Multi-agent reinforcement learning using echo-state network and its application to pedestrian dynamics
Abstract
In recent years, simulations of pedestrians using the multi-agent reinforcement learning (MARL) have been studied. This study considered the roads on a grid-world environment, and implemented pedestrians as MARL agents using an echo-state network and the least squares policy iteration method. Under this environment, the ability of these agents to learn to move forward by avoiding other agents was investigated. Specifically, we considered two types of tasks: the choice between a narrow direct route and a broad detour, and the bidirectional pedestrian flow in a corridor. The simulations results indicated that the learning was successful when the density of the agents was not that high.
1 Introduction
Motions of groups of people or animals have been studied in many fields such as transportation engineering and active matter physics. Comprehensively understanding such motions through only experiments and observations is challenging. Thus, several studies have conducted computer simulations for a better understanding. Traditionally, animals (including humans) are assumed to obey certain mathematical rules in these simulations[1, 2, 3]. However, with the recent development of machine learning, simulation methods that reproduce animals by agents of reinforcement learning (RL) have been proposed[4, 5, 6, 7, 8]. RL in an environment with several agents exist is referred to as multi-agent reinforcement learning (MARL), and has been studied intensively to realize the competition or cooperation between agents.
Currently, deep learning is usually used to implement RL agents, because it outperforms conventional methods of machine learning[9, 10, 11]. However, training of the deep learning incurs high computational costs even in the case of a single-agent RL. Thus, algorithms with lower computational costs are useful, particularly when considering numerous of agents.
This study proposed an RL algorithm using an echo-state network (ESN). ESN is a type of reservoir computing that uses recurrent neural networks (RNN) and trains only the output weight matrix. This restriction reduced the computational cost compared to that of deep learning, which trains all parameters of the neural network. Several methods have been proposed to implement RL using ESN[12, 13, 14, 15, 16]. Among these methods, this study adopted a method similar to, but simpler than that of Ref. [15]. As a specific task, we considered pedestrians proceeding along a road. All pedestrians were RL agents that received positive(negative) rewards when they travelled along the same(opposite) direction as their targeted direction. Although the task itself was simple, other agents were employed as the obstacles preventing each agent’s walking. Hence, the problem increased in complexity with increasing number of agents. We investigated whether the agents could proceed in the direction they wanted to by avoiding other agents.
2 Related work
2.1 Multi-agent reinforcement learning (MARL)
In environments with several agents, RL agents are required to cooperate or compete with other agents. Such environments appear in various fields, thus, MARL has been studied intensively[17]. In particular, methods of deep reinforcement learning (DRL) have been applied to MARL, as well as single-agent RL[19, 18, 20].
The simplest method to implement MARL is to allow the agents to learn their policies independently. However, independent learners cannot access the experiences of other agents, and consider other agents as a part of environment. This results in the non-stationarity of the environment from the perspective of each agent. To address this problem, many algorithms have been proposed. For example, the multi-agent deep deterministic policy gradient (MADDPG) algorithm adopts the actor-critic method, and allows the critic to observe all agents’ observations, actions, and target policies[27]. This algorithm was improved and applied to the pedestrian dynamics by Zheng and Liu[6]. Gupta et al. introduced a parameter sharing method wherein agents shared the parameters of their neural networks[22]. Their method exhibited high learning efficiency in environments with homogeneous agents.
This study adopted the parameter sharing method because it can be easily extended to a form suitable to ESN. Specifically, we considered one or two groups of agents that shared their experiences and policies but received rewards separately.
2.2 Echo-state network (ESN)
As mentioned earlier, ESN is a type of reservoir computing that uses RNN[23, 24, 25]:
| (1) | |||||
| (2) | |||||
| (5) |
where and are the input and output vectors at time , respectively, is the activation function, and is the constant called leaking rate. In the case of ESN, elements of matrices , , and are randomly fixed, and only the output weight matrix is trained. Through this restriction of the trainable parameters, the computational cost is considerably lowered compared with the deep learning. In addition, the exploding/vanishing gradient problem does not occur unlike the training of RNN using backpropagation. For example, in the case of supervised learning, training is typically conducted by the Ridge regression that minimizes the mean square error between the output vector and the training data . This calculation is considerably faster than the backpropagation used in the deep learning.
However, in the case of RL the training data should be collected by agents themselves. Hence, the training method is not as easy as in the case of the supervised learning. Many previous studies have proposed different algorithms to realize RL using ESN. For example, Szita et al. used the SARSA method[12], Oubbati et al. adopted ESN as a critic of the actor-critic method[13], Chang and Futagami used a covariance matrix adaptation evolution strategy (CMA-ES)[14], and Zhang et al. improved the least squares policy iteration (LSPI) method[15]. Previous studies have also utilized ESN to MARL. For example, Chang et al. trained ESN employing a method similar to that of a deep Q network(DQN), and applied it to the distribution of the radio spectra of telecommunication equipment[16]. In this study, we adopted the LSPI method, as in Ref. [15]; however, we used a simpler algorithm. Note that the absence of the exploding/vanishing gradient problem in the ESN comes from the point that the weight matrices involved in this problem are fixed. Hence, although the above-mentioned training algorithms including LSPI are more complex than those of supervised learning, such problem still does not appear.
Typically, the recurrent weight is a sparse matrix with spectral radius . To generate such a matrix, first, a random matrix must be created whose components are expressed as:
| (6) |
where is a predetermined probability distribution and is a hyperparameter called sparsity. Regularizing this matrix such that its spectral radius is expressed as , we obtain :
| (7) |
where is the spectral radius of . According to Ref. [24], the input weights and are usually generated as dense matrices. However, we also rendered them sparse, as has been explained later.
2.3 Least squares policy iteration (LSPI) method
The LSPI method is an RL algorithm that was proposed by Lagoudakis and Parr[26]. It approximates the state-action value function as the linear combination of given functions of and , :
| (8) |
where is the coefficient vector that is to be trained. Using this value, action of the agent at each time step is decided by the -greedy method:
| (9) |
where is the state at this step. Usually, is initially set as a relatively large value , and gradually decreases.
To search the appropriate policy, the LSPI method updates iteratively. Let the -th update be executed after the duration . Then the form of after the -th duration, , is expressed as:
| (10) |
where
| (11) | |||||
| (12) |
is the reward at this step, and is the discount factor. We let if the episode ends at time . The constant is a forgetting factor that is introduced because the contributions of old experiences collected under the old policy do not reflect the response of the environment under the present policy. This factor has also been adopted by previous studies such as Ref. [15].
3 Proposed method and settings of simulations
3.1 Application of ESN to the LSPI method
In this study, we considered the partially observable Markov decision process (POMDP), a process wherein each agent observed only a part of the state. As the input of the -th agent, we set its observation , the candidate of the action , and the bias term:
| (13) | |||||
| (14) | |||||
| (17) |
where is the one-hot expression of and activation function is ReLU. We expressed the number of neurons of the reservoir as , i.e. . The initial condition of reservoir was set as . We assumed that all agents shared the common input and reservoir matrices , , , and . For later convenience, , , and , that is, the parts of the input matrix are denoted separately. The action was decided by the -greedy method, Eq. (9), under this . Here, should be calculated for all possible candidate of action . Using the accepted action, is updated as follows:
| (18) |
In the actual calculation of Eq. (13), it is convenient to calculate for all candidates of action at once using the following relation:
| (19) | |||||
| (20) |
Here, is the number of candidates of the action, and is a matrix constructed by repeating the column vector, , -times. To derive the last line of Eq. (19), we should remind that is the one-hot expression:
| (21) |
Comparing Eqs. (8), (17) and (18), we can apply the LSPI method by substituting and . Thus, taking the transpose of Eq.(10), can be calculated by the following relation
| (22) |
where
| (23) | |||||
| (24) |
and
| (25) |
Here, we divided the agents into one or several groups, and let all members of the same group share their experiences when we calculated . In Eqs. (22), (23) and (24), indicates the group to which the -th agent belongs. In Eq. (23), we let if the episode ended at time , as in Section 2.3. The second term of the right-hand side of Eq. (23) was introduced to avoid the divergence of the inverse matrix of Eq. (22). The constant is a small hyperparameter, and is the identity matrix. As the duration , we adopted one episode in this study. In other words, the output weight matrix was updated at the end of each episode. The agents of the same group shared the common output weight matrix by Eq. (22). Considering that all agents had the same input and reservoir matrices, as explained above, agents of the same group shared all parameters of neural networks. Thus, this is a form of parameter sharing suitable for ESN. As mentioned in Section 2.2, Ref. [15] also applied LSPI method to train ESN. They calculated the output weight matrix using the recursive least squares(RLS) method to avoid the calculation of the inverse matrix of Eq. (22), which incurred a computational cost of . However, we did not adopt RLS method, because an additional approximation called mean-value approximation is required for this method. In addition, when each duration is long and the parameter sharing method is introduced, the effect of the computational cost mentioned above on the total computation time is limited.
In the actual calculation, we made the matrices
| (46) | |||
| (47) |
and
| (48) |
, and performed the operation
| (49) | |||||
| (50) |
at the end of each episode . Here, we used the fact that the reward after the end of the episode is zero: . However, the term should not be ignored. After this manipulation, we calculated using Eq. (22), multiplying forgetting factors to matrices and :
| (51) | |||||
| (52) |
and updated the value of used for the -greedy method as:
| (53) |
if was larger than the predetermined threshold value . Training is dependent on the information in past state, action, and reward only through Eqs. (49) and (50). Thus, matrices and can be deleted after the update of and using these equations. Note that, in principle, we can update and by adding the increments every time step even if we do not prepare matrices and . However, the number of calculations of large matrices multiplication should be reduced to lower the computational cost, at least when the calculation is implemented by Python. The algorithm explained above is summarized in Algorithm 1.
3.2 environment and observation of each agent
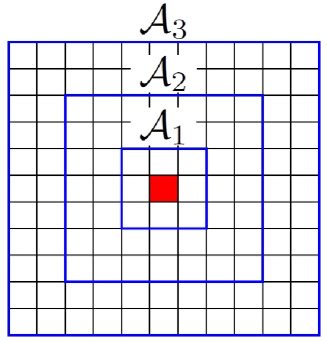
We constructed a grid-world environment wherein each cell could have three states: “vacant,” “wall,” and “occupied by an agent.” At each step, each agent chose one of the four adjacent cells: up, down, right, and left, and attempted to move into it. This move succeeded if and only if the candidate cell was vacant and no other agents attempted to move there. Each agent observed cells centering on the agent itself as 2-channel bitmap data. Here, agents including observer itself are indicated as pairs of numbers , walls are as , and vacant cells are as . Hence, the observation of -th agent, , was -dimensional vector. Although several previous studies have proposed a method that combined ESN with untrained convolutional neural networks when it is used for image recognition[14, 28, 29], we input the observation directly into ESN. Instead, we improved the sparsity of input weight matrix to reflect the spatial structure. Specifically, we first called the , , and cells centering on agent as , and respectively, as in Fig. 1. Then, we changed the sparsity of the components of depending on which cell they combined with. Namely, components of are generated as:
| (54) |
and the sparsity is expressed as follows:
| (55) |
where the hyperparameters , , and obey . Thus, information on cells near the agent combined with the reservoir more densely than that on cells far from the agent. Further, we let be a sparse matrix with sparsity , but made dense. In addition, was generated as a sparce matrix with its spectral radius , by the process explained in Section 2.2. Here, , , , and , the distribution of nonzero components of , , , and were expressed as gaussian functions , , , and , respectively. The list of hyperparameters are presented in Table 1.
| character | meaning | value |
|---|---|---|
| the number of neurons of the reservoir | 1024 | |
| leaking rate | 0.8 | |
| sparsity of corresponding to | 0.6 | |
| sparsity of corresponding to | 0.8 | |
| sparsity of corresponding to | 0.9 | |
| sparsity of | 0.9 | |
| sparsity of | 0.9 | |
| stantard deviation of | 1.0 | |
| stantard deviation of | 2.0 | |
| stantard deviation of | 1.0 | |
| stantard deviation of | 1.0 | |
| spectral radius of | 0.95 | |
| number of time steps during one episode | 500 | |
| discount factor | 0.95 | |
| initial value of | 1.0 | |
| decay rate of | 0.95 | |
| threshold value that stop decaying | 0.02 | |
| forgetting factor | 0.95 | |
| coefficient used for the initial value of |
As the specific tasks, we considered the following two situations, changing the number of agents, . Note that we did not execute any kinds of pretraining in the simulations.
3.2.1 Task. I : Choice between a narrow direct route and a broad detour
We first considered a forked road (Fig. 2), which was composed of a narrow direct route and a broad detour. The right and left edges were connected by the periodic boundary condition. In the initial state, agents were arranged in the checkerboard pattern on the part where the road was not forked, as shown in Fig. 3.

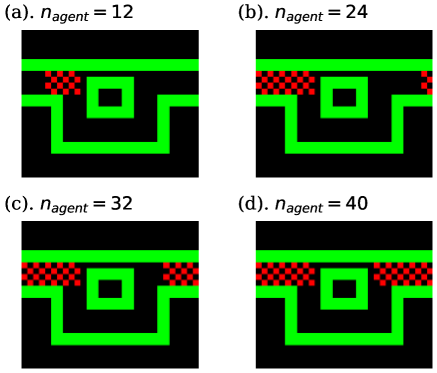
Here, the case wherein every agent attempted to go right was considered. Thus, we let the reward of -th agent, , be +1(-1) when it went right(left), and 0 otherwise. The number of groups was set as 1 because the aim of the agents was similar. Namely, all agents shared one policy, and all of their experiences were reflected in the update of , , and . The sharing of the experiences was realized only through Eqs. (22), (23), and (24), and the reward of each agent itself was not affected by those of other agents. In this environment, agents were believed to go through the direct route when they were not disturbed by other agents. However, if the number of agents increases and the road becomes crowded, limited number of agents can use the direct route, and others should choose the detour. We investigated whether the agents could learn this choice between two routes.
3.2.2 Task. II : Bidirectional pedestrian flow in a corridor
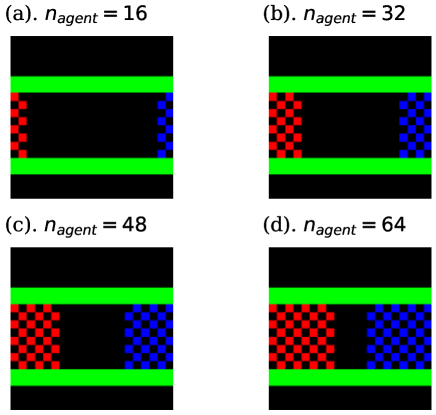
We next considered the case where two types of agents, those trying to go right and left, existed in a corridor with width 8 and length 20. As in the task. I, the right and left edges were connected by the periodic boundary condition, and the agents were arranged in the checkerboard pattern in the initial state, as shown in Fig. 4. Here, we divided the agents into two groups, those of the right and left-proceeding agents. The reward of the right-proceeding agent was the same as that of the previous case. Whereas, that of the left-proceeding agent was -1(+1) when it went right(left), and 0 otherwise. Note that the parameter sharing through Eq. (22) was executed only among the agents of the same group. In this case, agents should go through the corridor avoiding oppositely-proceeding agents. We investigated whether and how agents achieve this task.
4 Results
In this section, we present the results of the simulations explained in the previous section.
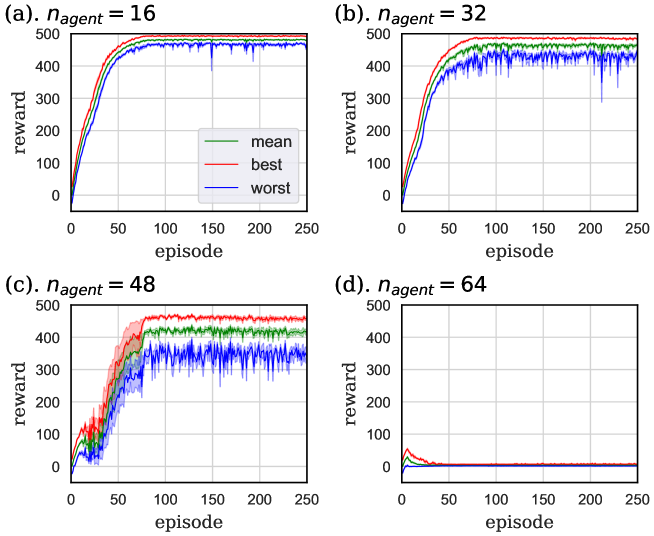
4.1 Performance in task. I
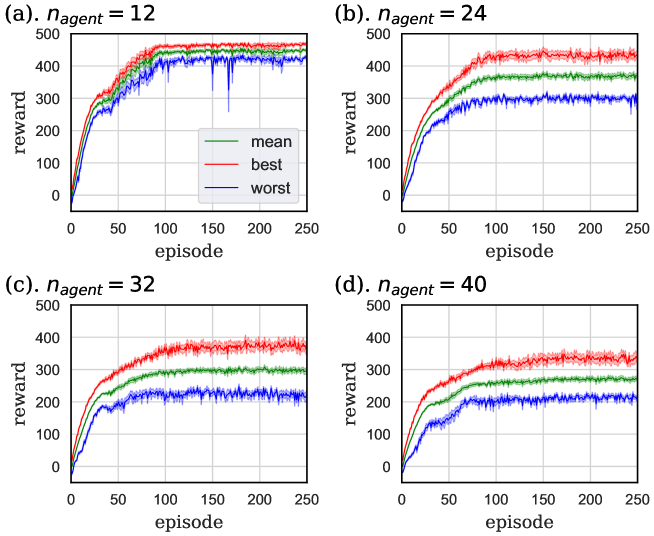
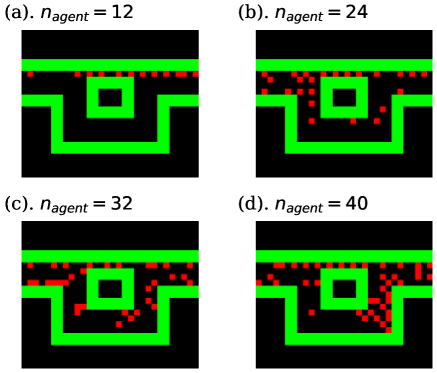
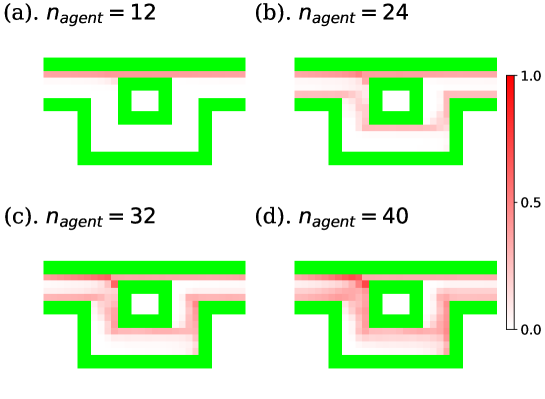
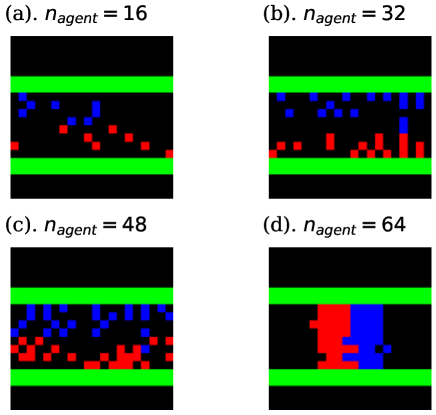
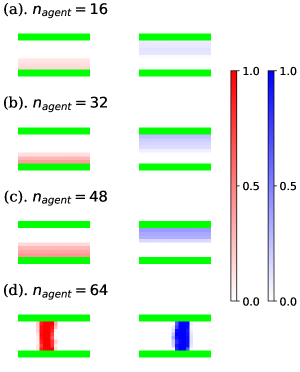
The learning curves of task. I are shown in Fig. 5. In these graphs, the green curve is the mean value of all agents’ rewards, and the red and blue curves indicate the rewards of the best and worst-performing agents. In each case, we executed 8 independent trials and averaged the values of the graphs, and painted the standard errors taken from these trials in pale colors. As shown in Fig. 5, the performance of each agent appeared to worsen with increasing . This is because each agent was prevented from proceeding by other agents. In the case that , the direct route was excessively crowded and certain agents had no choice but to go to the detour, as shown in snapshots and density colormaps in Figs. 6 and 7. (b)-(d). Thus, the difference in the performance between the best and worst agents increased compared to the case where . In addition, seeing the density colormaps of Fig. 7, some agents tend to get stuck in the bottom-right corner of the detour when is large. Considering that there is no benefit for agents in staying at this corner, it is thought to be the misjudgment resulting from the low information processing capacity of ESN.
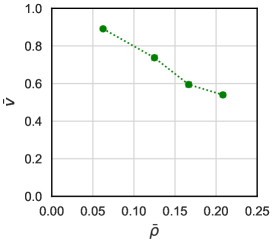
From the definition of reward in this study, the total reward that one agent gets during one episode is equal to the displacement along the direction it tries to go. Hence, the average velocity of agents, , can be calculated as
| (56) |
Note that the upper bound of this value is 1, which can be realized when all agents always proceed in the direction they want to. In addition, considering that simulations of this study impose the periodic boundary condition and the number of agents does not change, the average density is expressed as
| (57) |
Here, note that the phrase “the number of cells that agents can walk into” means the area that is not devided from agents by walls, and does not mean the number of cells that a certain agent can move into at a certain step. In the case of task. I, for example, this number can be counted as 192, by Fig. 2. Using these equations, we can plot the fundamental diagram[30], the graph that draw the relation between velocity and density , as Fig. 8. These data are averaged over the 151-250 episodes of 8 independent trials. In this graph, we estimated the error bars by calculating the standard error of the mean over 8 independent trials, but these error bars are smaller than the points. Seeing Fig. 8, has the value near its upper bound when is small, and gradually decreases with increasing . This decrease itself is observed in many situations of pedestrian dynamics. However, considering that agents get stuck in the corner under present calculation, the improvement of the algorithm and neural network is thought to be required before quantitative comparisons with previous studies.
4.2 Performance in task. II
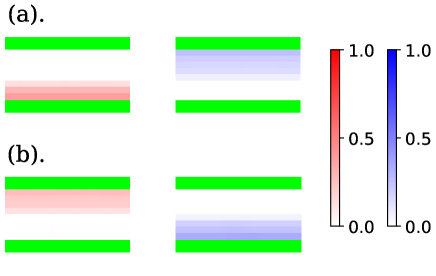
The learning curves of task. II are shown in Fig. 9. Here, as discussed in Section 4.1, we averaged the values of the rewards over 8 independent trials, and painted the standard errors among these trials in pale colors. According to Fig. 9, the training itself was successful except when . The corresponding snapshots and density colormaps shown in Figs. 10 and 11 show that in the case of , agents of the same group created lanes and avoided collisions with agents in the opposite direction. Such lane formation was also observed in various previous studies that used mathematical models[2], experiments[21, 31, 32], and other types of RL agents [4, 8]. Note that the lanes had different shapes depending on the seed of random values, i.e. the right-proceeding agents walked on the upper side of the corridor in some trials, and on the lower side in others, for example. Hence, the colormap of Fig. 11 indicates the time average of one representative trial. To show the dependency on the random seed, we also drew the colormaps of the case that with different seeds as Fig. 12.
When , two groups of agents failed to learn how to avoid each other and collided. In this case, each agent cannot move forward after the collision, and the reward they obtained was limited to that for the first few steps. Note that in this task, each agent cannot access the experiences of agents of the other group. Thus, thinking from the perspective of MARL, there is a possibility that the non-stationarity of the environment (in the viewpoint of agents) worsened the learning efficiency, as with the case of the independent learners. However, from the perspective of soft matter physics, this stagnation of the movement under high density resembles the jamming transition observed in wide range of granular or active matters[3, 33, 34, 35]. Nevertheless, to investigate whether it is really related with the jamming transition, simulations with larger scale are required.
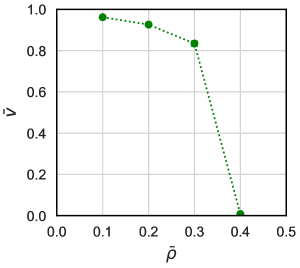
As in task. I, we can plot the fundamental diagram shown in Fig. 13 using Eqs. (56) and (57). This graph shows the sudden decrease of the average velocity between and 64 (i.e. and 0.4), reflecting the stagnation of the movement discussed above. Similar behavior is also reported in previous researches that considered the jamming transition in mathematical models of pedestrians[3].
4.3 Comparison with independent learners
As explained in Section 3.1, we adopted the parameter sharing method in our calculations. In this section, we calculate the two tasks discussed above considering the case that the parameter sharing was not adopted, and compare the results with those of previous sections to investigate the effect of this method. Specifically, equations
| (58) |
| (59) | |||||
and
| (60) |
were used to calculate in this section. Thus, each agent learned independently. To observe the effect of replacing Eq.(22) by Eq.(58), input and reservoir weight matrices, , , , and , were still shared by all agents, and the hyperparameters were the same as listed in Table 1.
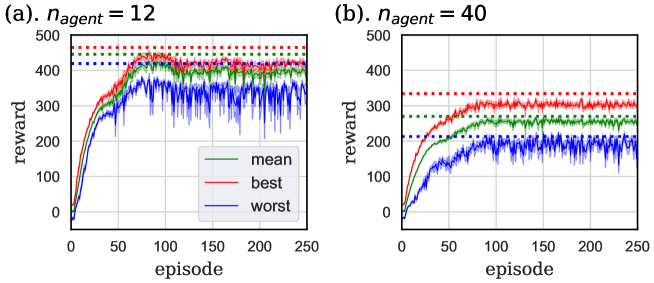
The learning curves of tasks. I and II are shown in Figs. 14 and 15, respectively. In these graphs, scores when using the parameter sharing method averaged over the 151–250 episodes of 8 independent trials are drawn as the dotted lines. A comparison of the learning curves with these dotted lines revealed that the performance when the parameter sharing was not used was almost the same as or slightly lower than that under the parameter sharing. Hence, the parameter sharing method did not result in the drastic improvement of the learning. The advantage of this method is rather the reduction in the number of inverse matrix calculations, at least in the case of our tasks. We actually calculated the case of task. II under , but did not plot the graph because agents failed to make lanes like the case of Section 4.2.
4.4 Comparison with the case that two groups share the parameters in task. II
As we explained in Section 3.2.2, in the case of task. II, we divided the pedestrians into two groups by the direction they want to proceed in. Here, the training of each group was executed independently. However, we can also implement the MARL agents even in the case that the parameters of neural networks are shared between two groups. Specifically, we first define a two-dimensional one-hot vector or , which represents the information on each agent’s group. Adding this vector to agents’ observation and modifying eq. (13) as follows:
| (61) |
the learning process can be executed even if parameters are shared between two groups. To share the parameters, equations
| (62) |
| (63) | |||||
and
| (64) |
are used to calculate , instead of eqs. (22), (23), and (24). Here, we let , the input weight matrix corresponding to , be a dense matrix, and used the same standard deviation as . Namely, the distribution of each component of is . In this section, we investigate whether this method work. The hyperparameters themselves were the same as listed in Table 1.
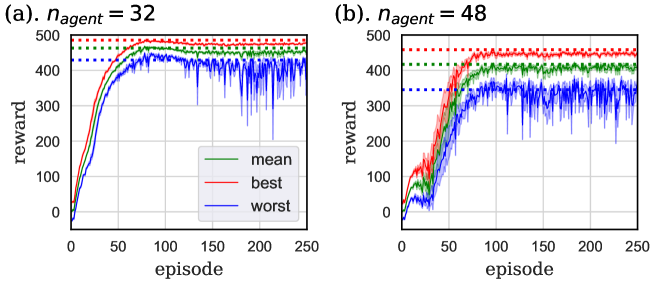
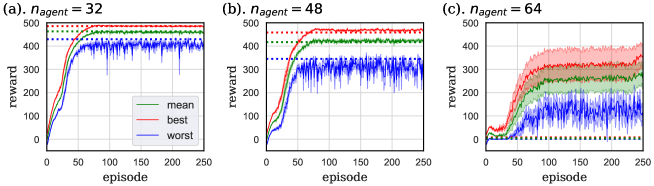
The result is shown in Fig. 16. In this figure, the dotted lines are the scores of Section 4.2, the case that two groups do not share their parameters, averaged over the 151–250 episodes of 8 independent trials. Seeing Fig. 16 (a) and (b), in the case that and 48, the parameter sharing between two groups slightly improved or hardly changed the mean and best scores compared with those under the training without parameter sharing between different groups, whereas the worst score was lowered. It is thought that the additional information, , led to the confusion of the neural network and wrong action choice, especially under subtle situations that is difficult to evaluate . The result under shown in Fig. 16 (c) is interesting. As we saw in Section 4.2, agents that did not share their parameters between different groups failed to learn to make lanes in all trials in this case. However, agents of this section succeeded in making lanes in some trials. We can think two possible factors that cause this difference. One is the number of agents choosing wrong actions. Blockage of agents in this task is caused when they learn wrong strategy that “go straight and earn rewards for first few steps”, before they learn to make lanes. As we discussed above, agents of this section are thought to be sometimes confused by the additional information, . Even if agents learn the wrong strategy, blockage is eased compared with that of Section 4.2 because such “confused” agents do not simply go straight. The other possible factor is the sharing of the experience. Agents of this section share the experience between different groups by the parameter sharing, whereas those of Section 4.2 share it only among the same group. This experience sharing is thought to promote the efficient learning of correct strategy that “agents of different groups should go to different lanes”. It is difficult to identify which of these two factors plays the significant role, only by this task.
4.5 Comparison with deep reinforcement learning (DRL) algorithms
In this section, we calculated the same tasks using representative DRL algorithms, DQN[9], advantage actor-critic(A2C)[10], and proximal policy optimization (PPO)[11] methods, and compare the performance with our algorithm. In these calculations, we prepared the neural network with the same size as the reservoir of our ESN, i.e., the network has 1 hidden layer (of perceptron) with 1024 neurons. Each agent observed 2-channel bitmap data with cells centering on itself and agents of the same group shared the experience by parameter sharing, as in our algorithm. Parameter sharing between different groups like Section 4.4 is not introduced. Note that in the A2C and PPO methods, actor- and critic-networks shared the parameters except for the output weight matrices.
As the optimizer, we adopted Adam[36]. The codes were implemented using Pytorch (torch 2.2.0), and we used the default values of this library for the initial distribution of the parameters of neural network and the hyperparameters of the optimizer except for the learning rate. The parameters related to environment or reward, such as and , were the same as our method. In addition, we used the same value of as our method for DQN. Other hyperparameters used for this section are listed in Table 2. Here, the learning rate for PPO was set smaller than those of other methods except the cases of task II. with and 64 to stabilize the learning. In addition, we let the minibatch size of DQN for task II. with and 64 larger than other tasks. The reason why we let these tasks be the exception is explained later.
| meaning | value |
|---|---|
| learning rate for DQN | for task II. with |
| otherwise | |
| learning rate for A2C | |
| learning rate for PPO | for task II. with |
| for task II. with | |
| otherwise | |
| replay-memory size for DQN | |
| minibatch size for DQN | 1024 for task II. with |
| 64 otherwise | |
| number of steps between updates of network for A2C | 5 |
| number of steps between updates of network for PPO | 125 |
| replay-memory size for PPO | 500 |
| minibatch size for PPO | 125 |
| number of epochs for PPO | 4 |
| value-loss coefficient for A2C and PPO | 0.5 |
| entropy coefficient for A2C and PPO | 0.01 |
| clipping value for PPO | 0.2 |
| for PPO | 0.95 |
| maximum gradient norm for DQN and A2C | 50 |
| maximum gradient norm for PPO | 1 |
The result is shown in Figs. 17 and 18. Here we plotted the mean value of all agents’ rewards for each algorithm, and all graphs are averaged over 8 independent trials. Seeing this figures, performance of our method on easy tasks, i.e. task. I with and task. II with resembles that of DQN, and slightly worse than the policy gradient methods. In addition, the learning speed of ours is slower than these methods. These points are thought to result from the -greedy method, which decreases gradually and keeps this constant larger than the threshold value, . However, the performance on the task. I with is explicitly worse than all DRL algorithms. As we discussed in Sec. 4.1, the low information processing capacity of ESN is thought to be the cause of this phenomenon.
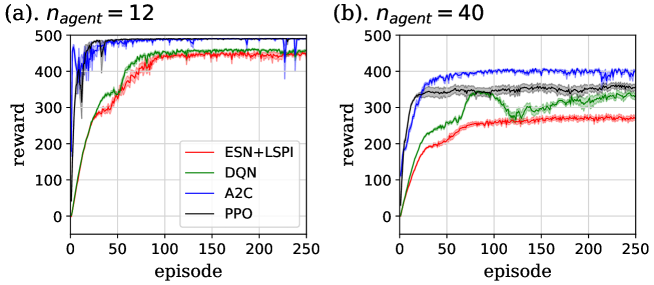
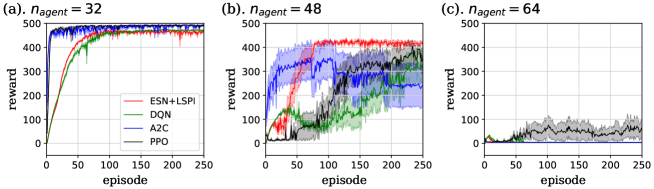
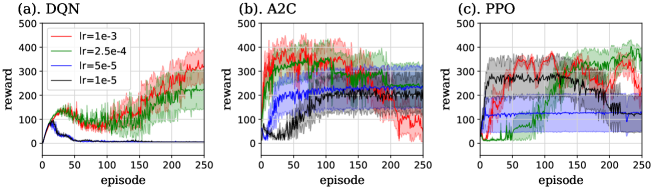
In task. II with , the performance of DRL methods were worse than our method. It is because DRL methods failed to learn to make lanes and stagnated in some trials, whereas our method succeeded in learning in all trials. In this task, we investigated the performance of each DRL method for four values of the learning rate, , , and , because it was possible that choice of appropriate hyperparameter led to improve the learning. The result is shown in Fig. 19. As we can see from this figure, stagnation happened in almost all learning rates of every method. Note that the case of PPO with succeeded in learning to make lanes in every trial exceptionally, however, of this case was so large that the learning became unstable. In Fig. 18 (b), we chose the learning rate for DQN (the red curve of Fig. 19 (a)), and for A2C and PPO (the green curves of Fig. 19 (b) and (c)), because these values seemed to perform better than other values in each method. We actually executed the similar calculation for DQN in the case that minibatch size is 64, the same size used for other tasks. However, all trials for each of four learning rate failed to learn to make lanes in this case. Hence we increased the minibatch size to improve the sampling efficiency. The similar investigation was also executed for the case of task. II with , i.e. we calculated the performance of each DRL method for four learning rates for this case. However, in this case, only PPO with succeeded or began to secceed in making lanes in some trials, while the other methods and other learning rates failed in all trials.
It is difficult to interpret the result of task. II because there are many unknown points on the algorithm combining ESN and LSPI method. One possibility is that agents choosing wrong actions cause the unclogging, as we discussed in Section 4.4. Indeed, ESN has lower information processing capacity and choose the wrong action more frequently than DRL methods, as we saw in task. I with . This point is thought to led to the unclogging and final success in learning under . In addition, PPO with , which succeeded in making lanes in all trials of and some trials of , has unstable learning curves because of large learning rate, as we explained above. It is thought that such unstable behavior of agents also results in the unclogging. The other possible factor of the success of our method under is that sampling efficiency of the LSPI method is higher than the gradient descent method, because it utilizes all experiences gathered by agents completely by the linear regression. However, our method failed in making lanes under , and the performance of this case was reversed by that of PPO with . Considering this point, effects of the above mentioned two factors on the final performance are thought to be complex. Hence, these effects should be studied also in other RL tasks we did not consider.
We also measured the computational time of whole simulation in task. I at and 12 for each method, and summarize the result in Table 3 (a). The calculation was executed by a laptop equipped with 12th Gen Intel(R) Core(TM) i9-12900H, and application software other than resident one was closed during the measurement of time. The real computational time for each simulation shown in Table 3 (a) includes the time spent on the calculation not related to the neural network, such as updating of the environment. Hence, to evaluate the computational cost of the calculation on the neural network including both training and forward propagation, we calculated the computational time of the case when agents choose their action randomly, and showed the difference of each simulation from this case in Table 3 (b). Here, in the random-action case, the neural network itself was not implemented. According to this table, computational cost of our method is less than half of that of each DRL method in both cases of and 12. However, as for the difference of time between these two cases, which corresponds to increase in computational time due to increase in agents, DQN with its minibatch size 64 is better than other methods and our method is second to this. This is because the time spent for the calculation of backpropagation for DQN under fixed minibatch size does not depend on , whereas minibatch size for A2C, replay-memory size for PPO, and the size of matrices used in our method, , and given by eqs. (47) and (48), are all proportional to . Considering the possibility that fixing minibatch size of DQN results in the worsening of sampling efficiency, we cannot say that DQN is more efficient algorithm than ours under a large number of agents, only from Table 3 (b). Indeed, in the case of difficult tasks such as task. II with , we should increase the minibatch size for DQN at the cost of the computational time, as we explained above. Hence, the computational cost of our method under large is lower than those of DRL methods, whose sampling efficiency do not reduce as increases.
| (a). real computational time | |||
| method | difference | ||
| ESN+LSPI | 52.14(8) | 420(7) | 368(7) |
| DQN (minibatch size ) | 715(7) | 898(5) | 183(9) |
| DQN (minibatch size ) | 2645(4) | 4215(9) | 1570(10) |
| A2C | 202(2) | 1159(1) | 958(2) |
| PPO | 164(1) | 1301(21) | 1137(21) |
| random action | 1.516(6) | 11.1(2) | 9.6(2) |
| (b). difference from the random-action case | |||
|---|---|---|---|
| method | difference | ||
| ESN+LSPI | 50.62(8) | 409(7) | 358(7) |
| DQN (minibatch size ) | 713(7) | 886(5) | 173(9) |
| DQN (minibatch size ) | 2643(4) | 4204(9) | 1560(10) |
| A2C | 200(2) | 1148(1) | 948(2) |
| PPO | 163(1) | 1290(21) | 1127(21) |
5 Summary
In this study, we implemented MARL using ESN, and applied it to a simulation of pedestrian dynamics. The LSPI method was utilized to calculate the output weight matrix of the reservoir. As the environment, the grid-world composed of vacant space and walls was considered, and several agents were placed in it. Specifically, we investigated two types of tasks: I. a forked road composed of a narrow direct route and a broad detour, and II. a corridor where two groups of agents proceeded in the opposite directions. The simulations confirmed that the agents could learn to move forward by avoiding other agents, provided the density of the agents was not that high.
In this study, we considered the case wherein the number of agents were at most 64. However, hundreds of agents are required for the simulations of real roads, intersections, or evacuation routes. Furthermore, to investigate certain phenomena such as the jamming transition mentioned in Section 4.2, larger number of agents should be considered. Using deep learning, implementing such numerous RL agents may result in the enormous computational complexity. Hence, it is expected that reservoir computing including ESN, which can reflect agents’ experiences efficiently with comparatively low computational cost, can be utilized to execute these studies in future. Note that RL-based methods including ours require time for training, compared with the traditional pedestrian simulations where agents obey the previously given rules. However, these methods have advantage that agents can automatically learn the appropriate actions without complex rule settings. In this study, for example, agents learned to avoid obstacles such as other agents without introducing repulsive forces or additional rewards for avoiding itself. Hence, the proposed method is thought to be useful in complex tasks such as the evacuation route flittered with obstacles. In addition, we believe that this method is applicable not only to the case of the pedestrian dynamics, but also to other behaviors of animal groups such as competition for food and territories.
Along with such applied studies, the improvement in the performance of reservoir computing itself is also important. Presently, the performance of reservoir computing tends to be poor under difficult tasks because of its low information processing capacity. For example, in image recognition, reservoir computing-based approaches exhibit low accuracy rates at CIFAR-10, although they succeed in recognizing simpler tasks such as MNIST[25, 29]. In this context, in the case of the video games that use images as input data, reservoir computing-based RL has yielded only a few successful examples[14]. In our study, we observed lower performance than DRL methods in some tasks, as we saw in Sec. 4.5. In addition, considering that the learning speed under -greedy method is limited by the value of , we should study effective algorithms for exploration so that we can decrease this value fast. However, as we discussed in Sec. 4.5, it is possible that our method has advantages not only in computational cost but also in other points such as sampling efficiency, compared to DRL ones. Hence, if the disadvantages mentioned above is improved in the future studies, MARL-based simulations of group behaviors of humans or animals will be further promoted.
In addition, whether the parameter sharing between different groups like Section 4.4 improve the sampling efficiency remains to be unknown. This point should also be studied in the future works, to improve the performance of MARL itself.
The source code for this work is uploaded to https://github.com/Hisato-Komatsu/MARL_ESN_pedestrian.
Acknowledgements
We would like to thank Editage for English language editing.
References
References
- [1] Vicsek T, Czirók A, Ben-Jacob E, Cohen I, and Shochet O, 1995 Phys. Rev. Lett. 75(6) 1226
- [2] Helbing D and Molnar P, 1995 Phys. Rev. E 51(5) 4282
- [3] Muramatsu M, Irie T, and Nagatani T, 1999 Physica A 267(3-4) 487-498
- [4] Martinez-Gil F, Lozano M, and Fernández F, 2014 Simul. Model. Pract. Theory 47 259-275
- [5] Martinez-Gil F, Lozano M, and Fernández F, 2017 Simul. Model. Pract. Theory 74 117-133
- [6] Zheng S and Liu H, 2019 IEEE Access 7 147755–147770
- [7] Bahamid A and Ibrahim A M, 2022 Neural Comput. Applic. 34 21641–21655
- [8] Huang Z, Liang R, Xiao Y, Fang Z, Li X, and Ye R, 2023 Physica A 625 129011
- [9] Mnih V, Kavukcuoglu K, Silver D, Rusu A A, Veness J, Bellemare M G, Graves A, Riedmiller M, Fidjeland A K, Ostrovski G, Petersen S, Beattie C, Sadik A, Antonoglou I, King H, Kumaran D, Wierstra D, Legg S, and Hassabis D, 2015 Nature 518 529-533
- [10] Mnih V, Badia A P, Mirza M, Graves A, Lillicrap T, Harley T, Silver D, and Kavukcuoglu K, 2016 In International conference on machine learning, vol. 48, (pp. 1928-1937) PMLR.
- [11] Schulman J, Wolski F, Dhariwal P, A Radford A, Klimov O, 2017 arXiv preprint, arXiv:1707.06347
- [12] Szita I, Gyenes V, and Lörincz A, 2006 In International Conference on Artificial Neural Networks, (pp.830-839)
- [13] Oubbati M, Kächele M, Koprinkova-Hristova P, and Palm G, 2011 In European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning , (pp. 117-122)
- [14] Chang H, and Futagami K, 2020 Appl. Intell. 50 2400-2410.
- [15] Zhang C, Liu C, Song Q, and Zhao J, 2021 In 4th International Conference on Artificial Intelligence and Big Data (ICAIBD), (pp. 104-108) IEEE.
- [16] Chang H H, Song H, Yi Y, Zhang J, He H, and Liu L, 2018 IEEE Internet Things J. 6(2) 1938-1948
- [17] Buşoniu L, Babuška R, and De Schutter B, 2008 IEEE Trans. Syst. Man Cybern. Part C 38(2) 156-172
- [18] Gronauer S., and Diepold K. (2022). Artif. Intell. Rev. 55 895-943.
- [19] Du W, and Ding S, 2021 Artif. Intell. Rev. 54 3215–3238
- [20] Oroojlooy A, and Hajinezhad D, 2023 Appl. Intell. 53 13677–13722
- [21] Feliciani C and Nishinari K, 2016 Phys. Rev. E 94(3) 032304.
- [22] Gupta J K, Egorov M, and Kochenderfer M, 2017 In Autonomous Agents and Multiagent Systems, (pp. 66-83)
- [23] Jaeger H, 2001 GMD Technical Report 148
- [24] Lukoševičius M, 2012 In Neural Networks: Tricks of the Trade, (pp. 659–686), Springer Berlin, Heidelberg.
- [25] Zhang H and Vargas D V, 2023 IEEE Access 11 81033-81070.
- [26] Lagoudakis M G, and Parr R, 2003 J. Mach. Learn. Res. 4 1107-1149.
- [27] Lowe R, Wu Y, Tamar A, Harb J, Abbeel P, and Mordatch I, 2017 In Advances in neural information processing systems, (pp. 6379-6390)
- [28] Tong Z and Tanaka G, 2018 In 2018 24th International Conference on Pattern Recognition (ICPR), (pp. 1289–1294). IEEE
- [29] Tanaka Y and Tamukoh H, 2022 Nonlinear Theory and Its Applications, IEICE, 13(2) 397–402
- [30] Seyfried A, Steffen B, Klingsch W, and Boltes M, 2005 J. Stat. Mech. P10002
- [31] Kretz T, Grünebohm A, Kaufman M, Mazur F, and Schreckenberg M, 2006 J. Stat. Mech. P10001
- [32] Murakami H, Feliciani C, Nishiyama Y, and Nishinari K, 2021 Sci. Adv. 7(12) eabe7758
- [33] O’Hern C S, Silbert L E, Liu A J, and Nagel S R, 2003 Phys. Rev. E 68(1) 011306
- [34] Majmudar T S, Sperl M Luding S, and Behringer R P, 2007 Phys. Rev. Lett. 98(5) 058001
- [35] Henkes S, Fily Y, and Marchetti M C, 2011 Phys. Rev. E 84(4) 040301
- [36] Kingma D P and Ba J, 2014 arXiv preprint, arXiv:1412.6980