MVP-Human Dataset for 3D Clothed Human Avatar Reconstruction from Multiple Frames
Abstract
In this paper, we consider a novel problem of reconstructing a 3D clothed human avatar from multiple frames, independent of assumptions on camera calibration, capture space, and constrained actions. We contribute a large-scale dataset, Multi-View and multi-Pose 3D human (MVP-Human in short) to help address this problem. The dataset contains subjects, each of which has scans in different poses and -view images for each pose, providing 3D scans and images in total. In addition, a baseline method that takes multiple images as inputs, and generates a shape-with-skinning avatar in the canonical space, finished in one feed-forward pass is proposed. It first reconstructs the implicit skinning fields in a multi-level manner, and then the image features from multiple images are aligned and integrated to estimate a pixel-aligned implicit function that represents the clothed shape. With the newly collected dataset and the baseline method, it shows promising performance on 3D clothed avatar reconstruction. We release the MVP-Human dataset and the baseline method in https://github.com/TingtingLiao/MVPHuman, hoping to promote research and development in this field.
Index Terms:
3D avatar reconstruction, 3D human, 3D body reconstruction, 3D human database.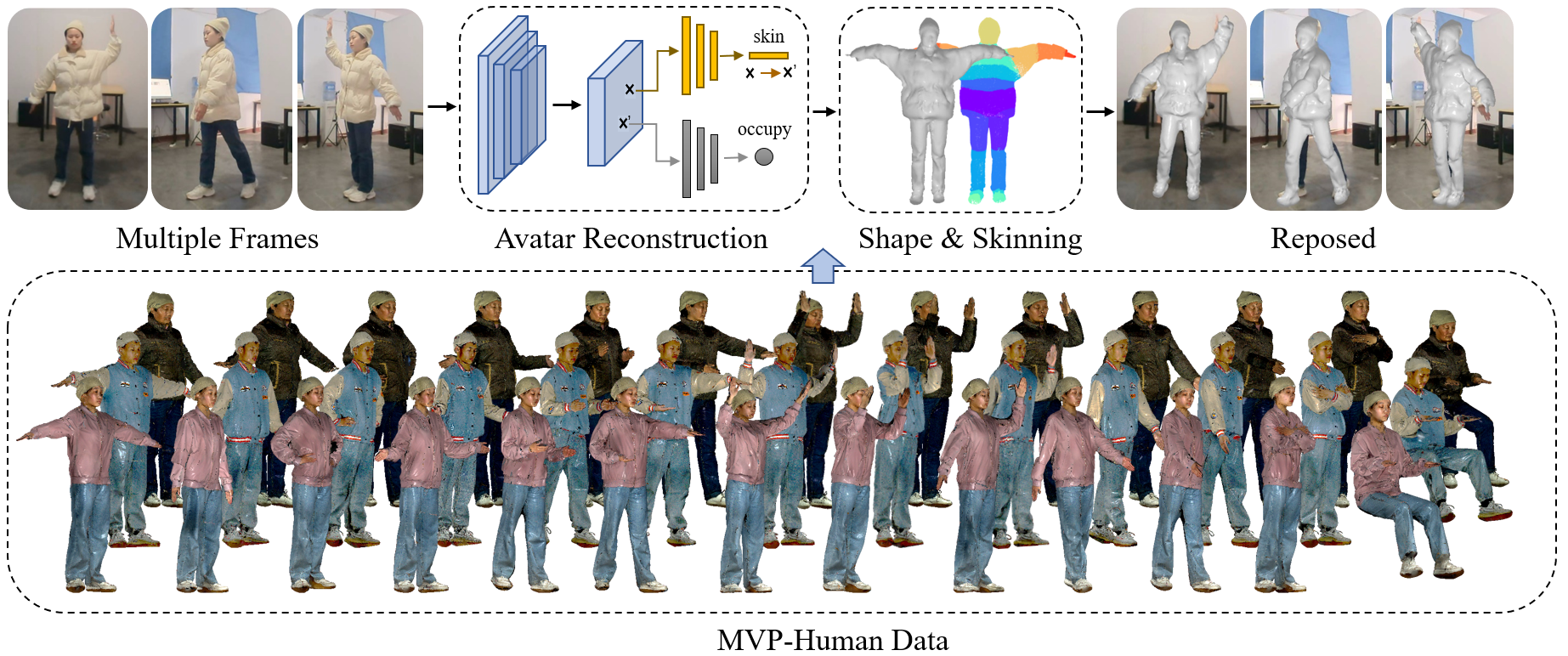
I Introduction
Image based 3D human reconstruction has been widely applied in many fields such as VR/AR experience (e.g., movies, sports, games), video editing and virtual dressing [1, 2, 3, 4, 5]. To reconstruct 3D humans, current methods always hold some strong assumptions about the input. 3D stereo [6, 7, 8] relies on camera calibration and a fully constrained environment. Human performance capture [9, 10], which tracks human motion and deforms the 3D surface using weak multi-view supervision, needs a person-specific template before reconstruction. 3D reconstruction from single-view video fuses dynamic human appearances into a canonical 3D model, which is related to our task. However, the subject is asked to hold a rough A-pose during images collection, which limits its applications. Besides, they either fit the SMPL model [11, 12] or coarsely morph the minimally-clothed body according to the silhouette [13], which loses the fine-grained detail. Recently, single-image-based reconstruction [14, 15, 16, 17] learns the implicit 3D surface based on aligned image features, recovering remarkable clothes details. However, as an ill-posed problem, single-image reconstruction suffers from unsatisfactory artifacts on the back. When these methods are extended to a multi-view setting, the camera calibration is still needed [14, 15].
To make 3D avatar reconstruction more accessible, we explore a novel problem that reconstructs a 3D avatar from unspecific frames. The ’unspecific’ here means there is no requirement for camera calibration, capture space or special actions. This task is extremely challenging due to the requirement of fusing multiple snapshots in diverse views and poses into a single reconstruction. Besides, when reconstructing the geometry details, the local feature in each frame may not be reliable due to the inevitable misalignment in free poses and views, leading to overly smooth reconstruction results. Moreover, the model training relies on special training data that each person should have multi-view-and-pose images and the corresponding 3D shape in T-pose, which is inaccessible to the public.
In this work, we first create a new Multi-View multi-Pose 3D Human dataset (MVP-Human) with subjects, each having scans in different poses and -view images for each pose, providing 3D scans and images in total. The linear blend skinning weights are also provided not only for supervising the model training, but also for reposing the captured T-pose meshes to the strict canonical pose, which is regarded as the target of 3D reconstruction models. Besides, benefitting from the collected multi-view images, we enable quantitative evaluation on real-world inputs, which is more reliable than the commonly used rendered meshes [14, 15, 16].
Based on MVP-Human, we introduce a deep learning-based baseline method for 3D Avatar reconstruction from multiple frames without a camera and action specification. We propose a SKinning weights Network (SKNet) to predict the Linear Blend Skinning (LBS) [18] in T-pose, by which each 3D point finds the corresponding pixel in each frame. Then the aligned image features are adaptively fused by a Surface Reconstruction Network (SRNet) to predict the final 3D shape as an implicit function [14]. A brief view of the framework is shown in Fig. 1.
The main contributions of the work mainly include two folds:
-
1.
We create a large 3D clothed human dataset where high-resolution 3D scans and real images are collected in a multi-pose and multi-view setting. Sophisticated labels including 3D skeleton landmarks and linear blend skinning weights are also provided. We will make it available upon acceptance.
-
2.
We propose a baseline method to reconstruct a clothed 3D avatar from multiple frames, independent of any camera calibration, person-specific template or specified actions. We hope the MVP-Human dataset associated with the baseline method can extend the deployment of passive 3D human reconstruction and benefit the development of this field.
| Dataset | Year | # of subjects | # of scans | vertices per. scan | multi-pose scans per. | multi-view images per. |
|---|---|---|---|---|---|---|
| BUFF [19] | 2017 | k | ✓ | - | ||
| MTC [20] | 2019 | k | - | ✓ | ||
| Multi-Garment [1] | 2019 | k | - | - | ||
| THuman [21] | 2019 | k | ✓ | - | ||
| CAPE [22] | 2020 | k | ✓ | - | ||
| HUMBI [23] | 2020 | k | - | ✓ | ||
| THuman 2.0 [24] | 2021 | k | - | - | ||
| MVP-Human (ours) | 2022 | k | ✓ | ✓ |
II Related Work
3D human reconstruction methods can be roughly classified by the assumptions hold on the input, including special equipment, person-specific template, and constrained actions. In this section, only the methods that take RGB inputs are discussed.
II-A Multi-view Stereo Reconstruction
Multi-view acquisition approaches capture the scene from multiple synchronized cameras, and build the 3D shape from photometric cues. Stereo based methods [25, 26, 27, 7, 28] achieve remarkable performance by optimizing multi-view stereo constraints from a large number of cameras. The geometric detail can be further improved by active illumination [29, 30, 31]. However, its hardware configuration is inaccessible to general consumers due to its special equipment and complexity. Benefit from deep learning, recent works [32, 33, 34, 35, 36] reduce the camera number to very sparse views. Yi et.al [37] propose a novel multiview method for human pose and shape reconstruction that scales up to an arbitrary number of uncalibrated camera views (including the single view), guided by dense keypoints. StereoPIFu [38] introduces a stereo vision-based network fusing multi-view images to extract voxel-aligned features. However, this work focuses on statistical reconstruction from multi-view images in the same pose. Compared with these methods, our method can be applied to reconstruct 3D avatars from monocular frames in free views and poses without camera calibration.
II-B Human Performance Capture
Most of the methods assume a pre-scanned human template and reconstruct dynamic human shapes by deforming the template to fit the images. Prior methods [39, 40, 7] require a number of multi-view images as inputs, and align the template to observations using non-rigid registration. MonoPerfCap [41] and LiveCap [9] enable posed body deformation from a single-view video by optimizing the deformation to fit the silhouettes. Recently, DeepCap [10] employs deep learning to estimate the skeletal pose and non-rigid surface deformation in a weakly supervised manner, constrained by the multi-view keypoint and silhouette losses. DeepMultiCap [42] further extends DeepCap to the multi-person scenario. Template-based methods need a pre-scanned template and thus focus on pose tracking and deformation, and template-free capture methods aim to estimate poses and reconstruct surface geometry at the same time. However, most approaches [43, 44, 45, 46, 47] are based on depth sensors which provide surface information for reconstruction, and these methods have difficulty in working on outdoor scenarios. Recently, some approaches [14, 15, 48, 49, 50] utilize the technique of implicit function to generate high-fidelity meshes from single or multi-view RGB images. However, the reconstructed results can not be articulated and applied in scenarios where an avatar is needed. We introduce a template-free method which reconstructs an avatar from merely unconstrained RGB frames. Our method shares the same input formulation, single-view RGB video, with some of these methods, but we do not need a pre-scanned template.
II-C 3D Avatar Reconstruction
Early works [51, 52, 53] employ statistical body models such as SCAPE [54] or SMPL [55] to recover human models which are typically animatable. However, parametric models cover limited shape variations due to the restriction of PCA shape space. Recently, some methods try to recover a clothed 3D avatar from a monocular video in which a person is moving. Alldieck et.al [13] ask the target subject to turn around in front of the camera while roughly holding the A-pose. Then the dynamic human silhouettes are transformed into a canonical frame of reference, where the visual hull is estimated to deform the SMPL model. This method is further improved by [11] on fine-level details reconstruction by introducing more constraints like shape from shading. Octopus [12] encodes the images of the person into pose-invariant latent codes by deep learning, and fuses the information to a canonical T-pose shape, achieving faster prediction. Such methods share the same goal of reconstructing canonical-pose shape from monocular video with our method, but we do not require the subject to perform specific actions.
Recently, neural-network-based implicit function [56] is introduced to represent 3D humans, demonstrating significant improvement in representation power and fine-grained details than voxel [57] and parametric models [55]. PIFu [14] aligns individual local features at the pixel level to regress the implicit field (inside/outside probability of a 3D coordinate), enabling the 3D reconstruction from a single image. PIFuHD [15] extends PIFu to a coarse-to-fine framework so that a higher resolution input can be leveraged for achieving high fidelity. MonoPort[58] proposes a faster rendering method to accelerate inference time. Yang et.al [59] represent the pedestrian’s shape, pose, and skinning weights as neural implicit functions that are directly learned from data. PHORHUM [60] presents an end-to-end methodology for photorealistic 3D human reconstruction given just a monocular RGB image. FloRen [61] initially recovers a coarse-level implicit geometry, which is then refined using a neural rendering framework that leverages appearance flow. ARCH [16, 17] reconstructs a human avatar in the canonical pose from a single image, where the image features are aligned by a semantic deformation field. These methods hold the minimum assumptions, one unconstrained image, on the input, and show state-of-the-art performance, but they suffer from depth ambiguity and unsatisfactory artifacts on the back. It is worth noting that, PIFu can be extended to multiple views [14, 15], but camera calibration is still needed in the scenario.
NeRF has attracted much attention in learning scene representations for novel view synthesis from 2D images. Recently, some methods introduce NeRF in 3D human reconstruction. NeRF– [62] aims to learn a neural radiance field without known camera parameters. AvatarGen [63] and Zheng et al. [64] incorporate NeRF with the human body prior to enabling animatable human reconstruction. FLAG [65] focuses on the pose generation task for avatar animation from sparse observation by developing a flow-based generative model. Marwah [66] presents a two-stream methodology to infer both the texture and geometry of a person from a single image and combines the outputs of the two streams using a differentiable renderer.
II-D 3D Human Data
Several works have released their 3D clothed human data, summarized in Tab. I. Multi-Garment [1] and THuman 2.0 [24] release a large number of scans with various body shapes and natural poses, which have been well employed in single-view and multiview reconstructions [48, 21]. However, the single scan for each subject is not suitable for our task that depends on multi-pose scans. BUFF [19] and CAPE [22] capture 4D people performing a variety of pose sequences, which are compatible with our task but the subject number is rather limited. THuman [21] consists of people in rich poses, but the captured 3D meshes lose fine-grained geometry with only k points. HUMBI [23] is a large multiview image dataset of the human body with various expressions. However, the HUMBI dataset only published minimally-clothed SMPL models while the real scans are not released. Instead, our dataset has released both clothed 3D meshes and skinning weights for users to train avatar reconstruction models. MTC [20] provides a social interaction dataset but only image sequences and 3D skeletons are available. Compared with existing datasets, MVP-Human demonstrates particularity by its multi-pose scans of hundreds of people, high-quality scans ( vertices) and unique multiview real (not rendering) images.

III Multi-pose Multi-view 3D Human Dataset
Reconstructing a 3D avatar from unspecific frames usually relies on the 3D textured scans of one subject in rich poses and its T-pose canonical mesh with skinning weights, which cannot be provided by existing datasets. Among existing datasets in Table. I, BUFF [67], CAPE [22], and THuman [21] are related datasets that provide multi-pose meshes for each subject, but the models in CAPE and THuman have about k and k 3D points, respectively, which are insufficient to model cloth details. Besides, the BUFF has limited subjects which are insufficient to train a generalized neural network. Besides, we wish to improve quantitative evaluation from rendered synthetic images to realistic inputs, requiring real-world multi-view and multi-pose images, and the corresponding ground-truth 3D shape. To this end, we create a Multi-View multi-Pose 3D Human dataset (MVP-Human), a large 3D human dataset containing rich variations in poses and identities, together with the multi-view images for each subject.
III-A Data Capture
Capture Setting: The capturing of the dataset took place in a custom-built multi-camera system. As shown in Fig. 2(a), the venue was m m, and within it we obtained a capture space of m m, where subjects were fully visible in all video cameras. Totally capture components were placed around the area at equal intervals to give full-body capture for a wide range of motions. Each component consisted of one Shenzhen D-VITEC RGB camera of resolution, FOV, and FPS for image collection, and one Wiiboox Reeyee Pro 2X 3D body scanner for 3D capture. The outputs of the system were multi-view images and 3D meshes with approximately vertices, faces, and texture maps. Then, 3D landmarks with points are manually labelled for each 3D mesh (Fig. 2(b)). The 3D landmarks are the combination and extension of MPII [68] human body landmarks and FreiHAND [69] hand landmarks. Specifically, the 62-landmarks contain MPII landmarks, FreiHand landmarks (without the wrist), and additional landmarks on the upper chest, chest, left upper arm, right upper arm, left toe, and right toe defined by ours. The 3D landmarks are annotated by well-trained Maya engineers, and all the results are checked by a quality inspector to ensure consistency. Besides, optimized canonical mesh and skinning weights serve as the target of avatar reconstruction (Fig. 2(c)). More samples are demonstrated in Fig. 3, where each subject is captured in poses, and each pose has a 3D textured scan (first column), annotated 3D landmarks (second column), and multi-view images (other columns).

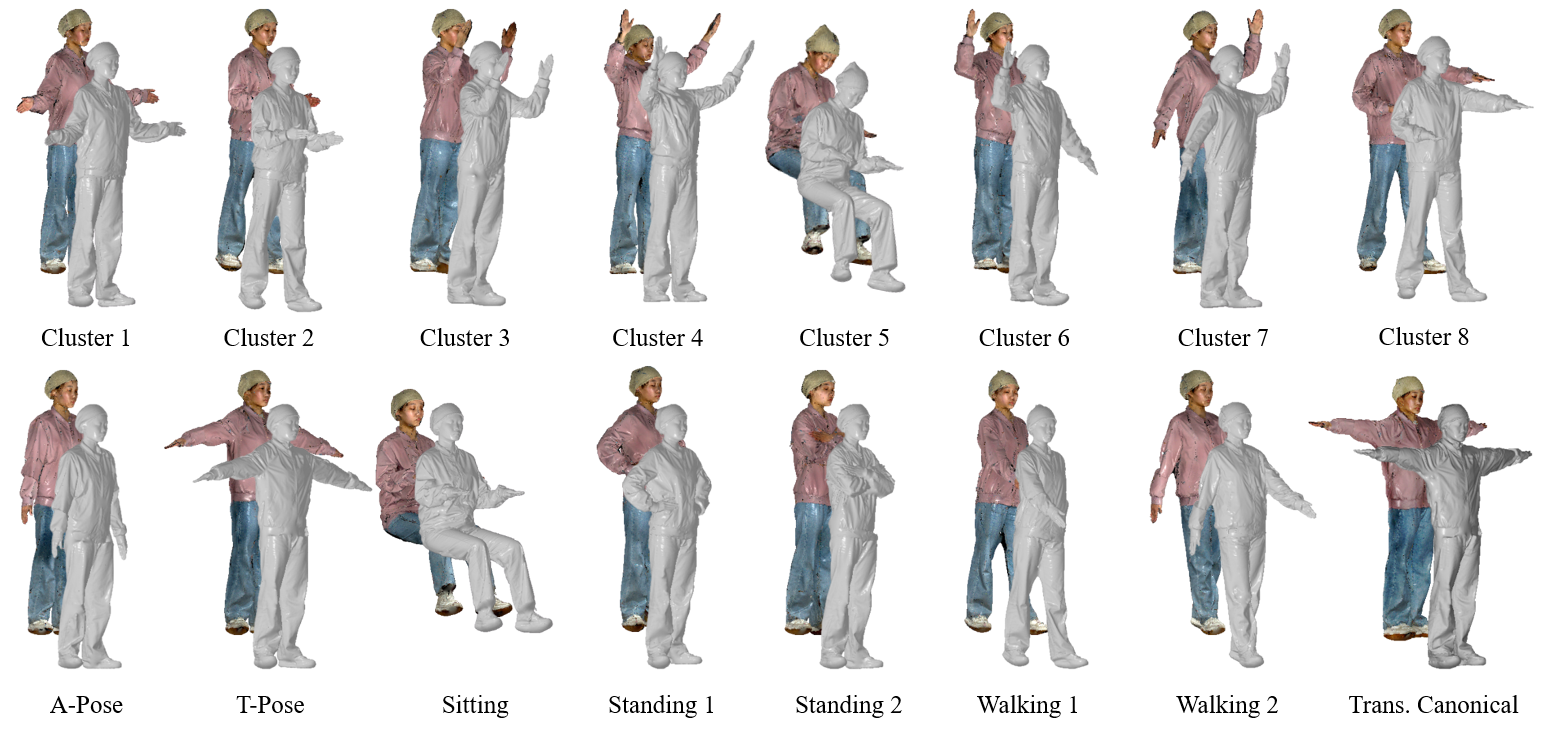
Subjects and Poses: For the creation of the dataset, distinctive actors with balanced gender and age were recruited. The statistics are summarized in Fig. 2(d). Most of the subjects wore their own clothes, and some of them were asked to wear prepared clothes like common jackets, pants, and tracksuits to maintain realism. This choice provides rich variability in body shape and mobility. Besides, to reflect the common actions in daily life, we obtained typical poses by clustering the SMPL pose parameters of AMASS [70] and added common poses, including T-pose, A-pose, sitting, standing with arms akimbo, standing with crossed arms, and two walking poses, which did not emerge in the clustering results. Finally, we get poses as in Fig. 4.
Generally, the MVP-Human provides poses and -view images for subjects, proving 3D scans and images in total. To the best of our knowledge, MVP-Human is the largest 3D human dataset in terms of the number of subjects along with high-quality 3D body meshes and multi-view RGB images.

III-B Skinning Weights Construction
To create the linear blend skinning weights as the supervision of SKNet, we optimize the canonical 3D model with the skinning weights for each subject following the recent SCANimate [71], shown in Fig. 2(c). Under the support of MVP-Human, where every subject has multiple scans in different poses with labeled 3D landmarks, we do not employ the original circle consistency loss and modify SCANimate in two aspects: 1) we directly optimize the chamfer errors brought by reposing, calculated by the distances between the reposed shape and the target-pose scan. 2) The reposing is guided by hand-labeled 3D landmarks rather than detected landmarks. The advanced SCANimate provides more reliable skinning weights, which are not only utilized as the target of SKNet but also used to repose the scanned T-pose shape to the strict T-pose as the target of SRNet. We also cut the edge in self-intersection regions according to [71] and fill the hole using smooth signed distance surface reconstruction [72].
IV Avatar Reconstruction Baseline with MVP-Human Dataset
We first present our method and describe its dependence on our data. Our goal is to estimate the T-pose shape in the canonical space from multiple frames without constraint on camera, space, and actions. We employ the implicit function [14] as the 3D representation to formulate the task as:
| (1) |
where for a 3D point in the canonical space, is its 2D perspective projection on the th image , is the corresponding local image feature and is the inside/outside probability of the 3D point. The camera poses for projection are estimated together with the human body poses during SMPL fitting. In this section, we propose a baseline method equipped with two sub-networks to achieve this goal: a skinning weights network that learns the blend skinning weights for pixel alignment, and a surface reconstruction network that fuses image and geometry features to a canonical 3D shape.
IV-A Pixel Alignment via Skinning Weights
PIFu [14] has demonstrated that the pixel-aligned image feature is the key to reconstructing detailed 3D surfaces. In posed 3D human reconstruction [14, 15], the image feature of a 3D point can be naturally retrieved on the of the image plane. However, in avatar reconstruction, the retrieval of 2D projected coordinates for the 3D point is not straightforward due to the unknown views and poses of the input frames.
To rebuild the canonical-to-image correspondence, we employ a skeleton-driven deformation method, as shown in Fig. 5. Specifically, each 3D vertex on the body surface can be transformed to any pose using a weighted influence of its neighboring bones, defined as on joints , called Linear Blend Skinning (LBS) [18]. For each 3D surface point in the canonical space, given the target pose parameters represented by relative rotations and the projection matrix calculated by the camera external parameters, its projected location is:
| (2) |
where is the skinning weight and is the affine transformation that transforms the th joint from the canonical pose to the target pose [16]. Thanks to the development of human model fitting, we can estimate the pose , the corresponding , and the projection by fitting the SMPL to each frame [73] independently. Therefore, the main challenge is the unknown skinning weights , especially the 3D shape is inaccessible by now.
Skinning Weights Network (SKNet): To estimate the Linear Blend Skinning (LBS) without 3D shape, we extend the definition of LBS beyond the body surface, and each in the space is assigned skinning weights. Intuitively, since the regions close to the human body are highly correlated with the nearest body parts, we can place a mean-shape template in the canonical space and estimate the skinning weights according to the closest point on the template, whose skinning weights are provided by the SMPL [55]. This Nearest Neighbor Skinning weights (NN-Skin) [16], as shown in Fig. 6(a), are not reliable due to two drawbacks. First, the skinning weights on the boundary of body parts are not continuous due to the nearest-neighbor criterion. After deformation, surfaces may be ripped or adhered due to the error on the NN matching, as shown in Fig. 6(b). Second, this error can be further amplified when the mean template does not resemble the ground-truth shape.

To address this problem, we propose the SKinning weights Network (SKNet) to learn an implicit skinning field [71] in the canonical space from multiple images. Given a 3D point , we build the SKNet to regress the skinning weights by:
| (3) | |||
where for each 3D point in the canonical space, the Network takes the corresponding image feature in each frame and regresses the skinning weights through an MLP architecture. The 2D projection on each frame is achieved as in Eqn. 2, where the NN-Skin is employed. Particularly, the SKNet outputs ( is the joint number) channels, where the first channels are the skinning weights and the last channel holds the inside/outside probability as auxiliary supervision. The label is for an inside point and for an outside point. The target skinning weights are provided by the new MVP-Human dataset. Compared to NN-Skin, SKNet enables more accurate 2D projection and avoids cracks during avatar animation, which is validated in the experiments.
IV-B Surface Reconstruction via Adaptive Fusion
Surface Reconstruction Network: For surface reconstruction, we follow Eqn. 1 and use the occupancy function to implicitly represent the 3D clothed human [16]:
| (4) |
where denotes the occupancy value for one point in the canonical space. In this paper, the is represented by a Surface Reconstruction Network (SRNet):
| (5) |
where the network takes the point , its multi-frame image feature , and a spatial feature as inputs and estimates occupancy as the 3D shape.
Image Feature: After the estimation of SKNet, the 2D projections for each frame can be achieved by Eqn. 2, and the image feature can be extracted by bilinear sampling on the feature map of the image encoder. However, under unconstrained scenarios, the image features may not share the same importance since 1) the image feature may not describe the 3D point due to self-occlusion, and 2) the fitted SMPL may provide an unreliable pose and view, leading to the sampling on the background. So directly averaging inferred features [15] is improper. In this paper, we do not estimate blending weights by hand-crafted criteria but leverage the attention mechanism [74] for adaptive feature fusion.
Transformer [74] is originally proposed to capture the correlations across input sequences, and its self-attention mechanism is naturally extendable to our task. We employ a multi-head attention network as [75] to encode the relevance between features:
| (6) | ||||
where is the fused image feature, is the input token of the transformer, and each token is the concatenation of the retrieved image feature and its visibility, represented by the surface normal on the fitted SMPL. The normal can encode visibility because when the z of normal is negative, it means the vertex faces inward and it is invisible. Otherwise, if the z is positive, the vertex is visible. We can see that the image feature is extracted from the top-level feature map of the image encoder. Even if the skinning weights are sub-optimal, each feature has a receptive field that implicitly aligns the error.
Spatial Feature: Recent methods [16, 17] have proved the effectiveness of the spatial feature that represents the geometric primitive of those points. In this work, we directly employ the estimated skinning weights as the spatial feature since it encodes the relationship of that point to each of the body landmarks. This mechanism avoids any external computation cost like hand-crafted features [16] and PointNet [17].
The training and testing of avatar reconstruction models depend on a sophisticated dataset equipped with multi-pose scans, multi-view images, and the strict T-pose shape for each subject, which is described as follows.

V Experiments
V-A Implementation Details
The two sub-network follow the same MLP architecture [14] with the intermediate neuron dimensions of and use the Stacked Hourglass [76] as the image encoder. The SKNet has a -dimensional input including -dimensional averaged image feature and -dimensional position encoding from the 3D coordinate [77]. The output is the -dimensional skinning weights plus an inside-outside probability. The input of SRNet has an additional -dimension spatial features, and the output is occupancy. The transformer for image fusion follows the architecture of [74] with heads and layers, which takes image features as inputs and outputs a -dimensional fused feature. During training, we first train the SKNet, whose parameters are utilized to initialize SRNet, and then jointly train the two sub-networks. The L2 loss is employed for both SKNet and SRNet. The Adam optimizer is adopted with the learning rate of , decayed by the factor of at the th epoch, and the total number of epochs is . Each mini-batch is constructed by images of subjects, with images randomly selected from one subject, and points are sampled around the canonical mesh with a standard deviation of cm.
V-B Dataset
We split the MVP-Human into a training set of subjects and a testing set of subjects. For the training set, we create the rendering images of 3D meshes following [14], where images are produced by rotating the camera around the vertical axis with intervals of , generating images. The ground-truth canonical shape and skinning weights are used for supervision. For the testing set, images are randomly selected from the image collection of a subject as one testing sample, which is repeated times to generate testing samples. It is worth noting that, this testing set first enables the quantitative evaluation of real-world images. Besides MVP-Human, we also employ People-Snapshot [13] in qualitative evaluation, where the subjects are asked to rotate while holding an A-pose, whose scenario can be considered as an easier case of ours.
V-C Comparisons
We evaluate the proposed baseline method for clothed 3D avatar reconstruction from multiple unspecific frames on MVP-Human dataset. To perform the comparison, we introduce a method solving a highly related task, and a modification of a state-of-the-art method.
VideoOpt (Video based Optimization) [13] takes a monocular RGB video where a subject rotates in an A-pose and generates the SMPL model with per-vertex offset by aligning rendered silhouettes to observations. This method can be generalized to the inputs without an A-pose assumption but suffers from performance deterioration due to complicated silhouettes in the unconstrained environment.
Octopus [12] fits the SMPL+D model from semantic segmentation and 2D keypoints. Similar to VideoOpt, Octopus also employs the shape offsets to represent personal details, such as hair and wrinkles, but is much faster by employing a deep learning model.
ARCH is denoted as a multi-frame extension of the state-of-the-art method ARCH [16]. The original ARCH learns to reconstruct a clothed avatar from a single image, which is extended by us to take multiple images. The main difference between ARCH and our baseline method is that we try to estimate skinning weights rather than approximating that by the nearest neighbor, and we fuse the image features by a sophisticated model to adapt to the complicated unconstrained environment.
PIFu [14] is a single-image reconstruction method that is designed to reconstruct the human body in its original posed space. However, it faces challenges in handling the MVP-Human dataset due to the lack of prior knowledge about the human body. The error is large because PIFu cannot reconstruct strict T-pose mesh as other avatar reconstruction methods.
ICON [50] performs better than PIFu due to its incorporation of prior knowledge about the human body. However, the absence of a global image encoder in ICON leads to a reduction in surface smoothness, resulting in a slightly bumpy surface for the reconstructed 3D avatar.

For quantitative comparison, we evaluate the accuracy of the reconstructed canonical 3D shape on the testing set of MVP-Human (real images), with three metrics similar to [14], including the normal error, point-to-surface (P2S) distance, and Chamfer error. For fairness, the ARCH is fine-tuned on the MVP-Human training set. As shown in Table II, we achieve the best results.
For qualitative comparison, Fig. 7 shows the reconstructed shapes from rendering and real images of MVP-Human, and Fig. 8 shows the results in People-Snapshot, respectively. It can be seen that Octopus [12] and VideoOpt [13], which attempt to learn SMPL offset, have difficulty in capturing fine-grained geometry due to the limited representation power of the shape space. ARCH retains some distinctive shapes but suffers artifacts like discontinuous surfaces and distorted body parts, which come from misaligned image features.
PIFu [14] cannot well capture poses due to the depth ambiguity. ICON generates 3D shapes with lumpy surfaces, and the overall shapes are similar to SMPL bodies without clothes. In contrast, our method generates more realistic avatars with estimated skinning weights and better image fusion. Besides, our method shows good generalization by reconstructing pants in People-Snapshot even without the clothes in the training set. The reconstruction results on the challenging poses including walking, standing, and running are illustrated in Fig. 9. Existing methods for single-image reconstruction often fail in generating a complete human body, resulting in a backside that appears overly smooth. When introducing multi-view images for reconstruction, current methods typically rely on accurate camera calibration, which may not be practical in real-world scenarios. Our proposed method enables the reconstruction of an animatable human body from multiple images with unconstrained poses and cameras, providing a more practical solution. Besides, We show some failure cases when SMPL fitting is inaccurate in Fig. 10. The primary limitation of our proposed method is the potential risk that inaccurate pose estimation brings errors in mapping 3D points to different image planes for feature fusion. This may cause irrelevant features to be fused, which could potentially deteriorate the quality of the 3D reconstruction.


We also evaluate the effectiveness of better skinning weights in animation. As shown in Fig. 11, compared with the common Nearest Neighbor Skinning weights (NN-Skin) [16], we learn continuous skinning weights which can articulate a mesh smoothly while retaining coherent geometric details.

V-D Performance Analysis
Ablation Study: We evaluate our method with several alternatives to assess the factors that contribute to the performance. First, with the fitted SMPL, our baseline employs NN-Skin to sample the image features across frames, which are concatenated to regress a pixel-aligned implicit function [14]. Second, the proposed SKNet is employed to refine the skinning weights. Third, the spatial features (Spatial) extracted from the implicit skinning fields are concatenated to the image features. Finally, the self-attention based feature fusion (FA) module is utilized to improve the robustness of inaccurate fitting and self-occlusion. As observed in Table III, each proposed component improves the final performance.
| Components | Metrics | ||||
|---|---|---|---|---|---|
| SKNet | Spatial | FA | Normal | P2S | Chamfer |
| 0.0217 | 1.4103 | 1.7981 | |||
| ✓ | 0.0232 | 1.3760 | 1.7595 | ||
| ✓ | ✓ | 0.0215 | 1.3455 | 1.7243 | |
| ✓ | ✓ | ✓ | 0.0214 | 1.3418 | 1.7192 |
Analysis on Input Number: Fig. 12 shows the 3D reconstruction errors with the growing number of inputs, from to . We can see that the performance becomes better as the number of inputs increases and approximately saturates at about inputs. For efficiency, the -way inputs are utilized in our method.

Analysis on Distance: We analyze the robustness of inputs from different distances. Considering the main difference brought by distance is resolution, we render the test scans in three distance settings, close (1.2x resolution), medium (1.0x resolution), and far (0.6x resolution), and evaluate the performances. In Fig. 13, we can see that when training and testing share the same distance (1.0x resolution), the performance is the best, followed by close (1.2x resolution) and far (0.6 resolution). The experiments validate that distance has an influence on accuracy.

VI Conclusion
In this work, we create a large 3D human dataset MVP-Human with 3D scans, and images for subjects, which is one of the largest 3D human datasets equipped with multi-pose high-quality scans for each subject. We consequently propose a method that introduces the skinning weights network and surface reconstruction network to learn a 3D human clothed avatar from unspecific frames, providing a good baseline performance in this field. Since many previous works are conducted on private datasets, we do hope the publicly available MVP-Human dataset and the baseline method can well promote the development of the avatar reconstruction.
Acknowledgement
This work was supported in part by the National Key Research & Development Program (No. 2020YFC2003901), Chinese National Natural Science Foundation Projects #62176256, #62276254, #62206280, #62106264, #62206276, the Youth Innovation Promotion Association CAS (#Y2021131) and the InnoHK program.
References
- [1] B. L. Bhatnagar, G. Tiwari, C. Theobalt, and G. Pons-Moll, “Multi-garment net: Learning to dress 3d people from images,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019, pp. 5420–5430.
- [2] I. Santesteban, M. A. Otaduy, and D. Casas, “Learning-based animation of clothing for virtual try-on,” Computer Graphics Forum (CGF), vol. 38, no. 2, pp. 355–366, 2019.
- [3] P. Hu, E. Ho, and A. Munteanu, “3dbodynet: Fast reconstruction of 3d animatable human body shape from a single commodity depth camera,” IEEE Transactions on Multimedia, vol. PP, pp. 1–1, 04 2021.
- [4] H. Zhang, Y. Meng, Y. Zhao, X. Qian, Y. Qiao, X. Yang, and Y. Zheng, “3d human pose and shape reconstruction from videos via confidence-aware temporal feature aggregation,” IEEE Transactions on Multimedia, pp. 1–1, 2022.
- [5] T. Zhao, S. Li, K. N. Ngan, and F. Wu, “3-d reconstruction of human body shape from a single commodity depth camera,” IEEE Transactions on Multimedia, vol. 21, no. 1, pp. 114–123, 2018.
- [6] Y. Liu, Q. Dai, and W. Xu, “A point-cloud-based multiview stereo algorithm for free-viewpoint video,” IEEE Transactions on Visualization and Computer Graphics (TVCG), vol. 16, no. 3, pp. 407–418, 2009.
- [7] J. Starck and A. Hilton, “Surface capture for performance-based animation,” IEEE Computer Graphics and Applications, vol. 27, no. 3, pp. 21–31, 2007.
- [8] C. Wu, K. Varanasi, Y. Liu, H.-P. Seidel, and C. Theobalt, “Shading-based dynamic shape refinement from multi-view video under general illumination,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2011, pp. 1108–1115.
- [9] M. Habermann, W. Xu, M. Zollhoefer, G. Pons-Moll, and C. Theobalt, “Livecap: Real-time human performance capture from monocular video,” ACM Transactions on Graphics (TOG), vol. 38, no. 2, pp. 1–17, 2019.
- [10] M. Habermann, W. Xu, M. Zollhofer, G. Pons-Moll, and C. Theobalt, “Deepcap: Monocular human performance capture using weak supervision,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 5052–5063.
- [11] T. Alldieck, M. Magnor, W. Xu, C. Theobalt, and G. Pons-Moll, “Detailed human avatars from monocular video,” in Proceedings of International Conference on 3D Vision (3DV), 2018, pp. 98–109.
- [12] T. Alldieck, M. Magnor, B. L. Bhatnagar, C. Theobalt, and G. Pons-Moll, “Learning to reconstruct people in clothing from a single rgb camera,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 1175–1186.
- [13] T. Alldieck, M. Magnor, W. Xu, C. Theobalt, and G. Pons-Moll, “Video based reconstruction of 3d people models,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 8387–8397.
- [14] S. Saito, Z. Huang, R. Natsume, S. Morishima, A. Kanazawa, and H. Li, “Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019, pp. 2304–2314.
- [15] S. Saito, T. Simon, J. Saragih, and H. Joo, “Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 84–93.
- [16] Z. Huang, Y. Xu, C. Lassner, H. Li, and T. Tung, “Arch: Animatable reconstruction of clothed humans,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 3093–3102.
- [17] T. He, Y. Xu, S. Saito, S. Soatto, and T. Tung, “Arch++: Animation-ready clothed human reconstruction revisited,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2021, pp. 11 046–11 056.
- [18] L. Kavan, S. Collins, J. Žára, and C. O’Sullivan, “Skinning with dual quaternions,” in Proceedings of the 2007 symposium on Interactive 3D graphics and games, 2007, pp. 39–46.
- [19] C. Zhang, S. Pujades, M. J. Black, and G. Pons-Moll, “Detailed, accurate, human shape estimation from clothed 3d scan sequences,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 4191–4200.
- [20] D. Xiang, H. Joo, and Y. Sheikh, “Monocular total capture: Posing face, body, and hands in the wild,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 10 965–10 974.
- [21] Z. Zheng, T. Yu, Y. Wei, Q. Dai, and Y. Liu, “Deephuman: 3d human reconstruction from a single image,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019, pp. 7739–7749.
- [22] Q. Ma, J. Yang, A. Ranjan, S. Pujades, G. Pons-Moll, S. Tang, and M. J. Black, “Learning to dress 3d people in generative clothing,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 6469–6478.
- [23] Z. Yu, J. S. Yoon, I. K. Lee, P. Venkatesh, J. Park, J. Yu, and H. S. Park, “Humbi: A large multiview dataset of human body expressions,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 2990–3000.
- [24] T. Yu, Z. Zheng, K. Guo, P. Liu, Q. Dai, and Y. Liu, “Function4d: Real-time human volumetric capture from very sparse consumer rgbd sensors,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 5746–5756.
- [25] Y. Furukawa and J. Ponce, “Accurate, dense, and robust multiview stereopsis,” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 32, no. 8, pp. 1362–1376, 2009.
- [26] M. Waschbüsch, S. Würmlin, D. Cotting, F. Sadlo, and M. Gross, “Scalable 3d video of dynamic scenes,” The Visual Computer, vol. 21, no. 8, pp. 629–638, 2005.
- [27] C. L. Zitnick, S. B. Kang, M. Uyttendaele, S. Winder, and R. Szeliski, “High-quality video view interpolation using a layered representation,” ACM Transactions on Graphics (TOG), vol. 23, no. 3, pp. 600–608, 2004.
- [28] L. Chen, S. Peng, and X. Zhou, “Towards efficient and photorealistic 3d human reconstruction: a brief survey,” Visual Informatics, vol. 5, no. 4, pp. 11–19, 2021.
- [29] D. Vlasic, P. Peers, I. Baran, P. Debevec, J. Popović, S. Rusinkiewicz, and W. Matusik, “Dynamic shape capture using multi-view photometric stereo,” in Proceedings of the ACM SIGGRAPH Asia, 2009, pp. 1–11.
- [30] J. Liang and M. C. Lin, “Shape-aware human pose and shape reconstruction using multi-view images,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 4352–4362.
- [31] C. Wu, K. Varanasi, and C. Theobalt, “Full body performance capture under uncontrolled and varying illumination: A shading-based approach,” in Proceedings of the European Conference on Computer Vision (ECCV), 2012, pp. 757–770.
- [32] C. B. Choy, D. Xu, J. Gwak, K. Chen, and S. Savarese, “3d-r2n2: A unified approach for single and multi-view 3d object reconstruction,” in Proceedings of the European Conference on Computer Vision (ECCV), 2016, pp. 628–644.
- [33] M. Ji, J. Gall, H. Zheng, Y. Liu, and L. Fang, “Surfacenet: An end-to-end 3d neural network for multiview stereopsis,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2307–2315.
- [34] A. Kar, C. Häne, and J. Malik, “Learning a multi-view stereo machine,” 2017.
- [35] A. Gilbert, M. Volino, J. Collomosse, and A. Hilton, “Volumetric performance capture from minimal camera viewpoints,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 566–581.
- [36] Z. Huang, T. Li, W. Chen, Y. Zhao, J. Xing, C. LeGendre, L. Luo, C. Ma, and H. Li, “Deep volumetric video from very sparse multi-view performance capture,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 336–354.
- [37] Z. Yu, L. Zhang, Y. Xu, C. Tang, L. Tran, C. Keskin, and H. S. Park, “Multiview human body reconstruction from uncalibrated cameras,” in Advances in Neural Information Processing Systems, 2022.
- [38] Y. Hong, J. Zhang, B. Jiang, Y. Guo, L. Liu, and H. Bao, “Stereopifu: Depth aware clothed human digitization via stereo vision,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [39] E. De Aguiar, C. Stoll, C. Theobalt, N. Ahmed, H.-P. Seidel, and S. Thrun, “Performance capture from sparse multi-view video,” in Proceedings of the ACM SIGGRAPH, 2008, pp. 1–10.
- [40] A. Collet, M. Chuang, P. Sweeney, D. Gillett, D. Evseev, D. Calabrese, H. Hoppe, A. Kirk, and S. Sullivan, “High-quality streamable free-viewpoint video,” ACM Transactions on Graphics (TOG), vol. 34, no. 4, pp. 1–13, 2015.
- [41] W. Xu, A. Chatterjee, M. Zollhöfer, H. Rhodin, D. Mehta, H.-P. Seidel, and C. Theobalt, “Monoperfcap: Human performance capture from monocular video,” ACM Transactions on Graphics (TOG), vol. 37, no. 2, pp. 1–15, 2018.
- [42] Y. Zheng, R. Shao, Y. Zhang, T. Yu, Z. Zheng, Q. Dai, and Y. Liu, “Deepmulticap: Performance capture of multiple characters using sparse multiview cameras,” Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2021.
- [43] Z. Zheng, T. Yu, H. Li, K. Guo, Q. Dai, L. Fang, and Y. Liu, “Hybridfusion: Real-time performance capture using a single depth sensor and sparse imus,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 384–400.
- [44] B. Allain, J.-S. Franco, and E. Boyer, “An efficient volumetric framework for shape tracking,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 268–276.
- [45] V. Leroy, J.-S. Franco, and E. Boyer, “Multi-view dynamic shape refinement using local temporal integration,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 3094–3103.
- [46] K. Guo, F. Xu, T. Yu, X. Liu, Q. Dai, and Y. Liu, “Real-time geometry, albedo, and motion reconstruction using a single rgb-d camera,” ACM Transactions on Graphics (ToG), vol. 36, no. 4, p. 1, 2017.
- [47] M. Innmann, M. Zollhöfer, M. Nießner, C. Theobalt, and M. Stamminger, “Volumedeform: Real-time volumetric non-rigid reconstruction,” in European conference on computer vision. Springer, 2016, pp. 362–379.
- [48] T. He, J. Collomosse, H. Jin, and S. Soatto, “Geo-pifu: Geometry and pixel aligned implicit functions for single-view human reconstruction,” Advances in Neural Information Processing Systems, vol. 33, pp. 9276–9287, 2020.
- [49] Z. Zheng, T. Yu, Y. Liu, and Q. Dai, “Pamir: Parametric model-conditioned implicit representation for image-based human reconstruction,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–1, 2021.
- [50] Y. Xiu, J. Yang, D. Tzionas, and M. J. Black, “ICON: Implicit Clothed humans Obtained from Normals,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 13 296–13 306.
- [51] C. Zhang, S. Pujades, M. J. Black, and G. Pons-Moll, “Detailed, accurate, human shape estimation from clothed 3d scan sequences,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 4191–4200.
- [52] G. Pons-Moll, J. Romero, N. Mahmood, and M. J. Black, “Dyna: A model of dynamic human shape in motion,” ACM Transactions on Graphics (TOG), vol. 34, no. 4, pp. 1–14, 2015.
- [53] J. Yang, J.-S. Franco, F. Hétroy-Wheeler, and S. Wuhrer, “Estimation of human body shape in motion with wide clothing,” 2016, pp. 439–454.
- [54] D. Anguelov, P. Srinivasan, D. Koller, S. Thrun, J. Rodgers, and J. Davis, “Scape: shape completion and animation of people,” ACM Transactions on Graphics (TOG), vol. 24, no. 3, pp. 408–416, 2005.
- [55] M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black, “Smpl: A skinned multi-person linear model,” ACM Transactions on Graphics (TOG), vol. 34, no. 6, pp. 1–16, 2015.
- [56] Z. Chen and H. Zhang, “Learning implicit fields for generative shape modeling,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 5939–5948.
- [57] G. Varol, D. Ceylan, B. Russell, J. Yang, E. Yumer, I. Laptev, and C. Schmid, “Bodynet: Volumetric inference of 3d human body shapes,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 20–36.
- [58] R. Li, Y. Xiu, S. Saito, Z. Huang, K. Olszewski, and H. Li, “Monocular real-time volumetric performance capture,” in Proceedings of the European Conference on Computer Vision (ECCV), 2020, pp. 49–67.
- [59] Z. Yang, S. Wang, S. Manivasagam, Z. Huang, W.-C. Ma, X. Yan, E. Yumer, and R. Urtasun, “S3: Neural shape, skeleton, and skinning fields for 3d human modeling,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 13 284–13 293.
- [60] T. Alldieck, M. Zanfir, and C. Sminchisescu, “Photorealistic monocular 3d reconstruction of humans wearing clothing,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1506–1515.
- [61] R. Shao, L. Chen, Z. Zheng, H. Zhang, Y. Zhang, H. Huang, Y. Guo, and Y. Liu, “Floren: Real-time high-quality human performance rendering via appearance flow using sparse rgb cameras,” in SIGGRAPH Asia 2022 Conference Papers, 2022, pp. 1–10.
- [62] Z. Wang, S. Wu, W. Xie, M. Chen, and V. A. Prisacariu, “Nerf–: Neural radiance fields without known camera parameters,” arXiv preprint arXiv:2102.07064, 2021.
- [63] J. Zhang, Z. Jiang, D. Yang, H. Xu, Y. Shi, G. Song, Z. Xu, X. Wang, and J. Feng, “Avatargen: a 3d generative model for animatable human avatars,” in Computer Vision–ECCV 2022 Workshops: Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part III. Springer, 2022, pp. 668–685.
- [64] Z. Zheng, H. Huang, T. Yu, H. Zhang, Y. Guo, and Y. Liu, “Structured local radiance fields for human avatar modeling,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 15 893–15 903.
- [65] S. Aliakbarian, P. Cameron, F. Bogo, A. Fitzgibbon, and T. J. Cashman, “Flag: Flow-based 3d avatar generation from sparse observations,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 13 253–13 262.
- [66] T. Marwah, “Generating 3d human animations from single monocular images,” Master’s thesis, Carnegie Mellon University, Pittsburgh, PA, May 2019.
- [67] C. Zhang, S. Pujades, M. J. Black, and G. Pons-Moll, “Detailed, accurate, human shape estimation from clothed 3d scan sequences,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 4191–4200.
- [68] M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele, “2d human pose estimation: New benchmark and state of the art analysis,” in Proceedings of the IEEE Conference on computer Vision and Pattern Recognition, 2014, pp. 3686–3693.
- [69] C. Zimmermann, D. Ceylan, J. Yang, B. Russell, M. Argus, and T. Brox, “Freihand: A dataset for markerless capture of hand pose and shape from single rgb images,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 813–822.
- [70] N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black, “Amass: Archive of motion capture as surface shapes,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019, pp. 5442–5451.
- [71] S. Saito, J. Yang, Q. Ma, and M. J. Black, “Scanimate: Weakly supervised learning of skinned clothed avatar networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 2886–2897.
- [72] F. Calakli and G. Taubin, “Ssd: Smooth signed distance surface reconstruction,” Computer Graphics Forum (CGF), vol. 30, no. 7, pp. 1993–2002, 2011.
- [73] N. Kolotouros, G. Pavlakos, M. J. Black, and K. Daniilidis, “Learning to reconstruct 3d human pose and shape via model-fitting in the loop,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019, pp. 2252–2261.
- [74] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proceedings of Advances in Neural Information Processing Systems (NIPS), 2017, pp. 5998–6008.
- [75] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” 2021.
- [76] A. Newell, K. Yang, and J. Deng, “Stacked hourglass networks for human pose estimation,” in Proceedings of the European Conference on Computer Vision (ECCV), 2016, pp. 483–499.
- [77] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,” in ECCV, 2020.