NetFlick: Adversarial Flickering Attacks on Deep Learning based Video Compression
Abstract
Video compression plays a significant role in IoT devices for the efficient transport of visual data while satisfying all underlying bandwidth constraints. Deep learning-based video compression methods are rapidly replacing traditional algorithms and providing state-of-the-art results on edge devices. However, recently developed adversarial attacks demonstrate that digitally crafted perturbations can break the Rate-Distortion relationship of video compression. In this work, we present a real-world LED attack to target video compression frameworks. Our physically realizable attack, dubbed NetFlick, can degrade the spatio-temporal correlation between successive frames by injecting flickering temporal perturbations. In addition, we propose universal perturbations that can downgrade performance of incoming video without prior knowledge of the contents. Experimental results demonstrate that NetFlick can successfully deteriorate the performance of video compression frameworks in both digital- and physical-settings and can be further extended to attack downstream video classification networks.
1 Introduction
Deep Neural Networks (DNNs) are utilized for a myriad of media-related tasks, such as video and image classification Carreira & Zisserman (2017); Feichtenhofer et al. (2019) and audio transcription Gupta et al. (2014). Over the past years, DNNs have evolved in performance, but several works have shown their susceptibility to adversarial perturbations. Initial works Szegedy et al. (2013); Carlini & Wagner (2017) in this field have shown that image classification systems can be attacked with carefully crafted and imperceptible adversarial additions to the inputs. Furthermore, physical adversarial examples such as adversarial patches Eykholt et al. (2018); Chen et al. (2019), have been utilized to disrupt real-world image classification models deployed in autonomous cars.
For the success of media-related tasks, video compression plays a significant role in minimizing redundancy for video content delivery services, e.g., video surveillance Wang et al. (2018), AR/VR Jang et al. (2019), remote surgery Hassan et al. (2019), etc. Video compression typically follows R-D optimization that minimizes the distortion (D) at a given bit rate (), where is the available bit rate budget. With this optimal trade-off between video quality and bit rate, video streaming and classification systems can handle four-step workflows: (1) Input data from a front-end video sources (camera) (2) Video encoder to compress data into a bitstream for communication to the final destination (3) Video decoder to decompress bitstream back into video format (4) Downstream services (streaming and classification). Recently, DNN-based video compression Lu et al. (2019) has been explored by Moving Picture Experts Group (MPEG) for adoption in the next-generation of video delivery systems MPEG (2023) due to its higher performance than conventional codecs Sullivan et al. (2012). However, Chang et al. (2023) have shown that DNN-based video compression is vulnerable to imperceptible adversarial perturbations which when added to digital input video frames, can manipulate the R-D relationship. When considering video compression, studies that realize attacks in the physical world have not yet been investigated.
In this work, we present a physical adversarial attack- NetFlick as a new threat to video compression systems in the real-world. We find that the carefully crafted flickering effect of NetFlick using WiFi-controlled RGB LED light bulb, can severely threaten video compression efficiency. In summary, our contributions are:
-
•
We propose NetFlick, a novel physical attack to video compression systems, relying on adversarial flickering perturbations via a smart RGB LED light bulb.
-
•
We evaluate the NetFlick attack scheme on several video compression and downstream video classification frameworks to highlight its effectiveness.
-
•
We present online and offline attack schemes that both heavily degrade compression and classification, alongside a physical framework to realize NetFlick in the real world.
2 Preliminaries
2.1 Deep Learning-based Video Compression
Video compression techniques focus on predicting the temporal relationships between frames in order to minimize the amount of data that needs to be transmitted. The encoder generates a stream of bits that conform to a specific channel standard, which is then sent to the decoder. The decoder then uses this stream of bits to reconstruct the compressed video. Over the past few decades, many video compression standards have been introduced, such as VP8 Bankoski et al. (2011), H.264 Wiegand et al. (2003) and H.265 Sullivan et al. (2012). Traditionally, techniques for reducing the spatial and temporal redundancies in video sequences relied on manually crafted algorithms. Recently, the use of DNNs in video compression frameworks, such as those proposed by Lu et al. (2019); Hu et al. (2021); Yang et al. (2020), has gained significant attention due to its superior performance. This relies on three main design components: (1) motion estimation network for predicting the temporal motion, (2) motion compensation network to generate the predicted frame, and (3) auto-encoder based network for compressing the motion and residual data into bitstream.
2.2 Adversarial Attacks
Several existing studies Szegedy et al. (2013); Carlini & Wagner (2017); Moosavi-Dezfooli et al. (2017); Shamsabadi et al. (2020); Qiu et al. (2020); Hussain et al. (2021); Pony et al. (2021) have demonstrated the vulnerability of DL based-image and video classification models to adversarial attacks. These attacks can be either digital Szegedy et al. (2013); Moosavi-Dezfooli et al. (2017) or physical Chen et al. (2019); Lovisotto et al. (2021) depending on their feasibility in the real world. To be specific, Chen et al. (2019) printed out perturbed traffic signs and pasted them onto victim traffic sign boards to conduct physical attacks on traffic sign recognition systems. Lovisotto et al. (2021) projected adversarially crafted physical perturbations onto real-world objects using a projector. Recently, Chang et al. (2023) demonstrated the first adversarial attacks on video compression to manipulate the R-D relationship in a digital setting. However, studies on the effectiveness of physical adversarial attacks to video compression have not yet been conducted.
3 Methodology
3.1 Victim Models
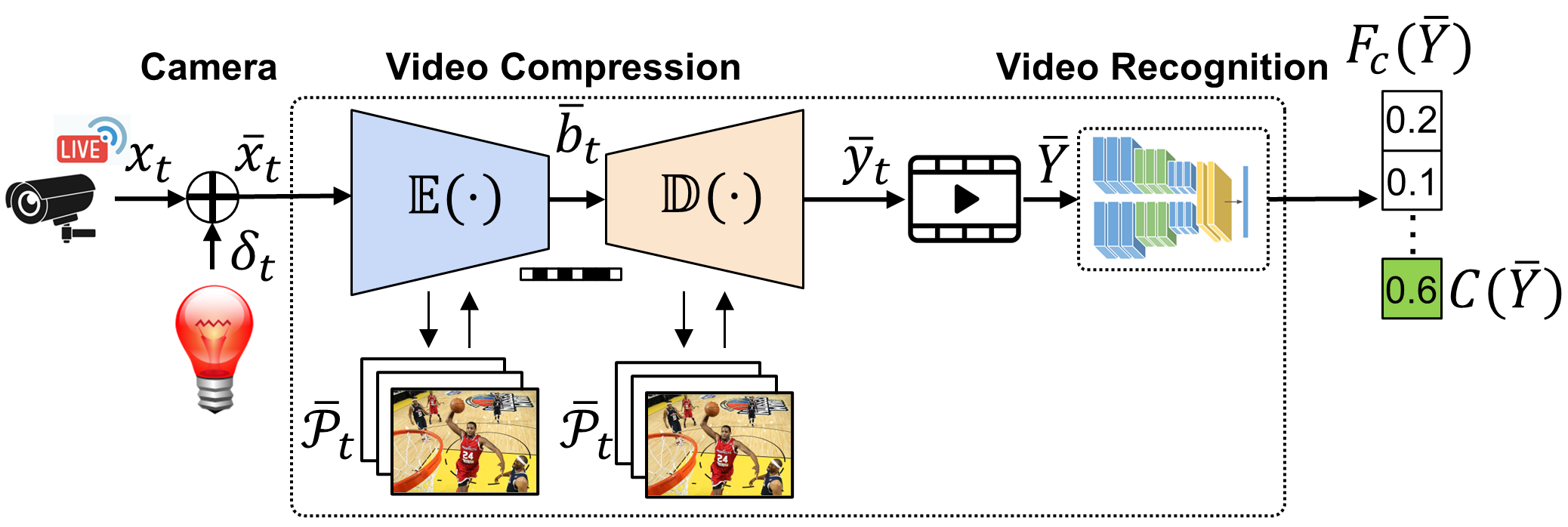
To demonstrate the effectiveness of the proposed NetFlick attack on video compression, we choose state-of-the-art models that employ temporal prediction to minimize the difference between a previously decoded video frame and the current video frame. Let denote a video clip containing consecutive frames, where is the frame at a time step which has rows, columns, and color channels. The goal of a victim DL-based video compression model is to efficiently remove the spatio-temporal information within the -th group of pictures (GOP), where and is the total number of frames in the GOP. Each frame is efficiently represented by coding a difference from a reference frame, rather than repeatedly coding each individual frame.
Accordingly, we formulate the video encoder as a function that compresses the current frame into a bitstream according to a compression rate and reference frames which are previously compressed. Here where is the output of the decoder at a certain time step. Note that since the first frame, dubbed the I-frame, is coded independently using DL-based image compression. Video decoder can be formulated as a function that reconstructs the decoded frame from the bitstream using the reference frames at a given compression rate . Optionally, the downstream video classification service receives as input the decoded frames from the video compression pipeline.
 |
 |
| (a) | (b) |
3.2 Threat Model
Attack Goal: IoT devices such as surveillance cameras are equipped with a microprocessor for video compression. NetFlick attack aims to create physical adversarial perturbations using LED bulb flicker to target neural video compression frameworks that are optionally followed by video classification models. While prior work Pony et al. (2021) has shown adversarially crafted flickering light to be an effective attack on video classification, they do not consider any video compression framework in their threat model. We extend this work by formulating the first physically realizable attack to compromise both the video compression and video classification performance using the attack objective described in Section 3.3 and Section 3.4.
Attack Scenarios: We consider two attack scenarios- online and offline. In an offline attack setting, we assume that the adversary can arbitrarily inject perturbations into the target frame by an RGB LED bulb. In an online attack setting, the adversary performs untargeted attack using an RGB LED bulb to negatively impact the video compression performance of an IoT device located in the same room. Specifically, the attacker installs a WiFi-controlled RGB LED bulb in a room to interfere with a camera of a victim device situated in the same room, by projecting adversarially crafted light onto it when a person streams. An overview of the NetFlick framework to video compression modules is presented in Figure 1(a), along with corresponding inputs, outputs and the perturbation.
Adversary’s Capabilities: For offline attacks, we assume a white-box attack scenario where the architecture and weights of the video compression model are known to adversary. This is a realistic assumption since video compression models are standardized by various organizations, e.g., ISO/IEC and MPEG, and are open-source to the community. However, in reality, it is difficult for attackers to fully grasp the structure and all parameters of the video compression model and classification model. Thus, we consider a black-box attack scenario for online attacks, i.e. the adversary does not have knowledge about the architecture or parameters of the victim DNN models. In addition, we assume that the adversary has access to a public dataset to train the online attack.
3.3 Offline Attacks
Adversarial loss. Let denote flickering perturbations for a given video . is designed to be spatial-constant on the color channels, so can be represented by three scalars. We denote the resulting adversarial video by which consists of adversarial frames . Upon receiving the adversarial input , the video encoder outputs an adversarial bitstream using perturbed reference frames stored in the the buffer . Finally, the video decoder restores the adversarial decoded frame from the perturbed bitstream . The objective of our attack is to find that can simultaneously target R and D to increase the bit rate and video distortion as follows:
| (1) |
where is the perturbation for the -th GOP.
After decoding the adversarial video, the back-end user may use a video classification as the target downstream task. Let denote a discriminant function that outputs a probability distribution over a set . is the probability that belongs to a specific class . Then, the video classifier maps an adversarial video to the class with the maximum probability. Thus, the adversarial loss for the untargeted and targeted attacks can be obtained from
| (2) |
Undetectability Constraint. We incorporate two regularization terms () proposed by Pony et al. (2021) to craft the imperceptible flickering perturbations, where denotes the magnitude of perturbations, and is the amount of change in flickering perturbations between adjacent frames. We obtain each regularization term as follows:
| (3) |
where is a Tensor p-norm defined in Pony et al. (2021). can be obtained by , where a permutation function produces a cyclic temporal shift of the original perturbation by an offset . We find the second order temporal derivative from .
Objective Function. In the offline attack scenario, injecting the adversarial perturbations is not latency bound. The adversary can therefore formulate the below adversarial function to minimize the adversarial loss:
|
|
(4) |
where adjusts the scale of the two loss functions. determines the importance of and . To ensure the injected noise is imperceptible to humans, the norm of the perturbation is upper bounded by a pre-defined small value .
3.4 Online Attacks
For online attack settings, we assume that the adversary does not have access to any user data, meaning that a per-video perturbation cannot be formed. Therefore, the adversary may not be able to align the flickering perturbations with the desired video sequences. To address this challenge, we follow RoVISQ Chang et al. (2023) to craft universal perturbation that has input-invariant characteristics using the permutation function . We also set the temporal length of the perturbation to the GOP size (). Considering a black-box attack scenario, we demonstrate the extent to which our universal perturbations trained on a surrogate open-source video compression model, are transferable to unseen models and architectures. These universal perturbations are trained to minimize the adversarial loss in Equation 4 using a publicly available training dataset.
4 Attack Evaluation
4.1 Evaluation Setup
Victim Model We evaluate our attacks on the state-of-the-art video compression model DVC Lu et al. (2019). In a video compression pipeline, the first video frame is always encoded using DNN-based image compression Liu et al. (2020). Video quality is measured as peak signal-to-noise ratio (PSNR) and the bit-rate is calculated by bits per pixel (Bpp). For downstream video classification, we further extend our attack to three state-of-the-art video classification models, specifically I3D Carreira & Zisserman (2017), SlowFast Feichtenhofer et al. (2019), and TPN Yang et al. (2020).
Dataset We use the Vimeo-90K dataset for training the victim video compression model. We set the GOP size to 10 following prior work Lu et al. (2019). NetFlick is evaluated on the hand gesture recognition dataset 20BN-JESTER (Jester) Materzynska et al. (2019). We split the Jester dataset into train, validation, and test set in the ratio 8:1:1. We set our adversarial perturbation bound to by following prior attack proposed by Pony et al. (2021).
4.2 Experimental Results
Video Compression. Figure 2 shows the PSNR-based R-D performance evaluated on the Jester dataset. We change the values of to analyze how the attack performance is affected by the norm of the flickering perturbations. Each point in the Figure 2 represents the result (PSNR, Bpp) of video compression according to a total of four values (). We observe that the attack causes a larger drop in both PSNR and Bpp for smaller values of . This is because the compression rate decreases as increases, so that the video compression model encodes less information in the current frame. Furthermore, the attack is more effective because there is less loss to the perturbations present in the frame. Specifically, our attack increases Bpp by up to 2.23 and results in distortion up to 25.81dB. In addition, we compare our attacks with uniformly sampled noise . Injecting random noise to videos can only achieve -10.47dB and 1.6 on average. When applying our online perturbations to unseen models (black-box attack), the average PSNR drop and Bpp increase are -13.01dB and 2.34 on average.
 |
 |
 |
 |
| (a) | (b) | (c) | (d) |
|
Type | Dataset | Attack | Surrogate | ASR (%) | ACC (%) | |||
|---|---|---|---|---|---|---|---|---|---|
| SlowFast Feichtenhofer et al. (2019) | T | Jester | 0.2 | Offline | - | 92.6 | 89.5 | ||
| U | Offline | - | 96.3 | ||||||
| U | Online | TPN | 83.3 | ||||||
| TPN Yang et al. (2020) | T | Jester | 0.2 | Offline | - | 93.5 | 90.5 | ||
| U | Offline | - | 97.2 | ||||||
| U | Online | I3D | 86.1 | ||||||
| I3D Carreira & Zisserman (2017) | T | Jester | 0.2 | Offline | - | 95.3 | 91.2 | ||
| U | Offline | - | 98.1 | ||||||
| U | Online | SlowFast | 85.1 |
 |
 |
 |
| (a) | (b) | (c) |
 |
 |
| (a) | (b) |
Downstream Video Classification. We evaluate the performance of offline and online attacks respectively, when the back-end user queries the video classifiers for analysis. We measure the attack success rate (ASR) by counting misclassified test videos for the untargeted attack. For the targeted attack, the success rate is the portion of the sample mapped to the class the adversary wants. We summarizes the ASR of NetFlick on Jester dataset in Table 1. In the offline attack settings, we obtain over 90 ASR. We also consider an online attack scenario, where the video sequences continuously captured by a camera are classified in real-time. Even in such real-time scenarios, our online attacks that inject universal perturbations into the video are highly effective with 86.1 ASR.
Convergence Process. Figure 3 shows how our flickering perturbations converge to the optimization point considering several terms. We can see that the adversarial perturbation drastically shifts the starting point(Initial BPP, PSNR and Probability) of the optimization function to a path that significantly lowers the R-D performance and then stops to reflect the regularization terminals.
4.3 Real-world Deployment
We test NetFlick in the real-world using a Kasa KL130 Smart Bulb Kasa (2023), which supports a wide array of colors and can be controlled by Wi-Fi. As shown in Figure 4 (a), we conduct an experimental design to physically test the effect of RGB bulb on video compression. Figure 4 (b) shows the visualization of the PSNR and Bpp of continuous video frames, where online attacks are performed by attackers from the 75th frame. Note that video compression encodes the first frame of each GOP to a higher Bpp than the others for the efficiency of spatio-temporal prediction. Comparing between the same frame types (e.g., I-frame, P-frame), we observe that NetFlick successfully degrades video quality and compression rates by up to 6.5dB and 1.6, respectively.
5 Conclusion and Future Works
We present NetFlick, the first physical adversarial attack to DNN-based video compression pipelines in the real-world. NetFlick utilizes a simple, yet effective, setup to project adversarially crafted flickering perturbations onto a victim IoT camera. We show NetFlick’s efficacy by evaluating the attack’s effects on both PSNR and Bpp when applied to a state-of-the-art video compression framework. Our results indicate that such an attack not only causes a significant drop in video compression performance, but also achieves high attack success rate on downstream video classifiers. Finally, we show the real-world applicability of our physical attack on video compression, by utilizing an RGB LED light bulb to project imperceptible adversarial patterns in real-time onto camera sensors capturing video. This work presents an important first step in a paradigm shift towards physical and realizable adversarial attacks on IoT video streaming devices. In future work, we aim to build a strong defense against NetFlick that will further secure the video compression and classification pipeline in IoT, ensuring security and robustness against attacks.
Acknowledgement
This work was supported by the U.S. Army/Department of Defense under award number W911NF2020267 and ARO MURI under award number W911NF-21-1-0322.
References
- Bankoski et al. (2011) Jim Bankoski, Paul Wilkins, and Yaowu Xu. Technical overview of vp8, an open source video codec for the web. In 2011 IEEE International Conference on Multimedia and Expo. IEEE, 2011.
- Carlini & Wagner (2017) Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In 2017 ieee symposium on security and privacy (sp). Ieee, 2017.
- Carreira & Zisserman (2017) Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6299–6308, 2017.
- Chang et al. (2023) Jung-Woo Chang, Mojan Javaheripi, Seira Hidano, and Farinaz Koushanfar. Rovisq: Reduction of video service quality via adversarial attacks on deep learning-based video compression. The 2023 Network and Distributed System Security Symposium (NDSS’23), 2023.
- Chen et al. (2019) Shang-Tse Chen, Cory Cornelius, Jason Martin, and Duen Horng Chau. Shapeshifter: Robust physical adversarial attack on faster r-cnn object detector. In Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2018, Dublin, Ireland, September 10–14, 2018, Proceedings, Part I 18. Springer, 2019.
- Eykholt et al. (2018) Kevin Eykholt, Ivan Evtimov, Earlence Fernandes, Bo Li, Amir Rahmati, Chaowei Xiao, Atul Prakash, Tadayoshi Kohno, and Dawn Song. Robust physical-world attacks on deep learning visual classification. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1625–1634, 2018.
- Feichtenhofer et al. (2019) Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF international conference on computer vision, 2019.
- Gupta et al. (2014) Vishwa Gupta, Patrick Kenny, Pierre Ouellet, and Themos Stafylakis. I-vector-based speaker adaptation of deep neural networks for french broadcast audio transcription. In 2014 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2014.
- Hassan et al. (2019) Ali Hassan, Mubeen Ghafoor, Syed Ali Tariq, Tehseen Zia, and Waqas Ahmad. High efficiency video coding (hevc)–based surgical telementoring system using shallow convolutional neural network. Journal of Digital Imaging, 2019.
- Hu et al. (2021) Zhihao Hu, Guo Lu, and Dong Xu. Fvc: A new framework towards deep video compression in feature space. In CVPR, pp. 1502–1511, June 2021.
- Hussain et al. (2021) Shehzeen Hussain, Paarth Neekhara, Malhar Jere, Farinaz Koushanfar, and Julian McAuley. Adversarial deepfakes: Evaluating vulnerability of deepfake detectors to adversarial examples. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), January 2021.
- Jang et al. (2019) Euee S Jang, Marius Preda, Khaled Mammou, Alexis M Tourapis, Jungsun Kim, Danillo B Graziosi, Sungryeul Rhyu, and Madhukar Budagavi. Video-based point-cloud-compression standard in mpeg: From evidence collection to committee draft [standards in a nutshell]. IEEE Signal Processing Magazine, 2019.
- Kasa (2023) Kasa. https://www.kasasmart.com/us/products/smart-lighting/kasa-smart-light-bulb-multicolor-kl130. 2023.
- Liu et al. (2020) Jiaheng Liu, Guo Lu, Zhihao Hu, and Dong Xu. A unified end-to-end framework for efficient deep image compression. arXiv preprint arXiv:2002.03370, 2020.
- Lovisotto et al. (2021) Giulio Lovisotto, Henry Turner, Ivo Sluganovic, Martin Strohmeier, and Ivan Martinovic. Slap: Improving physical adversarial examples with short-lived adversarial perturbations. USENIX, 2021.
- Lu et al. (2019) Guo Lu, Wanli Ouyang, Dong Xu, Xiaoyun Zhang, Chunlei Cai, and Zhiyong Gao. Dvc: An end-to-end deep video compression framework. In CVPR, June 2019.
- Materzynska et al. (2019) Joanna Materzynska, Guillaume Berger, Ingo Bax, and Roland Memisevic. The jester dataset: A large-scale video dataset of human gestures. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, pp. 0–0, 2019.
- Moosavi-Dezfooli et al. (2017) Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, Omar Fawzi, and Pascal Frossard. Universal adversarial perturbations. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1765–1773, 2017.
- MPEG (2023) MPEG. Explorations: Neural network-based video compression. https://www.mpeg.org/standards/Explorations/36/. 2023.
- Pony et al. (2021) Roi Pony, Itay Naeh, and Shie Mannor. Over-the-air adversarial flickering attacks against video recognition networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 515–524, 2021.
- Qiu et al. (2020) Haonan Qiu, Chaowei Xiao, Lei Yang, Xinchen Yan, Honglak Lee, and Bo Li. Semanticadv: Generating adversarial examples via attribute-conditioned image editing. In European Conference on Computer Vision, pp. 19–37. Springer, 2020.
- Shamsabadi et al. (2020) Ali Shahin Shamsabadi, Ricardo Sanchez-Matilla, and Andrea Cavallaro. Colorfool: Semantic adversarial colorization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1151–1160, 2020.
- Sullivan et al. (2012) Gary J Sullivan, Jens-Rainer Ohm, Woo-Jin Han, and Thomas Wiegand. Overview of the high efficiency video coding (hevc) standard. IEEE Transactions on circuits and systems for video technology, 2012.
- Szegedy et al. (2013) Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199, 2013.
- Wang et al. (2018) Gang Wang, Bo Li, Yongfei Zhang, and Jinhui Yang. Background modeling and referencing for moving cameras-captured surveillance video coding in hevc. IEEE Transactions on Multimedia, 2018.
- Wiegand et al. (2003) Thomas Wiegand, Gary J Sullivan, Gisle Bjontegaard, and Ajay Luthra. Overview of the h. 264/avc video coding standard. IEEE Transactions on circuits and systems for video technology, 13(7), 2003.
- Yang et al. (2020) Ren Yang, Fabian Mentzer, Luc Van Gool, and Radu Timofte. Learning for video compression with hierarchical quality and recurrent enhancement. In CVPR, June 2020.