Multi-Object Grasping – Generating Efficient Robotic Picking and Transferring Policy
Abstract
Transferring multiple objects between bins is a common task for many applications. In robotics, a standard approach is to pick up one object and transfer it at a time. However, grasping and picking up multiple objects and transferring them together at once is more efficient. This paper presents a set of novel strategies for efficiently grasping multiple objects in a bin to transfer them to another. The strategies enable a robotic hand to identify an optimal ready hand configuration (pre-grasp) and calculate a flexion synergy based on the desired quantity of objects to be grasped. This paper also presents an approach that uses the Markov decision process (MDP) to model the pick-transfer routines when the required quantity is larger than the capability of a single grasp. Using the MDP model, the proposed approach can generate an optimal pick-transfer routine that minimizes the number of transfers, representing efficiency. The proposed approach has been evaluated in both a simulation environment and on a real robotic system. The results show the approach reduces the number of transfers by 59% and the number of lifts by 58% compared to an optimal single object pick-transfer solution.
I Introduction
Transferring multiple objects from one bin to another can be considered a menial task for humans. Using the sense of touch and experience, we can simply grasp multiple objects from a pile and move them to a bin. We face these types of tasks in multiple situations. When we cook, based on the recipe, we grasp and transfer multiple cloves of garlic into a pot. In logistics, workers are expected to transfer objects such as bulbs from a pile to fill 10-pack or 5-pack bins. In all these tasks, we grasp several objects at a time and transfer them together because it is more efficient than grasping and transferring an object one at a time.
However, we have not observed many works on multiple-object grasping (MOG) or multiple-object bin-picking in robotics. A significant amount of works have been focusing on single object bin-picking, pick-and-place, and grasping for manipulations. In traditional single object picking/grasping, an object’s pose would be estimated using a vision system [1, 2, 3, 4] to guide a robotic hand/gripper. Since humans have demonstrated outstanding grasping skills, several approaches extract grasping strategies and use them to reduce the complexity of grasp planning [5, 6, 7, 8]. More recently, deep-learning-based approaches use large labeled datasets and deep neural networks to directly find good grasp points from dense 3D point clouds [9, 10, 11, 12]. A comprehensive review can be found in [13].
Only a limited amount of work on grasping multiple objects has been carried out for static grasp stability analysis. [14] discusses the enveloping grasp of multiple objects under rolling contacts and [15] studied force closure of multiple objects. It builds the theoretical basis for later work on active force closure analysis for the manipulation of multiple objects in [15]. [16, 17, 18] try to achieve stably grasping of multiple objects through force-closure-based strategies. In their studies, the target objects are already in the air and traditional grasp quality measures were used to analyze the grasps [19, 20, 21, 22]. Our recent work [23] has studied the tactile sensing aspect of MOG and developed a deep learning approach to estimate the object quantity in the grasp.
There are several technical challenges in MOG. Firstly, estimating the object quantity and their pose in a bin is very challenging. Occlusion among objects of similar color and texture makes a computer-vision-based approach prone to error. For example, in the 2019-2020 IROS Robotic Grasping and Manipulation Competition (RGMC) [24], all teams failed at picking ice cubes from an ice bucket. Secondly, The displacement of objects within the bin in contact with the hand voids previously estimated poses. When the hand makes contact with the object pile in the bin, it displaces the objects. If we only rely on a computer vision system, the eye of the hand-eye system can no longer view the majority of the hand. Therefore, it can no longer update the estimated pose of the objects to be grasped.
A robot will have to use tactile sensors and torque sensors when grasping objects from a bin. Tactile sensing has widely been recognized as a critical perception component in object grasping and manipulation. It has been used with vision sensors to estimate the location of an object relative in a world coordinate system [25, 26], embedded force sensors on a robotic hand [27], and a 6-axis force/torques sensor on a robot’s wrist [28, 29, 30, 31, 32]. In those works, tactile/force sensors are used to reduce the uncertainty in the perception of the vision system or are only used for single object grasping. For picking the desired quantity, the robot would need to predict how many objects will remain in grasp after lifting the hand out of the bin. The robot needs to make the prediction before lifting the hand so that it can adjust or simply try again without lifting the hand if the predicted quantity is different from the desired one.
When the desired quantity is small, MOG once could be sufficient. However, if the desired quantity is large, one grasp and transfer would not produce it. We would need to develop an approach that can produce a large quantity MOG policy to ensure both the precision of the total outcome of several MOGs and transfers, and the efficiency of the combined MOGs and transfers.
The contribution of this paper includes two novel procedures for transferring a targeted quantity of objects from a pile into a bin using MOG. It also introduces several new techniques that are designed for MOG, including a pre-grasp selection, end-grasp selection, maximum capability grasp selection, and in-grasp object quantity estimation. Compared to single object transferring, our approach reduces the total number of transfers between bins by 59% and the number of lifts from the bin by 58% assuming that the single object grasping algorithm has a 100% success rate.
II Problem Description and Approaches

In this paper, we focus on transferring a large quantity of uniformly shaped and sized objects from one bin to another. An example setup is illustrated in Figure 1. The objects in the original bin are randomly piled up. The pick-and-transfer process for a large quantity can be solved in several different ways. This paper compares three different approaches. The first approach is the basic single-object grasping approach to pick and transfer one object at a time. If the quantity is , it would need at least times of picking and transferring.
The second approach is a naive multi-object grasping approach that first grasps as many objects as possible to quickly reach or get close to the desired target quantity and then grasps the remaining number. If a robot can grasp and hold objects at the most, the robot will first perform times of picking and placing objects and then grasp the remaining number of objects. For example, if the demanded quantity is and a robotic hand can grasp objects at the most, the robot will grasp and transfer objects twice and then pick and transfer the remaining objects. However, in reality, even if a robotic hand can grasp objects at the most, it can rarely do it successfully and consistently. It may need many re-grasps (open and close the hand in the pile) to achieve it. On the other hand, because of the perception error, a robot may think it holds objects and lifts the hand, but it may have grasped or or even objects in the hand. Therefore, the naive multi-object grasping approach may not be the most efficient approach for those two reasons.
This paper introduces another approach that models the picking and transferring process as a Markov decision process (MDP) because of the stochastic feature in grasping multiple objects. As illustrated in Figure 1, the states are the object quantity in the receiving bin and the actions are grasping actions for a different number of objects. Since the grasping action may pick up different quantities with different probabilities, it is an MDP. The optimization goal is to reach the desired quantity while minimizing the number of grasps and transfers between bins. The model may generate a policy that requires the robot to perform a grasp action for any number of objects at a particular step. We call this approach the Markov-decision-process-based multi-object grasping and transferring or MDP-MOGT.
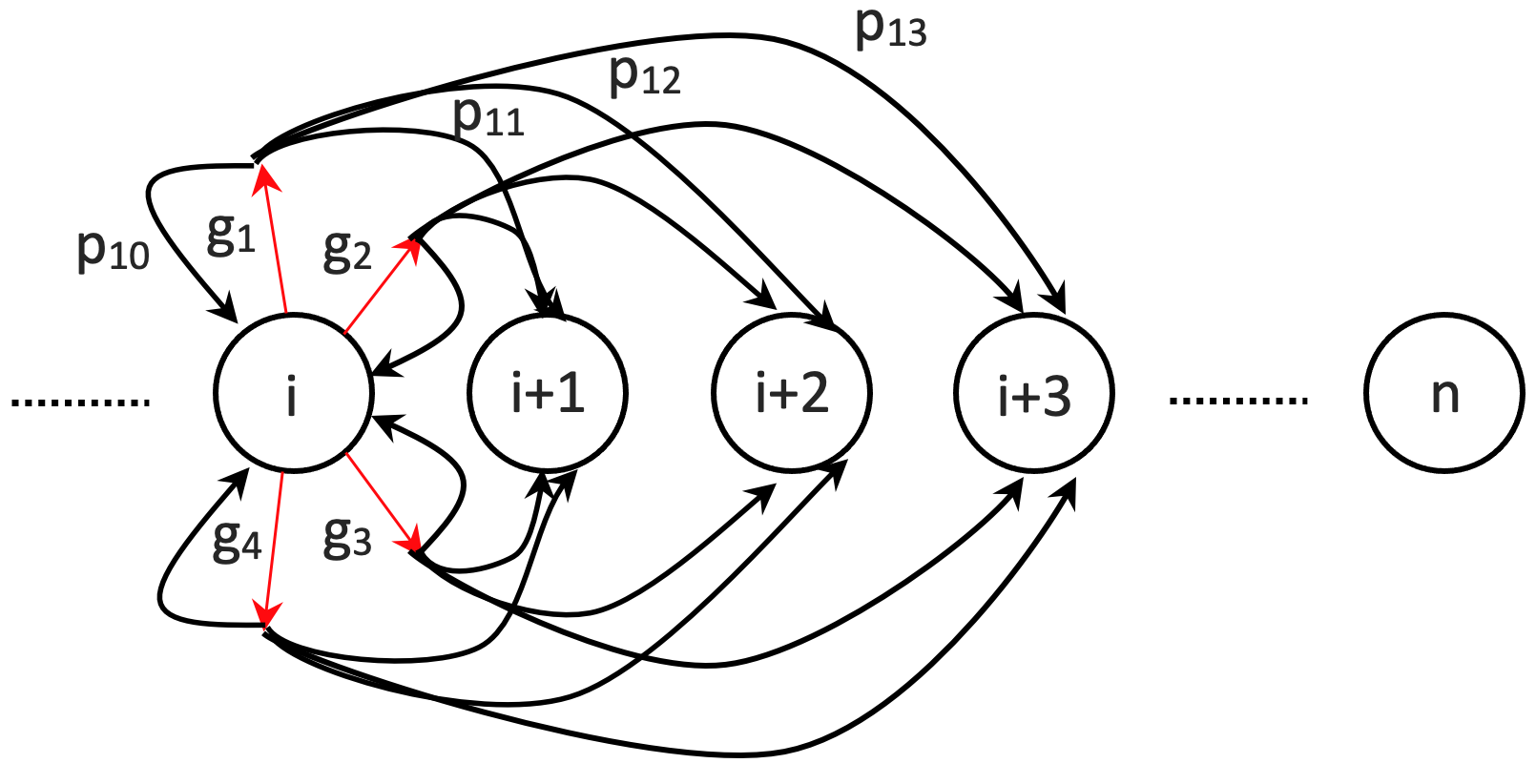
III Markov-decision-process-based multi-object grasping and transferring
III-A State space and rewards
The state is the object quantity in the receiving bin. If the receiving bin has the desired quantity, we reach the goal state. The start state is zero that represents an empty bin. At a given step, a robot takes an action of MOG and transfers objects to the receiving bin if there are objects grasped. At the end of each step after the robot has taken an action, the state of the robot will change. As illustrated in Figure 2, the states are from to , where is the desired quantity.
The reward is associated with the new state. We define the reward as follows:
| (1) |
where is the reward of taking action at state resulting in the new state .
III-B MOGT action space
A MOGT action contains three sub-actions: MOG, lifting, and transferring. Any sequence of finger flexion and extension could be a grasping action. However, some sequences can rarely pick up any objects, while a small few can grasp multiple objects with a high success rate. Therefore, first, we must explore the grasping action space and identify several grasps that are suitable for multiple object grasping.
To fully explore the grasp action space, we have developed a stochastic flexing routine (SFR) in [23] and used it to perform a bias random walk grasp from several pre-grasps. The pre-grasps set has a dense sample of feasible hand configurations. In our experiment, we use uniform sampling to obtain 9,000 pre-grasps for a Barrett hand. Figure 3 shows the upper and lower bounds of the spread angle and finger angle that form the pre-grasp set. For the set, we choose /step for the spread angle and /step for the finger base joint. These step sizes were chosen to reduces the sample size, yet be extensive enough for our search.
III-B1 Selecting pre-grasps based on potentials
Not all pre-grasps lead to good MOGs. To pick the best ones, the robot would perform SFR times from every pre-grasp in the pre-grasp set. We use their grasping results to calculate the potential pre-grasp value (PPG).
| (2) |
where is the robotic hand’s joint angle vector, is the object’s geometry model, ’s are the probabilities of the pre-grasp leading to a successful grasp of objects.
We compare the average of each spread to define the best spread for grasping the target quantity of objects. We filter the pre-grasps within that spread based on their success rate for grasping the target quantity of objects and apply K-mean clustering on the remaining data to obtain clusters of hand configurations.
We perform the SFR on the centroids of the clusters 100 times and compute the for the centroids. Finally, we select the best pre-grasp from the centroids based on its to give us the clustered-probability-based pre-grasp (CPPG) for each targeted grasp
III-B2 Selecting pre-grasps based on expectations
We can also find the pre-grasp that can successfully transfer a large quantity of objects at once based on the best expectation pre-grasp (BEPG). We define the BEPG as the pre-grasp that, on average, yields the highest quantity of objects. The strategy we propose to acquire the BEPG also relies on the pre-grasp set mentioned in section III-B1.
We use the to calculate the average grasp potential (AGP) or grasp number expectation for each spread within the pre-grasp set.
| (3) |
where the AGP is the weighted sum of the quantity of grasped objects and the weights are their probabilities. Therefore, we select the spread with the best average AGP. We filter the pre-grasps within that spread based on their AGP and apply K-mean clustering to obtain clusters of hand configuration that have a high potential for grasping large quantities of objects.
Similar to the strategy in section III-B1, we perform the SFR on the centroids of the clusters 100 times and select the pre-grasp with the highest AGP value. This pre-grasp would be the BEPG.
III-B3 Selecting pre-grasps based on volume
When transferring a large quantity of objects between bins, humans usually grasp a handful of objects in each attempt. We try to expand our hands as large as we can and attempt to grasp the maximum quantity in each transfer. We call this pre-grasp, the maximum capability pre-grasp (MCPG). We believe that during the preliminary transfers between bins, the robot hand should grasp as many objects as possible. One approach for finding this pre-grasp is to compute the volume of the in-grasp space of the hand. Therefore, we can use the grasp with the largest volume to get the MCPG for a hand.
We use the strategy mentioned in [23] to compute the volume of every pre-grasp in the pre-grasp set. We can use the pre-grasp with the largest volume as the MCPG for the hand.
III-B4 Selecting finger flexion synergy
Using SFR, for a single pre-grasp we discovered several distinct end-grasp types associated with the quantity of objects in the hand. We define the end-grasp as the hand configuration when the grasping routine has been completed. Based on our observation, some end-grasps have a higher chance of grasping a particular quantity of objects compared to others. Therefore, to compare the end-grasps we define a success rate for the grasp type with
| (4) |
where is the index of a grasp type, is the success rate that the grasp type has in grasping objects. Therefore, a end-grasp type can be selected based on its values.
Using the data collected, we apply K-mean clustering on the end-grasps to obtain clusters of hand configurations that are likely to fit the desired quantity of objects. We use the centroids with the highest neighbors as the end-grasp. This end-grasp is used to compute the finger flexion synergy.
III-B5 Lifting based on prediction
Before the robot lifts the hand, it must sense the objects in the grasp and predict how many objects will remain in the grasp after lifting. It is primary for successful MOG and consequently, successful transfer of objects between bins. It is part of the MOG action because the robot will continuously re-grasp until the robot senses that the desired number has been reached and it can lift the hand from the original bin.
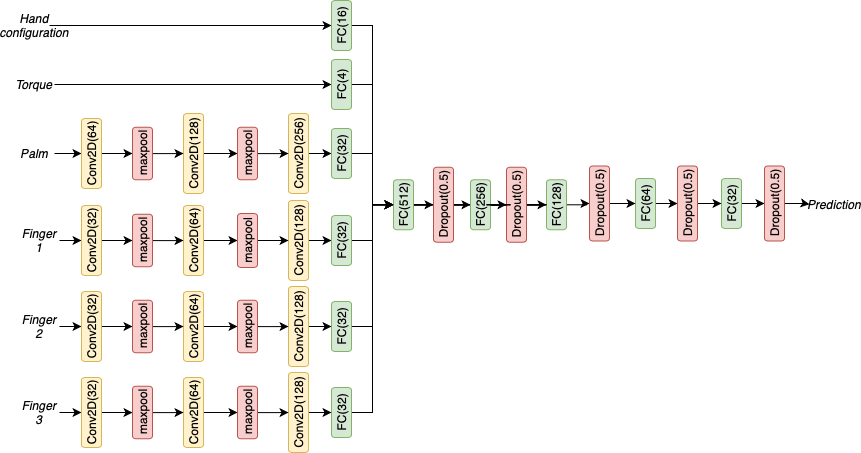
Since modeling the physics of the objects within the bin is computationally expensive, we decided to develop a data-driven deep learning approach to estimate the quantity of objects within the grasp when the hand is inside the bin.
We train five classifiers that estimate zero or non-zero objects, two or non-two objects, three or non-three objects, and greater than or equal to 2 objects or lesser than 2 objects in the hand. The structure of the classifier is shown in Figure 4. The input data dimension of the model is . The input data contains the pre-grasp and the current hand configuration (), the tactile sensor information (), and the readings from the strain gauges present in the couple joints of the hand (). The activation function used for the output layer is sigmoid with a single class as the output. The whole model can be represented as
| (5) |
where is a vector representing the hand configuration, is the vector representing the tactile sensor array, and is the vector containing the three strain gauge readings. The output is the prediction of whether the grasp would contain the desired quantity of objects. The shape for the tactile sensor array is rearranged to account for the spatial information. We represent the tactile sensors in the palm as a by matrix and the tactile sensors in each finger as a by matrix. The result of the prediction models can be found in section IV-D
To reduce the number of false positives when performing the grasping routine, we use the non-zero model along with either of the models to estimate when to lift the hand. If the non-zero model estimates non-zero for three consecutive time steps and the other model estimates True for one time-step we lift the hand. We define this as the voting algorithm. We use the model when grasping the most quantity of objects and the , , and object models when we grasp their respective quantity of objects.
III-B6 Transfer sub-action
The last part of the MOGT action is the transfer sub-action. If the number of objects in the grasp after lifting is desirable, we transfer them to the destination bin. If it is not, we drop the objects in the origin bin and repeat the grasping routine. For the sake of this paper, we assume that we can detect the quantity of objects within the hand once it has been lifted from the pile.
III-C State transition probability
After a MOGT action, a number of objects could be added to the receiving bin. So the system will transit to a new state with a probability. The actions we focus on are to grasp a maximum quantity of objects, object, objects, and objects. We obtain the state transition probability distribution for each action through data collection.
III-D Obtaining and Applying MDP-MOGT Policy
We utilize the value iteration method based on the Bellman equation in equation 6 to compute the optimal policy when we are at each state of the MDP-MOGT model. After we have got the policy we will follow the algorithm in Algorithm 1.
| (6) |
IV Experiments and Results
We have evaluated our proposed approach in simulation as well as the real world using spheres. The robotic hand used in the evaluation is the Barrett Hand. Based on our data collection, the hand is capable of grasping a maximum of 5 objects, therefore, we use a target of objects, to showcase the advantage of high quantity transferring using MOG.
The two metrics we use for evaluating the entire approach are the number of transfers made between the two bins and the total number of lifts performed from the pile. These two metrics highlight the efficiency of the transfer approach.
IV-A System setup
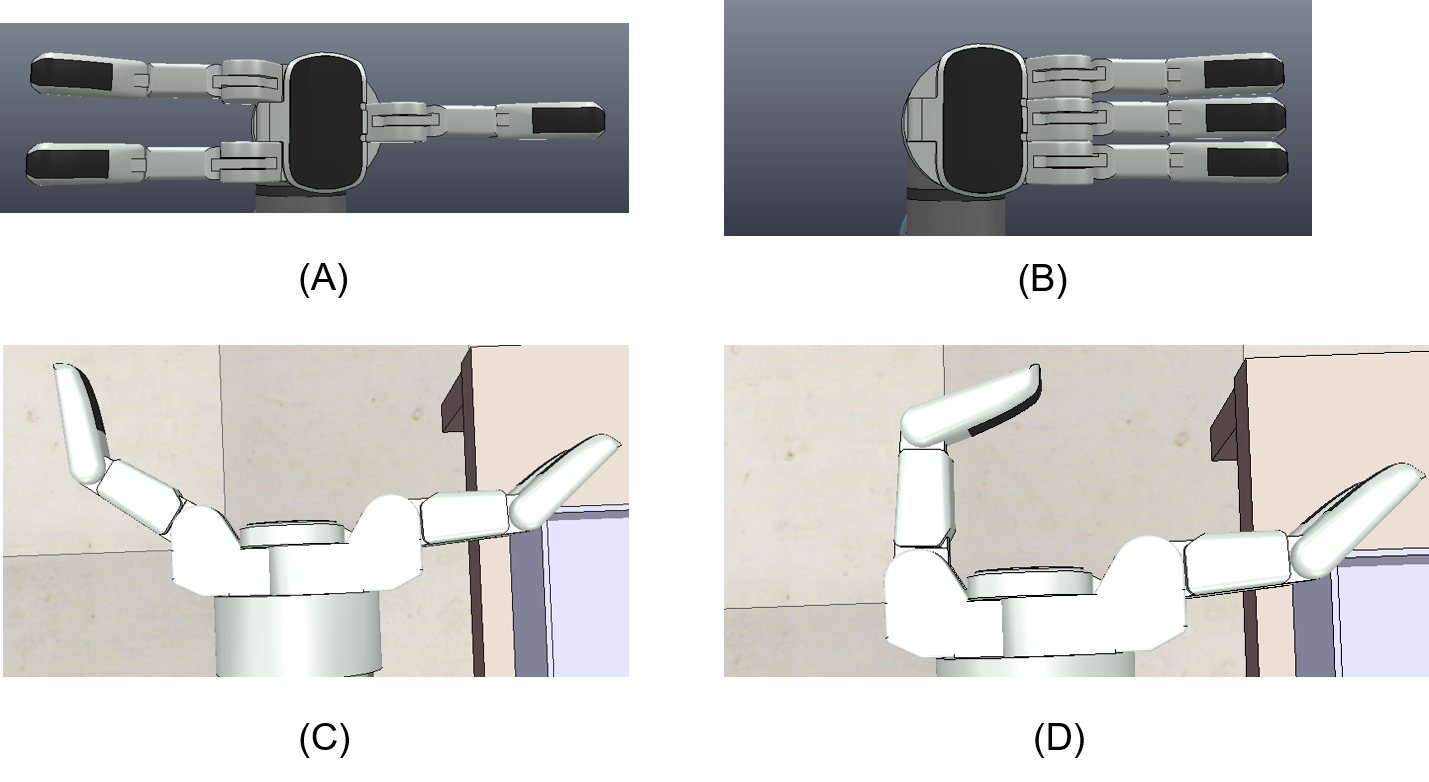
The system for data collection was set up within simulation and the real world. We used CoppeliaSim as the simulation software. The setup within the simulation is shown in Figure 5. We attach the Barrett hand to the UR5e robot arm and place the objects in a bin in front of the robot. The Barrett hand model provided in CoppeliaSim only contains one tactile sensor on each tactile sensing region. Therefore, we attached tactile sensors to the region to replicate the Barrett hand within the real system. The setup for the real system is also shown in Figure 5.


We used spheres in both the simulation and the real system for our experiments. The spheres in both the systems have a radius of and a weight of .
IV-B Data collection
IV-B1 Data collection for CPPG and BEPG
To gather the data for computing the pre-grasps, we used the simulation and the real system.
In the simulation, we repeat each of the hand configurations from the pre-grasp set times using SFR. For CPPG and BEPG, we use the data as described in sections III-B1 and III-B2 respectively to get the best pre-grasps. For computing CPPG, we focus on selecting the pre-grasps for grasping , , and objects. For selecting the number of clusters within each section, we visualize the inertia and distortion of the data and select the number of clusters where the inertia and distortion are decreasing linearly. Inertia can be defined as the sum of the squared distances of the data sample to their closest centroids. Distortion can be defined as the average of the squared distances from the centroid of each cluster.
For collecting data in the real system, we used the top 3 pre-grasps for the spheres from the simulation data for both CPPG and BEPG. We then performed SFR using those pre-grasps times using the real system to select the best pre-grasp for each grasp type for the real system.
IV-B2 Data collection for the finger flexion synergy
For getting the end-grasp for the pre-grasps within the simulation, we used the data collected within the simulation for the pre-grasps and use the approach in section IV-B. We use inertia and distortion to select the clusters here as well. For getting the end-grasp for the grasps in the real system, we used the data collected within the real system for each of the real system pre-grasps and perform the same approach as we do for getting the simulation end-grasps.
IV-B3 Data collection for MDP-MOGT
For the MDP-MOGT approach, we need to possess the state transition probabilities for each of the pre-grasps in the action space. Therefore, to get the state transition probabilities for the pre-grasps within the simulation, we used each pre-grasp and its corresponding end-grasp along with the estimation model to grasp the spheres times. This data provides us with the state transition probabilities for each pre-grasp when performing the grasping routine with the model and the finger flexion synergy. We also computed the state transition probabilities for each pre-grasp with SFR. We performed the same procedure in the real system to collect data and compute the state transition probabilities for the real system pre-grasps.
IV-C Results of grasping maximum quantity of objects
For grasping the maximum quantity of objects, we described two approaches in section III-B2 and III-B3, BEPG, and MCPG. We performed each grasp type times using SFR on the spheres in the real system. The results can be found in table I. The percentages within the table represent the percentage of times the pre-grasp was able to grasp the corresponding number of spheres. Based on the results, BEPG significantly outperforms MCPG in yielding more quantity of objects on average.
|
|
|
||||
|---|---|---|---|---|---|---|
| 0 | 6% | 80% | ||||
| 1 | 16% | 10% | ||||
| 2 | 16% | 10% | ||||
| 3 | 42% | 0% | ||||
| 4 | 20% | 0% |
IV-D Results of estimation models
We train a total of estimation models. The models are for estimating if the grasp contains at least 1 object (non-zero), object, objects, objects or at least objects. The precision and the RMSE for each model can be found in table II. Precision represents the percentage of the correct predictions among all predictions. RMSE represents the standard deviation of the prediction error.
For training each model, we use early stopping on the validation loss to prevent over-fitting. We also use the Adam optimizer with a learning rate of and use binary cross-entropy as our loss function. We apply SMOTE [33] on the training data to fix the imbalanced classes. Lastly, we perform transfer learning using the real-system data to acquire the models for the real system.
Based on the results, the precision for all the models reduces when performing transfer learning, except the model trained to estimate objects. We believe the reduction in the precision is because of the noise within the real system data. The reduction can also be attributed to limited real system data.
|
|
|
|
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| non-zero | 95.1% | 96.09% | NA | NA | ||||||||||
| 1 | 85.97% | 51.72% | 0.6 | 0.69 | ||||||||||
| 2 | 67.18% | 51.46% | 0.97 | 0.87 | ||||||||||
| 3 | 40.95% | 38.24% | 1.84 | 0.92 | ||||||||||
| 78.97% | 83.04% | NA | NA |
IV-E Results of transfer approach
For transferring objects between the bins, we have evaluated two approaches, the naive transfer approach, and the proposed MDP-MOGT approach. For MDP-MOGT, we collected data to compute the state transition probability for each pre-grasp and defined the problem as an MDP to acquire an optimum policy.
For the experiments on both approaches, we used the BEPG as the pre-grasp to grasp the maximum quantity of objects and the CPPG for grasping the target quantity of objects. The results for the experiments are shown in table III.
Based on the results, when using the SFR with the pre-grasp in the real system, MDP-MOGT reduced the number of transfers by 6.38% and the number of lifts by 9.26% when compared to the naive approach. Similar results were observed when comparing the two transfer approaches using the grasping routine with the model and the finger flexion synergy. This showcases the superiority of the MDP-MOGT approach. Similarly, When comparing the MDP-MOGT results between the SFR with the pre-grasp and the grasping routine using the pre-grasps, finger flexion synergy, and the models, the routine with models outperformed the SFR routine by 6.81% in the number of transfers and 14.28% in the number of lifts in the real system. Similar results were observed in simulations as well. This showcases the improvement made because of the models and the finger flexion synergy.
|
|
|
|
|||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Naive | SFR (Real) | 4.7 | 5.4 | |||||||
| MDP-MOGT | SFR (Real) | 4.4 | 4.9 | |||||||
| Naive | Estimation models (Real) | 4.2 | 4.9 | |||||||
| MDP-MOGT | Estimation models (Real) | 4.1 | 4.2 | |||||||
| MDP-MOGT | SFR (Simulation) | 6.0 | 7.6 | |||||||
| MDP-MOGT | Estimation models (Simulation) | 5.9 | 6.8 |
V Discussion & Conclusion
This paper proposed several new MOG techniques and two object transferring approaches that take advantage of MOG. The MOG techniques include clustered-probability-based pre-grasp, best expectation pre-grasp, maximum capability pre-grasp, and a data-driven deep learning model to predict the quantity of objects in a grasp after the hand lifts, when the hand is in the pile. The two object transferring approaches introduced is the naive transfer approach and the Markov-decision-process-based multi-object grasping transfer approach. We have evaluated the proposed strategies for transferring spheres in a simulation environment and the real system. The experiment results show that our approach outperforms single object transferring and the naive transfer approach. We also discovered that a large volume grasp does not translate to grasping a higher quantity of objects. In the future, we will test our approach on different shapes of objects and explore other deep neural network architectures to increase the precision of the models.
Acknowledgment
This material is based upon work supported by the National Science Foundation under Grants Nos. 1812933 and 191004.
References
- [1] D. G. Lowe et al., “Fitting parameterized three-dimensional models to images,” IEEE transactions on pattern analysis and machine intelligence, vol. 13, no. 5, pp. 441–450, 1991.
- [2] D. F. DeMenthon and L. S. Davis, “Model-based object pose in 25 lines of code,” International journal of computer vision, vol. 15, no. 1-2, pp. 123–141, 1995.
- [3] M. Zhu, K. G. Derpanis, Y. Yang, S. Brahmbhatt, M. Zhang, C. Phillips, M. Lecce, and K. Daniilidis, “Single image 3d object detection and pose estimation for grasping,” in 2014 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2014, pp. 3936–3943.
- [4] A. Agrawal, Y. Sun, J. Barnwell, and R. Raskar, “Vision-guided robot system for picking objects by casting shadows,” The International Journal of Robotics Research, vol. 29, no. 2-3, pp. 155–173, 2010.
- [5] Y. Lin, S. Ren, M. Clevenger, and Y. Sun, “Learning grasping force from demonstration,” in Robotics and Automation (ICRA), 2012 IEEE International Conference on. IEEE, 2012, pp. 1526–1531.
- [6] Y. Huang and Y. Sun, “A dataset of daily interactive manipulation,” The International Journal of Robotics Research, vol. 38, no. 8, pp. 879–886, 2019.
- [7] Y. Lin and Y. Sun, “Robot grasp planning based on demonstrated grasp strategies,” The International Journal of Robotics Research, vol. 34, no. 1, pp. 26–42, 2015.
- [8] ——, “Grasp planning based on strategy extracted from demonstration,” in Intelligent Robots and Systems (IROS 2014), 2014 IEEE/RSJ International Conference on. IEEE, 2014, pp. 4458–4463.
- [9] J. Mahler and K. Goldberg, “Learning deep policies for robot bin picking by simulating robust grasping sequences,” in Conference on robot learning. PMLR, 2017, pp. 515–524.
- [10] I. Lenz, H. Lee, and A. Saxena, “Deep learning for detecting robotic grasps,” The International Journal of Robotics Research, vol. 34, no. 4-5, pp. 705–724, 2015.
- [11] A. ten Pas and R. Platt, “Using geometry to detect grasp poses in 3d point clouds,” in Robotics Research. Springer, 2018, pp. 307–324.
- [12] D. Kappler, J. Bohg, and S. Schaal, “Leveraging big data for grasp planning,” in 2015 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2015, pp. 4304–4311.
- [13] R. Li and H. Qiao, “A survey of methods and strategies for high-precision robotic grasping and assembly tasks—some new trends,” IEEE/ASME Transactions on Mechatronics, vol. 24, no. 6, pp. 2718–2732, 2019.
- [14] K. Harada and M. Kaneko, “Enveloping grasp for multiple objects—kinematics and shovelling up condition—,” Journal of the Robotics Society of Japan, vol. 16, no. 6, pp. 860–867, 1998.
- [15] K. Harada, M. Kaneko, and T. Tsuji, “Active force closure for multiple objects,” Journal of Robotic Systems, vol. 19, no. 3, pp. 133–141, 2002.
- [16] T. Yoshikawa, T. Watanabe, and M. Daito, “Optimization of power grasps for multiple objects,” in Proceedings 2001 ICRA. IEEE International Conference on Robotics and Automation (Cat. No. 01CH37164), vol. 2. IEEE, 2001, pp. 1786–1791.
- [17] T. Yamada, T. Ooba, T. Yamamoto, N. Mimura, and Y. Funahashi, “Grasp stability analysis of two objects in two dimensions,” in Proceedings of the 2005 IEEE International Conference on Robotics and Automation. IEEE, 2005, pp. 760–765.
- [18] T. Yamada and H. Yamamoto, “Static grasp stability analysis of multiple spatial objects,” Journal of Control Science and Engineering, vol. 3, pp. 118–139, 2015.
- [19] Y. Lin and Y. Sun, “Grasp planning to maximize task coverage,” The International Journal of Robotics Research, vol. 34, no. 9, pp. 1195–1210, 2015.
- [20] ——, “Task-oriented grasp planning based on disturbance distribution,” in ISRR, 2013.
- [21] ——, “Task-based grasp quality measures for grasp synthesis,” 2015, pp. 485–490.
- [22] Y. Sun, Y. Lin, and Y. Huang, “Robotic grasping for instrument manipulations,” in The 13th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), 2016, pp. 1–3 (Invited, in press).
- [23] T. Chen, A. Shenoy, A. Kolinko, S. Mutahar Shah, and Y. Sun, “Multi-object grasping – estimating the number of objects in a robotic grasp,” in Intelligent Robots and Systems (IROS), 2021 IEEE/RSJ International Conference on. IEEE, 2021, p. in press.
- [24] Y. Sun, Falco, M. A. Roa, and B. Calli, “Research challenges and progress in the latest robotic grasping and manipulation competitions,” RA-L, pp. 1–8,under review, 2021.
- [25] S. R. Chhatpar and M. S. Branicky, “Particle filtering for localization in robotic assemblies with position uncertainty,” in 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2005, pp. 3610–3617.
- [26] Y. Chebotar, O. Kroemer, and J. Peters, “Learning robot tactile sensing for object manipulation,” in 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2014, pp. 3368–3375.
- [27] C. Corcoran and R. Platt, “A measurement model for tracking hand-object state during dexterous manipulation,” in 2010 IEEE International Conference on Robotics and Automation. IEEE, 2010, pp. 4302–4308.
- [28] A. Petrovskaya, O. Khatib, S. Thrun, and A. Y. Ng, “Bayesian estimation for autonomous object manipulation based on tactile sensors,” in Proceedings 2006 IEEE International Conference on Robotics and Automation, 2006. ICRA 2006. IEEE, 2006, pp. 707–714.
- [29] S. Javdani, M. Klingensmith, J. A. Bagnell, N. S. Pollard, and S. S. Srinivasa, “Efficient touch based localization through submodularity,” in 2013 IEEE International Conference on Robotics and Automation. IEEE, 2013, pp. 1828–1835.
- [30] J. Bimbo, P. Kormushev, K. Althoefer, and H. Liu, “Global estimation of an object’s pose using tactile sensing,” Advanced Robotics, vol. 29, no. 5, pp. 363–374, 2015.
- [31] A. Petrovskaya and O. Khatib, “Global localization of objects via touch,” IEEE Transactions on Robotics, vol. 27, no. 3, pp. 569–585, 2011.
- [32] B. Saund, S. Chen, and R. Simmons, “Touch based localization of parts for high precision manufacturing,” in 2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017, pp. 378–385.
- [33] N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “Smote: synthetic minority over-sampling technique,” Journal of artificial intelligence research, vol. 16, pp. 321–357, 2002.