Multi-Modal Fusion-Based Multi-Task Semantic Communication System
Abstract
In recent years, there has been significant progress in semantic communication systems empowered by deep learning techniques. It has greatly improved the efficiency of information transmission. Nevertheless, traditional semantic communication models still face challenges, particularly due to their single-task and single-modal orientation. Many of these models are designed for specific tasks, which may result in limitations when applied to multi-task communication systems. Moreover, these models often overlook the correlations among different modal data in multi-modal tasks. It leads to an incomplete understanding of complex information, causing increased communication overhead and diminished performance. To address these problems, we propose a multi-modal fusion-based multi-task semantic communication (MFMSC) framework. In contrast to traditional semantic communication approaches, MFMSC can effectively handle various tasks across multiple modalities. Furthermore, we design a fusion module based on Bidirectional Encoder Representations from Transformers (BERT) for multi-modal semantic information fusion. By leveraging the powerful semantic understanding capabilities and self-attention mechanism of BERT, we achieve effective fusion of semantic information from different modalities. We compare our model with multiple benchmarks. Simulation results show that MFMSC outperforms these models in terms of both performance and communication overhead.
Index Terms:
multi-modal fusion, multi-task, semantic communicationI Introduction
With the rapid development of communication technology, data rates in wireless communications are rapidly approaching Shannon’s capacity limit[1]. The continuously increasing demand for communication causes the explosion of wireless data traffic, placing a heavy burden on the current infrastructure of communication systems[2]. Researchers have explored innovative approaches to optimize the efficiency of communication systems[3, 4, 2]. Among them, semantic communications[2] have emerged as a promising solution. Different from traditional communication systems that primarily emphasize the accurate transmission of bit streams, semantic communications only transmit task-related semantic information from the source data. By focusing on the semantic features, semantic communication systems can achieve superior performance while transmitting less data. Many works[5, 6, 2, 7] have shown its outstanding capabilities, especially in adverse channel conditions, making it an important technology for the future of communications.
At present, most existing works on semantic communications focus on a specific task[5, 6, 2]. However, in practical scenarios, we usually need to handle multiple tasks. This poses a challenge for single-task semantic communication systems. The feasible approaches are to continuously update the model or store multiple task-specific models. Continuous model updating requires a significant amount of computational resources, whereas storing multiple task-specific models increases the complexity of systems and storage resource consumption[8]. Another noteworthy limitation of existing models is that they overlook the significance of correlations among multiple modalities. In the context of multi-modal tasks, models such as those proposed by Zhang et al. [8], Wang et al. [9], and Xie et al. [10] fail to capture the correlations among various modal data. This means that there is a lack of clear and accurate knowledge of the target task. In multi-modal tasks, different types of data (such as text, image, speech, and video) often contain complementary information. Understanding the correlations among these modalities is critical to perform tasks accurately. Moreover, multi-modal data will increase communication overhead. These two reasons hinder the development of semantic communication technologies. Therefore, we need to develop a multi-modal fusion-based multi-task semantic communication framework which can adapt to multi-task scenarios and effectively utilize the complementary information provided by different modalities. At the same time, this is also expected to enhance performance and wider usability in real-world scenarios. However, the application of this framework has the following challenges:
I-1 Communication latency and bandwidth overhead
The transmission of information across various modal data often requires greater bandwidth. It leads to higher communication latency, significantly impacting the real-time responsiveness.
I-2 Semantic fusion among heterogeneous data
Different data modalities encompass a wide array of data types. It is important to mine the complex semantic correlations among heterogeneous data. How to effectively fuse multi-modal data is a complex challenge.
I-3 Complexity in multi-task and multi-modal framework
The addition of tasks and modalities escalates the complexity of communication systems, which may influence performance on tasks. As the complexity increases, it is crucial to ensure that task performance is not affected.
Inspired by prior research, we propose a multi-modal fusion-based multi-task semantic communication (MFMSC) framework. Unlike traditional single-task models or those ignore multi-modal semantic complementarity, our model can not only handle different tasks, but also exploit the semantic relationships among different modal data. The effectiveness of the proposed framework is verified by extensive experiments. Simulation results show that our framework outperforms multiple benchmarks in terms of communication overhead and task performance. The main contributions are summarized as follows.
-
•
We construct an innovative semantic communication architecture to mitigate the performance impact of growing tasks and data modalities. Specifically, we design dedicated semantic encoders for each data modality, enabling more accurate capture of modality-specific features. Moreover, we introduce task embeddings for each task, which can effectively prevent mutual interference among different tasks. This design ensures that the designed model can still maintain high performance along with increasing tasks and data modalities.
-
•
In order to solve the inherent challenges in multi-modal task scenarios, we further design a novel and efficient fusion module based on Bidirectional Encoder Representations from Transformers (BERT). It effectively fuses multi-modal semantic information extracted by the semantic encoder corresponding to each modality, resulting in a significant improvement in task performance. Moreover, the fusion module can greatly reduce communication overhead by eliminating the redundancy. It effectively solves the delay problem and improves the efficiency of our framework
-
•
In this work, we select 8 datasets and conduct extensive experiments. We compare various baselines and existing methods. Experimental results show that the MFMSC framework has superior performance, consistently achieving or approaching the state-of-the-art (SOTA) level across various tasks. Especially in multi-modal tasks, our framework improves performance by about 10% compared to those do not consider multi-modal fusion, and greatly reduces the amount of data transmitted. These results demonstrate the application prospects of our framework.
The rest of this paper is organized as follows: Section II introduces the related works and explores previous reasearch in related fields. MFMSC system is presented and a corresponding problem is formulated in Section III. Section IV details the architecture of MFMSC framework. Section V shows the performance of MFMSC by simulation results. Section VI concludes this paper.
II Related Works
II-A Semantic Communications
According to Weaver[11], communications can be categorized into three levels: the technical level, which ensures the accuracy of bit sequence transmission; the semantic level, which ensures transmitted symbols accurately convey the desired meaning; and the effectiveness level, which ensures the received meaning affect conduct in the desired way. In the contemporary field of wireless communications, data rates are approaching Shannon’s capacity limit. Traditional data transmission methods established at the technical level often require high communication overhead, especially when dealing with large datasets or multi-modal data[12]. Therefore, we need a more efficient communication method. Building upon Weaver’s seminal categorization[11], many studies [5, 2, 6, 7] are dedicated to studying a new paradigm at the semantic level, namely semantic communications.
Semantic communication systems show great promise. They interpret information at the semantic level rather than mere bit sequences[2], which aims to achieve more intelligent, efficient, and reliable data transmission. The benefits of semantic communications mainly lie in reducing communication overhead and improving downstream task performance. They eliminate redundant content and focus on the meaningful information for downstream tasks, thus preventing the impact of irrelevant information on task performance. On the other hand, by transmitting task-related information, the bandwidth and communication latency are reduced.
The opening work on semantic communications is DeepSC[2], which is developed for text reconstruction. This research applies Transformer[13] to communications. Due to the self-attention mechanism, the performance of DeepSC far exceed traditional communication methods. As more and more semantic communication models are proposed[5, 6, 7], semantic communications have expanded beyond text transmission and are now active in the transmission of other modal data such as speech, image, and video.
However, existing works mainly concentrate on single-task or single-modal scenarios. Due to the growing diversity of data, information is no longer limited to a single format or target. Image, text, speech, and video data often coexist, and we need to use them together to perform various tasks. Moreover, current research often overlooks the correlations among multi-modal data. This reduces the ability of models to understand tasks. By solving the challenges posed by multiple modalities and multiple tasks, communication systems can represent semantic information more deeply and accurately. In this paper, we delve into these shortcomings, aiming to bridge the gap between existing semantic communication research and the demands of real-world applications, thereby creating a more comprehensive and effective multi-modal and multi-task semantic communication framework.
II-B Deep Learning for Multiple Tasks and Multiple Modalities
Recent research has made significant strides in multi-task models[14, 15]. Various techniques like soft sharing[16] and hard sharing[17] have been explored to enhance the performance of individual tasks through cross-task knowledge transfer. Hard sharing is the most widely used sharing mechanism. It embeds the data representations of multiple tasks into the same semantic space, and then uses a task-specific layer to extract task-specific representations. Hard sharing is suitable for processing tasks with strong correlations, but it often performs poorly when encountering tasks that are less related[18]. Soft sharing builds a unique neural network for each task. It is suitable for situations where the correlations among tasks are not strong[18] but increases storage overhead. In addition to the inherent shortcomings, these approaches often face challenges when applied to tasks involving multi-modal data.
In multi-modal tasks, the focus is on leveraging complementary information from different data modalities. Fusion techniques such as early fusion, intermediate fusion, and late fusion have shown promise[19]. Many researchers use architectures such as Multilayer Perceptron (MLP) and Convolutional Neural Network (CNN)[19] in multi-modal fusion, which has indeed made some progress. Nevertheless, these methods are difficult to adapt to the changing relationships among different data[20]. With the deepening of research, the attention mechanism[13] has gradually attracted researchers.
In various fields, the attention mechanism has shown excellent results. The Transformer[13] model improves the ability of text understanding, and models such as Vision Transformer[21], Speech Transformer[22], and Video Vision Transformer[23] introduce self-attention mechanism into image, speech and video processing, significantly improving the performance of corresponding tasks. These studies show that the attention mechanism exhibits outstanding performance and application potential, whether in different tasks or in different modal data.
Considering that tasks with the same modal data are usually more closely related, while tasks with different data modalities are relatively weakly related. Related tasks often have inter-dependence and perform better when solved in a joint framework[24]. Therefore, we propose to use a combination of hard sharing and soft sharing. We design independent semantic encoders for different modalities while utilizing shared channel encoder and channel decoder to achieve unified compression and recovery. In order to prevent negative transfer among unrelated tasks, we add additional task embeddings[25] for each task to enhance the distinction. To fully exploit the complementarity of multi-modal data and reduce the cost of transmission, we propose an innovative fusion module based on BERT[26] to fuse multi-modal semantic information. In multi-modal tasks, the semantic features of each modality are extracted by corresponding semantic encoders. These features are concatenated as input sequences which are then semantically fused by the fusion module. This exploration improves the task performance and provides a new paradigm for multi-modal tasks in semantic communications.
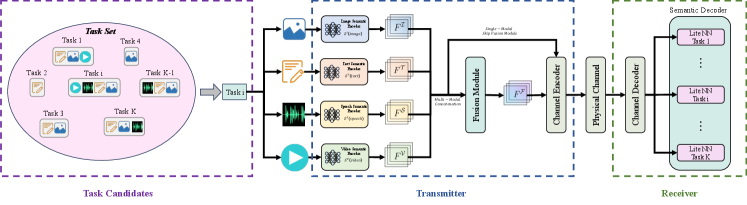
III System Model and Problem Formulation
III-A Multi-Modal Fusion-Based Multi-Task Semantic Communication System
Unlike traditional approaches that usually deal with single-modal data and single-task data, we consider multi-modal and multi-task scenarios that require processing different data modalities and performing multiple tasks simultaneously. Our multi-modal fusion-based multi-task semantic communication system is shown in Fig. 1. The system encompasses a task set comprising numerous tasks, each contains various modal data. It is designed to support four modalities: image, text, speech, and video. In the system, three components play essential roles: transmitter, physical channel, and receiver.
The transmitter consists of semantic encoder and channel encoder. In the semantic encoder, we build four distinct encoders, a text encoder, an image encoder, a speech encoder, and a video encoder. Each encoder is tailored to one modality. This architecture can better extract semantic information from different modal data. In addition, we design a BERT-based fusion module to fuse multi-modal semantic information. It takes the concatenation of different modal semantic information as input sequences, and further uses the self-attention mechanism to fuse them. This module enhances the processing capabilities for multi-modal tasks and significantly reduces the cost of data transmission.
The primary function of the channel encoder is to compress the high-dimensional semantic information obtained from the semantic encoder. Utilizing neural network techniques, the channel encoder can effectively reduce the dimension of the data. This reduction eases bandwidth demands while maintaining the semantic integrity of the original semantic information.
The compressed semantic information will be transmitted to the physical channel. We mainly consider two channels, the Additive White Gaussian Noise (AWGN) channel and the Rayleigh fading channel. Both of them represent typical wireless channel environments. The AWGN channel is widely used to simulate an ideal wireless environment, and the Rayleigh fading channel is more suitable for modeling complex wireless environments, such as heavily built-up urban environments. By studying both wireless transmission environments, we can fully evaluate the performance of our system.
The semantic information reaches the receiver after passing through the physical channel. The receiver incorporates channel decoder and semantic decoder. The channel decoder based on deep learning is a key component of the semantic recovery. Its main responsibility is to reconstruct undistorted high-dimensional semantic information. The recovered semantic information is fed into the semantic decoder, which consists of a series of lite neural network task heads. Each task head is optimized for a specific task. The use of lite task heads can ensure fast response of the entire system.
III-B Problem Formulation
In this work, we consider tasks, denoted by a set . In the task set, there are multiple tasks , where represents the -th task and . The modality of source data in is . We consider four modalities, namely .
We employ Deep Neural Network (DNN) to design both the transmitter and receiver. The transmitter consists of two parts, the semantic encoder and the channel encoder. They are designed to extract semantic information from and ensure the successful transmission over the physical channel. For task , the encoded symbol stream can be represented as
| (1) |
where is the semantic encoder network with the parameter set and is the channel encoder network with the parameter set . Then is transmitted over the physical channel. This process can be modeled as
| (2) |
where represents the channel matrix and is the Gaussian noise.
The semantic information is sent to the receiver after passing through the physical channel. The channel decoder first restore semantic information and the semantic decoder processes the recovered semantic information to perform intelligent tasks. This process can be denoted as
| (3) |
where is the semantic decoder network with the parameter set and is the channel decoder network with the parameter set . is the predicted result of task .
For task , its performance metric function is given as , where represents the ground truth. Our goal is to maximize the metric function for every task
| (4) |
In order to maximize the metric function of each task, it actually means that we need to minimize the loss function of them, which is given by
| (5) |
represents the loss function of .
We strive to design a comprehensive semantic communication system to meet this objective. The system can adapt to the needs of different tasks and take advantage of the complementarity among various data modalities.
III-C Task Description
To comprehensively analyze the system, we consider single-modal tasks of image, text, speech, and video as well as some multi-modal tasks.
III-C1 Text Tasks
We consider sentiment analysis task and text reconstruction task. We utilize the GLUE-SST2 dataset for binary sentiment classification and the Europarl dataset for text reconstruction.
III-C2 Image Tasks
For image modal, we focus on classification and reconstruction tasks, employing the CIFAR-10 dataset for both. The classification task is to identify the category, while the reconstruction task is to restore transmitted images.
III-C3 Speech Task
The speech modal is centered on speech recognition using the LibriSpeech dataset, which provides rich spoken English recordings.
III-C4 Video Task
We use the widely used HMDB51 dataset for our analysis. It serves to identify and classify human activities.
III-C5 Multi-modal Tasks
To evaluate the effectiveness of the system in multi-modal tasks, we choose two multi-modal datasets: Visual Question Answering v2 (VQA v2) and Multimodal IMDb (MM-IMDb)[27]. The VQA v2 dataset contains images, question text, and corresponding answer text. Its task is to answer correctly based on the given image and question. MM-IMDb is a classification dataset of film and television short dramas. Its task is to perform genre classification based on the poster image and plot text.
We use distinct metric functions and loss functions for different task types. For classification tasks like text sentiment analysis, image classification, and video classification, we use accuracy to measure performance and cross entropy as loss function. We transform the VQA task into a classification task by treating each answer as a label, and we use the same loss and metric function. Since MM-IMDb is a multi-label dataset, we use cross entropy as loss function while using F1-score as the evaluation metric to balance precision and recall.
We also approach text reconstruction as a classification task and use cross entropy loss. We construct a vocabulary where words are assigned numerical values that function as class labels. In order to better evaluate the quality of reconstructed text, we use BLEU score as the metric function. It ranges from 0 to 1 and is used to assess the similarity between source and reconstructed text. Higher scores denote greater similarity.
Similarly, in speech recognition, we build a vocabulary and convert this task into a classification task. We adopt connectionist temporal classification (CTC) loss specifically designed for speech recognition. And we utilize the word accuracy as the evaluation metric. Word accuracy measures the difference between the predicted transcriptions and the ground truth.
Lastly, image reconstruction is assessed using PSNR (Peak Signal-to-Noise Ratio), calculated as
| (6) |
where MAX represents the maximum pixel value of the image, and MSE denotes the mean squared error between the original and reconstructed images.
IV Semantic Communication Transceiver Design
To address the issues of high communication latency, increased bandwidth demands, and the complexity of semantic fusion across different modal data, we propose a novel multi-modal fusion-based multi-task semantic communication framework. In this section, we elaborate the detailed design of the semantic transceiver.
IV-A Semantic Encoder Design
In our multi-modal fusion-based multi-task semantic communication framework, the semantic encoder plays a crucial role. In the design of semantic encoder, our innovation is mainly reflected in two places. First, we design specialized semantic encoders for different modalities, and each encoder aims to effectively extract corresponding semantic features. This is because we need to take into account the heterogeneity of data from different modalities. Using a single encoder for all modalities will ignore specific information. By designing dedicated encoders for each modal data, the framework can adapt to the complexity of different modalities. Tasks with the same modal data can also enhance knowledge sharing by using the same encoders. Second, considering the complementarity and redundancy of different modal semantic information in multi-modal tasks, we design a fusion module. Information across various modalities is typically complementary, with each providing distinct details. Through the fusion module, we can effectively integrate the semantic information of these different modalities to generate a more comprehensive feature representation. In addition, through multi-modal fusion, the amount of data in the communication can be significantly reduced. In the following, we detail the semantic encoder corresponding to each modality.
IV-A1 Image Semantic Encoder
Images have complex features, including color, texture, and high-level semantic content. Due to this complexity, an effective image semantic encoder must be capable of capturing both low-level details and high-level information. Deepening the network enhances image feature extraction but also introduces the challenge of gradient vanishing. ResNet[28] solves this problem through residual connections. Therefore, in terms of image data processing, we design our image semantic encoder based on the ResNet, which is shown in Fig. 2.
During preprocessing, we use data augmentation techniques to further improve the robustness of the image semantic encoder. Assuming that the input image data is , where represents the number of channels, is the height, and is the width of the image. The data passes through multiple convolutional layers and residual layers. The image semantic encoder has excellent semantic feature extraction capabilities by using residual layers. Consequently, we can obtain the semantic feature map of the image data, where , represents the height and width of the feature map, respectively.

IV-A2 Text Semantic Encoder
Text data has complex structures. In text, we need to consider grammar, polysemy, and contextual information. Complex text data requires a powerful model that can understand the meaning and relationships of words in different contexts. In order to better extract semantic information from text data, we build the text semantic encoder based on BERT[26], which is demonstrated in Fig. 3. Unlike previous language models, BERT takes into account both the context of the text and the semantic information of each word, enabling a comprehensive grasp of sentence structure and meaning to extract precise semantic features.
To process the input text data , which is composed of sequences of words, our text semantic encoder employs the following steps. The first is tokenization. A tokenizer is used to decompose text into tokens. Assuming that contains words, which is denoted as . The tokenizer maps words to their corresponding tokens. These tokens are then transformed into word embeddings, which serve as vector representations that capture the meaning and context of each token. The embedding vectors can be represented as . denotes the dimension of embedding vectors. In actual training and testing process, the number of words in each batch is different. To align text data, vectors are truncated or zero-padded as necessary to ensure uniform dimensionality of for each data instance.
Subsequently, we enhances the representation of each token by adding segment embeddings and position embeddings , which is given by
| (7) |
where is the input embeddings. Segment embeddings help our encoder distinguish different sentences in the same input, while position embeddings provide the information about token order. These embeddings are all learnable parameters.
Following this, the text semantic encoder processes the through multiple layers, each comprising multi-head self-attention mechanism and feedforward neural network. The result is an extraction of semantic features , which contain rich contextual information.

IV-A3 Speech Semantic Encoder
Speech signals are inherently temporal sequences. It typically influenced by speaker-specific characteristics and environmental noise. To handle this complexity, we build speech semantic encoder by combining Convolutional Neural Network (CNN) and Transformer[13], which is depicted in Fig. 4.
In the preprocessing stage, we first extract the FBank (Filter Bank) features of the speech data, which can retain the key spectrum information of the speech signal. In order to enhance the ability of the encoder to extract speech information, many studies introduce CNN for further feature extraction. This is because one of the keys to improving the performance of speech tasks is to overcome the diversity of speech signals. The FBank features still remain this diversity. CNN has spatio and temporal translation invariance. Applying CNN to acoustic modeling can overcome the diversity. Therefore, we design the speech semantic encoder based on VGGNet[29] for further feature extraction, which is widely used in speech domain. Moreover, we replace the original convolution with causal convolution[30] for better processing temporal characteristics. Different from origin convolution, the core idea of causal convolution is that the output at the current time point can only depend on the current and past inputs. This ensures the causality of the signal processing. At the same time, this can also better capture the time-varying information in speech data. The entire process can transform raw speech data into feature map . and denote the length and width of the feature map, respectively.
The application of CNN advances feature extraction from the spectrum of speech signals. However, for speech data with temporal properties, features extracted by CNN are shallow features. To bridge this gap, we add another Transformer-based part to the speech semantic encoder. The architecture of Transformer is suitable for processing problems with temporal characteristics and can extract higher-level semantic features. We treat the feature map as sequence embeddings. and are seen as the length of the sequence and the dimension of the embedding vector, respectively. The feature map is sent to multiple transformer encoder layers for further feature extraction, and the semantic features can be obtained.
IV-A4 Video Semantic Encoder
Video modal data can be viewed as a collection of images, which are stored according to time. It means that video modal data has temporal characteristics. The difficulty in video modal data also lies in processing the temporal characteristics.
To solve this problem, we build our video semantic encoder based on Video Vision Transformer (ViViT)[23], which is shown in Fig. 5. ViViT is a model based on Transformer architecture, which is good at capturing rich semantic information from videos. During preprocessing, we sample frames from video data and apply data augmentation techniques to each frame. The input data can be denoted as , where , , and are the number of sampled frames, the number of channels, width and height, respectively. Our video semantic encoder first needs to embed into token embeddings and we adopt tubelet embedding[23] here. Each time we take a small patch along the length and width of a frame, and take patches located in the same region of subsequent frames along the time dimension. All patches are merged together to form a tube. All tubes have no overlapping parts. For the tube of dimension , the total count is given by , where , , and . Then all tubes are projected into -dimensional token embeddings

. For token embeddings, we incorporate position embeddings to introduce sequence position information, which is given by
| (8) |
where is the input embeddings. These embeddings are all learnable parameters.
The input embeddings combine both spatial and temporal information. To better extract semantic features from them, our video semantic encoder decomposes embeddings into two dimensions for processing: space and time. In the video semantic encoder, each layer is composed of two self-attention blocks, namely a spatial self-attention block and a temporal self-attention block.
Note that the input embeddings are from token embeddings and token embeddings are linearly mapped from tubes. It means that some input embeddings are from the same time series while some are from the same spatial region. In each layer, input embeddings are first fed into a spatial self-attention block. Only input embeddings from the same spatial region will participate in the operations in the spatial self-attention block, and those from different spatial regions will not compute attention for each other. Then we can derive the spatial features . is sent to the temporal self-attention block, and the temporal attention is calculated for all input embeddings from the same time series. Then the temporal features can be acquired. Through such alternating extraction of spatial and temporal features, we are ultimately able to obtain the semantic features of video modal data. This method fuses spatial and temporal features, which is more beneficial for tasks in the video modality.
To prevent negative transfer among unrelated or even conflicting tasks, we introduce task embeddings[25] for each task to enhance the differentiation among tasks. We number the tasks sequentially and embed serial numbers into -dimensional vectors, which are denoted as . represents the task serial number and . For semantic features of task , we concat and them together. This design can reduce negative interference among tasks and improve learning outcomes.

IV-B Fusion Module Design
The semantic encoder we design for each modality takes into account the characteristics of each modal data. It aims at extracting distinct semantic features. For multi-modal tasks, semantic features of different modalities provide different details, and fusing them can improve the performance of the model while reducing redundancy. However, due to the heterogeneity of different modal data, these semantic features are not in the same semantic space. This means that neglecting multi-modal fusion and simply concatting them together will cause misalignment of semantic information. To solve this problem, we design a fusion module based on BERT[26], which is depicted in Fig. 6. The key of this method is to use the self-attention mechanism to achieve fusion of multi-modal semantic features. The self-attention mechanism is adept at capturing the interdependencies among different modalities. It dynamically weights the importance of each modal semantic features, effectively realigning them into a unified semantic space. This enables the model to leverage complementary information.
Assume that is a multi-modal dataset, where and are the source data with modality and its corresponding labels, respectively. Input the data into the corresponding semantic encoder, we can obtain the corresponding semantic features. These semantic features are represented as . In this case, we regard the semantic features extracted from each modality as sequence features. is the length of the sequence and is the dimension of feature vecotors, where is between and . Subsequently, these features are sent to the fusion module for fusion. The steps for our fusion module to fuse different modal semantic features are as follows.
-
•
Step 1 (Concatenation): First, we need to concat semantic features of different modalities. We can get the concatenation of semantic features given by
(9) where and .
-
•
Step 2 (Segment Embeddings): Unlike the traditional Transformer models, our fusion module does not incorporate position embeddings. This is because position embeddings have been added in the text, speech, and video semantic encoder. And image semantic features are essentially the feature map, so there is no need for position embeddings. Moreover, for the concatenated features, we think they are all equally important and the sequence order should have no effect on the task performance. Therefore, we only consider segment embeddings. In this context, we treat different modalities of semantic features as distinct segments. Each modal has a unique segment embedding vector . For each sequence vector in , we select the corresponding segment embedding vector. All segment embedding vectors are concatenated together to get the segment embeddings . Then, the input embeddings are denoted as
(10) Through segment embeddings, the distinction of semantic features of different modalities can be enhanced, allowing our fusion module to better capture the distinct semantic features of each modality and cross-modal interdependencies. In addition to segment embeddings, we concat the task embedding vector and to prevent negative transfer of effects. Therefore, the dimension of are , where .
-
•
Step 3 (Attention Layer): is then input into multiple attention layers. We design 6 attention layers in our fusion module. Each layer consists of two parts: multi-head self-attention (MSA) and feedforward neural network (FFN). Suppose that is the output by the -th attention layer, and is . Then can be denoted as
(11) where LN is the layer normalization and is the intermediate features of -th layer that passes through MSA. MSA mechanism allows the fusion module to focus on different parts of input sequences, enabling it to capture a wide range of dependencies. This is given by
(12) is a learnable parameter matrix and is calculated by self-attention (SA). is the dimension of each head. In our work, we consider 12 heads, and . For each head output by SA, it can be represented as
(13) where , , are weight matrices for the query , key and value , respectively. Since we use self-attention mechanism, , , are actual is . In softmax, we added a scaling factor , which is to prevent the gradient vanishing problem caused by excessive attention value. The output of MSA is then processed by the FFN, which applies two linear layers with the GeLU activation function:
(14) where are parameters of the two linear layers.
-
•
Step 4 (Average Aggregation): After six attention layers, we derive the features . Then, we perform an average aggregation on the first dimension to obtain a fused feature vector . The fused semantic features then are sent to channel encoder. For single-modal tasks, the semantic features do not go through the fusion module, but are directly dispatched to the channel encoder.
Semantic features from differenct modalities often face misalignment issues in multi-modal fusion due to discrepancies in semantic spaces. Employing the attention mechanism enables the fusion module to align these varied semantic features, enhancing multi-modal task performance while reducing transmission redundancy.



IV-C Channel Encoder
In the channel encoder, we use two layers of Multilayer Perceptron (MLP), which is shown in Fig. 7. The first MLP layer is used to receive the original semantic features and compress them. The second MLP layer is used to further compress the output of the first layer. This layer has fewer neurons, resulting in a lower output dimension compared to the first layer. In this way, the network can learn more abstract feature representations. The output of the second MLP layer can be considered a compact representation of the original semantic features, with higher information density, while further reducing communication overhead of semantic communication.

IV-D Channel Decoder
The compressed semantic features contain the core information of the original features but have lower dimensions. To restore the information, we also use two layers of MLP for channel decoding, which is depicted in Fig. 8. The first MLP layer restores the information of the original features. The second MLP layer is used to further improve the decoding process. This layer has more neurons, enabling it to learn more complex feature reconstruction patterns.

IV-E Semantic Decoder
We choose a simplified and efficient approach, avoiding complex neural networks as the semantic decoder. It is demonstrated in Fig. 9. We design specific lite neural networks for each task head which only contains one or two linear layers. This simplified design is based on the following considerations: First, we find that a complex architecture does not necessarily bring significant improvements in performance. Instead, using simple linear layers, sufficient accuracy requirements can be achieved. Furthermore, the simple linear layer architecture allows us to significantly reduce the consumption of computing resources without sacrificing too much accuracy. This design makes our framework excel in flexibility.
IV-F Training and Testing
We conduct joint training for all tasks. Each time, we randomly select one task for training. During the training process, we employ the Adam[31] optimizer for parameter optimization. Specifically, we create a separate Adam optimizer for each task. This allows the model to adjust the learning rate and parameter updates for each task more effectively. The whole process is shown in Algorithm 1. During this process, the semantic encoder of each modality , fusion module , channel encoder , channel decoder , and semantic decoder will be optimized. We evaluate the performance of the previously trained model in AWGN channel and Rayleigh fading channel under various SNR (signal-to-noise) conditions. The whole process is shown in Algorithm 2.

V Simulation Results
In this section, we compare the performance of the proposed MFMSC with several benchmarks, MMSC, T-DeepSC and U-DeepSC, traditional methods under the AWGN and Rayleigh fading channels.
V-A Simulation Settings
To avoid the conflits of different tasks, we set an Adam optimizer for each task. Except for the speech recognition task, where the learning rate is 2e-4, the learning rates of other tasks are set to 1e-4. To better verify the effectiveness of MFMSC, we include multiple baselines and existing models for comparison.
V-A1 MFSC
We construct an MFSC (multi-modal fusion-based semantic communication) framework for comprision of multi-task capabilities. The architecture of this framework is exactly the same as MFMSC, whereas the difference lies in the training and testing process. MFMSC employs a joint training, and the performance is tested after training is completed. Whereas MFSC uses independent training and testing for each task.
V-A2 MMSC
To evaluate the effectiveness of the fusion module in MFMSC, we introduce the MMSC (multi-modal multi-task semantic communication) framework. MMSC differs from our proposed MFMSC in its semantic encoder design. MMSC retains the semantic encoders of each modality in MFMSC while removing the fusion module. For single-modal tasks, the raw data is still extracted through the corresponding semantic encoder to extract semantic features in MMSC. This process is consistent with MFMSC. For multi-modal tasks, different modal data is sent to the corresponding semantic encoder to extract semantic features. Then, MMSC concats the semantic features together and there is no fusion module. The concatenation of semantic features is input into the channel encoder. The processing on the receiver side of the MMSC model is the same as MFMSC. In addition, the training strategy of MMSC is still joint training.
V-A3 U-DeepSC
U-DeepSC[8] is a unified multi-task multi-modal semantic communication framework proposed by Zhang et al. It is based on Transformer and supports three modal data of image, text and speech. Video modal data is treated as multi-modal data of these three modalities. It should be noted that the multi-modal processing in U-DeepSC is similar to MMSC, which is direct concatenation without a fusion module.








V-A4 T-DeepSC
The architecture of T-DeepSC[8] and U-DeepSC is the same. The difference between them is the training process. T-DeepSC is trained independently for each task and finally multiple models are saved, while U-DeepSC is trained jointly.
V-A5 Traditional Methods
This is the traditional separate source-channel coding. For different modal data, we adopt different communication encoding methods. For image data, we use Joint Photographic Experts Group (JPEG) and Low Density Parity Check Code (LDPC) as image source encoding and image channel encoding, respectively. For video data, we adopt the H.264 video compression codec for source encoding. For text data, we use 8-bit Unicode Transform Format (UTF-8) encoding and Turbo encoding as text source encoding and text channel encoding, respectively. For speech signals, 16-bit pulse code modulation (PCM) and LDPC are used as source coding and channel coding, respectively.
V-B Comparison of Task Performance
We conduct extensive evaluation on multiple tasks. Fig. 10 illustrates the performance of our proposed framework under AWGN channel. Traditional communication methods perform poorly under low SNR conditions, while those semantic communication models show good performance. Each of them demonstrates the ability of maintaining the semantic integrity against the backdrop of noise. As the SNR increases to higher levels, the MFMSC stands out, often achieving the highest performance. Furthermore, the performance of our proposed MFMSC is close to MFSC. This shows that MFMSC has good support for multi-task semantic communication systems. Moreover, we extend the test to Rayleigh fading channel conditions, which is depicted in Fig. 11. Since we pay more attention to multi-modal tasks, only the performance of VQA v2 and MM-IMDb is shown in this figure. MFMSC once again demonstrates strong performance, showing no significant performance degradation. The findings indicate that our framework effectively extracts the semantic information, showcasing its application potential.


V-C Effectiveness of Fusion Module
In order to better compare the effect of our multi-modal fusion, we set up a baseline model MMSC. Our experimental results are demonstrated in the Fig. 10(g), Fig. 10(h), Fig. 11(a) and Fig. 11(b). Whether it is the AWGN channel or the Rayleigh fading channel, the performance of MFMSC is significantly stronger than that of MMSC. This is beacuse that MMSC lacks the fusion module and often fail to capture the complementary features of different modalities. The drawback results in reduced task performance and higher communication overhead. Compared with the MMSC, MFMSC successfully achieves data fusion among different modalities through the fusion module. In addition, for single-modal tasks, we can find that the fusion module has almost no impact on the performance of them. From Fig. 10, it is apparent that the performance of MFMSC and MMSC is essentially on par in single-modal tasks. We extend our study analysis to T-DeepSC and U-DeepSC. These two models that similarly do not take advantage of modal fusion in their architectures. Like MMSC, U-DeepSC and T-DeepSC concat multi-modal semantic features together and then transmit them into the physical channel. We find that their performance is also significantly inferior to our MFMSC model. Clearly, the lack of fusion mechanism limits their ability to exploit complementary features. Our experiments demonstrate that MFMSC greatly enhances multi-modal task outcomes. And this is due to our BERT-based fusion module. This module uses the self-attention mechanism to align and fuse the semantic features in different semantic spaces of each modality, thereby realizing the interaction of modal information and making full use of the complementary information among modalities.
V-D Comparison of Communication Overhead
For semantic communication, the evaluation of task performance is important, but equally important is the communication overhead. In practical applications, especially when resources are limited, communication overhead often determine whether a system has practical value. Considering that multi-modal tasks will bring additional communication overhead, in this work, we compare the communication overhead between the MFMSC and other models in multi-modal tasks.
In MFMSC, the fusion module plays a great role in eliminating redundancy. For the multi-modal data, each modality is extracted semantic features through a semantic encoder and the dimension is represented as . represents the sequence length of modal , and represents the feature dimension. Then we concat them and task embedding vecotor together. The concatenation is sent to the fusion module. Assuming that there is modalities in total, then the dimension of concatenated semantic features is , where . We fuse these modalities into a more compact representation, and the dimension of fused data is . Therefore, compared with MMSC, we can reduce the amount of transmitted data to of the original amount through multi-modal fusion.
| Model | VQA v2 | MM-IMDb |
|---|---|---|
| MMSC | 6.400 KB | 3.968 KB |
| TDeepSC | 0.240 KB | 0.352 KB |
| UDeepSC | 0.240 KB | 0.352 KB |
| MFMSC | 0.128 KB | 0.128 KB |
We calculate the amount of data transmitted per task instance in the VQA v2 and MM-IMDb datasets, which is shown in Table I. Compared with MMSC, T-DeepSC and U-DeepSC, our MFMSC reduces the communication overhead by 98.0%, 46.7%, and 46.7% on the VQA task, respectively. On the MM-IMDb task, the communication overhead are reduced by 96.8%, 63.6%, and 63.6%, respectively. This shows that MFMSC can reduce the communication overhead while improving multi-modal task performance, giving it better application prospects.
VI Conclusion
In this paper, we present a multi-modal fusion-based multi-task semantic communication framework. Unlike traditional methods, our model demonstrates excellent performance on multiple tasks and shows superiority on various evaluation metrics. Notably, when compared with other benchmarks, our method takes advantage of the complementarity among different modalities through multi-modal fusion. It significantly improves the performance of the model while effectively reducing redundant information. We successfully reduce the amount of data transmitted to of the original amount. Compared with U-DeepSC and T-DeepSC, our framework also provides better performance and lower communication overhead. This makes it more competitive in multi-task and multi-modal communication systems.
References
- [1] C. E. Shannon, “A mathematical theory of communication,” The Bell system technical journal, vol. 27, no. 3, pp. 379–423, 1948.
- [2] H. Xie, Z. Qin, G. Y. Li, and B.-H. Juang, “Deep learning enabled semantic communication systems,” IEEE Transactions on Signal Processing, vol. 69, pp. 2663–2675, 2021.
- [3] P. Wang, Y. Li, L. Song, and B. Vucetic, “Multi-gigabit millimeter wave wireless communications for 5g: From fixed access to cellular networks,” IEEE Communications Magazine, vol. 53, no. 1, pp. 168–178, 2015.
- [4] C. Han and Y. Chen, “Propagation modeling for wireless communications in the terahertz band,” IEEE Communications Magazine, vol. 56, no. 6, pp. 96–101, 2018.
- [5] Z. Weng and Z. Qin, “Semantic communication systems for speech transmission,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 8, pp. 2434–2444, 2021.
- [6] C. Dong, H. Liang, X. Xu, S. Han, B. Wang, and P. Zhang, “Semantic communication system based on semantic slice models propagation,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 202–213, 2022.
- [7] S. Wang, J. Dai, Z. Liang, K. Niu, Z. Si, C. Dong, X. Qin, and P. Zhang, “Wireless deep video semantic transmission,” IEEE Journal on Selected Areas in Communications, vol. 41, no. 1, pp. 214–229, 2022.
- [8] G. Zhang, Q. Hu, Z. Qin, Y. Cai, G. Yu, X. Tao, and G. Y. Li, “A unified multi-task semantic communication system for multimodal data,” arXiv preprint arXiv:2209.07689, 2022.
- [9] S. Wang, Q. Yang, Z. Shi, Z. Yang, and Z. Zhang, “Cooperative task-oriented communication for multi-modal data with transmission control,” arXiv preprint arXiv:2302.02608, 2023.
- [10] H. Xie, Z. Qin, and G. Y. Li, “Task-oriented multi-user semantic communications for vqa,” IEEE Wireless Communications Letters, vol. 11, no. 3, pp. 553–557, 2021.
- [11] W. Weaver, “Recent contributions to the mathematical theory of communication,” ETC: a review of general semantics, pp. 261–281, 1953.
- [12] W. Yang, H. Du, Z. Q. Liew, W. Y. B. Lim, Z. Xiong, D. Niyato, X. Chi, X. S. Shen, and C. Miao, “Semantic communications for future internet: Fundamentals, applications, and challenges,” IEEE Communications Surveys & Tutorials, 2022.
- [13] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [14] S. Liu, E. Johns, and A. J. Davison, “End-to-end multi-task learning with attention,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 1871–1880.
- [15] X. Xu, H. Zhao, V. Vineet, S.-N. Lim, and A. Torralba, “Mtformer: Multi-task learning via transformer and cross-task reasoning,” in European Conference on Computer Vision. Springer, 2022, pp. 304–321.
- [16] I. Misra, A. Shrivastava, A. Gupta, and M. Hebert, “Cross-stitch networks for multi-task learning,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3994–4003.
- [17] X. Liu, P. He, W. Chen, and J. Gao, “Multi-task deep neural networks for natural language understanding,” arXiv preprint arXiv:1901.11504, 2019.
- [18] T. Sun, Y. Shao, X. Li, P. Liu, H. Yan, X. Qiu, and X. Huang, “Learning sparse sharing architectures for multiple tasks,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 05, 2020, pp. 8936–8943.
- [19] P. K. Atrey, M. A. Hossain, A. El Saddik, and M. S. Kankanhalli, “Multimodal fusion for multimedia analysis: a survey,” Multimedia systems, vol. 16, pp. 345–379, 2010.
- [20] Z. Xue and R. Marculescu, “Dynamic multimodal fusion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2574–2583.
- [21] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [22] L. Dong, S. Xu, and B. Xu, “Speech-transformer: a no-recurrence sequence-to-sequence model for speech recognition,” in 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 5884–5888.
- [23] A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lučić, and C. Schmid, “Vivit: A video vision transformer,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 6836–6846.
- [24] M. S. Akhtar, D. S. Chauhan, D. Ghosal, S. Poria, A. Ekbal, and P. Bhattacharyya, “Multi-task learning for multi-modal emotion recognition and sentiment analysis,” arXiv preprint arXiv:1905.05812, 2019.
- [25] A. Achille, M. Lam, R. Tewari, A. Ravichandran, S. Maji, C. C. Fowlkes, S. Soatto, and P. Perona, “Task2vec: Task embedding for meta-learning,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6430–6439.
- [26] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [27] J. Arevalo, T. Solorio, M. Montes-y Gómez, and F. A. González, “Gated multimodal units for information fusion,” arXiv preprint arXiv:1702.01992, 2017.
- [28] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [29] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [30] A. Van Den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, K. Kavukcuoglu et al., “Wavenet: A generative model for raw audio,” arXiv preprint arXiv:1609.03499, vol. 12, 2016.
- [31] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.