Multifile Partitioning for Record Linkage and Duplicate Detection
Abstract
Merging datafiles containing information on overlapping sets of entities is a challenging task in the absence of unique identifiers, and is further complicated when some entities are duplicated in the datafiles. Most approaches to this problem have focused on linking two files assumed to be free of duplicates, or on detecting which records in a single file are duplicates. However, it is common in practice to encounter scenarios that fit somewhere in between or beyond these two settings. We propose a Bayesian approach for the general setting of multifile record linkage and duplicate detection. We use a novel partition representation to propose a structured prior for partitions that can incorporate prior information about the data collection processes of the datafiles in a flexible manner, and extend previous models for comparison data to accommodate the multifile setting. We also introduce a family of loss functions to derive Bayes estimates of partitions that allow uncertain portions of the partitions to be left unresolved. The performance of our proposed methodology is explored through extensive simulations.
Code implementing the methodology is available at https://github.com/aleshing/multilink.
Keywords: data matching; data merging; entity resolution; microclustering.
1 Introduction
When information on individuals is collected across multiple datafiles, it is natural to merge these to harness all available information. This merging requires identifying coreferent records, i.e., records that refer to the same entity, which is not trivial in the absence of unique identifiers. This problem arises in many fields, including public health (Hof et al., 2017), official statistics (Jaro, 1989), political science (Enamorado et al., 2019), and human rights (Sadinle, 2014, 2017; Ball & Price, 2019).
Most approaches in this area have thus far focused on one of two settings. Record linkage has traditionally referred to the setting where the goal is to find coreferent records across two datafiles, where the files are assumed to be free of duplicates. Duplicate detection has traditionally referred to the setting where the goal is to find coreferent records within a single file. In practice, however, it is common to encounter problems that fit somewhere in between or beyond these two settings. For example, we could have multiple datafiles that are all assumed to be free of duplicates, or we might have duplicates in some files but not in others. In these general settings, the data collection processes for the different datafiles possibly introduce different patterns of duplication, measurement error, and missingness into the records. Further, dependencies among these data collection processes determine which specific subsets of files contain records of the same entity. We refer to this general setting as multifile record linkage and duplicate detection.
Traditional approaches to record linkage and duplicate detection have mainly followed the seminal work of Fellegi & Sunter (1969), by modeling comparisons of fields between pairs of records in a mixture model framework (Winkler, 1994; Jaro, 1989; Larsen & Rubin, 2001). These approaches work under, and take advantage of, the intuitive assumption that coreferent records will look similar, and non-coreferent records will look dissimilar. However, these approaches output independent decisions for the coreference status of each pair of records, necessitating the use of ad hoc post-processing steps to reconcile incompatible decisions that ignore the logical constraints of the problem.
Our approach to multifile record linkage and duplicate detection builds on previous Bayesian approaches where the parameter of interest is defined as a partition of the records. These Bayesian approaches have been carried out in two frameworks. In the direct-modeling framework, one directly models the fields of information contained in the records (Matsakis, 2010; Tancredi & Liseo, 2011; Liseo & Tancredi, 2011; Steorts, 2015; Steorts et al., 2016; Tancredi et al., 2020; Marchant et al., 2021; Enamorado & Steorts, 2020), which requires a custom model for each type of field. While this framework can provide a plausible generative model for the records, it can be difficult to develop custom models for complicated fields like strings, so most approaches are limited to modeling categorical data, with some exceptions (Liseo & Tancredi, 2011; Steorts, 2015). In the comparison-based framework, following the traditional approaches, one models comparisons of fields between pairs of records (Fortini et al., 2001; Larsen, 2005; Sadinle, 2014, 2017). By modeling comparisons of fields, instead of the fields directly, a generic modeling approach can be taken for any field type, as long as there is a meaningful measure of similarity for that field type.
Sadinle & Fienberg (2013) generalized Fellegi & Sunter (1969) by linking files with no duplicates. However, in addition to inheriting the issues of traditional approaches, their approach does not scale well in the number of files or the file sizes encountered in practice. Steorts et al. (2016) presented a Bayesian approach in the direct-modeling framework for the general setting of multifile record linkage and duplicate detection, which has been extended by Steorts (2015) and Marchant et al. (2021). This approach uses a flat prior on arbitrary labels of partitions, which incorporates unintended prior information.
In light of the shortcomings of existing approaches, we propose an extension of Bayesian comparison-based models that explicitly handles the setting of multifile record linkage and duplicate detection. We first present in Section 2 a parameterization of partitions specific to the context of multifile record linkage and duplicate detection. Building on this parameterization, in Section 3 we construct a structured prior for partitions that can incorporate prior information about the data collection processes of the files in a flexible manner. As a by-product, a family of priors for -partite matchings is constructed. In Section 4 we construct a likelihood function for comparisons of fields between pairs of records that accommodates possible differences in the datafile collection processes. In Section 5 we present a family of loss functions that we use to derive Bayes estimates of partitions. These loss functions have an abstain option which allow portions of the partition with large amounts of uncertainty to be left unresolved. Finally, we explore the performance of our proposed methodology through simulation studies in Section 6. In the Appendix we present an application of our proposed approach to link three Colombian homicide record systems.
2 Multifile Partitioning
Consider files , each containing information on possibly overlapping subsets of a population of entities. The goal of multifile record linkage and duplicate detection is to identify the sets of records in , , that are coreferent, as illustrated in Figure 1. Identifying coreferent records across datafiles represents the goal of record linkage, and identifying coreferent records within each file represents the goal of duplicate detection.

We denote the number of records contained in datafile as , and the total number of records across all files as . We label the records in all datafiles in a consecutive order, that is, those in as , those in as , and so on, finally labeling the records in as . We denote , where it is clear that , which represents all the records coming from all datafiles.
Formally, multifile record linkage and duplicate detection is a partitioning problem. A partition of a set is a collection of disjoint subsets, called clusters, whose union is the original set. In this context, the term coreference partition refers to a partition of all the records in , , , or equivalently a partition of , such that each cluster is exclusively composed of all the records generated by a single entity (Matsakis, 2010; Sadinle, 2014). This implies that there is a one-to-one correspondence between the clusters in and the entities represented in at least one of the datafiles. Estimating is the goal of multifile record linkage and duplicate detection.
2.1 Multifile Coreference Partitions
In the setting of multifile record linkage and duplicate detection, the datafiles are the product of data collection processes, which possibly introduce different patterns of duplication, measurement error, and missingness. This indicates that records coming from different datafiles should be treated differently. To take this into account, we introduce the concept of a multifile coreference partition by endowing a coreference partition with additional structure to preserve the information on where records come from. Each cluster can be decomposed as , where is the subset of records in cluster that belong to datafile , which leads us to the following definition.
Definition 1.
The multifile coreference partition of datafiles is obtained from the coreference partition by expressing each cluster as a -tuple , where represents the records of that come from datafile .
For simplicity we will continue using the notation to denote a multifile coreference partition, although technically this new structure is richer and therefore different from a coreference partition that does not preserve the datafile membership of the records. The multifile representation of partitions is useful for decoupling the features that are important for within-file duplicate detection or for across-files record linkage.
For duplicate detection, the goal is to identify coreferent records within each datafile. This can be phrased as estimating the within-file coreference partition of each datafile . Clearly, these can be obtained from the multifile partition by extracting the th entry of each cluster . Two useful summaries of a given within-file partition are the number of within-file clusters , which is the number of unique entities represented in datafile , and the within-file cluster sizes , which represent the number of records associated with each entity in datafile .
On the other hand, in record linkage the goal is to identify coreferent records across datafiles. Given the within-file partitions, , the goal can be phrased as identifying which clusters across these partitions represent the same entities. This across-datafiles structure can be formally represented by a -partite matching. Given sets , a -partite matching is a collection of subsets from such that each contains maximum one element from each . If we think of each as the set of clusters representing the entities in datafile , then it is clear that the goal is to identify the -partite matching that puts together the clusters that refer to the same entities across datafiles. This structure can be extracted from a multifile coreference partition , given that each element contains the coreferent clusters across all within-file partitions. Indeed, a multifile coreference partition can be thought of as a -partite matching of within-file coreference partitions.
A useful summary of the across-datafile structure is the amount of entity-overlap between datafiles, represented by the number of clusters with records in specific subsets of the files. We can concisely summarize the entity-overlap of the datafiles through a contingency table. In particular, consider a contingency table with cells indexed by and corresponding cell counts . Here, represents a pattern of inclusion of an entity in the datafiles, where a 1 indicates inclusion and a 0 exclusion. For instance, if , is the number of clusters representing entities with records in datafiles and but without records in datafile . We let and denote the (incomplete) contingency table of counts as , which we refer to as the overlap table. We ignore the cell which would represent entities that are not recorded in any of the files. This cell is not of interest in this article, although it is the parameter of interest in population size estimation (see e.g. Bird & King, 2018).
Example. To illustrate the concept of a multifile partition, consider two files with five and seven records respectively, so that contains records and contains records . Suppose the coreference partition is . The corresponding multifile partition is . As illustrated in Figure 2, the within-file partitions can be extracted as and , and the within-file cluster sizes are and . The overlap table in this case is , indicating that entities are represented in both datafiles, entity is represented only in the first datafile, and entities are represented only in the second datafile. In total, there are unique entities represented in , unique entities represented in , and entities among both datafiles.

3 A Structured Prior for Multifile Partitions
Bayesian approaches to multifile record linkage and duplicate detection require prior distributions on multifile coreference partitions. We present a generative process for multifile partitions, building on our representation introduced in Section 2.1. The idea is to generate a multifile partition by first generating summaries that characterize it, as follows:
-
1.
Generate the number of unique entities represented in the datafiles, which also corresponds to the number of clusters of the multifile partition.
-
2.
Given , generate an overlap table so that , where . From we can derive the number of entities in datafile as , where is the th entry of .
-
3.
For each , given , independently generate a set of counts , representing the number of records associated with each entity in file . From , we can derive the number of records in file as . Index the records as .
-
4.
For each , given , induce a within-file partition by randomly allocating into clusters of sizes .
-
5.
Given the overlap table and within-file partitions , generate a -partite matching of the within-file partitions by selecting uniformly at random from the set of all -partite matchings with overlap table . By definition, the result is a multifile coreference partition.
By parameterizing each step of this generative process, we can construct a prior distribution for multifile partitions, as we now show.
3.1 Parameterizing the Generative Process
Prior for the Number of Entities or Clusters. In the absence of substantial prior information, we follow a simple choice for the prior on the number of clusters, by taking a uniform distribution over the integers less than some upper bound, , i.e. . In practice, we set to be the actual number of records across all datafiles , which is observed. More informative specifications are discussed in Appendix A.
Prior for the Overlap Table. Conditional on , we use a Dirichlet-multinomial distribution as our prior on the overlap table . Given a collection of positive hyperparameters for each cell of the overlap table, , and letting , the prior for the overlap table under this choice is Due to conjugacy, can be interpreted as prior cell counts, which can be used to incorporate prior information about the overlap between datafiles. In the absence of substantial prior information, when the number of files is not too large and the overlap table is not expected to be sparse, we recommend setting . In Appendix A we discuss alternative specifications when the overlap table is expected to be sparse.
Prior for the Within-File Cluster Sizes. Given the number of entities in datafile , , we generate the within-file cluster sizes assuming that . Here represents the probability mass function of a distribution on the positive integers, so that . We do not expect a-priori many duplicates per entity, and therefore we expect the counts in to be mostly ones or to be very small (Miller et al., 2015; Zanella et al., 2016). We therefore use a similar approach to Klami & Jitta (2016), and use distributions truncated to the range , where is a file-specific upper bound on cluster sizes. We further use distributions where prior mass is concentrated at small values. A default specification is to use a Poisson distribution with mean truncated to , i.e. . More informative options could be used for by using any distribution on , where this could vary from file to file if some files were known to have more or less duplication.
Prior for the Within-File Partitions. Given the within-file cluster sizes , the number of ways of assigning records to clusters , respectively, is given by the multinomial coefficient , with . However, the ordering of the clusters is irrelevant for constructing the within-file partition of . There are ways of ordering the clusters of , which leads to partitions of into clusters of sizes . We then have .
Prior for the -Partite Matching. Given the overlap table and the within-file partitions , our prior over -partite matchings of the within-file partitions is uniform. Thus we just need to count the number of -partite matchings with overlap table . This is taken care of by Proposition 1, proven in Appendix A.
Proposition 1.
The number of -partite matchings that have the same overlap table, , is . Thus
The Structured Prior for Multifile Partitions. Letting quantities followed by mean they are computable from , the density of our structured prior for multifile partitions is
| (1) |
3.2 Comments and Related Literature
The structured prior for multifile partitions allows us to incorporate prior information about the total number of clusters, the overlap between files, and the amount of duplication in each file. If we restrict the prior for the within-file cluster sizes to be for a given datafile , then we enforce the assumption that there are no duplicates in that file. Imposing this restriction for all datafiles leads to the special case of a prior for -partite matchings, which is of independent interest, as we are not aware of any such constructions outside of the bipartite case (Fortini et al., 2001; Larsen, 2005; Sadinle, 2017).
Our prior construction, where priors are first placed on interpretable summaries of a partition and then a uniform prior is placed on partitions which have those summaries, mimics the construction of the priors on bipartite matchings of Fortini et al. (2001); Larsen (2005) and Sadinle (2017), and the Kolchin and allelic partition priors of Zanella et al. (2016) and Betancourt, Sosa & Rodríguez (2020). While the Kolchin and allelic partition priors could both be used as priors for multifile partitions, these do not incorporate the datafile membership of records. Using these priors in the multifile setting would imply that the sizes of clusters containing records from only one file have the same prior distribution as the sizes of clusters containing records from two files, which should not be true in general.
Miller et al. (2015) and Zanella et al. (2016) proposed the microclustering property as a desirable requirement for partition priors in the context of duplicate detection: denoting the size of the largest cluster in a partition of by , a prior satisfies the microclustering property if in probability as . A downside of priors with this property is that they can still allow the size of the largest cluster to go to as increases. For this reason Betancourt, Sosa & Rodríguez (2020) introduced the stronger bounded microclustering property, which we believe is more practically important: for any , is finite with probability . Our prior satisfies the bounded microclustering property as .
While our parameter of interest is a partition of records, the prior developed in this section is a prior for a partition of a random number of records. In practice we condition on the file sizes, , and use the prior , which alters the interpretation of the prior. A similar problem occurs for the Kolchin partition priors of Zanella et al. (2016). This motivated the exchangeable sequences of clusters priors of Betancourt, Zanella & Steorts (2020), which are similar to Kolchin partition priors, but lead to a directly interpretable prior specification. It would be interesting in future work to see if an analogous prior could be developed for our structured prior for multifile partitions. Despite this limitation, we demonstrate in simulations in Section 6 that incorporating strong prior information into our structured prior for multifile partitions can lead to improved frequentist performance over a default specification.
4 A Model for Comparison Data
We now introduce a comparison-based modeling approach to multifile record linkage and duplicate detection, building on the work of Fellegi & Sunter (1969); Jaro (1989); Winkler (1994); Larsen & Rubin (2001); Fortini et al. (2001); Larsen (2005) and Sadinle (2014, 2017). Working under the intuitive assumption that coreferent records will look similar, and non-coreferent records will look dissimilar, these approaches construct statistical models for comparisons computed between each pair of records.
There are two implications of the multifile setting described in Section 2 that are important to consider when constructing a model for the comparison data. First, models for the comparison data should account for the fact that the distribution of the comparisons between record pairs might potentially change across different pairs of files. For example, if files and are not accurate, whereas files and are, then the distribution of comparisons between and will look very different compared with the distribution of comparisons between and . Second, the fields available for comparison will vary across pairs of files. For example, files and may have collected information on a field that file did not. In this scenario, we would like a model that is able to utilize this extra field when linking and , even though it is not available in . In this section we introduce a Bayesian comparison-based model that explicitly handles the multifile setting by constructing a likelihood function that models comparisons of fields between different pairs of files separately. The separate models are able to adapt to the level of noise of each file pair, and the maximal number of fields are able to be compared for each file pair.
4.1 Comparison Data
We construct comparison vectors for pairs of records to provide evidence for whether they correspond to the same entity. For , let denote the set of all record pairs between files and , and let be the total number of different fields available from the files. For each file pair , , and record pair , we compare each field using a similarity measure , which will depend on the data type of field . For unstructured categorical fields such as race, can be a binary comparison which checks for agreement. For more structured fields containing strings or numbers, should be able to capture partial agreements. For example, string fields can be compared using a string metric like the Levenshtein edit distance (see e.g. Bilenko et al., 2003), and numeric fields can be compared using absolute differences. Comparison will be missing if field is not recorded in record or record , which includes the case where field is not recorded in datafiles or
While we could directly model the similarity measures , this would require a custom model for each type of comparison, which inherits similar problems to the direct modeling of the fields themselves. Instead, we follow Winkler (1990) and Sadinle (2014, 2017) in dividing the range of into intervals that represent varying levels of agreement, with representing the highest level of agreement, and representing the lowest level of agreement. We then let if , where larger values of represent larger disagreements between records and in field . Finally, we form the comparison vector . Constructing the comparison data this way allows us to build a generic modeling approach. In particular, extending Fortini et al. (2001); Larsen (2005) and Sadinle (2014, 2017), our model for the comparison data is
where is a multifile partition, denotes record ’s cluster in , indicates that records and are coreferent, is a model for the comparison data among coreferent record pairs from the file pair and , is a model for the comparison data among non-coreferent record pairs from datafile pair and , and and are vectors of parameters.
In the next section we make two further assumptions that simplify the model parameterization. Before doing so, we note a few limitations of our comparison-based model. First, computing comparison vectors scales quadratically in the number of records. Second, comparison vectors for different record pairs are not actually independent conditional on the partition (see Section 2 of Tancredi & Liseo, 2011). Third, modeling discretized comparisons of record fields represents a loss of information. While the first limitation is computational and unavoidable in the absence of blocking (see Appendix B), the other two limitations are inferential. Despite these limitations, we find in Section 6 that the combination of our structured prior for multifile partitions and our comparison-based model can produce linkage estimates with satisfactory frequentist performance.
4.2 Conditional Independence and Missing Data
Under the assumptions that the fields in the comparison vectors are conditionally independent given the multifile partition of the records and that missing comparisons are ignorable (Sadinle, 2014, 2017), the likelihood of the observed comparison data, , becomes
| (2) |
Here , , is an indicator of whether its argument was observed, and where collects all of the and collects all of the . For a given multifile partition , represents the number of record pairs in that belong to the same cluster with observed agreement at level in field , and represents the number of record pairs in that do not belong to the same cluster with observed agreement at level in field .
5 Bayesian Estimation of Multifile Partitions
Bayesian estimation of the multifile coreference partition is based on the posterior distribution , where is our structured prior for multifile partitions (3.1), is the likelihood from our model for comparison data (2), and represents a prior distribution for the model parameters. We now specify this prior , outline a Gibbs sampler to sample from , and present a strategy to obtain point estimates of the multifile partition .
5.1 Priors for and
We will use independent, conditionally conjugate priors for and , namely and . In this article we will use a default specification of . We believe this prior specification is sensible for the parameters, following the discussion in Section 3.2 of Sadinle (2014), as comparisons amongst non-coreferent records are likely to be highly variable and it is more likely than not that eliciting meaningful priors for them is too difficult. For the parameters, it might be desirable in certain applications to introduce more information into the prior. For example, one could set to incorporate the prior belief that higher levels of agreement should have larger prior probability than lower levels of agreement. Another route would be to use the sequential parameterization of the parameters, and the associated prior recommendations, described in Sadinle (2014).
5.2 Posterior Sampling
In Appendix B we outline a Gibbs sampler that produces a sequence of samples from the posterior distribution , which we will use to obtain Monte Carlo approximations of posterior expectations involved in the derivation of point estimates , as presented in the next section. In Appendix B, we discuss the computational complexity of the Gibbs sampler, how computational performance can be improved through the usage of indexing techniques, and the initialization of the Gibbs sampler.
5.3 Point Estimation
In a Bayesian setting, one can obtain a point estimate of the multifile partition using the posterior and a loss function . The Bayes estimate is the multifile partition that minimizes the expected posterior loss , although in practice such expectations are approximated using posterior samples. Previous examples of loss functions for partitions included Binder’s loss (Binder, 1978) and the variation of information (Meilă, 2007), both recently surveyed in Wade & Ghahramani (2018). The quadratic and absolute losses presented in Tancredi & Liseo (2011) are special cases of Binder’s loss, and Steorts et al. (2016) drew connections between their proposed maximal matching sets and the losses of Tancredi & Liseo (2011).
In many applications there may be much uncertainty on the linkage decision for some records in the datafiles. For example, in Figure 1 it is unclear which of the records with last name “Smith” are coreferent. It is thus desirable to leave decisions for some records unresolved, so that the records can be hand-checked during a clerical review, which is common in practice (see e.g. Ball & Price, 2019). In the classification literature, leaving some decisions unresolved is done through a reject option (see e.g. Herbei & Wegkamp, 2006), which here we will refer to as an abstain option. We will refer to point estimates with and without abstain option as partial estimates and full estimates, respectively. We now present a family of loss functions for multifile partitions which incorporate an abstain option, building upon the family of loss functions for bipartite matchings presented in Sadinle (2017).
5.3.1 A Family of Loss Functions with an Abstain Option
For the purpose of this section we will represent a multifile partition as a vector of labels, where , such that if . We represent a Bayes estimate here as a vector , where , with representing an abstain option intended for records whose linkage decisions are not clear and need further review. We assign different losses to using the abstain option and to different types of matching errors. We propose to compute the overall loss additively, as . To introduce the expression for the th-record-specific loss , we use the notation , and likewise .
The proposed individual loss for record is
| (3) |
That is, represents the loss from abstaining from making a decision; is the loss from a false non-match (FNM) decision, that is, deciding that record does not match any other record () when in fact it does (); is the loss from a type 1 false match (FM1) decision, that is, deciding that record matches other records () when it does not actually match any other record (); and is the loss from a type 2 false match (FM2), that is, a false match decision when record is matched to other records () but it does not match all of the records it should be matching ().
The posterior expected loss is where
| (8) |
and quantities computed with respect to the posterior distribution, , can all be approximated using posterior samples. While this presentation is for general positive losses and , these only have to be specified up to a proportionality constant (Sadinle, 2017). If we do not want to allow the abstain option, then we can set and the derived full estimate will have a linkage decision for all records. Although we have been using partition labelings , the expressions in (3) and (8) are invariant to different labelings of the same partition. In the two-file case, Sadinle (2017) provided guidance on how to specify the individual losses and in cases where there is a notion of false matches being worse than false non-matches or vise versa. Sadinle (2017) also gave recommendations for default values of these losses that lead to good frequentist performance in terms not over- or under-matching across repeated samples. In Appendix C, we discuss how our proposed loss function differs from the loss function of Sadinle (2017) and propose a strategy for approximating the Bayes estimate.
6 Simulation Studies
To explore the performance of our proposed approach for linking three duplicate-free files, as in the application to the Colombian homicide record systems of Appendix E, we present two simulation studies under varying scenarios of measurement error and datafile overlap. The two studies correspond to scenarios with equal and unequal measurement error across files, respectively. Both studies present results based on full estimates. In Appendix D we further explore the performance of our proposed approach for linking three files with duplicates, with results based on full and partial estimates.
6.1 General Setup
We start by describing the general characteristics of the simulations. For each of the simulation scenarios we conduct 100 replications, for each of which we generate three files as follows. For each of entities, is drawn from a categorical distribution with probabilities , where represents the subset of files the entity appears in, and so we change the values of across simulation scenarios to represent varying amounts of file overlap. Files are then created by generating the implied number of records for each entity. In the additional simulations considered in Appendix D, the generated number of records for each entity depends not only on , but also on the duplication mechanism.
All records are generated using a synthetic data generator developed in Tran et al. (2013), which allows for the incorporation of different forms of measurement error in individual fields, along with dependencies between fields we would expect in applications. The data generator first generates clean records before distorting them to create the observed records. In particular, each observed record will have a fixed number of erroneous fields, where errors selected uniformly at random from a set of field dependent errors displayed in Table 3 of Sadinle (2014) (reproduced in Appendix D), with a maximum of two errors per field. We generate records with seven fields of information: sex, given name, family name, age, occupation, postal code, and phone number.
For each simulation replicate, we construct comparison vectors as given in Table 4 of Sadinle (2014) (reproduced in Appendix D). We use the model for comparison data proposed in Section 4 with flat priors on and as discussed in Section 5.1, and the structured prior proposed in Section 3 with a uniform prior on the number of clusters and as described in Section 3.1. Using the Gibbs sampler presented in Appendix B we obtain samples from the posterior distribution of multifile partitions, and discard the first as burn-in. In Appendix D we discuss convergence of the Gibbs sampler, present running times of the proposed approach, and present an extra simulation exploring the running time of the approach with a larger number of records. We then approximate the Bayes estimate for multifile partitions using the loss function described in Section 5.3.1 as described in Appendix C. For full estimates, we use the default values of and recommended by Sadinle (2017). In Appendix D we explore alternative specifications of the loss function.
We will assess the performance of the Bayes estimate using precision and recall with respect to the true coreference partition . Let be the set of all record pairs. Using notation from Section 5.3.1, let be the number of true matches (record pairs correctly declared coreferent), be the number of false matches (record pairs incorrectly declared coreferent), and the number of false non-matches (record pairs incorrectly declared non-coreferent). Then precision is , the proportion of record pairs declared as coreferent that were truly coreferent, and recall is , the proportion of record pairs that were truly coreferent that were correctly declared as coreferent. Perfect performance corresponds to precision and recall both being 1. In the simulations, we computed the median, nd, and th percentiles of these measures over the 100 replicate data sets. Additionally, in Appendix D, we assess the performance of the Bayes estimate when estimating the number of entities, .
6.2 Duplicate-Free Files, Equal Errors Across Files
In this simulation study we explore the performance of our methodology by varying the number of erroneous fields per record over , and also varying , which determines the amount of overlap, over four scenarios:
-
•
High Overlap: ,
-
•
Medium Overlap: ,
-
•
Low Overlap: ,
-
•
No-Three-File Overlap: .
These are intended to represent a range of scenarios that could occur in practice. In the high overlap scenario 60% of the entities are expected to be in more than one datafile, in the low overlap scenario 80% of the entities are expected to be represented in a single datafile, and in the no-three-file overlap scenario no entities are represented in all datafiles.
To implement our methodology, in addition to the general set-up described in Section 6.1, we restrict the prior for the within-file cluster sizes so that they have size one with probability one, incorporating the assumption of no-duplication within files (see Section 3.2). Imposing this restriction for all datafiles leads to a prior for tripartite matchings. To illustrate the impact of using our structured prior, we compare with the results obtained using our model for comparison data with a flat prior on tripartite matchings.
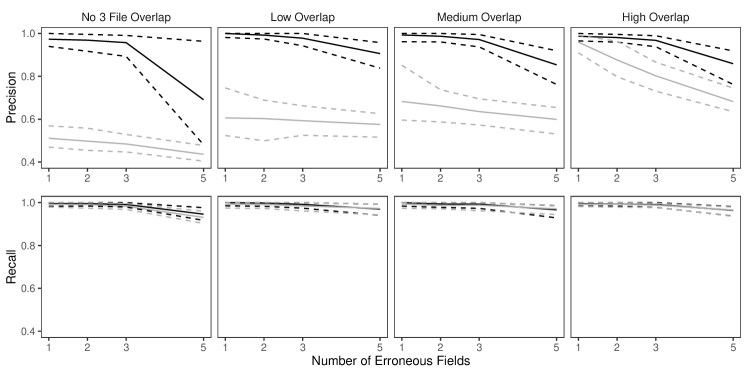
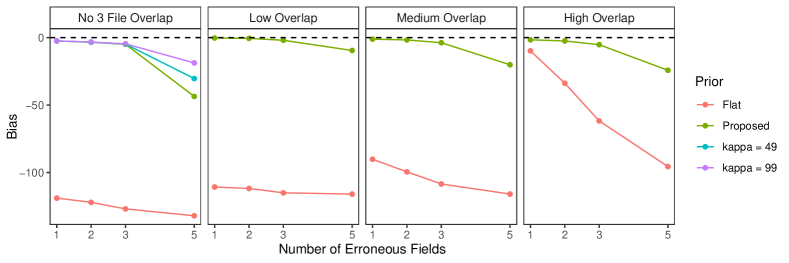
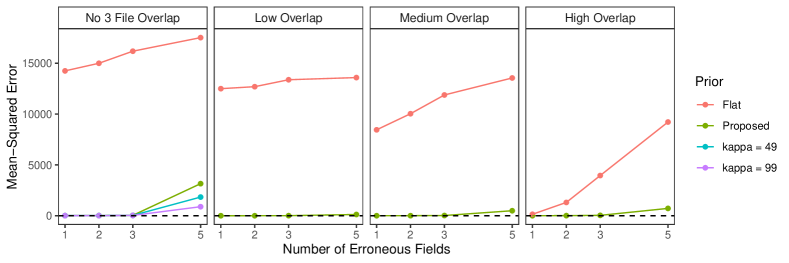
The results of the simulation are seen in Figure 3. We see that our proposed approach performs consistently well across different settings, with the exception of the no-three-file overlap setting under high measurement error, where the precision decreases dramatically. The approach using a flat prior on tripartite matchings has poor precision in comparison, and it is particularly low when the amount of overlap is low. This suggests that our structured prior improves upon the flat prior by protecting against over-matching (declaring noncoreferent record pairs as coreferent). In Appendix D we demonstrate how the performance in the no-three-file overlap setting can be improved through the incorporation of an informative prior for the overlap table through .
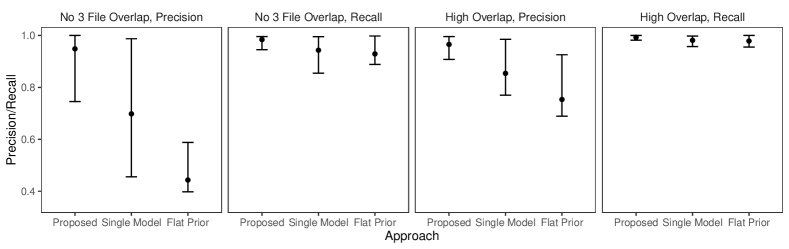
6.3 Duplicate-Free Files, Unequal Errors Across Files
In this simulation study we have different patterns of measurement error across the three files. Rather than each field in each record having a chance of being erroneous according to Table 3 of Sadinle (2014), we will use the following measurement error mechanism to generate the data. For each record in the first file, age is missing, given name has up to seven errors, and all other fields are error free. For each record in the second file, sex and occupation are missing, last name has up to seven errors, and all other fields are error free. For each record in the third file, phone number and postal code have up to seven errors and all other fields are error free. Under this measurement error mechanism, there is enough information in the error free fields to inform pairwise linkage of the files. We further vary over the no-three-file and high overlap settings from Section 6.2.
Our goal in this study is to demonstrate that having both the structured prior for partitions and the separate models for comparison data from each file-pair can lead to better performance than not having these components. We will compare our model as described in Section 6.2 to both our model for comparison data with a flat prior on tripartite matchings (as in Section 6.2) and a simplification of our model for comparison data using a single model for all file-pairs but with our structured prior for partitions.
The results of the simulation are given in Figure 4. We see that our proposed approach outperforms both alternative approaches in both precision and recall in both overlap settings. This suggests that both the structured prior for tripartite matchings and the separate models for comparison data from each file-pair can help improve performance over alternative approaches. We note that in the no-three-file (high) overlap setting the precision of the proposed approach is greater than or equal to the precision of the approach using a single model for all file-pairs in () of the replications.
7 Discussion and Future Work
The methodology proposed in this article makes three contributions. First, the multifile partition parameterization, specific to the context of multifile record linkage and duplicate detection, allows for the construction of our structured prior for partitions, which provides a flexible mechanism for incorporating prior information about the data collection processes of the files. This prior is applicable to any Bayesian approach which requires a prior on partitions, including direct-modeling approaches such as Steorts et al. (2016). We are not aware of any priors for -partite matchings when , so we hope our construction will lead to more development in this area. The second contribution is an extension of previous comparison-based models that explicitly handles the multifile setting. Allowing separate models for comparison data from each file pair leads to higher quality linkage. The third is a novel loss function for multifile partitions which can be used to derive Bayes estimates with good frequentist properties. Importantly, the loss function allows for linkage decisions to be left unresolved for records with large matching uncertainty. As with our structured prior on partitions, the loss function is applicable to any Bayesian approach which requires point estimates of partitions, including direct-modeling approaches.
There are a number of directions for future work. One direction is the modeling of dependencies between the comparison fields (see e.g. Larsen & Rubin, 2001), which should further improve the quality of the linkage. Another direction is the development of approaches to jointly link records and perform a downstream analysis, thereby propagating the uncertainty from the linkage. See Section 7.2 of Binette & Steorts (2020) for a recent review of such joint models. In this direction, a natural task to consider next is population size estimation, where the linkage of the datafiles plays a central role (Tancredi & Liseo, 2011; Tancredi et al., 2020).
Supplementary Appendices for Multifile Partitioning for Record Linkage and Duplicate Detection
Appendix A Structured Prior Appendix
In this appendix, we prove Proposition 1 from the main text and provide additional guidance for the specification of the structured prior for multifile partitions.
A.1 Proof of Proposition 1
In this section, we restate and prove Proposition 1 from the main text.
Proposition 1.
The number of -partite matchings that have the same overlap table, , is , where is the number of entities in datafile . Thus
Proof.
Let us first count all of the ways that we can place the clusters in file into the overlap table cells that is included in, . This is just a multinomial coefficient, . Thus the number of ways we can place all of the clusters from all of the files into the cells in is Given that there are clusters from each file with in cell , now all we have to count is how many distinct complete matchings are possible between them, which is just . Thus the number of -partite matchings is ∎
A.2 Prior Specification Guidance
In this section we provide additional guidance for the specification of the structured prior for multifile partitions described in Section 3 of the main text. In particular, we further discuss the priors for the number of clusters, the overlap tables, and the within-file cluster sizes.
Prior for the Number of Entities or Clusters. In the main text we recommended, in the absence of substantial prior information, to use a uniform prior on for the number of clusters, for some upper bound . Our default recommendation was to set , i.e. the total number of records. If one has substantive prior information about the number of clusters, this could instead be incorporated using other distributions on the positive integers. Miller et al. (2015) and Zanella et al. (2016) both suggest to use a negative-binomial distribution with parameters and truncated to the positive integers, i.e. . Zanella et al. (2016) further suggest a weakly informative specification for this Negative-binomial prior where and are selected such that . We follow Miller et al. (2015) and Zanella et al. (2016) and suggest a negative-binomial prior for the number of clusters when incorporating substantive prior information.
Prior for the Overlap Table. In the main text we recommended using a Dirichlet-multinomial prior for the overlap table, specified by a collection of positive hyperparameters. In the absence of substantial prior information we recommended setting . Due to conjugacy of the Dirichlet distribution with the multinomial, can be interpreted as prior cell counts, and thus our recommendation amounts to incorporating a prior count of to each cell and an overall prior sample size of .
In our simulations and application, we found across a variety of overlap settings that this default prior performed satisfactorily. However, in the no-three-file-overlap setting, our approach struggled when there was a large amount of measurement error. We find in Appendix D.2 that we can improve performance in this setting by using informative prior cell counts, rather than using our default specification. What sets this no-three-file-overlap simulation setting apart from the other settings is that it is sparse, i.e. in this setting the count for the three-file-overlap cell of the overlap table is truly .
When linking a large number of files , the size of the overlap table, , becomes large very quickly, which makes it likely that the true overlap table is sparse. Our default prior specification may not be appropriate in these settings as using a prior cell count of for each cell may be incorporating prior information that is too strong, as illustrated in Example 1.4 of Berger et al. (2015). One possible alternative as a default specification when the overlap table is potentially sparse, would be to set (see Section 3.2 of Berger et al. (2015) for justification). If one has prior information concerning which cells of the overlap table are likely to be sparse, based on the results in Appendix D.2, we recommend attempting to incorporate this information into the prior. For example, if it is believed that some combination of files are likely not to have collected information on the same set of entities, one can incorporate this information by making the corresponding prior cell counts close to .
Another route one could take would be to replace the Dirichlet-multinomial prior on with a multinomial prior on , with a non-Dirichlet prior on the multinomial cell probabilities. For example, one could use the tensor-factorization priors of Dunson & Xing (2009) and Zhou et al. (2015), which have been shown to have lead to estimates of cell probabilities with good performance in large sparse contingency tables.
Prior for the Within-File Cluster Sizes. Given that in a joint record linkage and duplicate detection scenario we do not expect there to be many duplicates per entity in any given file, in the main text we recommended specifying i.i.d. priors for the sizes of the within-file clusters, i.e. for a given file . Here represents the probability mass function of a distribution on , where is a file-specific upper bound on cluster sizes.
When a given file is assumed to have no duplicates, in the main text we recommended enforcing this restriction that there are no duplicates in that file by setting and . When a given file is assumed to have duplicates, in the main text we recommended a Poisson distribution with parameter , i.e. . This prior places most of the prior mass close to , where various properties such as prior mean and standard deviation can be computed numerically (e.g. when the prior mean is ). If one has information on the average amount of duplication in file , given a specified upper bound , one could specify the parameter of the Poisson prior such that the prior mean is equal to the average amount of duplication. Alternatively, one could place a hyperprior on . This is similar approach to Zanella et al. (2016), who used a negative-binomial distribution with parameters and truncated to the positive integers, with a gamma hyperprior for and a beta hyperprior for . Indeed, the negative-binomial prior of Zanella et al. (2016) can be seen as a generalization of our Poisson prior, based on well-known connections between the Poisson and negative-binomial, and could be used instead of our Poisson recommendation if desired.
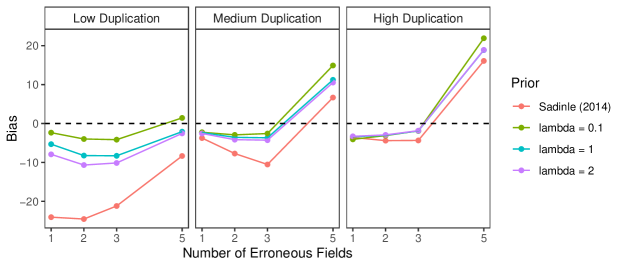
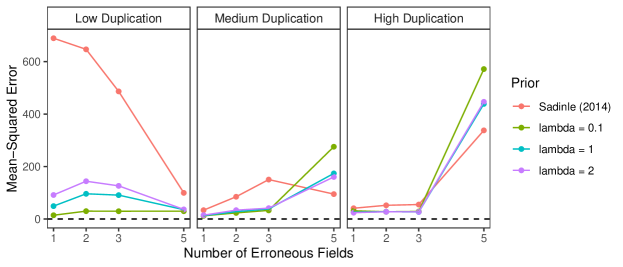
In the simulations presented in Appendix D.3 we explore using a Poisson prior with parameter varying over , when the within-file cluster sizes are generated from a Poisson with parameter varying over . We find in these simulations that when there is medium or high duplication (i.e. the within-file cluster sizes are generated from a Poisson with mean in ), the results are not sensitive to , whereas when there is low duplication (i.e. the within-file cluster sizes are generated from a Poisson with mean ), the results are sensitive to . This suggests that model performance is more sensitive to the specification of the prior distribution for within-file cluster sizes when there is a low amount of duplication, and that care should be taken when specifying the prior for the within-file cluster sizes for files which are expected to have very little duplication.
Appendix B Posterior Inference Appendix
In this appendix, we first derive full conditional distributions of our structured prior for partitions, and then use the full conditional distributions to derive a Gibbs sampler for posterior inference in our model. We then discuss the computational complexity of our approach to posterior inference, how computational performance can be improved through the usage of indexing techniques, and the initialization of the Gibbs sampler.
B.1 Conditional Assignment Probabilities
In this section we use the form of the prior distribution in Equation (1) of the main text to derive the conditional probability for assigning a record from file to a given cluster of an existing multifile partition of the other records. Specifically, we derive , where denotes adding record to a cluster or to an empty cluster. Let a quantity followed by denote that it is derived from analogously to in Section 3.1 of the main text. Let denote the inclusion pattern indicating inclusion only in file , that is, is a vector of zeroes except for its th entry which equals 1. Further, let denote the inclusion pattern of the cluster , that is, the th entry of is . Finally, let denote the inclusion pattern of the cluster after adding record to it. Then the conditional assignment probability is
B.2 Gibbs Sampler
We will now derive a Gibbs sampler to explore the posterior of and . Suppose we are at iteration of the sampler, with current samples and . Then we obtain the samples for iteration through the following steps:
-
1.
For and , sample
and
Call these samples .
-
2.
We now sample the cluster assignment for each record sequentially. Suppose we have sampled the first records, and are sampling the cluster assignment for record from file . Let denote the current partition of , without record , after sampling the first records. Then we sample the cluster assignment for record according to the following probabilities:
where, letting denote the file that record is in,
B.3 Computational Complexity
The computational complexity of posterior inference in our proposed approach can be broken up into the complexity of pre-computing comparison vectors, and the complexity of individual steps of the Gibbs sampler presented in Appendix B.2.
-
•
The computational complexity of pre-computing comparison vectors is , where rp is the number of valid record pairs. To be more specific, when we assume there are duplicates in every file, , and when we assume there are no duplicates in each file, . For in between situations where we assume there are no duplicates in some files and duplicates in the remaining files, it can be shown that . Thus in the most general case, pre-computing comparison vectors scales quadratically in the number of records. We discuss in the following section how the cost of this step can be reduced through the usage of blocking.
-
•
The computational complexity of step 1 of the Gibbs sampler presented in Appendix B.2, i.e. sampling the and parameters, is , where fp is the number of valid file pairs, and is the total number of agreement levels across all fields. We have that , where is the number of files that are assumed to have duplicates. This follows as the and summaries of the partition can be calculated from a matrix multiplication of a matrix and a matrix, and given these and summaries the complexity of sampling the and parameters from their full conditionals is .
-
•
The computational complexity of step 2 of the Gibbs sampler presented in Appendix B.2, i.e. sampling the partition , is difficult to analyze in general. In the most general case, where we assume there are duplicates in each file, in the worst case scenario, each record could be placed in its own cluster. The complexity of sampling the cluster assignment for a single record would then be , and the complexity of sampling the cluster assignment for all records would then be . However, the number of clusters potentially changes whenever a new cluster assignment is sampled, which complicates this analysis. Further, once introduces constraints on the partition space, either through assuming there are no duplicates in some files, or using indexing as described in the next section, the number of clusters available for a specific record’s cluster assignment step will depend on these constraints. In general the best we can say is that this step will be faster when each record has on average (with respect to the posterior) a small number of clusters to which it can be assigned, and slower when each record has on average a large number of clusters to which it can be assigned.
In our current implementation of the proposed approach, we have found that even though both steps of the Gibbs sampler scale quadratically in the number of records in the worst case, the cost of sampling the partition generally dominates the cost of sampling the and parameters, and is the main bottleneck of our approach. We note that the sampling of the partition will essentially have the same computational complexity regardless of whether one uses a comparison-based model for records, as we have proposed in the main text, or one uses a direct-modeling approach, as in Steorts et al. (2016).
B.4 Blocking, Indexing, and Scalability
As described in the previous section, there are two main bottlenecks to scalability in our proposed approach: pre-computing the comparison vectors and sampling the partition from its full conditional in the Gibbs sampler presented in Appendix B.2. Both of these bottlenecks can be sped up through the use of indexing techniques, which declare certain pairs of records non-coreferent a priori based on comparisons of a small number of fields (Christen, 2012; Steorts et al., 2014; Murray, 2015). This both reduces the number of record pairs under consideration, and reduces on average the number of clusters to which each record can be assigned in the Gibbs sampler presented in Appendix B.2.
In particular, if is the set of all possible record pairs, indexing techniques generate a set , such that , where record pairs in are candidate coreferent pairs, and record pairs in are fixed as non-coreferent. Thus when performing posterior inference, this truncates our prior on multifile partitions to the set .
We briefly review two common indexing techniques from Murray (2015), blocking and indexing by disjunction. Blocking declares pairs of records to be non-coreferent when they disagree on a set of error-free fields. The use of error-free fields guarantees that the candidate coreferent pairs output from blocking are transitive, so that forms a partition of the records. Indexing by disjunction declares pairs of records to be non-coreferent when they disagree at a certain threshold for each field in a given set of reliable fields. Candidate coreferent pairs output from indexing by disjunction are not guaranteed to be transitive.
When a set of error-free fields are available, we recommend blocking. Blocking schemes can be implemented without constructing comparison vectors for each record pair, thus reducing the cost of pre-computing comparison vectors for all record pairs to just the cost of pre-computing comparison vectors for record pairs within each block. Our proposed approach can then be run independently in each block, drastically reducing on average the number of clusters to which each record can be assigned in the Gibbs sampler presented in Appendix B.2.
Within blocks, there is no further way to reduce cost of the pre-computing the comparison vectors. However, it is still possible to reduce the cost of sampling the partition from its full conditional in the Gibbs sampler presented in Appendix B.2 through the use of indexing by disjunction. By fixing certain pairs of records to be non-coreferent, one reduces on average the number of clusters to which each record can be assigned in the Gibbs sampler presented in Appendix B.2. Note that the comparisons for record pairs fixed as non-coreferent in still contribute to the model through the term in the likelihood in Equation (2) of the main text, avoiding many of the issues presented in Murray (2015).
However, the non-transitivity of output from indexing by disjunction can be problematic, as it suggests that the thresholds used in indexing by disjunction are too stringent, and that they may be excluding true coreferent pairs. Non-transitivity can also cause problems for Markov chain Monte Carlo samplers (like our Gibbs sampler in Appendix B.2), as it can make traversing the constrained space of multifile partitions difficult. To avoid the issue of non-transitivity, we propose to use the transitive closure of the candidate coreferent pairs, , generated by indexing by disjunction, which we refer to as transitive indexing. Transitive indexing has been used before in the post-hoc blocking methodology of McVeigh et al. (2019) for two-file record linkage.
B.5 Initialization
Due to the nature of the Gibbs sampler in Appendix B.2, we can initialize the multifile partition without needing to initialize . A simple initialization for is to let each record belong to its own cluster, which works well when indexing is used. However, we observed during some preliminary simulations that when sampling -partite matchings without using indexing, the sampler can take a large number of iterations to mix if we initialize in this way, where the number of iterations depends on the partition the data was simulated from. This problem can not be avoided as in Appendix B.4, as the constraints on the space of -partite matchings cannot be relaxed. In this case, we constructed a simple alternative initialization. The idea is to use an indexing scheme for initialization, even if indexing is not being used to reduce the number of candidate coreferent pairs. In particular, we first generate a set of record pairs through transitive indexing as described in Appendix B.4. For each block of records in , we sample a random -way matching of records in that block. We then initialize such that each record belongs to its own cluster, except for the sampled -way matchings.
Appendix C Point Estimation Appendix
In this appendix we discuss how our proposed loss function differs from the loss function of Sadinle (2017), and propose a strategy for approximating the Bayes estimate under our proposed loss function.
C.1 Comparison to Sadinle (2017)
Unlike our loss function construction, in the two-file set-up Sadinle (2017) constructed the loss function from individual losses for the records in the smaller datafile only. Such construction however leads to an asymmetry in the loss function that is arbitrary. Consider an example of two datafiles, where the first file has records and , and the second file has records and . In that case the role of the datafiles can be arbitrarily interchanged. If the true matching has a link between and but the matching estimate has a link between and , the loss will be if file two is chosen not to contribute to the loss, but it will be if file one is chosen not to contribute to the loss. Our new construction presented in the main text does not lead to such issues.
C.2 Approximating the Bayes Estimate
Finding a partition such that is minimized corresponds to an optimization problem closely related to graph partitioning problems (e.g., Brandes et al., 2007; Lancichinetti & Fortunato, 2009; Newman, 2013) or correlation clustering (e.g., Bansal et al., 2004; Demaine et al., 2006), both of which are known to be NP-complete. Thus, unlike in Sadinle (2017), we cannot minimize exactly in general. All approaches for graph partitioning problems or for correlation clustering instead rely on heuristic algorithms whose performance is evaluated empirically via simulation studies and benchmark datasets. We will follow a similar approach.
We take advantage of the fact that in practice a large number of record pairs will have zero or close to zero posterior probability of matching . Based on this, we propose to threshold at a small value to create a graph where an edge represents a non-negligible probability of matching between two records. We then break the records up into connected components of this graph, each component representing groups of records that are more likely to be coreferent. We then find the Bayes estimate by minimizing separately within each of these connected components. We can think of as a way of trading-off between accuracy of the Bayes estimate and computational tractability: larger values of decrease the size of the resulting connected components, making the minimization more tractable within each component, while smaller make the resulting approximation more accurate as using the threshold is no longer an approximation. We recommend setting as the smallest probability such that the largest connected component is smaller than some pre-specified upper bound that captures a computational budget. To minimize within the connected components, we propose to do so over posterior samples, , and find the sample which minimizes . As this minimization is happening separately within each connected component, the final Bayes estimate of the partition of all records does not itself have to be a posterior sample.
To minimize when searching for partial estimates, let denote the power set of , and let denote the posterior draw where the records in are set to abstain, . Then in order to accommodate partial estimates, we can minimize over .
Unless stated otherwise, in all simulations and in the application, for full (partial) estimates, we find the Bayes estimate separately within connected components of records with posterior probability larger than of matching, where is the smallest probability such that the largest connected component is smaller than ().
Appendix D Simulation Appendix
D.1 Tables 3 and 4 from Sadinle (2014)
Table 3 of Sadinle (2014) is reproduced in Table 1. In this table, edit errors are insertions, deletions, or substitutions of characters in a string, OCR errors are optical character recognition errors, keyboard errors are typing errors that rely on a certain keyboard layout, and phonetic errors are errors using a list of predefined phonetic rules. Table 4 of Sadinle (2014) is reproduced in Table 2.
| Type of error | ||||||
| Field | Missing values | Edits | OCR | Keyboard | Phonetic | Misspelling |
| Given name | ||||||
| Family name | ||||||
| Age interval | ||||||
| Sex | ||||||
| Occupation | ||||||
| Phone number | ||||||
| Postal code | ||||||
| Levels of disagreement | |||||
| Field | Similarity measure | ||||
| Given name | Levenshtein | 0 | |||
| Family name | Levenshtein | 0 | |||
| Age interval | Binary comparison | Agree | Disagree | ||
| Sex | Binary comparison | Agree | Disagree | ||
| Occupation | Binary comparison | Agree | Disagree | ||
| Phone number | Levenshtein | 0 | |||
| Postal code | Levenshtein | 0 | |||
D.2 Prior Sensitivity Analysis for Simulation with Duplicate-Free Files, Equal Errors Across Files
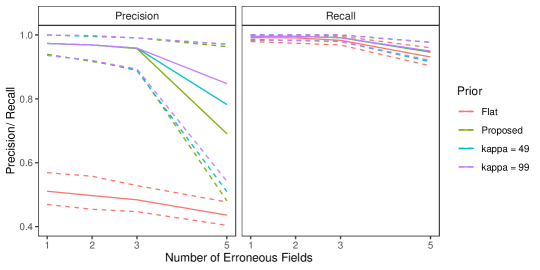
In Section 6.2 of the main text, we saw that our proposed approach struggled in the no-three-file overlap setting when there was high measurement error. In practice, if we knew that no entity is represented in all three datafiles we could enforce that restriction just like we enforce that there are no duplicates in given files, which would likely lead to better performance. While it is reasonable to assume in some applications that there are no duplicates in a given file (for example the application considered in Section 7 of the main text), it is less reasonable to assume with absolute certainty that there is no entity represented in all three datafiles. Thus we want to instead incorporate the weaker information that there is a low amount of three way overlap. We can achieve this through an informative specification of .
In the no-three-file overlap setting, the overlap table was generated from a multinomial distribution with probability vector where . Note that our Dirichlet-multinomial prior can be motivated as the result of first drawing from a Dirichlet distribution with hyperparameters , then drawing from a multinomial distribution of size with probabilities . As discussed in Appendix A.2, can be interpreted as prior cell counts, which can be used to incorporate prior information about the amount of overlap between datafiles. Thus when specifying an informative , we want the Dirichlet prior for to be centered roughly around . We can accomplish this by setting . represents the sum of prior cell counts. As increases, the Dirichlet prior for becomes more concentrated near .
We repeated the no-three-file overlap setting simulation from Section 6.2 of the main text using this informative specification with . The results are presented in Figure 5. We see that when there is high measurement error, these more informative specifications improve upon the performance of the default specification of .
D.3 Files with Duplicates, Full Estimates
This simulation study consists of linkage and duplicate detection for three datafiles, so that the target of inference is a general multifile partition. We conduct this study with probabilities fixed at , representing a very low overlap setting, which can be challenging as seen in Section 6.2 of the main text. For each entity represented in the datafiles we generated a within-file cluster size from a Poisson distribution with mean truncated to . In this study, in addition to varying the number of erroneous fields per record over to explore different amounts of measurement error, and we vary over to explore low, medium, and high amounts of duplication.
To implement our methodology, in addition to the general set-up described in Section 6.1 of the main text, we use a Poisson prior with mean truncated to on the within-file cluster sizes. For comparison we use the comparison-based model of Sadinle (2014), which treats all of the records as coming from one file and uses a flat prior on partitions. For both models we use transitive indexing as in described Appendix B.4 to reduce the number of comparisons, where the initial indexing scheme declares record pairs as non-coreferent if they disagree in either given or family name at the highest level (according to Table 4 of Sadinle (2014)).
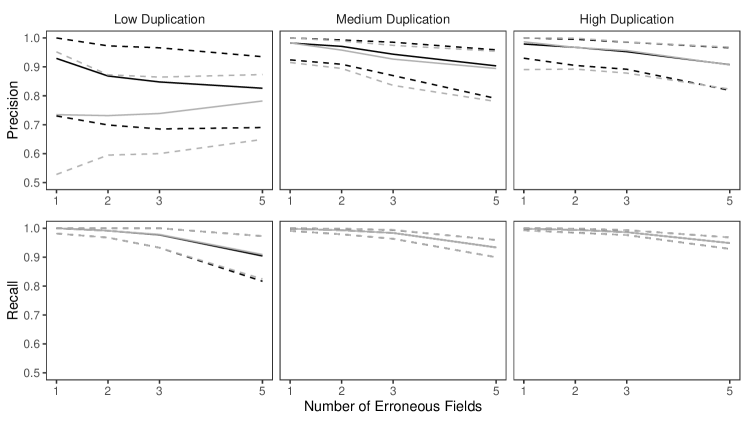
The results of the simulation are seen in Figure 6. In the medium and high duplication settings, the models have similarly good performance. We believe that the similar performance between models in these settings is due to the use of the indexing, which significantly reduces the size of the space of possible multifile partitions, so that the influence of the structured prior is minimized. However, in the low duplication setting we see that the precision of the proposed model is better across the varying measurement error settings than the model of Sadinle (2014). This suggests that in low duplication settings, our approach once again improves upon an approach that uses flat priors for partitions by protecting against over-matching.
We now explore the sensitivity of our approach to changes in the prior for the number within-file cluster sizes, and demonstrate how the performance in the low duplication setting can be further improved through the incorporation of an informative prior for the within-file cluster sizes. In the simulation that was just described, we used a Poisson prior with mean truncated to for the within-file cluster sizes. In the simulation, the within-file cluster sizes were generated from Poisson distributions with mean truncated to , where varied over . We now repeat the same simulation using Poisson priors with mean truncated to for the within-file cluster sizes, where . The results are presented in Figure 7. The results for the medium and high duplication settings are very robust to the within-file cluster size prior specification. In the low duplication setting we see that the performance among the different within-file cluster size prior specifications is best when , and worst when (but still better than the approach of Sadinle (2014)). This behavior is expected as the within-file cluster size prior with is informative in the low duplication setting.
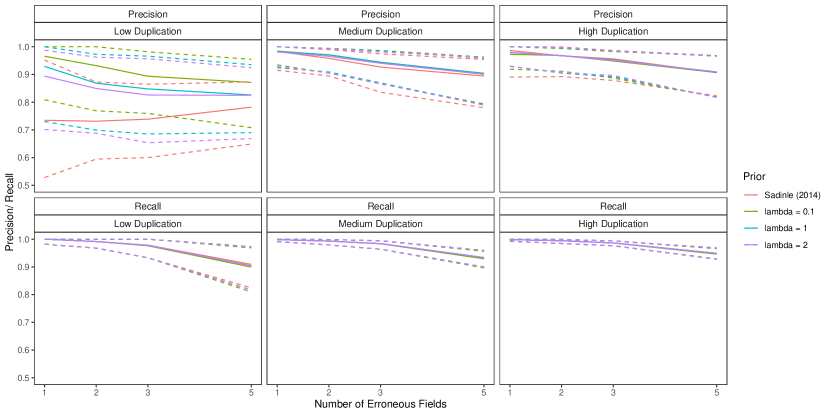
D.4 Files with Duplicates, Partial Estimates
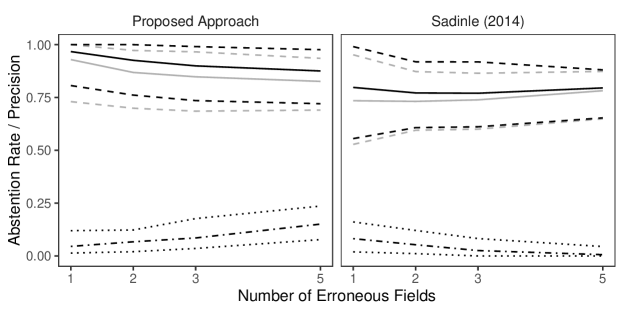
We now examine the performance of partial estimates in the low duplication setting of the simulation presented in the previous section, where both the proposed approach and the approach of Sadinle (2014) struggled the most. For partial estimates, we use , , and , so that abstaining from making a linkage decision is as costly as making a false non-match. We will assess the performance of the Bayes estimate using precision and the abstention rate, , the proportion of records which the Bayes estimate abstained from making a linkage decision. Recall is no longer useful when using partial estimates, as we are not trying to find all true matches.
In Figure 8 we see that, for both approaches, using partial estimates leads to improved precision in comparison with full estimates, while maintaining a relatively low abstention rate. This result is expected, as the records to which our partial estimate assigns the abstain option are the most ambiguous in terms of which records they should be linked to, and therefore they are the most likely to lead to false matches which decrease the precision. Using partial estimates with an abstain option is therefore a good way of compromising between automated and manual linkage: records for which linkage decisions are difficult are left to be handled via clerical review.
D.5 Results for an Alternative Metric
When evaluating the performance of the full estimates in the simulations thus far, we have focused on the metrics of precision and recall, which are global measures of how well the true partition is being estimated. One could also be interested in how well other summaries of the partition are being estimated, e.g. the number of entities (i.e. the number of clusters), the sizes of the clusters, the overlap table, etc. In this section we report the performance of the full estimates in the previous simulations when estimating the number of entities.
For each replicate data set in each simulation scenario considered thus far, we obtained a full estimate of the partition, which can be used to derive an estimate of the number of entities. For a given simulation scenario, let denote the true number of entities (in all the scenarios considered thus far, ), and let denote the estimate of the number of entities based on the full estimate of the partition for replicate data set . For each simulation scenario, we can thus estimate the bias of these estimates, , and the mean-squared error of these estimates, .
D.5.1 Duplicate-Free Files, Equal Errors Across Files
The results for estimating the number of latent entities in the simulations conducted in Section 6.2 of the main text and Appendix D.2 are seen in Figures 9 and 10. We see that that across the different simulation settings the proposed approach has a slight negative bias, and the approach using a flat prior has a very large negative bias. In the no-three-file overlap settings, we see that the more informative prior specifications are less biased than the proposed approach when there are a larger number of erroneous fields, which mirrors the results from Appendix D.2. Across all approaches, the bias increases as the number of erroneous fields increases. The results for the mean-squared error estimates are very similar to the results for the bias estimates.
D.5.2 Duplicate-Free Files, Unequal Errors Across Files
The results for estimating the number of latent entities in the simulation conducted in Section 6.3 of the main text are seen in Figures 9 and 10. We see that that across the two simulation settings all approaches have a negative bias, with the proposed approach having the smallest bias and the approach using a flat prior having the largest bias in both scenarios. The results for the mean-squared error estimates are very similar to the results for the bias estimates.
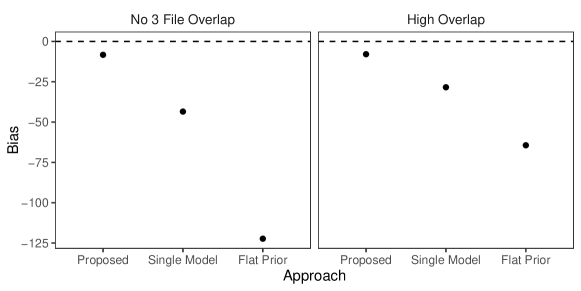
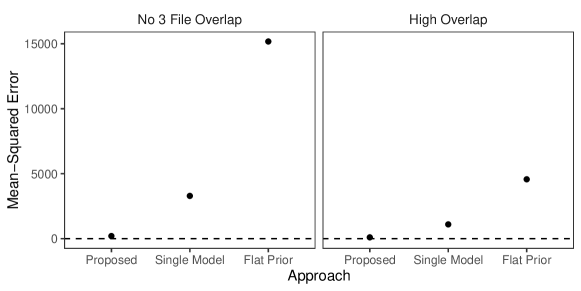
D.5.3 Files with Duplicates, Full Estimates
The results for estimating the number of latent entities in the simulation conducted in Appendix D.3 are seen in Figures 13 and 14. In the low duplication setting, we see that the proposed approach with has the smallest bias across error settings, followed by the proposed approach with , then the proposed approach with , and then the approach of Sadinle (2014) with the largest bias across error settings. This mirrors the results from Appendix D.3. In the medium and high duplication settings we see that all approaches have a slight negative bias when there are a small number of erroneous fields, and a slight positive bias when there are a large number of erroneous fields. The different variants of the proposed approach all have similar performance in these settings. The proposed approach performs best when there are a small number of erroneous fields, and the approach of Sadinle (2014) performs best when there are a large number of erroneous fields. The results for the mean-squared error estimates are very similar to the results for the bias estimates.
D.6 Simulation Running Times
In this section we present the average running time of our proposed Gibbs sampler across the various simulations settings (i.e. the average time it takes to draw 1000 samples for each simulation setting). The running times are based on the implementation in the R package multilink which can be downloaded on GitHub at https://github.com/aleshing/multilink, with the Gibbs sampler described in Appendix B.2 written in C++, running on a laptop with a 3.1 GHz processor.
D.6.1 Duplicate-Free Files, Equal Errors Across Files
The average running times of our approach in the simulations conducted in Section 6.2 of the main text are presented in Table 3. The average number of records was 725 in the settings with no-three-file overlap, 676 in the settings with low overlap, 725 in the settings with medium overlap, and 875 in the settings with high overlap.
| Number of Erroneous Fields | No 3 File Overlap | Low Overlap | Medium Overlap | High Overlap |
|---|---|---|---|---|
| 1 | 111.0 | 77.6 | 83.7 | 108.6 |
| 2 | 112.9 | 77.7 | 83.7 | 109.2 |
| 3 | 111.8 | 77.4 | 83.0 | 109.4 |
| 5 | 95.7 | 73.8 | 77.3 | 101.1 |
D.6.2 Duplicate-Free Files, Unequal Errors Across Files
The average running time of our proposed approach in the simulations conducted in Section 6.3 of the main text was 121.8 seconds in the no-three-file overlap setting and 104.1 seconds in the high overlap setting. The average number of records was 725 in the settings with no-three-file overlap and 875 in the settings with high overlap.
D.6.3 Files with Duplicates, Full Estimates
The average running times of our approach in the simulations conducted in Appendix D.3 are presented in Table 4. The average number of records was 590 in the settings with low duplication, and 889 in the settings with medium duplication, and 1260 in the settings with high duplication. We note here that in this simulation, compared to the simulations with duplicate-free files, we used indexing, which sped up the running time.
| Number of Erroneous Fields | Low Duplication | Medium Duplication | High Duplication |
|---|---|---|---|
| 1 | 1.5 | 8.0 | 20.9 |
| 2 | 1.1 | 7.7 | 20.8 |
| 3 | 1.0 | 7.4 | 21.0 |
| 5 | 0.9 | 6.6 | 19.2 |
D.7 Larger Sample Size Simulation
All of the simulations thus far had fixed the true number of latent entities, , to . To explore the running time of our proposed approach further, we now present an additional set of simulations where the number of latent entities varies over . For concreteness we will focus on the simulation setting with duplicate-free files, equal errors across files, medium overlap, and erroneous field per record (i.e. one of the settings from the simulation conducted in Section 6.2 of the main text). For this chosen simulation setting, we repeat the simulation as conducted in Section 6.2 of the main text, varying the number of latent entities over . For the setting we conduct , rather than , replications (due to how long each replication takes). The average number of records was 146 when , 725 when , 1452 when , and 3629 when . In addition to fitting the proposed approach without indexing as in Section 6.2 of the main text, we additionally fit the proposed approach using the indexing scheme described in Appendix D.3 to demonstrate the utility of indexing for improving the running time or our proposed approach, as discussed in Appendix B.4.
The average running time for each setting of the number of entities, , is presented in Figure 15. Our proposed approach without indexing runs relatively quickly in the settings with , for example it only takes around minutes on average to draw samples when . However, when our proposed approach without indexing runs takes roughly an hour and a half on average to draw samples. While this running time is manageable, it indicates that the running time in settings with more records than this would prohibitively slow. When looking at the running time of our proposed approach using indexing, we see that the average running is reduced drastically. For example, when , the average running time is only around 100 seconds.
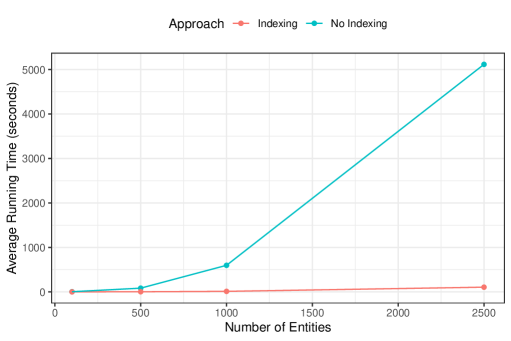
These results suggest that our approach without indexing can be run in a manageable amount of time for thousands of records, but would be prohibitively slow when the number of records is much larger than a few thousand. Our proposed approach with indexing however can scale to larger file sizes, potentially in the tens of thousands. Using our approach, with or without indexing, in conjunction with blocking, as suggested in Appendix B.4, can help to further scale our approach to large file sizes.
We note that the precision and recall in these simulations, across the different settings of the number of entities, were comparable to the results for the medium overlap, erroneous field per record setting from the simulation results in Section 6.2 of the main text.
D.8 Alternative Loss Function Specifications
In this section explore the impact of varying the specification of the losses and on the performance of our proposed approach across the different simulation settings. For full estimates, we follow Sadinle (2017) and consider the following specifications of the losses and (with ).
-
A)
. This is the specification used in all of the simulations thus far.
-
B)
. Compared to specification A, this specification does not penalize type 2 false matches as heavily.
-
C)
. This specification penalizes false non-matches more heavily than false matches.
-
D)
. This specification penalizes false matches more heavily than false non-matches, and type 2 false matches more heavily than type 1 false matches.
-
E)
. Compared to specification E, this specification does not penalizes false matches as heavily.
-
F)
. Compared to specification A, this specification penalizes type 2 false matches more heavily.
For partial estimates, we consider combining with the six specifications of and that we have just introduced.
D.8.1 Duplicate-Free Files, Equal Errors Across Files
The performance of our proposed approach in the simulations conducted in Section 6.2 of the main text, using the different loss function specifications, are seen in Figure 16. So that the figure is easier to scrutinize, we do not plot the results under specifications E and F, as the results under specifications E are very similar to the results under specification D, and the results under specifications F are very similar to the results under specifications A and B.
We see that when there are a low number of erroneous fields, the results are fairly robust to the loss function specification. When there are a high number of erroneous fields, we see that specification D leads to the highest precision and the lowest recall, specification C leads to the lowest precision and the highest recall, and specifications A and B are somewhere in between. These results are expected, as specification C penalizes false non-matches much more than false matches, and will thus decide to match records more often than the other specifications, and specification D penalizes false matches much more than false non-matches, and thus will decide to match records less often than the other specifications.
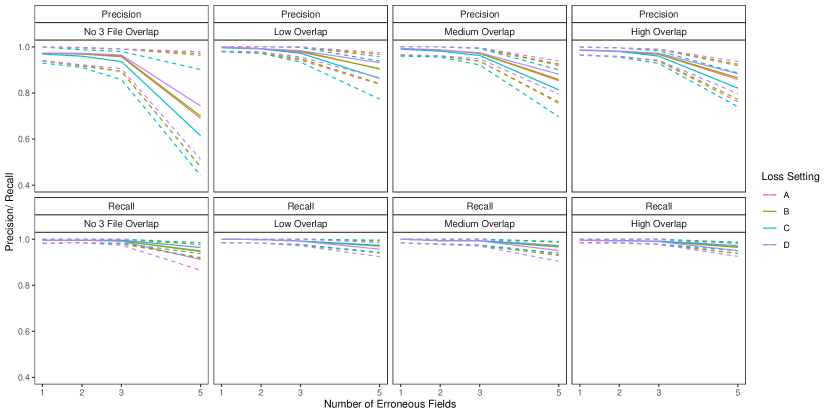
D.8.2 Duplicate-Free Files, Unequal Errors Across Files
The performance of our proposed approach in the simulations conducted in Section 6.3 of the main text, using the different loss function specifications, are seen in Figure 17. Overall the results are fairly robust to the loss function specification. The results under specifications A, B and F are very similar and the results under specifications D and E are very similar. Similar to the last section, specifications D and E lead to the highest precision and the lowest recall, specification C leads to the lowest precision and the highest recall, and specifications A, B, and F are somewhere in between.
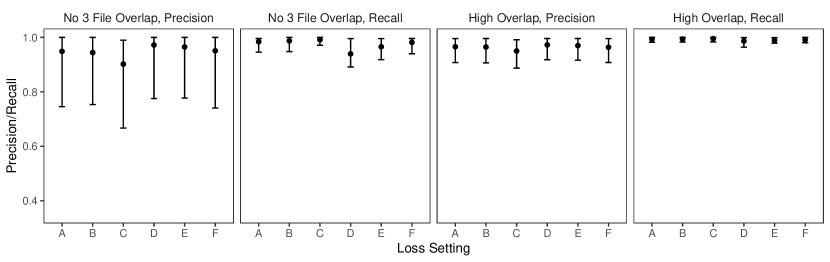
D.8.3 Files with Duplicates, Full Estimates
The performance of our proposed approach in the simulations conducted in Appendix D.3, using the different loss function specifications, are seen in Figure 16. So that the figure is easier to scrutinize, we do not plot the results under specifications E and F, as the results under specifications E are very similar to the results under specification D, and the results under specifications F are very similar to the results under specifications A and B.
We see that when there is medium and high duplication, the results are fairly robust to the loss function specification. When there is low duplication, we see that specification D leads to the highest precision and the lowest recall, specification C leads to the lowest precision and the highest recall, and specifications A and B are somewhere in between. These results are expected, as described in the previous sections.
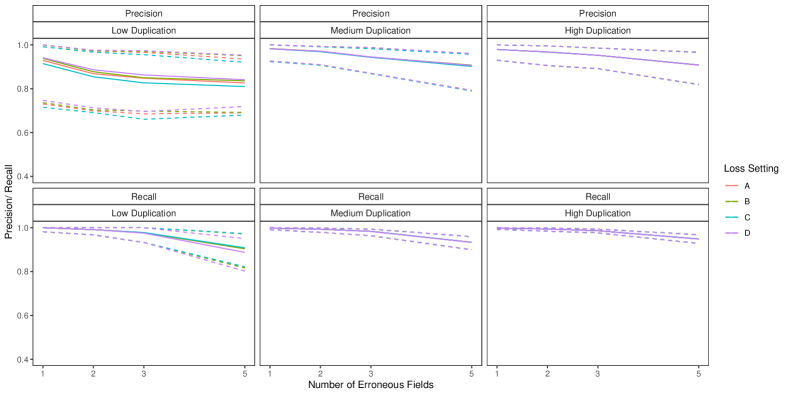
D.8.4 Files with Duplicates, Partial Estimates
The performance of our proposed approach in the simulations conducted in Appendix D.4, using the different loss function specifications, are seen in Figure 19. So that the figure is easier to scrutinize, we do not plot the results under specifications F, as the results under specifications F are very similar to the results under specifications A and B.
We see that as we increase , the abstention rate decreases and the precision decreases across the different specifications of and . Further, for each loss specification the abstention rate increases as the number of erroneous fields increases, as there is more uncertainty in the linkage. For a given setting of , the precision is fairly robust to the different specifications of and , with specifications D and E having slightly higher precision that specifications A, B and C. For a given setting of , the abstention rate is highest under specifications D and E, lowest under specifications A and B, with specification C somewhere in between.
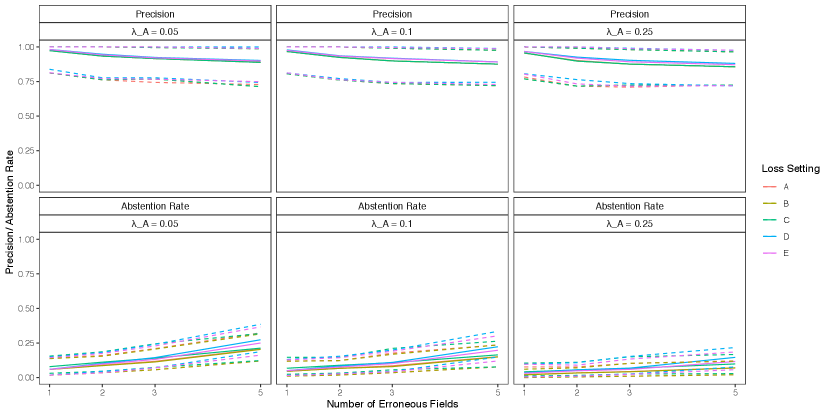
D.9 Convergence Diagnostics
For all simulations we ran the Gibbs sampler described in Appendix B.2 for iterations, discarding the first samples as burn-in. We initially came up with these sampling and burn-in lengths based on a small number of test runs for each simulation scenario. In particular, for each simulation scenario we ran a small number of test runs and examined the trace plots for the number of entities, . As the chains for appeared to converge quickly based on these trace plots, we determined that a burn-in period of samples was appropriate. To illustrate this procedure, for each simulation scenario we now present trace plots for the number of entities, , for a small number of runs.
D.9.1 Duplicate-Free Files, Equal Errors Across Files
For the simulations conducted in Section 6.2 of the main text with erroneous fields per record, for each overlap setting we present the trace plots for for the last of the simulation runs in Figure 20. The chains for the other scenarios with and erroneous fields per record converged similarly quickly.
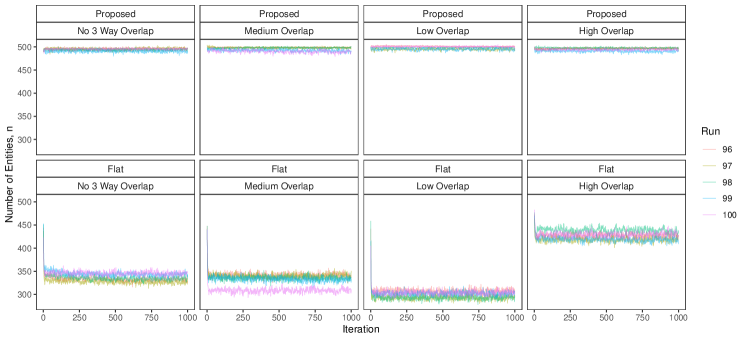
D.9.2 Duplicate-Free Files, Unequal Errors Across Files
For the simulations conducted in Section 6.3 of the main text, for each overlap setting we present the trace plots for for the last of the simulation runs in Figure 21.
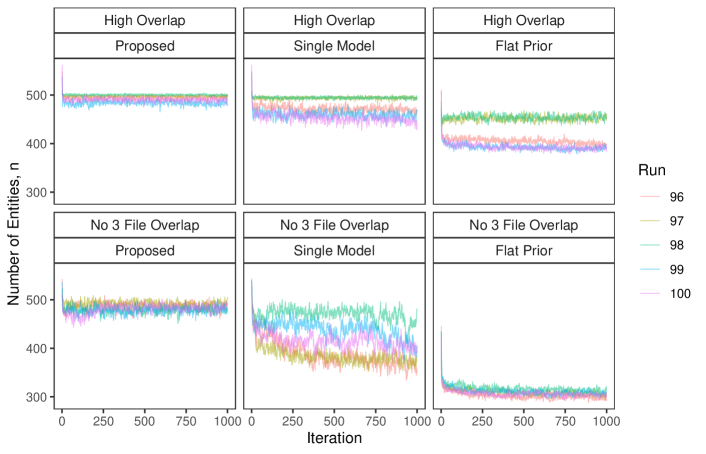
D.9.3 Files with Duplicates, Full Estimates
For the simulations conducted in Appendix D.3 with erroneous fields per record, for each overlap setting we present the trace plots for for the last of the simulation runs in Figure 22. The chains for the other scenarios with and erroneous fields per record converged similarly quickly.
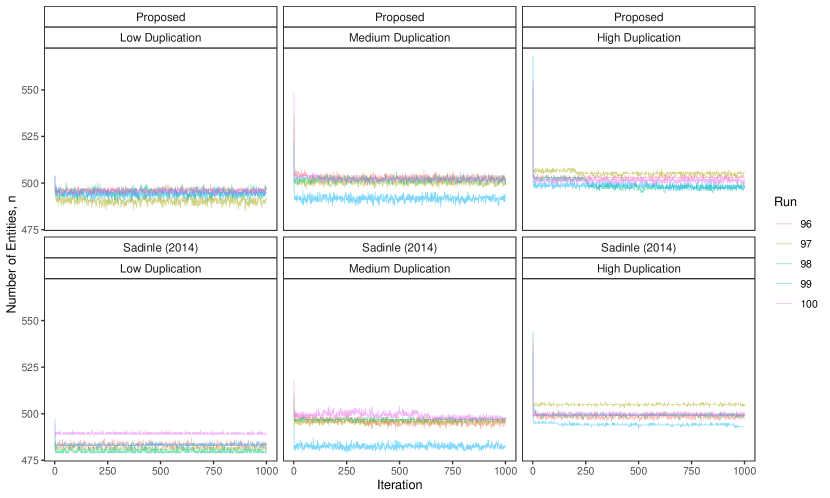
Appendix E Colombia Application
In this appendix we re-examine the three record systems containing information on homicides from 2004 in the Quindio province of Colombia, previously studied in Sadinle & Fienberg (2013). These record systems, provided by the Conflict Analysis Resource Center (CERAC), were maintained by the Colombian National Statistics Office (Departamento Administrativo Nacional de Estadistica, DANE), the Colombian National Police (Policia Nacional de Colombia, PN), and the Colombian Forensics Institute (Instituto Nacional de Medicina Legal y Ciencias Forenses, ML). While the purpose of DANE is to record all homicides occurring in Colombia, PN and ML only record homicides obtained from their daily activities (Departamento Administrativo Nacional de Estadisticas, DANE, 2009; Restrepo & Aguirre, 2007). Linking DANE to PN and ML is thus an important step in assessing the coverage of DANE and arriving at better estimates of the number of homicides in Colombia. Previously the records were linked by hand, which gives us a ground truth to assess the performance of our proposed approach. The linkage methodology of Sadinle & Fienberg (2013) did not scale to a large number of records, so the authors restricted their analysis to the records from the last three months of 2004. We will now use our proposed approach to link all the records from 2004.
E.1 Implementation Details
The three record systems are believed to be free of duplicates, so the target of inference is a tripartite matching. The fields available from all three record systems are municipality and date of the homicide, whether the location of the homicide was urban or rural, and the age, sex, and marital status of the victim. Additionally, educational status of the victim is available in DANE and ML, which we are able to use despite it being missing in PN, as explained in Section 4. Although we have seven fields available for the linkage, none of them provide a large amount of discriminative information, which comparison-based approaches rely on. Thus we expect there to be significant uncertainty in the linkage, making the proposed approach particularly relevant.
There are records in DANE, records in ML, and records in PN, so there are record pairs for which we construct comparison data, according to Table 5. We use transitive indexing as described in Appendix B, where the initial indexing scheme declares record pairs as non-coreferent if they disagree in either municipality, sex, date by more than 60 days, or age by more than 9 years. This reduces the number of candidate coreferent record pairs down to .
| Levels of disagreement | |||||
| Field | Similarity measure | ||||
| Date | Absolute Difference | 0 | |||
| Age | Absolute Difference | 0 | |||
| Other Fields | Binary comparison | Agree | Disagree | ||
We present results from our approach under two prior specifications. The first is the default specification used in the simulations in Sections 6.2 and 6.3. The second specification differs from the default by placing a more informative prior on the overlap table through . In particular, based on characteristics of the record systems described in Restrepo & Aguirre (2007), we specify a prior that captures the beliefs that: 1) if a homicide is recorded in PN or ML, it is highly likely to also be recorded in DANE, and 2) DANE and PN are expected to have a high coverage of homicides. This prior is described in more detail in the following section. We used the same loss function specification as outlined in Section 6.1 and Appendix D. We ran iterations of the Gibbs sampler presented in Appendix B, discarding the first as burn-in. In Section E.5 we discuss convergence of the Gibbs sampler for this application.
E.2 An Informative Prior Specification
We will guide our prior specification using the following two passages from Restrepo & Aguirre (2007) (translated to English):
-
•
“According to DANE, ‘The differences in the Legal Medicine and DANE data are mainly due to the fact that the latter organization receives, in addition to the death certificates sent by Legal Medicine (which are sent to DANE after a technical examination), the homicide reports made by police inspectors, nurses or health promoters - in places where there are no legal doctors - who arrive at the site where the body is found and register the cases as homicide without a technical examination and according to the picture that presents the corpse’. So we find here a reason for the increased coverage of vital statistics” (Restrepo & Aguirre, 2007, p. 331).
-
•
“The National Police assures to have coverage at the national level, making an institutional presence in all the municipalities of the country: ‘We have a presence throughout the country and we know all the cases; Legal Medicine does not have the same coverage and thus their data is not exact’ ” (Restrepo & Aguirre, 2007, p. 330).
Note that our Dirichlet-Multinomial prior for the overlap table can be motivated as the result of first drawing from a Dirichlet distribution with hyperparameters , then drawing from a multinomial distribution of size with probabilities . Based on these passages we specify as follows, referring in our notation to DANE as list , ML as list , and PN as list :
-
•
If a homicide is going to be recorded by one of the three record systems, it is very likely that it will be known by DANE. Therefore, we choose and such that and , where is the prior probability of a homicide being recorded in DANE given it is recorded in one of the three systems.
-
•
If a homicide is recorded by PN, then it is very likely that it will be recorded by DANE. Therefore, we choose and such that and , where is the prior probability of a homicide being recorded in DANE given it is recorded in PN.
-
•
If a homicide is recorded by ML, then it is very likely that it will be known by DANE. Therefore, we choose and such that and , where is the prior probability of a homicide being recorded in DANE given it is recorded in ML.
-
•
The above induce six constraints, which determine , , and , but we need one extra constraint to determine the remaining . We thus choose the configuration of , , , and that maximizes , which controls the prior probability of a homicide being jointly recorded by DANE and PN, given that these systems that are supposed to have the largest coverage of homicides.
Under this specification we arrive at the setting . For the sake of propriety, we set .
E.3 Results
Under the default prior specification the precision and recall of the full estimate are and respectively. Recall is no longer useful when using partial estimates, as we are not trying to find all true matches. Thus we will assess the performance of the partial estimates using precision and the abstention rate, the proportion of records which the Bayes estimate abstained from making a linkage decision. The partial estimate has an abstention rate of , and improves the precision of the estimate to . Under the informative prior specification the precision and recall of the full estimate are and respectively. The partial estimate has an abstention rate of , and improves the precision of the estimate to . Due to the performance difference, we will focus on the results under the informative prior specification for the rest of this section. Analogous results under the default specification are provided in the next section.
The total number of homicides based on the hand labelling is . Under the informative prior specification a credible interval for the number of unique homicides is , with an estimate based on the full estimate of the tripartite matching of . In Table 6 we display the posterior distribution for the overlap table and the overlap table derived from the full estimate, along with the overlap table derived from the ground truth hand labelling. We can see that , the number of homicides recorded in all three files, and , the number of homicides recorded in just DANE, are overestimated, and the remaining cells of the overlap table (and ) are underestimated.
| In PN | Out PN | |||||||
| DANE | In ML | Out ML | In ML | Out ML | ||||
| In |
|
|
|
|
||||
| Out |
|
|
|
|||||







While the performance of the estimated matching is fairly good, with precision of both the full and partial estimate (before clerical review) above , the overestimation of and the underestimation of is indicative of over-matching. We believe this over-matching occurrs due to the low amount of discriminative information provided by the fields. In particular, the only fields we believe can be fully trusted are municipality of the homicide (of which there are ) and sex of the victim (which is coded as binary), which can only partition the records into blocks of candidate coreferent records (there are no records of female homicide victims in two municipalities). The remaining fields all have some amount of error and do not provide highly discriminative information since they are either low dimensional categorical fields (urban/rural location of the homicide has two categories, marital status has five categories, and educational status has six categories) or numeric fields that are essentially ordinal categorical (date of homicide and age of victim). Therefore, records of different homicides may look similar based on the comparisons of these fields, causing them to be mistakenly matched. In these low-information settings, clerical review becomes especially important for the record linkage workflow, which our proposed approach of using partial estimates incorporates by design.
E.4 Results Under Default Prior
Under the default prior specification a credible interval for the number of unique homicides is , with an estimate based on the full estimate of the tripartite matching of . Thus we see that is better estimated under the default prior compared to the informative prior (though the point estimate is still an underestimate). In Table 7 we display the posterior distribution for the overlap table and the overlap table derived from the full estimate, along with the overlap table derived from the ground truth hand labelling. We can see that, as with the informative prior specification, and are overestimated, and the remaining cells of the overlap table (and ) are underestimated.
| In PN | Out PN | |||||||
| DANE | In ML | Out ML | In ML | Out ML | ||||
| In |
|
|
|
|
||||
| Out |
|
|
|
|||||






E.5 Convergence Diagnostics
In the application, we ran the the Gibbs sampler described in Appendix B.2 for iterations, discarding the first samples as burn-in, under a default and an informative prior specification. In Figure 23 we present the the trace plots for the number of entities, , under each of these prior specifications. The chains for appear to converge quickly based on these trace plots. For each of these chains we computed Geweke’s convergence diagnostic as implemented in the R package coda (Plummer et al., 2006). The Geweke’s Z-scores indicated it was reasonable to treat these chains as drawn from their stationary distributions.
References
- (1)
- Ball & Price (2019) Ball, P. & Price, M. (2019), ‘Using statistics to assess lethal violence in civil and inter-state war’, Annual review of statistics and its application 6, 63–84.
- Bansal et al. (2004) Bansal, N., Blum, A. & Chawla, S. (2004), ‘Correlation Clustering’, Machine Learning 56(1), 89–113.
- Berger et al. (2015) Berger, J. O., Bernardo, J. M. & Sun, D. (2015), ‘Overall objective priors’, Bayesian Analysis 10(1), 189–221.
- Betancourt, Sosa & Rodríguez (2020) Betancourt, B., Sosa, J. & Rodríguez, A. (2020), ‘A Prior for Record Linkage Based on Allelic Partitions’, arXiv preprint arXiv:2008.10118 .
- Betancourt, Zanella & Steorts (2020) Betancourt, B., Zanella, G. & Steorts, R. C. (2020), ‘Random Partition Models for Microclustering Tasks’, arXiv preprint arXiv:2004.02008 .
- Bilenko et al. (2003) Bilenko, M., Mooney, R. J., Cohen, W. W., Ravikumar, P. & Fienberg, S. E. (2003), ‘Adaptive Name Matching in Information Integration’, IEEE Intelligent Systems 18(5), 16–23.
- Binder (1978) Binder, D. A. (1978), ‘Bayesian cluster analysis’, Biometrika 65(1), 31–38.
- Binette & Steorts (2020) Binette, O. & Steorts, R. C. (2020), ‘(Almost) All of Entity Resolution’, arXiv preprint arXiv:2008.04443 .
- Bird & King (2018) Bird, S. M. & King, R. (2018), ‘Multiple systems estimation (or capture-recapture estimation) to inform public policy’, Annual review of statistics and its application 5, 95–118.
- Brandes et al. (2007) Brandes, U., Delling, D., Gaertler, M., Görke, R., Hoefer, M., Nikoloski, Z. & Wagner, D. (2007), On Finding Graph Clusterings with Maximum Modularity, in ‘Graph-Theoretic Concepts in Computer Science’, Springer Berlin Heidelberg, pp. 121–132.
- Christen (2012) Christen, P. (2012), ‘A Survey of Indexing Techniques for Scalable Record Linkage and Deduplication’, IEEE Transactions on Knowledge and Data Engineering 24(9), 1537–1555.
- Demaine et al. (2006) Demaine, E. D., Emanuel, D., Fiat, A. & Immorlica, N. (2006), ‘Correlation clustering in general weighted graphs’, Theoretical Computer Science 361(2), 172 – 187.
-
Departamento Administrativo Nacional de Estadisticas,
DANE (2009)
Departamento Administrativo Nacional de Estadisticas, DANE (2009), Metodologia Estadisticas Vitales, Technical
Report 82, Direccion de Censos y Demografia.
http://www.dane.gov.co/files/investigaciones/fichas/Estadisticas_vitales.pdf - Dunson & Xing (2009) Dunson, D. B. & Xing, C. (2009), ‘Nonparametric Bayes modeling of multivariate categorical data’, Journal of the American Statistical Association 104(487), 1042–1051.
- Enamorado et al. (2019) Enamorado, T., Fifield, B. & Imai, K. (2019), ‘Using a probabilistic model to assist merging of large-scale administrative records’, American Political Science Review 113(2), 353–371.
- Enamorado & Steorts (2020) Enamorado, T. & Steorts, R. C. (2020), Probabilistic Blocking and Distributed Bayesian Entity Resolution, in ‘International Conference on Privacy in Statistical Databases’, Springer, pp. 224–239.
- Fellegi & Sunter (1969) Fellegi, I. P. & Sunter, A. B. (1969), ‘A theory for record linkage’, Journal of the American Statistical Association 64(328), 1183–1210.
- Fortini et al. (2001) Fortini, M., Liseo, B., Nuccitelli, A. & Scanu, M. (2001), ‘On Bayesian record linkage’, Research in Official Statistics 4(1), 185–198.
- Herbei & Wegkamp (2006) Herbei, R. & Wegkamp, M. H. (2006), ‘Classification with reject option’, Canadian Journal of Statistics 34(4), 709–721.
- Hof et al. (2017) Hof, M. H., Ravelli, A. C. & Zwinderman, A. H. (2017), ‘A probabilistic record linkage model for survival data’, Journal of the American Statistical Association 112(520), 1504–1515.
- Jaro (1989) Jaro, M. A. (1989), ‘Advances in Record-Linkage Methodology as Applied to Matching the 1985 Census of Tampa, Florida’, Journal of the American Statistical Association 84(406), 414–420.
- Klami & Jitta (2016) Klami, A. & Jitta, A. (2016), Probabilistic size-constrained microclustering, in ‘Proceedings of the Thirty-Second Conference on Uncertainty in Artificial Intelligence’, AUAI Press, pp. 329–338.
- Lancichinetti & Fortunato (2009) Lancichinetti, A. & Fortunato, S. (2009), ‘Community detection algorithms: A comparative analysis’, Phys. Rev. E 80, 056117.
- Larsen (2005) Larsen, M. D. (2005), Advances in Record Linkage Theory: Hierarchical Bayesian Record Linkage Theory, in ‘Proceedings of the Section on Survey Research Methods’, American Statistical Association, pp. 3277–3284.
- Larsen & Rubin (2001) Larsen, M. D. & Rubin, D. B. (2001), ‘Iterative Automated Record Linkage Using Mixture Models’, Journal of the American Statistical Association 96(453), 32–41.
- Liseo & Tancredi (2011) Liseo, B. & Tancredi, A. (2011), ‘Bayesian Estimation of Population Size via Linkage of Multivariate Normal Data Sets’, Journal of Official Statistics 27(3), 491–505.
- Marchant et al. (2021) Marchant, N. G., Kaplan, A., Elazar, D. N., Rubinstein, B. I. & Steorts, R. C. (2021), ‘d-blink: Distributed end-to-end Bayesian entity resolution’, Journal of Computational and Graphical Statistics pp. 1–16.
- Matsakis (2010) Matsakis, N. E. (2010), Active Duplicate Detection with Bayesian Nonparametric Models, PhD thesis, Massachusetts Institute of Technology.
- McVeigh et al. (2019) McVeigh, B. S., Spahn, B. T. & Murray, J. S. (2019), ‘Scaling bayesian probabilistic record linkage with post-hoc blocking: An application to the california great registers’, arXiv preprint arXiv:1905.05337 .
- Meilă (2007) Meilă, M. (2007), ‘Comparing clusterings—an information based distance’, Journal of multivariate analysis 98(5), 873–895.
- Miller et al. (2015) Miller, J., Betancourt, B., Zaidi, A., Wallach, H. & Steorts, R. C. (2015), ‘Microclustering: When the cluster sizes grow sublinearly with the size of the data set’, arXiv preprint arXiv:1512.00792 .
- Murray (2015) Murray, J. S. (2015), ‘Probabilistic record linkage and deduplication after indexing, blocking, and filtering’, Journal of Privacy and Confidentiality 7(1).
- Newman (2013) Newman, M. E. J. (2013), ‘Spectral methods for community detection and graph partitioning’, Phys. Rev. E 88, 042822.
- Plummer et al. (2006) Plummer, M., Best, N., Cowles, K. & Vines, K. (2006), ‘CODA: convergence diagnosis and output analysis for MCMC’, R news 6(1), 7–11.
- Restrepo & Aguirre (2007) Restrepo, J. A. & Aguirre, K. (2007), ‘Homicidios y Muertes Violentas: Un Analisis Comparativo de las Fuentes en Colombia’, Forensis: Datos Para La Vida .
- Sadinle (2014) Sadinle, M. (2014), ‘Detecting duplicates in a homicide registry using a Bayesian partitioning approach’, The Annals of Applied Statistics 8(4), 2404–2434.
- Sadinle (2017) Sadinle, M. (2017), ‘Bayesian estimation of bipartite matchings for record linkage’, Journal of the American Statistical Association 112(518), 600–612.
- Sadinle & Fienberg (2013) Sadinle, M. & Fienberg, S. E. (2013), ‘A Generalized Fellegi-Sunter Framework for Multiple Record Linkage With Application to Homicide Record Systems’, Journal of the American Statistical Association 108(502), 385–397.
- Steorts (2015) Steorts, R. C. (2015), ‘Entity Resolution with Empirically Motivated Priors’, Bayesian Analysis 10(4), 849–875.
- Steorts et al. (2016) Steorts, R. C., Hall, R. & Fienberg, S. E. (2016), ‘A Bayesian approach to graphical record linkage and deduplication’, Journal of the American Statistical Association 111(516), 1660–1672.
- Steorts et al. (2014) Steorts, R. C., Ventura, S. L., Sadinle, M. & Fienberg, S. E. (2014), A comparison of blocking methods for record linkage, in ‘International Conference on Privacy in Statistical Databases’, Springer, pp. 253–268.
- Tancredi & Liseo (2011) Tancredi, A. & Liseo, B. (2011), ‘A Hierarchical Bayesian Approach to Record Linkage and Size Population Problems’, Annals of Applied Statistics 5(2B), 1553–1585.
- Tancredi et al. (2020) Tancredi, A., Steorts, R. & Liseo, B. (2020), ‘A Unified Framework for De-Duplication and Population Size Estimation (with Discussion)’, Bayesian Analysis 15(2), 633–682.
- Tran et al. (2013) Tran, K.-N., Vatsalan, D. & Christen, P. (2013), GeCo: an online personal data generator and corruptor, in ‘Proceedings of the 22nd ACM International Conference on Information & Knowledge Management’, pp. 2473–2476.
- Wade & Ghahramani (2018) Wade, S. & Ghahramani, Z. (2018), ‘Bayesian cluster analysis: Point estimation and credible balls (with discussion)’, Bayesian Analysis 13(2), 559–626.
- Winkler (1990) Winkler, W. E. (1990), String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage, in ‘Proceedings of the Section on Survey Research Methods’, American Statistical Association, pp. 354–359.
- Winkler (1994) Winkler, W. E. (1994), Advanced Methods for Record Linkage, in ‘Proceedings of the Section on Survey Research Methods’, American Statistical Association, pp. 467–472.
- Zanella et al. (2016) Zanella, G., Betancourt, B., Miller, J. W., Wallach, H., Zaidi, A. & Steorts, R. C. (2016), Flexible models for microclustering with application to entity resolution, in ‘Advances in Neural Information Processing Systems’, pp. 1417–1425.
- Zhou et al. (2015) Zhou, J., Bhattacharya, A., Herring, A. H. & Dunson, D. B. (2015), ‘Bayesian factorizations of big sparse tensors’, Journal of the American Statistical Association 110(512), 1562–1576.