MVLayoutNet: 3D layout reconstruction with multi-view panoramas
Abstract
We present MVLayoutNet, an end-to-end network for holistic 3D reconstruction from multi-view panoramas. Our core contribution is to seamlessly combine learned monocular layout estimation and multi-view stereo (MVS) for accurate layout reconstruction in both 3D and image space. We jointly train a layout module to produce an initial layout and a novel MVS module to obtain accurate layout geometry. Unlike standard MVSNet [32], our MVS module takes a newly-proposed layout cost volume, which aggregates multi-view costs at the same depth layer into corresponding layout elements. We additionally provide an attention-based scheme that guides the MVS module to focus on structural regions. Such a design considers both local pixel-level costs and global holistic information for better reconstruction. Experiments show that our method outperforms state-of-the-arts in terms of depth rmse by 21.7% and 20.6% on the 2D-3D-S [1] and ZInD [4] datasets. Finally, our method leads to coherent layout geometry that enables the reconstruction of an entire scene.
1 Introduction
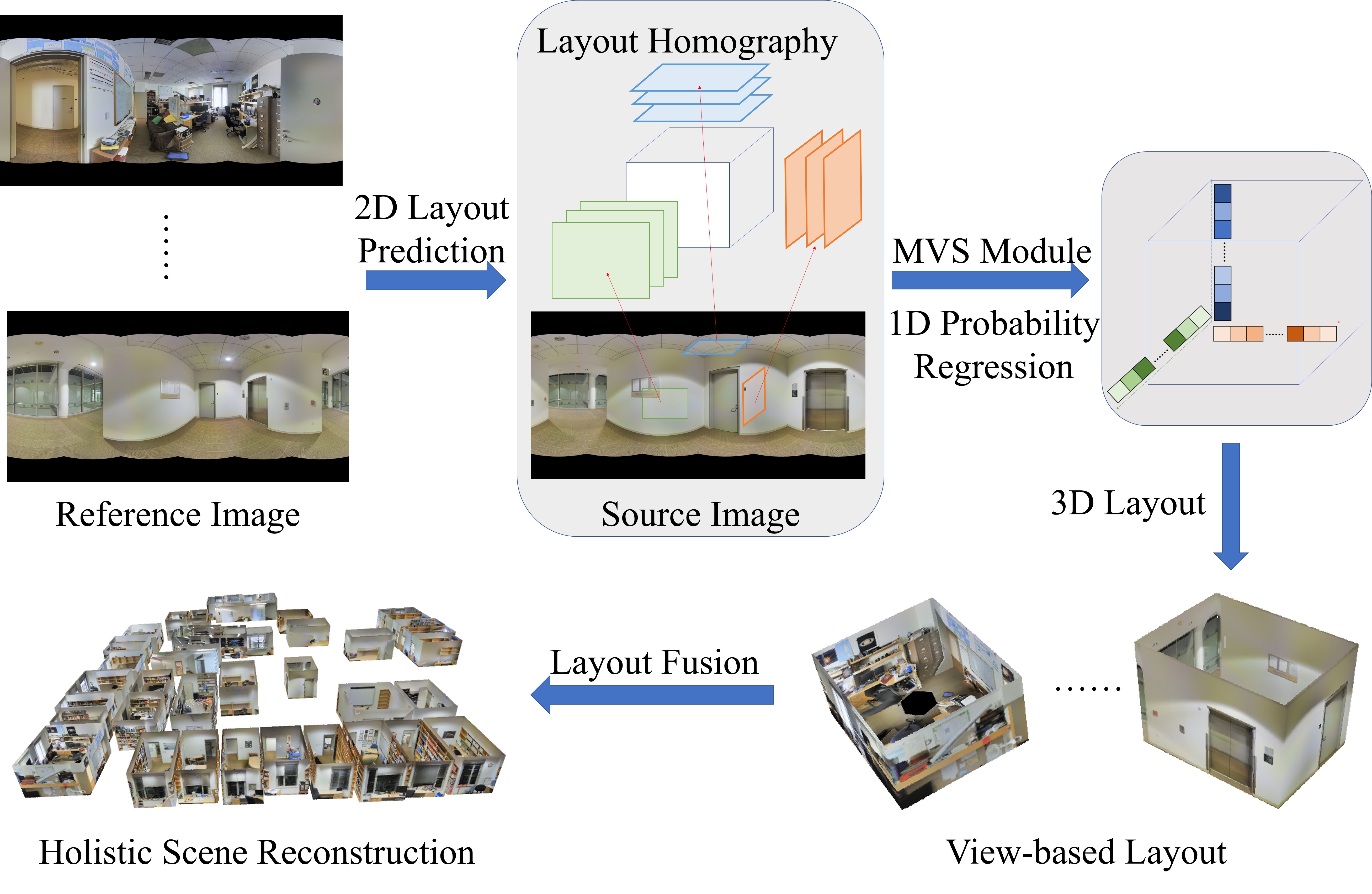
Holistic reconstruction of the 3D environment is a fundamental problem in the computer vision and graphics community. It aims to produce abstract and clean models to support various applications, including simulation, gaming, and virtual/augmented reality. While many devices are suitable for 3D reconstruction, commodity RGB cameras are still one of the most popular choices since they are usually available to common people. Multiview stereo (MVS) is the standard technique for image-based 3D reconstruction and has been studied for decades, including traditional methods [10, 8] and learning-based methods [32, 33]. Results produced by traditional approaches often lack integrity caused by smooth texture, reflections, and transparent materials. Learning-based methods [32, 33] aims to alleviate these problems by building deep feature volumes, but their results still suffer from noises and incompletion. While various post-processing methods filter the point cloud from the MVS by surface reconstruction [14, 15], primitive fitting [19, 11] or shape generation [21, 13], the produced quality is still not guaranteed to satisfy user demands.
Recently, a new set of approaches directly estimate holistic layouts from monocular panoramas [25, 27, 34, 35]. Since the layout representation enforces a well-formulated room shape, the methods guarantee the integrity of the produced reconstruction. However, a monocular panorama can only cover a limited space, which prevents these methods from reconstructions of large-scale scenes or complex environments with occlusions. Further, since a monocular view lacks multiview information, the 3D network can only learn from limited RGB information, leading to inaccurate 3D estimation in various environments.
Intuitively, an ideal solution would be to fully take advantage of both layout estimation and MVS to address the integrity and accuracy limitations. Some works tried to consider both techniques: [18, 2] assumes reconstructed geometry from MVS or range data and estimates layouts. [20] improves MVS from local planarity constraints that are relevant to layout information. However, neither of them compensates limitations of each technique from the other. To our knowledge, this fundamental problem has not been seriously answered. Our goal is to seamlessly combine both MVS and monocular layouts for accurate holistic reconstruction.
We present MVLayoutNet as an end-to-end network to tackle the problem as shown in Figure 1. Our network mainly consists of a layout module followed by an MVS module. Our layout module serves to predict an initial layout and can be implemented by existing methods [25, 27, 34, 35]. Our key contribution is the MVS module built upon estimated 2D layouts. We first build a novel layout cost volume by computing feature costs via newly-proposed layout homography transforms. To tackle a cluttered environment where structures are partially occluded, we incorporate explicit semantic information and an attention branch to highlight contributions of layout cost volumes corresponding to structural regions. The layout cost volume adjusted by the learned attention is passed through our MVS module to predict a single depth value for each layout element. The key idea of this module is to perform cost aggregation and compress information into a one-dimensional probability map for each layout element. It leads to a highly abstract representation of volume information and enforces the network to analyze the overall structure rather than untrustworthy local regions. More importantly, the probability regression is performed in 1D, which narrows the space for depth search and leads to more robust and generalizable layout reconstruction.
Comparisons on the 2D-3D-Semantics Dataset (2D-3D-S) [1] and Zillow Indoor Dataset (ZInD) [4] show that we significantly improve the geometric accuracy of the 3D layout reconstruction. Specifically, we achieve a significant improvement of 21.7% and 20.6% in terms of depth root mean square error (RMSE) on the 2D-3D-S and ZInD datasets. We observe that our MVS module leads to more robust depth estimation in challenging environments where layout boundaries are with smooth textures. This advantage still holds when comparing our layout-based MVS with the standard pixel-level MVS Network [32]. From our ablation studies (Sec. 4.2), wrong predictions from [32] at textureless regions seriously decrease the quality of the layout. This problem is resolved in our design which focuses on overall structures. Experiments also show that specific semantic filtering with weakly supervised self-attention can further improve the accuracy of the 3D layout.
To sum up, our contributions are as follows:
-
•
We present an end-to-end network that seamlessly combines layout estimation and multiview stereo for large-scale scene layout reconstruction.
-
•
We propose a layout cost volume with a novel MVS module that performs 1D probability regression on abstract layout elements.
-
•
We use explicit semantics and weakly supervised self-attention to enforce structural analysis.
-
•
Experiments highlight contributions of our key designs and significant quality improvement from the state-of-the-arts.
2 Related Works
Multi-view stereo
Multi-view stereo (MVS) has been a hot topic in the vision community for decades. The core problem of MVS is how to find the reliable correspondences.
Traditional methods designed many kinds of photo-consistency measures (e.g. Normalized Cross Correlation) and reconstruction schemes (e.g. Semi-Global Matching [10] and Patch Match [8]). These methods can achieve very good results when the textures are rich. However, it is hard to recover reliable dense correspondences for traditional MVS methods due to the commonly existing texture-less areas in indoor scenes.
With the development of Convolutional Neural Network (CNN), many learning based MVS methods have been proposed. For example, MVSNet [32] estimates the depth maps from multi-view images with learned features, differentiable homography and 3D cost volume regularization. PVA-MVSNet [33] utilizes the pyramid network and self-adaptive view aggregation to improve the completeness and accuracy of the reconstructions. However, reliable dense correspondences still cannot be obtained in the texture-less areas.
Room layout estimation
Generally, there are two ways to reconstruct the room layouts from images: one is firstly recovering the point clouds with MVS and then estimating the layout from the point clouds while the others treat the layout estimation task as a segmentation or feature (plane boundaries or room corners) extraction problem and estimate the layout directly from the perspective or panoramic image.
There are few works focused on the former pipelines. The authors of [2] propose a method to reconstruct piecewise planar and compact floorplans from multiple images through a structure classification technique and solve the shortest path problem on a specially crafted graph. However, it is hard to obtain satisfied estimation results when there are not enough reliable 3D points, especially with sparse multi-view images.
Instead, many researchers explored the latter pipelines which estimate the room layout directly from the monocular image. Since the 2D layout in image space can be represented with lines or corner points, the earlier layout estimation methods focus on extracting lines and corner points of images [9, 17, 24] and formulate the layout estimation problem as an optimization problem [5, 6]. Recently, many learning based methods have been proposed and show better estimation results compared to traditional methods [12, 16].
Starting from the work of [34], researchers have focused on estimating layouts from monocular panorama due to the wide FOV of it. Similar to layout estimation from perspective images, geometric and semantic cues [7, 23, 28, 29, 31] have been explored to better estimate the room layouts. Also, methods based on CNN gradually dominate the layout estimation from monocular panorama with the better performance [35, 25, 22, 27, 26].
Room layouts estimated with monocular image generally have no scale information. To obtain the 3D layout, assumptions about the camera height are often made, e.g. the camera heights are set to 1.6 m [25]. However, the real camera height can be arbitrary which will lead to imprecise and inconsistent 3D layouts. In addition, the accurate layout boundaries are hard to be estimated from the monocular image due to the occlusions from the clutters such as tables and chairs.
In this paper, we present a learning based 3D layout reconstruction method with multi-view panoramas to address these issues. We combine the advantages of MVS and monocular layout estimation to achieve accurate and coherent 3D layout reconstruction. We leverage the layout estimated from monocular panorama and directly reconstruct the layout elements instead of point or pixel with multi-view panoramas. Furthermore, semantics from images and self-attention mechanisms have been incorporated to achieve better results with the existence of clutters.
3 Approach
3.1 Overview
The input to our problem is a set of calibrated panoramas with given camera extrinsic . Our goal is to reconstruct the global 3D layout , and our system design borrows both ideas from layout estimation and multi-view stereo (MVS). We first estimate a 2D layout from each panorama through a 2D network (Section 3.2). Similar to MVS, we treat each view as a reference view where several related source views are aggregated as a cost volume. Section 3.3 introduces the formulation of our layout cost volume given as a basis, and our MVS module which reconstruct the 3D layout from . The 3D layout can further be improved with semantic information and weakly-supervised self-attention (Section 3.4). All network modules are trained in an end-to-end manner. Finally, we aggregate 3D layouts to get via layout fusion (Section 3.5).
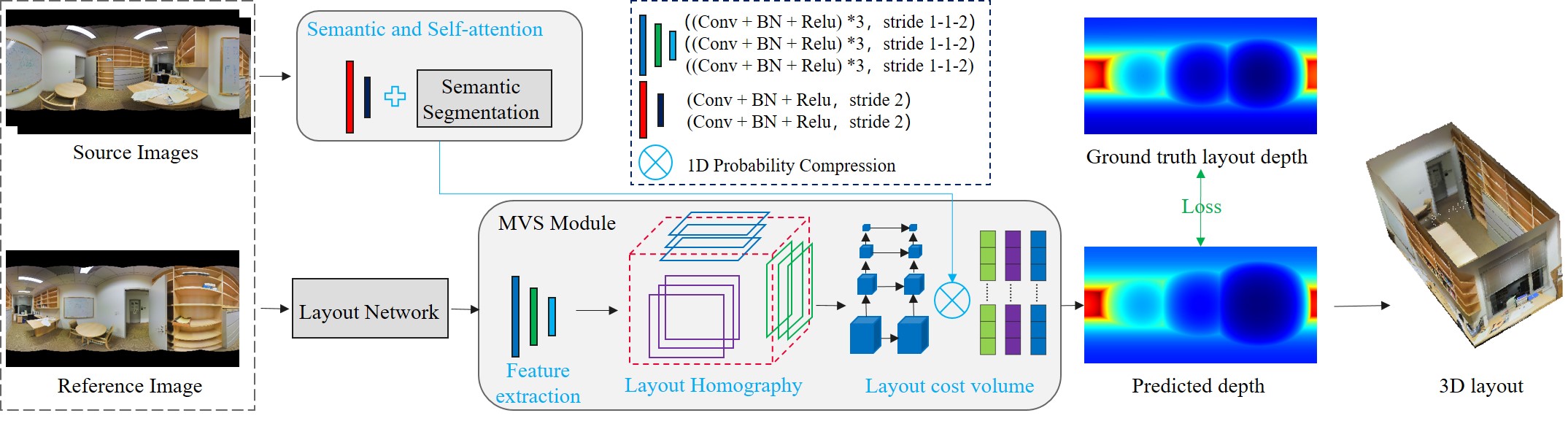
3.2 2D Layout Estimation
A 2D Layout can be viewed as a piecewise planar model covering the whole panorama, where each plane is a layout element consisting of a planar region in the image space with a plane orientation . We make reasonable assumptions that is either horizontal or vertical, and the y-axis of the panorama is aligned with the up-vector in the scene. Such a layout can be estimated from existing layout networks [35, 25, 22, 27, 26] and our network design can accept any of them, as shown in Figure 2. Although these methods provide additional 3D layout prediction, they assume connectivity and fixed camera height and need only predict relative scales. We find that such a prediction is still inaccurate, and argue that these strong assumptions prevent more general environment topology reconstruction. Therefore, our design does not impose any of these constraints and only borrows their capability to predict layouts in 2D, thereby extensible to complex settings in the future.
We use [25] as our layout module, which produces 2D layout corner points, their relative depths, and edges connecting point pairs among them. can be determined by applying a breadth-first search in the image space until reaching the layout boundaries specified by edges. Since orientation is not relevant to the absolute geometry scale, we can compute layout element orientation as the normal of the polygon formed by layout corners with predicted relative depths. The 2D layout loss can be computed with the corner points and edges as Equation 1:
| (1) |
Where the and are the corner points and edges of the ground truth layout.
3.3 3D Layout Reconstruction
Our MVS module consists of three components. We apply layout homography given 2D layout prediction of the reference view and multiple source panorama views. Feature volumes are aggregated and compressed into a layout cost volume, which is passed through a probability estimation module to get a one-dimensional probability map. Layout depth is finally determined by integrating depth intervals with probabilities.
Layout Homography
We treat each panorama as the reference view with a set of associated source views . Details of view selection are described in Section 4.1. Standard cost volume is constructed by enumerating several depth planes orthogonal to the reference view, efficiently warping source views to the reference camera space via homography, and measuring differences based on local patches [8] or deep features [32]. However, it does not precisely model the physical world where the orientation of an ideally-aligned patch should be specified by the surface normal. Therefore, we determine the cost for each pixel and a depth in the reference view using homography specified by more accurate layout element orientation instead of the vanilla optical axis, described in Equation 2. We slightly abuse the term “depth” here as the distance between the layout element plane and the camera location.
| (2) |
where is any source view in related to reference view . is determined by the layout element from whose region covers pixel .
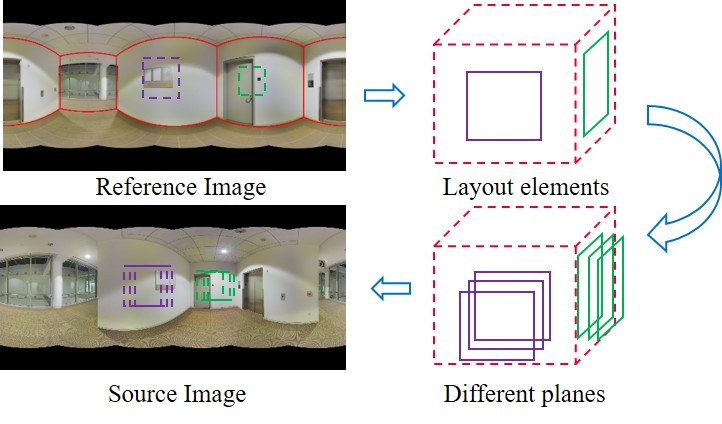
(a) Layout homography
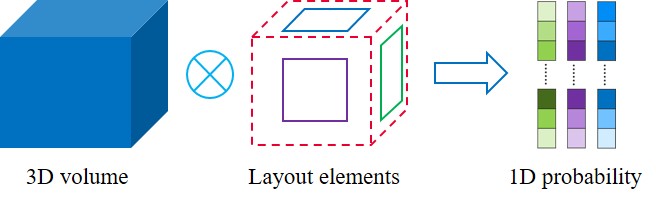
(b) 1D probability compression
Although local homography depends on pixel locations, layout regions are often continuous and clustered. Therefore, we need only enumerate all layout element orientation , apply homography transformation to regions in the source views which overlaps with the corresponding layout element in the reference view. The overall computation cost is almost the same as a single homography applied to the whole image. Figure 3(a) illustrates how we apply homography from different planes. Regions in reference views overlapping with different layout elements are highlighted with different colors and applied with separate layout homography given different orientations.
Layout cost volume
Since our goal is to describe the overall geometry of the layout, we compress the probability volume to describe the layout element feature. First, we build a deep feature volume in the reference camera space for each source view similar to MVSNet [32] but via our layout homography. Then, the cost volume passes through a 3D-UNet to derive a volume probability , which is further compressed into a one-dimensional probability map for each layout element by aggregating information at the same depth layer as shown in the Figure 3(b). Mathematical details are described in Equation 3.
| (3) |
is a learned confidence to adjust the contribution of pixel to the layout depth estimation, which is discussed in Section 3.4.
We regress the layout depth by aggregating the one-dimensional probability map in Equation 4.
| (4) |
During training, the regressed depth is supervised by ground truth layout depth using L1 norm (Equation 5).
| (5) |
3.4 Semantics and Self-attention
Since real environments are usually cluttered, layout structures are partially occluded by objects in panoramas. Therefore, it is beneficial to highlight contributions of useful regions and deemphasize the influence of object regions when reconstructing the 3D layout. We rely on confidence score (Equation 3) to adjust contributions at the pixel level. We incorporate semantic information as explicit supervision and adopt a weakly-supervised self-attention module to learn such an adjustment.
In detail, we use HoHoNet [26] to extract the semantic label map for all input panoramas . Each semantic label corresponds to a confidence that is learned or specified by the user. When layout semantics are explicitly defined, we straightforwardly set depending on whether the semantic belongs to the layout. Otherwise, we learn a MLP layer that translates semantic features into . We discuss details of the choices in Section 4.2. In the meanwhile, we pass through a self-attention module which is a four-layer CNN to determine a learned confidence for each pixel. We multiply them to obtain the final contribution by considering both first principles and learned statistics.
3.5 Implementation
During training, we optimize all aforementioned network parameters in an end-to-end manner by minimizing the loss in Equation 6.
| (6) |
At inference time, we extract a 3D layout for each view by combining the 2D layout from the layout module and depth prediction from the MVS module. Layouts from each view are finally aggregated into a global world. In our implementation, layout elements from different views are fused if they are close and visible to both views given a depth threshold (0.1m). This fusion step leads to a clean, unified, and holistic reconstruction of an entire scene.
4 Experiments
We compare our method with the state-of-the-art methods in Section 4.1, where we show a clear advantage from absolute 3D accuracy and relative geometry coherency. Section 4.2 performs ablation studies and shows that our proposed ideas can dramatically improve the reconstruction quality. We demonstrate a large-scale 3D layout reconstruction in Section 4.3.
4.1 Comparison
Baselines
Since our goal is to reconstruct 3D layouts of the scene, we aim to compare with the state-of-the-arts sharing the same task [25, 26]. To our knowledge, these works are the best candidates for comparison since there are no studies that combine MVS with network inference of the layout as we do. Since absolute depth is not available from these methods, we apply a standard scale prediction proposed by [30], denoted as “SP” in all following experiments. We notice that it is also possible to build 3D layouts as a postprocessing step after multi-view stereo, which we will discuss in Section 4.2.
Datasets
We propose to use 2D-3D-S [1] and ZInD [4] as commonly used or recently released datasets for experiments. In 2D-3D-S, all panorama images from the same room are mutually visible and grouped together as related views. We set 112 groups of images in scene 5 as test data and all other 401 groups as training data. For ZInD, images are grouped based on their associated floor ID. As a result, we obtain 7536 groups of images for training and 945 groups of images for testing. Matterport3D [3] is another commonly used dataset. But it lacks camera poses for skybox images and thus is not appropriate for our multi-view setting.
Metrics
We propose several metrics to evaluate the quality of the 3D layout. The depth RMSE is the rooted mean square error of the estimated layout depth map and the ground truth layout depth map. It measures the mean error between the predicted layout and the ground truth. The scale error is the absolute difference between the estimated and real camera heights. It serves as an overall metric reflecting how close the predicted scale of environment is to the ground truth. Finally, it is crucial that layouts from different views are consistent in the 3D world, which is measured by coherency as the mean distance of pairs of 3D points extracted from corresponding pixels in the reference and the source images.
Results
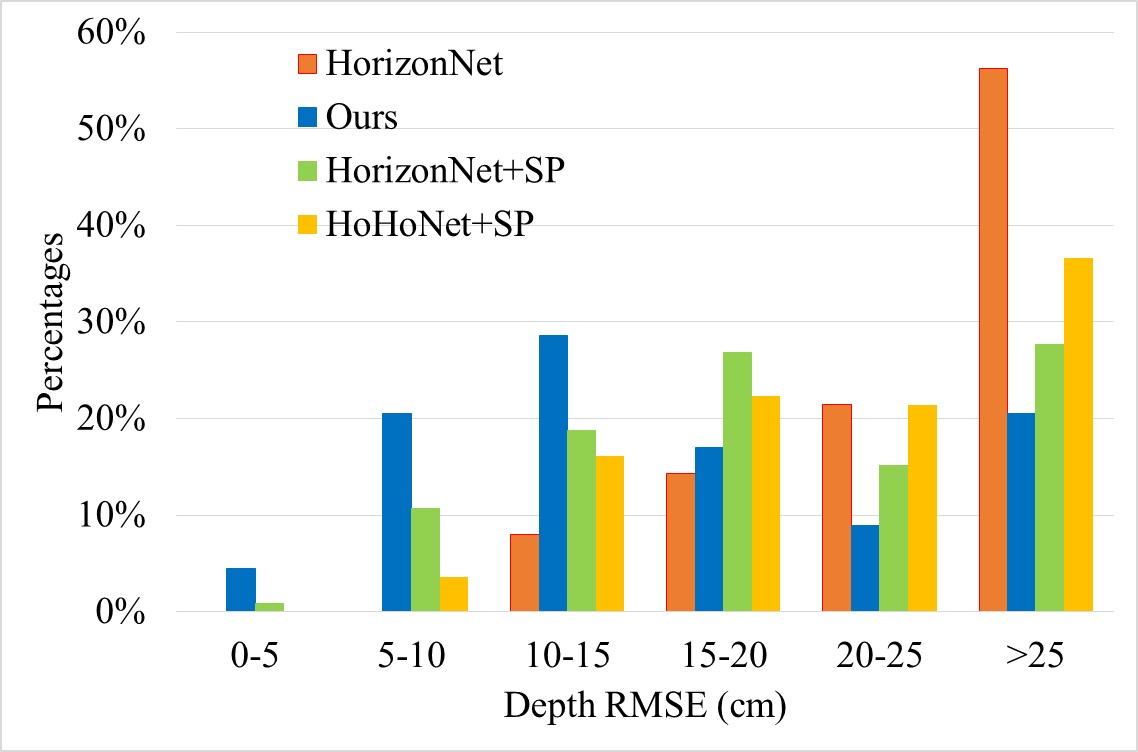
Table 1 shows that our method outperforms the state-of-the-art methods in all metrics on the 2D-3D-S dataset [1]. Worth mentioning, we achieve an improvement of 21.7% in terms of depth RMSE, and 50.0% in the scale error. We observe that 2D-3D-S is captured at quite similar camera heights, which reduces the discrepancy of coherency scores among compared methods. As shown in the Figure 4, we can reconstruct more scenes in low depth RMSE which indicates the effectiveness of the proposed method. When the depth RMSE is larger than 25 cm, we have nearly 10% less scenes which suggests that the our method is more robust.
We visualize the reconstructed layouts and the depth error maps for 2D-3D-S in Figure 5. Figure 5(a) plots the layout boundaries predicted from different methods, where the ground truth, HoHoNet [26], HorizonNet [25] and ours are visualized with red, purple, blue, and green colors respectively. As expected, the quality of layouts projected into the image space is quite similar among different methods. However, our improvement of 3D accuracy is significant as shown in Figure 5(b-d).
| 2D-3D-S | Depth RMSE | Scale error | Coherency |
|---|---|---|---|
| HorizonNet | 0.28 | 0.17 | 0.11 |
| HorizonNet+SP | 0.23 | 0.10 | 0.10 |
| HoHoNet+SP | 0.26 | 0.10 | 0.12 |
| Ours | 0.18 | 0.05 | 0.09 |




(a) 2D layouts

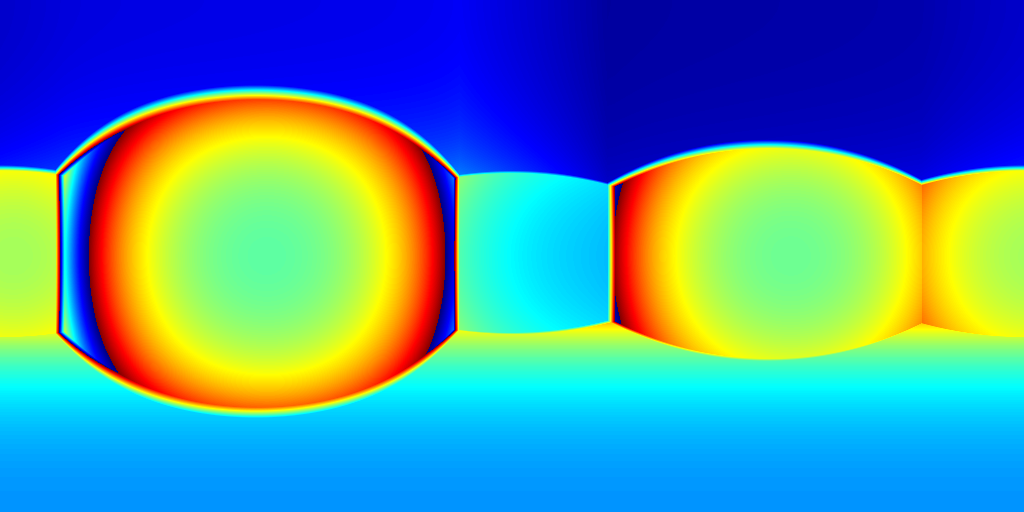


(b) HoHoNet+SP




(c) HorizonNet+SP




(d) Ours
For ZInD dataset, we show even more salient improvement compared to the state-of-the-art methods as shown in Table 2. This dataset contains more unfurnished and extremely texture-less regions. Such challenging environments highlight the robustness of our network against monocular prediction. We achieve an improvement of 20.6% in terms of depth RMSE, and 64.3% in the scale error. Compared to experiments on 2D-3D-S, our method shows a bigger improvement in terms of coherency on ZInD with a wider range of heights the images are captured. We visualize the reconstructed layouts and the depth error maps in Figure 6 similar to what we do for 2D-3D-S. Note that even when 3D layouts from existing methods are far from ground truth as shown in the first row, our method still derives accurate layout depth from multi-view information. Such a challenging dataset suggests that our method can reconstruct the 3D layouts with much higher quality.
| ZInD | Depth RMSE | Scale error | Coherency |
|---|---|---|---|
| HorizonNet | 0.45 | 0.27 | 0.25 |
| HorizonNet+SP | 0.34 | 0.14 | 0.23 |
| HoHoNet+SP | 0.35 | 0.14 | 0.23 |
| Ours | 0.27 | 0.05 | 0.18 |




(a) 2D layouts
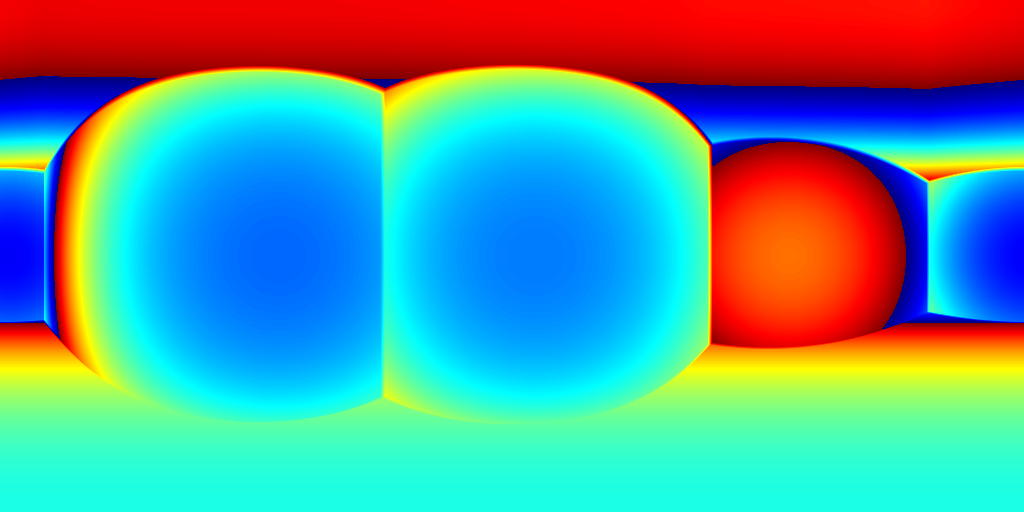
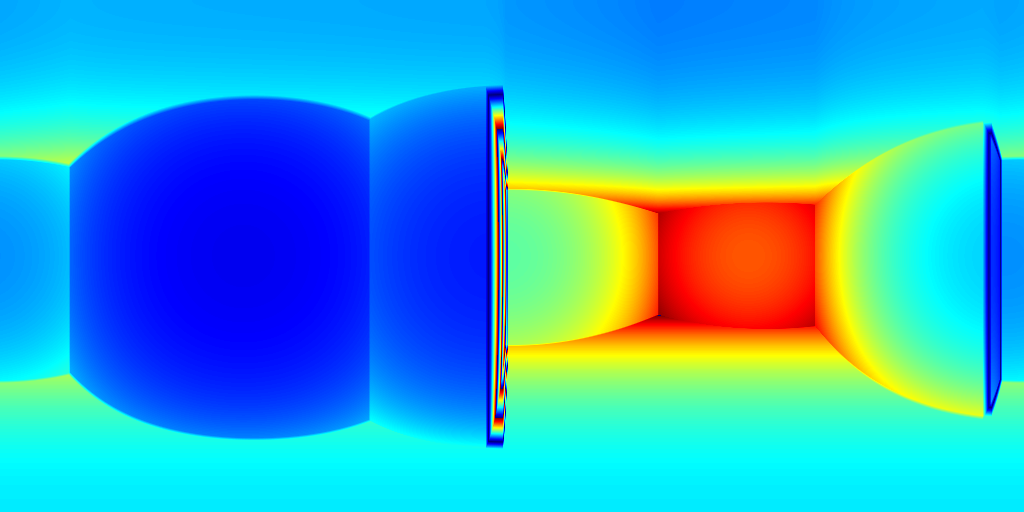
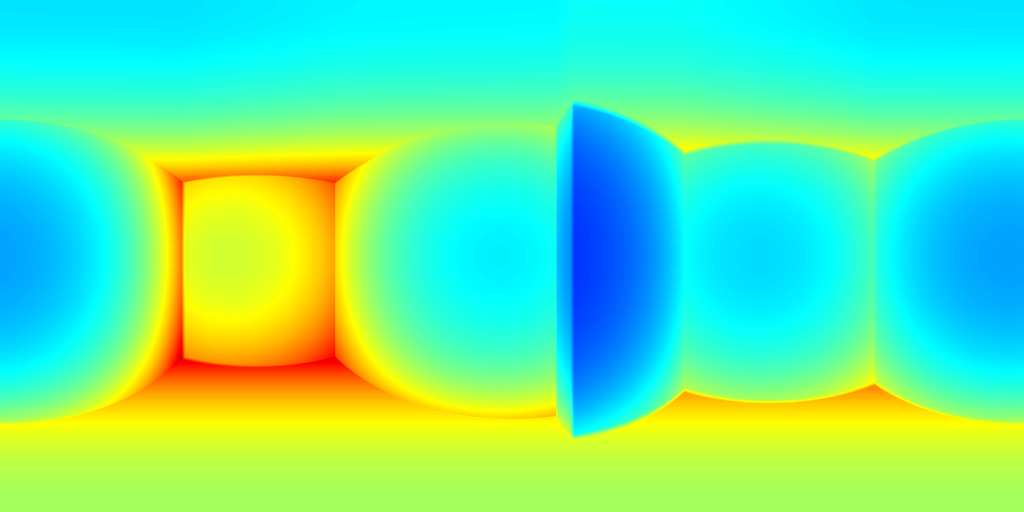
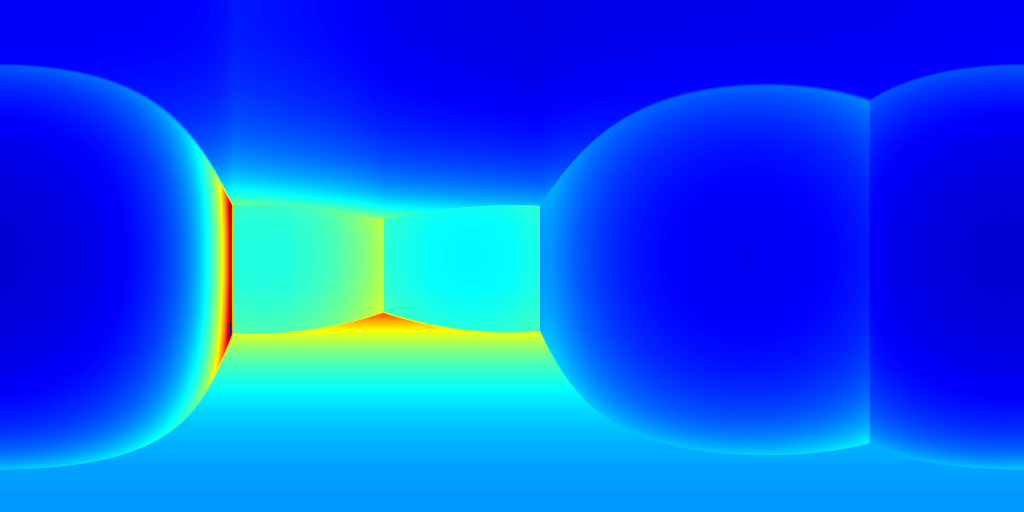
(b) HoHoNet+SP
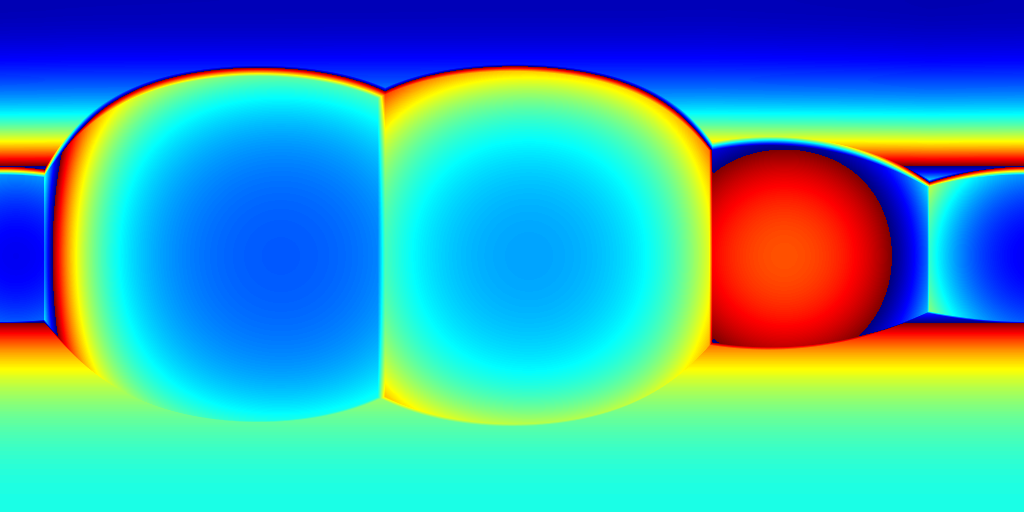
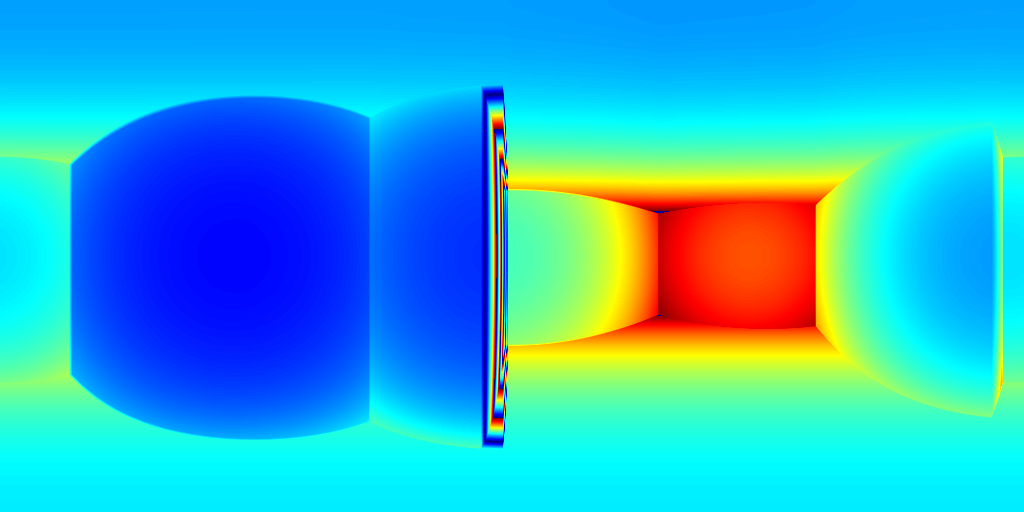
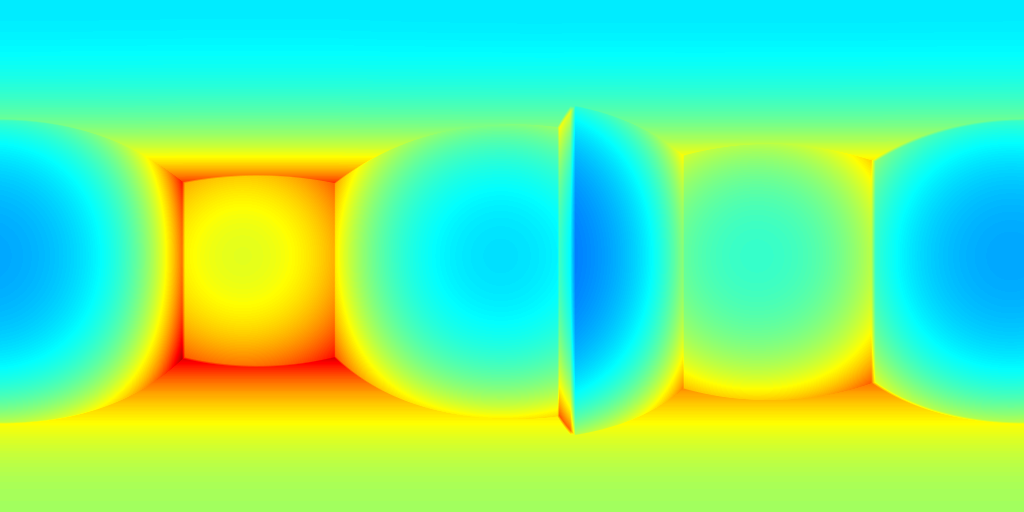
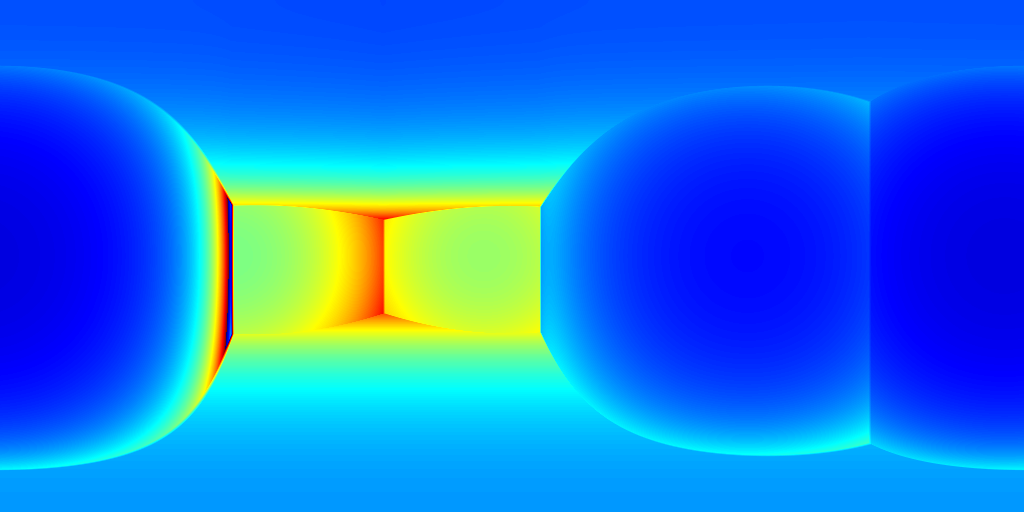
(c) HorizonNet+SP




(d) Ours

4.2 Ablation study
Semantic information
While semantic information is important to layout estimation, there are potentially multiple solutions to introduce them into our system. The most straightforward way which we suggest is to directly specify the confidence of regions according to predicted semantics. Specifically, we treat ceilings, floors, and walls as layout structures and set their confidence as one and others zero. An alternative solution is to learn the confidence from semantic features, in which case we pass semantic features through an MLP layer to obtain . We compare these two choices with a version where is always set to one. We set to focus on semantic confidence and keep other settings the same as discussed in Section 3. Table 3 shows evaluation of different choices of using semantics on 2D-3D-S dataset. We find both learned semantics or user-specified semantic confidence helps improve the accuracy, where our user-specified version performs the best. Another interesting finding is that coherency is nearly the same among all methods, suggesting that our MVS module robustly produces coherent geometry no matter whether cluttered regions are taken into consideration.
| 2D-3D-S | Depth RMSE | Scale error | Coherency |
|---|---|---|---|
| Without sem | 0.24 | 0.08 | 0.10 |
| Learned sem | 0.22 | 0.07 | 0.10 |
| User spec sem | 0.21 | 0.06 | 0.10 |
Self-attention confidence
Besides semantics information, we add additional degrees of freedom for the network to adjust confidence with a self-attention module. We aim to study the effectiveness of the self-attention confidence and its relationship to semantic confidence . In Table 4, we evaluate a vanilla version by setting both confidence to one, a version where and are learned by our network, and a full version where both and are activated. We find attention helps to improve the performance, and the full version achieves the best performance. This suggests that attention is beneficial and should be jointly considered with semantic information.
| 2D-3D-S | Depth RMSE | Scale error | Coherency |
|---|---|---|---|
| Fix and | 0.24 | 0.08 | 0.10 |
| Activate | 0.21 | 0.06 | 0.09 |
| Activate and | 0.18 | 0.05 | 0.09 |
MVS with postprocessing
An important question is whether it is feasible to derive a clean and accurate 3D layout by post-processing the MVS results. We design an experiment where MVS is processed with an orientation-fixed plane fitting to obtain the layout, where orientation is produced from our 2D layout network. We evaluate results from MVSNet [32], post-processed by plane fitting (PF), and our network by comparing them with the ground truth depth map. Detailed statistics are shown in Table 5. While it is possible to obtain a clean 3D layout from MVS, the accuracy is not satisfying. Specifically, the depth RMSE is similar to the monocular prediction from a monocular view with a scale prediction (e.g. Table 1, HorizonNet+SP). In contrast, our direct layout-based MVS module can significantly improve the 3D accuracy.
| 2D-3D-S | Depth RMSE | Scale error | Coherency |
|---|---|---|---|
| MVSNet | 0.24 | - | 0.10 |
| MVSNet+PF | 0.22 | 0.06 | 0.09 |
| Ours | 0.18 | 0.05 | 0.09 |
4.3 Scene-level Reconstruction
Finally, we demonstrate a holistic reconstruction of the entire 2D-3D-S dataset given thousands of panoramas. Due to accurate view-based 3D layout predictions, we are able to apply layout fusion (Section 3.5) and obtain globally consistent layout geometry of the scene. As shown in Figure 7, we obtain coherent and reasonable structure layouts almost everywhere in such a big building, opening the potential for robust and abstract reconstruction of large scenes from pure RGB cameras.
5 Conclusion
We present a novel end-to-end framework for 3D layout reconstruction with multi-view panoramas. We seamlessly combine monocular layout estimation and an MVS network to obtain an accurate 3D layout of scenes in a large scale. Technically, we build a layout cost volume from layout homography, compress the volume into a 1D probability map and regress a single depth value for each layout element. Our solution significantly improves the geometry accuracy of the reconstructed layout.
References
- [1] Iro Armeni, Sasha Sax, Amir R Zamir, and Silvio Savarese. Joint 2d-3d-semantic data for indoor scene understanding. arXiv preprint arXiv:1702.01105, 2017.
- [2] Ricardo Cabral and Yasutaka Furukawa. Piecewise planar and compact floorplan reconstruction from images. In 2014 IEEE Conference on Computer Vision and Pattern Recognition, pages 628–635, 2014.
- [3] Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments. International Conference on 3D Vision (3DV), 2017.
- [4] Steve Cruz, Will Hutchcroft, Yuguang Li, Naji Khosravan, Ivaylo Boyadzhiev, and Sing Bing Kang. Zillow indoor dataset: Annotated floor plans with 360º panoramas and 3d room layouts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2133–2143, June 2021.
- [5] E. Delage, Honglak Lee, and A.Y. Ng. A dynamic bayesian network model for autonomous 3d reconstruction from a single indoor image. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), volume 2, pages 2418–2428, 2006.
- [6] Alex Flint, Christopher Mei, David Murray, and Ian Reid. A dynamic programming approach to reconstructing building interiors. In Kostas Daniilidis, Petros Maragos, and Nikos Paragios, editors, Computer Vision – ECCV 2010, pages 394–407, Berlin, Heidelberg, 2010. Springer Berlin Heidelberg.
- [7] Kosuke Fukano, Yoshihiko Mochizuki, Satoshi Iizuka, Edgar Simo-Serra, Akihiro Sugimoto, and Hiroshi Ishikawa. Room reconstruction from a single spherical image by higher-order energy minimization. In 2016 23rd International Conference on Pattern Recognition (ICPR), pages 1768–1773, 2016.
- [8] Yasutaka Furukawa and Jean Ponce. Accurate, dense, and robust multiview stereopsis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(8):1362–1376, 2010.
- [9] Varsha Hedau, Derek Hoiem, and David Forsyth. Recovering the spatial layout of cluttered rooms. In 2009 IEEE 12th International Conference on Computer Vision, pages 1849–1856, 2009.
- [10] Heiko Hirschmuller. Stereo processing by semiglobal matching and mutual information. IEEE Transactions on Pattern Analysis and Machine Intelligence, 30(2):328–341, 2008.
- [11] Jingwei Huang, Yanfeng Zhang, and Mingwei Sun. Primitivenet: Primitive instance segmentation with local primitive embedding under adversarial metric. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15343–15353, October 2021.
- [12] Hamid Izadinia, Qi Shan, and Steven M. Seitz. Im2cad. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- [13] Chiyu Max Jiang, Avneesh Sud, Ameesh Makadia, Jingwei Huang, Matthias Nießner, and Thomas A. Funkhouser. Local implicit grid representations for 3d scenes. CoRR, abs/2003.08981, 2020.
- [14] Michael Kazhdan, Matthew Bolitho, and Hugues Hoppe. Poisson surface reconstruction. In Proceedings of the fourth Eurographics symposium on Geometry processing, volume 7, 2006.
- [15] Michael Kazhdan and Hugues Hoppe. Screened poisson surface reconstruction. ACM Transactions on Graphics (ToG), 32(3):29, 2013.
- [16] Chen-Yu Lee, Vijay Badrinarayanan, Tomasz Malisiewicz, and Andrew Rabinovich. Roomnet: End-to-end room layout estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Oct 2017.
- [17] David C. Lee, Martial Hebert, and Takeo Kanade. Geometric reasoning for single image structure recovery. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 2136–2143, 2009.
- [18] Jeong-Kyun Lee, Jae-Won Yea, Min-Gyu Park, and Kuk-Jin Yoon. Joint layout estimation and global multi-view registration for indoor reconstruction. CoRR, abs/1704.07632, 2017.
- [19] Lingxiao Li, Minhyuk Sung, Anastasia Dubrovina, Li Yi, and Leonidas J. Guibas. Supervised fitting of geometric primitives to 3d point clouds. CoRR, abs/1811.08988, 2018.
- [20] Branislav Micusik and Jana Kosecka. Piecewise planar city 3d modeling from street view panoramic sequences. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 2906–2912, 2009.
- [21] Jeong Joon Park, Peter Florence, Julian Straub, Richard A. Newcombe, and Steven Lovegrove. Deepsdf: Learning continuous signed distance functions for shape representation. CoRR, abs/1901.05103, 2019.
- [22] Giovanni Pintore, Marco Agus, and Enrico Gobbetti. Atlantanet: Inferring the 3d indoor layout from a single 360 image beyond the manhattan world assumption. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm, editors, Computer Vision – ECCV 2020, pages 432–448, Cham, 2020. Springer International Publishing.
- [23] Giovanni Pintore, Valeria Garro, Fabio Ganovelli, Enrico Gobbetti, and Marco Agus. Omnidirectional image capture on mobile devices for fast automatic generation of 2.5d indoor maps. In 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1–9, 2016.
- [24] Srikumar Ramalingam and Matthew Brand. Lifting 3d manhattan lines from a single image. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), December 2013.
- [25] Cheng Sun, Chi-Wei Hsiao, Min Sun, and Hwann-Tzong Chen. Horizonnet: Learning room layout with 1d representation and pano stretch data augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- [26] Cheng Sun, Min Sun, and Hwann-Tzong Chen. Hohonet: 360 indoor holistic understanding with latent horizontal features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2573–2582, June 2021.
- [27] Fu-En Wang, Yu-Hsuan Yeh, Min Sun, Wei-Chen Chiu, and Yi-Hsuan Tsai. Led2-net: Monocular 360deg layout estimation via differentiable depth rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12956–12965, June 2021.
- [28] Jiu Xu, Björn Stenger, Tommi Kerola, and Tony Tung. Pano2cad: Room layout from a single panorama image. In 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 354–362, 2017.
- [29] Hao Yang and Hui Zhang. Efficient 3d room shape recovery from a single panorama. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- [30] Shang-Ta Yang, Fu-En Wang, Chi-Han Peng, Peter Wonka, Min Sun, and Hung-Kuo Chu. Dula-net: A dual-projection network for estimating room layouts from a single rgb panorama. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- [31] Yang Yang, Shi Jin, Ruiyang Liu, Sing Bing Kang, and Jingyi Yu. Automatic 3d indoor scene modeling from single panorama. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- [32] Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), September 2018.
- [33] Hongwei Yi, Zizhuang Wei, Mingyu Ding, Runze Zhang, Yisong Chen, Guoping Wang, and Yu-Wing Tai. Pyramid multi-view stereo net with self-adaptive view aggregation. In ECCV, 2020.
- [34] Yinda Zhang, Shuran Song, Ping Tan, and Jianxiong Xiao. Panocontext: A whole-room 3d context model for panoramic scene understanding. In David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuytelaars, editors, Computer Vision – ECCV 2014, pages 668–686, Cham, 2014. Springer International Publishing.
- [35] Chuhang Zou, Alex Colburn, Qi Shan, and Derek Hoiem. Layoutnet: Reconstructing the 3d room layout from a single rgb image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.