Nomad: Non-Exclusive Memory Tiering via Transactional Page Migration
Abstract
With the advent of byte-addressable memory devices, such as CXL memory, persistent memory, and storage-class memory, tiered memory systems have become a reality. Page migration is the de facto method within operating systems for managing tiered memory. It aims to bring hot data whenever possible into fast memory to optimize the performance of data accesses while using slow memory to accommodate data spilled from fast memory. While the existing research has demonstrated the effectiveness of various optimizations on page migration, it falls short of addressing a fundamental question: Is exclusive memory tiering, in which a page is either present in fast memory or slow memory, but not both simultaneously, the optimal strategy for tiered memory management?
We demonstrate that page migration-based exclusive memory tiering suffers significant performance degradation when fast memory is under pressure. In this paper, we propose non-exclusive memory tiering, a page management strategy that retains a copy of pages recently promoted from slow memory to fast memory to mitigate memory thrashing. To enable non-exclusive memory tiering, we develop Nomad, a new page management mechanism for Linux that features transactional page migration and page shadowing. Nomad helps remove page migration off the critical path of program execution and makes migration completely asynchronous. Evaluations with carefully crafted micro-benchmarks and real-world applications show that Nomad is able to achieve up to 6x performance improvement over the state-of-the-art transparent page placement (TPP) approach in Linux when under memory pressure. We also compare Nomad with a recently proposed hardware-assisted, access sampling-based page migration approach and demonstrate Nomad’s strengths and potential weaknesses in various scenarios. Through the evaluation of Nomad, we discover a serious issue facing all tested approaches, unfortunately including Nomad, and call for further research on tiered memory-aware memory allocation.
1 Introduction
As new memory devices, such as high bandwidth memory (HBM) [hbm, jun2017hbm], DRAM, persistent memory [optane, p2cache], Compute Express Link (CXL)-based memory [cxl, Maruf_23asplos_tpp, memtis], and storage-class memory [optane_study, xiang2022characterizing] continue to emerge, future computer systems are anticipated to feature multiple tiers of memory with distinct characteristics, such as speed, size, power, and cost. Tiered memory management aims to leverage the strength of each memory tier to optimize the overall data access latency and bandwidth. Central to tiered memory management is page management within operating systems (OS), including page allocation, placement, and migration. Efficient page management in the OS is crucial for optimizing memory utilization and performance while maintaining transparency for user applications.
Traditionally, the memory hierarchy consists of storage media with at least one order of magnitude difference in performance. For example, in the two-level memory hierarchy assumed by commercial operating systems for decades, DRAM and disks differ in latency, bandwidth, and capacity by 2-3 orders of magnitude. Therefore, the sole goal of page management is to keep hot pages in, and maximize the hit rate of the “performance” tier (DRAM), and migrate (evict) cold pages to the “capacity” tier (disk) when needed. As new memory devices emerge, the performance gap in the memory hierarchy narrows. Evaluations on Intel’s Optane persistent memory [pmperf] and CXL memory [Sun2023DemystifyingCM] reveal that these new memory technologies are able to can achieve comparable performance to DRAM in both latency and bandwidth, within a range of 2-3x. As a result, the assumption on of the performance gap, which has guided the design of OS page management for decades, may not hold. It is no longer beneficial to promote a hot page to the performance tier if the migration cost is too high.
Furthermore, unlike disks which must be accessed through the file system as a block device, new memory devices are byte-addressable and can be directly accessed by the processor via ordinary load and store instructions. Therefore, for a warm page on the capacity tier, accessing the page directly and avoiding migration to the performance tier could be a better choiceoption. Most importantly, while the performance of tiered memory remains hierarchical, the hardware is no longer hierarchical. Both the Optane persistent memory and CXL memory appear to the processor as CPUless memory nodes, enabling the OS to manage them a CPUless memory node and thus can be used by the OS as ordinary DRAMnodes.
These unique challenges facing emerging tiered memory systems have inspired research on improving page management in the OS. Much focus has been on expediting page migrations between memory tiers. Nimble [Yan_19asplos_nimble] improves page migration by utilizing transparent huge pages (THP), multi-threaded migration of a page, and concurrent migration of multiple pages. Transparent page placement (TPP) [Maruf_23asplos_tpp] extends the existing NUMA balancing scheme in Linux to support asynchronous page demotion and synchronous page promotion between fast and slow memory. Memtis [memtis] and TMTS [Padmapriya_23asplos] use hardware performance counters to mitigate the overhead of page access tracking and use background threads to periodically and asynchronously promote pages.
However, these approaches have two fundamental limitations. First, the existing page management for tiered memory assumes that memory tiers are exclusive to each other – hot pages are allocated or migrated to the performance tier while cold pages are demoted to the capacity tier. Therefore, each page is only present in one tier. As memory tiering seeks to explore the tradeoff between performance and capacity, the working set size of workloads that benefit most from tiered memory systems likely exceeds the capacity of the performance tier. Exclusive memory tiering inevitably leads to excessive hot-cold page swapping or memory thrashing when the performance tier is not large enough to hold hot data.
Second, there is a lack of an efficient page migration mechanism to support tiered memory management. As future memory tiers are expected to be addressable by the CPU, page migrations are similar to serving minor page faults and involve three steps: 1) ummap unmap a page from the page table; 2) copy the page content to a different tier; 3) remap the page on the page table, pointing to the new memory address. Regardless of whether page migration is done synchronously upon accessing a hot page in the slower capacity tier or asynchronously in the background, the 3-step migration process is expensive. During the migration, an unmapped page cannot be accessed by user programs. If page migration is done frequently, e.g., due to memory thrashing, user-perceived bandwidth, including accesses to the migrating pages, is significantly lower (up to 95% lower) than the peak memory bandwidth [Yan_19asplos_nimble].
This paper advocates non-exclusive memory tiering that allows a subset of pages on the performance tier to have shadow copies on the capacity tier 111We assume that page migrations only occur between two adjacent tiers if there are more than two memory tiers.. Note that non-exclusive tiering is different from inclusive tiering which strictly uses the performance tier as a cache of the capacity tier. The most important benefit is that under memory pressure, page demotion is made less expensive by simply remapping a page if it is not dirty and its shadow copy exists on the capacity tier. This allows for smooth performance transition when memory demand exceeds the capacity of the performance tier.
To reduce the cost of page migration, especially for promotion, this paper proposes transactional page migration (TPM), a novel mechanism to enable page access during migration. Unlike current page migrations, TPM starts page content copy without unmapping the page from the capacity tier so that the migrating page is still accessible by user programs. After page content is copied to a new page on the performance tier, TPM checks whether the page has been dirtied during the migration. If so, the page migration (i.e., the transaction) is invalidated and the copied page is discarded. Failed page migrations will be retried at a later time. If successful, the copied new page is mapped in the page table and the old page is unmapped, becoming a shadow copy of the new page.
We have developed Nomad, a new page management mechanism framework for tired memory that integrates non-exclusive memory tiering and transactional page migration. Nomad safeguards page allocation to prevent out-of-memory (OOM) errors due to page shadowing. When the capacity tier is under memory pressure, Nomad prioritizes the reclamation of shadow pages before evicting ordinary pages. We have implemented a prototype of Nomad in Linux and performed a thorough evaluation. Experimental results show that, compared to two representative page management schemes: TPP and Memtis, Nomad achieves up to 6x performance improvement over TPP during memory thrashing and consistently outperforms Memtis by as much as 130% when the working set size fits into fast memory. However, we also discover a potential problem that prevents applications from expanding memory allocations beyond fast memory. This finding motivates more research on the memory allocator in the OS to truly embrace tiered memory.
2 Motivation and Related Work
We introduce the background of page management in tiered memory systems and use TPP [Maruf_23asplos_tpp], a state-of-the-art page placement system designed for CXL-enabled tiered memory, as a motivating example to highlight the main limitations in of current page management approaches.
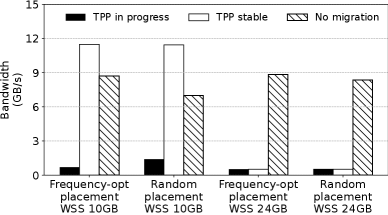
Time breakdown during the initial phase of TPP (i.e., TPP in progress): A significant portion of runtime ( 34%) is consumed by TPP’s synchronous page migration.
2.1 The Memory HierarchyTiering
Caching and tiering are two traditional software approaches to manage a memory, or storage hierarchy, consisting of various types of storage media (e.g., CPU caches, DRAM, and hard disks) differing in performance, capacity, and cost. Without loss of generality, we consider a two-layer two-level memory hierarchy with 1) a performance layer tier (i.e., fast tierthe fast tier), backed with smaller, faster, but more expensive storage media; and 2) a capacity layer tier (i.e., slow tierthe slow tier) with larger, slower, and cheaper storage media. For caching, data is stored in the capacity layertier, and copies of frequently accessed or “hot” data are strategically replicated to the performance layertier. For tiering, frequently accessed data is new data is first allocated to the performance layertier and remains there if it is frequently accessed, while less accessed data is may be relegated to the capacity layertier when needed. At any moment, a unique data copy is maintained exclusively .
Caching and tiering share the same goal – to ensure most accesses occur at the performance layer. But, they differ in how they manage data, in the form of pages within an OS. Caching relies on page replacement algorithms to detect hot (or cold) pages and accordingly populate (or evict from) the performance layer while tiering migratespages between the performance/capacity layers based on the observed page access pattern (hot or cold)data resides exclusively in one of the tiers but not both. Essentially, caching operates in an inclusive page placement mode and retains pages in its original location, merely their original locations, only temporarily storing a copy in the performance layer temporarily tier for fast access. Conversely, tiering operates in an exclusive mode, actively relocating pages across various memory/storage mediums.
Diverse memory/storage devices, such as high bandwidth memory (HBM) [hbm], CXL-based memory [cxl], persistent memory (PM) [optane], and fast, byte-addressable NVMe SSDs [pcieovercxl], have emerged recently. While they still make a tradeoff between speed, size, and cost, the distinction between them gap between their performance narrows. For example, Intel Optane DC persistent memory (PM), available in a DIMM package on the memory bus enabling programs to directly access data in non-volatile memory from the CPU using load and store instructions, provides (almost) an order of magnitude higher capacity than DRAM (e.g., 8x) and offers performance within an order of magnitude a range of 2-3x of DRAM, e.g., write latency as low as 80 ns ns and read latency around 170 nsns [pmperf]. More recently, CXL, an open, industry-supported interconnect compute express link (CXL), an open-standard interconnect technology based on PCI Express (PCIe)interface [cxl], offers a general interface for disaggregating various types of storage devices (e.g., DRAM, PM, and PCIe devices) to the CPU with provides a memory-like, byte-addressable interface (i.e., via the CXL.mem protocol) ; it allows cache-line granularity access to the connected devices and maintains data coherency and consistency by the underlying hardware. for connecting diverse memory devices (e.g., DRAM, PM, GPUs, and smartNICs). Real-world CXL-based CXL memory offers comparable memory access latency (<2x) and throughput (50%) to local ordinary DRAM [Sun2023DemystifyingCM].
CXL memory (or PM ), with high throughput and low latency, is often treated as an extension of local DRAMFrom the perspective of OS memory management, CXL memory or PM appears to be a remote, CPUless memory node, similar to a multi-socket Non-Uniform Memory Access non-uniform memory access (NUMA) nodes. Hence, a tieringbased approach is commonly used to manage such a memory hierarchy. Indeed, state-of-the-art node. State-of-the-art tiered memory systems, such as TPP [Maruf_23asplos_tpp], Memtis [memtis], Nimble [Yan_19asplos_nimble], and AutoTiering[Jonghyeon_21fast], unanimously all adopt tiering to exclusively manage data on different memory tiers, i.e. , via dynamically migrating pages between fast/slow tiers to ensure efficient access to faster local DRAM .
However, CXL-based tiered memory has its unique characteristics. CXL memory dramatically increases the capacity Unlike the traditional two-level memory hierarchy involving DRAM and disks, in which DRAM acts as a cache for the much larger storage tier, current CXL memory tiering treats CXL memory as an extension of local DRAM, accommodating a broader array of applications with data distributed across both fast and slow memory tiers. As data temperature changes over time. While exclusive memory tiering avoids data redundancy, it necessitates data movement between memory tiers to optimize the performance of data access, i.e., promoting hot data to the fast tier and demoting cold data to the slow tier. Given that all memory tiers are byte-addressable by the CPU and the performance gap between tiers narrows, it remains to be seen whether exclusive tiering is the optimal strategy considering the cost of data movement.
We evaluate the performance of transparent page placement (TPP) [Maruf_23asplos_tpp], more frequent data migrations would occur in a state-of-the-art and the default tiered memory management in Linux. Figure 1 shows the bandwidth of a micro-benchmark that accesses a configurable working set size (WSS) following a Zipfian distribution in a CXL-based memory tiers. It is especially true when the fast-tier memory is under pressure and incapable of holding all hot data. A high frequency of data migration can cause memory thrashing, hurting overall systemperformance. As depicted in Figure 1, the involvement of TPP [Maruf_23asplos_tpp] in page migration (i.e., TPP in progress) has a significant, negative impact on the performance of a memory-intensive workload. In comparison, when most of the hot data have been moved to the fast tier(i. tiered memory system. More details of the benchmark and the hardware configurations can be found in Section 4. We compare the performance of TPP while it actively migrates pages between tiers for promotion and demotion (denoted as TPP in progress) and when it has finished page relocation (TPP stable) with that of a baseline that disables page migration (no migration). The baseline does not optimize page placement and directly accesses hot pages from the slow tier. The tiered memory testbed is configured with 16GB fast memory (local DRAM) and 16GB slow memory (remote CXL memory). We vary the WSS to fit in (e.g., 10GB) and exceed (e., TPP stable with the g., 24GB) fast memory capacity. Note that the latter requires continuous page migrations between tiers since hot data spills into slow memory. Additionally, we explore two initial data placement strategies in the benchmark. First, the benchmark pre-allocates 10GB WSS) , the workload achieves higher performance than the case without TPP (i.e., No migration) of data in fast memory to emulate the existing memory usage from other applications. Frequency-opt is an allocation strategy that places pages according to the descending order of their access frequencies (hotness). Thus, the hottest pages are initially placed in fast memory until the WSS spills into slow memory. In contrast, Random employs a random allocation policy and may place cold pages initially in fast memory. However, if the
We have important observations from results in Figure 1. First, page migration in TPP incurs significant degradation in application performance. When WSS fits in fast memory, TPP stable, which has successfully migrated all hot pages to fast memory, achieves more than an order of magnitude higher bandwidth than TPP in progress. Most importantly, no migration is consistently and substantially better than TPP in progress, suggesting that the overhead of page migration outweighs its benefit until the migration is completed. Second, TPP never reaches a stable state and enters memory thrashing when WSS is larger than the capacity of fast memory. Third, page migration is crucial to achieving optimal performance if it is possible to move all hot data is larger than the size of the fast tier (the 24GB WSS case), memory thrashing happens, leading to extremely poor performance (i.e. , TPP stable with the 24GB WSS ). Furthermore, given that CXL-based lower-tier memorycan substantially exceed the size of local DRAM [Sun2023DemystifyingCM], the advantage of storing data exclusively for the sake of efficient memory usage becomes less compelling. Instead, more focus should be placed on reducing the overhead when frequent page migration occurs.
to fast memory and the initial placement is sub-optimal, as evidenced by the wide gap between Insight 1: In tiered memorysystems, adopting an exclusive, NUMA-like approach for data management can be less effective, particularly when the fast-tier memorycannot accommodate all the hot data .TPP stable and no migration in the 10GB WSS and random placement test.
2.2 Page Management
Page management has been widely studied to optimize data placement among tiered memory/storage. An effective page management scheme must tackle two primary challenges: In this section, we delve into the design of page management in Linux and analyze its overhead during page migration. We focus our discussions on 1) transparent and accurate identification of the hotness of pageswith minimal overhead used for page placement; how to effectively track memory accesses and identify hot pages, and 2) efficient migration of pages between fast and slow tierswithout adversely impacting application-level performancethe mechanism to migrate a page between memory tiers.
Tracking memory access can be conducted by software (via the kernel) and/or with hardware assistance. Specifically, the kernel can keep track of page accesses via page faults [autoNUMA, Maruf_23asplos_tpp, Jonghyeon_21fast], scanning page tables [Bergman_22ismm, autoNUMA, Adnan_22hpca, Yan_19asplos_nimble, thermostat], or both. Capturing each memory access for precise tracking can be prohibitively slow. For example, the page-fault-based tracking approach traps each memory access expensive. Page fault-based tracking traps memory accesses to selected pages (i.e., whose page table entry permissions are set to no access) via hint page faulthint (minor) page faults. Thus, it allows the kernel to obtain the accurate accurately measure the recencyand and frequency of each pagethese pages. However, page faults reside invoking a page fault on every memory access incurs high overhead on the critical path of memory accesses, incurring high latencyprogram execution. On the other hand, the scanning-based approach periodically scans page table (PT) scanning periodically checks the access bit in all page table entries (PTE) and relies on the reference bit to determine which page has been accessed between scanningintervals. However, it monitors page accesses at a coarser granularity, i.e., a longer scanning interval fails to differentiate the frequency and recency of pages, while a short interval incurs high CPU overhead (up to 70% [memtis])to determine recently accessed pages since the last scanning. Compared to page fault-based tracking, which tracks every access on selected pages, PT scanning has to make a tradeoff between scanning overhead and tracking accuracy by choosing an appropriate scanning interval [memtis].
To reduce such overhead,
Linux adopts a lazy scanning mechanism, which defers the scanning until memory is tight, e.g., when the fast-tier memory is under pressure, and the swapping mechanism is invoked for page demotion (e.g., via kswapd). In addition, the kernel maintains two separate PT scanning mechanism to track hot pages, which lays the foundation for its tiered memory management. Linux maintains two LRU lists for each memory tiera memory node: an active list to store hot pages and an inactive list to store for cold pages. Pages can be moved between these two lists during (lazy) scanning. The kernel uses two bits (i.e.By default, all new pages go to the inactive list and will be promoted to the active list according to two flags, PG_referenced and PG_active) to maintain the frequency of each page– a cold page, after two accesses (detected by two scans), will be moved to the active list , in the per-page struct page. Due to lazy scanning, it takes a long time to detect hot pages – PG_reference is set when the access bit in the corresponding PTE is set upon a PTE check and PG_active is set after PG_reference is set for two consecutive times. A page is promoted to the active list when its PG_active flag is set. For file-backed pages, their accesses are handled by the OS through the file system interface, e.g., read() and write(). Therefore, their two flags are updated each time they are accessed. For anonymous pages, e.g., application memory allocated through malloc, since page accesses are directly handled by the MMU hardware and bypass the OS kernel, the updates to their reference flags and LRU list management are only performed during memory reclamation. Under memory pressure, the swapping daemon kswapd scans the inactive list and the corresponding PTEs to update inactive pages’ flags, and reclaims/swaps out those with PG_reference unset. Additionally, kswapd promotes hot pages (i.e., lack of recency. However, timely detecting hot pages for the slow tier is critical. those with PG_active set) to the active list. This lazy scanning mechanism delays access tracking until it is necessary to reduce the tracking overhead, but undermines tracking accuracy.
TPP [Maruf_23asplos_tpp] tackles this problem by tracking page accesses of the slow tier using hint page faults. However, we observed that TPP ’s synchronous page migration approach unexpectedly amplifies its page-fault overhead, leverages Linux’s PT scanning to track hot pages and employs page fault-based tracking to decide whether to promote pages from slow memory. Specifically, TPP sets all pages residing in slow memory (e.g., up to 15 page faults were involved in migrating a single detected hot page from the slow to the fast tiers. This is manifested in Figure 2 – a significant portion of time is consumed by “non-migration page faults” (more details in 3.1) . CXL memory) as inaccessible, and any user access to these pages will trigger a minor page fault, during which TPP decides whether to promote the faulting page. If the faulting page is on the active list, it is migrated (promoted) to the fast tier. Page demotion occurs when fast memory is under pressure and kswapd migrates pages from the inactive list to slow memory.

Accurate and lightweight memory access tracking can be achieved with hardware support, e.g., by adding a PTE count field in hardware that records the number of memory accesses(by hardware) for the associated page [7056027]. However, the proposed approach could be too invasive for hardware-based tracking can increase the complexity and require extensive hardware changes in mainstream architectures (e.g., x86). In practice, the hardware-assisted samplingapproach, , such as via Processor Event-Based Sampling (PEBS) [memtis, Padmapriya_23asplos] on Intel platforms, has been recently proposed to obtain employed to record page access (virtual address) information from sampled hardware events (e.g., LLC misses or store instructions). However, PEBS-based profiling also requires a careful balance between the frequency of sampling and the accuracy of profiling. We observed that the PEBS-based approach [memtis], with a sampling rate incurring low CPU optimized for minimizing overhead, remains coarse-grained and fails to capture many hot pages. Further, the sampling-based approach may not obtain recency of memory access (with a low sampling rate)accurately measure access recency, thus limiting the its ability to make timely migration decisions. Last, PEBS is not accessible across CPU vendors [Padmapriya_23asplos], making the PEBS-based profiling not generic.
Insight 2: A practical, lightweight memory tracking mechanism that can capture both frequency and recency information of page accesses is highly desired.
Page migration – i.e., the process of promoting hot pages from the slow tier to the fast tier or demoting cold pages from the fast tier to the slow tier – between memory tiers involves a complex procedure: ① The system needs to must trap to the kernel (e.g., via page faults) to handle migration; ② The PTEs of selected pages PTE of a migrating page must be locked (to avoid others accessing the pages during migration ) and to prevent others from accessing the page during migration and be ummapped from the page table; ③ A translation lookaside buffer (TLB) shootdown must be issued to each processor (via IPIinter-processor interrupts (IPIs)) that may have cached copies of stale PTEsthe stale PTE; ④ The content of the pages are page is copied between tiers; ⑤ Finally, their corresponding PTEs must be updated and the PTE must be remapped . In addition, page to point to the new location. Page migration can be initiated in a done synchronously or asynchronouslymanner. The triggering mode is also linked with the memory tracking mechanisms.
Typically, scanning-based tracking supports asynchronous, batch-based page promotion /demotion, which redistributes pages among fast/slow tiers based on the periodic updates of data temperature [memtis]. While batching multiple pages for asynchronousmigration could reduce migrationoverhead, it does not favor temporal locality. To migrate . Synchronous migration, e.g., page promotion in TPP, is on-demand pages more promptly, page-fault-based, synchronouspage migration is often used in both Linux and recent research projects [Maruf_23asplos_tpp, Yan_19asplos_nimble]: When a “tagged” page is touched for the first time, page migration is synchronously conducted during handling the hint page fault.Despite being timely, synchronous migration is very costly. First, it resides in the triggered by user access to a page and on the critical path of program execution. During migration, the user program is blocked until migration is completed. Asynchronous migration, e.g., page demotion in TPP, is handled by a kernel thread (i.e., critical pathkswapdof memory access, slowing down the execution of the process requesting such memory access. Further, due to locking (in ), others trying to access the same page must enter a oftentimes off programs’ critical path, when certain criteria are met. Synchronous migration is costly not only because pages are inaccessible during migration but also may involve a large number of page faults.
Figure 2 shows the run time breakdown of the aforementioned benchmark while TPP is actively relocating pages between the two memory tiers. Since page promotion is synchronous, page fault handling and page content copying (i.e., promotion) are executed on the same CPU as the application thread. Page demotion is done through busy-waitkswapd state until the page becomes available remapped).Last, page migration may fail, e.g., due to insufficient space on the destination memory tier, and the need to synchronously re-try further worsens this situation.
This exactly explains the extremely poor performance caused by TPP, as and uses a different core. As shown in Figure 1, i.e. , the cases in “TPP in progress” and “TPP stable” with the 24 GB WSS. The breakdown of time consumption, in Figure 2, further shows that almost 30% of the execution time was spent in the synchronous page promotion (and related) operations, significantly slowing down the workload. synchronous promotion together with page fault handling incurs significant overhead on the application core. In contrast, the demotion core remains largely idle and does not present a bottleneck. As will be discussed in Section 3.1, userspace run time can also be prolonged due to repeated minor page faults (as many as 15) to successfully promote one page. This overhead analysis explains the poor performance of TPP observed in Figure 1.
Insight 3: How can we achieve prompt pagemigration without delaying/pausing the execution of applications?
2.3 Related Work
A long line of pioneering work has explored a wide range of of tiered storage/memory systems, built upon SSDs and HDDs [266253, 8714805, chen2011hystor, 5749736, 10.5555/1855511.1855519, 6557143, 5581609, 6005391, 267006], DRAM and disks [270689, 270754, 269067, papagiannis2020optimizing], HBM and DRAMs [7056027, batman, 6493624], NUMA memory [autoNUMA, damon], PM and DRAM [288741, abulila2019flatflash, Adnan_22hpca, thermostat], local and far memory [Bergman_22ismm, 180194, 180727, 7266934, ruan2020aifm], DRAM and CXL memory [li2023pond, Maruf_23asplos_tpp, memtis], and multiple tiers [wu2021storage, Jonghyeon_21fast, Yan_19asplos_nimble, 288741, kwon2017strata]. We focus on tiered memory systems consisting of DRAM and emerging CXL memory , though the proposed approaches in the emerging byte-addressable memory devices, e.g., CXL memory and PM. Nomad also apply applies to other tiered memory systems such as HBM/DRAM and DRAM/PM. We discuss the most related works as follows.
Lightweight memory access tracking: To mitigate software overhead associated with memory access tracking, Hotbox [Bergman_22ismm] employs two separate scanners for fast and slow tiers to scan the slow tier at a fixed rate while the local fast tier at an adaptive rate, configurable based on the local memory pressure. Memtis [memtis] adjusts its PEBS-based sampling rate to ensure its overhead is under a threshold control (e.g., < 3%). TMTS [Padmapriya_23asplos] also adopts a periodic scanning mechanism to detect frequency along with hardware sampling to more timely detect newly hot pages. While these approaches balance scanning/sampling overhead and tracking accuracy, an “always-on” profiling component does not seem practical, especially for high-pressure workloads. Instead, thermostat [thermostat] samples a small fraction of pages, while DAMON [damon] monitors memory access at a coarser-grained granularity (i.e., region). Although both can effectively reduce the scanning overhead, coarse granularity leads to lower accuracy regarding page access patterns. On the other hand, to reduce the overhead associated with frequent hint page faults like AutoNUMA [autoNUMA], TPP [Maruf_23asplos_tpp] enables the page-fault based detection only for CXL memory (i.e., the slow tier) and tries to promote a page promptly (e.g., when it encounters a page fault)via synchronous migration; prompt page promotion avoids subsequent page faults on the same page.
Inspired by existing lightweight tracking systems, such as Linux’s active and inactive lists and hint page faults, Nomad advances them by incorporating more recency information with no additional CPU overhead. Unlike hardware-assisted approaches [memtis, Padmapriya_23asplos, Loh2012ChallengesIH], Nomad does not require any additional hardware support.
Page migration optimizations: To hide reclamation overhead from applications, TPP [Maruf_23asplos_tpp] decouples page allocation and reclamation; however, page migration remains in the critical path, incurring significant slowdowns. Nimble [Yan_19asplos_nimble] focuses on mitigating page migration overhead with new migration mechanisms, including transparent huge page migration and concurrent multi-page migration. Memtis [memtis] further moves page migration out of the critical path using a kernel thread to promote/demote pages in the background. TMTS [Padmapriya_23asplos] leverage a user/kernel collaborative approach to control page migration. In contrast, Nomad aims to achieve prompt, on-demand page migration while moving page migration off the critical path. It is orthogonal to and can benefit from existing page migration optimizations. The most related work is [concurrent], which leverages hardware support to pin data in caches, enabling access to pages during migration. Again, Nomad does not need additional hardware support.
3 Nomad Design and Implementation
Nomad is a new page management mechanism for tiered memory that features non-exclusive memory tiering and transactional page migration. The goal of Nomad design is to enable the processor to freely and directly access pages from both fast and slow memory tiers and move the cost of page migration off the critical path of users’ data access. Note that Nomad does not make page migration decisions and relies on memory tracing in the OS to determine hot and cold pages. Furthermore, Nomad does not impact the initial memory allocation in the OS and assumes a standard page placement policy. Pages are allocated from the fast tier whenever possible and are placed in the slower tier only when there is an insufficient number of free pages in the fast tier, and attempts to reclaim memory in the fast tier have failed. After the initial page placement, Nomad gradually migrates hot pages to the fast tier and old cold pages to the slow tier. Nomad seeks to address two key issues: 1) how to minimize the cost of page migration? 2) how to minimize the number of migrations?
Overview. Inspired by multi-level cache management in modern processors, which do not employ a purely inclusive or exclusive caching policy between tiers [Alian-micro21] to facilitate the sharing of or avoid the eviction of certain cache lines, Nomad embraces a non-exclusive memory tiering policy to prevent memory thrashing when under memory pressure. Unlike the existing page management schemes that move pages between tiers and require that a page is only present in one tier, Nomad instead copies pages from the slow tier to the fast tier and keeps a shadow copy of the migrated pages at the slow tier. The non-exclusive tiering policy maintains shadow copies only for pages that have been promoted to the fast tier, thereby not an inclusive policy. The advantage of the non-exclusive policy is that the demotion of clean, cold pages can be simplified to remapping the page table entry (PTE) without the need to actually copy the cold page to the slower tier.
The building block of Nomad is a new transactional page migration (TPM) mechanism to reduce the cost of page migrations. Unlike the existing unmap-copy-remap 3-step page migration, TPM opportunistically copies a page without unmapping it from the page table. During the page copy, the page is not locked and can be accessed by a user program. After the copy is completed, TPM checks if the page has been dirtied during the copy. If not, TPM locks the page and remaps it in the PTE to the faster tier. Otherwise, the migration is aborted and will be tried at a later time. TPM not only minimizes the duration during which a page is inaccessible but also makes page migration asynchronous, thereby removing it from the critical path of users’ data access.
Without loss of generality, we describe Nomad design in the context of Linux. We start with transactional page migration and then delve into page shadowing – an essential mechanism that enables non-exclusive memory tiering.

3.1 Transactional Page Migration
The motivation to develop TPM is to make page migration entirely asynchronous and decoupled from users’ access to the page. As discussed in Section 2.2, the current page migration in Linux is synchronous and on the critical path of users’ data access. For example, the default tiered memory management in Linux, TPP, attempts to migrate a page from the slow tier whenever a user program accesses the page. Since the page is in “protected” mode, the access triggers a minor page fault, leading TPP to attempt the migration. The user program is blocked and makes no progress until the minor page fault is handled and the page is remapped to the fast tier, which can be a time-consuming process. Worse, if the migration fails, the OS remains in function migrate_pages and retries the aforementioned migration until it is successful or reaching a maximum of 10 attempts.
TPM decouples page migration from the critical path of user programs by making the migrating page accessible during the migration process. Therefore, users will access the migrating page from the slow tier before the migration is complete. While accessing a hot page from the slow tier may lead to sub-optimal memory performance, it avoids blocking user access due to the migration, thereby leading to superior user-perceived performance. Figure 3 shows the workflow of TPM. Before migration commences, TPM clears the protection bit of the page frame and adds the page to a migration pending queue. Since the page is no longer protected and it is not yet unmapped from the page table, following accesses to the page will not trigger additional page faults.
TPM starts a migration transaction by clearing the dirty bit of the page (step ❶) and checks the dirty bit after the page is copied to the fast tier to determine whether the transaction was successful. After changing the dirty bit in PTE, TPM issues a TLB shootdown to all cores that ever accessed this page (step ❷). This is to ensure that subsequent writes to the page can be recorded on the PTE. After the TLB shootdown is completed, TPM starts copying the page from the slow tier to the fast tier (step ❸). To commit the transaction, TPM checks the dirty bit by loading the entire PTE using atomic instruction get_and_clear (step ❹). Clearing the PTE is equivalent to unmapping the page and thus another TLB shootdown is needed (step ❺). Note that after unmapping the page from PTE, it becomes inaccessible by users. TPM checks whether the page was dirtied during the page copy (step ❻) and either commits the transaction by remapping the page to the fast tier if the page is clean (step ❼) or otherwise aborts the transaction (step ❽). If the migration is aborted, the original PTE is restored and waits for the next time when TPM is rescheduled to retry the migration. The duration in which the page is inaccessible is between ❹ and ❼/ ❽, significantly shorter than that in TPP (possibly multiple attempts between ❶ and ❼).
Page migration is a complex procedure that involves memory tracing and updates to the page table for page remapping. The state-of-the-art page fault-based migration approaches, e.g., TPP in Linux [Maruf_23asplos_tpp], employs synchronous page migration, a mechanism in the Linux kernel for moving pages between NUMA nodes. In addition to the extended migration time affecting the critical path of user programs, this mechanism causes excessive page faults when integrated with the existing LRU-based memory tracing. TPP makes per-page migration decisions based on whether the page is on the active LRU list. Nevertheless, in Linux, memory tracing adds pages from the inactive to the active LRU list in batches of 15 requests 222The 15 requests could be repeated requests for promoting the same page to the active LRU list, aiming to minimize the queue management overhead. Due to synchronous page migration, TPP may submit multiple requests (up to 15 if the request queue was empty) for a page to be promoted to the active LRU list to initiate the migration process. In the worst case, migrating one page may generate as many as 15 minor page faults.
TPM provides a mechanism to enable asynchronous page migration but requires additional effort to interface with memory tracing in Linux to minimize the number of page faults needed for page migration. As shown in Figure 4, in addition to the inactive and active LRU lists in memory tracing, TPM maintains a separate promotion candidate queue (PCQ) for pages that 1) have been tried for migration but 2) not yet promoted to the active LRU list. Upon each time a minor (hint) page fault occurs and the faulting page is added to PCQ, TPM checks if there are any hot pages in PCQ that have both the active and accessed bits set. These hot pages are then inserted to a migration pending queue, from where they will be tried for asynchronous, transactional migration by a background kernel thread kpromote. Note that TPM does not change how Linux determines the temperature of a page. For example, in Linux, all pages in the active LRU list, which are eligible for migration, have the two memory tracing bits set. However, not all pages with these bits set are in the active list due to LRU list management. TPM bypasses the LRU list management and provides a more efficient method to initiate page migration. If all transactional migrations were successful, TPM guarantees that only one page fault is needed per migration in the presence of LRU list management.

3.2 Page Shadowing

To enable non-exclusive memory tiering, Nomad introduces a one-way page shadowing mechanism to enable a subset of pages resident in the performance tier to have a shadow copy in the capacity tier. Only pages promoted from the slow tier have shadow copies in the slow tier. Shadow copies are the original pages residing on the slow tier before they are unmapped in the page table and migrated to the fast tier. Shadow pages play a crucial role in minimizing the overhead of page migration during periods of memory pressure. Instead of swapping hot and cold pages between memory tiers, page shadowing enables efficient page demotion through page table remapping. This would eliminate half of the page migration overhead, i.e., page demotion, during memory thrashing.
Indexing shadow pages. Inspired by the indexing of file-based data in the Linux page cache, Nomad builds an XArray for indexing shadow pages. An XArray is a radix-tree like, cache-efficient data structure that acts as a key-value store, mapping from the physical address of a fast tier page to the physical address of its shadow copy on the slow tier. Upon successfully completing a page migration, Nomad inserts the addresses of both the new and old pages into the XArray. Additionally, it adds a new shadow flag to the struct page of the new page, indicating that shadowing is on for this page.
Shadow page management. The purpose of maintaining shadow pages is to assist page demotion. Fast or efficient page demotion is possible via page remapping if the master page, i.e., the one on the fast tier, is clean and consistent with the shadow copy. Otherwise, the shadow copy should be discarded. To track inconsistency between the master and shadow copies, Nomad sets the master page as read-only and a write to the page causes a page fault. To simplify system design and avoid additional cross-tier traffic, Nomad discards the shadow page if the master page is written.
However, tracing updates to the master page poses a significant challenge. Page management in Linux relies heavily on the read-write permission of a page to perform various operations on the page, such as copy-on-write (CoW). While setting master pages as read-only effectively captures all writes, it may affect how these master pages are managed in the kernel. To address this issue, Nomad introduces a procedure called shadow page fault. It still designates all master pages as read-only but preserves the original read-write permission in an unused software bit on the page’s PTE (as shown in Figure 5). We refer to this software bit as shadow r/w. Upon a write to a master page, a page fault occurs. Unlike an ordinary page fault that handles write violation, the shadow page fault, which is invoked if the page’s shadow flag is set in its struct page, restores the read-write permission of the faulting page according to the shadow r/w bit and discards/frees the shadow page on the slow tier. The write may proceed once the shadow page fault returns and reinstates the page to be writable. For read-only pages, tracing shadow pages does not impose additional overhead; for writable pages, it requires one additional shadow page fault to restore their write permission.
Reclaiming shadow pages. Non-exclusive memory tiering introduces space overhead due to the storage of shadow pages. If shadow pages are not timely reclaimed when the system is under memory pressure, applications may encounter out-of-memory (OOM) errors, which would not occur under exclusive memory tiering. There are two scenarios in which shadow pages should be reclaimed. First, the Linux kernel periodically checks the availability of free pages and if free memory falls below low_water_mark, kernel daemon kswapd is invoked to reclaim memory. Nomad instructs kswapd to prioritize the reclamation of shadow pages. Second, upon a memory allocation failure, Nomad also tries to free shadow pages. To avoid OOM errors, the number of freed shadow pages should exceed the number of requested pages. However, frequent memory allocation failures could negatively affect system performance. Nomad employs a straightforward heuristic to reclaim shadow pages, targeting 10 times the number of requested pages or until all shadow pages are freed. While excessive reclamation may have a negative impact on Nomad’s performance, it is crucial to prevent Out-of-Memory (OOM) errors. Experiments in Section 4 demonstrate the robustness of Nomad even under extreme circumstances.
3.3 LimitationLimitations
Nomad relies on two rounds of TLB shootdown to effectively track updates to a migrating page during transactional page migration. When a page is used by multiple processes or mapped by multiple page tables, its migration involves multiple TLB shootdowns, per each mapping, that need to happen simultaneously. The overhead of handling multiple IPIs could outweigh the benefit of asynchronous page copy. Hence, Nomad deactivates transactional page migration for multi-mapped pages and resorts to the default synchronous page migration mechanism in Linux. As high-latency TLB shootdowns based on IPIs continue to be a performance concern, modern processors, such as ARM, future AMD, and Intel x86 processors, are equipped with ISA extensions for faster broadcast-based [arm_tlb_broadcast, amd_tlb_broadcast] or micro-coded RPC-like [intelcpurpc] TLB shootdowns. These emerging lightweight TLB shootdown methods will greatly reduce the overhead of TLB coherence in tiered memory systems with expanded memory capacity. Nomad will also benefit from the emerging hardware and can be extended to scenarios where more intensive TLB shootdowns are necessary.
4 Evaluation

This section presents a thorough evaluation of Nomad, focusing on its performance, overhead, and robustness. Most importantly, we aim at understanding Our primary goal is to understand tiered memory management through the comparison between by comparing Nomad and the with existing representative approaches in three scenarios. We study to reveal the benefits and potential limitations of current page management appraches for emerging tiered memory.
We analyze two types of memory footprints: 1) resident set size (RSS) – – the total size of memory occupied by a program; , and 2) working set size (WSS) – – the amount of memory a program actively uses during execution. RSS determines the initial page placement, while WSS dictates the number of pages that should be migrated to the fast tier. Since we focus on in-memory computing, WSS is typically smaller than RSS. Figure 6 shows 6 illustrates the three scenarios we study to understand the tradeoff between migrating pages to the fast tier and accessing them directly from the slow tier. RSS determines the initial page placement while WSS decides the number of pages that should be migrated tothe fast tier with the WSS size smaller, close to, and larger than fast tier memory size.
| Platform A | Platform B | Platform C | Platform D | |
| (engineering sample) | ||||
| CPU | 4th Gen Xeon Gold 2.1GHz | 4th Gen Xeon Platinum 3.5GHz | 2nd Gen Xeon Gold 3.9GHz | AMD Genoa 3.7GHz |
| DRAM Performance layer (DRAM) | 16 GB DDR5 | 16 GB DDR5 | 16 GB DDR4 | 16GB DDR5 |
| Capacity layer (CXL or PM Memory) | Agilex 7 16 GB DDR4 | Agilex 7 16 GB DDR4 | Optane 100 256 GB DDR-T ×6 | Micron CXL memory 256GB ×4 |
| Performance layer read latency | 316 cycles | 226 cycles | 249 cycles | 391 cycles |
| Capacity layer read latency | 854 cycles | 737 cycles | 1077 cycles | 712 cycles |
| Performance layer bandwidth (GB/s) Single Thread / Peak performance | Read: 12/31.45 Write: 20.8/28.5 | Read: 12/31.2 Write: 22.3/23.67 | Read: 12.57/116 Write: 8.67/85 | Read: 37.8/270 Write: 89.8/272 |
| Capacity layer bandwidth (GB/s) Single Thread/Peak performance | Read: 4.5/21.7 Write: 20.7/21.3 | Read: 4.45/22.3 Write: 22.3/22.4 | Read: 4/40.1 Write: 8.1/13.6 | Read: 20.25/83.2 Write: 57.7/84.3 |
Micro-benchmark: performance comparisons between TPP, Memtis, and Nomad with a WSS of 10 GB and a total of 20 GB of RSS data.
Micro-benchmark: performance comparisons between TPP, Memtis, and Nomad with a WSS of 13.5 GB and a total of 27 GB RSS.
| Workload Type | In progress Promotion | In progress Demotion | Steady Promotion | Steady demotion |
| Small WSS | (2.6M|1.5M)/((1.5M|1.48M) (1.2M|1M)/(15.9K|134K)/ (1.16M|781K) | (3.3M|654K)/(1.63M|1.49M) (2.4M|2.2M)/(15.9K|140K)/ (2.7M|1.5M) | (2|0)/(1|2) (0|3.3K)/(7.7K|104K)/ (82|74) | (0|0)/(0|0) (424K|56K)/(0|104K)/ (48K|0) |
| Medium WSS | (6M|6M)(3.7M|3.9M) (4M|6M)/(0|0)/ (1.6M|5M) | (6M|5.8M)/(3.7M|3.9M) (4.7M|6M)/(2|512)/ (2.5M|4.8M) | (2.1M|2.3M)/(119K|3.35M) (1.8M|3.2M)/(17.4K|0)/ (417K|1.6M) | (2.1M|2M)/(116K|3.36M) (1.9M|3.2M)/(16.9K|0)/ (293K|1.4M) |
| Large WSS | (12.5M|12.3M)/(11.6M|11.5M) (7M|5.9M)/(0|0)/ (4.5M|7M) | (13M|13M)/(12.3M|12M) (7.2M|6.5M)/(0|15)/ (4.1M|7.2M) | (11.8M|11.6M)/(7.2M|11.3M) (7.1M|5.2M)/(0|143K)/ (6.8M|8.8M) | (11.9M|11.7M)/(7.2M|11.3M) (7.1M|5.3M)/(0|143K)/ (6.8M|8.9M) |
Micro-benchmark: performance comparisons between TPP, Memtis, and Nomad with a WSS of 27 GB and the same 27 GB RSS.
| Workload type | Success : Aborted |
| 10GB WSS: read | 148 : 1 |
| 10GB WSS: write | 197 : 1 |
| 13.5GB WSS: read | 151 : 1 |
| 13.5GB WSS: write | 267 : 1 |
| 27GB WSS: read | 167 : 1 |
| 27GB WSS: write | 153 : 1 |
| Workload type | Success : Aborted |
| Liblinear (large RSS) on platform C | 1:1.9 |
| Liblinear (large RSS) on platform D | 2.6:1 |
| Redis (large RSS) on platform C | 153:1 |
| Redis (large RSS) on platform D | 278.2:1 |
We compared Nomad with two state-of-the-art tired memory systems: TPP [Maruf_23asplos_tpp] and Memtis [memtis]. Testbeds: We conducted experiments upon three four platforms with different configurations in CPU, local DRAM, CXL memory, and persistent memory, as listed detailed in Table 1. Notably, we used a real-world, Agilex-7
-
•
Platform A was built with commercial off-the-shelf (COTS) Intel Sapphire Rapids processors and a 16 GB Agelix-7 FPGA-based CXL memory device [agilex]and Intel Optane 100 Series Persistent Memory(PM) . The
-
•
Platform B featured an engineering sample of the Intel Sapphire Rapids processors with the same FPGA-based CXL memory device. The prototype processors have engineering tweaks that have the potential to enhance the performance of CXL memory, which were not available on Platform A.
-
•
Platform C included an Intel Alder Lake processor and six 128 GB 100 series Intel Optane Persistent Memory. This platform enabled the full tracking capability of Memtis and allowed for a comprehensive comparison between page fault- and sampling-based page migration approaches.
-
•
Platform D had an AMD Genoa 9634 processor and four 256 GB Micron’s (pre-market) CXL memory modules. This platform allowed us to evaluate Nomad with more realistic CXL memory configurations.
Since the FPGA-based CXL memory device has had only 16 GB of memory. Hence, we configured local DRAM with a size of to 16 GB for all platforms 333Owing to the limited availability of Although Platform C and D have larger PM or CXL memory devicessizes, we could not test Nomad configured them with a larger CXL memory tier. However, Nomad’s non-exclusive design would benefit more from a large-capacity slow tierthe same 16 GB DRAM to be consistent with Platform A and B for ease of comparison.. The size of the Intel Optane PM was 256 GBNote that Platform C was installed with DDR4 (i.e., compatible with older processors), while the other platforms were installed with DDR5. In this tiered memory, local DRAM serves served as the fast memory tier, while CXL or PM serves served as the slow memory tier. In addition, each of the three four platforms was equipped with a single socket, and we configured the number of CPU cores to 32. We evaluate 32 for Intel processors and 84 for AMD. Table 1 also lists the main performance characteristics for the tiered memory of different platforms, including memory access latency and throughput (under single-threaded and peak performance).
Baselines for comparison: We compared Nomad with two state-of-the-art tired memory systems: TPP [Maruf_23asplos_tpp] and Memtis [memtis]. We evaluated both TPP and Nomad on Linux kernel v5.15, and run .13-rc6 and ran Memtis on kernel v5.15.19. We first used micro-benchmarks to investigate the performance of Nomad’s transactional page migration and page shadowing mechanisms. Further, we used real-world applications to assess the overall performance of Nomad. , the kernel version upon which Memtis was built and released. We tested two versions of Memtis – Memtis-Default and Memtis-QuickCool – with different data cooling speeds (i.e., the period to halve a page’s access counter). Specifically, Memtis-Default chose the default cooling period (of 2,000,000), while Memtis-QuickCool was configured with a much smaller cooling period (of 2,000). A shorter cooling period instructs Memtis to retain fewer pages in the hot list and demote pages more quickly when the fast tier is under memory pressure.
Note that Memtis relies on Intel’s Processor Event-Based Sampling (PEBS) to track memory access patterns. Using PEBS, Memtis samples various hardware events, such as LLC misses, TLB misses, and retired store instructions. By sampling these events, Memtis can detect which pages (from the fast or slow tier) are accessed by walking through the process’s page table. We observed two facts with Memtis: 1) It does not work on Platform D, which is equipped with the AMD processor – although AMD has a PEBS-equivalent feature called Instruction-Based Sampling (IBS), Memtis does not support it. Hence, we did not evaluate Memtis on Platform D. 2) Memtis works slightly differently between CXL-memory platforms (Platform A and B) and PM platforms (Platform C). It is because some hardware events related to CXL memory, e.g., LLC misses to CXL memory, are not supported by PEBS and cannot be captured by Memtis. As a result, Memtis relies solely on TLB misses and retired store instructions to track CXL memory access patterns. However, we also noticed that too many LLC misses to local DRAM may overshadow TLB misses stemming from accessing CXL memory, reducing the accuracy of memory access tracking.
4.1 Micro-benchmarks
We first used micro-benchmarks to investigate the performance of Nomad’s transactional page migration and page shadowing mechanisms. To do this, we developed a micro-benchmark to precisely assess Nomad in a controlled manner. This micro-benchmark involves 1) allocating data to specific segments of the tiered memory, 2) running tests with various working set sizes (WSS) and resident set sizes (RSS); and 3) generating memory accesses to the WSS data that mimic real-world memory access patterns with a Zipfian distribution. We created three distinct scenarios , which represent the representing small, medium, and large WSS , for the micro-benchmarking. We conducted all the micro-benchmarking on Platform B – a tiered memory system with 16 GB local DRAM and 16 GB remote CXL memory. all platforms. Note that Platform B produced similar results as A (hence not listed).
A small WSS: We began with a scenario by running the micro-benchmark with a small WSS of 10 GB and a total RSS of 20 GB. Initially, we filled the first 10 GB of local DRAM with the first half of the RSS data. Subsequently, we allocated 10 GB of WSS data as the second half of the RSS data: 6 GB on the local DRAM and 4 GB on the CXL memory (Platform A and D) and the PM (Platform C). The micro-benchmark , during its operation, continuously executed continuously performed memory reads or writes (following a Zipfian distribution) to this 10 GB WSS data, spread across both the local DRAM and CXL memory or PM. The frequently accessed data, or “hot” data, was uniformly distributed along the 10 GB WSS. For both TPP and Nomad, accessing data on the CXL memory or PM triggered its migration to the local DRAM, with TPP doing so performing this migration synchronously and Nomad asynchronously. In contrast, Memtis used a background thread to migrate hot data from the CXL memory or PM to the local DRAM. Due to page migration, the 4 GB data on the CXL memory or PM gradually moved to the local DRAM– i.e., a , while part of the cold RSS data was demoted to the CXL memory . As the total or PM. Since the WSS was small (i.e., 10 GB), it was would be completely stored in the local DRAM fast tier (i.e., local DRAM) after the micro-benchmark ran for a while, reaching a stable state.
Figure LABEL:fig:smallwss illustrates Figures 7 (a) (Platform A), 8 (a) (Platform C), and 9 (a) (Platform D) show that in the initial phase, where intensive during which page migration was conducted intensively (i.e., migration in progress), both Nomad and Memtis demonstrated equivalent similar performance regarding memory bandwidth for readsand writes . During this period, they outperformed TSS significantly , with improvements ranging from 100% to 300%. It indicates that although page-fault-based page migration in Nomad could incur more overhead than the PEBS-based approach in Memtis, a timely page migration (when the WSS is small) could offset this disadvantage. In contrast, for writes (especially on Platform A), Nomad achieved lower bandwidth than Memtis due to additional overhead to support page shadowing (Section 3.2). That is, Nomad sets the master page (migrated to the fast tier) as read-only, and the first write to this page causes a page fault, hence detrimental to write-intensive workloads. The observation also applies to other write-intensive test cases, as will be discussed shortly. On the other hand, Nomad outperformed TPP significantly on Platform A and D and achieved similar performance on Platform C. The performance benefit came stemmed from the asynchronous , transactional page migration for Nomad, which does not prevent workloads from accessing pages during migration (Section 3.1)and asynchronous, background page migration for Memtis, which merely blocked the execution of the micro-benchmark. .
Figure LABEL:fig:smallwss further shows the results in In the stable phase (i.e., migration stable), where most of the WSS data was had been migrated from the CXL memory or PM to the local DRAM. Both , both Nomad and TPP achieved equivalent similar read/write performance bandwidth. This was because memory accesses were all primarily served by the local DRAMand there were few or no page migrations , as listed , with few page migrations occurring, as shown in Table LABEL:tab:pagemigrationnumb. Surprisingly, the performance of Memtis was the worst(less than 2. Memtis performed the worst, achieving as low as 40% of the other two). In fact, the performance with Memtisdid not change much performance of the other two approaches. We further observed that, in most cases, Memtis’s performance increased only slightly from the initial phase to the stable phase. Possible reasons include Furthermore, with a higher rate of cooling down hot pages, Memtis-QuickCool performed better than Memtis-Default. Possible reasons for Memtis’s low performance include: 1) Memtis’’s PEBS-based sampling was too coarse-grained and failed to capture most hot pages on the CXL memory ; (i.e., as stated earlier, LLC misses to CXL memory cannot be captured by Memtis); and 2) Memtis’’s background migration thread could not timely migrate pages from the local DRAM to the CXL memory . We only observed promptly. We observed only a small number of page migrations occurring conducted by Memtis during both the initial and stable phases(not , as listed in Table LABEL:tab:pagemigrationnumb). Hence, in 2. Consequently, in the stable phase, many memory accesses were still served by the slow CXL memory , the slow memory tier still handled many memory accesses, leading to low performance.
A medium WSS: We continued to increase the WSS and the RSS to a larger size, setting both larger sizes, setting them at 13.5 GB and 27 GBseparately, respectively. Once again, we placed the first half of the RSS data (13.5 GB) at the start of the local DRAM, followed by 2.5 GB of the WSS on the local DRAM, with the remaining 11 GB residing on the CXL memory or PM. However, as the system (e.g., the kernel) required approximately 3-4 GB of memory, the entire WSS could not be fully held in the fast tier during the stable state, resulting in constant page migrations.
Similar to Unlike the small WSS case, Figure LABEL:fig:mediumwss demonstrates Figures 7 (b), 8 (b), and 9 (b) show that during the initial phase, where heavy page migrations were conducted (migration in progress), both Nomad and Memtis achieved comparable memory bandwidths TPP generally achieved lower memory bandwidth for read and write operations . In this period, they significantly outperformed TPP, showing improvements in the range of 2x to 3x. Compared with the small WSScase, in the medium compared to Memtis. This is because, under the medium WSS, the system experienced higher memory pressure than in the small WSS case, causing Nomad and TPP to conduct more page migrations were conducted in the initial phase – e.g., more than (2x as listed - 6x) and incur higher overhead than Memtis, as shown in Table LABEL:tab:pagemigrationnumb. This is because a larger portion of the WSS data was initially allocated in the CXL memory 2. Conversely, Memtis performed fewer page migrations than the small WSS case(11 GB vs. 4 GB).
Figure LABEL:fig:mediumwss presents the findings from the stable phase (migration stable). In this phase, Nomad and Memtis exhibited nearly the same performance in terms of write operations. However, for read operations, Nomad notably excelled, outperforming the other two approaches substantially – for instance, it achieved 4x the performance of TSS and 2x the performance of Memtis. In . One possible reason is that: It did not capture the LLC misses of CXL memory and mostly relied on TLB misses for tracking memory access, but the events of TLB misses were overshadowed by extensive local LLC miss events in the medium WSS case. The less effective PEBS-based approach in Memtis, resulting in fewer page migrations, we observed that, during the stable phase, a significant number of page migrationswere still triggered, as listed in Table LABEL:tab:pagemigrationnumb. The reason is that although the WSS of 13.5 GB is smaller than the local DRAM capacity of 16 GB, the combined size of the WSS data and the system’s data exceeds the threshold for space reclaiming, triggering the demotion thread to begin migrating pages to the CXL memory. The demoted pages belonging to the WSS were promptly promoted back to the local DRAM shortly, leading to memory thrashing. redemptively maintained the system’s performance under high memory pressure.
As the system entered the stable phase, Nomad can significantly mitigate the performance degradation for read operations (resulting from memory thrashing) due to its achieved higher performance for both reads and writes than the initial phase due to 1) most hot pages residing in the fast tier and thus 2) fewer page migrations being triggered. Compared to Memtis-Default, Nomad achieved higher read performance and similar write performance. The reason that Nomad was particularly superior in read performance – the read bandwidth was the highest among all test cases during the stable state across all three platforms – was due to Nomad’s non-exclusive memory tiering. Recall that Nomad’s page shadowing mechanism enables a subset of pages resident in the local DRAM to have a shadow copy in the CXL memory or PM (Section 3.2). This mechanism benefits the read operations when thrashing occurs (e.g., with a medium WSS) – when a page is selected for demotion and meanwhile Nomad retains its copy in the CXL memory or PM, the page is discarded rather than migrated. Unfortunately for writes, as the local version has been modified during demotion, the new version needs to be migrated to the CXL memory. But However, as discussed earlier, the page shadowing mechanism could be detrimental to write operations due to additional page faults. This explains why Nomad still managed to deliver the best performance among the three approaches. achieved similar write performance as Memtis-Default and sometimes worse than Memtis-QuickCool. Finally, Nomad again significantly outperformed TPP in all cases.
A large WSS: In our final test using micro-benchmarks, we We scaled up the WSS (and the RSS) to a size of 27 GB . In this scenario, all the data accessed in the micro-benchmark constituted the WSS data. We arranged this data sequentially, starting and arranged the data from the local DRAM and extending to the CXL memory , allocating or PM, with 16 GB of the WSS on the local DRAM and the remaining 11 GB on the CXL memory or PM. This created an extreme scenario that caused case causing severe memory thrashing, as the total hot data greatly (27 GB) exceeded the capacity of the local DRAM(16 GB).
Figure LABEL:fig:largewss presents
 \subcaption
\subcaption
(a) Small working set size
 \subcaption
\subcaption
(b) Medium working set size
 \subcaption
\subcaption
(c) Large working set size
 \subcaption
\subcaption
(a) Small working set size
 \subcaption
\subcaption
(b) Medium working set size.
 \subcaption
\subcaption
(c) Large working set size
 \subcaption
\subcaption
(a) Small working set size
 \subcaption
\subcaption
(b) Medium working set size
 \subcaption
\subcaption
(c) Large working set size
Figures 7 (c), 8 (c), and 9 (c) present the performance in both the initial phase and the the stable phase. InterestinglyAs expected, both Nomad and TPP, tending which tend to promptly migrate detected hot data from the CXL memory , or PM, performed worse than Memtis, which only conducted background promotion/demotion. This is because , the severe memory thrashing caused by the large WSS made Nomad and TPP , frequently migrated frequently migrate pages between the local and remote memory, greatly degrading the micro-benchamrk’micro-benchmark’s performance. In contrast, much far fewer page migrations occurred with Memtis. HoweverAdditionally, Nomad consistently outperformed TPP by a range of 2x - 5x, again due to its asynchronous, transactional page migration. In additionAgain, Nomad’s page shadowing ’s page shadowing helped achieve higher performanceread performance, especially during the stable state on Platform A. Regardless, frequent page migrations become counterproductive when the WSS significantly exceeds the capacity of fast memory.

A PEBS-tailored scenario: Our observations from the above test cases showed that Memtis performed page migrations much less frequently than Nomad and TPP. In the final micro-benchmarking test, we created a PEBS-tailored scenario designed to generate a PEBS event for each memory access, potentially allowing PEBS-based Memtis to capture memory access more accurately and result in more page migrations. We used a random pointer-chasing memory access pattern, where 1) each memory access resulted in a cache miss (a PEBS event on Platform C equipped with PM) and 2) access to memory blocks (at the granularity of 1 GB) exhibited temporal locality. That is, each page would be accessed multiple times (4KB / 64B = 64 times) within a memory block, and the same memory block might be accessed repeatedly in the future. This way, accurate page migration would significantly benefit the workload. Figure 10 shows that, under the medium and large WSS on Platform C, Memtis exhibited the slow-tier latency (i.e., most pages in the slow tier), while TPP and Nomad showed the fast-tier latency (i.e., most pages in the fast tier). It indicates that even with sufficient PEBS events, sampling-based PEBS Memtis still cannot accurately track memory access patterns and perform timely page migrations.
Migration success rate: As discussed in Section 3.1, there exists a possibility that Nomad’s transactional page migration might not succeed due to simultaneous modification (dirtying) of the page by a process. Table 3 demonstrates that, across various scenarios tested with micro-benchmarks, Nomad maintains a notably high success rate in page migrations.
| RSS | 23GB | 25GB | 27GB | 29GB |
| Total shadow page size | 3.93GB | 2.68GB | 2.2GB | 0.58GB |
Robustness: Page shadowing can potentially increase memory usage and in the worst case can cause OOM errors. In this test, we evaluated the effectiveness of Nomad’s shadow page reclamation. We measured the total memory usage and the size of shadow memory using a micro-benchmark that sequentially scans a predefined RSS area. Table 5 shows the change of shadow pages as we varied the RSS. The results suggest that Nomad was able to effectively reclaim shadow pages as the benchmark approached the capacity of the total memory. We further pushed the RSS (not shown in the table) beyond the total memory size. The system started swapping but encountered no OOM errors. We repeated the tests for a large number of times and no OOM errors were observed.
Summary: When the WSS is smaller than the performance tier, Nomad enables applications to sustain high performance via workloads to sustain higher performance than Memtis through asynchronous, transactional page migrationswhen the WSS is smaller than the performance tier. Additionally. However, when the WSS is comparable to or exceeds the capacity of the performance tier, causing memory thrashing, page-fault-based migration in Nomad becomes detrimental to workload performance, falling short of Memtis for write operations. Notably, Nomad’s page shadowing feature notably enhances retains the efficiency of read operations . Performance comparisons using Redis and YCSB between TPP and Nomad. Despite our best efforts, we could not execute Memtis on Redis successfully. even in situations with severe memory thrashing, maintaining comparable or even better performance than Memtis in most cases. In all test cases, Nomad significantly outperformed the state-of-the-art page-fault-based migration approach, TPP.
Performance comparisons with PageRank between non-migration, TPP, Memtis, and Nomad.
Performance comparisons with Liblinear between non-migration, TPP, Memtis, and Nomad.
4.2 Real-world Applications
We continued the evaluation of Nomad using three representative real-world applications with unique memory access patterns: Redis [redis], PageRank [pagerankwiki], and Liblinear [liblinear]. We ran these three applications on top of three four different platforms (Table 1) to reveal the benefits and potential limitations of current page management systems for emerging tiered with two cases: 1) a small RSS (under 32 GB) working with all platforms and 2) a large RSS (over 32 GB) that only Platform C and D can run due to larger PM or CXL memory.

Key-value store: We first conducted experiments on a latency-sensitive key-value database, Redis [redis]. The workload was generated from YCSB [ycsb], using its update heavyupdate-heavy workload A, , with a 50/50 distribution of read and write operations. We carefully crafted three cases with different RSS and total operations. Note that the parameters of YCSB were set as default if they were not specifiedas follows.
unless otherwise specified. Case 1: We set recordcount recordcount to 6 million and operationcount operationcount to 8 million. After pre-loading the dataset into the database, we used a customized tool to demote all Redis’ memory pages to the slow memory tier . Then, we started to run tier before starting the experiment. The RSS of this case was 13GB.
Case 2: We increased the RSS by setting recordcount recordcount to 10 million and operationcount operationcount to 12 million. We used the same way to demote demoted all the memory pages to the slow tier in the same way. The RSS of this case was 24GB.
Case 3: We increased the total operations while keeping the same RSS by setting recordcount to 10 million and operationcount to 12 million. After kept the same total operations and RSS as Case 2. However, after pre-loading the dataset, we did not not demote any memory pages. The RSS was 24GB.
Figure LABEL:ycsb shows that , compared to TPP, Consistent with the micro-benchmarking results, Figure 11 shows that Nomad consistently delivered superior performance for the latency-sensitive key-value store across all tested platforms in the three cases. The enhanced performance attributable to (in terms of operations per second) compared to TPP across all platforms in all cases. In addition, Nomad stems from its asynchronous, transactional page migration and page shadowing approaches , which merely block the execution of applications. Notably,outperformed Memtis when the WSS was small (i.e., for Case 1), but suffered more performance degradation as the WSS increased (i.e., for Case 2 and 3) due to an increased number of page migrations and additional overhead. Finally, all the page migration approaches underperformed compared to the “no migration” scenario. It is because the memory accesses generated by the YCSB workload were mostly “random,” rendering migrating pages to the fast tier less effective, as those pages were unlikely to be accessed again during the test. It indicates once again that page migration could incur nontrivial overhead, and a strategy to smartly switch it on/off is needed.
We further increased the RSS of the database and operations of YCSB by setting the recordcount to 20 million and operationcount to 30 million. The RSS for this case was 36.5GB, exceeding the total size of the tiered memory on Platforms A and B, thus only being able to run on Platforms C and D. We tested two initial memory placement strategies for the database – Thrashed (demoting all memory pages to the slow tier) and Normal (placing the memory pages starting from local DRAM). In this larger-scale case with more severe memory thrashing, as shown in Figure 16, Nomad demonstrated the highest performance in case 3. This is due to that a smaller amount of data (8 GB) was initially allocated onthe slower tier in case 3, compared to the larger initial allocations (13 GB and 16 GB)in the other two cases. led to lower performance compared to Memtis due to massive page migration operations but still outperformed TPP.

Graph-based computation: We further used PageRank [pagerankwiki], an application used to rank web pages. It involves iterative computations to determine the rank of each page, based on the link structures of the entire web. As the size of the dataset increases, the computational complexity also increases, making it both memory-intensive and compute-intensive. We used a benchmark suite [pagerank] to generate a synthetic uniform-random graph comprising vertices, each with an average of 20 edges. The RSS in this experiment was 22 GB, indicating that the memory pages were distributed at both the local DRAM and remote CXL memory or PM.
Figure LABEL:pagerank 12 illustrates that there is was negligible variance in performance between scenarios with page migrations (using Nomad and TPP) and without page migrations (no migration). The results suggest that: 1) For non-latency-sensitive applications, such as PageRank, using CXL memory (as in Platform A) can significantly expand the local DRAM capacity without adversely impacting application-level performance. 2) In such scenarios, page migration appears to be unnecessary. In addition, the application-level performance diminishes with PM (as observed in Platform C), partly due to PM’s higher latency compared to the CXL memory. These findings also reveal that the overhead associated with Nomad’s page migration minimally influences PageRank’s performance. Additionally, it is was observed that among all evaluated scenarios, Memtis exhibits exhibited the least efficient performance.
Figure 16 shows the case when we scaled the RSS to a very large scale on Platform C & D. When the PageRank program started, it first used up to 100GB memory, then its RSS size dropped to 45GB to 50GB. Nomad achieved 2x the performance of TPP (both platforms) and slightly better than Memtis (Plactform C), due to more frequent page migrations – the local DRAM (16 GB) was not large enough to accommodate the WSS in this case.




Machine learning: Our final evaluation of Nomad involved using the machine learning library Liblinear [liblinear], known for its large-scale linear classification capabilities. We executed Liblinear with an L1 regularized logistic regression workload, using 16 threads with an RSS of 10 GB. Prior to each execution, we used our tool to demote all memory pages associated with the Liblinear workload to the slower memory tier.
Figure LABEL:liblinear illustrates 13 demonstrate that both Nomad and TPP significantly outperformed the “no migration” scenario on Platform B, which utilizes CXL-based memory tiering. However, this performance advantage was not evident on Platform C, featuring PM-based memory tiering, where all approaches exhibited comparable performance. Further analysis revealed a sharp difference in page promotions between the platforms: 12 million on Platform B compared to just 1 million on Platform C. This discrepancy is attributable to the differing speeds of CXL memory and PM. This observation indicates that the efficacy of page migration is closely linked to the performance characteristics of the underlying memory media. and Memtis across all platforms, with performance improvement ranging from 20% to 150%. This result further illustrates that when the WSS is smaller than the local DRAM, Nomad and TPP can substantially enhance application performance by timely migrating hot pages to the faster memory tier. Figure 16 shows that with a much larger model and RSS when running Liblinear, NOMAD consistently achieved high performance across all cases. In contrast, TPP’s performance significantly declined, likely due to inefficiency issues, as frequent, high bursts in kernel CPU time were observed during TPP execution.
Our observations from Figure LABEL:pagerank and Figure LABEL:liblinear also reveal that the
Impacts of platforms: Our observations of application evaluation results across four different platforms reveal that application-level performance was related to is influenced by the distinct characteristics of platforms. For instanceeach platform. For example, Platform A represents a standard off-the-shelf machine, whereas while Platform B is an engineering sample with undisclosed features , which that may affect various applications differently. This implies that the presence of other prominent suggests that other significant performance-related factors could potentially overshadow the effects of page migrations.
Migration success rate: Unlike micro-benchmarks, the success rate in Nomad’s page migrations varied across different applications, as shown in Table 4. We observed a low success rate for Liblinear, while Redis had a very high success rate. Interestingly, this contrasted with Nomad’s performance: it was excellent with Liblinear but poor with Redis both under the large RSS condition. This suggests that a high success rate in page migrations does not necessarily equate to high performance. A low success rate can indicate that the pages being migrated by Nomad are also being modified by other processes, implying their “hotness”. Timely migration of such pages can benefit ongoing and future access.
5 Discussions and Future Work
The key insight from Nomad’s evaluation is that page migration, especially under memory pressure, has a detrimental impact on overall application performance. While Nomad achieved graceful performance degradation and much higher performance than TPP, an approach based on synchronous page migration, its performance is sub-optimal compared to that without page migration. When the program’s working set exceeds the capacity of the fast tier, the most effective strategy is to access pages directly from their initial placement, completely disabling page migration. It is straightforward to detect memory thrashing, e.g., frequent and equal number of page demotions and promotions, and disable page migrations. However, estimating the working set size to resume page migration becomes challenging, as the working set now spans multiple tiers. It requires global memory tracking, which could be prohibitively expensive, to identify the hot data set that can potentially be migrated to the fast tier. We plan to extend Nomad to unilaterally throttle page promotions and monitor page demotions to effectively manage memory pressure on the fast tier. Note that this would require the development of a new page migration policy, which is orthogonal to the Nomad page migration mechanisms proposed in this work.
Impact of Platform Characteristics: There exist difficult tradeoffs between page fault-based access tracking, such as TPP and Nomad, and hardware performance counter-based memory access sampling like Memtis. While page fault-based tracking effectively captures access recency, it can be potentially expensive and on the critical path of program execution. In comparison, hardware-based access sampling is off the critical path and captures access frequency. However, it is not responsive to workload changes and its accuracy relies critically on the sampling rate. One advantage of Nomad is that it is a page fault-based migration approach that is asynchronous and completely off the critical path. A potential future work is to integrate integrating Nomad with hardware-based, access frequency tracking, such as Memtis, to enhance the current migration policy.
Lastly, we have observed application and system crashes on platform-C which has almost an order of magnitude more (persistent) memory on the capacity tier than the performance tier. The crashes occurred to all tested approaches including the vanilla Linux kernel, and to applications whose working set size is significantly larger than the capacity of fast memory. Intuitively, the Linux kernel should utilize tiered memory equally when under memory pressure. However, after reviewing system logs and Linux kernel source code, we found that Linux, and provably many other commercial OSes, follows a hierarchical approach in managing the performance and memory allocation of tiered memory – attempting to cache or allocate data from fast memory if at all possible and resorting to slow memory if failed. Although there are guardrails to spill data into slow memory, such as kswapd, these mechanisms are often not responsive enough to prevent an OOM error. It is worth noting that Nomad has robust shadow page reclamation and does not cause OOM errors due to page shadowing. This finding motivates further research on tiered memory allocation that takes into account both non-hierarchical strategies for reliability and hierarchical strategies for performance.
6 Conclusion
This paper introduces non-exclusive memory tiering as an alternative to the common exclusive memory tiering strategy, where each page is confined to either fast or slow memory. The proposed approach, implemented in Nomad, leverages transactional page migration and page shadowing to enhance page management in Linux. Unlike traditional page migration, Nomad ensures asynchronous migration and retains shadow copies of recently promoted pages. Through comprehensive evaluations, Nomad demonstrates up to 6x performance improvement over existing methods, addressing critical performance degradation issues in exclusive memory tiering, especially under memory pressure. The paper calls for further research in tiered memory-aware memory allocation.