Multi-turn Response Selection with Commonsense-enhanced Language Models
Abstract.
As a branch of advanced artificial intelligence, dialogue systems are prospering. Multi-turn response selection is a general research problem in dialogue systems. With the assistance of background information and pre-trained language models, the performance of state-of-the-art methods on this problem gains impressive improvement. However, existing studies neglect the importance of external commonsense knowledge. Hence, we design a Siamese network where a pre-trained Language model merges with a Graph neural network (SinLG). SinLG takes advantage of Pre-trained Language Models (PLMs) to catch the word correlations in the context and response candidates and utilizes a Graph Neural Network (GNN) to reason helpful common sense from an external knowledge graph. The GNN aims to assist the PLM in fine-tuning, and arousing its related memories to attain better performance. Specifically, we first extract related concepts as nodes from an external knowledge graph to construct a subgraph with the context response pair as a super node for each sample. Next, we learn two representations for the context response pair via both the PLM and GNN. A similarity loss between the two representations is utilized to transfer the commonsense knowledge from the GNN to the PLM. Then only the PLM is used to infer online so that efficiency can be guaranteed. Finally, we conduct extensive experiments on two variants of the PERSONA-CHAT dataset, which proves that our solution can not only improve the PLM’s performance but also achieve an efficient inference.
1. Introduction

One of the most significant tasks of advanced artificial intelligence has been building a dialogue system possessing the cognitive ability which can communicate with humans coherently. Recent dialogue systems can be categorized into generation-based and retrieval-based according to the methodologies applied. Retrieval-based dialogue systems are usually given a dialog corpus and the user’s current utterance, and then a small response candidate set would be returned via a retrieval algorithm while generation-based methods often produce a diverse response candidate set first. Then both kinds of dialogue systems come to the situation where a response candidate set would be obtained before responding to users. Unfortunately, not all response candidates are rational under the current dialogue context. Hence, it is very necessary to provide matching scores for these response candidates and choose the best ones. Obviously, obtaining accurate matching scores for response candidates lies at the core of most dialogue systems.
In this paper, we investigate the specific problem named Multi-turn Response Selection (MRS) which evaluates and filters response candidates for multi-turn dialogues. Traditional methods focus on generating more comprehensive representations for the context and response separately and obtaining the final matching score via a matching layer. Specifically, hand-crafted features are utilized at first to provide clues for the selection of the best response, e.g., sentence length, the number of common words for sentence-level representation (Wang et al., 2017) and topic information (Wu et al., 2018b). With the prosperity of deep neural networks, researchers employ Convolution Neural Network (CNN), Recurrent Neural Network (RNN), and self-attention mechanisms coupled with Multi-Layer Perceptron (MLP) and pooling layers to learn effective representations (Yan et al., 2018). Under the multi-turn scenario, it is vital to effectively catch the relationships between different sentences in the context, as well as those between contexts and response candidates to yield a comprehensive embedding of them. A multi-turn dialogue system is required to be capable of following topic changes from time to time and returning fluent responses to users. For instance, Fig.1 shows a multi-turn dialogue between A and B from PERSONA-CHAT (Zhang et al., 2018). In the first round, they are talking about B’s current state and job; then the topic transfers to their hobbies and families in the following rounds gradually. Therefore, we need to consider a multi-turn context, so as to determine which response candidate is more suitable for the current context. However, the above methods may catch the relationships between different sentences in the context but fail to conduct sufficient interactions among the context and response candidates, which makes it hard to learn the relationships among the context and response candidates comprehensively.
As both the context and response candidates carry complex semantics, diverse new frameworks (Zhou et al., 2018; Tao et al., 2019; Yuan et al., 2019) are presented to mine the interactions between them so that the matching accuracy can be improved. The recent Pre-trained Language Model (PLM)s (Devlin et al., 2019; Liu et al., 2019) exploit the interactions between all context sentences and response candidates via the attention mechanism in a more comprehensive way. Variants of PLM-based models (Henderson et al., 2019; Whang et al., 2020; Xu et al., 2021a) for MRS are proposed recently. Particularly, (Henderson et al., 2019) learns representations for the context and response separately via Bidirectional Encoder Representations from Transformers (BERT) and aggregates them to compute the final matching score. Further, Xu et al. (2021a) design several self-supervised tasks and jointly pre-train the PLM-based model with them for MRS in a multi-task manner. As the application scenarios of dialogue systems are diversifying, MRS involves more complicated information, e.g., background or persona restrictions. Hence, there has been an increasing need for moving beyond learning only the dialogue features, towards capturing relationships between such complicated context and response candidates.
Simultaneously, various methodologies (Zhao et al., ; Gu et al., 2020; Liu et al., 2020; Zhang et al., 2021a; Zhu et al., 2021) are proposed to employ background information for MRS, such as profiles of users and entity infoboxes from Wikipedia. For instance, Gu et al. (2020) propose FIRE which filters context and knowledge at first, and their embeddings are generated severally by bidirectional and global attention mechanisms. Liu et al. (2020) incorporate knowledge triplets into the utterances and feed them into BERT while they use soft position and visible matrix to restrain the effect of noise from the knowledge. Unfortunately, these methods overlook a significant problem: how to select a rational response candidate consistent with common sense? Human beings talk to each other with common sense besides the given background knowledge, which is absent in the above methods. There is a lack of trustworthy reasoning from the background to response candidates. Referring to the example in Fig.1, B’s persona is given in four sentences as a knowledge supplement. With P1-1 and P1-4, we can recognize B2 and B6 are the correct responses consistent with B’s persona. It is relatively easy for both humans and a state-of-art model to associate the information about twenty books read in a year in both the persona and conversation, so as “single parent” and “one parent”. However, the persona might not necessarily be as well-structured, where a typical example is shown in Fig.1 (marked as B’s revised persona). In this case, “two dozen” in P2-1 and “about 20” in B2, “mom and dad divorced” in P2-4, and “one parent” in B6 immediately make it challenging for a language model to precisely match the context without guidance from commonsense knowledge. Therefore, trustworthy reasoning ability usually needs to be equipped with external common sense which can help understand the relevance between background information and response candidates so as to enhance the performance of models on the MRS task. In addition, complex MRS tasks like persona-based chat tend to be more demanding on sophisticated and labor-intensive annotations. Consequently, with the substantially limited training data, a method that can take advantage of commonsense reasoning would be highly desirable for optimizing the conversation responses selected.
In view of the challenges and deficiencies of existing studies, we design a framework called Siamese network combining pre-trained Language model with Graph neural network (i.e., SinLG). As is well-known, PLMs can accumulate lots of language principles and knowledge according to the pre-training process via its powerful memorization ability from enormous parameters. PLMs possess the strong capability of language representation and understanding, but its performance gain compared with previous studies might be restrained because of improper applications, especially when the target task needs specific background knowledge. Therefore, we propose to enhance the performance of PLMs by incorporating common sense from an external knowledge graph with a Graph Neural Network (GNN) so that the related knowledge memories of PLMs can be aroused. The GNN is responsible for augmenting useful commonsense information from the extra knowledge graph and assists the PLM in fine-tuning. With the supplement of commonsense knowledge, the performance of PLMs can be improved even on more difficult understanding tasks. Instead of appending the representation learned from a Knowledge Graph (KG) after the PLM’s representation directly, we propose the KG guided training for efficient inference where a similarity-based and self-supervised objective function is optimized to help PLMs achieve better performance. In this way, we can not only transfer the commonsense knowledge from the GNN to PLMs but also augment the supervision signal, which enables our framework to generalize better amid the limited training data. By this means, the PLM can better exploit its strong capability of language representation and understanding to model the dialogue text where the multi-head attention mechanism can fully catch the relationships between each utterance in the context, as well as response candidates to yield a comprehensive understanding for the response selection. Meanwhile, the heavy computations in the GNN part can be omitted during the inference, such as entity linking, concept ranking, and so on, which is so time-consuming that would lead to high latency and poor user experience.
The main contributions of this work are summarized as follows:
-
•
Considering the challenges and insufficiencies of state-of-the-art approaches to the MRS problem, we propose to supplement common sense from the external knowledge graph to PLMs so that their performance can be enhanced by specific background information.
-
•
In order to optimize the inference efficiency, we propose the KG-guided training which employs a similarity-based and self-supervised objective function to arouse the related knowledge memories of PLMs to obtain a better performance.
-
•
We conduct extensive experiments on different variants of a public dataset, which testifies the superiority of our proposed solution from several different perspectives.
The paper is organized as follows. Section 2 introduces some basic definitions of MRS problem. The details of our solution on MRS are presented in Section 3. In Section 4, we provide extensive experimental results to analyze the effectiveness of our model from various perspectives. Section 5 reviews the development of existing related works and Section 6 concludes the paper and proposes the prospects and limitations of this work.
2. Problem Statement
In this section, we define some basic notations and mathematically formulate our problem.
2.1. Definitions
Definition 2.1.
Token . In order to process the natural language into codes that computers can understand, the common operation usually divides them into word-by-word pieces, called tokens which can map into ids as inputs of models. Here we denote a token as in this paper.
Definition 2.2.
Utterance . An utterance is a chronological sequence of tokens and usually expresses a complete thought, which is denoted as where is the number of tokens in this utterance.
Definition 2.3.
Persona . Persona is a set of utterances that describe the profile of one side in a given dialogue. It provides background information for the dialogue. In particular, we define this kind of utterance as , and persona .
Definition 2.4.
Context . A dialogue’s context is a chronological sequence of utterances, which is denoted as where is the number of utterances in this context.
Definition 2.5.
Response Candidate Set . According to the context, a dialogue system can obtain a series of utterances as response candidates. Specially, we represent a response candidate as which also can be denoted as . Similar to the above, the response candidate set can be represented as .
Definition 2.6.
Knowledge Graph . We define the external knowledge graph that we extract common sense from as a multi-relational graph , , where is the set of entity/concept nodes (which are usually composed of a meaningful word or phrase. A token in dialogues can correspond to an entity in during the knowledge extraction.), is the set of edges between nodes, and is the set of relation types in .
2.2. Multi-turn Response Selection (MRS)
Problem 1.
Multi-turn Response Selection (MRS). Given a dialogue dataset , where } represents the rational scores of response candidates in (note ), and an external knowledge graph with common sense, our goal is to learn a matching model that measures the relevance between and the candidates in . In the following part of this paper, we refer to a sample as a mrsSample.
3. SOLUTION
In order to incorporate common sense into the dialogue system, we design a framework which is a siamese network combining a pre-trained language model (PLM) with a graph neural network (GNN). An overview is shown in Fig.2. The framework is inspired by both Siamese network architecture (Chen and He, 2021), and the dual process theory from the cognitive process of humans (Evans, 1984, 2003, 2008; Sloman, 1996). In the Siamese network architecture, a PLM is employed to capture the relationships among different utterances of the context, as well as the relationships between the context and response candidates via its strong capability of language representation and understanding. Meanwhile, a GNN is in place to gather useful common sense from the external knowledge graph and assists the PLM in the fine-tuning process. To endow the PLM with the common sense extracted by the GNN when selecting the next response, we additionally incorporate a term in the training loss that encourages the similarity between the representations generated by these two components. Through this framework, we can leave out the commonly adopted process (Yasunaga et al., 2021; Feng et al., 2020) that extracts and ranks related nodes from the external knowledge graph during the inference, which is time-consuming and would lead to high latency and poor user experience.
The whole technical process of SinLG is composed of the following steps. First, we extract relevant concepts from the knowledge graph via linking and scoring. Specifically, entity linking is conducted between tokens in the conversation context and concepts in , and then a PLM is employed to score the abstracted concepts via computing the similarity between them and the corresponding context (Yasunaga et al., 2021). Combing the dialogue text with extracted relevant concepts as the model input, we conduct two different transformations on them to respectively generate the inputs of the PLM and GNN. Each of them learns a unique representation for the context-response pair. A similarity score between them is computed as one part of the final loss. Finally, the representation vector from the PLM is fed into the prediction layer to obtain matching scores of context-response pairs. The general form of PLMs that we used in our framework is defined as a composition of two functions:
| (1) |
where encoder separates the utterance u as tokens, represents it with a sequence of token ids, and learns a contextualized representation h for u; then is a layer to fit for a desired task taking h as its input.


3.1. Knowledge Extraction
Dialogue systems, especially those open-domain ones, are expected to converse with humans in an engaging way, so common sense is very necessary to be integrated into the model effectively (Young et al., 2018). When coming across a specific context, dialogue systems are usually incapable of reasoning according to corresponding background information unless we empower them with specific means. This section aims to extract useful commonsense concepts from an external knowledge graph and rank them based on their relevance to the dialogue context.
First of all, we need to select an external knowledge graph which would include useful common sense as much as possible. As the Fig.2(a) shows, we retrieve a subgraph from for each response candidate and its context, i.e., , following prior works (Feng et al., 2020; Yasunaga et al., 2021). The extraction process includes four steps. First, given , the concept set is obtained by entity linking between tokens in the dialogue text and concept nodes in . Second, the few-hop neighbors of elements in are extracted to form , which is a set of extra nodes containing high-order external knowledge from the knowledge graph. The complete node set of the subgraph is the union of the two, . Third, we calculate a score for each concept node in to measure the relevance between the dialogue text and corresponding concept through the PLM:
| (2) |
where and represent concatenation and dot product, respectively, and is the dot-product similarity function. Since a longer average text length of multi-turn dialogues leads to more related concepts from , calculating such pairwise scores becomes computationally impractical for a large set of concepts. As the equations show, we employ a bi-encoder that first encodes the context and concepts into embeddings, and then computes their similarity scores through their embedding vectors. Compared with the cross-encoder, a bi-encoder is more convenient and efficient under our multi-turn scenario where there are more candidate concepts to score because of the longer context and it allows to pre-compute the embeddings of candidate concepts first (Humeau et al., 2019; Li et al., 2021). In practice, we pre-compute the embeddings of all concepts in and conduct a dot product between the embedding of dialogue text and its corresponding concept embeddings to obtain their final scores. Both embeddings of the concepts and dialogue text are computed by the PLM. Then we rank these concepts according to their similarity scores with the context and choose the top ones as useful inputs of the GNN. The embeddings of chosen top concepts will be updated via GNN’s message passing in Eq.(7). Finally, the edges and relation types are abstracted based on , that is, , , .
3.2. SinLG
To effectively inject common sense into the PLM for response selection, we utilize GNN to learn the structural information from in SinLG. Meanwhile, GNN transfers the commonsense knowledge to the PLM by maximizing the similarity between the different embeddings from the PLM and GNN where the design of Siamese network structure aims to realize the augmentation effect for the same input. In this way, the performance of the PLM can be enhanced.
3.2.1. Two Transformations
Above all, besides the dialogue text , the input of our model also includes its subgraph . The two components of SinLG manage different available information that they are good at. The PLM models the dialogue text so we propose Trans a to preprocess , while the GNN models common sense from the KG and Trans b is to deal with the graph-structured knowledge. In the left part of Fig.2(a), we conduct Trans a which means concatenating , , one by one:
| (3) |
In the right part of Fig.2(a), a virtual and super node representing the context is created and added into . The relationships between and all other nodes are measured by their scores calculated via Eq.(2). Then we assume the super node connects with all other concept nodes and the weights of their edges are the ranking scores of concepts. The relations between and other concept nodes belong to one type. The initial embeddings of concept nodes in are pre-computed by a PLM directly without fine-tuning. Exceptionally, the initial embedding of node is the embedding of its corresponding dialogue context (i.e., the concatenation of , and , ) via the PLM in SinLG, which is actually the output of Eq.(5), . In summary, Trans b includes the following operation:
| (4) |
where is the initial embedding set of all nodes in , , denotes the edges and relation types that are derived from the context node .
3.2.2. Natural Language Understanding via PLM
In our framework, the PLM is utilized to encode the dialogue text which is fed forward into the PLM after the concatenation in Trans a:
| (5) |
| (6) |
where is the first hidden state from the PLM’s output, and is the final prediction layer which is a multi-layer perceptron where , are learnable parameters, and represents the activation function. Note that here is different from the one we utilize in Eq.(2). The encoder in Eq.(2) is used in zero-shot learning style while the one in Eq.(5) will be fine-tuned in the subsequent training process. The rationale that we use a PLM in different styles is the directed employment of the PLM in Eq.(2) allows all scores to be pre-computed, and then the efficiency of SinLG can be guaranteed.
3.2.3. Structured Knowledge Learning via GNN
In this section, the transformation result via Trans b, is fed into a GAT-based (Veličković et al., 2017) graph neural network where the representation of the context node is learned via aggregating the messages passed from its neighbors. Taking the context node as an example, we formulate a single layer of propagation operation in a subgraph as:
| (7) |
where denotes the embedding of the context node for -th layer, and its initial embedding is the output of the PLM, i.e., . represents the neighbors’ set of and is a learnable parameter. is the attention aggregating function where the node type, relation, and concept score are all considered during this process (Yasunaga et al., 2021). Finally, we denote as the final embedding of the context node after the message passing from subgraph , which fuses the external commonsense knowledge into the dialogue context’s representation from the PLM.
3.3. KG-Guided Training
Although PLMs have achieved various impressive results on all kinds of downstream NLP tasks, they are not so trustworthy when facing complicated understanding tasks that require advanced reasoning ability based on external commonsense knowledge (Liu et al., 2021; Zhang et al., 2021b). Hence, we design the KG-guided training process in our framework to enhance the reasoning ability of PLMs with extra common sense from KG. As Fig.2(a) depicts, both the PLM and GNN generate a representation vector of the context, i.e., and , respectively. The final predicted scores of different candidate responses are obtained via the representation vectors from the PLM. We design two sub-functions for the final loss in the following sections.
3.3.1. Similarity Loss.
As we all have known, PLMs have memorized all kinds of knowledge and language statistics rules during their pre-training process and exhibited extraordinary performance on many downstream tasks, which makes it impossible to ignore their strong capability. Therefore, we regard the PLM as our main backbone and assist its fine-tuning with the latent space acquired via GNN’s information augmentation from external KG. Specifically, we define a similarity loss between the two representation vectors, and :
| (8) |
where denotes the loss based on cosine similarity, represents the normalization, and is a small additive term in case the denominator is 0, for instance, . In this way, the external commonsense knowledge aggregated via GNN can be transferred into the PLM to arouse its related memories and obtain a better performance on reasoning-required tasks. As an augmentation of the supervision signal, the similarity loss enables our framework to better deal with data scarcity.
3.3.2. Inference Loss.
After the KG guidance via the similarity loss, we optimize the final performance of the PLM through the inference loss. The final predicted scores of different candidate responses have been obtained via the representation vector from the PLM according to Eq.(6). Then the inference loss is defined as follows:
| (9) |
where represents the loss function based on binary cross entropy.
3.3.3. Optimization Strategy.
With the definitions based on the similarity between , and inference results, our final loss function is formulated as:
| (10) |
where refers to weighting factors, aiming to prioritize the output of a certain loss function over the other, which will be discussed in the evaluation. Above all, the model parameters are optimized by minimizing the loss defined in Eq.(10). All parameters are updated via the Stochastic Gradient Descent (SGD) method. In specific, we utilize AdamW (Loshchilov and Hutter, 2017), one of the SGD’s variants to optimize the model parameters of SinLG.
3.4. Efficient Inference
We design the KG-guided training process via adding similarity loss instead of a direct embedding fusion (e.g., concatenating from the GNN with the dialogue context embedding, from the PLM) so that we can conduct inference with only the PLM part as shown in Fig.2(b). The similarity loss helps the PLM part obtain the knowledge from the GNN part and achieve better performance. Hence, it is not only an effective way of incorporating commonsense knowledge into the PLM for the MRS task, but also beneficial for inference efficiency. In order to utilize the commonsense knowledge from KG, we need to conduct a bunch of tedious procedures: tokenization of the dialogue context, entity linking between context tokens and concepts in KG, similarity calculation between concepts and the dialogue context, ranking and filtering of those concepts, and construction of subgraphs with related concepts. With our designed framework, during inference, we can not only get rid of the heavy preprocessing operations but also bypass the generation and representation learning for any subgraphs, because the knowledge memory of the PLM is now aroused by maximizing the similarity loss. This will help increase the inference efficiency as well as reduce the computational complexity of the dialogue system.
4. Evaluation
In this section, we showcase the advantages of SinLG on the MRS task with auxiliary information from a public commonsense knowledge graph through extensive experiments. In specific, we try to answer the following research questions:
-
RQ1
: How is the effectiveness of SinLG on MRS task compared with existing methods?
-
RQ2
: How is the effectiveness of SinLG on MRS task under varying levels of understanding difficulty?
-
RQ3
: How is the effectiveness of SinLG on MRS task under low data availability?
-
RQ4
: How does SinLG benefit from each component of the proposed architecture?
-
RQ5
: How does the major hyper-parameter affect the performance of SinLG?
4.1. Datasets
| Category | PERSONA-CHAT | ||
| Train | Dev | Test | |
| Dialogues | 8,939 | 1,000 | 968 |
| Personas | 955 | 100 | 100 |
| mrsSamples | 65,719 | 7,801 | 7,512 |
-
1
The mrsSample is defined in PROBLEM 1.
| Dataset | |||||||
| Original | Train | 35 | 608 | 160 | 79.866% | 6.054% | 0.010% |
| Dev | 51 | 388 | 168 | 82.504% | 9.037% | 0% | |
| Test | 50 | 406 | 165 | 81.373% | 7.238% | 0% | |
| Revised | Train | 36 | 603 | 160 | 79.939% | 5.920% | 0.010% |
| Dev | 50 | 394 | 169 | 82.981% | 9.253% | 0% | |
| Test | 52 | 401 | 166 | 82.039% | 7.873% | 0% | |
-
1
, , represent minimum, maximum, and average length of mrsSamples in each dataset.
-
2
, , indicate the ratios of mrsSamples with context lengths more than , , and among every dataset.
We conduct experiments on two variants of PERSONA-CHAT (Zhang et al., 2018), that is, the dialogues with original personas and its revised version whose detail statistics are listed in Table 1 and Table 2. The revised version is rephrased from the original one in an implicit way which is more challenging than the original one in the understanding complexity so that we can testify the effectiveness of our model under different levels. We choose ConceptNet (Speer et al., 2017) as our auxiliary knowledge graph, which is a widely-used (Jain and Lobiyal, 2022; Zhou et al., 2022; Yasunaga et al., 2021; Huang et al., 2020; Sap et al., 2019; Bosselut et al., 2019) commonsense source.
As Table 1 shows, PERSONA-CHAT possesses complete conversations, for training, for development, and for test, where dialogues have conversation turns. Response selection is conducted at each round of a complete conversation, which leads to mrsSamples (which is defined in the definition of PROBLEM 1.) in total, for training, for development, and for testing. The response candidate set of each turn includes 20 choices, where a positive response is the true one from human beings while negative ones are stochastically selected. As shown in Fig.1, the revised version has the same dialogue context as the original one but its personas are rephrased, generalized, or specialized, which no doubt increases the difficulty of the MRS task. We conduct statistics about the context lengths of mrsSamples where , , represent the minimum, maximum, and average lengths of each dataset and the last three columns are the ratios of mrsSamples with context lengths more than , , and among every dataset. As Table 2 shows, the context lengths of training datasets vary more, ranging from to while those in development and test datasets range from to . This could increase the robustness of the model after training on these training datasets but the development and test datasets seem not that comprehensive because they leave out the validating chance of extreme cases. Moreover, we can observe that samples with lengths between and take up the maximum proportion and the second category is , then , , orderly. These statistics are good references for the experiment setting, i.e., the maximum sequence lengths of PLMs, which have a significant impact on their performance. For instance, if the hardware resources are limited, the max sequence length can be chosen between 100 and 256 to test uniformly.
ConceptNet is a public multilingual graph of commonsense knowledge where labeled edges connect phrases and words. With the combination of several different sources (i.e., Facts acquired from Open Mind common sense (Singh et al., 2002), a subset of DBpedia (Auer et al., 2007), JMDict (Breen, 2004), Open Multilingual WordNet (Bond and Foster, 2013), etc.), ConceptNet possesses over million edges and over million nodes, whose English vocabulary consists of about nodes.
4.2. Baselines
To evaluate the effectiveness of SinLG on MRS, we make comparisons with state-of-the-art results from (Gu et al., 2020, 2021). Their brief introductions are listed as follows:
-
•
Starspace: Starspace (Wu et al., 2018a) learns entity embeddings separately and scores the response candidates by computing the similarity between them and the conversation.
-
•
PM: Ranking Profile Memory network (PM) is proposed in the publishing paper of PERSONA-CHAT, (Zhang et al., 2018) which uses an attention mechanism to identify the relevant lines of the profile with the dialogue context.
-
•
KV-PM: As an improvement of PM, the Key-Value Profile Memory network (KV-PM) is put forward (Miller et al., 2016). It calculates attention scores over keys and obtains the values instead of using the same keys as the original one, which can exceed the profile memory network according to the definition of key-value pairs on specific tasks.
-
•
Transformer: Transformer (Vaswani et al., 2017) is an encoder-decoder memory network based only on the attention mechanism. It achieves state-of-the-art performance on the next utterance retrieval task under multi-turn dialogues. The experiment of the transformer employs the setting in (Mazare et al., 2018), which only utilizes the encoding architecture.
-
•
DGMN: Document-Grounded Matching Network (DGMN) (Zhao et al., ) is one of the several pioneering studies that incorporate extra information (a related document) into the context besides the dialogue text itself. DGMN constructs rich representation for the context and document via self-attention to do matching for the dialogue and candidate response better.
-
•
DIM: Dually Interactive Matching network (DIM) (Gu et al., 2019) ranks response candidates via interactive matching for both response-context pairs and response-persona pairs respectively.
-
•
FIRE: FIRE Gu et al. (2020) identifies relative knowledge for context bidirectionally before matching response candidates with the conversation context and corresponding knowledge.
-
•
BERT: BERT (Devlin et al., 2019) is developed by Google, which is based on the encoder module of the transformer, targeting the pre-training of natural language processing (NLP). It exhibited state-of-the-art performance on many natural language understanding tasks, including GLUE, SQuAD, and SWAG, regarded as the SOTA baseline.
-
•
Roberta: According to proposing a set of important design choices and training strategies, and introducing alternatives, Roberta (Liu et al., 2019) achieves better downstream task performance than BERT. Roberta employed a novel dataset, CCNEWS, which testifies that utilizing more data for pre-training further boosts performance on downstream tasks.
4.3. Experiment Setting
We evaluate the model performance with the identical metrics and MRR which are commonly used on the MRS task (Tao et al., 2020; Gu et al., 2021; Whang et al., 2021). The equations of them are as follows:
| (11) |
| (12) |
where represents the total number of samples in the target dataset and denotes the rank of the ground-truth response in the sample. As there are response choices in PERSONA-CHAT, we choose , , and MRR as our final metrics.
The data splitting of PERSONA-CHAT is fixed, which is shown in Table 1. According to the statistics of datasets in Table 2, the default max sequence length of PLM is set as 512 which will cover nearly all samples’ lengths. The default number of nodes, embedding size, and the number of layers number in the GNN is set as 200, 200, and 5. For the sake of fairness, we set the batch size of all models as 64 and use the learning rate that literature (Yasunaga et al., 2021) recommends. The loss weight is set as 0.5 by default. We implement our solutions with Pytorch 1.9 and Python 3.8.
4.4. Performance Analysis
4.4.1. The Effectiveness of SinLG
In order to evaluate the effectiveness of SinLG, we conduct extensive experiments on the two variants of PERSONA-CHAT original and revised. We will analyze its effectiveness from three perspectives: comparisons with existing methods, comparisons under varying levels of understanding difficulty, and comparisons under the low-resource scenario.
| Model | Original | Revised | ||||||
| MRR | MRR | |||||||
| Starspace (Wu et al., 2018a) | 49.1 | 60.2 | 76.5 | - | 32.2 | 48.3 | 66.7 | - |
| PM (Zhang et al., 2018) | 50.9 | 60.7 | 75.7 | - | 35.4 | 48.3 | 67.5 | - |
| KV-PM (Miller et al., 2016) | 51.1 | 61.8 | 77.4 | - | 35.1 | 45.7 | 66.3 | - |
| Transformer (Mazare et al., 2018) | 54.2 | 68.3 | 83.8 | - | 42.1 | 56.5 | 75.0 | - |
| DGMN (Zhao et al., ) | 67.6 | 80.2 | 92.9 | - | 58.8 | 62.5 | 87.7 | - |
| DIM (Gu et al., 2019) | 78.8 | 89.5 | 97.0 | - | 70.7 | 84.2 | 95.0 | - |
| FIRE (Gu et al., 2020) | 81.6 | 91.2 | 97.8 | - | 74.8 | 86.9 | 95.9 | - |
| BERT (Devlin et al., 2019) | 85.49 | 94.0 | 98.52 | 91.27 | 79.41 | 90.27 | 97.5 | 87.25 |
| Roberta (Liu et al., 2019) | 85.22 | 94.36 | 98.67 | 91.19 | 80.62 | 90.52 | 97.66 | 87.94 |
| SinLG (ours) | 86.91 | 94.61 | 98.91 | 92.16 | 82.59 | 91.97 | 97.94 | 89.29 |
-
1
The experimental results of compared models under , , and MRR is on the test datasets of PERSONA-CHAT original and revised.
- 2
-
3
Note that the results of BERT, Roberta, and SinLG (based on Roberta) is the best ones under the provided default settings.
-
4
Numbers in boldface are the best results for corresponding metrics with p-value ¡ 0.05.
| Model | Original | |||||||
| Dev | Test | |||||||
| MRR | MRR | |||||||
| BERT-256 | 80.94 | 88.75 | 94.03 | 86.97 | 81.16 | 89.63 | 94.94 | 87.46 |
| SinLG-bert-256 | 82.19 | 91.31 | 97.31 | 88.8 | 81.67 | 91.59 | 97.83 | 88.71 |
| Roberta-256 | 80.73 | 87.89 | 93.12 | 86.45 | 81.32 | 88.91 | 94.57 | 87.27 |
| SinLG-roberta-256 | 85.39 | 92.71 | 97.67 | 90.75 | 84.28 | 92.53 | 97.88 | 90.2 |
| BERT-512 | 86.04 | 93.87 | 98.23 | 91.45 | 85.49 | 94.0 | 98.52 | 91.27 |
| SinLG-bert-512 | 85.04 | 93.73 | 98.3 | 90.93 | 84.57 | 93.89 | 98.67 | 90.78 |
| Roberta-512 | 86.23 | 93.76 | 98.13 | 91.49 | 85.22 | 94.36 | 98.67 | 91.19 |
| SinLG-roberta-512 | 87.64 | 94.48 | 98.77 | 92.47 | 86.91 | 94.61 | 98.91 | 92.16 |
-
1
Model means the maximum sequence length of the context is set as 256 or 512.
| Model | Revised | |||||||
| Dev | Test | |||||||
| MRR | MRR | |||||||
| BERT-256 | 75.84 | 85.82 | 93.05 | 83.59 | 75.29 | 86.02 | 93.54 | 83.47 |
| SinLG-bert-256 | 77.95 | 88.73 | 96.42 | 85.98 | 78.0 | 88.97 | 96.82 | 86.13 |
| Roberta-256 | 75.99 | 85.28 | 92.94 | 83.39 | 76.44 | 85.74 | 92.94 | 83.87 |
| SinLG-roberta-256 | 80.12 | 89.77 | 96.67 | 87.31 | 78.65 | 89.46 | 96.98 | 86.57 |
| BERT-512 | 79.98 | 90.5 | 97.69 | 87.6 | 79.41 | 90.27 | 97.5 | 87.25 |
| SinLG-bert-512 | 80.03 | 90.48 | 97.54 | 87.63 | 80.06 | 90.84 | 97.71 | 87.69 |
| Roberta-512 | 81.43 | 90.86 | 97.32 | 88.36 | 80.62 | 90.52 | 97.66 | 87.94 |
| SinLG-roberta-512 | 83.36 | 92.17 | 97.97 | 89.72 | 82.59 | 91.97 | 97.94 | 89.29 |
-
1
Model means the maximum sequence length of the context is set as 256 or 512.
Comparisons with existing methods (RQ1).
Table 3 summarize the results of all compared methods under four metrics on the test datasets of PERSONA-CHAT original and revised. Note that results of the former seven models (i.e., Starspace, PM, KV-PM, Transformer, DGMN, DIM, FIRE) are referred to the literature (Gu et al., 2020, 2021). The models in Table 3 are in chronological order from top to bottom. We make the following observations:
-
•
Research on MRS achieves impressive progress from simple unidirectional encoders (i.e., Starspace, PM, KV-PM, Transformer) to interactional and bidirectional ones (i.e., DGMN, DIM, FIRE, BERT, Roberta, SinLG). The performance gains from Transformer to DGMN and then DIM are remarkable, which means that interactional fusions and bidirectional semantic distinguishing are very significant operations for natural language understanding.
-
•
Previous works employ all kinds of detailed mechanisms to refine their models. Then PLMs show absolute predominance because of their bidirectional attention architecture and huge parameters, defeating all the previous models and completing the MRS task with good results.
-
•
The performance gain of our SinLG from PLMs shows that the external commonsense knowledge could provide auxiliary information bias to improve the performance of PLMs. This indicates that PLMs do not always exhibit their best performance via fine-tuning, and extra knowledge can assist to arouse their related memory for some specific tasks.
As a result, our method can achieve state-of-the-art results on both variants of PERSONA-CHAT with reasonable superiority. In order to illustrate the effectiveness of SinLG more specifically, we provide Table 4 and Table 5 where we compare PLM base models with SinLG under different max sequence lengths. From the results, we can see that SinLG outperforms base models steadily, especially on PERSONA-CHAT revised or when the max sequence length is 256.
Comparisons under varying levels of understanding difficulty (RQ2).
In the above perspective, we compare our model with existing methods. In this part, we will analyze the effectiveness of our model on the two variants of PERSONA-CHAT, which are under varying levels of understanding difficulty. As aforementioned in Section 4.1, PERSONA-CHAT revised is more difficult than PERSONA-CHAT original. Its persona descriptions are written in a more obscure way, which makes it need more complicated common sense to understand.
-
•
From Table 3, we can observe that our proposed model SinLG achieves more performance promotion on PERSONA-CHAT revised than PERSONA-CHAT original, and the same goes for all the other models. These improvements indicate that our proposed model could better handle more complicated understanding tasks. Hence, the difference value of Starspace’s results on PERSONA-CHAT original and revised is up to 16.9 at while it is only 4.35 with SinLG.
-
•
From Table 4 and Table 5, it can be observed that BERT-based SinLG achieves more performance gain compared with BERT on PERSONA-CHAT revised than PERSONA-CHAT original under both experimental setting with the maximum sequence length of 256 and 512. This phenomenon illustrates that BERT can well handle simple datasets via fine-tuning while under the more challenging understanding scenario, extra common sense would help it to perform better. However, the results of Roberta-based SinLG show even performance gains compared with Roberta on both PERSONA-CHAT original and revised, which indicates that Roberta needs extra common sense to arouse its related memory even on the simple dataset. Fortunately, this auxiliary operation can assist Roberta to achieve better results than BERT, which means the extra knowledge can help Roberta more.
-
•
Comparing the same metrics in Fig.3 and Fig.4, it is easy to find that the performance gain of our model on PERSONA-CHAT revised is more than on PERSONA-CHAT original under both full and low data resource scenarios, which testifies the effectiveness of our model on the more difficult understanding task again.
Overall, SinLG can obtain more promotion on PERSONA-CHAT revised than PERSONA-CHAT original. Nevertheless, in some specific cases, the performance gain of SinLG compared with its base models depends on the various sensitivity of base models to datasets and incorporating knowledge. In order to explore the effectiveness of SinLG more deeply, we identify such examples and perform comparisons upon cases that need external common sense and cases that do not need it. Specifically, we filter out samples whose score sums of related concepts from KG are within or out of the top 10% to testify the performance of SinLG. Then we find that the performance gain of our model from KG is more outstanding on the top 10% samples and trivial on the rest samples. The results are shown in Table 6 and Table 7.
| Model | Original | |||||||
| Top 10% | Remaining | |||||||
| MRR | MRR | |||||||
| BERT | 84.69 | 93.74 | 99.47 | 91.04 | 86.88 | 94.57 | 99.38 | 92.26 |
| SinLG-bert | 87.08 | 95.07 | 99.33 | 92.41 | 86.75 | 94.71 | 99.42 | 92.27 |
| Roberta | 84.02 | 93.16 | 99 | 91.1 | 87.74 | 95.54 | 99.52 | 92.7 |
| SinLG-roberta | 86.42 | 96.01 | 99.6 | 92.24 | 88.31 | 95.8 | 99.11 | 93.01 |
-
1
The maximum sequence length of the context is set as 512 in this comparison.
-
2
SinLG-bert/roberta represents the PLM part of our model that employs BERT or Roberta.
| Model | Revised | |||||||
| Top 10% | Remaining | |||||||
| MRR | MRR | |||||||
| BERT | 78.96 | 91.48 | 98 | 87.32 | 80.77 | 91.45 | 97.81 | 88.1 |
| SinLG-bert | 81.09 | 92.68 | 98.8 | 88.8 | 80.82 | 91.75 | 97.98 | 88.43 |
| Roberta | 77.63 | 91.32 | 97.89 | 87 | 81.03 | 91.39 | 98.4 | 89.06 |
| SinLG-roberta | 80.56 | 92.68 | 98.93 | 88.62 | 81.97 | 92.6 | 98.78 | 89.17 |
-
1
The maximum sequence length of the context is set as 512 in this comparison.
-
2
SinLG-bert/roberta represents the PLM part of our model that employs BERT or Roberta.
Comparisons under low data availability (RQ3).
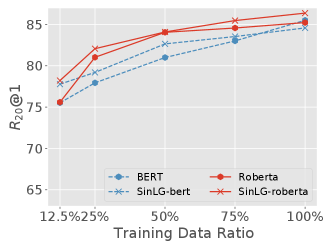
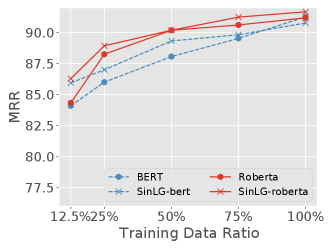
In this section, we will discuss the effectiveness of SinLG under low data availability, i.e., the shortage of the training corpus. The limited training data will bring unexpected performance loss for PLMs. Hence, we split the training set into several subsets, i.e., , , , and of the whole quantity to examine the performance of each method. We keep the development and test sets unchanged in these experiments. Their results are illustrated with Fig.3 and Fig.4 and the ranges of the same metrics on PERSONA-CHAT original and revised are set to the same for convenient comparisons.
-
•
From Fig.3, we can see that our model SinLG achieves an obvious performance gain with both PLM base models on PERSONA-CHAT original, especially when only and of the training data are provided. With the increase of training data, the performance of SinLG and the base models tend to be closer.
-
•
As Fig.4 displays, the performance gain of SinLG compared with the base models is more outstanding on PERSONA-CHAT revised, especially that between SinLG and Roberta. This indicates that our proposed method has more advantages when low-data availability and more difficultly-understanding datasets come together.
According to the above results and analysis, we can conclude that our proposed method could achieve superior performance when it is facing data scarcity.






4.4.2. Ablation Study (RQ4).
| Variant | PLM-base | KG | GNN | SL | QO-free | Original-Test | |||
| MRR | |||||||||
| Roberta | 83.56 | 92.73 | 98.12 | 89.94 | |||||
| SinLG-S0 | 83.67 | 92.28 | 97.62 | 89.79 | |||||
| SinLG-S1 | 86.16 | 94.36 | 98.95 | 91.73 | |||||
| SinLG-S2 | 85.8 | 94.08 | 98.8 | 91.47 | |||||
| SinLG-S3 | 86.31 | 94.26 | 99.86 | 91.8 | |||||
| SinLG-roberta | 86.91 | 94.61 | 98.91 | 92.16 | |||||
-
1
Checked KG indicates the model employs knowledge from the knowledge graph.
-
2
Checked SL means the model utilizes similarity loss to assist the training process of PLMs. Consequently, the QO-free item is checked, too, that is to say, there is no need to query entities from KG during the inference.
-
3
Numbers in boldface are the best results for corresponding metrics.
| Variant | PLM-base | KG | GNN | SL | QO-free | Revised-Test | |||
| MRR | |||||||||
| Roberta | 80.25 | 90.83 | 97.42 | 87.86 | |||||
| SinLG-S0 | 77.85 | 89.12 | 96.63 | 86.07 | |||||
| SinLG-S1 | 81.82 | 91.75 | 97.82 | 88.87 | |||||
| SinLG-S2 | 81.7 | 91.48 | 97.84 | 88.83 | |||||
| SinLG-S3 | 81.98 | 91.69 | 97.99 | 88.95 | |||||
| SinLG-roberta | 82.59 | 91.97 | 97.94 | 89.29 | |||||
-
1
Checked KG indicates the model employs knowledge from the knowledge graph.
-
2
Checked SL means the model utilizes similarity loss to assist the training process of PLMs. Consequently, the QO-free item is checked, too, that is to say, there is no need to query entities from KG during the inference.
-
3
Numbers in boldface are the best results for corresponding metrics.


To validate the performance gain from each component of SinLG, we conduct the ablation study which means cutting off some components from SinLG each time to form a simple-version model and check its performance via experiments. In other words, increasing our devised components step by step from the base model is also an alternative way to verify their effectiveness. We implement several simple variants of SinLG via the above ways, comparing with the PLM base model (Roberta) and SinLG (Roberta-based):
-
•
SinLG-S0: A straightforward baseline, where we perform entity linking and then append the extracted commonsense knowledge to the input utterance directly. In this way, the GNN part is not in use.
-
•
SinLG-S1: In this variant, we obtain the concatenation of the mean pooling results of concept embeddings and the context representation from Roberta, and feed it into an MLP layer to make the prediction. The concept embeddings are pre-computed via Roberta without fine-tuning.
-
•
SinLG-S2: Although the implementation of SinLG-S1 seems simple and valid, it needs to query related knowledge from KG even online and this process is complicated and time-consuming, which will lead to high latency and bad experience for users. Referring to the auxiliary function of the GNN in our model, we design the second variant to fulfill the query-online-free target. Based on SinLG-S1, we add the similarity loss between the mean pooling results of concept embeddings and the context representation and conduct inference with Roberta only.
-
•
SinLG-S3: Compared with SinLG, this variant omits the similarity loss part so that we can testify if the GNN part is useful in the whole architecture. The final matching scores are calculated according to the concatenation of representations from both the GNN and Roberta through an MLP layer.
In Table 8 and Table 9, we summarize the components that each model contains besides giving the test results. Especially, SL represents similarity loss while QO-free means query-online- free, that is, there is no need to extract related concepts from the knowledge graph when the model conducts inference online or on validation and test datasets. The time cost with/without QO-free (i.e., SinLG-S3 and SinLG) is given in Fig.5.
-
•
According to the results of SinLG-S1, we can observe that the commonsense knowledge extracted from ConceptNet is useful for improving the performance of the model because it gains obvious promotion on both datasets. This is consistent with our assumption at the beginning. Compared with the other variants’ performance gain, SinLG-S1’s is the largest one, which indicates that the most effective part of our model is the incorporation of commonsense knowledge from KG. The simple operation, concatenation of the knowledge embeddings’ mean pooling, and the representation of the PLM can improve by about 2 points.
-
•
Compared with SinLG-S1, the results of SinLG-S2 are regressed on both PERSONA-CHAT original and revised, which illustrates that the combination of similarity loss and the SinLG-S1 is not that suitable. The straightforward operation, i.e., mean pooling could not be able to strengthen the knowledge signal from external KG sufficiently.
-
•
From the result comparisons of SinLG-S3 and SinLG, it is obvious that the model’s performance even improved with the similarity loss between representations from the GNN and PLM. The augmented representations from GNN can arouse the PLM’s related memories more effectively so that it can attain better performance. The possible reason is that GNN can enhance the representation of relevant knowledge via message passing.
-
•
As Fig.5 shows, the inference time is correspond to instances. For each instance with response candidates, the average, worst, and best time costs of SinLG-S3 are , , and while those of SinLG are , and , respectively. Both SinLG-S3 and SinLG exhibit linearly-growth time costs with the increase of data, but with the QO process, SinLG-S3 needs to consume times SinLG’s cost. This enlightens us that the similarity loss component is very desirable especially when the online delay is considered.
Through the ablation study, we can draw a conclusion that the most effective part of our model is the fusion of extra common sense from the knowledge graph while GNN is also a strong assistant for the query-online-free target.








4.4.3. The Analysis of Hyperparameter Sensitivity (RQ5).
In this section, we would show the performance changing of our model when the hyperparameters choose different values. This section discusses two worth-discussing hyperparameters which are the maximum number of concept nodes to construct the subgraph , i.e., (10, 50, 100, 200, 300) in Eq.(4) and the loss weight (0.1, 0.3, 0.5, 0.7, 0.9) in Eq.(10).
Maximum node number
-
•
From Fig.6, we can observe that the best maximum node numbers for the two variant datasets are different. The model achieves relatively better performance on PERSONA-CHAT original when the maximum node number is set as 10 and the model performance decreases from 10 to 100 and then increases a bit between 100 and 300. According to the analysis, we consider there are two possible reasons that lead to this phenomenon. First, PERSONA-CHAT original is a simpler dataset whose persona information is so easy to understand for PLMs that not much extra commonsense knowledge is needed. Second, the concepts extracted from KG between 10 to 100 contain some impactive noises, which leads to the performance drop.
-
•
From the blue line with crosses in Fig.6, it is obvious that our model performs best on PERSONA-CHAT revised when the maximum node number is set as 200. As the maximum node number determines the message passing distance in the GNN part and the amount of extra commonsense knowledge from KG, it is reasonable that this depends on the attributes of specific datasets.
Loss weight
-
•
According to the curve of the red line with dots in Fig.7, our model obtains the best performance on PERSONA-CHAT original when the loss weight is 0.7, which demonstrates that the binary cross entropy plays a more important role than the cosine similarity in the loss function. This is consistent with the assumption that we mentioned above that PERSONA-CHAT original is easier and not much extra commonsense knowledge is needed.
-
•
According to the curve of the blue line with crosses in Fig.7, our model achieves the best performance when the loss weight is set as 0.5, which indicates that our proposed cosine similarity has an equal influence on the final results on PERSONA-CHAT revised. This testifies the effectiveness of extra commonsense knowledge for difficult understanding tasks.
In summary, our model is sensitive to these two hyperparameters which depend on the difficult levels of target datasets. Both the performance rangeability of our model and the optimal values of hyperparameters would be affected by the difficult levels of target datasets.
5. State-of-the-art
In this section, we introduce existing studies from two categories: the development of models on MRS, and some recent knowledge reasoning methods that provide us with insights and inspirations in this work.
5.1. Methods on Multi-turn Response Selection
In order to solve the multi-turn response selection problem, existing studies propose various context-response matching models which include traditional methods and PLM-based ones (Tao et al., 2021).
Traditional methods first focus on learning better embeddings for both the context and response. The concatenation of them is fed into a matching layer to make the final prediction (Wang et al., 2017; Wu et al., 2018b; Yan et al., 2018; Xu et al., 2021b). Specifically, Wang et al. (2017) utilize hand-craft features, i.e., sentence length, the number of common words for sentence-level representation while Wu et al. (2018b) employ topic features to provide clues for the selection of the best response. With the prosperity of deep neural networks, researchers propose employing CNN, RNN, and self-attention mechanism, combining with MLP, pooling layers to learn effective representations. For instance, Yan et al. (2018) extract features from three different levels, that is, word, phrase, and sentence and propose an attention-based CNN model to match the dialogue context with response candidates. Different from the previous methods that use topic-agnostic n-gram utterances as processing elements, Xu et al. (2021b) propose capturing topic shift at a discourse level and then effectively tracking the topic flow in the multi-turn dialogue.
Then the interactions between context and response draw intensive attention. Diverse new frameworks (Wu et al., 2017, 2018c; Tay et al., 2018; Zhou et al., 2018; Tao et al., 2019; Yuan et al., 2019) are presented to mine the interaction between them so that the matching accuracy can be improved. The study (Tay et al., 2018) designs the CARAN, stacked recurrent encoders, which consist of a bidirectional alignment and a multi-level attention refinement mechanism. Inspired by the rationale of Transformer, Zhou et al. (2018) propose a deep network based entirely on attention. Specifically, they create embeddings of context utterances at different granularities and then distill the highly-relative segment pairs with attention scores. Previous studies usually conduct interactions between context and response only on time, but Tao et al. (2019) raise this is conducted in a shallow way. Hence, they propose an interaction-over-interaction network to further the context-response interaction. Typically, Yuan et al. (2019) analyze the negative effects of involving exceeded context sentences and propose MSN to filter out the most relative sentences. As expected, the above methods keep trying to go deep into interactions fully and even among each word within the context while this can be accomplished well via PLMs.
Since the release of the first PLM (Devlin et al., 2019), various impressive results on downstream Natural Language Processing (NLP) tasks are achieved due to its strong capability in language representation and understanding. PLM-based models (Henderson et al., 2019; Whang et al., 2020; Wu et al., 2020; Xu et al., 2021a; Song et al., 2021) for MRS also emerge and lead to outstanding performance. Typically, the study (Henderson et al., 2019) learns embedding for both context and response severally via BERT and computes the dot product of them as the final matching score. Although BERT is conveniently adapted to various NLP tasks, Whang et al. (2020) believe it still has limitations for tasks on a certain domain so they first post-train BERT on their task-specific corpora with two objectives, i.e., Masked Language Model (MLM) and Next Sentence Prediction (NSP), and then fine-tune BERT on the response selection task to achieve a better performance than the previous state-of-the-art. Considering the generalization of PLMs and the particularity of specific tasks, Wu et al. (2020) propose TOD-BERT that incorporates speaker and system tokens into the masked language modeling during pre-training to model the dialogue attributes better. Further, Xu et al. (2021a) design several self-supervised tasks to pre-train the PLM-based model in a multi-task manner for MRS where remarkable results have been obtained.
Meanwhile, external knowledge in paragraphs (such as profiles of speakers, and entity infobox from Wikipedia) is employed to assist in solving MSR problem (Zhao et al., ; Gu et al., 2019, 2020; Liu et al., 2020; Gu et al., 2021; Zhang et al., 2021a). To overcome the challenge of grounding dialogue contexts with background texts and distinguishing significant information, DGMN (Zhao et al., ) encodes three contents (i.e., sentences from the document, utterances in the dialogue context, and the target response candidate) simultaneously via self-attention, and contains attention mechanism for document-aware contexts and context-aware documents so that it can learn a rich representation for both dialogue contexts and candidate responses. Different from existing persona fusion approaches that enhance the context representation by calculating the similarity between it and a predefined persona, Gu et al. (2019) propose DIM which ranks response candidates via interactive matching between responses and contexts, as well as responses and personas respectively. In order to make full use of the background knowledge, and simultaneously match response candidates with both the context and its knowledge, Gu et al. (2020) propose FIRE. They build two filters for the knowledge and the context, which generate representations for both knowledge and context under the other’s ground. Liu et al. (2020) incorporate knowledge triplets into the utterances and feed them into BERT while they use soft position and visible matrix to optimize the knowledge noise issues. Gu et al. (2021) explore the effect of utilizing persona information based on the PERSONA-CHAT dataset and design four persona fusion strategies which are implemented into three existing models to testify their effectiveness. However, the above studies haven’t considered the effectiveness of common sense from extra knowledge graphs so we propose a model to incorporate this information and assist the training of PLMs.
5.2. Knowledge Reasoning Methods
As a prevalent and effective method (Chen et al., 2019; Lin et al., 2019; Du et al., 2021; Zhang et al., 2022; Yu et al., 2022) in natural language processing and knowledge discovery domain, knowledge reasoning provides us with many insights for our work. Especially, Lin et al. (2019) present an inference framework for commonsense question answering, which first projects the question-answer text from the semantic way to the knowledge-based symbolic way, forming a subgraph of an external knowledge graph. Then, it embeds schema graphs with a network based on GCN, LSTM, and a hierarchical attention mechanism. At last, it scores each answer conditioned on graph representations. The intermediate attention scores lead to transparent, interpretable, and trustworthy inferences. Chen et al. (2019) put forward KBRD, which capacitates interactions between recommender and dialogue systems. In this framework, informative entities are connected to an extra knowledge graph and input into the recommender besides items and they are transmitted on the KG through a relational graph convolutional network to enrich the user interest’s representation. Moreover, the knowledge-enhanced representation is put back to the dialogue system as a form of vocabulary bias, capacitating it to select responses that match the user’s interest. Few previous studies pay attention to the relation types in the knowledge graph when extracting new facts from them, especially only one or few instances are given, Du et al. (2021) propose CogKR, which summarizes the underlying relations of the provided instances first and then builds a cognitive graph through coordinating retrieval and reasoning iteratively. Existing subgraph-retrieval methods from KG tend to increase reasoning bias, so Zhang et al. (2022) design a trainable subgraph retriever separated with the following reasoning process, which can broaden paths to induce the subgraph and stop automatic expansion. Above this, any subgraph-oriented reasoners can be utilized to delicately deduce more reasonable answers from the subgraph. Yu et al. (2022) design a knowledge-grounded dialogue system, called XDAI 111https://github.com/THUDM/XDAI which possesses the prompt-aware PLM exploitation without fine-tuning and is equipped with open-domain knowledge and domain-specific mechanism. It is convenient for developers to quickly create an open-domain or domain-oriented dialogue system without heavy fine-tuning of PLMs.
Inspiring by the dual process theory from the cognitive process of humans (Evans, 1984, 2003, 2008; Sloman, 1996), frameworks (Ding et al., 2019; Feng et al., 2020; Lv et al., 2020; Yasunaga et al., 2021; Liu et al., 2021; Zhang et al., 2021b; Zhou et al., 2022) combining PLM with GNN are presented to enhance both the reasoning ability and interpretability of intelligent systems. Specifically, Ding et al. (2019) propose CogQA for multi-hop question answering with the help of web-scale documents, which iteratively constructs a cognitive graph through the implicit extraction module (BERT) and conducts explicit reasoning via GNN. Yasunaga et al. (2021) present QA-GNN, another PLM+KG model for question answering, which first encodes the QA context via a PLM and then retrieves a KG subgraph that includes all multi-hop neighbor entities of QA. As some entities are always more relevant to the QA, a PLM is directly used to score them. In addition, the QA context is regarded as a super node of its KG subgraph, and its representation from PLM is the initial feature. Finally, the representation of the super node via graph attention network and PLMs, as well as the subgraph’s representation are concatenated together to obtain the inference through an MLP layer. Liu et al. (2021) propose GRN which pre-trains an ALBERT with two self-supervised tasks and then fine-tunes it with a graph reasoning module together. Beyond combining PLM and GNN simply, Zhang et al. (2021b) present GREASELM which fuses and exchanges information from all the PLM and KG in multiple layers. An interactive mechanism to bi-directionally exchange information is designed between each layer of the PLM and GNN. Therefore, the inputs of two modalities can interact with each other directly.
The studies introduced in this section not only provide us with many inspirations for our current work but also enlighten us about prospects in relevant domains.
6. CONCLUSION
In recent years, dialogue systems are attracting more and more attention from the public. MRS is a general research problem during developing a dialogue system. Combining the practice of the dialogue system, we find three main challenges of MRS. How to comprehensively understand the relationships between different utterances in the context, response candidates, and background information under the multi-turn scenario; how to select a rational response consistent with common sense; how to achieve a performance gain even under the low-resource scenario. In this work, we propose the framework SinLG where Pre-trained Language Models (PLMs) aim to understand the language correlation among different utterances in context, response candidates, and background information while the Graph Neural Network (GNN) is responsible for reasoning useful commonsense information from the extra knowledge base and assists PLMs in fine-tuning. We testify the enhancing effects of common sense from the knowledge graph and the GNN to PLMs on the public dataset, which demonstrates that our framework can not only improve PLMs’ performance on tasks with different levels of understanding difficulty but also achieve more performance gain under the low resource scenario.
However, one sufficiency of our model is the operation of the dialogue context is too coarse. If the length of the conversation extends to more than the maximum length of the model, some information may be lost. In the future, we can design a more reasonable and practical component to catch the whole dialogue’s information as much as possible. For example, we can learn the relationships of different sentences, get rid of the useless parts, and simplify the conversation before inputting the model.
Acknowledgements.
The authors would like to thank Ming Ding and Yangli-ao Geng for their empirical suggestions on this work. The authors would also like to thank the anonymous reviewers for their insightful comments provided.References
- Auer et al. [2007] Sören Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak, and Zachary Ives. Dbpedia: A nucleus for a web of open data. In The semantic web, pages 722–735. Springer, 2007.
- Bond and Foster [2013] Francis Bond and Ryan Foster. Linking and extending an open multilingual wordnet. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1352–1362, 2013.
- Bosselut et al. [2019] Antoine Bosselut, Hannah Rashkin, Maarten Sap, Chaitanya Malaviya, Asli Celikyilmaz, and Yejin Choi. Comet: Commonsense transformers for automatic knowledge graph construction. arXiv preprint arXiv:1906.05317, 2019.
- Breen [2004] Jim Breen. Jmdict: a japanese-multilingual dictionary. In Proceedings of the workshop on multilingual linguistic resources, pages 65–72, 2004.
- Chen et al. [2019] Qibin Chen, Junyang Lin, Yichang Zhang, Ming Ding, Yukuo Cen, Hongxia Yang, and Jie Tang. Towards knowledge-based recommender dialog system. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 1803–1813, 2019.
- Chen and He [2021] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15750–15758, 2021.
- Devlin et al. [2019] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, 2019.
- Ding et al. [2019] Ming Ding, Chang Zhou, Qibin Chen, Hongxia Yang, and Jie Tang. Cognitive graph for multi-hop reading comprehension at scale. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2694–2703, 2019.
- Du et al. [2021] Zhengxiao Du, Chang Zhou, Jiangchao Yao, Teng Tu, Letian Cheng, Hongxia Yang, Jingren Zhou, and Jie Tang. Cogkr: Cognitive graph for multi-hop knowledge reasoning. IEEE Transactions on Knowledge and Data Engineering, 2021.
- Evans [1984] Jonathan St BT Evans. Heuristic and analytic processes in reasoning. British Journal of Psychology, 75(4):451–468, 1984.
- Evans [2003] Jonathan St BT Evans. In two minds: dual-process accounts of reasoning. Trends in cognitive sciences, 7(10):454–459, 2003.
- Evans [2008] Jonathan St BT Evans. Dual-processing accounts of reasoning, judgment, and social cognition. Annu. Rev. Psychol., 59:255–278, 2008.
- Feng et al. [2020] Yanlin Feng, Xinyue Chen, Bill Yuchen Lin, Peifeng Wang, Jun Yan, and Xiang Ren. Scalable multi-hop relational reasoning for knowledge-aware question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1295–1309, 2020.
- Gu et al. [2019] Jia-Chen Gu, Zhen-Hua Ling, Xiaodan Zhu, and Quan Liu. Dually interactive matching network for personalized response selection in retrieval-based chatbots. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 1845–1854, 2019.
- Gu et al. [2020] Jia-Chen Gu, Zhenhua Ling, Quan Liu, Zhigang Chen, and Xiaodan Zhu. Filtering before iteratively referring for knowledge-grounded response selection in retrieval-based chatbots. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings (EMNLP:Findings), pages 1412–1422, 2020.
- Gu et al. [2021] Jia-Chen Gu, Hui Liu, Zhen-Hua Ling, Quan Liu, Zhigang Chen, and Xiaodan Zhu. Partner matters! an empirical study on fusing personas for personalized response selection in retrieval-based chatbots. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, pages 565–574. ACM, 2021.
- Henderson et al. [2019] Matthew Henderson, Ivan Vulić, Daniela Gerz, Iñigo Casanueva, Paweł Budzianowski, Sam Coope, Georgios Spithourakis, Tsung-Hsien Wen, Nikola Mrkšić, and Pei-Hao Su. Training neural response selection for task-oriented dialogue systems. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5392–5404, 2019.
- Huang et al. [2020] Shanshan Huang, Kenny Q Zhu, Qianzi Liao, Libin Shen, and Yinggong Zhao. Enhanced story representation by conceptnet for predicting story endings. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, pages 3277–3280, 2020.
- Humeau et al. [2019] Samuel Humeau, Kurt Shuster, Marie-Anne Lachaux, and Jason Weston. Poly-encoders: Transformer architectures and pre-training strategies for fast and accurate multi-sentence scoring. arXiv preprint arXiv:1905.01969, 2019.
- Jain and Lobiyal [2022] Goonjan Jain and DK Lobiyal. Word sense disambiguation using cooperative game theory and fuzzy hindi wordnet based on conceptnet. Transactions on Asian and Low-Resource Language Information Processing, 21(4):1–25, 2022.
- Li et al. [2021] Dan Li, Yang Yang, Hongyin Tang, Jingang Wang, Tong Xu, Wei Wu, and Enhong Chen. Virt: Improving representation-based models for text matching through virtual interaction. arXiv preprint arXiv:2112.04195, 2021.
- Lin et al. [2019] Bill Yuchen Lin, Xinyue Chen, Jamin Chen, and Xiang Ren. Kagnet: Knowledge-aware graph networks for commonsense reasoning. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2829–2839, 2019.
- Liu et al. [2020] Weijie Liu, Peng Zhou, Zhe Zhao, Zhiruo Wang, Qi Ju, Haotang Deng, and Ping Wang. K-bert: Enabling language representation with knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 2901–2908, 2020.
- Liu et al. [2019] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- Liu et al. [2021] Yongkang Liu, Shi Feng, Daling Wang, Kaisong Song, Feiliang Ren, and Yifei Zhang. A graph reasoning network for multi-turn response selection via customized pre-training. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 13433–13442, 2021.
- Loshchilov and Hutter [2017] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Lv et al. [2020] Shangwen Lv, Daya Guo, Jingjing Xu, Duyu Tang, Nan Duan, Ming Gong, Linjun Shou, Daxin Jiang, Guihong Cao, and Songlin Hu. Graph-based reasoning over heterogeneous external knowledge for commonsense question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8449–8456, 2020.
- Mazare et al. [2018] Pierre-Emmanuel Mazare, Samuel Humeau, Martin Raison, and Antoine Bordes. Training millions of personalized dialogue agents. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2775–2779, 2018.
- Miller et al. [2016] Alexander Miller, Adam Fisch, Jesse Dodge, Amir-Hossein Karimi, Antoine Bordes, and Jason Weston. Key-value memory networks for directly reading documents. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1400–1409, 2016.
- Sap et al. [2019] Maarten Sap, Ronan Le Bras, Emily Allaway, Chandra Bhagavatula, Nicholas Lourie, Hannah Rashkin, Brendan Roof, Noah A Smith, and Yejin Choi. Atomic: An atlas of machine commonsense for if-then reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 3027–3035, 2019.
- Singh et al. [2002] Push Singh et al. The public acquisition of commonsense knowledge. In Proceedings of AAAI Spring Symposium: Acquiring (and Using) Linguistic (and World) Knowledge for Information Access, 2002.
- Sloman [1996] Steven A Sloman. The empirical case for two systems of reasoning. Psychological bulletin, 119(1):3, 1996.
- Song et al. [2021] Haoyu Song, Yan Wang, Kaiyan Zhang, Wei-Nan Zhang, and Ting Liu. Bob: Bert over bert for training persona-based dialogue models from limited personalized data. arXiv preprint arXiv:2106.06169, 2021.
- Speer et al. [2017] Robyn Speer, Joshua Chin, and Catherine Havasi. Conceptnet 5.5: An open multilingual graph of general knowledge. In Thirty-first AAAI conference on artificial intelligence, 2017.
- Tao et al. [2019] Chongyang Tao, Wei Wu, Can Xu, Wenpeng Hu, Dongyan Zhao, and Rui Yan. One time of interaction may not be enough: Go deep with an interaction-over-interaction network for response selection in dialogues. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), pages 1–11, 2019.
- Tao et al. [2020] Chongyang Tao, Wei Wu, Yansong Feng, Dongyan Zhao, and Rui Yan. Improving matching models with hierarchical contextualized representations for multi-turn response selection. In Proceedings of the 43rd International ACM Conference on Research and Development in Information Retrieval (SIGIR), pages 1865–1868, 2020.
- Tao et al. [2021] Chongyang Tao, Jiazhan Feng, Rui Yan, Wei Wu, and Daxin Jiang. A survey on response selection for retrieval-based dialogues. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI, volume 21, pages 4619–4626, 2021.
- Tay et al. [2018] Yi Tay, Anh Tuan Luu, and Siu Cheung Hui. Co-stack residual affinity networks with multi-level attention refinement for matching text sequences. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4492–4502, 2018.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Veličković et al. [2017] Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. arXiv preprint arXiv:1710.10903, 2017.
- Wang et al. [2017] Ziliang Wang, Si Li, Guang Chen, and Zhiqing Lin. Deep and shallow features learning for short texts matching. In 2017 International Conference on Progress in Informatics and Computing (PIC), pages 51–55. IEEE, 2017.
- Whang et al. [2020] Taesun Whang, Dongyub Lee, Chanhee Lee, Kisu Yang, Dongsuk Oh, and Heuiseok Lim. An effective domain adaptive post-training method for bert in response selection. In INTERSPEECH, pages 1585–1589, 2020.
- Whang et al. [2021] Taesun Whang, Dongyub Lee, Dongsuk Oh, Chanhee Lee, Kijong Han, Dong-hun Lee, and Saebyeok Lee. Do response selection models really know what’s next? utterance manipulation strategies for multi-turn response selection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 14041–14049, 2021.
- Wu et al. [2020] Chien-Sheng Wu, Steven CH Hoi, Richard Socher, and Caiming Xiong. Tod-bert: Pre-trained natural language understanding for task-oriented dialogue. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 917–929, 2020.
- Wu et al. [2018a] Ledell Yu Wu, Adam Fisch, Sumit Chopra, Keith Adams, Antoine Bordes, and Jason Weston. Starspace: Embed all the things! In Thirty-Second AAAI Conference on Artificial Intelligence, 2018a.
- Wu et al. [2017] Yu Wu, Wei Wu, Chen Xing, Ming Zhou, and Zhoujun Li. Sequential matching network: A new architecture for multi-turn response selection in retrieval-based chatbots. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 496–505, 2017.
- Wu et al. [2018b] Yu Wu, Zhoujun Li, Wei Wu, and Ming Zhou. Response selection with topic clues for retrieval-based chatbots. Neurocomputing, 316:251–261, 2018b.
- Wu et al. [2018c] Yu Wu, Wei Wu, Can Xu, and Zhoujun Li. Knowledge enhanced hybrid neural network for text matching. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018c.
- Xu et al. [2021a] Ruijian Xu, Chongyang Tao, Daxin Jiang, Xueliang Zhao, Dongyan Zhao, and Rui Yan. Learning an effective context-response matching model with self-supervised tasks for retrieval-based dialogues. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 14158–14166, 2021a.
- Xu et al. [2021b] Yi Xu, Hai Zhao, and Zhuosheng Zhang. Topic-aware multi-turn dialogue modeling. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 14176–14184, 2021b.
- Yan et al. [2018] Zhao Yan, Nan Duan, Junwei Bao, Peng Chen, Ming Zhou, and Zhoujun Li. Response selection from unstructured documents for human-computer conversation systems. Knowledge-Based Systems, 142:149–159, 2018.
- Yasunaga et al. [2021] Michihiro Yasunaga, Hongyu Ren, Antoine Bosselut, Percy Liang, and Jure Leskovec. Qa-gnn: Reasoning with language models and knowledge graphs for question answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 535–546, 2021.
- Young et al. [2018] Tom Young, Erik Cambria, Iti Chaturvedi, Hao Zhou, Subham Biswas, and Minlie Huang. Augmenting end-to-end dialogue systems with commonsense knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018.
- Yu et al. [2022] Jifan Yu, Xiaohan Zhang, Yifan Xu, Xuanyu Lei, Xinyu Guan, Jing Zhang, Lei Hou, Juanzi Li, and Jie Tang. A tuning-free framework for exploiting pre-trained language models in knowledge grounded dialogue generation. In Proceedings of the 28th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’22), 2022.
- Yuan et al. [2019] Chunyuan Yuan, Wei Zhou, Mingming Li, Shangwen Lv, Fuqing Zhu, Jizhong Han, and Songlin Hu. Multi-hop selector network for multi-turn response selection in retrieval-based chatbots. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 111–120, 2019.
- Zhang et al. [2021a] Chen Zhang, Hao Wang, Feijun Jiang, and Hongzhi Yin. Adapting to context-aware knowledge in natural conversation for multi-turn response selection. In Proceedings of the Web Conference (WWW), pages 1990–2001, 2021a.
- Zhang et al. [2022] Jing Zhang, Xiaokang Zhang, Jifan Yu, Jian Tang, Jie Tang, Cuiping Li, and Hong Chen. Subgraph retrieval enhanced model for multi-hop knowledge base question answering. arXiv preprint arXiv:2202.13296, 2022.
- Zhang et al. [2018] Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. Personalizing dialogue agents: I have a dog, do you have pets too? arXiv preprint arXiv:1801.07243, 2018.
- Zhang et al. [2021b] Xikun Zhang, Antoine Bosselut, Michihiro Yasunaga, Hongyu Ren, Percy Liang, Christopher D Manning, and Jure Leskovec. Greaselm: Graph reasoning enhanced language models. In International Conference on Learning Representations, 2021b.
- [60] Xueliang Zhao, Chongyang Tao, Wei Wu, Can Xu, Dongyan Zhao, and Rui Yan. A document-grounded matching network for response selection in retrieval-based chatbots. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, August 10-16, 2019, pages 5443–5449.
- Zhou et al. [2018] Xiangyang Zhou, Lu Li, Daxiang Dong, Yi Liu, Ying Chen, Wayne Xin Zhao, Dianhai Yu, and Hua Wu. Multi-turn response selection for chatbots with deep attention matching network. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1118–1127, 2018.
- Zhou et al. [2022] Yucheng Zhou, Xiubo Geng, Tao Shen, Guodong Long, and Daxin Jiang. Eventbert: A pre-trained model for event correlation reasoning. In Proceedings of the ACM Web Conference 2022, pages 850–859, 2022.
- Zhu et al. [2021] Yutao Zhu, Jian-Yun Nie, Kun Zhou, Pan Du, and Zhicheng Dou. Content selection network for document-grounded retrieval-based chatbots. In Advances in Information Retrieval: 43rd European Conference on IR Research, ECIR 2021, Virtual Event, March 28–April 1, 2021, Proceedings, Part I 43, pages 755–769. Springer, 2021.