A.7.
(Matrix Inversions Lemma) Let be a ():
| (42) |
where the sum-matrices have dimension , , etc. Suppose are non-singular; and partition the inverse in the same way as ,
| (43) |
Then
| (48) |
Lemma A.8.
(Conditional Gaussian distributions) Let , , be jointly Gaussian random vectors with distribution
| (49) |
where
| (50) |
Then the conditional Gaussian distributions density functions are
| (51) |
where
| (52) | |||
| (53) |
According to above Lemma, we have the condition distribution
Lemma A.9.
| (54) |
where
| (55) | |||
| (56) |