Multi-view X-ray Image Synthesis with Multiple Domain Disentanglement from CT Scans
Abstract.
X-ray images play a vital role in the intraoperative processes due to their high resolution and fast imaging speed and greatly promote the subsequent segmentation, registration and reconstruction. However, over-dosed X-rays superimpose potential risks to human health to some extent. Data-driven algorithms from volume scans to X-ray images are restricted by the scarcity of paired X-ray and volume data. Existing methods are mainly realized by modelling the whole X-ray imaging procedure. In this study, we propose a learning-based approach termed CT2X-GAN to synthesize the X-ray images in an end-to-end manner using the content and style disentanglement from three different image domains. Our method decouples the anatomical structure information from CT scans and style information from unpaired real X-ray images/ digital reconstructed radiography (DRR) images via a series of decoupling encoders. Additionally, we introduce a novel consistency regularization term to improve the stylistic resemblance between synthesized X-ray images and real X-ray images. Meanwhile, we also impose a supervised process by computing the similarity of computed real DRR and synthesized DRR images. We further develop a pose attention module to fully strengthen the comprehensive information in the decoupled content code from CT scans, facilitating high-quality multi-view image synthesis in the lower 2D space. Extensive experiments were conducted on the publicly available CTSpine1K dataset and achieved 97.8350, 0.0842 and 3.0938 in terms of FID, KID and defined user-scored X-ray similarity, respectively. In comparison with 3D-aware methods (-GAN, EG3D), CT2X-GAN is superior in improving the synthesis quality and realistic to the real X-ray images.
1. Introduction
Due to the high resolution and rapid imaging speed, X-ray images are commonly utilized for visualizing the internal anatomical structures of the human body and are regarded as the golden standard for disease diagnosis and treatment. In the X-ray imaging processes, according to the different attenuation coefficients, organs and tissues present various grey distributions(Tsoulfanidis and Landsberger, 2021; Schmitt et al., 2024; Syryamkin et al., 2020). However, the commonly used mono-plane imaging system can only capture the X-ray image from a single view each time. Due to the projecting principle, much spatial information has been lost in the X-ray images and repeated or multiple imaging procedures are further needed to visualize the rich and comprehensive information of human structures(Pasveer, 1989; Louati et al., 2024). In such processes, excessive doses of X-rays pose unavoidable potential risks to the human body. Besides these, X-ray images play a vital role in the segmentation(Yu et al., 2023; Butoi et al., 2023), registration(Zhu et al., 2023; Xu et al., 2023), reconstruction (Kasten et al., 2020; Koetzier et al., 2023; Huang et al., 2024) and synthesis (Li et al., 2020). Along with the explosive development of deep learning, large amounts of X-ray image databases are needed to extensively improve the performance of the above researches(Withers et al., 2021; Bhosale and Patnaik, 2023). Hence, synthesizing X-ray images from volume data is desperately needed.

In the synthesizing process of X-ray images, attenuation coefficients of different parts and interaction between X-rays and structures both need to be accurately modelled. Digital reconstructed radiography (DRR) is a common solution to tackle the problem by computing the attenuation coefficients and modifying the ray-casting approach(Dhont et al., 2020). However, DRR is highly dependent on the accuracy of each structure segmentation which reduces the generalization ability. Besides, particle numerical models are also essential to simulate the interaction between X-rays and structures which further increases the difficulty and complexity of imaging procedure(Unberath et al., 2019; Wen et al., 2024). Hence, improving the reality of synthesized X-ray images still faces great challenges.
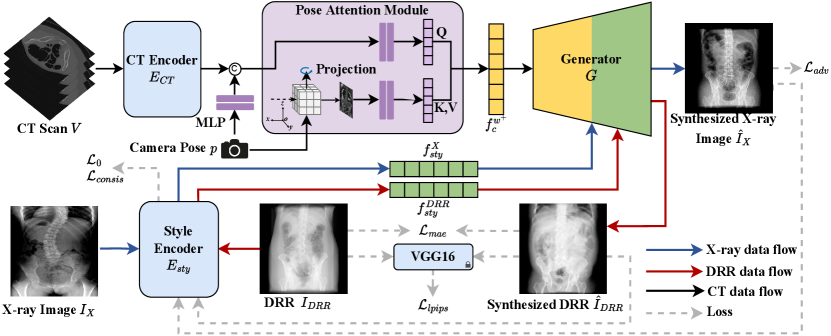
In this study, we propose a novel and practical task termed CT-to-X-ray (CT2X) synthesis, aiming to generate high-quality and realistic X-ray images from multiple view angles. The goal is to learn the intricate mapping relationship from CT scans to X-ray images. As depicted in Figure 1, the CT scan is directly fed into the generator to synthesize X-ray images, instead of modelling the complicated processes including segmentation, ray-casting, and post-processing in traditional methods. To reach this purpose, CT2X-GAN is realized from the perspectives of style decoupling and pose perception.
To achieve style decoupling, we propose a multiple domain style decoupling encoder, which is capable of decoupling anatomy structure and texture style from 2D X-ray images. To guide the style decoupling encoder in learning content commonalities and style differences across multiple domains, we introduce a novel consistency regularization term to constrain the training process. Additionally, zero loss is introduced to minimize the similarity of style features among reference images from different domains, ensuring the style decoupling encoder focuses on domain-independent style features. For pose perception, we propose a CT encoder incorporating a pose attention module (PAM), enabling the multi-view consistency of X-ray images from multiple view angles using 2D networks.
In summary, our contributions can be summarized as fourfold:
-
•
A novel pipeline is proposed for end-to-end X-ray image synthesis from CT scans without modelling the whole X-ray imaging procedure.
-
•
A style decoupling encoder is introduced to extract style features from real X-ray images, relieving the difficulty of collecting paired CT scans and X-ray images.
-
•
A novel regularization method is developed by utilizing consistency and zero loss to improve style accuracy, improving the structural consistency in multi-views and style decoupling capabilities.
-
•
A PAM is designed to calculate attention based on the projection of the target pose, enabling the network to improve the perception ability of structural content at multiple view angles.
1.1. Related Works
1.2. Traditional X-ray Image Synthesis
The synthesis of X-ray images from volume data aims to obtain realistic X-ray images with consistent structures and styles, thereby reducing patient exposure to X-ray radiation. Mainstream methods are reached by modelling X-ray imaging procedures to generate DRRs (Dhont et al., 2020). Early research primarily employed ray-casting for synthesizing X-ray images (Kügler et al., 2020). More sophisticated methods explored the Monte Carlo (MC) (Csébfalvi and Szirmay-Kalos, 2003; Andreu Badal and Badano, 2009) method to accurately simulate the interaction between X-ray particles and tissue organs. Li et al. (Li et al., 2006) devised an adaptive MC volume Rendering algorithm, partitioning the volume into multiple sub-domains for sampling, thus accelerating the MC simulation.
1.3. Learning-based X-ray Image synthesis
Recent advancements in deep learning have significantly promoted X-ray image synthesis performance. Methods such as DeepDRR (Mathias Unberath et al., 2018) utilize convolutional neural networks for tissue segmentation in CT scans, alongside ray-casting and MC methods to compute tissue absorption rates. Gopalakrishnan et al. (Vivek Gopalakrishnan and Polina Golland, 2022) accelerated the synthesis of DRRs by reformulating the ray-casting algorithm as a series of vectorized tensor operations, facilitating DRRs interoperable with gradient-based optimization and deep learning frameworks. It is noteworthy that existing methods heavily rely on the segmentation results from the CT scans. Fixed absorption coefficients are assigned to different structures to calculate X-ray beam attenuation rates. Recent advancements in X-ray projections synthesis have revealed that deep learning models trained on simulated DRRs struggle to generalize to actual X-ray images (Mathias Unberath et al., 2018; Ying et al., 2019). However, recent progress in image translation has demonstrated that utilizing condition features extracted from representation learning models can markedly reduce the disparity between synthesized DRRs and real X-ray images (Dhont et al., 2020). Inspired by this, our model diverges from traditional approaches to modelling of imaging procedures. Instead, it employs style-based generative models, offering a robust approach for disentangled synthesis, thus improving the performance and image quality of X-ray synthesis.
1.4. GAN-based Image synthesis
In recent years, generative adversarial networks (GANs) have achie-ved remarkable success in image synthesis (Zhang et al., 2018b), image translation (Isola et al., 2017), and image editing (Alaluf et al., 2021). Building upon progressive GAN (Karras et al., 2017), Karras et al. proposed StyleGAN (Karras et al., 2019), which enhanced the quality of the generated image and allowed the network to decouple different features, providing a more controllable synthesis strategy. StyleGAN2 (Karras et al., 2020) redesigned the instance normalization scheme to remove the water droplet-like artefacts existing in StyleGAN, leading to higher-quality outputs. Some methods have attempted to control generated images by exploring the latent space of GANs (Collins et al., 2020; Shen et al., 2020; Roich et al., 2022). Despite their remarkable process, most deviations of GANs still concentrate on data augmentation in medical imaging, with limited research conducted on synthesizing cross-dimension medical images (Iglesias et al., 2023). One of the primary challenges inhibiting GANs from the CT2X task is the synthesis of multi-view results, as GANs have limited awareness of pose information (Iglesias et al., 2023; Liao et al., 2024).
Recently, there has been a trend to incorporate 3D representations into GANs, enabling them to capture pose information in 3D space (Liao et al., 2024). Such approaches, known as 3D-aware GANs, facilitate multi-view image synthesis. Methods that introduced explicit 3D representations, such as tree-GAN (Zhang et al., 2020), MeshGAN (Cheng et al., 2019), and SDF-StyleGAN (Zheng et al., 2022), are capable of synthesizing the 3D structure of the target object, which allows them to explicitly define poses in 3D space. However, the use of explicit 3D representations has constrained their resolution. -GAN (Chan et al., 2021) and EG3D (Chan et al., 2022) introduced radiance fields to endow networks with the capability of pose awareness. Nonetheless, the high computational cost of stochastic sampling required for radiance fields introduces training complexity and may lead to noise (Kerbl et al., 2023). In contrast, our approach aims to improve the capability of the network to perceive spatial poses by involving the projections at the target view angles.
2. Methods
2.1. Problem Definition
The purpose of X-ray image synthesis is to predict the X-ray image at any arbitrary view angle from the 3D CT scan. Let us denote the input CT scan with , the X-ray image for styles with , the referenced DRR for structures with . , and represent the height, width and depth, respectively. represents the camera pose of the target view angle. Hence, A mapping function from CT scan to X-ray images can be expressed as follows:
| (1) |
In this study, two main challenges in X-ray image synthesis will be tackled: (1) How to conduct end-to-end synthesis using unpaired CT and X-ray data? (2) How to realize X-ray image synthesis from multiple view angles? To address them, we train the network using images from three domains, including CT scans, X-ray images, and DRR images. In Section 2.3, we utilize the CT encoder to extract anatomical information from CT data, while the disentangled encoder processes X-ray images to extract X-ray style features. Our generator seamlessly integrates unpaired information for synthesis. Moreover, we leverage the style features extracted from DRRs to produce style reconstructed syntheses and hence provide supervision. The integration of information from three domains enables the tackling of end-to-end training with unpaired data. Additionally, a consistency regularization is employed in Section 2.4 to further constrain the training of the decoupling encoder, ensuring comprehensive extraction of domain-specific style information. A PAM is introduced to focus the content code on the target view angle, facilitating multi-view synthesis, as depicted in section 2.5. In Section 2.6, we employ a pose-aware adversarial training strategy by feeding the corresponding DRRs into the discriminator, further improving the quality of multi-view synthesis.
2.2. Overview of CT2X-GAN
CT2X-GAN synthesizes multi-view X-ray images by incorporating images from three domains: CT scans , X-ray images , and DRRs as inputs during training, as depicted in Figure 2. The CT scan is employed to compute the CT content code through a CT encoder , whereas the X-ray image is sent to a style decoupling encoder, denoted as , to extract the X-ray style code and X-ray content code . The CT content code and X-ray style code are then fed into distinct layers of the generator to conduct the X-ray image synthesis . The synthesized X-ray results lack corresponding ground truth (GT). To provide supervision to the network training, we utilize the DeepDRR (Mathias Unberath et al., 2018) framework to generate target view angle DRRs from CT scans, which also serve as the GT DRRs. These DRR images are then sent into the style decoupling encoder to obtain DRR style code and DRR content code . Forwarding the DRR style code and the CT content code into the generator produces a DRR stylized image . Reconstruction loss can then be computed between the reconstructed and the GT DRR for supervision. A consistency regularization is next introduced to constrain the training and improve the disentanglement by minimizing the discrepancy between the style code and content code between the real and synthesized images. Furthermore, to improve the perception of CT content code to the information of the target pose , a PAM is utilized to modify the CT content code by the maximum intensity projection at the target pose.
2.3. Style Decoupling Encoder
To address the challenge of limited paired CT and X-ray data, we propose a style decoupling encoder to separate images into content and style code. This allows the generator to control the style feature in the synthesized images. Specifically, for X-ray reference images , the style decoupling encoder consists of two branches, including an X-ray style branch and a content branch. The two branches separate the X-ray image into style code and content code as follows:
| (2) | ||||
| (3) |
where and denote the X-ray style branch and content branch of the style decoupling encoder, respectively.
The X-ray style code describes the low-level style and intensity information of the X-ray image, while the modified content code contains the high-level anatomical information. The generator synthesizes the X-ray images by combining the X-ray style code with the content code as follows:
| (4) |
To provide auxiliary supervision to the network training, we employ the DRRs computed from the input CT scan as the GT. The reconstructed images synthesized by the style code from such DRRs and the content code from CT scans should be consistent with . To realize this, we introduce a DRR style branch into the style decoupling encoder to be distinct from the X-ray style branch, thus enabling the style decoupling encoder. The style decoupling encoder is utilized to extract style code and content code from DRRs as follows:
| (5) | ||||
| (6) |
where denotes the DRR style branch of the style decoupling encoder.
The reconstructed DRRs can be obtained by feeding the DRR style code and the modified CT content code into the generator:
| (7) |
To improve the preservation of anatomical structures and improve the quality of image synthesis, we compute the supervised reconstruction loss between the reconstructed DRRs and GT DRRs as follows:
| (8) | ||||
Here, is the mean absolute error (mae) loss, denotes the learned perceptual image patch similarity (lpips) (Zhang et al., 2018a). and are the hyperparameters controlling the weight of the loss items.

2.4. Consistency Regularization
In decoupling the style information, it is challenging and unstable to supervise and train the decoupling encoder due to the absence of paired X-ray images. Hence, to extract domain-specific style features, we propose a novel consistency regularization approach by combining disentanglement learning and consistency to constrain the decoupling encoder. To ensure that the synthesized images obtain style information only from the style code while preserving the original structure, the decoupling encoder should thoroughly disentangle style and content information from the style image as much as possible. This implies that style branches should extract all essential style information, while structural information can only be extracted by content branch . We compel the network to extract consistent style codes from the generated image and input style image , simultaneously ensuring consistency of content codes and . Therefore, we formulate the following consistency constraints:
| (9) | ||||
| (10) | ||||
| (11) | ||||
where describes the content consistency and represents style consistency. and control the weight of the regularization term.
For the purpose of ensuring that the style encoders can thoroughly disentangle domain-specific style information, we incorporate zero loss (Benaim et al., 2019) as an auxiliary constraint during training. As discussed in Section 2.3, we have designed two domain-specific style branches within the decoupling encoder: one for capturing features of X-ray style and the other for capturing DRR style features. Ideally, the X-ray branch should extract appearance features specific to the real X-ray images, while the DRR branch should extract appearance features specific to the DRRs. Therefore, when a style reference image is inputted into the corresponding branch that does not pertain to the domain, the objective is to minimize the errors extracted by the style encoder.
| (12) |
To ensure that each branch extracts style-specific features effectively, the extracted style information should be zero when the input style image belongs to a different domain.
2.5. Pose Attention Module
While CT scans contain rich spatial information in 3D space, encoding it into latent space can incur notable information loss. Fully exploiting the 3D inherent in CT scans can lead to a more accurate anatomical structure in the synthesis. Therefore, we introduce a PAM, which is capable of accentuating distribution information of a specific view angle in the CT code , thereby obtaining an modified content code .
Given that the CT scan encompasses comprehensive anatomical information about the human body, the information within the generated X-ray image at a specific view angle should encompass the position, tissue size and morphology of anatomical structures that appeared in the CT scans. Thus, we can project the CT scans to the imaging plane of a target view angle and utilize the projection as auxiliary information to modify the content code through attention mechanisms. Initially, we encode the input CT scan into a CT code using an encoder. Next, the camera parameters are fed into a multi-layer perceptron (MLP) and concatenated with as conditional input. Subsequently, the conditional information is merged with the CT code using an MLP and denoted as . We then rotate the input volume in 3D space to align with the target pose for maximum intensity projection. The resulting projection is encoded via an MLP and utilized as and . Thus, the PAM can be represented as follows:
| (13) | ||||
| (14) | ||||
| (15) |
where refers to the concatenation, denotes the 3D rotation operation, represents the maximum intensity projection and is a small-valued constant preventing the extreme magnitude.
Overall, our proposed PAM enhances the generator capability of robust multi-view synthesis. By intensifying specific pose features, the PAM facilitates high-quality multi-view synthesis, empowering the 2D network with enhanced 3D perceptual capabilities without the need for 3D representations in the network.
2.6. Loss Function
Pose-aware adversarial training
To further promote pose consistency between the pose of generated X-ray image and the target pose , we integrate pose information into the adversarial training process. This integration enables the model to learn both the anatomical features and positional characteristics essential for precise multi-view image synthesis. Conditioning the synthesis process on the specified camera pose enables the model to effectively capture geometric details and orientation of the target anatomy, yielding synthesized images with increased fidelity and realism. The overall quality of the generated X-ray images can be improved, facilitating more accurate and clinically relevant interpretations. We formulate the pose-aware adversarial loss as follows:
| (16) | ||||
| (17) | ||||
where is the distribution of CT scans. and are the distributions of X-ray and DRR images. During training, the synthesis requires a pose sampling from the pose distribution . is the loss following (Mescheder et al., 2018) to stable the training process. is the balancing weights.
Final loss
The final losses for training the generator and the discriminator are then defined as:
| (18) | ||||
| (19) |
where and are weights balancing the terms.
3. Experiments
To evaluate the proposed method, we conduct experiments using a publicly available dataset (Deng et al., 2021). As there are no prior studies exploring the end-to-end solutions in X-ray image synthesis from volume data, we benchmark our proposed method against the state-of-the-art (SOTA) 3D-aware GANs, including -GAN (Chan et al., 2021) and EG3D (Chan et al., 2022). The experimental settings are presented in Section 3.1. The evaluation of the proposed method and the ablation study are included in Section 3.2 and Section 3.3, respectively.
3.1. Experimental Settings
Implementation Details
For the CT encoder, we comprise an input layer, three downsampling layers and a latent layer. Each layer comprises two 3D convolutions (Conv3D) followed by BatchNorm (BN) and activated by LeakyReLU with a slope of 0.2. After the latent layer of the CT encoder, a transformation layer flattens the output feature map into a 1D vector. AdaIN (Huang and Belongie, 2017) is employed to form the synthesis layer of our generator. The style decoupling encoder includes seven 2D convolution (Conv2D) layers in each of its two style branches. Before reaching the final layer, features are aggregated into a feature map through adaptive average pooling. The map is then passed through the final Con2D layer and activated by Tanh. The generator comprises a total of fourteen synthesis layers. These layers are sequentially numbered based on the resolution increasing of intermediate feature maps. Layers one to eight are designated as the content layers, primarily responsible for generating anatomical structures of the X-ray image. Conversely, the ninth to fourteenth layers, characterized by higher resolutions, serve as fine layers for injecting style information. The framework is trained with a batch size of on a single NVIDIA RTX A6000 GPU with GB of GPU memory. The proposed method utilizes the Adam optimizer with a learning rate of and is trained for epochs.
Dataset
Due to the lack of public datasets for our task, we construct the dataset to train our model. Specifically, public dataset CTSpline1K(Deng et al., 2021) includes spine CT scans and is regarded as our CT data source. The scans are resampled to a resolution mm3 and reshaped into . Multi-view DRRs are generated from the CTSpine1K dataset. We utilize the DeepDRR (Mathias Unberath et al., 2018) framework to generate DRRs. Considering the clinical emphasis on horizontal camera angles in C-arm imaging, we fix the camera angle at vertically and project the CT from to horizontally at intervals of to create the DRR dataset. The parameters for DeepDRR are set as follows: step size of , spectral intensity of 60KV_AL35, photon count of , source-to-object distance (SOD) of mm, and source-to-detector distance (SDD) of mm. As for the X-ray images, a total of real X-ray images are collected in the anterior-posterior (AP) and lateral (Lat) views from patients.
Baselines
Currently, there are no available methods for the CT2X synthesis to serve as baselines. Hence, we selected SOTA 3D-aware image generation methods for comparison. -GAN (Chan et al., 2021) generates multi-view images from view-consistent radiance fields based on volumetric rendering. EG3D (Chan et al., 2022) introduces a dedicated neural render for tri-plane hybrid 3D representation to generate high-quality multi-view images, enabling unsupervised multi-view synthesis. Both methods produce high-quality multi-view consistent images, which is particularly crucial for X-ray synthesis tasks (Shen et al., 2022). These methods are not originally designed for the CT2X task and thus cannot directly process CT data. To bridge this gap and conduct a unfair comparison, we utilize the same CT encoder as our method to encode the CT scan into a latent code. The latent code can then be sent into -GAN and EG3D and generate the X-ray results. The learning rate and number of epochs are also set to and , respectively.
Evaluation Metrics
We evaluated and compared the proposed method with regard to the metrics of image similarity and synthesis quality, respectively. For image similarity, we utilize LPIPS(Zhang et al., 2018a), which compares the semantic similarity between the generated images with reference images at a perceptual level through a pre-trained deep network. For assessing the synthesis quality, we utilize the commonly used Frechet inception distance (FID) metric (Heusel et al., 2017), which evaluates the distribution similarity by comparing reference and synthesized image distributions. Additionally, for evaluating the consistency with human visual perception, we employ the kernel inception distance (KID) metric (Bińkowski et al., 2018) to assess the visual quality of synthesized images.
3.2. Experimental Results
Qualitative Comparisons

Figure 4 illustrates the qualitative comparison results with the baseline methods. From the figure, we can discern several noteworthy observations. Firstly, for image synthesis methods using 3D-aware networks, whether employing implicit-based (-GAN) or hybrid-based (EG3D) 3D representations, difficulties arise in maintaining the accuracy of anatomical structures despite their ability to generate multi-view images. Furthermore, both -GAN and EG3D are unable to perform style-decoupling injection and can only utilize DRRs as target images to train the model, limiting them to generating results close to the DRR domain. In contrast, our method enhances feature information associated with the target pose in the content code through the incorporation of PAM. This enables multi-view image synthesis based on the corresponding view angle projection. Moreover, the style decoupling encoder extracts style features from X-ray images, facilitating the synthesis of results more closely resembling real X-ray images. In summary, our approach yields superior quality and clearer anatomical structures, making them more time-efficient and clinically applicable.
| Method | FID | KID | LPIPS |
|---|---|---|---|
| -GAN | 277.3511 | 0.3131 | 0.4681 |
| EG3D | 224.3884 | 0.2535 | 0.2970 |
| Ours | 97.8350 | 0.0842 | 0.2366 |
Quantitative Comparisons
Table 1 presents the FID, KID and LPIPS values of our method and the SOTA methods, respectively. As can be seen from the table, the proposed method achieves the highest FID and KID scores, demonstrating that CT2X-GAN effectively captures the anatomical structure from the 3D CT scan and utilizes it to synthesize high-quality X-ray images. Besides, our method achieves the highest LPIPS for perceptual-level evaluation. This indicates that CT2X-GAN can successfully inject the style information of real X-ray images, corroborating the practicality of our approach. In summary, CT2X-GAN both achieves high anatomical structure fidelity and is realistic of the synthesized X-ray images.
3.3. Ablation Study
To understand the role of each component in CT2X-GAN, we conduct a series of ablation studies. Table 2 presents the quantitative results under all configurations, while Figure 5 illustrates the visualization examples of the outcomes.
| Method | FID | KID | LPIPS |
|---|---|---|---|
| w/o | 160.0366 | 0.1736 | 0.3678 |
| w/o PAM | 156.5380 | 0.1715 | 0.3371 |
| w/o | 141.6687 | 0.1419 | 0.2966 |
| Ours | 97.8350 | 0.0842 | 0.2366 |
Effect of Style Decoupling Encoder
Referring to the first row of Table 2 and the first column of Figure 5, we verify the effectiveness of the style decoupling encoder. Removal of the decoupling encoder results in generated images resembling DRR with significant differences from X-ray images. Additionally, by comparing the first and last columns of Figure 5, it is evident that the style decoupling encoder introduces style disentanglement, enabling the generator to combine structural information from CT scans with style information from reference X-ray images. This can effectively make the reduced internal brightness and enhanced contrast in the skeletal parts of the generated results, as shown in the last column of Figure 5.
Effect of Pose Attention Module
From the second row of Table 2, we validate the effectiveness of PAM. It can be found that introducing PAM enhances the network awareness of pose information, resulting in better-synthesized X-ray images from multiple view angles. Results in Figure 5 show that the boundaries between skeletal and soft tissue parts become blurry. This indicates that PAM not only preserves the 3D spatial information in CT scans but also further pays more attention to anatomical structure information during the encoding process, further enhancing the quality of synthesized X-ray images.

Effect of Consistency Regularization
In this ablation study, we validate the effectiveness of the consistency regularization term. As shown in the third row of Table 2, removing style and content consistency regularization during training greatly harms the synthesis ability of our CT2X-GAN. The right two columns of Figure 5 demonstrate the results before and after introducing consistency regularization. It can be concluded the introduction of consistency regularization during training ensures the decoupling encoder. It avoids encoding anatomical information from the style reference images into the style code without affecting the final synthesis quality. The results indicate the ability of our proposed method to inject style while preserving anatomical structures.
3.4. Style Disentanglement Evaluation
X-ray Style Synthesis
To confirm the decoupling ability of the proposed style encoder, we evaluate the results given different style reference images for the same input CT scan. As depicted in Figure 6, using style images from the same domain yields similar results, while using style images from different domains notably affects the style and intensity of the synthesized results.

DRR Style Reconstruction
To quantitatively assess the style disentanglement capability of CT2X-GAN, we extract the DRR style information and incorporate it into the generator. The CT2X-GAN can generate high-quality reconstructed DRR images, as shown in Figure 7. In terms of quantitative metrics, we opted for structural similarity index measure (SSIM) and peak signal-to-noise ratio (PSNR). SSIM is employed to assess the structural accuracy of generated results in a manner of perceptual-level comparison, while PSNR provides a measure of the synthesis quality. It is noted that -GAN and EG3D do not have the capability for style injection and are trained directly on DRR images. In such a way, their predictions are deemed suitable for use solely as reconstruction results. The quantitative results are presented in Table 3. It can be seen that our method outperforms others in all metrics, encompassing both SSIM and PSNR. This suggests that style disentanglement not only achieves stylized synthesis but also improves the network representation of anatomical information in CT data, reflecting anatomical structures more accurately.
| Method | PSNR | SSIM |
|---|---|---|
| -GAN | 11.6527 | 0.2251 |
| EG3D | 15.0620 | 0.5046 |
| Ours | 23.5093 | 0.7013 |

3.5. User Study
| Method | DRR | -GAN | EG3D | Ours |
| X-ray Similarity | 2.6403 | 1.6406 | 1.7656 | 3.0938 |
We run a user study by randomly selecting 20 instances from the synthesized images and inviting 47 users to score them. Specifically, the participants are required to rate the synthesized images produced by various methods on a scale of 1-5, where higher scores signify greater resemblance to actual X-ray images. Subsequently, we compute the average score as the X-ray image similarity measure. The results are depicted in Table 4. The table reveals that the images synthesized by -GAN and EG3D are notably distorted, as users predominantly perceive them to deviate substantially from authentic X-ray data. While superior to the 3D-aware methods, the DRRs still fall short compared to our method, which further demonstrates that our approach yields results more closely resembling to real X-ray images.
4. Discussion
Conclusion
This study introduces a baseline method for multi-view X-ray image synthesis from CT scans. Our objective is to train a model that integrates content information with style features from unpaired CT and X-ray data in an end-to-end manner. This is accomplished by employing a novel decoupling learning method and consistency constraints. In addition, our method encourages the model to fully exploit the abundant spatial information included in CT scans through the PAM module. Compared to existing multi-view synthesis methods including -GAN and EG3D, our approach can obtain multi-view X-ray results much more realistic.
Limitations and future work
Considering our method endeavours to tackle the challenge of limited paired data through disentanglement, it is inevitable leading to the sacrifice of anatomical information. Additionally, our method lacks distance awareness, resulting in scale distortion. To enhance the versatility and applicability of the synthesis process across diverse scenarios, investigating methods to perceive distances is needed and also will be our future work.
Acknowledgements.
This work was supported in part by grants from National Key Research and Development Program of China (2023YFC2508800), National Natural Science Foundation of China (62176268), Beijing Natural Science Foundation-Joint Funds of Haidian Original Innovation Project (L232022) and Fundamental Research Funds for the Central Universities (FRF-TP-24-022A). Thanks to OpenBayes.com for providing model training and computing resources.References
- (1)
- Alaluf et al. (2021) Yuval Alaluf, Or Patashnik, and Daniel Cohen-Or. 2021. Restyle: A residual-based stylegan encoder via iterative refinement. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 6711–6720.
- Andreu Badal and Badano (2009) Andreu Badal and Aldo Badano. 2009. Accelerating Monte Carlo Simulations of Photon Transport in a Voxelized Geometry Using a Massively Parallel Graphics Processing Unit: Monte Carlo Simulations in a Graphics Processing Unit. Medical Physics 36, 11 (2009), 4878–4880.
- Benaim et al. (2019) Sagie Benaim, Michael Khaitov, Tomer Galanti, and Lior Wolf. 2019. Domain intersection and domain difference. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 3445–3453.
- Bhosale and Patnaik (2023) Yogesh H Bhosale and K Sridhar Patnaik. 2023. Bio-medical imaging (X-ray, CT, ultrasound, ECG), genome sequences applications of deep neural network and machine learning in diagnosis, detection, classification, and segmentation of COVID-19: a Meta-analysis & systematic review. Multimedia Tools and Applications 82, 25 (2023), 39157–39210.
- Bińkowski et al. (2018) Mikołaj Bińkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. 2018. Demystifying mmd gans. arXiv preprint arXiv:1801.01401 (2018).
- Butoi et al. (2023) Victor Ion Butoi, Jose Javier Gonzalez Ortiz, Tianyu Ma, Mert R Sabuncu, John Guttag, and Adrian V Dalca. 2023. Universeg: Universal medical image segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 21438–21451.
- Chan et al. (2022) Eric R. Chan, Connor Z. Lin, Matthew A. Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas Guibas, Jonathan Tremblay, Sameh Khamis, Tero Karras, and Gordon Wetzstein. 2022. Efficient Geometry-Aware 3D Generative Adversarial Networks. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, New Orleans, LA, USA, 16102–16112.
- Chan et al. (2021) Eric R. Chan, Marco Monteiro, Petr Kellnhofer, Jiajun Wu, and Gordon Wetzstein. 2021. Pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis. arXiv:2012.00926
- Cheng et al. (2019) Shiyang Cheng, Michael Bronstein, Yuxiang Zhou, Irene Kotsia, Maja Pantic, and Stefanos Zafeiriou. 2019. Meshgan: Non-linear 3d morphable models of faces. arXiv preprint arXiv:1903.10384 (2019).
- Collins et al. (2020) Edo Collins, Raja Bala, Bob Price, and Sabine Susstrunk. 2020. Editing in style: Uncovering the local semantics of gans. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5771–5780.
- Csébfalvi and Szirmay-Kalos (2003) Balázs Csébfalvi and László Szirmay-Kalos. 2003. Monte carlo volume rendering. In IEEE Visualization, 2003. VIS 2003. IEEE, 449–456.
- Deng et al. (2021) Yang Deng, Ce Wang, Yuan Hui, Qian Li, Jun Li, Shiwei Luo, Mengke Sun, Quan Quan, Shuxin Yang, You Hao, et al. 2021. Ctspine1k: A large-scale dataset for spinal vertebrae segmentation in computed tomography. arXiv preprint arXiv:2105.14711 (2021).
- Dhont et al. (2020) Jennifer Dhont, Dirk Verellen, Isabelle Mollaert, Verdi Vanreusel, and Jef Vandemeulebroucke. 2020. RealDRR – Rendering of Realistic Digitally Reconstructed Radiographs Using Locally Trained Image-to-Image Translation. Radiotherapy and Oncology 153 (2020), 213–219.
- Heusel et al. (2017) Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems 30 (2017).
- Horan et al. (2021) Daniella Horan, Eitan Richardson, and Yair Weiss. 2021. When is unsupervised disentanglement possible? Advances in Neural Information Processing Systems 34 (2021), 5150–5161.
- Huang et al. (2024) Jiaxin Huang, Qi Wu, Yazhou Ren, Fan Yang, Aodi Yang, Qianqian Yang, and Xiaorong Pu. 2024. Sparse Bayesian Deep Learning for Cross Domain Medical Image Reconstruction. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 2339–2347.
- Huang and Belongie (2017) Xun Huang and Serge Belongie. 2017. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE international conference on computer vision. 1501–1510.
- Iglesias et al. (2023) Guillermo Iglesias, Edgar Talavera, and Alberto Díaz-Álvarez. 2023. A survey on GANs for computer vision: Recent research, analysis and taxonomy. Computer Science Review 48 (2023), 100553.
- Isola et al. (2017) Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. 2017. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1125–1134.
- Karras et al. (2017) Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. 2017. Progressive growing of gans for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196 (2017).
- Karras et al. (2019) Tero Karras, Samuli Laine, and Timo Aila. 2019. A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv:1812.04948
- Karras et al. (2020) Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8110–8119.
- Kasten et al. (2020) Yoni Kasten, Daniel Doktofsky, and Ilya Kovler. 2020. End-to-end convolutional neural network for 3D reconstruction of knee bones from bi-planar X-ray images. In Machine Learning for Medical Image Reconstruction: Third International Workshop, MLMIR 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, October 8, 2020, Proceedings 3. Springer, 123–133.
- Kerbl et al. (2023) Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 2023. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics 42, 4 (2023), 1–14.
- Koetzier et al. (2023) Lennart R Koetzier, Domenico Mastrodicasa, Timothy P Szczykutowicz, Niels R van der Werf, Adam S Wang, Veit Sandfort, Aart J van der Molen, Dominik Fleischmann, and Martin J Willemink. 2023. Deep learning image reconstruction for CT: technical principles and clinical prospects. Radiology 306, 3 (2023), e221257.
- Kügler et al. (2020) David Kügler, Jannik Sehring, Andrei Stefanov, Anirban Mukhopadhyay, and Jrg Schipper. 2020. i3PosNet: instrument pose estimation from X-ray in temporal bone surgery. International Journal of Computer Assisted Radiology and Surgery 15, 7 (2020), 1–9.
- Li et al. (2020) Han Li, Hu Han, Zeju Li, Lei Wang, Zhe Wu, Jingjing Lu, and S Kevin Zhou. 2020. High-resolution chest x-ray bone suppression using unpaired CT structural priors. IEEE transactions on medical imaging 39, 10 (2020), 3053–3063.
- Li et al. (2006) Xiaoliang Li, Jie Yang, and Yuemin Zhu. 2006. Digitally Reconstructed Radiograph Generation by an Adaptive Monte Carlo Method. Physics in Medicine and Biology 51, 11 (2006), 2745–2752.
- Liao et al. (2024) Jingbo Zhang3 Zhihao Liang4 Jing Liao, Yan-Pei Cao, and Ying Shan. 2024. Advances in 3D Generation: A Survey. arXiv preprint arXiv:2401.17807 (2024).
- Locatello et al. (2019) Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar Raetsch, Sylvain Gelly, Bernhard Schölkopf, and Olivier Bachem. 2019. Challenging common assumptions in the unsupervised learning of disentangled representations. In international conference on machine learning. PMLR, 4114–4124.
- Louati et al. (2024) Hassen Louati, Ali Louati, Rahma Lahyani, Elham Kariri, and Abdullah Albanyan. 2024. Advancing Sustainable COVID-19 Diagnosis: Integrating Artificial Intelligence with Bioinformatics in Chest X-ray Analysis. Information 15, 4 (2024), 189.
- Mathias Unberath et al. (2018) Mathias Unberath, Jan-Nico Zaech, Sing Chun Lee, Bastian Bier, Javad Fotouhi, Mehran Armand, and Nassir Navab. 2018. DeepDRR – A Catalyst for Machine Learning in Fluoroscopy-Guided Procedures. arXiv:1803.08606 [physics] (2018). arXiv:1803.08606
- Mescheder et al. (2018) Lars Mescheder, Andreas Geiger, and Sebastian Nowozin. 2018. Which Training Methods for GANs do actually Converge?. In Proceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 80), Jennifer Dy and Andreas Krause (Eds.). PMLR, 3481–3490. https://proceedings.mlr.press/v80/mescheder18a.html
- Pasveer (1989) Bernike Pasveer. 1989. Knowledge of shadows: the introduction of X-ray images in medicine. Sociology of Health & Illness 11, 4 (1989), 360–381.
- Roich et al. (2022) Daniel Roich, Ron Mokady, Amit H Bermano, and Daniel Cohen-Or. 2022. Pivotal tuning for latent-based editing of real images. ACM Transactions on graphics (TOG) 42, 1 (2022), 1–13.
- Schmitt et al. (2024) Niclas Schmitt, Lena Wucherpfennig, Jessica Jesser, Ulf Neuberger, Resul Güney, Martin Bendszus, Markus A Möhlenbruch, and Dominik F Vollherbst. 2024. Sine Spin flat detector CT can improve cerebral soft tissue imaging: a retrospective in vivo study. European Radiology Experimental 8, 1 (2024), 1–8.
- Shen et al. (2022) Liyue Shen, Lequan Yu, Wei Zhao, John Pauly, and Lei Xing. 2022. Novel-view X-ray projection synthesis through geometry-integrated deep learning. Medical image analysis 77 (2022), 102372.
- Shen et al. (2020) Yujun Shen, Jinjin Gu, Xiaoou Tang, and Bolei Zhou. 2020. Interpreting the latent space of gans for semantic face editing. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9243–9252.
- Syryamkin et al. (2020) VI Syryamkin, SA Klestov, and SB Suntsov. 2020. Digital X-ray Tomography: Edited by VI Syryamkin. Red Square Scientific, Ltd.
- Tsoulfanidis and Landsberger (2021) Nicholas Tsoulfanidis and Sheldon Landsberger. 2021. Measurement and detection of radiation. CRC press.
- Unberath et al. (2019) Mathias Unberath, Jan-Nico Zaech, Cong Gao, Bastian Bier, Florian Goldmann, Sing Chun Lee, Javad Fotouhi, Russell Taylor, Mehran Armand, and Nassir Navab. 2019. Enabling machine learning in X-ray-based procedures via realistic simulation of image formation. International journal of computer assisted radiology and surgery 14 (2019), 1517–1528.
- Vivek Gopalakrishnan and Polina Golland (2022) Vivek Gopalakrishnan and Polina Golland. 2022. Fast Auto-Differentiable Digitally Reconstructed Radiographs for Solving Inverse Problems in Intraoperative Imaging. In Workshop on Clinical Image-Based Procedures. Switzerland. arXiv:2208.12737
- Wen et al. (2024) Ruxue Wen, Hangjie Yuan, Dong Ni, Wenbo Xiao, and Yaoyao Wu. 2024. From Denoising Training to Test-Time Adaptation: Enhancing Domain Generalization for Medical Image Segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 464–474.
- Withers et al. (2021) Philip J Withers, Charles Bouman, Simone Carmignato, Veerle Cnudde, David Grimaldi, Charlotte K Hagen, Eric Maire, Marena Manley, Anton Du Plessis, and Stuart R Stock. 2021. X-ray computed tomography. Nature Reviews Methods Primers 1, 1 (2021), 18.
- Xu et al. (2023) Han Xu, Jiteng Yuan, and Jiayi Ma. 2023. Murf: Mutually reinforcing multi-modal image registration and fusion. IEEE transactions on pattern analysis and machine intelligence (2023).
- Ying et al. (2019) Xingde Ying, Heng Guo, Kai Ma, Jian Wu, Zhengxin Weng, and Yefeng Zheng. 2019. X2CT-GAN: reconstructing CT from biplanar X-rays with generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10619–10628.
- Yu et al. (2023) Ying Yu, Chunping Wang, Qiang Fu, Renke Kou, Fuyu Huang, Boxiong Yang, Tingting Yang, and Mingliang Gao. 2023. Techniques and challenges of image segmentation: A review. Electronics 12, 5 (2023), 1199.
- Zhang et al. (2018b) Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dimitris N Metaxas. 2018b. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE transactions on pattern analysis and machine intelligence 41, 8 (2018), 1947–1962.
- Zhang et al. (2018a) Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. 2018a. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition. 586–595.
- Zhang et al. (2020) Ruisi Zhang, Luntian Mou, and Pengtao Xie. 2020. TreeGAN: Incorporating Class Hierarchy into Image Generation. arXiv preprint arXiv:2009.07734 (2020).
- Zheng et al. (2022) Xinyang Zheng, Yang Liu, Pengshuai Wang, and Xin Tong. 2022. SDF-StyleGAN: Implicit SDF-Based StyleGAN for 3D Shape Generation. In Computer Graphics Forum, Vol. 41. Wiley Online Library, 52–63.
- Zhu et al. (2023) Bai Zhu, Liang Zhou, Simiao Pu, Jianwei Fan, and Yuanxin Ye. 2023. Advances and challenges in multimodal remote sensing image registration. IEEE Journal on Miniaturization for Air and Space Systems (2023).
Appendix A Overview
In our supplementary material, we present additional experimental results in Appendix B. Specifically, we present visualizations on multi-view X-ray image synthesis in Appendix B.1. To further illustrate the effectiveness of our method, we provide additional qualitative comparisons in Appendix B.2. Finally, we present the limitations of current study and future work in Appendix C.
Appendix B Additional Experiments
B.1. Results on Multi-view Image Synthesis
In this section, we evaluate the performance of multi-view image synthesis by the proposed model. In detail, we randomly selected several volume datas from the CTSpine1K dataset and synthesize seven views with uniformly distributed camera poses for each volume. The multi-view synthesis results are presented in Figure 8. As shown in the Figure, our method can synthesize X-ray images from different view angles.

B.2. Qualitative Comparisons on X-ray Image Synthesis
We provide more qualitative results in this section. Figure 9 illustrates more qualitative comparisons of our method with other state-of-the-art 3D-aware generation methods, including -GAN and EG3D. From left to right of the Figure, we show multi-view results from to . For each method, we provide X-ray synthesis results from volumes obtained from two patients.

Appendix C Failure Cases
Recent studies have shown that it is fundamentally impossible to fully disentangle features (Locatello et al., 2019; Horan et al., 2021). Therefore, the use of unpaired X-ray image style information extracted by the style decoupling encoder would unavoidably introduce structural information from the X-ray image and impose an influence on the performance of our model. Despite adding supervised constraints during training, this approach still results in inaccuracies for faulty structures. For instance, as shown in the top row of Figure 10, the model fails to generate bone structures in the correct positions. Furthermore, our model lacks distance perception. In the training dataset, as CT Volumes occupy various physical positions in space, the resulting DRR images exhibit varying scales, which the model erroneously interprets as style cues, leading to inaccurately scaled generated outputs, illustrated in the bottom row of Figure 10. Exploring generative models with better structural constraints and awareness of distance would further improve the performance of our model.
