Named Entity Linking with Entity Representation by Multiple Embeddings
Abstract
We propose a simple and practical method for named entity linking (NEL), based on entity representation by multiple embeddings. To explore this method, and to review its dependency on parameters, we measure its performance on Namesakes, a highly challenging dataset of ambiguously named entities. Our observations suggest that the minimal number of mentions required to create a knowledge base (KB) entity is very important for NEL performance. The number of embeddings is less important and can be kept small, within as few as 10 or less. We show that our representations of KB entities can be adjusted using only KB data, and the adjustment can improve NEL performance. We also compare NEL performance of embeddings obtained from tuning language model on diverse news texts as opposed to tuning on more uniform texts from public datasets XSum, CNN / Daily Mail. We found that tuning on diverse news provides better embeddings.
1 Introduction
Named entity linking (NEL) is a task of linking a mention of an entity in a text to the correct reference entity in the knowledge base (KB) Rao et al. (2012); Yang and Chang (2015); Sorokin and Gurevych (2018); Kolitsas et al. (2018); Logeswaran et al. (2019); Wu et al. (2020); Li et al. (2020); Sevgili et al. (2021). Here we consider NEL in a specific setting, with the intention to present our NEL method, and to probe the difficulty of dealing with namesakes:
-
1.
The mention of interest is assumed to be located in the text, i.e. the named entity recognition task is done.
-
2.
Only the local context surrounding the mention of interest is used for the linking, no other mentions in the text are used.
-
3.
KB is fixed and built on reliable data.
-
4.
Both KB and the pool of mentions are mostly composed of namesakes.
-
5.
A mention may have the corresponding entity in KB, or may not. We call the former mention familiar, and the latter stranger.
The point 1 means that the named entity recognition task is assumed to be done, leaving us NEL in a narrow sense Rao et al. (2012); Wu et al. (2020); Logeswaran et al. (2019). The point 2 makes the problem better defined. Using other mentions of the same entity or related entities can help NEL, but our focus is on imitating the more difficult cases of lone mentions (with no related mentions in the vicinity in the text). For using related named entities see for example Zaporojets et al. (2022).
The point 3 leaves out the question of growing or improving KB by the encountered mentions (familiar or stranger). KB built on reliable data allows to isolate the effect of KB pollution by intentionally adding wrong data, as we will do in this paper. The point 4 makes it easier to reveal NEL errors and to observe dependencies of our method on parameters.
Both the points 3 and 4 are satisfied by choosing recent dataset Namesakes Vasilyev et al. (2021b, a), as a dataset with human labeled ambiguously named entities. Another recent dataset - Ambiguous Entity Retrieval (AmbER) Chen et al. (2021) - does include subsets of identically named entities (for the purpose of fact checking, slot filling, and question-answering tasks), but it is automatically generated. Most existing NEL-related datasets do not focus on highly ambiguous names Ratinov et al. (2011); Hoffart et al. (2011); Ferragina and Scaiella (2012); Ji et al. (2017); Guo and Barbosa (2018).
In this paper we focus on presenting our NEL method. We test it on KB entities and mentions taken from Namesakes: the challenging dataset is helpful in revealing the behavior of our NEL method and its dependencies on parameters. Our contribution:
-
1.
We introduce a simple and practical representation of entity in KB, and explore NEL to such representations on example of highly ambiguous mentions from Namesakes.
-
2.
We suggest an adjustment of KB based on its entities, and show that it helps in reducing NEL errors.
In Section 2 we introduce our entity representation and NEL for KB with such representations. In Section 3 we explain how we use Namesakes dataset in our NEL evaluation experiments. In Section 4 we present the experiments and results.
2 Named Entity as a Set of Embeddings
2.1 Knowledge Base Entity
A named entity can be described in very different contexts Ma et al. (2021); FitzGerald et al. (2021). The same person can be a scientist and a dissident, the same location can be described by its nature and by its social events and so on. This is the motivation to represent an entity by multiple embeddings - at least if each embedding is created from a mention in specific context.
Our representation of KB entity is composed of multiple embeddings, and consists of:
-
1.
Normalized embeddings , their norms and assigned thresholds , initially set . The number of the embeddings is restricted by agglomerative clustering (Appendix B), .
-
2.
Entity threshold .
-
3.
Entity surface names .
-
4.
References to similar entities .
In this and the next subsections we explain the details of this representation, and our NEL procedure that uses it.
A fundamental element used in building an entity is an embedding of a mention of this entity in some context. We tuned a pretrained BERT Devlin et al. (2019) language model ’bert-base-uncased’, accessed via the transformers library ((Wolf et al., 2020)), on generic random news, with named entities located in the texts. The only goal of tuning is to enhance LM performance on the mentions of named entities, without changing LM goal or making LM specialized on any particular set of named entities. The tuning and inference are as following:
-
1.
At tuning only the named entities - all the located mentions within the input window in the text - serve as the labels for prediction. In input the mentions are being either left unchanged (probability 0.5) or replaced by another random mention from the same text.
-
2.
At inference the text is kept as it is, and the model is run only once on each input-size chunk of the text. The embeddings are picked up from the first token of the entity surface form - for each named entity that happened to occur in the input-size chunk.
Through all the paper, except Section 4.3, we use the model tuned on random generic news. In Section 4.3 we use the model tuned on texts of more uniform style: the texts from XSum Narayan et al. (2018) and CNN / Daily Mail Hermann et al. (2015); Nallapati et al. (2016) datasets. This allowed us to observe effect of using embeddings from a model exposed to a lesser variety of styles. For more details of the tuning see Appendix A.
There can be many mentions available for building a KB entity, even if only reliable verified mentions are used. If the number of the embeddings obtained from the mentions is higher than , the embeddings are clustered, and only ’central’ embeddings (closest to the centers of the clusters) are stored. We use agglomerative clustering (Appendix B). The surface names of all the mentions used for creating an entity are stored in the entity.
2.2 Linking a Mention to KB
In linking a mention to KB we use only the normalized embedding of the mention. We define similarity of the mention to an entity by the scalar products with its embeddings :
| (1) |
Here all the thresholds are set to , and are irrelevant unless adjusted as described in Section 2.3; the entity’s threshold is defined further below.
The KB entity with the highest similarity is the candidate for linking the mention to. We set a linking threshold : The mention is linked to the candidate-entity only if
| (2) |
Otherwise the mention is left unlinked (unassociated with any KB entity). It is natural to assume , but our results will show that we had to lower it.
The entity’s threshold is defined from the assumption that any embedding of the entity would have to successfully link to the entity (with ):
| (3) |
This definition makes sense only if there are at least two embeddings in the entity, hence we create a KB entity only if there are at least two mentions available (our observations in Section 4 suggest a more strict requirement).
When linking a mention to KB we find the similarities not to all KB entities, but only to the entities that have a surface name at least somewhat similar to the mention. For this purpose, KB stores a map of all words from all the surface names to the entities that have any such word in their surface names:
| (4) |
When linking a mention to KB, all KB entities that are mapped from at least one word of the mention’s surface name are considered as the candidates for linking. The similarities of the mention’s embedding to these candidates are calculated then by Eq.1; the mention is linked to the candidate with the strongest similarity if exceeds the threshold Eq.2. Generally, KB entities with similar (by some measure) embeddings can be considered in selecting the candidates, but we focus here on the namesakes.
2.3 Knowledge Base Adjustment
Can we improve KB right after it is created, even without using any knowledge about the texts and mentions on which NEL will be used or evaluated? We suggest adjusting the thresholds in each entity by considering the relation of with its similar entities .
Each entity stores references to its most ’similar’ entities . For an entity with surface names we select its similar entities using a (non-symmetric) surface-similarity, which we define as
| (5) |
where are the surface names of another KB entity, w is any word in also existing in , and is the number of characters in the word . For each KB entity we find entities having the highest (may be less than 10 because of the requirement ). References to these ’surface-similar’ entities are stored in the entity .
In order to adjust a KB entity , we impose a requirement on each embedding from each similar entity : the embedding should not be able to link to the entity (because and are different entities).
KB is adjusted to satisfy this requirement, by iterating through all KB entities ; for each entity iterating through its similar entities ; for each pair and iterating through the embeddings of and of . The threshold for is adjusted as:
| (6) |
Here is the threshold of the entity . We use , just enough to make the linking impossible. For clarity, the adjustment procedure is also explained by pseudo-code in Figure 1.
| Given: Knowledge Base ; |
| Each entity includes: |
| Threshold T = |
| Embeddings |
| Each has its own threshold |
| Similar entities |
| Adjustment coefficient (e.g. ): |
| Adjustment procedure: |
| for in : |
| for in in : |
| for in : |
| for in : |
| if : |
| if : |
For definiteness, we iterate through entities in KB in order from larger to smaller dissimilarity of the entity; where we defined ’dissimilarity’ of as the sum
| (7) |
with summation over all the pairs of embeddings from . The motivation for this order is to start with entities that might be more prone to the conflicts and adjustments in KB. However, in the experiments described in this paper there were no any noticeable difference between this version and versions with somewhat different definitions of ’dissimilarity’, and even with the opposite order of the iteration.
We do not consider here an alternative possibility: instead of increasing an embedding’s threshold, we can rotate the embeddings from each other with the purpose of decreasing their product below the threshold; for more detail see Appendix C.
3 Evaluation on Namesakes
Namesakes dataset consists of three parts Vasilyev et al. (2021b):
-
1.
Entities: human-labeled mentions of named entities from Wikipedia entries.
-
2.
News: human-labeled mentions of named entities from news.
-
3.
Backlinks: mentions of entities linked to the entries used in Entities.
According to Vasilyev et al. (2021a), the mentions in all the parts are selected with the goal of creating high ambiguity of their surface names.
We are creating KB from Entities, and using News and Backlinks as sources of the mentions for evaluating NEL. These evaluation mentions are a mix of familiar and stranger mentions. The stranger mentions appear for two reasons: First, a part of the labeled mentions in News have the same surface names as the labeled mentions in Entities, but represent entities not existing in Entities. Second, the requirement to have a certain minimal number of mentions for creating a KB entity can leave some mentions in both News and Backlinks without their counterpart KB entities.
Performance of NEL evaluation can be represented by three indicators:
-
1.
Fraction of familiar mentions linked to incorrect KB entity.
-
2.
Fraction of familiar mentions not linked to KB.
-
3.
Fraction of stranger mentions linked to KB.
For clarity: if NEL of familiar mentions resulted in linking mentions to wrong KB entities, and in not linking mentions to KB, then and . And if NEL of stranger mentions resulted in linked mentions, then .
The lower each of these indicators, the better. The first indicator accounts for the worst kind of error: the mention is familiar, but it is wrongly identified. In a scenario of growing KB this would also lead to degrading KB quality. The second indicator accounts for the most innocent error: the mention is not identified (despite it could be), but at least no wrong identity is given. The third indicator accounts for the errors that are as bad as the first kind, with an arguable excuse that the stranger mentions are more difficult for NEL.
4 Experiments
4.1 Linking to Entities of Namesakes
We present here evaluation results in terms of the three indicators introduced in the previous section. In Figure 2 we show the level of NEL errors for evaluating all the mentions from News.

We observe that the minimal number of mentions allowed to create a KB entity plays an important role in reducing the amount of errors, even though the entity mentions were clustered into only 4 embeddings.
The role of the linking threshold , as expected, is the trade-off between the performance for familiar mentions and for stranger mentions. A higher threshold decreases the fraction of stranger mentions linked to KB, while increasing the fraction of familiar mentions not linked to KB.
In Figure 3 we show again the dependency of NEL errors on the minimal number of mentions per KB entity, but now we evaluate linking of Backlinks mentions to KB (this is the only difference between the settings for the figures 3 and 2).

We observe a comparable level of errors in linking a familiar mention to wrong KB entity and in wrongly linking a stranger mention to KB, but there is a much higher fraction of unlinked familiar mentions. We speculate that the reason is in the less context usually given for a named entity mention in a Wikipedia backlink, as opposed to a mention in the news.
The number of samples participating in the evaluation is presented in left panes of Tables 1 and 2. Relaxed requirement on minimal number of mentions per entity allows for larger KB, and makes more familiar mentions. Backlinks part of Namesakes provides more mentions for evaluation.


In Figure 4 we show that the limit on the number of stored embeddings can be as low as 4 - at least judging by evaluation on Namesakes News. Evaluation on Namesakes Backlinks - in Figure 5 - show only a very weak dependency on the maximal number of embeddings. We suggest that it may be helpful to store more embeddings, depending on the type and cleanness of the data involved in creating KB. We observe more evidence for this in Section 4.2.
The number of samples involved in the evaluations in Figures 4 and 5 are presented by the last rows in the left panes in Tables 1 and 2 correspondingly.


Increase of the linking threshold , as expected, suppresses wrong linking, but increases the fraction of unlinked mentions. We show an example of such dependency for wide range of threshold values in Figure 6 for NEL applied to the mentions from News, and in Figure 7 for NEL applied to the mentions from Backlinks. The main difference between the figures is in higher fraction of unlinked familiar mentions from Backlinks; this again suggests that too many mentions in Namesakes Backlinks must have a limited context. The choice of should be guided by a required trade-off between the errors vs and .
4.2 Linking to Polluted KB
We consider here the effect of lowering KB quality on NEL. When creating KB entities, we add erroneous mentions, imitating the real life situation of not fully reliable sources. Such polluted KB should increase NEL errors. We also expect that KB adjustment described in Section 2.3 can alleviate the effect of the pollution.
We use for pollution the "Other"-tagged mentions from Namesakes Entities Vasilyev et al. (2021a): these mentions have the surface names of the considered entity (Wikipedia entry) but represent some different entity mentioned in the same entry. The pollution can be characterized by the fraction of the polluted KB entities, and by the average fraction of the wrong mentions used in creating a polluted KB entity. We set both these pollution levels to 0.5, meaning that we pollute each second entity, and that we are creating each polluted entity by making it with up to 50% added wrong mentions (subject to availability of ’Other’ mentions in the corresponding document in Namesakes Entities).
In Figure 8 we show how much KB pollution affects NEL, and how much our KB adjustment, described in Section 2.3, can alleviate the effect of pollution.
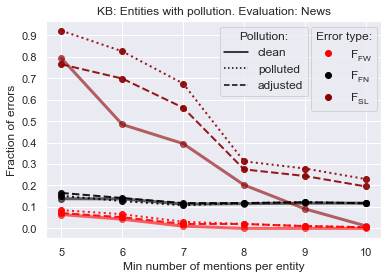
The pollution somewhat increases the fraction of familiar mentions linked to wrong KB entities. Pollution increases even more the fraction of stranger mentions wrongly linked to KB. The KB adjustment reduces this effect.

Figure 9 shows the evaluation for linking Backlinks mentions to the clean, polluted and polluted-and-adjusted KB. Here we observe that the effect of pollution and adjustment on unlinked familiar mentions is opposite: polluted KB entities encourage linking, wrong or not. Of course the effects on wrongly linked familiar mentions and wrongly linked stranger mentions are more important.
| clean | polluted | |||||
|---|---|---|---|---|---|---|
| M | KB | familiar | stranger | KB | familiar | stranger |
| 5 | 2129 | 217 | 58 | 2440 | 224 | 51 |
| 6 | 1560 | 211 | 64 | 2034 | 212 | 63 |
| 7 | 1086 | 194 | 81 | 1509 | 195 | 80 |
| 8 | 733 | 191 | 84 | 1037 | 195 | 80 |
| 9 | 483 | 187 | 88 | 778 | 189 | 86 |
| 10 | 318 | 187 | 88 | 547 | 188 | 87 |
| clean | polluted | |||||
|---|---|---|---|---|---|---|
| M | KB | familiar | stranger | KB | familiar | stranger |
| 5 | 2129 | 18203 | 10409 | 2440 | 22473 | 6139 |
| 6 | 1560 | 15071 | 13541 | 2034 | 20793 | 7819 |
| 7 | 1086 | 10756 | 17856 | 1509 | 15806 | 12806 |
| 8 | 733 | 8171 | 20441 | 1037 | 13345 | 15267 |
| 9 | 483 | 5528 | 23084 | 778 | 12139 | 16473 |
| 10 | 318 | 3986 | 24626 | 547 | 8895 | 19717 |
Pollution changes dependency of NEL performance on max number of entity embeddings : in Figure 10 the stranger mentions errors still decrease by .


4.3 Embeddings Tuned on More Uniform Texts
In previous subsections we observed NEL where the evaluation mentions are quite different from the mentions used in creating KB entities: KB entities were created from mentions of the entity on its own Wikipedia page; Backlinks mentions come from mentioned entities on Wikipedia backlinks; News mentions come from generic news texts. The difference between KB entities and evaluation mentions added to the difficulty of NEL.
In this subsection we consider one more variation that may cause additional difficulty for NEL: we will use a model tuned not on generic news (see Section 2.1), but on texts of more uniform style - a mix of texts from XSum Narayan et al. (2018) and CNN / Daily Mail Hermann et al. (2015); Nallapati et al. (2016) datasets (we take the texts of the documents, not the summaries.) The details of the data and tuning are in Appendix A.
From Figure 12 we observe that the optimal value of threshold is now different, and that NEL is more sensitive to threshold.

From Figure 13 we observe that effect of KB adjustment can be stronger. The adjustment, while strongly reducing the most serious errors - and - increases the fraction of unlinked familiar mentions . The latter is understandable as a conseqeunce of increasing individual embedding thresholds in KB entities.

From Figure 14 we observe that choosing the KB entity’s max number of embeddings may also be affected by the type of model used for embeddings (compare with Figure 4).

5 Conclusion
We introduced a simple and practical representation of named entities by multiple embeddings. We reviewed NEL performance for linking text mentions to KB of such entities, using Namesakes dataset Vasilyev et al. (2021a) as the source both for the mentions and for building the KB. As a dataset of ambiguous named entities, Namesakes makes NEL difficult and helps to reveal the errors and to observe the behavior and the dependencies of our NEL method.
We observed that a requirement of a minimal number of mentions for creating KB entity is important for NEL performance: a requirement of minimum 10 mentions gives much better results than more relaxed settings (Figures 2, 3). We described a KB adjustment based on only KB data; we have shown that the adjustment helps to reduce NEL errors when KB entities are polluted by admix of wrong mentions (Figures 8, 9, 13).
Through the paper we evaluated our NEL method with static small KB (albeit on intentionally challenging data). More general scenarios can be considered, such as growing and adjusting KB with linked mentions. Even within the limits of static KB, there are interesting issues left out of our consideration here. The KB pollution can be moderated by heuristic algorithms that filter the mentions for KB entities. Also, in realistic ingestion of data to large scale KB (e.g. all Wikipedia named entities), there are much more available mentions for some entities. From our preliminary observations (not included in the paper) we speculate that the optimal number of embeddings can be higher but still within reasonable limits (up to 20), and that the effect of KB adjustment can be stronger.
Limitations
We acknowledge the following limitations of this work:
-
1.
Our observations are limited to the case of fixed KB. We left out the consideration of accepting new linked mentions to KB and of the corresponding changes in KB entity representations, and in NEL quality.
-
2.
We considered linking of ’lone’ mentions, not using advantages of coreference with mentions of the same entity or related entities in the text.
-
3.
We investigated the behavior and dependencies of NEL with our representations on a specific dataset (Namesakes), the dataset is being challenging by having high concentration of namesakes. Evaluation of the method on a large scale KB (for example, KB of all Wikipedia named entities or of entities from some other documents) is left out of this paper. An immediate difference is that such KB is inevitably polluted, albeit not as much as in our considerations in the paper.
-
4.
We explored linking of mentions from two kinds of texts: news and backlinks, the latter is fairly artificial example. Realistically, mentions come from documents of very different formats and styles. While we did imitated here the difference between the mentions on which KB is built (the mentions from their own Wikipedia entries) and the evaluation mentions (the mentions from news or backlinks), this is still just a two examples.
Acknowledgments
We thank Randy Sawaya for review of the paper and valuable feedback.
References
- Chen et al. (2021) Anthony Chen, Pallavi Gudipati, Shayne Longpre, Xiao Ling, and Sameer Singh. 2021. Evaluating entity disambiguation and the role of popularity in retrieval-based nlp. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, pages 4472–4485, Brussels, Belgium. Association for Computational Linguistics.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Ferragina and Scaiella (2012) Paolo Ferragina and Ugo Scaiella. 2012. Fast and accurate annotation of short texts with wikipedia pages. IEEE Software, 29:70–75.
- FitzGerald et al. (2021) Nicholas FitzGerald, Dan Bikel, Jan Botha, Daniel Gillick, Tom Kwiatkowski, and Andrew McCallum. 2021. MOLEMAN: Mention-only linking of entities with a mention annotation network. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 278–285, Online. Association for Computational Linguistics.
- Guo and Barbosa (2018) Zhaochen Guo and Denilson Barbosa. 2018. Robust named entity disambiguation with random walks. Semantic Web, 9:459–479.
- Hermann et al. (2015) Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. 2015. Teaching machines to read and comprehend. In Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc.
- Hoffart et al. (2011) Johannes Hoffart, Mohamed Amir Yosef, Ilaria Bordino, Hagen Fürstenau, Manfred Pinkal, Marc Spaniol, Bilyana Taneva, Stefan Thater, and Gerhard Weikum. 2011. Robust disambiguation of named entities in text. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, pages 782–792, Edinburgh, Scotland, UK. Association for Computational Linguistics.
- Ji et al. (2017) Heng Ji, Xiaoman Pan, Boliang Zhang, Joel Nothman, James Mayfield, Paul McNamee, and Cash Costello. 2017. Overview of tac-kbp2017 13 languages entity discovery and linking. In Text Analysis Conference TAC 2017.
- Kolitsas et al. (2018) Nikolaos Kolitsas, Octavian-Eugen Ganea, and Thomas Hofmann. 2018. End-to-end neural entity linking. In Proceedings of the 22nd Conference on Computational Natural Language Learning, page 519–529, Brussels, Belgium. Association for Computational Linguistics.
- Li et al. (2020) Belinda Z. Li, Sewon Min, Srinivasan Iyer, Yashar Mehdad, and Wen-tau Yih. 2020. Efficient one-pass end-to-end entity linking for questions. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6433–6441, Online. Association for Computational Linguistics.
- Logeswaran et al. (2019) Lajanugen Logeswaran, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, Jacob Devlin, and Honglak Lee. 2019. Zero-shot entity linking by reading entity descriptions. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3449–3460, Florence, Italy. Association for Computational Linguistics.
- Ma et al. (2021) Xinyin Ma, Yong Jiang, Nguyen Bach, Tao Wang, Zhongqiang Huang, Fei Huang, and Weiming Lu. 2021. MuVER: Improving first-stage entity retrieval with multi-view entity representations. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 2617–2624, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Nallapati et al. (2016) Ramesh Nallapati, Bowen Zhou, Cicero Nogueira dos santos, Caglar Gulcehre, and Bing Xiang. 2016. Abstractive text summarization using sequence-to-sequence rnns and beyond.
- Narayan et al. (2018) Shashi Narayan, Shay B. Cohen, and Mirella Lapata. 2018. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1797–1807, Brussels, Belgium. Association for Computational Linguistics.
- Rao et al. (2012) Delip Rao, Paul McNamee, and Mark Dredze. 2012. Entity linking: Finding extracted entities in a knowledge base. Multi-source, Multilingual Information Extraction and Summarization, pages 93–115.
- Ratinov et al. (2011) Lev Ratinov, Dan Roth, Doug Downey, and Mike Anderson. 2011. Local and global algorithms for disambiguation to Wikipedia. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 1375–1384, Portland, Oregon, USA. Association for Computational Linguistics.
- Sevgili et al. (2021) Ozge Sevgili, Artem Shelmanov, Mikhail Arkhipov, Alexander Panchenko, and Chris Biemann. 2021. Neural entity linking: A survey of models based on deep learning. arXiv, arXiv:2006.00575v3.
- Sorokin and Gurevych (2018) Daniil Sorokin and Iryna Gurevych. 2018. Mixing context granularities for improved entity linking on question answering data across entity categories. In Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics, pages 65–75, New Orleans, Louisiana. Association for Computational Linguistics.
- Vasilyev et al. (2021a) Oleg Vasilyev, Aysu Altun, Nidhi Vyas, Vedant Dharnidharka, Erika Lam, and John Bohannon. 2021a. Namesakes: Ambiguously named entities from wikipedia and news. arXiv, arXiv:2111.11372.
- Vasilyev et al. (2021b) Oleg Vasilyev, Aysu Altun, Nidhi Vyas, Vedant Dharnidharka, Erika Lampert, and John Bohannon. 2021b. Namesakes. figshare. Dataset, 10.6084/m9.figshare.17009105.v1.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45. Association for Computational Linguistics (2020).
- Wu et al. (2020) Ledell Wu, Fabio Petroni, Martin Josifoski, Sebastian Riedel, and Luke Zettlemoyer. 2020. Scalable zero-shot entity linking with dense entity retrieval. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6397–6407, Online. Association for Computational Linguistics.
- Yang and Chang (2015) Yi Yang and Ming-Wei Chang. 2015. S-MART: Novel tree-based structured learning algorithms applied to tweet entity linking. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 504–513, Beijing, China. Association for Computational Linguistics.
- Zaporojets et al. (2022) Klim Zaporojets, Johannes Deleu, Yiwei Jiang, Thomas Demeester, and Chris Develder. 2022. Towards consistent document-level entity linking: Joint models for entity linking and coreference resolution. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 778–784, Dublin, Ireland. Association for Computational Linguistics.
Appendix A Tuning LM on Named Entities
A.1 Tuning
We obtained embeddings by using a pretrained language model (LM) tuned on located mentions of entities (Section 2.1). The texts for the tuning (9831 texts) were taken randomly from generic news, and processed by the named entity recognition (NER) model ’dbmdz/bert-large-cased-finetuned-conll03-english’, accessed via the transformers library (Wolf et al., 2020)). (As explained in Introduction, we are focused on NEL under the assumption that the mentions of named entities are already located in the text.)
The purpose is only in tuning the pretrained model for doing LM task on already located mentions of named entities, without specializing on some specific dataset of named entities. The number of different identified types of the located mentions were comparable: approximately 7.6 locations, 10.4 persons, 11.8 organizations and 6.4 miscellaneous named entities per text, with the average length of text 3300 characters. In this work we do not use the types of locations.
The located mentions in the texts are marked by enveloping them into square brackets, e.g. "… Minority Leader [Kevin McCarthy] and other…" (after making sure in advance that any such brackets in the text are replaced by round brackets). This procedure is done both for tuning LM, and for inference. During the tuning the name in the brackets is sometimes (with probability 0.5) replaced by another random name from the text. At inference there are no replacements (Section A.2).
The labels for tuning are all the tokens within all the square brackets that happen to occur (located by NER model) within the input of LM. We tuned the pretrained ’bert-base-uncased’ LM (Wolf et al., 2020) on texts from random daily news. Each input for tuning is composed of whole sentences - as many sentences as fits into the maximal input size (512 tokens for the LM).
A.2 Inference
At inference the procedure is similar: The text must be processed by NER model; the recognized named entities must be bracketed ’[]’ (but never replaced). Then the text must be processed by chunks, each chunk consisting of whole sentences - as many sentences as fits into the LM maximal input size. Then for each named entity mention (name in the brackets) the embedding is taken for the first token of the mention, from the last hidden layer of LM.
However, for the inference in our experiments here on Namesakes, we are using already recognized and labeled named entities of Namesakes, so the step with running NER is not needed. We have all the mentions already located, both for creating KB entities and for NEL evaluation.
A.3 Tuning on texts from XSum, CNN / Daily Mail
In order to have a model trained on less varied, more uniform style texts, we also tuned the same model bert-base-uncased on a mix of texts from well known datasets XSum Narayan et al. (2018) and CNN / Daily Mail Hermann et al. (2015); Nallapati et al. (2016). (We observed effects of switching to such model in Section 4.3.)
We created a training set of 33,000 texts comprised of 11,000 randomly selected texts from each of the primary sources (XSum, CNN, and Daily Mail) with a validation set of 1,500 texts as well as a test set of 1,500 texts (500 texts randomly selected from each primary source). Entity extraction and model tuning were conducted using the same models and strategy described in A.1. This resulted in a training set of 65,530 individual samples (a single sample being a context window of 512 tokens containing at least one entity) with a validation set of 3,005 samples and a test set of 3,030 samples. Model tuning was conducted for a single epoch on an NVIDIA Tesla T4 GPU, and optimized for the validation set.
Appendix B Clustering Embeddings for KB Entity
As explained in Section 2.1, KB entity stores a limited number of embeddings. When the number of available reliable mentions exceeds , the corresponding normalized embeddings are clustered. For this purpose we are using agglomerative clustering with euclidean affinity and with average linkage.
From each cluster we select one representation embedding: the embedding closest (by euclidean distance) to the center of the cluster. The center is defined as the average of all embeddings of the cluster.
Appendix C Adjustment of KB by rotation of embeddings
KB adjustment considered in the paper is defined in Section 2.3. We adjusted individual thresholds for entity representation embeddings, in order to prevent linking of one KB entity to another. Here we point out an alternative possibility to prevent such linking: we can rotate embeddings away from each other.
Suppose that an embedding from an entity is able to link to the entity , by being too similar:
| (8) |
Here is one of embeddings of , and is the threshold of . We can then replace the embedding by the embedding
| (9) |
with the goal of having
| (10) |
where the coefficient is slightly higher than , for example . The solution is simple:
| (11) |
| (12) |
There can be also a variation where we change both and . Such alternatives are as simple for processing as the adjustment version that we have considered through the paper. However, the adjustment of thresholds can be undone and redone at any time, while to do the same after rotating embeddings we would have to store the original embeddings. This makes the rotation version more expensive for storage. Performance-wise, for NEL on Namesakes, we have not seen advantages of rotations over threshold adjustments.
Both the thresholds adjustment version and the adjustment by rotations version can be made more ’iterative’: Each individual adjustment (the increase of a threshold or the angle of rotation) can be made smaller, but there would be multiple passes of iterations over all KB entities - possibly even in random order. The passes stop when the number of adjustments made over the pass is zero or below a certain limit. In case of larger data such versions may give better results, but the expensiveness of multiple passes makes this impractical.