toltxlabel
Nonparametric estimation of continuous DPPs
with kernel methods
Abstract
Determinantal Point Process (DPPs) are statistical models for repulsive point patterns. Both sampling and inference are tractable for DPPs, a rare feature among models with negative dependence that explains their popularity in machine learning and spatial statistics. Parametric and nonparametric inference methods have been proposed in the finite case, i.e. when the point patterns live in a finite ground set. In the continuous case, only parametric methods have been investigated, while nonparametric maximum likelihood for DPPs – an optimization problem over trace-class operators – has remained an open question. In this paper, we show that a restricted version of this maximum likelihood (MLE) problem falls within the scope of a recent representer theorem for nonnegative functions in an RKHS. This leads to a finite-dimensional problem, with strong statistical ties to the original MLE. Moreover, we propose, analyze, and demonstrate a fixed point algorithm to solve this finite-dimensional problem. Finally, we also provide a controlled estimate of the correlation kernel of the DPP, thus providing more interpretability.
1 Introduction
Determinantal point processes (DPPs) are a tractable family of models for repulsive point patterns, where interaction between points is parametrized by a positive semi-definite kernel. They were introduced by Macchi [1975] in the context of fermionic optics, and have gained a lot of interest since the 2000s, in particular in probability [Hough et al., 2006], spatial statistics [Lavancier et al., 2014], and machine learning [Kulesza and Taskar, 2012]. In machine learning at large, DPPs have been used essentially for two purposes: as statistical models for diverse subsets of items, like in recommendation systems [Gartrell et al., 2019], and as subsampling tools, like in experimental design [Derezinski et al., 2020], column subset selection [Belhadji et al., 2020b], or Monte Carlo integration [Gautier et al., 2019, Belhadji et al., 2019]. In this paper, we are concerned with DPPs used as statistical models for repulsion, and more specifically with inference for continuous DPPs.
DPP models in Machine Learning (ML) have so far mostly been finite DPPs: they are distributions over subsets of a (large) finite ground set, like subsets of sentences from a large corpus of documents [Kulesza and Taskar, 2012]. Since Affandi et al. [2014], a lot of effort has been put into designing efficient inference procedures for finite DPPs. In particular, the fixed point algorithm of Mariet and Sra [2015] allows for nonparametric inference of a finite DPP kernel, thus learning the features used for modelling diversity from the data. DPP models on infinite ground sets, say , while mathematically and algorithmically very similar to finite DPPs, have been less popular in ML than in spatial statistics. It is thus natural that work on inference for continuous DPPs has happened mostly in the latter community; see e.g. the seminal paper [Lavancier et al., 2014]. Inference for continuous DPPs has however focused on the parametric setting, where a handful of interpretable parameters are learned. Relatedly, spatial statisticians typically learn the correlation kernel of a DPP, which is more interpretable, while machine learners focus on the likelihood kernel, with structural assumptions to make learning scale to large ground sets.
In this paper, we tackle nonparametric inference for continuous DPPs using recent results on kernel methods. More precisely, maximum likelihood estimation (MLE) for continuous DPPs is an optimization problem over trace-class operators. Our first contribution is to show that a suitable modification of this problem is amenable to the representer theorem of Marteau-Ferey, Bach, and Rudi [2020]. Further drawing inspiration from the follow-up work [Rudi, Marteau-Ferey, and Bach, 2020], we derive an optimization problem over matrices, and we prove that its solution has a near optimal objective in the original MLE problem. We then propose, analyze, and demonstrate a fixed point algorithm for the resulting finite problem, in the spirit [Mariet and Sra, 2015] of nonparametric inference for finite DPPs. While our optimization pipeline focuses on the so-called likelihood kernel of a DPP, we also provide a controlled sampling approximation to its correlation kernel, thus providing more interpretability of our estimated kernel operator. A by-product contribution of independent interest is an analysis of a sampling approximation for Fredholm determinants.
The rest of the paper is organized as follows. Since the paper is notation-heavy, we first summarize our notation and give standard definitions in Section 1.1. In Section 2, we introduce DPPs and prior work on inference. In Section 3, we introduce our constrained maximum likelihood problem, and study its empirical counterpart. We analyze an algorithm to solve the latter in Section 4. Statistical guarantees are stated in Section 5, while Section 6 is devoted to numerically validating the whole pipeline. Our code is freely available111https://github.com/mrfanuel/LearningContinuousDPPs.jl.
1.1 Notation and background
Sets.
It is customary to define DPPs on a compact Polish space endowed with a Radon measure , so that we can define the space of square integrable functions for this measure [Hough et al., 2009]. Outside of generalities in Section 2, we consider a compact and the uniform probability measure on . Let be an RKHS of functions on with a bounded continuous kernel , and let . Denote by the canonical feature map. For a Hilbert space , denote by the space of symmetric and positive semi-definite trace-class operators on . By a slight abuse of notation, we denote by the space of real positive semi-definite matrices. Finally, all sets are denoted by calligraphic letters (e.g. ).
Operators and matrices.
Trace-class endomorphisms of , seen as integral operators, are typeset as uppercase sans-serif (e.g. ), and the corresponding integral kernels as lowercase sans-serif (e.g. ). Notice that and are distinct functions. Other operators are written in standard fonts (e.g. ), while we write matrices and finite-dimensional vectors in bold (e.g. ). The identity operator is written commonly as , whereas the identity matrix is denoted by . When is a subset of and is an matrix, the matrix is the square submatrix obtained by selecting the rows and columns of indexed by .
Restriction and reconstruction operators.
Following Rosasco et al. [2010, Section 3], we define the restriction operator as Its adjoint is the reconstruction operator The classical integral operator given by , seen as an endomorphism of , thus takes the simple expression . Similarly, the so-called covariance operator , defined by writes . In the tensor product notation defining , is an element of the dual of and is the endomorphism of defined by ; see e.g. Sterge et al. [2020]. Finally, for convenience, given a finite set , we also define discrete restriction and reconstruction operators, respectively, as such that and for any . In particular, we have where is a kernel matrix, which is defined for a given ordering of the set . To avoid cumbersome expressions, when several discrete sets of different cardinalities, say and , are used, we simply write the respective sampling operators as and .
2 Determinantal point processes and inference
Determinantal point processes and L-ensembles.
Consider a simple point process on , that is, a random discrete subset of . For , we denote by the number of points of this process that fall within . Letting be a positive integer, we say that has -point correlation function w.r.t. to the reference measure if, for any mutually disjoint subsets ,
In most cases, a point process is characterized by its correlation functions . In particular, a determinantal point process (DPP) is defined as having correlation functions in the form of a determinant of a Gram matrix, i.e. for all . We then say that is the correlation kernel of the DPP. Not all kernels yield a DPP: if is the integral kernel of an operator , the Macchi-Soshnikov theorem [Macchi, 1975, Soshnikov, 2000] states that the corresponding DPP exists if and only if the eigenvalues of are within . In particular, for a finite ground set , taking the reference measure to be the counting measure leads to conditions on the kernel matrix; see Kulesza and Taskar [2012].
A particular class of DPPs is formed by the so-called L-ensembles, for which the correlation kernel writes
| (1) |
with the likelihood operator taken to be of the form . The kernel of is sometimes called the likelihood kernel of the L-ensemble, to distinguish it from its correlation kernel . The interest of L-ensembles is that their Janossy densities can be computed in closed form. Informally, the -Janossy density describes the probability that the point process has cardinality , and that the points are located around a given set of distinct points . For the rest of the paper, we assume that is compact, and that is the uniform probability measure on ; our results straightforwardly extend to other densities w.r.t. Lebesgue. With these assumptions, the -Janossy density is proportional to
| (2) |
where the normalization constant is a Fredholm deteminant that implicitly depends on . Assume now that we are given i.i.d. samples of a DPP, denoted by the sets in the window . The associated maximum log-likelihood estimation problem reads
| (3) |
Solving (3) is a nontrivial problem. First, it is difficult to calculate the Fredholm determinant. Second, it is not straightforward to optimize over the space of operators in a nonparametric setting. However, we shall see that the problem becomes tractable if we restrict the domain of (3) and impose regularity assumptions on the integral kernel of the operator . For more details on DPPs, we refer the interested reader to Hough et al. [2006], Kulesza and Taskar [2012], Lavancier et al. [2014].
Previous work on learning DPPs.
While continuous DPPs have been used in ML as sampling tools [Belhadji et al., 2019, 2020a] or models [Bardenet and Titsias, 2015, Ghosh and Rigollet, 2020], their systematic parametric estimation has been the work of spatial statisticians; see Lavancier et al. [2015], Biscio and Lavancier [2017], Poinas and Lavancier [2021] for general parametric estimation through (3) or so-called minimum-contrast inference. Still for the parametric case, a two-step estimation was recently proposed for non-stationary processes by Lavancier et al. [2021]. In a more general context, non-asymptotic risk bounds for estimating a DPP density are given in Baraud [2013].
Discrete DPPs have been more common in ML, and the study of their estimation has started some years ago [Affandi et al., 2014]. Unlike continuous DPPs, nonparametric estimation procedures have been investigated for finite DPPs by Mariet and Sra [2015], who proposed a fixed point algorithm. Moreover, the statistical properties of maximum likelihood estimation of discrete L-ensembles were studied by Brunel et al. [2017b]. We can also cite low-rank approaches [Dupuy and Bach, 2018, Gartrell et al., 2017], learning with negative sampling [Mariet et al., 2019], learning with moments and cycles [Urschel et al., 2017], or learning with Wasserstein training [Anquetil et al., 2020]. Learning non-symmetric finite DPPs [Gartrell et al., 2019, 2021] has also been proposed, motivated by recommender systems.
At a high level, our paper is a continuous counterpart to the nonparametric learning of finite DPPs with symmetric kernels in Mariet and Sra [2015]. Our treatment of the continuous case is made possible by recent advances in kernel methods.
3 A sampling approximation to a constrained MLE
Using the machinery of kernel methods, we develop a controlled approximation of the MLE problem (3). Let us outline the main landmarks of our approach. First, we restrict the domain of the MLE problem (3) to smooth operators. On the one hand, this restriction allows us to develop a sampling approximation of the Fredholm determinant. On the other hand, the new optimization problem now admits a finite rank solution that can be obtained by solving a finite-dimensional problem. This procedure is described in Algorithm 1 and yields an estimator for the likelihood kernel. Finally, we use another sampling approximation and solve a linear system to estimate the correlation kernel of the fitted DPP; see Algorithm 2.
Restricting to smooth operators.
In order to later apply the representer theorem of Marteau-Ferey et al. [2020], we restrict the original maximum likelihood problem (3) to “smooth” operators , with and the restriction operator introduced in Section 1.1. Note that the kernel of now writes
| (4) |
With this restriction on its domain, the optimization problem (3) now reads
| (5) |
Approximating the Fredholm determinant.
We use a sampling approach to approximate the normalization constant in (5). We sample a set of points i.i.d. from the ambient probability measure . For definiteness, we place ourselves on an event happening with probability one where all the points in and for are distinct. We define the sample version of as
where the Fredholm determinant of has been replaced by the determinant of a finite matrix involving .
Theorem 1 (Approximation of the Fredholm determinant).
Let . With probability at least ,
with
where and .
The proof of Theorem 1 is given in Supplementary Material in Section C.2. Several remarks are in order. First, the high probability222We write if there exists a constant such that . in the statement of Theorem 1 is that of the event Importantly, all the results given in what follows for the approximation of the solution of (5) only depend on this event, so that we do not need any union bound. Second, we emphasize that , defined in Section 1.1, should not be confused with the correlation kernel (1). Third, to interpret the bound in Theorem 1, it is useful to recall that , since . Thus, by penalizing , one also improves the upper bound on the Fredholm determinant approximation error. This remark motivates the following infinite dimensional problem
| (6) |
for some . The penalty on is also intuitively needed so that the optimization problem selects a smooth solution, i.e., such a trace regularizer promotes a fast decay of eigenvalues of . Note that this problem depends both on the data and the subset used for approximating the Fredholm determinant.
Finite-dimensional representatives.
In an RHKS, there is a natural mapping between finite rank operators and matrices. For the sake of completeness, let be a kernel matrix and let be a Cholesky factorization. Throughout the paper, kernel matrices are always assumed to be invertible. This is not a strong assumption: if is the Laplace, Gaussian or Sobolev kernel, this is true almost surely if for are sampled e.g. w.r.t. the Lebesgue measure; see Bochner’s classical theorem [Wendland, 2004, Theorem 6.6 and Corollary 6.9]. In this case, we can define a partial isometry as It satisfies , and is the orthogonal projector onto the span of for all . This is helpful to define
| (7) |
the finite-dimensional representative of for all . This construction yields a useful mapping between an operator in and a finite matrix, which is instrumental for obtaining our results.
Lemma 2 (Finite dimensional representatives, extension of Lemma 3 in Rudi et al. [2020]).
Let . Then, the matrix is such that and , as well as .
Finite rank solution thanks to a representer theorem.
The sampling approximation of the Fredholm determinant also yields a finite rank solution for (6). For simplicity, we define and recall . Then, write the set of points as , with , and denote the corresponding restriction operator . Consider the kernel matrix . In particular, since we used a trace regularizer, the representer theorem of Marteau-Ferey et al. [2020, Theorem 1] holds: the optimal operator is of the form
| (8) |
In this paper, we call the representer matrix of the operator . If we do the change of variables , we have the following identities: and , thanks to Lemma 7 in Supplementary Material. Therefore, the problem (6) boils down to the finite non-convex problem:
| (9) |
where . We assume that there is a global minimizer of (9) that we denote by . The final estimator of the integral kernel of the likelihood depends on and reads The numerical strategy is summarized in Algorithm 1.
Estimation of the correlation kernel.
The exact computation of the correlation kernel of the L-ensemble DPP
| (10) |
requires the exact diagonalization of . For more flexibility, we introduced a scale parameter which often takes the value . It is instructive to approximate in order to easily express the correlation functions of the estimated point process. We propose here an approximation scheme based once again on sampling. Recall the form of the solution of (6), and consider the factorization with where is the Cholesky factorization of . Let be sampled i.i.d. from the probability measure and denote by the corresponding restriction operator. The following integral operator
| (11) |
gives an approximation of . The numerical approach for solving (11) relies on the computation of with and is a rectangular kernel matrix, associated to a fixed ordering of and . Our strategy is described in Algorithm 2.
4 Implementation
We propose an algorithm for solving the discrete problem (9) associated to (6). To simplify the discussion and relate it to Mariet and Sra [2015], we define the objective with the change of variables . Then we can rephrase (9) as
| (12) |
where we recall that . Define for convenience as the matrix obtained by selecting the columns of the identity matrix which are indexed by , so that, we have in particular . Similarly, define a sampling matrix associated to the subset . Recall the Cholesky decomposition . To minimize (12), we start at some and use the following iteration
| (13) |
where and We dub this sequence a regularized Picard iteration, as it is a generalization of the Picard iteration which was introduced by Mariet and Sra [2015] in the context of learning discrete L-ensemble DPPs. In Mariet and Sra [2015], the Picard iteration, defined as , is shown to be appropriate for minimizing a different objective given by: . The following theorem indicates that the iteration (13) is a good candidate for minimizing .
Theorem 3.
Let for integer be the sequence generated by (13) and initialized with . Then, the sequence is monotonically decreasing.
For a proof, we refer to Section C.4. In practice, we use the iteration (13) with the inverse change of variables and solve
| (14) |
where is given hereabove. For the stopping criterion, we monitor the objective values of (9) and stop if the relative variation of two consecutive objectives is less than a predefined precision threshold . Contrary to (12), the objective (9) does not include the inverse of , which might be ill-conditioned. The interplay between and is best understood by considering (9) with the change of variables , yielding the equivalent problem
where is a matrix whose -th column is for as defined in (7). Notice that, up to a factor, is the in-sample Gram matrix of evaluated on the data set ; see Algorithm 1. Thus, in the limit , the above expression corresponds to the MLE estimation of a finite DPP if . This is the intuitive connection with finite DPP: the continuous DPP is well approximated by a finite DPP if the ground set is a dense enough sampling within .
5 Theoretical guarantees
We now describe the guarantees coming with the approximations presented in the previous section.
Statistical guarantees for approximating the maximum likelihood problem
Next, we give a statistical guarantee for the approximation of the log-likelihood by its sample version.
Theorem 4 (Discrete optimal objective approximates full MLE objective).
The above result, proved in Section C.3, shows that, with high probability, the optimal objective value of the discrete problem is not far from the optimal log-likelihood provided is large enough. As a simple consequence, the discrete solution also yields a finite rank operator whose likelihood is not far from the optimal likelihood , as it can be shown by using a triangle inequality.
Corollary 5 (Approximation of the full MLE optimizer by a finite rank operator).
Approximation of the correlation kernel
An important quantity for the control of the amount of points necessary to approximate well the correlation kernel is the so-called effective dimension which is the expected sample size under the DPP with correlation kernel .
Theorem 6 (Correlation kernel approximation).
The proof of Theorem 6, given in Section C.5, mainly relies on a matrix Bernstein inequality. Let us make a few comments. First, we can simply take in Theorem 6 to recover the common definition of the correlation kernel (1). Second, the presence of in the logarithm is welcome since it is the expected subset size of the L-ensemble. Third, the quantity directly influences the typical sample size to get an accurate approximation. A worst case bound is with and where we used that in the light of (8). Thus, the lower bound on may be large in practice. Although probably more costly, an approach inspired from approximate ridge leverage score sampling [Rudi et al., 2018] is likely to allow lower ’s. We leave this to future work.
6 Empirical evaluation
We consider an L-ensemble with correlation kernel defined on with . Following Lavancier et al. [2014], this is a valid kernel if . Note that the intensity, defined as , is constant equal to ; we shall check that the fitted kernel recovers that property.




We draw samples333We used the code of Poinas and Lavancier [2021], available at https://github.com/APoinas/MLEDPP. It relies on the R package spatstat [Baddeley et al., 2015], available under the GPL-2 / GPL-3 licence. from this continuous DPP in the window . Two such samples are shown as hexagons in the first column of Figure 1, with respective intensity and . For the estimation, we use a Gaussian kernel with . The computation of the correlation kernel always uses uniform samples. Iteration (14) is run until the precision threshold is achieved. For stability, we add to the diagonal of the Gram matrix . The remaining parameter values are given in captions. We empirically observe that the regularized Picard iteration returns a matrix such that is low rank; see Figure 2 (left). A lesson from Figure 1 is that the sample size of the DPP has to be large enough to retrieve a constant intensity . In particular, the top row of this figure illustrates a case where is too small. Also, due to the large regularization and the use of only one DPP sample, the scale of is clearly underestimated in this example. On the contrary, in Figure 3, for a smaller regularization parameter , the intensity scale estimate is larger. We also observe that a large regularization parameter tends to smooth out the local variations of the intensity, which is not surprising.



A comparison between a Gram matrix of and is given in Figure 2 corresponding to the example of Figure 1. The short-range diagonal structure is recovered, while some long-range structures are smoothed out. More illustrative simulations are given in Section D, with a study of the influence of the hyperparameters, including the use of DPP samples. In particular, the estimation of the intensity is improved if several DPP samples are used with a smaller value of .


7 Discussion
We leveraged recent progress on kernel methods to propose a nonparametric approach to learning continuous DPPs. We see three major limitations of our procedure. First, our final objective function is nonconvex, and our algorithm is only guaranteed to increase its objective function. Experimental evidence suggests that our approach recovers the synthetic kernel, but more work is needed to study the maximizers of the likelihood, in the spirit of Brunel et al. [2017a] for finite DPPs, and the properties of our fixed point algorithm. Second, the estimated integral kernel does not have any explicit structure, other than being implicitly forced to be low-rank because of the trace penalty. Adding structural assumptions might be desirable, either for modelling or learning purposes. For modelling, it is not uncommon to assume that the underlying continuous DPP is stationary, for example, which implies that the correlation kernel depends only on . For learning, structural assumptions on the kernel may reduce the computational cost, or reduce the number of maximizers of the likelihood. The third limitation of our pipeline is that, like most nonparametric methods, it still requires to tune a handful of hyperparameters, and, in our experience, the final performance varies significantly with the lengthscale of the RKHS kernel or the coefficient of the trace penalty. An automatic tuning procedure with guarantees would make the pipeline turn-key.
Maybe unexpectedly, future work could also deal with transferring our pipeline to the finite DPP setting. Indeed, we saw in Section 4 that in some asymptotic regime, our regularized MLE objective is close to a regularized version of the MLE objective for a finite DPP. Investigating this maximum a posteriori inference problem may shed some new light on nonparametric inference for finite DPPs. Intuitively, regularization should improve learning and prediction when data is scarce.
Acknowledgements
We thank Arnaud Poinas and Guillaume Gautier for useful discussions on the manuscript. We acknowledge support from ERC grant Blackjack (ERC-2019-STG-851866) and ANR AI chair Baccarat (ANR-20-CHIA-0002).
Supplementary Material
Roadmap.
In Section A, we present useful technical results. Next, in a specific case, we show that the discrete problem (6) admits a closed-form solution that we discuss in Section B. Noticeably, this special case allows the understanding of the behaviour of the estimated DPP kernel in both the small and large regularization () limits. In Section C, all the deferred proofs are given. Finally, Section D provides a finer analysis of the empirical results of Section 6 as well as a description of the convergence of the regularized Picard algorithm to the closed-form solution described in Section B.
Appendix A Useful technical results
A.1 Technical lemmata
We preface the proofs of our main results with three lemmata.
Lemma 7.
Let be a strictly positive definite kernel of a RKHS and let be a symmetric matrix. Assume that are such that the Gram matrix is non-singular. Then, the non-zero eigenvalues of correspond to the non-zero eigenvalues of .
Proof.
By definition of the sampling operator (see Section 1.1), it holds that and we have . Thus, we need to show that the non-zero eigenvalues correspond to the non-zero eigenvalues of .
Let be an eigenvector of with eigenvalue . First, we show that is an eigenvector of with eigenvalue . We have . By acting on both sides of the latter equation with , we find . This is equivalent to . Second, since , remark that is related by a similarity to , which is diagonalizable. Since is at most of rank , the non-zero eigenvalues of match the non-zero eigenvalues of , which in turn are the same as the non-zero eigenvalues of . ∎
Lemma 8.
Let and let be a subset of . Then, the function
| (15) |
is strictly concave on .
Proof.
To simplify the expression, we do the change of variables and analyse which differs from the original function by an additive constant. Let be the matrix obtained by selecting the columns of the identity matrix which are indexed by . We rewrite the second term in (15) as
by Sylvester’s identity. This leads to
To check that is strictly concave on , we verify that its Hessian is negative any direction . Its first order directional derivative reads . Hence, the second order directional derivative in the direction of writes
which is indeed a negative number. ∎
The following result is borrowed from Mariet and Sra [2015, Lemma 2.3.].
Lemma 9.
Let and let be a matrix with orthonormal columns. Then, the function is concave on .
Proof.
The function is concave on since is convex on for any such that as stated in Mariet and Sra [2015, Lemma 2.3.]. ∎
A.2 Use of the representer theorem
We here clarify the definition of the representer theorem used in this paper.
A.2.1 Extended representer theorem
In Section 3, we used a slight extension of the representer theorem of Marteau-Ferey et al. [2020] which we clarify here. Let us first define some notations. Let be a RKHS with feature map and be a data set such as defined in Section 1.1. Define
In this paper, we consider the problem
| (16) |
where is a loss function (specified below). In contrast, the first term of the problem considered in Marteau-Ferey et al. [2020] is of the following form: . In other words, the latter loss function involves only diagonal elements for while (16) also involves off-diagonal elements. Now, denote by the projector on , and define
Then, we have the following proposition.
Proposition 10 (Extension of Proposition 7 in Marteau-Ferey et al. [2020]).
Let be a lower semi-continuous function such that is bounded below. Then (16) has a solution which is in .
Proof sketch.
The key step is the following identity
which is a direct consequence of the definition of . Also, we have . The remainder of the proof follows exactly the same lines as in Marteau-Ferey et al. [2020]. Notice that, compared with Marteau-Ferey et al. [2020, Proposition 7], we do not require the loss to be lower bounded but rather ask the full objective to be lower bounded, which is a weaker assumption but does not alter the argument. ∎
A.2.2 Applying the extended representer theorem
Now, let us prove that the objective of (6), given by is lower bounded. We recall that
For clarity, we recall that and . Then, write the set of points as with . Recall that we placed ourselves on an event happening with probability one where the sets are disjoint. Now, we denote by the orthogonal projector on , which writes
| (17) |
First, we have . Second, we use
Thus, a lower bound on the objective (6) is
Now we define the matrix with elements for and notice that
Remark that the matrix defined by associated with the -th DPP sample for is a principal submatrix of the matrix . Since the sets are disjoint, we have . Denoting , by using the last inequality, we find
Finally, we use the following proposition to show that each term in the above sum is bounded from below.
Proposition 11.
Let . The function satisfies for all .
A.3 Boundedness of the discrete objective function
At first sight, we may wonder if the objective of the optimization problem (12) is lower bounded. We show here that the optimization problem is well-defined for all regularization parameters . The lower boundedness of the discrete objective follows directly from Section A.2.2 in the case of a finite rank operator. For completeness, we repeat below the argument in the discrete case. Explicitly, this discrete objective reads
for all . First, since , we have . Next, we use that by assumption, which implies that . Denote . Thus, we can lower bound the objective function as follows:
where we used that with for . Hence, by using Proposition 11, is bounded from below by a sum of functions which are lower bounded.
Appendix B Extra result: an explicit solution for the single-sample case
We note that if the dataset is made of only one sample (i.e., ), and if that sample is also used to approximate the Fredholm determinant (i.e., ), then the problem (6) admits an explicit solution.
Proposition 12.
Proof.
By the representer theorem in Marteau-Ferey et al. [2020, Theorem 1], the solution is of the form where is the solution of
Define and denote the objective by . Let be a symmetric matrix. By taking a directional derivative of the objective in the direction , we find a first order condition with Since this condition should be satisfied for all , we simply solve the equation . Thanks to the invertibility of , we have equivalently
A simple algebraic manipulation yields . To check that is minimum, it is sufficient to analyse the Hessian of the objective in any direction . Let small enough such that . The second order derivative of writes
By using the first order condition , we find
with and
Notice that since . Therefore, it holds . Since this is true for any direction , the matrix is a local minimum of . ∎
While the exact solution of Proposition 12 is hard to intepret, if the regularization parameter goes to zero, the estimated correlation kernel tends to that of a projection DPP. In what follows, the notation stands for .
Proposition 13 (Projection DPP in the low regularization limit).
Under the assumptions of Proposition 12, the correlation kernel with and given in Proposition 12, has a range that is independent of . Furthermore, converges to the projection operator onto that range when . In particular, the integral kernel of has the following asymptotic expansion
pointwisely, with .
Proof.
As shown in Lemma 7, the non-zero eigenvalues of are the eigenvalues of since is non-singular. The eigenvalues of are where is the -th eigenvalue of for . Thus, the operator is of finite rank, i.e., , where the normalized eigenvectors are independent of . The eigenvalues satisfy as , such that is finite. Note that is of finite rank and does not depend on . Hence, the operator
converges to the projector on the range of as . ∎
On the other hand, as the regularization parameter goes to infinity, the integral kernel of behaves asymptotically as an out-of-sample Nyström approximation.
Proposition 14 (Large regularization limit).
Under the assumptions of Proposition 12, the integral kernel of has the following asymptotic expansion
pointwisely, with .
The proof of this result is a simple consequence of the series expansion .
Appendix C Deferred proofs
C.1 Proof of Lemma 2
Proof of Lemma 2.
Since is the orthogonal projector onto the span of , , we have
By Sylvester’s identity, and since , it holds
Similarly, it holds that . ∎
C.2 Approximation of the Fredholm determinant
Before giving the proof of Theorem 1, we remind a well-known and useful formula for the Fredholm determinant of an operator. Let be a trace class endomorphism of a separable Hilbert space. Denote by its (possibly infinitely many) eigenvalues for , including multiplicities. Then, we have
where the (infinite) product is uniformly convergent, see Bornemann [2010, Eq. (3.1)] and references therein. Now, let and be two separable Hilbert spaces. Let such that is trace class. Note that is self-adjoint and positive semi-definite. Then, and have the same non-zero eigenvalues (Jacobson’s lemma) and Sylvester’s identity
holds. This can be seen as a consequence of the singular value decomposition of a compact operator; see Weidmann [1980, page 170, Theorem 7.6]. We now give the proof of Theorem 1.
Proof of Theorem 1.
To begin, we recall two useful facts. First, If and are two trace class endomorphisms of the same Hilbert space, then ; see e.g. Simon [1977, Thm 3.8]. Second, if is a trace class endomorphisms of a Hilbert space, we have , and thus, is a well-defined Fredholm determinant since is trace class. Now, define and . Using Sylvester’s identity and the aforementioned facts, we write
| (18) |
By a direct substitution, we verify that with
Note that, in view of (18), is a positive real number. Next, by using and Sylvester’s identity, we find
The latter bound is finite, since for a trace-class operator, we have , where is the trace (or nuclear) norm. By exchanging the roles of and , we also find
and thus, by combining the two cases, we find
Now, in order to upper bound with high probability, we use the following Bernstein inequality for a sum of random operators; see Rudi et al. [2015, Proposition 12] and Minsker [2017].
Proposition 15 (Bernstein’s inequality for a sum of i.i.d. random operators).
Let be a separable Hilbert space and let be a sequence of independent and identically distributed self-adjoint positive random operators on . Assume that and that there exists a real number such that almost surely. Let be a trace class positive operator such that . Then, for any ,
with probability . If there further exists an such that almost surely, then, for any ,
holds with probability .
To apply Proposition 15 and conclude the proof, first recall the expression of the covariance operator
and of its sample version
Define . It is easy to check that since . Then, using the triangle inequality and that , we find the bound
Next, we compute a bound on the variance by bounding the second moment, namely
where we used . Also, we have
Moreover,
where we used that is the integral operator on with integral kernel . We are finally ready to apply Proposition 15. Since
it holds, with probability at least ,
This concludes the proof of Theorem 1. ∎
C.3 Statistical guarantee for the approximation of the log-likelihood by its sampled version
Proof of Theorem 4.
The proof follows similar lines as in Rudi et al. [2020, Proof of Thm 5], with several adaptations. Let be the solution of (9). Notice that and are distinct operators. Let as in Lemma 2. Since has an optimal objective value, we have
Now we use the properties of given in Lemma 2, namely that and . Then it holds
By combining the last two inequalities, we have and therefore
| (19) |
We will use (19) to derive upper and lower bounds on the gap .
Lower bound.
Upper bound.
We have the bound with high probability (for the same event as above)
| (21) |
By combining this with (20), we find
Since, by assumption, we have , the latter inequality becomes
| (22) |
By using (22) in the bound in (21), we obtain
Thus, the upper and lower bound yield together
where we used once more . This is the desired result. ∎
C.4 Numerical approach: convergence study
Proof of Theorem 3.
This proof follows the same technique as in Mariet and Sra [2015], with some extensions. Let . We decompose the objective
as the following sum: , where is a strictly convex function on and
is concave on . We refer to Lemma 8 and 9 for the former and latter statements, respectively. Then, we use the concavity of to write the following upper bound
where the matrix-valued gradient is
Define the auxillary function which satisfies and . We define the iteration where
so that it holds . Thus, this iteration has monotone decreasing objectives. It remains to show that this iteration corresponds to (13). The solution of the above minimization problem can be obtained by solving the first order optimality condition since is strictly convex. This gives
Now, we replace in the above condition. After a simple algebraic manipulation, we obtain the following condition
where, as defined in (13), and
Finally, we introduce the Cholesky decomposition , so that we have an equivalent identity
Let and . The positive definite solution of this second order matrix equation write
which directly yields (13). ∎
C.5 Approximation of the correlation kernel
We start by proving the following useful result.
Theorem 16 (Correlation kernel approximation, formal version).
Let be the failure probability and let be a scale factor. Let be the approximation defined in (11) with i.i.d. sampling of points. Let be large enough so that with where and Then, with probability it holds that
Furthermore, if we assume , we can take
Proof.
For simplicity, define as , which is such that . Then, we write
where we recall that . Next, we used the following result.
Proposition 17 (Proposition 5 in Rudi et al. [2018] with minor adaptations).
Let and with be identically distributed random vectors on a separable Hilbert space , such that there exists for which almost surely. Denote by the Hermitian operator . Let . Then for any , the following holds
with probability and .
Then, we merely define the following vector for so that
Furthermore, we define . Also, we have , so that . Hence, it holds . First, by using , we have
almost surely. Next, we calculate the following quantity
where we used the push-through identity at the next to last equality.
For obtaining the bound on , we first write
To lower bound the latter quantity we require and hence . For the remainder of the proof, we show the main matrix inequality. For convenience, define the upperbound in Proposition 17 as
| (23) |
Thanks to Proposition 17, we know that with probability , we have
or equivalently
By simply adding to these inequalities, we obtain
Hence, if , by a simple manipulation, we find
By acting with on the left and on the right, and then, using the push-through identity
the desired result follows. ∎
Proof of Theorem 6.
Consider the upper bound given in (23). We will simplify it to capture the dominant behavior as . Assume , or equivalently In this case, we give a simple upper bound on as follows
so that we avoid manipulating cumbersome expressions. Thus, if we want the latter bound to be smaller than , we require
which is indeed larger than since . Thus, by using the same arguments as in the proof of Theorem 16, we have the multiplicative error bound
with probability at least if
where the last equality is obtained by substituting and given in Theorem 16. ∎
Appendix D Supplementary empirical results
D.1 Finer analysis of the Gaussian L-ensemble estimation problem of Section 6
In this section, we report results corresponding to the simulation setting of Section 6 with .
Intensity estimation from several DPP samples.
In Figure 4, we replicate the setting of Figure 1 with and DPP samples and a smaller regularization parameter. The estimated intensity is then closer to the ground truth () for a large value of , although there are small areas of high intensity at the boundary of the domain . A small improvement is also observed by increasing from (left) to (right), namely the variance of the estimated intensity tends to decrease when increases.







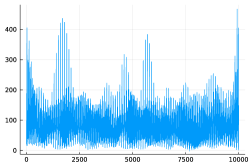
In Figure 5, we illustrate the intensity estimation in the case of a large and small , respectively on the left and right columns. As expected, a large value of has a regularization effect but also leads to an underestimation of the intensity. On the contrary, a small value of seems to cause inhomogeneities in the estimated intensity.




Correlation structure estimation.
The general form of the correlation kernel is also important. In order to visualize the shape of the correlation kernel , we display in Figure 6 the Gram matrices of the estimated and ground truth correlation kernels on a square grid, for the same parameters as in Figure 4 (RHS). After removing the boundary effects, we observe that the estimated correlation kernel shape closely resembles the ground truth although the decay of the estimated kernel seems to be a bit slower. Moreover, we observe some ‘noise’ in the tail of the estimated kernel. Again, the intensity of the estimated process is also a bit underestimated.
In the context of point processes, it is common to compute summary statistics from samples to ‘understand’ the correlation structure of a stationary process. It is strictly speaking not possible to calculate e.g. Ripley’s K function (see Baddeley et al. [2015]) since our estimated correlation kernel is not stationary, that is, there exits no function such that .
D.2 Convergence of the regularized Picard iteration
In particular, we illustrate the convergence of the regularized Picard iteration to the exact solution given in Proposition 12. In Figure 7, we solve the problem (6) in the case with where is the unique DPP sample. For simplicity, we select the DPP sample used in Figure 1 (, bottom row).


This illustrates that the regularized Picard iteration indeed converges to the unique solution in this special case.
D.3 Complexity and computing ressources
Complexity.
The space complexity of our method is dominated by the space complexity of storing the kernel matrix in Algorithm 1, namely where we recall that with . The time complexity of one iteration of (14) is dominated by the matrix square root, which is similar to the eigendecomposition, i.e., . The time complexity of Algorithm 2 is dominated by the Cholesky decomposition and the linear system solution, i.e., .
Computing ressources.
A typical computation time is minutes to solve the example of Figure 1 (bottom row) on virtual cores of a server with two core Intel Xeon E5-2695 v4s ( Ghz). The computational bottleneck is the regularized Picard iteration.
References
- Affandi et al. [2014] R. H. Affandi, E. Fox, R. Adams, and B. Taskar. Learning the parameters of determinantal point process kernels. In E. P. Xing and T. Jebara, editors, Proceedings of the 31st International Conference on Machine Learning, volume 32 of Proceedings of Machine Learning Research, pages 1224–1232, Bejing, China, 22–24 Jun 2014. PMLR. URL http://proceedings.mlr.press/v32/affandi14.html.
- Anquetil et al. [2020] L. Anquetil, M. Gartrell, A. Rakotomamonjy, U. Tanielian, and C. Calauzènes. Wasserstein learning of determinantal point processes. In Learning Meets Combinatorial Algorithms at NeurIPS2020, 2020. URL https://openreview.net/forum?id=fabfWf3JJQi.
- Baddeley et al. [2015] A. Baddeley, E. Rubak, and R. Turner. Spatial Point Patterns: Methodology and Applications with R. Chapman and Hall/CRC Press, London, 2015. URL https://www.routledge.com/Spatial-Point-Patterns-Methodology-and-Applications-with-R/Baddeley-Rubak-Turner/9781482210200/.
- Baraud [2013] Y. Baraud. Estimation of the density of a determinantal process. Confluentes Mathematici, 5(1):3–21, 2013. doi: 10.5802/cml.1. URL http://www.numdam.org/articles/10.5802/cml.1/.
- Bardenet and Titsias [2015] R. Bardenet and M. K. Titsias. Inference for determinantal point processes without spectral knowledge. In Advances in Neural Information Processing Systems (NIPS), pages 3375–3383, 2015. URL https://proceedings.neurips.cc/paper/2015/file/2f25f6e326adb93c5787175dda209ab6-Paper.pdf.
- Belhadji et al. [2019] A. Belhadji, R. Bardenet, and P. Chainais. Kernel quadrature with determinantal point processes. In Advances in Neural Information Processing Systems (NeurIPS), 2019. URL https://proceedings.neurips.cc/paper/2019/file/7012ef0335aa2adbab58bd6d0702ba41-Paper.pdf.
- Belhadji et al. [2020a] A. Belhadji, R. Bardenet, and P. Chainais. Kernel interpolation with continuous volume sampling. In International Conference on Machine Learning (ICML), 2020a. URL http://proceedings.mlr.press/v119/belhadji20a.html.
- Belhadji et al. [2020b] A. Belhadji, R. Bardenet, and P. Chainais. A determinantal point process for column subset selection. Journal of Machine Learning Research (JMLR), 2020b. URL http://jmlr.org/papers/v21/19-080.html.
- Biscio and Lavancier [2017] C. A. N. Biscio and F. Lavancier. Contrast estimation for parametric stationary determinantal point processes. Scandinavian Journal of Statistics, 44(1):204–229, 2017. doi: https://doi.org/10.1111/sjos.12249. URL https://onlinelibrary.wiley.com/doi/abs/10.1111/sjos.12249.
- Bornemann [2010] F. Bornemann. On the numerical evaluation of Fredholm determinants. Mathematics of Computation, 79(270):871–915, 2010. URL https://www.ams.org/journals/mcom/2010-79-270/S0025-5718-09-02280-7/.
- Brunel et al. [2017a] V.-E. Brunel, A. Moitra, P. Rigollet, and J. Urschel. Maximum likelihood estimation of determinantal point processes. arXiv preprint arXiv:1701.06501, 2017a. URL https://arxiv.org/abs/1701.06501.
- Brunel et al. [2017b] V.-E. Brunel, A. Moitra, P. Rigollet, and J. Urschel. Rates of estimation for determinantal point processes. In Proceedings of the 2017 Conference on Learning Theory, volume 65 of Proceedings of Machine Learning Research, pages 343–345. PMLR, 2017b. URL http://proceedings.mlr.press/v65/brunel17a/brunel17a.pdf.
- Derezinski et al. [2020] M. Derezinski, F. Liang, and M. Mahoney. Bayesian experimental design using regularized determinantal point processes. In S. Chiappa and R. Calandra, editors, Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 of Proceedings of Machine Learning Research, pages 3197–3207. PMLR, 26–28 Aug 2020. URL http://proceedings.mlr.press/v108/derezinski20a.html.
- Dupuy and Bach [2018] C. Dupuy and F. Bach. Learning determinantal point processes in sublinear time. In A. Storkey and F. Perez-Cruz, editors, Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84 of Proceedings of Machine Learning Research, pages 244–257. PMLR, 09–11 Apr 2018. URL http://proceedings.mlr.press/v84/dupuy18a.html.
- Gartrell et al. [2017] M. Gartrell, U. Paquet, and N. Koenigstein. Low-rank factorization of determinantal point processes. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, AAAI’17, page 1912–1918. AAAI Press, 2017. URL https://ojs.aaai.org/index.php/AAAI/article/view/10869.
- Gartrell et al. [2019] M. Gartrell, V.-E. Brunel, E. Dohmatob, and S. Krichene. Learning nonsymmetric determinantal point processes. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper/2019/file/cae82d4350cc23aca7fc9ae38dab38ab-Paper.pdf.
- Gartrell et al. [2021] M. Gartrell, I. Han, E. Dohmatob, J. Gillenwater, and V.-E. Brunel. Scalable Learning and MAP Inference for Nonsymmetric Determinantal Point Processes. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=HajQFbx_yB.
- Gautier et al. [2019] G. Gautier, R. Bardenet, and M. Valko. On two ways to use determinantal point processes for monte carlo integration. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper/2019/file/1d54c76f48f146c3b2d66daf9d7f845e-Paper.pdf.
- Ghosh and Rigollet [2020] S. Ghosh and P. Rigollet. Gaussian determinantal processes: A new model for directionality in data. Proceedings of the National Academy of Sciences, 117(24):13207–13213, 2020. ISSN 0027-8424. doi: 10.1073/pnas.1917151117. URL https://www.pnas.org/content/117/24/13207.
- Hough et al. [2006] J. B. Hough, M. Krishnapur, Y. Peres, and B. Virág. Determinantal processes and independence. Probability surveys, 2006. URL https://doi.org/10.1214/154957806000000078.
- Hough et al. [2009] J. B. Hough, M. Krishnapur, Y. Peres, and B. Virág. Zeros of Gaussian analytic functions and determinantal point processes, volume 51. American Mathematical Society, 2009. URL https://doi.org/http://dx.doi.org/10.1090/ulect/051.
- Kulesza and Taskar [2012] A. Kulesza and B. Taskar. Determinantal point processes for machine learning. Foundations and Trends in Machine Learning, 2012. URL http://dx.doi.org/10.1561/2200000044.
- Lavancier et al. [2014] F. Lavancier, J. Møller, and E. Rubak. Determinantal point process models and statistical inference. Journal of the Royal Statistical Society, Series B, 2014. URL http://www.jstor.org/stable/24775312.
- Lavancier et al. [2015] F. Lavancier, J. Møller, and E. Rubak. Determinantal point process models and statistical inference. Journal of the Royal Statistical Society. Series B (Statistical Methodology), 77(4):853–877, 2015. ISSN 13697412, 14679868. URL http://www.jstor.org/stable/24775312.
- Lavancier et al. [2021] F. Lavancier, A. Poinas, and R. Waagepetersen. Adaptive estimating function inference for non-stationary determinantal point processes. Scandinavian Journal of Statistics, 48(1):87–107, Mar. 2021. doi: 10.1111/sjos.12440. URL https://hal.archives-ouvertes.fr/hal-01816528.
- Macchi [1975] O. Macchi. The coincidence approach to stochastic point processes. Advances in Applied Probability, 7:83–122, 1975. URL http://www.jstor.org/stable/1425855.
- Mariet and Sra [2015] Z. Mariet and S. Sra. Fixed-point algorithms for learning determinantal point processes. In F. Bach and D. Blei, editors, Proceedings of the 32nd International Conference on Machine Learning, volume 37 of Proceedings of Machine Learning Research, pages 2389–2397, Lille, France, 07–09 Jul 2015. PMLR. URL http://proceedings.mlr.press/v37/mariet15.html.
- Mariet et al. [2019] Z. Mariet, M. Gartrell, and S. Sra. Learning determinantal point processes by corrective negative sampling. In K. Chaudhuri and M. Sugiyama, editors, Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, volume 89 of Proceedings of Machine Learning Research, pages 2251–2260. PMLR, 16–18 Apr 2019. URL http://proceedings.mlr.press/v89/mariet19b.html.
- Marteau-Ferey et al. [2020] U. Marteau-Ferey, F. R. Bach, and A. Rudi. Non-parametric models for non-negative functions. In Advances in Neural Information Processing Systems 33, 2020. URL https://arxiv.org/abs/2007.03926.
- Minsker [2017] S. Minsker. On some extensions of Bernstein’s inequality for self-adjoint operators. Statistics & Probability Letters, 127:111–119, 2017. URL https://www.sciencedirect.com/science/article/pii/S0167715217301207.
- Poinas and Lavancier [2021] A. Poinas and F. Lavancier. Asymptotic approximation of the likelihood of stationary determinantal point processes. working paper or preprint, Mar. 2021. URL https://hal.archives-ouvertes.fr/hal-03157554.
- Rosasco et al. [2010] L. Rosasco, M. Belkin, and E. D. Vito. On learning with integral operators. Journal of Machine Learning Research, 11(30):905–934, 2010. URL http://jmlr.org/papers/v11/rosasco10a.html.
- Rudi et al. [2015] A. Rudi, R. Camoriano, and L. Rosasco. Less is more: Nyström computational regularization. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems 28, pages 1657–1665. Curran Associates, Inc., 2015. URL http://papers.nips.cc/paper/5936-less-is-more-nystrom-computational-regularization.pdf.
- Rudi et al. [2018] A. Rudi, D. Calandriello, L. Carratino, and L. Rosasco. On fast leverage score sampling and optimal learning. In Advances in Neural Information Processing Systems, pages 5673–5683, 2018. URL https://arxiv.org/abs/1810.13258.
- Rudi et al. [2020] A. Rudi, U. Marteau-Ferey, and F. Bach. Finding global minima via kernel approximations. In Arxiv preprint arXiv:2012.11978, 2020. URL https://arxiv.org/abs/2012.11978.
- Simon [1977] B. Simon. Notes on infinite determinants of Hilbert space operators. Advances in Mathematics, 24(3):244–273, 1977. ISSN 0001-8708. doi: https://doi.org/10.1016/0001-8708(77)90057-3. URL https://www.sciencedirect.com/science/article/pii/0001870877900573.
- Soshnikov [2000] A. Soshnikov. Determinantal random point fields. Russian Mathematical Surveys, 55:923–975, 2000. URL https://doi.org/10.1070/rm2000v055n05abeh000321.
- Sterge et al. [2020] N. Sterge, B. Sriperumbudur, L. Rosasco, and A. Rudi. Gain with no pain: Efficiency of kernel-pca by nyström sampling. In S. Chiappa and R. Calandra, editors, Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 of Proceedings of Machine Learning Research, pages 3642–3652. PMLR, 26–28 Aug 2020. URL http://proceedings.mlr.press/v108/sterge20a.html.
- Urschel et al. [2017] J. Urschel, V.-E. Brunel, A. Moitra, and P. Rigollet. Learning determinantal point processes with moments and cycles. In D. Precup and Y. W. Teh, editors, Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 3511–3520. PMLR, 06–11 Aug 2017. URL http://proceedings.mlr.press/v70/urschel17a.html.
- Weidmann [1980] J. Weidmann. Linear Operators in Hilbert Spaces. 68. Springer-Verlag, 1980. doi: 10.1007/978-1-4612-6027-1. URL https://www.springer.com/gp/book/9781461260295.
- Wendland [2004] H. Wendland. Scattered Data Approximation. Cambridge Monographs on Applied and Computational Mathematics. Cambridge University Press, 2004. doi: 10.1017/CBO9780511617539. URL https://doi.org/10.1017/CBO9780511617539.