Neuromophic High-Frequency 3D Dancing Pose Estimation in Dynamic Environment
Abstract.
As a beloved sport worldwide, dancing is getting integrated into traditional and virtual reality-based gaming platforms nowadays. It opens up new opportunities in the technology-mediated dancing space. These platforms primarily rely on passive and continuous human pose estimation as an input capture mechanism. Existing solutions are mainly based on RGB or RGB-Depth cameras for dance games. The former suffers in low-lighting conditions due to the motion blur and low sensitivity, while the latter is too power-hungry, has a low frame rate, and has limited working distance. With ultra-low latency, energy efficiency, and wide dynamic range characteristics, the event camera is a promising solution to overcome these shortcomings. We propose YeLan, an event camera-based 3-dimensional high-frequency human pose estimation(HPE) system that survives low-lighting conditions and dynamic backgrounds. We collected the world’s first event camera dance dataset and developed a fully customizable motion-to-event physics-aware simulator. YeLan outperforms the baseline models in these challenging conditions and demonstrated robustness against different types of clothing, background motion, viewing angle, occlusion, and lighting fluctuations.
1. Introduction
Dancing is a popular activity, loved by people all over the world. In recent years, Technology Mediated Dancing (TMD) is gaining popularity as it supports remote playful and healthy physical activities in the form of dancing (López-Rodríguez et al., 2013; Cheng et al., 2017; Marquez et al., 2017). From remote control-based gaming console games to Virtual Reality (VR) platforms, different forms of TMD are finding their way into users’ living spaces. For all of these TMDs, human pose estimation (HPE) plays a critical role as it infers the user’s unique, complex, and fast-changing dance poses to interact with the computer. To adapt to as many players as possible, TMD requires high-fidelity HPE that works robustly in various challenging and realistic indoor environments (e.g., in dynamic lighting and background conditions).
The state of the art HPE systems are generally developed based on depth and RGB cameras. However, both the standard RGB camera-based and depth-based monocular HPE systems (Chen et al., 2022, 2020b; Hassan et al., 2019) fails to generate ultra-fast/high-speed human pose inferences with its limited frame rate which is a critical requirement for many real world applications (e.g., virtual reality dance game, high frequency motion characterization for tremor monitoring applications). In one hand RGB based HPE fails to operate in low-lighting conditions due to the severe motion blur-related issues, on the other hand the depth camera can only operate upto a limited distance and often fails with darker clothing and skin tone. Additionally, both cameras do not inherently differentiate between static and moving objects. Consequently, both static and dynamic (or moving) objects in the background are captured as well as the target human body which impacts the robustness of HPE in dynamic settings. The depth camera uses an active infrared light and consequently has high power requirement. In this proposed work, we aim to develop a high-speed/low latency and low power 3D human pose estimation framework that can operate in dynamic lighting and motion situations.
Event camera (Lichtsteiner et al., 2008), also known as Dynamic Vision Sensor(DVS) or neuromorphic camera, is a silicon retina design based on one of the core mechanisms of mammalian vision that makes it particularly sensitive to moving targets and changing lighting conditions. Event cameras are based on the premise that for mammals, moving objects often contain more valuable information for hunting and escaping from predators, while relatively static backgrounds do not deserve much attention for constant monitoring and processing. By imitating this dynamic vision characteristic, each pixel of an event camera works asynchronously and keeps track of extremely subtle brightness changes independently in log-scale, allowing event cameras to be equally sensitive to motion in both high and low-lighting conditions. This mechanism automatically filters out the static background and does not need to wait to transmit the entire, detailed but bulky frame every time something happens. Alternatively, moving targets can rapidly trigger a significant number of events with super-high time resolution, making event cameras more sensitive to dynamic targets. The wide dynamic range makes event cameras robust to various situations, from night to glaring noon, from the tunnel to night driving. Beyond advantages with low-light conditions, event cameras also are less affected by skin color, and brightness change (Posch et al., 2008; Gallego et al., 2020).
DVS HPE has attracted much attention recently due to these advantages described, and in response, some significant datasets have been collected (Calabrese et al., 2019; Scarpellini et al., 2021). Besides the fact that these datasets use fixed patterns for motion guidance instead of dances, they also have significant issues around utility for developing practical systems. The data collection in these studies is conducted in ideal lab environments, with no background moving contents to serve as interference. The lighting is adequate and stable, limiting them to address low-and/or-changing lighting conditions. These uncertainties and noise reflect the real world, and introduce realistic challenges that must be answered to make this technology more practical and generalizable. We introduce two newly collected datasets. One is a real-world dataset with dynamic background under high and low-lighting conditions. The other is a simulated dataset with a fully controllable and customizable pipeline to generate new data pieces on demand. These datasets serve this work requirement perfectly, and will also be beneficial to the community as they will be made publicly accessible. The comparison between existing event camera-based HPE dataset and our collected datasets are listed below in Table. 1.
| Study | Human3.6M(Ionescu et al., 2013) | MKV(Zimmermann et al., 2018) | DHP19(Calabrese et al., 2019) | YeLan | |||||
| Modality | RGB Camera | RGBD Camera | Event Camera | Event Camera | |||||
| Inference Rate | 50 FPS | 10 FPS |
|
|
|||||
| Lighting | High | High | High | Low to High | |||||
| Data Type | Real World | Real World | Real World | Synthetic | Real World | ||||
| Background | Static | Static | Static | Dynamic | Static & Dynamic | ||||
| View | Arbitrary | Arbitrary | Arbitrary | Arbitrary | Front | ||||
| Clothing | Arbitrary | Arbitrary | Tight | Arbitrary | Tight | ||||
| Data Size | 3,600,000 | 22406 | 350,860 | 3,958,169 | 446,158 | ||||
Beyond datasets being too idealistic, previous DVS HPE works are also limited by the missing torso problem, which is fundamental to the dynamic characteristics of the event camera. When some parts of the human body stay still, event cameras will only capture other moving parts of the body and ignore these static parts. Therefore, the event representation during this period contains little or no information about them, resulting in significant estimation errors.
To build a DVS HPE system that could work in more realistic environments, we proposed a two-stage system YeLan that accurately estimates human poses under low-lighting conditions with noisy background contents. The name YeLan is derived from the character name in an anime game, Genshin Impact, which literally means “night orchid”. Interestingly, it can also be interpreted as another Chinese word “night viewing”. An early-exit-style mask prediction network is implemented in the first stage to help remove the moving background objects while saving as much energy as possible. BiConvLSTM is applied in the second stage to enable the flow of information between frames, which helps with the missing torso problem. Also, TORE volume is adopted to build denser and more informative input tensors and help solve the low event rate problem in low-light conditions. We conducted massive experiments to compare our method with baseline DVS HPE methods and achieved SOTA on the proposed two new datasets.
In summary, the core contribution of the paper are as follows.
-
(1)
We proposed YeLan, which to the best of our knowledge, is the first event camera-based 3D human pose estimation solution specially for dance. It works robustly under various challenging conditions, including low-lighting and occlusion. YeLan overcame the inherent disadvantages of the event camera and fully exploited its strengths.
-
(2)
We built an end-to-end simulator that enables precise and low-level control of the generated events. The simulator is garment physics-aware, highly customizable, and extensible.
-
(3)
As far as we know, the generated synthetic dataset from our simulator is the first event camera dataset designed for dance, and is also the largest event camera HPE dataset till now. It has unprecedented variability compared to existing datasets.
-
(4)
We conducted a human subject study and collected a real-world dance HPE dataset with low-lighting conditions and mobile background content considered.
-
(5)
An early-exit-style network is adopted in our mask prediction module, which boosts efficiency significantly.
-
(6)
We validated YeLan on both datasets, and it outperform all baseline models.
2. Related Work
Dance and Its Effect: From teenagers to elders, dance is a beloved communication and sport modality by people worldwide with a long history. Due to the high practicality and the cultural difference, dance develops a wide range of variations in different regions and times containing diverse styles, rhythms, intensities, and steps. Dance is proven to have a prominent positive influence on physical and mental health, with many solid studies as evidence (Sánchez et al., 2021). A recent study (Teixeira-Machado et al., 2019) demonstrated that dance could positively impact neuroplasticity and enhance neural activation in several brain regions. As a result, dance can be used as a rehabilitation tool for various brain-related pathologies (Sánchez et al., 2021). Recent literature has documented that dance as therapy has a significant positive effect on depression (Akandere and Demir, 2011), schizophrenia (Cheng et al., 2017), Parkinson’s (Hashimoto et al., 2015), fibromyalgia (López-Rodríguez et al., 2013; del Mar López-Rodríguez et al., 2012), dementia (Borges et al., 2018), cognitive deterioration (Marquez et al., 2017; Zhu et al., 2018), stress (Pinniger et al., 2012) and chronic stroke (Patterson et al., 2018).
Digital and mobile technology assist dancers in all aspects. Technology-assisted dance is increasingly becoming popular in recent years (Hsueh et al., 2019). It makes the dance more accessible and easier to learn (Rüth and Kaspar, 2020; Romero-Hernandez et al., [n. d.]). Dance has been combined with different video games (Hsueh et al., 2019; Kloos et al., 2013; Rüth and Kaspar, 2020; Adcock et al., 2020), including Just Dance Series (Jus, [n. d.]), Dance Dance Revolution (Dan, [n. d.]b), and Dance Central (Dan, [n. d.]a). Moreover, there are some other movement-based VR rhythm games like Beat Saber (Bea, [n. d.]), Synth Riders (Syn, [n. d.]), and Dance Collider (DAN, [n. d.]). Technology-assisted dance also includes video-based remote coaching, Virtual Reality (VR) or Augmented Reality (AR)-based dance games.
High fidelity 3D human pose estimation is a crucial component of Technology-Assisted Dance as they can turn dance gestures as input or commands (Alaoui et al., 2013, 2012) to the AR/VR or traditional video-based dance games. The 3D human pose estimates assist in performance evaluation, personalized feedback, and choreography (Hsueh et al., 2019). However, traditional RGB and depth camera-based 3D human pose estimates often fail to capture the rapid/high-speed changes in poses during a dance performance in challenging conditions (e.g., low light, dynamic background). In this work, we introduce an Event camera-based 3D human pose estimation to support technology-mediated dance in these challenging and dynamic conditions.
Human Pose Estimation: Depending on taxonomy, existing methods for 3D human pose estimation can be classified by modality and the number of used sensors. If classified by modality, the majority of approaches are RGB-based (Hassan et al., 2019; Chen et al., 2020b; Omran et al., 2018) or RGB-Depth-based (Rim et al., 2020; Srivastav et al., 2018; Michel et al., 2017; Zimmermann et al., 2018). Generally speaking, RGB image-based methods have fewer requirements on equipment and are more comprehensively explored. On the other hand, the RGB-Depth camera gains an advantage by introducing additional depth information, which is beneficial to detection, segmentation, and parts localization. However, depth cameras rely heavily on IR projectors to build the depth map, which is highly power-hungry and vulnerable to bright environmental light, limiting the RGBD cameras’ working distance and FOV, making them hard to be applied on the outside. For the second classification method, the resulting two categories are: monocular (Chen et al., 2020b; Zimmermann et al., 2018) and multi-view (Rhodin et al., 2018; Srivastav et al., 2018) methods. The multi-view method observes subjects from multiple views/cameras from different vantage points (Ge et al., 2016). The multi-view method requires significantly more power. More importantly, setting up a multi-view event camera data collection system is complex and expensive, making applications outside the lab very difficult. The monocular method estimates human pose from a single camera view. Methods for human pose estimation methods can also be classified in another way: model-based (Omran et al., 2018), and skeleton-based (Chen et al., 2022) methods. While the model-based method attempts to reconstruct the full 3D body shape of a human model (Hassan et al., 2019), skeleton-based methods use a bone skeleton as an intermediate representation and regress the joint locations in 3D space. In this work, we use a monocular skeleton-based approach that can allow us to achieve a more efficient and practical solution for 3D human pose estimation in real-world settings.
Dynamic Vision Sensor(DVS), or event camera was originally proposed by Lichtsteiner et al. (Lichtsteiner et al., 2008). In recent years, event camera has gained more attention increasingly. It has been applied to many computer vision tasks, including object recognition (Li et al., 2021; Kim et al., 2021), segmentation (Alonso and Murillo, 2019), corner detection (Yılmaz et al., 2021; Mohamed et al., 2021), gesture recognition (Calabrese et al., 2019; Wang et al., 2019; Ghosh et al., 2019), optical flow estimation (Brebion et al., 2021; Liu and Delbruck, 2022), depth estimation (Gehrig et al., 2021; Hidalgo-Carrió et al., 2020), Simultaneous Localization And Mapping (SLAM) (Jiao et al., 2021; Bertrand et al., 2020), and autonomous driving (Li et al., 2019; Chen et al., 2020a). While RGB cameras struggle due to motion blur, event camera, by design, is highly sensitive to lux variation in both extremely overexposed and underexposed scene (Berthelon et al., 2018).
While the event camera has already been proposed for human pose estimation in existing literature, the prior works have primarily focused on designing algorithms that are relatively noise-free, background-activity-less, and well-lit settings. For example, a recent event camera HPE dataset, DHP19 (Calabrese et al., 2019) contains a series of event recordings of human movements, poses, and moving objects. Some event camera datasets are used in gesture recognition (Amir et al., 2017), and action recognition (Hu et al., 2016). However, these datasets capture a limited number of motion trajectories in noise-free controlled environments. The lack of a diversified dataset in realistic conditions under low and dynamic light is a major bottleneck for developing a robust event camera-based sensing system. In this work, we will demonstrate how an Event Camera-based mobile sensing platform can effectively capture high-frequency 3D human poses during a dance performance while being highly resilient to different real-world challenging conditions, including low light, dynamic moving background, higher sensor field of view, longer distance between the sensor and target human, and diverse outfit or clothing.
3. Design Consideration
People can dance or play games in various environments, which is not controllable by developers. Dancers or gamers may dance in a low light indoor environment or be disturbed by surrounding moving objects. Estimating human pose in low-lighting conditions in the presence of surrounding activities with an event camera brings many new challenges. While low-lighting condition results in fewer events for the same movement and lowers the signal-noise ratio of the event representation, background activities and motion from surrounding objects introduce additional events. These events baffle the human pose estimation model to differentiate the target human body motion-related events from the background activities. In some cases, events triggered by background objects’ movements are even an order of magnitude larger than by the foreground subject, especially in low-lighting conditions. YeLan proposes to solve this challenge with an event filtering mechanism that predicts binary-mask over the target human body and rejects all events that are not generated due to the user’s body movement.
One of the significant strengths of the event camera is that each pixel can asynchronously respond to a tiny amount of light intensity change and trigger events with minimal latency. Consequently, the entire imaging grid can produce a massive event sequence from a single camera. One fundamental challenge is learning a representation that will preserve meaningful spatio-temporal information about the human pose. Another major challenge for event camera-based human pose estimation is the “missing torso problem”. Even during physical activity, we do not move our body parts equally. For example, the upper body might be in motion while the lower body is stationary. This partial immobility results in the silence of corresponding pixels within the event camera, which may further result in higher error in predicting these missing joints.
Prior work on event camera proposed different representations, including event frame (Rebecq et al., 2017), constant-count frame (Maqueda et al., 2018), time surface (Benosman et al., 2013), and voxel grid (Zhu et al., 2019). Time surface is a 2D representation where each pixel records the most recent event’s timestamp as its pixel value. Each pixel stores the timestamp of the last event (Lagorce et al., 2017) in that location. A voxel grid is a 3D histogram of events. Each voxel represents the number of events in an interval at a pixel location. Voxel grid prevents information loss by preserving spatial-temporal information of the whole history instead of collapsing the history into a 2D grid representation. However, event frame, event count, or voxel grid do not preserve relatively distant historical information, which gives rise to the missing torso problem. Time surface, on the other hand, can discard the temporal information and cannot keep the information from multiple events at the same pixel. Moreover, these existing representations suffer from a low signal-to-noise ratio (SNR) in low-lighting conditions. In this work, we have used a modified Time Ordered Recent Event (TORE) volume representation (Baldwin et al., 2021) that can simultaneously preserve both the latest and short historical information, which can then compensate for the missing torso problem. It also serves as a noise filter for noises like salt and paper without affecting other informative signals.
4. Proposed System
4.1. Event Preprocessing and TORE Volume
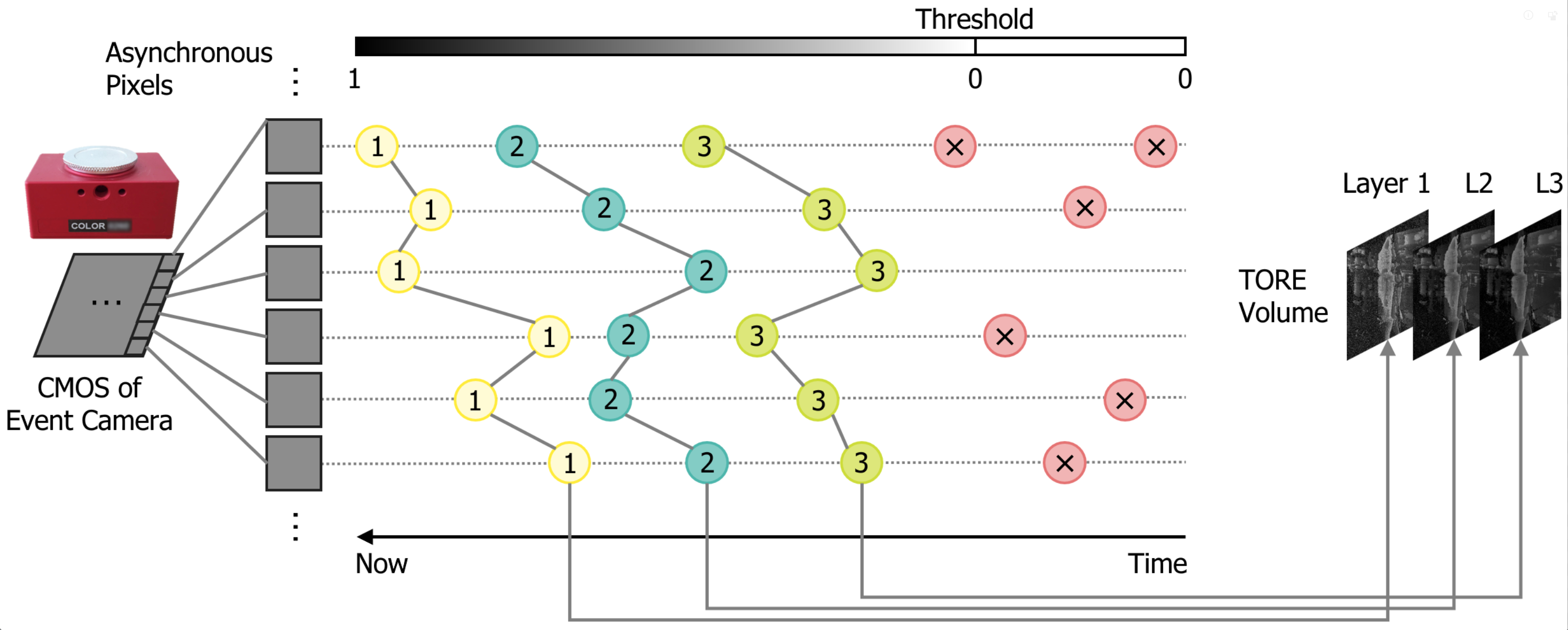
TORE (Baldwin et al., 2021) attempts to mimic the human retina by preserving the membrane’s potential properties. A fixed-length(e.g., ) First-In-First-Out (FIFO) queue is adopted to record the relative timestamp of the most recent events. When a new event comes into a pixel’s queue, its relative timestamp is pushed in, and the oldest event in the queue gets popped out. TORE computes the logarithm of these timestamps in the FIFO buffer. TORE transforms the sparse events stream into a dense and bio-inspired representation with minimum information loss and achieves SOTA in many DVS tasks(e.g., classification, denoising, human pose estimation). An exhaustive comparison of different representations could be found in (Baldwin et al., 2021).
We use a modified TORE volume representation: Normalization, 0-1 Flip, and a range scaling. Firstly, values inside the TORE volume are normalized to the range [0,1] for faster convergence. Then we flipped the normalized maximum and minimum values. By default, the oldest events and pixels with no event recorded are given the maximum value , which is counter-intuitive and may harm the convergence speed. We can easily solve this problem by letting the value in TORE be set to . With this modification, older events have a smaller value while newer events have a greater value, and the pixel where no event is recorded is set to 0. Lastly, because logarithm is applied in the TORE calculation, the most recent 4.63s takes the range of , and 4.63s is smaller than the DVS camera’s sensitivity time (150ms is used in the original TORE paper (Baldwin et al., 2021)). So here is our modification formula:
| (1) |
where and represents the original and modified TORE value, while the notation means the value of is clamped within the range .
TORE holds a first-in-first-out queue separately for each pixel, and the value in the queue drops as time goes on. TORE can keep the history of pixels up to five seconds. These characteristics make it suitable to work in dynamic conditions. TORE can drop redundant histories on the same pixel when in high-lighting conditions, relieving the model’s computational pressure. When in low-lighting conditions, the event histories captured in the past could compensate and help decide the position of some joints that do not move significantly during the last time window and thus help solve the missing torso problem. Fig. 1 shows the details to generate the modified TORE volumes.
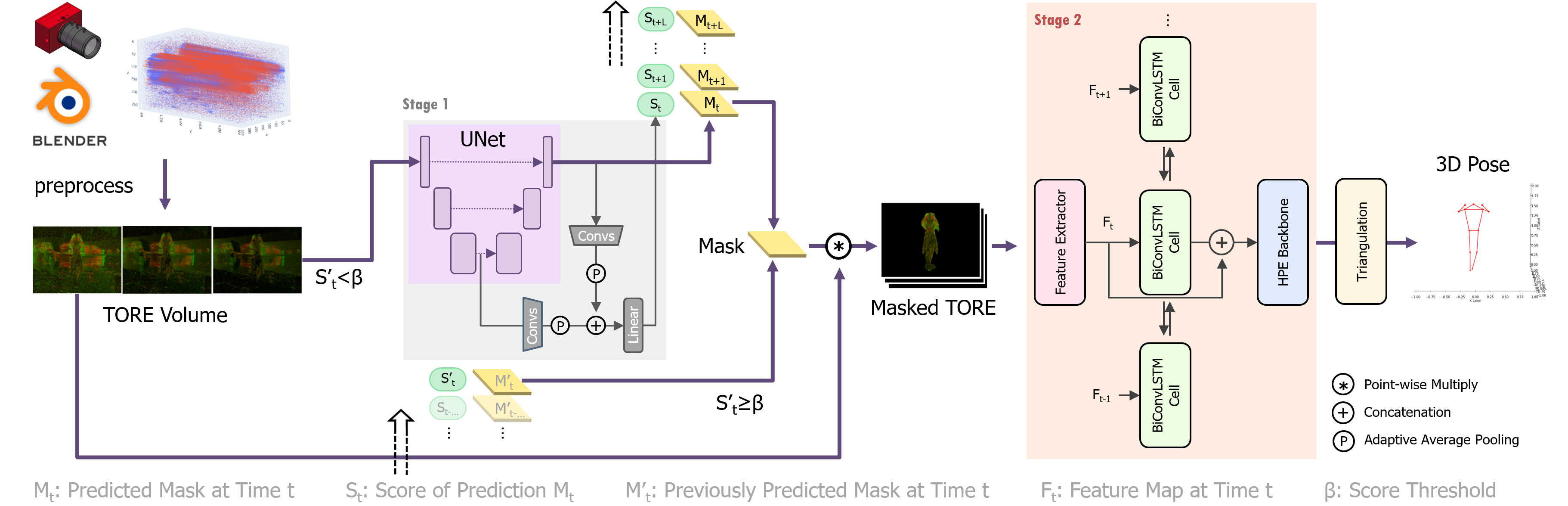
4.2. Event Filtering with Human Body Mask Prediction Network
In order to filter out events triggered by background activities and event camera hardware noise (e.g., hot pixel and leak noise (Hu et al., 2021)), a mask prediction network is used that can predict a human body mask from the TORE volume representation.
For the mask prediction network, a modified version of U-Net (Ronneberger et al., 2015) proposed by Olaf et al. is adopted. Unlike the original version, our modified version can predict the mask for the current input frame and a series of masks after this frame. Each predicted mask is generated together with a confidence score. The primary rationale behind predicting the human body mask of future frames is that future motion trajectories of different human body parts are generally predictable with information about current and previous motion trajectories. Time-Ordered Recent Event (TORE) volume representation efficiently captures current and previous motion history. It allows the mask prediction network to estimate human body masks of the current and future frames and their corresponding confidence scores. The confidence scores provide an early-exit-like mechanism where the computational pipeline bypass mask prediction of a certain frame if the mask predicted based on a previous frame’s TORE volume achieves a high confidence score. This mechanism significantly saves computational cost and energy consumption (more results in section 7.4). For the predicted mask, the U-Net generates float numbers between 0 and 1, and a binarization process with a small threshold of is applied. The small threshold was used to ensure that the generated mask misses no parts of the human body since failing to cover the entirety will lead to more error than allowing a small amount of noise.
One major challenge for training the mask prediction network in an end-to-end scheme is the lack of a realistic event camera dataset with labeled human body mask sequences for recorded event streams. However, as our proposed motion-to-event simulator (described in section 5) could generate paired pixel-level human masks with a high frame rate, they can be fed into the mask prediction network to train it fully.
4.3. Human Pose Estimation Network
The human pose estimation network consists of a ResNet-based feature extractor, a Bidirectional convolutional LSTM (BiConvLSTM) layer, an HPE backbone, and a triangulation module. The head part of ResNet34 serves as the feature extractor, followed by a BiConvLSTM layer with a skip connection. As the human body does not have abrupt changes during a relatively small time window, adjacent frames usually have similar ground truth labels. This continuity in human joint movements makes it helpful to refer to neighboring frames when estimating the joints’ position. BiConvLSTM is a bidirectional version of ConvLSTM (Shi et al., 2015), where ConvLSTM is a type of recurrent neural network for spatio-temporal prediction that has convolutional structures in both the input-to-state and state-to-state transitions. Lastly, the HPE backbone is made up of three hourglass-like CNN blocks. Each block outputs a series of marginal heatmaps to reconstruct the human joints’ coordinates in 3D space. All the intermediate outputs from these three blocks are used to calculate the loss with the ground truth heatmaps, and the last two blocks could be considered refine networks. The feature extractor and the backbone network architecture have been developed based on a model proposed in (Scarpellini et al., 2021). For each joint, YeLan generates three heatmaps showing the probability of its projected position on xy, xz, and yz planes. Then a soft-argmax operator is applied to extract the normalized coordinates of the joint. Lastly, predictions from the xy plane are used as the final prediction for x and y coordinates, while values for z are calculated by averaging the yz and xz predictions.
The ground truth labels used in the training and testing are normalized before being fed to the network. For a specific joint, we first project it to a plane parallel to the camera’s image plane and have the same depth as the depth reference. The head joint’s depth value is used as the depth reference. Then the 3D space in the DVS camera’s view is mapped to a cube whose range is . Lastly, as the network does not directly predict the 3D coordinates of a joint but predicts its marginal heatmaps instead, we also extract the joints’ projection on three orthogonal faces of the normalized space cube to generate the ground truth for marginal heatmaps. The final marginal heatmaps are then calculated using a Gaussian filter on these projection images (Scarpellini et al., 2021).
4.4. Loss
For the mask prediction network, the loss function consists of three components. The first component is the Binary Cross Entropy(BCE) loss calculated between the predicted mask series and the corresponding ground truth masks . This loss is applied to guarantee the accuracy of all the generated masks. Next, a Mean Square Error(MSE) loss is calculated over the predicted confidence scores and their ground truth. The ground truth score is the Mean Absolute Error(MAE) between a predicted mask and its ground truth mask. Lastly, although we want to predict the mask series for the current frame and frames following it, they are not equally important. We need to guarantee that closer frames’ masks get weighted more, especially for the current frame. Therefore, another BCE loss is calculated between the predicted mask for the current frame () and its corresponding ground truth . The overall loss is:
| (2) |
We adopted the loss introduced in (Scarpellini et al., 2021) for the human pose estimation network. As the marginal heatmaps can be interpreted as probability distributions of joint locations, Jensen-Shannon Divergence(JSD) can be applied between the predicted heatmaps by each block (, where represents the block index) and the ground truth heatmaps on each projection plane (). Also, a geometrical loss is calculated between the reconstructed 3D joints’ coordinates and their ground truth . The loss for this stage can be written as follows:
| (3) |
5. Synthetic Data Generation with Comprehensive Motion-to-Event Simulator
First of all, although there are some event camera-based HPE datasets (Calabrese et al., 2019), these datasets mainly focus on fixed everyday movements (e.g., walking, jumping, waving hands), making models trained on that fail when encountering complex movements. A dance performance will generally include fast and complex gestures, which are rare in a general everyday gesture dataset such as (Calabrese et al., 2019). Moreover, these datasets have been collected in ideal lighting conditions with blank or static backgrounds that do not represent the real-world environment. Moreover, the existing dataset suffers from the lack of diversity in participants, motion dynamics, clothing style, and types of background activities. For clothes, all the participants wear the same black close-fit clothes. For motion, the participants follow a fixed set of pre-defined activities, which are relatively standardized, simple, and repetitive. However, in dance, human moves in way more dynamic, complex, and challenging patterns. To bridge this critical gap, we propose to generate synthetic data with a comprehensive motion-to-event simulator.
As for simulators, although there are some existing event camera simulators (Mueggler et al., 2017; Rebecq et al., 2018; Hu et al., 2021; Joubert et al., 2021), there is a common and crucial problem. Almost all of them only work to turn existing pictures or videos into event streams instead of making highly customized event streams directly based on the research problem needs. Moreover, for existing simulators, if the original video does not come with human joint labels, the generated event stream is also label-less. However, in this work, the simulator we build adapts a physics-aware rendering system and makes all the concerned parameters fully controlled and customized, including lighting, motion, human gender, body shape, skin color, clothes and accessories, background, and scenes. This enables us to apply complex dance movements, and all the data we generate is paired with accurate labels.
5.1. Advantages of Synthetic Data
Several significant advantages of using a synthetic data generator are highlighted by a recent work (Goyal et al., 2022). Real-world data collection is expensive and time-consuming. The cost per participant is high, limiting the sample size, the scale of scenes, and the diversity in physical and environmental characteristics. The synthetic dataset generation process is fully controllable. The human models, background scenes, movements, lighting conditions, blur scale, camera distance, and camera view angle can all be precisely controlled, making it practical to modify a specific condition while keeping all the other factors unchanged. The output video file can be rendered with a very high frame per second (FPS) without blur problems caused by under or over-exposure in dynamic lighting conditions. Lastly, the ground truth of human joints’ 3D location can be extracted inside the software for different dances and human models.
5.2. Tools used in the simulator
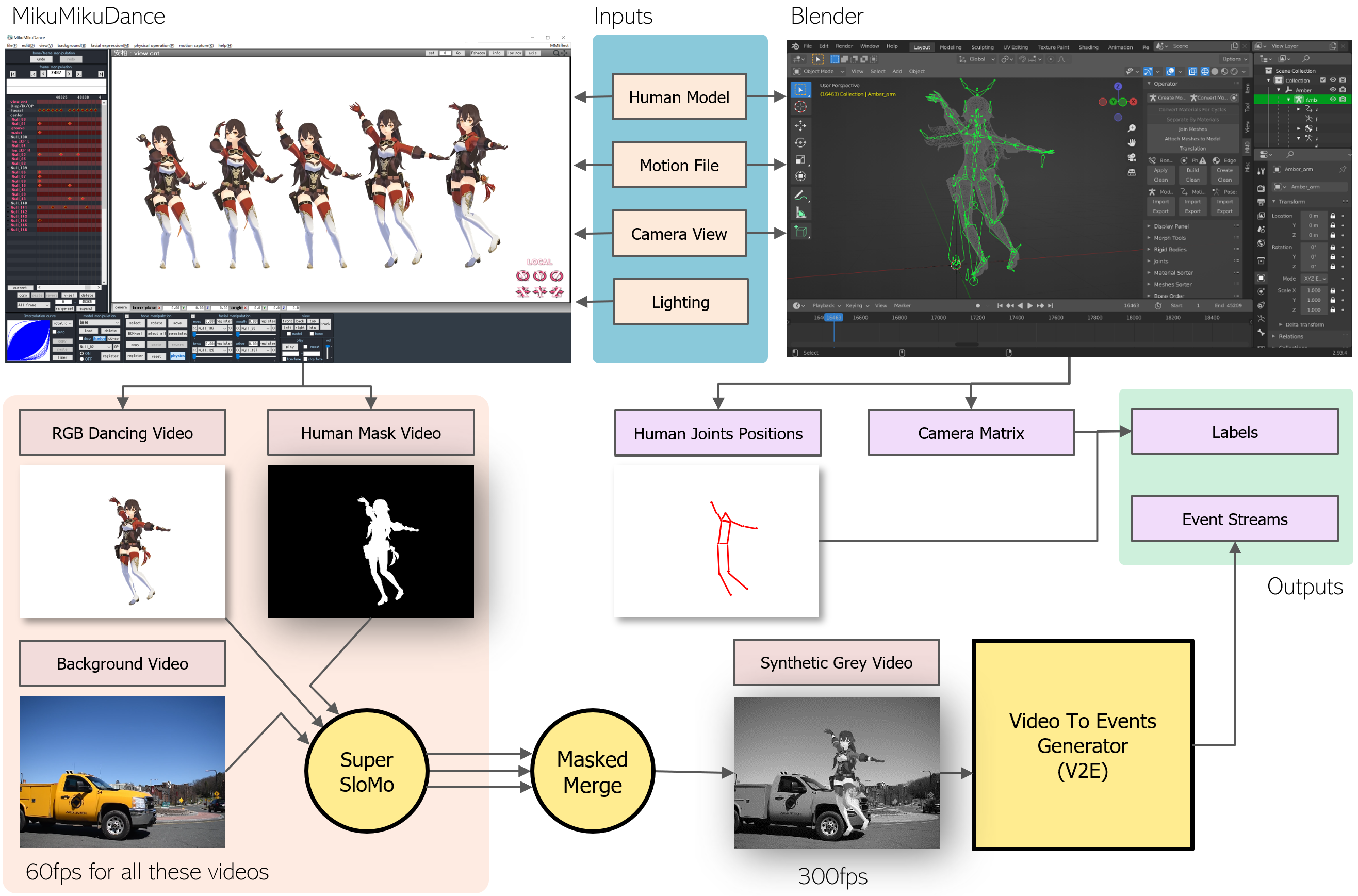
Synthetic data generation consists of RGB dance video rendering, human joints’ position extraction, and events generation. MikuMikuDance (MMD), Blender, and V2E are chosen for each step, respectively.
MMD is a freeware animation program that lets users animate and creates 3D animated movies. This software is simple but powerful, with a long history and a big open-source community behind it. Plenty of human models, scenes, and movement data can be easily accessed for free. In addition, it can automatically handle clothing physics and interaction with the body in a decent manner with minimal manual adjustment.
Software Blender is adopted to generate human joints’ ground truth labels and camera matrix. Blender is a free and open-source 3D computer graphics software for creating animated films, motion graphics, etc. It is highly customizable, and all essential information can be accessed during rendering, including the 6-degrees of freedom coordinates of human joints and the camera center. The 13 key points’ ground truth coordinates are extracted at 300 frames per second (FPS).
Lastly, Video to Event (V2E) is used for event generation. V2E is a toolset released in 2021 by Delbruck et al. (Hu et al., 2021). It can synthesize realistic event data from any conventional frame-based video using an accurate pixel model that mimics the event camera’s nonidealities. According to its author, V2E supports an extensive range of customizable parameters and is currently the only tool to model event cameras realistically under low illumination conditions.
5.3. Comprehensive Motion-to-Event Simulator
As Fig. 3 shows, our proposed motion-to-event generator takes 3D character models, motion files, camera views, and lighting conditions as inputs. MMD renders RGB dance videos and their paired human mask videos given these inputs, while Blender generates corresponding ground truths. For each camera view, a camera intrinsic and extrinsic matrix is calculated by Blender as well.
Then our simulator combines these rendered dance videos with collected background videos by referring to the paired mask videos. According to (Hu et al., 2021), if a video’s temporal resolution is low, generated event stream will be less realistic. However, due to the software limitation and background video quality, the synthesized videos are at 60 FPS. This gap in FPS is compensated using SuperSlowMo(Jiang et al., 2018), which can interpolate videos to a high FPS with convincing results. To reduce the time and computation cost, we only apply SuperSlowMo to dance and background videos before the merging. This way, we do not have to interpolate synthesized videos for each human and background combination.
After the RGB video rendering, merged videos are sent to the V2E events stream generator. Many parameters, like event trigger thresholds, noise level, and slow-motion interpolation scale, can be modified in detail. These features enable us to generate many highly customizable DVS event streams at a meager cost in a short time. To simulate situations in the real world, we increase the noise as the brightness decreases.
For human joints’ ground truth, as mentioned above, we write our customized scripts and inject them into Blender to collect the exact position of all joints while rendering scenes at 300 FPS. Also, scripts help extract the camera’s intrinsic and extrinsic matrix used in the label pre-processing. Besides the advantages mentioned above, 3D human models have even more flexibility initially. Skin color, height, body style, clothing, hair color and style, and accessories are all easily modifiable - which is very difficult to do in real-world data collection.

5.4. Synthetic Dataset Description
With the comprehensive motion-to-event simulator, we have generated about 4 million data pieces (more specifically, 3,958,169 snippets). Examples of the synthetically generated RGB frames are shown in figure 5. The total dataset size is about three terabytes. This data was synthesized from 1320 combinations of a few different variables, including 10 human models, 8 pieces of one-minute dance motions, 11 background videos, 4 camera views (i.e., front, back, left, right), and 3 different lighting conditions (i.e., high, medium, low). This dataset contains processed TORE volume, paired labels and masks, constant-time frames with the same time step (20ms), and raw event stream files for generating any other customized representations. Due to the computational resources and training time limitation, only 30% of data instances from selected 330 setting combinations are used for training and validation. They are shuffled and divided with a ratio of 8:2. Then we randomly select 82 setting combinations from the rest 990 unused combinations as the test set.
6. Human Subject Study with Dynamic Lighting and Background
6.1. Real-World Dataset in Motion Capture Facility
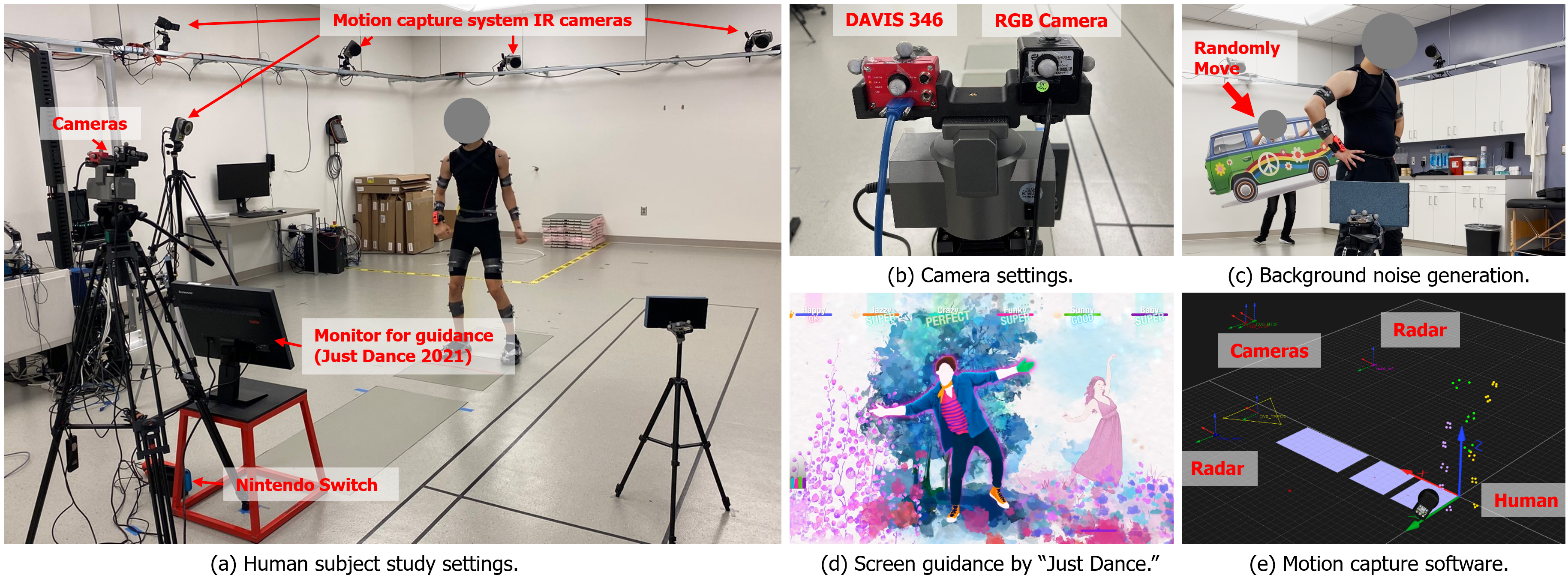
In addition to the synthetic dataset, we have conducted an Institutional Review Board (IRB)-approved human subject study to collect a real-world human pose dataset from nine participants. Seven of them are male, and the other two are female. The participants were 20-31 years old and recruited from a university campus using a snowball sampling technique. During this study, our participants were asked to play a Nintendo dance game “Just Dance 2021”. Each participant selected five songs to dance to during the study after a short training period with the tutorial dances in the Nintendo dance game. A monitor was used to provide the participants with further guidance/cues for participants to follow along.
A 9-camera-based 3D motion capture system (Qualisys AB, Göteburg, Sweden) is used to obtain ground truth 3D kinematics data of the human body, which provides us with the 3D absolute coordinates for all selected human joints at a frame rate of 200 frames per second (FPS). An event camera (DAVIS 346 (Brandli et al., 2014)) and an RGB camera are simultaneously run to record the participants’ movements. Other necessary equipment includes a flicker-free LED light, IR filter, cardboard background, Monitor, and Nintendo Switch. During the dataset collection, the lighting condition was strictly controlled to induce low-lighting and high-lighting conditions. All the lights except a dim flicker-free lamp are turned off during the low-lighting conditions session. The IR filter is attached in front of the event camera’s lens to filter out the events caused by IR light emitted by the motion capture system. Figure 4 illustrates the data collection settings, hardware, sensor arrangements, and mechanisms to generate background noise.

In the dynamic background condition, a person behind the target participant moved randomly with a large cardboard (that depicts a bus or car). For static background cases, on the other hand, no other movable contents appear in the background during recording. On average, each participant danced for about 20 minutes, and the time was distributed equally to the four conditions sessions mentioned above. We divided the real-world dataset simply by selecting all the events generated by participants seven and eight as test sets. Participant seven is male, and eight is female. All other data is shuffled and divided into training and validation sets with the same 8:2 ratio. We prepared a short video To illustrate further the rich synthetic and real-world data, which can be found at bit.ly/yelan-research.
7. Experiments and Results
| Synthetic | Real-world | ||||||
| Methods | Representation | MPJPE | PCK(%) | AUC(%) | MPJPE | PCK(%) | AUC(%) |
| Scarpellini et al., 2021 | Constant Time | 91.88 | 83.92 | 80.95 | 111.57 | 78.12 | 77.03 |
| Baldwin et al., 2021 | TORE | 59.34 | 93.17 | 86.97 | 101.967 | 82.22 | 78.90 |
| Our Model | TORE | 46.57 | 96.34 | 89.37 | 96.61 | 81.88 | 79.78 |
| Our Model w/i pre-training | TORE | - | - | - | 90.94 | 85.14 | 80.91 |
| on synthetic & fine-tuning | |||||||
| on real data | |||||||
7.1. Training Details
All models are trained on eight 1080ti or 2080ti graphic cards. The batch size is identical over all the training: Stage one has a batch size of 128, and stage two has a batch size of 16. All stages are trained with the following parameters: 0.001 learning rate, Adam optimizer with weight decay, early stopping with the patience of 10 epochs. A learning rate scheduler is applied to halve the learning rate every epoch. is set to 5 in stage one and 10 in stage two, considering the training pattern and convergence speed difference. This project is implemented in Pytorch-Lightning. Stage one and two in YeLan are trained separately. For the mask prediction network, due to the ground truth limitation, it is only trained on synthetic data and used directly in both synthetic and real-world datasets. For stage two, it is pretrained on synthetic dataset at first, and then fine-tuned on real-world dataset.
7.2. Evaluation metrics
Following the convention, we used Mean Per-Joint Position Error(MPJPE), the most commonly used metric in HPE, as our primary evaluation metric. Another two popular metrics, PCK and AUC, are also compared in the major comparison. MPJPE is calculated by averaging the Euclidean distance between each predicted joint and its corresponding ground-truth joint, usually at the millimeter level. PCK stands for Percentage of Correct Keypoints according to a threshold value of 150mm, which is commonly used. If the predicted joint is within a 150mm cube centered at the ground truth joint, it is treated as correctly predicted and returns 1; otherwise, it returns 0 for the wrong case. AUC means the Area Under the Curve for the PCK metric at different thresholds. We also use the standard threshold sets, 30 evenly spaced numbers from 0 to 500mm. When calculating the AUC, we will first calculate the PCK at all these threshold values, and their mean value is the target AUC.
| (4) | ||||
| (5) | ||||
| (6) |
Where and represent the ground truth and predicted 3D joint position, and means the number of skeleton joints. In PCK and AUC’s formula, and mean the threshold and the maximum threshold in AUC calculation. in AUC stands for the number of the different thresholds used.
7.3. Baselines

The baseline methods selected for this work are (Scarpellini et al., 2021) and (Baldwin et al., 2021), proposed by Scarpellini et al. and Baldwin et al. (originally published in 2021). For (Scarpellini et al., 2021), They used two event-count-based representations: constant event count frames and voxel grid, which have a variable time step and thus lose synchronization with our labels and TORE volumes. Therefore, the original work is modified to take constant time representations as input instead. The time step for this representation is set to 20 ms as well to guarantee that the labels are matched. Baldwin et al. proposed TORE volume, and they evaluated on the model and dataset proposed in (Calabrese et al., 2019) with a replaced representation to show their new representation’s superiority on multi-view human pose estimation task. Since in this paper we are interested in developing a monocular human pose estimation framework, we use the same monocular HPE model in (Scarpellini et al., 2021) with the representation switched to TORE to show the performance of (Baldwin et al., 2021) in this new task.
7.4. Evaluation
Table 2 illustrates the performance comparison between the proposed YeLan and baseline models on both synthetic and real-world datasets. The table shows that the baseline models consistently underperform the proposed YeLan model in both conditions. In the synthetic dataset, the model proposed by the Scarpellini et al. (Scarpellini et al., 2021) achieves an MPJPE and PCK of respectively 91.88 and 83.92% while the model proposed by the Baldwin et al. (Baldwin et al., 2021) with TORE representations have a slightly improved performance of respectively 59.34 MPJPE and 93.17% PCK. The proposed YeLan system outperforms the baseline models by a significant margin and achieves the lowest MPJPE of 46.57 and the highest PCK of 96.34% on the synthetic dataset.
Compared to the synthetic data, the performance of all the models on the real-world data is significantly worse. For example, while our proposed model (trained and tested on the same type of data) achieves an MPJPE of 46.57 with the synthetic data, the performance in the real-world dataset is 96.61 MPJPE. The real-world data comes with its own challenges and unique characteristics. Real human motion trajectories are slightly different from simulated trajectories. There is also substantial heterogeneity in the skeletal formations and impedance matching states in the real-world data. Lastly, another researcher is inside the view generating background activities, who sometimes get recognized and masked as an additional human, which could confuse the models. Consequently, the performance of the real-world data will be expected to be lower than that of the synthetic data. However, the proposed YeLan still achieves the lowest metrics compared to the baseline models. The baseline models are designed to work in ideal environments which do not suffer from dynamic lighting conditions and moving background content problems, which contributes to their poor performance in more realistic environments.
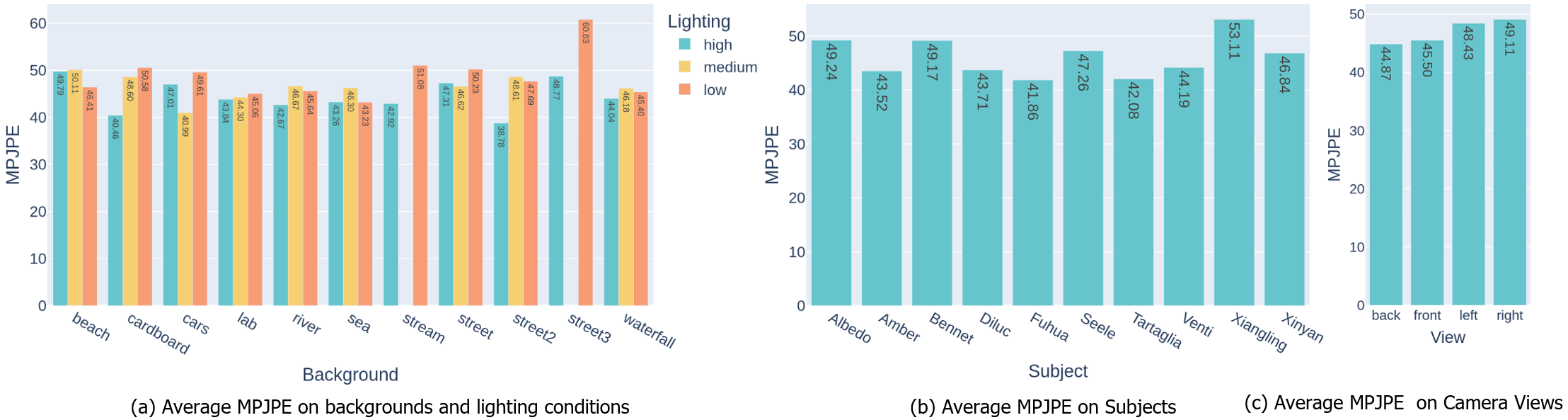
As Fig. 7 shows, YeLan has strong stability over the changes in lighting conditions and camera views, while more complicated background contents cast an impact on the results. Different human models also show an impact on performance. From the statistics on human models, we know that human models “Albedo”, “Seele,” and “Xiangling” performs less well than other human models. By looking at the original 3D model and test data composition, the reason becomes obvious: Albedo wears a long coat reaching his knee, while Seele wears a fluffy dress with a complex structure. These factors make their joint position harder to estimate. As for Xiangling, though she does not have clothing-related problems, we find some body deformation that happened during the simulation. Also, the randomly selected test cases for Xiangling contain more difficult backgrounds and lighting combinations, such as two busy city street environments in low-lighting conditions, according to Fig. 7 (a).
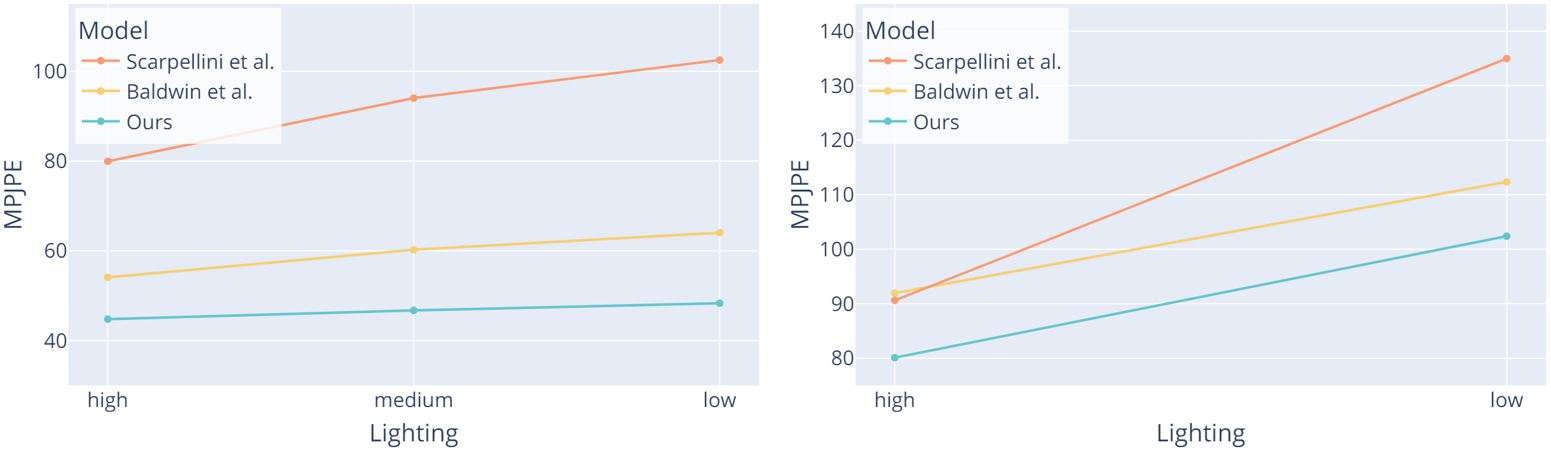
Moreover, Fig. 9 shows that our model behaves better constantly in all lighting conditions compared to baseline models. This feature is significant in real-world applications as the pipeline could generate convincing predictions regardless of the lighting conditions.
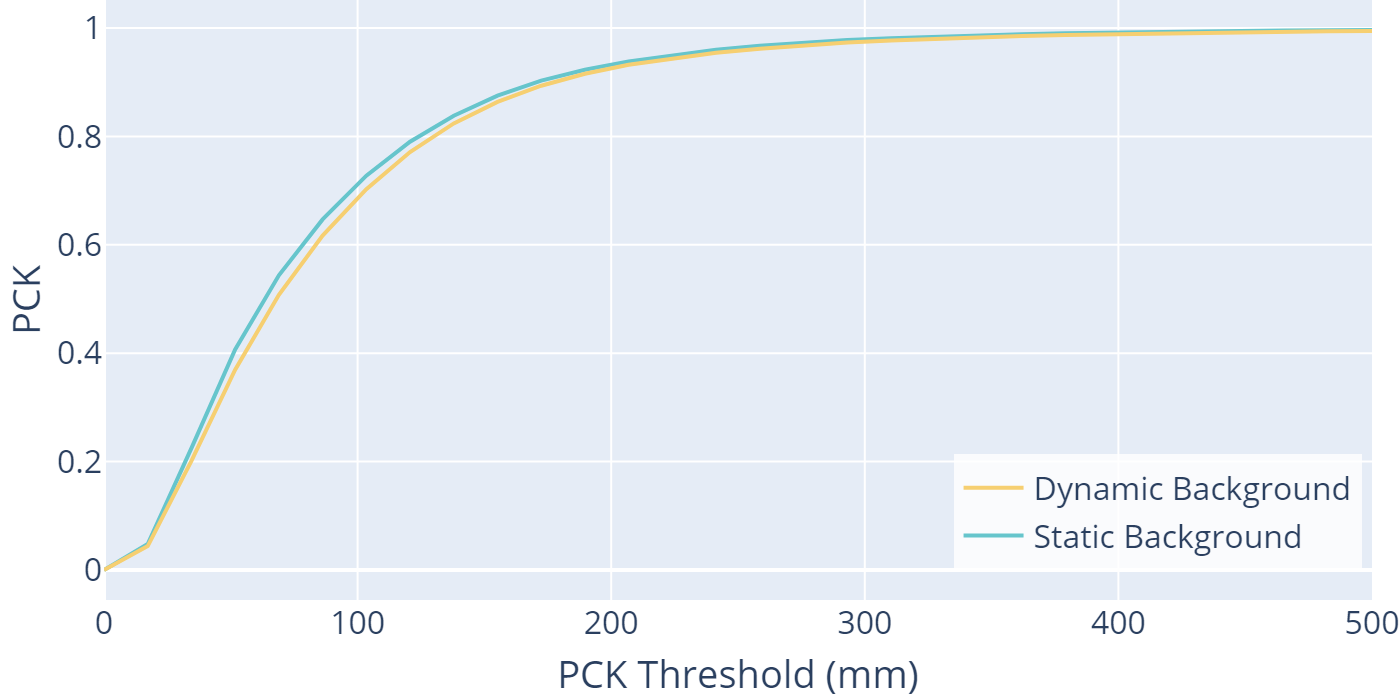
The mask prediction network in YeLan enables it to reach a similar level of PCK and AUC when the background is dynamic and static. We compared on NiDHP test set with dynamic and static background cases using the model pretrained on MiDHP and fine-tuned on NiDHP. Fig. 10 depicts that YeLan get a comparable result on dynamic background cases with static ones.
7.5. Ablation Study
As introduced in section 4, there are two most essential modules in YeLan: a mask prediction network and the BiConvLSTM. We do an ablation study by removing one module each time and comparing their performance on the synthetic dataset. If the mask prediction network is removed, the resulting MPJPE is 63.99; if the BiConvLSTM is removed, the corresponding MPJPE is 49.08. In contrast, the complete YeLan pipeline gets an MPJPE of 46.57, which proves the effectiveness of these modules.
7.6. Impact of Pretraining on Synthetic Data
Synthetic data from the physics-based simulator is a core contribution of this work which allows us to generate event streams from diverse virtual 3D characters in different simulated settings. They include different clothing, lighting conditions, camera viewing angle, dynamic background, and movement sequence. The generated synthetic data is faithful to physics and can provide essential data for pretraining YeLan since running real-world experiments with too many participants is expensive and time-consuming. To this end, we hypothesize that the pretraining on synthetic data will allow YeLan to learn better feature representation of physical conditions in diverse simulated settings and achieve superior performance on the real-world dataset.
Table 2 demonstrates that our proposed model achieves superior performance (concerning the MPJPE/PCK/AUC metrics) on the real-world dataset if the model is pretrained on the synthetic dataset from the simulator. The model trained only on the real-world dataset achieves 96.61 MPJPE and 81.88% PCK. On the other hand, if the model is pretrained on the synthetic data and then fine-tuned on the real-world dataset, it achieves 90.94 MPJPE and 85.14% PCK, which clearly shows the benefit of pretraining on synthetic data from a simulator.
7.7. Occlusion

In the real world, occlusion is also an inevitable problem. In our synthetic dataset, different types of clothes and accessories like hats, long hair, fluffy skirts, and long coats already occluded the human body to a relatively large extent. Moreover, the camera’s side views also introduced many self-occlusion. The excellent performance over all these scenarios shows a solid ability to survive occlusion.
To further prove the occlusion resiliency of the system, we augmented the dataset with more block occlusions. In the eye of the event camera, if a static object is placed in front of a human and shadows him, the corresponding area shoots no event due to the object’s immobility. Regarding the input TORE volume, the occluded area becomes pure black, as no event activity is recorded. To simulate the occlusion like this, we trained a model with the value of random areas set to zero. These rectangular occlusion areas have random sizes and locations, and the occlusion is also applied randomly with a probability of 80% during the training. When testing on the test set with random occlusion enabled, the MPJPE is 96.794. During the test, the occlusion probability is set to 100%. There is an accuracy drop, but considering that the maximum random occlusion area is (where the frame size is ), it makes sense as sometimes the majority of the human body could be occluded. Fig. 11 shows samples from the test set.
7.8. Systems Benchmarking
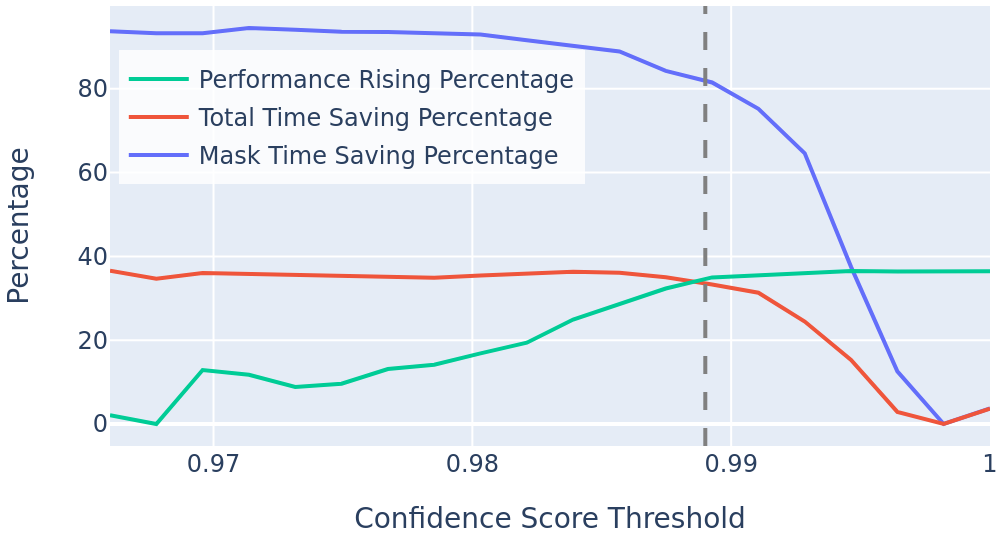
As is introduced in 4.2, the first stage of YeLan is an early-exit-style human mask prediction network, where a threshold is used to decide when to start a new inference. The selection of is a trade-off. If the threshold is set too high, the mask prediction process will be executed too many times, resulting in a longer inference time. On the contrary, many defective masks will be used if the threshold is too low, which harms the overall accuracy. In order to select the best threshold, we ran an experiment to do human pose estimation on a continuous one-minute event stream with a series of different thresholds. The accuracy and time consumption are recorded and made into Fig. 12. From this figure, we can observe that as we increase the threshold, accuracy goes up and time consumption goes down, while we can achieve a balanced accuracy and time consumption at near 0.99.
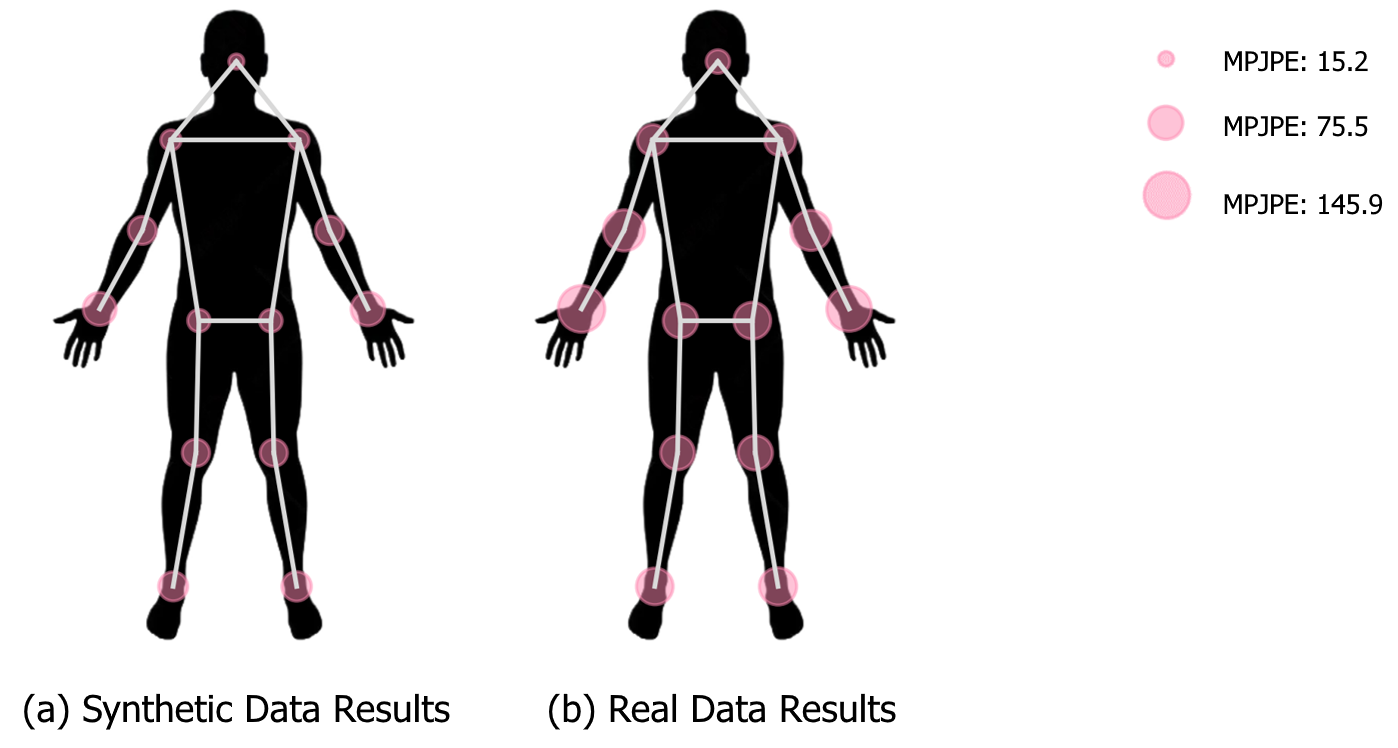
Moreover, to understand the error distribution across different joints, we calculated the mean MPJPE for all 13 joints. As Fig. 13 shows, the head joint has the lowest MPJPE, and the shoulder joints enjoy the second-lowest error. On the other hand, the left and right hands have the highest MPJPE, and foot joints come next. From our observation, this happens because the head and shoulders share the most stable contours across different characters and overlap less with other body parts. However, as hands and feet locates farthest from the human center and move the most during the dancing, they are harder to estimate due to more possible movements and patterns. More patterns lead to more uncertainty, which harms the accuracy even more when occlusion happens.
The total model size of YeLan is 234 MB. As for the time consumption, we run a full test on the MiDHP test set with a batch size of one, and the average time cost on each frame is about 29.1 ms when running on a 2080ti graphic card.
8. Comparison between Different Modalities
8.1. RGB Camera
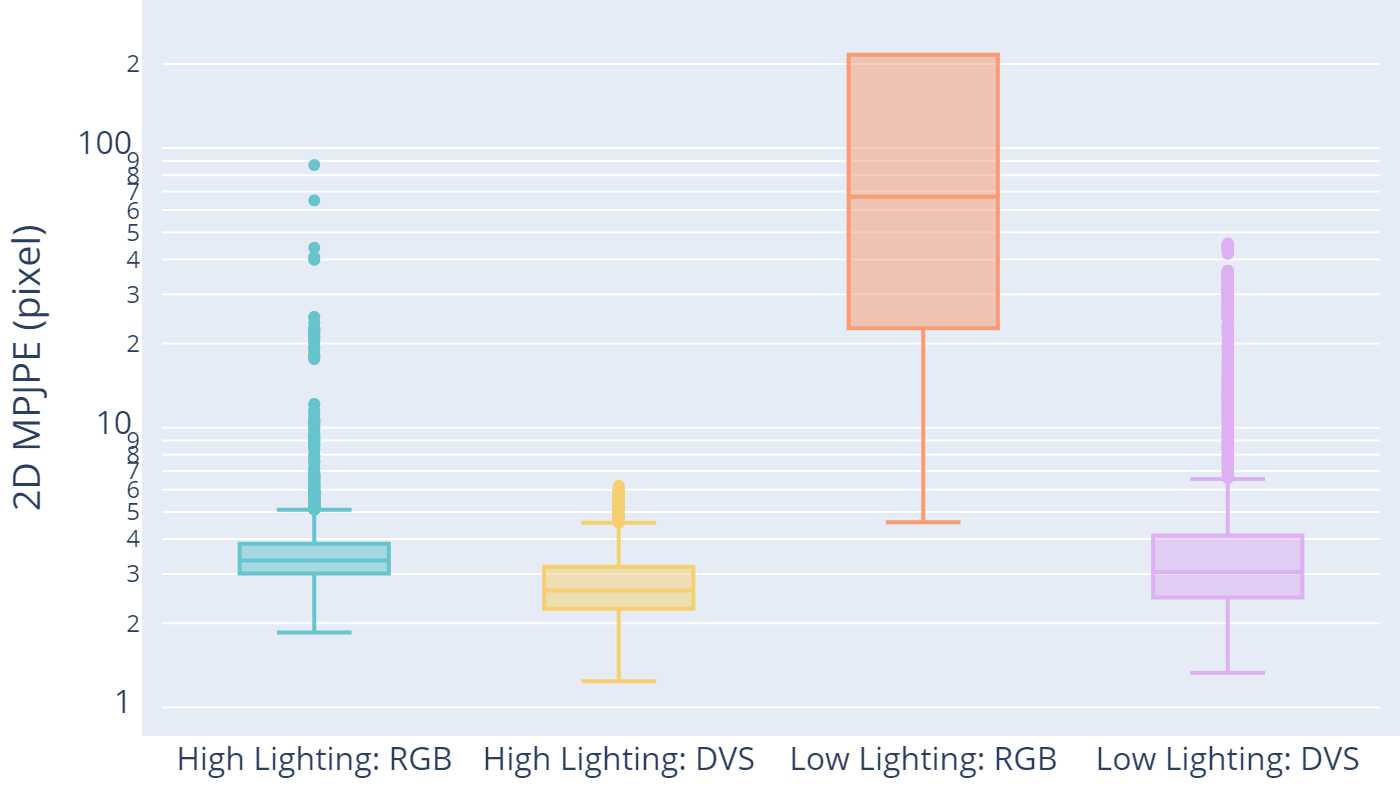
In order to show the superiority of DVS in low-lighting conditions, we also compare our result with RGB frame-based human pose estimation algorithm. We use the DVS camera DAVIS346, where both events and RGB frames are recorded synchronously. As the same device records both modalities via the same lens, there is no difference in the quantity of light captured by RGB and DVS. OpenPose (Cao et al., 2019) proposed and implemented by Cao et al. is adopted as our RGB baseline. OpenPose is an accurate, fast, and robust 2D human pose estimation algorithm. Although there are differences in joint number and dimension, we calculated the 2D projection of 3D joints generated by YeLan. We picked the closest 13 joints from all 25 OpenPose output joints to compare. The comparison is conducted on paired DVS and RGB recordings from the dataset collected in the motion capture lab. Both high and low-lighting condition cases are included, and qualitative comparison is shown in Fig. 14. Furthermore, we made a box plot showing the 2D MPJPE of DVS and RGB in two lighting conditions in 15. From this figure, it is evident that YeLan generates better and more stable predictions in all cases. Although the RGB-based method achieves good performance (marked by the low 2D MPJPE) in high-lighting conditions, the performance deteriorates significantly in the low lighting conditions. OpenPose fails to detect any human from frames due to motion blur and low SNR sensor data when the illumination is lower than a certain threshold. On the other hand, YeLan shows strong robustness against lighting conditions changes and constantly generates high-quality predictions (marked by the low MPJPE in both cases).

8.2. RGB-Depth Camera
| Camera Type | RGB (In DAVIS 346) | RGBD (Intel RealSense 435i) | Event Camera (DAVIS346) | ||||||||||||||||
| Update Rate | 40 Frames / Second | 30 Frames / Second | <12 MEvents / second | ||||||||||||||||
| FOV |
|
|
|
||||||||||||||||
| Dynamic Range | 56.7 dB | N/A | 120 dB | ||||||||||||||||
| Power Consumption | 140mW |
|
|
||||||||||||||||
| Working Distance | N/A |
|
N/A |
Besides the RGB camera, the depth camera is also widely used in digital dancing games. (Yun et al., 2014; Kamel Boulos, 2012) These cameras are usually paired with RGB cameras, which grant them information from both domains. Compared to RGB cameras, these cameras have a better understanding of the 3D space, which results in a more accurate human segmentation and joint location estimation. RGBD camera-based human pose estimation is a well-established problem with many commercial products and pipelines (Rallis et al., 2018; Kitsikidis et al., 2014; Alexiadis et al., 2011), like the Kinect from Microsoft and the RealSense from Intel.
However, the depth camera also has several disadvantages. Depth cameras actively emit and recapture the reflected infrared to build the 3D point cloud. This procedure is significantly more power-hungry (about 200 times higher power consumption than the event camera) and suffers from many limitations. Firstly, due to the manufacturing and power consumption consideration, depth cameras’ field of view (FOV) is usually fixed and small. Small FOV limits the sensing space coverage and restricts the dancer movement in a smaller space. Secondly, the distance between the target and the depth camera strongly impacts the detection accuracy. If the sensor is too close to the target (smaller than 0.5m), the two IR receivers have overlapped IR patterns which saturate the IR camera and result in an estimation failure (Jiao et al., 2017). Moreover, when the distance is far, the detection rate drops drastically after a certain point, as the IR receiver cannot receive enough reflected IR light. The first two points together limit the functional dancing area and cause a substantial restriction on relative distance.
Thirdly, since the camera emits light itself, it could also be interfered with by other light sources, which is especially true for strong light sources like stage lights and solar lights. This characteristic restricts the application of depth cameras in outdoor and indoor spaces near the light source.
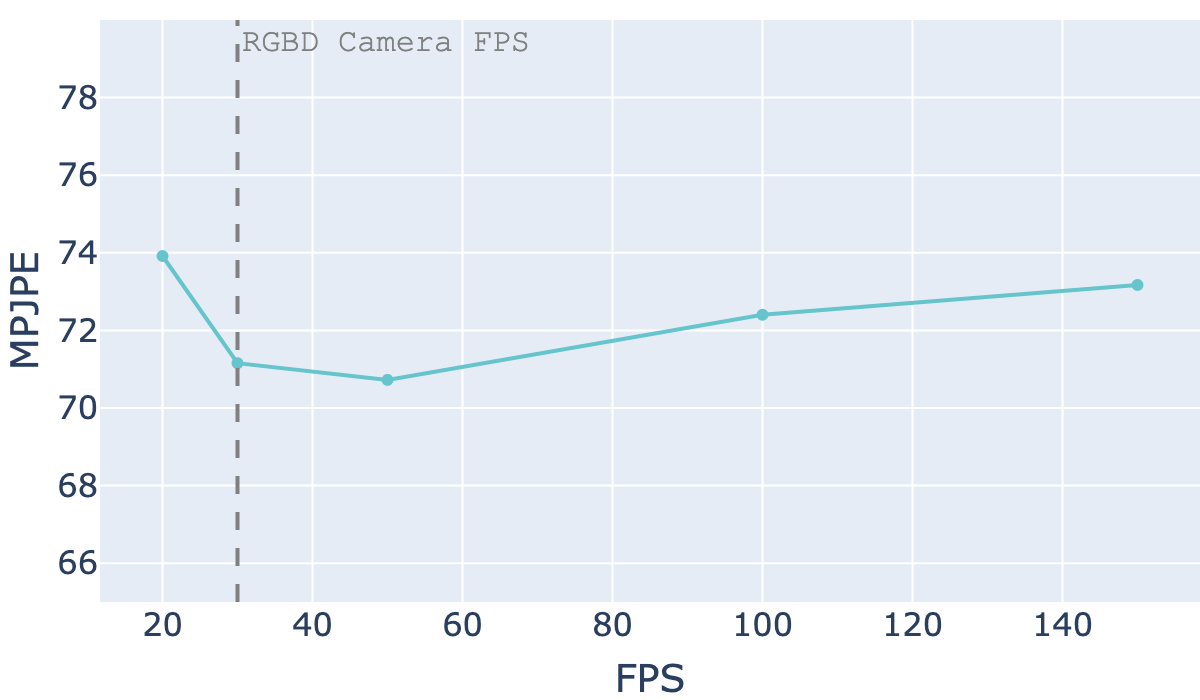
Fourthly, compared with the event camera, the maximum RGBD camera FPS is usually very low, making it hard to be applied to track fast-paced dances or generate high-fidelity 3D digital dances. The two most commonly used RGBD cameras, i.e., Microsoft Azure Kinect and Intel RealSense, support at most 30 FPS when capturing full RGBD streams. On the contrary, event cameras can easily receive ten-millions level events per second, which gives them overwhelmingly huge advantages over RGBD cameras. We tested our model by generating representations from 20FPS to 150FPS (due to the restriction of ground truth label rate) on all the event streams from test subject eight. The result shows that the estimation accuracy is pretty stable on various frame rate settings (Fig. 16).
Although we wanted to quantitatively compare RGBD and event camera for human pose estimation, we found out that these two types of cameras can not work together. When the depth camera is turned on, its built-in IR projector emits a grid of IR rays 30 times per second. In the eye of the event camera, the IR projection of the depth camera is visible and everything in the surrounding is constantly flickering at a high frequency with meshed dots, which negatively impacts the performance. Therefore, we made a qualitative comparison by separately recording two sessions of human dance by Intel RealSense 435i and DAVIS 346. During these two sessions, the participant moves from 2.5m to 3.5m with some dynamic dance patterns, and the results are shown in Fig. 17. As the figure shows, as the distance between the camera and the human increases, the RGB-Depth camera gradually fails to capture valid human shapes. The human pose estimation program also stops generating valid predictions from a certain point. The RGB-Depth camera-based 3D human pose estimation we chose for comparison is Nuitrack (Nui, [n. d.]), a commercial product designed specifically for RGBD camera-based HPE problems. Although RGB and depth channels are all used, here, for visualization convenience, only the depth channel is shown, and the estimated human masks are shown in green.

9. Limitation and Future Works
Overall, YeLan clearly highlights the promise of the 3D human pose estimation in the context of dancing in the presence of different confounding factors. However, the current study has several limitations and we plan to systematically address them in future works. In the current work, one assumption was that the event camera is stationary and attached to a fixed tripod. Consequently, YeLan framework is not readily transferable to scenarios where the event camera can move and is mounted on a car or a drone. The current version of YeLan has been primarily tested in a single-person scenario and does not support a multiplayer dancing game. By including a multiperson segmentation and masking, we plan to extend YeLan for multi-person scenario. We also aim to explore energy efficient implementation in a neuromorphic computing platform such as Intel Loihi 2 (Loi, [n. d.]).
10. Acknowledgement
We would like to thank the Institute of Applied Life Sciences and the College of Information and Computer Sciences at UMass Amherst for providing start-up funds and laboratory support. Moreover, we wish to show our appreciation to the HDSI department at UCSD for their startup funding. The work was also partially funded by the DARPA TAMI grant (Project ID HR00112190041) and the directorate for computer science and engineering of NSF (Award Number 2124282). Lastly, I wish to extend my special thanks to miHoYo Co., Ltd. for providing high-quality character models used in synthetic data generation.
11. Conclusion
This work discussed the existing 3D HPE techniques applied in dance games, their strength, and limitations. We proposed an alternative and novel event camera-based method to tackle these shortcomings. We collected a real-world dance dataset by human subject studies and built a comprehensive motion-to-event simulator to generate massive fully-controllable, customizable, and labeled synthetic dance data to help pre-train the model. YeLan outperforms all baseline models in various challenging scenarios on both datasets. Lastly, we also did a thorough analysis as well as a comparison between different modalities, which clearly shows the superiority of YeLan in many aspects.
References
- (1)
- DAN ([n. d.]) DANCE COLLIDER [n. d.]. DANCE COLLIDER. DANCE COLLIDER. https://www.dancecollider.com
- Bea ([n. d.]) [n. d.]. Beat Saber. https://en.wikipedia.org/w/index.php?title=Beat_Saber&oldid=1120839189
- Dan ([n. d.]a) [n. d.]a. Dance Central. https://en.wikipedia.org/w/index.php?title=Dance_Central&oldid=1116869192
- Dan ([n. d.]b) [n. d.]b. Dance Dance Revolution. https://en.wikipedia.org/w/index.php?title=Dance_Dance_Revolution&oldid=1118129088
- Jus ([n. d.]) [n. d.]. Just Dance (Video Game Series). https://en.wikipedia.org/w/index.php?title=Just_Dance_(video_game_series)&oldid=1121254502
- Loi ([n. d.]) [n. d.]. Loihi 2 - Intel - WikiChip. https://en.wikichip.org/wiki/intel/loihi_2
- Nui ([n. d.]) [n. d.]. Nuitrack Full Body Skeletal Tracking Software. https://nuitrack.com/
- Syn ([n. d.]) Synth Riders [n. d.]. Synth Riders - A Freestyle-Dance VR Rhythm Game. Synth Riders. https://synthridersvr.com/
- Adcock et al. (2020) Manuela Adcock, Floriana Sonder, Alexandra Schättin, Federico Gennaro, and Eling D de Bruin. 2020. A usability study of a multicomponent video game-based training for older adults. European review of aging and physical activity 17, 1 (2020), 1–15.
- Akandere and Demir (2011) Mehibe Akandere and Banu Demir. 2011. The effect of dance over depression. Collegium antropologicum 35, 3 (2011), 651–656.
- Alaoui et al. (2013) Sarah Fdili Alaoui, Frédéric Bevilacqua, Bertha Bermudez Pascual, and Christian Jacquemin. 2013. Dance interaction with physical model visuals based on movement qualities. Int. J. Arts Technol. 6 (2013), 357–387.
- Alaoui et al. (2012) Sarah Fdili Alaoui, Baptiste Caramiaux, Marcos Serrano, and Frédéric Bevilacqua. 2012. Movement qualities as interaction modality. In DIS ’12.
- Alexiadis et al. (2011) Dimitrios S Alexiadis, Philip Kelly, Petros Daras, Noel E O’Connor, Tamy Boubekeur, and Maher Ben Moussa. 2011. Evaluating a dancer’s performance using kinect-based skeleton tracking. In Proceedings of the 19th ACM international conference on Multimedia. 659–662.
- Alonso and Murillo (2019) Inigo Alonso and Ana C Murillo. 2019. EV-SegNet: Semantic segmentation for event-based cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 0–0.
- Amir et al. (2017) Arnon Amir, Brian Taba, David J. Berg, Timothy Melano, Jeffrey L. McKinstry, Carmelo di Nolfo, Tapan Kumar Nayak, Alexander Andreopoulos, Guillaume Garreau, Marcela Mendoza, Jeffrey A. Kusnitz, Michael V. DeBole, Steven K. Esser, Tobi Delbrück, Myron Flickner, and Dharmendra S. Modha. 2017. A Low Power, Fully Event-Based Gesture Recognition System. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017), 7388–7397.
- Baldwin et al. (2021) Robert W. Baldwin, Ruixu Liu, Mohammed Bakheet Almatrafi, Vijayan K. Asari, and Keigo Hirakawa. 2021. Time-Ordered Recent Event (TORE) Volumes for Event Cameras. ArXiv abs/2103.06108 (2021).
- Benosman et al. (2013) Ryad Benosman, Charles Clercq, Xavier Lagorce, Sio-Hoi Ieng, and Chiara Bartolozzi. 2013. Event-based visual flow. IEEE transactions on neural networks and learning systems 25, 2 (2013), 407–417.
- Berthelon et al. (2018) Xavier Berthelon, Guillaume Chenegros, Thomas Finateu, Sio-Hoi Ieng, and Ryad B. Benosman. 2018. Effects of Cooling on the SNR and Contrast Detection of a Low-Light Event-Based Camera. IEEE Transactions on Biomedical Circuits and Systems 12 (2018), 1467–1474.
- Bertrand et al. (2020) Johan Bertrand, Arda Yiğit, and Sylvain Durand. 2020. Embedded Event-Based Visual Odometry. In 2020 6th International Conference on Event-Based Control, Communication, and Signal Processing (EBCCSP). IEEE, 1–8.
- Borges et al. (2018) Eliane Gomes da Silva Borges, Rodrigo Gomes de Souza Vale, Carlos Soares Pernambuco, Samaria Ali Cader, Selma Pedra Chaves Sá, Francisco Miguel Pinto, Isabel Cristina Ribeiro Regazzi, Virginia Maria de Azevedo Oliveira Knupp, and Estélio Henrique Martin Dantas. 2018. Effects of dance on the postural balance, cognition and functional autonomy of older adults. Revista brasileira de enfermagem 71 (2018), 2302–2309.
- Brandli et al. (2014) Christian Brandli, Raphael Berner, Minhao Yang, Shih-Chii Liu, and Tobi Delbruck. 2014. A 240 × 180 130 dB 3 µs Latency Global Shutter Spatiotemporal Vision Sensor. IEEE Journal of Solid-State Circuits 49 (2014), 2333–2341.
- Brebion et al. (2021) Vincent Brebion, Julien Moreau, and Franck Davoine. 2021. Real-Time Optical Flow for Vehicular Perception with Low-and High-Resolution Event Cameras. IEEE Transactions on Intelligent Transportation Systems (2021).
- Calabrese et al. (2019) Enrico Calabrese, Gemma Taverni, Christopher Awai Easthope, Sophie Skriabine, Federico Corradi, Luca Longinotti, Kynan Eng, and Tobi Delbrück. 2019. DHP19: Dynamic Vision Sensor 3D Human Pose Dataset. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2019), 1695–1704.
- Cao et al. (2019) Z. Cao, G. Hidalgo Martinez, T. Simon, S. Wei, and Y. A. Sheikh. 2019. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. IEEE Transactions on Pattern Analysis and Machine Intelligence (2019).
- Chen et al. (2020a) Guang Chen, Hu Cao, Jorg Conradt, Huajin Tang, Florian Rohrbein, and Alois Knoll. 2020a. Event-based neuromorphic vision for autonomous driving: a paradigm shift for bio-inspired visual sensing and perception. IEEE Signal Processing Magazine 37, 4 (2020), 34–49.
- Chen et al. (2022) Tianlang Chen, Chengjie Fang, Xiaohui Shen, Yiheng Zhu, Zhili Chen, and Jiebo Luo. 2022. Anatomy-Aware 3D Human Pose Estimation With Bone-Based Pose Decomposition. IEEE Transactions on Circuits and Systems for Video Technology 32 (2022), 198–209.
- Chen et al. (2020b) Yucheng Chen, Yingli Tian, and Mingyi He. 2020b. Monocular human pose estimation: A survey of deep learning-based methods. Comput. Vis. Image Underst. 192 (2020), 102897.
- Cheng et al. (2017) Shu-Li Cheng, Huey-Fang Sun, and Mei-Ling Yeh. 2017. Effects of an 8-week aerobic dance program on health-related fitness in patients with schizophrenia. journal of nursing research 25, 6 (2017), 429–435.
- del Mar López-Rodríguez et al. (2012) María del Mar López-Rodríguez, Adelaida María Castro-Sánchez, Manuel Fernández-Martínez, Guillermo A Matarán-Penarrocha, and María Encarnación Rodríguez-Ferrer. 2012. Comparación entre biodanza en medio acuático y stretching en la mejora de la calidad de vida y dolor en los pacientes con fibromialgia. Atención Primaria 44, 11 (2012), 641–649.
- Gallego et al. (2020) Guillermo Gallego, Tobi Delbrück, Garrick Orchard, Chiara Bartolozzi, Brian Taba, Andrea Censi, Stefan Leutenegger, Andrew J Davison, Jörg Conradt, Kostas Daniilidis, et al. 2020. Event-based vision: A survey. IEEE transactions on pattern analysis and machine intelligence 44, 1 (2020), 154–180.
- Ge et al. (2016) Liuhao Ge, Hui Liang, Junsong Yuan, and Daniel Thalmann. 2016. Robust 3D Hand Pose Estimation in Single Depth Images: From Single-View CNN to Multi-View CNNs. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016), 3593–3601.
- Gehrig et al. (2021) Daniel Gehrig, Michelle Rüegg, Mathias Gehrig, Javier Hidalgo-Carrió, and Davide Scaramuzza. 2021. Combining events and frames using recurrent asynchronous multimodal networks for monocular depth prediction. IEEE Robotics and Automation Letters 6, 2 (2021), 2822–2829.
- Ghosh et al. (2019) Rohan Ghosh, Anupam Kumar Gupta, Andrei Nakagawa Silva, Alcimar Barbosa Soares, and Nitish V. Thakor. 2019. Spatiotemporal Filtering for Event-Based Action Recognition. ArXiv abs/1903.07067 (2019).
- Goyal et al. (2022) Priya Goyal, Quentin Duval, Isaac Seessel, Mathilde Caron, Mannat Singh, Ishan Misra, Levent Sagun, Armand Joulin, and Piotr Bojanowski. 2022. Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision.
- Hashimoto et al. (2015) Hiroko Hashimoto, Shinichi Takabatake, Hideki Miyaguchi, Hajime Nakanishi, and Yasuo Naitou. 2015. Effects of dance on motor functions, cognitive functions, and mental symptoms of Parkinson’s disease: a quasi-randomized pilot trial. Complementary therapies in medicine 23, 2 (2015), 210–219.
- Hassan et al. (2019) Mohamed Hassan, Vasileios Choutas, Dimitrios Tzionas, and Michael J. Black. 2019. Resolving 3D Human Pose Ambiguities With 3D Scene Constraints. 2019 IEEE/CVF International Conference on Computer Vision (ICCV) (2019), 2282–2292.
- Hidalgo-Carrió et al. (2020) Javier Hidalgo-Carrió, Daniel Gehrig, and Davide Scaramuzza. 2020. Learning monocular dense depth from events. In 2020 International Conference on 3D Vision (3DV). IEEE, 534–542.
- Hsueh et al. (2019) Stacy Hsueh, Sarah Fdili Alaoui, and Wendy E Mackay. 2019. Understanding kinaesthetic creativity in dance. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems. 1–12.
- Hu et al. (2016) Yuhuang Hu, Hongjie Liu, Michael Pfeiffer, and Tobi Delbruck. 2016. DVS Benchmark Datasets for Object Tracking, Action Recognition, and Object Recognition. Frontiers in Neuroscience 10 (2016).
- Hu et al. (2021) Y Hu, S C Liu, and T Delbruck. 2021. v2e: From Video Frames to Realistic DVS Events. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE. http://arxiv.org/abs/2006.07722
- Ionescu et al. (2013) Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. 2013. Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE transactions on pattern analysis and machine intelligence 36, 7 (2013), 1325–1339.
- Jiang et al. (2018) Huaizu Jiang, Deqing Sun, Varun Jampani, Ming-Hsuan Yang, Erik Learned-Miller, and Jan Kautz. 2018. Super slomo: High quality estimation of multiple intermediate frames for video interpolation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 9000–9008.
- Jiao et al. (2021) Jianhao Jiao, Huaiyang Huang, Liang Li, Zhijian He, Yilong Zhu, and Ming Liu. 2021. Comparing representations in tracking for event camera-based slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1369–1376.
- Jiao et al. (2017) Jichao Jiao, Libin Yuan, Weihua Tang, Zhongliang Deng, and Qi Wu. 2017. A Post-Rectification Approach of Depth Images of Kinect v2 for 3D Reconstruction of Indoor Scenes. ISPRS International Journal of Geo-Information 6, 11 (2017). https://doi.org/10.3390/ijgi6110349
- Joubert et al. (2021) Damien Joubert, Alexandre Marcireau, Nic Ralph, Andrew Jolley, André van Schaik, and Gregory Cohen. 2021. Event camera simulator improvements via characterized parameters. Frontiers in Neuroscience (2021), 910.
- Kamel Boulos (2012) Maged N Kamel Boulos. 2012. Xbox 360 Kinect exergames for health. Games for Health: Research, Development, and Clinical Applications 1, 5 (2012), 326–330.
- Kim et al. (2021) Junho Kim, Jaehyeok Bae, Gangin Park, Dongsu Zhang, and Young Min Kim. 2021. N-imagenet: Towards robust, fine-grained object recognition with event cameras. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2146–2156.
- Kitsikidis et al. (2014) Alexandros Kitsikidis, Kosmas Dimitropoulos, Stella Douka, and Nikos Grammalidis. 2014. Dance analysis using multiple kinect sensors. In 2014 international conference on computer vision theory and applications (VISAPP), Vol. 2. IEEE, 789–795.
- Kloos et al. (2013) Anne D Kloos, Nora E Fritz, Sandra K Kostyk, Gregory S Young, and Deb A Kegelmeyer. 2013. Video game play (Dance Dance Revolution) as a potential exercise therapy in Huntington’s disease: a controlled clinical trial. Clinical rehabilitation 27, 11 (2013), 972–982.
- Lagorce et al. (2017) Xavier Lagorce, G. Orchard, Francesco Galluppi, Bertram E. Shi, and Ryad B. Benosman. 2017. HOTS: A Hierarchy of Event-Based Time-Surfaces for Pattern Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (2017), 1346–1359.
- Li et al. (2019) Jianing Li, Siwei Dong, Zhaofei Yu, Yonghong Tian, and Tiejun Huang. 2019. Event-based vision enhanced: A joint detection framework in autonomous driving. In 2019 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 1396–1401.
- Li et al. (2021) Yijin Li, Han Zhou, Bangbang Yang, Ye Zhang, Zhaopeng Cui, Hujun Bao, and Guofeng Zhang. 2021. Graph-based Asynchronous Event Processing for Rapid Object Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 934–943.
- Lichtsteiner et al. (2008) Patrick Lichtsteiner, Christoph Posch, and Tobi Delbruck. 2008. A 128 128 120 dB 15 s latency asynchronous temporal contrast vision sensor. IEEE journal of solid-state circuits 43, 2 (2008), 566–576.
- Liu and Delbruck (2022) Min Liu and Tobi Delbruck. 2022. EDFLOW: Event Driven Optical Flow Camera with Keypoint Detection and Adaptive Block Matching. IEEE Transactions on Circuits and Systems for Video Technology (2022), Epub–ahead.
- López-Rodríguez et al. (2013) María Mar López-Rodríguez, Manuel Fernández-Martínez, Guillermo A Matarán-Peñarrocha, María Encarnación Rodríguez-Ferrer, Genoveva Granados Gámez, and Encarnación Aguilar Ferrándiz. 2013. Efectividad de la biodanza acuática sobre la calidad del sueño, la ansiedad y otros síntomas en pacientes con fibromialgia. Medicina Clínica 141, 11 (2013), 471–478.
- Maqueda et al. (2018) Ana I Maqueda, Antonio Loquercio, Guillermo Gallego, Narciso García, and Davide Scaramuzza. 2018. Event-based vision meets deep learning on steering prediction for self-driving cars. In Proceedings of the IEEE conference on computer vision and pattern recognition. 5419–5427.
- Marquez et al. (2017) David X Marquez, Robert Wilson, Susan Aguiñaga, Priscilla Vásquez, Louis Fogg, Zhi Yang, JoEllen Wilbur, Susan Hughes, and Charles Spanbauer. 2017. Regular Latin dancing and health education may improve cognition of late middle-aged and older Latinos. Journal of aging and physical activity 25, 3 (2017), 482–489.
- Michel et al. (2017) Damien Michel, Ammar Qammaz, and Antonis A Argyros. 2017. Markerless 3d human pose estimation and tracking based on rgbd cameras: an experimental evaluation. In Proceedings of the 10th International Conference on PErvasive Technologies Related to Assistive Environments. 115–122.
- Mohamed et al. (2021) Sherif AS Mohamed, Jawad N Yasin, Mohammad-hashem Haghbayan, Antonio Miele, Jukka Heikkonen, Hannu Tenhunen, and Juha Plosila. 2021. Dynamic resource-aware corner detection for bio-inspired vision sensors. In 2020 25th International Conference on Pattern Recognition (ICPR). IEEE, 10465–10472.
- Mueggler et al. (2017) Elias Mueggler, Henri Rebecq, Guillermo Gallego, Tobi Delbruck, and Davide Scaramuzza. 2017. The event-camera dataset and simulator: Event-based data for pose estimation, visual odometry, and SLAM. The International Journal of Robotics Research 36, 2 (2017), 142–149.
- Omran et al. (2018) Mohamed Omran, Christoph Lassner, Gerard Pons-Moll, Peter V. Gehler, and Bernt Schiele. 2018. Neural Body Fitting: Unifying Deep Learning and Model Based Human Pose and Shape Estimation. 2018 International Conference on 3D Vision (3DV) (2018), 484–494.
- Patterson et al. (2018) Kara K Patterson, Jennifer S Wong, Thi-Ut Nguyen, and Dina Brooks. 2018. A dance program to improve gait and balance in individuals with chronic stroke: a feasibility study. Topics in Stroke Rehabilitation 25, 6 (2018), 410–416.
- Pinniger et al. (2012) Rosa Pinniger, Rhonda F Brown, Einar B Thorsteinsson, and Patricia McKinley. 2012. Argentine tango dance compared to mindfulness meditation and a waiting-list control: A randomised trial for treating depression. Complementary therapies in medicine 20, 6 (2012), 377–384.
- Posch et al. (2008) Christoph Posch, Daniel Matolin, and Rainer Wohlgenannt. 2008. An asynchronous time-based image sensor. (2008), 2130–2133. https://doi.org/10.1109/ISCAS.2008.4541871
- Rallis et al. (2018) Ioannis Rallis, Apostolos Langis, Ioannis Georgoulas, Athanasios Voulodimos, Nikolaos Doulamis, and Anastasios Doulamis. 2018. An embodied learning game using kinect and labanotation for analysis and visualization of dance kinesiology. In 2018 10th international conference on virtual worlds and games for serious applications (VS-Games). IEEE, 1–8.
- Rebecq et al. (2018) Henri Rebecq, Daniel Gehrig, and Davide Scaramuzza. 2018. ESIM: an open event camera simulator. In Conference on robot learning. PMLR, 969–982.
- Rebecq et al. (2017) Henri Rebecq, Timo Horstschaefer, and Davide Scaramuzza. 2017. Real-time visual-inertial odometry for event cameras using keyframe-based nonlinear optimization. (2017).
- Rhodin et al. (2018) Helge Rhodin, Jörg Spörri, Isinsu Katircioglu, Victor Constantin, Frédéric Meyer, Erich Müller, Mathieu Salzmann, and Pascal V. Fua. 2018. Learning Monocular 3D Human Pose Estimation from Multi-view Images. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (2018), 8437–8446.
- Rim et al. (2020) Beanbonyka Rim, Nak-Jun Sung, Jun Ma, Yoo-Joo Choi, and Min Hong. 2020. Real-time human pose estimation using RGB-D images and deep learning. Journal of Internet Computing and Services 21, 3 (2020), 113–121.
- Romero-Hernandez et al. ([n. d.]) Alejandro Romero-Hernandez, Manuel Gonzalez-Riojo, Meriem El Yamri, and Borja Manero. [n. d.]. The Effectiveness of a Video Game as an Educational Tool in Incrementing Interest in Dance among Younger Generations. ([n. d.]).
- Ronneberger et al. (2015) Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention. Springer, 234–241.
- Rüth and Kaspar (2020) Marco Rüth and Kai Kaspar. 2020. Exergames in formal school teaching: A pre-post longitudinal field study on the effects of a dance game on motor learning, physical enjoyment, and learning motivation. Entertainment Computing 35 (2020), 100372.
- Sánchez et al. (2021) María Fernanda Hincapié Sánchez, Edward David Buriticá Marín, and Leidy Tatiana Ordoñez Mora. 2021. Characterization of dance-based protocols used in rehabilitation-A systematic review. Heliyon (2021), e08573.
- Scarpellini et al. (2021) Gianluca Scarpellini, Pietro Morerio, and Alessio Del Bue. 2021. Lifting Monocular Events to 3D Human Poses. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1358–1368.
- Shi et al. (2015) Xingjian Shi, Zhourong Chen, Hao Wang, Dit-Yan Yeung, Wai-Kin Wong, and Wang-chun Woo. 2015. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Advances in neural information processing systems 28 (2015).
- Srivastav et al. (2018) Vinkle Srivastav, Thibaut Issenhuth, Abdolrahim Kadkhodamohammadi, Michel de Mathelin, Afshin Gangi, and Nicolas Padoy. 2018. MVOR: A multi-view RGB-D operating room dataset for 2D and 3D human pose estimation. arXiv preprint arXiv:1808.08180 (2018).
- Teixeira-Machado et al. (2019) Lavinia Teixeira-Machado, Ricardo Mario Arida, and Jair de Jesus Mari. 2019. Dance for neuroplasticity: A descriptive systematic review. Neuroscience & Biobehavioral Reviews 96 (2019), 232–240.
- Wang et al. (2019) Yanxiang Wang, Bowen Du, Yiran Shen, Kai Wu, Guangrong Zhao, Jianguo Sun, and Hongkai Wen. 2019. EV-Gait: Event-Based Robust Gait Recognition Using Dynamic Vision Sensors. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2019), 6351–6360.
- Yılmaz et al. (2021) Özgün Yılmaz, Camille Simon-Chane, and Aymeric Histace. 2021. Evaluation of Event-Based Corner Detectors. Journal of Imaging 7, 2 (2021), 25.
- Yun et al. (2014) Hye-jeong Yun, Kwang-il Kim, Jeong-hun Lee, and Hae-Yeoun Lee. 2014. Development of experience dance game using kinect motion capture. KIPS transactions on software and data engineering 3, 1 (2014), 49–56.
- Zhu et al. (2019) Alex Zihao Zhu, Liangzhe Yuan, Kenneth Chaney, and Kostas Daniilidis. 2019. Unsupervised event-based learning of optical flow, depth, and egomotion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 989–997.
- Zhu et al. (2018) Yi Zhu, Han Wu, Ming Qi, Sheng Wang, Qin Zhang, Li Zhou, Shiyan Wang, Wei Wang, Ting Wu, Ming Xiao, et al. 2018. Effects of a specially designed aerobic dance routine on mild cognitive impairment. Clinical interventions in aging 13 (2018), 1691.
- Zimmermann et al. (2018) Christian Zimmermann, Tim Welschehold, Christian Dornhege, Wolfram Burgard, and Thomas Brox. 2018. 3d human pose estimation in rgbd images for robotic task learning. In 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 1986–1992.