Multi-facet Contextual Bandits: A Neural Network Perspective
Abstract.
Contextual multi-armed bandit has shown to be an effective tool in recommender systems. In this paper, we study a novel problem of multi-facet bandits involving a group of bandits, each characterizing the users’ needs from one unique aspect. In each round, for the given user, we need to select one arm from each bandit, such that the combination of all arms maximizes the final reward. This problem can find immediate applications in E-commerce, healthcare, etc. To address this problem, we propose a novel algorithm, named MuFasa, which utilizes an assembled neural network to jointly learn the underlying reward functions of multiple bandits. It estimates an Upper Confidence Bound (UCB) linked with the expected reward to balance between exploitation and exploration. Under mild assumptions, we provide the regret analysis of MuFasa. It can achieve the near-optimal regret bound where is the number of bandits and is the number of played rounds. Furthermore, we conduct extensive experiments to show that MuFasa outperforms strong baselines on real-world data sets.
1. introduction
The personalized recommendation is ubiquitous in web applications. Conventional approaches that rely on sufficient historical records, e.g., collaborative filtering (Su and Khoshgoftaar, 2009; Zhou et al., 2020b), have proven successful both theoretically and empirically. However, with the cold-start problem and the rapid change of the recommendation content, these methods might render sub-optimal performance (Li et al., 2010; Gentile et al., 2014). To solve the dilemma between the exploitation of historical data and the exploration of new information, Multi-Armed Bandit (MAB) (Langford and Zhang, 2008; Auer et al., 2002a; Abbasi-Yadkori et al., 2011; Auer et al., 2002b; Ban and He, 2020) turns out to be an effective tool, which has been adapted to personalized recommendation (Li et al., 2010; Gentile et al., 2014), online advertising (Wu et al., 2016), clinical trials (Durand et al., 2018; Bastani and Bayati, 2020), etc.
In the conventional contextual bandit problem setting (Li et al., 2010), i.e., single MAB, the learner is presented with a set of arms in each round, where each arm is represented by a feature vector. Then the learner needs to select and play one arm to receive the corresponding reward that is drawn from an unknown distribution with an unknown mean. To achieve the goal of maximizing the accumulated rewards, the learner needs to consider the arms with the best historical feedback as well as the new arms for potential gains. The single MAB problem has been well studied in various settings. With respect to the reward function, one research direction (Li et al., 2010; Abbasi-Yadkori et al., 2011; Dimakopoulou et al., 2019; Gentile et al., 2014; Li et al., 2016a) assumes that the expected reward is linear with respect to the arm’s feature vector. However, in many real applications, this assumption fails to hold. Thus many exiting works turn to focus on the nonlinear or nonparametric bandits (Srinivas et al., 2009; Bubeck et al., 2011) with mild assumptions such as the Lipschitz continuous property (Bubeck et al., 2011) or embedding in Reproducing Kernel Hilbert Space (Valko et al., 2013; Deshmukh et al., 2017). Furthermore, the single MAB problem has been extended to best arm identification (Auer et al., 2002a; Audibert and Bubeck, 2010), outlier arm identification (Gentile et al., 2017; Ban and He, 2020), Top-K arm problems (Buccapatnam et al., 2013), and so on.
In this paper, we define and study a novel problem of multi-facet contextual bandits. In this problem, the users’ needs are characterized from multiple aspects, each associated with one bandit. Consider a task consisting of bandits, where each bandit presents a set of arms separately and the learner needs to choose and play one arm from each bandit. Therefore, a total of arms are played in one round. In accordance with the standard bandit problem, the learner can observe a reward after playing one arm from the bandit, which we call "sub-reward", and thus sub-rewards are received in total. In addition, a reward that is a function with respect to these sub-rewards, called "final reward", is observed to represent the overall feedback with respect to the selected arms. Note that the functions of final reward and sub-rewards are allowed to be either linear or non-linear. The goal of the learner in the multi-facet bandit problem is to maximize the final rewards of all the played rounds.
This problem finds many applications in real-world problems. For instance, in the recommender system, instead of the single item recommendation, an E-commerce company launches a promotion campaign, which sells collections of multiple types of products such as snacks, toiletries, and beverages. Each type of item can be formulated as a multi-armed bandit and the learner aims to select the best combination of snack, toiletry, and beverage. As a result, the final reward is the review of this combined recommendation, while the sub-reward is the review for a particular product . This problem also exists in healthcare. For a diabetes patient, the doctor usually provides a comprehensive recommendation including medication, daily diet, and exercise, where each type has several options. Here, the final reward can be set as the change of key biomarkers for diabetes (e.g., HbA1c) and the sub-reward can be the direct impact of each type of recommendation (e.g., blood pressure change for a medicine).
A major challenge of the proposed multi-facet bandit problem is the partial availability of sub-rewards, as not every sub-reward is easy to observe. For example, regarding the combined recommendation of E-commerce, the user may rate the combination but not individual items; regarding the comprehensive recommendation for a diabetes patient, some sub-rewards can be difficult to measure (e.g., the impact of low-calorie diets on the patient’s overall health conditions). Therefore, in our work, we allow only a subset of all sub-rewards to be observed in each round, which increases the flexibility of our proposed framework.
To address these challenges, we aim to learn the mappings from the selected arms (one from each bandit) to the final rewards, incorporating two crucial factors: (1) the collaborative relations exist among these bandits as they formulate the aspects from one same user; (2) the bandits contribute to the task with various weights because some aspects (bandits) are decisive while some maybe not. Hence, we propose a novel algorithm, MuFasa, to learn bandits jointly. It utilizes an assembled neural networks to learn the final reward function combined with bandits. Although the neural networks have been adapted to the bandit problem (Riquelme et al., 2018; Zahavy and Mannor, 2019; Zhou et al., 2020a), they are designed for the single bandit with one selected arm and one reward in each round. To balance the exploitation and exploration of arm sets, we provide a comprehensive upper confidence bound based on the assembled network linking the predicted reward with the expected reward. When the sub-rewards are partially available, we introduce a new approach to leverage them to train bandits jointly. Furthermore, we carry out the theoretical analysis of MuFasa and prove a near-optimal regret bound under mild assumptions. Our major contributions can be summarized as follows:
(1) Problem. We introduce the problem of multi-facet contextual bandits to characterize the users’ needs from multiple aspects, which can find immediate applications in E-commerce, healthcare, etc.
(2) Algorithm. We propose a novel algorithm, MuFasa, which exploits the final reward and up to sub-rewards to train the assembled neural networks and explores potential arm sets with a UCB-based strategy.
(3) Theoretical analysis. Under mild assumptions, we provide the upper confidence bounds for a neural network and the assembled neural networks. Then, we prove that MuFasa can achieve the regret bound, which is near-optimal compared to a single contextual bandit.
(4) Empirical performance. We conduct extensive experiments to show the effectiveness of MuFasa, which outperforms strong baselines on real-world data sets even with partial sub-rewards.
2. related work
Multi-armed bandit. The multi-armed bandit was first introduced by (Thompson, 1933) and then further studied by many works that succeeded in both theory and practice such as -greedy (Langford and Zhang, 2008), Thompson sampling(Agrawal and Goyal, 2013), and upper confidence bound (Auer et al., 2002a). In the contrast with traditional bandits (Auer et al., 2002a; Ban and He, 2020), the contextual bandit (Li et al., 2010; Abbasi-Yadkori et al., 2011; Wu et al., 2016) has the better representation capacity where each arm is represented by a context vector instead of a scalar to infer the reward. Among them, the linear contextual bandits are extensively studied and many of them use the UCB strategy, achieving regret bound (Abbasi-Yadkori et al., 2011; Gentile et al., 2014; Ban and He, 2021). To further generalize the reward function, many works use a nonlinear regression model drawn from the reproducing kernel Hilbert space to learn the mapping from contexts to rewards such as the kernel-based methods (Deshmukh et al., 2017; Valko et al., 2013).
Neural bandits. The authors of (Allesiardo et al., 2014) use a neural work to model an arm and then applied -greedy strategy to select an arm. In contrast, MuFasa utilizes a UCB-based strategy working on bandits instead of one set of arms. In addition, the Thompson sampling has been combined with deep neural networks (Lipton et al., 2018; Azizzadenesheli et al., 2018; Riquelme et al., 2018; Zahavy and Mannor, 2019). For instance, (Riquelme et al., 2018; Zahavy and Mannor, 2019) regard the last layer of the neural network as the embeddings of contexts and then apply the Thompson sampling to play an arm in each round. NeuUCB (Zhou et al., 2020a) first uses the UCB-based approach constructed on a fully-connected neural network, while it only fits on the single bandit with one set of arms. On the contrary, MuFasa constructs an assembled neural networks to learn bandits jointly. Deep neural network in multi-view learning has been well-studied (Zhou et al., 2015, 2020c; Fu et al., 2020; Zheng et al., 2021; Jing et al., 2021), to extract useful information among multiple sources, which inspires one of the core ideas of MuFasa.
Other variant bandit setting. In the non-contextual bandit, a number of works (Chen et al., 2013, 2016; Liu et al., 2011) study playing arms at the same time in a single bandit, while these approaches have limited representation power in the recommender system. The most similar setting is the contextual combinatorial MAB problem(Qin et al., 2014; Li et al., 2016b), where the learner tends to choose the optimal subset of arms with certain constraints like the -size. One key difference is that all the arms are from the same single bandit where only one reward function exists. On the contrary, in the multi-faced bandits, the selected arms come from different bandits with different reward functions and the sub-rewards are allowed to be partially available. There is another line of works (Gentile et al., 2014; Li et al., 2016a; Ban and He, 2021) for bandit clustering, where a bandit is constructed for each user. They try to leverage the dependency among users to improve the recommendation performance. However, in these works, they still play one arm in each round and the reward function is required to be linear.
3. Problem Definition
In this section, we formulate the problem of multi-facet bandits, with a total of bandits, where the learner aims to select the optimal set of arms in each round, in order to maximize the final accumulated rewards.
Suppose there are rounds altogether. In each round (), the learner is faced with bandits, and each bandit has a set of arms , where is the number of arms in this bandit. In the bandit , for each arm , it is represented by a -dimensional feature vector and we assume . Subsequently, in each round , the learner will observe arm sets and thus a total of arms. As only one arm can be played within each bandit, the learner needs to select and play arms denoted as in which represents the selected arm from .
Once the selected arm is played for bandit , a sub-reward will be received to represent the feedback of this play for bandit separately. The sub-reward is assumed to be governed by an unknown reward function:
where can be either a linear (Li et al., 2010; Abbasi-Yadkori et al., 2011) or non-linear reward function (Deshmukh et al., 2017; Valko et al., 2013). As a result, in each round , the learner needs to play arms in and then receive sub-rewards denoted by .
As the bandits characterize the users’ needs from various aspects, after playing arms in each round , a final reward will be received to represent the overall feedback of the group of bandits. The final reward is considered to be governed by an unknown function with respect to :
where is a noise drawn from a Gaussian distribution with zero mean. In our analysis, we make the following assumptions regarding and :
-
(1)
If , then ; If , then .
-
(2)
-Lipschitz continuity. is assumed to be -Lipschitz continuous with respect to the . Formally, there exists a constant such that
Both assumptions are mild. For (1), if the input is zero, then the reward should also be zero. For (2), the Lipschitz continuity can be applied to many real-world applications. For the convenience of presentation, given any set of selected arms , we denote the expectation of by:
| (1) |
Recall that in multi-facet bandits, the learner aims to select the optimal arms with the maximal final reward in each round. First, we need to identify all possible combinations of arms, denoted by
| (2) |
where because bandit has arms for each . Thus, the regret of multi-facet bandit problem is defined as
| Reg | |||
where . Therefore, our goal is to design a bandit algorithm to select arms every round in order to minimize the regret. We use the standard to hide constants and to hide logarithm.
Availability of sub-rewards. In this framework, the final is required to be known, while the sub-rewards are allowed to be partially available. Because the feedback of some bandits cannot be directly measured or is simply not available in a real problem. This increases the flexibility of our proposed framework.
More specifically, in each round , ideally, the learner is able to receive rewards including sub-rewards and a final reward . As the final reward is the integral feedback of the entire group of bandits and reflects how the bandits affect each other, is required to be known. However, the sub-rewards are allowed to be partially available, because not every sub-reward is easy to obtain or can be measured accurately.
This is a new challenge in the multi-facet bandit problem. Thus, to learn , the designed bandit algorithm is required to handle the partial availability of sub-rewards.
4. Proposed Algorithm
In this section, we introduce the proposed algorithm, MuFasa. The presentation of MuFasa is divided into three parts. First, we present the neural network model used in MuFasa; Second, we detail how to collect training samples to train the model in each round; In the end, we describe the UCB-based arm selection criterion and summarize the workflow of MuFasa.
4.1. Neural network model
To learn the reward function , we use fully-connected neural networks to learn bandits jointly, where a neural network is built for each bandit to learn its reward function , and a shared neural network is constructed to learn the mapping from the neural networks to the final reward .
First, in round , for each bandit , given any context vector , we use a -layer fully-connected network to learn , denoted by :
where is the rectified linear unit (ReLU) activation function. Without loss of generality, we assume each layer has the same width for the sake of analysis. Therefore, , where , , and . Note that , where is set as a tuneable parameter to connect with the following network . Denote the gradient by .
Next, to learn the final reward function , we use a -layer fully-connected network to combine the outputs of the above neural networks, denoted by :
where . Also, we assume that each layer has the same width . Therefore, , where , and , Denote the gradient by .
Therefore, for the convenience of presentation, the whole assembled neural networks can be represented by to learn (Eq.(6)), given the selected arms :
where .
Initialization. is initialized by randomly generating each parameter from the Gaussian distribution. More specifically, for , is set to for any where is drawn from . For , is set to for any where is drawn from ; is set to where is drawn from .
4.2. Training process
Only with the final reward and selected arms , the training of the neural network model is the following minimization problem:
| (3) |
where is essentially -regularized square loss function and is the randomly initialized network parameters. However, once the sub-rewards are available, we should use different methods to train , in order to leverage more available information. Next, we will elaborate our training methods using the gradient descend.
Collection of training samples. Depending on the availability of sub-rewards, we apply different strategies to update in each round. When the sub-rewards are all available, the learner receives one final reward and sub-rewards. We apply the straightforward way to train each part of accordingly based on the corresponding input and the ground-truth rewards in each round, referring to the details in Algorithm 2, where in should be set as .
However, when the sub-rewards are partially available, the above method is not valid anymore because the bandits without available sub-rewards cannot be trained. Therefore, to learn the bandits jointly, we propose the following training approach focusing on the empirical performance.
As the final reward is always available in each round, we collect the first training sample . Then, suppose there are available sub-rewards , . For each available sub-reward and the corresponding context vector , we construct the following pair:
We regard as a new input of . Now, we need to determine the ground-truth final reward .
Unfortunately, is unknown. Inspired by the UCB strategy, we determine by its upper bound. Based on Lemma 4.1, we have . Therefore, we set as:
because it shows the maximal potential gain for the bandit . Then, in round , we can collect additional sample pairs:
where denotes the bandits with available sub-rewards.
Accordingly, in each round , we can collect up to samples for training , denoted by ,:
| (4) |
Therefore, in each round, we train integrally, based on , as described in Algorithm 3.
Lemma 4.1.
Let and . Given and , then we have .
Prove 4.1.
As is -Lipschitz continuous, we have
4.3. Upper confidence bound
In this subsection, we present the arm selection criterion based on the upper confidence bound provided in Section 5 and then summarize the high-level idea of MuFasa.
In each round , given an arm combination , the confidence bound of with respect to is defined as:
where UCB() is defined in Theorem 5.3 and usually is a small constant. Then, in each round, given the all possible arm combinations , the selected arms are determined by:
| (5) |
With this selection criterion, the workflow of MuFasa is depicted in Algorithm 1.
5. Regret Analysis
In this section, we provide the upper confidence bound and regret analysis of MuFasa when the sub-rewards are all available.
Before presenting Theorem 5.3, let us first focus on an -layer fully-connected neural network to learn a ground-truth function , where . The parameters of are set as , , and . Given the context vectors by and corresponding rewards , conduct the gradient descent with the loss to train .
Built upon the Neural Tangent Kernel (NTK) (Jacot et al., 2018; Cao and Gu, 2019), can be represented by a linear function with respect to the gradient introduced in (Zhou et al., 2020a) as the following lemma.
Lemma 5.1 (Lemma 5.1 in (Zhou et al., 2020a)).
There exist a positive constant such that with probability at least , if for any , there exists a such that
Then, with the above linear representation of , we provide the following upper confidence bound with regard to .
Lemma 5.2.
Given a set of context vectors and the corresponding rewards , for any . Let be the -layers fully-connected neural network where the width is , the learning rate is , and . Assuming , then, there exist positive constants such that if
then, with probability at least , for any , we have the following upper confidence bound:
Now we are ready to provide an extended upper confidence bound for the proposed neural network model .
Theorem 5.3.
Given the selected contexts , the final rewards , and all sub-rewards , let be the neural network model in MuFasa. In each round , with the conditions in Lemma 5.2 and suppose , then, with probability at least , for any , we have the following upper confidence bound:
With the above UCB, we provide the following regret bound of MuFasa.
Theorem 5.4.
Given the number of rounds and suppose that the final reward and all the sub-wards are available, let be the neural network model of MuFasa, satisfying the conditions in Theorem 5.3. Then, assuming , , and thus , with probability at least , the regret of MuFasa is upper bounded by:
where is the effective dimension defined in Appendix (Definition 8.3).
Prove 5.4. First, the regret of one round :
where the third inequality is due to the selection criterion of MuFasa, satisfying Thus, it has
| Reg |
First, for any , we bound
Because the Lemma 11 in (Abbasi-Yadkori et al., 2011), we have
where the last inequality is based on Lemma 8.4 and the choice of . Then, applying Lemma 11 in (Abbasi-Yadkori et al., 2011) and Lemma 8.4 again, we have
As the choice of , . Then, as is sufficiently large, we have
Then, because , and , we have
Putting everything together proves the claim.
is the effective dimension defined by the eigenvalues of the NTK ( Definition 8.3 in Appendix). Effective dimension was first introduced by (Valko et al., 2013) to analyze the kernelized context bandit, and then was extended to analyze the kernel-based Q-learning(Yang and Wang, 2020) and the neural-network-based bandit (Zhou et al., 2020a). can be much smaller than the real dimension , which alleviates the predicament when is extremely large.
Theorem 5.4 provides the regret bound for MuFasa, achieving the near-optimal bound compared with a single bandit ( ) that is either linear (Abbasi-Yadkori et al., 2011) or non-linear (Valko et al., 2013; Zhou et al., 2020a). With different width and the Lipschitz continuity , the regret bound of MuFasa becomes .
6. experiments
To evaluate the empirical performance of MuFasa, in this section, we design two different multi-facet bandit problems on three real-world data sets. The experiments are divided into two parts to evaluate the effects of final rewards and availability of sub-rewards. The code has been released 111https://github.com/banyikun/KDD2021_MuFasa.
Recommendation:Yelp222https://www.yelp.com/dataset. Yelp is a data set released in the Yelp data set challenge, which consists of 4.7 million rating entries for restaurants by million users. In addition to the features of restaurants, this data set also provides the attributes of each user and the list of his/her friends. In this data set, we evaluate MuFasa on personalized recommendation, where the learner needs to simultaneously recommend a restaurant and a friend (user) to a served user. Naturally, this problem can be formulated into bandits in which one set of arms represent the candidate restaurants and the other set of arms formulates the pool of friends for the recommendation. We apply LocallyLinearEmbedding(Roweis and Saul, 2000) to train a -dimensional feature vector for each restaurant and a -dimensional feature vector for each user. Then, for the restaurant, we define the reward according to the rating star: The reward is if the number of rating stars is more than 3 (5 in total); Otherwise, the reward is . For friends, the reward if the recommended friend is included in the friend list of the served user in fact; Otherwise . To build the arm sets, we extract the rating entries and friends lists of top-10 users with the most ratings. In each round , we build the arm set and by picking one restaurant/friend with reward and then randomly picking the other restaurants/friends with rewards. Thus .
Classification:Mnist (LeCun et al., 1998) + NotMnist. These are two well-known 10-class classification data sets. The evaluation of contextual bandit has been adapted to the classification problem (Zhou et al., 2020a; Deshmukh et al., 2017; Valko et al., 2013). Therefore, we utilize these two similar classification data sets to construct bandits, where the 10-class classification is converted into a -armed contextual bandit. Considering a sample figure , we tend to classify it from classes. Under the contextual bandit setting, is transformed into arms: matching the classes. In consequence, the reward is if the learner plays the arm that matches the real class of ; Otherwise, the reward is . Using this way, we can construct two contextual bandits for these two data sets, denoted by and . Then, in each round, the arm pools will be .
To evaluate the effect of different final reward function, with the sub-rewards , we design the following final reward function:
| (6) |
For (1), it describes the task where each bandit contributes equally. Of (2), it represents some tasks where each bandit has different importance.
As the problem setting is new, there are no existing algorithms that can directly adapt to this problem. Therefore, we construct baselines by extending the bandit algorithms that work on a single bandit, as follows:
-
(1)
(K-)LinUCB. LinUCB (Li et al., 2010) is a linear contextual bandit algorithm where the reward function is assumed as the dot product of the arm feature vector and an unknown user parameter. Then, apply the UCB strategy to select an arm in each round. To adapt to the multi-facet bandit problem, we duplicate LinUCB for bandits. For example, in Yelp data set, we use two LinUCB to recommend restaurants and friends, respectively.
-
(2)
(K-)KerUCB . KerUCB (Valko et al., 2013) makes use of a predefined kernel matrix to learn the reward function and then build a UCB for exploration. We replicate KerUCB to adapt to this problem.
-
(3)
(K-)NeuUCB. NeuUCB(Zhou et al., 2020a) uses a fully-connected neural network to learn one reward function with the UCB strategy. Similarly, we duplicate it to bandits.
Configurations. For MuFasa, each sub-network is set as a two-layer network: , where , and . Then, the shared layers , where and . For the , is set as and set as for . To learn bandits jointly, in the experiments, we evaluate the performance of Algorithm . For K-NeuUCB, for each NeuUCB, we set it as a -layer fully-connected network with the same width for the fair comparison. The learning rate is set as and the upper bound of ground-truth parameter for these two methods. To accelerate the training process, we update the parameters of the neural networks every rounds. For the KerUCB, we use the radial basis function (RBF) kernel and stop adding contexts to KerUCB after 1000 rounds, following the same setting for Gaussian Process in (Riquelme et al., 2018; Zhou et al., 2020a). For all the methods, the confidence level , the regularization parameter . All experiments are repeatedly run times and report the average results.
6.1. Result 1: All sub-rewards with different


With the final reward function (Eq.(6)), Figure 1 and Figure 3 report the regret of all methods on Yelp and Mnist+NotMnist data sets, where the first top-two sub-figure shows the regret of each bandit and the bottom sub-figure shows the regret of the whole task (2 bandits). These figures show that MuFasa achieves the best performance (the smallest regret), because it utilizes a comprehensive upper confidence bound built on the assembled neural networks to select two arms jointly in each round. This indicates the good performance of MuFasa on personalized recommendation and classification. Among these baselines, NeuUCB achieves the best performance, which thanks to the representation power of neural networks. However, it chooses each arm separately, neglecting the collaborative relation of bandits. For KerUCB, it shows the limitation of the simple kernels like the radial basis function compared to neural network. LinUCB fails to handle each task, as it assume a linear reward function and thus usually cannot to learn the complicated reward functions in practice.
With the final reward function (Eq.(6)), Figure 2 and Figure 4 depict the regret comparison on Yelp and Mnist+NotMnist data sets. The final reward function indicates that the bandit 1 weights more than bandit 2 in the task. Therefore, to minimize the regret, the algorithm should place the bandit 1 as the priority when making decisions. As the design of MuFasa, the neural network can learn the relation among the bandits. For example, on the Mnist and NotMnist data sets, consider two optional select arm sets and . The first selected arm set receives reward on Mnist while reward on NotMnist. In contrast, the second selected arm set receives reward on Mnist while reward on NotMnist. However, these two bandits have different weights and thus the two arm sets have different final rewards, i.e., and , respectively. To maximize the final reward, the learner should select the first arm set instead of the second arm set. As MuFasa can learn the weights of bandits, it will give more weight to the first bandit and thus select the first arm set. On the contrary, all the baselines treat each bandit equally, and thus they will select these two arm sets randomly. Therefore, under the setting of , with this advantage, MuFasa further decreases the regret on both Yelp and Mnist+NotMnist data sets. For instance, on Mnist+NotMnist data sets, MuFasa with decrease regret over NeuUCB while MuFasa with decrease regret over NeuUCB.


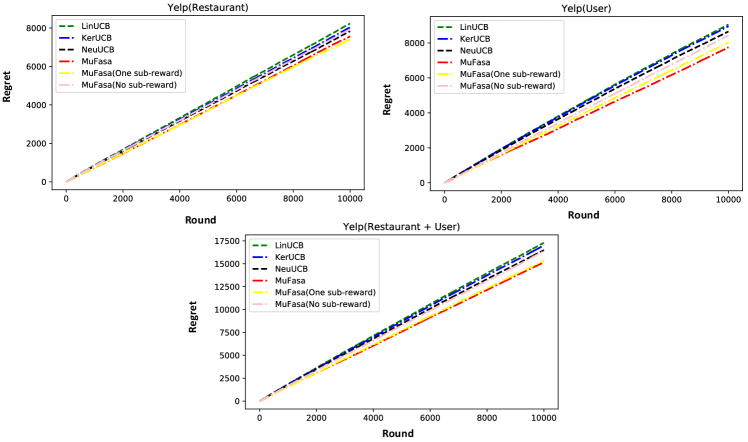
6.2. Result 2: Partial sub-rewards
As the sub-rewards are not always available in many cases, in this subsection, we evaluate MuFasa with partially available sub-rewards on Yelp and Mnist+NotMnist data sets. Therefore, we build another two variants of MuFasa: (1) MuFasa (One sub-reward) is provided with the final reward and one sub-reward of the first bandit; (2) MuFasa (No sub-reward) does not receive any sub-rewards except the final reward. Here, we use the as the final reward function.
Figure 5 and Figure 6 show the regret comparison with the two variants of MuFasa, where MuFasa exhibits the robustness with respect to the lack of sub-rewards. Indeed, the sub-reward can provide more information to learn, while MuFasa (One sub-reward) still outperforms all the baselines, because the final reward enables MuFasa to learn the all bandits jointly and the sub-reward strengthens the capacity of learning the exclusive features of each bandit. In contrast, all the baselines treat each bandit separately. Without any-rewards, MuFasa still achieves the acceptable performance. On the Yelp data set, the regret of MuFasa (No sub-reward) is still lower than the best baseline NeuUCB while lacking considerable information. On the Mnist+NotMnist data set, although MuFasa (No sub-reward) does not outperform the baselines, its performance is still closed to NeuUCB. Therefore, as long as the final reward is provided, MuFasa can tackle the multi-facet problem effectively. Moreover, MuFasa can leverage available sub-rewards to improve the performance.

7. Conclusion
In this paper, we define and study the novel problem of the multi-facet contextual bandits, motivated by real applications such as comprehensive personalized recommendation and healthcare. We propose a new bandit algorithm, MuFasa. It utilizes the neural networks to learn the reward functions of multiple bandits jointly and explores new information by a comprehensive upper confidence bound. Moreover, we prove that MuFasa can achieve the regret bound under mild assumptions. Finally, we conduct extensive experiments to show the effectiveness of MuFasa on personalized recommendation and classification tasks, as well as the robustness of MuFasa in the lack of sub-rewards.
Acknowledgement
This work is supported by National Science Foundation under Award No. IIS-1947203 and IIS-2002540, and the U.S. Department of Homeland Security under Grant Award Number 17STQAC00001-03-03. The views and conclusions are those of the authors and should not be interpreted as representing the official policies of the funding agencies or the government.
References
- (1)
- Abbasi-Yadkori et al. (2011) Yasin Abbasi-Yadkori, Dávid Pál, and Csaba Szepesvári. 2011. Improved algorithms for linear stochastic bandits. In Advances in Neural Information Processing Systems. 2312–2320.
- Agrawal and Goyal (2013) Shipra Agrawal and Navin Goyal. 2013. Thompson sampling for contextual bandits with linear payoffs. In International Conference on Machine Learning. PMLR, 127–135.
- Allen-Zhu et al. (2019) Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. 2019. A convergence theory for deep learning via over-parameterization. In International Conference on Machine Learning. PMLR, 242–252.
- Allesiardo et al. (2014) Robin Allesiardo, Raphaël Féraud, and Djallel Bouneffouf. 2014. A neural networks committee for the contextual bandit problem. In International Conference on Neural Information Processing. Springer, 374–381.
- Arora et al. (2019) Sanjeev Arora, Simon S Du, Wei Hu, Zhiyuan Li, Russ R Salakhutdinov, and Ruosong Wang. 2019. On exact computation with an infinitely wide neural net. In Advances in Neural Information Processing Systems. 8141–8150.
- Audibert and Bubeck (2010) Jean-Yves Audibert and Sébastien Bubeck. 2010. Best arm identification in multi-armed bandits. In Conference on Learning Theory (COLT). 41–53.
- Auer et al. (2002a) Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer. 2002a. Finite-time analysis of the multiarmed bandit problem. Machine learning 47, 2-3 (2002), 235–256.
- Auer et al. (2002b) Peter Auer, Nicolo Cesa-Bianchi, Yoav Freund, and Robert E Schapire. 2002b. The nonstochastic multiarmed bandit problem. SIAM journal on computing 32, 1 (2002), 48–77.
- Azizzadenesheli et al. (2018) Kamyar Azizzadenesheli, Emma Brunskill, and Animashree Anandkumar. 2018. Efficient exploration through bayesian deep q-networks. In 2018 Information Theory and Applications Workshop (ITA). IEEE, 1–9.
- Ban and He (2020) Yikun Ban and Jingrui He. 2020. Generic Outlier Detection in Multi-Armed Bandit. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 913–923.
- Ban and He (2021) Yikun Ban and Jingrui He. 2021. Local Clustering in Contextual Multi-Armed Bandits. arXiv preprint arXiv:2103.00063 (2021).
- Bastani and Bayati (2020) Hamsa Bastani and Mohsen Bayati. 2020. Online decision making with high-dimensional covariates. Operations Research 68, 1 (2020), 276–294.
- Bubeck et al. (2011) Sébastien Bubeck, Rémi Munos, Gilles Stoltz, and Csaba Szepesvári. 2011. X-Armed Bandits. Journal of Machine Learning Research 12, 5 (2011).
- Buccapatnam et al. (2013) Swapna Buccapatnam, Atilla Eryilmaz, and Ness B Shroff. 2013. Multi-armed bandits in the presence of side observations in social networks. In 52nd IEEE Conference on Decision and Control. IEEE, 7309–7314.
- Cao and Gu (2019) Yuan Cao and Quanquan Gu. 2019. Generalization bounds of stochastic gradient descent for wide and deep neural networks. In Advances in Neural Information Processing Systems. 10836–10846.
- Chen et al. (2013) Wei Chen, Yajun Wang, and Yang Yuan. 2013. Combinatorial multi-armed bandit: General framework and applications. In International Conference on Machine Learning. PMLR, 151–159.
- Chen et al. (2016) Wei Chen, Yajun Wang, Yang Yuan, and Qinshi Wang. 2016. Combinatorial multi-armed bandit and its extension to probabilistically triggered arms. The Journal of Machine Learning Research 17, 1 (2016), 1746–1778.
- Deshmukh et al. (2017) Aniket Anand Deshmukh, Urun Dogan, and Clay Scott. 2017. Multi-task learning for contextual bandits. In Advances in neural information processing systems. 4848–4856.
- Dimakopoulou et al. (2019) Maria Dimakopoulou, Zhengyuan Zhou, Susan Athey, and Guido Imbens. 2019. Balanced linear contextual bandits. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33. 3445–3453.
- Durand et al. (2018) Audrey Durand, Charis Achilleos, Demetris Iacovides, Katerina Strati, Georgios D Mitsis, and Joelle Pineau. 2018. Contextual bandits for adapting treatment in a mouse model of de novo carcinogenesis. In Machine Learning for Healthcare Conference. 67–82.
- Fu et al. (2020) Dongqi Fu, Zhe Xu, Bo Li, Hanghang Tong, and Jingrui He. 2020. A View-Adversarial Framework for Multi-View Network Embedding. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2025–2028.
- Gentile et al. (2017) Claudio Gentile, Shuai Li, Purushottam Kar, Alexandros Karatzoglou, Giovanni Zappella, and Evans Etrue. 2017. On context-dependent clustering of bandits. In Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 1253–1262.
- Gentile et al. (2014) Claudio Gentile, Shuai Li, and Giovanni Zappella. 2014. Online clustering of bandits. In International Conference on Machine Learning. 757–765.
- Jacot et al. (2018) Arthur Jacot, Franck Gabriel, and Clément Hongler. 2018. Neural tangent kernel: Convergence and generalization in neural networks. In Advances in neural information processing systems. 8571–8580.
- Jing et al. (2021) Baoyu Jing, Chanyoung Park, and Hanghang Tong. 2021. HDMI: High-order Deep Multiplex Infomax. arXiv preprint arXiv:2102.07810 (2021).
- Langford and Zhang (2008) John Langford and Tong Zhang. 2008. The epoch-greedy algorithm for multi-armed bandits with side information. In Advances in neural information processing systems. 817–824.
- LeCun et al. (1998) Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. 1998. Gradient-based learning applied to document recognition. Proc. IEEE 86, 11 (1998), 2278–2324.
- Li et al. (2010) Lihong Li, Wei Chu, John Langford, and Robert E Schapire. 2010. A contextual-bandit approach to personalized news article recommendation. In Proceedings of the 19th international conference on World wide web. 661–670.
- Li et al. (2016a) Shuai Li, Alexandros Karatzoglou, and Claudio Gentile. 2016a. Collaborative filtering bandits. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. 539–548.
- Li et al. (2016b) Shuai Li, Baoxiang Wang, Shengyu Zhang, and Wei Chen. 2016b. Contextual combinatorial cascading bandits. In International conference on machine learning. PMLR, 1245–1253.
- Lipton et al. (2018) Zachary Lipton, Xiujun Li, Jianfeng Gao, Lihong Li, Faisal Ahmed, and Li Deng. 2018. Bbq-networks: Efficient exploration in deep reinforcement learning for task-oriented dialogue systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 32.
- Liu et al. (2011) Haoyang Liu, Keqin Liu, and Qing Zhao. 2011. Logarithmic weak regret of non-bayesian restless multi-armed bandit. In 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1968–1971.
- Qin et al. (2014) Lijing Qin, Shouyuan Chen, and Xiaoyan Zhu. 2014. Contextual combinatorial bandit and its application on diversified online recommendation. In Proceedings of the 2014 SIAM International Conference on Data Mining. SIAM, 461–469.
- Riquelme et al. (2018) Carlos Riquelme, George Tucker, and Jasper Snoek. 2018. Deep bayesian bandits showdown: An empirical comparison of bayesian deep networks for thompson sampling. arXiv preprint arXiv:1802.09127 (2018).
- Roweis and Saul (2000) Sam T Roweis and Lawrence K Saul. 2000. Nonlinear dimensionality reduction by locally linear embedding. science 290, 5500 (2000), 2323–2326.
- Srinivas et al. (2009) Niranjan Srinivas, Andreas Krause, Sham M Kakade, and Matthias Seeger. 2009. Gaussian process optimization in the bandit setting: No regret and experimental design. arXiv preprint arXiv:0912.3995 (2009).
- Su and Khoshgoftaar (2009) Xiaoyuan Su and Taghi M Khoshgoftaar. 2009. A survey of collaborative filtering techniques. Advances in artificial intelligence 2009 (2009).
- Thompson (1933) William R Thompson. 1933. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika 25, 3/4 (1933), 285–294.
- Valko et al. (2013) Michal Valko, Nathaniel Korda, Rémi Munos, Ilias Flaounas, and Nelo Cristianini. 2013. Finite-time analysis of kernelised contextual bandits. arXiv preprint arXiv:1309.6869 (2013).
- Wu et al. (2016) Qingyun Wu, Huazheng Wang, Quanquan Gu, and Hongning Wang. 2016. Contextual bandits in a collaborative environment. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. 529–538.
- Yang and Wang (2020) Lin Yang and Mengdi Wang. 2020. Reinforcement learning in feature space: Matrix bandit, kernels, and regret bound. In International Conference on Machine Learning. PMLR, 10746–10756.
- Zahavy and Mannor (2019) Tom Zahavy and Shie Mannor. 2019. Deep neural linear bandits: Overcoming catastrophic forgetting through likelihood matching. arXiv preprint arXiv:1901.08612 (2019).
- Zheng et al. (2021) Lecheng Zheng, Yu Cheng, Hongxia Yang, Nan Cao, and Jingrui He. 2021. Deep Co-Attention Network for Multi-View Subspace Learning. arXiv preprint arXiv:2102.07751 (2021).
- Zhou et al. (2015) Dawei Zhou, Jingrui He, K Selçuk Candan, and Hasan Davulcu. 2015. MUVIR: Multi-View Rare Category Detection.. In IJCAI. Citeseer, 4098–4104.
- Zhou et al. (2020a) Dongruo Zhou, Lihong Li, and Quanquan Gu. 2020a. Neural contextual bandits with UCB-based exploration. In International Conference on Machine Learning. PMLR, 11492–11502.
- Zhou et al. (2020c) Dawei Zhou, Lecheng Zheng, Yada Zhu, Jianbo Li, and Jingrui He. 2020c. Domain adaptive multi-modality neural attention network for financial forecasting. In Proceedings of The Web Conference 2020. 2230–2240.
- Zhou et al. (2020b) Yao Zhou, Jianpeng Xu, Jun Wu, Zeinab Taghavi Nasrabadi, Evren Korpeoglu, Kannan Achan, and Jingrui He. 2020b. GAN-based Recommendation with Positive-Unlabeled Sampling. arXiv preprint arXiv:2012.06901 (2020).
8. appendix
Definition 8.1.
Given the context vectors and the rewards , then we define the estimation via ridge regression:
Definition 8.2 ( NTK (Jacot et al., 2018; Cao and Gu, 2019)).
Let denote the normal distribution. Define
Then, given the contexts , the Neural Tangent Kernel is defined as .
Definition 8.3 (Effective Dimension (Zhou et al., 2020a)).
Given the contexts , the effective dimension is defined as
Proof of Lemma 5.2. Given a set of context vectors with the ground-truth function and a fully-connected neural network , we have
where is the estimation of ridge regression from Definition 8.1. Then, based on the Lemma 5.1, there exists such that . Thus, we have
where the final inequality is based on the the Theorem 2 in (Abbasi-Yadkori et al., 2011), with probability at least , for any .
Second we need to bound
To bound the above inequality, we first bound
where due to the random initialization of . The first inequality is derived by Lemma 8.5. According to the Lemma 8.7, it has . Then, replacing by , we obtain the second inequality.
Next, we need to bound
Due to the Lemma 8.6 and Lemma 8.7, we have
where the last inequality is because is sufficiently large. Therefore, we have
Finally, putting everything together, we have
Proof of Theorem 5.3. First, considering an individual bandit with the set of context vectors and the set of sub-rewards , we can build upper confidence bound of with respect to based on the Lemma 5.2. Denote the UCB by , with probability at least , for any we have
Next, apply the union bound on the networks, we have in each round .
Next we need to bound
where the first inequality is because is a -lipschitz continuous function. Therefore, we have
This completes the proof of the claim.
Lemma 8.4.
Proof of Lemma 8.4.
For (1), based on the Lemma 8.6, for any ,
.
Then, for the first item:
Same proof workflow for . For (2), we have
where .
According to the Theorem 3.1 in (Arora et al., 2019), when , with probability at least , for any , it has
Therefore, we have
Then, we have
The first inequality is because the concavity of ; The third inequality is due to ; The last inequality is because of the choice the ; The last equality is because of the Definition 8.3.
Lemma 8.5 ( Lemma 4.1 in (Cao and Gu, 2019) ).
There exist constants such that for any , if satisfies that
then with probability at least , for all satisfying and for any , we have
Lemma 8.6 (Lemma B.3 in (Cao and Gu, 2019) ).
There exist constants such that for any , if satisfies that
then, with probability at least , for any and we have .
Lemma 8.7 (Lemma B.2 in (Zhou et al., 2020a) ).
For the -layer full-connected network , there exist constants such that for , if for all , satisfy
then, with probability at least , it has
Lemma 8.8 (Theorem 5 in (Allen-Zhu et al., 2019)).
With probability at least , there exist constants such that if , for , we have
8.1. Empirical Setting of UCB
UCB is the key component of MuFasa, determining the empirical performance. (Lemma 5.2) can be formulated as
where is the gradient at initialization, is the gradient after iterations of gradient descent, and is a tunable parameter to trade off between them. Intuitively, has more bias as the weights of neural network function are randomness initialized, which brings more exploration portion in decision making of each round. In contrast, has more variance as the weights should be nearer to the optimum after gradient descent.
In the setting where the set of arms are fixed, given an arm , let be the number of rounds that has been played before. When is small, the learner should explore more ( is expected to be large). Instead, when is large, the leaner does not need more exploration on it. Therefore, can be defined as a decreasing function with respect to , such as and . In the setting without this condition, we can set as a decreasing function with respect to the number of rounds , such as and .
8.2. Future Work
This paper introduces a novel bandit problem, multi-facet contextual bandits. Based on empirical experiments and theoretical analysis, at least three factors play important roles in multi-facet bandits: (1) As all bandits are serving the same user, mutual influence does exist among bandits. Thus, how to extract and harness the mutual influence among bandits is one future-work direction; (2) The weights of bandits usually determine the final reward, since each bandit has a different impact on the serving user. For example, in the diabetes case, the bandit for selecting medications should have a higher weight than the bandit for recommending diabetes articles; (3) Sub-rewards contain crucial information and thus exploiting sub-rewards matters in this problem.
To solve multi-facet bandit problem, we propose the algorithm, MuFasa. However, there are three limitations implicitly shown in this paper: (1) For leveraging the sub-rewards, we assume the -lipschitz continuity of final reward function, while is usually unknown; (2) In the selection criteria of MuFasa, it needs to select one arm with the highest score from all possible combinations (Eq. (2) and Eq. (5)). However, the size of grows exponentially with respect to the number of bandits . (3) MuFasa only uses fully-connected work to exploit rewards, while many more advanced neural network models exist such as CNN, residual net, self-attention, etc.