Multi-Adversarial Safety Analysis for Autonomous Vehicles
Abstract
This work in progress considers reachability-based safety analysis in the domain of autonomous driving in multi-agent systems. We formulate the safety problem for a car following scenario as a differential game and study how different modelling strategies yield very different behaviors regardless of the validity of the strategies in other scenarios. Given the nature of real-life driving scenarios, we propose a modeling strategy in our formulation that accounts for subtle interactions between agents, and compare its Hamiltonian results to other baselines. Our formulation encourages reduction of conservativeness in Hamilton-Jacobi safety analysis to provide better safety guarantees during navigation.
I Introduction
If autonomous vehicles are to serve as traffic management systems [5], safe navigation around human vehicles on highways and in cities is crucial. However, safe navigation can be difficult to provide because a lot of uncertainty exists in real driving scenarios that complicate the driving problem. Typically, Hamilton-Jacobi reachability analysis (HJI) can be used to find safe strategies around unknown components of a dynamical system [1]. In previous work, researchers develop [2] a framework to protect a system against one known source of uncertainty using Hamilton-Jacobi reachability, with the goal of protecting the system from the worst-case scenario. However, in real driving scenarios, it may be necessary to consider multiple sources of uncertainty. As depicted in figure 1 and 2, extreme worst-case scenarios may never provide a feasible safety strategy, and it may be the case that establishing safety is impossible.
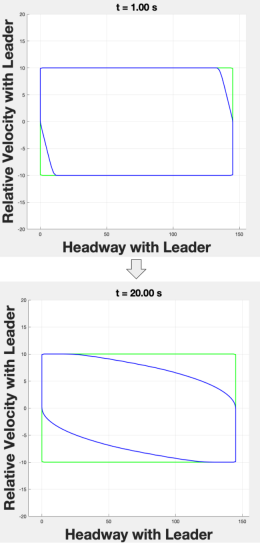


Therefore, in this work, we study the reduction of conservativeness in Hamilton-Jacobi safety analysis by introducing structure into some or all of the human models. Specifically, we study a modeling strategy around the second disturbance that takes advantage of the structure of human behavior in a way that allows us to use differential game theory in more dense dynamic driving environments.
II System dynamics
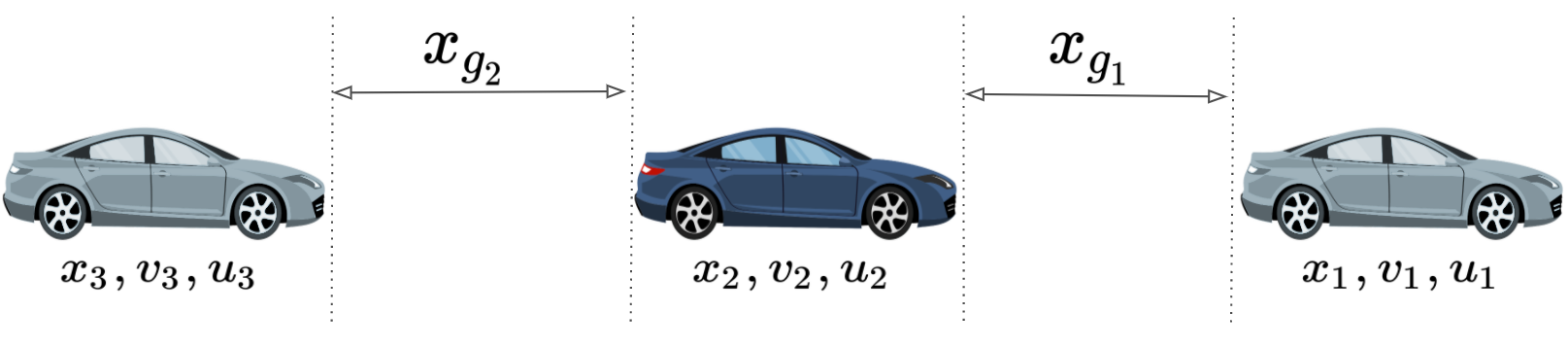
We consider a dynamical system with state , and three inputs, , , , which we refer to as the controls, disturbance 1, and disturbance 2 respectively. Our system dynamics are generally defined as:
| (1) |
Disturbance 1 and 2 represent the uncertainty around the leading and following human vehicle respectively. In our car following scenario in figure 3, the goal for the autonomous agent is to establish safety and remain in between the other two players given their actions. Thus, the dynamics between all three vehicles can be described using their relative position , relative speed , and relative accelerations as in the following:
| (2) |
s.t.
In the next section, Section III, we discuss how we choose our uncertainty and how we pose our safety problem.
III Three-Player Differential Game
The safety problem is posed as a differential game between three players, where the system controller, , plays against two adversaries, and , also known as the system’s uncertainty. To obtain a safe policy for the system, we chose a function, , that assigns a safety value to the current state, z and formulate a game whose outcome is given by the function . assigns each initial state z and player strategies , , , the lowest value of ever achieved by a trajectory from state z.
| (3) |
The goal of system is to maximize the objective, while the goal of the active adversaries is to minimize the objective. Thus, the game formulation that we want to solve is111Technically, as in [3], we restrict each disturbance to a set of nonanticipative strategies. Therefore, and in eq. 4 are actually maps, and , that respectively maps our control input to their corresponding disturbance input.:
| (4) |
III-A Player Strategies
We formulate uncertainties and around the two human driving actions, for example and , to represent behavioral properties that are trying to perturb the autonomous system. More specifically:
-
1.
First, we consider a baseline assignment:
-
•
where
-
•
where
-
•
-
2.
Then, we consider an alternative assignment for by taking advantage of the structure of human driving and modeling using a car following model :
-
•
where
-
•
-
•
In our second strategy, uses psycho-physiological characteristics in human driving as an alternative modeling strategy [4]. Additionally, we ensure that the values of are within realistic bounds given all possible autonomous agent’s actions . This modelling strategy relaxes unrealistic extremities of the previous dynamic game formulation and implicitly models interaction effects between agents for realistic safety. We model the following vehicle’s driving behavior using the Intelligent Driver’s car following model and explicitly model as safe-reaction time, T, as follows:
| (5) |
| (6) |
where:
: safe reaction-time
: desired headway of the following vehicle
: minimum desired headway (ie. to allow crashes)
: maximum acceleration and deceleration respectively
: acceleration exponent (usually 4) and desired velocity respectively
III-B Resulting policies
The optimal control strategy, , and the optimal disturbance strategy for the first human vehicle, are calculated from (4) using the Hamiltonian numerics to be:
| (7) |
| (8) |
and the optimal disturbance strategy for the second human vehicle is likewise calculated to be:
| (9) |
| (10) |
where: = and = .
IV Results and Conclusion
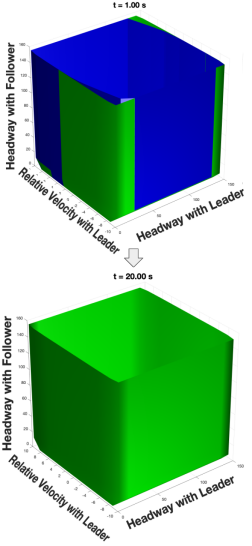
As depicted in figure 4, the alternative formulation for the second disturbance is able to uncover hidden safe strategies for the 3-car scenario. Setting the disturbance and control bounds to [-1.5, 1.5] and [-2, 2] respectively, the baseline produces an empty blue set, meaning there are no guaranteed safe states for the simulation with this particular disturbance/control setting. However, by taking advantage of psycho-physiological characteristics and driver influences on the road, we discover that a non-empty blue set does exist.
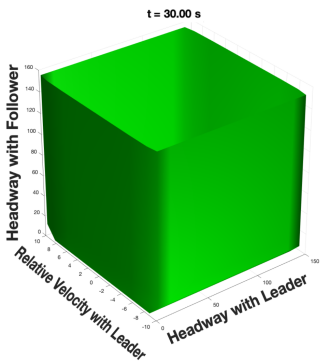
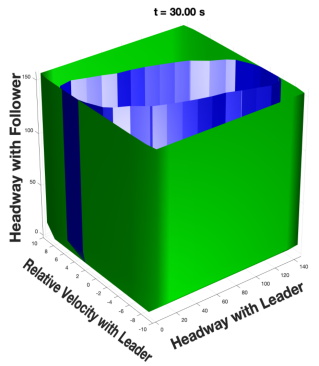
In conclusion, when considering worst-case uncertainty in human driving, if we are to guarantee safety in the chaotic world of driving, we may need to incorporate better information structures of human behavior in our analysis and update our assumptions as we uncover more knowledge about the system. However, by choosing a specific model structure to reduce conservativeness of reachability analysis, we run the risk of not being able to capture human behavior some of the time due to the limitations of our chosen model ( which serves to capture only approximations). The performance of a chosen model will vary greatly depending on the particular type of driver and circumstance. Therefore, to tackle this trade-off, we further aim to incorporate real-time analysis and data-driven models to learn disturbances (and how they accurately evolve), and maintain formal and robust safety guarantees using different learning strategies such as deep reinforcement learning.
Acknowledgments
This material is based upon work supported by the U.S. Department of Energy’s Office of Energy Efficiency and Renewable Energy (EERE) under the Vehicle Technologies Office award number CID DE-EE0008872. The views expressed herein do not necessarily represent the views of the U.S. Department of Energy or the United States Government.
References
- Bansal et al. [2017] Somil Bansal, Mo Chen, Sylvia Herbert, and Claire J Tomlin. Hamilton-jacobi reachability: A brief overview and recent advances. In 2017 IEEE 56th Annual Conference on Decision and Control (CDC), pages 2242–2253. IEEE, 2017.
- Fisac et al. [2018] Jaime F Fisac, Anayo K Akametalu, Melanie N Zeilinger, Shahab Kaynama, Jeremy Gillula, and Claire J Tomlin. A general safety framework for learning-based control in uncertain robotic systems. IEEE Transactions on Automatic Control, 64(7):2737–2752, 2018.
- Mitchell and Templeton [2005] Ian M Mitchell and Jeremy A Templeton. A toolbox of hamilton-jacobi solvers for analysis of nondeterministic continuous and hybrid systems. In International Workshop on Hybrid Systems: Computation and Control, pages 480–494. Springer, 2005.
- Treiber and Thiemann [2013] M. Treiber and C. Thiemann. Traffic Flow Dynamics: Data, Models and Simulation. Springer-Verlag Berlin Heidelberg, Berlin, Germany, 2013.
- Wu et al. [2017] Cathy Wu, Aboudy Kreidieh, Kanaad Parvate, Eugene Vinitsky, and Alexandre M Bayen. Flow: Architecture and benchmarking for reinforcement learning in traffic control. arXiv preprint arXiv:1710.05465, 2017.