University of Arizona, Tucson, United [email protected] University of Michigan, Ann Arbor, United [email protected] University of Arizona, Tucson, United [email protected] University of Texas at Arlington, Arlington, United [email protected] University of Arizona, Tucson, United [email protected] University of Arizona, Tucson, United [email protected] \CopyrightReyan Ahmed, Greg Bodwin, Faryad Darabi Sahneh, Keaton Hamm, Stephen Kobourov, and Richard Spence {CCSXML} <ccs2012> <concept> <concept_id>10003752.10003809</concept_id> <concept_desc>Theory of computation Design and analysis of algorithms</concept_desc> <concept_significance>300</concept_significance> </concept> </ccs2012> \ccsdesc[300]Theory of computation Design and analysis of algorithms \supplementAll algorithms, implementations, the ILP solver, experimental data and analysis are available on Github at https://github.com/abureyanahmed/multi_level_weighted_additive_spanners.
Acknowledgements.
The research for this paper was partially supported by NSF grants CCF-1740858, CCF1712119, and DMS-1839274.Multi-level Weighted Additive Spanners111This paper has been accepted in the 19th Symposium on Experimental Algorithms, SEA 2021.
Abstract
Given a graph , a subgraph is an additive spanner if for all . A pairwise spanner is a spanner for which the above inequality only must hold for specific pairs given on input, and when the pairs have the structure for some subset , it is specifically called a subsetwise spanner. Spanners in unweighted graphs have been studied extensively in the literature, but have only recently been generalized to weighted graphs.
In this paper, we consider a multi-level version of the subsetwise spanner in weighted graphs, where the vertices in possess varying level, priority, or quality of service (QoS) requirements, and the goal is to compute a nested sequence of spanners with the minimum total number of edges. We first generalize the subsetwise spanner of [Pettie 2008, Cygan et al., 2013] to the weighted setting. We experimentally measure the performance of this and several other algorithms for weighted additive spanners, both in terms of runtime and sparsity of output spanner, when applied at each level of the multi-level problem. Spanner sparsity is compared to the sparsest possible spanner satisfying the given error budget, obtained using an integer programming formulation of the problem. We run our experiments with respect to input graphs generated by several different random graph generators: Erdős–Rényi, Watts–Strogatz, Barabási–Albert, and random geometric models. By analyzing our experimental results we developed a new technique of changing an initialization parameter value that provides better performance in practice.
keywords:
multi-level, graph spanner, approximation algorithmscategory:
\relatedversion1 Introduction
This paper studies spanners of undirected input graphs with edge weights. Given an input graph, a spanner is a sparse subgraph with approximately the same distance metric as the original graph. Spanners are used as a primitive for many algorithmic tasks involving the analysis of distances or shortest paths in enormous input graphs; it is often advantageous to first replace the graph with a spanner, which can be analyzed much more quickly and stored in much smaller space, at the price of a small amount of error. See the recent survey [5] for more details on these applications.
Spanners were first studied in the setting of multiplicative error, where for an input graph and an error (“stretch”) parameter , the spanner must satisfy for all vertices . This setting was quickly resolved in a seminal paper by Althöfer, Das, Dobkin, Joseph, and Soares [8], where the authors proved that for all positive integers , all -vertex graphs have spanners on edges with stretch , and that this tradeoff is best possible. Thus, as expected, one can trade off error for spanner sparsity, increasing the stretch to pay more and more error for sparser and sparser spanners.
For very large graphs, purely additive error is arguably a much more appealing paradigm. For a constant , a spanner of an -vertex graph is a subgraph such that for all vertices . Thus, for additive error the excess distance in is independent of the graph size and of , which can be large when is large. Additive spanners were introduced by Liestman and Shermer [28], and followed by three landmark theoretical results on the sparsity of additive spanners in unweighted graphs: Aingworth, Chekuri, Indyk, and Motwani [7] showed that all graphs have spanners on edges, Chechik [17, 13] showed that all graphs have spanners on edges, and Baswana, Kavitha, Mehlhorn, and Pettie [11] showed that all graphs have spanners on edges.
Despite the inherent appeal of additive error, spanners with multiplicative error remain much more commonly used in practice. There are two reasons for this.
-
1.
First, while the multiplicative spanner of Althöfer et al [8] works without issue for weighted graphs, the previous additive spanner constructions hold only for unweighted graphs, whereas the metrics that arise in applications often require edge weights. Addressing this, recent work of the authors [3] and in two papers of Elkin, Gitlitz, and Neiman [22, 23] gave natural extensions of the classic additive spanner constructions to weighted graphs. For example, the spanner bound becomes the following statement: for all -vertex weighted graphs , there is a subgraph satisfying , where denotes the maximum edge weight along an arbitrary shortest path in . The spanner generalizes similarly, and the spanner does as well with the small exception that the error increases to , for arbitrarily small which trades off with the implicit constant in the spanner size.
-
2.
Second, factors in spanner size can be quite serious in large graphs, and so applications often require spanners of near-linear size, say edges for an -vertex input graph. The worst-case spanner sizes of or greater for additive spanner constructions are thus undesirable, and unfortunately, there is a theoretical barrier to improving them: Abboud and Bodwin [1] proved that one cannot generally trade off more additive error for sparser spanners, as one can in the multiplicative setting. Specifically, for any constant , there is no general construction of spanners for -node input graphs on edges. However, the lower bound construction is rather pathological, and it is not likely to arise in practice. It is known that for many practical graph classes, e.g., those with good expansion, near-linear additive spanners always exist [11]. Thus, towards applications of additive error, it is currently an important open question whether modern additive spanner constructions on practical graphs of interest tend to exhibit performance closer to the worst-case bounds from [1], or bounds closer to the best ones available for the given input graphs. (We remark here that there are strong computational barriers to designing algorithms that achieve the sparsest possible spanners directly, or which even closely approximate this quantity in general [18]).
The goal of this work is to address the second point, by measuring the experimental performance of the state-of-the-art constructions for weighted additive spanners on graphs generated from various popular random models and measuring their performance. We consider both spanners (where is the maximum edge weight) and spanners, whose additive error is for each pair . We are interested both in runtime and in the ratio of output spanner size to the size of the sparsest possible spanner (which we obtain using an ILP, discussed in Section 5). We specifically consider generalizations of the three staple constructions for weighted additive spanners mentioned above, in which the spanner distance constraint only needs to be satisfied for given pairs of vertices.
In particular, the following extensions are considered. A pairwise spanner is a subgraph that must satisfy the spanner error inequality for a given set of vertex pairs taken on input, and a subsetwise spanner is a pairwise spanner with the additional structure for some vertex subset . See [31, 21, 27, 26, 12, 20, 14, 15] for recent prior work on pairwise and subsetwise spanners. We also discuss a multi-level version of the subsetwise additive spanner problem where we have an edge-weighted graph , a nested sequence of terminals and a real number as input. We want to compute a nested sequence of subgraphs such that is a subsetwise spanner of over . The objective is to minimize the total number of edges in all subgraphs. Similar generalizations have been studied for the Steiner tree problem under various names including Multi-level Network Design [9], Quality of Service Multicast Tree (QoSMT) [16, 25], Priority Steiner Tree [19], Multi-Tier Tree [29], and Multi-level Steiner Tree [2, 6]. However, multi-level or QoS generalizations of spanner problems appear to have been much less studied in literature. Section 2 generalizes the subsetwise construction [21], and Section 4 generalizes to the multi-level setting.
2 Subsetwise spanners
All unweighted graphs have polynomially constructible subsetwise spanners over on edges [31, 21]. For weighted graphs, Ahmed et al. [3] recently give a subsetwise spanner construction, also using edges. In this section we show how to generalize the subsetwise construction [31, 21] to the weighted setting by giving a construction which produces a subsetwise spanner of a weighted graph (with integer edge weights in ) on edges. Due to space, we omit most proof details here but describe the construction instead.
A clustering is a set of disjoint subsets of vertices. Initially, every vertex is unclustered. The subsetwise construction has two steps: the clustering phase and the path buying phase. The clustering phase is exactly the same as that of [31, 21] in which we construct a cluster subgraph as follows: set , and while there is a vertex with at least unclustered neighbors, we add a cluster to containing exactly unclustered neighbors of (note that ). We add to all edges () and (). When there are no more vertices with at least unclustered neighbors, we add all the unclustered vertices and their incident edges to .
In the second (path-buying) phase, we start with a clustering and a cluster subgraph . There are unordered pairs of vertices in ; let , , …, denote the shortest paths between these vertex pairs where has endpoints . As in [21], we iterate from to and determine whether to add path to the spanner. Define the cost and value of a path as follows:
| contains at least one vertex in , | |||
If , then we add (“buy”) to the spanner by letting . Otherwise, we do not add , and let . The final spanner returned is .
Lemma 2.1.
For any , we have .
Proof 2.2 (Proof sketch.).
The proof is largely the same as in [21] except with one main difference: in the unweighted case, the distance between any two points within the same cluster is at most 2, and it is shown in [21] that using this property, if there are edges in missing from , then there are at least clusters containing at least one vertex on . In the weighted case, assuming is constant, there are clusters of which contain at least one vertex on .
Corollary 2.3.
Let be a weighted graph with integer edge weights in . Then has a pairwise spanner on edges.
3 Pairwise spanner constructions [3]
Here, we provide pseudocode (Algorithms 1–3) describing the , , and pairwise spanner constructions222Using a tighter analysis or the above subsetwise construction in place of the construction in Algorithm 3, the additive error can be improved to , , and for integer edge weights. by Ahmed et al. [3]. These spanner constructions have a similar theme: first, construct a -light initialization, which is a subgraph obtained by adding the lightest edges incident to each vertex (or all edges if the degree is at most ). Then for each pair , consider the number of edges in which are absent in the current subgraph . Add to if the number of missing edges is at most some threshold , or otherwise randomly sample vertices and either add a shortest path tree rooted at these vertices, or construct a subsetwise spanner among them.
4 Multi-level spanners
Here we study a multi-level variant of graph spanners. We first define the problem:
Definition 4.1 (Multi-level weighted additive spanner).
Given a weighted graph with maximum weight , a nested sequence of subsets of vertices , and , a multi-level additive spanner is a nested sequence of subgraphs , where is a subsetwise spanner over .
Observe that Definition 4.1 generalizes the subsetwise spanner, which is a special case where . We measure the size of a multi-level spanner by its sparsity, defined by
The problem can equivalently be phrased in terms of priorities and rates: each vertex has a priority between 1 and (namely, ), and we wish to compute a single subgraph containing edges of different rates such that for all , there is a spanner path consisting of edges of rate at least . With this, we will typically refer to the priority of to denote the highest such that , or 0 if . In this section, we show that the multi-level version is not significantly harder than the ordinary “single-level” version: a subroutine which can compute an additive spanner can be used to compute a multi-level spanner whose sparsity is comparably good. Let OPT denote the minimum sparsity over all candidate multi-level additive spanners.
We first describe a simple rounding-up approach based on an algorithm by Charikar et al. [16] for the QoSMT problem, a similar generalization of the Steiner tree problem. For this approach, assume we have a subroutine which computes an exact or approximate single-level subsetwise spanner. Given , let denote the priority of . The rounding-up approach is as follows: for each , round up to the nearest power of 2. This effectively constructs a “rounded-up” instance where all vertices in have priority either 1, 2, 4, …, . The sparsity of the optimum solution in the rounded-up instance is at most ; given the optimum solution to the original instance with sparsity OPT, a feasible solution to the rounded-up instance with sparsity at most can be obtained by rounding up the rate of each edge to the nearest power of 2.
For each , use the subroutine to compute a level- subsetwise spanner over all vertices whose rounded-up priority is at least . The final multi-level additive spanner is obtained by taking the union of these computed spanners, by keeping an edge at the highest level it appears in.
Theorem 4.2.
Assuming an exact subsetwise spanner subroutine, the solution computed by the rounding-up approach has sparsity at most .


This is proved using the same ideas as the -approximation for QoSMT [16]. As mentioned earlier, in practice we use an approximation algorithm to compute the subsetwise spanner instead of computing the minimum spanner.
Theorem 4.3.
There exists a -approximation algorithm to compute multi-level weighted additive spanners with additive stretch when .
This follows from using the subsetwise construction in Section 2. The approximation ratio of this subsetwise spanner algorithm is as the construction produces a spanner of size , while the sparsest additive spanner trivially has at least edges.
We now show that, under certain conditions, if we have a subroutine which computes a subsetwise spanner of , of size where and are absolute constants, a very naïve algorithm can be used to obtain a multi-level spanner also with sparsity .
Theorem 4.4.
Suppose there is an absolute constant such that for all . Then we can compute a multi-level spanner with sparsity .
Proof 4.5.
Consider the following simple construction: for each , compute a level- subsetwise spanner of size . Consider the union of these spanners, by keeping each edge at the highest level it appears. The sparsity of the returned multi-level spanner is at most
where we used the arithmetico-geometric series which is constant for fixed , . Note that and , which implies .
The assumption that for some constant is fairly natural, as many realistic networks tend to have significantly fewer hubs than non-hubs.
Corollary 4.6.
Under the assumption for all , there exists a poly-time algorithm which computes a multi-level spanner of sparsity .
Proof 4.7.
This follows by using the construction by Cygan et al. [21] on edges as the subroutine.
5 Exact algorithm
To compute a minimum size additive spanner, we utilize a slight modification of the ILP in [5, Section 9], wherein we choose the specific distortion function and minimize the sparsity rather than total weight of the spanner. For completeness, we present the full ILP for computing a single-level additive subsetwise spanner below along with a brief description of the multi-level extension. Here represents the bidirected edge set, obtained by adding directed edges and for each edge . The binary variable is 1 if edge is included on the selected - path and 0 otherwise, and is the weight of edge .
| (1) | |||||
| (2) | |||||
| (3) | |||||
| (4) | |||||
| (5) | |||||
| (6) | |||||
Inequalities (3)–(4) enforce that for each , , the selected edges corresponding to , form a path; inequality (2) enforces that the length of this path is at most (note that may be replaced with ). Inequality (5) ensures that if or , then edge is taken.
To generalize the ILP formulation to the multi-level problem, we take a similar set of variables for every level. The rest of the constraints are similar, except we define if edge is present on level and the variables are also indexed by level. We add the constraint for all which enforces that if edge is present on level , it is also present on all lower levels. Finally, the objective is to minimize the sparsity .
6 Experiments
In this section, we provide experimental results involving the rounding-up framework described in Section 4. This framework needs a single level subroutine; we use the subsetwise construction in Section 2 and the three pairwise , , constructions provided in [3]333Note that, one can show that the , , spanners in [3] are actually and spanners respectively by using a tighter analysis [4]. (see Appendix 3). We generate multi-level instances and solve the instances using our exact algorithm and the four approximation algorithms. We consider natural questions about how the number of levels , number of vertices , and decay rate of terminals with respect to levels affect the running times and (experimental) approximation ratios, defined as the sparsity of the returned multi-level spanner divided by OPT.
We used CPLEX 12.6.2 as an ILP solver in a high-performance computer for all experiments (Lenovo NeXtScale nx360 M5 system with 400 nodes). Each node has 192 GB of memory. We have used Python for implementing the algorithms and spanner constructions. Since we have run the experiment on a couple of thousand instances, we run the solver for four hours.
6.1 Experiment Parameters
We run experiments first to test experimental approximation ratio vs. the parameters, and then to test running time vs. parameters. Each set of experiments has several parameters: the graph generator, the number of levels , the number of vertices , and how the size of the terminal sets (vertices requiring level or priority at least ) decrease as decreases.
In what follows, we use the Erdős–Rényi (ER) [24], Watts–Strogatz (WS) [32], Barabási–Albert (BA) [10], and random geometric (GE) [30] models. Let be the edge selection probability. If we set , then the generated Erdős–Rényi graph is connected with high probability for [24]). For our experiments we use . In the Watts-Strogatz model, we initially create a ring lattice of constant degree . For our experiments we use and . In the Barabási–Albert model, a new node is connected to existing nodes. For our experiments we use . In the random geometric graph model, two nodes are connected to each other if their Euclidean distance is not larger than a threshold . For with , the synthesized graph is connected with a high probability[30]. We generate a set of small graphs () and a set of large graphs (). We only compute the exact solutions for the small graphs since the ILP has an exponential running time. In this paper, we provide the results of Erdős–Rényi graphs since it is the most popular model. However, the radius444The minimum over all of where is the graph distance (by number of edges, not total weight) between and of Erdős–Rényi graphs is relatively small. In our dataset, the range of the radius is 2-4. Hence, we also provide the results of random geometric graphs which have larger radius (4-12). The remaining results and the radius distribution of different generators are available at the supplement Github link. We consider number of levels for small graphs, for large graphs, and adopt two methods for selecting terminal sets: linear and exponential. A terminal set with lowest priority of size in the linear case and in the exponential case is chosen uniformly at random. For each subsequent level, vertices are deleted at random in the linear case, whereas half the remaining vertices are deleted in the exponential case. Levels/priorities and terminal sets are related via . We choose edge weights randomly, independently, and uniformly from .
An experimental instance of the multi-level problem here is thus characterized by four parameters: graph generator, number of vertices , number of levels , and terminal selection method . As there is randomness involved, we generated five instances for every choice of parameters (e.g., ER, , , Linear). For each instance of the small graphs, we compute the approximate solution using either the , , , or spanner subroutine, and the exact solution using the ILP described in Section 5. We compute the experimental approximation ratio by dividing the sparsity of the approximate solution by the sparsity of the optimum solution (OPT). For large graphs, we only compute the approximate solution.
6.2 Results
We consider different spanner constructions as the single level subroutine in the multi-level spanner. We first consider the subsetwise construction (Section 2).
6.2.1 The Subsetwise Construction-based Approximation
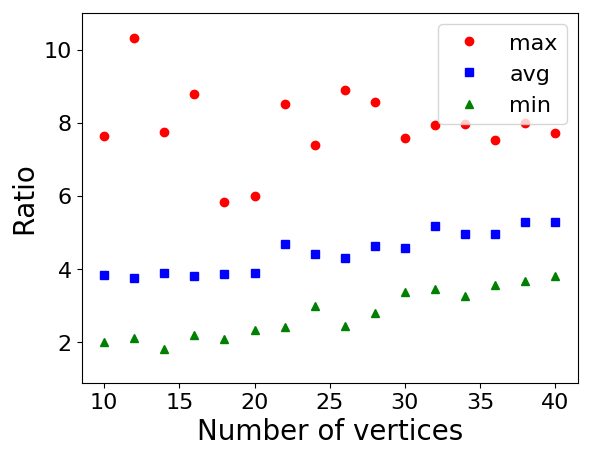
We first describe the experimental results on Erdős–Rényi graphs w.r.t. , , and terminal selection method in Figure 2. The average experimental ratio increases as increases. This is expected since the theoretical approximation ratio of is proportional to . The average and minimum experimental ratio does not change that much as the number of levels increases; however, the maximum ratio increases. The experimental ratio of the linear terminal selection method is slightly better compared to that of the exponential method.



We describe the experimental results on random geometric graphs w.r.t. , , and terminal selection methods in Figure 3. In both cases the average ratio increases as and increases. The average ratio is relatively lower for the linear terminal selection method.


The plots of Watts–Strogatz and Barabási–Albert graphs are available in the Github repository.
6.2.2 The Pairwise Construction-based Approximation
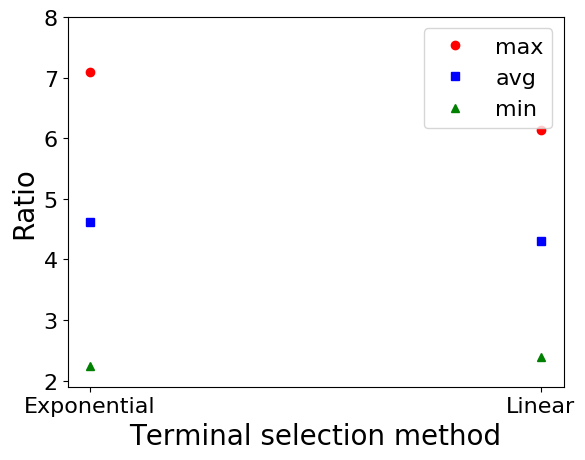
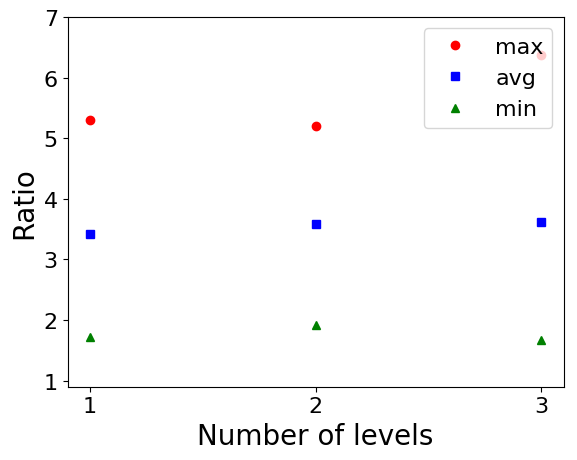
We now consider the pairwise construction [3] (Algorithm 1). We first describe the experimental results on Erdős–Rényi graphs w.r.t. , , and terminal selection method in Figure 4. The average experimental ratio increases as increases. This is expected since the theoretical approximation ratio is proportional to . The average and minimum experimental ratio do not change that much as the number of levels increases, however, the maximum ratio increases. The experimental ratio of the linear terminal selection method is also slightly better compared to that of the exponential method.


We describe the experimental results on random geometric graphs w.r.t. , , and terminal selection method in Figure 5. The average experimental ratio increases as increases. The maximum ratio increases as increases. Again, the experimental ratio of the linear terminal selection method is relatively smaller compared to the exponential method.


6.2.3 Comparison between Global and Local Setups
One major difference between the subsetwise and pairwise construction is the subsetwise construction considers the (global) maximum edge weight of the graph in the error. On the other hand, the spanners consider the (local) maximum edge weight in a shortest path for each pair of vertices . We provide a comparison between the global and local settings.
We describe the experimental results on Erdős–Rényi graphs w.r.t. , , and the terminal selection method in Figure 6. The average experimental ratio increases as increases for both global and local settings. However, the ratio of the local setting is smaller compared to that of the global setting. One reason for this difference is the solution to the global exact algorithm is relatively smaller since the global setting considers larger errors. The ratio of the global setting increases as the number of levels increases and for the exponential terminal selection method. For the local setting, the ratio does not change that much.



We describe the experimental results on random geometric graphs w.r.t. , , and the terminal selection method in Figure 7. The ratio of the local setting is smaller compared to the global setting.



6.2.4 The Pairwise Construction-based Approximation
We now consider the pairwise construction [3] (Algorithm 2) as a single level subroutine. We first describe the experimental results on Erdős–Rényi graphs w.r.t. , , and terminal selection method in Figure 8. The average experimental ratio increases as increases. This is expected since the theoretical approximation ratio is proportional to . The average experimental ratio does not change that much as the number of levels increases; however, the maximum ratio increases. The experimental ratio of the linear terminal selection method is also slightly better compared to that of the exponential method.



We describe the experimental results on random geometric graphs w.r.t. , , and terminal selection method in Figure 9. The experimental ratio increases as the number of vertices increases. The maximum ratio increases as the number of levels increases. Again, the experimental ratio of the linear terminal selection method is relatively smaller compared to the exponential method.



6.2.5 Comparison between and Setups
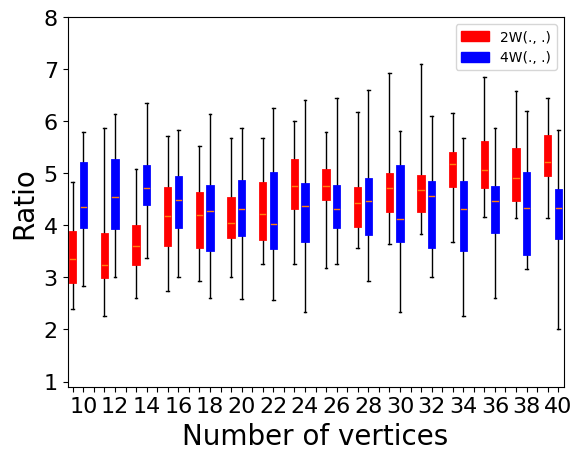
We now provide a comparison between the pairwise and construction-based approximation algorithms. We first describe the experimental results on Erdős–Rényi graphs w.r.t. , , and the terminal selection method in Figure 10. The average experimental ratio increases as increases for both and settings. As increases, the ratio of the construction-based algorithm decreases slightly. The construction-based algorithm slightly outperforms the algorithm for and exponential selection method.


We describe the experimental results on random geometric graphs w.r.t. , , and the terminal selection method in Figure 11. As increases the average ratio of -based approximation algorithm becomes smaller compared to the -based algorithm. The average ratio of is relatively smaller for the exponential terminal selection method.



6.2.6 The Pairwise Construction-based Approximation
We now consider the pairwise construction [3] (Algorithm 3) as a single level solver. We first describe the experimental results on Erdős–Rényi graphs w.r.t. , , and terminal selection method in Figure 12. The average experimental ratio increases as increases. This is expected since the theoretical approximation ratio is proportional to . The average experimental ratio does not change that much as the number of levels increases; however, the maximum ratio increases. The maximum and average experimental ratios of the linear terminal selection method are slightly better compared to that of the exponential method.



We describe the experimental results on random geometric graphs w.r.t. , , and terminal selection method in Figure 13. The experimental ratio increases as the number of vertices increases. The maximum ratio increases as the number of levels increases. Again, the experimental ratio of the linear terminal selection method is relatively smaller compared to the exponential method.



6.2.7 Comparison between and Setups
We now provide a comparison between pairwise and construction-based approximation algorithms. We first describe the experimental results on Erdős–Rényi graphs w.r.t. , , and the terminal selection method in Figure 14. The average experimental ratio increases as increases for both and settings. As the number of vertices increases, the ratio of the construction-based algorithm gets smaller. This is expected since a larger error makes the problem easier to solve. Similarly, as increases, the construction-based algorithm outperforms the algorithm. The average experimental ratio of the construction based algorithm is smaller both in the linear and exponential terminal selection methods.



We describe the experimental results on random geometric graphs w.r.t. , , and the terminal selection method in Figure 15. We can see that as gets larger the ratio of gets smaller. The situation is similar when increases.



6.2.8 Experiment on Large Graphs
We generate some large instances on up to 500 vertices and run different multi-level spanner algorithms on them. We use and . We describe the experimental results on Erdős–Rényi graphs w.r.t. , , and the terminal selection method in Figure 16. We are comparing four multi-level algorithms, namely those using the subsetwise and , , pairwise constructions [3] as subroutines with . Since computing the optimal solution exactly via ILP is computationally expensive on large instances, we report the ratio in terms of relative sparsity, defined as the sparsity of the multi-level spanner returned by one algorithm divided by the minimum sparsity over the spanners returned by all four. The ratio of the construction based algorithm is lowest and the construction based algorithm is highest. This is expected since a higher additive error generally reduces the number of edges needed. Overall the ratio decreases as increases. This is because the significance of small additive error reduces as the graph size and distances get larger. The relative ratio for the construction increases as increases, and for the exponential terminal selection method.



We describe the experimental results on random geometric graphs w.r.t. , , and the terminal selection method in Figure 17.



6.2.9 Impact of Initial Parameters
It is worth mentioning that the subsetwise spanner [21] and subsetwise spanner (Section 2) begin with a clustering phase, while the algorithms described in Appendix 3 begin with a -light initialization. In -light initialization, we add the lightest edges incident to each vertex; these edges tend to be on shortest paths. In practice, there may be relatively few edges which appear on shortest paths and some of these edges might be redundant. Hence, we compute spanners with different values of . We describe the experimental results on Erdős–Rényi graphs w.r.t. , , and the terminal selection method in Figure 18. We have computed the ratio as described in Section 6.2.8. From the figures, we see that as we reduce the value of exponentially, the ratio decreases: in particular, the optimal choice of parameter in practice might be significantly smaller than the optimal value of in theory. Generally, it could make sense in practical implementations of spanner algorithms to try all values , computing different spanners, and then use only the sparsest one. This costs only a factor in the running time of the algorithm, which is typically reasonable.



We describe the experimental results on random geometric graphs w.r.t. , , and the terminal selection method in Figure 19. Again, the experiment suggests that we can exponentially reduce the value of and take the solution that has a minimum number of edges.



6.3 Running Time
We now provide the running times of the different algorithms. We show the running time of the ILP on Erdős–Rényi graphs w.r.t. , , and terminal selection method in Figure 20. The running time of the ILP increases exponentially as increases, as expected. The execution time of a single level instance with 45 vertices is more than 64 hours using a 28 core processor. Hence, we kept the number of vertices less than or equal to 40 for our small graphs. The experimental running time should increase as increases, but we do not see that pattern in these plots because some of the instances were not able to finish in four hours.



We provide the experimental running time of the approximation algorithm on Erdős–Rényi graphs in Figure 21. The running time of the construction-based algorithm is the largest. Overall, the running time increases as increases. There is no straightforward relation between the running time and . Although the number of calls to the single level subroutine increases as increases, it also depends on the size of the subset in a single level. Hence, if the subset sizes are larger, then it may take longer for small . The running time of the linear method is larger.



The running times appear reasonable in other settings too; see the supplemental Github repository for details and experimental results.
7 Conclusion
We have provided a framework where we can use different spanner subroutines to compute multi-level spanners of varying additive error. We additionally introduced a generalization of the subsetwise spanner [21] to integer edge weights, and illustrate that this can reduce the error in [3] to . A natural question is to provide an approximation algorithm that can handle different additive error for different levels. We also provided an ILP to find the exact solution for both global and local settings. Using the ILP and the given spanner constructions, we have run experiments and provided the experimental approximation ratio over the graphs we generated. The experimental results suggest that the clustering-based approach is slower than the initialization based approaches. We provided a method of changing the initialization parameter which reduces the sparsity in practice.
References
- [1] Amir Abboud and Greg Bodwin. The 4/3 additive spanner exponent is tight. Journal of the ACM (JACM), 64(4):1–20, 2017.
- [2] Abu Reyan Ahmed, Patrizio Angelini, Faryad Darabi Sahneh, Alon Efrat, David Glickenstein, Martin Gronemann, Niklas Heinsohn, Stephen Kobourov, Richard Spence, Joseph Watkins, and Alexander Wolff. Multi-level Steiner trees. In 17th International Symposium on Experimental Algorithms, (SEA), pages 15:1–15:14, 2018. URL: https://doi.org/10.4230/LIPIcs.SEA.2018.15, doi:10.4230/LIPIcs.SEA.2018.15.
- [3] Reyan Ahmed, Greg Bodwin, Faryad Darabi Sahneh, Stephen Kobourov, and Richard Spence. Weighted additive spanners. In Isolde Adler and Haiko Müller, editors, Graph-Theoretic Concepts in Computer Science, pages 401–413, Cham, 2020. Springer International Publishing.
- [4] Reyan Ahmed, Greg Bodwin, Keaton Hamm, Stephen Kobourov, and Richard Spence. Weighted sparse and lightweight spanners with local additive error. arXiv preprint arXiv:2103.09731, 2021.
- [5] Reyan Ahmed, Greg Bodwin, Faryad Darabi Sahneh, Keaton Hamm, Mohammad Javad Latifi Jebelli, Stephen Kobourov, and Richard Spence. Graph spanners: A tutorial review. Computer Science Review, 37:100253, 2020.
- [6] Reyan Ahmed, Faryad Darabi Sahneh, Keaton Hamm, Stephen Kobourov, and Richard Spence. Kruskal-Based Approximation Algorithm for the Multi-Level Steiner Tree Problem. In Fabrizio Grandoni, Grzegorz Herman, and Peter Sanders, editors, 28th Annual European Symposium on Algorithms (ESA 2020), volume 173 of Leibniz International Proceedings in Informatics (LIPIcs), pages 4:1–4:21, Dagstuhl, Germany, 2020. Schloss Dagstuhl–Leibniz-Zentrum für Informatik. URL: https://drops.dagstuhl.de/opus/volltexte/2020/12870, doi:10.4230/LIPIcs.ESA.2020.4.
- [7] Donald Aingworth, Chandra Chekuri, Piotr Indyk, and Rajeev Motwani. Fast estimation of diameter and shortest paths (without matrix multiplication). SIAM Journal on Computing, 28:1167–1181, 04 1999. doi:10.1137/S0097539796303421.
- [8] Ingo Althöfer, Gautam Das, David Dobkin, and Deborah Joseph. Generating sparse spanners for weighted graphs. In Scandinavian Workshop on Algorithm Theory (SWAT), pages 26–37, Berlin, Heidelberg, 1990. Springer Berlin Heidelberg.
- [9] Anantaram Balakrishnan, Thomas L. Magnanti, and Prakash Mirchandani. Modeling and heuristic worst-case performance analysis of the two-level network design problem. Management Sci., 40(7):846–867, 1994. doi:10.1287/mnsc.40.7.846.
- [10] Albert-László Barabási and Réka Albert. Emergence of scaling in random networks. science, 286(5439):509–512, 1999.
- [11] Surender Baswana, Telikepalli Kavitha, Kurt Mehlhorn, and Seth Pettie. Additive spanners and (, )-spanners. ACM Transactions on Algorithms (TALG), 7(1):5, 2010.
- [12] Greg Bodwin. Linear size distance preservers. In Proceedings of the Twenty-Eighth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 600–615. Society for Industrial and Applied Mathematics, 2017.
- [13] Greg Bodwin. A note on distance-preserving graph sparsification. arXiv preprint arXiv:2001.07741, 2020.
- [14] Greg Bodwin and Virginia Vassilevska Williams. Better distance preservers and additive spanners. In Proceedings of the Twenty-seventh Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 855–872. Society for Industrial and Applied Mathematics, 2016. URL: http://dl.acm.org/citation.cfm?id=2884435.2884496.
- [15] Hsien-Chih Chang, Pawel Gawrychowski, Shay Mozes, and Oren Weimann. Near-Optimal Distance Emulator for Planar Graphs. In Proceedings of 26th Annual European Symposium on Algorithms (ESA 2018), volume 112, pages 16:1–16:17, 2018.
- [16] M. Charikar, J. Naor, and B. Schieber. Resource optimization in QoS multicast routing of real-time multimedia. IEEE/ACM Transactions on Networking, 12(2):340–348, April 2004. doi:10.1109/TNET.2004.826288.
- [17] Shiri Chechik. New additive spanners. In Proceedings of the twenty-fourth annual ACM-SIAM symposium on Discrete algorithms (SODA), pages 498–512. Society for Industrial and Applied Mathematics, 2013.
- [18] Eden Chlamtáč, Michael Dinitz, Guy Kortsarz, and Bundit Laekhanukit. Approximating spanners and directed steiner forest: Upper and lower bounds. In Proceedings of the Twenty-Eighth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 534–553. SIAM, 2017.
- [19] Julia Chuzhoy, Anupam Gupta, Joseph (Seffi) Naor, and Amitabh Sinha. On the approximability of some network design problems. ACM Trans. Algorithms, 4(2):23:1–23:17, 2008. doi:10.1145/1361192.1361200.
- [20] Don Coppersmith and Michael Elkin. Sparse sourcewise and pairwise distance preservers. SIAM Journal on Discrete Mathematics, 20(2):463–501, 2006.
- [21] Marek Cygan, Fabrizio Grandoni, and Telikepalli Kavitha. On pairwise spanners. In Proceedings of 30th International Symposium on Theoretical Aspects of Computer Science (STACS 2013), volume 20, pages 209–220, 2013. URL: http://drops.dagstuhl.de/opus/volltexte/2013/3935, doi:10.4230/LIPIcs.STACS.2013.209.
- [22] Michael Elkin, Yuval Gitlitz, and Ofer Neiman. Almost shortest paths and PRAM distance oracles in weighted graphs. arXiv preprint arXiv:1907.11422, 2019.
- [23] Michael Elkin, Yuval Gitlitz, and Ofer Neiman. Improved weighted additive spanners. arXiv preprint arXiv:2008.09877, 2020.
- [24] Paul Erdős and Alfréd Rényi. On random graphs, i. Publicationes Mathematicae (Debrecen), 6:290–297, 1959.
- [25] Marek Karpinski, Ion I. Mandoiu, Alexander Olshevsky, and Alexander Zelikovsky. Improved approximation algorithms for the quality of service multicast tree problem. Algorithmica, 42(2):109–120, 2005. doi:10.1007/s00453-004-1133-y.
- [26] Telikepalli Kavitha. New pairwise spanners. Theory of Computing Systems, 61(4):1011–1036, Nov 2017. URL: https://doi.org/10.1007/s00224-016-9736-7, doi:10.1007/s00224-016-9736-7.
- [27] Telikepalli Kavitha and Nithin M. Varma. Small stretch pairwise spanners and approximate -preservers. SIAM Journal on Discrete Mathematics, 29(4):2239–2254, 2015. URL: https://doi.org/10.1137/140953927, arXiv:https://doi.org/10.1137/140953927, doi:10.1137/140953927.
- [28] Arthur Liestman and Thomas Shermer. Additive graph spanners. Networks, 23:343 – 363, 07 1993. doi:10.1002/net.3230230417.
- [29] Prakash Mirchandani. The multi-tier tree problem. INFORMS J. Comput., 8(3):202–218, 1996.
- [30] Mathew Penrose. Random geometric graphs. Number 5. Oxford university press, 2003.
- [31] Seth Pettie. Low distortion spanners. ACM Transactions on Algorithms (TALG), 6(1):7, 2009.
- [32] Duncan J Watts and Steven H Strogatz. Collective dynamics of ‘small-world’networks. Nature, 393(6684):440, 1998.