Multi-Evidence based Fact Verification via A Confidential Graph Neural Network
Abstract
Fact verification tasks aim to identify the integrity of textual contents according to the truthful corpus. Existing fact verification models usually build a fully connected reasoning graph, which regards claim-evidence pairs as nodes and connects them with edges. They employ the graph to propagate the semantics of the nodes. Nevertheless, the noisy nodes usually propagate their semantics via the edges of the reasoning graph, which misleads the semantic representations of other nodes and amplifies the noise signals. To mitigate the propagation of noisy semantic information, we introduce a Confidential Graph Attention Network (CO-GAT), which proposes a node masking mechanism for modeling the nodes. Specifically, CO-GAT calculates the node confidence score by estimating the relevance between the claim and evidence pieces. Then, the node masking mechanism uses the node confidence scores to control the noise information flow from the vanilla node to the other graph nodes. CO-GAT achieves a 73.59% FEVER score on the FEVER dataset and shows the generalization ability by broadening the effectiveness to the science-specific domain.
Index Terms:
Fact verification, graph reasoning, confidence score, multi-head attention.I Introduction
Recently, the proliferation of fake news and rumors on the internet has become increasingly prevalent [1, 2, 3], which potentially misguides the public, induces panic, and harms the reputation of individuals, organizations, or companies. Automatic fact-checking [4, 5, 6] plays a pivotal role in enhancing information verification efficiency, reducing the workload on human labor, and mitigating the risks associated with human biases. Therefore, the fact verification systems [7, 8, 9, 10, 11, 12] are proposed to automatically verify the truthfulness and credibility of the given claim with the trust-worthy corpus [13, 14, 15], such as Wikipedia [16, 17] and knowledge graph [18].

Existing work usually employs a three-step pipeline model [19, 20, 21] to verify the given claims. Specifically, they design a document retrieval model [22, 23] to search relevant documents for the given claim. Subsequently, they utilize a sentence retrieval model [24, 25] to select multiple relevant evidence sentences from the retrieved documents to validate the given claim. Lots of previous work [26, 27, 28, 29] pays more attention to the claim verification step, which conducts multi-evidence reasoning model to verify the integrity of the claim. However, the retrieval models inevitably involve noise information and stimulate the claim verification models to exhaust their efforts to filter out the unrelated evidence pieces. Most claim verification models [27, 26, 30, 31] employ the Graph Attention Network (GAT) [32] to conduct multi-evidence reasoning. They regard each claim-evidence pair as a node and establish full connections among the graph nodes to facilitate the propagation of semantics among different evidence pieces. Such an attention mechanism establishes deep interactions among nodes, but provides opportunities for semantic information propagation of noisy nodes, leading to an additional noise channel during the node representation learning.
This paper introduces the Confidential Graph Neural Network Reasoning Model (CO-GAT)111The code is available at https://github.com/NEUIR/CO-GAT. As shown in Fig. 1, we design an additional node representation masking mechanism before the graph reasoning modeling, which controls the evidence information flow into the graph reasoning model. Specifically, CO-GAT learns the node confidence by estimating the claim-evidence relevance. It integrates the semantic information of blank nodes based on confidence scores to erase noise information of the vanilla node, thereby controlling the flow of evidence information and preventing the propagation of noise signals. Finally, these masked node representations are fed into the graph attention neural network for claim verification, alleviating the unnecessary noise propagation from the evidence pieces unrelated to the given claim.
Our experiments demonstrate CO-GAT’s effectiveness in identifying factual agreements on the FEVER [16] and SCIFACT [8] datasets. CO-GAT prefers to classify claims as “NOT ENOUGH INFO” (NEI) when the model uncertainty is high or the model prediction is incorrect, which thrives on insufficient evidence for fact verification prediction. Our studies indicate the node masking mechanism effectively erases the noise information of nodes, preventing noise information propagation in the reasoning graph. This leads to a more concentrated edge attention distribution while a more scattered node attention distribution.
II Related Work
The fact verification task aims to develop automatic fact verification systems, which check the veracity of the claims by retrieving evidence pieces from the trustworthy corpus. It has numerous applications, including question answering [33] and abstract summarization [34]. Current fact verification models commonly follow a three-step pipeline system [21], which includes document retrieval, sentence retrieval, and claim verification. Most fact verification systems follow the document retrieval model and the sentence retrieval model of previous work [23, 24, 26] and primarily concentrate on the claim verification step. These claim verification models can be grouped into two categories: the sequential models and the graph reasoning based models.
II-A Sequential Models
Previous research on the fact verification task adapts existing Natural Language Inference (NLI) models to predict the label of the given claim [23, 35, 36, 37, 38, 39, 40, 24, 41]. The NLI task aims to classify the relationship between a pair of premises and hypotheses as entailment, contradiction, or neutral, similar to the fact verification task. One of the most commonly used models is the Enhanced Sequential Inference Model (ESIM) [42] and its variants.
Recently, pre-trained language models (PLMs) [43, 25, 44, 45, 46] have shown their strong effectiveness in fact verification [47, 48]. Some researchers directly use language models to verify claims without any evidence [49]. Other researchers use the Retrieval-augmented generation (RAG) methods for fact verification tasks [50, 51]. They use a retriever to retrieve claim-related evidence, and then integrate the claim and evidence knowledge into the generation task to verify the claim. Then, some researchers use data augmentation methods to train on the generated datasets based on the FEVER dataset to improve the effectiveness of claim verification [52, 53]. Most fact verification systems use pre-trained language models to encode the claim and the evidence [54, 55]. Then they combine attention mechanisms [55, 56] or some neural network architectures [54, 57] to construct classification layers for label prediction.
In addition, some claim verification models are formulated based on logical rules of language. LOREN [28] decomposes the claim into a series of phrases and then uses the logical aggregation rules to validate the phrases and predict the claim label. ProoFVer [58] uses a seq2seq model to generate a natural logic proof to verify the claim. CLEVER [57] utilizes counterfactual theory to achieve claim verification by mitigating bias introduced from solely relying on claims for prediction during the inference stage.
II-B Graph Reasoning based Models
Other works adopt graph-based modeling methods for multi-evidence reasoning. An early attempt to use a graph-based reasoning model for fact verification is GEAR [27], which regards the evidence-claim pair as a graph node to construct a fully connected evidence graph. It proposes an evidence reasoning network, similar to a graph attention neural network [32] to propagate evidence information. Then, KGAT [26] proposes a fine-grained fact verification model based on a kernel graph attention neural network. It utilizes both token-level and sentence-level kernel attention mechanisms to capture fine-grained evidence information for claim verification. EvidenceNet [59] utilizes the evidence fusion network to capture different levels of global contextual information filtered by the gating mechanism. ICMI [60] is inspired by the multi-relational graph convolutional network and then uses dual evidence fusion graphs to capture multi-view information within and between documents, thereby solving the problem of multi-hop fact verification. CGAT [61] constructs a phrase-level graph by introducing a knowledge graph to obtain a node representation with detailed semantic information and then uses the graph attention network (GAT) model for inference. FACTKG [18] creates a dataset by using a knowledge graph, which provides an evidence graph composed of entities and entity relations. It uses GEAR [27] for factual verification reasoning.
In addition, some work introduces semantic graphs for factual verification. It uses the semantic role labeling (SRL) toolkit to parse the evidence sentences into structural relation triples as the nodes. DREAM [62] constructs semantic graphs for claim and evidence, which encodes them using the XLNET model [46]. Meanwhile, it uses graph convolutional network (GNN) [63] and the GAT model to propagate and aggregate evidence information. GLAF [64] constructs an evidence graph based on triple-level nodes. It combines the local fission reasoning layer and global evidence aggregation layer to establish logical relations between clues, share information, and exchange evidence clues for claim verification. RoEG [65] uses an entity recognizer to extract entities from the evidence. It then constructs an entity graph to capture fine-grained evidence features and semantic relations. SISER [29] incorporates sentence-level graph reasoning, sequence reasoning, and semantic graph reasoning to verify the claim.
III Methodology

In this section, we provide an overview of the Confidential Graph Attention Network (CO-GAT) framework and its application in the fact verification task.
CO-GAT aims to predict the factual label of the given claim with the graph neural network (Sec. III-A). Similar to the previous work [27, 26, 29], we regard the claim-evidence pair as the node . We construct a fully connected graph using nodes, . As shown in Fig. 2, the CO-GAT model initially employs a pre-trained language model to encode the graph nodes. Subsequently, CO-GAT utilizes the node masking mechanism (Sec. III-B) to erase the noise semantic information before feeding the node representations into the graph attention neural network. Finally, we use the multi-task modeling methods (Sec. III-C) to train CO-GAT.
III-A Graph Reasoning for Fact Verification
The CO-GAT model uses the retrieved evidence and the given claim to construct the evidence reasoning graph for the fact verification task.
Node Encoding. The node representation is initialized by feeding the concatenated sequence to the pre-trained language models, such as ELECTRA [66] and RoBERTa [43].
| (1) |
where denotes the concatenation operation. As shown in Fig. 2, contains the retrieved evidence sentence and the document (Wiki) title. Both “[CLS]” and “[SEP]” are special tokens in the pre-trained language models, such as ELECTRA and RoBERTa. We take the last hidden state of the “[CLS]” token as the initial node representation of the node .
Graph Reasoning. Following the previous work [27, 32], the evidence reasoning graph uses the edge attention mechanism to propagate evidence information and the node attention mechanism to aggregate node information for claim prediction.
For the edge attention mechanism, each node receives attention from neighbor nodes and uses this attention score to aggregate semantic information from neighbor nodes to update the node representation. CO-GAT utilizes the multi-head attention mechanism [67] to construct the edge attention mechanism. Specifically, the scaled dot product attention model is used to calculate the edge attention:
| (2) |
| (3) |
where represents the -th head edge attention that the node receives from the node . The weight matrix . represents the dimension of each head, which is calculated by Eq. 3. denotes the hidden size of the pre-trained language models. represents the number of attention heads.
Subsequently, the node uses the edge attention score to aggregate the semantic information from neighbor nodes. CO-GAT concatenates the node representation obtained from each attention head as the updated node representation :
| (4) |
| (5) |
where . Through the edge attention mechanism, each node obtains semantic information from the neighbor nodes. Consequently, the node attention mechanism assigns each node with an attention weight to aggregate the semantic information of graph nodes for claim verification. We use the Eq. 6 to calculate the node attention score of the node :
| (6) |
Then, we employ the node aggregator to gather the semantic information from all graph nodes to get the final hidden state :
| (7) |
Label Prediction. The factual classification label of the given claim is predicted according to the probability :
| (8) |
where the labels are categorized into three classes: 0, 1, and 2, representing SUPPORTS, REFUTES, and NOT ENOUGH INFO, respectively. These labels signify whether the provided evidence supports, refutes, or lacks sufficient information to predict the claim.
III-B Confidential Graph Reasoning of Node Masking
The task of fact verification requires the utilization of multiple pieces of evidence for reasoning. However, the retrieval evidence pieces inevitably contain noise information. As the attention layer deepens, the node representation tends to become homogeneous [68, 69]. Therefore, the noise semantic information is easily captured by other nodes during graph reasoning, consequently affecting the representation learning of the graph nodes. Therefore, the CO-GAT model proposes a node masking mechanism to erase the noise information from the initial node representations and alleviate the noisy semantic information propagated in the graph neural network.
The model assesses the confidence score (CO-SCO) of nodes and adjusts the information flow of blank nodes according to this score. This process aims to conduct the denoised node presentation of the node by adding the representation of blank node to the initial node representations using CO-SCO:
| (9) |
where is the node representation of the blank node . The blank node only contains the claim without any evidence. Similarity to Eq. 1, we utilize the same pre-trained language model for encoding the node .
The confidence score (CO-SCO) can be calculated:
| (10) |
where . The indicates that the model recognizes the given evidence as the golden evidence for the claim . CO-SCO represents the relevance between the claim and evidence . A higher confidence score indicates that the evidence piece is more effective in supporting or refuting the claim, indicating the necessity to retain more semantic information from the initial node representation.
III-C Multi-Task Modeling Methods
The CO-GAT model utilizes a multi-task training strategy, in which the final loss function consists of two loss functions: the cross entropy loss function for claim verification, and the cross entropy loss function for node prediction:
| (11) |
Claim Verification Loss. The claim verification model can be trained by minimizing the cross entropy loss with the claim prediction label :
| (12) |
where is the ground truth verification label for the given claim . The labels and can categorized into three classes, representing SUPPORTS, REFUTES, and NOT ENOUGH INFO, respectively.
To obtain the prediction label , CO-GAT employs the graph attention network as the reasoning model to integrate the evidence information:
| (13) |
The final hidden state of the evidence graph is obtained by Eq. 7 using the denoised node representation (Eq. 9):
| (14) |
Node Prediction Loss. For each node in the evidence graph, we predict its confidential label . we minimize the node prediction loss to help language models judge the relevance between claims-evidence pair and predict the node confidence score:
| (15) |
where denotes the ground truth confidence label for the graph node . and can be categorized into two groups: 0 and 1, signifying whether the provided evidence can provide sufficient clues to verify the claim. The claim-evidence relevance probability is calculated:
| (16) |
where denotes the initial node representation of node .
IV Experimental Methodology
This section describes the datasets, evaluation metrics, baselines, and implementation details used in our experiments.
IV-A Dataset
In our experiments, we leverage the FEVER [70] dataset and SCIFACT [8] dataset, which focuses on the general domain and the science-specific domain, respectively. They are publicly available collections for the fact verification task. FEVER employs Wikipedia as its trustworthy corpus for claim verification. It comprises 185,455 annotated claims classified into SUPPORTS, REFUTES, or NOT ENOUGH INFO categories. SCIFACT comprises 1,409 annotated claims sourced from 5,183 scientific articles. These claims are categorized as SUPPORT, CONTRADICT, or NOT ENOUGH INFO. The data statistics of the FEVER dataset and the SCIFACT dataset are shown in TABLE I.
| Dataset | Split | SUPPORT | REFUTE | NEI |
| FEVER | Train | 80,035 | 29,775 | 35,639 |
| Dev | 6,666 | 6,666 | 6,666 | |
| Test | 6,666 | 6,666 | 6,666 | |
| SCIFACT | Train | 332 | 173 | 304 |
| Dev | 124 | 64 | 112 | |
| Test | 100 | 100 | 100 |
Similar to the previous fact verification systems [28, 29], our experiment employs the identical experimental configuration as KGAT [26] on the FEVER dataset. We directly employ the document retrieval model and evidence retrieval model from KGAT. During the TEST stage, we need to submit our results to the designated website222https://codalab.lisn.upsaclay.fr/competitions/7308 for blind evaluation. We utilize the same experimental configuration as SCIKGAT [71] on the SCIFACT dataset. we also submit our results to the designated website333https://leaderboard.allenai.org/scifact/submissions/public for blind evaluation. The experimental data can be obtained via GitHub444https://github.com/thunlp/KernelGAT.
IV-B Evaluation Metrics
FEVER: The same as the previous research [49, 26], CO-GAT uses the official evaluation metrics555https://github.com/sheffieldnlp/fever-scorer FEVER score (FEVER) and Label Accuracy (ACC) to estimate the label prediction performance of model on the FEVER dataset. FEVER score is the primary evaluation metric of the CO-GAT model on the FEVER dataset, which offers a more comprehensive reflection of the inference capability.
SCIFACT: Precision, Recall, and F1 score are employed to assess the performance of the CO-GAT model on the SCIFACT dataset. It is evaluated at abstract and sentence levels.
IV-C Baselines
In our experiments, we compare the CO-GAT model with some fact verification work that focuses on graph reasoning or achieves fine performance on the FEVER dataset and SCIFACT dataset.
Athene [24], UNC NLP [23] and UCL MRG [30] are three top models in FEVER 1.0 shared task [16]. They are based on the NLI model to establish factual reasoning models. In addition, they use attention mechanisms to focus on the semantic information of the claim and evidence.
The prevalence of pre-trained language models and graph neural network architectures has led to their integration into fact verification tasks, resulting in notable performance improvements. GEAR [27] represents an early attempt to establish a reasoning model for fact verification based on the graph neural network. It utilizes the graph-based evidence reasoning network to aggregate evidence information. The BERT model [25] is used to encode the claim and evidence sentence pairs. Subsequently, KGAT [26] proposes a fine-grained graph inference model with a kernel-based graph attention network. It can utilize BERT [25], RoBERTa [43], and CorefRoBERTa [72] models to encode graph nodes. KGAT employs both the token-level and sentence-level kernel attention mechanisms to capture fine-grained evidence information. EvidenceNet [59] employs the gating mechanism to filter redundant evidence information and utilizes the evidence fusion network to capture global contextual information from different levels of evidence. ICMI [60] uses the graph neural network to integrate multi-view contextual information for fact verification, which includes the intra-document context of evidence sentences from the same document and the inter-document context of sentences from other documents. DREAM [62] is different from previous work, which establishes a semantic graph by employing a semantic role labeler to decompose claims and evidence sentences. Crucially, we build a graph-based baseline model MHA-GAT as our main baseline. It only uses the multi-head attention mechanism [67] to establish a graph attention model to aggregate evidence information.
Different from the graph-based inference models, MLA [55] proposes a sequence inference model. It utilizes both token-level and sentence-level self-attentions to capture information and incorporates the static positional encoding mechanism into the input of the multi-head attention mechanism. LOREN [28] propose an interpretable fact verification at the phrase level. The veracity of the phrases serves as an explanation and is aggregated into the final verdict according to the logical rules.
IV-D Implementation Details
The rest of this section describes the implementation details of the CO-GAT model on the FEVER dataset and SCIFACT dataset.
| Model | Prec@5 | Rec@5 | F1@5 | |
| Dev | UNC NLP | 36.49 | 86.79 | 51.38 |
| GEAR | 40.60 | 86.36 | 55.23 | |
| DREAM | 26.67 | 87.64 | 40.90 | |
| MLA | 25.63 | 88.64 | 39.76 | |
| ICMI | 25.74 | 92.86 | 40.30 | |
| CO-GAT | 27.29 | 94.37 | 42.34 | |
| Test | MLA | 25.33 | 87.58 | 39.29 |
| CO-GAT | 25.21 | 87.47 | 39.14 |
| Model | FEVER | SCIFACT | |||||||||||||||
| Dev | Test | Dev | Test | ||||||||||||||
| ACC | FEVER | ACC | FEVER | SentenceLevel | AbstractLevel | SentenceLevel | AbstractLevel | ||||||||||
| Prec | Rec | F1 | Prec | Rec | F1 | Prec | Rec | F1 | Prec | Rec | F1 | ||||||
| Athene [24] | 68.49 | 64.74 | 65.46 | 61.58 | - | - | - | - | - | - | - | - | - | - | - | - | |
| UCL MRG [30] | 69.66 | 65.41 | 67.62 | 62.50 | - | - | - | - | - | - | - | - | - | - | - | - | |
| UNC NLP [23] | 69.72 | 66.49 | 68.21 | 64.21 | - | - | - | - | - | - | - | - | - | - | - | - | |
| Base | GEAR (BERT) [27] | 74.84 | 70.69 | 71.60 | 67.10 | 55.32 | 14.21 | 22.61 | 64.29 | 17.22 | 27.17 | 53.77 | 15.41 | 23.95 | 67.21 | 18.47 | 28.98 |
| KGAT (BERT) [26] | 78.02 | 75.88 | 72.81 | 69.40 | 54.50 | 29.78 | 38.52 | 60.71 | 32.54 | 42.37 | 53.42 | 33.78 | 41.39 | 65.57 | 36.04 | 46.51 | |
| MLA (RoBERTa) [55] | 77.54 | 74.41 | - | - | 59.07 | 38.25 | 46.43 | 62.96 | 40.67 | 49.42 | 52.35 | 39.19 | 44.82 | 64.00 | 43.24 | 51.61 | |
| [62] | 79.16 | - | 76.85 | 70.60 | - | - | - | - | - | - | - | - | - | - | - | - | |
| [59] | 78.53 | 75.65 | 73.31 | 70.85 | - | - | - | - | - | - | - | - | - | - | - | - | |
| MHA-GAT (RoBERTa) | 74.67 | 72.51 | 70.61 | 66.88 | 61.20 | 30.60 | 40.80 | 62.39 | 32.54 | 42.77 | 56.28 | 32.70 | 41.37 | 63.79 | 33.33 | 43.79 | |
| CO-GAT (RoBERTa) | 77.74 | 75.86 | 73.27 | 70.41 | 62.07 | 34.43 | 44.29 | 66.95 | 37.80 | 48.32 | 55.79 | 35.14 | 43.12 | 66.41 | 39.19 | 49.29 | |
| MHA-GAT (ELECTRA) | 78.14 | 76.05 | 73.67 | 70.28 | 58.44 | 36.89 | 45.23 | 65.19 | 42.11 | 51.16 | 55.30 | 39.46 | 46.06 | 67.13 | 43.24 | 52.60 | |
| CO-GAT (ELECTRA) | 78.84 | 76.77 | 74.56 | 71.43 | 63.39 | 38.80 | 48.14 | 72.00 | 43.06 | 53.89 | 58.08 | 40.81 | 47.94 | 67.11 | 45.05 | 53.91 | |
| Large | KGAT (BERT) [26] | 77.91 | 75.86 | 73.61 | 70.24 | 51.33 | 31.69 | 39.19 | 58.06 | 34.45 | 43.24 | 46.86 | 34.32 | 39.63 | 58.87 | 37.39 | 45.73 |
| LOREN (BERT) [28] | 78.44 | 76.21 | 74.43 | 70.71 | - | - | - | - | - | - | - | - | - | - | - | - | |
| KGAT (RoBERTa) [26] | 78.29 | 76.11 | 74.07 | 70.38 | 69.70 | 37.70 | 48.94 | 79.28 | 42.11 | 55.00 | 58.42 | 44.05 | 50.23 | 72.67 | 49.10 | 58.60 | |
| LOREN (RoBERTa) [28] | 81.14 | 78.83 | 76.42 | 72.93 | - | - | - | - | - | - | - | - | - | - | - | - | |
| [59] | 81.46 | 78.29 | 76.95 | 73.78 | - | - | - | - | - | - | - | - | - | - | - | - | |
| [60] | - | - | 77.25 | 73.96 | - | - | - | - | - | - | - | - | - | - | - | - | |
| MLA (RoBERTa) [55] | 79.31 | 75.96 | 77.05 | 73.72 | 73.54 | 44.81 | 55.69 | 80.62 | 49.76 | 61.54 | 59.64 | 45.14 | 51.38 | 74.32 | 49.55 | 59.46 | |
| MHA-GAT (RoBERTa) | 80.21 | 77.82 | 76.24 | 72.17 | 66.96 | 41.53 | 51.26 | 73.48 | 46.41 | 56.89 | 59.78 | 44.59 | 51.08 | 73.97 | 48.65 | 58.70 | |
| CO-GAT (RoBERTa) | 81.56 | 79.21 | 76.95 | 73.48 | 66.67 | 46.45 | 54.75 | 75.86 | 52.63 | 62.15 | 55.52 | 44.86 | 49.63 | 70.00 | 50.45 | 58.64 | |
| MHA-GAT (ELECTRA) | 80.99 | 78.47 | 76.95 | 72.56 | 71.01 | 46.17 | 55.96 | 78.99 | 52.15 | 62.82 | 51.64 | 38.38 | 44.03 | 65.33 | 44.14 | 52.69 | |
| CO-GAT (ELECTRA) | 81.65 | 79.32 | 77.27 | 73.59 | 71.49 | 48.63 | 57.89 | 79.58 | 54.07 | 64.39 | 55.31 | 47.84 | 51.30 | 69.64 | 52.70 | 60.00 | |
IV-D1 FEVER
CO-GAT implements the document retrieval model following the previous fact verification systems [24, 47, 27]. Firstly, we utilize the constituency parser of AllenNLP [73] to extract phrases from claims. Subsequently, these phrases serve as queries and use the online MediaWiki API666https://www.mediawiki.org/wiki/API:Main_page to retrieve the wiki pages, whose titles exhibit the most significant overlap with the queries. The seven highest-ranked results of each query are selected as the candidate set. Finally, we filter out the candidate set by removing the pages whose title is longer than the phrase mentioned and does not overlap with the rest of the claim [24].
In our experiments, CO-GAT uses the BERT-based sentence retrieval model, which is proposed by the KGAT model [26]. Firstly, it leverages the last hidden state of the “[CLS]” token to represent the claim and evidence pair. Then, the rank model projects the “[CLS]” representation to a rank score. Finally, we use the pairwise loss for training the retrieval model. The sentence retrieval performances of the baseline models are shown in TABLE II.
For the claim verification step, we inherit huggingface’s implementation777https://github.com/huggingface/transformers of the pre-trained language models to encode the claim and evidence pairs. When the claim-evidence pair exceeds the maximum length of 256, we employ the tail truncation method. During training, we set the epoch to 10 and the evaluation step to 1,000. Additionally, we employ the early stopping training method and set patience to 5. For the base model, we set the batch size to 16 and the accumulation step to 1. For the large model, we set the batch size to 8 and the accumulation step to 2. The Adam optimizer is employed for training CO-GAT. For the base model, the learning rate is set to 5e-5. For the large model, we implement a warm-up training strategy. Initially, we set the learning rate to 5e-5 and only train the attention layer. Subsequently, we load the checkpoint trained from the first stage and set the learning rate to 2e-6 to fine-tune all layers. The number of the attention head equals the dimension of the pre-trained language model divided by 64.
IV-D2 SCIFACT
For the abstract retrieval model, we retrieve the top-100 abstracts using the TF-IDF, the same as the previous work [8]. Subsequently, it utilizes the hidden state of the ”[CLS]” token as the representation of the claim and abstract pairs. Finally, we introduce a ranking model to select the top-3 abstracts. We kept the same setting as SCIKGAT [71], which set the max length to 256, learning rate to 2e-5, batch size to 8, and accumulate steps to 4.
The rationale selection model aims to select the relevant sentence from the retrieved abstract for claim verification. Specifically, we use the pre-trained model to encode the claim and evidence pairs and use the last hidden state of the “[CLS]” token to predict the relevance label. We keep the same setting as the previous work [71, 8].
For the claim verification model, CO-GAT used the same settings implemented on the FEVER dataset. The pre-trained language models also inherit huggingface’s PyTorch implementation to encode the claim and evidence pairs. The difference is that for evidence selection, we exclusively selected evidence sentences without incorporating titles from wiki documents.
V Evaluation Result
In this section, we describe the experiments, which are conducted on the FEVER dataset and SCIFACT dataset, to evaluate the performance of CO-GAT on the fact verification task. Firstly, we present the overall performance of the CO-GAT model on the fact verification task. Then we conduct ablation studies and explore the tendency of the prediction label. We also study the effectiveness of the node masking mechanism and the mode of the CO-GAT attention mechanism. Finally, we present case studies.
V-A Overall Performance
The fact verification performance of CO-GAT on the FEVER dataset and SCIFACT dataset are compared with several baseline models. The results are shown in TABLE III.
Overall, CO-GAT confirms its effectiveness by achieving a 73.59% FEVER score on the blind test set. Compared to these graph-based claim verification models [27, 62, 26], our CO-GAT model achieves a 3.35% improvement. It shows that our node masking mechanism is effective in enhancing the graph reasoning process and does not change the vanilla graph modeling architecture. Compared with the MHA-GAT model, CO-GAT achieves a 1.03% improvement by keeping the same graph reasoning module as the MHA-GAT model. It shows that the node masking mechanism can help filter out the noise information and conduct more calibrated node representations before feeding the node representations to the reasoning graph. Furthermore, CO-GAT also demonstrates its effectiveness by keeping the vanilla GAT architecture for graph reasoning and conducting competitive performance with EvidenceNET and IMCI models. CO-GAT avoids conducting repetitive encoding [59] and building an additional reasoning graph in the fact verification model [60].
Besides the FEVER dataset, we also conduct experiments on the SCIFACT dataset, which focuses on scientific claim verification. CO-GAT also outperforms baseline models on the SCIFACT dataset, which also confirms its effectiveness. The better fact verification results show the generalization ability of CO-GAT by broadening its effectiveness to the science-specific domain.
| Model | Dev | Test | |||
| ACC | FEVER | ACC | FEVER | ||
| ELECTRA | 81.12 | 78.53 | 77.10 | 72.70 | |
| CO-GAT | 79.32 | 77.27 | 73.59 | ||
| 77.59 | 73.42 | ||||
| 80.99 | 78.47 | 76.95 | 72.56 | ||
| T5-Large | Concat | 79.61 | 77.64 | 75.61 | 72.43 |
| MHA-GAT | 80.38 | 78.01 | 75.72 | 72.05 | |
| CO-GAT | 80.45 | 78.26 | 76.01 | 72.60 | |
| GPT2 | Concat | 76.30 | 74.08 | 72.06 | 68.09 |
| MHA-GAT | 76.28 | 74.12 | 71.34 | 67.73 | |
| CO-GAT | 76.57 | 74.54 | 71.75 | 68.35 | |
V-B Ablation Study
This section investigates the effectiveness of different modules and backbone models of the CO-GAT model through ablation studies.
V-B1 The Effect of Using Node Masking Mechanism
In this experiment, we conduct two models, the CO-GAT (hard CO-SCO) model and the CO-GAT w/o Node Mask model to explore the efficacy of the node masking mechanism used in the CO-GAT model.
Different from the confidence score used in the CO-GAT model, which sets the probability between 0 and 1, the CO-GAT (hard CO-SCO) model sets the node mask probability to 0 or 1. If the confidence score is 0, the model will cover up the entire piece of evidence with the blank node, otherwise, the evidence nodes will maintain their initial representation.
As shown in TABLE IV, the CO-GAT model achieves 0.85% improvements of the FEVER score, compared with the CO-GAT model w/o Node Mask model (MHA-GAT). This demonstrates the effectiveness of utilizing the node masking mechanism, which avoids the propagation of noise information in the graph reasoning. The CO-GAT model improves the fact verification performance by 0.79% compared with the CO-GAT (hard CO-SCO) model. Due to the inevitable occurrence of incorrect hard-label predictions, the claim-related node may be completely erased. Therefore, a soft score that partly erases the node information can achieve more precision in the claim verification model. In the following section (Sec. V-D), we further explore the sensitivity of the confidential score.


V-B2 The Effectiveness of Multi-Task Modeling Methods
In this experiment, we change the training strategy to evaluate the effectiveness of the multi-task training and compare CO-GAT with the CO-GAT w/o model.
During training, the CO-GAT w/o model only uses the claim verification loss (), while the CO-GAT model uses both the claim verification loss () and the node prediction loss (). Compared with the CO-GAT w/o model, the CO-GAT model achieves a 0.18% improvement of 0.18%, showing that the claim-evidence relevance signals can benefit the node masking mechanism by learning a more accurate confidence score (CO-SCO).
V-B3 The Effectiveness of Different Backbone Models
In this experiment, we investigate the influence of the backbone model. We employ the encoder-base models (ELECTRA and RoBERTa), decoder-based model (GPT2), and encoder-decoder based model (T5) to assess the performance of CO-GAT. The concat model combines claims and all evidence pieces. Following sentence-t5 [76], the CO-GAT (T5) model utilizes T5 [45] to encode the claim-evidence pairs and get the node representation by using the encoded representation of the first input token of the T5 decoder module. The GPT2 model feeds claim-evidence pairs and uses the end token of the text to obtain the node representation. When employing the GPT2 model and T5 model as the backbone model, the CO-GAT model also exhibits an improving fact verification performance compared with MHA-GAT, which further confirms the effectiveness of CO-GAT and demonstrates its generalization ability.


V-C Label Prediction Behaviors of CO-GAT
In Fig. 3, we conduct two experiments: the initial experiment investigates the correlation between NEI label prediction probability and the cross entropy score; the subsequent one analyses the NEI prediction ratio of the cases that belong to SUPPORT and REFUTE.
As shown in Fig. 3a, when the cross entropy is low, both MHA-GAT and CO-GAT exhibit a similar probability distribution in predicting the claim label as NEI. However, different from the MHA-GAT model, the CO-GAT model conducts a notably higher probability of predicting the claim label as NEI when the cross entropy score increases, which indicates that the CO-GAT model prefers to predict the claim label as NEI when the cross entropy is higher. Such a phenomenon demonstrates that the reasoning ability of CO-GAT relies more on sufficient information and calibrates the uncertain predictions to the NEI, making CO-GAT conduct more reliable predictions.
Furthermore, we analyze the NEI prediction ratios of the cases that belong to the SUPPORT and REFUTE classes. As shown in Fig. 3b, the results indicate that, in comparison to the MHA-GAT model, CO-GAT exhibits a higher tendency to predict the claim label as NEI. This further confirms the calibration behavior of our CO-GAT model, which predicts some confusing cases as the NEI label.
V-D The Effectiveness of Confidence Score in Controlling the Information Flows that from Node Representations to the Graph Reasoning Module
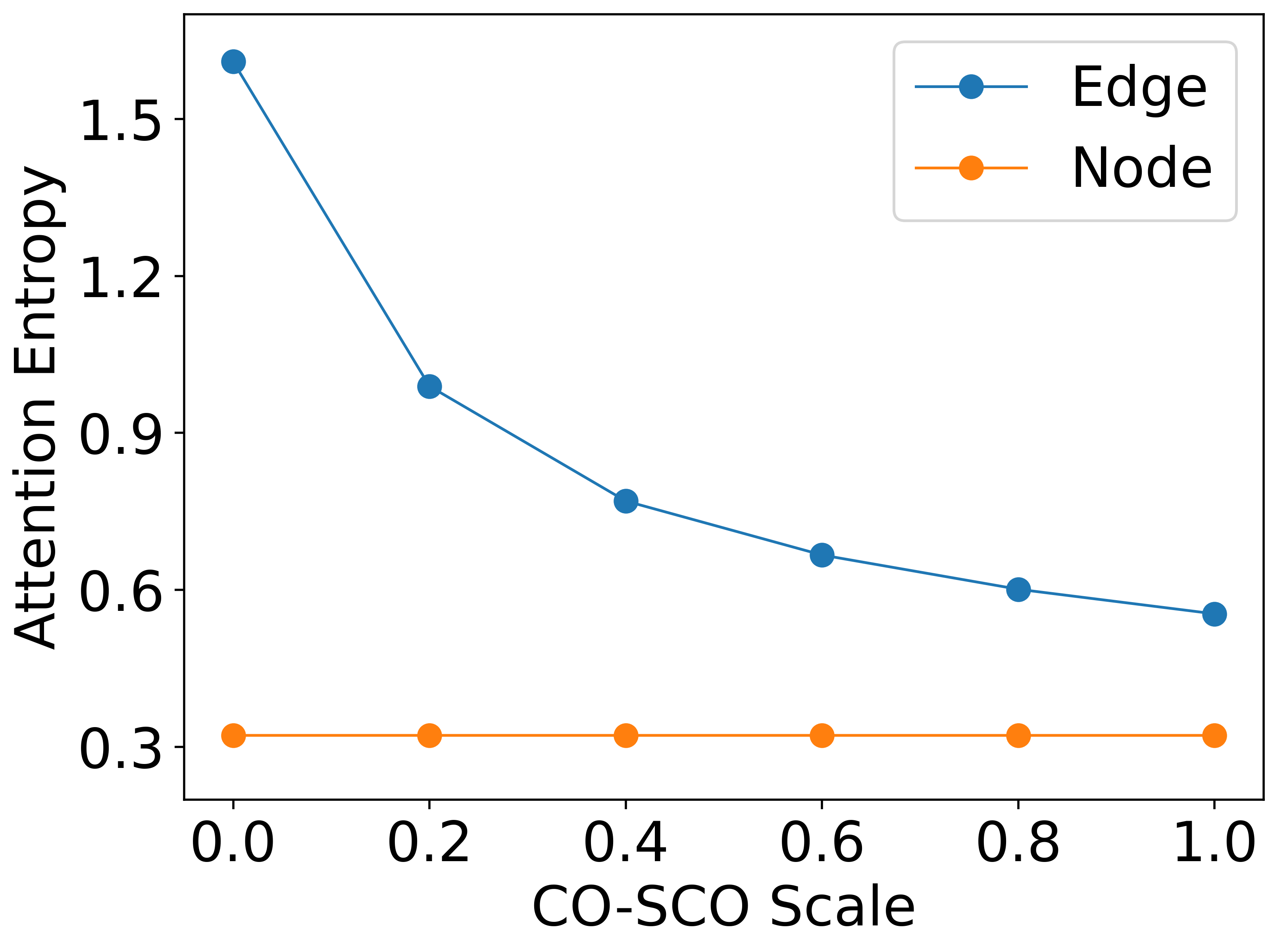
In Fig. 4, we scale the confidence score to explore the effectiveness of the confidence score in controlling the semantic information flow from the node representations to the graph reasoning module.
As shown in Fig. 4a, we scale the CO-SCO by multiplying it with a coefficient , which changes from 1.0 to 0.0 results with the interval of 0.2. As the confidence score decreases, more evidence information flows from blank nodes into the graph nodes. In this case, the reasoning model lacks sufficient evidence information to make a correct fact verification prediction, leading to the tendency of the NEI prediction of CO-GAT. Nonetheless, as shown in Fig. 4b, the label accuracy exhibits only a slight decrease while the scaling factor varies from 1.0 to 0.4. Despite inevitable errors in node confidence assessment, it ensures that CO-GAT can preserve useful semantic information of node representations and feed them to the reasoning graph, indicating its strong tolerance of the CO-SCO prediction in our node masking mechanism.
As shown in Fig. 4c, we analyze the change of cross entropy scores by scaling the CO-SCO to control the information flow from the blank node to these initial node representations. The lower attention entropy score indicates a more concentrated attention mechanism. The evaluation results show that, as the scaling coefficient decreases from 1.0 to 0.0, the edge attention entropy gradually increases, which illustrates that the semantic information gradually flows from blank nodes to vanilla nodes. In this case, the node representations tend to become more homogeneous, making the edge attention mechanism unable to identify these useful nodes. On the contrary, the node attention entropy remains relatively stable regardless of changes in the scaling coefficient. It demonstrates that the node representations become more homogenized after multi-layer graph attention encoding. This indicates that the edge attention mechanism is primarily responsible for node selection and the node attention mechanism does not pay attention to node selection. This further demonstrates the necessity of utilizing the node masking mechanism to erase noise information before the graph reasoning, preventing its impact on the learned representations of other nodes during graph reasoning.



V-E The Analyses on Attention Mechanisms of CO-GAT
In this experiment, we investigate the comparison of the attention mechanisms between the CO-GAT model and the MHA-GAT model.
As shown in Fig. 5a, the node attention entropy scores of MHA-GAT and CO-GAT are almost the same, which indicates that both of them have a similar node attention distribution. This shows that CO-GAT has little effect on node attention. On the contrary, the edge attention entropy of CO-GAT is notably smaller than that of MHA-GAT. It demonstrates that the edge attention mechanism of CO-GAT helps to conduct a more concentrated distribution while using edge attention to encode node representations. The main reason may lie in that the node masking mechanism has the ability to erase some unnecessary information from the initial node representations, make these node representations more distinguished, and finally conduct a more concentrated attention distribution.
Furthermore, we analyze the attention distribution of edge attention and node attention by sorting the attention weights. As shown in Fig. 5b, during the graph reasoning process, CO-GAT assigns more attention weights to some nodes, which demonstrates that our attention masking mechanism can expose the valuable node representations by alleviating the effect of noise node representations. As shown in Fig. 5c, it illustrates that the node attention weights of the CO-GAT model are more stable, compared to the MHA-GAT model. These encoded node representations become more homogeneous after edge attention based encoding, which thrives on erasing the noise information from the initial node representations.
| CO-SCO | CO-GAT | MHA-GAT | |||
| Node | Edge | Node | Edge | ||
| Case #1 | |||||
| Claim: CHiPs was created in May 2017. | |||||
| : [CHiPs (film)] The film was released on March 24, 2017 by Warner Bros. | 0.01 | 0.2032 | 0.0467 | 0.1890 | 0.1148 |
| : [CHiPs (film)] CHiPs is a 2017 American action comedy buddy cop film written and directed by Dax Shepard, based on the 1977 1983 television series of the same name created by Rick Rosner. | 0.02 | 0.2030 | 0.0467 | 0.1925 | 0.1078 |
| : [CHiPs]CHiPs is an American television drama series that originally aired on NBC from September 15, 1977, to May 1, 1983. | 0.04 | 0.2020 | 0.0490 | 0.2133 | 0.3304 |
| : [CHiPs] The series ran for 139 episodes over six seasons, plus one reunion TV movie from October 27, 1998. | 0.12 | 0.1995 | 0.0562 | 0.2019 | 0.1449 |
| : [CHiPs (film)] Principal photography began on October 21, 2015 in Los Angeles. | 0.28 | 0.1923 | 0.8013 | 0.2033 | 0.3020 |
| Actual Label: NEI CO-GAT: NEI MHA-GAT: REFUTES | |||||
| Case #2 | |||||
| Claim: Aphrodite is the daughter of a Titaness in Homer’s Iliad. | |||||
| : (Golden) [Aphrodite] In Homer’s Iliad, however, she is the daughter of Zeus and Dione. | 0.84 | 0.2046 | 0.1725 | 0.2341 | 0.5542 |
| : (Golden) [Aphrodite] Dione was an ancient Greek goddess, an oracular Titaness primarily known from Book V of Homer’s Iliad, where she tends to the wounds suffered by her daughter Aphrodite. | 0.95 | 0.1982 | 0.7960 | 0.0258 | 0.0990 |
| : [Aphrodite] She played a role in the Eros and Psyche legend, and was both lover and surrogate mother of Adonis. | 0.01 | 0.1991 | 0.0105 | 0.3794 | 0.1155 |
| : [Aphrodite] Aphrodite is the Greek goddess of love, beauty, pleasure, and procreation. | 0.01 | 0.1990 | 0.0105 | 0.0235 | 0.1048 |
| : [Aphrodite] Many lesser beings were said to be children of Aphrodite. | 0.01 | 0.1991 | 0.0105 | 0.3373 | 0.1264 |
| Actual Label: SUPPORTS CO-GAT: SUPPORTS MHA-GAT: REFUTES | |||||
| Case #3 | |||||
| Claim: The Nice Guys is a romantic comedy. | |||||
| : (Golden)[The Nice Guys] The Nice Guys is a 2016 American neo noir action comedy film directed by Shane Black and written by Black and Anthony Bagarozzi. | 0.29 | 0.1979 | 0.8055 | 0.1957 | 0.5625 |
| :[The Nice Guys] The film stars Russell Crowe, Ryan Gosling, Angourie Rice, Matt Bomer, Margaret Qualley, Keith David and Kim Basinger. | 0.01 | 0.2005 | 0.0485 | 0.2057 | 0.1071 |
| :[The Nice Guys] The Nice Guys premiered on May 15, 2016, at the 2016 Cannes Film Festival and was released by Warner Bros. | 0.01 | 0.2003 | 0.0494 | 0.1882 | 0.0688 |
| :[The Nice Guys] Set in Los Angeles, 1977, the film focuses on a private eye LRB Gosling RRB and a tough enforcer LRB Crowe RRB who team up to investigate the disappearance of a teenage girl. | 0.01 | 0.2007 | 0.0474 | 0.2111 | 0.1383 |
| :[The Nice Guys] It received positive reviews from critics but grossed just 57 million against its 50 million budget. | 0.01 | 0.2006 | 0.0492 | 0.1993 | 0.1233 |
| Actual Label: REFUTES CO-GAT: NEI MHA-GAT: REFUTES | |||||
V-F Case Studies
TABLE V shows three claim examples in the FEVER dataset.
In the first case, “CHIPs” is ambiguous, which indicates two meanings: movies and TV dramas. However, this claim does not specify which was mentioned. The MHA-GAT model assigns approximately 0.3 edge attention weight to and . Yet, states “CHIPs aired from September 15, 1977, to May 1, 1983”, declares “ CHIPs began on October 21, 2015”. The timing of these two pieces of evidence is different from the “2017” in the claim. The presence of interference information “1977” and “2015” leads to incorrect prediction results in the MHA-GAT model, which predicts the claim label as “REFUTES”. On the contrary, although the CO-GAT model assigns more edge attention weight to the , it predicts the confidence score of to be 0.28. It erases the majority of noise information based on confidence scores and makes it more inclined to the blank node. Due to the lack of sufficient information remaining in the reasoning model, the CO-GAT model correctly predicts that the label of this claim is “NEI”.
As shown in the second case, the MHA-GAT model pays more attention weight to the evidence and the other four pieces of evidence receive similar attention weights. indicates that “Aphrodite is the daughter of Dione, as mentioned in Homer’s Iliad”. illustrates that “Dione is an oracular Titaness primarily known from Book V of Homer’s Iliad”. and can jointly infer that the label of this claim should be “SUPPORTS”. However, in the MHA-GAT model, the obtains a minimal node attention weight, which is only 0.02. It leads to the MHA-GAT model not obtaining sufficient effective information for claim verification. Meanwhile, and have a higher node attention weight compared to the , which indicates “Aphrodite” is a “mother”. This introduces additional noise semantic information, resulting in the MHA-GAT model predicting that the claim label is “REFUTES”. In contrast, the and in the CO-GAT model have high confidence scores, which allows them to retain more useful information. Furthermore, and receive higher edge attention weights than the other evidence pieces, thus CO-GAT predicts the correct label “SUPPORTS”.
In the third case, the MHA-GAT model and the CO-GAT model pay more attention to the golden evidence . The evidence states “The Nice Guys is a 2016 American action comedy film”. Consequently, the MHA-GAT model predicts the claim label as “REFUTES”. However, the CO-GAT model mistakenly evaluates the correlation between and the claim, leading to erasing the majority of its semantic information. Thus, the CO-GAT model makes a mistake prediction of the claim label as “NEI”.
VI Conclusion
This paper proposes CO-GAT, a confidential graph reasoning model to verify the claim. It uses the blank node to erase the noise information of the initial node based on the confidential score. Our experiments show the model tends to predict the claim label as NEI when there is insufficient information to support or refute the claim. Our studies illustrate the node masking mechanism realized reasonable confidence score modeling, which controls the evidence information flow into the graph reasoning and prevents the propagation of noise signals in the graph reasoning. Our studies illustrate the node attention mechanism has a scattered distribution, which equally aggregates the node evidence representation. While, the edge attention mechanism plays the role of selecting useful nodes, which assigns more attention weight to the nodes that are related to the claim.
Acknowledgments
This work is supported by the National Natural Science Foundation of China under Grant (No. U23B2019, No. 62072083, No. 62206042), the Joint Funds of Natural Science Foundation of Liaoning Province (No. 2023-MSBA-081) and the Fundamental Research Funds for the Central Universities under Grant (No. N2216017).
References
- [1] L. Cheng, R. Guo, K. Shu, and H. Liu, “Causal understanding of fake news dissemination on social media,” in Proceedings of KDD, 2021.
- [2] R. Zafarani, X. Zhou, K. Shu, and H. Liu, “Fake news research: Theories, detection strategies, and open problems,” in Proceedings of KDD, 2019.
- [3] C. Yang, M. Sun, W. X. Zhao, Z. Liu, and E. Y. Chang, “A neural network approach to jointly modeling social networks and mobile trajectories,” ACM Trans. Inf. Syst., 2017.
- [4] S. Vosoughi, D. Roy, and S. Aral, “The spread of true and false news online,” science, no. 6380, 2018.
- [5] N. Hassan, C. Li, and M. Tremayne, “Detecting check-worthy factual claims in presidential debates,” in Proceedings of CIKM, 2015.
- [6] A. Vlachos and S. Riedel, “Fact checking: Task definition and dataset construction,” in Proceedings of the ACL 2014 Workshop on Language Technologies and Computational Social Science, 2014.
- [7] Z. Guo, M. Schlichtkrull, and A. Vlachos, “A survey on automated fact-checking,” Transactions of the Association for Computational Linguistics, 2022.
- [8] D. Wadden, S. Lin, K. Lo, L. L. Wang, M. van Zuylen, A. Cohan, and H. Hajishirzi, “Fact or fiction: Verifying scientific claims,” in Proceedings of EMNLP, 2020.
- [9] Y. Jiang, S. Bordia, Z. Zhong, C. Dognin, M. Singh, and M. Bansal, “HoVer: A dataset for many-hop fact extraction and claim verification,” in Proceedings of EMNLP Findings, 2020.
- [10] J. Park, S. Min, J. Kang, L. Zettlemoyer, and H. Hajishirzi, “Faviq: Fact verification from information-seeking questions,” in Proceedings of ACL, 2022.
- [11] J. Ma, W. Gao, S. Joty, and K.-F. Wong, “Sentence-level evidence embedding for claim verification with hierarchical attention networks,” in Proceedings of ACL, 2019.
- [12] H. Wan, H. Chen, J. Du, W. Luo, and R. Ye, “A DQN-based approach to finding precise evidences for fact verification,” in Proceedings of ACL, 2021.
- [13] G. Bekoulis, C. Papagiannopoulou, and N. Deligiannis, “A review on fact extraction and verification,” ACM Comput. Surv., no. 2, 2023.
- [14] I. Augenstein, C. Lioma, D. Wang, L. Chaves Lima, C. Hansen, C. Hansen, and J. G. Simonsen, “MultiFC: A real-world multi-domain dataset for evidence-based fact checking of claims,” in Proceedings of EMNLP, 2019.
- [15] T. Schuster, A. Fisch, and R. Barzilay, “Get your vitamin C! robust fact verification with contrastive evidence,” in Proceedings of NAACL-HLT, 2021.
- [16] J. Thorne, A. Vlachos, O. Cocarascu, C. Christodoulopoulos, and A. Mittal, “The fact extraction and VERification (FEVER) shared task,” in Proceedings of the First Workshop on Fact Extraction and VERification (FEVER), 2018.
- [17] T. Schuster, D. Shah, Y. J. S. Yeo, D. Roberto Filizzola Ortiz, E. Santus, and R. Barzilay, “Towards debiasing fact verification models,” in Proceedings of EMNLP, 2019.
- [18] J. Kim, S. Park, Y. Kwon, Y. Jo, J. Thorne, and E. Choi, “FactKG: Fact verification via reasoning on knowledge graphs,” in Proceedings of ACL, 2023.
- [19] M. Fajcik, P. Motlicek, and P. Smrz, “Claim-dissector: An interpretable fact-checking system with joint re-ranking and veracity prediction,” in Proceedings of ACL Findings, 2023.
- [20] W. Yin and D. Roth, “TwoWingOS: A two-wing optimization strategy for evidential claim verification,” in Proceedings of EMNLP, 2018.
- [21] D. Chen, A. Fisch, J. Weston, and A. Bordes, “Reading Wikipedia to answer open-domain questions,” in Proceedings of ACL, 2017.
- [22] R. Aly and A. Vlachos, “Natural logic-guided autoregressive multi-hop document retrieval for fact verification,” in Proceedings of EMNLP, 2022.
- [23] Y. Nie, H. Chen, and M. Bansal, “Combining fact extraction and verification with neural semantic matching networks,” in Proceedings of AAAI, 2019.
- [24] A. Hanselowski, H. Zhang, Z. Li, D. Sorokin, B. Schiller, C. Schulz, and I. Gurevych, “UKP-athene: Multi-sentence textual entailment for claim verification,” in Proceedings of the First Workshop on Fact Extraction and VERification (FEVER), 2018.
- [25] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Proceedings of NAACL-HLT, 2019.
- [26] Z. Liu, C. Xiong, M. Sun, and Z. Liu, “Fine-grained fact verification with kernel graph attention network,” in Proceedings of ACL, 2020.
- [27] J. Zhou, X. Han, C. Yang, Z. Liu, L. Wang, C. Li, and M. Sun, “GEAR: Graph-based evidence aggregating and reasoning for fact verification,” in Proceedings of ACL, 2019.
- [28] J. Chen, Q. Bao, C. Sun, X. Zhang, J. Chen, H. Zhou, Y. Xiao, and L. Li, “Loren: Logic-regularized reasoning for interpretable fact verification,” in Proceedings of AAAI, no. 10, 2022.
- [29] E. Park, J. Lee, D. H. Jeon, S. Kim, I. Kang, and S. Na, “SISER: semantic-infused selective graph reasoning for fact verification,” in Proceedings of COLING, 2022.
- [30] T. Yoneda, J. Mitchell, J. Welbl, P. Stenetorp, and S. Riedel, “UCL machine reading group: Four factor framework for fact finding (HexaF),” in Proceedings of the First Workshop on Fact Extraction and VERification (FEVER), 2018.
- [31] J. Si, D. Zhou, T. Li, X. Shi, and Y. He, “Topic-aware evidence reasoning and stance-aware aggregation for fact verification,” in Proceedings of ACL, 2021.
- [32] P. Velickovic, G. Cucurull, A. Casanova, A. Romero, P. Liò, and Y. Bengio, “Graph attention networks,” in Proceedings of ICLR, 2018.
- [33] L. Wang, P. Zhang, X. Lu, L. Zhang, C. Yan, and C. Zhang, “Qadialmoe: Question-answering dialogue based fact verification with mixture of experts,” in Proceedings of EMNLP Findings, 2022.
- [34] Y. Zhang, D. Merck, E. Tsai, C. D. Manning, and C. Langlotz, “Optimizing the factual correctness of a summary: A study of summarizing radiology reports,” in Proceedings of ACL, 2020.
- [35] A. Parikh, O. Täckström, D. Das, and J. Uszkoreit, “A decomposable attention model for natural language inference,” in Proceedings of EMNLP, 2016.
- [36] A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” in Proceedings of Technical report, OpenAI, 2018.
- [37] Q. Chen, X. Zhu, Z.-H. Ling, S. Wei, H. Jiang, and D. Inkpen, “Enhanced LSTM for natural language inference,” in Proceedings of ACL, 2017.
- [38] R. Ghaeini, S. A. Hasan, V. Datla, J. Liu, K. Lee, A. Qadir, Y. Ling, A. Prakash, X. Fern, and O. Farri, “DR-BiLSTM: Dependent reading bidirectional LSTM for natural language inference,” in Proceedings of NAACL-HLT, 2018.
- [39] M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contextualized word representations,” in Proceedings of NAACL-HLT, 2018.
- [40] T. Li, X. Zhu, Q. Liu, Q. Chen, Z. Chen, and S. Wei, “Several experiments on investigating pretraining and knowledge-enhanced models for natural language inference,” ArXiv preprint, 2019.
- [41] C. Hidey and M. Diab, “Team SWEEPer: Joint sentence extraction and fact checking with pointer networks,” in Proceedings of the First Workshop on Fact Extraction and VERification (FEVER), 2018.
- [42] Q. Chen, X. Zhu, Z.-H. Ling, S. Wei, H. Jiang, and D. Inkpen, “Enhanced LSTM for natural language inference,” in Proceedings of ACL, 2017.
- [43] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” ArXiv preprint, 2019.
- [44] M. Lewis, Y. Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V. Stoyanov, and L. Zettlemoyer, “BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension,” in Proceedings of ACL, 2020.
- [45] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” Journal of Machine Learning Research, 2020.
- [46] Z. Yang, Z. Dai, Y. Yang, J. G. Carbonell, R. Salakhutdinov, and Q. V. Le, “Xlnet: Generalized autoregressive pretraining for language understanding,” in Proceedings of NeurIPS, 2019.
- [47] A. Soleimani, C. Monz, and M. Worring, “BERT for evidence retrieval and claim verification,” in Proc. of ECIR, 2020.
- [48] K. Jiang, R. Pradeep, and J. Lin, “Exploring listwise evidence reasoning with t5 for fact verification,” in Proceedings of ACL, 2021.
- [49] N. Lee, Y. Bang, A. Madotto, and P. Fung, “Towards few-shot fact-checking via perplexity,” in Proceedings of NAACL-HLT, 2021.
- [50] W. Yu, D. Iter, S. Wang, Y. Xu, M. Ju, S. Sanyal, C. Zhu, M. Zeng, and M. Jiang, “Generate rather than retrieve: Large language models are strong context generators,” in Proceedings of ICLR, 2023.
- [51] P. S. H. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W. Yih, T. Rocktäschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Proceedings of NeurIPS, 2020.
- [52] M. Lee, S. Won, J. Kim, H. Lee, C. Park, and K. Jung, “Crossaug: A contrastive data augmentation method for debiasing fact verification models,” in Proceedings of CIKM, 2021.
- [53] L. Pan, W. Chen, W. Xiong, M.-Y. Kan, and W. Y. Wang, “Zero-shot fact verification by claim generation,” in Proceedings of ACL, 2021.
- [54] A. Soleimani, C. Monz, and M. Worring, “Bert for evidence retrieval and claim verification,” in Advances in Information Retrieval, 2020.
- [55] C. Kruengkrai, J. Yamagishi, and X. Wang, “A multi-level attention model for evidence-based fact checking,” in Proceedings of ACL Findings, 2021.
- [56] R. Pradeep, X. Ma, R. Nogueira, and J. Lin, “Scientific claim verification with VerT5erini,” in Proceedings of the 12th International Workshop on Health Text Mining and Information Analysis, 2021.
- [57] W. Xu, Q. Liu, S. Wu, and L. Wang, “Counterfactual debiasing for fact verification,” in Proceedings of ACL, 2023.
- [58] A. Krishna, S. Riedel, and A. Vlachos, “Proofver: Natural logic theorem proving for fact verification,” Trans. Assoc. Comput. Linguistics, 2022.
- [59] Z. Chen, S. C. Hui, F. Zhuang, L. Liao, F. Li, M. Jia, and J. Li, “Evidencenet: Evidence fusion network for fact verification,” in Proceedings of the ACM Web Conference 2022, 2022.
- [60] H. Wang, Y. Li, Z. Huang, and Y. Dou, “IMCI: Integrate multi-view contextual information for fact extraction and verification,” in Proceedings of COLING, 2022.
- [61] A. M. Barik, W. Hsu, and M. L. Lee, “Incorporating external knowledge for evidence-based fact verification,” in Companion Proceedings of the Web Conference 2022, 2022.
- [62] W. Zhong, J. Xu, D. Tang, Z. Xu, N. Duan, M. Zhou, J. Wang, and J. Yin, “Reasoning over semantic-level graph for fact checking,” in Proceedings of ACL, 2020.
- [63] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in Proceedings of ICLR, 2017.
- [64] Z. Ma, J. Li, G. Li, and Y. Cheng, “GLAF: global-to-local aggregation and fission network for semantic level fact verification,” in Proceedings of COLING, 2022.
- [65] C. Chen, F. Cai, X. Hu, J. Zheng, Y. Ling, and H. Chen, “An entity-graph based reasoning method for fact verification,” Information Processing & Management, no. 3, 2021.
- [66] K. Clark, M. Luong, Q. V. Le, and C. D. Manning, “ELECTRA: pre-training text encoders as discriminators rather than generators,” in Proceedings of ICLR, 2020.
- [67] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proceedings of NeurIPS, 2017.
- [68] K. Clark, U. Khandelwal, O. Levy, and C. D. Manning, “What does BERT look at? an analysis of BERT’s attention,” in Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, 2019.
- [69] S. Brody, U. Alon, and E. Yahav, “How attentive are graph attention networks?” in Proceedings of ICLR, 2021.
- [70] J. Thorne, A. Vlachos, C. Christodoulopoulos, and A. Mittal, “FEVER: a large-scale dataset for fact extraction and VERification,” in Proceedings of NAACL-HLT, 2018.
- [71] Z. Liu, C. Xiong, Z. Dai, S. Sun, M. Sun, and Z. Liu, “Adapting open domain fact extraction and verification to COVID-FACT through in-domain language modeling,” in Proceedings of EMNLP Findings, 2020.
- [72] D. Ye, Y. Lin, J. Du, Z. Liu, P. Li, M. Sun, and Z. Liu, “Coreferential Reasoning Learning for Language Representation,” in Proceedings of EMNLP, 2020.
- [73] M. Gardner, J. Grus, M. Neumann, O. Tafjord, P. Dasigi, N. F. Liu, M. Peters, M. Schmitz, and L. Zettlemoyer, “AllenNLP: A deep semantic natural language processing platform,” in Proceedings of Workshop for NLP Open Source Software (NLP-OSS), 2018.
- [74] S. Wang, Y. Liu, C. Wang, H. Luan, and M. Sun, “Improving back-translation with uncertainty-based confidence estimation,” in Proceedings of EMNLP, 2019.
- [75] M. Ott, M. Auli, D. Grangier, and M. Ranzato, “Analyzing uncertainty in neural machine translation,” in Proceedings of ICML, 2018.
- [76] J. Ni, G. Hernandez Abrego, N. Constant, J. Ma, K. Hall, D. Cer, and Y. Yang, “Sentence-t5: Scalable sentence encoders from pre-trained text-to-text models,” in Proceedings of ACL Findings, 2022.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/00ac9c48-cd9f-4976-a473-aff6baa97ea0/yuqinglan.jpg) |
Yuqing Lan received the M.S. degree in computer Application Technology from Northeastern University, China, in 2020. She is currently working toward her Ph.D. degree in the School of Computer Science and Engineering of Northeastern University. Her current research interests include fact verification. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/00ac9c48-cd9f-4976-a473-aff6baa97ea0/zhenghaoliu.jpg) |
Zhenghao Liu received the Ph.D. degree in computer science and technology from Tsinghua University, China, in 2021. He is currently an associate professor at Northeastern University, China. His current research interests include natural language processing and information retrieval. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/00ac9c48-cd9f-4976-a473-aff6baa97ea0/yugu.jpg) |
Yu Gu received the Ph.D. degree in computer software and theory from Northeastern University, China, in 2010. He is currently a professor at Northeastern University, China. His current research interests include big data processing and graph data management. He is a senior member of China Computer Federation (CCF). |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/00ac9c48-cd9f-4976-a473-aff6baa97ea0/yixiaoyuan.png) |
Xiaoyuan Yi received the Ph.D. degree in computer software and theory from Tsinghua University, China, in 2021. He is currently at Microsoft Research Asia, Beijing, China. His current research interests Natural Language Generation (NLG). |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/00ac9c48-cd9f-4976-a473-aff6baa97ea0/xiaohuali.jpg) |
Xiaohua Li received the Ph.D. degree in computer software and theory from Northeastern University, China, in 2018. She is currently an associate professor at Northeastern University, China. Her current research interests include information security and block chain. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/00ac9c48-cd9f-4976-a473-aff6baa97ea0/yang.png) |
Liner Yang received the Ph.D. degree in computer science from Tsinghua University, Beijing, China, in 2018. He is currently an associate professor at the National Language Resources Monitoring and Research Center for Print Media, Beijing Language and Culture University, Beijing, China. His current research interests include artificial intelligence, natural language processing, and NLP for educational applications. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/00ac9c48-cd9f-4976-a473-aff6baa97ea0/yuge.png) |
Ge Yu received the Ph.D. degree in computer science from the Kyushu University of Japan, in 1996. He is currently a professor at the Northeastern University of China. His research interests include distributed and parallel database, data integration, and graph data management. He is a fellow of CCF and a member of the IEEE and ACM |