Nearly Optimal Linear Convergence of Stochastic Primal-Dual Methods for Linear Programming
Abstract
There is a recent interest on first-order methods for linear programming (LP). In this paper, we propose a stochastic algorithm using variance reduction and restarts for solving sharp primal-dual problems such as LP. We show that the proposed stochastic method exhibits a linear convergence rate for solving sharp instances with a high probability. In addition, we propose an efficient coordinate-based stochastic oracle, which has per iteration cost and improves the complexity of the existing deterministic and stochastic algorithms. Finally, we show that the obtained linear convergence rate is nearly optimal (upto terms) for a wide class of stochastic primal-dual methods. Numerical performance verifies the theoretical guarantees of the proposed algorithms.
1 Introduction
Linear programming (LP), as one of the most fundamental tools in operations research and computer science, has been extensively studied in both academia and industry since 1940s. The applications of LP span various fields, including pricing and revenue management, transportation, network flow, scheduling, and many others [14, 27, 9, 42, 4, 40].
The dominant solvers of LP are essentially based on either the simplex method or interior-point method, which are very mature nowadays and can usually provide reliable solutions to LP. However, the success of both methods heavily relies on efficient solving linear systems using factorization, which has the following major drawbacks: (i) the factorization may run out of memory even though the original LP can fit in memory; (ii) it is highly challenging to take advantage of modern computing resources, such as distributed system and GPUs when solving linear systems. These drawbacks make it highly challenging to further scale up LP.
Recently, it was shown that first-order methods (FOMs) with proper enhancements can also identify high-quality solutions to LP problem quickly [5], which provides an alternative to the traditional simplex and barrier methods for LP. FOMs utilize only the gradient information of the objective function to update the iterates (in contrast to second-order methods where Hessian is used). The basic operation in FOMs is matrix-vector multiplication, which can avoid the two major drawbacks of traditional methods mentioned above, thus it is suitable for solving larger LP.
In this work, we further push this line of research and study stochastic FOMs for LP. In contrast to deterministic first-order methods [5], the basic operation per iteration in stochastic FOMs is a vector operation. Such operation is very cheap in general and is a common practice for modern machine learning applications. As a drawback, the number of iterations of stochastic algorithms to obtain an approximate solution is typically higher than its deterministic counterpart.
Due to such a fundamental distinction, Nesterov [48] formally defines methods that require matrix factorization (or matrix inversion) as handling medium-scale problems, methods that require matrix vector multiplication as handling large-scale problems, and methods that require vector operations as handling huge-scale problems. Based on this definition, in the context of LP, the simplex method and interior point method are classified as handling medium-scale problems (this definition perhaps belie the practical efficiency of the two methods, but it is a fact that it is challenging to further scale up them as mentioned above), deterministic FOMs [5, 39] are classified as handling large-scale problems, and in the paper we instead look at huge-scale problems.
While our motivation is LP, we here consider a more general class of primal-dual problems with the form
| (1) |
where is convex in and concave in , is a simple convex function in and is a simple convex function in . In particular, the primal-dual formulation of standard form LP is
| (2) |
and a highly related problem is the unconstrained bilinear problem
| (3) |
For notational convenience, we define , and . We here assume there is an unbiased stochastic oracle such that (see Section 5 for examples on how to construct the stochastic oracles). To efficiently solve (2), our key ideas are variance reduction and restarts:
Variance reduction is a successful technique for finite sum stochastic minimization problems [31, 19, 55]. The basic idea is to reduce the variance in the stochastic gradient estimation by comparing it with the snapshots of the true gradient. Variance reduction can usually improve the convergence property of stochastic minimization algorithms [31, 19, 55]. Recently, [3] extends the variance reduction scheme to EGM for solving monotonic variational inequality (with some ambiguity, we call this algorithm sEGM), which was shown to have convergence rate.
Restart is another standard technique for minimization problems, which is used to speed up the convergence of multiple deterministic and stochastic algorithms [49, 24, 59, 51, 60]. Recently, [7] introduces the sharpness of primal-dual problems, and presents a simple restart scheme to accelerate the linear convergence rate of primal-dual algorithms for solving sharp problems.
This paper extends the restarted algorithm in [7] to stochastic algorithms (in particular sEGM [3]) for solving sharp primal-dual problems, such as LP. We further show that the obtained linear convergence rate is nearly optimal (upto terms) for a wild class of stochastic algorithms. It turns out that while LP is sharp on any bounded region [7], LP is not globally sharp (see Appendix A.1 and Appendix A.2 for a counter example). A fundamental difficulty of restarted stochastic algorithm is that, unlike deterministic algorithms, the iterates may escape from any bounded region, thus there is no guarantee that local sharpness can be helpful for the convergence of stochastic algorithms. We overcome this issue by presenting a high-probability argument and show the linear convergence of the proposed restarted algorithms with high probability.
The performance of randomized algorithms depends on the realization of stochasticity. The traditional convergence analysis of these algorithms usually measures the expected performance, namely, running the algorithm multiple times and looking at the average performance. In contrast, we present high probability results, namely, running the algorithm multiple times, and study the performance of all trajectories with a certain probability. In particular, when choosing the probability as , we obtain the convergence guarantee of the median trajectory, which can be viewed as an alternative to the expected performance studied in the related literature.
| Algorithm | Per-iteration Cost | Number of Iteration to find an solution | Total Cost111 The total cost is sometimes more than the product of the per-iteration cost and the number of iterations due to the snapshot step in variance reduction. |
|---|---|---|---|
| Deterministic [33] | |||
| Deterministic Restart [7] | |||
| SPDHG [12] | |||
| SPDHG222 The complexity of SPDHG [3] involves complicated terms. In the table, we present a lower bound on the number of iterations and the total cost, i.e., they need at least this number of iterations (or total cost) to find an -accuracy solution based on their analysis (see Appendix A.4 for more details). [2] | |||
| Conceptual Proximal [10] | |||
| sEGM [3] | |||
| RsEGM Oracle II (This Paper) | |||
| RsEGM Oracle IV (This Paper) |
| Algorithm | Per-iteration Cost | Number of Iteration | Total Cost |
|---|---|---|---|
| Deterministic [33] | |||
| Deterministic Restart [7] | |||
| sEGM [3] | |||
| RsEGM Oracle II (This Paper) | |||
| RsEGM Oracle IV (This Paper) |
Table 1 and Table 2 present the per iteration cost, complexity of the algorithm, and the total flop counts for our proposed algorithm, Restarted sEGM (RsEGM), and compare it with multiple deterministic and stochastic algorithms for solving unconstrained bilinear problem (3) and LP (2), respectively. For unconstrained bilinear problems (3), deterministic algorithms require to compute the gradient of the objective, thus the per iteration cost is . Standard stochastic algorithms are usually based on row/column sampling, and the iteration cost is . We also present a stochastic coordinate scheme (oracle IV) where the per-iteration cost is . While stochastic algorithms have low per-iteration cost, it usually requires more iterations to identify an -close solution compared to its deterministic counterparts. As we see in Table 1, compared with the optimal deterministic algorithms [7], the total flop count of RsEGM with stochastic Oracle II is better when the matrix is dense and of low rank. With the coordinate gradient estimator Oracle IV, the total cost of RsEGM is even lower and improves optimal deterministic algorithms by at least a factor of when A is dense. For standard LP, as seen in Table 2, stochastic algorithms require more iterations to achieve -accuracy than the unconstrained bilinear problem due to the existence of inequality constrains. Similar to the unconstrained bilinear setting, when matrix is low-rank and dense, the total flop cost of RsEGM improves the optimal deterministic algorithm. On the other hand, most of the previous works on stochastic algorithms have sublinear rate. The only exception is [3], where the authors show the linear convergence of SPDHG for solving problems satisfying global metric sub-regularity. Indeed, unconstrained bilinear problems satisfy the global metric sub-regularity, while LP does not satisfy it globally. The complexity of SPDHG involves more complicated notations and we present a more detailed comparison in Appendix A.2 and Appendix A.4, but our proposed algorithms are at least better than SPDHG by a factor of condition number .
1.1 Summary of Contributions
The contributions of the paper can be summarized as follow:
(i) We propose a restarted stochastic extragradient method with variance reduction for solving sharp primal-dual problems. We show that the proposed algorithm exhibit linear convergence rate with high probability, in particular,
-
•
For linear programming and unconstrained bilinear problems, our restarted scheme improves the complexity of existing linear convergence of stochastic algorithms [3] by a factor of the condition number. The improvement comes from restarts.
-
•
To the best of our knowledge, this is the first stochastic algorithm with linear rate for the general standard-form LP problems (2). To prove this result, we introduce a high-probability analysis to upper-bound distance between the iterates and the optimal solution set.
(ii) We present the complexity lower bound of a class of stochastic first-order methods for solving sharp primal-dual problems, which matches the upper bound we obtained for RsEGM (upto terms). This showcases RsEGM achieves a nearly optimal linear convergence rate for sharp primal-dual problems.
1.2 Assumptions
Throughout the paper, we have two assumptions on the problem and the stochastic oracle. The first one is on the primal-dual problem:
Assumption 1.
The problem (1) satisfies:
(i) is convex in and concave in .
(ii) is proper convex lower semi-continuous.
(iii) The stationary solution set .
As a stochastic first-order method, we assume there exists a stochastic gradient oracle:
Assumption 2.
We assume there exists a stochastic oracle such that
(i) it is unbiased: ;
(ii) it is -Lipschitz (in expectation): .
1.3 Related Literature
Convex-concave primal-dual problems. There has been a long history of convex-concave primal-dual problems, and many of the early works study a more general problem, monotone variational inequalities. Rockafellar proposed a proximal point method (PPM) [53] for solving monotone variational inequalities. Around the same time, Korpelevich proposed the extragradient method (EGM) [33] for convex-concave primal-dual problems. After that, there have been numerous results on the convergence analysis of these methods. In particular, Tseng [58] shows that PPM and EGM have linear convergence for strongly-convex-strongly-concave primal-dual problems or for unconstrained bilinear problems. Nemirovski proposes Mirror Prox algorithm in the seminal work [45], which is a more general form of EGM, and shows that EGM has sublinear convergence rate for solving general convex-concave primal-dual problems over a bounded and compact set. [45] also build up the connection between EGM and PPM: EGM is an approximation to PPM.
Another line of research is to study a special case of (1) where is a bilinear term. Two well-known algorithms are Douglas-Rachford splitting [20, 21] (Alternating Direction Method of Multiplier (ADMM) as a special case) and Primal-dual Hybrid Gradient Method (PDHG) [13].
Very recently, there is a renewed interest on primal-dual methods, motivated by machine learning applications. For bilinear problems with full rank matrix , [17] shows that the Optimistic Gradient Descent Ascent (OGDA) converges linearly and later on [43] shows that OGDA , EGM and PPM all enjoy a linear convergence rate. [43] also presents an interesting observation that OGDA approximates PPM on bilinear problems. Lu [41] analyzes the dynamics of unconstrained primal-dual algorithms under an ODE framework and yields tight conditions under which different algorithms exhibit linear convergence. However, an important caveat is that not all linear convergence rates are equal. [7] shows that a simple restarted variant of these algorithms can improve the dependence of complexity on condition number in their linear convergence rate, as well as the empirical performance of the algorithms.
Linear programming. Linear programming is a fundamental tool in operations research. Two dominating methods to solve LP problems are simplex method [16] and interior-point method [32], and the commercial LP solvers based on these methods can provide reliable solutions even for fairly large instances. While the two methods are quite different, both require solving linear systems using factorization. As a result, it becomes very challenging to further scale up these two methods, in particular to take advantage of distributed computing. Recently, there is a recent trend on developing first-order methods for LP only utilizing matrix-vector multiplication [8, 25, 39, 5, 6]. In general, these methods are easy to be parallelized and do not need to store the factorization in memory.
The traditional results of first-order methods for LP usually have sublinear rate, due to the lack of strong convexity, which prevents them to identify high-accuracy solutions. To deal with this issue, [22] presents a variant of ADMM and shows the linear convergence of the proposed method for LP. More recently [36, 37] show that many primal-dual algorithms under a mild non-degeneracy condition have eventual linear convergence, but it may take a long time before reaching the linear convergence regime. [7] propose a restarted scheme for LP in the primal-dual formulation. They introduce a sharpness condition for primal-dual problems based on the normalized duality gap and show that the primal-dual formulation of LP is sharp on any bounded region. Then they provide restarted schemes for sharp primal-dual problems and show that their proposed algorithms have the optimal linear convergence rate (in a class of deterministic first-order methods) when solving sharp problems. A concurrent work [56] studies stochastic algorithms for generalized linear programming, but the focus is on sublinear rate, while our focus is on the linear rate.
Sharpness conditions and restart schemes. The concept of sharpness was first proposed by Polyak [52] on minimization problem. Recently, there is a trend of work on developing first-order method with faster convergence rates using sharpness. For example, [59] shows linear convergence of restarted subgradient descent on sharp non-smooth functions and there are other works on sharp non-convex minimization [18]. Sharpness can also be viewed as a certain error bound condition [54]. Recently [7] introduces sharpness condition for primal-dual problems. A highly related concept is the metric subregularity for variational inequalities, which is a weaker condition than the sharpness condition proposed in [7] (see Appendix A.1 for a discussion). Under such conditions, [2, 23] present the linear convergence for stochastic PDHG and deterministic PDHG, respectively.
Restarting is a powerful technique in optimization. It can improve the practical and theoretical convergence of a base algorithm without modification to the base algorithm [51]. Recently, there have been extensive works on this technique in smooth convex optimization [49, 54], non-smooth convex optimization [24, 59] and stochastic convex optimization [31, 38, 57]. For sharp primal-dual problems, [7] propose fixed-frequency and adaptive restart on a large class of base primal-dual algorithms including PDHG, ADMM and EGM.
Variance reduction and primal-dual problem. Variance reduction technique [19, 31] is developed to improve the convergence rate for stochastic algorithms upon pure SGD for minimization problems. There are extensive works on variants of stochastic variance reduction for minimization problems under various settings (see [26] for a recent overview).
Compared with the extensive works on minimization problem, the research of variance-reduced methods on primal-dual problems is fairly limited. [50] studies stochastic forward-backward algorithm with variance reduction for primal-dual problems and, more generally, monotone inclusions. Under strong monotonicity, they prove a linear convergence rate and improve the complexity of deterministic methods for bilinear problems. [10] proposes a randomized variant of Mirror Prox algorithm. They focus on matrix games and improve complexity over deterministic methods in several settings. However, beyond matrix games, their method requires extra assumptions such as bounded domain and involves a three-loop algorithm. More recently, [3] proposes a stochastic extragradient method with variance reduction for solving variational inequalities. Under Euclidean setting, their method is based on a loopless variant of variance-reduced method [29, 34]. Their algorithm offers a similar convergence guarantee as [10] but does not require assumptions such as bounded region.
After the first version of this paper, there have been several recent works on stochastic primal-dual methods that can be applied to LP. For example, [30, 44] propose variants of variance-reduced extra-gradient methods for finite-sum variational inequality. In particular, [30] derives the sublinear rate of the proposed method under the finite-sum convex-concave setting, while [44] derives the linear convergence rate of Algorithm 1 under the projection-type error-bound condition. [1] studies complexity bounds for the primal-dual algorithm with random extrapolation and coordinate descent and obtains sub-linear rate for general convex-concave problems with bilinear coupling.
1.4 Notations
Let and refer to the natural log and exponential function, respectively. Let and denote the minimum singular value and minimum nonzero singular value of a matrix . Let be the norm of vector . Let and denote the 2-norm and Frobenius norm of a matrix . Let be the -th standard unit vector. Let denote for sufficiently large , there exists constant such that and denote for sufficiently large , there exists constant such that . if and . Denote , where refers to a polynomial in . For set , denote the ball centered at with radius intersected with the set . is the indicator function of convex set .
2 Preliminaries
In this section, we present two results in the recent literature (i) the sharpness condition for primal-dual problems based on the normalized duality gap introduced in [7], and (ii) the stochastic EGM with variance reduction that was introduced in [3]. We will utilize these results to develop our main theory in later sections.
2.1 Sharpness Condition for Primal-Dual Problems
Sharpness is a central property of the objective in minimization problems that can speed up the convergence of optimization methods. Recently, [7] introduces a new sharpness condition of primal-dual problems based on a normalized duality gap. They show that linear programming (among other examples) in the primal-dual formulation is sharp. Furthermore, [7] proposes a restarted algorithm that can accelerate the convergence of primal-dual algorithms such as EGM, PDHG and ADMM, and achieve the optimal linear convergence rate on sharp primal-dual problems.
More formally, the sharpness of a primal-dual problem is defined as:
Definition 1.
We say a primal-dual problem is -sharp on the set if is -sharp on for all , i.e. it holds for all that
where is a ball centered at with radius intersected with the set .
In particular, the following examples are shown to be sharp instances [7]:
Example 2.1.
Consider a primal-dual problem with a bounded feasible region, i.e., and encode a bounded feasible region of and , respectively. Suppose is -sharp in and is -sharp in . Then problem (1) is -sharp in the feasible region, where and is the diameter of the region.
Example 2.2.
Consider an unconstrained bilinear problem with , then problem (1) is -sharp in , where .
2.2 Stochastic EGM with Variance Reduction
In this subsection, we present the stochastic EGM with variance reduction introduced in [3], and restate their two major convergence results.
Algorithm 1 presents the stochastic EGM with variance reduction (sEGM). The algorithm keeps track of two sequences and . can be viewed as a snapshot, which is updated rarely and we evaluate the full gradient . Then we calculate as a weighted average of and . Similar to deterministic EGM, the algorithm computes an intermediate solution . We then use the full gradient of the snapshot to compute , and use the variance reduced stochastic gradient to compute .
We here restate the descent lemma of Algorithm 1 ([3, Lemma 2.2]), which is the key component in the sublinear convergence rate proof of sEGM:
Lemma 1.
Next, we restate the sublinear convergence of Algorithm 1 in terms of the duality gap. The theorem and its proof can be obtained by a simple modification of [3, Theorem 2.5].
Theorem 1.
Let Assumptions hold, and . Let . Then for any compact set ,
3 Restarted Stochastic EGM with Variance Reduction
In this section, we first present our main algorithm, the nested-loop restarted stochastic EGM algorithm (RsEGM, Algorithm 2), in section 3.1. Then we show that with high probability, the restarted algorithm exhibits linear convergence to an optimal solution for sharp primal-dual problems both with and without bounded region. This linear convergence result accelerates the linear convergence of stochastic algorithms without restart.
3.1 Algorithm
Algorithm 2 presents the nested-loop restarted stochastic EGM algorithm (RsEGM). We initialize the algorithm with probability parameter , a stochastic sample oracle , step size for sEGM, length of inner loop and outer iteration . In each outer loop, we run sEGM for iterations and restart the next outer loop using the output of sEGM from the previous outer loop.
3.2 Convergence Guarantees for Problems with Global Sharpness
Theorem 2 presents the high probability linear convergence rate of Algorithm 2 for solving primal-dual problem (1) with global sharpness conditions. Recall that the global sharpness holds for unconstrained bilinear problems and bilinear problems with bounded region (an economic example is two-player matrix game), this implies the linear convergence of Algorithm 2 for these two cases.
Theorem 2.
Consider RsEGM (Algorithm 2) for solving a sharp primal-dual problem (1). Suppose Assumption 1 and Assumption 2 hold. Let be the global sharpness constant of the primal-dual problem and be the Lipschitz parameter of the stochastic oracle. Denote the initial distance to optimal set as , and choose step-size . For any and , if the outer loop count and the inner loop count of RsEGM satisfy
then it holds with probability at least that
Furthermore, the total number of iteration to get accuracy with probability at least is of order
Remark 1.
The performance of stochastic algorithms depends on the realization of stochasticity. The traditional convergence analysis of these algorithms usually measures the expected performance, namely, running the algorithm multiple times and looking at the average performance. In contrast, when choosing , Theorem 2 provides the complexity of the median performance of the algorithm.
Remark 2.
In this remark, we consider the finite-sum model where . Suppose the stochastic oracle computes for that is uniformly random in set . Then evaluating needs one stochastic oracle and evaluating the true gradient need stochastic oracles. With a careful calculation, we obtain that one outer iteration of RsEGM requires stochastic oracle calls. Thus, the average total oracle cost of RsEGM to reach -accuracy with probability at least becomes
| (4) |
Choosing and , the number of stochastic oracle calls for the median trajectory to achieve accuracy becomes
In contrast, the total oracle cost of deterministic restarted methods solving primal-dual problem with global sharpness [7] (which is the optimal deterministic algorithm) is
where is the Lipschitz constant for . In the context of finite-sum model, is generally of the same order of (upto a variance term that is independent of ). This shows that RsEGM in general needs less stochastic oracles to find an -solution than its deterministic counterpart after ignoring the terms.
We know from Example 2.1 and Example 2.2 that bilinear problems with bounded region and unconstrained bilinear problem are both globally sharp. A direct application of Theorem 2 gives:
Corollary 1.
For bilinear problems with bounded region and for unconstrained bilinear problem, the total number of iteration to get accuracy with probability at least is of order
To prove Theorem 2, we first introduce two properties of sEGM. The next lemma bounds the expected distance between the iterates of sEGM and initial point by the distance between initial point and optimal solution.
Lemma 2.
Proof.
It follows from Lemma 1
thus
We can also derive from the monotonicity of that
thus
By triangle inequality we have
∎
Next, we present the sublinear rate of sEGM on localized duality gap:
Lemma 3.
Proof.
Notice that
where the first two inequalities are from the convexity-concavity of and the last inequality is due to Theorem 1. ∎
Now we are ready to prove Theorem 2.
Proof of Theorem 2.
Consider the -th outer iteration, and define . To prove the theorem, we’ll show that the event is a high probability event and the key is to use the global sharpness on a carefully controlled region.
Suppose . It follows from Markov inequality that for any inner iteration
Furthermore, it follows from Lemma 2 that
| (6) |
Thus, if is chosen to be sufficiently large, the probability can be arbitrarily close to . Given the high probability event , we can upper bound the normalized duality gap as
| (7) |
By -sharpness and the fact that is deterministic given , we have for any constant and function that
The next step is to upper bound the last term in the right hand side of (8). Denote and choose , then we have because , thus
| (9) | ||||
where the first inequality follows from Markov inequality, the second one utilizes Lemma 3 and . Combine Equation (8) with (9), we obtain
where the last inequality uses Equation (6). Thus, we obtain by substituting the value of , and that
Let , and function , then we have
| (10) |
When , we have . Let and be the probability conditioned on , then
| (11) | ||||
where the second inequality is from Equation (10) and the third one uses Bernoulli inequality. Thus, if we obtain
| (12) | ||||
where the last inequality is from . Combine (11) and (12) we arrive at
Finally, by choosing , , the total number of iteration to get accuracy with probability at least is which is of order
∎
3.3 Convergence Guarantees for Standard-Form LP
In this subsection, we establish the high probability convergence rate of RsEGM for LP (2). Unfortunately, LP is not globally sharp (see Appendix A.2), thus the result in Section 3.2 cannot be directly applied to LP. Instead, [7] shows that LP is sharp on any bounded region. Unlike deterministic methods as studied in [7], where the iterates of a primal dual algorithm always stay in a bounded region, the iterates of stochastic methods may escape from any bounded region. Theorem 3 overcomes this difficulty by presenting a high probability argument.
Theorem 3.
Consider RsEGM (Algorithm 2) for solving LP (2). Suppose Assumption 1 and Assumption 2 hold. Let be the Lipschitz parameter of the stochastic oracle and be the Hoffman constant of the KKT system of LP (see Example 2.3). Denote the initial distance to optimal set as , and choose step-size . For any and , if the outer loop count and the inner loop count of RsEGM satisfy
then it holds with probability at least that
Furthermore, the total number of iteration to get accuracy with probability at least is of order
Remark 3.
Similar to Remark 1, we can obtain the complexity of the median trajectory of the algorithm by choosing .
Remark 4.
As shown in [7, Lemma 5], LP is sharp with in the ball with any radius . Notice that for deterministic primal-dual methods, the iterates usually stay in a ball centered at with radius (see Section 2 in [7]), thus the effective sharpness constant on deterministic algorithms for LP is given by . Theorem 3 shows that the complexity of RsEGM is
In the following we prove Theorem 3. The key is to show that the iterates stay in a bounded region with a high probability, thus we can utilize the sharpness condition of LP.
Proof of Theorem 3.
Suppose . Denote and consider event , where we determine the value of later. By definition:
Let , then is the probability conditioned on . For convenience, we denote, . It follows from Lemma 2.3 and the sharpness of LP that
| (13) | ||||
Note that given the event , we have for any that
| (14) |
Furthermore, we have conditioned on that , thus
| (15) |
Next, we set , and , then we know there exists an optimal solution such that , because . Then we can upper bound the second term in the right hand side of (16) by Markov inequality:
| (17) | ||||
where the second inequality follows from Lemma 3, by noticing , and the last inequality uses . Combining Equation (6), (16) and (17), we obtain
Furthermore, by recalling , we obtain
where the last inequality comes from for . Thus we have
Recall and , thus
In summary, choosing , , the total number of iteration to get accuracy with probability at least is which is of order
∎
4 Lower Bound
In this section, we establish the complexity lower bound of stochastic first-order algorithms (with variance reduction) for solving sharp primal-dual problems. Together with the results shown in Section 3 , we demonstrate that RsEGM has nearly optimal convergence rate (upto log terms) among a large class of stochastic primal-dual methods.
Since we study the lower bound in this section, we can assume is differentiable everywhere, thus is well defined. Recall that in deterministic first-order primal-dual methods, we utilize the gradient information to update the iterates. Thus, the iterates of first-order methods always stay in the subspace spanned by the gradient, and we call this behavior first-order span-respecting (see for example [7] ) defined as below:
Definition 2.
A deterministic primal dual algorithm is called first-order span-respecting if its iterates satisfy
Many classic primal dual first-order methods, such as GDA, AGDA and EGM, are first-order span-respecting when applying unconstrained problems.
In this paper, we study stochastic algorithms with variance reduction. As a result, we consider a general class of stochastic algorithms where the span includes both the deterministic gradient (for variance reduction sake) and the stochastic oracle . More formally, we introduce stochastic span-respecting algorithms, defined as below:
Definition 3.
A randomized primal dual algorithm is called first-order stochastic span-respecting with respect to a stochastic oracle if the iterates in satisfy:
are random variables.
Remark 5.
The above definition consists of both deterministic gradient together with the stochastic gradient estimator. The reason is to include the variance reduction method into the algorithm class. Obviously the above algorithm class is larger than the one only with deterministic or stochastic gradient. As a result, the lower bound is generally higher than a pure stochastic algorithm.
Remark 6.
If is bilinear, then with appropriate indexing of iterates, sEGM and RsEGM are first-order stochastic span-respecting.
Theorem 4.
Remark 7.
Theorem 4 implies the following lower complexity bound for a stochastic first-order method to achieve an -accuracy solution:
Proof of Theorem 4.
Set . We consider a primal-dual problem of the form
| (18) |
The matrix and vector have the structure
where and are determined later. Rewriting the problem using and , we obtain:
where , .
For any given Lipschitz parameter and sharpness parameter such that , we denote , , and
Note that it holds for any that Denote
where is the first standard unit vector. One can check that the solution of the linear system is unique and given by
with . Furthermore, it holds that
Choose , and consider (18). The optimal solution to (18) is given by which is equivalent to
and thus
The optimal solution to (18) is given by . Moreover, the primal-dual problem (18) is -sharp, because
Without loss of generality we assume . Consider the stochastic oracle
| (19) | ||||
Then we know that is unbliased and , thus the stochastic gradient oracle satisfies Assumption 2.
By definition of span-respecting for randomized algorithms with the above oracle:
thus it holds that
Therefore, we have when is sufficiently large that
where the last inequality uses , and the fact that .
Similar result holds for :
| (20) |
To sum up, for any there exists an integer such that
| (21) | ||||
where second inequality is from Equation (21). Last equality uses . Taking square root we finally reach
| (22) |
∎
Remark 8.
RsEGM with the stochastic gradient oracle given in the proof (see (19)) has upper bound equal to . Compared with the above lower bound for unconstrained bilinear problem, , we conclude that RsEGM is tight up to logarithmic factors.
5 Stochastic Oracles
In this section, we propose four stochastic oracles and apply the main results to compute their total flop counts to obtain an approximate solution to the unconstrained bilinear problems and standard-form LP.
5.1 Unconstrained Bilinear Problems
We consider unconstrained bilinear problems
Without loss of generality, we drop the linear terms because this can be achieved by shifting the origin. Now we consider the unconstrained bilinear problems of the form
where . For comparison sake, we assume .
Converting to (1) and calculating , we have
First, we restate the total flop count of the optimal deterministic first-order primal dual method (it is achieved by restart primal-dual algorithms [7]). In order to obtain accuracy solution, the number of primal-dual iterations is , thus the total flop counts is (by noticing the flop count of one primal-dual iteration is )
To ease the comparison of the flop counts, we state the following simple fact ([50]):
| (23) |
Next, we describe four different stochastic oracles that satisfies Assumption 2. We will discuss their flop counts and how they improve deterministic restarted methods in different regimes.
The first two oracles are based row/column sampling, i.e. the stochastic oracle is constructed using one row and one column. The stochastic oracle is given by the following
where for and for are parameters of the sampling scheme with . Notice that
Thus the Lipschitz constant of stochastic oracle is bounded by
| (24) |
Oracle I: Uniform row-column sampling. In the first oracle, we uniformly randomly choose row and columns, i.e.,
Plugging in the choice of and into Equation (24), the Lipschitz constant of is upper bounded by
| (25) |
Combine Equation (4) together with (25) and set . The total flop count of RsEGM to find an -optimal solution using Oracle I is upper bounded by
Up to logarithmic factors, the RsEGM with uniformly sampled stochastic oracle is no worse than the deterministic method when A is dense according to Equation (23). And it improves the deterministic method when A is dense and .
Oracle II: Importance row-column sampling. In the second oracle, we use importance sampling to set the probability to select rows and columns:
Plugging in the choice of and into Equation (24), the Lipschitz constant of is upper bounded by
| (26) |
Combining equation (4) with (26) and setting , the total flop count of RsEGM with Oracle II to find an -optimal solution is
It follows from (23) that if is dense, RsEGM with importance sampled stochastic oracle is no worse than the optimal deterministic method up to a logarithmic factor. Furthermore, it improves the deterministic method when the stable rank , which is the case for low-rank dense matrix .
In the above two oracles, the flop cost of computing the stochastic oracle is . This can be further improved by using coordinate based sampling, where the flop cost per iteration is (See Appendix A.3 for details on efficient implementation of a more generic coordinate oracle).
Oracle III: Coordinate gradient estimator [11]. The third oracle only updates a primal coordinate and a dual coordinate, thus the cost per iteration can be as low as . The idea follows from [11]. More formally, we set
| (27) |
where , , and
It is easy to check that and are unbiased estimators for and respectively. Furthermore, one can show the Lipschitz constant of the Oracle III (in expectation) is (see [11] for more details):
| (28) |
where is the matrix with entry-wise absolute value of . Thus Oracle III satisfies Assumption 2 with Lipschitz constant .
For entry-wise non-negative dense matrix , RsEGM with Oracle III improve deterministic methods by a factor of . Unfortunately, there is no guaranteed improvement for a general matrix that involves negative value due to the definition of Lipschitz constant .
Oracle IV: Coordinate gradient estimator with a new probability distribution. Inspired by Oracle III, we propose Oracle IV, where we utilize the same gradient estimation (27) but with different probability values and :
Similarly, we know and are unbiased estimators for and respectively. Furthermore, the Lipschitz constant of Oracle IV can be computed by:
Thus, . Combine Equation (4) with and set . The total flop cost of RsEGM with Oracle IV to find an -solution becomes
Note that when the matrix in the unconstrained bilinear problem is dense, RsEGM improves the total flop counts of deterministic primal-dual method (upto log terms) by at least a factor of . The improvement does NOT require extra assumptions on the spectral property of (such as Oracle II) nor non-negativity of entries of (such as Oracle III).
5.2 Linear programming
Consider the primal-dual formulation of standard form LP (2). For the ease of comparison, we assume . Furthermore, we set
| (29) |
Recall that . The total flop count of restarted primal-dual algorithms is (see [7] for details)
(i) Consider RsEGM with stochastic Oracle II (importance sampling)
Similar to the unconstrained bilinear case (Section 5.1), we can obtain the flop count
(ii) Consider RsEGM with Oracle IV, i.e.,
With a similar calculation (Section 5.1), we can obtain the flop count:
Note that , thus RsEGM always has a complexity no worse than the deterministic primal-dual methods (upto log terms). In the case when the constraint matrix is dense, the improvement of the total flop counts over its deterministic counterpart is by at least a factor of .
6 Numerical Experiment
In this section, we present numerical experiments on two classes of problems: matrix games and linear programming.
6.1 Matrix games
Problem instances. Matrix games can be formulated as a primal-dual optimization problem with the following form:
where and are -dimensional and -dimensional simplex respectively and matrix . In the experiment, we generate three matrix game instances with scale using the instance-generation code from [3], which generated matrix game instances from classic literature [47, 46].
Progress metric. We use duality gap, i.e., as the performance measure for different algorithms. The duality gap can be easily evaluated by noticing it equals .
Projection and stochastic oracle. We use the projection oracle developed in [15] for the projection step onto standard simplex. We utilize the importance row-column sampling (i.e., Oracle II in Section 5.1) to implement RsEGM.
Results. We compare RsEGM with several notable methods in literature for solving matrix games with simplex constraint, namely, stochastic extragradient method with variance reduction (sEGM) [3], variance-reduced method for matrix games (EG-Car+19) [10] and deterministic restarted extragradient method (REGM) [7]. Figure 1 presents the numerical performance of different methods on the three matrix game instances. The -axis is the number of iterations for a deterministic gradient step (a stochastic gradient step is adjusted proportionally), and the -axis is the duality gap. We can observe that the proposed RsEGM exhibits the fastest convergence to obtain a high-accuracy solution and clearly exhibits a linear convergence rate, which verifies our theoretical guarantees. Furthermore, we can observe that both sEGM and EG-Car+19 exhibit slow convergence compared to RsEGM. Moreover, although REGM also enjoys linear convergence theoretically, the linear rate is only shown up in instance nemirovski2 and has not yet been triggered in the other two instances within 10000 iterations.
 |
 |
 |
6.2 Linear programming
Problem instances. In the experiments, we utilize the instances from MIPLIB 2017 to compare the performance of different algorithms. We randomly select six instances from MIPLIB 2017 and look at its root-node LP relaxation. For these instances, we first convert the instances to the following form:
| (30) | ||||
and consider its primal-dual formulation
| (31) | ||||
where , , and . We then compare the numerical performance of different primal-dual algorithms for solving (31). This is the problem format supported by the PDHG-based LP solver PDLP [5].
Progress metric. We use KKT residual of (31), i.e., a combination of primal infeasibility, dual infeasibility and primal-dual gap, to measure the performance of current iterates. More formally, the KKT residual of (30) is given by
Stochastic oracles. Similar to matrix games, we utilize the importance row-column sampling scheme to implement RsEGM, namely, stochastic Oracle II presented in Section 5.2.
Results. We compare RsEGM with two methods for solving linear programming: stochastic extragradient method with variance reduction without restart (sEGM) [3] and deterministic restarted extragradient method (REGM) [7]. Note that the variance-reduced method for matrix games (EG-Car+19) [10] compared in Section 6.1 is not considered for linear programming since it requires bounded domain, which is in general not satisfied by real-world LP instances, as those in the MIPLIB 2017 dataset.
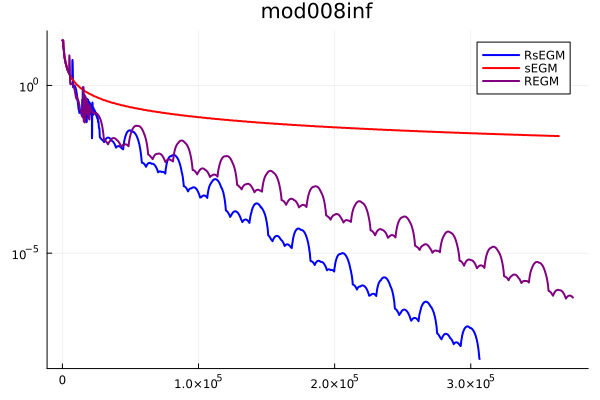
Figure 2 presents the convergence behaviors of different methods on the six instances. The -axis is the number of iterations for a deterministic gradient step (a stochastic gradient step is adjusted proportionally), and the -axis is the KKT residual. Again, we can see that RsEGM exhibits the fastest convergence to achieve the desired accuracy , and sEGM has slow sublinear convergence. REGM has competitive performance with linear convergence, but RsEGM enables earlier triggers of linear convergence and a faster eventual rate in general.
 |
 |
 |
 |
 |
 |
7 Conclusions
In this work, we introduce a stochastic algorithm for sharp primal-dual problems, such as linear programming and bilinear games, using variance reduction and restart. We show that our proposed stochastic methods enjoy a linear convergence rate, which improves the complexity of the existing algorithms in the literature. We also show that our proposed algorithm achieves the optimal convergence rate (upto a log term) in a wide class of stochastic algorithms.
Acknowledgement
The authors would like to thank Warren Schudy for proposing and discussing the efficient update of the coordinate stochastic oracle (Oracle IV) for LP.
References
- [1] Ahmet Alacaoglu, Volkan Cevher, and Stephen J Wright, On the complexity of a practical primal-dual coordinate method, arXiv preprint arXiv:2201.07684 (2022).
- [2] Ahmet Alacaoglu, Olivier Fercoq, and Volkan Cevher, On the convergence of stochastic primal-dual hybrid gradient, arXiv preprint arXiv:1911.00799 (2019).
- [3] Ahmet Alacaoglu and Yura Malitsky, Stochastic variance reduction for variational inequality methods, arXiv preprint arXiv:2102.08352 (2021).
- [4] Randy I Anderson, Robert Fok, and John Scott, Hotel industry efficiency: An advanced linear programming examination, American Business Review 18 (2000), no. 1, 40.
- [5] David Applegate, Mateo Díaz, Oliver Hinder, Haihao Lu, Miles Lubin, Brendan O’Donoghue, and Warren Schudy, Practical large-scale linear programming using primal-dual hybrid gradient, arXiv preprint arXiv:2106.04756 (2021).
- [6] David Applegate, Mateo Díaz, Haihao Lu, and Miles Lubin, Infeasibility detection with primal-dual hybrid gradient for large-scale linear programming, arXiv preprint arXiv:2102.04592 (2021).
- [7] David Applegate, Oliver Hinder, Haihao Lu, and Miles Lubin, Faster first-order primal-dual methods for linear programming using restarts and sharpness, arXiv preprint arXiv:2105.12715 (2021).
- [8] Kinjal Basu, Amol Ghoting, Rahul Mazumder, and Yao Pan, ECLIPSE: An extreme-scale linear program solver for web-applications, Proceedings of the 37th International Conference on Machine Learning (Virtual) (Hal Daumé III and Aarti Singh, eds.), Proceedings of Machine Learning Research, vol. 119, PMLR, 13–18 Jul 2020, pp. 704–714.
- [9] Edward H Bowman, Production scheduling by the transportation method of linear programming, Operations Research 4 (1956), no. 1, 100–103.
- [10] Yair Carmon, Yujia Jin, Aaron Sidford, and Kevin Tian, Variance reduction for matrix games, arXiv preprint arXiv:1907.02056 (2019).
- [11] , Coordinate methods for matrix games, 2020 IEEE 61st Annual Symposium on Foundations of Computer Science (FOCS), IEEE, 2020, pp. 283–293.
- [12] Antonin Chambolle, Matthias J Ehrhardt, Peter Richtárik, and Carola-Bibiane Schonlieb, Stochastic primal-dual hybrid gradient algorithm with arbitrary sampling and imaging applications, SIAM Journal on Optimization 28 (2018), no. 4, 2783–2808.
- [13] Antonin Chambolle and Thomas Pock, A first-order primal-dual algorithm for convex problems with applications to imaging, Journal of mathematical imaging and vision 40 (2011), no. 1, 120–145.
- [14] Abraham Charnes and William W Cooper, The stepping stone method of explaining linear programming calculations in transportation problems, Management science 1 (1954), no. 1, 49–69.
- [15] Laurent Condat, Fast projection onto the simplex and the l 1 ball, Mathematical Programming 158 (2016), no. 1-2, 575–585.
- [16] George Bernard Dantzig, Linear programming and extensions, vol. 48, Princeton university press, 1998.
- [17] Constantinos Daskalakis, Andrew Ilyas, Vasilis Syrgkanis, and Haoyang Zeng, Training GANs with optimism, International Conference on Learning Representations, 2018.
- [18] Damek Davis, Dmitriy Drusvyatskiy, Kellie J MacPhee, and Courtney Paquette, Subgradient methods for sharp weakly convex functions, Journal of Optimization Theory and Applications 179 (2018), no. 3, 962–982.
- [19] Aaron Defazio, Francis Bach, and Simon Lacoste-Julien, Saga: A fast incremental gradient method with support for non-strongly convex composite objectives, Advances in neural information processing systems, 2014, pp. 1646–1654.
- [20] Jim Douglas and Henry H Rachford, On the numerical solution of heat conduction problems in two and three space variables, Transactions of the American mathematical Society 82 (1956), no. 2, 421–439.
- [21] Jonathan Eckstein and Dimitri P Bertsekas, On the Douglas—Rachford splitting method and the proximal point algorithm for maximal monotone operators, Mathematical Programming 55 (1992), no. 1-3, 293–318.
- [22] Jonathan Eckstein, Dimitri P Bertsekas, et al., An alternating direction method for linear programming, (1990).
- [23] Olivier Fercoq, Quadratic error bound of the smoothed gap and the restarted averaged primal-dual hybrid gradient, (2021).
- [24] Robert M Freund and Haihao Lu, New computational guarantees for solving convex optimization problems with first order methods, via a function growth condition measure, Mathematical Programming 170 (2018), no. 2, 445–477.
- [25] Jacek Gondzio, Interior point methods 25 years later, European Journal of Operational Research 218 (2012), no. 3, 587–601.
- [26] Robert M Gower, Mark Schmidt, Francis Bach, and Peter Richtárik, Variance-reduced methods for machine learning, Proceedings of the IEEE 108 (2020), no. 11, 1968–1983.
- [27] Fred Hanssmann and Sidney W Hess, A linear programming approach to production and employment scheduling, Management science (1960), no. 1, 46–51.
- [28] Alan J Hoffman, On approximate solutions of systems of linear inequalities, Journal of Research of the National Bureau of Standards 49 (1952), 263–265.
- [29] Thomas Hofmann, Aurelien Lucchi, Simon Lacoste-Julien, and Brian McWilliams, Variance reduced stochastic gradient descent with neighbors, arXiv preprint arXiv:1506.03662 (2015).
- [30] Kevin Huang, Nuozhou Wang, and Shuzhong Zhang, An accelerated variance reduced extra-point approach to finite-sum vi and optimization, arXiv preprint arXiv:2211.03269 (2022).
- [31] Rie Johnson and Tong Zhang, Accelerating stochastic gradient descent using predictive variance reduction, Advances in neural information processing systems 26 (2013), 315–323.
- [32] Narendra Karmarkar, A new polynomial-time algorithm for linear programming, Proceedings of the sixteenth annual ACM symposium on Theory of computing, 1984, pp. 302–311.
- [33] Galina M Korpelevich, The extragradient method for finding saddle points and other problems, Matecon 12 (1976), 747–756.
- [34] Dmitry Kovalev, Samuel Horváth, and Peter Richtárik, Don’t jump through hoops and remove those loops: Svrg and katyusha are better without the outer loop, Algorithmic Learning Theory, PMLR, 2020, pp. 451–467.
- [35] Puya Latafat, Nikolaos M Freris, and Panagiotis Patrinos, A new randomized block-coordinate primal-dual proximal algorithm for distributed optimization, IEEE Transactions on Automatic Control 64 (2019), no. 10, 4050–4065.
- [36] Adrian S Lewis and Jingwei Liang, Partial smoothness and constant rank, arXiv preprint arXiv:1807.03134 (2018).
- [37] Jingwei Liang, Jalal Fadili, and Gabriel Peyré, Local linear convergence analysis of primal–dual splitting methods, Optimization 67 (2018), no. 6, 821–853.
- [38] Hongzhou Lin, Julien Mairal, and Zaid Harchaoui, A universal catalyst for first-order optimization, Advances in neural information processing systems, 2015, pp. 3384–3392.
- [39] Tianyi Lin, Shiqian Ma, Yinyu Ye, and Shuzhong Zhang, An admm-based interior-point method for large-scale linear programming, Optimization Methods and Software 36 (2021), no. 2-3, 389–424.
- [40] Qian Liu and Garrett Van Ryzin, On the choice-based linear programming model for network revenue management, Manufacturing & Service Operations Management 10 (2008), no. 2, 288–310.
- [41] Haihao Lu, An -resolution ODE framework for discrete-time optimization algorithms and applications to convex-concave saddle-point problems, arXiv preprint arXiv:2001.08826 (2020).
- [42] Alan S Manne, Linear programming and sequential decisions, Management Science 6 (1960), no. 3, 259–267.
- [43] Aryan Mokhtari, Asuman Ozdaglar, and Sarath Pattathil, A unified analysis of extra-gradient and optimistic gradient methods for saddle point problems: Proximal point approach, International Conference on Artificial Intelligence and Statistics, 2020.
- [44] Tianlong Nan, Yuan Gao, and Christian Kroer, Extragradient svrg for variational inequalities: Error bounds and increasing iterate averaging, arXiv preprint arXiv:2306.01796 (2023).
- [45] Arkadi Nemirovski, Prox-method with rate of convergence O(1/t) for variational inequalities with lipschitz continuous monotone operators and smooth convex-concave saddle point problems, SIAM Journal on Optimization 15 (2004), no. 1, 229–251.
- [46] , Mini-course on convex programming algorithms, Lecture notes (2013).
- [47] Arkadi Nemirovski, Anatoli Juditsky, Guanghui Lan, and Alexander Shapiro, Robust stochastic approximation approach to stochastic programming, SIAM Journal on optimization 19 (2009), no. 4, 1574–1609.
- [48] Yurii Nesterov, Gradient methods for minimizing composite functions, Mathematical Programming 140 (2013), no. 1, 125–161.
- [49] Brendan O’Donoghue and Emmanuel Candes, Adaptive restart for accelerated gradient schemes, Foundations of computational mathematics 15 (2015), no. 3, 715–732.
- [50] Balamurugan Palaniappan and Francis Bach, Stochastic variance reduction methods for saddle-point problems, Advances in Neural Information Processing Systems, 2016, pp. 1416–1424.
- [51] Sebastian Pokutta, Restarting algorithms: Sometimes there is free lunch, International Conference on Integration of Constraint Programming, Artificial Intelligence, and Operations Research, Springer, 2020, pp. 22–38.
- [52] Boris Polyak, Sharp minima, Proceedings of the IIASA Workshop on Generalized Lagrangians and Their Applications, Laxenburg, Austria. Institute of Control Sciences Lecture Notes, Moscow, 1979.
- [53] R. Tyrrell Rockafellar, Monotone operators and the proximal point algorithm, SIAM Journal on Control and Optimization 14 (1976), no. 5, 877–898.
- [54] Vincent Roulet and Alexandre d’Aspremont, Sharpness, restart, and acceleration, SIAM Journal on Optimization 30 (2020), no. 1, 262–289.
- [55] Mark Schmidt, Nicolas Le Roux, and Francis Bach, Minimizing finite sums with the stochastic average gradient, Mathematical Programming 162 (2017), no. 1-2, 83–112.
- [56] Chaobing Song, Cheuk Yin Lin, Stephen Wright, and Jelena Diakonikolas, Coordinate linear variance reduction for generalized linear programming, Advances in Neural Information Processing Systems 35 (2022), 22049–22063.
- [57] Junqi Tang, Mohammad Golbabaee, Francis Bach, et al., Rest-katyusha: exploiting the solution’s structure via scheduled restart schemes, Advances in Neural Information Processing Systems, 2018, pp. 429–440.
- [58] Paul Tseng, On linear convergence of iterative methods for the variational inequality problem, Journal of Computational and Applied Mathematics 60 (1995), no. 1-2, 237–252.
- [59] Tianbao Yang and Qihang Lin, RSG: Beating subgradient method without smoothness and strong convexity, The Journal of Machine Learning Research 19 (2018), no. 1, 236–268.
- [60] Renbo Zhao, Optimal stochastic algorithms for convex-concave saddle-point problems, arXiv preprint arXiv:1903.01687 (2020).
Appendix A Appendix
A.1 Sharpness and metric sub-regularity
In this subsection we establish a connection between sharpness based on the normalized duality gap [7] and metric sub-regularity [35]. The result is summarized in the following proposition.
Proposition 1.
Consider primal-dual problem . If for any the primal-dual problem is sharp with constant , i.e. for all , then it satisfies metric sub-regularity at for 0, i.e. .
Proof. For any
where the first inequality utilizes the definition of sharpness, the third one is due to the convexity-concavity of .
Take infimum over we have
∎
A.2 LP does not satisfy metric sub-regularity globally
In this subsection, we present a counter-example to show that the Lagrangian’s generalized gradient of LP does not satisfy metric sub-regularity globally.
Consider an LP
where and . The optimal solution is unique . The primal dual form is
and the optimal primal-dual solution . Notice that
thus
If the Lagrangian’s generalized gradient of LP satisfies global metric sub-regularity, i.e., there exists a constant such that , then
However, this is impossible by fixing and letting . This leads to a contradiction.
Therefore LP does not satisfy the global metric sub-regularity. Although we use Euclidean norm for illustration, due to the equivalence of norms on , LP does not satisfy the global metric sub-regularity under any norm. Notice that metric subregularity is a weaker condition than sharpness (see Appendix A.1). A direct consequence is that LP is not globally sharp.
A.3 Efficient update for coordinate sampling
In Section 5.1, we propose two coordinate gradient estimators, Oracle III and Oracle IV. Here, we present an efficient computation approach that flops for a snapshot step (i.e., the steps when updating the snapshot ), and flops for a non-snapshot step (i.e., the steps between two snapshot steps). With such efficient update rules, we obtain the total cost computation for the Oracle IV rows in Table 1 and Table 2.
Consider a generic coordinate stochastic oracle
where are standard unit vectors in and , respectively, and are two arbitrary scalars. Oracle III and IV are special cases for this generic coordinate stochastic oracle.
Let be the -th snapshot step, i.e., the -th updates of . Consider a non-snapshot step with , i.e., the steps between two consecutive snapshot steps, then we know and do not change for any . Furthermore, it is easy to check that has update
Generalizing this simple observation, a closed-form update rule holds for iterates with that
| (32) |
Thus motivated, we can run Algorithm 1 with an efficient update rule using the following procedure:
Snapshot steps. In a snapshot step (i.e., ), we compute using (32), set the iteration of last update of coordinate (denoted as ) to , namely, for , record in memory, and set . The computational cost is . Then we compute and store in memory. The computational cost is . Finally, we compute the running average of iterates , and the cost is by taking advantage of the sum over geometric series.
Non-snapshot steps. In a non-snapshot step (i.e, ), if updates coordinate and , we compute using (32) and update and . Then set . We store in memory. The cost is .
As such, the cost when updating the snapshot is and the cost for a non-snapshot step is for Oracle III and Oracle IV discussed in Section 5.
A.4 Comparison with SPDHG
[2, Theorem 4.6] shows the linear convergence of SPDHG for problems with global metric sub-regularity, such as the unconstrained bilinear problem. However, the obtained linear convergence rate may involve parameters that are not easy to interpret. We here apply their results to unconstrained bilinear problems with more transparent parameters so that we make a comparison with our Theorem 2.
Using the notation in [2], they obtained
where , , , . For simplicity, we consider the uniform sampling scheme with , and thus (the other schemes follow with a similar arguments). The total number of iterations for SPDHG to achieve -accuracy is of order
where the definitions of and are defined in [2, Lemma 4.4]. The operators and are indeed a bit complicated so that the upper bound is hard to derive. Now we lower bound the term .
where the first inequality is due to the definition of operator norm, the second inequality follows from the choice of and the last equality is from the choice of such that .
Thus we have the complexity of SPDHG is at least
In contrast, the complexity of RsEGM is . This showcase RsEGM has an improved linear convergence rate for solving unconstrained bilinear problems compared to SPDHG in terms of the condition number (after ignoring the terms). Such an improvement comes from the restarted scheme, similar to the deterministic case [7]. Lastly, we would like to mention that SPDHG is a semi-stochastic algorithm, where the primal is a full gradient update and the dual is a stochastic gradient update, while RsEGM takes stochastic gradient steps in both primal and dual space (except the snapshot steps).