NLHD: A Pixel-Level Non-Local Retinex Model for Low-Light Image Enhancement
Abstract
Retinex model has been successfully applied to low-light image enhancement in many existing methods. More appropriate decomposition of a low-light image to illumination and reflectance components can help achieve better image enhancement. In this paper, we propose a new pixel-level non-local Haar transform based illumination and reflectance decomposition method (NLHD). The unique low-frequency coefficient of Haar transform on each similar pixel group is used to reconstruct the illumination component, and the rest of all high-frequency coefficients are employed to reconstruct the reflectance component. The complete similarity of pixels in a matched similar pixel group and the simple separable Haar transform help to obtain more appropriate image decomposition; thus, the image is hardly sharpened in the image brightness enhancement procedure. The exponential transform and logarithmic transform are respectively implemented on the illumination component. Then a minimum fusion strategy on the results of these two transforms is utilized to achieve more natural illumination component enhancement. It can alleviate the mosaic artifacts produced in the darker regions by the exponential transform with a gamma value less than 1 and reduce information loss caused by excessive enhancement of the brighter regions due to the logarithmic transform. Finally, the Retinex model is applied to the enhanced illumination and reflectance to achieve image enhancement. We also develop a local noise level estimation based noise suppression method and a non-local saturation reduction based color deviation correction method. These two methods can respectively attenuate noise or color deviation usually presented in the enhanced results of the extremely dark low-light images. Experiments on benchmark datasets show that the proposed method can achieve better low-light image enhancement results on subjective and objective evaluations than most existing methods.
Index Terms:
Pixel-level self-similarity; Haar transform; frequency decomposition; Retinex model; low-light image enhancement.I Introduction




The images captured under low-light environments contain unavoidable quality degradation such as poor visibility and intense noise [35], limiting the accuracy of subsequent applications like object recognition [22] and detection [28, 29, 31]. Intuitively, the visibility of the images captured in poor-light environments could be rescued by some camera work of good flash, high ISO, and the long exposure time, etc. However, these techniques produce other image degradation such as color deviation (by flash), intense noise (by high ISO), or blurring (by long exposure time), etc. To this end, many low-light image enhancement methods have been developed to achieve brightness enhancement on the captured low-light images.
Generally, a better low-light image enhancement method can effectively improve the visibility of the dark regions in a low-light image, which is usually achieved by increasing the brightness of the dark regions. In order to obtain satisfactory perceptual quality, the naturalness of the enhanced images is essential [11], especially, the image should not be over-sharpened in the procedure of brightness enhancement. Traditional low-light image enhancement methods are mainly formulated under the Retinex framework [18, 19, 11, 7, 21, 20, 6, 9, 12]. The early Retinex decomposition is achieved by smoothing techniques [18, 19], based on the assumption that the illumination component is piece-wisely smooth [18]. However, the over-smoothed illumination component must lead to a large amount of structure and texture information getting into the reflectance component, which further causes the image to sharpen within the brightness enhancement procedure. Since the early Retinex model based method regards illumination component removal as a default choice and does not limit the range of the reflectance component, it can not effectively maintain the naturalness of non-uniform illumination image [11].
To simultaneously estimate the illumination and reflectance components, in recent years, some new methods employ more reasonable image priors [7, 6, 12] or variational model [8] for low-light image enhancement, with the help of local derivative decomposition techniques. These methods decompose the low-light image into the illumination and reflectance components and then manipulate the illumination component to achieve the image enhancement. The recently proposed Structure and Texture Aware Retinex Model (STAR) [12] decomposes the image through local derivative to alleviate the over smoothing of illumination component, which can reduce the sharpening phenomenon of the enhanced images to a certain extent, an enhanced image by STAR can be seen from Fig. 1(b). Most of deep learning based low-light image enhancement methods [32, 1, 2, 24] are still based on the Retinex model ones. The illumination component is also obtained by local filtering [32] or convolution operation [1, 2, 24]. Some of these methods still over smooth the illumination component. The enhanced images by the latest Kindling the Darkness++ (KinD++) [24] method also produces an intense sharpening phenomenon. Please refer to the highlighted parts by the red and green boxes, respectively, in Fig. 1(c).
In summary, most existing methods can only represent the local singularity because the decomposition operation is restricted to local image blocks or patches. This kind of local filtering method is challenging to control the smoothness of illumination components effectively and generally generates excessive smoothness illumination components. Compared with the above local methods, the non-local filtering method [26, 27, 34, 5] can effectively control the smoothness, which has an excellent performance in image denoising in recent years. The application of the non-local idea to Retinex decomposition may also be a meaningful attempt.
This paper proposes a new pixel-level non-local Haar decomposition (NLHD) based Retinex model and further develops a new low-light image enhancement method. The NLHD method makes full use of the pixel-level non-local self-similarity in the images. The block-matching and row-matching operations are utilized to get 2D similar pixel groups; the Haar transform on these similar pixel groups can appropriately decompose the image into illumination and reflectance components to more effectively alleviate image sharpening in the image brightness enhancement procedure; an enhanced image by the proposed NLHD method can be seen from Fig. 1(d). Furthermore, a minimum fusion strategy is explored to fully use the advantages of logarithmic transformation and exponential transformation simultaneously to alleviate the mosaic artifacts in the darker regions and reduce over-exposure in the brighter regions.
The extremely dark low-light images or extremely dark regions in a low-light image generally accompany intense noise, such as the LOL dataset [1]. This paper proposes a local noise level estimation method and a simplified NLH version to suppress noise effectively. Noticing that the enhanced images of extremely dark low-light images usually suffer a color deviation problem, we also propose a new non-local saturation reduction based color deviation correction method to achieve better subjective visual quality and objective evaluation performance of the enhanced extremely dark low-light images.
The main contributions of this paper are summarized in three aspects:
-
•
We take full advantage of the NLH frequency decomposition ability to achieve more appropriate illumination and reflectance components in the Retinex model.
-
•
We propose to enhance illumination components by exponential transform and logarithmic transform synchronously, and a novel minimum fusion strategy to achieve much better low-light image enhancement results than most existing methods.
-
•
A local noise level estimation method and a simplified NLH version are utilized to effectively suppress noise in the low-light image enhancement procedure. A new non-local saturation reduction based color deviation correction method help achieve better subjective visual quality and objective evaluation performance of the enhanced extremely dark low-light images.
The rest of the paper is organized as follows: §II summarizes the related works, and §III elaborates the proposed NLHD method. §IV presents the proposed noise suppression method and color deviation correction method. Then, §V presents experimental details and reports comparison results on Retinex decomposition and low-light image enhancement. As a practical application, we conduct face detection experiments on enhanced low-light images of Dark Face dataset [13] to verify the effectiveness of the proposed method in §V-C. We also present the ablation study of the proposed method in §V-D. Finally, we make a conclusion remark in §VI.
II Related Work
II-A Retinex Model
Simplified Retinex theory assumes that we can decompose an observed image into an illumination component and a reflectance component. As a seminal work, Single Scale Retinex (SSR) [18] and Multi-Scale Retinex (MSR) [19] implement Gaussian filtering on the images, take the low-frequency results as the illumination component, and remove the filtered results from the original images to obtain reflectance component. However, these methods are prone to introduce color distortion and halo artifacts in regions with large brightness deviations. In addition, the over-smoothed illumination component results in excessive structural and texture information getting into the reflectance component so that the enhancement of the reflectance component produces an intense sharpening phenomenon.
In recent years, the Retinex model is still widely applied to the low-light image enhancement task. Multi-scale derived images Fusion (MF) [20] adjusts the illumination component by fusing multiple derivatives of its initial estimation. Low-Rank Regularized Retinex Model (LR3M) [14] suppresses the noise in the reflectance component by adding a low-rank constraint into the decomposition model but misses enough details from the illumination component. A Weighted Variational Model (WVM) [8] was proposed to estimate the reflectance and illumination simultaneously. The Joint intrinsic-extrinsic Prior model (JieP) [6] enhances the illumination component through exponential transformation and obtains ideal low-light image enhancement results. Low-Light Image Enhancement via Illumination Map Estimation (LIME) [21] estimates the brightness component of each pixel by finding the maximum value in the RGB channels. The structure prior is added to the initial illumination component to refine it into the final illumination component. Finally, the enhanced image is generated according to the illumination component. The Structure and Texture Aware Retinex model (STAR) [12] well estimates both the illumination and reflectance components for image enhancement. Because the above methods preserve part of the structure and texture information in the illumination component, the sharpening phenomenon has been alleviated.
Unlike previous Retinex-based methods, our Non-local Haar Decomposition (NLHD) method makes full use of the pixel-level non-local self-similarity prior to decompose the low-light images; it can achieve more appropriate illumination and reflectance components. Because the illumination component preserves much more structure and texture information, the enhanced image has almost no sharpening phenomenon.
II-B Deep Low-light Image Enhancement
Deep learning has achieved great success in many fields. Many deep learning based low-light image enhancement methods have also been developed in recent years.
Retinex Decomposition based Generative Adversarial Network (RDGAN) [10] integrates the Retinex model into a deep learning framework, splitting the Generative Adversarial Network (GAN) [33] into a Retinex decomposition network module and a fusion reinforcement network module. Deep Retinex Decomposition for Low-Light Enhancement Network (Retinex-Net) [15] combines Retinex model with semantic information perception to enhance segmented image regions. Low-light Net (LLNet) [25] achieves the low-light image enhancement based on a deep auto-encoder network. Multi-Branch Low-Light image Enhancement Network (MBLLEN) [2] extracts image features at different levels, enhances the image through multiple sub-networks, and finally generates the output image through multi-branch fusion. Kindling the Darkness (KinD) [3] added an adjustment network to adjust the illumination, which alleviates the problem of overexposure. Deep Light Enhancement Generative Adversarial Network (EnlightenGAN) [4] uses the information extracted from the input image itself to regularize the unpaired training and proposes a global-local discrimination structure, a self regularized perceptual loss fusion and attention mechanism; four non-reference loss functions are designed to satisfy the non-reference training. Because most of the above deep learning based methods combine the Retinex model, the Retinex decomposition is still achieved by convolution operation without considering non-local prior; the over-smoothed illumination component still causes sharpening.
II-C Non-local Self-Similarity
Generally, there are many similar image blocks in an image, which may not come from the same local region. This property is usually called non-local self-similarity. Non-local self-similarity was initially proposed by the Non-local Means (NLM) [26] to solve the image denoising problem. NLM estimates each pixel by computing a weighted average of some similar pixels obtained by implementing image block-matching, so NLM is a spatial domain method. BM3D [27, 34] is a transform domain non-local method that combines the non-local idea with discrete wavelet transform (DWT) and discrete cosine transform (DCT). BM3D is a patch-level non-local method, i.e., the signal in a single image patch is still local, so it is not an utterly non-local method. In order to better apply the non-local idea to the image denoising problem, NLH [5] proposed to further search similar pixels in a similar image patch group and can achieve better image denoising results.
In the NLH method, a similar image block group is obtained by block-matching as the same as NLM and BM3D, then scan each image block to a column vector, stack all the vectors to get a 2D matrix, finally implement row-matching to obtain similar pixel groups. A separable Haar transform is implemented on each similar pixel group to achieve the signal decomposition.
In this paper, we apply the NLH idea to decompose the image into illumination and reflectance components and further achieve low-light image enhancement. The proposed image decomposition method makes full use of the pixel-level non-local self-similarity in the images, so the enhanced images by our method look much more natural than the enhanced images by most existing local filtering based Retinex decomposition methods, especially the enhanced images by our method have almost no sharpening phenomenon.
III Proposed Method
The Retinex model has been proved to be an effective low-light image enhancement method, more appropriate illumination and reflectance decomposition is the key of the Retinex model. In order to better apply the Retinex model to achieve more effective low-light image enhancement, a new pixel-level non-local Haar transform based illumination and reflectance decomposition (NLHD) method is proposed in this section.
The proposed method includes the following four steps: (1) The similar pixel groups are obtained by image block-matching and row-matching; (2) The Haar transform is implemented on each similar pixel group, and the illumination component is obtained by low-frequency reconstruction of the transform coefficients, the high-frequency coefficients reconstruction obtains the reflectance component; (3) The illumination components are enhanced by exponential transform and logarithmic transform respectively, and then use a minimum fusion strategy on both of the enhanced illumination components to get the final enhanced illumination components; (4) The Retinex model is used to achieve the image enhancement by combining the enhanced illumination and reflectance components. Fig. LABEL:Frame shows the flow chart of the proposed low-light image enhancement method, and the details of NLHD can be seen in Fig. LABEL:Decomposition.
III-A Background on Retinex Model
Retinex model is developed based on the human visual cognition system. The model decomposes the image into two components: illumination and reflectance, i.e.,
| (1) |
where is an image, is the illumination component of , representing the incident light image, namely the brightness of the light on the object surface in the image, which determines the dynamic range that the pixel value can reach in the image; is the reflectance property image of the objects, representing the internal attribute of the image, namely the structure of the objects in the image. The basic idea of the Retinex model is to remove or reduce the influence of incident light on the image by some methods to preserve the object’s natural attribute as much as possible. Therefore, estimating or decomposing the illumination component and reflectance component is the key problem of the Retinex model.
In essence, the illumination component represents the brightness of the object surface in the image, which comes mainly from the smoother regions of the image; However, the reflectance component is generally distributed in the small structural parts such as texture in the image. Therefore, the Retinex decomposition should be attributed to better decomposing the image’s smooth regions and texture regions. Based on this prior knowledge, we propose a new Retinex decomposition method based on the pixel-level non-local Haar transform in this paper. We present the details of the proposed method in §III-B and §III-C.
III-B Similar Pixel Group
Given a low-light color image in RGB color space. We implement block-matching and row-matching in RGB space to obtain similar pixel groups. We firstly compute the mean value of a reference image block in each R, G, B channel, according to the maximum mean value to decide the block-matching channel . According to a certain sliding step size, a reference image block with the size of is selected in to implement block-matching by Euclidean distance to get a similar block group with blocks, then extract the same position’s blocks in other two channels, so we can get three similar block groups. Each image block with the size of is stretched into a column vector in each channel respectively. All are stacked into a matrix with rows and columns, we finally get three all together in three color channels respectively. In order to better mine the self-similarity in the images, we further implement row-matching in each . Each row is used as the reference row to calculate the Euclidean distance with all other rows to find the most similar rows, put together with the most similar rows to construct a dimension similar pixel matrix . Specifically, for the i-th row as the reference row, the Euclidean distance between the i-th row and all other rows is calculated as follows,
| (2) |
III-C Haar Transform and Image Decomposition
In order to effectively decompose the image into illumination and reflectance components in the Retinex model, we implement separable Haar transform on the similar pixel group , i.e., the vertical and horizontal separable lifting transformation. The transform can be represented as the following,
| (3) |
where is the transform spectral matrix of the Haar transform, and is the Haar transform matrix. Due to the characteristics of separable lifting Haar transform, is the weighted average of all the pixels in the , which we define as the low-frequency coefficient, we only use to reconstruct the ideal illumination component by the inverse Haar transform. Instead, use the rest of coefficients to reconstruct the reflectance component by the inverse Haar transform. The specific detail of NLHD is shown in Fig. LABEL:Decomposition.
III-D Illumination and Reflectance Enhancement
Because the illumination component and the reflectance component have their respective characteristics, we respectively implement different enhancement operations on illumination component and reflectance component . Three reflectance components , and can be initially obtained by , and channels respectively, one can use the minimum value fusion of these reflectance components as the final reflectance component , but the following method can achieve the best image enhancement results in our experiments,
| (4) |
where is the absolute value sign, and we finally get the enhanced reflectance component by simply adding 1.0 to , i.e., .
As for illumination component , we also initially obtained three illumination components , and , we firstly get bright illumination component by maximum value fusing among the above three illumination components as the following,
| (5) |
We use different index and to achieve enhancement respectively, where and are both adaptively calculated as follows,
| (6) |
we get by the two following situations: if
| (7) |
else
| (8) |
where means the number of non-zero elements. In this stage, we set , , , , , , , . Two different enhanced and can be obtained by the following formulas,
| (9) |
| (10) |
Here, if we only use exponential transformation to enhance the illumination component, the extremely dark regions in the low-light images are generally over-enhanced, some mosaic artifacts are usually introduced, the noise is amplified as well. If we only use logarithmic transformation to enhance the illumination components, the relatively bright regions in the low-light images usually present over-exposure phenomenon. In order to solve these problems, we propose to enhance the illumination component as the following,
| (11) |
Because real-world low-light images present various illumination levels, better-enhanced results of some extremely dark images could not be achieved just by the above procedure. We use a further algorithm 1 to achieve balanced enhancement results on various initial illumination levels.
Finally, the illumination component and the reflectance component are applied to the Retinex model, that is,
| (12) |
where is the initial enhancement image, is the element-wise multiplication operation. The V channel in HSV color space is replaced by , then HSV color space is converted to RGB color space to achieve the final RGB enhancement image.
IV Noise Suppression and Color Deviation Correction
The extremely dark low-light images or extremely dark regions in a low-light image generally accompany intense noise, such as the LOL dataset [1], the noise is usually further amplified in the process of enhancement, it seriously influences the subjective visual quality and objective evaluation of the enhancement results. Therefore, how to effectively suppress the noise in the low-light images is also a significant problem. In this paper, we propose a local noise level estimation method and a simplified NLH version to effectively suppress noise for achieving better low-light image enhancement.
The enhanced images of extremely dark low-light images usually suffer color deviation problems as well. In this section, we also propose a new non-local saturation reduction based color deviation correction method to achieve better subjective visual quality and objective evaluation performance of the enhanced images.
IV-A Noise Suppression
The noise distribution in the low-light images is usually uneven between brighter regions and darker regions. The darker the regions, the noise is the stronger. So the traditional image denoising method is not entirely suitable for the low-light image noise suppression problem. The pixel-level non-local Haar transform (NLH) was initially proposed to solve the image denoising problem. However, NLH estimates noise level on the whole image, so it is unsuitable for low-light image noise estimation.
In this paper, we further develop a new local noise estimation method and combine it with the NLH method to achieve better noise suppression in the low-light image enhancement procedure. The proposed method has a little bit different from the NLH method; we use the minimum row-matching distances to estimate local noise level, further use the mean value of the similar pixel group, the local noise level, and the standard deviation of minimum row-matching distances to decide the hard-thresholding parameter value. The local noise standard deviation is computed as the following,
| (13) |
where is the minimum row distance in each row-matching procedure referring to Eq.2, is the size of image block.
We adaptively select the hard-thresholding parameter according to the similar pixel group mean value . The smaller the mean value, the larger the hard-thresholding parameter. Besides, we also use minimum row-matching distance standard deviation to adaptively decide hard-thresholding parameter; the larger the distance standard deviation value, the smaller hard-thresholding parameter to better preserve the edge details in images, such as textures and contours. The local minimum row-matching distance standard deviation can be calculated as the following,
| (14) |
We use parameters , , , , in the noise suppression procedure, where is the image block size, is the sliding step size of reference image block, is the block-matching searching neighbor radius, is the number of similar image blocks, and is the number of the rows in each similar pixel group. The hard-thresholding parameter is computed as the following,
| (15) |
where is the mean value of the similar pixel group, the parameter adjusts value such that it is close to the value of , in our experiments. The role of this formula is that we allocate larger in the darker regions in the images; this corresponds to the fact that the darker the regions, the stronger the noise. Besides, the larger means the richer image details, so we should allocate the smaller to better preserve image details. On the contrary, we should use larger to improve the denoising ability. Meanwhile, we also use structural hard-thresholding similar to the original NLH method. We only implement two steps iteration here and remove the Wiener filtering stage in the original NLH method. Because we use a group of low complexity parameters and the simplified procedure, the running speed of this algorithm is relatively much faster than the original NLH denoising method.
IV-B Color Deviation Correction
In this subsection, we propose a non-local saturation reduction method to attenuate the color deviation problem. CIELab color space can be effectively used to measure the color deviation degree; we transform denoised RGB low-light image to CIELab color space, then compute the mean value of channel and channel, the global color deviation degree can be measured as the following,
| (16) |
where and are the mean values of channel and channel respectively. In channel , the positive values represent the red color; the negative values refer to the green color. Similarly, the positive values in channel represent the yellow color; the negative values refer to the blue color. The zero value of means that the color is well-balanced; the larger value means the stronger color deviation in the image.
We propose a pixel-level non-local color deviation correction method in this paper, input the channel of HSV space to illumination decomposition procedure, synchronously using the block-matching and row-matching results to get similar pixel group in channel, using the formula to reduce the saturation, where , the larger value, the stronger degree of the saturation reduction. The is computed as the following,
| (17) |
where is the minimum value of similar pixel group mean values , and for three channels in RGB color space, is the standard deviation of these three mean values, is an empirical parameter used to control the saturation reduction, we take its value as 0.013 in our experiments. is an upper limitation to void the over reduction of the saturation; we take its value as 4.5 in our experiments. Because the darker images or the darker regions in the images usually result in the stronger color deviation, and the smaller standard deviation among the three color channels means the stronger color deviation as well, so we use the larger value to reduce the saturation in these two situations. All the block-matching and row-matching parameters are the same ones as the illumination decomposition procedure.
V Experiments
In this section, we qualitatively and quantitatively evaluate the Retinex decomposition performance of the proposed NLHD method. We also conduct ablation experiments on some essential parameters of the proposed method to further explore and gain deep insight into the proposed NLHD model. All codes were run on a MacBook Pro laptop with an Intel Core i9-9900K CPU and 32GB memory except for KinD++ [24], the code of KinD++ was run on a computer equipped with Tesla-V100 GPU.
Datasets. In order to verify the effectiveness of the proposed NLHD Retinex decomposition method, we conduct extensive comparison experiments on low-light image enhancement problem. We use 35 low-light images collected in [6, 7, 8, 21] in [12] that is called 35images and 200 random extracted images from Dark Face dataset [13] that is called 200darkface here respectively. We also use the LOL dataset [1] including 500 extremely dark low-light images and their corresponding high-light version to further verify the effectiveness of the proposed noise suppression and color deviation correction method.
Objective metrics. We use different objective metrics to evaluate the performance of the low-light image enhancement. The comparison methods are evaluated according to the following two common indicators, the method of measuring natural image quality without reference image quality assessment (NIQE) [17] and the lightness order error (LOE) [11] between the original image and its enhanced version . The smaller the NIQE value is, the higher the image quality. The smaller the LOE value is, the better the lightness order is preserved. Because there is no ground truth in 35images and 200darkface datasets, we can not compute the peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) [SSIM]. As for the LOL dataset, we compare SSIM, PSNR, and E on this dataset to achieve a more objective evaluation because there is ground truth in this dataset.
V-A NLHD Based Retinex Decomposition
The proposed NLHD method can decompose images to illumination and reflectance components in Retinex model, the low frequency coefficients are used to reconstruct the illumination component, the high frequency coefficients are used to reconstruct the reflectance component. We have both 5 parameters in each reconstruction, take patch size , number of similar patches , number of rows in row matching , sliding step size of reference patches and the window size for searching similar patches to obtain reflectance component in each RGB channels. , , , and are used to obtain the illumination component in each RGB channels. We use Eq.4 and Eq.5 to achieve reflectance component and illumination component respectively.
The general Retinex algorithms assume that the illumination component is usually smooth, but that is not necessarily the case; one can see from the recent Retinex decomposition methods [6, 12] that the illumination component preserves much larger structure information, but better low-light image enhancement results can be achieved. Generally, there is no ground truth of illumination and reflectance [12], so the quantitative evaluation of the existing Retinex decomposition method has always been a difficult problem. In order to evaluate the effectiveness of the proposed NLHD method, we qualitatively compare the illumination and reflectance with some of the most advanced Retinex models, including CRM [23], SIRE [7], Weighted Variational Model (WVM) [8], Joint intrinsic-extrinsic Prior (JieP) model [6], Robust Retinex Model (RRM) [9], NPE [11], LIME [21], STAR [12], and the latest deep learning based method KinD++ [24]. Similar to these methods, we replace the decomposed illumination and reflectance component to the V channel of HSV color space and return the decomposed components to RGB space. We compare the Retinex decomposition results of the above methods in Fig. 4. We can see that the proposed NLHD method can effectively achieve the smoothing effect and preserve main structure information in the illumination component; the reflectance component can better extract the tiny details of the low-light images.
















V-B Low-light Image Enhancement
We run the codes provided by the authors or collected from the Internet of CRM [23], SIRE [7], Weighted Variational Model (WVM) [8], Joint intrinsic-extrinsic Prior (JieP) model [6], Robust Retinex Model (RRM) [9], NPE [11], LIME [21], STAR [12] and the latest deep learning based method KinD++ [24] on 35images and 200darkface datasets respectively. Table I compares Average NIQE value and average LOE value of these methods in the two datasets. One can see that our results are better than other methods. Fig. 5 and Fig. 6 respectively show an image from 35images enhancement result comparison among the proposed method and other existing methods; Fig. 7 shows an image from 200darkface enhancement result comparison among the proposed method and other existing methods. We can see from Fig. 5, Fig. 6 and Fig. 7 that the enhanced result images by the proposed method have better subjective visual quality than other methods. We also implement the proposed method on LOL dataset [1] to verify the effectiveness of extremely dark image enhancement; the objective evaluation results can be seen in Table II, the proposed method achieved much better objective evaluation results on SSIM, PSNR, and E. Fig. 8 shows an extreme dark low-light image, the corresponding ground truth image, and all the enhanced images by different methods; we can see from this figure that the proposed NLHD method achieved a much better enhancement result than all other methods; the proposed method effectively suppressed the noise and achieved the color deviation correction.

(a) Original










(f) RRM [9] (k) NLHD (ours)
(a) Original
(f) RRM [9] (k) NLHD (ours)
(a) Original
(f) RRM [9] (k) NLHD (ours)


| Dataset | 35images | 200darkface | ||
| Metric | NIQE | LOE | NIQE | LOE |
| CRM [23] | 3.13 | 744.61 | 3.66 | 531.16 |
| SIRE [7] | 3.01 | 637.70 | 3.14 | 482.42 |
| WVM [8] | 2.99 | 633.40 | 3.41 | 265.12 |
| JieP [6] | 2.99 | 724.52 | 3.44 | 362.79 |
| RRM [9] | — | — | 3.58 | 387.17 |
| NPE [11] | 3.22 | 710.21 | 4.29 | 920.02 |
| LIME [21] | 3.39 | 779.73 | 3.98 | 896.30 |
| STAR [12] | 2.93 | 677.43 | 3.84 | 390.42 |
| KinD++ [24] | — | — | 3.04 | 664.21 |
| NLHD | 2.76 | 546.63 | 2.80 | 250.79 |
| Metrics | CRM [23] | SIRE [7] | WVM [8] | JieP [6] | RRM [9] |
| PSNR | 16.3425 | 11.8140 | 11.4164 | 11.5782 | 13.0741 |
| SSIM | 0.6055 | 0.4771 | 0.4634 | 0.4789 | 0.6044 |
| E | 16.8154 | 24.8859 | 25.7354 | 25.3589 | 21.7515 |
| Metrics | NPE [11] | LIME [21] | STAR [12] | KinD++ [24] | NLHD |
| PSNR | 15.9962 | 15.8115 | 12.3084 | 16.9706 | 21.1121 |
| SSIM | 0.4830 | 0.5000 | 0.5026 | 0.6883 | 0.8101 |
| E | 17.1756 | 17.2276 | 24.1980 | 13.6101 | 9.4792 |
Comparison on Speed. Table III compares the running time of different Retinex decomposition methods on a low-light RGB image and the image enhancement procedure. We notice that the speed of our method is not faster than all other methods; we will further refine our algorithms and programs to improve the running speed in our future work.
| Method | CRM [23] | SIRE [7] | WVM [8] | JieP [6] | RRM [9] |
| Time | 0.68 | 2.91 | 34.77 | 10.81 | 85.09 |
| Method | NPE [11] | LIME [21] | STAR [12] | KinD++ [24] | NLHD |
| Time | 30.85 | 1.15 | 3.58 | 20.85 | 13.93 |
V-C Application to Object Detection
To further verify the effectiveness of the NLHD method, we compare the face detection results on the enhanced Dark Face dataset [13] with various low-light image enhancement methods. We choose the current excellent object detection method YOLOv5 [31] to achieve face detection on the original low-light images and enhanced images by various low-light enhancement methods, respectively. We firstly train the YOLOv5 model on the Wider Face dataset [30] and then use the Dark Face dataset to test. Since the label of the test set is not public, we randomly select 600 images from the training set of the Dark Face dataset for evaluation. These images are enhanced by various methods, including CRM [23], SIRE [7], Weighted Variational Model (WVM) [8], Joint intrinsic-extrinsic Prior (JieP) model [6], Robust Retinex Model (RRM) [9], NPE [11], LIME [21], STAR [12] and the latest deep learning based method KinD++ [24]. Fig. 10 compares the visual results of face detection between the original images and the enhanced images by the proposed NLHD method. It can be seen that the face detection results on the enhanced images can be improved to a certain extent; even many faces hidden in the darker regions can be detected. In order to more objectively compare the test results, we also depict the precision-recall (P-R) curves under 0.6 IoU threshold in Fig. 9. As shown in Fig. 9, the proposed NLHD based low-light image enhancement method effectively improved the low-light environment face detection performance by the YOLOv5 model. It can be seen that the face detection result of the proposed NLHD method achieved the best performance among all the compared methods listed in the figure; it can obtain the highest Average Precision (AP) score. So the proposed NLHD method can be used for the low-light environment object detection task.

(a)




(b)
(c)

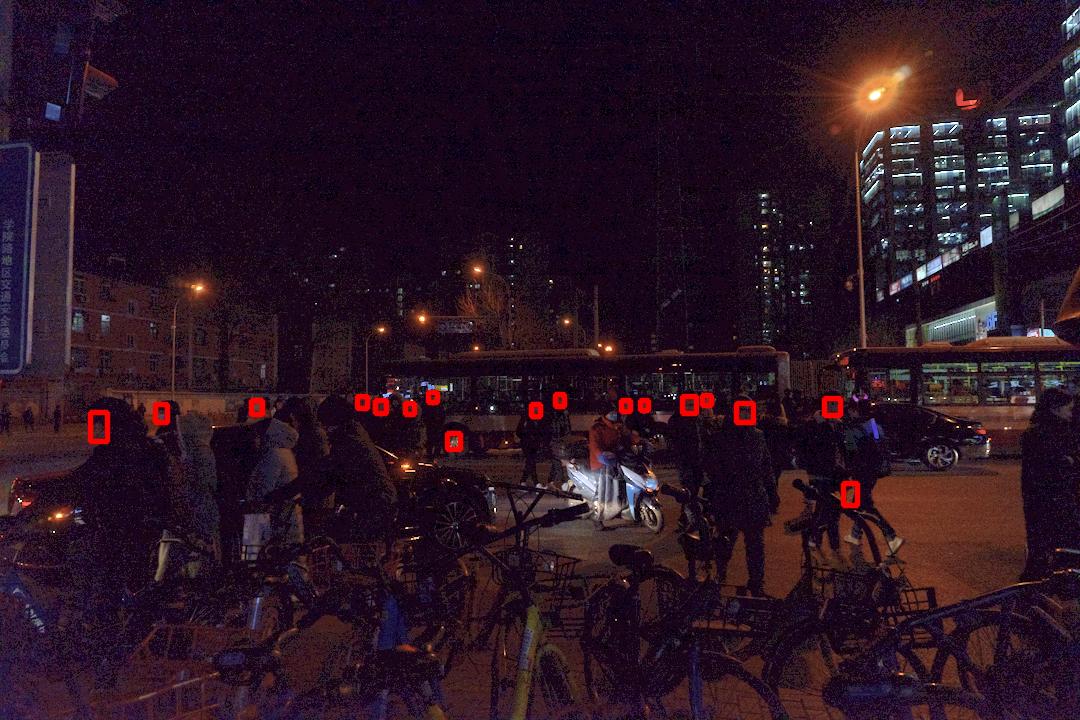


(d)
V-D Ablation Study
a) Is the proposed NLHD necessary? To show the necessity of NLHD, we implement low-light image enhancement experiments by the NLHD method (w/ NLHD) and directly image enhancement by the bright channel of RGB space (wo NLHD) on the 35images dataset and the 200darkface dataset, respectively. We first get the bright channel of RGB space, the maximum pixel values in R, G, and B channels are fused to construct a bright channel (Actually, channel V in HSV space is the bright channel of RGB space), then we implement the exponential transform and the logarithmic transform respectively on the bright channel with the same parameters as the NLHD based enhancement method. We use the minimum fusion result of the enhanced bright channel to replace the V channel in HSV space to achieve the final enhanced image. We compare NLHD with the above method; the objective evaluation results in Table IV show that the performance of the NLHD is much better than that of the above method. The results show that the NLHD method can use pixel-level non-local self-similarity to achieve better Retinex decomposition, thus achieving better low-light image enhancement results.
| Dataset | 35Images | 200darkface | ||
| Metric | NIQE | LOE | NIQE | LOE |
| wo NLHD | 3.31 | 636.86 | 3.58 | 262.99 |
| w/ NLHD | 2.76 | 546.63 | 2.80 | 250.79 |
b) Minimum fusion strategy v.s. separate exponential transform or separate logarithmic transform. The proposed exponential and logarithmic transform minimum fusion strategy can achieve better objective and subjective image enhancement results. In order to further verify the effectiveness of this strategy, we compare the three enhancement results, separate exponential transform (NLHD w/o exp), separate logarithmic transform (NLHD w/o log), and the minimum fusion (NLHD), as shown in Table V. We just use NIQE to evaluate the objective metric and use the 35images dataset here. Fig. 11 shows the comparison of the results with these three situations. We can see that the minimum fusion strategy achieved the best subjective visual image enhancement results.
| Metric | NLHD w/o exp | NLHD w/o log | NLHD |
| NIQE | 2.80 | 3.78 | 2.76 |
(a)





(b)





(c)





(d)





c) Retinex model v.s. separate illumination or separate reflectance. We reconstruct the enhanced image by separate illumination component (NLHD w/o illumination), separate reflectance component (NLHD w/o reflectance), and the whole Retinex model based NLHD method (NLHD). We use NIQE to evaluate the objective metric and use the 35images dataset here. We can see from Table VI that the NLHD method presents the best performance, NLHD w/o illumination can achieve a close result to the NLHD method, NLHD w/o reflectance result is the worst one. The objective evaluation results correspond to the subjective visual quality, partly referring to Fig. 4.
| Metric | NLHD w/o illumination | NLHD w/o reflectance | NLHD |
| NIQE | 2.98 | 3.94 | 2.76 |
VI Conclusion
This paper proposes a low-light image enhancement method based on pixel-level non-local Haar transform decomposition (NLHD) and the Retinex model. The proposed image decomposition method makes full use of the pixel-level self-similarity in images, thus achieving better illumination and reflectance decomposition results, further achieving better low-light image enhancement results by using the decomposition results to the Retinex model. The proposed exponential and logarithm transform enhancement results minimum fusion strategy achieved more natural enhancement results than existing most low-light image enhancement methods. The extensive experiments of Retinex decomposition and low-light image enhancement show the effectiveness of the proposed method. The experimental results of the application under low-light environment face detection show that our low-light image enhancement method is competitive with other computer vision based applications, such as object detection; the performance of our method is a competitive one.
References
- [1] C. Wei, W. Wang, W. Yang, and J. Liu, “Deep retinex decomposition for low-light enhancement,” in British Machine Vision Conference, 2018.
- [2] F. Lv, F. Lu, J. Wu, and C. Lim, “MBLLEN: Low-light image/video enhancement using cnns,” in British Machine Vision Conference (BMVC), 2018.
- [3] Y. Zhang, J. Zhang, and X. Guo, “Kindling the Darkness: A practical low-light image enhancer,” in Proceedings of the 27th ACM International Conference on Multimedia, ser. MM ’19. New York, NY, USA: ACM, 2019, pp. 1632–1640. [Online]. Available: http://doi.acm.org/10.1145/3343031.3350926
- [4] Y. Jiang, X. Gong, D. Liu, Y. Cheng, C. Fang, X. Shen, J. Yang, P. Zhou, and Z. Wang, “EnlightenGAN: Deep light enhancement without paired supervision,” IEEE Transactions on Image Processing, vol. 30, pp. 2340–2349, 2021.
- [5] Y. Hou, J. Xu, M. Liu, G. Liu, L. Liu, F. Zhu, and L. Shao, “NLH: A blind pixel-level non-local method for real-world image denoising,” IEEE Transactions on Image Processing, vol. 29, pp. 5121–5135, 2020.
- [6] B. Cai, X. Xu, K. Guo, K. Jia, B. Hu, and D. Tao, “A joint intrinsic-extrinsic prior model for retinex,” in 2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 4020–4029.
- [7] X. Fu, Y. Liao, D. Zeng, Y. Huang, X. Zhang, and X. Ding, “A probabilistic method for image enhancement with simultaneous illumination and reflectance estimation,” IEEE Transactions on Image Processing, vol. 24, no. 12, pp. 4965–4977, 2015.
- [8] X. Fu, D. Zeng, Y. Huang, X. Zhang, and X. Ding, “A weighted variational model for simultaneous reflectance and illumination estimation,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2782–2790.
- [9] M. Li, J. Liu, W. Yang, X. Sun, and Z. Guo, “Structure-revealing low-light image enhancement via robust retinex model,” IEEE Transactions on Image Processing, vol. 27, no. 6, pp. 2828–2841, 2018.
- [10] J. Wang, W. Tan, X. Niu, and B. Yan, “RDGAN: Retinex decomposition based adversarial learning for low-light enhancement,” in 2019 IEEE International Conference on Multimedia and Expo (ICME), 2019, pp. 1186–1191.
- [11] S. Wang, J. Zheng, H. Hu, and B. Li, “Naturalness preserved enhancement algorithm for non-uniform illumination images,” IEEE Transactions on Image Processing, vol. 22, no. 9, pp. 3538–3548, 2013.
- [12] J. Xu, Y. Hou, D. Ren, L. Liu, F. Zhu, M. Yu, H. Wang, and L. Shao, “STAR: A structure and texture aware retinex model,” IEEE Transactions on Image Processing, vol. 29, pp. 5022–5037, 2020.
- [13] ug2+ Challenge, http://cvpr2021.ug2challenge.org/dataset21_t1.html.
- [14] X. Ren, W. Yang, W. Cheng, and J. Liu, “LR3M: Robust low-light enhancement via low-rank regularized retinex model,” IEEE Transactions on Image Processing, vol. 29, pp. 5862–5876, 2020.
- [15] M. Fan, W. Wang, W. Yang, and J. Liu, “Integrating semantic segmentation and retinex model for low-light image enhancement,” in Proceedings of the 28th ACM International Conference on Multimedia, ser. MM ’20. Association for Computing Machinery, 2020, p. 2317–2325.
- [16] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004.
- [17] A. Mittal, R. Soundararajan, and A. C. Bovik, “Making a “completely blind” image quality analyzer,” IEEE Signal Processing Letters, vol. 20, no. 3, pp. 209–212, March 2013.
- [18] D. J. Jobson, Z. Rahman, and G. A. Woodell, “Properties and performance of a center/surround Retinex,” IEEE Transactions on Image Processing, vol. 6, no. 3, pp. 451–462, 1997.
- [19] D. J. Jobson, Z. Rahman, and G. A. Woodell, “A multiscale Retinex for bridging the gap between color images and the human observation of scenes,” IEEE Transactions on Image Processing, vol. 6, no. 7, pp. 965–976, 1997.
- [20] X. Fu, D. Zeng, Y. Huang, Y. Liao, X. Ding, and J. Paisley, “A fusion-based enhancing method for weakly illuminated images,” Signal Processing, vol. 129, pp. 82–96, 2016.
- [21] X. Guo, Y. Li, and H. Ling, “LIME: Low-light image enhancement via illumination map estimation,” IEEE Transactions on Image Processing, vol. 26, no. 2, pp. 982–993, Feb 2017.
- [22] G. Buchsbaum, “A spatial processor model for object colour perception,” Journal of the Franklin Institute, vol. 310, no. 1, pp. 1–26, 1980.
- [23] Z. Ying, G. Li, Y. Ren, R. Wang, and W. Wang, “A new low-light image enhancement algorithm using camera response model,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Oct 2017.
- [24] Y. Zhang, X. Guo, J. Ma, W. Liu, and J. Zhang, “Beyond brightening low-light images,” International Journal of Computer Vision, vol. 129, pp. 1013–1037, 2021.
- [25] K. G. Lore, A. Akintayo, and S. Sarkar, “LLNet: A deep autoencoder approach to natural low-light image enhancement,” Pattern Recognition, vol. 61, pp. 650–662, 2017.
- [26] A. Buades, B. Coll, and J.-M. Morel, “A non-local algorithm for image denoising,” in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), vol. 2, 2005, pp. 60–65 vol. 2.
- [27] K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian, “Image denoising by sparse 3-d transform-domain collaborative filtering,” IEEE Transactions on Image Processing, vol. 16, no. 8, pp. 2080–2095, 2007.
- [28] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You Only Look Once: Unified, real-time object detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- [29] J. Li, Y. Wang, C. Wang, Y. Tai, J. Qian, J. Yang, C. Wang, J. Li, and F. Huang, “DSFD: Dual shot face detector,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019.
- [30] S. Yang, P. Luo, C.-C. Loy, and X. Tang, “WIDER FACE: A face detection benchmark,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- [31] G. Jocher, A. Stoken, J. Borovec, NanoCode012, A. Chaurasia, TaoXie, L. Changyu, A. V, Laughing, tkianai, yxNONG, A. Hogan, lorenzomammana, AlexWang1900, J. Hajek, L. Diaconu, Marc, Y. Kwon, oleg, wanghaoyang0106, Y. Defretin, A. Lohia, ml5ah, B. Milanko, B. Fineran, D. Khromov, D. Yiwei, Doug, Durgesh, and F. Ingham, “ultralytics/yolov5: v5.0 - yolov5-p6 1280 models, aws, supervise.ly and youtube integrations,” Zenodo, Apr. 2021.
- [32] J. Cai, S. Gu, and L. Zhang, “Learning a deep single image contrast enhancer from multi-exposure images,” IEEE Transactions on Image Processing, vol. 27, no. 4, pp. 2049–2062, 2018.
- [33] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” 2014.
- [34] Y. Hou, C. Zhao, D. Yang, and Y. Cheng, “Comments on “image denoising by sparse 3-d transform-domain collaborative filtering”,” IEEE Transactions on Image Processing, vol. 20, no. 1, pp. 268–270, 2011.
- [35] K. Wei, Y. Fu, J. Yang, and H. Huang, “A physics-based noise formation model for extreme low-light raw denoising,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.