Nerfels: Renderable Neural Codes for Improved Camera Pose Estimation
Abstract
This paper presents a framework that combines traditional keypoint-based camera pose optimization with an invertible neural rendering mechanism. Our proposed 3D scene representation, Nerfels, is locally dense yet globally sparse. As opposed to existing invertible neural rendering systems which overfit a model to the entire scene, we adopt a feature-driven approach for representing scene-agnostic, local 3D patches with renderable codes. By modelling a scene only where local features are detected, our framework effectively generalizes to unseen local regions in the scene via an optimizable code conditioning mechanism in the neural renderer, all while maintaining the low memory footprint of a sparse 3D map representation. Our model can be incorporated to existing state-of-the-art hand-crafted and learned local feature pose estimators, yielding improved performance when evaluating on ScanNet for wide camera baseline scenarios.
1 Introduction
The choice of map representation used in Visual Simultaneous Localization and Mapping (Visual SLAM), Structure-from-Motion (SfM) and Visual Localization systems is paramount as it effects the accuracy and power consumption of the system [7]. Sparse feature-based approaches [35, 3, 32] detect feature points in images which are matched and triangulated across multiple images to form 3D maps. These sparse representations are lightweight and can be effectively used in low power systems like robotics and augmented reality. At the heart of sparse representations is a geometric (also known as indirect) reprojection error, used to optimise camera poses.
In contrast, direct methods work with the raw pixel information[34]. Dense-direct methods exploit all the information in the image, even from areas where gradients are small; thus, they can outperform feature-based methods in scenes with poor texture, defocus, and motion blur [7]. These methods use a photometric alignment objective function similar that used in the well-known Lucas Kanade optical flow algorithm [29]. Though dense-direct methods can add robustness where sparse feature-based methods struggle, they require good initial solution. This limits their performance in wide-baseline localization where a good initialization is difficult to obtain. Additionally, representing the scene densely results in a larger memory footprint of the map, which can lead to higher power consumption for embedded localization systems[33]. Thus deciding on the density of the map representation for SLAM and SfM systems can result in trading off various characteristics of accuracy versus power consumption.
We focus our work at the intersection of sparse feature based approaches and dense image alignment approaches by representing the scene in a globally sparse but locally dense manner. We aim to reap the benefits of a lightweight, sparse model that doesn’t require good pose initialisation, whilst using the power of generative models that leverage image measurements to constrain the pose estimation. Our approach is inspired by surface elements, also known as Surfels [38], which are point primitives that model scene attributes without explicit connectivity between elements. Surfels are used to efficiently render complex geometric shapes by modelling the scene locally as a small circular plane, and have been used in SLAM systems such as ElasticFusion [51]. In such works, the scene is modelled densely by many Surfels: each individual Surfel models a very small portion of the scene (i.e. one Surfel per pixel observed). An interesting approach might be to use a sparse set of Surfels with a larger extent, and integrate them into pose estimation. However, as the baseline between cameras increases, the local planarity assumption weakens for non-planar scenes, and a simple planar representation does not accurately explain the 3D structure (demonstrated experimentally in 6.3).
Alternatively, neural rendering offers the promise of novel view rendering for arbitrary 3D scenes. Methods such as NeRF [31] can generate high quality, high resolution images for a limited scale of scenes given enough compute and training views. Code conditioned neural rendering presents an attractive way to train on different scenes and learn generic representations that can work on related but unseen 3D data. Related approaches demonstrate the use of effective code-conditioning to learn re-usable priors of the geometry and appearance [44, 41]. Follow up work has shown that one can additionally invert such neural rendering approaches to optimise over the camera pose. However, rendering the scene densely for camera pose estimation can be computationally expensive. One such approach, iNeRF [27], shows that guiding the rendering to occur near local features can significantly improve run-time. This begs the question of whether it is necessary to keep a dense representation of the scene for pose estimation with neural renderers, or to use a more sparse representation with a lower memory footprint.
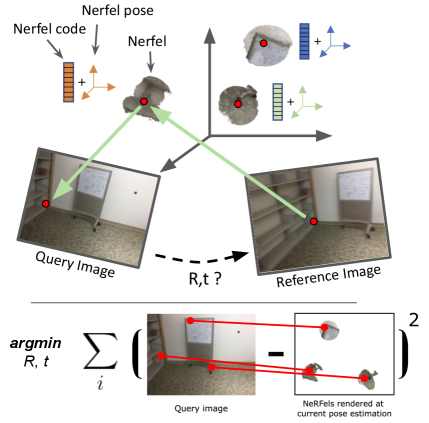
To this end, we propose Nerfels, a hybrid sparse and dense 3D representation designed for pose estimation that is inspired by neural rendering approaches like NeRF, and locally dense point primitives such as Surfels. Nerfels use a code conditioned neural rendering network to represent the local 3D sphere around a sparse 3D keypoint, resulting in a locally dense yet globally sparse 3D scene representation. The use of code conditioning allows each Nerfel to share memory and 3D priors though a single neural network. Each Nerfel has a local pose in the global coordinate frame, which can be explicitly optimized to result in the best rendering across different views. Nerfels are capable of rendering RGB patches around each 3D keypoint into arbitrary views of the 3D scene, which can be used as an additional constraint to a standard sparse 3D point cloud SLAM or SfM pipeline. We believe that the Nerfels representation is an effective compromise between sparse and dense representations for embedded SLAM and SfM applications that require high accuracy pose estimation with a small memory footprint for their 3D representation.
Contributions. Our contributions are twofold: (1) We present Nerfels, a novel representation of local shape and appearance of 3D sparse maps that enhances keypoints to be locally renderable; (2) An end-to-end camera pose estimation system using Nerfels through joint optimisation of reprojection error + photometric error, resulting in improvement of wide baseline pose estimation for both hand-crafted and learned local features.
2 Related Work
Sparse SLAM and SfM There is a large body of work that tackle camera pose by simultaneously estimating a sparse scene structure from keypoints detected in 2D images. Well-known SfM and SLAM works [23, 9, 1, 32] rely on triangulated 3D interest points to build a sparse structure of the scene using handcrafted local features [16, 28]. Neural networks have been used to learn local features [10, 11, 42] that are more robust to challenging scene changes such as lighting and viewpoint change. Our work is heavily based on such pose estimation approaches. In challenging pose estimation scenarios however, the accuracy of such approaches can degrade when few matches or inliers exist between the map and the image to be localized. We argue that by leveraging more local image information around the matched keypoints, we can improve pose accuracy.
Semi-Dense and Dense SLAM Early image registration work [29] used image gradients to align multiple images. More recently, SLAM approaches use direct image alignment [34, 14, 13] to jointly estimate a dense or semi-dense scene representation in a real-time pose estimation framework. Such approaches [51, 19] incrementally build a map from multiple observations that is able to render physically predictive representations of the scene. More recently, dense neural pose estimation approaches learn a lower dimensional code [6], basis function [47], or cost volumes [53] for the depth of each keyframe and optimise the depth jointly with the camera poses.
Neural Scene Representation Structure-less approaches [21, 5, 49] use a neural network to directly estimate camera poses without modelling a map. The localization of cameras is performed through a directly learned mapping from images to poses. More recent works [18, 4] similarly do not model 3D geometry but instead model a map through neural embeddings. Recent advances in implicit representation learning have demonstrated the power of coordinate-based multilayer perceptrons (MLPs) to map known world coordinates to signed distance fields [36, 20], occupancy grids [30] or RGB values [31, 48]. Such systems are capable of modelling physically predictive representations of 3D scenes. In one such work, NeRF, the pose of each camera is computed offline using COLMAP [43]. Follow up works [27, 26, 50] relax this constraint by optimising both the implicit function scene structure and the camera pose. These works represent the full scene with a single implicit function. The work of iMAP [45] builds a real-time RGB-D slam system using an implicit neural renderer. We extend this work by applying a similar invertible NeRF framework to multiple smaller NeRF fields simultaneously. Rather than train independent weights for each NeRF field, we use a code conditioning mechanism in an auto-decoder framework, similar to works such as DeepSDF and others [36, 45, 44, 41]. This helps to minimise the memory cost of the neural scene representation.
3 Nerfels
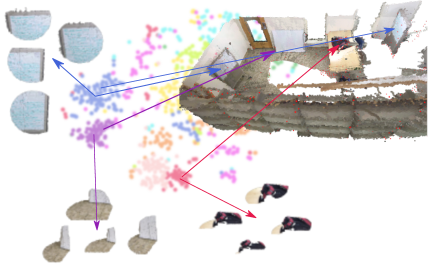
We define a Nerfel as latent code , to be a compact representation of a continuous radiance field contained in a 3D sphere with radius . In Figure 2, we show an example of Nerfels mind from a synthetic scene. Obtaining a projection of an individual Nerfels’ radiance field to an image canvas, , is obtained using a mapping function which we call neural rendering decoder and a given pose that the sphere is viewed from: . In addition, we define to be the set of image coordinates where the integrated rays over image have an alpha . The orientation of a Nerfel is defined by its own canonical coordinate system and isn’t bound to any particular global coordinate frame. This coordinate system is chosen so the Nerfels’ center of mass is located at the origin, and the orientation is derived by taking the Nerfels’ average normal vector and arbitrarily choosing an vector. Given single 3D point at the Nerfels’ origin, the Nerfels’ derived coordinate system, the camera poses in which the Nerfel is observed and the camera intrinsics, we can compute a set of canonical poses for a single Nerfel.

For illustration, the shelf looking Nerfel (top left Nerfel) in Figure 2 was extracted from a specific shelf of a synthetic frame after aligning the Nerfels’ pose to the shelf in the image. However, by changing that Nerfels’ pose it can also align to any similar looking shelf which share geometry and appearance. And thus, a Nerfel can act as a reusable component for describing parts of a scene; whilst one can think of a scene being sparsely described by a collection of Nerfels with a specific pose per Nerfel which aligns each one to that scene.
For the case of rendering a single Nerfel code, the decoder follows the rendering procedure outlined in [31]. In this procedure, a neural-network implicit function parameterised by maps the viewing pose together with a 3D coordinate location to an RGB value and density and is followed by a differentiable volumetric function that outputs the integrated RGB value along the viewing ray from the image canvas. In addition to the viewing direction and 3D location, our decoder also takes a code which is concatenated to the location positional encoding , where the viewing positional encodings are defined by [31, 46]. To ease notation we describe the process of rendering a single Nerfel code in a given pose by . We also define the operation of rendering multiple Nerfels as: where each Nerfel rendering provides an image coordinate set ; and the union of these sets is: . To resolve overlapping Nerfels when obtaining the RGB value in , one can compute the average RGB value of overlapping Nerfels, take a weighted average of Nerfels’ RGB and alpha projections or as done in this work arbitrarily select some Nerfels to proceed others (details in Section 6).
4 Mining Nerfels

We detail the process of mining Nerfel examples from a collection of scenes and how these are used to train a neural rendering decoder and a set of Nerfel codes. Specifically, we denote a set of Nerfel codes as and the decoder as . We note two important requirements on our set of codes and the coupled decoder. The first, every code should encode the associated 3D Nerfel shape, meaning the decoder should be able to render a Nerfel for any given pose, or conversely recover the code (Section 5.1) from any provided realisation of the code in an image. The latter, the given set of codes should encompass a broad variety of general 3D shapes that are detected with high probability by a given keypoint detector.
Nerfel Examples For mining a set of Nerfel examples we assume to have access to a collection of different scenes, where each scene has a set of RGB-D frames, , along with their ground-truth poses . In addition, we assume to have the intrinsic matrix which is unique for every scene. The process of collecting a set of Nerfel codes from a given scene is performed by first extracting keypoints in every image within the scene and running a process of retaining the keypoints that can be matched and triangulated between the frames. An example of a method that can extract such matches over a set of frames is COLMAP[43]. These matches can also be obtained by using the ground-truth poses and depth, as done in this work. The result of this process is a set of 3D keypoints with an additional dictionary of the indices of each keypoint’s frame. This representation allows us to sub-select a number of keypoints which appear in more than frames and are viewed from a wide variety of angles (selection of is discussed in Section 6). By knowing the 3D location of the remaining keypoints, we crop 2D regions around the keypoint within its observed frames and obtain a collection of patches for each Nerfel in a sequence. For each mined Nerfel, we store a set of image crops , where each crop has fixed dimensions . For each Nerfel with a set of image crops, poses are also extracted. Here, poses are set to be in a canonical coordinate frame so that a Nerfel becomes scene-agnostic.
Neural Rendering Decoder For constructing the neural rendering decoder we make use of neural implicit functions and a volumetric rendering technique discussed in Section 3. The implicit function is implemented by a MLP and is parameterised by while the Nerfel codes are initialised as . The implicit function parameters and the Nerfel codes are optimised as follows:
| (1) |
where is the NeRF[31] objective function modified with a code-condition mechanism described in Section 3. The RGB observations that are used in the optimisation procedure are the mined Nerfel crops together with the poses . We note that in the optimisation of Equation 1 a coarse to fine strategy is used; we refer the reader to [31] for further details. While we follow the MLP architecture from [31], the input to the implicit function is of dimension where positional encodings and the Nerfel code are concatenated before being fed to the implicit function. We note in Equation 1 the joint optimisation of the implicit function parameters and the set of codes . By allowing the Nerfel codes to be optimised jointly, similar Nerfels collected from the objects with similarities or partial spatial overlap are pulled together (see Figure 3). In the procedure of mining Nerfels, by adjusting the threshold , we can control the minimal number of image patches per Nerfel.
5 Nerfels for Pose Estimation
The following sections detail how Nerfels are leveraged for camera pose estimation. Figure 4 provides a high-level diagram of our Nerfel-based camera estimation pipeline.
5.1 Optimising Nerfel Codes
For an incoming reference image with detected keypoints, Nerfel codes are also extracted and associated with the extracted keypoints (In Figure 4 this is illustrated in 2). In section 4 we constructed a set of codes and a decoder in a process that is strongly coupled with the keypoints used to extract the Nerfels’ information for optimising the decoder. Following the work of [52] we perform an inverted optimisation using the decoder for recovering the Nerfel code and its canonical pose from an RGB measurement of a matched keypoint in the reference image. This optimisation objective is formulated as:
| (2) |
where is an image patch taken around a keypoint from a reference frame. We note that the recovered code may not be a member of the set of training codes .
For optimising Equation 2 we refer the reader to the pose parameterisation discussed in [52] where the pose is parameterised in exponential coordinates: to ensure the pose is a valid member. In practice, to improve convergence, we optimise Equation 2 a fixed number of times by sampling different initial poses on a sphere. The pose parameters are initialized by drawing , and the Nerfel code .
5.2 Joint PnP and Photometric Pose Optimisation
Given reference and query frames and respectively, we extract and match keypoints and . When formulating the PnP problem [25], we assume a model-based approach where the keypoints in the reference frame represent a map with sparse 3D reconstruction; this provides us with depth values associated with keypoints . Given the matched keypoints , and ’s Nerfel codes , we formulate the following optimization objective:
| (3) |
where is:
| (4) |
The operators and denote the perspective projection and unprojection operators respectively. The objective of Equation 4 is to recover the pose between a reference and a query frame (In Figure 4 this is illustrated in 3). The first component in this objective is the familiar re-projection error used in PnP, where the reference frame keypoints are projected to the query frame and the error is computed between the keypoints in image coordinates. The second component is a photometric error balanced with a regularisation term . The Nerfel codes c and their canonical pose in the reference frame are jointly rendered onto the query frame using the current pose estimate . The decoder is a neural network with a differentiable volumetric rendering, and hence recovering the pose from Equation 4 can be performed using gradient-descent with modern Autograd libraries [37].
6 Experiments
We evaluate our proposed method on a synthetic dataset using a simplified version of the method. This is followed by a real world dataset Scannet[8] evaluation with the full version of the method. When optimising the decoder, the available training data is RGB-D with ground truth poses. When evaluating, we use only RGB data with sparse depth for the reference image keypoints. For details regarding the network architecture used for the neural renderer decoder, training and evaluation settings refer to the supplementary material.
Hyperparameters For recovering the Nerfel codes when computing Equation 2 per Nerfel code, we sample pose initialisations on a sphere to maximise the probability of detecting the correct Nerfel pose . For each reference image, we limit the number of Nerfel codes to , due to the expensive nature of storing the decoder gradients for each Nerfel during the joint optimisation performed in Equation 4. For sub-selecting Nerfel codes, we use a similar strategy as done in [32] where we take a grid of , select the highest scoring keypoint in a grid cell and finally take the top scoring keypoints according to the amount of Nerfel limit. This procedure ensures Nerfels are well spaced out and land on a surface with a high chance of good fidelity when rendering, while avoiding the case where a Nerfel might occlude another Nerfel. For the real-world dataset, we set and for the synthetic one.
Runtime We consider our method to be model-based approach meaning we assume the Nerfel pose recovery discussed in Section 5.1 can be performed offline and we report the run-time of performing the joint optimisation (Section 5.2) to be (which is directly affected by the number of Nerfels used during the optimisation procedure). Note that due to the least square objective function, run-time can be further optimized using a second order solver such as Levenberg-Marquardt using packages such as Ceres Solver [2]. Additionally, because rendering occupies the majority of the compute time for our method, additional NeRF speed-up approaches such as [40, 15, 17] should significantly reduce run-time. We leave additional run-time optimisation for future work.
| Features | Matcher | Translation error (m) | Angle error (∘) | Translation error (m) | Angle error (∘) | Translation error (m) | Angle error (∘) |
|---|---|---|---|---|---|---|---|
| @0.25m | @0.25m | @0.5m | @0.5m | @1m | @1m | ||
| SIFT | NN + Ratio test | 0.0582 | 2.6863 | 0.0687 | 3.2767 | 0.0826 | 5.6018 |
| SIFT + Nerfels (Ours) | NN + Ratio test | 0.0568 | 2.1422 | 0.0628 | 2.2202 | 0.0717 | 2.8391 |
| \hdashline[3pt/3pt] D2Net | NN + Ratio test | 0.0565 | 1.5363 | 0.0626 | 1.7036 | 0.0786 | 2.4709 |
| D2Net + Nerfels (Ours) | NN + Ratio test | 0.0506 | 1.3034 | 0.0532 | 1.3737 | 0.0608 | 1.4878 |
| \hdashline[3pt/3pt] SP | Superglue | 0.0489 | 1.4317 | 0.0502 | 1.4669 | 0.0502 | 1.4669 |
| SP + Nerfels (Ours) | Superglue | 0.0389 | 1.0655 | 0.0389 | 1.0655 | 0.0389 | 1.0655 |
| \hdashline[3pt/3pt] Dense pixels | iNeRF | 0.1487 | 53.9162 | 0.2689 | 75.1078 | 0.4262 | 73.0027 |
| SP + Colour | Superglue | 0.0463 | 1.423 | 0.0535 | 1.6259 | 0.0547 | 1.6489 |
Error Metrics The errors we inspect are the translation error in metric scale and rotation error in degrees. For both of these error metrics, we examine the error in different cut-off thresholds, specifically: 0.25m, 0.5m and 1m of translation error.
6.1 Synthetic Results
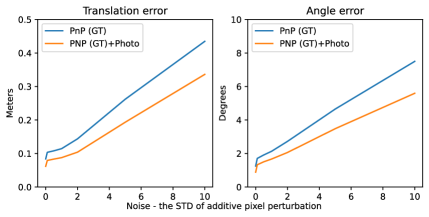
We use a synthetic dataset to motivate the joint optimisation procedure discussed in Section 5.2. To do so, we simplify the objective by replacing the neural rendering decoder in Equation 4 with a differentiable renderer that requires ground-truth depth for rendering a simulated Nerfel. This will bypass the neural rendering component which is required for recovering the Nerfel codes and re-rendering the Nerfel codes at different poses throughout the joint optimisation. By using the ground-truth depth we extract a simulated Nerfel, realised by a coloured point cloud, around each key-point from the reference frame. This means the Nerfels are extracted “on the fly” and there is no need to pre-train a decoder.
The Nerfels are rendered at each iteration using the PyTorch3D Pulsar renderer [39, 24] with the current pose estimation. For optimising Equation 4, we use Adam with a learning rate of , exponential decay of and the number of optimisation iterations performed was . The plots in Figure 5 show the results for this experiment. For this experiment we use SIFT [28] and a ground-truth matcher that uses the available ground-truth depth to provide the matches. The purpose of this experiment is to exemplify better robust behaviour of using the extracted Nerfels when the keypoints are not well localised. To do so noise is added to the ground-truth matches’ keypoints locations to simulate localization error from real-world matches. Figure 5 shows that when noise is added to the keypoints location, adding the photometric term to the optimisation (Equation 4) helps recover a more robust solution in case of inaccurate keypoint detection. This simulated experiment helps motivate how Nerfels are useful: Nerfels provide a boost to pose estimation accuracy that increases with more keypoint detector localization error.
6.2 Real-World Results

We evaluate our method on ScanNet[8] by selecting scenes and from those image pairs.
Comparison to Sparse Methods We select three off-the-shelf feature detectors for these experiments: SIFT[28], D2Net[11] and SuperPoint[10] (SP) as a baseline for adding the Nerfel component in the joint optimisation. A separate Nerfels network is trained for each scene as described in Section 4, resulting in 8 Nerfel models for each feature detector method, and 24 Nerfel models in total. These feature detectors provide a diverse assessment of classical and learned feature detectors. SIFT detects pixel accurate keypoints though provides few matches whilst learned methods, SuperPoint and D2Net, detect increased amount of keypoints though offer less pixel accurate keypoint with far more matches [12]. For feature matching of SIFT and D2Net we use nearest neighbor (NN) + ratio test as described in [28] with the ratio test values taken to be 0.7 and 0.9 respectively. For SuperPoint we use a recent state-of-the-art matcher Superglue[42] which was developed and evaluated to handle similar camera baseline cases with the same overlap ratio. For evaluating our Nerfel over each of the baselines we use Adam as the optimiser, a learning rate of , exponential decay of and the number of optimisation iterations were .
For each sparse matching method, we run two pose estimation experiments: one with and one without Nerfels. Inspecting Table 1, we note that adding the Nerfels via the joint optimisation improves results across all baselines. While D2Net baseline provides generally better results over the SIFT baseline, it is considered a less pixel accurate detector. Adding the Nerfels to D2Net provides a better relative performance vs. adding Nerfels to SIFT which in the 0.25m regime provides a modest improvement. Across all results the largest gains are seen when taking the error at a larger cut-off point (largest @). This improvement aligns well with the empirical results seen in the synthetic data and stems from the Nerfels ability to assist in cases where the error is large.
Comparison to iNerf A vanilla iNeRF[52] network was trained to capture an entire scene using the same network architecture and capacity that is used in our rendering decoder. iNerf as originally presented does not use depth information, but our method does. To make the comparison more fair, we we modify the iNeRF loss by adding a depth loss, similar to [45]. Accounting for our code conditioning mechanism, for a representative number of roughly codes at training time, and a 64 dimensional code, our Nerfel model capacity is higher than a Vanilla NeRF. By using a NeRF network to represent an entire scene we can then use iNeRF[52] for pose estimation. In comparison to our runtime, iNeRF runs at a .
For iNeRF, we generally saw that when less observations are provided in certain regions of a scene, pose estimation fails. This aligns well with how NeRF relies on dense sampling of radiance fields. On the contrary, our Nerfels by construction do not suffer from this issue, as the mining procedure enforces a dense radiance field when selecting keypoints for constructing Nerfel codes. Please refer to the supplementary material for qualitative results of our mined Nerfels and dense scene representation using a vanilla NeRF.
6.3 Ablation studies
Studying the joint optimisation We ran a study where the optimisation was initialised with the PnP result of SuperPoint+Superglue. The reprojection was turned off and only the Photometric component was used. When the initial pose was above 0.5m the optimisation failed in the majority of the cases. In the cases of below 0.25m partial success was noted with results of and . We conclude that the reprojection error is required to sufficiently provide a geometric constraint on Photometric term in all cases.
Naïve colour baseline To study the effect of importance in rendering fidelity we propose a naïve approach which samples the keypoint colour for the matching keypoints and performs the joint optimisation while using the colour value in the Photometric component instead of the Nerfels. The results are shown in Table 1 as “SP + Colour”. The empirical results indicate that when the pose initialisation is below the 0.25m this approach can improvement the vanilla PnP approach. However for pose initialisations above 0.5m performance degrades as the reference and query images might exhibit significant colour changes.
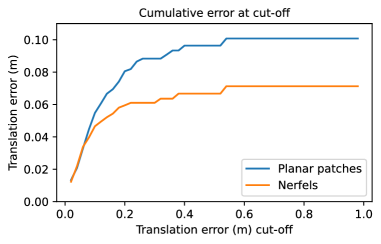
Nerfels vs. Planar patches The main strength of the Nerfel code is its ability to capture the 3D neighbourhood around a keypoint. We compare how the Nerfel code evaluates against planar patches sampled around a keypoint and re-rendered at the optimsation phase by assuming the patch’s normal is orthogonal to the camera. For incorporating the planar patches into the photometric term in Equation 4 we interpolate the pixel values given the projected patch. To highlight the benefits of the Nerfel code over planar patches, we re-select 100 test cases now with an overlap of . In addition, to faithfully compare planar patches vs. the 3D Nerfel spheres we by-pass optimising the code and codes’ pose and assume these were recovered. In Figure 7 we see a cumulative error plot where as the cut-off error increases the gap between using Nerfels vs. planar patches widens. This is due to Nerfels’ ability to render the rigid behaviour of the keypoints’ neighborhood in wider baseline cases as opposed to the planar patches (Qualitative examples shown in Figure 6).
7 Limitations
Our optimisation procedure on average runs at: . While providing an improvement over iNeRF, our method does not run in real-time when using a standard SGD optimiser (further discussed in Section 6). When optimising Equation 4 we use a photometric loss which is sensitive to illumination changes. We leave improvements on this matter to future work.
8 Conclusion
In this paper, we presented a framework for combining traditional geometric feature matching for pose estimation with local photometric alignment. The photometric alignment is performed using Nerfels, which use an underlying code-conditioned neural rendering mechanism. We verified experimentally that the additional constraints from the local photometric alignment improve pose estimation, especially in wide baseline scenarios. One key characteristic of this formulation is that by using a code-conditioned NeRF, we maintain the advantage of low-memory footprint maps, which is critical for applications like AR and Robotics, while gaining the advantages of a partially generative model. Additionally, relative to full scene neural rendering approaches, we reduce the required expressively of the neural renderer to local parts of the scene, enabling improved generalisation of the approach to unseen parts of the scene.
References
- [1] Sameer Agarwal, Yasutaka Furukawa, Noah Snavely, Ian Simon, Brian Curless, Steven M. Seitz, and Rick Szeliski. Building rome in a day. Communications of the ACM, 54:105–112, 2011.
- [2] Sameer Agarwal, Keir Mierle, and Others. Ceres solver. http://ceres-solver.org.
- [3] Sameer Agarwal, Noah Snavely, Steven M. Seitz, and Rick Szeliski. Bundle adjustment in the large. In ECCV, 2010.
- [4] Gil Avraham, Yan Zuo, Thanuja Dharmasiri, and Tom Drummond. Empnet: Neural localisation and mapping using embedded memory points. In IEEE International Conference on Computer Vision (ICCV), 2018.
- [5] Vassileios Balntas, Shuda Li, and V. Prisacariu. Relocnet: Continuous metric learning relocalisation using neural nets. In ECCV, 2018.
- [6] M Bloesch, J Czarnowski, R Clark, S Leutenegger, and AJ Davison. Codeslam—learning a compact, optimisable representation for dense visual slam. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2560–2568, 2018.
- [7] Cesar Cadena, Luca Carlone, Henry Carrillo, Yasir Latif, Davide Scaramuzza, José Neira, Ian Reid, and John J Leonard. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Transactions on robotics, 32(6):1309–1332, 2016.
- [8] Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017.
- [9] Andrew J. Davison, Ian D. Reid, Nicholas D. Molton, and Olivier Stasse. Monoslam: Real-time single camera slam. IEEE Transactions on Pattern Analysis and Machine Intelligence, 29(6):1052–1067, 2007.
- [10] Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 224–236, 2018.
- [11] Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Pollefeys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2-Net: A Trainable CNN for Joint Detection and Description of Local Features. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019.
- [12] Mihai Dusmanu, Johannes L Schönberger, and Marc Pollefeys. Multi-view optimization of local feature geometry. In European Conference on Computer Vision, pages 670–686. Springer, 2020.
- [13] Jakob Engel, V. Koltun, and D. Cremers. Direct sparse odometry. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40:611–625, 2018.
- [14] Jakob Engel, Thomas Schöps, and D. Cremers. Lsd-slam: Large-scale direct monocular slam. In ECCV, 2014.
- [15] Stephan J. Garbin, Marek Kowalski, Matthew Johnson, Jamie Shotton, and Julien P. C. Valentin. Fastnerf: High-fidelity neural rendering at 200fps. arXiv:2103.10380, 2021.
- [16] Chris Harris and Mike Stephens. A combined corner and edge detector. In Alvey vision conference, volume 15, pages 10–5244. Manchester, UK, 1988.
- [17] Peter Hedman, Pratul P. Srinivasan, Ben Mildenhall, Jonathan T. Barron, and Paul Debevec. Baking neural radiance fields for real-time view synthesis. ICCV, 2021.
- [18] João F. Henriques and Andrea Vedaldi. Mapnet: An allocentric spatial memory for mapping environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- [19] Peter Henry, Michael Krainin, Evan Herbst, Xiaofeng Ren, and Dieter Fox. Rgb-d mapping: Using kinect-style depth cameras for dense 3d modeling of indoor environments. The International Journal of Robotics Research, 2012.
- [20] Chiyu Max Jiang, Avneesh Sud, Ameesh Makadia, Jingwei Huang, Matthias Nießner, and Thomas Funkhouser. Local implicit grid representations for 3d scenes. In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2020.
- [21] Alex Kendall, M. Grimes, and R. Cipolla. Posenet: A convolutional network for real-time 6-dof camera relocalization. 2015 IEEE International Conference on Computer Vision (ICCV), pages 2938–2946, 2015.
- [22] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [23] Georg Klein and David Murray. Parallel tracking and mapping for small ar workspaces. In 2007 6th IEEE and ACM international symposium on mixed and augmented reality, pages 225–234. IEEE, 2007.
- [24] Christoph Lassner and Michael Zollhöfer. Pulsar: Efficient sphere-based neural rendering. arXiv:2004.07484, 2020.
- [25] Vincent Lepetit, Francesc Moreno-Noguer, and Pascal Fua. Epnp: An accurate o (n) solution to the pnp problem. International journal of computer vision, 81(2):155, 2009.
- [26] Chen-Hsuan Lin, Wei-Chiu Ma, Antonio Torralba, and Simon Lucey. Barf: Bundle-adjusting neural radiance fields. In IEEE International Conference on Computer Vision (ICCV), 2021.
- [27] Yen-Chen Lin, Peter R. Florence, J. T. Barron, Alberto Rodriguez, Phillip Isola, and Tsung-Yi Lin. inerf: Inverting neural radiance fields for pose estimation. ArXiv, abs/2012.05877, 2020.
- [28] David G Lowe. Distinctive image features from scale-invariant keypoints. International journal of computer vision, 60(2):91–110, 2004.
- [29] Bruce D. Lucas and Takeo Kanade. An iterative image registration technique with an application to stereo vision. In In IJCAI81, pages 674–679, 1981.
- [30] Lars M. Mescheder, Michael Oechsle, Michael Niemeyer, S. Nowozin, and Andreas Geiger. Occupancy networks: Learning 3d reconstruction in function space. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4455–4465, 2019.
- [31] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In European Conference on Computer Vision, pages 405–421. Springer, 2020.
- [32] Raul Mur-Artal, Jose Montiel, and Juan D Tardos. ORB-SLAM: a versatile and accurate monocular SLAM system. IEEE Transactions on Robotics, 2015.
- [33] Luigi Nardi, Bruno Bodin, M Zeeshan Zia, John Mawer, Andy Nisbet, Paul HJ Kelly, Andrew J Davison, Mikel Luján, Michael FP O’Boyle, Graham Riley, et al. Introducing slambench, a performance and accuracy benchmarking methodology for slam. In 2015 IEEE international conference on robotics and automation (ICRA), pages 5783–5790. IEEE, 2015.
- [34] Richard A. Newcombe, Steven Lovegrove, and Andrew J. Davison. Dtam: Dense tracking and mapping in real-time. In IEEE International Conference on Computer Vision (ICCV), 2011.
- [35] David Nistér, Oleg Naroditsky, and James Bergen. Visual odometry. pages 652–659, 2004.
- [36] Jeong Joon Park, Peter R. Florence, J. Straub, Richard A. Newcombe, and S. Lovegrove. Deepsdf: Learning continuous signed distance functions for shape representation. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 165–174, 2019.
- [37] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32:8026–8037, 2019.
- [38] H. Pfister, M. Zwicker, J. van Baar, and M. Gross. Surfels-surface elements as rendering primitives. In ACM Transactions on Graphics (Proc. ACM SIGGRAPH), pages 335–342, 7/2000 2000.
- [39] Nikhila Ravi, Jeremy Reizenstein, David Novotny, Taylor Gordon, Wan-Yen Lo, Justin Johnson, and Georgia Gkioxari. Accelerating 3d deep learning with pytorch3d. arXiv:2007.08501, 2020.
- [40] Christian Reiser, Songyou Peng, Yiyi Liao, and Andreas Geiger. Kilonerf: Speeding up neural radiance fields with thousands of tiny mlps. In International Conference on Computer Vision (ICCV), 2021.
- [41] Konstantinos Rematas, Ricardo Martin-Brualla, and Vittorio Ferrari. Sharf: Shape-conditioned radiance fields from a single view. volume abs/2102.08860, 2021.
- [42] Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4938–4947, 2020.
- [43] Johannes Lutz Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. In Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [44] Katja Schwarz, Yiyi Liao, Michael Niemeyer, and Andreas Geiger. Graf: Generative radiance fields for 3d-aware image synthesis. In Advances in Neural Information Processing Systems (NeurIPS), 2020.
- [45] Edgar Sucar, Shikun Liu, Joseph Ortiz, and Andrew Davison. iMAP: Implicit mapping and positioning in real-time. In arXiv preprint arXiv:2103.12352, 2021.
- [46] Matthew Tancik, Pratul P Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. arXiv preprint arXiv:2006.10739, 2020.
- [47] Chengzhou Tang and Ping Tan. BA-Net: Dense Bundle Adjustment Network. In ICLR, 2019.
- [48] Qianqian Wang, Zhicheng Wang, Kyle Genova, Pratul Srinivasan, Howard Zhou, Jonathan T. Barron, Ricardo Martin-Brualla, Noah Snavely, and Thomas Funkhouser. Ibrnet: Learning multi-view image-based rendering. In CVPR, 2021.
- [49] Sen Wang, Ronald Clark, Hongkai Wen, and Niki Trigoni. End-to-end, sequence-to-sequence probabilistic visual odometry through deep neural networks. In Journal of Robotics Research (IJRR), 2018.
- [50] Zirui Wang, Shangzhe Wu, Weidi Xie, Min Chen, and Victor Adrian Prisacariu. NeRF: Neural radiance fields without known camera parameters. arXiv preprint arXiv:2102.07064, 2021.
- [51] Thomas Whelan, Stefan Leutenegger, Renato Salas Moreno, Ben Glocker, and Andrew Davison. Elasticfusion: Dense slam without a pose graph. In Proceedings of Robotics: Science and Systems, Rome, Italy, July 2015.
- [52] Lin Yen-Chen, Pete Florence, Jonathan T Barron, Alberto Rodriguez, Phillip Isola, and Tsung-Yi Lin. inerf: Inverting neural radiance fields for pose estimation. arXiv preprint arXiv:2012.05877, 2020.
- [53] Huizhong Zhou, Benjamin Ummenhofer, and Thomas Brox. Deeptam: Deep tracking and mapping. In ECCV, 2018.
Appendix A Algorithm Outline
Appendix B Cumulative Error Curves
We provide cumulative error curves corresponding to the feature extractors from Table 1 (SIFT, D2Net, Superpoint). These curves add additional detail to the evaluation performed in the main paper, which selected operating points of 0.25, 0.5, and 1.0 meters along the x-axis. In each of the three cases, the addition of the photometric term into the optimisation provided by Nerfel rendering improves across all thresholds. Additionally, as the difficulty of the pose estimation increases, the gap widens.
 |
 |
 |
Appendix C Implementation Details
Network Architecture For constructing the neural rendering decoder, we follow a similar network architecture as done in [31] with the additional Nerfel code , concatenated to the encodings of the queried points. The queried points and view directions are encoded using the positional encodings with . The point encodings are fed to an layer FC network with hidden dimension with point encodings being skipped and concatenated to the features every layers. This is followed by concatenating the view positional encodings with a single FC layer and the outputs result from head and an RGB () head.
Training Settings The decoder was trained over iterations using Adam optimiser [22] with a learning rate of and a decay factor of annealed through the training iterations. The size of an image in the decoder training phase is , and the number of rays batched in each iteration is set to . The number of coarse rays sampled during training is followed by fine rays using the stratified sampling approach. Within the volume rendering function a STD of noise is used for perturbing the radiance field. When collecting the Nerfel codes (Section 4), the radius of a Nerfel sphere in metric measurement and given a set of keypoints over an entire scene the threshold is adaptively chosen so that .
Evaluation Settings For both synthetic and real datasets, image pairs were chosen with overlap of to simulate wide-baseline scenarios. The overlap value was computed by symmetrically taking the reference frame and re-projecting it’s 3D points onto the query image and and vice versa. We check the percentage of the points that fall within the opposing frame and the average of both is the overlap value.
Appendix D Nerfel Samples
In the following we provide qualitative samples of Nerfels with frontal rotation poses.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9b243e9f-a956-4a50-8b38-d1947f627679/shapes707_0.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9b243e9f-a956-4a50-8b38-d1947f627679/shapes707_1.png)
Appendix E Nerf Full-Scene Rendering Samples
Here we provide different locations in full-scenes that are implicitly represented using a Nerf network. For each location the camera was perturbed to show the surroundings. From the renderings it can be seen that attempting to model a full-scene using a Nerf with a similar capacity to that used for Nerfels results in low quality scene representation. This causes the pose-estimation optimisation converge to incorrect solutions.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9b243e9f-a956-4a50-8b38-d1947f627679/nerf_fullscene_0191.png)
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/9b243e9f-a956-4a50-8b38-d1947f627679/nerf_fullscene_0230.png)