Neural Delay Differential Equations
Abstract
Neural Ordinary Differential Equations (NODEs), a framework of continuous-depth neural networks, have been widely applied, showing exceptional efficacy in coping with some representative datasets. Recently, an augmented framework has been successfully developed for conquering some limitations emergent in application of the original framework. Here we propose a new class of continuous-depth neural networks with delay, named as Neural Delay Differential Equations (NDDEs), and, for computing the corresponding gradients, we use the adjoint sensitivity method to obtain the delayed dynamics of the adjoint. Since the differential equations with delays are usually seen as dynamical systems of infinite dimension possessing more fruitful dynamics, the NDDEs, compared to the NODEs, own a stronger capacity of nonlinear representations. Indeed, we analytically validate that the NDDEs are of universal approximators, and further articulate an extension of the NDDEs, where the initial function of the NDDEs is supposed to satisfy ODEs. More importantly, we use several illustrative examples to demonstrate the outstanding capacities of the NDDEs and the NDDEs with ODEs’ initial value. Specifically, (1) we successfully model the delayed dynamics where the trajectories in the lower-dimensional phase space could be mutually intersected, while the traditional NODEs without any argumentation are not directly applicable for such modeling, and (2) we achieve lower loss and higher accuracy not only for the data produced synthetically by complex models but also for the real-world image datasets, i.e., CIFAR10, MNIST, and SVHN. Our results on the NDDEs reveal that appropriately articulating the elements of dynamical systems into the network design is truly beneficial to promoting the network performance.
1 Introduction
A series of recent works have revealed a close connection between neural networks and dynamical systems (E, 2017; Li et al., 2017; Haber & Ruthotto, 2017; Chang et al., 2017; Li & Hao, 2018; Lu et al., 2018; E et al., 2019; Chang et al., 2019; Ruthotto & Haber, 2019; Zhang et al., 2019a; Pathak et al., 2018; Fang et al., 2018; Zhu et al., 2019; Tang et al., 2020). On one hand, the deep neural networks can be used to solve the ordinary/partial differential equations that cannot be easily computed using the traditional algorithms. On the other hand, the elements of the dynamical systems can be useful for establishing novel and efficient frameworks of neural networks. Typical examples include the Neural Ordinary Differential Equations (NODEs), where the infinitesimal time of ordinary differential equations is regarded as the “depth” of a considered neural network (Chen et al., 2018).
Though the advantages of the NODEs were demonstrated through modeling continuous-time datasets and continuous normalizing flows with constant memory cost (Chen et al., 2018), the limited capability of representation for some functions were also studied (Dupont et al., 2019). Indeed, the NODEs cannot be directly used to describe the dynamical systems where the trajectories in the lower-dimensional phase space are mutually intersected. Also, the NODEs cannot model only a few variables from some physical or/and physiological systems where the effect of time delay is inevitably present. From a view point of dynamical systems theory, all these are attributed to the characteristic of finite-dimension for the NODEs.
In this article, we propose a novel framework of continuous-depth neural networks with delay, named as Neural Delay Differential Equations (NDDEs). We apply the adjoint sensitivity method to compute the corresponding gradients, where the obtained adjoint systems are also in a form of delay differential equations. The main virtues of the NDDEs include:
-
•
feasible and computable algorithms for computing the gradients of the loss function based on the adjoint systems,
-
•
representation capability of the vector fields which allow the intersection of the trajectories in the lower-dimensional phase space, and
-
•
accurate reconstruction of the complex dynamical systems with effects of time delays based on the observed time-series data.
2 Related Works
NODEs Inspired by the residual neural networks (He et al., 2016) and the other analogous frameworks, the NODEs were established, which can be represented by multiple residual blocks as
where is the hidden state of the -th layer, is a differential function preserving the dimension of , and is the parameter pending for learning. The evolution of can be viewed as the special case of the following equation
with . As suggested in (Chen et al., 2018), all the parameters are unified into for achieving parameter efficiency of the NODEs. This unified operation was also employed in the other neural networks, such as the recurrent neural networks (RNNs) (Rumelhart et al., 1986; Elman, 1990) and the ALBERT (Lan et al., 2019). Letting and using the unified parameter instead of , we obtain the continuous evolution of the hidden state as
which is in the form of ordinary differential equations. Actually, the NODEs can act as a feature extraction, mapping an input to a point in the feature space by computing the forward path of a NODE as:
where is the original data point or its transformation, and is the integration time (assuming that the system starts at ).
Under a predefined loss function , (Chen et al., 2018) employed the adjoint sensitivity method to compute the memory-efficient gradients of the parameters along with the ODE solvers. More precisely, they defined the adjoint variable, , whose dynamics is another ODE, i.e.,
| (1) |
The gradients are computed by an integral as:
| (2) |
(Chen et al., 2018) calculated the gradients by calling an ODE solver with extended ODEs (i.e., concatenating the original state, the adjoint, and the other partial derivatives for the parameters at each time point into a single vector). Notably, for the regression task of the time series, the loss function probably depend on the state at multiple observational times, such as the form of . Under such a case, we must update the adjoint state instantly by adding the partial derivative of the loss at each observational time point.
As emphasized in (Dupont et al., 2019), the flow of the NODEs cannot represent some functions omnipresently emergent in applications. Typical examples include the following two-valued function with one argument: and . Our framework desires to conquer the representation limitation observed in applying the NODEs.

Optimal control As mentioned above, a closed connection between deep neural networks and dynamical systems have been emphasized in the literature and, correspondingly, theories, methods and tools of dynamical systems have been employed, e.g. the theory of optimal control (E, 2017; Li et al., 2017; Haber & Ruthotto, 2017; Chang et al., 2017; Li & Hao, 2018; E et al., 2019; Chang et al., 2019; Ruthotto & Haber, 2019; Zhang et al., 2019a). Generally, we model a typical task using a deep neural network and then train the network parameters such that the given loss function can be reduced by some learning algorithm. In fact, training a network can be seen as solving an optimal control problem on difference or differential equations (E et al., 2019). The parameters act as a controller with a goal of finding an optimal control to minimize/maximize some objective function. Clearly, the framework of the NODEs can be formulated as a typical problem of optimal control on ODEs. Additionally, the framework of NODEs has been generalized to the other dynamical systems, such as the Partial Differential Equations (PDEs) (Han et al., 2018; Long et al., 2018; 2019; Ruthotto & Haber, 2019; Sun et al., 2020) and the Stochastic Differential Equations (SDEs) (Lu et al., 2018; Sun et al., 2018; Liu et al., 2019), where the theory of optimal control has been completely established. It is worthwhile to mention that the optimal control theory is tightly connected with and benefits from the method of the classical calculus of variations (Liberzon, 2011). We also will transform our framework into an optimal control problem, and finally solve it using the method of the calculus of variations.
3 The framework of NDDEs
3.1 Formulation of NDDEs

In this section, we establish a framework of continuous-depth neural networks. To this end, we first introduce the concept of delay deferential equations (DDEs). The DDEs are always written in a form where the derivative of a given variable at time is affected not only by the current state of this variable but also the states at some previous time instants or time durations (Erneux, 2009). Such kind of delayed dynamics play an important role in description of the complex phenomena emergent in many real-world systems, such as physical, chemical, ecological, and physiological systems. In this article, we consider a system of DDE with a single time delay:
where the positive constant is the time delay and is the initial function before the time . Clearly, in the initial problem of ODEs, we only need to initialize the state of the variable at while we initialize the DDEs using a continuous function. Here, to highlight the difference between ODEs and DDEs, we provide a simple example:
where (with time delay) or (without time delay). As shown in Figure 2, the DDE flow can map -1 to 1 and 1 to -1; nevertheless, this cannot be made for the ODE whose trajectories are not intersected with each other in the - space in Figure 2.
3.2 Adjoint Method for NDDEs
Assume that the forward pass of DDEs is complete. Then, we need to compute the gradients in a reverse-mode differentiation by using the adjoint sensitivity method (Chen et al., 2018; Pontryagin et al., 1962). We consider an augmented variable, named as adjoint and defined as
| (3) |
where is the loss function pending for optimization. Notably, the resulted system for the adjoint is in a form of DDE as well.
Theorem 1
(Adjoint method for NDDEs). Consider the loss function . Then, the dynamics of adjoint can be written as
| (4) |
where is a typical characteristic function.
We provide two ways to prove Theorem 1, which are, respectively, shown in Appendix. Using and , we compute the gradients with respect to the parameters as:
| (5) |
Clearly, when the delay approaches zero, the adjoint dynamics degenerate as the conventional case of the NODEs (Chen et al., 2018).
We solve the forward pass of and backward pass for , and by a piece-wise ODE solver, which is shown in Algorithm 1. For simplicity, we denote by and the vector filed of and , respectively. Moreover, in this paper, we only consider the initial function as a constant function, i.e., . Assume that and denote , and .
Input: dynamics parameters , time delay , start time , stop time , final state , loss gradient
for in range():
def augdynamics([,…,, ,..,, .], , ):
return [, ,
]
=ODESolve(, augdynamics, , , )
return
In the traditional framework of the NODEs, we can calculate the gradients of the loss function and recompute the hidden states by solving another augmented ODEs in a reversal time duration. However, to achieve the reverse-mode of the NDDEs in Algorithm 1, we need to store the checkpoints of the forward hidden states for , which, together with the adjoint , can help us to recompute backwards in every time periods. The main idea of the Algorithm 1 is to convert the DDEs as a piece-wise ODEs such that one can naturally employ the framework of the NODEs to solve it. The complexity of Algorithm 1 is analyzed in Appendix.
4 Illustrative Experiments
4.1 Experiments on synthetic datasets
Here, we use some synthetic datasets produced by typical examples to compare the performance of the NODES and the NDDEs. In (Dupont et al., 2019), it is proved that the NODEs cannot represent the function , defined by
where and is the Euclidean norm. The following proposition show that the NDDEs have stronger capability of representation.
Proposition 1
The NDDEs can represent the function specified above.
To validate this proposition, we construct a special form of the NDDEs by
| (6) |
where is a constant and the final time point is supposed to be equal to the time delay with some sufficient large value. Under such configurations, we can linearly separate the two clusters by some hyper plane.

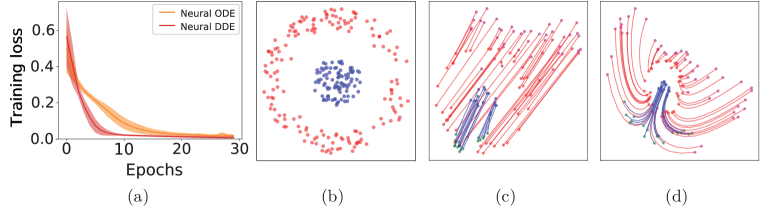
In Fig. 3, we, respectively, show the original data of for the dimension and the transformed data by the DDEs with the parameters , , , , and . Clearly, the transformed data by the DDEs are linearly separable. We also train the NDDEs to represent the for , whose evolutions during the training procedure are, respectively, shown in Fig. 4. This figure also includes the evolution of the NODEs. Notably, while the NODEs is struggled to break apart the annulus, the NDDEs easily separate them. The training losses and the flows of the NODEs and the NDDEs are depicted, respectively, in Fig. 5. Particularly, the NDDEs achieve lower losses with the faster speed and directly separate the two clusters in the original -D space; however, the NODEs achieve it only by increasing the dimension of the data and separating them in a higher-dimensional space.

In general, we have the following theoretical result for the NDDEs, whose proof is provided in Appendix.
Theorem 2
(Universal approximating capability of the NDDEs). For any given continuous function , if one can construct a neural network for approximating the map , then there exists an NDDE of -dimension that can model the map , that is, with the initial function for .
Additionally, NDDEs are suitable for fitting the time series with the delay effect in the original systems, which cannot be easily achieved by using the NODEs. To illustrate this, we use a model of -D DDEs, written as with for . Given the time series generated by the system, we use the NDDEs and the NODEs to fit it, respectively. Figure 6 shows that the NNDEs approach a much lower loss, compared to the NODEs. More interestingly, the NODEs prefer to fit the dimension of and its loss always sustains at a larger value, e.g. in Figure 6. The main reason is that two different trajectories generated by the autonomous ODEs cannot intersect with each other in the phase space, due to the uniqueness of the solution of ODEs.

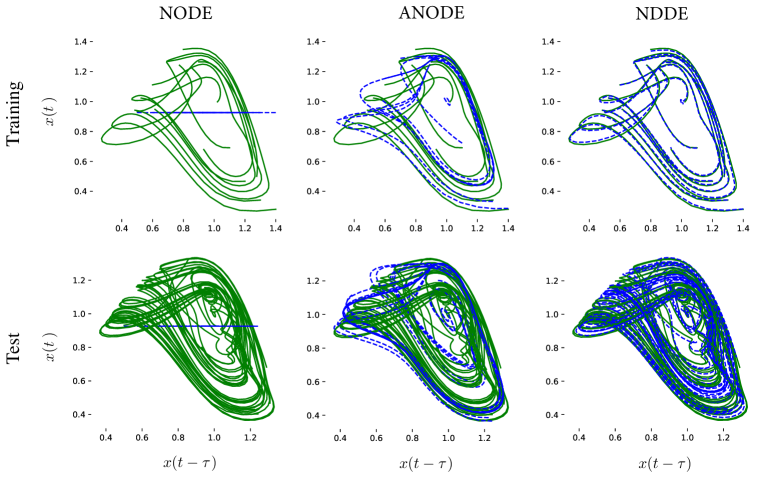
We perform experiments on another two classical DDEs, i.e., the population dynamics and the Mackey-Glass system (Erneux, 2009). Specifically, the equation of the dimensionless population dynamics is , where is the ratio of the population to the carrying capacity of the population, is the growth rate and is the time delay. The Mackey-Glass system is written as , where is the number of the blood cells, are the parameters of biological significance. The NODEs and the NDDEs are tested on these two dynamics. As shown in Figure 7, a very low training loss is achieved for the NDDEs while the the loss of the NODEs does not go down afterwards, always sustaining at some larger value. As for the predicting durations, the NDDEs thereby achieve a better performance than the NODEs. The details of the training could be found in Appendix.

4.2 Experiments on image datasets
For the image datasets, we not only use the NODEs and the NDDEs but also an extension of the NDDEs, called the NODE+NDDE, which treats the initial function as an ODE. In our experiments, such a model exhibits the best performance, revealing strong capabilities in modelling and feature representations. Moreover, inspired by the idea of the augmented NODEs (Dupont et al., 2019), we extend the NDDEs and the NODE+NDDE to the A+NDDE and the A+NODE+NDDE, respectively. Precisely, for the augmented models, we augment the original image space to a higher-dimensional space, i.e., , where , , , and are, respectively, the number of channels, height, width of the image, and the augmented dimension. With such configurations of the same augmented dimension and approximately the same number of the model parameters, comparison studies on the image datasets using different models are reasonable. For the NODEs, we model the vector filed as the convolutional architectures together with a slightly different hyperparameter setups in (Dupont et al., 2019). The initial hidden state is set as with respect to an image. For the NDDEs, we design the vector filed as , mapping the space from to , where executes the concatenation of two tensors on the channel dimension. Its initial function is designed as a constant function, i.e., is identical to the input/image for . For the NODE+NDDE, we model the initial function as an ODE, which follows the same model structure of the NODEs. For the augmented models, the augmented dimension is chosen from the set {1, 2, 4}. Moreover, the training details could be found in Appendix, including the training setting and the number of function evaluations for each model on the image datasets.
The training processes on MNIST, CIFAR10, and SVHN are shown in Fig. 8. Overall, the NDDEs and its extensions have their training losses decreasing faster than the NODEs/ANODEs which achieve lower training and test loss. Also the test accuracies are much higher than the that of the NODEs/ANODEs (refer to Tab. 1). Naturally, the better performance of the NDDEs is attributed to the integration of the information not only on the hidden states at the current time but at the previous time . This kind of framework is akin to the key idea proposed in (Huang et al., 2017), where the information is processed on many hidden states. Here, we run all the experiments for 5 times independently.

| CIFAR10 | MNIST | SVHN | |
|---|---|---|---|
| NODE | |||
| NDDE | |||
| NODE+NDDE | |||
| A1+NIDE | |||
| A1+NDDE | |||
| A1+NODE+NDDE | |||
| A2+NODE | |||
| A2+NDDE | |||
| A2+NODE+NDDE | |||
| A4+NODE | |||
| A4+NDDE | |||
| A4+NODE+NDDE |
5 Discussion
In this section, we present the limitations of the NDDEs and further suggest several potential directions for future works. We add the delay effect to the NDDEs, which renders the model absolutely irreversible. Algorithm 1 thus requires a storage of the checkpoints of the hidden state at every instant of the multiple of . Actually, solving the DDEs is transformed to solving the ODEs of an increasingly high dimension with respect to the ratio of the final time and the time delay . This definitely indicates a high computational cost. To further apply and improve the framework of the NDDEs, a few potential directions for future works are suggested, including:
Applications to more real-world datasets. In the real-world systems such as physical, chemical, biological, and ecological systems, the delay effects are inevitably omnipresent, truly affecting the dynamics of the produced time-series (Bocharov & Rihan, 2000; Kajiwara et al., 2012). The NDDEs are undoubtedly suitable for realizing model-free and accurate prediction (Quaglino et al., 2019). Additionally, since the NODEs have been generalized to the areas of Computer Vision and Natural Language Processing He et al. (2019); Yang et al. (2019); Liu et al. (2020), the framework of the NDDEs probably can be applied to the analogous areas, where the delay effects should be ubiquitous in those streaming data.
Extension of the NDDEs. A single constant time-delay in the NDDEs can be further generalized to the case of multiple or/and distributed time delays (Shampine & Thompson, 2001). As such, the model is likely to have much stronger capability to extract the feature, because the model leverages the information at different time points to make the decision in time. All these extensions could be potentially suitable for some complex tasks. However, such complex model may require tremendously huge computational cost.x
Time-dependent controllers. From a viewpoint of control theory, the parameters in the NODEs/NDDEs could be regarded as time-independent controllers, viz. constant controllers. A natural generalization way is to model the parameters as time-dependent controllers. In fact, such controllers were proposed in (Zhang et al., 2019b), where the parameters were treated as another learnable ODE , is a different neural network, and the parameters and the initial state are pending for optimization. Also, the idea of using a neural network to generate the other one was initially conceived in some earlier works including the study of the hypernetworks (Ha et al., 2016).
6 Conclusion
In this article, we establish the framework of NDDEs, whose vector fields are determined mainly by the states at the previous time. We employ the adjoint sensitivity method to compute the gradients of the loss function. The obtained adjoint dynamics backward follow another DDEs coupled with the forward hidden states. We show that the NDDEs can represent some typical functions that cannot be represented by the original framework of NODEs. Moreover, we have validated analytically that the NDDEs possess universal approximating capability. We also demonstrate the exceptional efficacy of the proposed framework by using the synthetic data or real-world datasets. All these reveal that integrating the elements of dynamical systems to the architecture of neural networks could be potentially beneficial to the promotion of network performance.
Author Contributions
WL conceived the idea, QZ, YG & WL performed the research, QZ & YG performed the mathematical arguments, QZ analyzed the data, and QZ & WL wrote the paper.
Acknowledgments
WL was supported by the National Key R&D Program of China (Grant no. 2018YFC0116600), the National Natural Science Foundation of China (Grant no. 11925103), and by the STCSM (Grant No. 18DZ1201000, 19511101404, 19511132000).
References
- Bocharov & Rihan (2000) Gennadii A Bocharov and Fathalla A Rihan. Numerical modelling in biosciences using delay differential equations. Journal of Computational and Applied Mathematics, 125(1-2):183–199, 2000.
- Chang et al. (2017) Bo Chang, Lili Meng, Eldad Haber, Frederick Tung, and David Begert. Multi-level residual networks from dynamical systems view. arXiv preprint arXiv:1710.10348, 2017.
- Chang et al. (2019) Bo Chang, Minmin Chen, Eldad Haber, and Ed H Chi. Antisymmetricrnn: A dynamical system view on recurrent neural networks. arXiv preprint arXiv:1902.09689, 2019.
- Chen et al. (2018) Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations. In Advances in neural information processing systems, pp. 6571–6583, 2018.
- Dupont et al. (2019) Emilien Dupont, Arnaud Doucet, and Yee Whye Teh. Augmented neural odes. In Advances in Neural Information Processing Systems, pp. 3140–3150, 2019.
- E (2017) Weinan E. A proposal on machine learning via dynamical systems. Communications in Mathematics and Statistics, 5(1):1–11, 2017.
- E et al. (2019) Weinan E, Jiequn Han, and Qianxiao Li. A mean-field optimal control formulation of deep learning. Research in the Mathematical Sciences, 6(1):10, 2019.
- Elman (1990) Jeffrey L Elman. Finding structure in time. Cognitive science, 14(2):179–211, 1990.
- Erneux (2009) Thomas Erneux. Applied delay differential equations, volume 3. Springer Science & Business Media, 2009.
- Fang et al. (2018) Leheng Fang, Wei Lin, and Qiang Luo. Brain-inspired constructive learning algorithms with evolutionally additive nonlinear neurons. International Journal of Bifurcation and Chaos, 28(05):1850068–, 2018.
- Ha et al. (2016) David Ha, Andrew Dai, and Quoc V Le. Hypernetworks. arXiv preprint arXiv:1609.09106, 2016.
- Haber & Ruthotto (2017) Eldad Haber and Lars Ruthotto. Stable architectures for deep neural networks. Inverse Problems, 34(1):014004, 2017.
- Han et al. (2018) Jiequn Han, Arnulf Jentzen, and E Weinan. Solving high-dimensional partial differential equations using deep learning. Proceedings of the National Academy of Sciences, 115(34):8505–8510, 2018.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- He et al. (2019) Xiangyu He, Zitao Mo, Peisong Wang, Yang Liu, Mingyuan Yang, and Jian Cheng. Ode-inspired network design for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1732–1741, 2019.
- Huang et al. (2017) Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4700–4708, 2017.
- Kajiwara et al. (2012) Tsuyoshi Kajiwara, Toru Sasaki, and Yasuhiro Takeuchi. Construction of lyapunov functionals for delay differential equations in virology and epidemiology. Nonlinear Analysis: Real World Applications, 13(4):1802–1826, 2012.
- Lan et al. (2019) Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942, 2019.
- Li & Hao (2018) Qianxiao Li and Shuji Hao. An optimal control approach to deep learning and applications to discrete-weight neural networks. arXiv preprint arXiv:1803.01299, 2018.
- Li et al. (2017) Qianxiao Li, Long Chen, Cheng Tai, and E Weinan. Maximum principle based algorithms for deep learning. The Journal of Machine Learning Research, 18(1):5998–6026, 2017.
- Liberzon (2011) Daniel Liberzon. Calculus of variations and optimal control theory: a concise introduction. Princeton University Press, 2011.
- Liu et al. (2019) Xuanqing Liu, Tesi Xiao, Si Si, Qin Cao, Sanjiv Kumar, and Cho-Jui Hsieh. Neural sde: Stabilizing neural ode networks with stochastic noise. arXiv preprint arXiv:1906.02355, 2019.
- Liu et al. (2020) Xuanqing Liu, Hsiang-Fu Yu, Inderjit Dhillon, and Cho-Jui Hsieh. Learning to encode position for transformer with continuous dynamical model. arXiv preprint arXiv:2003.09229, 2020.
- Long et al. (2018) Zichao Long, Yiping Lu, Xianzhong Ma, and Bin Dong. Pde-net: Learning pdes from data. In International Conference on Machine Learning, pp. 3208–3216, 2018.
- Long et al. (2019) Zichao Long, Yiping Lu, and Bin Dong. Pde-net 2.0: Learning pdes from data with a numeric-symbolic hybrid deep network. Journal of Computational Physics, 399:108925, 2019.
- Lu et al. (2018) Yiping Lu, Aoxiao Zhong, Quanzheng Li, and Bin Dong. Beyond finite layer neural networks: Bridging deep architectures and numerical differential equations. In International Conference on Machine Learning, pp. 3276–3285. PMLR, 2018.
- Pathak et al. (2018) Jaideep Pathak, Brian Hunt, Michelle Girvan, Zhixin Lu, and Edward Ott. Model-free prediction of large spatiotemporally chaotic systems from data: A reservoir computing approach. Physical Review Letters, 120(2), 2018.
- Pontryagin et al. (1962) LS Pontryagin, VG Boltyanskij, RV Gamkrelidze, and EF Mishchenko. The mathematical theory of optimal processes. 1962.
- Quaglino et al. (2019) Alessio Quaglino, Marco Gallieri, Jonathan Masci, and Jan Koutník. Snode: Spectral discretization of neural odes for system identification. arXiv preprint arXiv:1906.07038, 2019.
- Rumelhart et al. (1986) David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors. nature, 323(6088):533–536, 1986.
- Ruthotto & Haber (2019) Lars Ruthotto and Eldad Haber. Deep neural networks motivated by partial differential equations. Journal of Mathematical Imaging and Vision, pp. 1–13, 2019.
- Shampine & Thompson (2001) Lawrence F Shampine and Skip Thompson. Solving ddes in matlab. Applied Numerical Mathematics, 37(4):441–458, 2001.
- Sun et al. (2018) Qi Sun, Yunzhe Tao, and Qiang Du. Stochastic training of residual networks: a differential equation viewpoint. arXiv preprint arXiv:1812.00174, 2018.
- Sun et al. (2020) Yifan Sun, Linan Zhang, and Hayden Schaeffer. Neupde: Neural network based ordinary and partial differential equations for modeling time-dependent data. In Mathematical and Scientific Machine Learning, pp. 352–372. PMLR, 2020.
- Tang et al. (2020) Yang Tang, Jürgen Kurths, Wei Lin, Edward Ott, and Ljupco Kocarev. Introduction to focus issue: When machine learning meets complex systems: Networks, chaos, and nonlinear dynamics. Chaos: An Interdisciplinary Journal of Nonlinear Science, 30(6):063151, 2020.
- Yang et al. (2019) Guandao Yang, Xun Huang, Zekun Hao, Ming-Yu Liu, Serge Belongie, and Bharath Hariharan. Pointflow: 3d point cloud generation with continuous normalizing flows. In Proceedings of the IEEE International Conference on Computer Vision, pp. 4541–4550, 2019.
- Zhang et al. (2019a) Dinghuai Zhang, Tianyuan Zhang, Yiping Lu, Zhanxing Zhu, and Bin Dong. You only propagate once: Painless adversarial training using maximal principle. arXiv preprint arXiv:1905.00877, 2(3), 2019a.
- Zhang et al. (2019b) Tianjun Zhang, Zhewei Yao, Amir Gholami, Joseph E Gonzalez, Kurt Keutzer, Michael W Mahoney, and George Biros. Anodev2: A coupled neural ode framework. In Advances in Neural Information Processing Systems, pp. 5151–5161, 2019b.
- Zhu et al. (2019) Qunxi Zhu, Huanfei Ma, and Wei Lin. Detecting unstable periodic orbits based only on time series: When adaptive delayed feedback control meets reservoir computing. Chaos, 29(9):93125–93125, 2019.
Appendix A Appendix
A.1 The First Proof of Theorem 1
Here, we present a direct proof of the adjoint method for the NDDEs. For the neat of the proof, the following notations are slightly different from those in the main text.
Let obey the DDE written as
| (7) |
whose adjoint state is defined as
| (8) |
where is the loss function, that is, . After discretizing the above DDE, we have
| (9) | ||||
According to the definition of and applying the chain rule, we have
| (10) | ||||
which implies,
| (11) | ||||
where is a characteristic function. For the parameter , the result can be analogously derived as
| (12) | ||||
In this article, is considered to be a constant variable, i.e., , which yields:
| (13) | ||||
To summarize, we get the gradients with respect to and in a form of augmented DDEs. These DDEs are backward in time and written in an integral form of
| (14) | ||||
A.2 The Second Proof of Theorem 1
Here, we mainly employ the Lagrangian multiplier method and the calculus of variation to derive the adjoint method for the NDDEs. First, we define the Lagrangian by
| (15) |
We thereby need to find the so-called Karush-Kuhn-Tucker (KKT) conditions for the Lagrangian, which is necessary for finding the optimal solution of . To obtain the KKT conditions, the calculus of variation is applied by taking variations with respect to and .
For , let be a continuous and differentiable function with a scalar . We add the perturbation to the Lagrangian , which results in a new Lagrangian, denoted by
| (16) |
In order to obey the optimal condition for , we require the following equation
| (17) |
to be zero. Due to the arbitrariness of , we obtain
| (18) |
which is exactly the DDE forward in time.
Analogously, we can take variation with respect to and let be a continuous and differentiable function with a scalar . Here, for . We also denote by for . The new Lagrangian under the perturbation of becomes
| (19) |
We then compute the , which gives
| (20) | ||||
Notice that is satisfied for all continuous differentiable at the optimal . Thus, we have
| (21) |
Therefore, the adjoint state follows a DDE as well.
A.3 The Proof of Theorem 2
The validation for Theorem 2 is straightforward. Consider the NDDEs in the following form:
where equals to the final time . Due to for , then the vector field of the NDDEs in the interval is constant. This implies . Assume that the neural network is able to approximate the map . Then, we have . The proof is completed.
A.4 Complexity Analysis of the Algorithm 1
As shown in (Chen et al., 2018), the memory and the time costs for solving the NODEs are and , where is the number of the function evaluations in the time interval . More precisely, solving the NODEs is memory efficient without storing any intermediate states of the evaluated time points in solving the NODEs. Here, we intend to analyze the complexity of Algorithm 1. It should be noting that the state-of-the-art for the DDE software is not as advanced as that for the ODE software. Hence, solving a DDE is much difficult compared with solving the ODE. There exists several DDE solvers, such as the popular solver, the dde23 provided by MATLAB. However, these DDE solvers usually need to store the history states to help the solvers access the past time state . Hence, the memory cost of DDE solvers is , where is the number of the history states. This is the major difference between the DDEs and the ODEs, as solving the ODEs is memory efficient, i.e., . In Algorithm 1, we propose a piece-wise ODE solver to solve the DDEs. The underlying idea is to transform the DDEs into the piece-wise ODEs for every time periods such that one can naturally employ the framework of the NODEs. More precisely, we compute the state at time by solving an augmented ODE with the augmented initial state, i.e., concatenating the states at time into a single vector. Such a method has several strengths and has weaknesses as well. The strengths include:
-
•
One can easily implement the algorithm using the framework of the NODEs, and
-
•
Algorithm 1 becomes quite memory efficient , where we only need to store a small number of the forward states, , to help the algorithm compute the adjoint and the gradients in a reverse mode. Here, the final is assumed to be not very large compared with the time delay , for example, with a small integer .
Notably, we chosen (i.e., ) of the NDDEs in the experiments on the image datasets, resulting in a quite memory efficient computation. Additionally, the weaknesses involve:
-
•
Algorithm 1 may suffer from a high memory cost, if the final is extremely larger than the (i.e., many forward states, , are required to be stored), and
-
•
the increasing augmented dimension of the ODEs may lead to the heavy time cost for each evaluation in the ODE solver.
Appendix B Experimental Details
B.1 Synthetic datasets
For the classification of the dataset of concentric spheres, we almost follow the experimental configurations used in (Dupont et al., 2019). The dataset contain 2000 data points in the outer annulus and 1000 data points in the inner sphere. We choose , , and . We solve the classification problem using the NODE and the NDDE, whose structures are described, respectively, as:
-
1.
Structure of the NODEs: the vector field is modeled as
where , , and ;
-
2.
Structure of the NDDEs: the vector field is modeled as
where , , and .
For each model, we choose the optimizer Adam with 1e-3 as the learning rate, 64 as the batch size, and 5 as the number of the training epochs.
We also utilize the synthetic datasets to address the regression problem of the time series. The optimizer for these datasets is chosen as the Adam with as the learning rate and the mean absolute error (MAE) as the loss function. In this article, we choose the true time delays of the underlying systems for the NDDEs. We describe the structures of the models for the synthetic datasets as follows.
For the DDE , we generate a trajectory by choosing its parameters as , , for , the final time , and the sampling time period equal to . We model it using the NODE and the NDDE, whose structures are illustrated, respectively, as:
-
1.
Structure of the NODE: the vector field is modeled as
where and ;
-
2.
Structure of the NDDE: the vector field is modeled as
where and .
We use the whole trajectory to train the models with the total iterations equal to .
For the population dynamics with for and the Mackey-Glass systems with for , we choose the parameters as , , , , , and . We then generate different trajectories within the time interval with as the sampling time period for both the population dynamics and the Mackey-Glass systems. We split the trajectories into two parts. The first part within the time interval is used as the training data. The other part is used for testing. We model both systems by applying the NODE, the NDDE, and the ANODE, whose structures are introduced, respectively, as:
-
1.
Structure of the NODE: the vector field is modeled as
where , , and ;
-
2.
Structure of the NDDE: the vector field is modeled as
where , , and .
-
3.
Structure of the ANODE: the vector field is modeled as
where , , , and the augmented dimension is equal to . Notably, we need to align the augmented trajectories with the target trajectories to be regressed. To do it, we choose the data in the first component and exclude the data in the augmented component, i.e., simply projecting the augmented data into the space of the target data.
We train each model for the total iterations.
B.2 Image datasets
The image experiments shown in this article are mainly depend on the code provided in (Dupont et al., 2019). Also, the structures of each model almost follow from the structures proposed in (Dupont et al., 2019). More precisely, we apply the convolutional block with the following strutures and dimensions
-
•
conv, filters, paddings,
-
•
ReLU activation function,
-
•
conv, filters, paddings,
-
•
ReLU activation function,
-
•
conv, filters, paddings,
where is different for each model and is the number of the channels of the input images. In Tab. 2, we specify the information for each model. As can be seen, we fix approximately the same number of the parameters for each model. We select the hyperparamters for the optimizer Adam through 1e-3 as the learning rate, as the batch size, and as the number of the training epochs.
| CIFAR10 | MNIST | SVHN | |
|---|---|---|---|
| NODE | |||
| NDDE | |||
| NODE+NDDE | |||
| A1+NODE | |||
| A1+NDDE | |||
| A1+NODE+NDDE | |||
| A2+NODE | |||
| A2+NDDE | |||
| A2+NODE+NDDE | |||
| A4+NODE | |||
| A4+NDDE | |||
| A4+NODE+NDDE |
Appendix C Additional results for the experiments