NubbleDrop: A Simple Way to Improve Matching Strategy for Prompted One-Shot Segmentation
Abstract
Driven by large-data-trained segmentation models, such as SAM [13], research in one-shot segmentation has experienced significant advancements. Recent contributions like PerSAM [45] and MATCHER [21], presented at ICLR 2024, utilize a similar approach by leveraging SAM with one or a few reference images to generate high-quality segmentation masks for target images. Specifically, they utilize raw encoded features to compute cosine similarity between patches within reference and target images along the channel dimension, effectively generating prompt points or boxes for the target images—a technique referred to as the matching strategy. However, relying solely on raw features might introduce biases and lack robustness for such a complex task. To address this concern, we delve into the issues of feature interaction and uneven distribution inherent in raw feature-based matching. In this paper, we propose a simple and training-free method to enhance the validity and robustness of the matching strategy at no additional computational cost (NubbleDrop). The core concept involves randomly dropping feature channels (setting them to zero) during the matching process, thereby preventing models from being influenced by channels containing deceptive information. This technique mimics discarding pathological nubbles, and it can be seamlessly applied to other similarity computing scenarios. We conduct a comprehensive set of experiments, considering a wide range of factors, to demonstrate the effectiveness and validity of our proposed method. Our results showcase the significant improvements achieved through this simmple and straightforward approach.
1 Introduction
Research in Vision Foundation Models (VFMs) has made tremendous strides in recent times. Fueled by extensive image-text contrastive pre-training, CLIP (Radford et al., 2021) [30] and ALIGN (Jia et al., 2021) [12] demonstrate robust zero-shot transfer capabilities across a wide array of classification tasks. DINOv2 (Oquab et al., 2023) [26] showcases remarkable proficiency in visual feature matching, enabling it to comprehend intricate information at both the image and pixel levels, solely from raw image data. Furthermore, the Segment Anything Model (SAM) (Kirillov et al., 2023) [13] has achieved impressive class-agnostic segmentation performance by training on the SA-1B dataset, comprising 1 billion masks and 11 million images.
However, unlike Large Language Models (LLMs), which seamlessly integrate various language tasks using a unified model structure and pre-training approach, VFMs face challenges when directly addressing diverse perception tasks. For instance, these approaches often require a task-specific model architecture and fine-tuning for each specific task (He et al., 2022 [7]; Oquab et al., 2023 [26]).
To enhance the transferability of Vision Foundation Models (VFMs), efforts have been made by PerSAM [45] and Matcher [21] to prompt the VFM, specifically SAM. They employ a systematic approach where each category is prompted with a single reference photo. This process involves several key steps, including matching the target image with the reference images, extracting prompted points or boxes to guide SAM in generating segmentation masks, and utilizing the matched information to select segmentation masks and produce the final results.
Upon reevaluation of this process, we’ve identified two significant concerns. Firstly, Vision Foundation Models (VFMs) entail intricate feature interactions and fusion during feature extraction and processing, which may not accurately depict the similarity between patches at the channel level. In essence, not all individual channel-to-channel disparities can effectively capture the similarity between two patches. Secondly, we’ve observed that certain channels’ absolute values within the extracted features from the same patch are excessively large, exerting a dominant influence on the contrast while overshadowing information from numerous other channels.
Addressing the first issue, we conducted experiments to compute the matching degree of background points and target object points in a substantial number of images separately. The findings revealed that for numerous images, the optimal matching points for their target object points were situated within the background, highlighting significant deficiencies in the existing matching strategy. Concerning the second issue, we designed experiments to calculate the extreme values and variances of normalized channel values (absolute values) across a large dataset of images. These experiments demonstrated a highly unbalanced distribution of channel values, where certain channel values played a pivotal role in the matching process. Should these points also encounter the first issue, it could result in misjudgment, thereby significantly impairing the model’s performance.
To mitigate these two concerns without incurring substantial computational costs, we have introduced a straightforward method (NubbleDrop) that imposes minimal computational overhead. The crux of this approach involves randomly setting a small subset of feature channels to zero. We have demonstrated that for individual images, NubbleDrop has negligible impact on the model’s original performance. However, there exists a probability that dropping channels affected by either of the aforementioned issues can notably enhance the accuracy of image segmentation. Consequently, when applied to large-scale image datasets, this operation yields considerable improvements. Furthermore, even for datasets with a mean Intersection over Union (mIoU) approaching 90, this operation still delivers significant enhancements. Additionally, we discuss alternative operations for enhancing the matching strategy that entail slightly more computational complexity in the Methodology section.
Our comprehensive experiments underscore the superior generalization performance of NubbleDrop across various segmentation tasks. In the realm of one-shot semantic segmentation, Matcher with NubbleDrop (MN) achieves a remarkable 53.5 mIoU on COCO-20i [25], surpassing the state-of-the-art specialist model by 2.4 and the original model by 1.4. Similarly, MN achieves a notable 34.0 mIoU on LVIS-92i [21], outperforming the state-of-the-art generalist model SegGPT (Wang et al., 2023b) [40] by 15.4 and the original model by 0.3.
Furthermore, MN exhibits a substantial margin of improvement over PerSAM-F (Zhang et al., 2023) [45], with an increase of +30.0 mean mIoU on COCO-20i, +11.6 mIoU on FSS-1000 [17], and +21.7 mean mIoU on LVIS-92i. Moreover, when evaluated on three different foundation models—DINOv2 [26], Resnet50 [8], and Efficientnet [35]—MN demonstrates outstanding improvements in one-shot object part segmentation tasks. Specifically, MN outperforms the original models by an average of about 2 mean mIoU, showcasing the robust generality and flexibility of our method. Additionally, our thorough investigation into drop ratios has bolstered the credibility and robustness of our NubbleDrop experiment.
Our main contributions can be summarized as follows:
(i) Through a rigorous mathematical discourse on feature interaction and fusion, as well as the uneven distribution of channel values, we have elucidated significant issues associated with directly computing the similarity of two patches using raw features extracted by VFMs. To validate our assertions, we conducted separate experiments, thereby laying the groundwork for future improvement studies.
(ii) We introduced a method that necessitates no training, incurs minimal computational demand, and demonstrated its ability not only to preserve the original model’s capabilities but also to significantly address the aforementioned issues. Moreover, this method can be effortlessly implemented in various similarity computing scenarios.
(iii) We conducted extensive experiments to validate the effectiveness, robustness, and broad applicability of our approach. These experiments included assessing improvements achieved by NubbleDrop across different VFMs (such as ResNet, DINOv2, and Efficientnet), enhancements across various datasets, evaluation of performance at the image level, and exploration of the effects of discarding varying numbers of channels.
2 Related Work
Feature Interactions: Feature interactions refer to the contextual dependencies between features that collectively influence predictions. Various methods exist for extracting feature interactions in prediction models. Tsang et al. [36] introduce a novel framework for detecting statistical interactions captured by a feed-forward multi-layer neural network by directly interpreting its learned weights. Furthermore, Tsang et al. [37] propose an interaction attribution and detection framework called Archipelago, which offers more interpretable explanations for analyzing the impact of interactions on predictions, accompanied by visualizations of their approach.
Vision Foundation Models: Driven by extensive pre-training, foundational vision models have achieved remarkable success in computer vision. Drawing inspiration from the concept of masked language modeling [2, 20] in natural language processing, MAE [7] adopts an asymmetric encoder-decoder architecture and implements masked image modeling to efficiently train scalable vision Transformer models [4]. CLIP [30] learns image representations from a vast corpus of 400 million image-text pairs, demonstrating impressive zero-shot image classification capabilities. Through image and patch-level discriminative self-supervised learning, DINOv2 [26] acquires versatile visual features applicable to various downstream tasks. Recently, SAM [13], pre-trained with 1 billion masks and 11 million images, has emerged with remarkable zero-shot, class-agnostic segmentation performance. Despite the exceptional performance of vision foundation models in fine-tuning, their capabilities remain limited in various visual perception tasks.
Vision Generalist for Segmentation: In recent times, there has been a growing endeavor to consolidate various segmentation tasks into a unified model leveraging the Transformer architecture [38]. The versatile Painter model [39] reimagines the outcomes of diverse visual tasks as images and employs masked image modeling on continuous pixels for in-context training with labeled datasets. SegGPT [40], a variant of the Painter model, introduces a novel random coloring method for in-context training to enhance the model’s generalization capabilities. SEEM [47] effectively addresses various segmentation tasks by leveraging spatial queries such as points and textual prompts. More recently, PerSAM [45] extends SAM for personalized segmentation and video object segmentation with minimal training requirements, while Matcher [21], a training-free framework, endeavors to tackle various segmentation tasks in a single shot using all-purpose feature matching.
3 Problem Analysis
3.1 Feature Interactions
A statistical interaction describes a situation in which the joint influence of multiple variables on an output variable is not additive (Dodge, 2006 [3]; Sorokina et al., 2008 [33]). Let , be the features and be the response variable, a statistical interaction exists if and only if , which is a function of = (, ,…, ), contains a non-additive interaction between variables :
Definition (Non-additive Interaction). Consider a function with input variables , , and an interaction . Then is a non-additive interaction of function if and only if there does not exist a set of functions , where is not a function of , such that
| (1) |
Interaction Strength: In their work, Tsang et al. [36] demonstrate that the interaction strength of a potential interaction at the -th unit in the first hidden layer
| (2) |
where (.) is the averaging function for an interaction that represents the interaction strength and the aggregated weight is cumulative matrix multiplications of the absolute values of weight matrices.
| (3) |
More details and aggregating strengths across hidden units can be read in supplementary materials.
Due to the complex feature interactions and fusion inherent in extracted features, it is evident that we can not deem that any single channel can adequately represent the uniqueness of a patch. In other words, certain channels may not be suitable for computing similarity.
To illustrate our concern regarding this significant issue, we conducted an experiment on the COCO-20i dataset, wherein we computed the frequency of occurrences where not all target object points were best matched with foreground points (excluding themselves), as depicted in Figure 1. Our findings reveal that in a considerable number of image tests, there is a substantial proportion of instances where incorrect matching occurs, amounting to approximately 70%. This outcome strongly validates our hypothesis and underscores the prevalence of mismatches when directly employing raw features for matching purposes.

3.2 Uneven Distribution
Upon normalization, the Euclidean norm ( norm) of the tensor becomes 1. In theory, if the channel values are evenly distributed across each channel, a substantial amount of channel information will be effectively utilized. Conversely, if only a small number of channels dominate, they will exert a significant influence on computing cosine similarity, leaving the majority of channel information unused.
To validate this concern regarding uneven distribution in the feature channel dimension, we computed the extreme values and variances of channel values from features encoded across a large number of images. We define the phenomenon of "dominant channel" in the distribution of feature channel values when the maximum absolute channel value reaches 0.5 () with a sum of squares greater than 0.25, representing a quarter of the total value. In this scenario, certain channel values are excessively large and play a crucial role in computing cosine similarity. Additionally, if the variance exceeds 0.0004 (), it is deemed as the phenomenon of "channel submergence", wherein numerous channels possess values too small to be effectively utilized. Below is the mathematical representation:
| (4) |
| (5) |
where denotes the max value function and represents the total average variance, while signifies the channel dimension. denotes the feature tensors of reference images. It’s worth noting that we also computed the total average of the mean values of the feature channels across sample images, yielding a value of 0.0230. If the total average variance exceeds 0.0004 (), it indicates that, on average, each deviation surpasses 0.02, a value remarkably close to the mean. Hence, we can infer the existence of a "channel submergence" phenomenon, characterized by numerous channels with values too small to be effectively utilized.
The findings depicted in Figures 2 and 3 vividly illustrate the significant occurrences of "dominant channels" and "channel submergence" within the reference features.
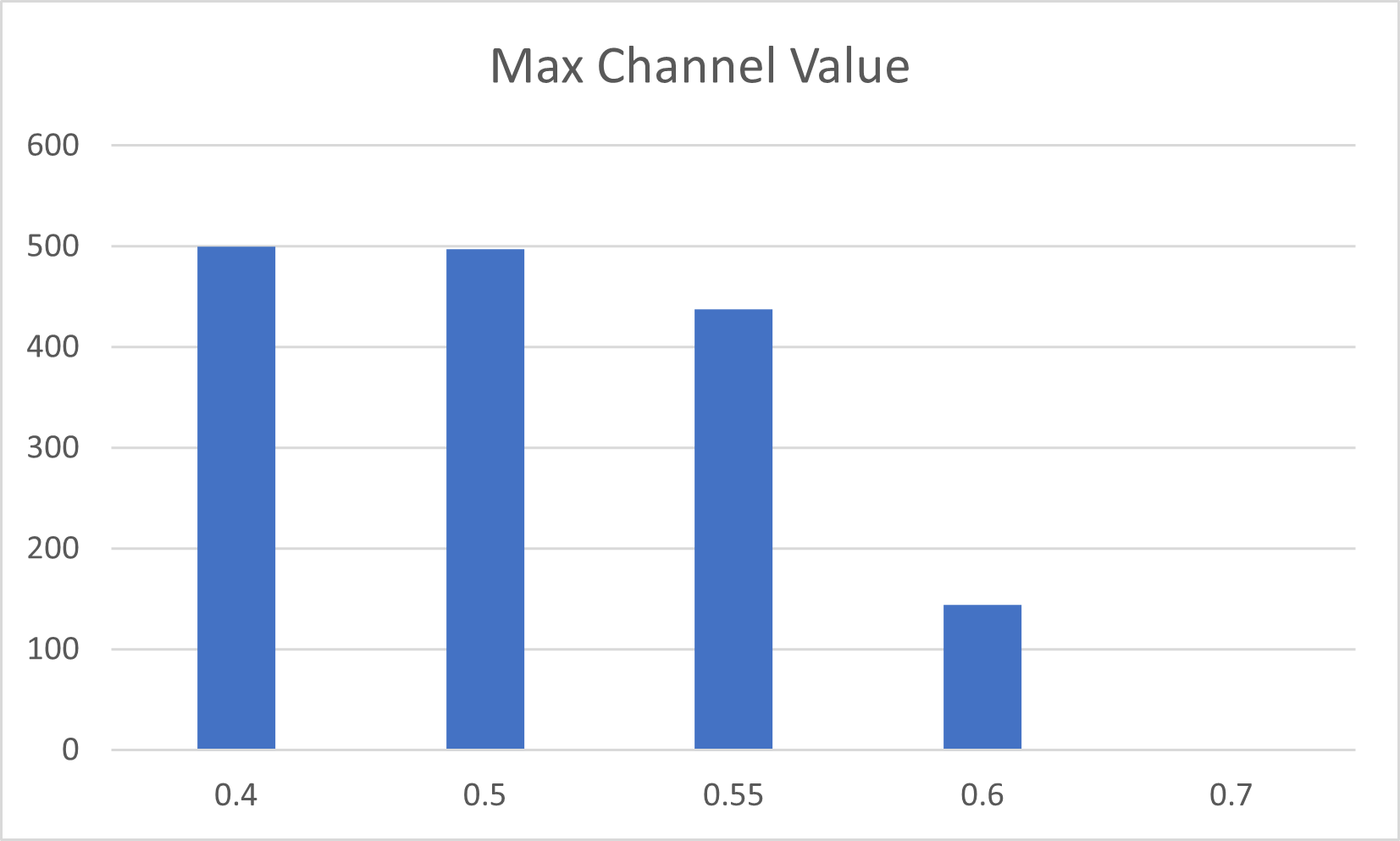

4 Methodology
4.1 Methods with Computational Lost
To tackle the aforementioned problems, several methods can be explored:
Aligning features and removing inappropriate channels for computing similarity appears to be effective. However, since research on specific channels is still evolving, it’s challenging to precisely determine the effects of each channel on every patch. Therefore, to implement this approach, we would need to calculate the similarity between a large number of target object patches and background patches. Then, iteratively removing inappropriate channels from each target patch would require a complexity close to , where and represent the height and width of the image patches, represents the number of compared background points per target object point, and represents the number of feature channels.
Additionally, trimming channels with extreme values is another strategy. To execute this idea, we would need to iterate through each channel value for every point, resulting in comparisons. It’s essential to consider both the number of channels to trim and the cumulative sum of trimmed channel values, as they significantly influence model performance. However, the impact of all these extreme channel values on comparison remains unclear. Discarding them all while retaining other small channel values might have a counterproductive effect. To enhance the effectiveness and robustness of this method, extensive large-scale research is imperative.
4.2 NubbleDrop with No Computation

Traversing tensors suffers from poor parallelism, significantly impacting computation speed. Additionally, the lack of interpretive studies on specific feature channels introduces numerous considerations when targeting certain channel values for processing. To preserve the original model’s exceptional performance while minimizing computational overhead and enhancing algorithm transferability and applicability, we propose NubbleDrop that randomly sets some channel values to zero.
Intuitively, if two features are very similar or very dissimilar, removing a small number of channels will likely have minimal impact on the original results. Therefore, NubbleDrop primarily affects ambiguous scenarios. As analyzed in Section 3, what influences the matching between patches are certain interaction channels or channels that play a decisive role. Since NubbleDrop randomly discards channels, if these problematic (Nubble) channels are retained, it’s difficult to avoid poor matching results. However, if they are discarded, it can significantly improve the matching process.
Therefore, NubbleDrop can maintain the outstanding performance of the original model with a rather simple operation, while also potentially enhancing the model’s performance to some extent. Furthermore, during a single test, matching between patch pairs is executed times (where and represent the height and width of the image patches). Consequently, the model’s performance typically improves when NubbleDrop is incorporated, as it’s implemented over 1000 times within a single test.
The mathematical representation of NubbleDrop can be formalized as:
| (6) |
| (7) |
| (8) |
| (9) |
where and represent the features extracted by VFMs () of the reference image and target image, and formula (9) denote selecting a certain number of channels to set to 0 in the channel dimension with a total of .

| Methods | Venue | COCO-20i | FSS-1000 | LVIS-92i |
| one-shot | one-shot | one-shot | ||
| specialist model | ||||
| HSNet [23] | ICCV’21 | 41.2 | 86.5 | 17.4 |
| VAT [9] | ECCV’22 | 41.3 | 90.3 | 18.5 |
| FPTrans [44] | NeurIPS’22 | 47.0 | - | - |
| MSANet [11] | arvix’22 | 51.1 | - | - |
| generalist model | ||||
| Painter [39] | CVPR’23 | 33.1 | 61.7 | 10.5 |
| SegGPT [40] | ICCV’23 | 56.1 | 85.6 | 18.6 |
| PerSAM-Fπ [45] | ICLR’24 | 23.5 | 75.6 | 12.3 |
| Matcherπ [21] | ICLR’24 | 52.1 | 87.0 | 33.7 |
| Matcher+NubbleDropπ | this work | 53.5 | 87.2 | 34.0 |
| Methods | Venue | PASCAL-Part | ||||
| animals | indoor | person | vehicles | mean | ||
| HSNet [23] | ICCV’21 | 21.2 | 53.0 | 20.2 | 35.1 | 32.4 |
| VAT [9] | ECCV’22 | 21.5 | 55.9 | 20.7 | 36.1 | 33.6 |
| Painter [39] | CVPR’23 | 20.2 | 49.5 | 17.6 | 34.4 | 30.4 |
| SegGPT [40] | ICCV’23 | 22.8 | 50.9 | 31.3 | 38.0 | 35.8 |
| PerSAMπ [45] | ICLR’24 | 19.9 | 51.8 | 18.6 | 32.0 | 30.1 |
| Matcherπ [21] | ICLR’24 | 37.1 | 56.3 | 32.4 | 45.7 | 42.9 |
| Matcher+NubbleDropπ | this work | 37.1 | 56.2 | 32.2 | 45.6 | 42.8 |
| Methods | VFM | COCO-20i | |
| - | + | ||
| Matcher | DINOv2 | 52.1 | 53.5 |
| Resnet50 | 18.59 | 22.75 | |
| Efficientnet | 23.36 | 23.76 | |
5 Experiments
5.1 Datasets
We assess the performance of Matcher with NubbleDrop across three benchmark datasets: COCO-20i [25], FSS-1000 [17], and LVIS-92i [21].
COCO-20i divides the 80 categories of the MSCOCO dataset [19] into four cross-validation folds, each comprising 60 training classes and 20 test classes. FSS-1000 comprises mask-annotated images from 1,000 classes, with 520, 240, and 240 classes in the training, validation, and test sets, respectively. LVIS-92i is a more challenging benchmark with a total of 920 classes, divided into 10 equal folds for testing purposes.
Additionally, we consider PASCAL-Part [21], a one-shot part segmentation dataset based on PASCAL VOC2010 and its body part annotations. This dataset consists of four superclasses—animals, indoor, person, and vehicles—with a total of 56 different object parts.
5.2 Results
We compare Matcher with the addition of NubbleDrop (MN) against a range of specialist models, including HSNet [23], VAT [9], FPTrans [44], and MSANet [11], as well as generalist models such as Painter [39], SegGPT [40], PerSAM [45], and Matcher [21].
As illustrated in Table 1, MN achieves a mean mIoU of 53.5% on COCO-20i, with a 1.4% enhancement over the original model, surpassing the state-of-the-art specialist model MSANet and performing comparably with SegGPT. It’s worth noting that SegGPT’s training data includes COCO. For FSS-1000, MN demonstrates highly competitive performance compared to specialist models and outperforms all generalist models without any performance degradation compared to the original model.
In the case of LVIS-92i, we evaluate the cross-dataset generalization abilities of MN and other models. MN achieves a mean mIoU of 34.0%, surpassing the state-of-the-art generalist model SegGPT by 15.4% and enhancing Matcher by 0.3 mean mIoU. These results underscore the remarkable robustness of NubbleDrop across different datasets.
Furthermore, we conduct experiments with NubbleDrop on three distinct vision foundation models, revealing that MN significantly outperforms those models utilizing raw features. Specifically, MN exhibits enhancements of 1.4, 4.16, and 0.4 mean mIoU in DINOv2, Resnet50, and Efficientnet, respectively, without any degradation in performance. These results underscore the remarkable flexibility and transferability of our method.
5.3 Further Experimentation
We’ve conducted two additional experiments and obtained two result graphs. One is a line graph depicting the average performance improvement as the number of test images increases. The other graph illustrates the impact of drop ratio variations on model performance.
The results of the first experiment indicate that the improvement achieved by our method with a small number of images is consistent with the overall improvement, demonstrating the effectiveness of our method on individual images and its ability to preserve the performance of the original model.


6 Conclusion
In this paper, we first analyze two existing problems in matching strategies and propose an exceptionally simple solution, NubbleDrop, which requires no training and minimal computational resources to address these issues. We also explore alternative methods that entail computational costs and conduct extensive experiments to validate the efficacy, scalability, and effectiveness of our approach.
Limitations and Future Research. Although our method is rather simple and does not introduce any computational overhead, the improvement in performance is not very significant. We have analyzed two problems we identify in existing matching strategies, providing useful directions for future research. We believe that there will be more effective methods to address these issues in the future.
References
- [1] David Arthur, Sergei Vassilvitskii, et al. k-means++: The advantages of careful seeding. In Soda, volume 7, pages 1027–1035, 2007.
- [2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [3] Yadolah Dodge. The Oxford dictionary of statistical terms. Oxford University Press, USA, 2003.
- [4] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [5] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88:303–338, 2010.
- [6] Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5356–5364, 2019.
- [7] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022.
- [8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [9] Sunghwan Hong, Seokju Cho, Jisu Nam, Stephen Lin, and Seungryong Kim. Cost aggregation with 4d convolutional swin transformer for few-shot segmentation. In European Conference on Computer Vision, pages 108–126. Springer, 2022.
- [10] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pages 448–456. pmlr, 2015.
- [11] Ehtesham Iqbal, Sirojbek Safarov, and Seongdeok Bang. Msanet: Multi-similarity and attention guidance for boosting few-shot segmentation. arXiv preprint arXiv:2206.09667, 2022.
- [12] Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pages 4904–4916. PMLR, 2021.
- [13] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4015–4026, 2023.
- [14] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213, 2022.
- [15] Aixuan Li, Jing Zhang, Yunqiu Lv, Bowen Liu, Tong Zhang, and Yuchao Dai. Uncertainty-aware joint salient object and camouflaged object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10071–10081, 2021.
- [16] Feng Li, Hao Zhang, Peize Sun, Xueyan Zou, Shilong Liu, Jianwei Yang, Chunyuan Li, Lei Zhang, and Jianfeng Gao. Semantic-sam: Segment and recognize anything at any granularity. arXiv preprint arXiv:2307.04767, 2023.
- [17] Xiang Li, Tianhan Wei, Yau Pun Chen, Yu-Wing Tai, and Chi-Keung Tang. Fss-1000: A 1000-class dataset for few-shot segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2869–2878, 2020.
- [18] Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190, 2021.
- [19] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- [20] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- [21] Yang Liu, Muzhi Zhu, Hengtao Li, Hao Chen, Xinlong Wang, and Chunhua Shen. Matcher: Segment anything with one shot using all-purpose feature matching. arXiv preprint arXiv:2305.13310, 2023.
- [22] Ben Mann, N Ryder, M Subbiah, J Kaplan, P Dhariwal, A Neelakantan, P Shyam, G Sastry, A Askell, S Agarwal, et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- [23] Juhong Min, Dahyun Kang, and Minsu Cho. Hypercorrelation squeeze for few-shot segmentation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6941–6952, 2021.
- [24] Keval Morabia, Jatin Arora, and Tara Vijaykumar. Attention-based joint detection of object and semantic part. arXiv preprint arXiv:2007.02419, 2020.
- [25] Khoi Nguyen and Sinisa Todorovic. Feature weighting and boosting for few-shot segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 622–631, 2019.
- [26] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- [27] Youwei Pang, Xiaoqi Zhao, Tian-Zhu Xiang, Lihe Zhang, and Huchuan Lu. Zoom in and out: A mixed-scale triplet network for camouflaged object detection. In Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 2160–2170, 2022.
- [28] Youwei Pang, Xiaoqi Zhao, Lihe Zhang, and Huchuan Lu. Multi-scale interactive network for salient object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9413–9422, 2020.
- [29] Imran Qureshi, Junhua Yan, Qaisar Abbas, Kashif Shaheed, Awais Bin Riaz, Abdul Wahid, Muhammad Waseem Jan Khan, and Piotr Szczuko. Medical image segmentation using deep semantic-based methods: A review of techniques, applications and emerging trends. Information Fusion, 90:316–352, 2023.
- [30] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- [31] Aimon Rahman, Jeya Maria Jose Valanarasu, Ilker Hacihaliloglu, and Vishal M Patel. Ambiguous medical image segmentation using diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11536–11546, 2023.
- [32] Amirreza Shaban, Shray Bansal, Zhen Liu, Irfan Essa, and Byron Boots. One-shot learning for semantic segmentation. arXiv preprint arXiv:1709.03410, 2017.
- [33] Daria Sorokina, Rich Caruana, Mirek Riedewald, and Daniel Fink. Detecting statistical interactions with additive groves of trees. In Proceedings of the 25th international conference on Machine learning, pages 1000–1007, 2008.
- [34] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1):1929–1958, 2014.
- [35] Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, pages 6105–6114. PMLR, 2019.
- [36] Michael Tsang, Dehua Cheng, and Yan Liu. Detecting statistical interactions from neural network weights. In International Conference on Learning Representations, 2018.
- [37] Michael Tsang, Sirisha Rambhatla, and Yan Liu. How does this interaction affect me? interpretable attribution for feature interactions. Advances in neural information processing systems, 33:6147–6159, 2020.
- [38] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [39] Xinlong Wang, Wen Wang, Yue Cao, Chunhua Shen, and Tiejun Huang. Images speak in images: A generalist painter for in-context visual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6830–6839, 2023.
- [40] Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, and Tiejun Huang. Seggpt: Segmenting everything in context. arXiv preprint arXiv:2304.03284, 2023.
- [41] Zhiyu Xu and Qingliang Chen. Glass segmentation with multi scales and primary prediction guiding. arXiv preprint arXiv:2402.08571, 2024.
- [42] Di Yuan, Zhenghua Xu, Biao Tian, Hening Wang, Yuefu Zhan, and Thomas Lukasiewicz. -net: Medical image segmentation using efficient and effective deep supervision. Computers in Biology and Medicine, 160:106963, 2023.
- [43] Chi Zhang, Guosheng Lin, Fayao Liu, Rui Yao, and Chunhua Shen. Canet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5217–5226, 2019.
- [44] Jian-Wei Zhang, Yifan Sun, Yi Yang, and Wei Chen. Feature-proxy transformer for few-shot segmentation. Advances in neural information processing systems, 35:6575–6588, 2022.
- [45] Renrui Zhang, Zhengkai Jiang, Ziyu Guo, Shilin Yan, Junting Pan, Hao Dong, Yu Qiao, Peng Gao, and Hongsheng Li. Personalize segment anything model with one shot. In The Twelfth International Conference on Learning Representations, 2023.
- [46] Yizhe Zhang, Tao Zhou, Shuo Wang, Peixian Liang, Yejia Zhang, and Danny Z Chen. Input augmentation with sam: Boosting medical image segmentation with segmentation foundation model. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 129–139. Springer, 2023.
- [47] Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Wang, Lijuan Wang, Jianfeng Gao, and Yong Jae Lee. Segment everything everywhere all at once. Advances in Neural Information Processing Systems, 36, 2024.