Not Just Object, But State: Compositional Incremental Learning without Forgetting
Abstract
Most incremental learners excessively prioritize coarse classes of objects while neglecting various kinds of states (e.g. color and material) attached to the objects. As a result, they are limited in the ability to reason fine-grained compositionality of state-object pairs. To remedy this limitation, we propose a novel task called Compositional Incremental Learning (composition-IL), enabling the model to recognize state-object compositions as a whole in an incremental learning fashion. Since the lack of suitable benchmarks, we re-organize two existing datasets and make them tailored for composition-IL. Then, we propose a prompt-based Composition Incremental Learner (CompILer), to overcome the ambiguous composition boundary problem which challenges composition-IL largely. Specifically, we exploit multi-pool prompt learning, which is regularized by inter-pool prompt discrepancy and intra-pool prompt diversity. Besides, we devise object-injected state prompting by using object prompts to guide the selection of state prompts. Furthermore, we fuse the selected prompts by a generalized-mean strategy, to eliminate irrelevant information learned in the prompts. Extensive experiments on two datasets exhibit state-of-the-art performance achieved by CompILer. Code and datasets are available at: https://github.com/Yanyi-Zhang/CompILer.
1 Introduction
Class Incremental Learning (class-IL) CL_survey_1 ; CL_survey_2 ; LwF ; EWC gathers increasing attention due to its ability to make the models learn new tasks rapidly, without forgetting previously acquired knowledge. Yet, traditional class-IL sets a strict limit on the old classes such that they should not recur in newly incoming tasks. To break such a strict limitation, recent studies develop a new setting mostly called Blurry Incremental Learning (blur-IL) MVP ; CLIB , where the incremental sessions allow the recurrence of previous classes, resulting in a more realistic and flexible scenario. Despite such empirical progresses on incremental learning, they aim to improve object classification only, while overlooking fine-grained states attached to the objects. For instance, analyzing how the clothing styles (akin to states) have changed over time is important for forecasting the future trends that will emerge.

To simultaneously model objects and their states, some efforts are dedicated to Compositional Learning whose aim is how to equip the models with compositionality CognitiveScience1 ; CognitiveScience2 ; CognitiveScience3 . The core of compositional learning lies in the structure of class labels, which conceptualizes a state-object pair (e.g. “Brown Pants” and “Yellow Dress”) as a whole, rather than a lonely object label. In this way, the model can dissect and reassemble learned knowledge, achieving a more fine-grained understanding about the objects. However, existing works are mainly focused on zero-shot generalization from seen compositions to unseen ones AttrAsOpe ; Task-driven ; CZSL_AAAI_2024 ; CZSL_CVPR_2024 , whereas none of them consider the challenging fact that the model must deal with a significantly larger number of composition classes than object classes. As a result, it is hardly feasible to learn all compositions by training the model once.
To remedy the limitations inherent in incremental learning and compositional learning, we conceive a novel task named Compositional Incremental Learning (composition-IL), enabling the model to continually learn new state-object compositions in an incremental fashion. As compared in Fig. 1, we can see that composition-IL integrates the characteristics of class-IL and blur-IL. Although the composition classes are disjoint across incremental tasks, the primitive classes (i.e. objects and states) encountered in old tasks are allowed to reappear in new tasks. Unfortunately, existing incremental learning approaches are challenged by such a compositional scenario, because their models excessively prioritize the object primitives while neglecting the state primitives. Consequently, the compositions with the same object but with different states become ambiguous and indistinguishable.
To tackle the problem, we propose a rehearsal-free and prompt-based Compositional Incremental Learner (CompILer). Specifically, our model comprises of three primary components: multi-pool prompt learning, object-injected state prompting, and generalized-mean prompt fusion. Firstly, we construct three prompt pools for learning the states, objects and compositions individually. Upon that, we add extra restrictions to regularize the inter-pool prompt discrepancy and intra-pool prompt diversity. This multi-pool prompt learning paradigm strengthens the fine-grained understanding and reasoning towards primitive concepts and their compositions. In addition, as the state classes are more difficult to distinguish than the object ones, we propose object-injected state prompting which incorporates object prompts to guide the selection of state prompts. Furthermore, we fuse the selected prompts by a generalized-mean fusion manner, which helps to adaptively eliminate irrelevant information learned in the prompts. Last but not least, we also leverage symmetric cross-entropy loss to alleviate the impact of noisy data during training.
In summary, the main contributions in this work are encapsulated as follows: (1) We devise a new task coined compositional incremental learning (composition-IL). It enables learning fine-grained state-object compositions continually while the isolated primitive concepts can randomly recur in incremental tasks. (2) To address the lack of datasets, we re-organize two existing datasets such that they are tailored specifically for composition-IL. For the two new datasets (Split-Clothing and Split-UT-Zappos), we split them into 5 and 10 incremental tasks for evaluating the methods. (3) We propose a novel learning-to-prompt model for composition-IL, namely CompILer. Our state-of-the-art results on Split-Clothing and Split-UT-Zappos validate the effectiveness of CompILer for incrementally learning new compositions without forgetting old ones.
2 Related Work
Incremental Learning. The approaches to addressing catastrophic forgetting for incremental learning can be broadly grouped into four categories: regularization based methods IL_regular_1 ; IL_regular_2 aim to protect influential weights of old experiences from updating; knowledge distillation based methods LwF ; IL_distill_1 distill knowledge from the model trained on the previous tasks and adapt it to new tasks; rehearsal based methods icarl ; IL_replay_1 ; IL_replay_2 require a memory buffer to store some old data, so as to make the network remember previous tasks; parameter isolation methods allocates different model parameters to each task, to prevent any possible interference. Different from the methods, L2P L2P proposes an innovative learning-to-prompt paradigm, which incorporates plasticity and stability through adapting a set of learnable prompt tokens on top of a frozen pre-trained backbone. Inspired by L2P L2P , more recent works Dual ; HiDe ; Consistent_Prompting ; Prompt_Gradient_Projectio take full advantage of various prompt tuning strategies, achieving new state-of-the-art performance for incremental learning. However, such methods take into account object classes solely, while neglecting various kinds of state classes associated with the objects. To this end, our work proposes compositional incremental learning with the purpose to continually identifying the composition classes of state-object pairs. Note that, Liao, et al CLC conduct an initial study toward the compositionality in incremental learning, whereas their attention is on the composition of multiple object classes (e.g. “Car” and “Person”) in one image, rather than the state-object compositions in this work
Compositional Learning. A major line of compositional learning research focuses on Compositional Zero-Shot Learning (CZSL) RedWine , which aims to infer unseen state-object compositions by acquiring knowledge from seen ones. Subsequent approaches building upon the CZSL setting further incorporate graph neural networks to model the dependency between primitives and compositions CGE , and employ cosine classifiers to avoid being overly biased toward seen compositions CompCos . Other approaches symnet ; symnet-pami ; SCEN propose training two classifiers to identify states and objects separately. The latest works PMGNet ; ADE ; CANet ; CoT ; CSCNet model both composition and primitives simultaneously, achieving state-of-the-art results. Albeit the numerous attempts made in compositional learning, they fail to consider an incremental learning paradigm given the increasing number of composition classes in open-world scenarios. Besides, directly applying CZSL methods to composition-IL might lead to a stale and decaying performance on forgetting. By contrast, our proposed CompILer markedly bypasses catastrophic forgetting with the help of multi-pool prompt learning.

3 Preliminaries
In this section, we firstly define the task of composition-IL, and then introduce two datasets we construct for the task, followed by revealing the ambiguous composition boundary problem.
3.1 Problem Definition
For composition-IL, a model sequentially learns tasks corresponding to a set of composition classes . We note that the composition classes between incremental tasks are always disjoint, which means for any . Different from the composition classes, the primitive classes are allowed to recur in different tasks. That means it allows the tasks to share some primitive concepts of objects and states. Therefore, we can define the set of all state and object classes with and , respectively. Given each image , it has a composition label which is constructed with a state label and an object label , i.e. , where , and . We take the example of “red shirt”, where “red” is denoted with , “shirt” corresponds to , and “red shirt” is expressed with .
3.2 Dataset Construction
As there are no existing datasets suitable for composition-IL, we re-organize the data in Clothing16K IVR and UT-Zappos50K ut-zappos , and construct two new datasets tailored for composition-IL, namely Split-Clothing and Split-UT-Zappos. To be more specific, we firstly sort the composition classes based on the number of their images, and then select the foremost 35 compositions from Clothing16K and the top 80 from UT-Zappos50K, so as to construct Split-Clothing and Split-UT-Zappos, respectively. In this way, Split-Clothing encompasses 9 states and 8 objects while Split-UT-Zappos consists of 15 states and 12 objects in total. For Split-Clothing, we randomly partition the compositions into 5 tasks. Regarding Split-UT-Zappos, the compositions are sorted by count and are evenly divided into 5 and 10 tasks. The image distribution for each task is shown in Fig. 2. Note that, we elaborate more details on both datasets in the following technical appendix.

3.3 Revealing the Ambiguous Composition Boundary
The main stumbling block in composition-IL is the ambiguous composition boundary. Although the composition label consists of two primitives (i.e. object and state), we note that the model excessively prioritizes the object primitive while neglecting the state primitive. Consequently, the compositions with the same object but with different states become ambiguous and indistinguishable. To prove that, we apply L2P L2P to composition-IL, whereas it is challenged by significant ambiguities in composition classification. As illustrated in Fig. 3 (a), the t-SNE visualization showcases the entanglement among the compositions like “white dress”, “black dress” and “blue dress”. We conjecture that this ambiguous problem tends to become more severe when more tasks are arriving incrementally. To address it, we propose a new model namely CompILer, which disentangles compositions and primitives via a multi-pool prompt learning. Advantageously, our method promotes the learning on the states and establishes clearer composition boundaries, as shown in Fig. 3 (b).
4 Methodology
Overview. We leverage the learning-to-prompt paradigm L2P and develop a novel compositional incremental learner (CompILer) tailored specifically for composition-IL. As depicted in Fig. 4, CompILer comprises three primary components: multi-pool prompt learning, object-guided state prompting, and generalized-mean prompt fusion. Firstly, we initialize three prompt pools dedicated to learning and storing visual information related to states, objects and their compositions. In order to differentiate the knowledge learned across and within prompt pools, we define inter-pool discrepant loss and intra-pool diversified loss jointly. We then employ object prompts to guide the selection of state prompts, thereby improving the state representation learning. Moreover, we utilize a generalized-mean fusion to integrate the selected prompts in a learnable manner. Ultimately, we optimize the classification objective with symmetric cross-entropy loss, to alleviate the effect of noisy data.
4.1 Multi-pool Prompt Learning
The learning-to-prompt paradigm L2P ; NotMeetStrongPT , especially suitable for large pre-trained backbones, has opened up a new path for incremental learning. It has proven to incorporate plasticity and stability better through adapting a set of learnable tokens in a prompt pool to a frozen pre-trained backbone. Nevertheless, existing prompt-based approaches are initially designed for class-IL, thereby building a single prompt pool for object classification solely. when dealing with state-object composition classification, they tend to excessively prioritize the object primitive while neglecting the state primitive. To this end, we propose to construct three discrepant and diversified prompt pools , and , which serve to learn visual information related to states, objects and their compositions, respectively. Besides, each pool is associated with a set of learnable keys for query-key prompt selection. The three prompt pools and their keys are defined as:
| (1) |
where is a single prompt with token length and embedding dimension . , the key of , is a learnable token with the same size. is the number of prompts in each pool.
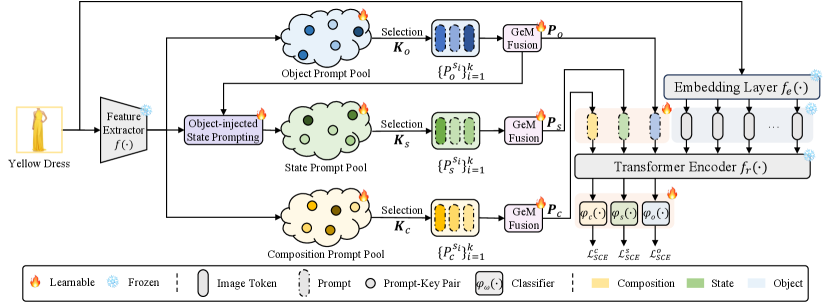
One important concern in such multi-pool prompt learning is how to enrich the prompts with the avoidance of identical pools. To achieve it, we consider integrating inter-pool prompt discrepancy and intra-pool prompt diversity jointly. On the one hand, the inter-pool prompts should be discrepant as the visual information about states, objects, and compositions should be different. One the other hand, within each pool, the intra-pool prompts should be diversified so to capture more comprehensive features from all the classes.
In practice, we formulate a unified objective to regularize both inter-pool discrepancy and intra-pool diversity, by leveraging a simple and effective directional decoupled loss used in PIP . The directional decoupled (dd) loss between any two pools (e.g. and ) is formulated as:
| (2) |
| (3) |
where measures the angle between any two prompts, and ; is a scalar to avoid division by zero. Note that, encourages the angles between each prompt to be at least degrees. Since is unordered Cartesian product of , i.e. , the inter-pool prompt discrepancy loss for the three pools can be expressed with , and the intra-pool prompt diversity loss becomes . As opposed to , computes the angle between any two prompts within the same pool. Thus, it contains the case when , for which we set .
4.2 Object-injected State Prompting
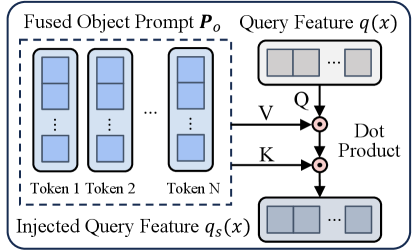
Akin to the query-key matching mechanism in other work L2P ; Dual ; s-prompt , we utilize a fixed feature extractor to obtain a query feature , determining which prompts in the pool to be selected. However, pre-trained backbones are typically trained for object classification, thus under-performing for state representation learning. In addition, it is more difficult to predict the state classes due to their more abstract and fine-grained characteristics. To tackle this problem, we strategically inject object prompts to guide the selection of state prompts. Intuitively, once we have learned knowledge about the object class, it may be easier to predict the correct state class and avoid mistaken results. For instance, given an object is “heels”, we can expect that the corresponding state is unlikely to be “canvas” or “plastic”. To summarize, we select object and composition prompts in each pool based on the original query feature, which means ; but for the selection of state prompts, we propose object-injected state prompting to ameliorate the query feature as shown in Fig. 5.
Specifically, we employ the fused object prompt (see Sec. 4.3) to perform cross attention on the query feature , resulting in object-injected query feature for the state prompt selection:
| (4) |
where , and are learnable projections. To establish alignment between the query and the selected prompts, we optimize a surrogate loss for state, object and composition prompting jointly:
| (5) |
where denotes cosine similarity, represents the subset of top-k keys selected from , and is a subset of top-k indices from (prompt number). Despite the simplicity of the object-injected state prompting, it facilitates more judicious prompt selection within the state prompt pool, alleviating the hurdles posed by state learning.
4.3 Generalized-mean Prompt Fusion
After obtaining the selected top-k prompts , the next step is fusing these prompts into a single prompt. It is general to utilize a simple mean pooling whereas it overlooks the relative importance of each prompt. Besides, when the prompts contain information that is unrelated or contradictory to current task, it is critical to strengthen useful prompts and eliminate irrelevant ones. To this end, we draw inspiration from generalized-mean pooling GeM and exploit generalized-mean (GeM) prompt fusion which is given by:
| (6) |
where is a learnable parameter. When , GeM becomes mean pooling; as approaches infinity (), it converges to max pooling. By taking over mean and max pooling, GeM learns to achieve an optimal fusion, mitigating the influence of irrelevant information present in the prompts.
4.4 Training and Inference
Classification Objective. We prepend three fused prompts (i.e. , and ) with , which is the output from a ViT embedding layer . The extended token sequence is . Then, we feed to a transformer encoder layer and achieve , and for classifying state, object and composition classes, respectively. We estimate the probability via a classifier : . For each image , we denote its ground-truth distribution over labels with . When is consistent with the ground truth, then ; otherwise, . As a result, the cross entropy (CE) loss used for classification objective is:
| (7) |
where represents the number of classes. However, the model optimized with a standard CE loss is easily affected by noisy samples during training. Instead, we advocate using a symmetric cross entropy loss (SCE) SCE , which incorporates an additional term called reverse cross entropy (RCE), to mitigate the impact of noisy data. Contrary to CE, the formula for RCE loss is defined as:
| (8) |
Then, the SCE loss combines two loss terms by , where is a hyper-parameter that controls the weight of the RCE term. As a result, the whole SCE loss becomes , where adjusts the weights between primitives and compositions.
Total Loss. The total loss for training the whole CompILer model is:
| (9) |
where , , are hyper-parameters balancing different terms.
Inference. During inference, we incorporate the primitive probabilities to aid the composition probability. Hence, the final probability for composition classification is expressed with:
| (10) |
where adjusts the probabilities.
| Datasets | Split-Clothing (5 tasks) | Split-UT-Zappos (5 tasks) | Split-UT-Zappos (10 tasks) | |||
|---|---|---|---|---|---|---|
| Metrics | Avg Acc(↑) | FTT(↓) | Avg Acc(↑) | FTT(↓) | Avg Acc(↑) | FTT(↓) |
| Upper Bound | 97.02±0.10 | - | 68.71±0.41 | - | 68.71±0.41 | - |
| \hdashlineEWC EWC | 47.89±0.87 | 52.75±0.44 | 37.59±2.06 | 55.70±2.76 | 24.63±0.94 | 61.31±2.29 |
| LwF LwF | 49.96±0.68 | 44.22±0.53 | 40.15±0.43 | 49.61±0.68 | 30.38±1.41 | 58.15±0.20 |
| iCaRL icarl | 68.65±0.41 | 31.74±1.89 | 37.78±2.14 | 55.06±3.50 | 31.40±1.96 | 59.65±2.40 |
| \hdashlineL2P L2P | 80.22±0.41 | 14.23±0.44 | 42.20±2.18 | 20.41±2.76 | 31.65±0.16 | 31.02±1.62 |
| Deep L2P++L2P ; CODA | 80.55±0.45 | 12.60±1.90 | 42.37±0.65 | 30.10±1.56 | 30.68±0.35 | 32.20±1.96 |
| Dual-Prompt Dual | 87.87±0.63 | 7.71±0.25 | 43.30±0.19 | 19.41±2.80 | 33.01±1.65 | 24.61±1.11 |
| CODA-Prompt CODA | 86.35±0.20 | 8.99±0.71 | 43.35±0.29 | 21.76±2.45 | 31.40±0.36 | 30.54±2.63 |
| LGCL Language_ICCV | 87.32±0.10 | 7.58±0.06 | - | - | 33.56±0.31 | 24.37±0.56 |
| \hdashlineSim-CompILer | 88.38±0.08 | 8.01±0.42 | 45.70±0.68 | 20.06±0.62 | 33.30±0.10 | 30.31±0.03 |
| CompILer | 89.21±0.24 | 7.26±0.60 | 46.48±0.26 | 19.27±0.75 | 34.43±0.07 | 28.69±0.82 |
| Datasets | Split-Clothing (5 tasks) | ||
|---|---|---|---|
| Metrics | State | Object | HM |
| Upper Bound | 97.44±0.08 | 97.09±0.10 | 97.26±0.08 |
| \hdashlineEWC EWC | 86.49±0.97 | 52.72±1.30 | 675.50±0.97 |
| LwF LwF | 87.11±0.66 | 54.57±0.69 | 67.10±0.33 |
| iCaRL icarl | 91.21±1.05 | 71.70±0.99 | 80.28±0.74 |
| \hdashlineL2P L2P | 83.03±0.42 | 95.56±0.57 | 88.85±0.16 |
| Dual-Prompt Dual | 90.77±0.25 | 94.18±0.31 | 92.45±0.20 |
| LGCL Language_ICCV | 91.45±0.20 | 94.87±0.33 | 93.13±0.10 |
| \hdashlineSim-CompILer | 91.15±0.10 | 96.32±0.02 | 93.66±0.02 |
| CompILer | 91.81±0.23 | 96.67±0.01 | 94.18±0.06 |
5 Experiments
5.1 Datasets and Metrics
We conduct experiments on two newly split datasets: Split-Clothing and Split-UT-Zappos as elucidated in Section 3.2. We assess the overall performance on compositions using Average Accuracy (Avg Acc) and Forgetting (FTT). A higher Avg Acc signifies stronger recognition abilities, while a lower FTT indicates improved resilience against forgetting. Additionally, we provide individual Average Accuracy scores on states and objects, denoted as State and Object for simplicity. These metrics imply the ability to recognize fine-grained primitives. Furthermore, we calculate the Harmonic Mean (HM) between State and Object, i.e. . We provide more emphasis to Avg Acc and HM due to their more comprehensive assessment. Avg Acc encompasses the plasticity and stability CODA ; Consistent_Prompting and HM provides a holistic evaluation on both state and object.
5.2 Implementation Details
For a fair comparison with previous works L2P ; Dual ; Consistent_Prompting ; CODA , we also employ ViT B/16 ViT_B16 pretrained on the ImageNet 1K dataset as the feature extractor and backbone. For multi-pool prompt learning, the size of each pool is set to , and each prompt has tokens. We select top-5 prompts from each pool and generate a fused prompt. During training, we utilize the Adam optimizer adam with a batch size of . The whole CompILer undergoes training for epochs on the Split-Clothing, for epochs on the 5-task Split-UT-Zappos, and for epochs on the 10-task Split-UT-Zappos. For the Split-Clothing and the 10-task Split-UT-Zappos, we set the learning rate to , while we use a learning rate of for the 5-task Split-UT-Zappos. Note that, for all the methods, their results are averaged over three runs with the corresponding standard deviations reported to mitigate the influence of random factors.
As there are a few hyper-parameters in the model, we conduct a rigorous tuning on them. For instance, we set to for all settings. For Split-Clothing, the loss weights and are set to ; is set to ; and for SCE loss are and , and the parameter during inference is . For 5-task Split-UT-Zappos, , , , , and are set to , , , , and , respectively. For 10-task Split-UT-Zappos, , , , , and are set to , , , , and . We elaborate more details on hyper-parameter analysis in the appendix.
5.3 Compared Baselines
To demonstrate the effectiveness of the proposed method, we compare CompILer with state-of-the-art incremental learning methods, including prompt-free approaches EWC ; LwF ; icarl and prompt-based methods L2P ; Dual ; CODA ; Language_ICCV . All the methods are rehearsal-free except iCaRL icarl . Note that, due to LGCL Language_ICCV relying on CLIP CLIP to achieve language guidance at the task level, it is limited by the length of class names per task. Thereby, LGCL fails to operate on the 5-task Split-UT-Zappos since the total length of class names exceeds the limitation.
To streamline our CompILer, we further implement a simplified version named Sim-CompILer and report its results. Sim-CompILer is optimized using cross entropy loss and is comprised solely of multi-pool prompt learning and generalized-mean prompt fusion. In other words, we exclude the object-injected prompting, directional decoupled loss, and reverse cross entropy loss, resulting in a large reduction of hyperparameters to only , , and .
5.4 Comparison with the State-of-the-arts
The compared results on Avg Acc and FTT are reported in Table 1. Overall, CompILer consistently outperforms all competitors on Avg Acc by a significant margin. For FTT scores, CompILer excels previous methods with 0.32% on the 5-task Split-Clothing and with 0.14% on the 5-task Split-UT-Zappos, while falling behind Dual-Prompt Dual and LGCL Language_ICCV for the 10-task Split-UT-Zappos. We notice that, the main reason is these methods sacrifice more plasticity for lower forgetting rates. Besides, the number of model parameters in these methods dynamically increases along with more incremental tasks arriving, whereas our CompILer does not rely on imposing task-specific parameters to reduce the forgetting.
We also report the primitives accuracy and their HM in Table 2 and Table 3. Likewise, our method surpasses other methods considerably in terms of State and HM. Interestingly, the prompt-free methods LwF ; EWC ; icarl achieve higher accuracy in state prediction than object prediction for Split-Clothing, which is contrary to other results. This is because the states in Split-Clothing are color-related descriptions, which are easier to capture with the help of parameter fine-tuning. The prompt-based methods do not exhibit this phenomenon because their pre-trained backbones are initially trained for object classification, and are frozen across incremental sessions. As the performance improvements are mainly attributed to the accuracy of state recognition, it suggests that our model enhances the understanding on fine-grained compositionality.
| Datasets | Split-UT-Zappos (5 tasks) | Split-UT-Zappos (10 tasks) | ||||
|---|---|---|---|---|---|---|
| Metrics | State | Object | HM | State | Object | HM |
| Upper Bound | 75.10±0.10 | 88.13±0.03 | 81.90±0.06 | 75.10±0.10 | 88.13±0.03 | 81.90±0.06 |
| \hdashlineEWC EWC | 47.95±1.26 | 76.53±0.91 | 58.90±0.53 | 39.29±2.69 | 67.64±1.97 | 49.69±2.30 |
| LwF LwF | 53.13±1.08 | 75.48±0.82 | 62.35±0.31 | 38.70±2.33 | 68.90±1.97 | 49.54±1.30 |
| iCaRL icarl | 51.71±0.95 | 75.03±0.49 | 61.22±0.78 | 38.94±2.01 | 67.10±1.05 | 49.27±1.58 |
| \hdashlineL2P L2P | 52.20±2.92 | 79.05±0.01 | 62.87±1.61 | 42.66±0.87 | 76.60±0.03 | 54.80±0.55 |
| Dual-Prompt Dual | 52.25±0.77 | 77.46±0.05 | 62.40±0.34 | 44.34±1.61 | 77.92±0.37 | 56.51±1.11 |
| LGCL Language_ICCV | - | - | - | 43.44±0.79 | 78.64±0.64 | 55.96±0.43 |
| \hdashlineSim-CompILer | 55.93±1.23 | 79.69±0.06 | 65.72±0.53 | 45.88±0.38 | 75.72±0.67 | 57.14±0.06 |
| CompILer | 56.85±0.34 | 79.56±0.04 | 66.31±0.15 | 46.27±1.56 | 76.65±1.19 | 57.69±0.42 |
| Prompt Pool | Split-Clothing (5 tasks) | ||||
|---|---|---|---|---|---|
| C | S | O | Avg Acc | FTT(↓) | HM |
| ✓ | 80.22±0.41 | 14.23±0.44 | 88.85±0.16 | ||
| ✓ | ✓ | 88.10±0.11 | 7.79±0.04 | 93.55±0.04 | |
| ✓ | ✓ | 88.09±0.50 | 7.26±0.54 | 93.52±0.13 | |
| ✓ | ✓ | ✓ | 88.38±0.08 | 8.01±0.42 | 93.66±0.02 |
5.5 Ablation Study and Analysis
Effect of multi-pool prompt learning. This experiment aims to delineate the contribution of three pools in CompILer. We firstly implement a baseline model with composition prompt pool only. Building upon the baseline, we develop two additional models, which incorporate either object or state prompt pool. As reported in Table 4, the inclusion of primitive prompt pool yields consistent gains over the baseline. Furthermore, the best results are achieved when the model integrates all three pools simultaneously. This experiment signifies the significant necessity of exploiting multiple prompt pools for composition-IL.
Dataset Split-Clothing (5 tasks) Metrics Avg Acc FTT(↓) HM None 88.45±0.10 7.93±0.11 93.70±0.03 SO 88.27±0.02 7.99±0.05 93.67±0.01 OS 89.21±0.24 7.26±0.60 94.18±0.06
Dataset Split-Clothing (5 tasks) Metrics Avg Acc FTT(↓) HM Max 84.70±0.64 12.24±2.25 91.54±0.30 Mean 87.80±0.12 7.82±0.01 93.38±0.03 GeM 89.21±0.24 7.26±0.60 94.18±0.06
Effect of object-injected state prompting. To provide insights into object-injected state prompting, we compare three models: None (vanilla model), SO (state-injected object prompting) and OS (object-injected state prompting). As shown in Table 5, compared to the None model, the SO exhibits a decrease in all metrics, implying that state prompts may interfere with the selection of object prompts. On the contrary, OS outperforms the None model as we expect. This phenomenon validates our motivation that state recognition is harder than object recognition, and thereby the former cannot help the latter easily. Yet, it is a promising direction for future research.
Effect of generalized-mean prompt fusion. This study aims to study the impact of prompt fusion on CompILer. As shown in Table 5, GeM performs better than both max and mean pooling across various metrics. It validates the benefit of GeM on mitigating irrelevant information in the selected prompts. as it may hamper the model’s attention on image tokens.
| Loss function | Split-Clothing (5 tasks) | Split-UT-Zappos (5 tasks) | |||||
| Avg Acc | FTT(↓) | Avg Acc | FTT(↓) | ||||
| ✓ | 88.17±0.08 | 8.08±0.27 | 44.83±0.15 | 19.49±2.93 | |||
| ✓ | ✓ | 88.36±0.37 | 8.33±0.11 | 45.47±0.07 | 20.14±0.43 | ||
| ✓ | ✓ | 88.32±0.56 | 7.82±0.64 | 45.58±0.04 | 19.64±0.37 | ||
| ✓ | ✓ | 88.42±0.30 | 8.23±0.06 | 45.62±0.13 | 20.13±0.14 | ||
| ✓ | ✓ | ✓ | 88.61±0.61 | 7.72±0.87 | 46.01±0.69 | 19.50±0.86 | |
| ✓ | ✓ | ✓ | ✓ | 89.21±0.24 | 7.26±0.60 | 46.48±0.26 | 19.27±0.75 |
Effect of loss functions. As shown in Table 6, we investigate the influence of loss functions used in our model, including directional decoupled loss ( and ) and symmetric cross entropy loss ( and ). The baseline model (the first row) includes all modules but is trained by cross entropy loss only. By adding the RCE loss, the model is equivalent to training with the SCE loss, which help to improve the robustness to noisy labels. The use of either or improves the performance on both datasets, and synchronously applying them witnesses all-around improvements compared to the baseline. Eventually, we achieve the best results when combing all the loss terms during training.
5.6 Additional Results and Analysis
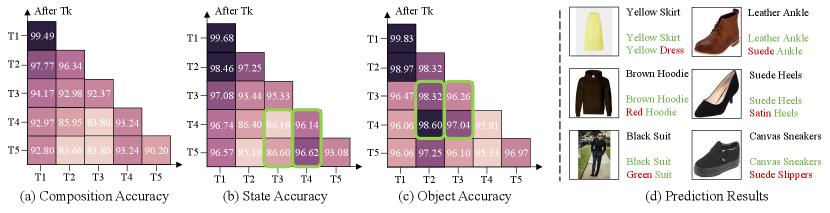
In order to study the repeatability characteristic in composition-IL, we exhibit more results on Split-Clothing in Fig. 6: in (a), it shows a decreasing trend in composition accuracy along with the introduction of new tasks; however, the green rectangles in (b) and (c) showcase that the accuracy occasionally increases as more tasks are learned. We conjecture the reason is mostly attributed to the re-occurrence of primitive concepts. This forward transfer is critical for incremental learners. We compare the composition predictions between CompILer and L2P L2P in Fig. 6 (d). CompILer predicts all the images correctly, while L2P makes some mistakes, particularly for state labels. This limitation arises from an excessive focus on the dominant object primitive, while weakening the attention toward state primitive. Fortunately, CompILer relieves the bias toward object classes, and enhances the perception on state classes.
6 Conclusion
In this paper, we have proposed a novel task coined compositional incremental learning (compostion-IL), which is stumbled by ambiguous composition boundary. To tackle it, we develop a learning-to-prompt model, namely CompILer. Our model exploits multi-pool prompt learning to model composition and primitive concepts, object-injected state prompting to improve the selection of state prompts, and generalized-mean prompt fusion to eliminate irrelevant information. Extensive experiments on two tailored datasets show that CompILer achieves state-of-the-art performance. In the future, it is challenging yet potential to consider reasoning multiple state classes per object.
7 Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grant Numbers 62102061, 62272083 and 62472066, and in part by the Open Projects Program of State Key Laboratory of Multimodal Artificial Intelligence Systems.
References
- (1) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2020.
- (2) Zhanxin Gao, Jun Cen, and Xiaobin Chang. Consistent prompting for rehearsal-free continual learning. In IEEE Conf. Comput. Vis. Pattern Recog., 2024.
- (3) Shaozhe Hao, Kai Han, and Kwan-Yee K Wong. Learning attention as disentangler for compositional zero-shot learning. In IEEE Conf. Comput. Vis. Pattern Recog., pages 15315–15324, 2023.
- (4) Geoffrey Hinton. Some demonstrations of the effects of structural descriptions in mental imagery. Cognitive Science, 3(3):231–250, 1979.
- (5) Chenchen Jing, Yukun Li, Hao Chen, and Chunhua Shen. Retrieval-augmented primitive representations for compositional zero-shot learning. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 2652–2660, 2024.
- (6) Sangwon Jung, Hongjoon Ahn, Sungmin Cha, and Taesup Moon. Continual learning with node-importance based adaptive group sparse regularization. Adv. Neural Inform. Process. Syst., 33:3647–3658, 2020.
- (7) Muhammad Gul Zain Ali Khan, Muhammad Ferjad Naeem, Luc Van Gool, Didier Stricker, Federico Tombari, and Muhammad Zeshan Afzal. Introducing language guidance in prompt-based continual learning. In Int. Conf. Comput. Vis., pages 11429–11439, 2023.
- (8) Hanjae Kim, Jiyoung Lee, Seongheon Park, and Kwanghoon Sohn. Hierarchical visual primitive experts for compositional zero-shot learning. In Int. Conf. Comput. Vis., pages 5675–5685, 2023.
- (9) Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- (10) James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526, 2017.
- (11) Hyunseo Koh, Dahyun Kim, Jung-Woo Ha, and Jonghyun Choi. Online continual learning on class incremental blurry task configuration with anytime inference. In International Conference on Learning Representations, 2022.
- (12) Xiangyu Li, Xu Yang, Kun Wei, Cheng Deng, and Muli Yang. Siamese contrastive embedding network for compositional zero-shot learning. In IEEE Conf. Comput. Vis. Pattern Recog., pages 9326–9335, 2022.
- (13) Yong-Lu Li, Yue Xu, Xiaohan Mao, and Cewu Lu. Symmetry and group in attribute-object compositions. In IEEE Conf. Comput. Vis. Pattern Recog., pages 11316–11325, 2020.
- (14) Yong-Lu Li, Yue Xu, Xinyu Xu, Xiaohan Mao, and Cewu Lu. Learning single/multi-attribute of object with symmetry and group. IEEE Trans. Pattern Anal. Mach. Intell., 44(12):9043–9055, 2021.
- (15) Yun Li, Zhe Liu, Hang Chen, and Lina Yao. Context-based and diversity-driven specificity in compositional zero-shot learning. In IEEE Conf. Comput. Vis. Pattern Recog., 2024.
- (16) Zhizhong Li and Derek Hoiem. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell., 40(12):2935–2947, 2017.
- (17) Zilong Li, Yiming Lei, Chenglong Ma, Junping Zhang, and Hongming Shan. Prompt-in-prompt learning for universal image restoration. arXiv preprint arXiv:2312.05038, 2023.
- (18) Weiduo Liao, Ying Wei, Mingchen Jiang, Qingfu Zhang, and Hisao Ishibuchi. Does continual learning meet compositionality? new benchmarks and an evaluation framework. Adv. Neural Inform. Process. Syst., 2023.
- (19) Yu Liu, Jianghao Li, Yanyi Zhang, Qi Jia, Weimin Wang, Nan Pu, and Nicu Sebe. Pmgnet: Disentanglement and entanglement benefit mutually for compositional zero-shot learning. Computer Vision and Image Understanding, 2024.
- (20) David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. Adv. Neural Inform. Process. Syst., 30, 2017.
- (21) Massimiliano Mancini, Muhammad Ferjad Naeem, Yongqin Xian, and Zeynep Akata. Open world compositional zero-shot learning. In IEEE Conf. Comput. Vis. Pattern Recog., pages 5222–5230, 2021.
- (22) Marc Masana, Xialei Liu, Bartłomiej Twardowski, Mikel Menta, Andrew D Bagdanov, and Joost Van De Weijer. Class-incremental learning: survey and performance evaluation on image classification. IEEE Trans. Pattern Anal. Mach. Intell., 45(5):5513–5533, 2022.
- (23) Ishan Misra, Abhinav Gupta, and Martial Hebert. From red wine to red tomato: Composition with context. In IEEE Conf. Comput. Vis. Pattern Recog., pages 1792–1801, 2017.
- (24) Jun-Yeong Moon, Keon-Hee Park, Jung Uk Kim, and Gyeong-Moon Park. Online class incremental learning on stochastic blurry task boundary via mask and visual prompt tuning. In IEEE Conf. Comput. Vis. Pattern Recog., pages 11731–11741, 2023.
- (25) Muhammad Ferjad Naeem, Yongqin Xian, Federico Tombari, and Zeynep Akata. Learning graph embeddings for compositional zero-shot learning. In IEEE Conf. Comput. Vis. Pattern Recog., pages 953–962, 2021.
- (26) Tushar Nagarajan and Kristen Grauman. Attributes as operators: factorizing unseen attribute-object compositions. In Eur. Conf. Comput. Vis., pages 169–185, 2018.
- (27) Senthil Purushwalkam, Maximilian Nickel, Abhinav Gupta, and Marc’Aurelio Ranzato. Task-driven modular networks for zero-shot compositional learning. In Int. Conf. Comput. Vis., pages 3593–3602, 2019.
- (28) Jingyang Qiao, Xin Tan, Chengwei Chen, Yanyun Qu, Yong Peng, Yuan Xie, et al. Prompt gradient projection for continual learning. In The Twelfth International Conference on Learning Representations, 2023.
- (29) Filip Radenović, Giorgos Tolias, and Ondřej Chum. Fine-tuning cnn image retrieval with no human annotation. IEEE transactions on pattern analysis and machine intelligence, 41(7):1655–1668, 2018.
- (30) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763, 2021.
- (31) Pasko Rakic, Jean-Pierre Bourgeois, and Patricia S Goldman-Rakic. The self-organizing brain: from growth cones to functional networks. Elsevier, 1994.
- (32) Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. In IEEE Conf. Comput. Vis. Pattern Recog., pages 2001–2010, 2017.
- (33) James Seale Smith, Leonid Karlinsky, Vyshnavi Gutta, Paola Cascante-Bonilla, Donghyun Kim, Assaf Arbelle, Rameswar Panda, Rogério Feris, and Zsolt Kira. Coda-prompt: Continual decomposed attention-based prompting for rehearsal-free continual learning. In IEEE Conf. Comput. Vis. Pattern Recog., pages 11909–11919, 2023.
- (34) Filip Szatkowski, Mateusz Pyla, Marcin Przewięźlikowski, Sebastian Cygert, Bartłomiej Twardowski, and Tomasz Trzciński. Adapt your teacher: Improving knowledge distillation for exemplar-free continual learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1977–1987, 2024.
- (35) Yu-Ming Tang, Yi-Xing Peng, and Wei-Shi Zheng. When prompt-based incremental learning does not meet strong pretraining. In IEEE Conf. Comput. Vis. Pattern Recog., pages 1706–1716, 2023.
- (36) Liyuan Wang, Jingyi Xie, Xingxing Zhang, Mingyi Huang, Hang Su, and Jun Zhu. Hierarchical decomposition of prompt-based continual learning: Rethinking obscured sub-optimality. Adv. Neural Inform. Process. Syst., 36, 2024.
- (37) Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application. IEEE Trans. Pattern Anal. Mach. Intell., 2024.
- (38) Qingsheng Wang, Lingqiao Liu, Chenchen Jing, Hao Chen, Guoqiang Liang, Peng Wang, and Chunhua Shen. Learning conditional attributes for compositional zero-shot learning. In IEEE Conf. Comput. Vis. Pattern Recog., pages 11197–11206, 2023.
- (39) Wenjin Wang, Yunqing Hu, Qianglong Chen, and Yin Zhang. Task difficulty aware parameter allocation & regularization for lifelong learning. In IEEE Conf. Comput. Vis. Pattern Recog., pages 7776–7785, 2023.
- (40) Yabin Wang, Zhiwu Huang, and Xiaopeng Hong. S-prompts learning with pre-trained transformers: An occam’s razor for domain incremental learning. Adv. Neural Inform. Process. Syst., 35:5682–5695, 2022.
- (41) Yisen Wang, Xingjun Ma, Zaiyi Chen, Yuan Luo, Jinfeng Yi, and James Bailey. Symmetric cross entropy for robust learning with noisy labels. In Int. Conf. Comput. Vis., pages 322–330, 2019.
- (42) Zifeng Wang, Zizhao Zhang, Sayna Ebrahimi, Ruoxi Sun, Han Zhang, Chen-Yu Lee, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer G. Dy, and Tomas Pfister. Dualprompt: Complementary prompting for rehearsal-free continual learning. In Eur. Conf. Comput. Vis., pages 631–648, 2022.
- (43) Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer G. Dy, and Tomas Pfister. Learning to prompt for continual learning. In IEEE Conf. Comput. Vis. Pattern Recog., pages 139–149, 2022.
- (44) Aron Yu and Kristen Grauman. Fine-grained visual comparisons with local learning. In IEEE Conf. Comput. Vis. Pattern Recog., pages 192–199, 2014.
- (45) Alan L Yuille and Chenxi Liu. Deep nets: What have they ever done for vision? Int. J. Comput. Vis., 129(3):781–802, 2021.
- (46) Tian Zhang, Kongming Liang, Ruoyi Du, Xian Sun, Zhanyu Ma, and Jun Guo. Learning invariant visual representations for compositional zero-shot learning. In Eur. Conf. Comput. Vis., pages 339–355, 2022.
- (47) Yanyi Zhang, Qi Jia, Xin Fan, Yu Liu, and Ran He. Cscnet: Class-specified cascaded network for compositional zero-shot learning. In IEEE International Conference on Acoustics, Speech and Signal Processing, pages 3705–3709, 2024.
- (48) Yaqian Zhang, Bernhard Pfahringer, Eibe Frank, Albert Bifet, Nick Jin Sean Lim, and Yunzhe Jia. A simple but strong baseline for online continual learning: Repeated augmented rehearsal. Adv. Neural Inform. Process. Syst., 35:14771–14783, 2022.