Near-perfect Coverage Manifold Estimation in Cellular Networks via conditional GAN
Abstract
This paper presents a conditional generative adversarial network (cGAN) that translates base station location (BSL) information of any Region-of-Interest (RoI) to location-dependent coverage probability values within a subset of that region, called the region-of-evaluation (RoE). We train our network utilizing the BSL data of India, the USA, Germany, and Brazil. In comparison to the state-of-the-art convolutional neural networks (CNNs), our model improves the prediction error ( difference between the coverage manifold generated by the network under consideration and that generated via simulation) by two orders of magnitude. Moreover, the cGAN-generated coverage manifolds appear to be almost visually indistinguishable from the ground truth.
Index Terms:
Coverage, Network Performance, Conditional GAN, Stochastic Geometry.I Introduction
Understanding how the topology of a network influences its performance is one of the central questions in communication networks. Topology-to-performance map is not only crucial for assessing the efficacy of existing networks but also important for designing future ones. One can measure the performance of a network by performing Monte Carlo (MC) simulations over a long time horizon. However, depending on the level of detail incorporated into the simulation framework, this process could demand a high execution time. For example, one way to model channels in the fifth generation and beyond (5GB) networks is via ray tracing methods [1] that require a large computation time to yield high-fidelity output. Another approach to evaluate the network performance is via stochastic geometry (SG) that yields spatially averaged value of a certain performance metric by incorporating some simplifying assumptions. For example, one of the earliest SG-based models [2] assumes that the base stations (BS) and users in outdoor wireless networks are placed according to two independent Poisson point processes (PPPs). This helps [2] to derive an analytical expression for computing the average coverage probability (ACP) of the entire network. The model of PPP was later replaced by more realistic -tier PPP [3], repulsion-based models [4], cluster-based models [5], -stable processes [6], etc. Although ACP provides aggregated information about a network’s performance, unlike simulation, it cannot characterize the performance metric as a function of users’ locations. We want to state that, alongside ACP, another metric, called the meta distribution (MD) [7], is also popularly used to evaluate a network’s performance. MD is defined to be the cumulative density function (cdf) of coverage values in the network. Although MD provides more information than ACP, the information is still spatially aggregated in nature. Hence, it is impossible to obtain location-specific values of the coverage probability solely from the knowledge of the MD. In summary, SG-based models cannot be true replacements for computation -hungry simulation methods. Moreover, recent SG-based models such as [6] require a fairly complex parameter calibration process, and their expression of ACP incorporates complicated complex integrals that itself could be difficult to evaluate.
It was shown in our previous work [8] that a properly trained convolutional neural network (CNN) can be significantly better at predicting location-specific coverage probability values than SG-based models. Despite this success, CNN-generated values appear to be noticeably different from the ground truth (Fig. 3 provides a comparison). In this paper, we introduce conditional Generative Adversarial Network (cGAN) architecture to bridge this gap. At its core, the task of predicting coverage probability is similar to the task of image translation which cGAN excels at [9]. In particular, the network’s topology can be represented as a binary matrix whose elements indicate either the presence or the absence of a BS while coverage values can be presented by another matrix with elements in . Clearly, both of these matrices can be treated as grayscale images and processed by cGAN. We train our proposed network using the BS location data of India, Brazil, the USA, and Germany and demonstrate that the error performance of our model is at least two orders of magnitude better than that of the CNN and SG-based models. We also show that the coverage values generated by our trained cGAN are visually indistinguishable from the ground truth. It clearly establishes that a properly trained NN can be used as an efficient and reliable replica of a simulator which dramatically accelerates the network evaluation and planning process.
II System Model
We consider a large area where the network performance needs to be evaluated. The space can be as large as a country depending on the available dataset. For ease of computation, is divided into multiple square-shaped region-of-interest (RoIs) of size where the exact value of is specified later. Let, be an arbitrary RoI, and be the locations of number of base stations (BSs) that are located within . In this paper, we solely focus on downlink communication and assume that each user is served by its closest BS. Hence, if the user located at is served by the -th BS, , then . The (random) channel gain between the user and the -th BS is denoted as . Clearly, the signal-to-interference-plus-noise-ratio (SINR) experienced at can be written as follows.
| (1) |
where is the pathloss coefficient, is the transmission power of the BSs, and is the noise variance. We would like to point out that the SINR expression does not include interferences caused by the BSs lying outside of the RoI, . This is a good approximation if is sufficiently large and is near the center of , thereby ensuring that it is far away from out-of-RoI BSs. However, if is located near the edges of , then may no longer be accurate. To account for this edge effect, we evaluate SINR only within a concentric square subset of the RoI of size which we term as the Region-of-Evaluation (RoE). Using , we can obtain the coverage probability at (located inside an RoE) as follows.
| (2) |
where is a pre-defined SINR threshold. Note that, by varying in , one can obtain the coverage manifold within the RoE by using the BS location information inside the associated RoI. Although the location variables are continuous in nature, we must discretize them for computational purposes. This is achieved by discretizing each RoI, and RoE into , and square grids respectively where the exact value of is provided later. Clearly, the BS locations inside an RoI can be described by a binary matrix of size such that the values of its elements denote either the presence or absence of a BS at the specified location. On the other hand, the coverage manifold inside an RoE can be treated as an sized matrix each of whose elements lies in .
III cGAN-based Coverage Manifold Prediction
It is clear from the above discussion that the task of translating BS locations (inside an RoI) to a coverage manifold (inside an RoE) is similar to the task of image-to-image translation. As stated earlier, we previously employed a convolutional neural network (CNN)-based auto-encoder to accomplish this job [8]. In this paper, we employ conditional GAN (cGAN) and exhibit that it improves the prediction error performance, as compared to that of the CNN, by two orders of magnitude.
III-A Preliminaries of the cGAN
Let the BS locations within an RoI be denoted as the matrix , and the simulated coverage manifold within its RoE be the matrix, . Our discussion in section II points out that there is a function, such that , i.e., can be fully constructed solely using . Conditional GAN (cGAN) is one of the popular neural network (NN) architectures that tries to mimic the map, via supervised learning. cGAN is primarily composed of two main components-the generator, , and the discriminator, , where and are associated neural network parameters. The objective of the generator is to generate a matrix, from a given input matrix, such that it is hard for the discriminator to distinguish from its corresponding real output matrix . The loss function of cGAN can be written as follows.
| (3) | ||||
where the expectations are computed over the joint distribution of , and defines the probability assigned by the discriminator of being the real output of . Mathematically, the objective function of cGAN be expressed as follows.
| (4) | ||||
The regularizer is added to ensure that, in addition to fooling the discriminator, the generator also generates matrices that are close to the real output. The function denotes the norm, and is a regularizer parameter. Fig. 1 portrays the working principle of cGAN.


III-B Proposed Architecture
We use U-Net [10] architecture for the generator. Note that the size of the input (BS locations in an RoI) is whereas that of the output (coverage manifold in an RoE) is . Thus, both can be used as grayscale images with one channel. We first pass the input through a convolutional layer with stride followed by a Leaky ReLU activation layer so that its output appears to be of the same size as that of the coverage manifold in an RoE. The resulting matrix is then passed through a series of encoders followed by a series of decoders. Each encoder is composed of a convolutional layer, a Leaky ReLU layer, and a BatchNorm Layer. Convolutional layers are further composed of convolution filters, each with kernel size , and stride . On the other hand, a decoder is composed of a ReLU module, a deconvolution layer (containing deconvolution filters with kernels of size , and stride ), and a BatchNorm layer. In the last decoder, BatchNorm operation is replaced by an activation function, where so that the elements of the output matrix lie in . Skip connections are added between pairwise encoder and decoder layers by concatenating the input of the encoder to the output of the decoder. This helps retain information at various depths/scales and circumvents the vanishing gradient problem.
The discriminator is modeled using a PatchGAN [9] architecture. Its input is sequentially passed through a convolution block, a Leaky ReLU function, and a series of encoder blocks. Each convolutional layer comprises filters with kernels of size , and stride . The primary characteristic of a PatchGAN discriminator is that it only attempts to identify whether a part of the given input is real. In contrast, an ordinary discriminator attempts to do the same for the entire input. In line with this philosophy, the output of the last encoder is passed through a convolution layer followed by the activation, defined earlier. This yields decision probabilities of the discriminator network corresponding to each receptive field of the convolution layer. We then average all these probabilities to produce the decision probability of the entire input. Fig. 2 depicts each component of the cGAN architecture.



III-C Training and Testing Procedures
In order to train the proposed cGAN architecture, we utilize BS location datasets111Collected from the website www.opencellid.org of four different countries, namely India, the USA, Germany, and Brazil. The coordinates of the BSs are projected onto a flat geometry via the following approach. Let the spherical coordinates of two closely located BSs be , and . In the flat geometry, their difference in coordinates maps to where indicates the average radius of the Earth. Now we partition each country into multiple RoIs of size . Next, we discard those RoIs that contain either less than or more than number of BSs where the values of and are specified later. The reason behind imposing the above thresholds is to remove the outlier cases. In the remaining pool of RoIs, we randomly select for training the proposed cGAN while the rest are used for testing its performance. We use stochastic gradient descent (SGD) with Adam optimizer to train the network.
The performance of cGAN is assessed via error. Specifically, if is the trained parameter of the generator, are the locations of BSs inside RoIs that are used in the testing phase and denote their associated simulated coverage manifolds, then the error is defined as,
| (5) |
To demonstrate the superiority of our method, we compare the error performance of cGAN, with that of a trained CNN model [8]. We also compare the performance of cGAN to that of a PPP and the best-fitted SG model (explained below). Note that all SG-based models estimate only the (spatially) averaged coverage probability (ACP) and not its location-specific value. For example, the ACP estimated by a PPP is given by Theorem 1 in [2] which is only dependent on the BS density. Therefore, if denotes the empirical BS density of the RoI, , and defines its ACP computed by the PPP model, then the associated estimated coverage manifold can be written as where is a square matrix of size with all entries equal to one. The error performance of the PPP can now be calculated following a similar equation to . On the other hand, the ACP of the RoI, , as estimated by the best-fitted SG (BFSG) model is given by where , as stated before, is the simulated coverage manifold of , and denotes the average function. Hence, the associated coverage manifold yielded by the BFSG is , and its performance can be quantified similar to . Note that the BFSG model provides an upper bound to the performances of all SG-based models as they attempt to estimate .
IV Numerical Results
Parameters: For the USA, and Germany, we take the size of an RoI to be km because of their dense BS deployment while for India, and Brazil, we use km. For all datasets, the discretization parameter is chosen as which leads to m of resolution for the USA, and Germany and m of resolution for India, and Brazil. The pathloss coefficient is taken as , and the BS-user channels gains are assumed to be exponentially distributed with mean . The minimum and maximum thresholds for the number of BS in an RoI are taken as respectively. We assign as the selected RoIs are interference limited. Finally, to project the BS coordinates onto a flat geometry, the Earth is presumed to be a perfect sphere with km radius.
| dB | dB | dB | dB | dB | |
|---|---|---|---|---|---|
| PPP | 0.2750 | 0.3700 | 0.3157 | 0.2233 | 0.1432 |
| BFSG | 0.2312 | 0.2944 | 0.2274 | 0.1561 | 0.0995 |
| CNN | 0.1977 | 0.1551 | 0.0940 | 0.0530 | 0.0331 |
| cGAN | 0.0068 | 0.0012 | 0.0011 | 0.0007 | 0.0004 |
| dB | dB | dB | dB | dB | |
|---|---|---|---|---|---|
| PPP | 0.2155 | 0.3160 | 0.3076 | 0.2376 | 0.1602 |
| BFSG | 0.1454 | 0.2962 | 0.2825 | 0.2152 | 0.1449 |
| CNN | 0.1279 | 0.2325 | 0.1527 | 0.0891 | 0.0560 |
| cGAN | 0.0065 | 0.0019 | 0.0014 | 0.001 | 0.0006 |
| dB | dB | dB | dB | dB | |
|---|---|---|---|---|---|
| PPP | 0.2034 | 0.2974 | 0.3056 | 0.2460 | 0.1698 |
| BFSG | 0.1512 | 0.2790 | 0.2989 | 0.2412 | 0.1676 |
| CNN | 0.1285 | 0.2479 | 0.1662 | 0.0970 | 0.0616 |
| cGAN | 0.0014 | 0.0017 | 0.0015 | 0.0011 | 0.0007 |
| dB | dB | dB | dB | dB | |
|---|---|---|---|---|---|
| PPP | 0.4266 | 0.4312 | 0.3268 | 0.2165 | 0.1338 |
| BFSG | 0.3039 | 0.2589 | 0.1786 | 0.1158 | 0.0716 |
| CNN | 0.1827 | 0.1420 | 0.0898 | 0.0523 | 0.0331 |
| cGAN | 0.0021 | 0.0018 | 0.001 | 0.0006 | 0.0004 |
The main result of our paper is provided in Table I where we list the error performance of four different approaches, namely cGAN, CNN, BFSG, and PPP for four different countries and a wide range of values of the SINR threshold, . Observe that in all of these cases, the error corresponding to cGAN is lower than that of other methods by at least two orders of magnitude. On the other hand, although the error performance of the CNN is better than that of PPP and BFSG, they are of the same order of magnitude. Another interesting trend observed in this result is that the performances of all models improve with an increase in . This may be because a high threshold shortens the typical range of coverage probabilities, thus making prediction easier. In Fig. 3, we visually compare the ground truth manifold with that generated by the cGAN and the CNN. It is noticed that the output of cGAN is visually indistinguishable from the ground truth and the output of the CNN is remarkably distinct. Though we report results here for Rayleigh distribution only for lack of space, we note similar results for other channel models such as Nakagami, probabilistic blocking, etc. cGAN architecture takes around 4 hours for training with a 64 GB RAM, 3.0 GHz processor, and an NVIDIA A100-SXM4-40GB GPU whereas an efficient implementation of CNN-AE takes around 3 hours to train. Since NNs are trained via an offline process, a slight increase in training time has little impact on network planning applications. After training, both CNN-AE and cGAN provide similar execution times (1.93 sec and 2.07 sec, respectively). However, the latter NN offers a significant improvement in the prediction accuracy as shown in Table I.





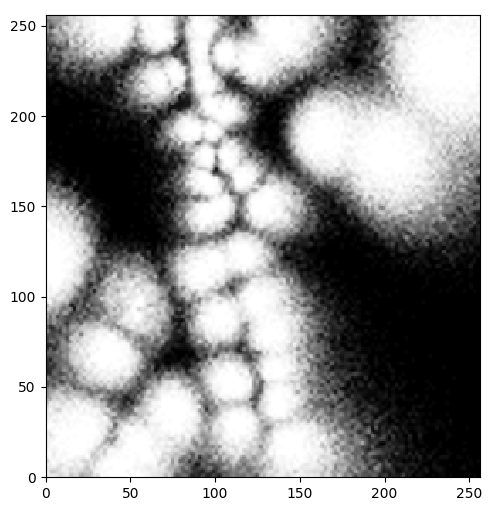



V Conclusion
We propose a cGAN architecture that uses BSL data to yield coverage manifolds. In comparison to the state-of-the-art NNs, our model improves the error by two orders of magnitude. This paper assumes an LTE technology with omnidirectional transmission of BSs. However, extending this study for directional coordinate multi-point (CoMP) transmissions in emerging 5G and O-RAN technologies is an important future consideration.
References
- [1] D. He, B. Ai, K. Guan, L. Wang, Z. Zhong, and T. Kürner, “The design and applications of high-performance ray-tracing simulation platform for 5g and beyond wireless communications: A tutorial,” IEEE communications surveys & tutorials, vol. 21, no. 1, pp. 10–27, 2018.
- [2] J. G. Andrews, F. Baccelli, and R. K. Ganti, “A tractable approach to coverage and rate in cellular networks,” IEEE Transactions on communications, vol. 59, no. 11, pp. 3122–3134, 2011.
- [3] H. S. Dhillon, R. K. Ganti, F. Baccelli, and J. G. Andrews, “Modeling and analysis of k-tier downlink heterogeneous cellular networks,” IEEE Journal on Selected Areas in Communications, vol. 30, no. 3, pp. 550–560, 2012.
- [4] N. Deng, W. Zhou, and M. Haenggi, “The ginibre point process as a model for wireless networks with repulsion,” IEEE Transactions on Wireless Communications, vol. 14, no. 1, pp. 107–121, 2014.
- [5] M. Afshang and H. S. Dhillon, “Poisson cluster process based analysis of hetnets with correlated user and base station locations,” IEEE Transactions on Wireless Communications, vol. 17, no. 4, pp. 2417–2431, 2018.
- [6] R. Li et al., “The stochastic geometry analyses of cellular networks with -stable self-similarity,” IEEE Transactions on Communications, vol. 67, no. 3, pp. 2487–2503, 2018.
- [7] M. Haenggi, “The meta distribution of the sir in poisson bipolar and cellular networks,” IEEE Transactions on Wireless Communications, vol. 15, no. 4, pp. 2577–2589, 2015.
- [8] W. U. Mondal, P. D. Mankar, G. Das, V. Aggarwal, and S. V. Ukkusuri, “Deep learning-based coverage and rate manifold estimation in cellular networks,” IEEE Transactions on Cognitive Communications and Networking, vol. 8, no. 4, pp. 1706–1715, 2022.
- [9] P. Isola et al., “Image-to-image translation with conditional adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, Hawaii, USA, 2017, pp. 1125–1134.
- [10] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in 2015 Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 2015, pp. 234–241.