NeRF++: Analyzing and Improving
Neural Radiance Fields
Abstract
Neural Radiance Fields (NeRF) achieve impressive view synthesis results for a variety of capture settings, including 360∘ capture of bounded scenes and forward-facing capture of bounded and unbounded scenes. NeRF fits multi-layer perceptrons (MLPs) representing view-invariant opacity and view-dependent color volumes to a set of training images, and samples novel views based on volume rendering techniques. In this technical report, we first remark on radiance fields and their potential ambiguities, namely the shape-radiance ambiguity, and analyze NeRF’s success in avoiding such ambiguities. Second, we address a parametrization issue involved in applying NeRF to 360∘ captures of objects within large-scale, unbounded 3D scenes. Our method improves view synthesis fidelity in this challenging scenario. Code is available at https://github.com/Kai-46/nerfplusplus.
1 Introduction
Recall your last vacation where you captured a few photos of your favorite place. Now at home you wish to walk around in this special place again, if only virtually. This requires you to render the same scene from different, freely placed viewpoints in a possibly unbounded scene. This novel view synthesis task is a long-standing problem in computer vision and graphics (Chen & Williams, 1993; Debevec et al., 1996; Levoy & Hanrahan, 1996; Gortler et al., 1996; Shum & Kang, 2000).
Recently, learning-based methods have led to significant progress towards photo-realistic novel view synthesis. The method of Neural Radiance Fields (NeRF), in particular, has attracted significant attention (Mildenhall et al., 2020). NeRF is an implicit MLP-based model that maps 5D vectors—3D coordinates plus 2D viewing directions—to opacity and color values, computed by fitting the model to a set of training views. The resulting 5D function can then be used to generate novel views with conventional volume rendering techniques.
In this technical report, we first present an analysis of potential failure modes in NeRF, and an analysis of why NeRF avoids these failure modes in practice. Second, we present a novel spatial parameterization scheme that we call inverted sphere parameterization that allows NeRF to work on a new class of captures of unbounded scenes.
In particular, we find that in theory, optimizing the 5D function from a set of training images can encounter critical degenerate solutions that fail to generalize to novel test views, in the absence of any regularization. Such phenomena are encapsulated in the shape-radiance ambiguity (Figure 1, left), wherein one can fit a set of training images perfectly for an arbitrary incorrect geometry by a suitable choice of outgoing 2D radiance at each surface point. We empirically show that the specific MLP structure used in NeRF plays an important role in avoiding such ambiguities, yielding an impressive ability to synthesize novel views. Our analysis offers a new view into NeRF’s impressive success.
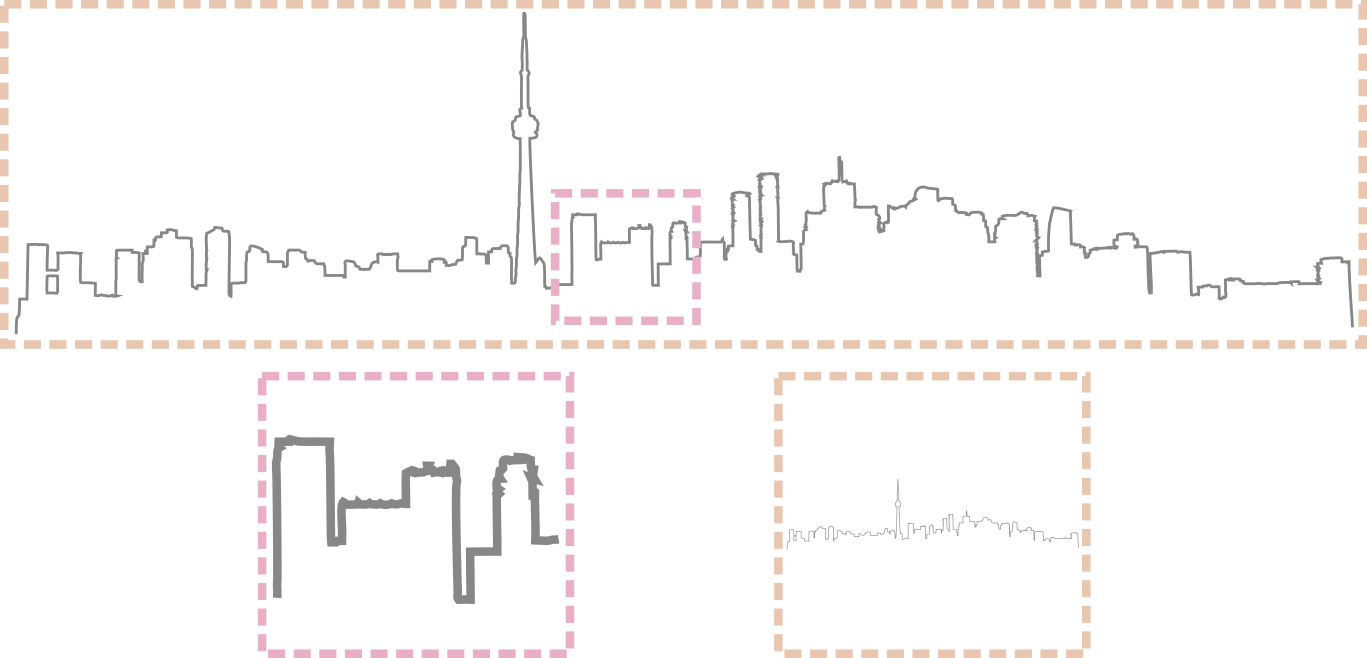
We also address a spatial parameterization issue that arises in challenging scenarios involving 360∘ captures around objects within unbounded environments (Figure 1, right). For 360∘ captures, NeRF assumes that the entire scene can be packed into a bounded volume, which is problematic for large-scale scenes: either we fit a small part of the scene into the volume and sample it in detail, but completely fail to capture background elements; or, we fit the full scene into the volume and lack detail everywhere due to limited sampling resolution. We propose a simple yet effective solution that separately models foreground and background, addressing the challenge of modeling unbounded 3D background content with an inverted sphere scene parameterization. We show improved quantitative and qualitative results on real-world captures from the Tanks and Temples dataset (Knapitsch et al., 2017) and from the light field dataset of Yücer et al. (2016).
In summary, we present an analysis on how NeRF manages to resolve the shape-radiance ambiguity, as well as a remedy for the parameterization of unbounded scenes in the case of 360∘ captures.

|
|
| Shape-Radiance Ambiguity | Parameterization of Unbounded Scenes |
2 Preliminaries
Given posed multi-view images of a static scene, NeRF reconstructs an opacity field representing a soft shape, along with a radiance field representing view-dependent surface texture. Both and are represented implicitly as multi-layer perceptrons (MLPs); the opacity field is computed as a function of 3D position, , and the radiance field is parameterized by both 3D position and viewing direction, (i.e., the set of unit 3-vectors). Hence, we use to refer to opacity as a function of position, and to refer to radiance as a function of position and viewing direction.
Ideally, should peak at the ground-truth surface location for opaque materials, in which case reduces to the surface light field (Wood et al., 2000). Given training images, NeRF uses stochastic gradient descent to optimize and by minimizing the discrepancy between the ground truth observed images , and the predicted images rendered from and at the same viewpoints:
| (1) |
The implicit volumes and are ray-traced to render each pixel of (Kajiya & Von Herzen, 1984). For a given ray , , its color is determined by the integral
| (2) |
To compensate for the network’s spectral bias and to synthesize sharper images, NeRF uses a positional encoding that maps and to their Fourier features (Tancik et al., 2020):
| (3) |
where is a hyper-parameter specifying the dimensionality of the Fourier feature vector.
3 Shape-radiance ambiguity
The capacity of NeRF to model view-dependent appearance leads to an inherent ambiguity between 3D shape and radiance that can admit degenerate solutions, in the absence of regularization. For an arbitrary, incorrect shape, one can show that there exists a family of radiance fields that perfectly explains the training images, but that generalizes poorly to novel test views.
To illustrate this ambiguity, imagine that for a given scene we represent the geometry as a unit sphere. In other words, let us fix NeRF’s opacity field to be 1 at the surface of the unit sphere, and 0 elsewhere. Then, for each pixel in each training image, we intersect a ray through that pixel with the sphere, and define the radiance value at the intersection point (and along the ray direction) to be the color of that pixel. This artificially constructed solution is a valid NeRF reconstruction that perfectly fits the input images. However, this solution’s ability to synthesize novel views is very limited: accurately generating such a view would involve reconstructing an arbitrarily complex view-dependent function at each surface point. The model is very unlikely to accurately interpolate such a complex function, unless the training views are extremely dense, as in conventional light field rendering works (Buehler et al., 2001; Levoy & Hanrahan, 1996; Gortler et al., 1996). This shape-radiance ambiguity is illustrated in Figure 2.
| GT training view | Prediction (PSNR: 25.4) | GT test view | Prediction (PSNR: 10.7) |
Why does NeRF avoid such degenerate solutions? We hypothesize that two related factors come to NeRF’s rescue: 1) incorrect geometry forces the radiance field to have higher intrinsic complexity (i.e., much higher frequencies) while in contrast 2) NeRF’s specific MLP structure implicitly encodes a smooth BRDF prior on surface reflectance.
Factor 1: As deviates from the correct shape, must in general become a high-frequency function with respect to to reconstruct the input images. For the correct shape, the surface light field will generally be much smoother (in fact, constant for Lambertian materials). The higher complexity required for incorrect shapes is more difficult to represent with a limited capacity MLP.
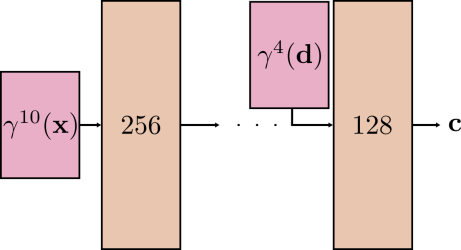
Factor 2: In particular, NeRF’s specific MLP structure encodes an implicit prior favoring smooth surface reflectance functions where is smooth with respect to at any given surface point . This MLP structure, shown in Figure 3, treats the scene position and the viewing direction asymmetrically: is injected into the network close to the end of the MLP, meaning that there are fewer MLP parameters, as well as fewer non-linear activations, involved in the creation of view-dependent effects. In addition, the Fourier features used to encode the viewing direction consist only of low-frequency components, i.e., vs. for encoding vs. (see Eq. 3). In other words, for a fixed , the radiance has limited expressivity with respect to .
To validate this hypothesis, we perform an experiment where we instead represent with a vanilla MLP that treats and symmetrically—i.e., accepting both as inputs to the first layer and encoding both with —to eliminate any implicit priors involving viewing direction that arise from the network structure. If we train NeRF from scratch with this alternate model for , we observe reduced test image quality compared with NeRF’s special MLP, as shown in Figure 4 and Table 1. This result is consistent with our hypothesis that implicit regularization of reflectance in NeRF’s MLP model of radiance helps recover correct solutions.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/7e43b227-13c0-444b-b683-fe31ed878d5c/x6.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/7e43b227-13c0-444b-b683-fe31ed878d5c/x7.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/7e43b227-13c0-444b-b683-fe31ed878d5c/x8.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/7e43b227-13c0-444b-b683-fe31ed878d5c/x9.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/7e43b227-13c0-444b-b683-fe31ed878d5c/x10.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/7e43b227-13c0-444b-b683-fe31ed878d5c/x11.png) |
| ground-truth | NeRF MLP | vanilla MLP |
| Scan 65 | Scan 106 | Scan 118 | |||||||
| LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | |
| NeRF MLP | 0.0258/0.0825 | 0.988/0.967 | 33.47/28.41 | 0.0641/0.0962 | 0.978/0.959 | 35.12/30.65 | 0.0380/0.0638 | 0.987/0.969 | 37.53/31.82 |
| Vanilla MLP | 0.0496/0.139 | 0.975/0.937 | 28.55/21.65 | 0.116/0.173 | 0.948/0.915 | 30.29/26.38 | 0.0609/0.094 | 0.979/0.952 | 35.31/29.58 |
4 Inverted Sphere Parametrization
The volumetric rendering formula in Eq. 2 integrates over Euclidean depth. When the dynamic range of the true scene depth is small, the integral can be numerically well-approximated with a finite number of samples. However, for outdoor, 360∘ captures centered on nearby objects that also observe the surrounding environment, the dynamic depth range can be extremely large, as the background (buildings, mountains, clouds, etc.) can be arbitrarily far away. Such a high dynamic depth range leads to severe resolution issues in NeRF’s volumetric scene representation, because to synthesize photo-realistic images, the integral in Eq. 2 needs sufficient resolution in both foreground and background areas, which is challenging to achieve by simply sampling points according to a Euclidean parameterization of 3D space. Fig. 5 demonstrates this tradeoff between scene coverage and capturing detail. In a more restricted scenario where all cameras are forward-facing towards a plane separating the cameras from the scene content, NeRF addresses this resolution issue by projectively mapping a subset of the Euclidean space, i.e., a reference camera’s view frustum, to Normalized Device Coordinates (NDC) (McReynolds & Blythe, 2005), and integrating in this NDC space. However, this NDC parameterization also fundamentally limits the possible viewpoints, due to its failure to cover the space outside the reference view frustum.
 |
 |
| (a) bounding volume for the truck only | (b) bounding volume for the entire scene |
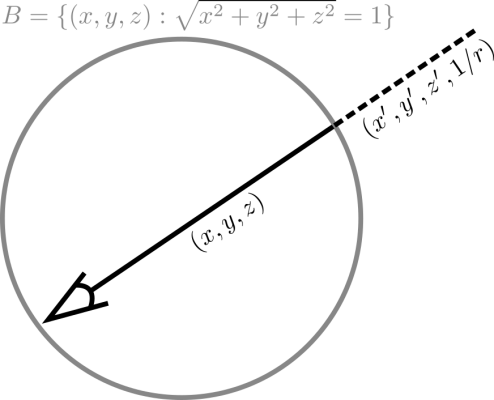
We address this restriction with an inverted sphere parameterization that facilitates free view synthesis. In our representation, we first partition the scene space into two volumes, an inner unit sphere and an outer volume represented by an inverted sphere covering the complement of the inner volume (see Figure 6 for an illustration and Figure 7 for a real-world example of a scene modeled in this way). The inner volume contains the foreground and all the cameras, while the outer volume contains the remainder of the environment.
 |
 |
 |
| (a) NeRF++ prediction | (b) predicted foreground | (c) predicted background |
These two volumes are modelled with two separate NeRFs. To render the color for a ray, they are raycast individually, followed by a final compositition. No re-parameterization is needed for the inner NeRF, as that part of the scene is nicely bounded. For the outer NeRF, we apply an inverted sphere parametrization.
Specifically, a 3D point in the outer volume can be re-parameterized by the quadruple , where is a unit vector along the same direction as representing a direction on the sphere, and is the inverse radius along this direction specifying the point outside the sphere. Unlike Euclidean space where objects can be at unlimited distance from the origin, all the numbers in the re-parametrized quadruple are bounded, i.e., . This not only improves numeric stability, but also respects the fact that farther objects should get less resolution. We can directly raycast this 4D bounded volume (only 3 degrees of freedom) to render a camera ray’s color. Note that the composite of foreground and background is equivalent to breaking the integral in Eq. 2 into two parts, integration inside the inner and outer volumes. In particular, consider that the ray is partitioned into two segments by the unit sphere: in the first, is inside the sphere; in the second, is outside the sphere. We can rewrite the volumetric rendering integral in Eq. 2 as
| (4) |
Terms (i) and (ii) are computed in Euclidean space, while term (iii) is computed in inverted sphere space with as the integration variable. In other words, we use in terms (i) and (ii), and in term (iii).
In order to compute term (iii) for the ray , we first need to be able to evaluate at any ; in other words, we need a way to compute corresponding to a given , so that can take as input. This can be achieved as follows.
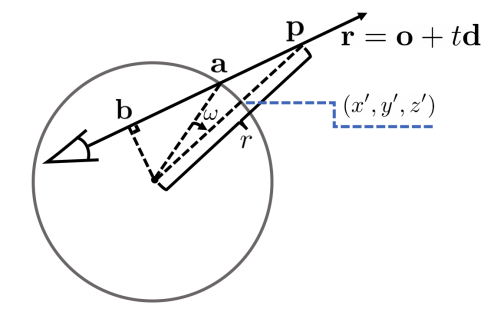
As shown in Fig. 8, let the ray intersect the unit sphere at point , and the midpoint of the chord aligning with the ray be the point . Point is computed by solving , while is acquired by solving . Then to get given , we can rotate the vector along the vector by the angle . Once we can evaluate at any , we simply sample a finite number of points from the interval to compute term (iii).
The inverted sphere parameterization for the outer volume has an intuitive physical explanation. It can be viewed in terms of a virtual camera whose image plane is the unit sphere at the scene origin. Hence, the 3D point is projected to the pixel on the image plane, while the term serves as the (inverse) depth, or disparity, of the point. From this perspective, the NDC parameterization suitable only for forward-facing capture is related to our representation, as it uses a virtual pinhole camera rather than a spherical projection surface. In this sense, our inverted sphere parameterization is related to the concept of multi-sphere images (a scene representation consisting of nested concentric spheres sampled according to inverse depth from the sphere centers) proposed in recent work on view synthesis (Attal et al., 2020; Broxton et al., 2020).
5 Experiments
We validate NeRF++ and compare it with NeRF on two real-world datasets captured with hand-held cameras: Tanks and Temples (T&T) (Knapitsch et al., 2017) and the Light Field (LF) dataset of Yücer et al. (2016). We report PSNR, SSIM, and LPIPS (Zhang et al., 2018) as our quantitative metrics for measuring the quality of synthesized test images.
T&T dataset. We use the training/testing images and SfM poses provided by Riegler & Koltun (2020). This dataset consists of hand-held 360∘ captures of four large-scale scenes; the camera poses are estimated by COLMAP SfM (Schönberger & Frahm, 2016). For NeRF, we normalize the scene such that all cameras are inside the sphere of radius . This normalization ensures that the unit sphere covers the majority of the background scene content (although some background geometry still lies outside the bounding unit sphere). To numerically compute the volumetric rendering integral for each camera ray, we uniformly sample points from the ray origin to its intersection with the unit sphere. Since NeRF++ ray-casts both inner and outer volumes and hence uses twice the number of samples per camera ray compared to a single volume, we also double the number of samples used by NeRF for the sake of fairness. Specifically, NeRF’s coarse-level MLP uses 128 uniform samples, while the fine-level MLP uses 256 additional importance samples. Under this hyper-parameter setting, NeRF has roughly the same computation cost and GPU memory footprint during training and testing as NeRF++. We randomly sample 2048 camera rays at each training iteration, and train NeRF and NeRF++ for 250k iterations with a learning rate of 5e-4.
LF dataset. We use four scenes from the LF dataset: Africa, Basket, Ship, and Torch. Each scene is densely covered by 2k–4k hand-held captured images, and camera parameters are recovered using SfM. We construct a sparse surrounding capture by temporally subsampling the images by a factor of 40. In particular, the training images are frames 0, 40, 80, …, and the testing images are frames 20, 60, 100, … . The scene normalization method, number of samples per camera ray, batch size, training iterations, and learning rate are the same as in the T&T dataset.
Results. As shown in Table 2, NeRF++ significantly outperforms NeRF in challenging scenarios involving 360∘ captures of objects within large-scale unbounded scenes. In Figure 9, we can see that images synthesized by NeRF++ have significantly higher fidelity.
| Truck | Train | M60 | Playground | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | |
| NeRF | 0.513 | 0.747 | 20.85 | 0.651 | 0.635 | 16.64 | 0.602 | 0.702 | 16.86 | 0.529 | 0.765 | 21.55 |
| NeRF++ | 0.298 | 0.823 | 22.77 | 0.523 | 0.672 | 17.17 | 0.435 | 0.738 | 17.88 | 0.391 | 0.799 | 22.37 |
| Africa | Basket | Torch | Ship | |||||||||
| LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | LPIPS | SSIM | PSNR | |
| NeRF | 0.217 | 0.894 | 26.16 | 0.377 | 0.805 | 20.83 | 0.347 | 0.811 | 22.81 | 0.372 | 0.801 | 23.24 |
| NeRF++ | 0.163 | 0.923 | 27.41 | 0.254 | 0.884 | 21.84 | 0.226 | 0.867 | 24.68 | 0.241 | 0.867 | 25.35 |
 |
 |
 |
 |
 |
 |
 |
 |
| NeRF | NeRF++ |
6 Open challenges
NeRF++ improves the parameterization of unbounded scenes in which both the foreground and the background need to be faithfully represented for photorealism. However, there remain a number of open challenges. First, the training and testing of NeRF and NeRF++ on a single large-scale scene is quite time-consuming and memory-intensive. Training NeRF++ on a node with 4 RTX 2080 Ti GPUs takes 24 hours. Rendering a single 1280x720 image on one such GPU takes 30 seconds at test time. Liu et al. (2020) have sped up the inference, but rendering is still far from real-time. Second, small camera calibration errors may impede photorealistic synthesis. Robust loss functions, such as the contextual loss (Mechrez et al., 2018), could be applied. Third, photometric effects such as auto-exposure and vignetting can also be taken into account to increase image fidelity. This line of investigation is related to the lighting changes addressed in the orthogonal work of Martin-Brualla et al. (2020).
References
- Attal et al. (2020) Benjamin Attal, Selena Ling, Aaron Gokaslan, Christian Richardt, and James Tompkin. MatryODShka: Real-time 6DoF video view synthesis using multi-sphere images. In ECCV, 2020.
- Broxton et al. (2020) Michael Broxton, John Flynn, Ryan Overbeck, Daniel Erickson, Peter Hedman, Matthew DuVall, Jason Dourgarian, Jay Busch, Matt Whalen, and Paul Debevec. Immersive light field video with a layered mesh representation. ACM Transactions on Graphics, 39(4), 2020.
- Buehler et al. (2001) Chris Buehler, Michael Bosse, Leonard McMillan, Steven Gortler, and Michael Cohen. Unstructured lumigraph rendering. In SIGGRAPH, 2001.
- Chen & Williams (1993) Shenchang Eric Chen and Lance Williams. View Interpolation for Image Synthesis. In SIGGRAPH, 1993.
- Debevec et al. (1996) Paul E. Debevec, Camillo J. Taylor, and Jitendra Malik. Modeling and rendering architecture from photographs: A hybrid geometry-and image-based approach. In SIGGRAPH, 1996.
- Gortler et al. (1996) Steven J Gortler, Radek Grzeszczuk, Richard Szeliski, and Michael F Cohen. The lumigraph. In SIGGRAPH, 1996.
- Jensen et al. (2014) Rasmus Jensen, Anders Dahl, George Vogiatzis, Engil Tola, and Henrik Aanæs. Large scale multi-view stereopsis evaluation. In CVPR, 2014.
- Kajiya & Von Herzen (1984) James T Kajiya and Brian P Von Herzen. Ray tracing volume densities. In SIGGRAPH, 1984.
- Knapitsch et al. (2017) Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Transactions on Graphics, 36(4), 2017.
- Levoy & Hanrahan (1996) Marc Levoy and Pat Hanrahan. Light field rendering. In SIGGRAPH, 1996.
- Liu et al. (2020) Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, and Christian Theobalt. Neural sparse voxel fields. arXiv:2007.11571, 2020.
- Martin-Brualla et al. (2020) Ricardo Martin-Brualla, Noha Radwan, Mehdi SM Sajjadi, Jonathan T Barron, Alexey Dosovitskiy, and Daniel Duckworth. NeRF in the wild: Neural radiance fields for unconstrained photo collections. arXiv:2008.02268, 2020.
- McReynolds & Blythe (2005) Tom McReynolds and David Blythe. Advanced graphics programming using OpenGL. Elsevier, 2005.
- Mechrez et al. (2018) Roey Mechrez, Itamar Talmi, and Lihi Zelnik-Manor. The contextual loss for image transformation with non-aligned data. In ECCV, 2018.
- Mildenhall et al. (2020) Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
- Riegler & Koltun (2020) Gernot Riegler and Vladlen Koltun. Free view synthesis. In ECCV, 2020.
- Schönberger & Frahm (2016) Johannes Lutz Schönberger and Jan-Michael Frahm. Structure-from-motion revisited. In CVPR, 2016.
- Shum & Kang (2000) Harry Shum and Sing Bing Kang. Review of image-based rendering techniques. In Visual Communications and Image Processing, 2000.
- Tancik et al. (2020) Matthew Tancik, Pratul P Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. arXiv:2006.10739, 2020.
- Wood et al. (2000) Daniel N Wood, Daniel I Azuma, Ken Aldinger, Brian Curless, Tom Duchamp, David H Salesin, and Werner Stuetzle. Surface light fields for 3D photography. In SIGGRAPH, 2000.
- Yücer et al. (2016) Kaan Yücer, Alexander Sorkine-Hornung, Oliver Wang, and Olga Sorkine-Hornung. Efficient 3D object segmentation from densely sampled light fields with applications to 3D reconstruction. ACM Transactions on Graphics, 35(3), 2016.
- Zhang et al. (2018) Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018.