Multimodal Federated Learning with Missing Modality
via Prototype Mask and Contrast
Abstract
In real-world scenarios, the challenge of random modality missing in multimodal federated learning (mFL) hampers the development of federated frameworks and significantly diminishes model inference accuracy. However, existing mFL methods are predominantly limited to specific scenarios with either unimodal clients or complete multimodal clients. They typically create modality-specific encoders on clients and train modality fusion modules on servers, suffering from severe task drift between clients and servers and struggling to generalize effectively in intricate modality-missing scenarios. In this paper, we introduce a prototype library into the FedAvg-based Federated Learning framework, thereby enabling mFL to alleviate the task drift and performance degradation resulting from modality missing during both training and inference. The proposed method utilizes prototypes as masks representing missing modalities to formulate a task-calibrated training loss and a model-agnostic uni-modality inference strategy. In addition, a proximal term based on prototypes is constructed to enhance local training. Extensive experiments demonstrate the state-of-the-art performance of our approach across a series of missingness settings. Code is available at https://github.com/BaoGuangYin/PmcmFL.
1 Introduction
Multimodal pre-trained models have exhibited superior performance in various downstream tasks (Wang et al., 2023b; Yu et al., 2022; Chen et al., 2023b), with the availability of large-scale data being a major contributing factor. However, collecting large-scale data in practical applications may result in privacy leakage. An alternative approach is to adopt a decentralized machine learning paradigm, such as federated learning (FL). In FL (McMahan et al., 2017), distributed clients collaborate to train a global model without sharing their private datasets. However, it faces practical challenges when dealing with complex real-world multimodal data. One such challenge is the widely-existing issue of missing modalities. The presence of missing modalities on each client poses constraints on local training thereby leading to a significant drop in global model inference accuracy. Furthermore, the non-independent and identically distributed (non-IID) nature of data among clients (Zhu et al., 2021; Mendieta et al., 2022; Li et al., 2020; Huang et al., 2022; Qu et al., 2022; Li et al., 2021) sharpens the challenges of modality missing, highlighting the urgent need to address the issue in practical multimodal data.


Some pioneer works (Yu et al., 2023; Zhao et al., 2022; Chen & Zhang, 2022; Feng et al., 2023) attempt to carry out multimodal federated learning with missing modalities. These approaches employ modality-specific encoders for each modality, such as visual encoders for images and language encoders for text, and train them using unimodal or self-supervised training tasks. These local encoders are then either aggregated into a global encoder (Zhao et al., 2022), or the global encoder is trained by aligning the local encoders through knowledge distillation (KD) on public data (Yu et al., 2023). To perform downstream tasks that require modality fusion, the server needs additional training data to train a modality fusion module and a downstream task head. These previous works focused on simple scenarios of modality missing, consisting of unimodal clients and modality-complete multimodal clients (as shown in Figure 1(a)). However, it is common for each client to have partial data with missing modalities (Feng et al., 2023), leading to more intricate practical scenarios. An example is observed in social media platforms where users generate three types of data: images only, text only, and image-text pairs.
Facing such intricate scenarios of modality missing, the existing multimodal FL frameworks encounter the following issues: 1) Clients cannot obtain fused representations due to only modality-specific encoders being deployed. 2) Severe task drift occurs between clients and server, e.g., image/text classification on clients but visual question answering (VQA) on the server, resulting in inconsistent optimization directions. 3) Lack of any strategy for addressing modality missing. 4) The availability of the server’s downstream task datasets has also been controversial in FL. These motivate us to propose a new general multimodal FL framework for real-world modality missing and fused representations learning.
In this paper, we aim to empower the FL framework with the ability to handle intricate modality-missing scenarios during both training and inference. Moreover, we develop modality-interactive encoders and fusion modules for each client to avoid the necessity of training data on the server (cf. Figure 1(b)). To this end, we need to address three challenges: CH1. How to handle complex missing patterns for interactive encoder? CH2. How to perform representation fusion when data is non-IID and modalities are missing? CH3. How to ensure the performance of the global model when there are missing modalities during inference?
Specifically, we innovatively utilize the flexible Multiway Transformers (Wang et al., 2023b; Peng et al., 2022; Bao et al., 2022) to construct our multimodal encoders. By selecting different modality expert networks, Multiway Transformers can serve as both modality-specific encoders and interactive encoders, thereby adapting to complex patterns of modality missing (CH1). Inspired by prototype learning in FL (Liao et al., 2023; Lyu et al., 2023; Huang et al., 2023; Dai et al., 2023; Xu et al., 2023; Chen et al., 2023a), we propose a novel prototype-based multimodal FL framework, termed PmcmFL (Prototype Mask and Contrast for Multimodal FL) to achieve fused representation learning with non-IID data and missing modalities (CH2). In PmcmFL, we construct and maintain a prototype library. During training, the prototypes act as global prior knowledge of the missing modality to compensate for cross-modal fusion and calibrate task drift. The prototype library also introduces a proximal item based on prototypes to reduce heterogeneity among clients. Consequently, we utilize prototypes for inference with missing modalities (CH3), where various matching algorithms are elaborately introduced to identify the prototype with the closest semantics.
Our experiments show that PmcmFL achieves state-of-the-art performance. Notably, it brings 0.2-3.7% accuracy improvements across different modality missing rates. Regarding inference with missing modalities, it achieves a remarkable 23.8% accuracy improvement.
The main contributions are summarized below:
-
•
Our work stands out as the first attempt to empower our FL framework with the capability to alleviate the global model performance degradation resulting from modality missing during both training and inference.
-
•
We propose PmcmFL to achieve task-calibrated training and higher inference accuracy when dealing with modality-incomplete data.
-
•
To the best of our knowledge, we are the first to adopt Multiway Transformer as a versatile encoder to address the complex patterns of modality missing.
2 Related Work

2.1 Multimodal Learning
Multimodal learning has attracted increasing attention from the research community. The model with dual-encoder architecture (Radford et al., 2021) uses separate encoders for each modality, with shallow modality interaction. On the contrary, the models with interactive-encoder architecture (Wang et al., 2023b; Kim et al., 2021) process input from different modalities and concentrate on modeling modality interactions via fuse tokens without modality-specific encoders.
In order to overcome the missing modality issue in multimodal learning, many methods have been developed. Ma et al. (Ma et al., 2021) propose the SMIL to train a feature reconstruction network using a meta-learning algorithm. Zhao et al. (Zhao et al., 2021) propose the MMIN to learn robust multimodal representations by training cascade residual autoencoders. Ma et al. (Ma et al., 2022) enhance the robustness of Transformer through multi-task learning and optimal fusion strategy search. Wang et al. (Wang et al., 2023a) propose the ShaSpec to generate features of missing modalities using a shared encoder. These methods have introduced additional branches and complex training algorithms to the model, which are unsuitable for FL.
2.2 Federated Learning with Prototype
Prototype refers to the centroid of the instances belonging to the identical class (Snell et al., 2017). Due to its scalability, prototypes are widely used to solve various problems in FL (Liao et al., 2023; Lyu et al., 2023; Liu et al., 2023; Li et al., 2023). Tan et al. (Tan et al., 2022) propose FedProto to conduct FL using prototypes rather than aggregation. Huang et al. (Huang et al., 2023) utilize prototypes to solve domain shift in FL. Dai et al. (Dai et al., 2023) utilize prototypes to alleviate the performance decline caused by heterogeneous data in FL. Some other FL frameworks (Xu et al., 2023; Chen et al., 2023a), while not explicitly mentioning prototypes, still leverage the concept of prototypes to address corresponding issues. In this paper, we primarily utilize prototypes to address modality missing issues.
2.3 Multimodal Federated Learning
Combining multimodal learning with federated learning is a novel research problem, with the key challenge being how to perform modality interactions when there are missing modalities for each client. Zhao et al. (Zhao et al., 2022) propose FedIoT to train autoencoders for each modality on every client and give more aggregation weight to multimodal clients. Chen et al. (Chen & Zhang, 2022) propose FedMSplit to construct a dynamic graph for adaptively selecting multimodal client models where some modalities may be missing. Yu et al. (Yu et al., 2023) propose CreamFL to conduct cross-modal interaction using inter-modal and intra-modal contrast. However, these studies only considered scenarios involving either unimodal or modality-complete multimodal clients. Feng et al. (Feng et al., 2023) propose FedMultimodal as the first attempt to consider scenarios where modalities of partial data may be missing on each client. They address this by masking the missing modalities using zero tensors. In this paper, we consider scenarios similar to FedMultimodal, with a focus on an efficient and versatile method for addressing modality missing.
3 Methodology
3.1 Overview
We consider a federated learning setting including multimodal clients. Without loss of generality, we take images and text as instances of multimodal data. In Appendix A, we analyze how to generalize our framework to other multimodal tasks. We decouple the model architecture into a representation encoder , a deep fusion layer , and a task head . In each image-text pair, the image or text will be missing with a probability of . In this case, all the images can be denoted as , where is the -th image on the -th client, is its corresponding label. Similarly, all the text can be denoted as , and all the image-text pairs can be denoted as . Furthermore, each client develops a local model , with the same architecture as the global model.
As shown in Figure 2, PmcmFL constructs or updates the prototype library on the server (operation ①) at the beginning of each federated communication round. Subsequently, the prototype library and the global model are broadcast to all participants. Then, each participating client performs local training and then updates local prototypes. Using prototypes as masks of missing modalities, a task-calibrated training loss will supervise the training (operation ②). Additionally, to tackle the non-IID issue and the resulting client drift, a prototype-based contrastive loss is proposed (operation ④). Finally, all participating clients transmit their local models and local prototypes back to the server, after which the global model is updated by aggregating those local models. During inference, the prototype library also assists inference with missing modalities by transmitting prototypes to the global model (operation ③). The complete algorithm is in Appendix B.
For local training, We use Multiway Transformer as encoder . This encoder (Bao et al., 2022; Peng et al., 2022; Wang et al., 2023b) handles different missing patterns by switching among various encoding modes. When only image or text input exists, the multiway encoder functions as a modality-specific encoder, like ViT (Dosovitskiy et al., 2021) or BERT (Devlin et al., 2019). When inputting an image-text pair, the multiway encoder functions as an interactive encoder, enabling the representation of one modality to fuse information from the other modality. More details on the Multiway Transformer are in Appendix C.
3.2 Constructing Prototype Library
Prototypes compact the semantics of data within the same class. Considering communication overhead in FL, low-dimension representations are used to construct the prototype library. As for the compacting strategy, we naively use the class centroids as the prototypes.
Selecting Hidden Representations. For , we denote as the output of the multiway transformer encoder, where is the number of output tokens, and is the dimension of each token. The image CLS token and the text CLS token are extracted from . We select the two CLS tokens along with the fused representation, i.e., , for constructing prototypes.
Construction and Update In the prototype library, we construct and maintain three types of prototypes: image prototypes , text prototypes , and fusion prototypes . All prototypes are initialized with zero tensors or random tensors. Subsequently, after local training in each federated communication round, all participating clients construct local prototypes by computing class centroids. Finally, the global prototypes are aggregated from the local prototypes with numbers of client samples as weights. The construction process is formalized as follows:
| (1) |
| (2) |
| (3) |
where denotes the data of class on the -th client, denotes the set of participating clients, and denotes all data of participating clients. For , denotes the local prototypes and denotes the global prototypes.
3.3 Prototypes as Masks of Missing Modalities
When missing modalities occur, previous work (Feng et al., 2023) masks missing data with zero tensors. In PmcmFL, prototypes are employed as masks for missing modality representations, thereby incorporating global prior knowledge. Based on this, a task-calibrated training loss and a model-agnostic unimodal inference strategy are proposed.
Task-Calibrated Training Loss. As shown in Figure 2, during local training with complete image-text pairs, the training loss is defined:
| (4) |
where denotes the task loss function. For classification tasks, cross-entropy is commonly used. In the case of local training with text missing, a task-calibrated training loss is constructed using the text prototypes as masks:
| (5) |
where has the same class as . Similarly, the task-calibrated training loss is defined when images are missing:
| (6) |
With supervision from the task-calibrated loss, the entire model is trained on the original multimodal task, even when there are missing modalities on clients. On the contrary, using zero masks will result in a task-drifted loss. For example, in the case where text is missing, the training loss with zero masks is denoted as . Essentially, this represents an unimodal training task that depicts the relationship between the unimodal representation and the ground truth , which leads to inconsistent optimization directions for the model training.
Model-Agnostic Unimodal Inference. During inference with missing modalities, prototypes are employed as masks to assist the global model. Unlike training, where labels are available, we must find corresponding cross-modal prototypes according to embedded representations. To this end, a matching function is established from hidden representations to prototypes. We use an example to describe the matching process of cross-modal prototypes. Without loss of generality, assume that the model only utilizes images for inference. First, the image is input for computing the image representation . Sequentially, the image prototype with the same class is determined using this matching function . Following this, the corresponding text prototype is determined according to class . Finally, the image representation and the text prototype are input into the subsequent modules.
As for matching function , we propose both model-free and model-based matching. Model-free matching involves matching the closest prototype for each representation using a distance metric, such as L1, L2 distance, or cosine similarity. And model-based matching involves training tiny models, treating the search of cross-modal prototypes as either a classification or a retrieval task. These tiny models are trained only in the final round of federated communication, incurring negligible overhead to the FL framework. For the classification task, we train a shallow MLP-Classifier using cross-entropy loss. For the retrieval task, inspired by DALLE2 (Ramesh et al., 2022), we sequentially use CLIP loss (Radford et al., 2021) and MSE loss to train an MLP-Prior to achieve transfer and retrieval. We attempt three aggregation strategies for tiny models from different clients: selecting the model with maximum client samples, model aggregation, and model ensemble.
Inspired by MixUp (Zhang et al., 2018), we propose ProtoMix to enrich the semantic information within prototypes used for inference. ProtoMix linearly combines the top- related prototypes with weights derived from applying the Softmax function to distance metrics, classification probabilities, or retrieval match scores.
3.4 Prototypes as Learned Representation Targets
Due to the non-IID issue, the learned representation distributions in latent space significantly differ among clients (i.e., client drift), leading to an uncoordinated model aggregation. To achieve model aggregation without conflicts, all clients must theoretically have similar local representation distributions. In PmcmFL, prototypes are used as learned representation targets to guide clients in learning fused representation distributions clustered by class. For this reason, we introduce a proximal term based on the unidirectional CLIP contrastive loss to regularize client training.
Sampling a batch from the local dataset, the proximal term can be denoted as:
| (7) |
where is the -th representation in batch, is its corresponding prototype, and is a temperature factor. As the global model gradually converges, the prototypes converge step by step. This proximal term works by pulling representations closer to the prototypes of the same class and pushing representations away from prototypes of different classes so that the learned representations are around the corresponding global prototypes.
Since prototypes are the centroids of class representations, maintaining a certain distance (i.e., fine-grained semantic difference) from each representation, we use CLIP loss to constrain their similarities rather than relying on MSE to constrain their distances. Although the prototype-based proximal term can theoretically be constructed on image representations, text representations, and fused representations separately, we only utilize the last one due to the difficulty in coordinating multiple proximal terms. In this case, the total training loss for each client is the sum of task loss and contrastive loss of fused representations:
| (8) |
where is the weighting hyper parameter for .
4 Experiment
| Methods | Accuracy (%) on 5K Testing Samples () | Acc@sum | ||||
|---|---|---|---|---|---|---|
| g | ||||||
| FedAvg + ignore | 56.444 | 53.936 | 49.990 | 45.024 | 38.898 | 244.292 |
| FedMultimodal | 55.360 | 52.804 | 49.246 | 46.378 | 41.034 | 244.822 |
| FedMultimodal + RM | 55.624 | 52.542 | 48.164 | 47.288 | 41.346 | 244.964 |
| FedProx + Mask | 52.506 | 49.546 | 46.502 | 46.862 | 41.140 | 236.556 |
| FedIoT + Mask | 55.010 | 52.180 | 47.558 | 47.582 | 41.838 | 244.168 |
| FedPAC + Mask | 55.028 | 50.742 | 46.916 | 45.930 | 40.242 | 238.858 |
| FedHKD + Mask | 56.286 | 53.546 | 50.544 | 47.832 | 43.376 | 251.584 |
| PmmFL(Ours) + FA | 56.144 | 54.366 | 50.556 | 48.796 | 46.168 | 256.030 |
| PmmFL(Ours) + HKD | 56.458 | 53.926 | 51.568 | 49.472 | 46.394 | 257.818 |
| PmcmFL (Ours) | 56.636* | 55.478* | 52.256* | 49.548* | 47.042* | 260.960* |
4.1 Experiment Setup
Dataset. Following CreamFL (Yu et al., 2023), we utilize the challenging VQAv2 dataset (Goyal et al., 2017) to evaluate our PmcmFL. For the efficiency of the experiments, we construct a tiny VQA task, one-tenth the scale of the original VQA task. The tiny VQA is a classification task of 310 classes, with 64,000 training samples and 5,000 testing samples. The training data is distributed to 30 clients, employing the Dirichlet distribution () for non-IID data partition (Hsu et al., 2019). Following suggestions from previous work (Feng et al., 2023), we set an equal training missing rate of for each modality. More details on the dataset are in Appendix D.
Model. For the encoder , we utilize the same architecture as BEIT3-base (Wang et al., 2023b) along with its pre-train parameters. For the deep fusion layer , the image CLS token and the text CLS token are concatenated and projected through an MLP. For the task head , the fusion representation is projected to logits using another MLP. More details on the model architecture are in Appendix E.
Baseline. We compare our PmcmFL with the most relevant existing FL frameworks. Among them, 1) FedAvg+ignore, where training is conducted only on modality-complete data, ignoring data with modality missing; 2) FedMultimodal (Feng et al., 2023), Essentially an extension of FedAvg, using Zero Mask for missing modalities; 3) Fedmultimodal+random mask, where replaces Zero Mask with Gaussian Random Mask; 4) FedIoT+mask, a framework the same as FedAvg, where Mask is applied to missing modalities, using aggregation strategy is designed for multimodal FL in FedIoT (Zhao et al., 2022). 5) FedPAC+mask, a framework based on FedAvg and Mask for missing modalities, using prototype-based feature alignment (FA) in FedPAC (Xu et al., 2023). 6) FedHKD+mask, a framework based on FedAvg and Mask for missing modalities, using prototype-based hyper knowledge distillation (HKD) in FedHKD (Chen et al., 2023a). To demonstrate the effectiveness of our Prototype Contrast, we ablate it to obtain the variant PmmFL(PmcmFL without Contrast), and introduce the following two baselines: 7) PmmFL+FA and 8) PmmFL+HKD, which replace Prototype Contrast with Feature Alignment (FA) and Hyper Knowledge Distillation (HKD), respectively. We future compare with 9) CreamFL in simple modality missing scenarios. More details on baselines are in Appendix F.
Implement. To enable fair comparisons, our experiments remain consistent on method-agnostic hyperparameters, including federated communication rounds, local training epochs, client selection rate, learning rate, optimizer parameters, and batch size. For hyperparameters introduced by PmcmFL, to prevent them from overfitting to specific tasks, we only conducted a simple parameter search. Only the weight is searched within to find the optimal value. More Implementation details for all experiments can be found in Appendix G.
Evaluation Metric. We fix the random seed and utilize optimal accuracy in the last ten communication rounds as the final performance. Note that all evaluations are conducted with modality-complete testing samples, except in experiments on inference with missing modalities (Sec. 4.4). Appendix H provides accuracy under varying degrees of modality missing during the inference phase.
| PC | PM | Accuracy (%) on 5K Testing Samples () | Acc@sum | ||||
| 55.624 | 52.542 | 48.164 | 47.288 | 41.346 | 244.964 | ||
| ✓ | 55.948 | 53.588 | 50.982 | 47.422 | 44.454 | 252.394 | |
| ✓ | 55.326 | 54.486 | 50.858 | 49.290 | 45.848 | 255.808 | |
| ✓ | ✓ | 56.636 | 55.478 | 52.256 | 49.548 | 47.042 | 260.960 |
| Methods | Accuracy (%) on Unimodal Data | |||
|---|---|---|---|---|
| Mix-1 | Mix-10 | Mix-20 | Mix-best | |
| Zero Mask | 0.996 | 0.996 | 0.996 | 0.996 |
| Random Mask | 3.662 | 3.662 | 3.662 | 3.662 |
| L1 Metric | 6.358 | 6.170 | 6.784 | 6.784 |
| L2 Metric | 5.454 | 5.238 | 5.782 | 6.106 |
| COS Metric | 5.524 | 6.062 | 6.676 | 6.938 |
| Classifier(max.) | 26.956 | 27.022 | 27.022 | 27.022 |
| Classifier(ens.) | 27.090 | 27.090 | 27.090 | 27.090 |
| Classifier(avg.) | 27.502 | 27.092 | 27.092 | 27.502 |
| MLP-Prior(max.) | 27.052 | 19.906 | 8.742 | 27.052 |
| MLP-Prior(ens.) | 27.260 | 27.280 | 27.280 | 27.280 |
| MLP-Prior(avg.) | 5.858 | 5.702 | 5.996 | 6.210 |
4.2 Main Results
Table 1 displays the accuracy of the global model in all baselines and our PmcmFL. Our PmcmFL framework generally achieves noticeable performance improvement over all baselines in all modality missing rates.
Compared to ignoring incomplete data, the Mask method significantly improves the performance of federated training with 50% modality missing (a 2.448% boost), indicating that Mask is effective in handling severe modality missing.
Compared to FedAvg, FedIoT leads to a performance decline (a 0.796% drop on Acc@sum), which indicates that assigning more aggregation weight to multimodal clients no longer works in our task scenarios. Similarly, FedPAC leads to a performance decline (a 6.106% drop on Acc@sum), which is because the feature alignment (FA) employed by FedPAC, a strong regularization that narrows the distance between representations and prototypes through MSE, disrupts the semantic distinctiveness of representations.
Compared to all the baselines, our PmcmFL achieves superior performance (9.376-24.404% boost on Acc@sum), demonstrating the effectiveness of our Prototype Mask and Contrast. Furthermore, as the modality missing rate increases, the performance improvement brought about by our PmcmFL tends to be more significant (a 0.192% boost in 10% missing but a 3.666% boost in 50% missing).
Compared to PmcmFL’s variants, slightly superior performance (3.14-4.93% boost on Acc@sum) indicates that our Prototype Contrast is more generalizable than Feature Alignment and Hyper Knowledge Distillation. We further validate the better performance of PmcmFL compared with CreamFL in scenarios with a 100% missing rate of either modality. The experimental results are in Appendix I.

4.3 Ablation Studies
We study the effect of each PmcmFL component during training. Table 2 displays the results of ablation studies under various training modality missing rates.
The results show that Prototype Contrast and Mask contribute to performance improvement over the baselines, with gains of 7.430% and 11.168% on Acc@sum, respectively. Moreover, combining Prototype Contrast and Prototype Mask assist local training yields further performance boost.
4.4 Inference with Missing Modalities
Table 3 shows the testing accuracy of the global model in 100% text missing, demonstrating intuitively the performance of PmcmFL in handling inference with missing modalities. We use the global model trained with 30% modality missing, and its accuracy is 52.256% in modality-complete testing samples. For ProtoMix, top-1, top-10, top-20, and best prototype mix are exhibited.
We can obviously see that the inference accuracy of Zero Mask and Random Mask, serving as baselines, is only 0.996% and 3.662%, respectively, which indicates that the modality missing issues severely impair the model’s inference accuracy. In contrast, Prototype Mask achieves the highest accuracy of 27.502% (a 23.840% boost), demonstrating that our method helps restore modal inference accuracy. Moreover, the experiments also demonstrate the effectiveness of our ProtoMix strategy. More results and discussions can be found in Appendix J.
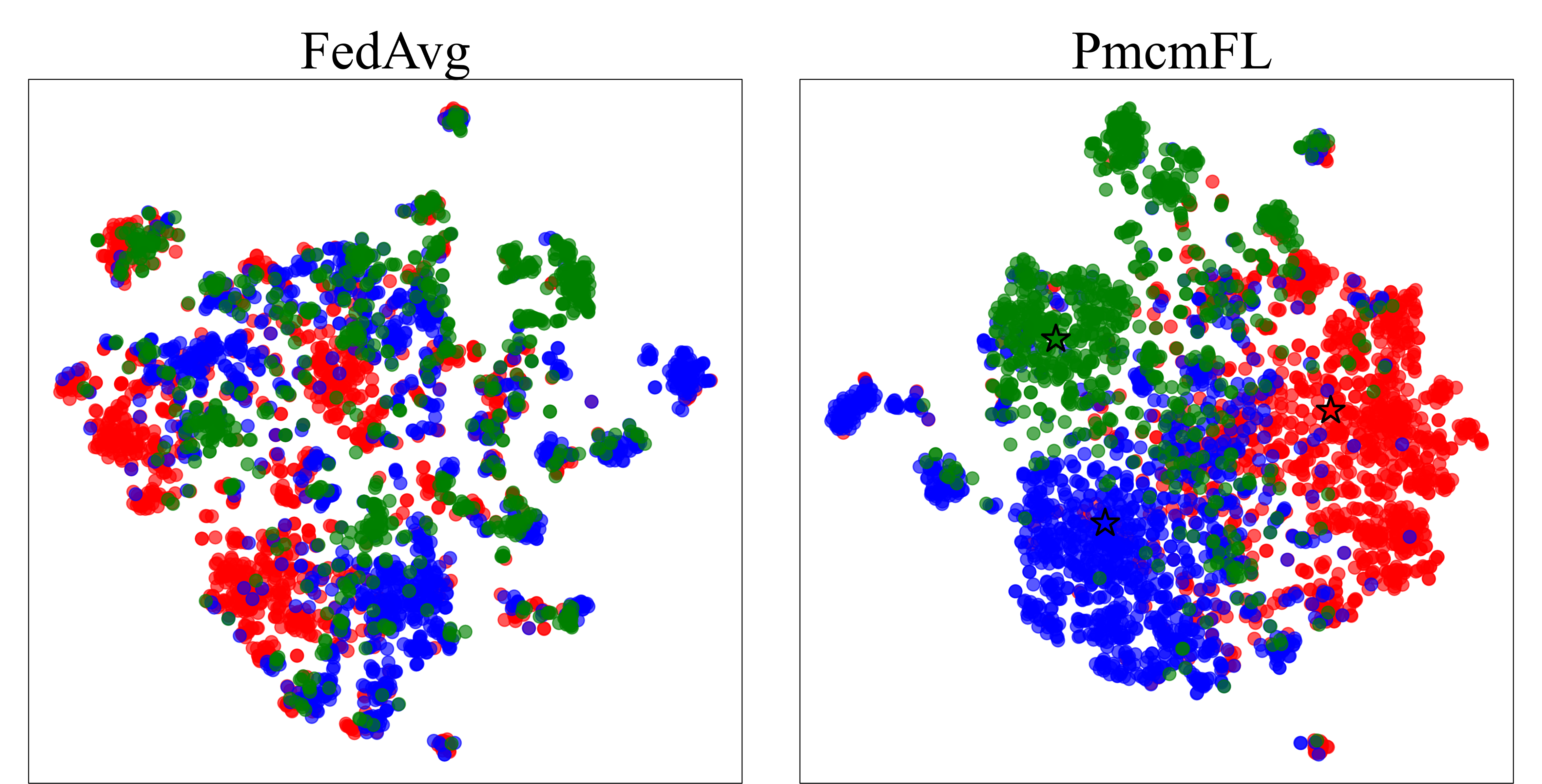
4.5 Qualitative Studies
We utilize T-SNE (Van der Maaten & Hinton, 2008) for visualization to qualitatively analyze the role of Prototypes Contrast in our FL framework.
Figure 3(a) visualizes fused representation distribution learned by different clients. We can observe that in FedAvg, some dots cluster by clients, indicating that each client forms its individual latent space. When local models are aggregated into a global model, individual latent spaces hinder the formation of a unified latent space. In contrast, in our PmcmFL, the heterogeneity of latent spaces among various clients is reduced due to prototypes acting as representation targets to guide local training.
Figure 3(b) visualizes the fused representation distribution learned by the global model. We randomly selected samples of three classes in the testing set. It can be observed that in FedAvg, dots from different classes are mixed, which is not conducive to subsequent classification tasks. In contrast, in our PmcmFL, dots from different classes cluster around their respective prototypes, which validates our starting point of using prototypes for constructing contrastive loss.


4.6 Overhead and Efficiency of Communication
In our PmcmFL, the parameters transmitted during each federated communication round include model weights and the prototype library.
Figure 4 illustrates different FL frameworks’ communication overhead and communication efficiency. As shown, in our tiny VQA task, PmcmFL introduces only negligible additional communication overhead (+0.32%). In the original VQA task, PmcmFL exhibits even lower communication overhead than FedHKD (+3.21% v.s. +5.43%). Furthermore, we can observe that when transmitting the same amount of parameters, PmcmFL achieves optimal performance, demonstrating that our framework has the highest communication efficiency.
4.7 Robustness to federated settings
Figure 5 illustrates the performance of various FL Frameworks across different communication rounds, client selection rates, local training epochs, and learning rates. We conduct experiments with 50% modality missing while keeping all federated settings constant except the one being investigated. Four representative FL frameworks are compared: 1) FedAvg with ignoring modality-incomplete data; 2) FedAvg with Gaussian Random Mask; 3) FedHKD, the existing one with optimal performance; 4) our PmcmFL. The experimental results demonstrate that, under different FL settings, our PmcmFL consistently achieved optimal performance, showcasing robustness to FL settings.




5 Conclusion
In this paper, we investigate multimodal federated learning with uncertain modality missing in both training and inference. Our work introduces a prototype library to empower the FL framework with the capability to alleviate performance degradation resulting from modality missing. Based on the prototype library, we construct a task-calibrated training loss, a model-agnostic unimodal inference strategy, and a proximal term. The effectiveness of our framework has been validated through comparisons with state-of-the-art methods under various missingness settings.
Our forthcoming efforts will center on riching semantics of prototypes, improving the prototype match accuracy, and extending Prototype Mask to a data augmentation method. Furthermore, we recognize the potential of using prototypes to tackle issues with missing or inaccurate labels, and we also intend to explore this avenue.
Impact Statements
This paper presents work whose goal is to advance the field of Machine Learning, thereby facilitating the practical application of multimodal learning in real-world scenarios. The dataset we use is publicly available and does not involve privacy issues.
References
- Bao et al. (2022) Bao, H., Dong, L., Piao, S., and Wei, F. BEiT: BERT pre-training of image transformers. In International Conference on Learning Representations, 2022.
- Chen et al. (2023a) Chen, H., Wang, C., and Vikalo, H. The best of both worlds: Accurate global and personalized models through federated learning with data-free hyper-knowledge distillation. In International Conference on Learning Representations, 2023a.
- Chen & Zhang (2022) Chen, J. and Zhang, A. Fedmsplit: Correlation-adaptive federated multi-task learning across multimodal split networks. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 87–96, 2022.
- Chen et al. (2023b) Chen, X., Wang, X., Changpinyo, S., Piergiovanni, A. J., Padlewski, P., Salz, D., Goodman, S., Grycner, A., Mustafa, B., Beyer, L., Kolesnikov, A., Puigcerver, J., Ding, N., Rong, K., Akbari, H., Mishra, G., Xue, L., Thapliyal, A. V., Bradbury, J., and Kuo, W. Pali: A jointly-scaled multilingual language-image model. In International Conference on Learning Representations, 2023b.
- Dai et al. (2023) Dai, Y., Chen, Z., Li, J., Heinecke, S., Sun, L., and Xu, R. Tackling data heterogeneity in federated learning with class prototypes. In Thirty-Seventh AAAI Conference on Artificial Intelligence, pp. 7314–7322, 2023.
- Devlin et al. (2019) Devlin, J., Chang, M., Lee, K., and Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, pp. 4171–4186, 2019.
- Dosovitskiy et al. (2021) Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021.
- Feng et al. (2023) Feng, T., Bose, D., Zhang, T., Hebbar, R., Ramakrishna, A., Gupta, R., Zhang, M., Avestimehr, S., and Narayanan, S. Fedmultimodal: A benchmark for multimodal federated learning. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 4035–4045, 2023.
- Goyal et al. (2017) Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., and Parikh, D. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6325–6334, 2017.
- Hsu et al. (2019) Hsu, T. H., Qi, H., and Brown, M. Measuring the effects of non-identical data distribution for federated visual classification. CoRR, abs/1909.06335, 2019.
- Huang et al. (2022) Huang, W., Ye, M., and Du, B. Learn from others and be yourself in heterogeneous federated learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10133–10143, 2022.
- Huang et al. (2023) Huang, W., Ye, M., Shi, Z., Li, H., and Du, B. Rethinking federated learning with domain shift: A prototype view. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16312–16322, 2023.
- Kim et al. (2021) Kim, W., Son, B., and Kim, I. Vilt: Vision-and-language transformer without convolution or region supervision. In Proceedings of the 38th International Conference on Machine Learning, pp. 5583–5594, 2021.
- Li et al. (2023) Li, J., Li, F., Zhu, L., Cui, H., and Li, J. Prototype-guided knowledge transfer for federated unsupervised cross-modal hashing. In Proceedings of the 31st ACM International Conference on Multimedia, pp. 1013–1022, 2023.
- Li et al. (2021) Li, Q., He, B., and Song, D. Model-contrastive federated learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10713–10722, 2021.
- Li et al. (2020) Li, T., Sahu, A. K., Zaheer, M., Sanjabi, M., Talwalkar, A., and Smith, V. Federated optimization in heterogeneous networks. In Proceedings of Machine Learning and Systems, 2020.
- Liao et al. (2023) Liao, X., Liu, W., Chen, C., Zhou, P., Zhu, H., Tan, Y., Wang, J., and Qi, Y. Hyperfed: Hyperbolic prototypes exploration with consistent aggregation for non-iid data in federated learning. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, pp. 3957–3965, 2023.
- Liu et al. (2023) Liu, J., Zhan, Y., Luo, X., Chen, Z., Wang, Y., and Xu, X. Prototype-based layered federated cross-modal hashing. In IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 1–2, 2023.
- Lyu et al. (2023) Lyu, F., Tang, C., Deng, Y., Liu, T., Zhang, Y., and Zhang, Y. A prototype-based knowledge distillation framework for heterogeneous federated learning. In 43rd IEEE International Conference on Distributed Computing Systems, pp. 1–11, 2023.
- Ma et al. (2021) Ma, M., Ren, J., Zhao, L., Tulyakov, S., Wu, C., and Peng, X. SMIL: multimodal learning with severely missing modality. In Thirty-Fifth AAAI Conference on Artificial Intelligence, pp. 2302–2310, 2021.
- Ma et al. (2022) Ma, M., Ren, J., Zhao, L., Testuggine, D., and Peng, X. Are multimodal transformers robust to missing modality? In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18156–18165, 2022.
- McMahan et al. (2017) McMahan, B., Moore, E., Ramage, D., Hampson, S., and y Arcas, B. A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, volume 54 of Proceedings of Machine Learning Research, pp. 1273–1282, 2017.
- Mendieta et al. (2022) Mendieta, M., Yang, T., Wang, P., Lee, M., Ding, Z., and Chen, C. Local learning matters: Rethinking data heterogeneity in federated learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8387–8396, 2022.
- Peng et al. (2022) Peng, Z., Dong, L., Bao, H., Ye, Q., and Wei, F. BEiT v2: Masked image modeling with vector-quantized visual tokenizers. 2022.
- Qu et al. (2022) Qu, L., Zhou, Y., Liang, P. P., Xia, Y., Wang, F., Adeli, E., Fei-Fei, L., and Rubin, D. L. Rethinking architecture design for tackling data heterogeneity in federated learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10051–10061, 2022.
- Radford et al. (2021) Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, pp. 8748–8763, 2021.
- Ramesh et al. (2022) Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., and Chen, M. Hierarchical text-conditional image generation with CLIP latents. CoRR, abs/2204.06125, 2022.
- Snell et al. (2017) Snell, J., Swersky, K., and Zemel, R. S. Prototypical networks for few-shot learning. In Advances in Neural Information Processing Systems, pp. 4077–4087, 2017.
- Tan et al. (2022) Tan, Y., Long, G., Liu, L., Zhou, T., Lu, Q., Jiang, J., and Zhang, C. Fedproto: Federated prototype learning across heterogeneous clients. In Thirty-Sixth AAAI Conference on Artificial Intelligence, pp. 8432–8440, 2022.
- Van der Maaten & Hinton (2008) Van der Maaten, L. and Hinton, G. Visualizing data using t-sne. Journal of machine learning research, 9(11), 2008.
- Wang et al. (2023a) Wang, H., Chen, Y., Ma, C., Avery, J., Hull, L., and Carneiro, G. Multi-modal learning with missing modality via shared-specific feature modelling. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15878–15887, 2023a.
- Wang et al. (2023b) Wang, W., Bao, H., Dong, L., Bjorck, J., Peng, Z., Liu, Q., Aggarwal, K., Mohammed, O. K., Singhal, S., Som, S., and Wei, F. Image as a foreign language: BEIT pretraining for vision and vision-language tasks. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 19175–19186, 2023b.
- Xu et al. (2023) Xu, J., Tong, X., and Huang, S. Personalized federated learning with feature alignment and classifier collaboration. In International Conference on Learning Representations, 2023.
- Yu et al. (2022) Yu, J., Wang, Z., Vasudevan, V., Yeung, L., Seyedhosseini, M., and Wu, Y. Coca: Contrastive captioners are image-text foundation models. Transactions on Machine Learning Research, 2022.
- Yu et al. (2023) Yu, Q., Liu, Y., Wang, Y., Xu, K., and Liu, J. Multimodal federated learning via contrastive representation ensemble. In International Conference on Learning Representations, 2023.
- Zhang et al. (2018) Zhang, H., Cissé, M., Dauphin, Y. N., and Lopez-Paz, D. mixup: Beyond empirical risk minimization. In International Conference on Learning Representations, 2018.
- Zhao et al. (2021) Zhao, J., Li, R., and Jin, Q. Missing modality imagination network for emotion recognition with uncertain missing modalities. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, pp. 2608–2618, 2021.
- Zhao et al. (2022) Zhao, Y., Barnaghi, P. M., and Haddadi, H. Multimodal federated learning on iot data. In Seventh IEEE/ACM International Conference on Internet-of-Things Design and Implementation, pp. 43–54, 2022.
- Zhu et al. (2021) Zhu, Z., Hong, J., and Zhou, J. Data-free knowledge distillation for heterogeneous federated learning. In Proceedings of the 38th International Conference on Machine Learning, pp. 12878–12889, 2021.
Appendix A Extend to Other Multimodal Tasks
In the main body, we illustrate the framework of PmcmFL using a text-image multimodal classification task (VQA) as an example and apply VQA to evaluate the framework’s performance. However, this does not imply that our PmcmFL is limited to specific modalities or tasks.
On the contrary, as the PmcmFL framework does not depend on specific model structures and only requires the model to be abstractly divided into modal encoders, fusion layers, and task heads, PmcmFL can be directly extended to almost all multimodal classification tasks.
In Table LABEL:other_task, we list some datasets to which PmcmFL can be extended, including the modalities and tasks associated with these datasets. The table represents just the tip of the iceberg for multimodal tasks that require modal fusion.
| Datasets | Modalities | Tasks | ||
|---|---|---|---|---|
| CrisisMMD | Image, Text | Crisis Information Classification | ||
| Hateful-Memes | Image, Text | Hateful Content Detection | ||
| MOSI | Video, Audio, Text | Multimodal Sentiment Analysis | ||
| MELD | Audio, Text | Multimodal Sentiment Analysis | ||
| UCF101 | Video, Audio | Multimodal Action Recognition |
We can see that the datasets to which PmcmFL can be extended encompass inputs from various modalities and involve a variety of task types.
As for the extension strategy, taking the multimodal sentiment classification task on the MOSI dataset as an example, one simply needs to replace the image-text encoder described in PmcmFL with a video encoder, speech encoder, and text encoder. The fusion module can be specially designed for the task, along with a corresponding classification task head.
Appendix B Algorithm of PmcmFL
Algorithm 1 and Algorithm 2 illustrate the flowcharts of our PmcmFL during training and inference, respectively.
Input: Number of federated communication rounds , number of clients , number of local epochs , server model, local model , local learning rate , dataset of the -th client and fraction of clients that are selected to perform computation in each round.
Output: The final server model’s parameters
ServerExecutes:
Initialize randomly;
Initialize global prototypes with zero tensors;
for do
Input: Server model , Testing set.
Output: Labels for classification tasks
if input is an image-text pair then
Search for the corresponding image prototype using matching function ;
Find the corresponding text prototype through the association in the prototype library;
Compute ;
Search for the corresponding text prototype using matching function ;
Find the corresponding text prototype through the association in the prototype library;
Compute ;
Appendix C Details on Multiway Transformer
We will first introduce the differences between Multiway Transformers and regular Transformers here. We will also emphasize that although we use multi-head Transformers as encoders, any encoder architecture is applicable within the PmcmFL framework.
C.1 Multiway Transformer
In summary, a typical Transformer consists of Multi-Head Self-Attention layers (Attention), Feedforward Networks (FFN), Layer Normalizations, and Residual Connections. The difference between Multiway Transformers and regular Transformers lies in the Attention layers and the FFNs. Specifically, the Attention layers in Multiway Transformer are modality-shared self-attention, and the FFNs are Modality-Specific Feedforward Networks (also known as Modality-Specific Experts Networks), meaning each modality has its own FFN.
We use images and text as examples to illustrate how Multiway Transformer switch encoding modes. The input images and text are initially processed into sequences of tokens involving patchify or tokenization, together with positional encoding. The initial token sequences (the image token sequence, the text token sequence, and the image-text token sequence) can be represented as:
| (9) |
| (10) |
| (11) |
where denotes the image token, denotes the text token, denotes the image CLS token, denotes the text CLS token, and denote the number of image tokens and text tokens respectively.
For the Shared Self-Attention layer at -th encoding layer, we represent it as . For the Modality-Specific Expert Networks at -th encoding layer, we use and to respectively represent the vision expert network and the language expert network. For the sake of clarity, we have omitted Residual Connections and Layer Normalizations.
When dealing with only image inputs, Multiway Transformer utilizes the attention module and the visual expert network at each encoding layer:
| (12) |
When dealing with only text inputs, Multiway Transformer utilizes the attention module and the language expert network at each encoding layer:
| (13) |
When dealing with image-text pairs, Multiway Transformer first employs the shared self-attention module for cross-modal interaction:
| (14) |
Subsequently, individual expert networks are applied to tokens from the corresponding modality:
| (15) |
By utilizing Modality-Specific Expert Networks, Multiway Transformers can switch to different encoders.
C.2 Decoupling Framework and Model
It is important to highlight that PmcmFL is a universal framework and the encoders used in our PmcmFL are not limited to the Multiway Transformer In fact, our framework is flexible to incorporate with encoders of other architectures.

Figure 6 illustrates the general architecture of multimodal models and the architecture we use. The same as ours, general multimodal models consist of three main parts: modality-specific encoders, a fusion module, and a task head.
Due to the similar architecture, general multimodal models can be easily developed in our PmcmFL. To elaborate, we can construct a prototype library by utilizing the outputs of modality-specific encoders and the fusion module. Based on the prototype library, PmcmFL can execute as usual.
It is worth noting that if the fusion module employs the Transformer architecture, it could be a wise move to integrate a module of bottleneck architecture after the modality-specific encoders to obtain low-dimension representation for computing prototypes, which will significantly reduce federated communication overhead.
The reason we adopt Multiway Transformer is due to its superior ability in handling multimodal interaction. In our PmcmFL, Multiway Transformer not only functions as modality-specific encoders but also functions as dual-stream interactive encoders to achieve better modality fusion.
Appendix D Details on the Dataset
In this section, we provide a detailed description of the construction process for ting VQA, along with visualizations for non-IID data and modality missing.
D.1 Tiny VQA
Due to the typically slower convergence of models in federated learning, the training cost is significantly increased. The full scale of VQAv2 is too extensive for evaluating federated learning frameworks. Therefore, we evaluate on a randomly selected subset of VQAv2. This approach has been demonstrated in prior works, such as CreamFL.
Our tiny VQA is a scaled-down version, reducing both label quantity and training data volume to one-tenth of the original VQA task. The original VQA is commonly seen as a classification task with over 3,000 classes, supported by a vast training dataset exceeding 640,000 samples. We refine the labels by excluding those with fewer than 180 occurrences, reshaping VQA into a classification challenge with 310 classes. For training, we randomly chose 64,000 image-text pairs, equivalent to one-tenth of the combined original VQA task training and validation sets. Additionally, our test set comprises 5,000 random image-text pairs randomly selected, ensuring none overlap with the training set. All experiments are conducted on ting VQA, except when compared with CreamFL.
D.2 Visualization for Data Distribution
To simulate real-world scenarios, we distributed the training data of tiny VQA across 30 clients, using a Dirichlet distribution with a hyperparameter of 0.1 as the basis for non-IID partitioning. Previous works involving non-IID have almost adopted this hyperparameter setting, which describes a severe non-IID scenario.
Additionally, to simulate uncertain modality missing, we assigned a fixed missing rate for each modality on every client, thereby conforming to the Bernoulli distribution. In our experiments, we considered five missing ratios: 10%, 20%, 30%, 40%, and 50%.
We visualized the data/modality distribution to illustrate the corresponding non-IIDness and modalities missingness as follows.


Visualization for Non-IIDness. We selected 40 classes from a pool of 310, visualizing their distribution across various clients. Figure 7 displays the diversified results of the visualization, indicating the heterogeneous class distribution across clients.
Visualization for Modality Missingness. We visualized the modality distribution on various clients under different modality missing rates. Figure 8 displays the visualization results, showing the diversified modality distribution.
Appendix E Details on the Model
In this section, we explain the model architecture used in our experiments.
For the Multiway Transformer encoder, we employ the architecture of BEIT3-base, which consists of 12 encoding layers. Detailed model architecture can be found in BEIT3’s GitHub repository111BEIT3’s GitHub repository: https://github.com/microsoft/unilm/tree/master/beit3. We make no modifications to the encoder architecture and utilize its pre-trained weight (pre-training data does not include VQAv2). It is worth noting that when the input is an image-text pair, the original model only uses the image CLS token for subsequent tasks, whereas we utilize both the image CLS and the text CLS token. We simply add an additional output to accommodate our PmcmFL.
For the fusion module, we first apply layer normalization to the image CLS token and the text CLS token separately, then concatenate them. Subsequently, a linear layer and activation layer are applied to obtain the corresponding fusion representation. The dimensions of both the CLS tokens and the fusion representations are 1×768.
For the task head, we use a linear layer to double the dimensions, followed by a layer normalization. After an activation layer, we then use another linear layer to reduce the dimensions to 310, which corresponds to the number of classification categories.
Appendix F Details on Baselines
In this section, we elaborate on the details of the baselines.
F.1 Principle of Selection
For training with modality missing, we propose two innovations: Prototype Mask and Prototype Contrast. Prototype Mask is a strategy to address modality missing, while Prototype Contrast is a strategy to alleviate client heterogeneity and enhance the global model performance. Based on these, we aim to select the most suitable baseline.
Handling modality missing. When modality is missing, the simplest approach is to ignore the incomplete data and only use the data with complete modalities for training. We refer to this approach as Ignore Missing. Previous works used zero tensors to replace the representation of the missing modality. We refer to this approach as zero Mask. A straightforward extension is to use a random tensor following a Gaussian distribution for masking, which we refer to as Random Mask. We consider these three strategies as baselines for handling the modality missing issue and compare them with our proposed Prototype Mask.
Improving the global model. Both non-independent and identically distributed (Non-IID) data and modality missing can lead to client heterogeneity, severely compromising the performance of the global model. FedAvg, as the fundamental federated learning algorithm, does not provide a solution to address non-IID issues. FedProx introduces a proximal term to constrain the updates of local models, demonstrating its effectiveness in mitigating the impact of non-IID scenarios. FedIoT tackles the problem from the perspective of model aggregation strategies, granting more aggregation weight to multimodal clients to alleviate the influence of modality-incomplete clients. Prototype-based Feature Alignment (FA) strategies in FedPAC and Prototype-based Hyper Knowledge Distillation (HKD) in FedHKD are both optimal approaches aimed at mitigating non-IID challenges. We consider these five federated learning frameworks as baselines for improving the global model and compare them with our proposed Prototype Contrast.
F.2 Implementation Details of Baselines
We will elaborate on the implementation details of each baseline.
FedAvg + Ignore. Within the FedAvg framework, the training process involves disregarding all training data on clients with incomplete modalities and using only the data with complete modalities for training.
FedMultimodal (FedAvg + Zero Mask). Based on FedAvg, we adopt the Random Mask as the strategy for handling missing modalities. This approach is consistent with FedMultimodal.
FedMultimodal + RM (FedAvg + Random Mask). Based on FedAvg, we adopt the Random Mask as the strategy for handling missing modalities. Random tensors are obtained from a Gaussian distribution.
We compare three strategies for handling missing data under FedAvg and find that using the Random Mask yields the best results. Therefore, subsequent baselines all adopt Random Mask.
FedProx + Random Mask. Based on FedAvg, we adopt the Random Mask as the strategy for handling missing modalities. According to the relevant paper, the weight of the proximal term is set to 1.0.
FedIoT + Random Mask. Based on FedAvg, we adopt the Random Mask as the strategy for handling missing modalities. According to the paper of FedIoT, we set 100 times the aggregation weight for image-text pairs.
FedPAC + Random Mask. Based on FedAvg, we adopt the Random Mask as the strategy for handling missing modalities. We implement a feature alignment strategy on the fused representations. According to the paper of FedPAC, the hyperparameter of feature alignment is set to 1.0.
FedHKD + Random Mask. Based on FedHKD, we adopt the Random Mask as the strategy for handling missing modalities. Hyper knowledge distillation is applied in the fused representations According to the paper of FedHKD, the hyperparameter of hyper knowledge distillation is set to 0.05.
PmmFL + FA. Based on FedAvg, we adopt the Prototype Mask as the strategy for handling missing modalities. Feature alignment is applied to the fused representations, with the hyperparameter set to 1.0.
PmmFL + HKD. Based on FedAvg, we adopt the Prototype Mask as the strategy for handling missing modalities. Hyper knowledge distillation is applied in the fused representations, with the hyperparameter set to 0.05.
CreamFL. We use the results reported by CreamFL.
Appendix G Implementation Details
We will go through the implementation details of each experiment one by one.
Main Experiments.
The main experiment establishes consistent missing rates for each modality, specifically 0.1, 0.2, 0.3, 0.4, and 0.5. We conducted testing using the modal complete test set and presented the results in Table 1 (We conducted testing with modal partially missing data in Appendix H.). All experiment results are averaged under five runs with fixed random seeds. We considered a conventional federated setting for the main experiment. We set the communication rounds to 30. In each round, 5 clients are selected to participate in training (client selection rate is 0.167). We referred to the BEIT3 GitHub repository for the learning rate and optimizer parameters. The learning rate is fixed at 3e-5. We use the AdamW optimizer with a weight decay set to 1e-4, a momentum of 0.9, and of [0.9, 0.98]. For the training loss, cross-entropy is used as the task loss, and the temperature for the prototype contrastive loss is set to 0.07, following the CLIP GitHub repository. We only perform simple hyperparameter optimization for the weight of the prototype contrastive loss, selecting the optimal value from the set [5.0, 1.0, 0.5, 0.1, 0.01]. All experiments are conducted on 4 NVIDIA RTX 4090 GPUs using distributed data parallelism, with a total batch size of 48 (12 per GPU).
Ablation Studies. We conducted ablation studies on the Prototype Mask and Prototype Contrast in our PmcmFL. The hyperparameter settings for the ablation experiments are the same as those for the main experiment. Note that Sec. 4.7 (Robustness to Federated Settings) can also be considered as an ablation study on federated settings.
Inference with Missing Modalities. To intuitively demonstrate the role of Prototype Masks during the inference phase, we conduct inference with the complete missing of one modality. The model used for this experiment is the best-performing model trained in the primary experiment with 30% modality missing. Without loss of generality, we omit 100% of the text modality during this experiment. In this case, this experiment can also be regarded as an image unimodal inference experiment.
As described in the method section, we need to train a tiny model in the final round of federated communication to achieve the matching from representation to prototype. For model-based matching, we trained tiny models on each client in the final round of federated communication. The classification-based matching utilizes a 2.2M MLP architecture, accounting for less than 1% of the communication round’s overhead. The model takes image representations as input for a 310-class classification task and undergoes 100 epochs of training on each client, with a single GPU training time of under 1 minute. Similarly, the retrieval-based matching employs a 2.9M MLP architecture, constituting approximately 1% of the communication round’s overhead. This model takes image representations as input and generates corresponding image prototypes. Its training involves an initial 200 epochs with contrastive loss, followed by 500 epochs of MSE loss. The training time on a single GPU is approximately 3-5 minutes.
The server needs to select or integrate these tiny models from the clients. We experimented with three strategies to explore the utilization of tiny models from various clients: selecting the model with the maximum client samples, model parameter aggregation through FedAvg, and model ensemble. The first strategy entails choosing the model from the client with the most data samples among the 30 clients. The model aggregation strategy combines the 30 small models through FedAvg. The model ensemble method merges classification probabilities or retrieval scores from individual models through weighted aggregation, with weights determined by the sample quantities of the respective clients.
Qualitative Studies. We choose the optimal model trained in the main experiment with 50% modality missing for quantitative experiments. Associated client models are also utilized.
To compare the heterogeneity among client models under FedAvg and PmcmFL, we randomly selected three models from five client models and visualized their fused representation distributions on the testing set. To compare the performance of the global models under FedAvg and PmcmFL, we selected three categories (with corresponding labels ’red’, ’blue’, and ’green’) from a total of 310 classes and visualized their fused representation distributions.
Communication Efficiency. The experiments on communication efficiency utilize the results derived from the main experiment with 50% modality missing.
Robustness for federated setting. This experiment can also be considered as an ablation study on federated settings. We test PmcmFL’s robustness for varying communication rounds, client selection rates, local training epochs, and learning rates. To evaluate the robustness for communication rounds, we set communication rounds to [5, 10, 15, 20, 25, 30], with a client selection rate fixed at 0.1, local training epochs set to 3, and a fixed learning rate of 3e-5. To evaluate the robustness for client selection rates, we set client selection rates to [0.1, 0.167, 0.233, 0.333], with communication rounds of 20, local training epochs set to 3, and a fixed learning rate of 3e-5. To evaluate the robustness for local training epochs, we set local training epochs to [1, 3, 5, 7], with communication rounds of 20, a client selection rate fixed at 0.1, and a fixed learning rate of 3e-5. To evaluate the robustness for learning rates, we set learning rates to [1e-5, 3e-5, 5e-5, 7e-5], with communication rounds of 20, a client selection rate fixed at 0.1, and local training epochs set to 3.
Appendix H Inference with Partial Modality Missing
We train the model with modalities missing at rates of [10%, 20%, 30%, 40%, 50%], and performed inference on test sets with modalities missing at the same rates.
In baselines, Random Mask serves as the strategy for handling missing modalities, except for FedMultimodal (FedAvg + Zero Mask), which employs Zero Mask. In our PmcmFL, the Prototype Mask is used for handling missing modalities.
The experimental results are shown in Table 5. We compare our PmcmFL with existing approaches, so the two variants of our framework (PmmFL+FA and PmmFL+HKD) are not presented in the table.
As can be seen, the experimental results demonstrate the superiority of our PmcmFL.
| Methods | Sum | ||||||
|---|---|---|---|---|---|---|---|
| 10% | 20% | 30% | 40% | 50% | |||
| FedAvg + Ignore | 10% | 52.016 | 50.756 | 46.812 | 42.254 | 36.720 | 228.558 |
| 20% | 47.904 | 47.318 | 43.198 | 39.386 | 34.278 | 212.084 | |
| 30% | 42.490 | 43.138 | 39.250 | 36.340 | 31.802 | 193.020 | |
| 40% | 38.938 | 40.462 | 36.964 | 34.218 | 30.040 | 180.622 | |
| 50% | 33.760 | 36.180 | 33.406 | 30.492 | 26.926 | 160.764 | |
| FedMultimodal | 10% | 52.822 | 50.288 | 47.234 | 44.478 | 39.766 | 234.588 |
| 20% | 50.310 | 47.624 | 45.056 | 42.280 | 38.366 | 223.636 | |
| 30% | 47.252 | 44.832 | 43.174 | 40.288 | 37.242 | 212.788 | |
| 40% | 45.496 | 43.034 | 41.904 | 38.824 | 36.228 | 205.486 | |
| 50% | 42.588 | 39.828 | 40.034 | 36.872 | 34.658 | 193.980 | |
| FedMultimodal + RM | 10% | 52.268 | 50.242 | 46.230 | 45.352 | 39.962 | 234.054 |
| 20% | 49.176 | 47.602 | 43.954 | 43.368 | 38.460 | 222.560 | |
| 30% | 45.290 | 44.862 | 41.614 | 41.120 | 36.966 | 209.852 | |
| 40% | 42.554 | 42.958 | 39.844 | 39.862 | 35.870 | 201.088 | |
| 50% | 38.568 | 39.964 | 37.348 | 37.536 | 34.082 | 187.498 | |
| FedProx + Mask | 10% | 50.382 | 47.392 | 44.790 | 45.234 | 39.940 | 227.738 |
| 20% | 48.094 | 44.978 | 42.848 | 43.170 | 38.462 | 217.552 | |
| 30% | 45.690 | 42.592 | 40.808 | 41.514 | 36.936 | 207.540 | |
| 40% | 44.300 | 41.002 | 39.414 | 40.240 | 35.806 | 200.762 | |
| 50% | 42.132 | 38.350 | 37.372 | 38.136 | 34.138 | 190.128 | |
| FedIoT + Mask | 10% | 52.714 | 49.910 | 45.698 | 45.664 | 40.604 | 234.590 |
| 20% | 50.278 | 47.112 | 43.544 | 43.486 | 39.130 | 223.550 | |
| 30% | 47.572 | 44.694 | 41.266 | 41.456 | 37.430 | 212.418 | |
| 40% | 45.606 | 43.016 | 39.726 | 39.968 | 36.226 | 204.542 | |
| 50% | 43.164 | 40.000 | 37.420 | 37.494 | 34.430 | 192.508 | |
| FedPAC + Mask | 10% | 52.044 | 48.640 | 45.266 | 43.950 | 39.142 | 229.042 |
| 20% | 49.738 | 46.094 | 43.266 | 41.934 | 37.618 | 218.650 | |
| 30% | 47.082 | 43.558 | 41.084 | 39.692 | 36.282 | 207.698 | |
| 40% | 45.402 | 42.024 | 39.656 | 38.258 | 35.376 | 200.716 | |
| 50% | 42.430 | 39.236 | 37.460 | 35.840 | 33.872 | 188.838 | |
| FedHKD + Mask | 10% | 53.774 | 51.708 | 48.298 | 46.060 | 42.256 | 242.096 |
| 20% | 51.222 | 49.654 | 45.826 | 44.004 | 40.946 | 231.652 | |
| 30% | 48.232 | 47.498 | 43.186 | 42.064 | 39.654 | 220.634 | |
| 40% | 46.524 | 45.306 | 41.590 | 40.962 | 37.908 | 212.290 | |
| 50% | 43.632 | 43.358 | 38.790 | 38.522 | 37.394 | 201.696 | |
| PmcmFL(Ours) | 10% | 53.810 | 52.846 | 49.710 | 47.206 | 45.106 | 248.678 |
| 20% | 51.552 | 50.606 | 47.584 | 45.428 | 43.300 | 238.470 | |
| 30% | 48.148 | 47.452 | 44.916 | 42.932 | 41.054 | 224.502 | |
| 40% | 45.792 | 45.812 | 42.874 | 41.014 | 39.404 | 214.896 | |
| 50% | 43.490 | 43.018 | 39.912 | 39.132 | 38.264 | 203.816 | |
Appendix I Compare with CreamFL
We compare PmcmFL with CreamFL, and due to the different task scenarios from the main experiment, we present the results here.
Similar to CreamFL, we conducted experiments in simple scenarios where there are only unimodal clients and modality-complete multimodal clients. We train models on over 3000 of the most frequent answers (the original VQA task) and report the inference accuracy on 5K testing samples. Table 6 shows the results.
| Methods | Accuracy |
|---|---|
| FedAvg | 52.54 |
| FedIoT | 53.06 |
| FedMD | 57.43 |
| FedET | 59.90 |
| FedGEMS | 60.23 |
| reamFL+Avg | 58.64 |
| reamFL+IoT | 59.64 |
| CreamFL | 62.12 |
| PmcmFL(Ours) | 65.53 |
The results show our framework also achieves SOTA performance (a 3.38% boost compared with CreamFL). This suggests that PmcmFL is equally applicable to specific task scenarios considered by previous works and outperforms methods specifically designed for such scenarios.
We believe that this performance improvement mainly stems from the utilization of the Multiway Transformer encoder, which excels in modality fusion and thus benefits the task. This reflects the advantage of our federated framework compared with CreamFL, which cannot train the modality fusion module on the client.
Appendix J Discussions on ProtoMix
We first present the testing set matching accuracy for each matching method, followed by an explanation of the results generated by ProtoMix.
J.1 Accuracy of Various Matching Strategies
Table 7 displays the matching accuracy of each matching strategy. The data presented corresponds directly to Table 3.
| Methods | Matching Accuracy (%) | |||
|---|---|---|---|---|
| Top1 | Top5 | Top10 | Top20 | |
| L1 Metric | 2.46 | 5.94 | 10.78 | 28.46 |
| L2 Metric | 1.04 | 3.14 | 4.94 | 11.86 |
| COS Metric | 1.04 | 3.32 | 6.84 | 27.04 |
| Classifier(max) | 19.10 | 46.28 | 50.80 | 55.16 |
| Classifier(ens) | 22.34 | 54.38 | 62.72 | 69.14 |
| Classifier(avg) | 23.20 | 51.16 | 57.18 | 62.74 |
| MLP-Piror(max) | 19.56 | 41.92 | 42.62 | 43.46 |
| MLP-Piror(ens) | 21.70 | 47.92 | 52.38 | 56.16 |
| MLP-Piror(avg) | 0.36 | 4.32 | 5.36 | 9.72 |
We can see that there is a significant difference in the matching accuracy of prototype matching strategies with different approaches. The top-1 matching accuracy of the model-free matching strategy is only around 1.04-2.46%, while the top-1 prototype matching accuracy of the model-based matching strategy is approximately 19.10-23.20% (except for MLP-Prior with parameter aggregation).
In addition, compared to the top-1 matching accuracy, the matching accuracy for top-k (k=5, 10, 20) shows significant improvement. This suggests that considering more prototypes may lead to obtaining more closely matched prototypes, which forms the basis for our proposal of Protomix.
Compared to Table 3 in the main text, we observe a positive correlation between top-1 prototype matching accuracy and accuracy of inference with missing modalities. The positive correlation is reasonable and the effect we desire, which also indicates that, for higher accuracy of inference with missing modalities, we should strive to improve the accuracy of prototype matching. In fact, when we perform unimodal inference using the corresponding prototypes (prototype matching accuracy is 100% ), its accuracy can reach 43.314%, which is only 8.942% lower than the modality-complete inference.
J.2 Analysis of ProtoMix
Figure 9 displays all possible ProtoMix results for nine matching strategies.

We observe that almost all matching strategies benefit from ProtoMix, indicating that our proposed strategy of augmenting prototype semantics is effective. However, the performance improvement brought by Top-k ProtoMix is very limited and does not correspond to the accuracy of Top-k prototype matching, which suggests that there is still significant space for improvement in our ProtoMix.
Additionally, we observed significant differences in the performance of ProtoMix under different matching strategies, and we will analyze them one by one. There are two key factors influencing the performance of ProtoMix: prototype matching accuracy and matching confidence.
For the three model-free matching strategies, both matching accuracy and confidence are relatively low. The results indicate that combining top-k prototypes with confidence-weighted fusion results in prototypes with more accurate semantics.
For the three classifier-based matching strategies, their matching accuracy is generally moderate, but the confidence in the top-1 match is exceptionally high. We observed that both a single classifier and a parameter-aggregated classifier have 19.10% matching accuracy but almost boast over 99% confidence in the top-1 class. The results in very little semantic information from other prototypes were obtained when combining top-k prototypes with confidence-weighted fusion. Consequently, the inference accuracy remains the same regardless of how many prototypes are fused. This limitation stems from the poor generalization ability of the classifier, as it tends to overfit the uneven distribution of client data during training on the client side.
For the three retrieval-based matching strategies, we observed that a single prior has 19.56% prototype matching accuracy and possesses a top-1 retrieval score with less prominent confidence, creating a difference between the maximum prior and the ensemble prior. However, since parameter aggregation does not apply to non-classification tasks, the aggregated model exhibits low matching accuracy and confidence, leading to performance comparable to model-free matching strategies.
Appendix K Additional Visualization
K.1 Representation Distribution among Clients
We visualized more representation distributions learned by various clients. Figure 10 displays the visualized results. We observe that, compared to the baseline method FedAvg, our PmcmFL reduces the heterogeneity in the feature space among clients (i.e., mitigates client drift).

K.2 Representation Distribution among Classes
We visualized more representation distributions learned by the global model among various classes. Figure 11 displays the visualized results. We can observe that, compared to the baseline method, our PmcmFL can cluster representations by class.
