Multi-view Deep One-class Classification:
A Systematic Exploration
Abstract
One-class classification (OCC), which models one single positive class and distinguishes it from the negative class, has been a long-standing topic with pivotal application to realms like anomaly detection. As modern society often deals with massive high-dimensional complex data spawned by multiple sources, it is natural to consider OCC from the perspective of multi-view deep learning. However, it has not been discussed by the literature and remains an unexplored topic. Motivated by this blank, this paper makes four-fold contributions: First, to our best knowledge, this is the first work that formally identifies and formulates the multi-view deep OCC problem. Second, we take recent advances in relevant areas into account and systematically devise eleven different baseline solutions for multi-view deep OCC, which lays the foundation for research on multi-view deep OCC. Third, to remedy the problem that limited benchmark datasets are available for multi-view deep OCC, we extensively collect existing public data and process them into more than 30 new multi-view benchmark datasets via multiple means, so as to provide a publicly available evaluation platform for multi-view deep OCC. Finally, by comprehensively evaluating the devised solutions on benchmark datasets, we conduct a thorough analysis on the effectiveness of the designed baselines, and hopefully provide other researchers with beneficial guidance and insight to multi-view deep OCC. Our data and codes are opened at https://github.com/liujiyuan13/MvDOCC-datasets and https://github.com/liujiyuan13/MvDOCC-code respectively to facilitate future research.
Index Terms:
One-class classification, deep anomaly detection, multi-view deep learning, multi-view deep one-class classification1 Introduction
One-class classification (OCC) [1, 2] is a classic machine learning problem that only data from one single class (termed as the positive class) are given during training, while very few or zero data from other classes (collectively called as the negative class) are available. For inference, the trained OCC model is expected to be capable of distinguishing whether an incoming datum is from the given positive class or the unknown negative class. In literature, OCC is also referred as anomaly detection [3], novelty detection [4] or out-of-distribution detection [5] and etc. It catches the eyes of researchers from both academia and industry for its pervasive applications in practice. For instance, a public video surveillance system has easy access to data of normal daily events, whilst abnormal events like robbery or vehicle intrusion are rare and extremely hard to predict. Therefore, it is often unrealistic to collect sufficient anomalous data from the negative class, which constitutes to one typical application scenario for OCC. Besides, OCC techniques have also been widely applied in various realms like information retrieval [6], fault detection [7], authorship verification [8], enhanced multi-class classification [9] and etc.
Compared with supervised binary/multi-class classification, OCC remains a special and challenging problem. This is mainly due to the lack of training data from the negative class, which makes it impossible to directly train a classifier by discriminating the positive and the negative class. Therefore, OCC often resorts to some unsupervised learning methods. Meanwhile, OCC is also different from classic unsupervised learning tasks like clustering, as OCC handles training data that share a common positive label, which serves as weak supervision. So far, various solutions have been proposed [10] to tackle OCC and will be reviewed in Sec. 2 and supplementary material.
Nevertheless, as the modern society has witnessed an explosive development in data acquisition capabilities, people find it increasingly difficult to perform learning tasks, which include but are not confined to OCC, with modern data via classic methods. In this paper, we will focus on two of the most important challenges: First, unlike traditional data, modern data such as images are often endowed with high dimension and complex latent structures. classic methods usually fail to exploit such latent information embedded in data, due to their shallow model architectures and limited representation power. Second, with significantly enriched sources to acquire data, one object is often described from multiple viewpoints such as different modalities, sensors or angles, which gives birth to a large amount of multi-view data. However, classic methods are usually designed for single-view data, and they lack the ability to exploit complementary information and cross-view correlation embedded in multi-view data. To handle the above two challenges posed by modern data, an emerging realm named multi-view deep learning has attracted surging attention from researchers. Specifically, multi-view deep learning resorts to artificial neural networks with deep architecture to conduct layer-wise data abstraction and representation learning [11], which is proven highly effective in vast applications. The remarkable success of deep learning has made it a standard tool to handle massive complex data. Meanwhile, multi-view deep learning methods usually leverage multi-view fusion or multi-view alignment techniques [12] to exploit inter-view information embedded in multi-view data. Multi-view deep learning has already been successfully applied to many tasks [12, 13, 14]. Therefore, it is quite natural for us to consider the intersection of OCC and multi-view deep learning, i.e. multi-view deep OCC. Multi-view deep OCC has a large potential to many practical problems, and a straightforward example is the aforementioned video surveillance system that aims to detect anomalies: The collected normal events can be described by both RGB and optical flow data, which are both high-dimensional data with rich underlying semantics, while OCC model needs to be trained with such data to build a normality model and discriminate the anomalies.
Although both OCC and multi-view deep learning methods have been thoroughly studied in literature, the problem of multi-view deep OCC has not been formally defined and systematically explored to our best knowledge. Such a blank constitutes to the biggest motivation of this paper. There are three major obstacles when looking into multi-view deep OCC: 1) Above all, the lack of formal formulation of the problem. Despite its huge application potential in various real-world scenarios, multi-view deep OCC has not been formally identified and formulated, which prevents researchers from giving sufficient attention to this novel but challenging problem. 2) Second, the lack of baseline methods. Although many attempts have been made to approach multi-view deep learning, they are typically designed for other tasks and therefore not explored for OCC. In the meantime, existing approaches for OCC are merely applicable to the single-view case. 3) Third, the lack of proper benchmark datasets for evaluation. Previous researches usually evaluate OCC models by the “one vs. all” protocol [15]. For any binary/multi-class benchmark datasets, it assumes data from a certain class as positive, while data from the rest of classes as negative. Besides, datasets that are specifically designed for OCC are also proposed recently [16]. However, frequently-used benchmark datasets in OCC are basically single-view. In the meantime, existing multi-view benchmark datasets are often too small, and none of them are specifically designed for the background of OCC. As a result, very few benchmarks are suitable for the evaluation of multi-view deep OCC.
To bridge the above gaps, this paper, for the first time, formally formulates the problem of multi-view deep OCC, and carries out a systematic study on this new area. Our contributions can be summarized as follows:
-
•
To our best knowledge, this is the first work that formally identifies and formulates the multi-view deep OCC problem, which points out a brand new area for both OCC and multi-view deep learning.
-
•
Inspired by recent literature of OCC and multi-view deep learning, we systematically design 11 different solutions to multi-view deep OCC, which provide informative baselines to this problem. We open the implementations of all baselines to facilitate further research on multi-view deep OCC.
-
•
To provide a standard evaluation platform of multi-view deep OCC, we extensively collect existing public data and process them into more than 30 new multi-view benchmark datasets via various means. All benchmark datasets are made publicly available.
-
•
We comprehensively evaluate the proposed multi-view deep OCC baselines on both constructed and existing multi-view datasets, and conduct in-depth analysis on their performance. It sheds the first light on multi-view deep OCC, and hopefully provides valuable guidance and insights to future research.
2 Related Work
In this section, we will focus on reviewing deep learning based OCC, multi-view anomaly/outlier and multi-view deep learning, which are the most relevant areas to multi-view deep OCC. In the Sec. 1 and Sec. 2 of supplementary material, we also briefly review classic methods for OCC and multi-view learning due to the limit of space.
2.1 Deep Learning based OCC
There is a surging interest to leverage deep neural networks to handle high-dimensional one-class data [17]. Since only data from a single class are available, the most frequently-used models for deep learning based OCC are generative deep neural networks (DNNs). A simple but effective way is to extend the shallow auto-encoder (AE) into a deep one. For example, stacked denoising auto-encoder (SDAE) [18] and deep convolutional auto-encoder (DCAE) [19] have been leveraged to perform OCC with raw video data. Meanwhile, many attempts are also made to improve AE’s OCC performance, such as using the ensemble technique [20] and combining AE with energy based model [21]. In addition to AE based methods, other popular generative neural networks like generative adversarial networks (GANs) [22, 23] and U-Net [24, 25] are also actively explored to perform OCC. Such generative models typically perform OCC by measuring the reconstruction error of the generated target data, while other methods (e.g. the discriminator outputs and latent representations of GANs) are also explored. Apart from generative deep models, several representative discriminative approaches are also proposed recently. Ruff et al. [3] extend the classic SVDD into deep SVDD (DSVDD), which learns to map latent representations of positive data into a hypersphere with minimal radius. Golan et al. [15] for the first time leverage self-supervised learning for image OCC. They impose multiple geometric transformations to create pseudo classes, which are classified by a discriminative DNN to enable highly effective representation learning. Statistics of the discriminative DNN outputs are then used to score each image. Bergman et al. [26] further extends self-supervised learning based deep OCC to generic tabular data by introducing random projection for creating pseudo classes. Goyal et al. [27] assume a low-dimensional manifold in given positive data, which can be utilized to sample accurate pseudo outliers to train a discriminative component. The detail review can be found in [28]. Despite that great progress has been made in deep OCC, existing researches are still limited to the single-view setting.
2.2 Multi-view Anomaly/Oultier Detection
Multi-view anomaly/outlier detection is a closely relevant but different area to multi-view deep OCC. The pioneer work of multi-view anomaly/outlier detction is proposed by Gao et al. [29], while a series of works follow their setup and propose improved solutions [30, 31, 32, 33, 34]. Although OCC is often discussed in the context of semi-supervised anomaly/outlier detection, multi-view anomaly/outlier detection here is actually a fully unsupervised task. It aims to detect either intra-view outliers (“attribute outlier”) or cross-view inconsistency (“class outlier”) from unlabeled data. By contrast, OCC adopts a setup that handles pure data from a single class, which makes them intrinsically different from each other. Recently, Wang et al. [35] for the first time discuss the case of “semi-supervised multi-view anomaly/detection”, which is essentially multi-view OCC, by a hierarchical Bayesian model. Nevertheless, their method cannot perform representation learning. Meanwhile, it is only tested on classic benchmarks and suffers from poor scalability to large data. Thus, their work still has a gap to the multi-view deep OCC discussed in this paper.
2.3 Multi-view Deep Learning
Since classic multi-view learning does not involve representation learning process and lack of the ability to handle with complex modern data, multi-view deep learning has rapidly become an emerging topic. Current multi-view deep learning methods are usually categorized into two groups, i.e. Multi-view fusion and multi-view alignment based methods. Multi-view fusion based methods fuse the learned representations from different views into a joint representation, which can be realized by either simple operations like max/sum/concatenation [12], or sophisticated means like a neural network. Specifically, the pioneer work of Ngiam et al. [36] proposes a multi-modal deep auto-encoder for multi-view deep fusion, while Srivastava et al. [37] perform the fusion by multi-modal deep boltzman machine (DBM). Such neural network based multi-view fusion can also be conducted on modern neural network architecture like convolutional neural networks (CNNs) [38] and recurrent neural networks (RNNs) [39]. Latest work from Sun et al. [40] employs a multi-view deep Gaussian Process to obtain the joint representation and perform classification. Apart from the prevalent neural network based fusion, Zadeh et al. [41] propose a novel tensor based fusion scheme, while Liu et al. [42] extend it to the generic multi-view case by low-rank decomposition. Unlike multi-view fusion, multi-view alignment intends to align the learned representations from each view, so as to exploit the common information among different views. The most popular and representative multi-view alignment method is canonical correlation analysis (CCA) [43] and its deep variant deep CCA (DCCA) [44], which seeks to maximize the correlation of two views. Wang et al. [45] later develop a variant named deep canonically correlated auto-encoders (DCCAE), which is regularized by the reconstruction objective, and Benton et al. [46] propose deep generalized CCA (DGCCA) to handle with the case of more than two views. In addition to correlation, deep multi-view alignment also leverages other metrics. For example, Frome et al. [47] maximize the dot-product similarity by a hinge rank loss, while Feng et al. [48] minimize the -norm distance between the learned representations of two views. Besides, inspired by GANs, adversarial training is also borrowed to improve multi-view representation learning by learning modality-invariant representations [49] or cross-view transformation [50]. Consequently, many solutions have been proposed for multi-view deep learning, and they are widely adopted to serve many tasks, such as action recognition, sentiment analysis and image captioning. However, none of those works has considered the marriage of OCC and multi-view deep learning, which is exactly the motivation of this paper.

3 Problem Formulation
To tackle the first obstacle mentioned in Sec. 1, we will provide a formal problem formulation of multi-view deep OCC in the first place. Given the positive class , a multi-view datum is sampled from for training, where is the number of views and is a -dimensional tensor with the shape . To be more specific, denotes the observation from the view, while and corresponds to tabular data and complex data (e.g. images or videos) respectively. Note that the observations from different views can be heterogeneous. With the training datum , the goal of multi-view deep OCC is to obtain a deep neural network (DNN) based model:
| (1) |
where represents the set of all learnable parameters for the model . In the inference phase, aims to classify whether an incoming multi-view testing datum belongs to the target distribution or not, where denotes the datum from the view, i.e.:
| (2) |
In practice, is usually supposed to obtain a score , which indicates the likelihood that belongs to the positive class. A threshold can be then chosen to binarize the score into the final decision of . It should be noted that the DNN based model can be constructed by either pure DNNs or a mixture of DNNs and classic OCC models. Since a mixture of DNNs and classic OCC often suffers from some issues, such as the decoupling of representation learning and classification, we will focus on discussing the the model that consists of pure DNNs. In other words, we discuss the case where is able to perform end-to-end one-class classification. An overview of multi-view deep OCC is presented in Fig. 1.
4 The Proposed Baselines
Having provided a formal problem formulation, we will address the second issue in Sec. 1 by designing baseline solutions to multi-view deep OCC, so as to provide the first sense to approach this topic. In this section, we systematically design four types of baseline solutions: Fusion based solutions, alignment based solutions, tailored deep one-class OCC and self-supervision based solutions.
4.1 Fusion based Solutions
A core issue for multi-view learning is how to maximally exploit the information embedded in different views to perform downstream tasks. To this end, the most straightforward idea is to fuse data from multiple views into a joint embedding. Therefore, it is natural for us to propose fusion based multi-view deep OCC solutions, which aim to fuse the data embeddings learned from different views into a joint embedding for OCC. We will discuss its framework and specific implementations of each component below.
4.1.1 Framework
Given a multi-view datum with views for training, fusion based solutions first introduce a set of DNN based encoders to encode the input observation of each view into their latent embeddings. For the view, an encoder encodes into a latent embedding with a dimension :
| (3) |
where is a -dimensional column vector. In this way, embeddings from different views can be collected as a set . Subsequently, fusion based methods select a fusion function to fuse the embeddings of different views into a -dimensional vector as the joint embedding of the multi-view datum:
| (4) |
Since only very weak supervision is available (i.e. all training data share a common positive label), discriminative information is unavailable for guiding the representation learning of encoders in multi-view deep OCC. Therefore, as a baseline, we propose to leverage the frequently-used reconstruction paradigm to guide the model training. To this end, a set of DNN based decoders are introduced to decode the input data of each view from the joint embedding : For the view, an decoder intends to map back to view’s original input :
| (5) |
where is the reconstructed input of view. To train the DNN based model, one can simply minimize the differences between original inputs and reconstructed inputs:
| (6) |
In addition to the commonly-used mean square errors (MSE) above, other types of reconstruction loss are also applicable, such as -norm reconstruction loss. During testing, an incoming multi-view datum is fed into the network to obtain the reconstructed datum by Eq. 3 - 5. As the DNN based model is trained with only data from the positive class , one can follow the standard practice in OCC to assume that lower reconstruction errors indicate a higher likelihood that the testing datum belongs to . In other words, a baseline score for the view can be directly obtained by . Finally, we can obtain a score function by the reconstruction errors of all views:
| (7) |
where is a late fusion function that combines scores of different views into a final score, which is discussed later. An intuitive illustration of the framework is given in Fig. 2.
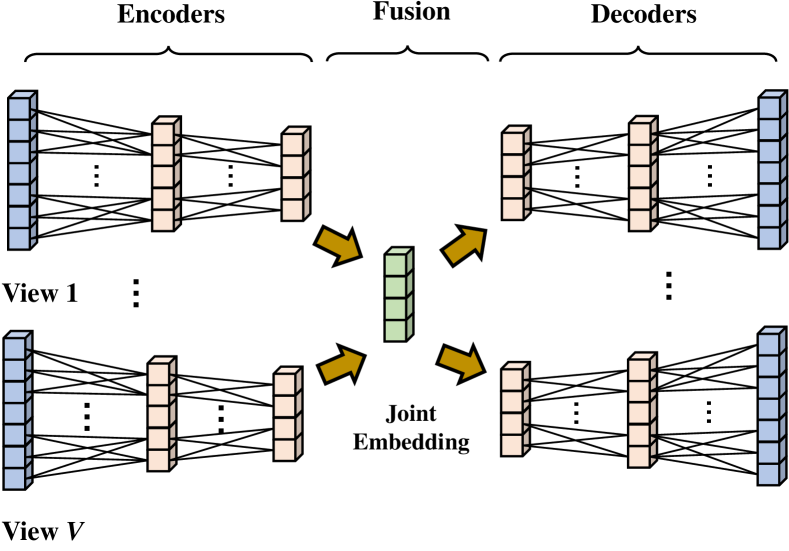
4.1.2 Implementations
The key to realize a fusion based multi-view deep OCC method is the implementation of fusion function . Thus, we design five specific ways to realize :
1) Summation based fusion (abbreviated as SUM, and the abbreviation of other methods are similarly given). Summation based fusion combines latent embeddings from different views by summing them up. Specifically, it assumes that embeddings of all views share the same dimension , and a joint embedding can be yielded by:
| (8) |
When the dimensions of embeddings are different, we can introduce a linear mapping parameterized by a learnable matrix to map the embedding to the shared dimension : . Since neural networks can flexibly map a datum into an embedding with any dimension with a linear mapping layer, we simply assume that all embeddings share the same dimension here to facilitate analysis in the rest parts of this paper.
2) Max based fusion (MAX). Similar to summation based fusion, max based fusion also assumes a shared dimension and use the maximum of embeddings of different views as the joint embedding :
| (9) |
3) Network based fusion (NN). It is easy to notice that both summation based fusion and max based fusion assume a shared embedding dimension across different views. To make the fusion more flexible, it is also natural to map all latent embeddings into the joint embedding by a fully-connected neural network with learnable parameters:
| (10) |
where and are learnable weights and biases of corresponding neurons, and and denote the concatenation operation and the activation function respectively. Note that we can also leverage a multi-layer fully-connected network to perform DNN based fusion.
4) Tensor based fusion (TF). Tensor based fusion [41] is an emerging method in multi-view deep learning. The core idea of tensor based fusion is to combine the embeddings of different views by the tensor outer product , where is a tensor. Afterwards, is fed into a linear layer with weight tensor and bias vector to obtain the unified representation :
| (11) |
Note here we slightly abuse the notation of matrix-vector multiplication by considering and as matrix and -dimensional vector, where . However, a severe practical problem is that tensor based fusion requires computing the tensor and recording , which incurs exponential computational cost. To address this problem, we leverage the low-rank approximation technique in [42] by considering the calculation of the unified representation ’s element, . Suppose that the weight is yielded by stacking tensors , where and . Thus, we have:
| (12) |
where is the element of . Then, can be approximated by a set of learnable vectors as follows:
| (13) |
where and is the rank of low-rank approximation. Since , tensor based fusion can be computed in a highly efficient manner by rearranging the order of inner product and outer product [42], which enables tensor based fusion to be computationally tractable.
4.2 Alignment based Solutions
Compared with multi-view fusion, multi-view alignment is another popular category of methods in multi-view deep learning. It does not require to obtain a joint embedding. Instead, they attempt to align the representations learned by different views, so as to make those representations share some common characteristics. Likewise, we also present the overall framework and specific implementations of alignment based multi-view deep OCC solutions below.
4.2.1 Framework
In a training batch with multi-view data, we denote the embeddings of the multi-view datum by , which are learned by a set of encoder networks . Then, an alignment function is defined to compute a quantitative measure of alignment across learned embeddings of different views:
| (14) |
where is the set of available alignment functions. As shown in Eq. 14, a key difference between alignment based solutions and fusion based solutions is that fusion usually occurs within one multi-view datum, while the alignment of two views can involve multiple multi-view data. To maximize the alignment across different views, we can equivalently minimize the alignment loss . Similar to fusion based solutions, we also resort to the reconstruction paradigm and a set of decoder networks to guide the training of DNNs. As a result, alignment based solutions minimize the following loss function:
| (15) |
where is the reconstruction loss defined in Eq. 6 and is the weight of alignment loss. Given a testing datum , we also leverage the reconstruction errors as baseline scores, which is the same as Eq. 7.

4.2.2 Implementations
The core issue for alignment based solutions is the design of alignment function . Inspired by the literature of multi-view deep learning, we propose to implement the alignment function by the following ways:
1) Distance based alignment (DIS). A commonly-seen technique to align two embeddings is to minimize their distance, as a smaller distance usually indicates better alignment. Therefore, we propose to adopt the widely-used pair-wise -norm distance of all embeddings to measure alignment:
| (16) |
where denotes the -norm and is a non-negative integer. As can be seen from Eq. 16, it requires the embeddings of different views to share a common dimension. Note that the alignment function in Eq. 16 is equivalent to the correspondent autoencoder proposed in [48], which leverages multi-view alignment for cross-modal retrieval. A drawback of such an alignment function is that it only performs the view alignment within one multi-view datum.
2) Similarity based alignment (SIM). In addition to distance, similarity is another intuitive way to measure the degree of alignment. Given a similarity function , we can similarly define an alignment function like Eq. 16. Nevertheless, such an alignment function only considers the view similarity within one multi-view datum. To consider the view similarity across different datum, we are inspired by [47] and propose to adopt a more sophisticated similarity measure between different views: For and view, a similarity loss is computed based on and a hinge loss:
| (17) |
where is a margin. The above similarity loss encourages the embeddings from the same multi-view datum to be similar, while embeddings from two different different multi-view data to be dissimilar. The similarity function can be realized by multiple forms, such as inner product and cosine similarity. Then, the final alignment function can be calculated by:
| (18) |
3) Correlation based alignment (DCCA). Canonical correlation analysis (CCA) is a classic statistical technique for finding the maximally correlated linear projections of two vectors. Thus, a natural way for us to align different views in deep learning is the CCA’s deep variant, deep CCA [44]. To conduct correlation based alignment, we intend to maximize the correlation between two views. Specifically, we stack view’s embeddings of multi-view data in a training batch into a embedding matrix: , while can be centered by , where is a all-1 matrix. With the embedding matrix and for the and view, we first estimate the covariance matrices , and , where is the coefficient for regularization and is an identity matrix. With estimated covariance matrices, we compute an intermediate matrix . It can be proved that the correlation of view and is the matrix trace norm of [44]:
| (19) |
The final alignment function can be calculated by:
| (20) |
4.3 Tailored Deep OCC Solutions
Apart from baselines based on multi-view deep learning, we design the third type of baseline solutions by tailoring existing deep OCC solutions. The basic idea is to train a deep OCC model for data from each view. During inference, the OCC results of each view are fused to yield the final results. The framework and specific implementations of tailored deep OCC solutions are presented below.
4.3.1 Framework
Suppose that the deep OCC model is trained with data from the view. Given a newly incoming multi-view datum , the OCC result for the view is given by:
| (21) |
The final score for the multi-view datum is computed by a late fusion function :
| (22) |

4.3.2 Implementations
The choice of deep OCC model plays a center role in designing tailored deep OCC solutions. This paper introduces two representative deep OCC methods in the literature to construct baseline models for multi-view deep OCC: Standard deep autoencoders (DAE) and the recent deep support vector data description (DSVDD) [3]:
1) DAE based solution (DAE). DAE leverages DNNs as the encoder and the decoder to reconstruct input data from a low-dimensional embedding. Formally, given training data from the view, DAE requires to minimize the reconstruction loss:
| (23) |
where and represent the learnable parameters of the encoder network and decoder network respectively, and is the weight for the -norm regularization term. For inference, the reconstruction errors are often directly used as scores:
| (24) |
DAE based baseline is also viewed as the most fundamental baseline for multi-view deep OCC.
2) DSVDD based solution (DSV). In general, DSVDD intends to map embeddings of data from the positive class to a hyper-sphere with minimal radius. To be more specific, DSVDD can be implemented by a simplified version or a soft-boundary version [3]. Since the simplified version enjoys less hyperparameters and better performance in practice, we choose it to perform multi-view deep OCC. Specifically, simplified DSVDD encourages embeddings of all data to be as close to a center as possible. Formally, simplified DSVDD requires to solve the following optimization problem:
| (25) |
where are the learnable parameters of DSVDD, and is the weight for the -norm regularization term. The encoder can be pre-trained in a DAE fashion. The non-zero center is initialized before training and can be adjusted during training. The above optimization problem can be efficiently solved by gradient descent. During inference, one can score a test datum by calculating the distance between its embedding and the center:
| (26) |
4.4 Self-supervision based Solutions
Self-supervised learning is a hot topic in recent research, and it has been demonstrated as a highly effective way to conduct unsupervised representation learning [51]. Specifically, self-supervised learning introduces a certain pretext task to provide additional supervision signal and enable better representation learning. Due to the lack of supervision signal in multi-view deep OCC, creating self-supervision can be an appealing solution. Multi-view data intrinsically contains richer information than single-view data, which makes it possible to design pretext tasks in a more flexible way. In this section, we mainly focus on designing generative pretext tasks to realize self-supervised multi-view deep OCC. We also explore discriminative pretext tasks in the supplementary material.
4.4.1 Framework
The basic intuition for generative pretext tasks is to generate data from some views based on data from other views. Formally, given a multi-view datum , we partition the view indices into two subsets and , which satisfy:
| (27) |
Note that the intersection of and may not be empty. By and , we can partition the multi-view data into two sets of data, and . The goal of generative pretext tasks is to generate by taking as inputs. To fulfill this task, we propose to introduce encoder networks and decoder networks, where denotes the number of elements in the set. is first mapped to the embedding set by encoders, and a joint embedding is then obtained by:
| (28) |
where can be any fusion function defined in Sec. 4.1.2. The decoder networks use as the input to infer the data , which aims to learn:
| (29) |
where is the set of learnable weights for decoder . In this way, is used as supervision signal to guide the training of encoders and decoders. Similarly, the generation errors can be used for scoring during inference.
4.4.2 Implementations
There are many ways to divide and , we select two of them to build our baseline solutions here:
1) Plain prediction (PPRD), where and . It means that we predict data from the view by data from the rest of views. Due to the lack of standard to select a specific , we vary from to , and alternatively use each view as learning target, which results in multiple rounds of prediction. To avoid excessive computational cost, we introduce encoders and decoders in total, and the encoder and decoder are specifically responsible for data of the view in each round of prediction. The final score is yielded by averaging the results of all rounds of prediction.
2) Split prediction (SPRD), where and . It means that we predict data of all views by a data from the view. Likewise, we also alternatively use data of each view to predict data of all views, and introduce encoders and decoders that are shared in different rounds of prediction. As shown above, generative pretext tasks aim to maximally capture the inter-view correspondence during representation learning, which cannot be realized by previous baseline solutions.
4.5 Additional Remarks
1) Late Fusion. Except for the self-supervision based solution that uses discriminative pretext tasks, all other baselines require to fuse the results yielded by different views via a late fusion function . For traditional tasks like classification and clustering [52, 53], numerous strategies have been proposed to carry out late fusion. However, since OCC lacks discriminative supervision information and trains the model with only data from the positive class, it is not straightforward to exploit prior knowledge or propose an assumption on different views to perform late fusion. Thus, considering that the average strategy is usually viewed as a non-trivial baseline in traditional multi-view learning [54, 55], we also adopt the simple averaging strategy for late fusion in our baseline solutions above, namely:
| (30) |
Apart from the simple averaging, one can certainly adopt more sophisticated late fusion strategy, such as the covariance based late fusion strategy proposed in [18]. However, our later empirical evaluations show that late fusion based averaging is a fairly strong baseline, which often prevails in both effectiveness and efficiency. 2) Other Potential Baselines. Actually, we have explored more ways to design baseline solutions for multi-view deep OCC. Twelve baseline solutions presented above are the most representative ones that enjoy easier implementation, satisfactory performance and sound extendibility. Due to the limit of pages, we introduce other potential baseline solutions in the supplementary material.
5 Benchmark Datasets
5.1 Limitations of Existing Datasets
Public benchmark datasets play an pivotal role in prompting the development of machine learning algorithms, and multi-view deep OCC is no exception. However, as we briefed in Sec. 1 (the third issue), existing datasets basically suffer from some important limitations when they are used for evaluating multi-view deep OCC algorithm: 1) First, existing multi-view datasets are not adequate for multi-view deep OCC. To be more specific, frequently-used multi-view benchmark datasets (e.g. Flower17/Flower102111https://www.robots.ox.ac.uk/~vgg/data/flowers/17/, BBC222http://mlg.ucd.ie/datasets/bbc.html) are originally designed to evaluate traditional multi-view learning algorithms, and the data number of them are too small to train DNNs (the average data number of a class is often less than 100). As a consequence, very few existing multi-view datasets can be directly adopted for multi-view deep OCC. 2) Second, popular benchmark datasets for deep learning are typically single-view. Recent years have witnessed a surging interest in deep learning, which gives rise to a rapid growth of available benchmark datasets. By contrast, multi-view deep learning is still relatively new area with much less applicable benchmark datasets. 3) Most importantly, almost no benchmark dataset is speficially designed for the background of multi-view deep OCC. As we introduced in Sec. 1, multi-view deep OCC actually enjoys broad applications in many realms, such as vision based anomaly detection and fault detection, but the establishment of benchmark datasets in such background is still a blank. In the literature, many works adopt the “one v.s. all” protocol to convert a binary/multi-class dataset into an OCC dataset, which is non-comprehensive for evaluation of multi-view deep OCC.
To address those issues above, we need to build new multi-view benchmark datasets for multi-view deep OCC. However, collecting multi-view data from scratch can be expensive and time-consuming, and it takes a long time to obtain sufficient and diverse benchmark datasets in this way. Therefore, our strategy is to extensively collect existing data that come from mature public benchmark datasets, and process them via various means into proper multi-view datasets, so as to construct sufficient benchmark datasets in a highly efficient manner. Collected data and processing techniques will be elaborated below.
5.2 Building New Multi-view Benchmark Datasets
We intend to build our new multi-view benchmark datasets based on vision data, which is due to the fact that computer vision is the earliest realm where deep learning is thoroughly studied and successfully applied. Hence, abundant accessible public vision data can be exploited in the realm. Specifically, we process existing data into image based multi-view datasets and video based multi-view datasets.
5.2.1 Image based Multi-view Datasets
Image data are the most fundamental data type in deep learning. We process image data into multi-view data by the following means:
1) Multiple image descriptors. Many image descriptors have been proposed to depict different attributes of images, such as texture, color and gradient. Therefore, it is natural to convert a single image into a multi-view data by describing it with different image descriptors. In this paper, we choose several popular image benchmark datasets with comparatively small images (e.g. images), which are less complex for image descriptors to depict: MNIST333http://yann.lecun.com/exdb/mnist/, FashionMNIST444https://github.com/zalandoresearch/fashion-mnist/, CIFAR10555https://www.cs.toronto.edu/~kriz/cifar.html, SVHN666http://ufldl.stanford.edu/housenumbers/, CIFAR1005 and nine image datasets from the MedMNIST dataset collection777https://medmnist.github.io/. To obtain multi-view data, we extract six types of features, i.e. color histogram, GIST, HOG2x2, HOG3x3, LBP and SIFT, which are implemented by a feature extraction Toolbox888https://github.com/adikhosla/feature-extraction.
2) Multiple pre-trained DNN models. Classic image descriptors often find it hard to describe high-resolution images effectively. Therefore, to convert high-resolution images to multi-view data, we propose to describe them by multiple pre-trained DNN models with different network architectures. Those DNN models are usually pretrained on a large-scale generic image benchmark dataset like ImageNet [56], while different network architectures enable them to acquire image knowledge from different views. We extract the outputs from the penultimate layer of each pretrained DNN model as the representations of the image. For high-resolution image data, we collect image data from the Cat_vs_Dog999www.diffen.com/difference/Cat_vs_Dog/ dataset and MvTecAD101010https://www.mvtec.com/company/research/datasets/mvtec-ad/ dataset collection that contains fifteen datasets. As to DNN architectures, we select VGGNet [57], Inceptionv3 [58], ResNet34 [59] and DenseNet121 [60] pretrained on ImageNet. In addition, it is worth mention that the MvTecAD dataset collection is specifically designed for evaluating OCC models, which makes it even more favorable for multi-view Deep OCC.
5.2.2 Video based Multi-view Datasets
Compared with image data, video data contain both spatial and temporal information, so it is even more natural to transform them into multi-view representation. Since anomaly detection is a representative application of OCC, we simply collect video data from benchmark datasets that are designed for the video anomaly detection (VAD) task [61]. To yield video data from a different view, we calculate the optical flow map of each video frame by a pretrained FlowNetv2 model [62]. In this way, each video frame is represented from the view of both RGB and optical flow, which depict videos by both appearance and motion. Afterwards, we leverage the joint foreground localization strategy from [63], so as to localize both daily and novel video foreground objects by bounding boxes. Based on those bounding boxes, we can extract both corresponding RGB and optical flow patches from the original video frame and optical flow map respectively, which serve as a two-view representation of each foreground object in videos. Extracted patches are then normalized into the same size ( patches). As to VAD datasets, we select UCSDped1/UCSDped2111111http://www.svcl.ucsd.edu/projects/anomaly/dataset.htm, Avenue121212http://www.cse.cuhk.edu.hk/leojia/projects/detectabnormal/dataset.html, UMN131313http://mha.cs.umn.edu/proj_events.shtml#crowd and ShanghaiTech141414https://svip-lab.github.io/dataset/campusdataset.html. For VAD datasets that provide pixel-level ground-truth mask for abnormal video foreground (UCSD ped1/ped2, Avenue and ShanghaiTech), those patches that are overlapped with any anomaly mask are labelled as , other patches are labelled as . Although UMN dataset does not provide pixel-level mask, its anomalies happen at a certain stage, and all foreground objects exhibit abnormal behavior at that stage. Therefore, we simply label each foreground patch in that stage as , otherwise labelled as . In this way, we can yield video based multi-view datasets, which are readily applicable to evaluate multi-view deep OCC with real-world application background.
5.3 Other Multi-view Benchmark Datasets
As a supplement to above multi-view datasets, we also review the literature extensively and select some existing multi-view datasets that are applicable to the evaluation of multi-view deep OCC. Since none of existing multi-view datasets is specifically designed for OCC, we adopt the “one v.s. all” protocol to evaulate multi-view deep OCC methods on them: At each round, a certain class of the dataset is viewed as the positive class, while all of other classes are viewed as the negative class. The final OCC performance can be obtained by averaging the performance of all rounds. The selection criterion is that at least one class in the multi-view dataset can provide more than data for training. With this criterion, we select eleven multi-view datasets: Citeseer151515http://lig-membres.imag.fr/grimal/data.html, Cora15, Reuters15, BBC161616http://mlg.ucd.ie/datasets/segment.html, Wiki171717http://www.svcl.ucsd.edu/projects/crossmodal/, BDGP181818http://ranger.uta.edu/~heng/Drosophila/, Caltech20191919http://www.vision.caltech.edu/Image_Datasets/Caltech101/, AwA202020https://cvml.ist.ac.at/AwA/, NUS-Wide212121https://lms.comp.nus.edu.sg/wp-content/uploads/2019/research/nuswide/NUS-WIDE.html, SunRGBD222222http://rgbd.cs.princeton.edu/ and YoutubeFace232323http://archive.ics.uci.edu/ml/datasets/YouTube+Multiview+Video+Games+Dataset (shorted as YtFace), which cover a wide range of scales and data types. Together with our newly-built multi-view dataset, we believe that we are able to provide a comprehensive evaluation platform for multi-view deep OCC. To facilitate future research, we process all multi-view datasets into a consistent format and provide them on a website242424https://github.com/liujiyuan13/MvDOCC-datasets. A summary of all multi-view benchmark datasets used in this paper is given in supplementary material.
| Type | MNIST | FashionMNIST | Cifar10 | Cifar100 | SVHN | Cat_vs_Dog | MedMNIST | MvTecAD | |
|---|---|---|---|---|---|---|---|---|---|
| Fusion | SUM | 97.57 | 92.76 | 81.10 | 76.04 | 77.89 | 97.88 | 78.63 | 89.83 |
| MAX | 97.53 | 92.60 | 80.24 | 75.41 | 77.37 | 97.89 | 78.62 | 89.62 | |
| NN | 97.61 | 92.87 | 79.61 | 75.42 | 77.93 | 97.99 | 78.68 | 89.22 | |
| TF | 97.58 | 92.54 | 80.60 | 75.47 | 78.40 | 97.74 | 78.42 | 89.06 | |
| Alignment | DIS | 97.52 | 92.69 | 80.77 | 75.72 | 78.80 | 97.96 | 78.86 | 89.28 |
| SIM | 97.57 | 92.67 | 81.22 | 76.00 | 79.03 | 98.01 | 78.71 | 89.58 | |
| DCCA | 97.59 | 91.97 | 76.53 | 73.58 | 79.06 | 95.11 | 78.78 | 89.81 | |
| Tailored | DAE | 97.57 | 92.64 | 81.05 | 75.70 | 79.06 | 98.02 | 78.52 | 89.44 |
| DSV | 97.20 | 91.89 | 75.15 | 70.70 | 70.48 | 86.07 | 77.57 | 80.43 | |
| Self-supervision | PPRD | 97.51 | 92.76 | 80.31 | 74.89 | 75.93 | 97.72 | 79.35 | 89.53 |
| SPRD | 97.63 | 92.98 | 81.30 | 75.52 | 77.29 | 97.90 | 79.59 | 89.50 | |
| Type | UCSDped1 | UCSDped2 | UMN_scene1 | UMN_scene2 | UMN_scene3 | Avenue | ShanghaiTech | |
|---|---|---|---|---|---|---|---|---|
| Fusion | SUM | 83.26 | 86.66 | 97.99 | 88.08 | 90.59 | 84.26 | 67.41 |
| MAX | 81.48 | 83.85 | 97.70 | 87.08 | 89.73 | 83.54 | 64.75 | |
| NN | 82.19 | 83.81 | 98.15 | 87.35 | 90.55 | 83.92 | 67.13 | |
| TF | 82.95 | 86.17 | 98.12 | 87.78 | 90.82 | 84.28 | 66.86 | |
| Alignment | DIS | 81.08 | 82.18 | 97.28 | 86.89 | 90.35 | 82.53 | 64.35 |
| SIM | 82.92 | 84.12 | 97.32 | 86.74 | 89.35 | 79.08 | 65.53 | |
| DCCA | 77.61 | 84.62 | 96.79 | 86.18 | 89.68 | 82.56 | 65.77 | |
| Tailored | DAE | 80.51 | 81.86 | 97.01 | 87.47 | 88.91 | 83.35 | 64.93 |
| DSV | 66.30 | 87.02 | 98.47 | 83.49 | 94.03 | 83.35 | 59.12 | |
| Self-supervision | PPRD | 78.40 | 89.62 | 98.45 | 86.31 | 94.76 | 80.73 | 49.89 |
| SPRD | 79.14 | 88.49 | 98.51 | 88.41 | 93.12 | 82.11 | 56.09 | |
6 Empirical Evaluations
Having established formulation, baselines and benchmark datasets for multi-view deep OCC, we perform empirical evaluations to give the first glimpse into this new topic. In addition to head-to-head performance comparison between different baselines, we also conduct in-depth analysis on the characteristics of each model.
6.1 Experimental Setup
For multi-view datasets that are specifically designed for OCC (MvTecAD and video based multi-view datasets), we directly use the given positive class to train the OCC model, and data from the negative class are used to evaluate OCC performance. For other binary or multi-class multi-view datasets, we apply the “one v.s. all” protocol (detailed in Sec. 5.3) for training and evaluating the OCC performance. For multi-class datasets that possess more than 10 classes, we select the first 10 qualified classes ( training data) for experiments. For those multi-view datasets that have already provided the train/test split, we simply use the data of positive class in the training set to train the OCC model, and the test set is used to evaluate the OCC performance. As to those datasets that do not provide train/test split, we randomly sample data of the current positive class as the training set, while the rest of positive class data are mixed with data of the negative class to serve as the testing set. The sampling process is repeated for ten times and the average performance is reported. Before training, training data from each view are normalized to the interval , while the testing set is similarly normalized by the statistics (i.e. min-max value) of the training set. For inference, the reconstruction error based scores of each view are further normalized by the input data dimension, which aims to make scores from different views share the same scale, so they can be comparable and applicable to averaging based late fusion. To quantify the OCC performance, we follow the deep OCC literature and utilize three commonly-used threshold-independent metrics: Area under the Receiver Operation Characteristic Curve (AUROC), Area under the Precision-Recall Curve (AUPR) and True Negative Rate at True Positive Rate (TNR@TPR). We also provide more implementation details in the supplementary material, and all of our implementations can be found at https://github.com/liujiyuan13/MvDOCC-code.
6.2 Head-to-head Comparison of Baselines
We test the designed 11 multi-view deep OCC solutions on both our new multi-view datasets and selected existing multi-view datasets. Due to the page limit, we report the most frequently-used AUROC of each baseline for the head-to-head comparison, while the results under other metrics are provided in the supplementary material. Since other metrics actually exhibit a similar trend to AUROC, we will focus on discussing the AUROC performance in this section. The experimental results on image based multi-view datasets, video based multi-view datasets and selected existing multi-view datasets are given in Table I-III. Note that the performance of MedMNIST and MvTecAD is given by averaging the performance of each datasets in a collection (detailed results of each dataset in those dataset collections is reported in supplementary material). From those results, we can draw the following observations:
| BBC | BDGP | Caltech20 | Citeseer | Cora | Reuters | Wiki | AwA | NUS-Wide | SunRGBD | YtFace | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| SUM | 88.12 | ||||||||||
| (1.00) | (0.06) | (0.23) | (0.89) | (0.98) | (0.88) | (0.00) | (0.32) | (0.02) | (1.00) | (-) | |
| MAX | 87.86 | ||||||||||
| (1.00) | (0.10) | (0.05) | (0.96) | (0.98) | (0.85) | (0.00) | (0.64) | (0.15) | (0.60) | (-) | |
| NN | 87.98 | ||||||||||
| (1.00) | (0.01) | (0.27) | (0.99) | (0.97) | (0.81) | (0.00) | (0.50) | (0.81) | (0.42) | (-) | |
| TF | 86.41 | ||||||||||
| (1.00) | (0.02) | (0.00) | (0.98) | (0.96) | (0.88) | (0.00) | (0.05) | (0.00) | (0.25) | (-) | |
| DIS | 88.41 | ||||||||||
| (1.00) | (1.00) | (1.00) | (0.94) | (0.96) | (0.90) | (0.00) | (0.13) | (0.00) | (0.07) | (-) | |
| SIM | 88.42 | ||||||||||
| (1.00) | (0.64) | (0.27) | (0.98) | (0.97) | (1.00) | (0.00) | (0.02) | (0.00) | (0.11) | (-) | |
| DCCA | 87.72 | ||||||||||
| (1.00) | (0.47) | (0.15) | (0.97) | (0.97) | (1.00) | (0.00) | (0.04) | (0.00) | 0.04 | (-) | |
| DAE | 88.33 | ||||||||||
| (1.00) | (0.93) | (0.60) | (0.95) | (1.00) | (0.87) | (0.00) | (0.07) | (0.00) | (0.08) | (-) | |
| DSV | 90.04 | ||||||||||
| (0.02) | (0.00) | (0.00) | (0.00) | (0.01) | (0.00) | (0.00) | (0.00) | (0.00) | (0.00) | (-) | |
| PPRD | 88.25 | ||||||||||
| (1.00) | (0.05) | (0.00) | (0.94) | (0.96) | (0.79) | (1.00) | (1.00) | (0.00) | (0.00) | (-) | |
| SPRD | 87.67 | ||||||||||
| (1.00) | (0.00) | (0.01) | (1.00) | (0.95) | (0.75) | (0.70) | (0.98) | (1.00) | (1.00) | (-) |
1) In some cases, most of baseline solutions actually achieve fairly close performance, despite of their difference in type and implementation. Concretely, as shown in Table III, baseline solutions attain almost identical performance on several existing multi-view datasets that are widely-used in the literature, e.g. BBC, Caltech20, Cora and Reuters. On many image based multi-view datasets, we also note that the best performer usually leads other counterparts by a less than AUROC. However, baselines could also obtain evidently different performance on other multi-view datasets, like some video based and image based datasets. This also justifies the necessity for a comprehensive evaluation. 2) There does not exist a single baseline that can consistently outperform other baselines. For example, we notice that self-supervision based baselines (PPRD and SPRD) attains the optimal or near-optimal performance (i.e. not significantly different from the best performer) on out of the total datasets (MedMNIST and MvTecAD are viewed as two datasets here). However, self-supervision based baselines also suffer from evidently inferior performance to other baselines on some datasets, such as UCSDped1 and ShanghaiTech. 3) Simple fusion functions (SUM and MAX) can readily compete with comparatively complex fusion functions (NN and TF). In fact, all fusion based baselines yield fairly comparable performance on most datasets. To our surprise, summation turns out to be the most effective way to conduct fusion in our evaluation. 4) Correlation based alignment undergoes more fluctuations than other ways of alignment. It can be observed that DCCA based alignment sometimes performs evidently worse than its two alignment based counterparts, e.g. on Cifar10/Cifar100, Cat_vs_Dog and YtFace. By contrast, distance based alignment maintains the most stable performance in the evaluation. 5) DAE proves to be a strong baseline, while the performance of DSV is typically unsatisfactory in most cases. Although DAE is a simple extension from the single-view deep autoencoder, it is able to produce acceptable or even superior performance to other baselines that are more sophisticated. However, DSVDD based baseline often achieves lower AUROC than other baselines, although it is the best performer on the recent YtFace dataset.
In the supplementary material, we also show the performance of baselines under other metrics (AUPR, TNR@TPR), as well as the performance of four miscellaneous baselines. We believe those results lay a firm foundation for future research on multi-view deep OCC.


| BBC | BDGP | Caltech20 | Citeseer | Cora | Reuters | Wiki | AwA | NUS-Wide | SunRGBD | |
|---|---|---|---|---|---|---|---|---|---|---|
| LF-AVG | ||||||||||
| LF-MIN | ||||||||||
| LF-MAX |
6.3 Further Analysis
6.3.1 Comparison with Single-view Performance
To enable a better insight to devised multi-view deep OCC baselines, we conduct an experiment to compare best baselines’ performance and the best single-view performance on each benchmark dataset in terms of AUROC. The best single-view performance is obtained by training a deep autoencoder with data from one single views and selecting the best performer among the obtained deep autoencoders. In particular, it should be noted that the best single-view performance is actually hindsight, i.e. it is usually not practically accessible due to the absence of the negative class in multi-view deep OCC. Therfore, it is merely used as a reference to reflect how existing baselines exploit multi-view information. The results are shown in Fig. 5, and we can come to an interesting conclusion: Despite of a systematic exploration, current baselines still suffer from insufficient capability to exploit multi-view information for multi-view deep OCC. Specifically, on 12 out of the total 26 datasets, the performance of best baseline is still inferior to the best single-view performance. However, an ideal multi-view learning model is supposed to be superior or comparable to the best single-view performance. Such results imply two facts: First, it is discovered that existing baselines are still unable to find a perfect way to exploit the contributing information embedded in each view. Second, redundant information in multi-view data could be detrimental to the multi-view deep OCC performance. As a consequence, there is a large room for developing improved multi-view deep OCC solutions.
6.3.2 Sensitivity Analysis
In this section, we will discuss the impact of typical hyperparameters for the devised baselines: The rank number for tensor based fusion, the margin for similarity based fusion and the weight of alignment loss for alignment based baselines (DIS, SIM and DCCA). We choose the , and value from , and respectively, and show the corresponding performance on representative datasets in Fig. 6. Surprisingly, we notice that the performance under different hyperparameter settings remains stable in the majority of cases. The performance fluctuations are usually within the range of , except for the case of DCCA on UCSDped1. Consequently, we can speculate that a breakthrough of performance requires progress on model design, and tuning hyperparameter may not produce a performance leap.
6.3.3 Influence of Late Fusion
As a common component for almost all baselines, late fusion has a major influence on the performance multi-view deep OCC. Since we assume that no datum from negative classes are available for validation, it is hard to apply many existing late fusion solutions here. As a preliminary effort, we take DAE for an example and explore three simple strategies for late fusion: Averaging strategy (LF-AVG, used by default), max-value strategy (LF-MAX) and min-value strategy (LF-MIN), which compute the final score by the mean, maximum and minimum of all views’ scores. For simplicity, we test them on existing multi-view datasets and show the results in Table IV. As it is shown by Table IV, the averaging strategy almost constantly outperforms max-value and min-value strategy (except for BDGP and Wiki). The min-value strategy also achieves acceptable results in most cases, which is consistent with our intuition that any abnormal view should signify an abnormal datum. However, it is noted that the max-value strategy can produce very poor fusion results, e.g. on Citeseer and Cora dataset. Therefore, the averaging strategy could still be an informative baseline late fusion strategy for multi-view deep OCC, which is somewhat similar to the case of multi-view learning.
7 Discussion
Based on the results of previous experiments, we would like to make the following remarks on the multi-view deep OCC, which may inspire further research on this new topic:
-
•
A non-trivial “killer” approach to multi-view deep OCC still requires exploration. As we have shown in Sec. 6.2, there is not a single baseline that can consistently outperforms its counterparts. In the meantime, the performance gap between different baselines can be very small in many cases. Thus, it will be very attractive to explore the possibility to design a new multi-view deep OCC solution. In particular, we believe that self-supervised learning can be a promising direction to find such a solution, considering its comparatively better performance among baselines and the remarkable progress achieved by the self-supervised learning community.
-
•
It will be interesting to assess the quality or contribution of each view to multi-view deep OCC. Since prior knowledge on negative classes is not given, it will be natural to describe a sample by as many views as possible. However, as it is shown in Sec. 6.3.1, it may degrade the performance when data of multiple views are blindly fused or aligned. Therefore, it is of high value to develop a strategy to perform knowledgeable multi-view fusion or alignment. This is also applicable to the late fusion stage.
-
•
The revolution of the learning paradigm may breed a breakthrough. The generative learning paradigm (i.e. generation or prediction) has been a standard practice in deep OCC, which is followed in this paper when designing most baselines. However, other learning paradigms, such as the discriminative learning [15] and contrastive learning [64] paradigm, have proved to be more effective than generative learning paradigm in realms like unsupervised representation learning. Naturally, a brand-new learning paradigm may be a good remedy to multi-view deep OCC.
-
•
Newly-emerging DNN models can be explored for enhancing multi-view deep OCC. In this paper, most baselines are developed based on the classic encoder-decoder like DNN models. This is due to the fact that deep autoencoder and its variants are the most commonly-used tool for deep OCC, and they can be good reference to understand multi-view deep OCC. However, the deep OCC realm also witness the emergence of many emerging DNN models, such as GANs [65] and transformers [66]. Such new techniques pave the way for better multi-view deep OCC. For example, it will be interesting to leverage the self-attention mechanism of transformers to capture the inter-view correspondence within multi-view data.
8 Conclusion
This paper investigates a pervasive but unexplored problem: Multi-view deep OCC. Within the scope of our best knowledge, we are the first to formally identify and formulate multi-view deep OCC. In order to overcome the practical difficulties to look into this problem, we systematically design baseline solutions by extensively reviewing relevant areas in the literature, and we also construct abundant new multi-view datasets by processing public data via various means. Together with some existing multi-view datasets, a comprehensive evaluation of designed baselines is carried out to provide the first glimpse to this new topic. To facilitate future research on this challenging problem, all benchmark datasets and implementations of baselines are open.
References
- [1] M. M. Moya, M. W. Koch, and L. D. Hostetler, “One-class classifier networks for target recognition applications,” NASA STI/Recon Technical Report N, vol. 93, p. 24043, 1993.
- [2] D. M. J. Tax, “One-class classification,” Ph.D. Thesis, June 2001.
- [3] L. Ruff, R. Vandermeulen, N. Goernitz, L. Deecke, S. A. Siddiqui, A. Binder, E. Müller, and M. Kloft, “Deep one-class classification,” in International conference on machine learning. JMLR, 2018, pp. 4393–4402.
- [4] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in Python,” Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011.
- [5] A. Sedlmeier, R. Müller, S. Illium, and C. Linnhoff-Popien, “Policy entropy for out-of-distribution classification,” in International Conference on Artificial Neural Networks. Springer, 2020, pp. 420–431.
- [6] L. M. Manevitz and M. Yousef, “One-class svms for document classification,” Journal of machine Learning research, vol. 2, no. Dec, pp. 139–154, 2001.
- [7] H. J. Shin, D.-H. Eom, and S.-S. Kim, “One-class support vector machines—an application in machine fault detection and classification,” Computers & Industrial Engineering, vol. 48, no. 2, pp. 395–408, 2005.
- [8] M. Koppel and J. Schler, “Authorship verification as a one-class classification problem,” in Proceedings of the twenty-first international conference on Machine learning, 2004, p. 62.
- [9] B. Krawczyk, M. Woźniak, and F. Herrera, “On the usefulness of one-class classifier ensembles for decomposition of multi-class problems,” Pattern Recognition, vol. 48, no. 12, pp. 3969–3982, 2015.
- [10] S. S. Khan and M. G. Madden, “One-class classification: taxonomy of study and review of techniques,” The Knowledge Engineering Review, vol. 29, no. 3, pp. 345–374, 2014.
- [11] Y. LeCun, Y. Bengio, and G. Hinton, “Deep learning,” nature, vol. 521, no. 7553, p. 436, 2015.
- [12] Y. Li, M. Yang, and Z. Zhang, “A survey of multi-view representation learning,” IEEE transactions on knowledge and data engineering, vol. 31, no. 10, pp. 1863–1883, 2018.
- [13] T. Baltrušaitis, C. Ahuja, and L.-P. Morency, “Multimodal machine learning: A survey and taxonomy,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 2, pp. 423–443, 2018.
- [14] W. Guo, J. Wang, and S. Wang, “Deep multimodal representation learning: A survey,” IEEE Access, vol. 7, pp. 63 373–63 394, 2019.
- [15] I. Golan and R. El-Yaniv, “Deep anomaly detection using geometric transformations,” in Advances in Neural Information Processing Systems, 2018, pp. 9758–9769.
- [16] S. Rayana, “ODDS library,” 2016. [Online]. Available: http://odds.cs.stonybrook.edu
- [17] G. Pang, C. Shen, L. Cao, and A. v. d. Hengel, “Deep learning for anomaly detection: A review,” arXiv preprint arXiv:2007.02500, 2020.
- [18] D. Xu, Y. Yan, E. Ricci, and N. Sebe, “Detecting anomalous events in videos by learning deep representations of appearance and motion,” Computer Vision and Image Understanding, vol. 156, pp. 117–127, 2017.
- [19] M. Hasan, J. Choi, J. Neumann, A. K. Roy-Chowdhury, and L. S. Davis, “Learning temporal regularity in video sequences,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 733–742.
- [20] J. Chen, S. Sathe, C. Aggarwal, and D. Turaga, “Outlier detection with autoencoder ensembles,” in Proceedings of the 2017 SIAM international conference on data mining. SIAM, 2017, pp. 90–98.
- [21] S. Zhai, Y. Cheng, W. Lu, and Z. Zhang, “Deep structured energy based models for anomaly detection,” international conference on machine learning, pp. 1100–1109, 2016.
- [22] T. Schlegl, P. Seeböck, S. M. Waldstein, U. Schmidt-Erfurth, and G. Langs, “Unsupervised anomaly detection with generative adversarial networks to guide marker discovery,” in International Conference on Information Processing in Medical Imaging. Springer, 2017, pp. 146–157.
- [23] S. Akcay, A. Atapour-Abarghouei, and T. P. Breckon, “Ganomaly: Semi-supervised anomaly detection via adversarial training,” in Asian conference on computer vision. Springer, 2018, pp. 622–637.
- [24] W. Liu, W. Luo, D. Lian, and S. Gao, “Future frame prediction for anomaly detection–a new baseline,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6536–6545.
- [25] M. Ye, X. Peng, W. Gan, W. Wu, and Y. Qiao, “Anopcn: Video anomaly detection via deep predictive coding network,” in Proceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 1805–1813.
- [26] L. Bergman and Y. Hoshen, “Classification-based anomaly detection for general data,” in International Conference on Learning Representations, 2019.
- [27] S. Goyal, A. Raghunathan, M. Jain, H. V. Simhadri, and P. Jain, “Drocc: Deep robust one-class classification,” in International Conference on Machine Learning. PMLR, 2020, pp. 3711–3721.
- [28] G. Pang, L. Cao, and C. Aggarwal, “Deep learning for anomaly detection: Challenges, methods, and opportunities,” in WSDM ’21, The Fourteenth ACM International Conference on Web Search and Data Mining, Virtual Event, Israel, March 8-12, 2021, L. Lewin-Eytan, D. Carmel, E. Yom-Tov, E. Agichtein, and E. Gabrilovich, Eds. ACM, 2021, pp. 1127–1130.
- [29] J. Gao, W. Fan, D. Turaga, S. Parthasarathy, and J. Han, “A spectral framework for detecting inconsistency across multi-source object relationships,” in 2011 IEEE 11th International Conference on Data Mining. IEEE, 2011, pp. 1050–1055.
- [30] A. Marcos Alvarez, M. Yamada, A. Kimura, and T. Iwata, “Clustering-based anomaly detection in multi-view data,” in Proceedings of the 22nd ACM international conference on Information & Knowledge Management, 2013, pp. 1545–1548.
- [31] H. Zhao and Y. Fu, “Dual-regularized multi-view outlier detection,” in Twenty-Fourth International Joint Conference on Artificial Intelligence, 2015.
- [32] T. Iwata and M. Yamada, “Multi-view anomaly detection via robust probabilistic latent variable models.” in NIPS, 2016, pp. 1136–1144.
- [33] S. Li, M. Shao, and Y. Fu, “Multi-view low-rank analysis with applications to outlier detection,” Acm Transactions on Knowledge Discovery from Data, vol. 12, no. 3, pp. 1–22, 2018.
- [34] X.-R. Sheng, D.-C. Zhan, S. Lu, and Y. Jiang, “Multi-view anomaly detection: Neighborhood in locality matters,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 4894–4901.
- [35] Z. Wang and C. Lan, “Towards a hierarchical bayesian model of multi-view anomaly detection,” in Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, 2020.
- [36] J. Ngiam, A. Khosla, M. Kim, J. Nam, H. Lee, and A. Y. Ng, “Multimodal deep learning,” in ICML, 2011.
- [37] N. Srivastava and R. Salakhutdinov, “Multimodal learning with deep boltzmann machines.” J. Mach. Learn. Res., vol. 15, no. 1, pp. 2949–2980, 2014.
- [38] C. Feichtenhofer, A. Pinz, and A. Zisserman, “Convolutional two-stream network fusion for video action recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1933–1941.
- [39] J. Mao, W. Xu, Y. Yang, J. Wang, Z. Huang, and A. Yuille, “Deep captioning with multimodal recurrent neural networks (m-rnn),” arXiv preprint arXiv:1412.6632, 2014.
- [40] S. Sun, W. Dong, and Q. Liu, “Multi-view representation learning with deep gaussian processes,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [41] A. Zadeh, M. Chen, S. Poria, E. Cambria, and L.-P. Morency, “Tensor fusion network for multimodal sentiment analysis,” in EMNLP, 2017.
- [42] Z. Liu, Y. Shen, V. B. Lakshminarasimhan, P. P. Liang, A. B. Zadeh, and L.-P. Morency, “Efficient low-rank multimodal fusion with modality-specific factors,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2018, pp. 2247–2256.
- [43] H. Hotelling, “Relations between two sets of variates,” in Breakthroughs in statistics. Springer, 1992, pp. 162–190.
- [44] G. Andrew, R. Arora, J. Bilmes, and K. Livescu, “Deep canonical correlation analysis,” in International conference on machine learning. PMLR, 2013, pp. 1247–1255.
- [45] W. Wang, R. Arora, K. Livescu, and J. Bilmes, “On deep multi-view representation learning,” in International conference on machine learning. PMLR, 2015, pp. 1083–1092.
- [46] A. Benton, H. Khayrallah, B. Gujral, D. A. Reisinger, S. Zhang, and R. Arora, “Deep generalized canonical correlation analysis,” in Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019), 2019, pp. 1–6.
- [47] A. Frome, G. Corrado, J. Shlens, S. Bengio, J. Dean, M. Ranzato, and T. Mikolov, “Devise: A deep visual-semantic embedding model,” 2013.
- [48] F. Feng, X. Wang, and R. Li, “Cross-modal retrieval with correspondence autoencoder,” in Proceedings of the 22nd ACM international conference on Multimedia, 2014, pp. 7–16.
- [49] B. Wang, Y. Yang, X. Xu, A. Hanjalic, and H. T. Shen, “Adversarial cross-modal retrieval,” in Proceedings of the 25th ACM international conference on Multimedia, 2017, pp. 154–162.
- [50] J. Gu, J. Cai, S. R. Joty, L. Niu, and G. Wang, “Look, imagine and match: Improving textual-visual cross-modal retrieval with generative models,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 7181–7189.
- [51] L. Jing and Y. Tian, “Self-supervised visual feature learning with deep neural networks: A survey,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [52] D. Liu, K.-T. Lai, G. Ye, M.-S. Chen, and S.-F. Chang, “Sample-specific late fusion for visual category recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 803–810.
- [53] X. Liu, X. Zhu, M. Li, L. Wang, C. Tang, J. Yin, D. Shen, H. Wang, and W. Gao, “Late fusion incomplete multi-view clustering,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 10, pp. 2410–2423, 2018.
- [54] J. Liu, X. Liu, Y. Yang, X. Guo, M. Kloft, and L. He, “Multiview subspace clustering via co-training robust data representation,” IEEE Transactions on Neural Networks and Learning Systems, pp. 1–13, 2021.
- [55] J. Liu, X. Liu, Y. Yang, S. Wang, and S. Zhou, “Hierarchical multiple kernel clustering,” in Proceedings of the Thirty-fifth AAAI Conference on Artificial Intelligence, (AAAI-21), Virtually, February 2-9, 2021, 2021.
- [56] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255.
- [57] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in International Conference on Learning Representations, 2015.
- [58] C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” IEEE, pp. 2818–2826, 2016.
- [59] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [60] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4700–4708.
- [61] B. Ramachandra, M. Jones, and R. R. Vatsavai, “A survey of single-scene video anomaly detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [62] E. Ilg, N. Mayer, T. Saikia, M. Keuper, A. Dosovitskiy, and T. Brox, “Flownet 2.0: Evolution of optical flow estimation with deep networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2462–2470.
- [63] G. Yu, S. Wang, Z. Cai, E. Zhu, C. Xu, J. Yin, and M. Kloft, “Cloze test helps: Effective video anomaly detection via learning to complete video events,” in Proceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 583–591.
- [64] Xiao, Liu, Fanjin, Zhang, and Tang, “Self-supervised learning: Generative or contrastive,” 2020.
- [65] J. Gui, Z. Sun, Y. Wen, D. Tao, and J. Ye, “A review on generative adversarial networks: Algorithms, theory, and applications,” arXiv preprint arXiv:2001.06937, 2020.
- [66] K. Han, Y. Wang, H. Chen, X. Chen, and D. Tao, “A survey on visual transformer,” 2020.