Not All Negatives Are Worth Attending to: Meta-Bootstrapping Negative Sampling Framework for Link Prediction
Abstract.
The rapid development of graph neural networks (GNNs) encourages the rising of link prediction, achieving promising performance with various applications. Unfortunately, through a comprehensive analysis, we surprisingly find that current link predictors with dynamic negative samplers (DNSs) suffer from the migration phenomenon between “easy” and “hard” samples, which goes against the preference of DNS of choosing “hard” negatives, thus severely hindering capability. Towards this end, we propose the MeBNS framework, serving as a general plugin that can potentially improve current negative sampling based link predictors. In particular, we elaborately devise a Meta-learning Supported Teacher-student GNN (MST-GNN) that is not only built upon teacher-student architecture for alleviating the migration between “easy” and “hard” samples but also equipped with a meta learning based sample re-weighting module for helping the student GNN distinguish “hard” samples in a fine-grained manner. To effectively guide the learning of MST-GNN, we prepare a Structure enhanced Training Data Generator (STD-Generator) and an Uncertainty based Meta Data Collector (UMD-Collector) for supporting the teacher and student GNN, respectively. Extensive experiments show that the MeBNS achieves remarkable performance across six link prediction benchmark datasets.
1. Introduction
The prevalence of graph structures attracts a surge of investigation on graph data, enabling several downstream applications including personalized recommendation (Ying et al., 2018a; He et al., 2020a; Hu et al., 2018; Zang et al., 2023), drug molecular design (Ioannidis et al., 2020), and supply chain finance (Yang et al., 2021b). In general, these tasks could unfold as a typical instance of link prediction on graph data, which essentially depends on the effective characterization of interactive structure for target node pairs (i.e., edges). In recent years, graph neural networks (GNNs) (Kipf and Welling, 2016; Liu et al., 2019; Hamilton et al., 2017) have emerged as a promising direction for driving the rapid development of link prediction, which flexibly incorporates structural information into representation learning, and thus achieves dramatic performance (Zhang and Chen, 2018; Yang et al., 2021a; Zhu et al., 2021).
In the typical flow of training a link predictor, only positive samples (i.e., observed edges) are involved, and considering all unobserved edges as negative samples is impractical for model learning in a real-world setting. Fundamentally, the quality of negative samples plays a decisive role in the capability of link predictors, which has recently spurred a fruitful line of related research (Yang et al., 2020a; Chen et al., 2018). Earlier works commonly focus on static negative sampling with heuristic fixed distributions, including uniform (Wang et al., 2019; He et al., 2020b) and degree-based distributions (Mikolov et al., 2013; Rendle and Freudenthaler, 2014). However, static negative samplers are incapable of adjusting the distributions of negatives within the training process, failing to explore more favorable negatives. As a comparison, dynamic negative sampling (DNS) is receiving a growing amount of attention, which addresses the issue of dynamic adaptation. In particular, DNS helps link predictors prioritize so-called “hard” negatives based on predictions of the current model (Bucher et al., 2016; Noh et al., 2018), structural correlations (Yang et al., 2023, 2020a; Wang et al., 2020) and PageRank scores (Ying et al., 2018b; Chen et al., 2019; Wang et al., 2021).
Despite the impressive improvement of DNS and its variants towards various applications, our empirical analysis on real-world datasets tells a rather different story. Specifically, we zoom into the capability of DNS in link prediction by conducting experiments on the Cora and CiteSeer datasets. Surprisingly, our empirical analysis discloses that the migration phenomenon between “easy” and “hard” samples (defined in Sec. 2.2) goes against the core idea of DNS that only selects “hard” negatives in each iteration. Intuitively, the issue may severely threaten the capability of the DNS based link predictor, on account of abundant worthless optimizations during iteration. Therefore, we naturally concentrate on such an essential question: Can we devise a bootstrapping 111In this paper, the term of bootstrap is used in its idiomatic sense instead of the statistical sense. framework tailored for improving the capability of negative sampler in link predictors by alleviating the migration phenomenon while retaining its original merits?
In light of this discovery, the bottleneck of designing such a desired bootstrapping framework mainly lies in i) alleviating the migration phenomenon and ii) encouraging link predictors to distinguish “hard” samples in a fine-grained manner. Towards this end, we propose a Meta-Bootstrapping Negative Sampling framework (MeBNS), which could be plugged in current negative samplers with different link predictors for promising prospects. In particular, the Meta learning Supported Teacher-student GNN (MST-GNN) serves as the heart of the MeBNS framework, which is equipped with two designs to correspondingly address the above challenges: i) teacher-student architecture222We just reuse the “teacher-student” term in studies of knowledge distillation (Hinton et al., 2015; Yim et al., 2017) for a clearer explanation, merely meaning the teacher GNN distills “hard” samples to the student GNN in our paper.. For alleviating the migration between “easy” and “hard” samples, it employs a well-trained teacher GNN to filter the “easy” samples and subsequently enforces a student GNN to specialize “hard" samples. ii) meta learning based sample re-weighting, which adopts a meta learner to impose samples with learnable meta weights, hopefully helping the student GNN distinguish “hard” samples in a fine-grained manner. Moreover, the training pipeline of the teacher GNN is supported by the Structure enhanced Training Data Generator (STD-Generator), which flexibly injects structural information into current negative sampler. Meanwhile, we come up with an Uncertainty based Meta Data Collector (UMD-Collector) for guiding the learning of meta learner in the student GNN by collecting meta data with high confidence based on Dropedge based graph augmentation. To summarize, we make the following contributions.
-
•
Inspirational Insights: We highlight the critical demands of alleviating the migration phenomenon in current negative samplers for link prediction through empirical analysis. The issue severely hinders the capability of link predictors, which is unexplored in previous works.
-
•
General Framework: We propose a novel meta-bootstrapping negative sampling framework (MeBNS) for alleviates the intractable migration phenomenon. It is noteworthy that MeBNS not only theoretically guarantees a better optimization landscape, but also potentially serves as a general plugin, benefiting existing negative samplers with various link predictors.
-
•
Multifaceted Experiments: We conduct extensive experiments on six benchmark datasets, demonstrating that MeBNS surpasses several state-of-the-art negative samplers with three classical link predictors as backbones. In-depth analysis reveals the contributions of MeBNS towards alleviating the migration phenomenon and specializing in “hard” samples.
2. Preliminary and Analysis
In this section, we first summarize the prevalent paradigm of a link predictor. Then we give an empirical analysis of the migration issue in DNS (Zhang et al., 2013), which potentially motivates the design of the Meta-Bootstrapping Negative Sampling (MeBNS) framework.
2.1. Recap Link Predictor
Let be an undirected graph consisting of the node set and the edge set . In practice, each node is commonly associated with a feature vector , where is the number of raw features. The goal of link prediction is learning a prediction function to estimate the likelihood of whether there is a connection between the target node pair , which commonly involves an encoder and a decoder component.
Encoder With the recent advent of graph neural networks (GNNs), a predominant encoder of link prediction is the use of node-centric method (Wu et al., 2020; Hamilton et al., 2017), which applies the recursive neighborhood aggregation and representation updating on the whole graph (i.e. ). Specifically, we describe the detailed iterations of a GNN for a node as follows:
| (1) |
where respectively denote the node representations as the and -th layer, and is initialized with its original feature vector , and represent the neighbors of node . Here, is formally parameterized by , which, in particular, is comprised of the -parameterized aggregation function and -parameterized updating function . As the core of GNNs, several efforts have been made towards the design of the aggregation and updating function (Velickovic et al., 2017; Liu et al., 2019).
Decoder After -layers iterations, a predictive decoder is built upon the final representations (i.e. ) for each node pair as follows:
| (2) |
where is the collection of graph’s learned node representations with -dimension in a matrix form. is implemented as the inner product in our paper, which supports fast retrieval.
Following common strategies in previous works (Kumar et al., 2020), a good link predictor could be effectively trained with cross entropy function with negative sampling in a point-wise manner:
| (3) |
where the training data includes observed edges as positive samples and unobserved edges as negative samples , where in and in . Since is usually huge, making the model training impractical, the design of an effective negative sampler has served as the fundamental driving force behind the promising performance of link predictors.
On the other hand, edge-centric link predictor has recently made exceptional progress, including SEAL (Zhang and Chen, 2018), GRAIL (Teru et al., 2020), PaGNN (Yang et al., 2021a) and NBFNet (Zhu et al., 2021). Specifically, this line of methods enables interactive structure learning by extracting enclosing subgraph for each pair of node , whose encoder could be formalized as .
It is worthwhile mentioning that our MeBNS framework is model-agnostic, which can naturally benefit both node- and edge-centric link predictors. For brevity, we introduce the MeBNS framework with the backbone of node-centric link predictor, which could be easily analogized to edge-centric backbones.




2.2. Empirical Analysis on Negative Sampler
Intuitively, the performance of link prediction greatly hinges on the quality of the negative sampler since only observed edges are involved in the training process. Compared to static samplers in earlier works (Wang et al., 2019; Mikolov et al., 2013; Rendle et al., 2014), recent evidence have demonstrated the superior performance of the dynamical negative sampling (DNS) strategy, which dynamically collects samples with high prediction score to form the set of negatives . These strategies are mainly based on predictions of the current models (Zhang et al., 2013; Wang et al., 2017b), graph structures (Yang et al., 2020a, 2023), GAN (Wang et al., 2017b; Cai and Wang, 2017; Wang et al., 2017a; Hu et al., 2019) and mixing techniques (Huang et al., 2021; Kalantidis et al., 2020). We direct the readers to Sec. 5 for a comprehensive discussion of related work toward link prediction and negative sampling. Although DNS and its variants have been widely adopted in various applications due to its dramatic performance, our empirical analysis on real-world datasets tells a rather different story.
As a motivated example, we conduct a link prediction experiment with DNS on the Cora dataset, and corresponding experimental settings are detailed in the “Experiment” and “Appendix” parts. Firstly, we present the learning curve of the link predictor in Fig 1 (a), in terms of the change of the loss and performance in the validation and test set. From the plot, we find the model rapidly converges within about 100 epochs and then the loss remains at a certain level. To further explore whether the link predictor with DNS sampler has converged to the optimal condition, we record the prediction scores in several specific epochs (i.e. Epoch 100, 150, and 250) and illustrate their correlations in Fig. 1 (c) and (d). Concretely, a sample in the figure is marked in green when the gap of its prediction score between two epochs is less than a fixed threshold, and marked in yellow or red otherwise 333In the experiment, we set the threshold of the gap as 0.3.. In the ideal situation, samples are expected to be distributed near the diagonal (i.e., all samples are marked as green dot (“●”) in Fig. 1 (c) and (d)) if the model has converged. Unfortunately, things go contrary to our wishes since there exist a number of samples with high deviation, marked as yellow (“▲”) or red (“▲”) triangle. What’s worse, DNS based methods have an intractable migration phenomenon, which means that a sample may be an “easy” or “hard” negative in a certain epoch (e.g., Epoch 100) while being an “hard” or “easy” negative in the subsequent epoch (e.g., Epoch 150), and we mark these samples in red as to distinguish from yellow. Here, in order to understand the migration between “hard” and “easy” samples more intuitively which are marked in red, we specify the definition that “hard” samples are those mistakenly considered as false positives 444We define negative samples greater than the threshold as false positives. The threshold here is the optimal value from ROC Curve. and “easy” samples are the remaining 50% of the tail true negatives with lower prediction scores and farther from the decision boundary. In summary, the above empirical analysis provides a surprising observation and the corresponding inspiration.
Observation Surprisingly, the migration phenomenon between “easy” and “hard” goes against the core idea of DNS (i.e. only select “hard” negatives in each iteration). It makes the DNS based link predictor mainly focuses on the worthless optimization after a few epochs, resulting in sub-optimal performance.
Inspiration A natural idea to tackle migration issues is enforcing the link predictor to optimize the “hard” samples after a certain converged state since “easy” samples may contribute little in the later stages of optimization. Fortunately, the observation in Fig. 1(b) also gives the encouraging result that the performance would be completely unaffected when 65% of “easy” samples are removed.
3. The Proposed Framework
In this section, we dive into the elaboration of the proposed novel MeBNS framework, as presented in Fig. 2.

3.1. Overall Pipeline of Meta learning Supported Teacher-student GNN (MST-GNN)
With the encouraging inspiration derived from our empirical analysis of current negative samplers, the core of the MeBNS framework is the elaborate MST-GNN architecture, which employs a teacher GNN to filter “easy” negatives, while a student GNN, equipped with a well-designed meta learner, is applied to further improve the capability on “hard” negative with learnable meta weights.
In particular, our MST-GNN involves two GNNs with the same architecture, detailed in the “Preliminary” part. Since our MeBNS framework is model-agnostic and can be directly plugged into current link predictors, we would not present its specific instantiation in this paper and just denote the teacher and student GNN as and , respectively. As mentioned above, the teacher GNN is responsible for converging to a stable state and then filtering a part of “easy” samples. Hence, the optimal teacher GNN can be easily obtained by minimizing the following loss:
| (4) |
Here, the capability of the teacher GNN greatly hinges on the construction of training data (i.e., ), which is derived from STD-Generator.
3.2. Structure Enhanced Training Data Generator (STD-Generator)
In the training data (i.e., ), following the common way in previous works, we regard the observed edges in graphs as positive samples (i.e., ). In terms of the negatives (i.e., ), we directly inherit the merits from the current negative sampler and adopt them as the base negative sampler, denoted as with the center node . On the other hand, with the usefulness of the structure prior in graphs, STD-Generator comes up with injecting more informative negatives with the help of the graph structure. Specifically, we denote the graph based negative sampler as for the center node , which aims at collecting -hops neighbors for node . Hence, for a center node , its negatives could be obtained by combining the base and graph negative sampler with a probability of as follows:
| (5) |
where is a hyper-parameter, controlling the proportion of negatives from the graph based negative sampler.
3.2.1. Filtering “easy” Samples for the Student GNN
The aforementioned observations have suggested that removing a part of “easy” samples would alleviate the unsatisfying migration phenomenon in current negative samplers for link prediction without harming the performance, and hopefully benefit the student GNN for focusing on “hard” samples. Specifically, given a well-trained teacher model after -epochs iteration, we firstly perform inference on train data , denoting the prediction result as , and then construct the sample set for the student GNN as follows:
| (6) |
where finds value of the -largest prediction score from , where is a hyper-parameter controlling the “hardness” of samples transferred to the student GNN.
As mentioned above, since the student GNN utilizes the same structure as the teacher GNN, and thus we naturally initialize its parameters with . In order to help the student GNN well distinguish “hard” negative, we introduce a meta learner to emphasize important samples in an adaptive manner. Hence, the optimization of student GNN can be formalized as follows:
| (7) |
where is automatically learned via the meta learner to emphasize and balance “hard” samples in the link prediction for the student GNN.
3.3. Diving into the Meta Learner for Sample Re-weighting in the Student GNN
Hopefully, the meta learner is designed to help the student GNN to locate a more crisp decision boundary. Actually, meta learning (Shu et al., 2019; Ren et al., 2018) has become a fast-growing research area in recent years, which is demonstrated to have rapid adaptability to new tasks only with few data and support robust training on biased data. Here, we borrow the main idea to automatically learn a -parameterized re-weighting function tailored for link prediction in a meta-learning manner. Specifically, due to its superior capability of complicated interaction, we implement the meta learner (Shu et al., 2019) as two layers MLPs with a ReLU activation function and an output layer with the sigmoid function.
3.3.1. Uncertainty based Meta Data Collector (UMD-Collector)
Generally, meta data is crucially important to guide the learning of the meta learner, and samples with high confidence are prone to benefit the stability of the learning procedure. Inspired by the observations in Fig. 1 (c), (d), we find samples with high confidence are always corresponding to the low deviation between two epochs, i.e., low uncertainty. Hence, we shift attention towards DropEdge based graph augmentation, which could be interpreted as an estimation of uncertainty (Liu et al., 2022). Formally, we describe the augmentation function as follows:
| (8) |
where is a mask vector, i.e. each edge is discarded from the graph with the probability of from a Gaussian distribution. Following the core idea of Monte-Carlo sampling, the above augmentation is executed times and we perform link prediction under each augmented graph as . Subsequently, the uncertainty for a node pair is estimated as follows:
| (9) |
Therefore, the meta data is constructed as , where is a fixed threshold.
3.3.2. Towards the Optimization of Student GNN with Meta Data
Since the above student optimization in Eq. 7 consists of meta learner parameters, the optimization of student GNN can be decomposed into two nested optimizations. The inner optimization aims to optimize the meta learner based on a single-step update of the student and the outer optimization performs optimizations on the student with the latest meta parameters.
Inner Optimization Following the normal meta manner, we first explicitly calculate a single-step gradient on “hard” data for further performing second-order gradient optimization on meta data. The explicit calculation is as follows:
| (10) |
where , denote the optimal student parameters and sample weights respectively at step k.
Then the meta learner optimize by using meta data with the following equation as is contained in :
| (11) |
Outer Optimization The outer optimization of the student can be calculated through the weighted loss defined in Eq.7 with the latest sample weights .
| (12) |
3.4. Why It Works
3.4.1. Theoretical Justification
For the sake of convenience, in our theoretical analysis, we choose to maximize the average utility (Hacohen and Weinshall, 2019) of the observed graph for choosing the optimal hypothesis (i.e., GNN) for link prediction. For the teacher GNN , the optimal from the data could be computed by maximizing the following formulation:
| (13) |
In terms of the student GNN, we regard it as imposing a prior distribution on the observed data for data sampling (e.g., DNS). Hence, this can be formalized as follows:
| (14) |
Then, we have the following theorem to depict the merit of the proposed MeBNS, potentially contributing to the learning.
Theorem 1.
With the ideal sampling strategy on observed data space satisfying (i) the non-increasing property of the difficulty level of pair and (ii) the positive correlation with the optimal utility , compared to , the optimization landscape of is inclined to enlarge the difference between the optimal parameters and all other parameter values whose covariance with the optimal solution is smaller than the variance of the optimum. More specifically,
| (15) |
Proof.
Firstly, we rewrite the Eq. 14 as follows:
| (16) |
where represents the the covariance between the two random variables and on graph data space .
Generally, the non-increasing sampling strategy of the difficulty level of pair on observed data space implies the positive correlation between and the utility . And in an ideal condition, is expected to be positively correlated to the utility with optimal parameters, i.e., In particular, we define the sampling strategy in the ideal case as follows:
| (17) |
Then, we rewrite Eq. LABEL:eq_proof_1 as follows:
| (18) |
where .
In short, the theorem clearly tells that our MeBNS framework generally obtains a better landscape of a link predictor, specifically making the optimization overall steeper. In particular, MeBNS is equipped with the remarkable ability to refine the optimization when the optimal parameter and other parameters are totally uncorrelated, and even negatively correlated. Hence, compared to traditional link predictors, MeBNS could achieve a further convergence with alleviating the migration phenomenon (See empirical evidence in Fig. 4 (a) & (c)). It is worthwhile to note the training pipeline of MeBNS naturally not only follows the non-increasing sampling strategy( i.e. “easy” (teacher GNN) “hard” (student GNN)), but also dedicates to imposing the sampling strategy close to the ideal case by over-sampling “hard” samples for student GNN with a converged teacher GNN.
3.4.2. Complexity Analysis
The overall training pipeline of MeBNS framework is presented in Algorithm. 1 Since MeBNS divides the whole training process into teacher and student phases, we separately analyze the time complexity of the two phases. Taking a single iteration for example, the training time complexity of teacher GNN is actually the same as the baseline . Extra computation occurs in the student phase due to the secondary gradient calculation on meta data. As shown in Eq. 10-Eq. 12, two back-propagation operations are required. Without loss of generality, time complexity of MeBNS is near = , where is a constant ( or ). In summary, the complexity of MeBNS is linearly comparable with the traditional negative sampling based link prediction. Through the evaluation on Pubmed dataset, we could observe with GCN backbone, with GAT backbone and with SEAL backbone, which reveals the scalability and efficiency of the proposed MeBNS. And a large OGB dataset is adopted for evaluation to prove this.
4. Experiments
| Dataset | Nodes | Edges | Features |
|---|---|---|---|
| Cora | 2, 708 | 10, 556 | 1, 433 |
| CiteSeer | 3, 327 | 9, 104 | 3, 703 |
| Pubmed | 19, 717 | 88, 648 | 500 |
| Amazon Photo | 7, 650 | 238, 162 | 745 |
| 4, 039 | 88, 234 | 1, 283 | |
| OGB-DDI | 4, 267 | 1, 334, 889 | N.A. |
| Datasets | Metrics | Uniform | +MeBNS | PNS | +MeBNS | DNS | +MeBNS | SANS | +MeBNS | RecNS | +MeBNS | MCNS | +MeBNS |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cora | Hits@20 | 0.3450 | 0.5815 | 0.4094 | 0.5023 | 0.4113 | 0.5184 | 0.2009 | 0.4748 | 0.2056 | 0.2398 | 0.5535 | 0.6075 |
| Hits@30 | 0.4436 | 0.6151 | 0.4928 | 0.5772 | 0.4815 | 0.5734 | 0.2682 | 0.5289 | 0.2606 | 0.2862 | 0.6388 | 0.6540 | |
| AUC | 0.9005 | 0.9117 | 0.9147 | 0.9224 | 0.9031 | 0.9114 | 0.8349 | 0.8825 | 0.8106 | 0.7940 | 0.9206 | 0.9302 | |
| CiteSeer | Hits@20 | 0.4758 | 0.5549 | 0.4747 | 0.5406 | 0.4857 | 0.5450 | 0.1516 | 0.4362 | 0.2164 | 0.3230 | 0.5670 | 0.6241 |
| Hits@30 | 0.5395 | 0.5846 | 0.5439 | 0.6098 | 0.5890 | 0.6043 | 0.2373 | 0.4879 | 0.2769 | 0.4054 | 0.6219 | 0.6934 | |
| AUC | 0.8936 | 0.9138 | 0.9191 | 0.9244 | 0.9047 | 0.9120 | 0.7874 | 0.8439 | 0.8324 | 0.8636 | 0.9319 | 0.9399 | |
| Pubmed | Hits@20 | 0.3333 | 0.4487 | 0.2814 | 0.2787 | 0.3272 | 0.3381 | 0.1327 | 0.2898 | 0.0822 | 0.0856 | 0.2824 | 0.3018 |
| Hits@30 | 0.3925 | 0.5004 | 0.3410 | 0.3378 | 0.4141 | 0.3921 | 0.1604 | 0.3479 | 0.1034 | 0.1053 | 0.3246 | 0.3551 | |
| AUC | 0.9688 | 0.9698 | 0.9588 | 0.9586 | 0.9556 | 0.9593 | 0.9308 | 0.9498 | 0.9139 | 0.9160 | 0.9605 | 0.9565 | |
| Photo | Hits@20 | 0.1056 | 0.1160 | 0.0509 | 0.0642 | 0.0753 | 0.0946 | 0.0604 | 0.1290 | 0.0348 | 0.0304 | 0.0304 | 0.0655 |
| Hits@30 | 0.1200 | 0.1389 | 0.0689 | 0.0798 | 0.1019 | 0.1208 | 0.0721 | 0.1609 | 0.0457 | 0.0395 | 0.0386 | 0.0885 | |
| AUC | 0.9353 | 0.9437 | 0.8507 | 0.8541 | 0.8760 | 0.9165 | 0.9010 | 0.9112 | 0.8136 | 0.8120 | 0.8124 | 0.8599 | |
| Hits@20 | 0.2216 | 0.2453 | 0.0987 | 0.1093 | 0.2432 | 0.2511 | 0.0619 | 0.2188 | 0.0588 | 0.1066 | 0.2222 | 0.2411 | |
| Hits@30 | 0.2902 | 0.3389 | 0.1595 | 0.2016 | 0.3034 | 0.3046 | 0.0888 | 0.2873 | 0.0848 | 0.1518 | 0.2997 | 0.2842 | |
| AUC | 0.9866 | 0.9894 | 0.9783 | 0.9786 | 0.9797 | 0.9813 | 0.9386 | 0.9529 | 0.9352 | 0.9423 | 0.9802 | 0.9706 | |
| OGB-DDI | Hits@20 | 0.4546 | 0.5227 | 0.1714 | 0.2333 | 0.2179 | 0.2386 | 0.1327 | 0.3700 | 0.3489 | 0.4789 | 0.1548 | 0.2214 |
| Hits@30 | 0.5420 | 0.6222 | 0.2157 | 0.2713 | 0.2619 | 0.2850 | 0.1327 | 0.5527 | 0.4211 | 0.5257 | 0.2301 | 0.2755 | |
| AUC | 0.9965 | 0.9968 | 0.9910 | 0.9911 | 0.9929 | 0.9931 | 0.9941 | 0.9950 | 0.9961 | 0.9962 | 0.9912 | 0.9918 |
Datasets and Evaluation Metrics We evaluate the proposed MeBNS on six benchmark datasets, including citation graphs 555https://github.com/kimiyoung/planetoid/raw/master/data (i.e., Cora, CiteSeer, Pubmed (Yang et al., 2016)), co-purchase graphs 666https://github.com/shchur/gnn-benchmark /blob/master/data/npz/amazon_electro nics_photo .npz (i.e., Amazon Photo (Shchur et al., 2018) ), social graphs 777https://docs.google.com/uc?export=download&id =12aJWAGCM4IvdGI2fiydDNy WzViEOLZH8 &confirm=t (i.e., Facebook (Yang et al., 2020b)) and drug-drug interaction networks (i.e., OGB-DDI (Hu et al., 2020)), which are publicly available. The details of the datasets are present in Table 1. Following normal settings (Yang et al., 2020a), we randomly split the entire edges of each dataset into training (70%), validation (10%) and test set (20%), and especially for OGB-DDI, we used the OGB official train/validation/test splits. Following the evaluation of link prediction tasks in OGB (Hu et al., 2020), we adopt the widely-used Hits@K ( in our paper) and AUC as the evaluation metrics.
Baselines Since MeBNS is a general plugin, we perform experiments on several link predictors with different negative samplers.
- •
- •
| Uniform sampler | MCNS sampler | ||||||
| Backbone | GAT | SEAL | GraIL | GAT | SEAL | GraIL | |
| Cora | - | 0.2928 | 0.5563 | 0.6009 | 0.5819 | 0.5260 | 0.2864 |
| + | 0.5298 | 0.5696 | 0.7061 | 0.6123 | 0.5270 | 0.2929 | |
| CiteSeer | - | 0.4615 | 0.5879 | 0.5263 | 0.5439 | 0.5483 | 0.1223 |
| + | 0.4890 | 0.5978 | 0.6599 | 0.6010 | 0.6274 | 0.1480 | |
| Pubmed | - | 0.1149 | 0.4123 | 0.4641 | 0.1296 | 0.4011 | 0.1686 |
| + | 0.1701 | 0.4615 | 0.5203 | 0.0927 | 0.4350 | 0.3967 | |




Parameter Settings We perform hyperparameters tuning on the validation set with the widely-used grid search strategy, and the optimal parameters as well as the experimental environment on different datasets are detailed in the A.1 and A.2. Also, a detailed analysis of hyperparameters is presented in A.4. Finally, we provide the source codes and demo datasets as the supplementary material for reproducibility.



4.1. Overall Performance
With the GCN as the link prediction backbone, we report the experimental results w.r.t. Hits@K of MeBNS and baseline negative samplers on six datasets in Table 2 (Performance comparison with the AUC metric is reported in A.3.). Moreover, we also present the comparison results under different link prediction backbones in Table 3. The major observations are summarized as follows:
-
•
Outstanding Performance MeBNS consistently and significantly outperform all baselines on all datasets, achieves performance gains over the best baseline by 9.75%, 10.07%, 34.62%, 22.15%, 3.24% and 14.98% on the six datasets w.r.t. the metric Hit20 respectively. The results indicate the effectiveness of MeBNS for exploring and exploiting informative negatives.
-
•
General Plugin for Negative Samplers In most cases, we could observe promising performance gains when integrating MeBNS with vanilla negative samplers. The underlying reason lies in that MeBNS overcome the bottleneck of current negative samplers by alleviating the migration phenomenon and specializing in “hard" samples.
-
•
Agnostic to Link Prediction Backbones Towards existing mainstream node- (i.e., GCN and GAT) and edge-centric (i.e., SEAL and GraIL) backbones, MeBNS could be naturally adapted and achieves consistent performance improvements on three datasets. The model-agnostic property provides excellent flexibility for MeBNS being adopted in various applications related to link prediction.
4.2. In-depth Analysis
In this section, we perform a series of in-depth analyses to better understand the merits of MeBNS.
Ablation Studies of MeBNS As the heart of the MeBNS, we take a closer look into the MST-GNN, consisting of a teacher-student design and a meta learner. Hence, we prepare two variants of MeBNS, namely MeBNS-M (i.e., MeBNS without the meta learner) and MeBNS-O (i.e., MeBNS without the teacher-student design). As reported in Fig. 3 (a) & (b), we find the overall performance is MeBNS MeBNS-M MeBNS-O. The observation reveals that MeBNS greatly benefits from our well-designed parts in MST-GNN: i) the teacher-student design helps alleviate the migration phenomenon (i.e., MeBNS-M MeBNS-O). ii) the meta learner further encourages the model to distinguish “hard” samples in a fine-grained manner (i.e., MeBNS MeBNS-M).
Analysis of UMD-Collector To verify the validity of UMD-Collector, we collect the meta data by randomly sampling from the training set. Fig. 3 (c) & (d) shows that compared with random sampling, uncertainty-based meta data can better guide the training process of the student model.
Qualitative Analysis of MeBNS To have a deep insight into MeBNS, we carefully design a qualitative experiment to provide explicit evidence for MeBNS in improving the capability of link prediction. As shown in Fig. 4 (a), compared to the original learning curve in Fig. 1 (a), we find the loss (AUC) indeed decreases (increases) after Epoch 100, attributed to that MeBNS alleviates the migration phenomenon with a better optimization landscape. On the other hand, the positive correlation between loss and meta weights in Fig. 4 (b) gives strong evidence that our meta leaner could help MeBNS locate “hard” samples in an adaptive way. Further, through the experimental results in Fig. 4 (c), we observe that MeBNS can alleviate the migration problem in DNS as the migration samples (i.e., “▲”) are significantly decreased.
5. Related Work
Link Prediction, Link Prediction has been deeply explored and achieves excellent performance in various scenarios. (Jeh and Widom, 2002) measure the similarity of links by defining heuristic features, (Perozzi et al., 2014; Grover and Leskovec, 2016) present the similarity by getting latent representations and (Ying et al., 2018a; Hamilton et al., 2017; Zhang and Chen, 2018) learning the way through GNN methods. Due to the powerful expressive ability of GNN, (Ying et al., 2018a; Hamilton et al., 2017; Zhang and Chen, 2018) reaches the SOTA. Among them can be roughly divided into node-centric and edge-centric methods according to whether using subgraph features. Node centric methods (Wu et al., 2020; Hamilton et al., 2017) obtain representations by modeling their respective neighborhood and self information. Unfortunately, these methods only independently characterize the target nodes and ignore the structural information in subgraph which always maintain rich interactive information. Seal (Zhang and Chen, 2018) extracts subgraph information by Node Labeling. Grail (Teru et al., 2020) mainly uses the Readout function to represent the subgraph. PaGNN (Yang et al., 2021a) and NBFNet (Zhu et al., 2021) methods automatically learn subgraph information through broadcast and aggregation operations. BUDDY (Chamberlain et al., 2023) represents with subgraph sketching and Neo-GNNs (Yun et al., 2021) identifies by modeling the information of common neighbors. CFLP (Zhao et al., 2022) investigates the impact of structural information from a causal perspective and deals with counterfactual samples.
Negative Sampling, There are sundry negative samplers like heuristics based (Wang et al., 2019; Mikolov et al., 2013), distribution based (Zhang et al., 2013; Yang et al., 2020a), GAN based (Wang et al., 2017b; Cai and Wang, 2017; Wang et al., 2017a) and synthesis based (Huang et al., 2021; Kalantidis et al., 2020) etc., and have achieved surprising results. Here, we mainly focus on distribution methods that have attracted attention in recent works as other methods are unstable and resource-consuming like GAN-based. Typically, distribution methods can be divided into two categories, namely static sampler and dynamic sampler in which the probability of each sample being sampled in static samplers will not vary with the iteration of the model. Static samplers like (Rendle et al., 2014; Mikolov et al., 2013; Ahrabian et al., 2020) choose samples from a uniform distribution or heuristic indicator (i.e. popularity, degrees, k-hops). Dynamic samplers continuously modify the sampling strategy as the model iterating. (Zhang et al., 2013) samples negatives with highest scores, (Yang et al., 2020a) conclude the optimal negative sampling distribution should be positively but sub-linearly correlated to positive sampling distribution. (Yang et al., 2023) proposes Three Region strategy based on graph and uses positive samples to aid learning.
6. Conclusion
In this paper, we propose the MeBNS framework, serving as a general plugin that can potentially improve current negative samplers based link predictors by alleviating the migration phenomenon and encouraging distinguishing “hard” samples in a fine-grained manner. Extensive experiments demonstrate the effectiveness of the MeBNS framework. Our work imparts interesting findings about the migration phenomenon for DNS based link prediction and paves the way for future researchers to further expand upon this area, e.g., more subtle designs to close in the ideal sampling strategy and more complicated graphs with multiple relations.
References
- (1)
- Ahrabian et al. (2020) Kian Ahrabian, Aarash Feizi, Yasmin Salehi, William L Hamilton, and Avishek Joey Bose. 2020. Structure aware negative sampling in knowledge graphs. In EMNLP.
- Bucher et al. (2016) Maxime Bucher, Stéphane Herbin, and Frédéric Jurie. 2016. Hard negative mining for metric learning based zero-shot classification. In ECCV. 524–531.
- Cai and Wang (2017) Liwei Cai and William Yang Wang. 2017. Kbgan: Adversarial learning for knowledge graph embeddings. In NAACL.
- Caselles-Dupré et al. (2018) Hugo Caselles-Dupré, Florian Lesaint, and Jimena Royo-Letelier. 2018. Word2vec applied to recommendation: Hyperparameters matter. In RecSys. 352–356.
- Chamberlain et al. (2023) Benjamin Paul Chamberlain, Sergey Shirobokov, Emanuele Rossi, Fabrizio Frasca, Thomas Markovich, Nils Hammerla, Michael M Bronstein, and Max Hansmire. 2023. Graph Neural Networks for Link Prediction with Subgraph Sketching. In ICLR.
- Chen et al. (2018) Jie Chen, Tengfei Ma, and Cao Xiao. 2018. Fastgcn: fast learning with graph convolutional networks via importance sampling. In ICLR.
- Chen et al. (2019) Jiawei Chen, Can Wang, Sheng Zhou, Qihao Shi, Yan Feng, and Chun Chen. 2019. Samwalker: Social recommendation with informative sampling strategy. In WWW. 228–239.
- Grover and Leskovec (2016) Aditya Grover and Jure Leskovec. 2016. node2vec: Scalable feature learning for networks. In SIGKDD. 855–864.
- Hacohen and Weinshall (2019) Guy Hacohen and Daphna Weinshall. 2019. On the power of curriculum learning in training deep networks. In ICML. 2535–2544.
- Hamilton et al. (2017) Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. In NeurIPS.
- He et al. (2020a) Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020a. Lightgcn: Simplifying and powering graph convolution network for recommendation. In SIGIR. 639–648.
- He et al. (2020b) Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020b. Lightgcn: Simplifying and powering graph convolution network for recommendation. In SIGIR. 639–648.
- Hinton et al. (2015) Geoffrey Hinton, Oriol Vinyals, Jeff Dean, et al. 2015. Distilling the knowledge in a neural network. In NeurIPS.
- Hu et al. (2019) Binbin Hu, Yuan Fang, and Chuan Shi. 2019. Adversarial learning on heterogeneous information networks. In SIGKDD. 120–129.
- Hu et al. (2018) Binbin Hu, Chuan Shi, Wayne Xin Zhao, and Philip S Yu. 2018. Leveraging meta-path based context for top-n recommendation with a neural co-attention model. In SIGKDD. 1531–1540.
- Hu et al. (2020) Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open graph benchmark: Datasets for machine learning on graphs. In NeurIPS. 22118–22133.
- Huang et al. (2021) Tinglin Huang, Yuxiao Dong, Ming Ding, Zhen Yang, Wenzheng Feng, Xinyu Wang, and Jie Tang. 2021. Mixgcf: An improved training method for graph neural network-based recommender systems. In SIGKDD. 665–674.
- Ioannidis et al. (2020) Vassilis N Ioannidis, Da Zheng, and George Karypis. 2020. Few-shot link prediction via graph neural networks for covid-19 drug-repurposing. ICML (2020).
- Jeh and Widom (2002) Glen Jeh and Jennifer Widom. 2002. Simrank: a measure of structural-context similarity. In SIGKDD. 538–543.
- Kalantidis et al. (2020) Yannis Kalantidis, Mert Bulent Sariyildiz, Noe Pion, Philippe Weinzaepfel, and Diane Larlus. 2020. Hard negative mixing for contrastive learning. In NeurIPS. 21798–21809.
- Kipf and Welling (2016) Thomas N Kipf and Max Welling. 2016. Semi-supervised classification with graph convolutional networks. In ICLR.
- Kumar et al. (2020) Ajay Kumar, Shashank Sheshar Singh, Kuldeep Singh, and Bhaskar Biswas. 2020. Link prediction techniques, applications, and performance: A survey. Physica A: Statistical Mechanics and its Applications (2020), 124289.
- Liu et al. (2022) Hongrui Liu, Binbin Hu, Xiao Wang, Chuan Shi, Zhiqiang Zhang, and Jun Zhou. 2022. Confidence May Cheat: Self-Training on Graph Neural Networks under Distribution Shift. In WWW. 1248–1258.
- Liu et al. (2019) Ziqi Liu, Chaochao Chen, Longfei Li, Jun Zhou, Xiaolong Li, Le Song, and Yuan Qi. 2019. Geniepath: Graph neural networks with adaptive receptive paths. In AAAI. 4424–4431.
- Mikolov et al. (2013) Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality. In NeurIPS.
- Noh et al. (2018) Junhyug Noh, Soochan Lee, Beomsu Kim, and Gunhee Kim. 2018. Improving occlusion and hard negative handling for single-stage pedestrian detectors. In ECCV. 966–974.
- Perozzi et al. (2014) Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. 2014. Deepwalk: Online learning of social representations. In SIGKDD. 701–710.
- Ren et al. (2018) Mengye Ren, Wenyuan Zeng, Bin Yang, and Raquel Urtasun. 2018. Learning to reweight examples for robust deep learning. In ICML. 4334–4343.
- Rendle and Freudenthaler (2014) Steffen Rendle and Christoph Freudenthaler. 2014. Improving pairwise learning for item recommendation from implicit feedback. In WSDM. 273–282.
- Rendle et al. (2014) Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars BPR Schmidt-Thieme. 2014. Bayesian personalized ranking from implicit feedback. In UAI. 452–461.
- Shchur et al. (2018) Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. 2018. Pitfalls of graph neural network evaluation. arXiv preprint arXiv:1811.05868 (2018).
- Shu et al. (2019) Jun Shu, Qi Xie, Lixuan Yi, Qian Zhao, Sanping Zhou, Zongben Xu, and Deyu Meng. 2019. Meta-weight-net: Learning an explicit mapping for sample weighting. In NeurIPS.
- Teru et al. (2020) Komal Teru, Etienne Denis, and Will Hamilton. 2020. Inductive relation prediction by subgraph reasoning. In ICML. 9448–9457.
- Velickovic et al. (2017) Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. 2017. Graph attention networks. In ICLR. 20.
- Wang et al. (2021) Can Wang, Jiawei Chen, Sheng Zhou, Qihao Shi, Yan Feng, and Chun Chen. 2021. SamWalker++: recommendation with informative sampling strategy. In IEEE Transactions on Knowledge and Data Engineering.
- Wang et al. (2017a) Hongwei Wang, Jia Wang, Jialin Wang, Miao Zhao, Weinan Zhang, Fuzheng Zhang, Xing Xie, and Minyi Guo. 2017a. Graphgan: graph representation learning with generative adversarial nets. AAAI (2017).
- Wang et al. (2017b) Jun Wang, Lantao Yu, Weinan Zhang, Yu Gong, Yinghui Xu, Benyou Wang, Peng Zhang, and Dell Zhang. 2017b. Irgan: A minimax game for unifying generative and discriminative information retrieval models. In SIGIR. 515–524.
- Wang et al. (2019) Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. 2019. Neural graph collaborative filtering. In SIGIR. 165–174.
- Wang et al. (2020) Xiang Wang, Yaokun Xu, Xiangnan He, Yixin Cao, Meng Wang, and Tat-Seng Chua. 2020. Reinforced negative sampling over knowledge graph for recommendation. In WWW. 99–109.
- Wu et al. (2020) Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu Philip. 2020. A comprehensive survey on graph neural networks. IEEE transactions on neural networks and learning systems (2020), 4–24.
- Yang et al. (2020b) Renchi Yang, Jieming Shi, Xiaokui Xiao, Yin Yang, Juncheng Liu, and Sourav S Bhowmick. 2020b. Scaling attributed network embedding to massive graphs. In Proceedings of the VLDB Endowment.
- Yang et al. (2021a) Shuo Yang, Binbin Hu, Zhiqiang Zhang, Wang Sun, Yang Wang, Jun Zhou, Hongyu Shan, Yuetian Cao, Borui Ye, Yanming Fang, et al. 2021a. Inductive Link Prediction with Interactive Structure Learning on Attributed Graph. In ECML PKDD. 383–398.
- Yang et al. (2021b) Shuo Yang, Zhiqiang Zhang, Jun Zhou, Yang Wang, Wang Sun, Xingyu Zhong, Yanming Fang, Quan Yu, and Yuan Qi. 2021b. Financial risk analysis for SMEs with graph-based supply chain mining. In IJCAI. 4661–4667.
- Yang et al. (2016) Zhilin Yang, William Cohen, and Ruslan Salakhudinov. 2016. Revisiting semi-supervised learning with graph embeddings. In ICML. 40–48.
- Yang et al. (2020a) Zhen Yang, Ming Ding, Chang Zhou, Hongxia Yang, Jingren Zhou, and Jie Tang. 2020a. Understanding negative sampling in graph representation learning. In SIGKDD. 1666–1676.
- Yang et al. (2023) Zhen Yang, Ming Ding, Xu Zou, Jie Tang, Bin Xu, Chang Zhou, and Hongxia Yang. 2023. Region or Global A Principle for Negative Sampling in Graph-based Recommendation. IEEE Transactions on Knowledge and Data Engineering (2023).
- Yim et al. (2017) Junho Yim, Donggyu Joo, Jihoon Bae, and Junmo Kim. 2017. A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In CVPR. 4133–4141.
- Ying et al. (2018a) Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L Hamilton, and Jure Leskovec. 2018a. Graph convolutional neural networks for web-scale recommender systems. In SIGKDD. 974–983.
- Ying et al. (2018b) Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L Hamilton, and Jure Leskovec. 2018b. Graph convolutional neural networks for web-scale recommender systems. In SIGKDD. 974–983.
- Yun et al. (2021) Seongjun Yun, Seoyoon Kim, Junhyun Lee, Jaewoo Kang, and Hyunwoo J Kim. 2021. Neo-gnns: Neighborhood overlap-aware graph neural networks for link prediction. NeurIPS, 13683–13694.
- Zang et al. (2023) Xiaoling Zang, Binbin Hu, Jun Chu, Zhiqiang Zhang, Guannan Zhang, Jun Zhou, and Wenliang Zhong. 2023. Commonsense Knowledge Graph towards Super APP and Its Applications in Alipay. In SIGKDD. 5509–5519.
- Zhang and Chen (2018) Muhan Zhang and Yixin Chen. 2018. Link prediction based on graph neural networks. In NeurIPS.
- Zhang et al. (2013) Weinan Zhang, Tianqi Chen, Jun Wang, and Yong Yu. 2013. Optimizing top-n collaborative filtering via dynamic negative item sampling. In SIGIR. 785–788.
- Zhao et al. (2022) Tong Zhao, Gang Liu, Daheng Wang, Wenhao Yu, and Meng Jiang. 2022. Learning from counterfactual links for link prediction. In ICML. 26911–26926.
- Zhu et al. (2021) Zhaocheng Zhu, Zuobai Zhang, Louis-Pascal Xhonneux, and Jian Tang. 2021. Neural bellman-ford networks: A general graph neural network framework for link prediction. In NeurIPS. 29476–29490.
Appendix A Appendix
A.1. Experiment Environments
All experiments are conducted with the following settings:
-
•
Operating system: CentOS Linux release 7.6
-
•
CPU: Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz
-
•
GPU: 1*Tesla P100
-
•
Software version: Python:3.6.8; Torch:1.8.1+cu101; Torch-geometric:2.0.3; Numpy:1.19.5; Scikit-learn:0.24.2; Scipy:1.5.4
A.2. Baseline Settings
Backbone Settings
The backbones used in MeBNS are mainly based on the public implementations in PyG which are available in the following URLs, and the overall model architecture based on the node-centric (GCN, GAT) and edge-centric (SEAL) GNN are presented in Algorithm 2 and Algorithm 3, respectively. Normally, we set the hidden channels to 128 and the output channels to 64 in GCN, the hidden channels to 128, the output channels to 64 and heads to 5 in GAT, the hidden channels to 32 and the number of layers to 3 in SEAL.
(1) GCN/GAT: https://github.com/pyg-team/pytorch_geometric
/blob/master/examples/link_pred.py
(2) SEAL: https://github.com/pyg-team/pytorch_geometric/blob
/master/examples/seal_link_pred.py
Input: Graph , Node feature matrix
Input: Subgraph , Node labeling matrix
Hyperparameters Settings
For MeBNS, we use the GNN architectures that are similar to the above settings in Sec. A.2, and we adopt an Adam optimizer in MST-GNN with setting learning rate to 0.01 while an SGD optimizer with learning rate 0.01. All hyperparameters settings are showed in Table 4:
| Parameters | |||||
|---|---|---|---|---|---|
| Cora | 100 | 15 | 50% | 5% | |
| CiteSeer | 200 | 15 | 50% | 30% | |
| Pubmed | 100 | 15 | 50% | 7% | |
| Amazon Photo | 200 | 15 | 50% | 3% | |
| 200 | 15 | 50% | 1% | ||
| OGB-DDI | 200 | 10 | 10% | 1% |
More specifically, we present the probability of each sample being sampled as for PNS, which is commonly used in previous works (Yang et al., 2020a). For SANS and RecNS, we set the subgraph hop . In particular, unlike the recommendation scenario, there is no exposure information in link prediction datasets, thus we just replace RecNS with RecNS-O.
A.3. Performance Comparison with the AUC Metric
As AUC is an important evaluation metric in link prediction tasks, we also present the performance comparison w.r.t AUC in Table LABEL:tab:auc_expert indicating that MeBNS gains on most datasets with various negative sampler.
A.4. Parameter Analysis
Since MeBNS involves several important parameters, i.e., the number of iterations of teacher GNN , the ratio of “hard” samples for student GNN , the probability of graph based negative sampler , we investigate their impacts in the following categories. We use the performance on Cora and CiteSeer as a reference, and similar patterns have been observed on the other datasets.
Firstly, we vary in the set of {50, 100, 150, 200, 250, 300}. As shown in Fig. 5, MeBNS achieves the optimal performance when the teacher GNN converges to a relatively stable state (i.e., in Cora and 200 in CiteSeer). A small or a large would cause the under-fitting or over-fitting of the teacher GNN, resulting in unpromising performance.
In terms of the parameter , we present the results in Fig. 6. We find that MeBNS achieves the optimal performance near 50% on both datasets and too small would harm the model by potentially filtering a number of informative samples.
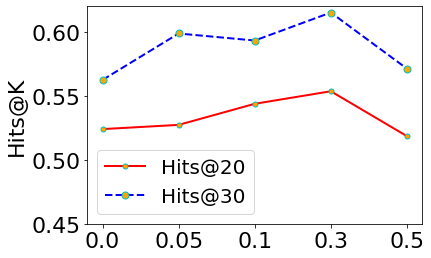
Lastly, we run a grid search over {0.0, 0.05, 0.1, 0.3, 0.5} for and plot their performance in Fig. 7. The optimal performance is yielded near 0.05 in Cora and 0.3 in CiteSeer showing the usefulness of graph-based negatives, although too large would hinder the capability of MeBNS due to the excessive involvement of false negatives.





A.5. Qualitative Analysis on CiteSeer
We also conduct qualitative analysis on the CiteSeer dataset in Fig. 8 and have similar findings with Sec. 2.2 that the model converges to a deeper landscape and alleviates migration with MeBNS.



