Multi-modal Sensor Fusion for Auto Driving Perception: A Survey
Abstract
Multi-modal fusion is a fundamental task for the perception of an autonomous driving system, which has recently intrigued many researchers. However, achieving a rather good performance is not an easy task due to the noisy raw data, underutilized information, and the misalignment of multi-modal sensors. In this paper, we provide a literature review of the existing multi-modal-based methods for perception tasks in autonomous driving. Generally, we make a detailed analysis including over 50 papers leveraging perception sensors including LiDAR and camera trying to solve object detection and semantic segmentation tasks. Different from traditional fusion methodology for categorizing fusion models, we propose an innovative way that divides them into two major classes, four minor classes by a more reasonable taxonomy in the view of the fusion stage. Moreover, we dive deep into the current fusion methods, focusing on the remaining problems and open-up discussions on the potential research opportunities. In conclusion, what we expect to do in this paper is to present a new taxonomy of multi-modal fusion methods for the autonomous driving perception tasks and provoke thoughts of the fusion-based techniques in the future.
1 Introduction
Perception is an essential module for autonomous cars [26, 71, 44]. The tasks include but are not limited to 2D/3D object detection, semantic segmentation, depth completion, and prediction, which rely on sensors installed on the vehicles to sample the raw data from the environment. Most existing methods [44], conduct the perception tasks on point cloud and image data captured by LiDAR and camera separately, showing some promising achievements.
However, perception by single-modal data suffers from inherent drawbacks [4, 26]. For example, camera data is mainly captured in the lower position of the front view [102]. Objects may be occluded in more complex scenes, bringing severe challenges to object detection and semantic segmentation. Moreover, limited to the mechanical structure, LiDAR has various resolutions at different distances [91], and it is vulnerable to extreme weather such as fogs and heavy rains [4]. Although the data of the two modalities excel in various areas when used separately [44], the complementarity of LiDAR and camera makes the combination result in a better performance on perception[4, 76, 90].
Recently, multi-modal fusion methods for perception tasks in autonomous driving have rapidly progressed [81, 77, 15], varying from more advanced cross-modal feature representations and more reliable sensors in different modalities to more complex and robust deep learning models and techniques of the multi-modal fusion. However, only a few literature reviews [81, 15] concentrate on the methodology of multi-modal fusion methodology itself, and most of them follow a traditional rule of separating them into three major classes as early-fusion, deep-fusion, and late-fusion, focusing on the stage of fusion feature in the deep learning model, whether it is at data-level, feature-level or proposal-level. Firstly, such taxonomy does not make a clear definition of the feature representation in each level. Secondly, it suggests that two branches, LiDAR and camera, are always symmetric in the processing procedure, obscuring the situation fusing proposal-level feature in the LiDAR branch and data-level feature in the camera branch [106]. In conclusion, traditional taxonomy may be intuitive but primitive to summarize more and more emerging multi-modal fusion methods recently, which prevents researchers study and analyzing them from a systematic view.
In this paper, we will give a brief review of the recent papers about the multi-modal sensor fusion for autonomous driving perception. We propose an innovative way to divide over 50 related papers into two major classes and four minor classes by a more reasonable taxonomy from the fusion stage perspective.
The main contribution of this work can be summarized as the following:
-
•
We propose an innovative taxonomy of multi-modal fusion methods for autonomous driving perception tasks, including two major classes, as strong-fusion and weak-fusion, and four minor classes in strong-fusion, as early-fusion, deep-fusion, late-fusion, asymmetry-fusion, which is clearly defined by the feature representations of LiDAR branch and camera branch.
-
•
We conduct an in-depth survey about the data format and representation of the LiDAR and camera branch and discuss their different characteristics.
-
•
We make a detailed analysis about the remaining problems and introduce several potential research directions about the multi-modal sensor fusion method, which may enlighten future research works.
The paper is organized by the following: In section 2, we give a brief introduction to the perception tasks in autonomous driving, including but not limited to object detection, semantic segmentation, as well as several widely-used open dataset and benchmarks. In section 3, we summarize all the data formats as the input of downstream models. Unlike the image branch, the LiDAR branch many vary in the format as the input, including different manually designed features and representations. We then describe in detail in section 4 the fusion methodology, which is an innovative and clear taxonomy of dividing all the current work into two major classes and four minor classes compared to traditional methods. In section 5, we deeply analyze some remaining problems, research opportunities, and plausible future works about the multi-modal sensor fusion for autonomous driving, which we can easily perceive some insightful attempts but still left to be solved. In section 6, we finally conclude the content of this paper.

2 Tasks, and Open Competitions
We will firstly introduce the commonly-known perception tasks in autonomous driving in this section. Besides, there is also some widely-used open benchmark dataset that we will give a glimpse of them here.
2.1 Multi-modal Sensor Fusion Perception Tasks
In general, a few tasks can be accounted for as Driving Perception Tasks, containing Object Detection, Semantic segmentation, Depth Completion & Prediction, and so on[26, 71]. Here, we mainly focus on the first two tasks as one of the most concentrated research areas. Also, they cover tasks such as the detection of obstacles, traffic lights, traffic signs, and the segmentation of lanes or free space. We also briefly introduce some remaining tasks. An overview of perception tasks in the autonoumous driving is shown in Figure 1.
Object Detection
It is crucial for autonomous driving cars to understand the surrounding environment. Unmanned vehicles need to detect both stationary and moving obstacles on the road for safe driving. Object Detection, a traditional computer vision task, is widely-used in autonomous driving systems[108, 61]. Researchers build such framework for Obstacle Detection (Cars, Pedestrians, Cyclist, etc.), Traffic Light Detection, Traffic Sign Detection, and so on.
Generally speaking, object detection uses rectangles or cuboids represented by parameters to tightly bound instances of predefined categories, as cars or pedestrians, which needs to both excel in localization and classification. Because of the lack of depth channel, 2D object detection is often expressed as simply while 3D object detection bounding box is often represented as .
Semantic Segmentation
Except for object detection, many autonomous driving perception tasks can be formulated as semantic segmentation. For example, free-space detection [35, 57, 107] is a basic module for many autonomous driving systems which classify the ground pixel into the drivable and non-drivable parts. Some Lane Detection [24, 84] methods also use the multi-class semantic segmentation mask to represent the different lanes on the road.
The essence of semantic segmentation is to cluster the basic components of input data, such as pixels and 3D points, into multiple regions containing specific semantic information. Specifically, semantic segmentation is that given a set of data, such as image pixels or LiDAR 3D point clouds , and a predefined set of candidate labels , we use a model to assign each pixel or point with selected one of the k semantic labels or the probabilities for all.
Other Perception Tasks
Besides the object detection and semantic segmentation mentioned above, the perception task in autonomous driving includes object classification [44], depth completion and prediction [26]. Object classification mainly solves the problem of determining the category given point clouds and images through a model. The depth completion and prediction tasks focus on predicting the distance for every pixel in the image from the viewer given LiDAR point cloud and image data. Although these tasks may benefit from multi-modal information, the fusion module is not widely discussed in these fields. As a result, we choose to omit such two tasks in this paper.
Although many other perception tasks are not covered in this paper, most can be regarded as object detection or semantic segmentation variants. Therefore, we focus on these two research works in this paper.
2.2 Open competitions and Datasets
Over ten datasets [50, 71, 30, 58, 88, 47, 52, 80, 10, 94, 97, 7, 27, 101, 93, 56, 64] are related to autonomous driving percception. However, only three datasets are commonly used, including KITTI[26], Waymo[71], and nuScenes[6]. Here we summarize the detailed characteristics of these datasets in Table 1.
| Dataset | Year | Hours | LiDARs | Cameras | Annotated LiDAR Frames | 3D Boxes | 2D Boxes | Traffic Scenario | Diversity |
| KITTI [26] | 2012 | 1.5 | 1 Velodyne HDL-64E | 2 color, 2 grayscale cameras | 15k | 80k | 80k | Urban, Suburban, Highway | - |
| Waymo [71] | 2019 | 6.4 | 5 LiDARs | 5 high-resolution pinhole cameras | 230k | 12M | 9.9M | Urban, Suburban | Locations |
| nuScenes [6] | 2019 | 5.5 | 1 Spinning 32-beams LiDAR | 6 RGB cameras | 40k | 1.4M | - | Urban, Suburban | Locations, Weather |
| ApolloScape [33] | 2018 | 2 | 2 VUX-1HA laser scanners | 2 front cameras | 144k | 70k | - | Urban, Suburban, Highway | Weather, Locations |
| PandaSet [89] | 2021 | - | 1 Mechanical spinning LiDAR and 1 Forward-facing LiDAR | 5 wide-angle cameras and 1 forward-facing long-focus camera | 6k | 1M | - | Urban | Locations |
| EU Long-term [95] | 2020 | 1 | 2 Velodyne HDL-32E LiDARs and 1 ibeo LUX 4L LiDARs | 2 stereo cameras and 2 Pixelink PL-B742F industrial cameras | - | - | - | Urban, Suburban | Season |
| Brno Urban [47] | 2020 | 10 | 2 Velodyne HDL-32e LiDARs | 4 RGB cameras | - | - | - | Urban, Highway | Weather |
| A*3D [59] | 2020 | 55 | 1 Velodyne HDL-64ES3 3D-LiDAR | 2 color cameras | 39k | 230k | - | Urban | Weather |
| RELLIS [34] | 2021 | - | 1 Ouster OS1 LiDAR and 1 Velodyne Ultra Puck | 1 3D stereo camera and 1 RGB camera | 13k | - | - | Suburban | - |
| Cirrus [82] | 2021 | - | 2 Luminar Model H2 LiDARs | 1 RGB camera | 6k | 100k | - | Urban | - |
| HUAWEI ONCE [51] | 2021 | 144 | 1 40-beam LiDAR | 8 high-resolution cameras | 16k | 417k | 769k | Urban, Suburban | Weather, Locations |
KITTI [26] open benchmark dataset, as one of the most used dataset for object detection in autonomous driving, contains 2D, 3D, and bird’s eye view detection tasks. Equipped with four high-resolution video cameras, a Velodyne laser scanner, and a state-of-the-art localization system, KITTI collected 7481 training images and 7518 test images as well as the corresponding point clouds. Only three objects are labeled as cars, pedestrians, and cyclists with more than 200k 3D object annotations divided into three categories: easy, medium, and hard by detection difficulty. For the KITTI object detection task, Average Precision is frequently used for comparison. Besides, Average Orientation Similarity is also used to assess the performance of jointly detecting objects and estimating their 3D orientation.
As one of the largest open datasets commonly used for autonomous driving benchmarks, the Waymo [71] open dataset was collected by five LiDAR sensors and five high-resolution pinhole cameras. Specifically, there are 798 scenes for training, 202 for validation, and 150 scenes for the test. Each scene spans 20 seconds with annotations in vehicles, cyclists, and pedestrians. For evaluating 3D object detection tasks, Waymo consists of four metrics: AP/L1, APH/L1, AP/L2, APH/L2. More specifically, AP and APH represent two different performance measurements, while L1 and L2 contain objects with different detection difficulties. As for APH, it is computed similar to AP but weighted by heading accuracy.
NuScenes [6] open dataset contains 1000 driving scenes with 700 for training, 150 for validation, and 150 for the test. Equipped with cameras, LiDAR, and radar sensors, nuScenes annotates 23 object classes in every key-frame, including different types of vehicles, pedestrians, and others. NuScenes uses AP, TP for detection performance evaluation. Besides, it proposed an innovative scalar score as the nuScenes detection score (NDS) calculated by AP, TP isolating different error types.
3 Representations for LiDAR and Image
The deep learning model is restricted to the representation of the input. In order to implement the model, we need to pre-process the raw data by an elaborate feature extractor before feeding the data into the model. Therefore, we firstly introduce the representations of both LiDAR and image data, and we will discuss the fusion methodology and models in the later section.
As for the image branch, most existing methods maintain the same format as the raw data for the input of the downstream modules [81]. However, the LiDAR branch is highly dependent on data format[44], which emphasizes different characteristics and influences downstream model design massively. As a result, we summarize them as point-based, voxel-based, and 2D-mapping-based point cloud data formats suiting heterogeneous deep learning models.
3.1 Image Representation
As the most commonly used sensor for data acquisition in 2D or 3D object detection and semantic segmentation tasks, the monocular camera provides RGB images rich in texture information [2, 36, 86]. Specifically, for every image pixel as , it has a multiple channel feature vector as which usually contains the camera capture color decomposing in the red, blue, green channel or other manually designed feature as the gray-scale channel.
However, direct detecting objects in 3D space is relatively challenging because of the limited depth information, which is hard to be extracted by a monocular camera. Therefore, many works[43, 103, 11] use binocular or stereo camera systems through the spatial and temporal space to exploit additional information for 3D object detection, such as depth estimation, optical flow, and so on. For the extreme driving environment such as night or fog, some work also uses gated or infra-red cameras to improve the robustness[4].
3.2 Point-based Point Cloud Representation
As for 3D perception sensors, LiDARs use a laser system to scan the environment and generate a point cloud. It samples the points in the world coordinate system that denotes the intersection of the laser ray and the opacity surface. Generally speaking, the raw data of the most LiDARs is quaternion like , which stands for the reflectance of each point. The different texture leads to different reflectance, which offers additional information in several tasks [31].
In order to incorporate the LiDAR data, some methods use points directly by a point-based feature extraction backbone[61, 62]. However, the quaternion representation of points suffers redundancy or speed drawbacks. Therefore, many researchers [108, 41, 66, 18] try to transform the point cloud into voxel or 2D projection before feeding it to the downstream modules.
3.3 Voxel-based Point Cloud Representation
Some work utilizes 3D CNN by discretizing the 3D space into 3D voxels, representing as , where each stands for a feature vector as . stands for the centorid of the voxelized cuboid while stands for some statistical-based local information.
The local density a commonly used feature defined by the quantity of 3D points in the local voxel [8, 75]. Local offset is commonly defined as the offset between the point real-word coordinates and the local voxel centroid. Others may contain local linearity and local curvature[65, 74].
Recent work may consider a more reasonable discretizing way as cylinder-based voxelization[91], but Voxel-based Point Cloud Representation, unlike mentioned Point-based Point Cloud Representation above, dramatically reduces the redundancy of the unstructured point cloud [41]. Besides, being able to utilize 3D sparse convolutional techniques, the perception tasks achieve not only faster-training speed but also higher accuracy [41, 18].
3.4 2D-mapping-based Point Cloud Representation
Instead of proposing a new network structure, some works utilize sophisticated 2D CNN backbones to encode the point cloud. Specifically, they tried to project the LiDAR data into image space as two common types, including camera plane map (CPM) and bird’s eye view (BEV) [96, 41].
A CPM can be obtained with the extrinsic calibration by projecting every 3D point as into the camera coordinate system as . Since the CPM has the same format as the camera image, they can be naturally fused by using the CPM as an additional channel. However, due to the lower resolution of LiDAR after the projection, the feature of many pixels in CPM is corrupted. Hence, some methods have been proposed to up-sample the feature map while others left them blank [39, 49].
Unlike CPM that directly projects LiDAR information into front-view image space, the BEV mapping provides an elevated view of a scene from above. It is utilized by the detection and localization tasks for two reasons. Firstly, unlike the camera installed behind the windscreen, most LiDARs are on the vehicle’s top with fewer occlusions [26]. Secondly, all objects are placed on the ground plane in the BEV, and models can generate predictions without distortion in length and width [26]. BEV components may vary. Some are directly converted from height, density, or intensity as point-based or voxel-based features [12], while others learn features of the LiDAR information in the pillars through feature extractor modules [41].
4 Fusion Methodology
In this section, we will review different fusion methodologies on LiDAR-camera data. In the perspective of traditional taxonomy, all multi-modal data fusion methods can be conveniently categorized into three paradigms, including data-level-fusion (early-fusion), feature-level-fusion (deep-fusion), and object-level-fusion (late-fusion )[81, 15, 23].
The data-level-fusion or early-fusion methods directly fuse the raw sensor data in different modalities by spatial alignment. The feature-level-fusion or deep-fusion methods mix cross-modal data in feature space by concatenation or element-wise multiplication. The object-level-fusion methods combine prediction results of models in each modality and make the final decision.
However, recent works [106, 40, 17, 83, 104] cannot be easily classified into these three categories. So in this paper, we propose a new taxonomy that divides all fusion methods into strong-fusion and weak-fusion, which we will elaborate on in detail. We show their relationships in Figure 2.
For the performance comparison, we are focusing on two main tasks in KITTI benchmark, as 3D Detection and Bird’s Eye View Object Detection. Table 2 and Table 3 present the experimental results on KITTI test dataset of BEV and 3D setup separately of recent multi-modal fusion methods.
| Method | Year | Car | Pedestrian | Cyclist | ||||||
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | ||
| Early-Fusion | ||||||||||
| PFF3D [87] | 2021 | 89.61 | 85.08 | 80.42 | 48.74 | 40.94 | 38.54 | 72.67 | 55.71 | 49.58 |
| Painted PointRCNN [76] | 2020 | 92.45 | 88.11 | 83.36 | 58.70 | 49.93 | 46.29 | 83.91 | 71.54 | 62.97 |
| PI-RCNN [90] | 2020 | 91.44 | 85.81 | 81.00 | - | - | - | - | - | - |
| Complexer-YOLO [68] | 2019 | 77.24 | 68.96 | 64.95 | 21.42 | 18.26 | 17.06 | 32.00 | 25.43 | 22.88 |
| MVX-Net(PF) [69] | 2019 | 89.20 | 85.90 | 78.10 | - | - | - | - | - | - |
| Deep-Fusion | ||||||||||
| RoIFusion [9] | 2021 | 92.88 | 89.03 | 83.94 | 46.21 | 38.08 | 35.97 | 83.13 | 67.71 | 61.70 |
| EPNet [32] | 2020 | 94.22 | 88.47 | 83.69 | - | - | - | - | - | - |
| MAFF-Net [105] | 2020 | 90.79 | 87.34 | 77.66 | - | - | - | - | - | - |
| SemanticVoxels [22] | 2020 | - | - | - | 58.91 | 49.93 | 47.31 | - | - | - |
| MVAF-Net [78] | 2020 | 91.95 | 87.73 | 85.00 | - | - | - | - | - | - |
| 3D-CVF [102] | 2020 | 93.52 | 89.56 | 82.45 | - | - | - | - | - | - |
| MMF [45] | 2019 | 93.67 | 88.21 | 81.99 | - | - | - | - | - | - |
| ContFuse [46] | 2018 | 94.07 | 85.35 | 75.88 | - | - | - | - | - | - |
| SparsePool [85] | 2017 | - | - | - | 43.33 | 34.15 | 31.78 | 43.55 | 35.24 | 30.15 |
| Late-Fusion | ||||||||||
| CLOCs [55] | 2020 | 92.91 | 89.48 | 86.42 | - | - | - | - | - | - |
| Asymmetry-Fusion | ||||||||||
| VMVS [40] | 2019 | - | - | - | 60.34 | 50.34 | 46.45 | - | - | - |
| MLOD [17] | 2019 | 90.25 | 82.68 | 77.97 | 55.09 | 45.40 | 41.42 | 73.03 | 55.06 | 48.21 |
| MV3D [12] | 2017 | 86.62 | 78.93 | 69.80 | - | - | - | - | - | - |
| Weak-Fusion | ||||||||||
| Faraway-Frustum [104] | 2020 | 91.90 | 88.08 | 85.35 | 52.15 | 43.85 | 41.68 | 79.65 | 64.54 | 57.84 |
| F-ConvNet [83] | 2019 | 91.51 | 85.84 | 76.11 | 57.04 | 48.96 | 44.33 | 84.16 | 68.88 | 60.05 |
| IPOD [99] | 2018 | 86.93 | 83.98 | 77.85 | 60.83 | 51.24 | 45.40 | 77.10 | 58.92 | 51.01 |
| F-PointNet [60] | 2017 | 91.17 | 84.67 | 74.77 | 57.13 | 49.57 | 45.48 | 77.26 | 61.37 | 53.78 |
| Method | Year | Car | Pedestrian | Cyclist | ||||||
| Easy | Mod | Hard | Easy | Mod | Hard | Easy | Mod | Hard | ||
| Early-Fusion | ||||||||||
| PFF3D [87] | 2021 | 81.11 | 72.93 | 67.24 | 43.93 | 36.07 | 32.86 | 63.27 | 46.78 | 41.37 |
| Painted PointRCNN [76] | 2020 | 82.11 | 71.70 | 67.08 | 50.32 | 40.97 | 37.87 | 77.63 | 63.78 | 55.89 |
| PI-RCNN [90] | 2020 | 84.37 | 74.82 | 70.03 | - | - | - | - | - | - |
| Complexer-YOLO [68] | 2019 | 55.93 | 47.34 | 42.60 | 17.60 | 13.96 | 12.70 | 24.27 | 18.53 | 17.31 |
| MVX-Net(PF) [69] | 2019 | 83.20 | 72.70 | 65.20 | - | - | - | - | - | - |
| Deep-Fusion | ||||||||||
| RoIFusion [9] | 2021 | 88.09 | 79.36 | 72.51 | 42.22 | 35.14 | 32.92 | 80.84 | 64.05 | 58.37 |
| EPNet [32] | 2020 | 89.81 | 79.28 | 74.59 | - | - | - | - | - | - |
| MAFF-Net [105] | 2020 | 85.52 | 75.04 | 67.61 | - | - | - | - | - | - |
| SemanticVoxels [22] | 2020 | - | - | - | 50.90 | 42.19 | 39.52 | - | - | - |
| MVAF-Net [78] | 2020 | 87.87 | 78.71 | 75.48 | - | - | - | - | - | - |
| 3D-CVF [102] | 2020 | 89.20 | 80.05 | 73.11 | - | - | - | - | - | - |
| MMF [45] | 2019 | 88.40 | 77.43 | 70.22 | - | - | - | - | - | - |
| SCANet [49] | 2019 | 76.09 | 66.30 | 58.68 | - | - | - | - | - | - |
| ContFuse [46] | 2018 | 83.68 | 68.78 | 61.67 | - | - | - | - | - | - |
| PointFusion [92] | 2018 | 77.92 | 63.00 | 53.27 | - | - | - | - | - | - |
| SparsePool [85] | 2018 | - | - | - | 37.84 | 30.38 | 26.94 | 40.87 | 32.61 | 29.05 |
| Late-Fusion | ||||||||||
| CLOCs [55] | 2020 | 89.16 | 82.28 | 77.23 | - | - | - | - | - | - |
| Asymmetry-Fusion | ||||||||||
| VMVS [40] | 2019 | - | - | - | 53.44 | 43.27 | 39.51 | - | - | - |
| MLOD [17] | 2019 | 77.24 | 67.76 | 62.05 | 47.58 | 37.47 | 35.07 | 68.81 | 49.43 | 42.84 |
| MV3D [12] | 2017 | 74.97 | 63.63 | 54.00 | - | - | - | - | - | - |
| Weak-Fusion | ||||||||||
| Faraway-Frustum [104] | 2020 | 87.45 | 79.05 | 76.14 | 46.33 | 38.58 | 35.71 | 77.36 | 62.00 | 55.40 |
| F-ConvNet [83] | 2019 | 87.36 | 76.39 | 66.69 | 52.16 | 43.38 | 38.80 | 81.98 | 65.07 | 56.54 |
| IPOD [99] | 2018 | 79.75 | 72.57 | 66.33 | 56.92 | 44.68 | 42.39 | 71.40 | 53.46 | 48.34 |
| F-PointNet [60] | 2018 | 82.19 | 69.79 | 60.59 | 50.53 | 42.15 | 38.08 | 72.27 | 56.12 | 49.01 |

4.1 Strong-fusion
We divide the strong-fusion into four categories, as early-fusion, deep-fusion, late-fusion, and asymmetry-fusion, by the different combination stages of LiDAR and camera data representations. As the most studied fusion method, strong fusion shows a lot of outstanding achievements in recent years [55, 76, 77]. From the overview in Figure 3, it is easy to notice that each minor class in strong-fusion is highly dependent on the LiDAR point cloud instead of the camera data. We will then discuss each of them in particular.
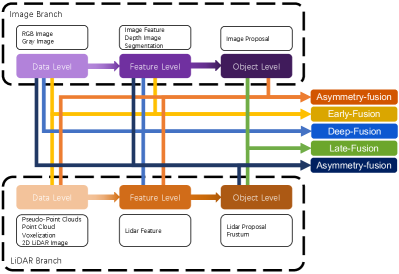
Early-fusion. Unlike the traditional definition of data-level-fusion, which is a method that fuses data in each modality directly by a spatial alignment and projection at the raw data level, early-fusion fuses LiDAR data at the data level and camera data at data-level or feature-level. One example of early-fusion can be the model in Figure 4.

As for the LiDAR branch mentioned above, the point cloud can be used in the form of 3D points with reflectance, voxelized tensor, front-view/ range-view/ bird’s eye view, as well as pseudo-point clouds. Though all these data have different intrinsic characteristics, which are highly associated with the latter LiDAR backbone, most of these data are produced with a rule-based procession except pseudo-point clouds[79]. Besides, all these data representations of LiDAR can be visualized straightforward because the data in this stage still have interpretability compared to the embedding in feature space.
As for the image path, the strict data-level definition should only contain data as RGB or Gray, which lacks generality and rationality. Compared to the traditional definition of early-fusion, we here loosen camera data to data-level and feature-level data. Especially, here we treat semantic segmentation task results in image branch benefiting the 3D object detection as feature-level representation since these kinds of ”object-level” features are different from the final object-level proposals for the whole task.
[76] and [90] fused semantic-feature in image branch and raw lidar point clouds together which results in a better performance in object detection tasks. [68], and [20] also utilize semantic-feature, but different from the above methods, it pre-processes raw lidar point cloud into voxelized tensor to further leverage a more advanced LiDAR backbone. [54] transforms 3D lidar point clouds into the 2D image and fuses feature-level representation in the image branch leveraging mature CNN techniques to achieve better performance. [87] fused raw RGB pixel with the voxelized tensor while [79] directly combines pseudo-point clouds generated from the image branch and raw point clouds from the LiDAR branch together to accomplish object detection tasks.
Based on the VoxelNet[108], [69] proposes one of the fusion methods as point-fusion, which directly attached the image feature vector of the corresponding pixel to the voxelized vector. [92] proposes the dense-fusion that attaches every original point with the global features from the image branch. [53] focuses on 2D pedestrian detection using CNN. As early-fusion, it directly fuses different branches before inputting into CNN. [105] proposes one fusion method named point attention fusion which fused image feature to a voxelized tensor in LiDAR point clouds.
Deep-fusion. Deep-fusion methods fuse cross-modal data at the feature level for the LiDAR branch but data-level and feature-level for the image branch. For example, some methods use feature extractor to acquire the embedding representation of LiDAR point cloud and camera image respectively and fuse the feature in two modalities by a series of downstream modules [102, 32]. However, unlike other strong-fusion methods, deep-fusion sometimes fuses features in a cascading way [32, 4, 46], which both leverage raw and high-level semantic information. One example of deep-fusion can be the model in Figure 5.

[92] proposes the global-fusion attached global LiDAR feature with the global features from the image branch. [69] proposes the other fusion methods as voxel-fusion, which attached the ROI pooling image feature vector to a dense feature vector for each voxel in LiDAR point clouds. [105] proposes another method named dense attention fusion that fuses pseudo images from multiple branches. [49, 45], propose two deep-fusion method each. EPNet [32] a deep LIDAR-Image fusion estimating the importance of corresponding image features to reduce the noisy influence. [4] presents a multi-modal data set in extreme weather and fused each branch in a deep-fusion way, which greatly improves the robustness of the autonomous driving model. Other deep-fusion work includes [102, 46, 16, 9, 78, 85, 37, 14, 73, 22] which have the seemingly same fusion module.
Late-fusion. Late-fusion, also known as object-level fusion, denotes the methods that fuse the result of pipelines in each modality. For example, some late-fusion methods leverage output from both the LiDAR point cloud branch and camera image branch and make the final prediction based on the result in two modalities[55]. Notice that both branch proposals should have the same data format as the final results but vary in quality, quantity, and precision. Late-fusion can be regarded as a kind of ensemble method that utilizes multi-modal information to optimize the final proposal. One example of late-fusion can be the model in Figure 6.

As mentioned above, [55] leverages late-fusion for secondly refining every 3D region proposal’s score combining 2D proposal in image branch with the 3D proposal in LiDAR branch. Besides, for every overlapping region, it utilized statistical features like confidence score, distance and IoU. [1] focuses on 2D object detection, it combines the proposals from two branches along with features like confidence score, and the model outputs the final IoU score. [29],[28] solves the road detection by combing the segmentation results together. As late-fusion in [53], it summarizes the scores from different branches for the same 3D detection proposal into one final score.
Asymmetry-fusion. Besides the early-fusion, deep-fusion, and late-fusion, some methods treat cross-modal branches with different privileges, so we define methods that fuse object-level information from one branch while data-level or feature-level from other branches as asymmetry-fusion. Unlike other methods in strong-fusion, which treat both branches in seemingly equal status, asymmetry-fusion has at least one branch dominating while other branches provide auxiliary information to conduct the final task. One example of late-fusion can be the model in Figure 7. Especially compared to late-fusion, though they might have the same extract feature using proposal [55], asymmetry-fusion only have one proposal from one branch while late-fusion have proposals from all the branches.

Such fusing methods are reasonable due to the excellent performance using convolutional neural network on camera data which filters semantically useless points in the point cloud and promotes the performance on 3D LiDAR backbone in a frustum perspective, such as [106]. It extracts frustum in raw point clouds along with corresponding pixel’s RGB information to output the parameters of the 3D bounding box. However, some works think outside the box and use the LiDAR backbone to guide the 2D backbone in a multi-view style and achieve higher accuracy. [40] focuses on pedestrian detection by the extracted multi-view image based on 3D detection proposals, which further utilizes CNN to refine the previous proposal. [12] and [17] refines the 3D proposal predicted solely by the LiDAR branch with ROI feature in other branches. [5] focuses on 2D detection, utilizing 3D region proposal from LiDAR branch and re-projecting to 2D proposal along with the image features for further refinement. [11] proposes a 3D potential bounding box by statistical and rule-based information. Combining with the image feature, it outputs the final 3D proposal.[70] is focusing on small object detection accomplished by a specially collected data set, which is essentially a 2D semantic segmentation task combining the proposal from LiDAR with the raw RGB image to output the final results.
4.2 Weak-fusion
Unlike strong-fusion, weak-fusion methods do not fuse data/ feature/ object directly from branches in multi-modalities but operate data in other ways. The weak-fusion-based methods commonly use rule-based methods to utilize data in one modality as a supervision signal to guide the interaction of another modality. Figure 8 demonstrates the basic framework of the weak-fusion schema. For example, the 2D proposal from the CNN in the image branch might result in a frustum in the raw lidar point cloud. However, unlike combining image features as asymmetry-fusion mentioned above, weak fusion directly input those raw LiDAR point cloud selected into the LiDAR backbone to output the final proposal [60].

[83] advance the techniques by dividing each frustum into several parts by fixed chosen stride which, further increases the 3D detection accuracy. [104] focuses on remote sparse-point-cloud object detection. [99] filters out all the background points of LiDAR point cloud in frustum from semantic segmentation results in an image. [72] focuses on semi-supervised and transfer learning where frustum is proposed according to 2D image proposal.
Other weak-fusion like [19] highlights the real-time detection performance of 2D objects by selecting only one model of the two branches at each time to predict the final proposal using a reinforcement learning strategy. In [21], multiple 3D box proposals are generated by 2D detection proposals in the image branch, and then the model outputs the final 3D detection box with its detection score. [67] uses an image to predict 2D bounding box and 3D pose parameters and further refines it utilizing the LiDAR point clouds in the corresponding area.
4.3 Other Fusion Methods
Some work could not be simply defined as any kind of fusion mentioned above because they possess more than one fusion method in the whole model framework, such as a combination of deep-fusion and late-fusion [39] while [77] combines early-fusion and deep-fusion together. These methods suffer from redundancy at the model design view, which is not the mainstream for fusion modules.
5 Opportunities in Multi-Modal Fusion
Multi-modal fusion methods for perception tasks in autonomous driving have achieved rapid progress in recent years, varying from more advanced feature representations to more complex deep learning models[81, 15]. However, there remains some more open problems to be fixed. We here summarize some critical and essential work to be done in the future into the following aspects.
5.1 More Advanced Fusion Methodology
Current fusion models suffer from the problem of misalignment and information loss [67, 98, 13]. Besides, the flat fusion operations [76, 20] also prevent the further improvement of perception task performance. We summarize them as two aspects: Misalignment and Information Loss, More Reasonable Fusion Operations.
Misalignment and Information Loss
The intrinsic and extrinsic of the camera and LiDAR are vastly different from each other. Data in both modalities need to be re-organized under a new coordinate system. Traditional early and deep fusion methods utilize an extrinsic calibration matrix to project all the LiDAR points directly to the corresponding pixels or vice versa [54, 76, 69]. However, this point-by-pixel alignment is not accurate enough because of the sensory noise. Therefore, we can see that in addition to such strict correspondence, some work [90] utilizing the surrounding information as a supplement results in better performance.
Besides, there exists some other information loss during the transformation of input and feature space. Generally, the projection of dimension reduction operation will inevitably lead to massive information loss, e.g., mapping the 3D LiDAR point cloud into the 2D BEV image. Therefore, by mapping the two modal data into another high-dimensional representation specially designed for fusion, future works can efficiently utilize the raw data with less information loss.
More Reasonable Fusion Operations
The current research works use intuitive methods to fuse cross-modal data, such as concatenation and element-wise multiply [69, 77]. These simple operations may not be able to fuse the data with a large distribution discrepancy, and as a result, hard to close the semantic gap between two modalities. Some work tries to use a more elaborated cascading structure to fuse the data and improve performance [12, 46]. In future research, mechanisms such as Bi-linear mapping[25, 38, 3] can fuse the feature with different characteristics.
5.2 Multi-Source Information Leverage
Single frame at the front view is the typical scenario for autonomous driving perception tasks[26]. However, most frameworks utilize limited information without elaborated designed auxiliary tasks to further understand the driving scenes. We summarize them as With More Potential Useful Information and Self-Supervision for Representation Learning.
With More Potential Useful Information
Existing methods [81] lack the effective use of the information from multiple dimensions and sources. Most of them focus on a single frame of multi-modal data at the front view. As a result, other meaningful information is under-utilized such as semantic, spatial, and scene contextual information.
Some models [76, 90, 20] try to use the results obtained from the image semantic segmentation task as additional features, while others may exploit the features in intermediate layers of a neural network backbone whether trained by specific downstream tasks or not [46]. In autonomous driving scenarios, many downstream tasks with explicit semantic information may greatly benefit the performance of object detection tasks. For example, lane detection can intuitively provide additional help for detecting vehicles between the lanes, and the semantic segmentation results can improve object detection performance [76, 90, 20]. Therefore, future research can jointly build a complete semantic understanding framework of the cityscape scenarios through various downstream tasks like detecting the lane, traffic light, and signs to assist perception tasks’ performance.
In addition, current perception tasks mainly rely on a single frame that overlooks the temporal information. Recent LiDAR-based method [63] combines a series of frames to improve the performance. The time-series information contains serialized supervision signals, which can provide more robust results than methods that use a single frame.
Therefore, future work may dig deeper into utilizing temporal, contextual, and spatial information for continuous frames with innovative model designs.
Self-Supervision for Representation Learning
The mutual-supervised signals naturally exist among the cross-modal data sampled from the same real-world scenarios but different perspectives. However, current methods cannot mine the co-relationship among each modality, suffering from lacking a deep understanding of data. In the future, the studies can be focused on how to use the multi-modal data for self-supervised learning, including pre-training, fine-tuning or contrastive learning. By implementing these state-of-the-art mechanisms, the fusion model will result in a deeper understanding of the data and achieve better results, which has already shown some promising signs in other areas while leaving a blank space for autonomous driving perception [48].
5.3 Intrinsic Problems in Perception Sensors
Domain bias and resolution are highly related to the real-world scenes and the sensors [26]. These unexpected flaws prevent large-scale training and implementation for autonomous driving deep learning models, which need to be solved in future work.
Data Domain Bias
In autonomous driving perception scenes, the raw data extracted by different sensors is accompanied by severe domain-related characteristics. Different camera systems have their optical properties, while LiDAR may vary from mechanical LiDAR to solid-state LiDAR. What is more, data itself may be domain-biased such as weather, season, or location [71, 6], even if it is captured by the same sensors. As a result, the detection model can not be adapted to new scenarios smoothly. Such defects prevent the collection of a large-scale dataset and the re-usability of the original training data due to the failures of generalization. Therefore, it is crucial to find a way to eliminate domain bias and integrate different data sources adaptively in future work.
Conflicts with Data Resolution
Sensors from different modalities often have different resolutions [42, 100]. For example, the spatial density of LiDAR is notably lower than that of the image. No matter what projection method is adopted, some information is eliminated because the corresponding relationship cannot be found. This may lead the model to be dominated by the data of one specific modality, whether it is due to the different resolution of the feature vector or the imbalance of original information. Therefore, future works can explore a new data representation system compatible with sensors in different spatial resolutions.
6 Conclusion
In this paper, we review over 50 related papers about the multi-modal sensor fusion for autonomous driving perception tasks. To be specific, we first propose an innovative way to classify these papers into three classes by a more reasonable taxonomy from the fusion perspective. Then we conduct an in-depth survey about the data format and representation of the LiDAR and camera and describe the different characteristics. Finally, we make a detailed analysis about the remaining problems of multi-modal sensor fusion and introduce several new possible directions, which may enlighten future research works.
References
- [1] Alireza Asvadi, Luis Garrote, Cristiano Premebida, Paulo Peixoto, and Urbano J Nunes. Multimodal vehicle detection: fusing 3d-lidar and color camera data. Pattern Recognition Letters, 115:20–29, 2018.
- [2] Esra Ataer-Cansizoglu, Yuichi Taguchi, Srikumar Ramalingam, and Tyler Garaas. Tracking an rgb-d camera using points and planes. In Proceedings of the IEEE International Conference on Computer Vision Workshops, pages 51–58, 2013.
- [3] Hedi Ben-Younes, Rémi Cadene, Matthieu Cord, and Nicolas Thome. Mutan: Multimodal tucker fusion for visual question answering. In Proceedings of the IEEE international conference on computer vision, pages 2612–2620, 2017.
- [4] Mario Bijelic, Tobias Gruber, Fahim Mannan, Florian Kraus, Werner Ritter, Klaus Dietmayer, and Felix Heide. Seeing through fog without seeing fog: Deep multimodal sensor fusion in unseen adverse weather. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11682–11692, 2020.
- [5] Markus Braun, Qing Rao, Yikang Wang, and Fabian Flohr. Pose-rcnn: Joint object detection and pose estimation using 3d object proposals. In 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), pages 1546–1551. IEEE, 2016.
- [6] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020.
- [7] Ming-Fang Chang, John Lambert, Patsorn Sangkloy, Jagjeet Singh, Slawomir Bak, Andrew Hartnett, De Wang, Peter Carr, Simon Lucey, Deva Ramanan, et al. Argoverse: 3d tracking and forecasting with rich maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8748–8757, 2019.
- [8] Erzhuo Che and Michael J Olsen. Fast ground filtering for tls data via scanline density analysis. ISPRS Journal of Photogrammetry and Remote Sensing, 129:226–240, 2017.
- [9] Can Chen, Luca Zanotti Fragonara, and Antonios Tsourdos. Roifusion: 3d object detection from lidar and vision. IEEE Access, 9:51710–51721, 2021.
- [10] Wen Chen, Zhe Liu, Hongchao Zhao, Shunbo Zhou, Haoang Li, and Yun-Hui Liu. Cuhk-ahu dataset: Promoting practical self-driving applications in the complex airport logistics, hill and urban environments. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4283–4288. IEEE, 2020.
- [11] Xiaozhi Chen, Kaustav Kundu, Yukun Zhu, Huimin Ma, Sanja Fidler, and Raquel Urtasun. 3d object proposals using stereo imagery for accurate object class detection. IEEE transactions on pattern analysis and machine intelligence, 40(5):1259–1272, 2017.
- [12] Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, and Tian Xia. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 1907–1915, 2017.
- [13] Yiqiang Chen, Feng Liu, and Ke Pei. Cross-modal matching cnn for autonomous driving sensor data monitoring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3110–3119, 2021.
- [14] Xuelian Cheng, Yiran Zhong, Yuchao Dai, Pan Ji, and Hongdong Li. Noise-aware unsupervised deep lidar-stereo fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6339–6348, 2019.
- [15] Yaodong Cui, Ren Chen, Wenbo Chu, Long Chen, Daxin Tian, Ying Li, and Dongpu Cao. Deep learning for image and point cloud fusion in autonomous driving: A review. IEEE Transactions on Intelligent Transportation Systems, 2021.
- [16] Arthur Daniel Costea, Robert Varga, and Sergiu Nedevschi. Fast boosting based detection using scale invariant multimodal multiresolution filtered features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6674–6683, 2017.
- [17] Jian Deng and Krzysztof Czarnecki. Mlod: A multi-view 3d object detection based on robust feature fusion method. In 2019 IEEE Intelligent Transportation Systems Conference (ITSC), pages 279–284. IEEE, 2019.
- [18] Jiajun Deng, Shaoshuai Shi, Peiwei Li, Wengang Zhou, Yanyong Zhang, and Houqiang Li. Voxel r-cnn: Towards high performance voxel-based 3d object detection. arXiv preprint arXiv:2012.15712, 2020.
- [19] Nicolai Dorka, Johannes Meyer, and Wolfram Burgard. Modality-buffet for real-time object detection. arXiv preprint arXiv:2011.08726, 2020.
- [20] Jian Dou, Jianru Xue, and Jianwu Fang. Seg-voxelnet for 3d vehicle detection from rgb and lidar data. In 2019 International Conference on Robotics and Automation (ICRA), pages 4362–4368. IEEE, 2019.
- [21] Xinxin Du, Marcelo H Ang, Sertac Karaman, and Daniela Rus. A general pipeline for 3d detection of vehicles. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 3194–3200. IEEE, 2018.
- [22] Juncong Fei, Wenbo Chen, Philipp Heidenreich, Sascha Wirges, and Christoph Stiller. Semanticvoxels: Sequential fusion for 3d pedestrian detection using lidar point cloud and semantic segmentation. arXiv preprint arXiv:2009.12276, 2020.
- [23] Di Feng, Christian Haase-Schütz, Lars Rosenbaum, Heinz Hertlein, Claudius Glaeser, Fabian Timm, Werner Wiesbeck, and Klaus Dietmayer. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges. IEEE Transactions on Intelligent Transportation Systems, 22(3):1341–1360, 2020.
- [24] C Fernández, Rubén Izquierdo, David Fernández Llorca, and MA Sotelo. Road curb and lanes detection for autonomous driving on urban scenarios. In 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), pages 1964–1969. IEEE, 2014.
- [25] Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, and Marcus Rohrbach. Multimodal compact bilinear pooling for visual question answering and visual grounding. arXiv preprint arXiv:1606.01847, 2016.
- [26] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
- [27] Tobias Gruber, Frank Julca-Aguilar, Mario Bijelic, and Felix Heide. Gated2depth: Real-time dense lidar from gated images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1506–1516, 2019.
- [28] Shuo Gu, Yigong Zhang, Jinhui Tang, Jian Yang, Jose M Alvarez, and Hui Kong. Integrating dense lidar-camera road detection maps by a multi-modal crf model. IEEE Transactions on Vehicular Technology, 68(12):11635–11645, 2019.
- [29] Shuo Gu, Yigong Zhang, Jinhui Tang, Jian Yang, and Hui Kong. Road detection through crf based lidar-camera fusion. In 2019 International Conference on Robotics and Automation (ICRA), pages 3832–3838. IEEE, 2019.
- [30] Qingyong Hu, Bo Yang, Sheikh Khalid, Wen Xiao, Niki Trigoni, and Andrew Markham. Towards semantic segmentation of urban-scale 3d point clouds: A dataset, benchmarks and challenges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4977–4987, 2021.
- [31] Pengdi Huang, Ming Cheng, Yiping Chen, Huan Luo, Cheng Wang, and Jonathan Li. Traffic sign occlusion detection using mobile laser scanning point clouds. IEEE Transactions on Intelligent Transportation Systems, 18(9):2364–2376, 2017.
- [32] Tengteng Huang, Zhe Liu, Xiwu Chen, and Xiang Bai. Epnet: Enhancing point features with image semantics for 3d object detection. In European Conference on Computer Vision, pages 35–52. Springer, 2020.
- [33] Xinyu Huang, Xinjing Cheng, Qichuan Geng, Binbin Cao, Dingfu Zhou, Peng Wang, Yuanqing Lin, and Ruigang Yang. The apolloscape dataset for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2018.
- [34] Peng Jiang, Philip Osteen, Maggie Wigness, and Srikanth Saripalli. Rellis-3d dataset: Data, benchmarks and analysis. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 1110–1116, 2021.
- [35] Narsimlu Kemsaram, Anweshan Das, and Gijs Dubbelman. An integrated framework for autonomous driving: object detection, lane detection, and free space detection. In 2019 Third World Conference on Smart Trends in Systems Security and Sustainablity (WorldS4), pages 260–265. IEEE, 2019.
- [36] Hyomin Kim, Jungeon Kim, Hyeonseo Nam, Jaesik Park, and Seungyong Lee. Spatiotemporal texture reconstruction for dynamic objects using a single rgb-d camera. In Computer Graphics Forum, volume 40, pages 523–535. Wiley Online Library, 2021.
- [37] Jaekyum Kim, Jaehyung Choi, Yechol Kim, Junho Koh, Chung Choo Chung, and Jun Won Choi. Robust camera lidar sensor fusion via deep gated information fusion network. In 2018 IEEE Intelligent Vehicles Symposium (IV), pages 1620–1625. IEEE, 2018.
- [38] Jin-Hwa Kim, Kyoung-Woon On, Woosang Lim, Jeonghee Kim, Jung-Woo Ha, and Byoung-Tak Zhang. Hadamard product for low-rank bilinear pooling. arXiv preprint arXiv:1610.04325, 2016.
- [39] Jason Ku, Melissa Mozifian, Jungwook Lee, Ali Harakeh, and Steven L Waslander. Joint 3d proposal generation and object detection from view aggregation. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1–8. IEEE, 2018.
- [40] Jason Ku, Alex D Pon, Sean Walsh, and Steven L Waslander. Improving 3d object detection for pedestrians with virtual multi-view synthesis orientation estimation. arXiv preprint arXiv:1907.06777, 2019.
- [41] Alex H Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12697–12705, 2019.
- [42] Ferdinand Langer, Andres Milioto, Alexandre Haag, Jens Behley, and Cyrill Stachniss. Domain transfer for semantic segmentation of lidar data using deep neural networks. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8263–8270. IEEE, 2020.
- [43] Peiliang Li, Xiaozhi Chen, and Shaojie Shen. Stereo r-cnn based 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7644–7652, 2019.
- [44] Ying Li, Lingfei Ma, Zilong Zhong, Fei Liu, Michael A Chapman, Dongpu Cao, and Jonathan Li. Deep learning for lidar point clouds in autonomous driving: a review. IEEE Transactions on Neural Networks and Learning Systems, 2020.
- [45] Ming Liang, Bin Yang, Yun Chen, Rui Hu, and Raquel Urtasun. Multi-task multi-sensor fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7345–7353, 2019.
- [46] Ming Liang, Bin Yang, Shenlong Wang, and Raquel Urtasun. Deep continuous fusion for multi-sensor 3d object detection. In Proceedings of the European Conference on Computer Vision (ECCV), pages 641–656, 2018.
- [47] Adam Ligocki, Ales Jelinek, and Ludek Zalud. Brno urban dataset-the new data for self-driving agents and mapping tasks. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pages 3284–3290. IEEE, 2020.
- [48] Yunze Liu, Li Yi, Shanghang Zhang, Qingnan Fan, Thomas Funkhouser, and Hao Dong. P4contrast: Contrastive learning with pairs of point-pixel pairs for rgb-d scene understanding. arXiv preprint arXiv:2012.13089, 2020.
- [49] Haihua Lu, Xuesong Chen, Guiying Zhang, Qiuhao Zhou, Yanbo Ma, and Yong Zhao. Scanet: Spatial-channel attention network for 3d object detection. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1992–1996. IEEE, 2019.
- [50] Yuexin Ma, Xinge Zhu, Sibo Zhang, Ruigang Yang, Wenping Wang, and Dinesh Manocha. Trafficpredict: Trajectory prediction for heterogeneous traffic-agents. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 6120–6127, 2019.
- [51] Jiageng Mao, Minzhe Niu, Chenhan Jiang, Hanxue Liang, Jingheng Chen, Xiaodan Liang, Yamin Li, Chaoqiang Ye, Wei Zhang, Zhenguo Li, et al. One million scenes for autonomous driving: Once dataset. arXiv preprint arXiv:2106.11037, 2021.
- [52] Julieta Martinez, Sasha Doubov, Jack Fan, Ioan Andrei Bârsan, Shenlong Wang, Gellért Máttyus, and Raquel Urtasun. Pit30m: A benchmark for global localization in the age of self-driving cars. arXiv preprint arXiv:2012.12437, 2020.
- [53] Gledson Melotti, Cristiano Premebida, Nuno MM da S Gonçalves, Urbano JC Nunes, and Diego R Faria. Multimodal cnn pedestrian classification: a study on combining lidar and camera data. In 2018 21st International Conference on Intelligent Transportation Systems (ITSC), pages 3138–3143. IEEE, 2018.
- [54] Gregory P Meyer, Jake Charland, Darshan Hegde, Ankit Laddha, and Carlos Vallespi-Gonzalez. Sensor fusion for joint 3d object detection and semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 0–0, 2019.
- [55] Su Pang, Daniel Morris, and Hayder Radha. Clocs: Camera-lidar object candidates fusion for 3d object detection. arXiv preprint arXiv:2009.00784, 2020.
- [56] Abhishek Patil, Srikanth Malla, Haiming Gang, and Yi-Ting Chen. The h3d dataset for full-surround 3d multi-object detection and tracking in crowded urban scenes. In 2019 International Conference on Robotics and Automation (ICRA), pages 9552–9557. IEEE, 2019.
- [57] Joel Pazhayampallil et al. Free space detection with deep nets for autonomous driving, 2014.
- [58] Quang-Hieu Pham, Pierre Sevestre, Ramanpreet Singh Pahwa, Huijing Zhan, Chun Ho Pang, Yuda Chen, Armin Mustafa, Vijay Chandrasekhar, and Jie Lin. A* 3d dataset: Towards autonomous driving in challenging environments. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pages 2267–2273. IEEE, 2020.
- [59] Quang-Hieu Pham, Pierre Sevestre, Ramanpreet Singh Pahwa, Huijing Zhan, Chun Ho Pang, Yuda Chen, Armin Mustafa, Vijay Chandrasekhar, and Jie Lin. A*3d dataset: Towards autonomous driving in challenging environments. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pages 2267–2273, 2020.
- [60] Charles R Qi, Wei Liu, Chenxia Wu, Hao Su, and Leonidas J Guibas. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 918–927, 2018.
- [61] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660, 2017.
- [62] Charles R Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv preprint arXiv:1706.02413, 2017.
- [63] Charles R Qi, Yin Zhou, Mahyar Najibi, Pei Sun, Khoa Vo, Boyang Deng, and Dragomir Anguelov. Offboard 3d object detection from point cloud sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6134–6144, 2021.
- [64] Vasili Ramanishka, Yi-Ting Chen, Teruhisa Misu, and Kate Saenko. Toward driving scene understanding: A dataset for learning driver behavior and causal reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7699–7707, 2018.
- [65] Radu Bogdan Rusu and Steve Cousins. 3d is here: Point cloud library (pcl). In 2011 IEEE international conference on robotics and automation, pages 1–4. IEEE, 2011.
- [66] Shaoshuai Shi, Chaoxu Guo, Li Jiang, Zhe Wang, Jianping Shi, Xiaogang Wang, and Hongsheng Li. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10529–10538, 2020.
- [67] Kiwoo Shin, Youngwook Paul Kwon, and Masayoshi Tomizuka. Roarnet: A robust 3d object detection based on region approximation refinement. In 2019 IEEE Intelligent Vehicles Symposium (IV), pages 2510–2515. IEEE, 2019.
- [68] Martin Simon, Karl Amende, Andrea Kraus, Jens Honer, Timo Samann, Hauke Kaulbersch, Stefan Milz, and Horst Michael Gross. Complexer-yolo: Real-time 3d object detection and tracking on semantic point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 0–0, 2019.
- [69] Vishwanath A Sindagi, Yin Zhou, and Oncel Tuzel. Mvx-net: Multimodal voxelnet for 3d object detection. In 2019 International Conference on Robotics and Automation (ICRA), pages 7276–7282. IEEE, 2019.
- [70] Aasheesh Singh, Aditya Kamireddypalli, Vineet Gandhi, and K Madhava Krishna. Lidar guided small obstacle segmentation. arXiv preprint arXiv:2003.05970, 2020.
- [71] Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2446–2454, 2020.
- [72] Yew Siang Tang and Gim Hee Lee. Transferable semi-supervised 3d object detection from rgb-d data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1931–1940, 2019.
- [73] Ruddy Théodose, Dieumet Denis, Thierry Chateau, Vincent Frémont, and Paul Checchin. R-agno-rpn: A lidar-camera region deep network for resolution-agnostic detection. arXiv preprint arXiv:2012.05740, 2020.
- [74] Hugues Thomas, François Goulette, Jean-Emmanuel Deschaud, Beatriz Marcotegui, and Yann LeGall. Semantic classification of 3d point clouds with multiscale spherical neighborhoods. In 2018 International conference on 3D vision (3DV), pages 390–398. IEEE, 2018.
- [75] Anh-Vu Vo, Linh Truong-Hong, Debra F Laefer, and Michela Bertolotto. Octree-based region growing for point cloud segmentation. ISPRS Journal of Photogrammetry and Remote Sensing, 104:88–100, 2015.
- [76] Sourabh Vora, Alex H Lang, Bassam Helou, and Oscar Beijbom. Pointpainting: Sequential fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4604–4612, 2020.
- [77] Chunwei Wang, Chao Ma, Ming Zhu, and Xiaokang Yang. Pointaugmenting: Cross-modal augmentation for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11794–11803, 2021.
- [78] Guojun Wang, Bin Tian, Yachen Zhang, Long Chen, Dongpu Cao, and Jian Wu. Multi-view adaptive fusion network for 3d object detection. arXiv preprint arXiv:2011.00652, 2020.
- [79] Jiarong Wang, Ming Zhu, Bo Wang, Deyao Sun, Hua Wei, Changji Liu, and Haitao Nie. Kda3d: Key-point densification and multi-attention guidance for 3d object detection. Remote Sensing, 12(11):1895, 2020.
- [80] Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Sebastian Scherer. Tartanair: A dataset to push the limits of visual slam. arXiv preprint arXiv:2003.14338, 2020.
- [81] Yingjie Wang, Qiuyu Mao, Hanqi Zhu, Yu Zhang, Jianmin Ji, and Yanyong Zhang. Multi-modal 3d object detection in autonomous driving: a survey. arXiv preprint arXiv:2106.12735, 2021.
- [82] Ze Wang, Sihao Ding, Ying Li, Jonas Fenn, Sohini Roychowdhury, Andreas Wallin, Lane Martin, Scott Ryvola, Guillermo Sapiro, and Qiang Qiu. Cirrus: A long-range bi-pattern lidar dataset. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 5744–5750. IEEE, 2021.
- [83] Zhixin Wang and Kui Jia. Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal 3d object detection. arXiv preprint arXiv:1903.01864, 2019.
- [84] Ze Wang, Weiqiang Ren, and Qiang Qiu. Lanenet: Real-time lane detection networks for autonomous driving. arXiv preprint arXiv:1807.01726, 2018.
- [85] Zining Wang, Wei Zhan, and Masayoshi Tomizuka. Fusing bird view lidar point cloud and front view camera image for deep object detection. arXiv preprint arXiv:1711.06703, 2017.
- [86] Zining Wang, Wei Zhan, and Masayoshi Tomizuka. Fusing bird’s eye view lidar point cloud and front view camera image for 3d object detection. In 2018 IEEE Intelligent Vehicles Symposium (IV), pages 1–6. IEEE, 2018.
- [87] Li-Hua Wen and Kang-Hyun Jo. Fast and accurate 3d object detection for lidar-camera-based autonomous vehicles using one shared voxel-based backbone. IEEE Access, 9:22080–22089, 2021.
- [88] Weisong Wen, Yiyang Zhou, Guohao Zhang, Saman Fahandezh-Saadi, Xiwei Bai, Wei Zhan, Masayoshi Tomizuka, and Li-Ta Hsu. Urbanloco: a full sensor suite dataset for mapping and localization in urban scenes. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pages 2310–2316. IEEE, 2020.
- [89] Pengchuan Xiao, Zhenlei Shao, Steven Hao, Zishuo Zhang, Xiaolin Chai, Judy Jiao, Zesong Li, Jian Wu, Kai Sun, Kun Jiang, Yunlong Wang, and Diange Yang. Pandaset: Advanced sensor suite dataset for autonomous driving. In 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), pages 3095–3101, 2021.
- [90] Liang Xie, Chao Xiang, Zhengxu Yu, Guodong Xu, Zheng Yang, Deng Cai, and Xiaofei He. Pi-rcnn: An efficient multi-sensor 3d object detector with point-based attentive cont-conv fusion module. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 12460–12467, 2020.
- [91] Liang Xie, Guodong Xu, Deng Cai, and Xiaofei He. X-view: Non-egocentric multi-view 3d object detector. arXiv preprint arXiv:2103.13001, 2021.
- [92] Danfei Xu, Dragomir Anguelov, and Ashesh Jain. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 244–253, 2018.
- [93] Jianru Xue, Jianwu Fang, Tao Li, Bohua Zhang, Pu Zhang, Zhen Ye, and Jian Dou. Blvd: Building a large-scale 5d semantics benchmark for autonomous driving. In 2019 International Conference on Robotics and Automation (ICRA), pages 6685–6691. IEEE, 2019.
- [94] Zhi Yan, Li Sun, Tomas Krajnik, and Yassine Ruichek. Eu long-term dataset with multiple sensors for autonomous driving. arXiv preprint arXiv:1909.03330, 2019.
- [95] Zhi Yan, Li Sun, Tomáš Krajník, and Yassine Ruichek. Eu long-term dataset with multiple sensors for autonomous driving. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10697–10704. IEEE, 2020.
- [96] Bin Yang, Wenjie Luo, and Raquel Urtasun. Pixor: Real-time 3d object detection from point clouds. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 7652–7660, 2018.
- [97] Guorun Yang, Xiao Song, Chaoqin Huang, Zhidong Deng, Jianping Shi, and Bolei Zhou. Drivingstereo: A large-scale dataset for stereo matching in autonomous driving scenarios. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 899–908, 2019.
- [98] Yi Yang. Automatic online calibration between lidar and camera, 2019.
- [99] Zetong Yang, Yanan Sun, Shu Liu, Xiaoyong Shen, and Jiaya Jia. Ipod: Intensive point-based object detector for point cloud. arXiv preprint arXiv:1812.05276, 2018.
- [100] Li Yi, Boqing Gong, and Thomas Funkhouser. Complete & label: A domain adaptation approach to semantic segmentation of lidar point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15363–15373, 2021.
- [101] Senthil Yogamani, Ciarán Hughes, Jonathan Horgan, Ganesh Sistu, Padraig Varley, Derek O’Dea, Michal Uricár, Stefan Milz, Martin Simon, Karl Amende, et al. Woodscape: A multi-task, multi-camera fisheye dataset for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9308–9318, 2019.
- [102] Jin Hyeok Yoo, Yecheol Kim, Ji Song Kim, and Jun Won Choi. 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. arXiv preprint arXiv:2004.12636, 3, 2020.
- [103] Yurong You, Yan Wang, Wei-Lun Chao, Divyansh Garg, Geoff Pleiss, Bharath Hariharan, Mark Campbell, and Kilian Q Weinberger. Pseudo-lidar++: Accurate depth for 3d object detection in autonomous driving. arXiv preprint arXiv:1906.06310, 2019.
- [104] Haolin Zhang, Dongfang Yang, Ekim Yurtsever, Keith A Redmill, and Ümit Özgüner. Faraway-frustum: Dealing with lidar sparsity for 3d object detection using fusion. arXiv preprint arXiv:2011.01404, 2020.
- [105] Zehan Zhang, Ming Zhang, Zhidong Liang, Xian Zhao, Ming Yang, Wenming Tan, and ShiLiang Pu. Maff-net: Filter false positive for 3d vehicle detection with multi-modal adaptive feature fusion. arXiv preprint arXiv:2009.10945, 2020.
- [106] Xin Zhao, Zhe Liu, Ruolan Hu, and Kaiqi Huang. 3d object detection using scale invariant and feature reweighting networks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 9267–9274, 2019.
- [107] Xiaodong Zhao, Qichao Zhang, Dongbin Zhao, and Zhonghua Pang. Overview of image segmentation and its application on free space detection. In 2018 IEEE 7th Data Driven Control and Learning Systems Conference (DDCLS), pages 1164–1169. IEEE, 2018.
- [108] Yin Zhou and Oncel Tuzel. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4490–4499, 2018.