MSAC-SERNet: A Reliable Unified Framework for Speaker-Independent Speech Emotion Recognition
Abstract
Despite notable progress, speech emotion recognition (SER) remains challenging due to the intricate and ambiguous nature of speech emotion, particularly in wild world. While current studies primarily focus on recognition and generalization abilities, our research pioneers an investigation into the reliability of SER methods in the presence of semantic data shifts and explores how to exert fine-grained control over various attributes inherent in speech signals to enhance speech emotion modeling. In this paper, we first introduce MSAC-SERNet, a novel unified SER framework capable of simultaneously handling both single-corpus and cross-corpus SER. Specifically, concentrating exclusively on the speech emotion attribute, a novel CNN-based SER model is presented to extract discriminative emotional representations, guided by additive margin softmax loss. Considering information overlap between various speech attributes, we propose a novel learning paradigm based on correlations of different speech attributes, termed Multiple Speech Attribute Control (MSAC), which empowers the proposed SER model to simultaneously capture fine-grained emotion-related features while mitigating the negative impact of emotion-agnostic representations. Furthermore, we make a first attempt to examine the reliability of the MSAC-SERNet framework using out-of-distribution detection methods. Experiments on both single-corpus and cross-corpus SER scenarios indicate that MSAC-SERNet not only consistently outperforms the baseline in all aspects, but achieves superior performance compared to state-of-the-art SER approaches.
Index Terms:
Speech emotion recognition, affective computing, multiple speech attribute control, reliability analysis, out-of-distribution detectionI Introduction
Human emotion, intricately woven from the threads of personal connections, environmental stimuli, and cognitive processes, stands as a captivating and complex facet of the human experience [1]. As a powerful catalyst, emotions not only steer human behavior but also weave their essence into the fabric of daily interactions and professional endeavors [2]. It is within this nuanced context that the fusion of emotion and technology takes center stage, giving rise to the significant field of speech emotion recognition (SER), of which primary goal is to automatically discern emotional states within spoken communication. Given the potential to profoundly impact both human well-being and technological advancements, SER plays a crucial role in diverse practical applications, such as human machine interaction [3], healthcare [4], education [5], business [6], and so forth.
In the realm of SER, diverse speech signals from speakers of different regions and recording environments usually exhibit distinct characteristics, yet there exists implicit similar emotional information within the same emotion category, as pointed out in [7]. Consequently, the fundamental challenge in SER lies in acknowledging the inherent variability within signals while identifying the intrinsic emotional representations in these information sources, aiming to construct robust models for prediction.
Under such scenarios, how to train an effective and robust classifier for SER based on these signals has been a subject of research for over two decades. Early studies usually focus on single-corpus tasks, where models were developed and evaluated within the confines of a singular emotion corpus. These approaches emphasize improving the discrimination of hand-crafted features [8, 9, 10], which are then input into conventional machine learning algorithms like support vector machine (SVM) [11, 12], decision trees [12, 13], or Bayesian classifiers [14]. In recent years, with the remarkable development of machine learning and deep learning technology, deep neural network (DNN) based methods, such as Long Short-term Memory (LSTM) [15, 16, 17], Recurrent Neural Network (RNN) [18, 19], Convolution Neural Network (CNN) [20, 21, 22], and others [23, 24, 25, 26, 27], have become the mainstream approach in SER. Benefiting from the robust feature learning capability of DNNs, the performance of these methods has undergone a significant enhancement compared to traditional approaches. Afterwards, researchers progressively shifted their attention towards cross-corpus SER tasks, which involve training SER models using one or more public datasets and then evaluating their recognition capabilities and generalization performance with unseen emotional corpora. These methods often prioritize paradigmatic design, typically integrating the comprehensive utilization of diverse speech attributes within the signal. For instance, Xiao et al [28] presented a generalized domain adversarial neural network (GDANN) and a class-aligned GDANN to learn domain-invariant representations for robust emotion recognition. Latif et al [22] introduced an adversarial dual discriminator (ADDi) network and a self-supervised learning based ADDi network to address the performance degradation of the cross-corpus and cross-language SER. Yu et al [25] advocated a gender-attribute-augmented contrastive language-audio pretraining SER framework with the guidance of natural language supervisions to identify emotions.
Nevertheless, notwithstanding impressive advancements, these approaches still have several limitations, and the SER task remains open and challenging.
-
•
First, there is limited research attention directed towards simultaneously addressing single-corpus and cross-corpus SER tasks [29], whereas the demand for such capabilities is imperative in complex real-world applications.
-
•
Second, despite numerous recent studies [30, 31, 28, 32, 22, 33, 34, 25] aiming to enhance the SER performance through the incorporation of various additional speech attributes (gender, speaker, language, etc) via adaptive or adversarial domain adaptation methods, correlations among different speech attributes are often overlooked. For instance, the commonly used voiceprint/speaker attribute based gradient reversal control method, while partially mitigating the speaker bias issue in SER [12, 35, 36], also impairs gender attribute information in the speech signal. However, according to many literature [33, 34, 25], gender attributes undoubtedly provide useful information for speech emotion classification.
-
•
Third, in comparison to other domains like computer vision (CV) [37, 38, 39], natural language processing (NLP) [40, 41, 42], or even tasks within speech processing such as automatic speech recognition [43, 44, 45], it is noteworthy that there is a scarcity of publicly available benchmarks for SER, with the majority being of a relatively modest scale. In this context, the trained SER methods will inevitably encounter unseen or unfamiliar data when deployed in the open world, thus placing high demands on the reliability of the SER methods. However, current SER field largely focuses on the approaches’ recognition and generalization performance, while ignoring the reliability performance which is of great importance in real-world applications, such as medical diagnosis, legal assistance, security monitoring, and so on.
Hence in this study, we pioneer an investigation into the reliability of SER methods in the presence of semantic data shifts, and introduce a novel unified SER workflow termed MSAC-SERNet that is able to simultaneously address both single-corpus and cross-corpus SER tasks. Our primary focus is on intricately modeling speech emotion by exercising precise control over diverse speech attributes. In summary, the main contributions of this paper are four-fold.
-
•
First, from the perspective of merely modeling speech emotion, a novel convolution neural network (CNN) based SER model is constructed, whose architecture is shown in Fig. 1. To ensure the discriminability of the acquired features, we design several modules such as shallow feature extraction with different receptive fields, deep feature extraction, and aggregation pooling. Besides, we adopt additive margin softmax (AM-Softmax) [46] loss to train the proposed SER model end-to-end, so as to alleviate issues of inter-class similarity and intra-class difference of emotion categories.
-
•
Second, considering the redundancy of various attributes in speech signals, we propose MSAC (multiple speech attribute control), a novel learning paradigm that can explicitly control different speech attributes, enabling the proposed SER model to be less affected by emotion-agnostic speech attributes and better capture nuanced emotion-associated representations. In this way, our proposed unified SER workflow MSAC-SERNet could enhance its overall performance.
-
•
Third, four state-of-the-art (SOTA) out-of-distribution (OOD) detection method, i.e., ODIN [47], Ma_Distance [48], MaxLogit [49], and ReACT [50] are employed to examine the reliability of our proposed SER models under both single-corpus and cross-corpus SER settings. Besides, we also propose a simple OOD detection method rODIN (reverse ODIN), which achieves the best results under both single and cross corpus SER settings. To the best of our knowledge, this is the first work to evaluate and analyze the reliability performance of SER methods in the presence of semantic data shifts.
-
•
Fourth, we conduct comprehensive experiments on both single-corpus and cross-corpus SER tasks, employing six public speech emotion corpora. The results illustrate that our proposed MSAC-SERNet attains superior performance in comparison to SOTA SER approaches across both single-corpus and cross-corpus SER scenarios. Notably, it consistently outperforms the baseline model in all facets within the speaker-independent mode.

The rest of this work is arranged as the following. In Section II, we provide the overview of related work. Section III describes the details of the proposed MSAC-SERNet which mainly consists of three parts, as depicted in Fig 1. In Section IV, we introduce the corresponding experimental settings, results, and analysis of the single-corpus and cross-corpus SER tasks. Section VI draws the conclusions.
II Related Work
In this section, we briefly present the related work for the speaker-dependent and speaker-independent SER, adversarial domain adaption, and out-of-distribution (OOD) detection for better legibility.
II-A Speaker-dependent and Speaker-independent SER
Current SER field can be categorized into speaker-dependent SER [51, 16, 52] and speaker-independent SER [18, 35, 53, 25] on the basis of whether the same speaker is utilized during both the training and testing phases.
In general, the former relies on training and testing data from the same or partially overlapping set of speakers, emphasizing the recognition of individualized emotional nuances. In [51], features extracted using a hybrid of pitch, formants, MFCC, and their statistical parameters were input into an SVM classifier. In [16], a 1D CNN LSTM network and a 2D CNN LSTM network were designed to capture local and global features for SER. Despite achieving great recognition results, when it comes to the speaker-independent SER task that is more analogous to real-world scenarios, their performance tends to exhibit significant degradation. The primary reason for this lies in the fact that individuals exhibit varying rhythms, tones, and styles when speaking. Even when expressing the same emotion, such as happiness in their utterances, the differences can be substantial. However, speaker-dependent SER methods, in their model design and training stages, have not taken this into account.
As a consequence, an increasing number of recent works have shifted their focus towards the speaker-independent SER task. In contrast, the speaker-independent SER task poses a more intricate challenge, as it not only requires accurate differentiation of diverse speech emotions but also demands the resolution or alleviation of feature distribution variations introduced by different speakers during training and testing phases. To solve this problem, numerous studies have been advocated. For example, [18] proposed an attention-based convolutional recurrent neural network to extract discriminative reprsentations for emotion recognition using Mel-spectrogram with deltas and delta-deltas. In [35], the authors presented a speaker normalization method based on the pre-trained HuBERT features for SER.
II-B Adversarial Domain Adaptation
The generalization of SER systems is particularly crucial within the SER domain, because it delineates the systems’ viability for deployment in real-world contexts.
Therefore, as one of the promising means to enhance the generalisation performance, adversarial domain adaptation (ADA) approaches [30, 31, 28, 32, 22] have gained much attention. Holistically, existing ADA approaches aim to enhance the performance of the SER methods by controlling various speech attributes of the speech signal via techniques such as multi-task learning, adversarial learning, and so on. For instance, Xiao et al [28] presented a generalized domain adversarial neural network (GDANN) and a class-aligned GDANN to learn the domain-invariant feature representations for robust emotion recognition. Latif et al [22] introduced an adversarial dual discriminator (ADDi) network and a self-supervised learning based ADDi network to address the performance degradation of the cross-corpus and cross-language SER. Ahn et al [32] proposed a few-shot learning and unsupervised domain adaptation based SER model, aiming to acquire emotion similarity by leveraging source samples adapted to the target domain.
Nonetheless, despite improved performance, they usually neglect the interconnections among various speech attributes. In contrast, our study endeavors to augment speech emotion modeling through a holistic consideration of the interrelationships among diverse speech attributes.
II-C Out-of-distribution Detection
With continuously deployment of deep learning techniques in practical applications, their reliability has become a growing concern, especially in the safety-critical and security-critical scenarios [54].
Hence, as one of fundamental tasks for ensuring the reliability of DNN-based systems, out-of-distribution (OoD) detection has attract the attention of numerous researchers. Generally speaking, OOD detection aims to enable the model to distinguish between known in-distribution (ID) samples and unseen OOD samples, while not changing the original architecture [55, 56]. Most of them [57, 58, 50, 49] will not compromise the original capabilities of the model, except for those attempting to establish better calibrated OOD models early in the training phase [59, 60]. At present, research on OOD detection predominantly concentrates on the fields of CV [57, 58, 59, 50, 49] and NLP [61, 62, 63, 64]. On the contrary, there is relatively limited research on OOD detection in the domain of speech processing, with the existing studies primarily centered around the speech recognition task [65, 66, 67].
III Methodology
This section delineates the detailed configuration of the proposed unified SER framework, MSAC-SERNet. Comprising three integral components, namely the input pipeline, the proposed SER model, and the MSAC learning paradigm, Fig. 1 illustrates the overall architecture. Further details about each component will be elaborated below.
III-A Input Pipeline
In contrast to prevalent SER methods that typically use MFCCs, we choose to utilize FilterBank features (FBanks) extracted from speech signals as input for the proposed MSAC-SERNet workflow. Because we believe that, compared to MFCCs, FBanks possess higher information density and pay greater attention to frequency energy, making them potentially more suitable for SER tasks. To be specific, all speech signals undergo normalization within the range of -1 to 1. Subsequently, we apply the framing operation and a Hamming window to segment each speech signal into frames with a length of 25ms and a shift of 10ms. Finally, we obtain the FBanks for each frame through a 1024-point fast Fourier transform and a mel-scale filter bank analysis.
III-B Discriminative Feature Extraction
Instinctively, the feature extraction component holds a pivotal role in the design of speech emotion modeling, since the quality of the acquired features pose an important impact on the final performance. In consequence, we design two shallow and deep feature extraction modules.
Specifically, we first designed three parallel convolution modules, each incorporating diverse receptive field sizes. This strategic design aims to guarantee the comprehensive utilization of spatial and temporal information inherent in the input Fbanks by the model. To be explicit, these three convolution modules are composed of parallel convolution layers with kernel sizes of 1, 3, and 1. Following this convolutional operation, one batch normalization (BN) and one rectified linear unit (ReLU) activation layers are applied. The resulting features undergo the concatenation operation and an additional convolution layer with a 5 kernel, followed by a downsampling operation through an average pooling layer.
Subsequently, in order to further augment the representational capacity and discriminability of shallow features, we additionally constructed a deep feature extraction module which consists of multiple convolution blocks. Its specific architecture is shown in Table. I.
| block name | kernel_size | channel_in | channel_out |
|---|---|---|---|
| conv block1 | 5 | 96 | 32 |
| 3 | 32 | 32 | |
| conv block2 | 3 | 32 | 64 |
| 1 | 64 | 64 | |
| conv block3 | 3 | 64 | 128 |
| 1 | 128 | 128 | |
| conv block4 | 3 | 128 | 256 |
| 1 | 256 | 256 | |
| conv block5 | 3 | 256 | 256 |
| 1 | 256 | 256 |
III-C Aggregation Pooling
After capturing the emotional feature representations, we constructed an aggregation pooling component based on statistical information, so as to eliminate the influence of time dimension features on the final emotion classification.

To be concrete, considering the importance of the variation and energy of speech signals for emotion recognition, we first extract and concatenate the mean and standard deviation of the temporal dimension within the emotional features . Then, a linear projection module which consists of two blocks is built to better leverage the above captured features. As illustrated in Fig. 2, each block contains one fully connected layer, one BN layer, and one LeakyReLU layer.
III-D Loss Function
Normally, SER methods employ cross-entropy loss for model training, whereas we contend that this approach is prone to inducing emotional confusion.
To mitigate this concern, we choose to adopt the additive margin softmax (AM-Softmax) loss to optimize our MSAC-SERNet, instead of employing conventional regularization methods like label smoothing. By doing so, the proposed SER model s able to enlarge the distance between different classes and minimize the distance within the same category.
| (1) |
| (2) |
where represents the final loss of the emotion attribute, and indicate the feature vector and label of the th sample, is the feature vector of class , denotes the angle between and , N denotes the batch size, s is the scaling factor, m is the additive margin. In our case, m and s are set as 0.2 and 30.
III-E Multiple Speech Attribute Control Method
Existing studies [68, 69, 70] have demonstrated the intricate challenge of decoupling speech signals, highlighting the inevitable overlap among different speech attributes. In this context, numerous researchers [30, 35, 22] have endeavored to enhance SER performance through the incorporation of attribute-based ADA methods. Nevertheless, we contend that their performance still falls short of optimal, as they predominantly utilize diverse speech attributes without adequately considering their interrelationships. To solve this issue, a novel and effective MSAC method that explicitly models and controls different speech attributes is proposed, as shown in Fig. 3.
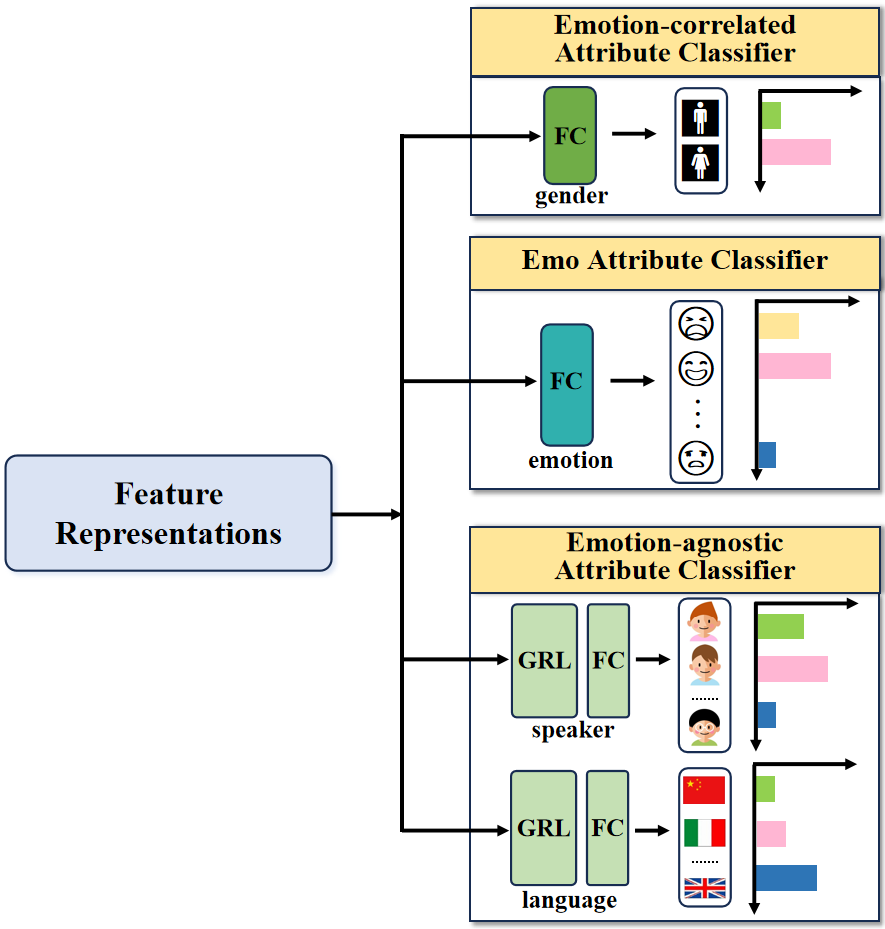
Unlike previous works, our proposed MSAC models speech emotion attribute based on correlations across additional speech attributes, aiming to simultaneously capture fine-grained emotion-related representations while mitigating the negative impact of emotion-agnostic features. More precisely, our proposed MSAC method first classifies different speech attributes into emotion, emotion-agnostic and emotion-correlated attributes. The speaker and language speech attributes are regarded as emotion-agnostic speech attributes, because they share fewer acoustic properties with the emotion attribute. In contrast, the gender attribute is an emotion-correlated speech attribute, as male and female speech signals usually exhibit substantial differences in energy, pitch, and other acoustic characteristics which are of great importance for SER. Then, for emotions and emotion-associated attributes, we employ a multi-task learning strategy to preserve valuable information for emotion identification, guided by the AM-Softmax loss. Meanwhile, regarding emotion-agnostic speech attributes, we not only utilize the multi-task learning strategy but also employ gradient reversal [30] which transmits data during forward propagation and reverses the sign of the gradient during backward propagation, thereby mitigating their influence on the emotion attribute. Moreover, it is essential to point out that all of these speech attributes should be optimized together since they are mutually influenced.
Therefore, the final classification loss can be formulated as follows:
| (3) |
| (4) |
| (5) |
where , , and are AM-Softmax classification loss of emotion-agnostic, emotion-correlated, and emotion attributes, and are emotion-agnostic attribute and its weight coefficient, and are emotion-correlated attribute and its weight coefficient, and represent the number of used emotion-agnostic and emotion-correlated attributes. Regarding the values for these hyper-parameters, please refer to the experiment section.
As a consequence, the proposed SER model using MSAC is capable of extracting more discriminative emotional feature representations, thus improving its overall performance.
IV Experimental Databases And Setup
In this section, the used experimental datasets for the single-corpus and cross-corpus SER tasks are first introduced. Then, the detailed configurations of all experiments are given. Last, we describe the overall experimental results and analysis.
IV-A Dtatbases
To verify the effectiveness of our proposed unified SER workflow, we totally use seven public speech emotion corpora and perform extensive experiments on both single-corpus and cross-corpus SER tasks. Details of these datasets are as follows:
-
1.
IEMOCAP [71]: IEMOCAP is a key resource in the realm of SER, consists of 12 hours of multimodal data featuring 10 performers. Across five sessions, both male and female actors participate in scripted and improvised scenes, providing transcriptions, speech waveforms, and visual frames for comprehensive analysis. IEMOCAP offers diverse emotional expressions, including angry, happy, sad, surprise, fear, disgust, neutral, frustration, and excitement. All speech signals are sampled at a rate of 16 kHz with 16-bit resolution.
-
2.
EMO-DB [72]: EMO-DB is a significant German emotional database which comprises 10 speakers delivering 535 utterances in the German language, totaling 25 minutes of audio. EMO-DB is characterized by 7 emotions which are angry, boredom, disgust, fear, happy, neutral, sad.
-
3.
EMOVO [73]: EMOVO, an Italian emotional dataset, features 6 speakers (3 males and 3 females), presenting 588 utterances at a 48 kHz sampling rate. This corpus encompasses 7 emotions, which are angry, disgust, joy, fear, sad, neutral, and surprise.
-
4.
CASIA [74]: CASIA, a Chinese emotion corpus, showcases recordings from four professional speakers (2 male and 2 female), portraying six emotions: angry, happy, fear, sad, surprise, and neutral. The dataset comprises 1,200 public sentences, sampled at a rate of 16 kHz.
-
5.
RAVDESS [75]: RAVDESS, the Ryerson Audio Visual Database of Emotional Speech and Song, encompasses 24 speakers delivering 2542 English utterances. The corpus has total 2 hours and 47 minutes of audio, with 8 emotions: happy, sad, angry, fear, surprise, disgust, calm, and neutral.
-
6.
TESS [76]: TESS, the Toronto Emotional Speech Set, comprises two actors (one male and one female), presenting 2800 English emotional utterances. This dataset, amounting to 1 hour and 36 minutes of audio, encompasses seven emotions: angry, disgust, joy, fear, sad, neutral, and happy.
To be explicit, in single-corpus SER, we first select the most challenging IEMOCAP corpus. To make fair comparisons, we likewise select four classes (happy + excited, angry, sad, and neutral) to evaluate the recognition performance of the proposed SER workflow. The remaining three classes (frustrated, fear, and surprised) are chosen to test the reliability performance of the proposed MSAC-SERNet. For a comprehensive comparison, we also choose EMO-DB to evaluate MSAC-SERNet’s recognition performance due to its widespread utilization.
As for the cross-corpus SER task, five classes (happy, angry, sad, fear, and neural) of five gender-balanced corpora (EMO-DB, EMOVO, IEMOCAP, CASIA, and RAVDESS) are employed to verify the recognition performance of the proposed SER method, while their remaining classes are utilized to examine the reliability performance of the proposed MSAC-SERNet. In terms of the generalization performance, the same five emotion classes of one unseen corpus TESS are chosen.
IV-B Implementation Details
In all experiments, AdamW [77] is adopted to optimize all models with an initial learning rate of 0.001 and a batch size of 64, and they are all trained for 100 epochs. Besides, SpecAugment [78] is applied to input Fbanks with a frequency mask width of 2 as well as a time mask width of 30 frames.
Concerning the best configurations of weight coefficients, we set =0.5, =0.3, =0.2 for IEMOCAP, =0.85, =0.1, =0.05 for EMODB, and =0.5, =0.15, =0.2, =0.15 for cross-corpus SER.
For a fair comparison with SOTA SER methods, we adopt the standard 10-fold speaker-independent cross-validation in the single-corpus SER task, which is the same as existing studies [79, 80, 81, 82]. As for the cross-corpus SER task, the holdout speaker-independent cross-validation is employed. Concretely, two randomly selected speakers from each experimental datasets of cross-corpus SER are respectively employed as the valid and test sets, while the remaining data of each datasets is utilized as the training set.
IV-C Evaluation Metrics
Different metrics are used to validate the recognition, generalization, and reliability performance of the proposed SER workflow.
To be precise, the weighted average recall (WAR) and unweighted average recall (UAR) are employed to evaluate the recognition and generalization performance. In terms of the reliability performance, the false positive rate at 95% true positive rate (FPR95) and Area Under the Receiver Operating Characteristic curve (AUROC) are adopted.
V Experimental Results And Discussion
V-A Comparison With Existing Works
V-A1 Single-corpus SER Task
To demonstrate the effectiveness of our proposed unified SER workflow MSAC-SERNet, we first compare its recognition performance with recent SOTA SER methods on the IEMOCAP and EMO-DB datasets. The results are shown in Table II and Table III.
| Algorithms | Year | UAR | WAR |
|---|---|---|---|
| CNN+Bi-GRU [79] | 2020 | 71.72 | 70.39 |
| SPU-MSCNN [80] | 2021 | 68.40 | 66.60 |
| Light-SERNet [20] | 2022 | 70.76 | 70.23 |
| ISNet [82] | 2022 | 70.43 | 65.02 |
| CMRN [81] | 2022 | 66.64 | - |
| SS-AAE [83] | 2022 | 66.70 | - |
| Dual-TBNet [17] | 2023 | 64.80 | - |
| Ours | 2023 | 71.76 | 72.97 |
| Algorithms | Year | UAR | WAR |
|---|---|---|---|
| SGMM-HMM [84] | 2019 | 90.48 | 88.25 |
| CNN-FA [80] | 2021 | 83.30 | 82.10 |
| DIFL [36] | 2022 | 89.72 | 88.49 |
| CMRN [81] | 2022 | 92.51 | - |
| Dual-TBNet [17] | 2023 | 84.10 | - |
| TFPE-SVM [1] | 2023 | 85.60 | - |
| RH-emo+Quat [24] | 2023 | 73.00 | 65.64 |
| CNN-CasA-Tri [85] | 2023 | 91.58 | 88.76 |
| Ours | 2023 | 92.11 | 93.21 |
From Table II and Table III, it can be easily seen that our proposed MSAC-SERNet achieves the best recognition performance among other SOTA methods. To be exact, MSAC-SERNet obtains the best WAR of 72.97% and UAR of 71.76% on IEMOCAP, and acquire the best WAR of 93.21% and secondary best UAR of 92.11% on EMO-DB, respectively. These achievements are attained through the fine-grained modeling of the emotion attribute present in speech signals. On one hand, our proposed MSAC learning paradigm takes into account the intricate interplay among diverse speech attributes, which enables the extraction of feature representations that encompass emotional information from speech signals to the fullest extent possible. On the other hand, the designed SER model not only captures discriminative features from speech signals, but extends the inter-class distance between different emotion categories while decreasing the intra-class distance within the same emotion category.
V-A2 Cross-corpus SER Task
For a fair comparison with other approaches, we present existing learning paradigms that share a similar conceptual framework as outlined in this paper, along with their respective performance metrics in Table IV.
| Models | Year | ID Recognition | OOD Generalization | |
| WAR | UAR | WAR/UAR | ||
| Base | 2023 | 44.64 | 44.42 | 54.25 |
| Base+GMT[33] | 2019 | 48.95 | 48.27 | 52.05 |
| Base+TAP[35] | 2022 | 49.22 | 46.98 | 57.55 |
| Base+AGR[86] | 2022 | 49.68 | 48.83 | 47.15 |
| Base+AMTL[86] | 2022 | 52.98 | 52.39 | 54.75 |
| Ours (Base+MSAC) | 2023 | 55.18 | 53.67 | 70.00 |
From Table IV, it is evident that our proposed MSAC consistently achieves the best ID recognition and OOD generalization results.
-
•
Concerning ID recognition performance, our base SER model achieves a WAR of 44.64% and a UAR of 44.42%. When incorporating recent learning paradigms [33, 35, 86], their WAR and UAR are all improved. Among them, AMTL demonstrated superior performance, with a 8.34% increase in WAR and a 7.97% increase in UAR. In comparison, our proposed MSAC achieves the best ID recognition performance, with absolute improvements of 10.54% WAR and 9.25% UAR.
-
•
In terms of the OOD generalization performance, the proposed SER base model attains a WAR/UAR of 54.25%. When using other speech attributes as auxiliary task, GMT and AGR exhibit lower performance compared to the proposed base model, while TAP and AMTL demonstrate slight performance enhancements.
V-B Ablation Study
To comprehensively assess and analyze the validity of our proposed MSAC-SERNet and its components, more detailed ablation study is performed.
V-B1 Single-corpus SER Task
We first compare the recognition performance of our MSAC-SERNet and its variants on IEMOCAP and EMODB within single-corpus SER, as presented in Table V and Table VI.
| Models | ID Recognition | |
|---|---|---|
| WAR | UAR | |
| Base | 68.40 | 68.42 |
| Base+ | 69.23 | 68.33 |
| Base+ | 69.02 | 68.10 |
| Ours (Base+MSAC) | 72.97 | 71.76 |
| Models | ID Recognition | |
|---|---|---|
| WAR | UAR | |
| Base | 85.71 | 80.48 |
| Base+ | 88.57 | 83.33 |
| Base+ | 87.76 | 87.25 |
| Ours (Base+MSAC) | 92.11 | 93.21 |
We can easily observe that with the increase of additional speech control, the ID recognition performance of the SER mdoel is gradually enhanced. The rationale behind this trend stems from the reasonable and stringent constraints imposed by learning paradigms, allowing the model to incorporate more useful information from diverse speech attributes. This approach, to some extent, facilitates the effective acquisition of speech emotion information, leading to an overall enhancement in the model’s performance. Besides, as evident from the tables above, the results clearly demonstrate the superior performance of our proposed MSAC over existing learning

paradigm such as [86]. This superiority is attributed to the fact that our MSAC is modeled based on the relationships among diverse speech attributes, representing a more rational approach that enables the capture of finer-grained emotional feature representation.
To scrutinize the recognition performance of each category, we further present the confusion matrices for MSAC-SERNet and its variants on IEMOCAP in Fig. 4, where ANG, SAD, HAP, NEU represent angry, sad, happy, and neutral. It illustrates that our proposed MSAC-SERNet gains a comparable or higher recognition accuracy for each emotion than its variants, which validates the effectiveness of the proposed SER model architecture and MSAC learning paradigm.
V-B2 Cross-corpus SER Task
Moreover, We also test the recognition and generalization performance of our proposed MSAC-SERNet and its variants in the cross-corpus SER task.
| Models | ID Recognition | OOD Generalization | |
| WAR | UAR | WAR/UAR | |
| Base | 44.64 | 44.42 | 54.25 |
| Base+ | 49.22 | 46.98 | 57.55 |
| Base+ | 48.95 | 48.27 | 52.05 |
| Base+ | 47.20 | 46.47 | 56.10 |
| Base++ | 51.24 | 52.87 | 58.35 |
| Base++ | 49.95 | 48.74 | 56.05 |
| Base++ | 51.24 | 50.74 | 53.65 |
| Ours (Base+MSAC) | 55.18 | 53.67 | 70.00 |
As illustrated in Table VII, it can be ascertained that the proposed MSAC-SERNet also consistently achieves the best performance in terms of ID recognition and OOD generalization performance, which further validates the effectiveness of the proposed unified SER workflow.
Concretely, in terms of the ID recognition and OOD generalization performance, our proposed SER model achieves a ID WAR of 44.64%, a ID UAR of 44.42%, and a OOD WAR/UAR of 54.25%, respectively. Then, when applying the commonly used ADA method which could enable the model to be less affected by the emotion-agnostic speaker attribute, the WAR and UAR of the model’s ID recognition performance are improved by 4.58% and 2.56%, the WAR/UAR of the model’s OOD generalization performance is improved by 3.3%. Afterward, when adding stragegy on top of SGR, the model is able to reduce the negative impact of the speaker attribute while retaining the useful emotion-correlated gender attribute information for SER. As a result, the WAR and UAR of ID recognition performance are further enhanced by 2.02% and 5.89%, the WAR/UAR of OOD generalization performance is further improved by 0.8% as well. In particular, when using our proposed MSAC method which simultaneously controls all known emotion-agnostic and emotion-correlated speech attributes, the proposed SER model achieves the best ID recognition and OOD generalization performance which outperforms the baseline by 8.61%, 9.29% and 7.35%, respectively.
V-C Reliability Comparison And Analysis
In recent years, as AI models continue to showcase substantial potential across diverse practical domains, their reliability has garnered significant attention. In this context, we initiate a preliminary analysis of the reliability of SER models when facing semantic data shifts. To be specific, we use four SOTA OOD detection methods and propose one simple OOD detection method rODIN which is a variant of ODIN, so as to verify the reliability performance of our MSAC-SERNet.
V-C1 Single-corpus SER Task
First, we compare the reliability of the proposed MSAC-SERNet and its variants in the single-corpus SER task, whose corresponding results are delineated in Table VIII.
| OOD Detector | Model | FPR95 | AUROC |
|---|---|---|---|
| rODIN | Base | 95.74 | 59.95 |
| Base+ | 81.36 | 63.83 | |
| Base+ | 93.49 | 62.91 | |
| Ours (Base+MSAC) | 68.29 | 73.23 | |
| MaxLogit | Base | 95.89 | 59.73 |
| Base+ | 81.66 | 63.77 | |
| Base+ | 93.49 | 62.81 | |
| Ours (Base+MSAC) | 68.49 | 72.95 | |
| ODIN | Base | 96.04 | 59.89 |
| Base+ | 81.46 | 63.93 | |
| Base+ | 92.74 | 62.77 | |
| Ours (Base+MSAC) | 69.09 | 72.61 | |
| ReACT | Base | 92.23 | 65.15 |
| Base+ | 85.47 | 63.64 | |
| Base+ | 97.34 | 49.59 | |
| Ours (Base+MSAC) | 78.66 | 65.45 | |
| Ma_Dis | Base | 100.0 | 41.18 |
| Base+ | 98.36 | 42.78 | |
| Base+ | 97.81 | 37.46 | |
| Ours (Base+MSAC) | 94.80 | 48.60 |
According to the reported results, it is apparent that as additional speech attributes are gradually controlled, the reliability performance of the proposed base model continuously improves, with the exception of the for the ReACT method. In general, the performs better than the learning paradigm, and our proposed MSAC achieves the best results. Take the commonly used MaxLogit OOD method as an example. Our proposed base model attains FPR95 of 95.74% and AUROC of 59.95% which hardly identifies any OOD samples. When exerting control over additional speech attributes, namely speaker and gender, their reliability performance has been gradually enhanced.

In particular, when utilizing our proposed MSAC learning paradigm, the proposed method realizes a remarkable 27.40% FPR95 reduction and a significant AUROC upgrade of 13.22% as opposed to the baseline, reaching a preliminary usable level for OOD detection. And it also indicates that by incorporating emotion-associated speech attributes and attenuating emotion-agnostic speech information, the proposed MSAC-SERNet can extract more robust emotional features, thereby enhancing the model’s OOD detection capabilities when facing semantic shifts.
Additionally, we observe an intriguing phenomenon where commonly used techniques in CV and NLP for enhancing OOD detection performance do not necessarily apply to the SER task. Concretely, the ODIN method, which introduces a positive perturbation to the input signal to some extent enlarging the confidence distribution of ID and OOD samples, exhibits undesirable effects in SER. Contrarily, our experiments show that our proposed rODIN method which introduces a reverse perturbation to the input signal, akin to generating adversarial examples [87], can slightly enhance the model’s OOD detection capabilities in the domain of SER.
Furthermore, to conduct an in-depth analysis of reliability performance, we employ the unsupervised t-SNE technique to visualize the features’ distribution of ID and OOD data from the IEMOCAP corpus. In particular, we perform a comparative analysis using our proposed SER base model, MSAC-SERNet and its variants, as depicted in Fig. 5. From the figure, it is evident that our proposed MSAC-SERNet exhibits a more pronounced disparity in the distribution of ID and OOD data compared to its baseline model and variants. This is attributed to the finer control over various speech attributes incorporated into the MSAC-SERNet, enabling the model to capture more nuanced emotional feature representations. Consequently, this enhancement contributes to improved reliability performance when facing semantic data shifts.
V-C2 Cross-corpus SER Task
Subsequently, the reliability comparison of the proposed MSAC-SERNet and its variants in the cross-corpus SER task is performed, and the results are illustrated in Table IX.
| OOD Detector | Model | FPR95 | AUROC |
|---|---|---|---|
| rODIN | Base | 95.34 | 59.10 |
| Base+ | 94.48 | 58.95 | |
| Base+ | 95.37 | 58.78 | |
| Base+ | 89.23 | 61.26 | |
| Base++ | 91.44 | 55.71 | |
| Base++ | 94.42 | 55.14 | |
| Base++ | 90.82 | 56.43 | |
| Ours (Base+MSAC) | 85.27 | 63.12 | |
| MaxLogit | Base | 95.28 | 59.08 |
| Base+ | 94.25 | 59.00 | |
| Base+ | 95.57 | 58.76 | |
| Base+ | 89.49 | 61.10 | |
| Base++ | 91.77 | 55.38 | |
| Base++ | 94.48 | 55.15 | |
| Base++ | 90.85 | 56.44 | |
| Ours (Base+MSAC) | 85.29 | 62.95 | |
| ODIN | Base | 95.41 | 59.08 |
| Base+ | 94.25 | 59.05 | |
| Base+ | 95.11 | 59.14 | |
| Base+ | 89.56 | 60.91 | |
| Base++ | 91.58 | 55.42 | |
| Base++ | 94.45 | 55.22 | |
| Base++ | 90.85 | 56.44 | |
| Ours (Base+MSAC) | 85.37 | 62.92 | |
| ReACT | Base | 94.38 | 56.31 |
| Base+ | 93.36 | 57.44 | |
| Base+ | 96.17 | 58.49 | |
| Base+ | 90.88 | 55.74 | |
| Base++ | 94.55 | 54.54 | |
| Base++ | 92.43 | 57.38 | |
| Base++ | 91.34 | 57.33 | |
| Ours (Base+MSAC) | 87.78 | 60.56 | |
| Ma_Dis | Base | 92.73 | 61.62 |
| Base+ | 95.48 | 53.92 | |
| Base+ | 97.12 | 41.93 | |
| Base+ | 93.25 | 48.47 | |
| Base++ | 93.19 | 49.94 | |
| Base++ | 94.11 | 51.37 | |
| Base++ | 94.37 | 56.01 | |
| Ours (Base+MSAC) | 91.55 | 56.97 |
Similarly, it can be easily perceived that, for all employed OOD detection methods, our proposed MSAC approach enables the proposed base SER model to achieve the highest reliability performance. Besides, compared with the existing four OOD detection methods, the proposed rODIN method attains the best reliability performance as well. Furthermore, we find that when using additional speech attribute based gradient reversal strategy to optimize the proposed base model, the reliability performance generally outperforms that of the multi-task learning strategy-based approaches. Consider the rODIN method, for instance. Our proposed base SER model acquires the FPR95 and AUROC of 95.34% and 59.10%. When adding one additional speech attribute control, it can be viewed that the performs even worse than the baseline, while the and achieve marginal enhancement over the baseline. When exerting control over two additional speech attributes, the outperforms and , yet, they all exhibit varying degrees of decline in AUROC performance. Comparatively, when incorporating the proposed MSAC, our proposed SER model obtains a 5.98% reduction in FPR95 and a 4.02% improvement in AUROC compared with the baseline.
VI Conclusions And Future Work
In this paper, we introduce a novel unified SER workflow, MSAC-SERNet, based on the data distribution of various speech attributes for both single-corpus and cross-corpus SER. In addition, we pioneer an exploration into the reliability performance of the proposed MSAC-SERNet framework and propose a new OOD detection method for the SER tasks. Comprehensive experiments conducted on six public emotion corpora demonstrate that our proposed MSAC-SERNet not only achieves superior recognition and generalization results compared to state-of-the-art (SOTA) single-corpus and cross-corpus SER approaches but also consistently outperforms the baseline SER model in all aspects, including recognition, generalization, and reliability. Our findings highlight that intricately modeling speech emotion by exerting additional precise control over diverse speech attributes consistently enhances the overall performance of the proposed SER workflow. Furthermore, we observe that commonly employed OOD detection techniques in CV and NLP fields, such as the input positive perturbation of the ODIN method, may not necessarily be applicable to the SER task. This implies the necessity for developing an OOD detection method more tailored to the inherent nature of SER tasks.
In future work, we will explore exerting control over a broader range of additional speech attributes and leverage the characteristics of SER tasks to propose more efficient OOD detection methods.
References
- [1] S. P. Mishra, P. Warule, and S. Deb, “Chirplet transform based time frequency analysis of speech signal for automated speech emotion recognition,” Speech Communication, vol. 155, p. 102986, 2023.
- [2] L. Zão, D. Cavalcante, and R. Coelho, “Time-frequency feature and ams-gmm mask for acoustic emotion classification,” IEEE signal processing letters, vol. 21, no. 5, pp. 620–624, 2014.
- [3] S. Zhang, S. Zhang, T. Huang, et al., “Speech emotion recognition using deep convolutional neural network and discriminant temporal pyramid matching,” IEEE Transactions on Multimedia, vol. 20, no. 6, pp. 1576–1590, 2018.
- [4] S. Latif, J. Qadir, A. Qayyum, et al., “Speech technology for healthcare: Opportunities, challenges, and state of the art,” IEEE Reviews in Biomedical Engineering, vol. 14, pp. 342–356, 2020.
- [5] E. Yadegaridehkordi, N. F. B. M. Noor, M. N. B. Ayub, et al., “Affective computing in education: A systematic review and future research,” Computers & Education, vol. 142, p. 103649, 2019.
- [6] A. Ando, R. Masumura, H. Kamiyama, et al., “Customer satisfaction estimation in contact center calls based on a hierarchical multi-task model,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 715–728, 2020.
- [7] X.-C. Wen, J.-X. Ye, Y. Luo, et al., “Ctl-mtnet: A novel capsnet and transfer learning-based mixed task net for the single-corpus and cross-corpus speech emotion recognition,” arXiv preprint arXiv:2207.10644, 2022.
- [8] M. Schmitt, F. Ringeval, and B. Schuller, “At the border of acoustics and linguistics: Bag-of-audio-words for the recognition of emotions in speech,” 2016.
- [9] F. Eyben, K. R. Scherer, B. W. Schuller, et al., “The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,” IEEE transactions on affective computing, vol. 7, no. 2, pp. 190–202, 2015.
- [10] M. B. Akçay and K. Oğuz, “Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers,” Speech Communication, vol. 116, pp. 56–76, 2020.
- [11] E. Mower, M. J. Matarić, and S. Narayanan, “A framework for automatic human emotion classification using emotion profiles,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 5, pp. 1057–1070, 2010.
- [12] B. Schuller, R. Müller, M. Lang, et al., “Speaker independent emotion recognition by early fusion of acoustic and linguistic features within ensembles,” 2005.
- [13] C.-C. Lee, E. Mower, C. Busso, et al., “Emotion recognition using a hierarchical binary decision tree approach,” Speech Communication, vol. 53, no. 9-10, pp. 1162–1171, 2011.
- [14] O. W. Kwon, K. Chan, J. Hao, et al., “Emotion recognition by speech signals,” in Interspeech, 2003. [Online]. Available: https://api.semanticscholar.org/CorpusID:18431863
- [15] Z. Zhang, B. Wu, and B. Schuller, “Attention-augmented end-to-end multi-task learning for emotion prediction from speech,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 6705–6709.
- [16] J. Zhao, X. Mao, and L. Chen, “Speech emotion recognition using deep 1d & 2d cnn lstm networks,” Biomedical signal processing and control, vol. 47, pp. 312–323, 2019.
- [17] Z. Liu, X. Kang, and F. Ren, “Dual-tbnet: Improving the robustness of speech features via dual-transformer-bilstm for speech emotion recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023.
- [18] M. Chen, X. He, J. Yang, et al., “3-d convolutional recurrent neural networks with attention model for speech emotion recognition,” IEEE Signal Processing Letters, vol. 25, no. 10, pp. 1440–1444, 2018.
- [19] S. Mirsamadi, E. Barsoum, and C. Zhang, “Automatic speech emotion recognition using recurrent neural networks with local attention,” in 2017 IEEE International conference on acoustics, speech and signal processing (ICASSP). IEEE, 2017, pp. 2227–2231.
- [20] A. Aftab, A. Morsali, S. Ghaemmaghami, et al., “Light-sernet: A lightweight fully convolutional neural network for speech emotion recognition,” in ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 6912–6916.
- [21] J. Ye, X. cheng Wen, Y. Wei, et al., “Temporal modeling matters: A novel temporal emotional modeling approach for speech emotion recognition,” 2023.
- [22] S. Latif, R. Rana, S. Khalifa, et al., “Self supervised adversarial domain adaptation for cross-corpus and cross-language speech emotion recognition,” IEEE Transactions on Affective Computing, 2022.
- [23] Y. Huang, K. Tian, A. Wu, et al., “Feature fusion methods research based on deep belief networks for speech emotion recognition under noise condition,” Journal of ambient intelligence and humanized computing, vol. 10, pp. 1787–1798, 2019.
- [24] E. Guizzo, T. Weyde, S. Scardapane, et al., “Learning speech emotion representations in the quaternion domain,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 1200–1212, 2023.
- [25] Y. Pan, Y. Hu, Y. Yang, et al., “Gemo-clap: Gender-attribute-enhanced contrastive language-audio pretraining for speech emotion recognition,” arXiv preprint arXiv:2306.07848, 2023.
- [26] A. Chatziagapi, G. Paraskevopoulos, D. Sgouropoulos, et al., “Data augmentation using gans for speech emotion recognition.” in Interspeech, 2019, pp. 171–175.
- [27] G. Yi, Y. Yang, Y. Pan, et al., “Exploring the power of cross-contextual large language model in mimic emotion prediction,” in Proceedings of the 4th on Multimodal Sentiment Analysis Challenge and Workshop: Mimicked Emotions, Humour and Personalisation, 2023, pp. 19–26.
- [28] Y. Xiao, H. Zhao, and T. Li, “Learning class-aligned and generalized domain-invariant representations for speech emotion recognition,” IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 4, no. 4, pp. 480–489, 2020.
- [29] X.-C. Wen, J.-X. Ye, Y. Luo, et al., “Ctl-mtnet: A novel capsnet and transfer learning-based mixed task net for the single-corpus and cross-corpus speech emotion recognition,” 2022.
- [30] M. Abdelwahab and C. Busso, “Domain adversarial for acoustic emotion recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 12, pp. 2423–2435, 2018.
- [31] H. Zhou and K. Chen, “Transferable positive/negative speech emotion recognition via class-wise adversarial domain adaptation,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 3732–3736.
- [32] Y. Ahn, S. J. Lee, and J. W. Shin, “Cross-corpus speech emotion recognition based on few-shot learning and domain adaptation,” IEEE Signal Processing Letters, vol. 28, pp. 1190–1194, 2021.
- [33] Y. Li, T. Zhao, T. Kawahara, et al., “Improved end-to-end speech emotion recognition using self attention mechanism and multitask learning.” in Interspeech, 2019, pp. 2803–2807.
- [34] J. Parry, E. DeMattos, A. Klementiev, et al., “Speech Emotion Recognition in the Wild using Multi-task and Adversarial Learning,” in Proc. Interspeech 2022, 2022, pp. 1158–1162.
- [35] I. Gat, H. Aronowitz, W. Zhu, et al., “Speaker normalization for self-supervised speech emotion recognition,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 7342–7346.
- [36] C. Lu, Y. Zong, W. Zheng, et al., “Domain invariant feature learning for speaker-independent speech emotion recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 2217–2230, 2022.
- [37] Y. Pan, L. Tang, and B. Zhao, “Lightweight fine-grained recognition method based on multilevel feature weighted fusion,” in 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS. IEEE, 2021, pp. 4767–4770.
- [38] Z. Zong, G. Song, and Y. Liu, “Detrs with collaborative hybrid assignments training,” in Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 6748–6758.
- [39] Z. Tian, C. Shen, H. Chen, et al., “Fcos: A simple and strong anchor-free object detector,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 4, pp. 1922–1933, 2020.
- [40] C. Wang, X. Liu, Z. Chen, et al., “Deepstruct: Pretraining of language models for structure prediction,” arXiv preprint arXiv:2205.10475, 2022.
- [41] T. Le, J. Lee, K. Yen, et al., “Perturbations in the wild: Leveraging human-written text perturbations for realistic adversarial attack and defense,” arXiv preprint arXiv:2203.10346, 2022.
- [42] C. Tao, L. Hou, W. Zhang, et al., “Compression of generative pre-trained language models via quantization,” arXiv preprint arXiv:2203.10705, 2022.
- [43] Y. Yang, Y. Pan, J. Yin, et al., “Lmec: Learnable multiplicative absolute position embedding based conformer for speech recognition,” arXiv preprint arXiv:2212.02099, 2022.
- [44] A. Gulati, J. Qin, C.-C. Chiu, et al., “Conformer: Convolution-augmented transformer for speech recognition,” arXiv preprint arXiv:2005.08100, 2020.
- [45] Y. Yang, Y. Pan, J. Yin, et al., “Hybridformer: Improving squeezeformer with hybrid attention and nsr mechanism,” in ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5.
- [46] F. Wang, J. Cheng, W. Liu, et al., “Additive margin softmax for face verification,” IEEE Signal Processing Letters, vol. 25, no. 7, pp. 926–930, 2018.
- [47] S. Liang, Y. Li, and R. Srikant, “Enhancing the reliability of out-of-distribution image detection in neural networks,” arXiv preprint arXiv:1706.02690, 2017.
- [48] K. Lee, K. Lee, H. Lee, et al., “A simple unified framework for detecting out-of-distribution samples and adversarial attacks,” Advances in neural information processing systems, vol. 31, 2018.
- [49] D. Hendrycks, S. Basart, M. Mazeika, et al., “Scaling out-of-distribution detection for real-world settings,” in Proceedings of the 39th International Conference on Machine Learning, 2022, pp. 8759–8773.
- [50] Y. Sun, C. Guo, and Y. Li, “React: Out-of-distribution detection with rectified activations,” Advances in Neural Information Processing Systems, vol. 34, pp. 144–157, 2021.
- [51] P. P. Dahake, K. Shaw, and P. Malathi, “Speaker dependent speech emotion recognition using mfcc and support vector machine,” in 2016 International Conference on Automatic Control and Dynamic Optimization Techniques (ICACDOT). IEEE, 2016, pp. 1080–1084.
- [52] J. Deng, X. Xu, Z. Zhang, et al., “Semisupervised autoencoders for speech emotion recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 1, pp. 31–43, 2017.
- [53] J. Wagner, A. Triantafyllopoulos, H. Wierstorf, et al., “Dawn of the transformer era in speech emotion recognition: closing the valence gap,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [54] D. Berend, X. Xie, L. Ma, et al., “Cats are not fish: Deep learning testing calls for out-of-distribution awareness,” in Proceedings of the 35th IEEE/ACM international conference on automated software engineering, 2020, pp. 1041–1052.
- [55] H. Lang, Y. Zheng, Y. Li, et al., “A survey on out-of-distribution detection in nlp,” 2023.
- [56] J. Yang, K. Zhou, Y. Li, et al., “Generalized out-of-distribution detection: A survey,” 2024.
- [57] D. Hendrycks and K. Gimpel, “A baseline for detecting misclassified and out-of-distribution examples in neural networks,” in International Conference on Learning Representations, 2017.
- [58] K. Lee, K. Lee, H. Lee, et al., “A simple unified framework for detecting out-of-distribution samples and adversarial attacks,” Advances in neural information processing systems, vol. 31, 2018.
- [59] R. Huang and Y. Li, “Mos: Towards scaling out-of-distribution detection for large semantic space,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8710–8719.
- [60] H. Wei, R. Xie, H. Cheng, et al., “Mitigating neural network overconfidence with logit normalization,” 2022.
- [61] Y. Zheng, G. Chen, and M. Huang, “Out-of-domain detection for natural language understanding in dialog systems,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 1198–1209, 2020.
- [62] Z. Zeng, K. He, Y. Yan, et al., “Modeling discriminative representations for out-of-domain detection with supervised contrastive learning,” arXiv preprint arXiv:2105.14289, 2021.
- [63] U. Arora, W. Huang, and H. He, “Types of out-of-distribution texts and how to detect them,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021, pp. 8759–8773.
- [64] D. Song, Z. Wang, Y. Huang, et al., “Deeplens: Interactive out-of-distribution data detection in nlp models,” in Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, 2023, pp. 1–17.
- [65] D. Qiu, Y. He, Q. Li, et al., “Multi-task learning for end-to-end asr word and utterance confidence with deletion prediction,” 2021.
- [66] A. Ragni, M. J. F. Gales, O. Rose, et al., “Increasing context for estimating confidence scores in automatic speech recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 1319–1329, 2022.
- [67] Q. Li, Y. Zhang, D. Qiu, et al., “Improving confidence estimation on out-of-domain data for end-to-end speech recognition,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6537–6541.
- [68] C. Wang, S. Chen, Y. Wu, et al., “Neural codec language models are zero-shot text to speech synthesizers,” arXiv preprint arXiv:2301.02111, 2023.
- [69] E. Kharitonov, D. Vincent, Z. Borsos, et al., “Speak, read and prompt: High-fidelity text-to-speech with minimal supervision,” arXiv preprint arXiv:2302.03540, 2023.
- [70] J. Yao, Y. Yang, Y. Lei, et al., “Promptvc: Flexible stylistic voice conversion in latent space driven by natural language prompts,” arXiv preprint arXiv:2309.09262, 2023.
- [71] C. Busso, M. Bulut, C.-C. Lee, et al., “Iemocap: Interactive emotional dyadic motion capture database,” Language resources and evaluation, vol. 42, pp. 335–359, 2008.
- [72] F. Burkhardt, A. Paeschke, M. Rolfes, et al., “A database of german emotional speech.” in Interspeech, vol. 5, 2005, pp. 1517–1520.
- [73] G. Costantini, I. Iaderola, A. Paoloni, et al., “Emovo corpus: an italian emotional speech database,” in Proceedings of the ninth international conference on language resources and evaluation (LREC’14). European Language Resources Association (ELRA), 2014, pp. 3501–3504.
- [74] J. Zhang and H. Jia, “Design of speech corpus for mandarin text to speech,” in The blizzard challenge 2008 workshop, 2008.
- [75] S. R. Livingstone and F. A. Russo, “The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english,” PloS one, vol. 13, no. 5, p. e0196391, 2018.
- [76] K. Dupuis and M. K. Pichora-Fuller, “Recognition of emotional speech for younger and older talkers: Behavioural findings from the toronto emotional speech set,” Canadian Acoustics, vol. 39, no. 3, pp. 182–183, 2011.
- [77] I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” 2019.
- [78] D. S. Park, W. Chan, Y. Zhang, et al., “Specaugment: A simple data augmentation method for automatic speech recognition,” arXiv preprint arXiv:1904.08779, 2019.
- [79] Y. Zhong, Y. Hu, H. Huang, et al., “A lightweight model based on separable convolution for speech emotion recognition.” in INTERSPEECH, vol. 11, 2020, pp. 3331–3335.
- [80] Z. Peng, Y. Lu, S. Pan, et al., “Efficient speech emotion recognition using multi-scale cnn and attention,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 3020–3024.
- [81] M. Hou, Z. Zhang, Q. Cao, et al., “Multi-view speech emotion recognition via collective relation construction,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 218–229, 2021.
- [82] W. Fan, X. Xu, B. Cai, et al., “Isnet: Individual standardization network for speech emotion recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 1803–1814, 2022.
- [83] S. Latif, R. Rana, S. Khalifa, et al., “Multi-task semi-supervised adversarial autoencoding for speech emotion recognition,” IEEE Transactions on Affective computing, vol. 13, no. 2, pp. 992–1004, 2022.
- [84] S. Mao, D. Tao, G. Zhang, et al., “Revisiting hidden markov models for speech emotion recognition,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 6715–6719.
- [85] Y. Liu, H. Sun, W. Guan, et al., “A discriminative feature representation method based on cascaded attention network with adversarial strategy for speech emotion recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 1063–1074, 2023.
- [86] J. Parry, E. DeMattos, A. Klementiev, et al., “Speech emotion recognition in the wild using multi-task and adversarial learning,” in Proc. Interspeech, vol. 2022, 2022, pp. 1158–1162.
- [87] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” 2015.