Multi-Scale Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition
Abstract
Skeleton data is of low dimension. However, there is a trend of using very deep and complicated feedforward neural networks to model the skeleton sequence without considering the complexity in recent year. In this paper, a simple yet effective multi-scale semantics-guided neural network (MS-SGN) is proposed for skeleton-based action recognition. We explicitly introduce the high level semantics of joints (joint type and frame index) into the network to enhance the feature representation capability of joints. Moreover, a multi-scale strategy is proposed to be robust to the temporal scale variations. In addition, we exploit the relationship of joints hierarchically through two modules, i.e., a joint-level module for modeling the correlations of joints in the same frame and a frame-level module for modeling the temporal dependencies of frames. With an order of magnitude smaller model size than most previous methods, MS-SGN achieves the state-of-the-art performance on the NTU60, NTU120, and SYSU datasets.
Index Terms:
Semantics-guided, multi-scale, efficient, joint-level module, frame-level module, efficient.I Introduction

Human action recognition is a hot topic in computer vision, which has a lot of application scenarios, e.g., human-computer interaction, video retrieval, and video understanding [37, 52, 1]. Skeleton-based action recognition [58, 8, 38, 60] has attracted increasing interests in recent years. Skeleton is a type of well structured data with each person represented by a set of key joints, where each joint is identified by a joint type, a frame index, and a 3D position. Skeleton-based representation has several advantages/characteristics. First, skeleton is a high level representation, where the pose and motion of the human body is abstracted by some key joints. Biologically, human are able to distinguish different action categories by observing the motion and configuration of joints even without the help of appearance information [18]. Second, skeleton data is easily available nowadays because of the cost effective depth cameras [64] and pose estimation models [40, 4, 45]. Third, compared with RGB video, the skeleton representation is robust to variation of appearance. Fourth, thanks to the low dimensional representation of the human body, the complexity and computation cost is friendly. Besides, RGB video data is complementary to skeleton data, where the combination of the two types of data can lead to better performance of action recognition [44]. In this work, we focus on skeleton-based action recognition.



In recent years, deep learning based models are designed to model the spatial and temporal dependencies of joints in a skeleton sequence for skeleton-based action recognition[12, 49]. Various network structures have been exploited, such as Recurrent Neural Networks (RNN) [8, 66, 38, 43, 59, 42], Convolutional Neural Networks (CNN) [19, 60, 31, 53], and Graph Convolutional Networks (GCN) [56, 42, 46]. In the early years, RNN/LSTM was widely used to exploit the short and long term temporal dynamics, in considering the powerful ability of RNNs for modeling temporal dependencies. Recently, there is a trend of using feedforward (i.e., non-recurrent) convolutional neural networks for modeling sequences in speech, language [36, 11, 55, 50], and skeleton [19, 60, 31, 53] due to their superior performance. To make the CNN network suitable for skeleton-based action recognition, most approaches reorganize the skeleton sequence by mapping it to a skeleton map and resizing the skeleton map to a certain size (e.g. 224224) suitable for the input of a CNN network (e.g. ResNet50 [13]), where the rows/columns of the skeleton map correspond to the different types of joints/frames indexes [19, 60, 31, 53]. In these methods, long-term dependencies and semantic information are expected to be captured by the large receptive fields of deep networks. Recently, a lot of works tend to adopt GCN to exploit the spatio-temporal dependencies of the joints in the skeleton sequence by taking the coordinate of each joint as a node of a graph and conducting massage passing among the nodes with a pre-defined or content-dependent adjacency matrix [56, 39, 41, 46, 33]. However, using only the coordinates of joints is less efficient to explore the structures of skeletons.
Intuitively, the semantic information of skeleton sequence, i.e., the joint type and the frame index, is beneficial for recognizing different action categories. The semantics together with dynamics (i.e., 3D coordinates) reveal the spatial and temporal configuration/structure of human body joints. As we know, if the coordinates of two joints are the same but the semantics is different, they could carry/deliver very different information. For example, for a joint above the head, if this joint is hand, the action is likely to be raising hand; if it is foot, the action may be kicking a leg. Besides, the temporal order of frames is also discriminative to the recognition of actions. It is a key factor to distinguish some kinds of actions, e.g., sitting down and standing up, where the only difference is the occurrence order of the frames. However, most approaches overlook the importance of the semantic information. In addition, different sequences present different temporal dynamics. Different subjects (with different ages, genders, and culture) tend to perform the same action in different motion patterns (e.g., different speeds) and such diversity should be exploited.
To address the above-mentioned problems, we propose a multi-scale semantics-guided neural network (MS-SGN) which explicitly exploits the semantics for efficient skeleton-based action recognition. The overall framework is shown in Fig. 2. A hierarchical network is proposed, which explores the joint-level and frame-level dependencies of the skeleton sequence. It consists of a dynamics representation (DR) module, a joint-level (JL) module and three frame-level (FL) modules, where the DR module and JL module are shared by different temporal scale inputs, and the FL modules are non-shared. For the frame-level (FL) modules.
As illustrated in Fig. 3, for better joint-level correlation modeling, besides the dynamics, we incorporate the semantics of joint type (e.g., ‘head’, and ‘hip’) to the GCN layers which enables the content adaptive graph construction and effective message passing among joints within each frame. As illustrated in Fig. 4, for better frame-level correlation modeling, we incorporate the semantics of temporal frame index to the network. Particularly, we perform a Spatial MaxPooling (SMP) operation over all the features of the joints within the same frame to obtain frame-level feature representation. Combined with the embedded frame index information, two temporal convolutional neural network layers are used to learn feature representations for classification. In order to deal with the temporal variation of different subjects and actions, we feed the FL modules with multi-scale information at input-level. In addition, we build a strong baseline with high performance and efficiency by exploiting some technologies. We introduce fine-grained movement (see Fig. 5 of joints in the same body part to the strong baseline, which enhances the ability of distinguishing the actions with similar poses. Thanks to the efficient exploration of semantic information, the hierarchical modeling, multi-scale information exploration, and the build of strong baseline, our proposed SGN achieves the state-of-the-art performance with a much smaller number of parameters.
The main contributions are summarized as follows:
-
•
We propose to explicitly explore the joint semantics (frame index and joint type) for efficient skeleton-based action recognition. Previous works overlook the importance of semantics and rely on deep networks with high complexity for action recognition.
-
•
We present a semantics-guided neural network (SGN) to exploit the spatial and temporal correlations at joint-level and frame-level hierarchically.
-
•
We explore the multi-scale information to be robust to the temporal variations of different subjects and actions.
-
•
We develop a lightweight strong baseline, which is more powerful than most previous methods. We hope the strong baseline will be helpful for the study of skeleton-based action recognition. In the strong baseline, we explore the fine-grained movement of joints in the same body part, which significantly improves the ability of recognizing actions with similar skeletons.
With the above technical contributions, we have obtained a high performance skeleton-based action recognition model with high computational efficiency. Extensive ablation studies demonstrate the effectiveness of the proposed model designs.
It should be mentioned that this paper is an extension of our previous conference paper [61]. As an extension, we explore the multi-scale information to be robust to the temporal variations of different subjects and actions. Moreover, we explore the fine-grained movement of joints in the same body part, which significantly improves the ability of recognizing actions with similar skeletons. On the three largest benchmark datasets for skeleton-based action recognition, our proposed model consistently achieves superior performance while having an order of magnitude smaller model size when compared with many algorithms (see Fig. 1).
II Related work
Recently, skeleton-based action recognition is developing rapidly and attracting growing interests. Recent works using neural networks [12] have significantly outperformed traditional approaches that use hand-crafted features [12, 54, 48, 57, 10]. Therefore, we will limit our review to the deep learning based methods.
Recurrent Neural Network based Methods. Recurrent neural networks (RNNs), such as LSTM [15] and GRU [6], are often used to model the temporal dynamics of skeleton sequence through the recurrent connections in RNN. [8, 38, 66, 43, 59, 62, 63]. They tend to concatenate all joints (in a certain order) represented by 3D coordinates in a frame to form a vector, which will be taken as the input of different RNN structures without explicitly telling the networks which dimensions belong to which joint. To make the networks aware of the spatial structural information, some other RNN-based works design special structures in RNN. Shahroudy et al. divide the cell of LSTM into five sub cells corresponding to five body parts, i.e., torso, two arms, and two legs, respectively [38]. Liu et al. feed one type of joint at each step into their proposed spatial-temporal LSTM [28]. To some extent, they implicitly distinguish the different types of joints and body parts.
Convolutional Neural Network based Methods. In recent years, convolutional neural networks are usually used to model the speech and language sequence, which lead to high performance and efficiency [36, 11, 55, 50, 47]. Compared with RNN-based methods, CNN-based methods show superiority in parallelism. This holds for skeleton-based action recognition [7, 23, 19, 3], which transform the skeleton sequence to a skeleton map of some target size. CNNs, such as ResNet [13], will be used to explore the spatial and temporal dynamics of joints by taking the skeleton map as the input. Some works obtain the skeleton map by directly treating the joint coordinate (x,y,z) as the R, G, and B channels of a pixel [7, 23]. Ke et al. transform the skeleton sequence to four 2D skeleton maps, which are represented by the relative position between four selected reference joints (i.e., the left/right shoulder, the left/right hip) and other joints [19]. Skeleton is well structured data with each joint owning its unique high level semantics, i.e., frame index and joint type. However, the kernels/filters of CNNs are translation invariant [34] and thus cannot directly perceive the semantics from such input skeleton maps. To be aware of such semantics, those CNN-based works tend to use a deep network with large receptive fields, which results in low computational efficiency.
Graph Convolutional Network based Methods. Graph convolutional networks [22], which have been proven to be effective for processing structured data, are suitable for modeling the dependencies of structural skeleton sequence. Yan et al. propose a spatial and temporal graph convolutional network, where each joint is treated as a node of the graph [56]. The adjacency matrix is pre-defined by human based on prior knowledge. For example, if two joints are adjacent within the human body, the weight between them is high in the adjacency matrix. To enhance predefined graph and make it more suitable for action recognition, Tang et al. not only assign high weight value between physical connected joints, but also high weight value between certain physical disconnected joints. For example, a high weight value between two hands is vital for the action of writing. Liu et al. model the long-range dependencies of joints better by forcing the closer and further nodes to have the same influence on the current joints [33]. However, the pre-defined graph is not optimal for all actions. A SR-TSL model [42] is proposed to learn the graph edge of five human body parts within each frame using a data-driven method instead of leveraging human definition. Shi et al. adopt non-local block to obtain graph for every skeleton sequence based on its content, followed by message passing in GCN layers with the learned graph [39].However, these data-driven methods overlook the importance of the informative semantics in learning the graph edge and message passing, which makes the networks less efficient.
Explicit Exploration of Semantics Information. In other fields, e.g., machine translation and image recognition, some works have exploited the semantics explicitly and demonstrated its effectiveness [47, 65]. Ashish et al. explicitly encode the position of the tokens in the sequence to make use of the order of the sequence in machine translation tasks [47]. Zheng et al. encode the group index into convolutional channel representation to preserve the information of group order [65]. For skeleton-based action recognition, however, the important high level semantics of joint type and frame index is overlooked. In our work, we propose to explicitly encode the joint type and frame index to the representation of joint, which preserves the important spatial and temporal body structure and makes the networks more efficient. As an initial attempt to explore such semantics, we hope it will inspire more investigation and exploration in the community.
III Semantics-Guided Neural Networks
A joint of the skeleton sequence can be identified by its semantics (joint type and frame index) and its dynamics (position/3D coordinates, velocity and fine-grained movement). Semantics is vital to preserve the important information of spatial and temporal structure and configuration of a human body. Previous works [19, 7, 60, 56, 42, 39], however, typically overlook the semantics. Moreover, the scalable motion dynamics are in general under-explored in skeleton based action recognition. For examples, for the same action, the pattern/speed of acting by a young man could be rather different from that of an old man.
We propose a multi-scale semantics-guided neural network (MS-SGN) for skeleton-based action recognition and show the overall end-to-end framework in Fig. 2. For a skeleton sequence, we first identify a joint in dynamics representation (DR) module by combining position, velocity, and fine-grained movement information together. Then, a joint-level (JL) module exploits the correlations of joints in the same frame under the guidance of the semantics of joint type. Afterward, three frame-level (FL) modules exploit the correlations of frames by exploring the temporal correlations of different scales under the guidance of the semantics of temporal index. For different scale information, the DR module and JL module are shared while the FL modules are non-shared across scales. We describe the details of the framework in the following subsections.
We denote a skeleton sequence as a set of joints = { }, where denotes the joint of type at time . denotes the number of frames of the skeleton sequence and denotes the total number of joints of a human body in a frame. It is noted that differs for different scale information and we omit the denotation of scale for simplicity.
III-A Dynamics Representation Module

For a given joint , we define its dynamics by the position in the 3D coordinate system, the velocity , and the fine-grained movement and , where and denote the referent joint of body part in time for position and velocity, respectively. As illustrated in Fig. 5, we divide the whole human body into 5 body parts. For each body part, we select one joint as its referent joint, i.e., left hand, right hand, left knee, right knee, and spine. The fine-grained movements capture the fine-gained relations and motions. We encode/embed the position, velocity, and the fine-grained movement to features, i.e., , , , and respectively, in the same high dimensional space. We fuse them together by summation as
| (1) |
where denotes the number of dimensions of a joint representation. We use the same network structure for the feature encoding of the four kinds of dynamical information, respectively. Taking the embedding of position as an example, two fully connected layers (FC) are used to encode the position to high dimension space, which is formulated as follows:
| (2) |
where and are weight matrices, and are the bias vectors, denotes the ReLU activation function [35]. Similarly, we obtain the embedding for velocity as and .
III-B Joint-level Module
The joint-module is designed for exploiting the dependencies of joints in the same frame, which is illustrated in Fig. 3. We adopt graph convolutional networks (GCN) to explore the correlations for the structural skeleton data. One key to apply GCN to skeleton-based action recognition is how to design suitable graph. Some previous GCN-based approaches obtain the graph by taking the joints as nodes with a pre-defined adjacency matrix based on prior knowledge [56] or a learned adaptive graph based on the input content [39]. We adopt the content adaptive strategy to obtain the adjacency matrix. Differently, we incorporate the semantics of joint type to the GCN layers for more effective learning.
We enhance the power of GCN layers by making full use of the semantics from two aspects. First, the semantics of joint type and the dynamics are combined together to learn the graph connections among the nodes (different joints) within a frame. The joint type information is helpful for learning suitable adjacent matrix (i.e., relations between joints in terms of connecting weights). Take two source joints, foot and hand, and a target joint head as an example, intuitively, the connection weight value from foot to head should be different from the value from hand to head even when the dynamics of foot and hand are the same. Second, as part of the information of a joint, the semantics of joint types takes part in the message passing process in GCN layers. Previous GCN is position-independent and it has no idea of the structural information of skeleton, which is less efficient for recognizing actions. In contrast, we take advantage of the semantics of joint type to make the GCN know the structural information of skeleton during massage passing.
We denote the type of the joint (also referred to as type ) as a one-hot vector , where the dimension is one and the others are all zeros. Similar to the encoding of position as in (2), we obtain the embedding of the joint type in high dimension space as .
For each skeleton frame consisting of joints, we build a graph of nodes. To enhance the representation ability of a joint, we encode it by fusing its dynamics and semantics of the joint type together, i.e., = [. All the joints of frame are then represented by .
Similar to [51, 50, 39], the edge weight from the joint to the joint in the same frame is computed by their similarity/affinity in the embeded space as
| (3) |
where and are implemented by two FC layers, i.e., and .
By computing the affinities of all the joint pairs in the same frame based on (3), we obtain the adjacency matrix . Normalization using SoftMax as [47, 50] is performed on each row of so that the sum of all the edge values connected to same target node is 1. The normalized adjacency matrix is denoted as . A graph convolution layer with the massage passing among nodes is formulated as
| (4) |
where and are transformation matrices. The weight matrices are shared for different temporal frames. is the output. Note that one can stack multiple residual graph convolution layers to enable further message passing among nodes with the same adjacency matrix .
III-C Frame-level Module
The frame-level module is designed for exploiting the dependencies across frames, which is shown in 4. To make the network aware of the order of frames, we incorporate the semantics of frame index to enhance the representation capability of a frame.
Similar to joint type, we denote the frame index by a one-hot vector . With the similar way of encoding position to high dimension space as shown in (2), we obtain the embedding of the frame index as . We denote the joint representation corresponding to joint type at frame with both the semantics of frame index and the learned feature as = , where .
A spatial MaxPooling layer is applied to merge the information of all joints in a frame. Therefore, joints in the same frame will be taken as a whole. The dimension of feature of the sequence is thus . Two CNN layers are applied. The first CNN layer is a temporal convolution layer to model the dependencies of frames. The second CNN layer is used to enhance the representation capability of learned features by mapping it to a high dimension space with temporal kernel size of 1. After the two CNN layers, we apply a temporal MaxPooling layer to aggregate the information of all frames and obtain the sequence level feature representation of dimensions. This is then followed by a fully connected layer with Softmax to perform the classification.
III-D Mulit-scale SGN
To better explore the temporal dynamics/variations, we propose a multi-scale strategy. As we know, different subjects tend to perform actions in different speeds/patterns, which leads to the temporal variation of one action varies in a large range. In order to alleviate the influence of temporal variation, we sample each sequence in multi temporal scales and feed them to the proposed MS-SGN at input-level. As illustrated in Fig. 2, in MS-SGN, we have multiple frame-level (FL) modules for tackling different temporal scaled actions. Note that DR module and JL module are shared for different scaled sequence while the FL modules not shared.
IV Experiments
In the following, we demonstrate the effectiveness of the proposed multi-scale semantics-guided neural networks for skeleton-based action recognition. We first describe the datasets and the implementation details in Subsection IV-A and IV-B. In Subsection IV-C, we perform ablation studies to analyze how our model works. In Subsection IV-D, we compare our SGN with the stat-of-the-art approaches on three benchmark datasets.
IV-A Datasets
NTU60 RGB+D Dataset (NTU60) [38]. This dataset is collected by the Kinect V2 camera for 3D action recognition. It contains 56,880 skeleton sequences in total, including 60 different action classes performed by 40 different subjects with different gender and age. There are 25 key joints in a human skeleton body and each joint is represented 3D coordinates. We use the same protocol settings [38], i.e., Cross Subject (CS) and Cross View (CV). For the CS setting, half of the 40 subjects are used for training and the rest for testing. For CV setting, the sequences captured by two of the three cameras are used for training and those captured by the other camera are used for testing. During training, 10% of the training sequences are randomly selected as validation sequences for both the CS and CV settings as [38].
NTU120 RGB+D Dataset (NTU120) [26]. As an extension of NTU60 dataset, NTU120 dataset contains 114,480 skeleton sequences in total, including 120 action classes performed by 106 distinct human subjects. We use the same protocol settings [38], i.e., Cross Subject (C-Subject) and Cross Setup (C-Setup). For C-Subject setting, half of the 106 subjects are used for training and the rest for testing. For C-Setup setting, half of the setups are used for training and the rest for testing.
SYSU 3D Human-Object Interaction Dataset (SYSU) [16]. It contains 480 skeleton sequences of 12 actions performed by 40 different subjects. There are 20 key joints in a human skeleton body and each joint is represented 3D coordinates. We use the same evaluation protocols as [16], i.e., Cross Subject (CS) and Same Subject (SS) setting. For the CS setting, half of the subjects are used for training and the rest for testing. For the SS setting, half of the samples of each activity are used for training and the rest for testing.30-fold cross-validation are used during training and we show the mean accuracy for each setting [16].
IV-B Implementation Details
Network Setting. In the dynamic representation (DR) module, the number of neurons of each FC layer is set to 64 (i.e., ). Note that the weights of FC layers are non-shared for position, velocity, and fine-grained movement. To encode the joint type, the number of neurons of the two FC layers are both set to 64. To encode the frame index, the numbers of neurons of the two FC layers are set to 64 and 256, respectively and . To compute the similarity in embed space as shown in (3), the number of neurons of each FC layer is set to 256, i.e., . In the joint-level module, the numbers of neurons of the three GCN layers are set to 128, 256, and 256, respectively. In the fame-level module, the number of neurons of the first CNN layer is set to 256 with kernel size of 3 along the temporal dimension, and the number of neurons of the second CNN layer is set to 512 with kernel size of 1 (i.e., ). After each GCN or CNN layer, we apply batch normalization [17] followed by ReLU nonlinear activation layer.
Training. All experiments are conducted on the Pytorch platform with one GPU card. We use the Adam [21] optimizer with the initial learning rate of 0.001. The learning rate decays by a factor of 10 at the 60th epoch, the 90th epoch, and the 110th epoch, respectively. The training is finished at the 120th epoch. We use a weight decay of 0.0001. The batch sizes for NTU60, NTU120, and SYSU datasets are set to 64, 64 and 16, respectively. Label smoothing [14] is utilized for all experiments and we set the smoothing factor to 0.1. Cross entropy loss for classification is used to train the networks.
Data Processing. Similar to [59], sequence level translation based on the first frame is performed to be invariant to the initial positions. If one frame contains two persons, we split the frame into two frames by making each frame contain one human skeleton. During training, we segment the each skeleton sequence into 15, 20, and 25 clips equally to obtain multi-scale skeleton sequences, and randomly select one frame from each clip, which make the final skeleton sequences contains 15, 20, and 25 frames, respectively. During testing, similar to [2], we randomly create 5 new sequences for each single-scale skeleton sequence in the same manner and then predict the final action class using the mean score.
To alleviate the influence of view variation, we perform data argumentation in the training procedure, i.e., rotating the 3D skeletons randomly by some degrees at sequence level. For the NTU60 (CS setting), NTU120, and SYSU datasets, we randomly select three degrees (around , , axes, respectively) between [] for a sequence. Considering the large view variation for NTU60 (CV setting), we randomly select three degrees between [].
IV-C Ablation Study
In Subsection IV-C1, we evaluate the effectiveness of explicitly exploiting semantics. The analysis of effectiveness of hierarchical model is presented in Subsection IV-C2. The strong baseline and its analyses are introduced in Subsection IV-C3. We evaluate the effectiveness of fine-grained movement in Subsection IV-C4. The analyses of the proposed multi-scale strategy is presented in IV-C4. The visualization of the responses of the spatial MaxPooling layer is shown in Subsection IV-C6. We compare the number of parameters between the proposed MS-SGN and eight other state-of-the-art methods in Subsection IV-C7
Considering NTU120 is the largest dataset for skeleton-based action recognition, we perform our ablation study based on it. We design two modules, i.e., single-scale semantics-guided neural network (SS-SGN), where each skeleton sequence contains 20 frames, and mulit-scale semantics-guided neural network (MS-SGN), where each skeleton sequence is sampled to have three temporal scales of 15, 20, and 25 frames, respectively. Both modules contain the fine-grained movement.
IV-C1 Effectiveness of Exploiting Semantics
Semantics contains the important structural information of a skeleton sequence which is important for skeleton-based action recognition. We use the SS-SGN to demonstrate the effectiveness of exploiting semantics by building eight neural networks and performing various experiments on the NTU120 dataset. Table I shows the results. For the eight models, JT denotes the semantics of joint type, FI denotes the semantics of frame index, G denotes the learning of graph (adjacency matrix), P denotes the graph convolutional operations which enable the massage passing. T-Conv denotes the temporal convolutional layer, i.e., the first CNN layer of the frame-level module. Three GCN layers and two CNN layers are used in the joint-level (JL) module and the frame-level (FL) module, respectively. w and w/o denote “with” and “without”, respectively.
Effectiveness of Exploiting Joint Type. To validate the effectiveness of the joint type on the joint-level module, we design four models based on SS-SGN as shown in rows 1 to 4 in Table I, where the semantics of temporal index is not used for all the four experiments. We explain the setting of one model in detail here, and the settings of the other three models can be obtained in a similar way. For the model “JL(G w/o JT & P w/o JT) & FL”, the semantics of joint type is not used for learning adjacency matrix () (i.e., G w/o JT) and not used for massage passing () in GCN layers (i.e., P w/o JT). We have three main observations about the effectiveness of the semantics of joint type on the joint-level module as follows.
1) For the learning of adjacency matrix of the graph, with the help of the semantics of joint type, “JL(G w JT & P w/o JT) & FL” outperforms “JL(G w/o JT & P w/o JT) & FL” by 0.4 for the CS setting. Intuitively, if the types of the joints are not introduced into the model, it cannot distinguish the joints with the same coordinates even though their semantics are different, which results in inferior edge weight between those joints. The semantics of joint type is beneficial for learning graph edges.
2) For the message passing in GCN layers, with the help of the semantics of joint type, “JL(G w/o JT & P w JT) & FL” is superior to “JL(G w/o JT & P w/o JT) & FL” by 0.8%. The reason is that GCN itself is not aware of the order (type) of joints which makes it hard to learn features of the skeleton data with high structural information. For example, the information contributed from foot joint and wrist joint to a target joint should be different even when the 3D coordinates of the two joints are the same during the message passing. Introducing the joint type information makes GCN more efficient.
3) Using the semantics of joint type for both learning adjacency matrix of the graph and the message passing at the same time (“JL(G w JT & P w JT) & FL”) does not bring further benefits in comparison with “JL(G w/o JT & P w JT) & FL”. For message passing in (4), the gradient back-propagated to will also be influenced by which contains joint type information. Actually, is aware of the joint type information implicitly even though we do not include joint type information in the similarity/affinity learning.
| Method | #Params(M) | CS |
| JL(G w/o JT & P w/o JT) & FL | 0.66 | 81.0 |
| JL(G w JT & P w/o JT) & FL | 0.70 | 81.4 |
| JL(G w/o JT & P w JT) & FL | 0.68 | 81.8 |
| JL(G w JT & P w JT) & FL | 0.71 | 81.8 |
| JL & FL(w/o T-Conv) w/o FI | 0.58 | 79.8 |
| JL & FL(w/o T-Conv) w FI | 0.60 | 80.9 |
| JL & FL(w T-Conv) w/o FI | 0.71 | 81.8 |
| JL & FL(w T-Conv) w FI | 0.73 | 82.3 |
Effectiveness of Exploiting Frame Index. To study the influence of the frame index, we design two models based on the SS-SGN as shown in rows 5 and 6 in Table I), where the temporal convolution is degraded by setting its kernel size to 1. “JL & FL(w/o T-Conv) w FI” denotes the model using the semantics of frame index. Both models have incorporated the semantics of joint type.
Moreover, we investigate two models (rows 7 and 8 in Table I) to study the influence of the frame index when the temporal convolution with kernel size of 3 is used. “JL & FL (w T-Conv) w FI” denotes the model using the semantics of frame index. Both models have incorporated the semantics of joint type.
For the effectiveness of the semantics of temporal index on the frame-level module, there are two observations.
1) When the temporal convolution is disabled (i.e., filter kernel size is 1 instead of 3), “JL & FL(w/o T-Conv) w FI” outperforms “JL & FL(w/o T-Conv) w/o FI” by 1.1% the CS setting. The frame index information “tells” the network the frame order of skeleton sequence which is beneficial for action recognition.
2) The frame index is helpful for temporal convolution. “JL & FL (w T-Conv) w FI” is superior to “JL & FL (w T-Conv) w/o FI” by 0.5% for the CS setting. The benefits from the semantics of frame index are smaller than those models without temporal convoluitonal (with filter kernel size of 1). The main reason is the temporal convolutional layer enables the network to know the frame order of skeleton sequence to some extent through large kernel size. However, “telling” the networks the semantics of frame index explicitly further improves the performance with negligible cost. We take the scheme “JL & FL (w T-Conv) w FI” as our final scheme, which is also referred to as “SGN”.
In summary, the explicit modeling of the joint type information benefits the learning of adjacent matrices and the message passing in the GCN layers. The frame index information enables the model to efficiently exploit the information of sequence order.
IV-C2 Effectiveness of Hierarchical Model
| Method | #Params(M) | CS |
|---|---|---|
| SS-SGN w G-GCN(1x3) | 0.72 | 81.4 |
| SS-SGN w G-GCN(3x3) | 1.11 | 81.2 |
| SS-SGN | 0.73 | 82.3 |
We hierarchically model the correlations of the joints by building the dependencies of joints in the same frame through joint-level module and building the dependencies of frames in the frame-level module, where joints in the same frame are taken as a whole. To demonstrate the effectiveness of hierarchical design, we compare the proposed SS-SGN with two different non-hierarchical models and show the results in Table II.
“SS-SGN w G-GCN(1x3)” denotes a non-hierarchical scheme where we remove the spatial MaxPooling layer (SMP), and use the combined semantics (i.e., joint type and frame index) and dynamics (position and velocity) in the GCN layers. Instead of constructing a graph for each frame, we build a global adaptive graph with all the joints in all the frames and conduct message passing among all those joints. In the frame-level module, the kernel size of the first CNN layer is set to 1x3, which is same with “SS-SGN”, which only models the dependencies of the joints temporally. “SS-SGN w G-GCN(3x3)” is similar to “SS-SGN w G-GCN(1x3)” and the only difference is that the kernel size of the first CNN layers is set to 3x3 in the frame-level module, which models the dependencies of the joints spatially and temporally. Without the first CNN layer with large kernel to build temporal relations in the frame-level module, the performance of the above two non-hierarchical models will decrease dramatically.
From Table II, we have the following observation.
Hierarchical design is much more powerful than non-hierarchical design in exploiting the dependencies of joints. Modeling the correlations of joints of the same frame by GCN is much more effective than modeling the correlations of all joints of all the frames. “SS-SGN” is superior to “SS-SGN w G-GCN(1x3)” and “SS-SGN w G-GCN(3x3)” by 0.8% and 1.0%, respectively. Learning a global content adaptive graph is more complicated and difficult.
| Method | #Params(M) | CS |
|---|---|---|
| Baseline | 0.64 | 67.7 |
| + DA | 0.64 | 69.0 |
| + Velocity | 0.65 | 75.5 |
| + Fine-grained movement | 0.66 | 79.1 |
| + MaxPooling | 0.66 | 80.9 |
IV-C3 Strong Baseline
Previous works usually adopt heavy networks for modeling skeleton sequence of low dimensions [42, 41, 39, 60]. We exploit some techniques which have been proven very effective in previous works and build a lightweight strong baseline, which has achieved comparable performance as most other state-of-the-art methods [42, 59, 56, 9]. We hope this serves as a strong baseline for future research in the skeleton-based action recognition field. All models do not use semantics in this section.
We first build a basic baseline (“Baseline”) with the overall pipeline similar to that in Fig. 2. There are three differences. 1) The velocity, fine-grained movement, joint type, and frame index information are not utilized. 2) Data augmentation (DA) (see Data Processing) is not adopted during training. 3) AveragePooling is used instead of Maxpooling as in [56, 39].
Table III shows the influence of our adopted techniques for constructing the strong baseline. We have the following three observations. 1) Data augmentation improves the performance significantly. Through the augmentation on the observed views, some “unseen” views could be “seen” during the training. 2) Two stream networks (using both position and velocity) [42] have proven effective, but two separate networks double the number of parameters. We fuse the two types of information in the early stage (in input) and it improves the performance significantly with only a negligible number of additional parameters (i.e., 0.01M). 3) We introduce fine-grained movement to the representation of joints in the same way with velocity. It further improves the performance by 3.6% with very little cost (i.e., additional 0.01M parameters). 4) MaxPooling is much more powerful than AveragePooling. The reason is that MaxPooling works like an attention module which drives the network to learn and select discriminative features.
IV-C4 Effectiveness of Fine-Grained Movement
To validate the effectiveness of using the fine-grained movement, we conduct two additional experiments, i.e., “SS-SGN w/o FGM” and “SS-SGN w CM”. “SS-SGN w/o FGM” denotes that we only use position and velocity information in the DR module. “SS-SGN w CM” denotes that we replace the fine-grained movement with coarse movement by selecting only one referent joint (“spine”) of the whole human body. The experimental results are shown in Table IV.
| Method | #Params(M) | CS |
|---|---|---|
| SS-SGN w/o FGM | 0.72 | 79.1 |
| SS-SGN w CM | 0.73 | 79.7 |
| SS-SGN | 0.73 | 82.3 |

With the help of fine-grained movement, “SS-SGN” outperforms “SS-SGN w/o FGM” by 3.2% in accuracy. In addition, the coarse movement (“SS-SGN w CM”) also brings gain of 0.6% in comparison with “SS-SGN w/o FGM”, but it is far inferior to fine-grained movement (“SS-SG”) by 2.6%. For the actions with similar poses, the significant difference is the local movement/configuration of some joints, which is much more important than the movement of the joints of the whole human body (“CM”). The fine-grained movement benefits the understanding of the actions with similar skeletons.
To further understand the fine-grained movement, we compare the accuracies of “SS-SGN” and and “SS-SGN w/o FGM” and obtain the performance gain for different classes caused by fine-grained movement by subtracting the accuracy of “SS-SGN” and “SS-SGN w/o FGM”. Fig. 6 shows the top 55 actions with the largest performance gains.
For make ok sign and make victory sign, the accuracies of two actions have gains of 22.6% and 17.8% with the help of fine-grained movement. For reading and writing, the accuracies of two actions have gains of 6.2% and 6.6%. The fine-grained movement boosts the recognition of those actions with similar skeletons significantly.
| Method | #Params(M) | CS |
|---|---|---|
| SS-SGN | 0.73 | 82.3 |
| MS-SGN(sep.) | 2.19 | 83.4 |
| MS-SGN | 1.50 | 84.5 |
IV-C5 Effectiveness of Mulit-Scale Strategy
We design three experiments to validate the effectiveness and efficiency of the proposed multi-scale strategy “MS-SGN” in Table V. “SS-SGN” denotes there are no multi-scale strategy. “MS-SGN (sep.)” denotes three modules are all not shared while “MS-SGN” denotes DR module and JL modules are shared while FL modules are not shared across scales.
We have the following observations.
1) “MS-SGN” outperforms “SS-SGN” by 2.2% significantly, which indicates that multi-scale strategy makes the network robust to temporal scale variations.
2) The method of sharing the DR module and JL module and isolating the FL module are more efficient than the method of isolating all the three modules, “MS-SGN” is superior to “MS-SGN (sep.)” by 0.9% with much fewer parameters.
IV-C6 Visualization of SMP
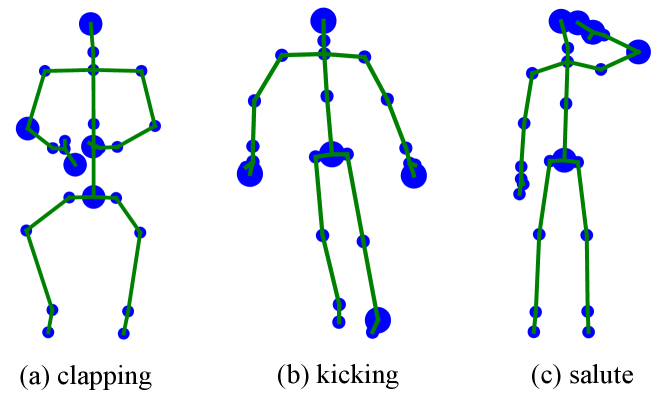
The spatial Maxpooling (SMP) plays a similar role to the attention mechanism. We visualize the selected joints by SMP for three actions i.e., clapping, kicking, and salute in Fig. 7. The dimensions of the responses are 256 and each dimension corresponds to one selected joint. We count the times each joint is selected by the SMP. The top five chosen joints are shown by large blue circles and the rest are shown by small blue circles. We observe that different actions correspond to different informative joints. The left foot is important for kicking. Only the left hand is of great value for salute, while both left and right hands are essential for clapping. These are consistent with human’s perception.
| Method | Year | CS | CV |
| STA-LSTM [43] | 2017 | 73.4 | 81.2 |
| GCA-LSTM [30] | 2017 | 74.4 | 82.8 |
| Clips+CNN+MTLN [19] | 2017 | 79.6 | 84.8 |
| VA-LSTM [59] | 2017 | 79.4 | 87.6 |
| ElAtt-GRU[62] | 2018 | 80.7 | 88.4 |
| ST-GCN [56] | 2018 | 81.5 | 88.3 |
| DPRL+GCNN [46] | 2018 | 83.5 | 89.8 |
| SR-TSL [42] | 2018 | 84.8 | 92.4 |
| HCN [24] | 2018 | 86.5 | 91.1 |
| AGC-LSTM (joint) [41] | 2019 | 87.5 | 93.5 |
| AS-GCN [25] | 2019 | 86.8 | 94.2 |
| GR-GCN [9] | 2019 | 87.5 | 94.3 |
| VA-CNN [60] | 2019 | 88.7 | 94.3 |
| SGN [61] | 2020 | 89.0 | 94.5 |
| MS-G3D(Joint) [33] | 2020 | 89.4 | 95.0 |
| 1s Shift-GCN [5] | 2020 | 87.8 | 95.1 |
| SS-SGN | - | 89.6 | 94.6 |
| MS-SGN | - | 90.1 | 95.2 |
IV-C7 Complexity of SGN
We discuss the complexity of SGN by comparing it with eight state-of-the-art methods for skeleton-based action recognition. As shown in Fig. 1, the number of parameters of VA-RNN [60] is the least, but the accuracy is the poorest. VA-CNN[60] and 2s-AGCN[39] achieve good accuracy, but the numbers of parameters are so large. In comparison with the RNN-based, GCN-based, and CNN-based methods, our proposed SGN achieves slightly better performance with much fewer parameters, which makes SGN attractive for many practical applications which have limited computational power.
IV-D Comparison with the State-of-the-arts
We compare the proposed “SS-SGN” and “MS-SGN” with other state-of-the-art methods on the NTU60, NTU 120, and SYSU datasets in Table VI, Table VII, and Table LABEL:tab:SYSU, respectively.
| Method | Year | C-Subject | C-Setup |
|---|---|---|---|
| Part-Aware LSTM [38] | 2016 | 25.5 | 26.3 |
| ST-LSTM + Trust Gate [28] | 2016 | 55.7 | 57.9 |
| GCA-LSTM [30] | 2017 | 58.3 | 59.2 |
| Clips+CNN+MTLN [19] | 2017 | 58.4 | 57.9 |
| Two-Stream GCA-LSTM [29] | 2017 | 61.2 | 63.3 |
| RotClips+MTCNN [20] | 2018 | 62.2 | 61.8 |
| Body Pose Evolution Map [32] | 2018 | 64.6 | 66.9 |
| 2s-AGCN [39] | 2019 | 82.9 | 84.9 |
| SGN [61] | 2020 | 79.2 | 81.5 |
| 1s Shift-GCN [5] | 2020 | 80.9 | 83.2 |
| SS-SGN | - | 82.3 | 83.4 |
| MS-SGN | - | 84.5 | 85.6 |
| Method | Year | CS | SS |
| VA-LSTM [59] | 2017 | 77.5 | 76.9 |
| ST-LSTM [27] | 2018 | 76.5 | - |
| GR-GCN [9] | 2019 | 77.9 | - |
| Two stream GCA-LSTM [29] | 2017 | 78.6 | - |
| SR-TSL [42] | 2018 | 81.9 | 80.7 |
| ElAtt-GRU* [62] | 2018 | 85.7 | 85.7 |
| SGN* [61] | 2020 | 90.6 | 89.3 |
| SS-SGN | - | 85.1 | 83.0 |
| MS-SGN | - | 84.3 | 82.8 |
| SS-SGN* | - | 91.9 | 90.2 |
| MS-SGN* | - | 92.8 | 91.3 |
As shown in Table VI, “AGC-LSTM(joint)” [41] and “VA-CNN” [60] are two representative methods for RNN-based and CNN-based methods, respectively. “MS-SGN” outperforms them by 2.6% and 0.4% in accuracy for the CS setting but uses only ten percent of their numbers of parameters as shown in Fig. 1. When compared to the GCN-based methods [39, 33, 5], the proposed “MS-SGN” achieves competitive performance and outperforms them in the number of parameters, training and inference speed.
As shown in Table VII and Table LABEL:tab:SYSU, the proposed SGN achieves the best accuracy on NTU120 and SYSU. It should be noted that [62] and [61] used the pre-trained model on the NTU60 dataset to initialize parameters for the SYSU dataset. The proposed “SS-SGN” and “MS-SGN” achieves the best performance with or without the pre-trained model.
V Conclusions
In this work, we have presented a simple yet effective end-to-end multi-scale semantics-guided neural network for high performance skeleton-based human recognition. We explicitly introduce the high level semantics, i.e., joint type and frame index, as part of the network input. To model the correlations of joints, we have proposed a joint-level module for capturing the correlations of joints in the same frame and a frame-level module for modeling the dependencies of frames where all joints in the same frame are taken as a whole. Semantics helps improve the capability of both the GCN and CNN. To be robust to the temporal scale variations, we propose a multi-scale strategy by using multi-scale frame-level modules. In addition, we have developed a strong baseline which is better than most previous methods. The fine-grained movement of joints, which is incorporated in the strong baseline, facilitates the understanding of fine-grained actions. With an order of magnitude smaller model size than some previous works, our proposed model achieves the state-of-the-art results on three benchmark datasets.
Acknowledgment
This work was partially supported by the National Natural Science Foundation of China (Grant No. 61751308 and 61773311).
References
- [1] J. K. Aggarwal and M. S. Ryoo. Human activity analysis: A review. ACM Computing Surveys, 2011.
- [2] F. Baradel, C. Wolf, J. Mille, and G. W. Taylor. Glimpse clouds: Human activity recognition from unstructured feature points. In CVPR, 2018.
- [3] C. Cao, C. Lan, Y. Zhang, W. Zeng, H. Lu, and Y. Zhang. Skeleton-based action recognition with gated convolutional neural networks. TCSVT, 29(11):3247–3257, 2019.
- [4] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh. Realtime multi-person 2d pose estimation using part affinity fields. In CVPR, 2017.
- [5] K. Cheng, Y. Zhang, X. He, W. Chen, J. Cheng, and H. Lu. Skeleton-based action recognition with shift graph convolutional network. In CVPR, pages 183–192, 2020.
- [6] K. Cho, B. Van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv, 2014.
- [7] Y. Du, Y. Fu, and L. Wang. Skeleton based action recognition with convolutional neural network. In ACPR, 2015.
- [8] Y. Du, W. Wang, and L. Wang. Hierarchical recurrent neural network for skeleton based action recognition. In CVPR, 2015.
- [9] X. Gao, W. Hu, J. Tang, J. Liu, and Z. Guo. Optimized skeleton-based action recognition via sparsified graph regression. In ACMMM, 2019.
- [10] G. Garcia-Hernando and T.-K. Kim. Transition forests: Learning discriminative temporal transitions for action recognition and detection. In CVPR, 2017.
- [11] J. Gehring, M. Auli, D. Grangier, D. Yarats, and Y. N. Dauphin. Convolutional sequence to sequence learning. In ICML, 2017.
- [12] F. Han, B. Reily, W. Hoff, and H. Zhang. Space-time representation of people based on 3d skeletal data: A review. CVIU, 2017.
- [13] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016.
- [14] T. He, Z. Zhang, H. Zhang, Z. Zhang, J. Xie, and M. Li. Bag of tricks for image classification with convolutional neural networks. In CVPR, 2019.
- [15] S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural computation, 1997.
- [16] J.-F. Hu, W.-S. Zheng, J. Lai, and J. Zhang. Jointly learning heterogeneous features for rgb-d activity recognition. In CVPR, 2015.
- [17] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv, 2015.
- [18] G. Johansson. Visual perception of biological motion and a model for its analysis. Perception & psychophysics, 1973.
- [19] Q. Ke, M. Bennamoun, S. An, F. Sohel, and F. Boussaid. A new representation of skeleton sequences for 3d action recognition. In CVPR, 2017.
- [20] Q. Ke, M. Bennamoun, S. An, F. Sohel, and F. Boussaid. Learning clip representations for skeleton-based 3d action recognition. TIP, 2018.
- [21] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv, 2014.
- [22] T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. arXiv, 2016.
- [23] C. Li, Q. Zhong, D. Xie, and S. Pu. Skeleton-based action recognition with convolutional neural networks. In ICMEW, 2017.
- [24] C. Li, Q. Zhong, D. Xie, and S. Pu. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. In IJCAI, 2018.
- [25] M. Li, S. Chen, X. Chen, Y. Zhang, Y. Wang, and Q. Tian. Actional-structural graph convolutional networks for skeleton-based action recognition. In CVPR, 2019.
- [26] J. Liu, A. Shahroudy, M. L. Perez, G. Wang, L.-Y. Duan, and A. K. Chichung. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. TPAMI, 2019.
- [27] J. Liu, A. Shahroudy, D. Xu, A. C. Kot, and G. Wang. Skeleton-based action recognition using spatio-temporal lstm network with trust gates. TPAMI, 2018.
- [28] J. Liu, A. Shahroudy, D. Xu, and G. Wang. Spatio-temporal lstm with trust gates for 3d human action recognition. In ECCV, 2016.
- [29] J. Liu, G. Wang, L.-Y. Duan, K. Abdiyeva, and A. C. Kot. Skeleton-based human action recognition with global context-aware attention lstm networks. TIP, 2017.
- [30] J. Liu, G. Wang, P. Hu, L.-Y. Duan, and A. C. Kot. Global context-aware attention lstm networks for 3d action recognition. In CVPR, 2017.
- [31] M. Liu, H. Liu, and C. Chen. Enhanced skeleton visualization for view invariant human action recognition. PR, 2017.
- [32] M. Liu and J. Yuan. Recognizing human actions as the evolution of pose estimation maps. In CVPR, 2018.
- [33] Z. Liu, H. Zhang, Z. Chen, Z. Wang, and W. Ouyang. Disentangling and unifying graph convolutions for skeleton-based action recognition. In CVPR, pages 143–152, 2020.
- [34] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015.
- [35] V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In ICML, 2010.
- [36] A. v. d. Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu. Wavenet: A generative model for raw audio. arXiv, 2016.
- [37] R. Poppe. A survey on vision-based human action recognition. Image and vision computing, 2010.
- [38] A. Shahroudy, J. Liu, T.-T. Ng, and G. Wang. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In CVPR, 2016.
- [39] L. Shi, Y. Zhang, J. Cheng, and H. Lu. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In CVPR, 2019.
- [40] J. Shotton, A. Fitzgibbon, M. Cook, T. Sharp, M. Finocchio, R. Moore, A. Kipman, and A. Blake. Real-time human pose recognition in parts from single depth images. 2011.
- [41] C. Si, W. Chen, W. Wang, L. Wang, and T. Tan. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In CVPR, 2019.
- [42] C. Si, Y. Jing, W. Wang, L. Wang, and T. Tan. Skeleton-based action recognition with spatial reasoning and temporal stack learning. In ECCV, 2018.
- [43] S. Song, C. Lan, J. Xing, W. Zeng, and J. Liu. An end-to-end spatio-temporal attention model for human action recognition from skeleton data. In AAAI, 2017.
- [44] S. Song, C. Lan, J. Xing, W. Zeng, and J. Liu. Skeleton-indexed deep multi-modal feature learning for high performance human action recognition. In ICME, 2018.
- [45] K. Sun, B. Xiao, D. Liu, and J. Wang. Deep high-resolution representation learning for human pose estimation. In CVPR, 2019.
- [46] Y. Tang, Y. Tian, J. Lu, P. Li, and J. Zhou. Deep progressive reinforcement learning for skeleton-based action recognition. In CVPR, 2018.
- [47] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. In NIPS, 2017.
- [48] J. Wang, Z. Liu, Y. Wu, and J. Yuan. Mining actionlet ensemble for action recognition with depth cameras. In CVPR, 2012.
- [49] P. Wang, W. Li, P. Ogunbona, J. Wan, and S. Escalera. Rgb-d-based human motion recognition with deep learning: A survey. CVIU, 2018.
- [50] X. Wang, R. Girshick, A. Gupta, and K. He. Non-local neural networks. In CVPR, 2018.
- [51] X. Wang and A. Gupta. Videos as space-time region graphs. In ECCV, 2018.
- [52] D. Weinland, R. Ronfard, and E. Boyer. A survey of vision-based methods for action representation, segmentation and recognition. CVIU, 2011.
- [53] J. Weng, M. Liu, X. Jiang, and J. Yuan. Deformable pose traversal convolution for 3d action and gesture recognition. In ECCV, 2018.
- [54] L. Xia, C.-C. Chen, and J. K. Aggarwal. View invariant human action recognition using histograms of 3d joints. In CVPRW, 2012.
- [55] W. Xiong, L. Wu, F. Alleva, J. Droppo, X. Huang, and A. Stolcke. The microsoft 2017 conversational speech recognition system. In ICASSP, 2018.
- [56] S. Yan, Y. Xiong, and D. Lin. Spatial temporal graph convolutional networks for skeleton-based action recognition. In AAAI, 2018.
- [57] G. Yu, Z. Liu, and J. Yuan. Discriminative orderlet mining for real-time recognition of human-object interaction. In ACCV, 2014.
- [58] K. Yun, J. Honorio, D. Chattopadhyay, T. L. Berg, and D. Samaras. Two-person interaction detection using body-pose features and multiple instance learning. In CVPRW, 2012.
- [59] P. Zhang, C. Lan, J. Xing, W. Zeng, J. Xue, and N. Zheng. View adaptive recurrent neural networks for high performance human action recognition from skeleton data. In ICCV, 2017.
- [60] P. Zhang, C. Lan, J. Xing, W. Zeng, J. Xue, and N. Zheng. View adaptive neural networks for high performance skeleton-based human action recognition. TPAMI, 2019.
- [61] P. Zhang, C. Lan, W. Zeng, J. Xing, J. Xue, and N. Zheng. Semantics-guided neural networks for efficient skeleton-based human action recognition. In CVPR, pages 1112–1121, 2020.
- [62] P. Zhang, J. Xue, C. Lan, W. Zeng, Z. Gao, and N. Zheng. Adding attentiveness to the neurons in recurrent neural networks. In ECCV, 2018.
- [63] P. Zhang, J. Xue, C. Lan, W. Zeng, Z. Gao, and N. Zheng. Eleatt-rnn: Adding attentiveness to neurons in recurrent neural networks. TIP, 2019.
- [64] Z. Zhang. Microsoft kinect sensor and its effect. IEEE multimedia, 2012.
- [65] H. Zheng, J. Fu, Z.-J. Zha, and J. Luo. Learning deep bilinear transformation for fine-grained image representation. In NIPS, 2019.
- [66] W. Zhu, C. Lan, J. Xing, W. Zeng, Y. Li, L. Shen, and X. Xie. Co-occurrence feature learning for skeleton based action recognition using regularized deep lstm networks. In AAAI, 2016.