Liam Parker
\Email[email protected]
\addrPrinceton University, Princeton, NJ, USA
and \NameEmre Onal \Email[email protected]
\addrPrinceton University, Princeton, NJ, USA
and \NameAnton Stengel \Email[email protected]
\addrPrinceton University, Princeton, NJ, USA
and \NameJacob Intrater \Email[email protected]
\addrPrinceton University, Princeton, NJ, USA
Neural Collapse in the Intermediate Hidden Layers of Classification Neural Networks
Abstract
Neural Collapse () gives a precise description of the representations of classes in the final hidden layer of classification neural networks. This description provides insights into how these networks learn features and generalize well when trained past zero training error. However, to date, has only been studied in the final layer of these networks. In the present paper, we provide the first comprehensive empirical analysis of the emergence of in the intermediate hidden layers of these classifiers. We examine a variety of network architectures, activations, and datasets, and demonstrate that some degree of emerges in most of the intermediate hidden layers of the network, where the degree of collapse in any given layer is typically positively correlated with the depth of that layer in the neural network. Moreover, we remark that: (1) almost all of the reduction in intra-class variance in the samples occurs in the shallower layers of the networks, (2) the angular separation between class means increases consistently with hidden layer depth, and (3) simple datasets require only the shallower layers of the networks to fully learn them, whereas more difficult ones require the entire network. Ultimately, these results provide granular insights into the structural propagation of features through classification neural networks.
1 Introduction
Modern, highly-overparameterized deep neural networks have exceeded human performance on a variety of computer vision tasks [1, 2, 3]. However, despite their many successes, it remains unclear how these overparameterized networks converge to solutions which generalize well. In a bid to demystify neural networks’ performance, a recent line of inquiry has explored the internally represented ‘features’ of these networks during the Terminal Phase of Training (TPT), i.e. when networks are trained past the point of zero error on the training data [4, 5, 6].
The phenomenon of Neural Collapse (), introduced by Papyan, Han, and Donoho [7, 8], represents one such avenue of inquiry. refers to the emergence of a simple geometry present in neural network classifiers that appears during TPT. Specifically, describes the phenomena by which neural network classifiers converge to learning maximally separated, negligible-variance representations of classes in their last layer activation maps. However, despite the extensive documentation of in the last-layer representations of classification neural networks [9, 10, 11, 12], there has been no exploration of its presence throughout the intermediate hidden layers of these networks.
In the present study, we provide a detailed account of the emergence of in the intermediate hidden layers of neural networks across a range of different settings. Specifically, we investigate the impact of varying architectures, datasets, and activation functions on the degree of present in the intermediate layers of classification networks. Our results show that some level of typically occurs in these intermediate layers in all explored settings, where the strength of in a given layer increases as the depth of that layer within the network increases. By examining the presence of not only in the final hidden layer but also the intermediate hidden layers of classification networks, we gain a more nuanced understanding of the mechanisms that drive the behavior of these networks.
2 Methodology
2.1 Network Architecture and Training
We examine the degree of present in the hidden layers of three different neural network classifiers. Two of these models are popular in the computer vision community, and have been extensively studied and widely adopted: VGG11 [13] and ResNet18 [14]. We also train a fully-connected (FC) classification network, MLP6, with network depth of and layer width of for each of its hidden layers. MLP6 serves as a toy model in which to more easily explore . In addition to varying network architecture, we also vary the activation functions. Specifically, we explore the effects on of the ReLU, Tanh, and LeakyReLU activation functions. We train these classification neural networks on five popular computer vision classification datasets: MNIST [15], CIFAR10 and CIFAR100 [16], SVHN [17], and FashionMNIST [18]. To rebalance the datasets, MNIST and SVHN were subsampled to , , and images per class, respectively. We normalize all datasets but do not perform any data augmentation. We use stochastic gradient descent with 0.9 momentum, Mean Square Error Loss (MSE) 111We use MSE loss rather than Cross Entropy loss as it has been shown to exhibit a greater degree of in classification neural networks while maintaining a greater degree of mathematical clarity [7, 19]., weight decay, and the one-cycle learning rate scheduler for all training [20].
2.2 Intermediate Layer Analysis
To assess the extent of in the hidden layers of our classifiers, we perform a step of “ analysis” at various points during training. This analysis involves freezing the network and passing all the training samples through it. We then collect the network’s post-activation representation of each sample after every hidden layer of interest. Specifically, we collect post-activations after each FC layer in MLP6, each convolutional layer in VGG11, and each convolutional layer in ResNet18. We then flatten these post-activation representations into vectors , where is the hidden layer, is the training sample, and is the class. We then compute four quantities in each of these hidden layer post-activation vectors to track : intra-class variance collapse , intra-class norm equality , inter-class maximal angular separation , and simplification to nearest-class center classifier following the general outline provided in [7]. The specifics of these quantities are provided in Appendix A.
3 Results
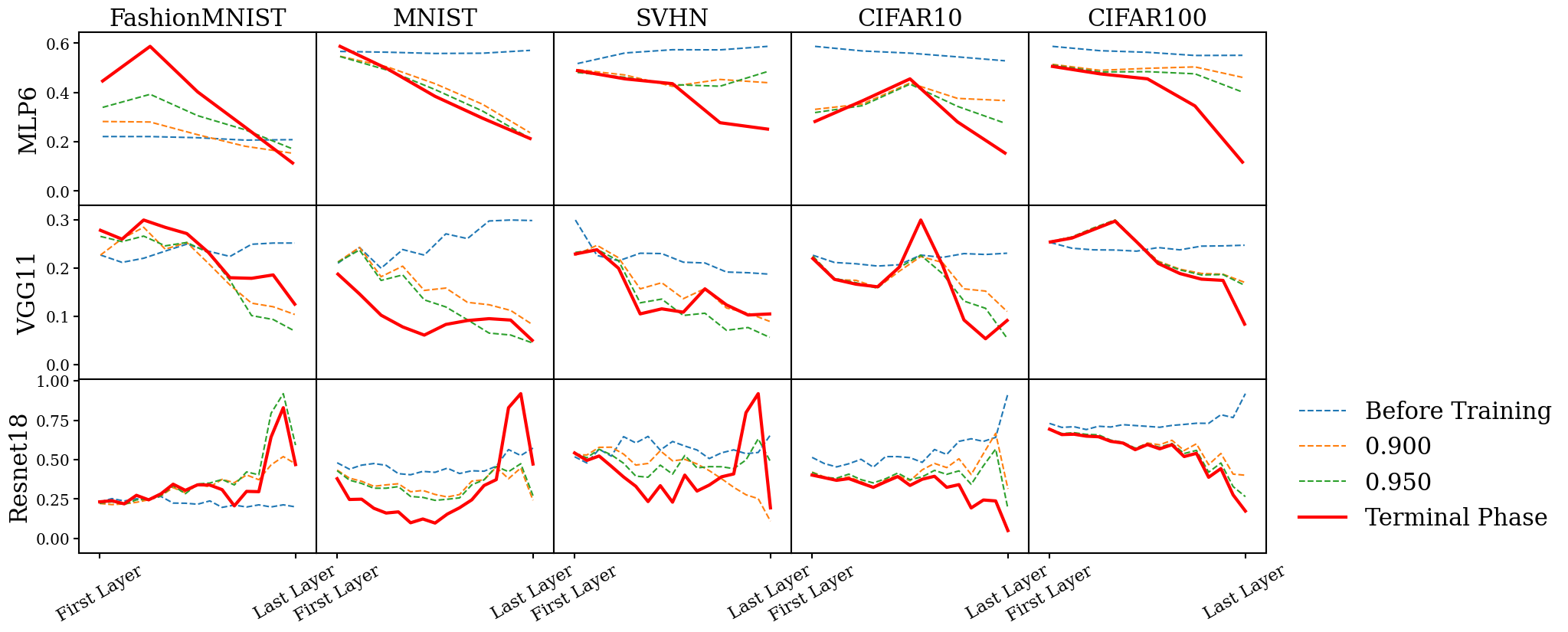
We present the results for each of the conditions for MLP6, VGG11, and ResNet18 with ReLU activation functions trained to TPT on FashionMNIST, MNIST, SVHN, CIFAR10, and CIFAR100 in Figure 1 to Figure 4.

: The within-class variability decreases linearly with layer depth in the shallower layers of the classification networks, indicating that the earlier fully-connected/convolutional layers are equally effective in clustering samples of the same class. However, in the deeper layers of the networks, the within-class variability plateaus, suggesting that the network has already maximally reduced the variance between same-class samples even when they have only partially propagated through the network. This behavior is observed in most tested network architectures and datasets, except for CIFAR100. Ultimately, the earlier layers of the classifiers primarily group same-class samples together and contribute to the generation of .
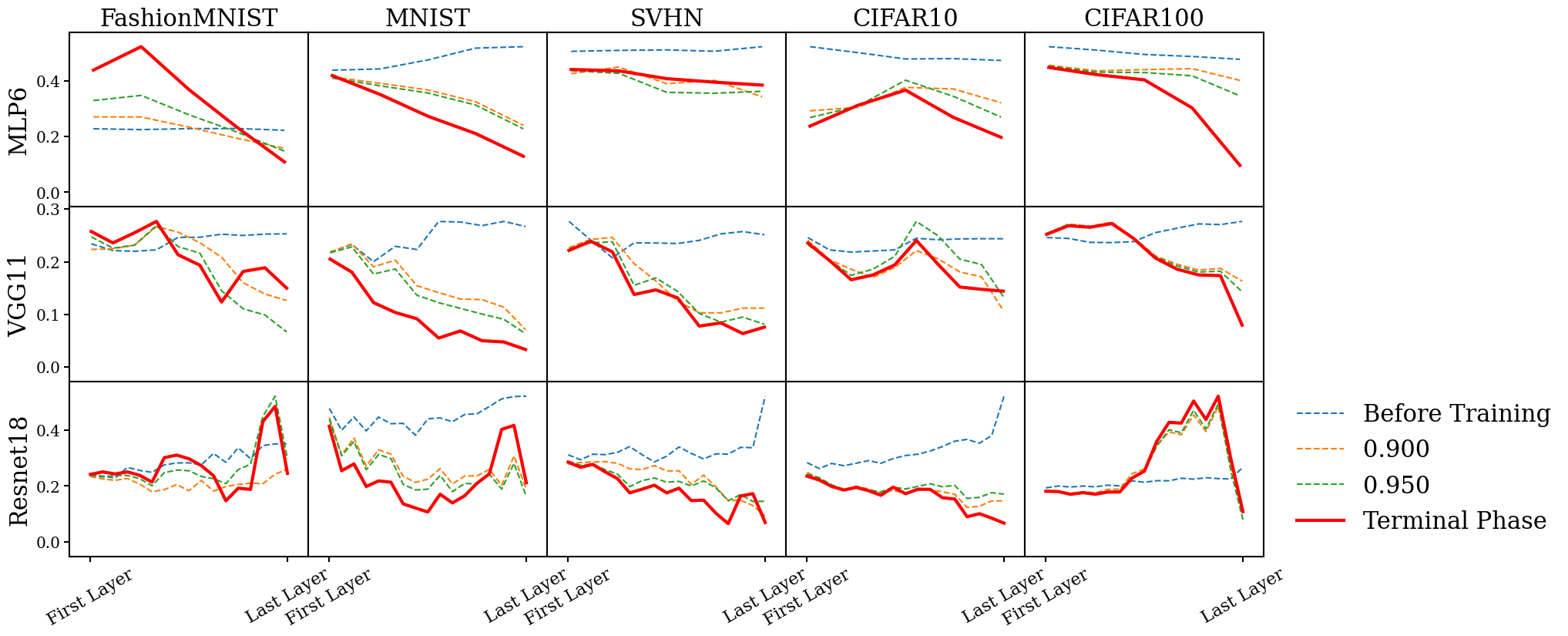

: The two phenomena related to the emergence of the simplex ETF structure in the class means, i.e. the convergence of class means to equal norms and to maximal equal angles, also exhibit a somewhat linear relationship between the degree of collapse in any given hidden layer and that layer’s depth in the network. However, unlike , the collapse continues to strengthen even in the deeper layers of the network, rather than plateauing after the first few layers; this is more prevalent for the angular separation between different class means than for the similarity between their norms. This phenomenon also persists across most architectures and datasets, and suggests that the network continues to separate classes as it feeds samples forward through its full depth. This makes sense, as features extracted in the shallower layers of the network can be used to learn more and more effective ways of separating different-class samples in deeper layers, leading to an increase in the recorded strength of over layer depth.

: The degree of in any given layer during training seems to be influenced by the presence of and in that layer. For the nearest class mean to accurately predict network output, samples need to be close to their class mean () and class means should be well-separated (). In most experiments, decreases linearly in the shallower layers and plateaus in the deeper layers. However, the plateauing occurs later than due to the additional angular separation between class means in these deeper layers, which contributes valuable information for classification. The degree of in the -th hidden layer indicates how much of the network’s classification ability is captured by its hidden layers. If the mismatch between the nearest neighbor classification in the -th layer and the total network classification is zero, then all of the network’s classification ability is already present by the -th layer. For simpler datasets like MNIST and SVHN, the NCC mismatch between shallower layers and the network output reaches zero, while for more complex datasets like CIFAR100, the NCC mismatch only reaches zero in the final layers. This observation aligns with the notion that complex datasets require the deeper networks for complete classification, while simpler datasets can achieve it with the shallower layers; however, it will be important for future studies to observe how this generalizes to test/validation datasets.
However, despite these general trends, we note that the models trained on CIFAR100 exhibit a number of unique behaviors not consistent with our broader observations on , most striking of which is no significant decrease in within-class variability over training. Instead, the data seems largely noisy for this condition. This merits future investigation across other challenging datasets such as TinyImageNet, as well as more exploratory analysis.
In addition to the experiments performed on the classification networks with ReLU activation functions above, we also perform the same set of experiments on Tanh and LeakyReLU classifiers in Appendix B and Appendix C respectively. These experiments largely demonstrate the same characteristics as the ReLU experiments.
4 Conclusions
Our work demonstrates that the Neural Collapse () phenomenon occurs throughout most of the hidden layers of classification neural networks trained through the terminal phase of training (TPT). We demonstrate these findings across a variety of settings, including varying network architectures, classification datasets, and network activations functions, and find that the degree of present in any hidden layer is typically correlated with the depth of that layer in the network. In particular, we make the following specific observations: (1) almost all of the reduction in intra-class variance in the samples occurs in the shallower layers of the classification networks, (2) the angular separation between class means is increased consistently as samples propagate through the entire network, and (3) simpler datasets require only the shallower layers of the networks to fully learn them, whereas more difficult ones require the entire network. Ultimately, these results provide a granular view of the structural propagation of features through classification networks. In future work, it will be important to analyze how these results generalize to held-out validation data. For example, do our observations of serve as a proxy for the network’s ability to classify data extend to validation data? Moreover, is there a broader relationship between and network generalization/over-training?
5 Contributions
Parker: Initiated problem concept; led experiments and analysis design; collaborated on computational work; collaborated on results analysis; wrote the paper. Onal: Collaborated on experiments and analysis design; collaborated on computational work; collaborated on results analysis. Stengel: Collaborated on background research and initial experiment design; collaborated on computational work. Intrater: Collaborated on problem concept and background research.
6 Acknowledgements
We would like to thank Professor Boris Hanin for his generous guidance and support in the completion of this paper as well as for his insightful and exciting class, Deep Learning Theory, which ultimately led to the creation of this project.
References
- [1] Ian Goodfellow, Yoshua Bengio and Aaron Courville “Deep learning” MIT press, 2016
- [2] Alex Krizhevsky, Ilya Sutskever and Geoffrey E Hinton “Imagenet classification with deep convolutional neural networks” In Communications of the ACM 60.6 AcM New York, NY, USA, 2017, pp. 84–90
- [3] Yann LeCun, Yoshua Bengio and Geoffrey Hinton “Deep learning” In nature 521.7553 Nature Publishing Group, 2015, pp. 436–444
- [4] Tolga Ergen and Mert Pilanci “Revealing the structure of deep neural networks via convex duality” In International Conference on Machine Learning, 2021, pp. 3004–3014 PMLR
- [5] Cong Fang, Hangfeng He, Qi Long and Weijie J Su “Exploring deep neural networks via layer-peeled model: Minority collapse in imbalanced training” In Proceedings of the National Academy of Sciences 118.43 National Acad Sciences, 2021, pp. e2103091118
- [6] Zhihui Zhu et al. “A geometric analysis of neural collapse with unconstrained features” In Advances in Neural Information Processing Systems 34, 2021, pp. 29820–29834
- [7] Vardan Papyan, XY Han and David L Donoho “Prevalence of neural collapse during the terminal phase of deep learning training” In Proceedings of the National Academy of Sciences 117.40 National Acad Sciences, 2020, pp. 24652–24663
- [8] XY Han, Vardan Papyan and David L Donoho “Neural collapse under mse loss: Proximity to and dynamics on the central path” In arXiv preprint arXiv:2106.02073, 2021
- [9] Dustin G. Mixon, Hans Parshall and Jianzong Pi “Neural collapse with unconstrained features” In arXiv, 2020 DOI: 10.48550/ARXIV.2011.11619
- [10] Jianfeng Lu and Stefan Steinerberger “Neural Collapse with Cross-Entropy Loss” In arXiv, 2020 DOI: 10.48550/ARXIV.2012.08465
- [11] Tom Tirer and Joan Bruna “Extended Unconstrained Features Model for Exploring Deep Neural Collapse” In arXiv, 2022 DOI: 10.48550/ARXIV.2202.08087
- [12] Jinxin Zhou et al. “Are All Losses Created Equal: A Neural Collapse Perspective” In arXiv, 2022 DOI: 10.48550/ARXIV.2210.02192
- [13] Karen Simonyan and Andrew Zisserman “Very Deep Convolutional Networks for Large-Scale Image Recognition” arXiv, 2014 DOI: 10.48550/ARXIV.1409.1556
- [14] Karen Simonyan and Andrew Zisserman “Very deep convolutional networks for large-scale image recognition” In arXiv preprint arXiv:1409.1556, 2014
- [15] Yann LeCun “The MNIST database of handwritten digits” In http://yann. lecun. com/exdb/mnist/, 1998
- [16] Alex Krizhevsky and Geoffrey Hinton “Learning multiple layers of features from tiny images” Toronto, ON, Canada, 2009
- [17] Yuval Netzer et al. “Reading digits in natural images with unsupervised feature learning”, 2011
- [18] Han Xiao, Kashif Rasul and Roland Vollgraf “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms” In arXiv preprint arXiv:1708.07747, 2017
- [19] Vardan Papyan “Measurements of three-level hierarchical structure in the outliers in the spectrum of deepnet hessians” In arXiv preprint arXiv:1901.08244, 2019 URL: https://arxiv.org/pdf/1901.08244.pdf
- [20] Leslie N. Smith and Nicholay Topin “Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates”, 2018 arXiv:1708.07120 [cs.LG]
Appendix A Intermediate Layer Analysis
In this section, we provide greater details on how the various conditions are computed from the flattened post-activation vectors after they have been randomly sampled (if they have been randomly sampled at all). Specifically, from these post-activation vectors, we first compute four preliminary quantities for each layer , which we will use later to calculate the metrics:
-
1.
-th layer global mean: ,
-
2.
-th layer class means: ,
-
3.
-th layer within-class covariance: ,
-
4.
-th layer between-class covariance: ,
From these quantities, we compute the following for each of the hidden layers across the entire training set, following the general outline provided by [7]. Importantly, we do not track , as it does not yield any meaningfully intuitive insights in the context of intermediate layer analysis:
Intra-Class Variance Collapse:
Here denotes the pseudoinverse calculated with singular value decomposition (SVD). Ignoring the first term, the variation becomes negligible as the weights approach their class means; thus, the vanishing of this quantity implies the vanishing of intra-class variance in the intermediate activation maps. This quantity is a more precise version of the one introduced in [7].
Convergence to Simplex ETF: The first quantity, ”Equal Norms”, is
As this quantity converges to zero, the coefficients of variation of class means similarly vanish, implying that the class-means become equinormal. The second quantity, ”Maximal Angles”, is
The first component in the average denotes , i.e. the angle between the average activation map of class and that of class in layer . Thus this represents the average difference between these angles and , and therefore the convergence to zero corresponds to maximum separation for globally centered vectors. Together, these terms represent convergence of the class means to a Simplex ETF.
Simplification to Nearest Class-Center:
Here is the indicator function. This quantity represents the proportion of times that the entire network disagrees with the result that would have been obtained by simply taking the nearest class mean for an activation map in the th layer. As this term goes to zero, it implies that the classifier’s behavior simplifies to a nearest class-mean decision rule. Importantly, as this quantity vanishes in intermediate layers, it implies that the features necessary for the classifier to correctly classify
Appendix B Tanh Activations
We present the results for each of the conditions for the various architectures with Tanh activation functions trained to TPT on the various datasets in Figure 9 to Figure 12.




Appendix C LeakyReLU Activations
We present the results for each of the conditions for the various architectures with LeakyReLU activation functions trained to TPT on the various datasets in Figure 9 to Figure 12.