Nonlinear Optimal Guidance for Cooperatively Imposing Relative Intercept Angles
Abstract
The optimal cooperative guidance in the nonlinear setting for intercepting a target by multiple pursuers is studied in the paper. As certain relative angles can improve observability, the guidance command is required to cooperatively control the pursuers to intercept the target with specific relative angles. By using the neural networks, an approach for real-time generation of the nonlinear cooperative optimal guidance command is developed. Specifically, the optimal control problem with constraints on relative intercepting angles is formulated. Then, Pontryagin’s maximum principle is used to derive the necessary conditions for optimality, which are further employed to parameterize the nonlinear optimal guidance law. As a result, the dataset for the mapping from state to nonlinear optimal guidance command can be generated by a simple propagation. A simple feedforward neural network is trained by the dataset to generate the nonlinear optimal guidance command. Finally, numerical examples are presented, showing that a nonlinear optimal guidance command with specific relative angles can be generated within a faction of a millisecond.
1 Introduction
The research on intercepting scenarios with multiple pursuers is becoming increasingly popular in recent years. Because single pursuer cannot satisfy the demand of various application, a cooperative guidance architecture for multiple pursuers manifests the superiority in temporal and spatial scale. Thus, a temporal cooperative scheme involving multiple pursuers is considered as an effective solution and has drawn much attention due to its improved interception performance and its high level of fault tolerance [1].
However, pure temporal cooperation for simultaneous arrival can not release the full effectiveness of multiple pursuers. Therefore, spatial cooperation for encirclement is also investigated [2]-[5]. Accordingly, a spatial cooperation for multi-directional interception is devised to effectively enhance the observability and limit the evasion of the opponent. Thus, the spatial cooperative attack helps to enhance the target identification and decrease its evasive probability.
The spatial cooperative interception enables the group of pursuers to formulate superior geometry relative to the target. Eventually, the purpose of spatial cooperation is to control the different angles of the pursuer-target collision triangle. In [6], an explicit cooperative guidance law by controlling the relative intercept angles to formulate angular geometry based on the linearized kinematics was proposed. And it is proved that explicit cooperation yields better performance than implicit ones. Fonod and Shima developed a cooperative guidance law to improve the observability of the target by imposing desired relative flight-path angles [7]. Meanwhile, in the game of pursuer and target, the evasive maneuver of the target may result in a large heading angle. Under these engagement conditions, the small angle assumption is violated and the performance of aforementioned algorithms that are based on linearized kinematics will deteriorate dramatically.
The nonlinear control theory has been used to develop cooperative guidance strategy to avoid the issue of linear optimal cooperative guidance laws. A sliding-mode control theory was leveraged by Song et al. [8] to realize implicit coordination of the line-of-sight (LOS) angle. Finite-time consensus theory and the super-twisting control algorithm were employed by Zhang et al. [9] to control each pursuer to reach the target with the desired LOS angle. In [10], the concept of encirclement was introduced in the field of cooperative guidance, and a pseudocontrol-effort optimal encirclement guidance law was derived in a relative virtual frame. Nonetheless, to the author’s best knowledge, it is not common to see the studies on real optimal explicit cooperative guidance laws.
In this paper, based on the work in [11, 12], the focus is on developing an explicit cooperative guidance law that is able to guide each pursuer to reach its desirable relative intercept angle with minimum control effort. By parameterizing the nonlinear optimal guidance law using Pontryagin’s Maximum Principle (PMP) [13], we can generate the dataset for the mapping from state to nonlinear optimal guidance command by solving some simple initial value problems. After training a basic feedforward neural network (FNN) with the dataset, it can swiftly produce an optimal guidance command within a fraction of a millisecond.
2 Problem Formulation
2.1 Engagement Geometry
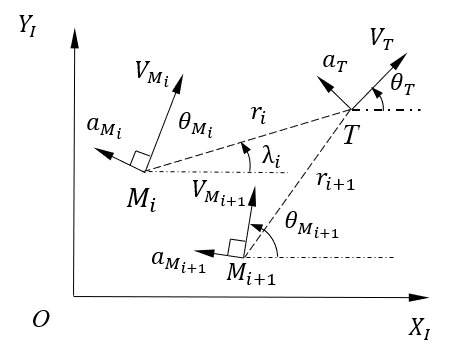
The planar engagement geometry for pursuers against one maneuvering target is depicted in Fig. 1. The inertial frame is denoted by , signifies the th pursuer, and represents the target. During the terminal guidance stage, the engaged pursuers are assumed to have a constant velocity. The speed is denoted by , and the acceleration is represented by . Symbol is called the heading angle. Those notations with subscript and refer to corresponding values for the th pursuer and the target, respectively.
The terminal intercept angles of the th pursuer and the th pursuer are and , respectively. The difference between these two intercept angles is the relative intercept angle between the two pursuers from the target’s perspective. This is the angle that will be forced between two consecutive pursuers. Note that, if the target does not maneuver between the two intercepts or the intercepts occur at the same time, this angle will be [6].
The differential equations for the relative motion are given by
| (1) |
where represents the range between the th pursuer and the target, denotes the LOS angle.
The nonlinear kinematics for the th pursuer is expressed as
| (2) | ||||
where denotes the position of the th pursuer in the frame .
Considering the system of the group of pursuers, the state equations can be obtained as
| (3) |
2.2 Optimal Cooperative Intercept Problem
For a single pursuer, it was proved that the global solution of free-time minimum-effort nonlinear optimal intercept problem does not exist [11]. This non-existence of global solutions holds true in the multi-pursuer scenarios. Thus, the objective function with a linear combination of control effort and engagement duration is considered. Then, let us consider the following optimal cooperative intercept problem (OCIP):
Problem 1(OCIP) Given an initial condition
| (4) |
where , and a free final time , the OCIP consists of steering the system in Eq. (3) by a measurable control vector on from the initial state to the final point , with the final heading angle satisfying
| (5) |
such that
| (6) |
is minimized where is a weighting factor.
3 Parametrization of Optimal Guidance Law
3.1 Pontryagin’s Maximum Principle
Denote by , , and as the costate variables of , , and , respectively. Then, the Hamiltonian for the OCIP is expressed as
| (7) |
In view of remark 2 from [11], we can consider in the remainder of the paper.
According to PMP, for , it holds that
| (8) | ||||
and
| (9) |
Explicitly rewriting Eq. (9) leads to
| (10) |
Because of the final heading angle in Eq. (5), the transversality condition implies
| (11) |
As the final time is free, along the optimal trajectory, it holds that
| (12) |
3.2 Parameterized System
Utilizing the canonical equations derived by PMP, we can establish a parameterized system with the gathered states of pursuers as
| (13) | ||||
In the following section, a mapping will be established for an FNN to generate the solution of OCIP.
4 Generation of Dataset
The parameterized system in Eq.(13) can be propagated backward with an initial value satisfying the terminal constraints
| (14) | ||||
and transversality conditions
| (15) | ||||
Thus, the nonlinear optimal guidance commands are able to be generated to satisfy the necessary conditions of optimality.
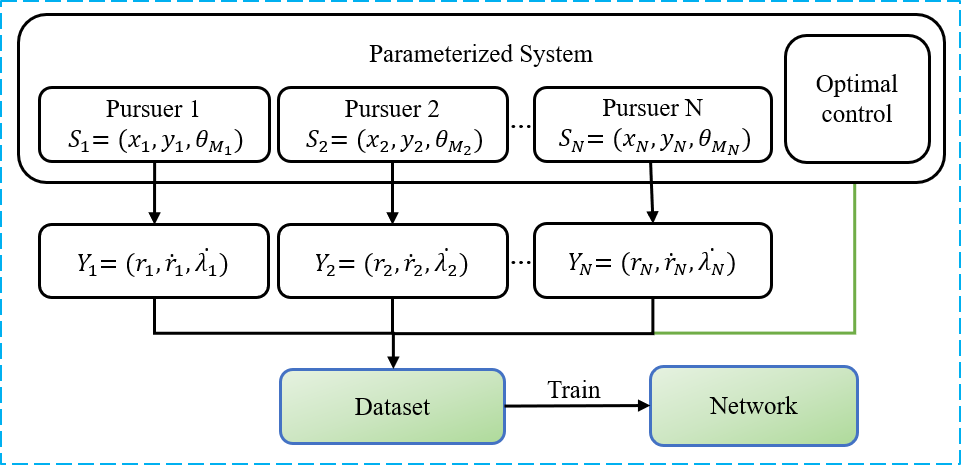
Given any appropriate initial value, we can obtain a list of nonlinear optimal guidance commands by solving an initial value problem in Eq. (13). As a result, by sampling some pairs in feasible regions as initial conditions, we are able to use the initial value problem in Eq. (13) to generate sampled data for optimal guidance law. Then, the dataset for the mapping from the flight state to the corresponding optimal feedback control can be immediately obtained.
In this paper, we assume an ideal condition that the pursuers in the group can communicate with each other. We denote the state of the th pursuer in a polar frame as . Let be the optimal feedback control vector of the OCIP at the combined state of pursuers . A simple FNN trained by the dataset is able to approximate the mapping
| (16) |
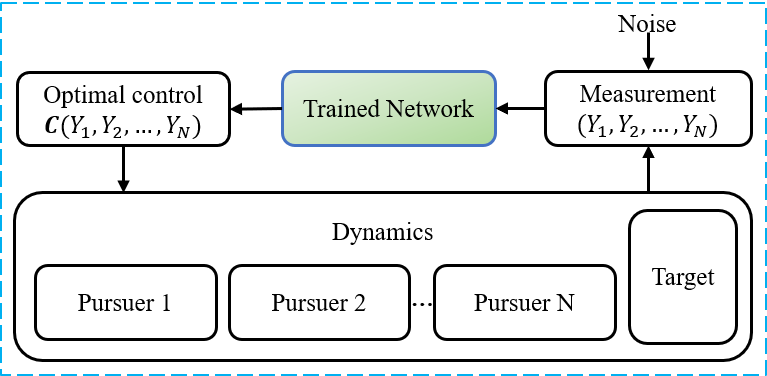
as shown by the diagram in Fig. 2. Thus, given a combined state of the group of pursuers , each pursuer can use the same FNN to generate the feedback control of the OCIP in a closed-loop guidance system, as shown in Fig. 3.
5 Numerical Applications
This section provides simulations of a two-on-one engagement () to demonstrate the performance of the proposed nonlinear cooperative optimal guidance strategy. The speed of each pursuer is set as m/s.
Set the weight as and the relative final heading angle as deg. We generated about trajectories by backward propagation of the differential equations in Eq. (13). An FNN with three hidden layers (each containing 20 neurons) was trained by the dataset to approximate the optimal feedback guidance commands. Given any feasible input, the trained FNN takes around ms to produce an output on an embedded system with MYC-Y6ULY2 CPU at 528 MHz.
Due to the transversality conditions in Eq. (11) and the formula of optimal control in Eq. (10), there must be a one-to-many mapping at the terminal of the OCIP. According to the universal approximation theorem (see, e.g., [14, 15, 16]), the FNN is unable to approximate the mapping. Therefore, we will switch to proportional navigation (PN) once the range between the th pursuer and the target is less than m.
5.1 Case
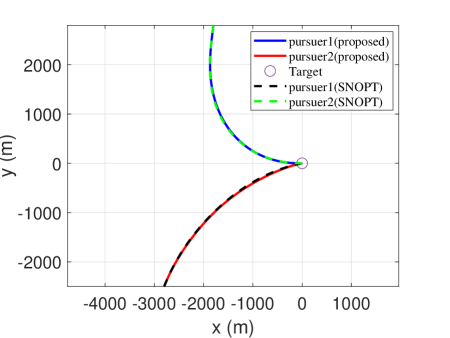
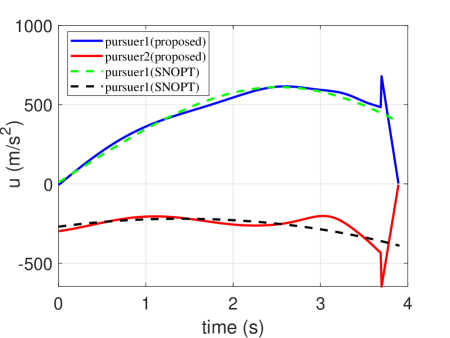
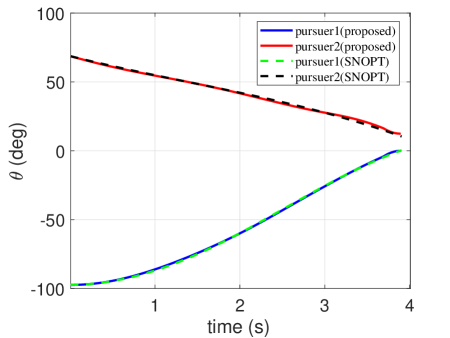
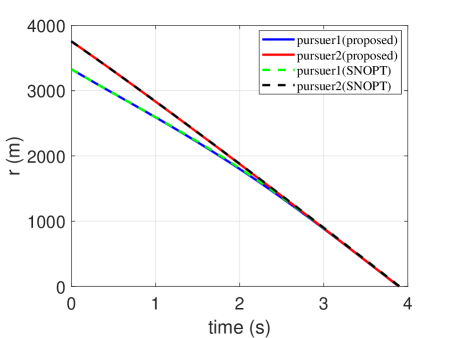
In order to show the capability of the trained network to generate optimal trajectories, an example of proximity is simulated by comparing it with the optimization methods (here, we employed the optimization toolbox: SNOPT). Their initial conditions of them are given in Table 1. The trajectories of the two pursuers are presented in Fig. 4. Their control profiles are demonstrated in Fig. 5. The heading angle profiles are presented in Fig. 6. The time histories of range between th pursuer and the target are depicted in Fig. 7. Note that the proposed guidance strategy should be switched to PN once the range m. Thus, the control profiles are not continuous for the proposed guidance strategy. It is seen that the trajectories generated by the trained network coincide with those obtained from optimization methods. However, as optimization methods suffer the convergence issue, they cannot be guaranteed to calculate the optimal command within a guidance period.
| state | |||
|---|---|---|---|
| pursuer | -1.8km | 2.8km | -97deg |
| pursuer | -2.8km | -2.5km | 69deg |
5.2 Case
| state | |||
|---|---|---|---|
| pursuer | -3.1km | -2.4km | 178deg |
| pursuer | -0.25km | -5km | 100deg |
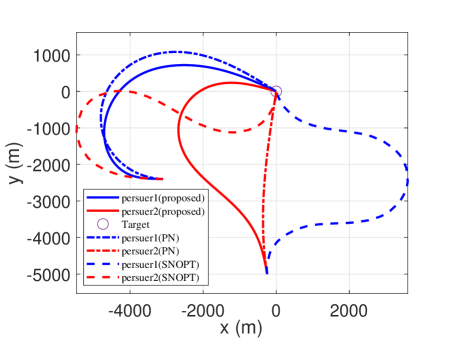
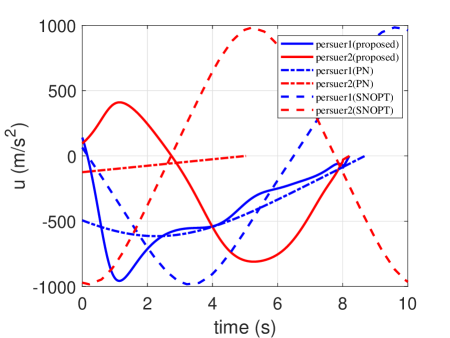
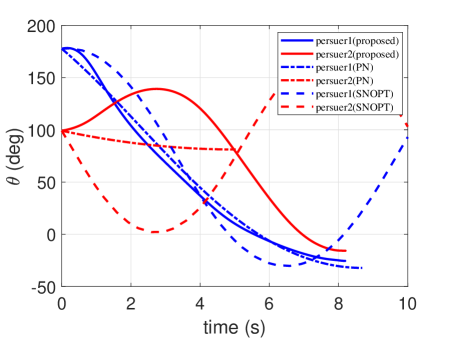
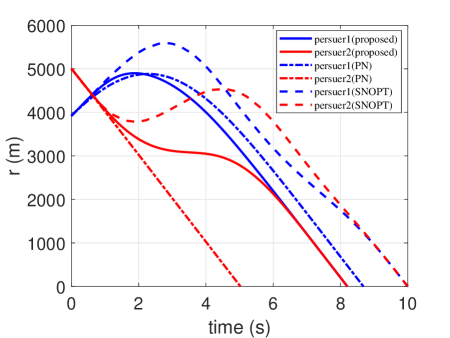
In this scenario, a simulation of engagement is considered by comparing it with the traditional PN and the optimization methods (SNOPT). Their initial conditions are given in Table 2. The generated trajectories are presented in Fig. 8, and the corresponding control profiles are reported in Fig. 9. The time histories of heading angle are presented in Fig. 10. The range profiles are depicted in Fig. 11. It can be seen that in Fig. 8 and Fig. 10, the constraint of relative intercept angle cannot be satisfied by the pure PN. The optimality of the results is compared with the optimal solutions solved by SNOPT. The total control effort by SNOPT
| (17) |
However, the corresponding total control effort by FNN is just . It means that the trajectories by FNN are better than that by SNOPT from the perspective of control effort.
6 Conclusions
The problem of optimal explicit cooperative guidance for imposing a relative intercept angle was investigated. The method of parametrization for nonlinear optimal guidance law was proposed. Necessary optimality conditions for optimal control policy were established by applying the PMP. Consequently, the optimal trajectories can be propagated from those equations, which can be used to generate the dataset of the mapping from state of the group of pursuers to optimal feedback guidance command. Then, a simple FNN trained from the dataset was utilized to generate the cooperative guidance command. Finally, two cases of simulations were presented, indicating that the proposed optimal guidance law can generate optimal trajectories within a constant time.
Acknowledgements.
This work was supported by the National Natural Science Foundation of China (61903331, 62088101), Key Research and Development Program of Zhejiang Province (2020C05001).References
- [1] I.-S. Jeon, J.-I. Lee, and M.-J. Tahk, “Impact-time-control guidance law for anti-ship missiles,” IEEE Transactions on control systems technology, vol. 14, no. 2, pp. 260–266, 2006.
- [2] V. Shaferman, “Near-optimal evasion from pursuers employing modern linear guidance laws,” Journal of Guidance, Control, and Dynamics, vol. 44, no. 10, pp. 1823–1835, 2021.
- [3] P. Dwivedi, P. Bhale, A. Bhattacharyya, and R. Padhi, “Generalized estimation and predictive guidance for evasive targets,” IEEE Transactions on Aerospace and Electronic Systems, vol. 52, no. 5, pp. 21 111–2122, 2016.
- [4] R. Ragesh, A. Ratnoo, and D. Ghose, “Decoy launch envelopes for survivability in an interceptor–target engagement,” Journal of Guidance, Control, and Dynamics, vol. 39, no. 3, pp. 667–676, 2016.
- [5] C. Zhai, F. He, Y. Hong, L. Wang, and Y. Yao, “Coverage-based interception algorithm of multiple interceptors against the target involving decoys,” Journal of Guidance, Control, and Dynamics, vol. 39, no. 7, pp. 1647–1653, 2016.
- [6] V. Shaferman and T. Shima, “Cooperative optimal guidance laws for imposing a relative intercept angle,” Journal of Guidance, Control, and Dynamics, vol. 38, no. 8, pp. 1395–1408, 2015.
- [7] R. Fonod and T. Shima, “Estimation enhancement by cooperatively imposing relative intercept angles,” Journal of Guidance, Control, and Dynamics, vol. 40, no. 7, pp. 1711–1725, 2017.
- [8] J. Song, S. Song, and S. Xu, “Three-dimensional cooperative guidance law for multiple missiles with finite-time convergence,” Aerospace Science and Technology, vol. 67, pp. 193–205, 2017.
- [9] S. Zhang, Y. Guo, Z. Liu, S. Wang, and X. Hu, “Finite-time cooperative guidance strategy for impact angle and time control,” IEEE Transactions on Aerospace and Electronic Systems, vol. 57, no. 2, pp. 806–819, 2020.
- [10] H. Li, S. He, J. Wang, and C.-H. Lee, “Optimal encirclement guidance,” IEEE Transactions on Aerospace and Electronic Systems, vol. 58, no. 5, pp. 4327–4341, 2022.
- [11] Z. Chen and T. Shima, “Nonlinear optimal guidance for intercepting a stationary target,” Journal of Guidance, Control, and Dynamics, vol. 42, no. 11, pp. 2418–2431, 2019.
- [12] K. Wang, Z. Chen, H. Wang, J. Li, and X. Shao, “Nonlinear optimal guidance for intercepting stationary targets with impact-time constraints,” Journal of Guidance, Control, and Dynamics, vol. 45, no. 9, pp. 1614–1626, 2022.
- [13] L. S. Pontryagin, Mathematical theory of optimal processes. Routledge, 2018.
- [14] K. Hornik, M. Stinchcombe, and H. White, “Multilayer feedforward networks are universal approximators,” Neural networks, vol. 2, no. 5, pp. 359–366, 1989.
- [15] G. Cybenko, “Approximation by superpositions of a sigmoidal function,” Mathematics of control, signals and systems, vol. 2, no. 4, pp. 303–314, 1989.
- [16] K. Hornik, “Approximation capabilities of multilayer feedforward networks,” Neural networks, vol. 4, no. 2, pp. 251–257, 1991.