Non-myopic Beam Scheduling for Multiple Smart Target Tracking in Phased Array Radar Network
Abstract
A smart target, also referred to as a reactive target, can take maneuvering motions to hinder radar tracking. We address beam scheduling for tracking multiple smart targets in phased array radar networks. We aim to mitigate the performance degradation in previous myopic tracking methods and enhance the system performance, which is measured by a discounted cost objective related to the tracking error covariance (TEC) of the targets. The scheduling problem is formulated as a restless multi-armed bandit problem (RMABP) with state variables, following the Markov decision process. In particular, the problem consists of parallel bandit processes. Each bandit process is associated with a target and evolves with different transition rules for different actions, i.e., either the target is tracked or not. We propose a non-myopic, scalable policy based on Whittle indices for selecting the targets to be tracked at each time. The proposed policy has a linear computational complexity in the number of targets and the truncated time horizon in the index computation, and is hence applicable to large networks with a realistic number of targets. We present numerical evidence that the model satisfies sufficient conditions for indexability (existence of the Whittle index) based upon partial conservation laws, and, through extensive simulations, we validate the effectiveness of the proposed policy in different scenarios.
Index Terms:
Target tracking, beam scheduling, restless bandits, Whittle index.I Introduction
State-of-the-art sensor scheduling approaches have enabled higher flexibility for tracking smart targets through phased array radar networks, where real-time beam direction control is handled electronically [1, 2, 3]. Dynamic tracking of smart targets, which have the ability to be aware that they are being tracked and adapt their dynamics accordingly to hinder tracking accuracy, has drawn recent research attention [4, 5, 6]. Hence, beam scheduling in radar networks with a trade-off between frequency of tracking and probability of maneuvering is complicated and of importance in smart-target tracking. In this paper, we address a model to minimize the expected total discounted error for tracking smart targets through dynamic beam scheduling [7, 8].
Resource scheduling in radar systems has been mostly addressed through myopic policies. In [9], the challenge of antenna selection within a distributed multi-radar system was formulated as a knapsack problem, with the Cramér–Rao lower bound (CRLB) being regarded as the objective function. By exploring the multi-start knapsack tree, a local search algorithm with a multi-start strategy was adapted to solve the problem. In [10, 11, 12, 13, 14, 15, 16, 17, 18], at each time, once obtaining the estimation of the target dynamic states, the predicted one-step posterior CRLB (PCRLB) is calculated and used as the optimization metric to allocate resources for the next time step. However, in general, myopic scheduling policies exhibit inevitable performance degradation in the long run [19].
Non-myopic scheduling policies based on predicted multi-step objective functions or on partially observed Markov decision processes (POMDPs) [20] have been investigated in a wide range of settings. In [19], a bee colony algorithm with particle swarm optimization (PSO) was introduced to optimize a multi-step objective function representing operational risk. In [21, 22], the joint multi-target probability density (JMPD) was recursively estimated by particle filtering methods, and the maximum expected Rényi divergence between the JMPD and the JMPD recalculated with a new derived measurement was considered for long-term performance optimization. In [21], two information-directed approaches were presented to approximate the long-term effects of each action. One is a path searching approach, aiming to reduce the computational complexity of a full Monte Carlo search. The other one approximates an action’s long-term benefit through a distinct function, expressed in relation to “opportunity cost” or “regret”. In [22], a non-myopic sensor scheduling method leveraging the POMDP framework was utilized to improve long-term performance. In [23], a smart target tracking problem was modeled as a POMDP using the PCRLB as system state and multi-step cost prediction over unscented sampling. An improved decision tree search algorithm leveraging branch and bound was used to achieve non-myopic scheduling optimization for maneuvering target tracking. Similarly as in [23], a branch-and-bound algorithm was considered in [24] for sensor scheduling to reduce the interception probability. In [25, 26], a POMDP-based branch-and-bound algorithm with worst-case exponential complexity was applied to a sensor allocation problem for reducing the risks of the sensor radiation interception and target threat level, which provided a non-myopic scheme with improved long-term performance.
Since computing optimal dynamic beam scheduling policies for POMDP multi-target tracking models is generally intractable and has worst-case exponential complexity, researchers have instead aimed to design suboptimal heuristic index policies with low computational complexity. An index policy is based on defining an index for each target, a scalar function of its state, and giving higher tracking priority at each time to targets with larger index values. A simple greedy index for tracking a target moving in one dimension is its tracking error variance (TEV), which is updated via scalar Kalman filter dynamics [27].
A versatile model for addressing optimal resource management problems and index policies are provided by the restless multi-armed bandit problem (RMABP) [28], which is an extension to the multi-armed bandit problem (MABP) [29, 30, 31]. The RMABP focuses on selecting a maximum of from a pool of projects (or bandits), which are versatile entities capable of being either active (i.e., chosen) or passive at each time. Different from MABP, in an RMABP, a bandit is able to change state while passive.
While solving optimally the RMABP is generally intractable [32], Whittle proposed in [28] a heuristic index policy, which has since been widely applied [33], where the index of a project depends only on its parameters. The Whittle index is implicitly defined as the state-dependent critical subsidy for passivity that makes both actions optimal in a single-project subproblem. Yet, neither existence nor uniqueness of such a critical subsidy is guaranteed, so the Whittle index is well defined only for the class of indexable projects. Whittle conjectured that, when all projects are indexable, this index policy should approach optimality asymptotically under the average criterion as and grow to infinity in a fixed ratio. [34] showed this not to be generally true, but gave sufficient conditions under which the conjecture holds.
Establishing indexability of a restless bandit model is widely considered a challenging task, which hinders the application of Whittle’s index policy. The currently dominant approach for proving indexability, mostly applied to one-dimensional state models, entails a two-step process: first, optimality of threshold policies is proven for single-project subproblems; and, second, the Whittle index is obtained from the optimal threshold under an appropriate monotonicity condition on the latter. Yet, some models have not yielded to such an approach, in particular restless bandit models for target tracking with Kalman filter dynamics, as considered here.
The RMABP formulation of multi-target tracking was first considered in [35], extending work in [27]. Given the lack of effective tools to prove indexability in such a setting, [35] addressed the greedy index policy and focused on identifying sufficient conditions for its optimality in scenarios with two symmetric scalar-state targets. [36] further investigated that model using the prevailing approach to indexability, encountering that it posed seemingly unsurmountable difficulties, so they assumed the optimality of threshold policies without proving it. The Whittle index policy has been studied via simulation to achieve near-optimality in related past studies [37, 38, 39].
Niño-Mora [40, 41, 42, 43] developed an alternative method to prove indexability and assess the Whittle index, circumventing the need to establish the optimality of threshold policies. It sufficed to show that certain project performance metrics under such policies satisfy PCL-indexability conditions —named after satisfaction of partial conservation laws (PCLs) [40, 44]. A verification theorem guarantees the optimality of threshold policies as well as the indexability of the model and its Whittle index was given by an explicitly defined marginal productivity (MP) index. This was proven in [40, 41, 42, 43] in increasingly general settings.
The PCL-indexability conditions for real-state restless bandits under the discounted criterion, which we shall apply here, were first outlined without proof in [45], and their application to multi-target tracking was numerically explored in [46, 47]. The verification theorem was proven in [48, 43]. [49] used such conditions to first establish the indexability of scalar-state Kalman-filter restless bandits.
In the more practically relevant case of multi-target tracking RMABP models with multi-dimensional state Kalman filter dynamics, indexability is currently an open problem. A heuristic approach was developed in [50], where scalar-state project approximations were considered by taking as system state the trace of the channel estimation mean square error (MSE).
For smart targets, sensor scheduling problems become substantially more complex, as such targets react to radar sensing by switching their dynamics between different modes, e.g., a constant velocity (CV) mode, a constant acceleration (CA) mode, a constant turn (CT) mode, etc. [4, 5, 6, 51]. In such scenarios, it might be beneficial to refrain from sensing too often those targets that are likely to hide or escape when tracked, as this would make them harder to track in the future. Therefore, proactive measures are necessary to effectively track smart targets. In [4], when a smart target is viewed by a sensor, it reacts by “hiding” itself. The tracking problem was formulated as a Markov decision process (MDP) with an infinite time horizon, which was addressed through a two-stage reinforcement-learning approach with separated optimizations for detection and tracking. In [5], a modified algebraic Riccati equation (MARE) was applied in a Kalman-based target tracking system with smart targets. This work considered game-theoretic methods that aimed to optimize waveform parameters and radar modes under imperfect measurement information, which was caused by the variation of the detection probability under target maneuvering. In [6], a POMDP model with multiple dynamics models was considered to minimize the interception risk during the tracking of multiple reactive targets. A roll-out method based on unscented transformation sampling (UTS) was introduced to approximate the long-term reward and to select sensors based on the closest distance policy. In [38], the problem of hunting hiding targets was formulated as an RMABP, where the state of a target is its posterior probability of being exposed. Experimental results were presented showing that the Whittle index policy outperforms greedy policies.
Hence, substantial research challenges remain in sensor scheduling for tracking smart targets, including: 1) Solving optimally Markov decision process (MDP) models with multiple smart targets entails a prohibitively high computational cost; 2) In models with multi-dimensional tracking error covariance (TEC) state, the application of the Whittle index policy is at present elusive; and 3) Increasing radar radiation for enhancing tracking performance needs to be optimally traded off with the potential of targets to react with evasive maneuvers in response to radiation detection.
In this paper, we consider a beam scheduling problem for tracking multiple smart targets that have a high probability of switching their dynamics when observed by phased array radars so as to hinder their tracking. Otherwise, targets have a high probability of selecting a CV dynamics model under non-observation. Similar to the interacting multiple models (IMM) method, the state of each target is defined as its sum-weighted TEC based on dynamics model probability vectors, which are assumed to be constant. To formulate the beam scheduling problem, we consider an infinite-horizon discounted MDP model of RMABP type, where each target corresponds to a restless project. The RMABP formulation is exploited to propose a non-myopic low-complexity scheduling policy. In particular, we aim to apply the Whittle index policy to the dynamic beam scheduling for tracking smart targets. Yet, such a goal is hindered by the fact that no proof of indexability (existence of the Whittle index) is at present available for this model. We partially circumvent this difficulty by presenting some numerical evidence supporting the conjecture that the model satisfies the aforementioned PCL-indexability conditions, and use the MP index policy resulting from them. Recall that, if it were proven that the model satisfied such conditions, this would imply that the model is indexable and the MP index would be its Whittle index. In addition, a different MP-based index policy is proposed in the multi-dimensional TEC state case. Through extensive simulation results, this index policy is shown to outperform baseline policies. The contributions of this paper are summarized as follows.
-
•
We formulate the beam scheduling problem for tracking multiple smart targets as an infinite-horizon discounted RMABP. The smart targets are characterized by tracking-action-dependent dynamics models with high maneuvering, which aim to hide themselves when being tracked. Each target is associated with a restless project, whose state is its sum-weighted TEC state based on the multiple-dynamic-model probability vectors.
-
•
We aim to minimize the multi-target tracking error measured by the sum of the TECs. To mitigate the maneuvering of the smart targets, the system should avoid overuse of tracking action. In the real-state case, we apply the Whittle index policy (using the MP index in the belief that it coincides with the Whittle index ) to this beam scheduling problem.
-
•
The Whittle index policy is analyzed in the real-valued state model, while in the multi-dimensional TEC state case, a different MP index policy is considered. The TEC states evolve through the Kalman filter. For the real-valued case, we present numerical evidence that the sufficient indexability conditions based on PCLs are satisfied, which is also used to evaluate the index. Furthermore, we provide the results of a simulation study assessing the sub-optimality gap of the Whittle index policy. The effectiveness of the proposed MP index policy for the multi-dimensional target state case is also assessed by a simulation study, where it is shown to outperform baseline policies.
The remainder of this paper is organized as follows. In Section II, the target dynamics models and measurement models are defined. Then, the state update under different actions and the discounted long-term objective of the scheduling problem are formulated. In Section III, the application of the Whittle index policy is discussed. The beam selection scheme is developed in the RMABP model based on MP indices for real-valued and multi-dimensional state cases. The computational method of the lower bound of optimization functions and the computational complexity of policies are presented. In Section IV, real-valued and multi-dimensional state cases are considered, and reckless and cautious targets with different dynamics model probabilities are also considered. The simulation results demonstrate the superiority of the proposed index policies. Section V concludes the paper.
II Model description and problem formulation
We update the target states via the Kalman filter and exploit the multiple dynamics model and corresponding model probabilities to represent the motion characteristics of smart targets. Subsequently, we formulate the beam scheduling problem as an RMABP, of which each bandit process is associated with a target.
II-A Target dynamics models
We consider smart targets labeled by and a radar network consisting of phased array radars, as illustrated in Fig. 1. In Fig. 1, targets 1 and will likely change their dynamics models in response to radar tracking, while target 2 will be likely to maintain its dynamics model. All radars are synchronized to operate over time slots . The radar network centrally steers beams to track at most targets at each time, as one radar beam can be only assigned to one target in a time slot.
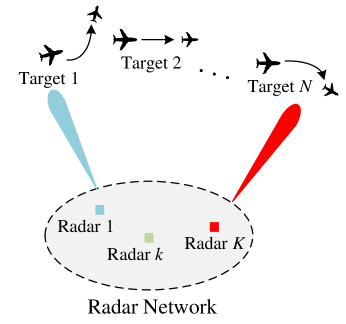
We assume that radars detect targets with unit probability. Denote the kinematic state of target at time by . Targets follow independent linear dynamics. Meanwhile, they are smart, that is, they react to radar radiation by switching between dynamics models, labeled by , e.g., CV, CA, CT, etc. Target ’s dynamics under model is
| (1) |
In (1), is the state transition matrix, and is process noise with mean being zero and covariance matrix being . We assume that for a covariance matrix , where and corresponds to the CV model, so the uncertainty of the dynamics model increases with .
At each time , we use a binary variable to denote the tracking action imposed on target . Let if target is not tracked. Conversely, when , the target is actively tracked, and a measurement is acquired following the subsequent measurement equation,
| (2) |
where is the measurement matrix, and is a zero-mean Gaussian white noise with covariance matrix .
II-B Probabilities of dynamics models
Targets are assumed to change their dynamics models depending only on whether they are being tracked. After action is applied on target at each time, its dynamics model is randomly drawn to be with probability , for . We write , where and is the transpose operator. We assume that , , so targets that are not being tracked are more likely to move into model (CV). We further assume that for , so targets that are being tracked are less likely to move into model .
Consequently, the smart targets are characterized by the dynamics model probability matrix, and the states of the targets are affected not only by the CV model but also by the other dynamics models.
II-C Kalman filter-based TEC update
Target TECs evolve based on the Kalman filter [52]. Denote by the TEC of target at the beginning of time slot . Starting from the initial TEC , is recursively updated over time slots being conditioned by the chosen actions, taking into account the dynamics models, as follows.
If the target is tracked at time (), then
| (3) |
where
| (4) |
| (5) |
| (6) |
and is the identity matrix.
If the target is not tracked at time (), then
| (7) |
Note that the TEC update recursion given by (3)–(7) is deterministic. It follows that action updates the TEC through sum-weighted method based on the model probability vector . When , the target maneuvers with higher probability , than CV with lower probability . It leads to a larger determinant of TEC state than that of solely calculated by CV model. If , then, since , , with larger in (7), the determinant of TEC state will be smaller than that with probability .
II-D RMABP model formulation
We next formulate the optimal beam scheduling problem for radars and smart targets as an infinite-horizon discrete-time RMABP, aiming to achieve the optimal dynamic selection of out of binary-action projects. For such a purpose, we identify a target with a project, which can be operated under the active action (track the target) and the passive action (do not track it). We take as the state of project the corresponding target’s TEC, , which moves over the state space of symmetric positive definite matrices, according to Kalman filter dynamics as shown in Section II-C.
For target at time , the immediate cost caused by imposing action is defined as
| (8) |
where denotes the trace of a matrix, is the target’s weight, which is used to model the importance of targets, and is a measurement cost.
The radar network selects at most out of smart targets to track in each time slot . We consider that each radar can only steer one beam to track one target at each time, which is formulated as the constraint
| (9) |
Given the joint model probabilities and a TEC state at the beginning , we consider the dynamic optimization problem with discounted cost over an infinite time horizon.
| (10) |
where is the discount factor, is expectation under policy conditioned on the initial state , and denote by the set of stationary scheduling policies that satisfy (9). We denote by the optimal cost of problem (10).
III RMABP-based beam scheduling policy
Generally, determining an optimal policy for problem (10) is a computationally intractable task, due both to the curse of dimensionality and to the continuous state space. We next discuss how Whittle’s [28] approach for obtaining a heuristic index policy would apply to this smart target tracking problem and discuss the challenges it poses. See also [46].
III-A Problem relaxation and decomposition
To obtain a relaxed version of problem (10), we replace the sample-path constraint (9) by the following constraint,
| (11) |
Now, consistently with the above notation , let represent the set of stationary scheduling policies capable of activating any quantity of projects (tracking any number of targets) at each time. Then, a relaxation of problem (10) is as follows.
| (12) | ||||
Therefore, the minimum cost derived from problem (12) establishes a lower bound on .
Attach now a Lagrange multiplier to the aggregate constraint (11). The Lagrangian relaxation applied to (12) is
| (13) |
Given a , the optimal value of the Lagrangian relaxation, denoted as , serves as a lower bound for .
If we search for an optimal Lagrange multiplier based on the Lagrangian relaxation, the best lower bound for is obtained. This defines the dual problem of (12):
| (14) |
III-B Computing the Lower bound
In the one-dimensional case with real-valued state space for a single bandit process, can be calculated through the value iteration approach [53]. In general, consider the lower bound in (14) which is the optimal value of the Lagrangian dual problem. Recall that we aim to minimize the expected total discounted (ETD) cost. Based on the Bellman equation, we firstly derive the optimal value function for the process of target in (15). Given the Lagrange multiplier , we obtain
| (16) | ||||
Subsequently given the Lagrange multiplier in (13), we can derive the multitarget optimal value function and substitute (16) into it, as given by
| (17) | ||||
where
| (18) |
representing the next-slot joint target states.
Based on the established value function and a given , we establish the -th iteration of value function as
| (19) | ||||
Then, we use the value iteration approach to continue the iterative process over the state space until convergence of values on diverse joint state . Finally, we obtain the optimal value in (16) and derive in (17). Given the initial joint state and a given , the minimum cost can be computed by . The lower bound of the dual problem in (14) can be computed by searching a to satisfy
| (20) |
III-C Indexability and Whittle index policy
Consider now the following structural property of subproblems (15), referred to as indexability in [28], which we formulate next as in [47, Section 3.2]. Note that target ’s subproblem (15) is indexable if there exists an index that characterizes its optimal policies, as follows: for any , when the target is in state , () is necessary and sufficient conditions for that taking action () is optimal.
If each subproblem were indexable, the Whittle index policy would be to track up to out of the targets with larger index values, among those with nonnegative indices. If the current index of a target is negative, it is not tracked.
Yet, at present it is unknown whether restless projects with multi-dimensional Kalman filter dynamics such as those above are indexable, even for a single dynamics model (). Indexability has only been established (in [49]) for the special case of target tracking with scalar Kalman filter dynamics and a single dynamics model, by applying the PCL-indexability approach for real-state projects in [43].
III-D PCL-indexability approach for real-state targets
We next outline the PCL-indexability approach for real-state restless bandit projects as it applies to the present model (so ). In the sequel we pay attention to the MP index of a single target with multiple dynamics models as described above, and drop the subscript from notations.
Starting from an initial state , for a policy , define the cost metric
| (21) |
which gives the ETD cost, where is the target’s tracking error variance (TEV) state.
The work metric is defined as
| (22) |
The subproblem (15) can be reformulated as
| (23) |
The indexability of subproblem (23) is studied under deterministic stationary policies and threshold policies. Deterministic stationary policies are represented as (Borel measurable) subsets of TEV states, where the corresponding target is tracked. We will employ an active set denoted as to characterize the -active policy. In particular, for any given threshold level , we will designate this as the -threshold policy. This means that, for a target in TEV state , if , the target is tracked; otherwise, it is not tracked. Therefore, a -threshold policy has active set . It is clear that, if , then ; if , then ; and if , then . We shall denote the corresponding cost and work metrics in (21) and (22) by and , respectively.
Given a threshold , the cost and work metrics are characterized by the functional equations.
| (24) |
and
| (25) |
In practice, such metrics can be approximately computed by a value-iteration scheme with a finite truncated time horizon , as discussed in [43, Section 11].
Next, we represent as the policy that executes action at time and subsequently follows the -threshold policy from onwards. Accordingly, we introduce the corresponding marginal metrics for the previously discussed measures. Specifically, we define the marginal cost metric and the marginal work metric . If , we further define the MP metric function by
| (26) |
If for all , we define the MP index by
| (27) |
As in [43, Definition 7], we say that the subproblem (23) is PCL-indexable (with respect to threshold policies) if the following PCL-indexability conditions hold:
-
•
(PCLI1) for every state and threshold ;
-
•
(PCLI2) is monotone non-decreasing, continuous, and bounded below;
-
•
(PCLI3) for each , the metrics , and the index are related by: for ,
where the right-hand side is a Lebesgue–Stieltjes integral.
The interest of the above PCL-indexability conditions lies in their applicability through the verification theorem in [43, Theorem 1], which ensures that, for a real-state project, conditions (PCLI1)–(PCLI3) above imply that the project is indexable, and the MP index is its Whittle index.
Corollary 1.
If subproblem (23) is PCL-indexable, then it is indexable with Whittle index .
This was the approach deployed in [49] to prove indexability for the special case of a single dynamics model (). Yet, proving that conditions (PCLI1)–(PCLI3) hold for the present model with is beyond the scope of this work. Still, we conjecture that the model satisfies such conditions, and will present partial numerical evidence supporting satisfaction of such conditions. We shall further use the MP index above as a surrogate of the Whittle index, and refer to it as the Whittle index. Note that only if it were proven that conditions (PCLI1)–(PCLI3) hold could we ensure that the MP index is indeed the Whittle index.
III-E A heuristic MP index for multi-dimensional state targets
In the case of target dynamic states moving over in a -dimensional state space , with , the TEC matrix indicates the tracking accuracy of the target state’s components, e.g., location and velocity. Since the TEC state is an matrix, a convenient scalar measure of tracking performance is given by its trace. The application of the PCL-indexability approach for proving indexability and evaluating the Whittle index in such a case remains an open problem, even in the case of single target dynamics (). This section leverages the past success of the PCL-indexability and extends a new heuristic approach to define an MP index for the multi-dimensional case.
In particular, we define the cost metric and the work metric by replacing the one-dimensional in (21) and (22) with the multi-dimensional . The target’s optimal tracking subproblem (15) becomes
| (28) |
We need to define the meaning of threshold policies in the present setting. For such a purpose, we shall consider that the -threshold policy tracks the target in state if and only if . Then, the corresponding cost metric and work metric are the unique solutions to the following functional equations:
| (29) |
| (30) |
Again, we can approximate such solutions through a value-iteration approach using a truncated time horizon .
Now, similar to the scalar case above, we define the marginal cost metric , the marginal work metric , and the MP metric
| (31) |
provided that .
The corresponding MP index is defined by
| (32) |
provided that for all .
However, there is currently no theory supporting any relation of the index with the Whittle index in the multi-dimensional case, assuming that both are well defined. Still, we will discuss in Section IV the results of a simulation study on the performance of the index policy based on the heuristic MP index .
III-F Scheduling scheme based on the Whittle index policy
In Sections III-D and III-E, we discussed the MP-based indices for a bandit process with real-valued and multi-dimensional state spaces, respectively. In general, the MP-based index policy prioritizes tracking specific targets based on their state-dependent MP indices, regardless of the dimensions of the state, in descending order. The pseudo-code of implementing the index policy with given indices is provided in Algorithm 1, which is applicable to both cases with one-dimensional and multi-dimensional state spaces.
III-G Computational complexity analysis
For the case with real-valued bandit states, the complexity for computing the indices in (32) is only linear in the number of targets and the truncated time . Nonetheless, for the case with multi-dimensional state space for each bandit process, the linearity does not hold in general due to the complex matrix operations in (3) and (7).
In the Whittle index policy, the truncated time horizon is the recursive horizon in (29) and (30). If the actions of each target across time horizon are all assumed as 0, the computational complexity of (31) is . Otherwise, the computational complexity is , where and () represent the complexity of updating matrix states when the corresponding action variable is set to and , respectively. Due to the diverse combination of actions across time horizon, the computational complexity of the Whittle index is less than . That is, we have a complexity of .
We introduce two greedy approaches as baseline policies. One is the TEC index policy, which defines the indices by
| (33) |
The computational complexity of the TEC index is . The other prioritizes actions according to the MP indices with , namely, the myopic index policy with the indices given by
| (34) |
The computational complexity for is . The baseline policies exhibit lower computational complexity but, in general, fail to take consideration of long future effects of the employed actions. Based on numerical results in [46, 47, 38], with appropriate (), the MP indices (described in (32)) with truncated horizon is sufficiently close to the analytical Whittle indices, for which the computational complexity is comparable to the greedy approaches.
IV Simulation and Analysis
In this section, we report on numerical experiments to assess the satisfaction of the PCL-indexability conditions and the effectiveness of the proposed Whittle (MP) index policy in the real-state case. We will compare the proposed index policy with the two greedy baselines, i.e., the TEC policy and the myopic policy, in the scalar and the multi-dimensional state cases.
IV-A PCL-indexability conditions and MP index evaluation for real-state smart targets
We start by considering the PCL-indexability conditions stated in Section III-D as they apply to scalar state targets. Recall that they are sufficient conditions for indexability (existence of the Whittle index) and further give an explicit expression of the Whittle index in the form of an MP index. Establishing analytically that the present model satisfies such conditions is beyond the scope of this work. Still, we present below a sample of numerical evidence supporting the conjecture that the model satisfies such conditions.
To test the conditions numerically, we consider targets with dynamics models, which we refer to as CV () and CT (), and parameter values , , , , , and . There are no measurement costs () and the weight is . We assume two types of smart targets, called reckless and cautious, where reckless targets have a higher probability of maneuvering (using the CT model) when tracked than cautious targets. Hence, the dynamics model probability matrix differs with the target types. Specifically, we take
| (35) |
where, if target belongs to reckless targets, target belongs to cautious targets, we can obtain and , .
In the following numerical experiments, the infinite series defining the metrics of interest have been approximately computed by using the truncated time horizon . The discount factor is , and the TEV state has been taken from a grid of values, each separated by a distance of .
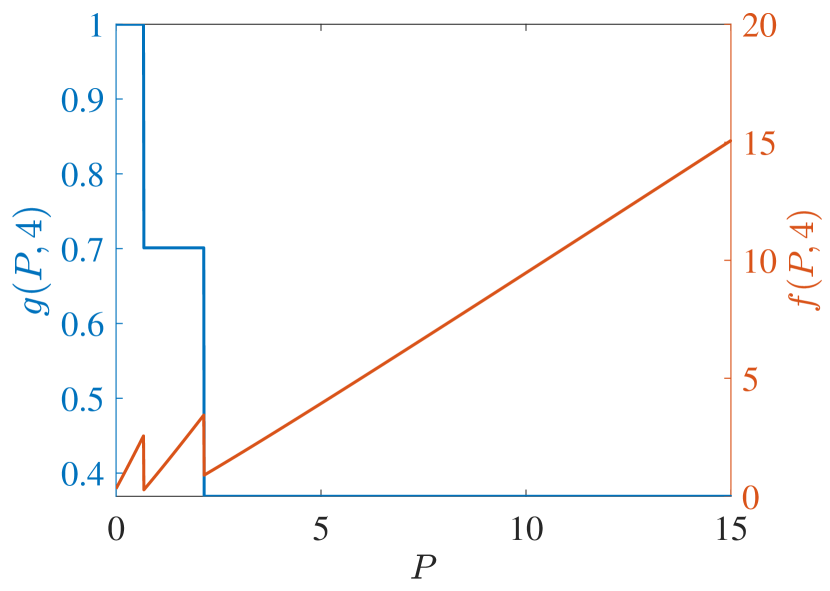
(a)
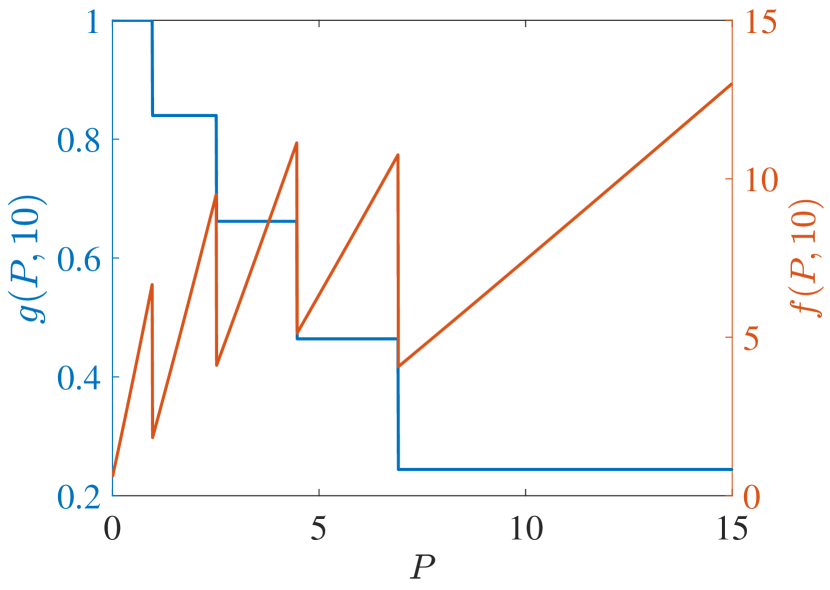
(b)
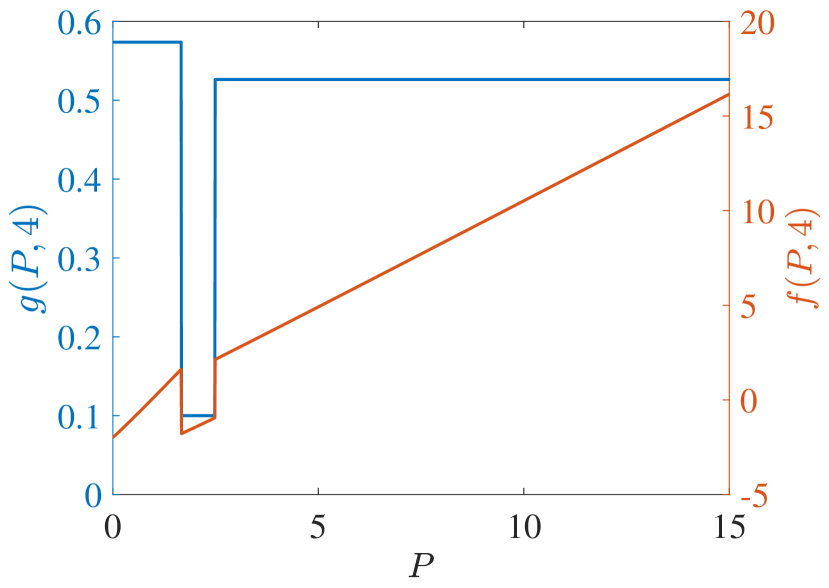
(c)
(d)
(a)
(b)
(c)
(d)
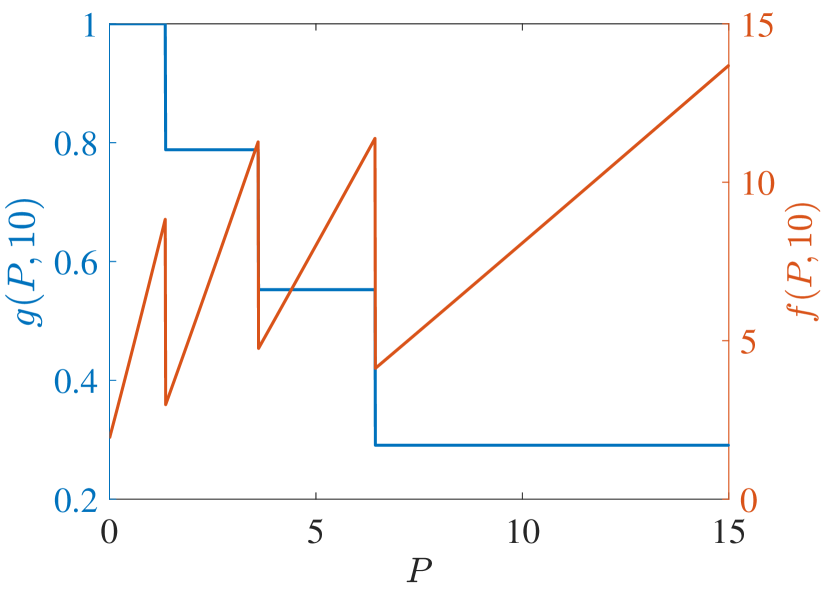
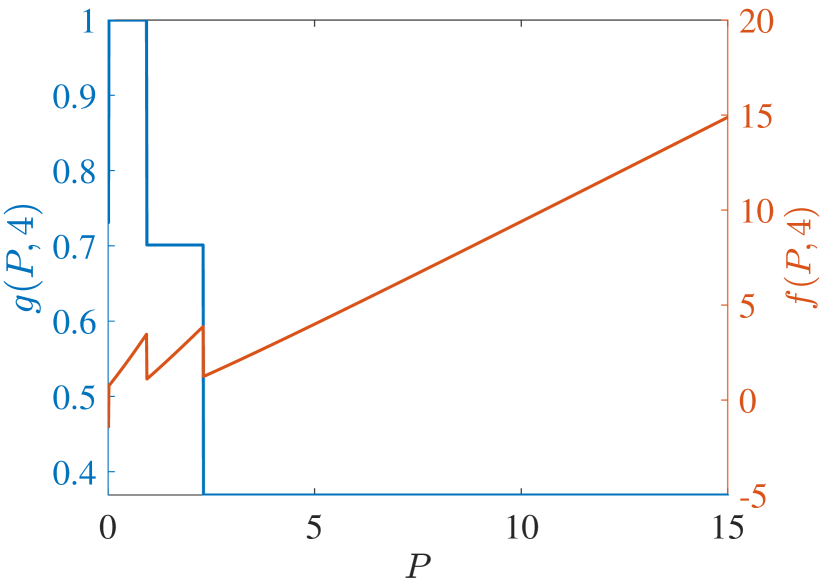
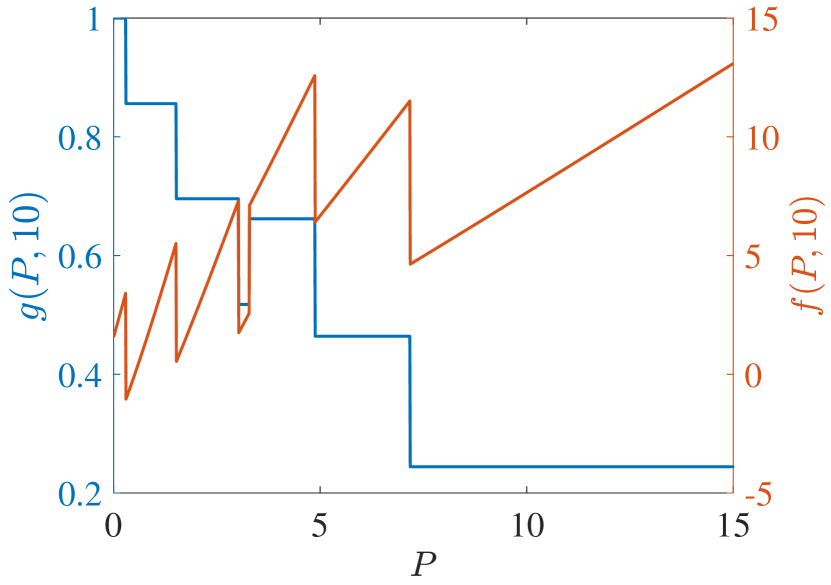
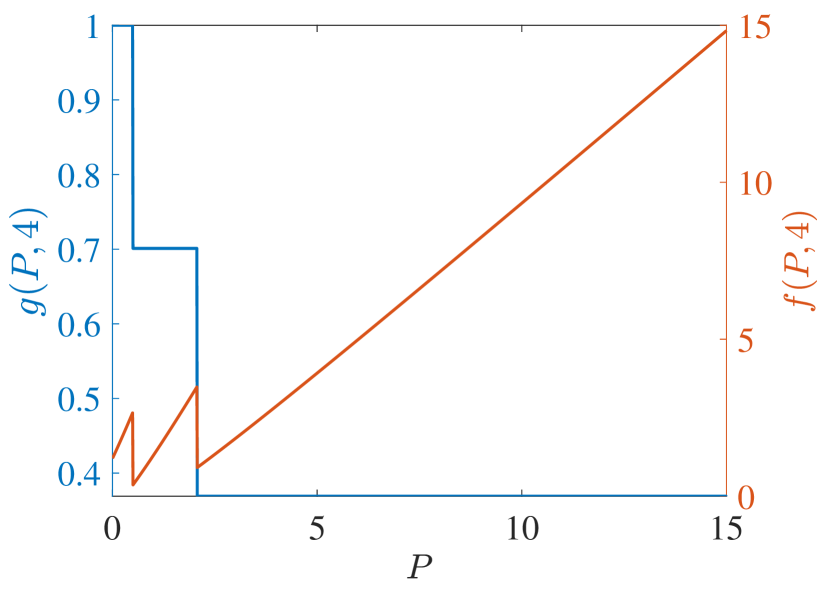
Start with PCL-indexability condition (PCLI1), namely that marginal work metric be positive for each TEV state and threshold . Figs. 2 and 3 plot both and the marginal cost metric against for several choices of threshold and of the parameter, for reckless targets and cautious targets in Fig. 2 and Fig. 3, respectively. The plots support the validity of condition (PCLI1), as in each instance, a result that has been observed under other parameter choices not reported here.
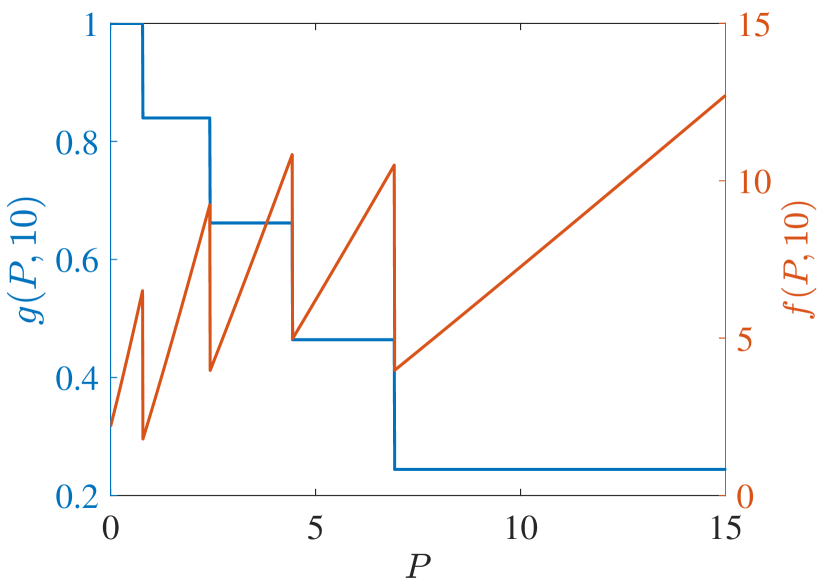
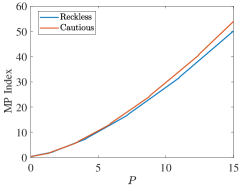
Regarding PCL-indexability condition (PCLI2), namely that the MP index defined by be bounded below, continuous and monotone non-decreasing, Fig. 4 plots the MP index with choices of and for the two target types considered. Figs. 4 (c) and (d) show the MP index vs. for , respectively. The plots are clearly consistent with condition (PCLI2), which has been observed in other instances not reported here.
(a)
(b)
(c)
(d)
Fig. 4 (a) and (b) further show the MP index vs. for states , respectively. When the state is small, the long-term cost is predominantly influenced by . Consequently, with the same , the reckless target with a higher will obtain a higher MP index value. Otherwise, with a large , prioritizing the long-term cost minimization, the MP index policy will sacrifice the immediate cost at the current time and track the target with higher after a certain number of time steps. That is, the target with a lower is tracked currently. Hence, the MP index will decrease over . Due to the higher probability of a cautious target acquiring a lower cost with the same state and under action 1, cautious targets obtain a higher index than reckless targets in all states, which indicates that the MP index policy takes the tracking action prudently for reckless targets.
In summary, the above partial numerical evidence that the model of concern satisfies PCL-indexability conditions (PCLI1) and (PCLI2), and hence we shall further use the MP index as a surrogate of the Whittle index, and refer to it as the Whittle index.
IV-B Performance results with real-valued states
In this subsection, smart targets are tracked by the radars network with radars. For each target, the radar tracking time horizon s and . We set up the Whittle index policy with the truncated time , the TEV index policy where , and the myopic policy that degenerates to to assess tracking performances.
The parameters , , , of target and , are assumed the same as Section IV-A, . The initial state . Then, we define three scenarios with only reckless type, cautious type, and each type of target accounting for 4, where the process noise variance and in the first two scenarios, respectively; Otherwise, and in the third scenario. We assume , and , in the first two scenarios. Moreover, for reckless targets and for cautious targets in the third scenario.
Table I, II, III show the discounted objective performance in three policies. Each policy is analyzed by varying the optional number of radars and Monte Carlo simulations. When all the targets are homogeneous and heterogeneous, the Whittle index policy can obtain the best scheduling performance and outperform the TEV index and myopic policies. The myopic policy considers the one-step cost optimization, which is beneficial to the different types of targets; While the TEV index policy is not insensitive to the variation of targets. Consequently, the performance of the myopic policy is better than the TEV policy. Hence, the simulation results of all the scenarios show the superiority of the Whittle index policies.
| Policies | ||||
| Whittle index | 823.19 | 400.53 | 284.65 | |
| myopic | 868.71 | 405.85 | 293.80 | |
| TEV | 871.19 | 406.17 | 293.72 | |
| Whittle index | 961.25 | 458.49 | 319.84 | |
| myopic | 993.93 | 464.43 | 326.04 | |
| TEV | 1009.15 | 465.12 | 334.06 |
| Policies | ||||
| Whittle index | 750.91 | 377.36 | 268.30 | |
| myopic | 790.61 | 381.92 | 275.81 | |
| TEV | 790.40 | 384.06 | 275.75 | |
| Whittle index | 817.23 | 406.26 | 285.67 | |
| myopic | 849.91 | 409.88 | 296.35 | |
| TEV | 861.88 | 410.56 | 296.19 |
| Policies | ||||
| Whittle index | 1554.35 | 772.19 | 547.38 | |
| myopic | 1614.41 | 807.35 | 567.14 | |
| TEV | 1622.97 | 808.89 | 567.94 | |
| Whittle index | 1664.83 | 821.05 | 581.47 | |
| myopic | 1731.69 | 859.02 | 605.75 | |
| TEV | 1733.95 | 860.42 | 605.73 |
IV-C Near optimality with real-valued states
Within this section, we validate the near optimality of the Whittle index policy discussed in Section III-C through different and , when the number of radars and targets increases with a fixed ratio . The parameters , , , of target and , are assumed the same as Section IV-B.
We first assume three scenarios, where , . Three scenarios are divided by the types of targets, including all the reckless targets, all the cautious targets, and each type of target accounts for . For each target , let . In addition, the process noise variances of the three scenarios are , , , , respectively. We modify the simulation population by letting vary. For each scenario, the Whittle index truncates the corresponding infinite series to terms with , and performances are evaluated by Monte Carlo simulations.
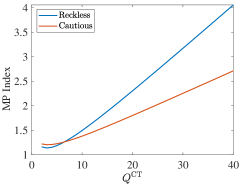
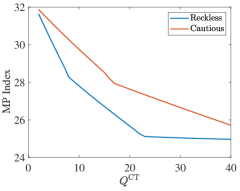
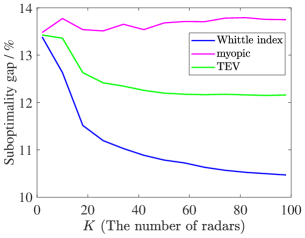
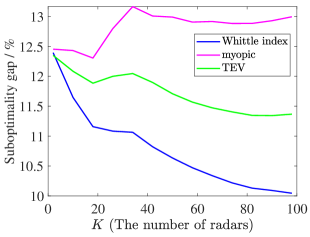
Through the calculations of the lower bound in Section III-B, we derive the simulation results about the suboptimality gap between the lower bound per target and the objective per target of index policies, as shown in Fig. 5, respectively.
(a)
(b)
(c)
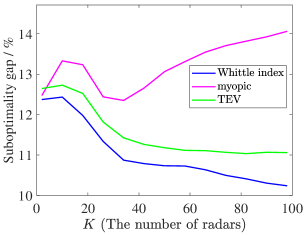
Different from the above three scenarios, we assume another scenario with the ratio . Firstly, there are reckless targets with in the population of and others are cautious with . Secondly, we assume that all of the targets share the identical process noise variance . Other simulation parameters of each target are the same as the above three scenarios. The initial state for each target is assumed to be . We modify the simulation population by letting vary. The results are shown in Fig. 6.
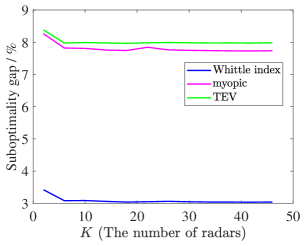
Fig. 5 shows that the suboptimality gaps of the Whittle index policy and the TEV index policy decrease as the radar system scale increases. However, the suboptimality gap of the Whittle index policy converges to a lower level, which is lower than , while the TEV index policy obtains a larger suboptimality gap. Unfortunately, the myopic policy has the worst performance and the suboptimality gap may increase as grows. In Fig. 6, the Whittle index policy also achieves the lowest suboptimality gap, which is stable at about . While the TEV index policy and the myopic policy obtain and , respectively. Consequently, the Whittle index policy obtains lower objectives per target than other policies and the lowest suboptimality gap in all four scenarios.
Above all, the near optimality of the Whittle index policy is validated in this beam scheduling problem. When all the targets are homogeneous in different groups related to the target type and target parameters in Fig. 6, except , and the suboptimality gap of the Whittle index policy is approximately stable at the lowest level. Accordingly, the Whittle index policy can efficiently solve the beam scheduling problem with real-valued TEV states and achieve better non-myopic performance than other greedy policies.
IV-D Performance results with multi-dimensional states
In this subsection, we attempt to expand the application of the MP index policy to the multi-dimensional states case. targets are tracked by the radar network with radars. For each target, the radar tracking time horizon s. The MP index policy, the TEC index policy, and the myopic policy are described in Section III-G to assess the tracking performance.
Let be the dynamic state of target at time , where represents the position of target at time , is the velocity of target at time . The state transition matrices corresponding to the CV and CT model are given by
| (36) |
| (37) |
where denotes the tracking time interval, denotes the turn rate, and represents the Kronecker product.
The process noise variance matrix
| (38) |
where denotes the amplitude of the process noise. denotes the identity matrix.
The measurement matrix is
| (39) |
We assume that , , , and measurement cost , . The initial state is generated by , where each element of follows the uniform distribution , ensuring that . Then, we define two scenarios with the reckless type and the cautious type of targets with , respectively, and another scenario with two types of targets with , where the number of each type of targets is 4, respectively. In the first two scenarios, the weight is assumed as , , and , . Otherwise, for reckless targets and for cautious targets in the third scenario.
The results with Monte Carlo simulations are shown in Table IV. As the value of varies from 1 to 3, While the number of targets remains constant at 8, the number of targets tracked will increase. Consequently, the tracking costs obtained by all policies naturally decrease, and the difference between the MP index policy and other greedy policies decreases. The MP index policy based on the trace of TEC matrices always obtains lower tracking errors and outperforms the TEC index policy and myopic policy.
| Type | Policies | |||
| Reckless | MP index | 4364.18 | 1142.87 | 610.10 |
| myopic | 4480.28 | 1153.19 | 613.15 | |
| TEC | 4436.27 | 1153.43 | 633.80 | |
| Cautious | MP index | 3468.00 | 902.06 | 492.69 |
| myopic | 3584.63 | 931.63 | 500.40 | |
| TEC | 3534.40 | 917.27 | 504.08 | |
| Reckless and Cautious | MP index | 6777.79 | 1824.24 | 990.12 |
| myopic | 7014.92 | 1895.25 | 1022.45 | |
| TEC | 6879.65 | 1860.21 | 1040.56 |
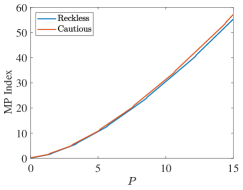
Here, we also analyze the performance of policies changing over the number of targets and radars. The initial state is generated by , where each element of follows the uniform distribution , ensuring that . The two scenarios are considered, where there are reckless targets and cautious targets, respectively. In the first scenario, in each type of targets, and for all of the targets. In the second scenario, the process noise variance for all of the targets, but particularly for reckless targets. The performance results under Monte Carlo simulations are shown in Fig. 7 and Fig. 8. As the number of radars and targets increases, the MP index policy obtains better tracking performance in all of the cases.
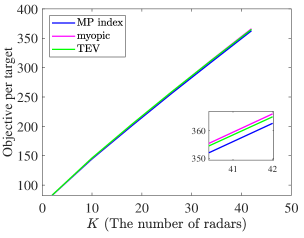
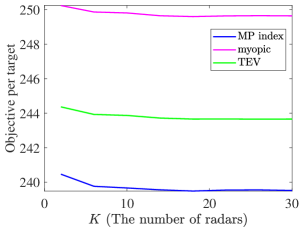
These simulation results of targets with multi-dimensional TEC states show that the MP index policy also can efficiently solve the beam scheduling problem. However, the indexability validation and the lower bound need further calculations and verifications.
Above all, the adapted MP index policy improves the non-myopic beam scheduling performance and outperforms other greedy policies. Numerical simulation results with different parameters of the problem model indicate the superiority of this policy.
V Conclusion
Considering the beam scheduling problem for multiple smart target tracking, we have formulated each target as an MDP, where the state transition is established based on the Kalman filter and the dynamics model probability parameters. Then the trade-off, which is between more observation of smart targets for better tracking performance and the maneuvering reaction of smart targets to elude themselves, was solved by the RMABP problem model based on the Whittle index policy. Through numerical simulation results for both one-dimensional and multi-dimensional TEC states, we have demonstrated the better performance of the MP index policy by comparing it with the baseline greedy policies. For future research, we plan to prompt the resource scheduling for smart targets tacking with multi-dimensional states in the RMABP model and prove the validity of the Whittle index policy by theoretical analysis.
References
- [1] A. M. Haimovich, R. S. Blum, and L. J. Cimini, “MIMO radar with widely separated antennas,” IEEE Signal Processing Magazine, vol. 25, no. 1, pp. 116–129, 2007.
- [2] W. Zhang, C. Shi, J. Zhou, and R. Lv, “Joint aperture and transmit resource allocation strategy for multi-target localization in phased array radar network,” IEEE Transactions on Aerospace and Electronic Systems, vol. 59, no. 2, pp. 1551–1565, 2023.
- [3] J. Yan, H. Jiao, W. Pu, C. Shi, J. Dai, and H. Liu, “Radar sensor network resource allocation for fused target tracking: a brief review,” Information Fusion, vol. 86, pp. 104–115, 2022.
- [4] C. Kreucher, D. Blatt, A. Hero, and K. Kastella, “Adaptive multi-modality sensor scheduling for detection and tracking of smart targets,” Digital Signal Processing, vol. 16, no. 5, pp. 546–567, 2006.
- [5] C. O. Savage and B. F. La Scala, “Sensor management for tracking smart targets,” Digital Signal Processing, vol. 19, no. 6, pp. 968–977, 2009.
- [6] Z. Zhang and G. Shan, “Non-myopic sensor scheduling to track multiple reactive targets,” IET Signal Processing, vol. 9, no. 1, pp. 37–47, 2015.
- [7] A. O. Hero, D. Castañón, D. Cochran, and K. Kastella, Foundations and applications of sensor management. Springer Science & Business Media, 2007.
- [8] M. R. Taner, O. E. Karasan, and E. Yavuzturk, “Scheduling beams with different priorities on a military surveillance radar,” IEEE Transactions on Aerospace and Electronic Systems, vol. 48, no. 2, pp. 1725–1739, 2012.
- [9] H. Godrich, A. P. Petropulu, and H. V. Poor, “Sensor selection in distributed multiple-radar architectures for localization: A knapsack problem formulation,” IEEE Transactions on Signal Processing, vol. 60, no. 1, pp. 247–260, 2011.
- [10] G. Zhang, J. Xie, H. Zhang, Z. Li, and C. Qi, “Dynamic antenna selection for colocated MIMO radar,” Remote Sensing, vol. 14, no. 12, p. 2912, 2022.
- [11] H. Zhang, J. Shi, Q. Zhang, B. Zong, and J. Xie, “Antenna selection for target tracking in collocated MIMO radar,” IEEE Transactions on Aerospace and Electronic Systems, vol. 57, no. 1, pp. 423–436, 2020.
- [12] J. Dai, J. Yan, W. Pu, H. Liu, and M. S. Greco, “Adaptive channel assignment for maneuvering target tracking in multistatic passive radar,” IEEE Transactions on Aerospace and Electronic Systems, vol. 59, no. 3, pp. 2780–2793, 2023.
- [13] W. Yi, Y. Yuan, R. Hoseinnezhad, and L. Kong, “Resource scheduling for distributed multi-target tracking in netted colocated MIMO radar systems,” IEEE Transactions on Signal Processing, vol. 68, pp. 1602–1617, 2020.
- [14] H. Zhang, W. Liu, J. Xie, Z. Zhang, and W. Lu, “Joint subarray selection and power allocation for cognitive target tracking in large-scale MIMO radar networks,” IEEE Systems Journal, vol. 14, no. 2, pp. 2569–2580, 2020.
- [15] M. Xie, W. Yi, T. Kirubarajan, and L. Kong, “Joint node selection and power allocation strategy for multitarget tracking in decentralized radar networks,” IEEE Transactions on Signal Processing, vol. 66, no. 3, pp. 729–743, 2017.
- [16] C. Shi, Y. Wang, S. Salous, J. Zhou, and J. Yan, “Joint transmit resource management and waveform selection strategy for target tracking in distributed phased array radar network,” IEEE Transactions on Aerospace and Electronic Systems, vol. 58, no. 4, pp. 2762–2778, 2021.
- [17] J. Yan, W. Pu, S. Zhou, H. Liu, and M. S. Greco, “Optimal resource allocation for asynchronous multiple targets tracking in heterogeneous radar networks,” IEEE Transactions on Signal Processing, vol. 68, pp. 4055–4068, 2020.
- [18] J. Yan, W. Pu, S. Zhou, H. Liu, and Z. Bao, “Collaborative detection and power allocation framework for target tracking in multiple radar system,” Information Fusion, vol. 55, pp. 173–183, 2020.
- [19] C. Pang and G. Shan, “Sensor scheduling based on risk for target tracking,” IEEE Sensors Journal, vol. 19, no. 18, pp. 8224–8232, 2019.
- [20] V. Krishnamurthy, Partially Observed Markov Decision Processes: From Filtering to Controlled Sensing. Cambridge, UK: Cambridge University Press, 2016.
- [21] C. Kreucher, A. O. Hero, K. Kastella, and D. Chang, “Efficient methods of non-myopic sensor management for multitarget tracking,” in 2004 43rd IEEE Conference on Decision and Control (CDC)(IEEE Cat. No. 04CH37601), vol. 1. IEEE, 2004, pp. 722–727.
- [22] C. M. Kreucher and A. O. Hero, “Monte Carlo methods for sensor management in target tracking,” in 2006 IEEE Nonlinear Statistical Signal Processing Workshop. IEEE, 2006, pp. 232–237.
- [23] X. Gongguo, S. Ganlin, and D. Xiusheng, “Non-myopic scheduling method of mobile sensors for manoeuvring target tracking,” IET Radar, Sonar & Navigation, vol. 13, no. 11, pp. 1899–1908, 2019.
- [24] G. Shan, G. Xu, and C. Qiao, “A non-myopic scheduling method of radar sensors for maneuvering target tracking and radiation control,” Defence Technology, vol. 16, no. 1, pp. 242–250, 2020.
- [25] Q. Dong and C. Pang, “Risk-based non-myopic sensor scheduling in target threat level assessment,” IEEE Access, vol. 9, pp. 76 379–76 394, 2021.
- [26] G. Shan and Z. Zhang, “Non-myopic sensor scheduling for low radiation risk tracking using mixed POMDP,” Transactions of the Institute of Measurement and Control, vol. 39, no. 2, pp. 230–243, 2017.
- [27] S. Howard, S. Suvorova, and B. Moran, “Optimal policy for scheduling of Gauss–Markov systems,” in Proceedings of the Seventh International Conference on Information Fusion. Citeseer, 2004, pp. 888–892.
- [28] P. Whittle, “Restless bandits: Activity allocation in a changing world,” Journal of Applied Probability, vol. 25, no. A, pp. 287–298, 1988.
- [29] J. C. Gittins, “Bandit processes and dynamic allocation indices,” Journal of the Royal Statistical Society: Series B (Methodological), vol. 41, no. 2, pp. 148–164, 1979.
- [30] V. Krishnamurthy and R. J. Evans, “Hidden Markov model multiarm bandits: A methodology for beam scheduling in multitarget tracking,” IEEE Transactions on Signal Processing, vol. 49, no. 12, pp. 2893–2908, 2001.
- [31] J. Gittins, K. Glazebrook, and R. Weber, Multi-armed bandit allocation indices. John Wiley & Sons, 2011.
- [32] C. H. Papadimitriou and J. N. Tsitsiklis, “The complexity of optimal queuing network control,” Mathematics of Operations Research, vol. 24, no. 2, pp. 293–305, 1999.
- [33] J. Niño-Mora, “Markovian restless bandits and index policies: A review,” Mathematics, vol. 11, no. 7, p. 1639, 2023.
- [34] R. R. Weber and G. Weiss, “On an index policy for restless bandits,” Journal of applied probability, vol. 27, no. 3, pp. 637–648, 1990.
- [35] B. F. La Scala and B. Moran, “Optimal target tracking with restless bandits,” Digital Signal Processing, vol. 16, no. 5, pp. 479–487, 2006.
- [36] C. R. Dance and T. Silander, “When are Kalman-filter restless bandits indexable?” in Proceedings of the 28th Conference on Neural Information Processing Systems (NIPS), Montreal, Canada. Cambridge, MA: MIT Press, 2015, pp. 1711–1719.
- [37] K. Liu and Q. Zhao, “Indexability of restless bandit problems and optimality of whittle index for dynamic multichannel access,” IEEE Transactions on Information Theory, vol. 56, no. 11, pp. 5547–5567, 2010.
- [38] J. Niño-Mora and S. S. Villar, “Sensor scheduling for hunting elusive hiding targets via Whittle’s restless bandit index policy,” in International Conference on NETwork Games, Control and Optimization (NetGCooP 2011). IEEE, 2011, pp. 1–8.
- [39] J. Wang, X. Ren, Y. Mo, and L. Shi, “Whittle index policy for dynamic multichannel allocation in remote state estimation,” IEEE Transactions on Automatic Control, vol. 65, no. 2, pp. 591–603, 2019.
- [40] J. Niño-Mora, “Restless bandits, partial conservation laws and indexability,” Advances in Applied Probability, vol. 33, no. 1, pp. 76–98, 2001.
- [41] ——, “Dynamic allocation indices for restless projects and queueing admission control: A polyhedral approach,” Mathematical programming, vol. 93, no. 3, pp. 361–413, 2002.
- [42] ——, “Restless bandit marginal productivity indices, diminishing returns and optimal control of make-to-order/make-to-stock M/G/1 queues,” Mathematics of Operations Research, vol. 31, no. 1, pp. 50–84, 2006.
- [43] ——, “A verification theorem for threshold-indexability of real-state discounted restless bandits,” Mathematics of Operations Research, vol. 45, no. 2, pp. 465–496, 2020.
- [44] ——, “Conservation laws and related applications,” in Wiley Encyclopedia of Operations Research and Management Science. New York, NY, USA: Wiley Online Library, 2011.
- [45] ——, “An index policy for dynamic fading-channel allocation to heterogeneous mobile users with partial observations,” in Proceedings of the 4th EuroNGI Conference on Next Generation Internet Networks (NGI), Krakow, Poland. New York, NY, USA: IEEE, 2008, pp. 231–238.
- [46] J. Niño-Mora and S. S. Villar, “Multitarget tracking via restless bandit marginal productivity indices and Kalman filter in discrete time,” in Proceedings of the Joint 48th IEEE Conference on Decision and Control (CDC) / 28th Chinese Control Conference (CCC), Shanghai, China. New York, NY, USA: IEEE, 2009, pp. 2905–2910.
- [47] J. Niño-Mora, “Whittle’s index policy for multi-target tracking with jamming and nondetections,” in Proceedings of the 23rd International Conference on Analytical and Stochastic Modelling Techniques and Applications (ASMTA), Cardiff, Wales. Cham, Switzerland: Springer, 2016, pp. 210–222.
- [48] ——, “A verification theorem for indexability of discrete time real state discounted restless bandits,” arXiv:1512.04403, 2015.
- [49] C. R. Dance and T. Silander, “Optimal policies for observing time series and related restless bandit problems,” The Journal of Machine Learning Research, vol. 20, no. 1, pp. 1218–1310, 2019.
- [50] F. Yang and X. Luo, “A restless MAB-based index policy for UL pilot allocation in massive MIMO over Gauss–Markov fading channels,” IEEE Transactions on Vehicular Technology, vol. 69, no. 3, pp. 3034–3047, 2020.
- [51] R. Visina, Y. Bar-Shalom, and P. Willett, “Multiple-model estimators for tracking sharply maneuvering ground targets,” IEEE Transactions on Aerospace and Electronic Systems, vol. 54, no. 3, pp. 1404–1414, 2018.
- [52] W. D. Blair and Y. Bar-Shalom, “MSE design of nearly constant velocity Kalman filters for tracking targets with deterministic maneuvers,” IEEE Transactions on Aerospace and Electronic Systems, vol. 59, no. 4, pp. 4180–4191, 2023.
- [53] D. B. Brown and J. E. Smith, “Index policies and performance bounds for dynamic selection problems,” Management Science, vol. 66, no. 7, pp. 3029–3050, 2020.
| Yuhang Hao received the B.Sc. degree and the M.Sc. degree in control theory and control engineering from Northwestern Polytechnical University, Xi’an, China, in 2016 and 2019 respectively. He is currently pursuing the Ph.D. degree with the Key Laboratory of information Fusion Technology, Ministry of Education, Northwestern Polytechnical University, Xi’an, China. His research interests include resource scheduling, multi-armed bandits, target tracking, and information fusion. |
| Zengfu Wang received the B.Sc. degree in applied mathematics, the M.Sc. degree in control theory and control engineering, the Ph.D. degree in control science and engineering from Northwestern Polytechnical University, Xi’an, China, in 2005, 2008, and 2013 respectively. From 2014 to 2017, he was a Lecturer with Northwestern Polytechnical University, where he is currently an Associate Professor. From 2014 to 2015, he was a Postdoctoral Research Fellow with the Department of Electronic Engineering, City University of Hong Kong, Hong Kong, China. Since December 2019, he has been a Visiting Researcher with the Faculty of Electrical Engineering, Mathematics and Computer Science, Delft University of Technology, Delft, The Netherlands. His research interests include path planning, discrete optimization, and information fusion. |
| José Niño-Mora earned a Lic. (B.Sc./M.Sc.) degree in Mathematical Sciences from Complutense University in Madrid, Spain, and a Ph.D. degree in Operations Research from Massachusetts Institute of Technology (MIT) on a Fulbright fellowship, in 1989 and 1995, respectively. After postdoc stints at MIT and at the Catholic University of Louvain at Louvain-la-Neuve, Belgium (as a Marie Curie fellow), he was a Visiting Professor at the Economics & Business Department of Pompeu Fabra University in Barcelona, and then joined in 2003 the Statistics Department at Carlos III University of Madrid, Spain, where he is Full Professor of Operations Research & Statistics. He was the recipient of the 1st Award for Best Methodological Contribution in Operations Research in 2020 by the Spanish Statistics and Operations Research Society and the BBVA Foundation. His research interests include dynamic resource allocation in stochastic systems, Markov decision models, restless bandit problems, and index policies. |
| Jing Fu received the B.Eng. degree in computer science from Shanghai Jiao Tong University, Shanghai, China, in 2011, and the Ph.D. degree in electronic engineering from the City University of Hong Kong in 2016. She has been with the School of Mathematics and Statistics, the University of Melbourne as a Post-Doctoral Research Associate from 2016 to 2019. She has been a lecturer in the discipline of Electronic & Telecommunications Engineering, RMIT University, since 2020. Her research interests now include energy-efficient networking/scheduling, resource allocation in large-scale networks, semi-Markov/Markov decision processes, restless multi-armed bandit problems, and stochastic optimization. |
| Min Yang received the B.Sc. degree from Shandong Agricultural University in 2015, Taian, China. She received the M.Sc. degree in Control science and engineering from University of Science and Technology Liaoning, Liaoning, China, in 2019. She is currently pursuing the Ph.D.degree with the Key Laboratory of information Fusion Technology, Ministry of Education, Northwestern Polytechnical University, Xi’an, China. Her research interests include multi-armed bandits, resource allocation, and target tracking. |
| Quan Pan received the B.Sc. degree from Huazhong Institute of Technology in 1991, and the M.Sc. and Ph.D. degrees from Northwestern Polytechnical University in 1991 and 1997, respectively. Since 1997, he has been a professor with the School of Automation, Northwestern Polytechnical University. His research interests include information fusion, hybrid system estimation theory, multi-scale estimation theory, target tracking and image processing. He is a Member of the International Society of Information Fusion, a Board Member of the Chinese Association of Automation, and a Member of the Chinese Association of Aeronautics and Astronautics. He was the recipient of the 6th Chinese National Youth Award for Outstanding Contribution to Science and Technology in 1998 and the Chinese National New Century Excellent Professional Talent in 2000. |