MotionAGFormer: Enhancing 3D Human Pose Estimation with a Transformer-GCNFormer Network
Abstract
Recent transformer-based approaches have demonstrated excellent performance in 3D human pose estimation. However, they have a holistic view and by encoding global relationships between all the joints, they do not capture the local dependencies precisely. In this paper, we present a novel Attention-GCNFormer (AGFormer) block that divides the number of channels by using two parallel transformer and GCNFormer streams. Our proposed GCNFormer module exploits the local relationship between adjacent joints, outputting a new representation that is complementary to the transformer output. By fusing these two representation in an adaptive way, AGFormer exhibits the ability to better learn the underlying 3D structure. By stacking multiple AGFormer blocks, we propose MotionAGFormer in four different variants, which can be chosen based on the speed-accuracy trade-off. We evaluate our model on two popular benchmark datasets: Human3.6M and MPI-INF-3DHP. MotionAGFormer-B achieves state-of-the-art results, with P1 errors of 38.4 mm and 16.2 mm, respectively. Remarkably, it uses a quarter of the parameters and is three times more computationally efficient than the previous leading model on Human3.6M dataset. Code and models are available at https://github.com/TaatiTeam/MotionAGFormer.
1 Introduction
Human pose estimation in 3D space is an active area of research with significant implications for numerous applications, from augmented [21] and virtual reality [26] to autonomous vehicles [43, 9, 2], human-computer interaction [27] and beyond. With this vast range of applications, the demand for more accurate and computationally efficient pose estimation models continues to grow. In most real-world scenarios, pose sequences are captured in 2D, primarily due to the prevalent use of standard RGB cameras. Consequently, one of the pivotal challenges in the field has been to effectively lift these 2D sequences into a 3D space. Accurate 3D human pose estimation enables the extraction of rich spatio-temporal information about human movements, and a deeper understanding of activities and interactions. Recent 3D lifting models leverage the inherent spatial and temporal coherence of human movements to enhance the precision of 3D pose predictions. Nonetheless, despite the considerable advancements, there are several significant challenges that require attention.
The Transformer architecture [41], originally designed for NLP tasks, has been adapted to various computer vision problems, including pose estimation. Its ability to capture long-range dependencies and its innate self-attention mechanism make it a promising candidate for this domain. However, a sole reliance on global attention mechanisms, as employed by standard Transformers, may not be optimal for pose estimation tasks. Human motion is inherently structured with local spatial and temporal dependencies.
One primary concern is the modeling of skeleton relations over time. Existing methods predominantly rely either on transformer architectures or graph-based models. While transformers excel at capturing long-term dependencies, graph models excel at local dependencies. So, there is an opportunity for a unified architecture that integrates the global perspective of transformers with the local precision of graph models.
Additionally, the race for achieving SOTA accuracy has often led to the development of increasingly complex models with a large number of parameters. Such models, despite their good accuracy, often become impractical for real-world applications where computational efficiency and swift response times are pivotal. Moreover, a predominant approach in recent models has been the prediction of a single 3D pose only for the central frame from a sequence of frames. This method, while seemingly efficient, leads to computational redundancy as it requires the reprocessing of several overlapping sequences. As a result, we instead employ a streamlined inference strategy that optimally exploits sequential data. This approach minimizes redundancy by predicting the complete 3D sequence of the input at a single forward pass.
In this paper, we introduce the MotionAGFormer, a novel transformer-graph hybrid architecture tailored for 3D human pose estimation. At its core, the MotionAGFormer harnesses the power of transformers to capture global information while simultaneously employing Graph Convolutional Networks (GCNs) to integrate local spatial and temporal relationships. We use an adaptive fusion to aggregate features from the transformer and graph streams. By doing so, we ensure a balanced and comprehensive representation of human motion, leading to enhanced accuracy in the 3D pose estimation (See Figure 1).
In summary, the main contributions of our paper are:
-
•
Novel Design: We propose the MotionAGFormer model, in which we introduce a new GCNFormer module that excels in representing local dependencies inherent in human pose sequences.
-
•
Efficiency and Flexibility: i) Our MotionAGFormer stands out due to its lightweight nature and faster speed with fewer parameters compared to previous SOTA methods, without compromising on accuracy. ii) Recognizing diverse needs, we offer different variants of MotionAGFormer, granting users the flexibility to make a balanced choice between accuracy and speed based on their specific requirements.
-
•
SOTA Performance: MotionAGFormer achieves SOTA on two challenging datasets, Human3.6M and MPI-INF-3DHP.
2 Related works
3D human pose estimation. Current approaches to tackle this problem can be understood from two perspectives. From one perspective, models can be categorized based on the input video, which can be either multi-view or monocular. Models that rely on multi-view inputs [48, 34, 7, 15, 35] necessitate the simultaneous use of multiple cameras from different angles, which can be less feasible in real-world scenarios. From another perspective, considering their methodology, these models can be categorized as either direct 3D estimation approaches or 2D-3D lifting approaches. Direct 3D estimation methods [31, 52, 39, 32] infer the joints in 3D coordinate from the video frames without any intermediate step. Inspired by the rapid development and availability of accurate 2D pose estimation models, more recently, 2D-3D lifting methods first use an off-the-shelf 2D pose detectors [4, 38, 28] then lift 2D coordinates to 3D space [51, 50, 53, 40, 47]. In this work, we are using 2D-3D lifting methods by having monocular video as the input.
Transformer-based methods. Transformers [41] have shown promising result in different visual tasks [10, 45, 37, 54]. In the field of 3D human pose estimation, PoseFormer [51] was the first purely transformer-based model. PoseFormerV2 [50] improved its computational efficacy by employing a frequency-domain representation that also made it robust against sudden movements in noisy data. MHFormer [20] addressed the problem of self-occlusion and depth ambiguity by proposing a module that learns multiple plausible pose hypotheses. P-STMO [36] proposed masked pose modeling and reduced the final error by self-supervised pretraining the model. Enfalt et al. [11] decreased the computational complexity by leveraging masked token modeling. StridedFormer [19] replaced fully-connected layers in the feed-forward network of the transformer encoder with strided convolutions to progressively shrink the sequence length and efficiently lift the central frame. Unlike the abovementioned models that estimate the 3D pose for only the center frame of a sequence, MixSTE [47] provided 3D estimates for every frame in the input sequence. STCFormer [40] decreased computational complexity by separating the correlation learning into spatial and temporal components. HSTFormer [33] proposed hierarchical transformer encoders for better capturing spatial-temporal correlations. In addition to joint-joint attention which is commonly used, HDFormer [3] included bone-joint and hyperbone-joint interactions. Some works exploited the output motion representation for various tasks. MotionBERT [53] fine-tuned the model learned for the task of 3D human pose estimation for tasks such as action recognition and 3D human mesh recovery, while UPS [12] trained a unified model for action recognition, 3D pose estimation, and early action prediction at the same time.
Graph Convolutional Network. GCN-based methods have achieved remarkable success within the domain of skeleton-based action recognition [22, 5, 18]. Despite their computational efficiency in 3D human pose estimation [6, 42, 49, 8], they usually cannot show competitive error compared to transformer-based counterparts. This is primarily due to their focus on local joints alone. Recently, GLA-GCN [44] introduced an adaptive GCN approach to leverage global representation. By employing a strided design to reduce its temporal scope, they achieve competitive 3D human pose estimation against various transformer-based models, all while maintaining a lighter memory load. However, the effectiveness of the proposed module in extracting global representation is not on par with that of an attention module.
Hybrid methods. These methods use different modules to capture distinct aspects of the input sequence and are not extensively explored yet. Recently, DC-GCT [16] proposed a Local Constraint Module based on GCN, and Global Constraint Module based onf self-attention to exploit both local and global dependecies of the input sequence. However, as their model is designed to operate with both individual input frames and sequences of frames, it does not distinguish between temporal and spatial dimensions. As a result, it falls short in delivering competitive outcomes when contrasted with transformer-based methods.
3 Method
3.1 Preliminary
We begin this section by reviewing the concept of MetaFormer [46], which forms the core of our encoders. A MetaFormer can be described as a generalization of the Transformer architecture [41], wherein the attention module is substituted with any mixer capable of transforming information among tokens. Specifically, for an input , with denoting the token numbers and representing the embedding dimension, the token mixer can be formally expressed as
| (1) |
where denotes a normalization method such as batch or layer normalization [13, 1], and denotes a module that combines information among tokens. Our approach uses two parallel token mixers: Multi-head Self-Attention (MHSA) and Graph Convolutional Networks (GCNs) [17], each contributing uniquely to the information transformation process.
3.2 Overall architecture
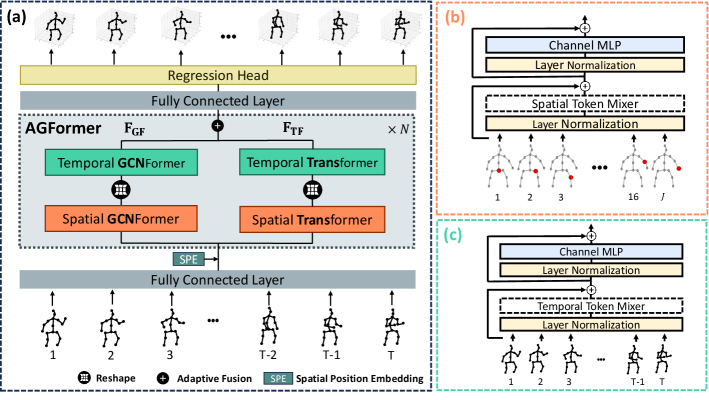
Our objective is to lift a 2D (pixel coordinate) skeleton sequence to accurate 3D pose sequences. To this end, we propose the MotionAGFormer architecture, which uses both attention (Transformer) and graph convolutional (GCNFormer) to lift motion sequences. An overview of this architecture is shown in Figure 2a.
The model takes a 2D input sequence with confidence score , where and refer to the number of frames and joint numbers, respectively. It then proceeds to map each joint in each time frame to a -dimensional feature, , using a linear projection layer. Then a spatial position embedding is added to the tokens. It is important to highlight here that our model does not disregard the temporal token order as that information is preserved in the GCNFormer stream (further discussion in ablation studies 4.5).
Subsequent to position embedding, we use blocks of AGFormer (Section 3.3) to compute () to effectively capture the underlying 3D structure of the skeleton sequence. Finally, we map to a higher dimension by applying a linear layer and activation to compute motion semantic and use a regression head to estimate 3D pose . The lifting loss contains position () and velocity () terms defined as
| (2) | ||||
where , . The total lifting loss is then defined as
| (3) |
where the constant coefficient is used to balance position accuracy and motion smoothness.
3.3 AGFormer Block
The AGFormer block uses a dual-stream architecture. Each stream consists of two components: a Spatial MetaFormer (Figure 2b) followed by a Temporal MetaFormer (Figure 2c). The Spatial MetaFormer processes individual body joints as distinct tokens, effectively capturing intra-frame relationships within a single frame. The Temporal MetaFormer, on the other hand, treats each frame as a single token, thus capturing inter-frame relationships over time. The key distinction between the two streams lies in their token mixer type. While one stream employs Transformers, the other stream uses GCNFormers.
Transformer stream. This stream employs a Spatial Multi-Head Self-Attention (S-MHSA) to capture spatial relationships, followed by a Temporal Multi-Head Self-Attention (T-MHSA) to capture temporal relationships. The S-MHSA is defined as
|
|
(4) |
where is a projection parameter matrix, is the number of parallel attention heads, and is the feature dimension of . For computing the query matrix , the key matrix , and the value matrix , we have
|
|
(5) |
where is spatial feature and , , are projection matrices and is the batch size. The S-MHSA result is subsequently fed into a multilayer perceptron (MLP), followed by a residual connection and LayerNorm. This completes the first MetaFormer, i.e. the Spatial Transformer.
Next, we reshape into to prepare per-joint temporal feature as the input of T-MHSA. Here we have
|
|
(6) |
where , , and are calculated similar to Eqn. (5).
GCNFormer stream. Unlike the Transformer stream, which aggregates global information, the GCNFormer stream focuses on local spatial and temporal relationships present within the skeleton sequence. While the local information is also available to the Transformers, the inclusion of this parallel stream allows the model to more effectively balance the integration of local and global information (see ablation analysis 4.5). The customized GCN module [24] used in our GCNFormer is defined as:
|
|
(7) |
Where represents the adjacency matrix with self-connections added, stands for the identity matrix, is defined as the sum of elements along the diagonal of , and , denote trainable weight matrices specific to each layer. The activation function , such as ReLU, is applied, along with Batch Normalization [13]. The GCN’s output is then passed through an MLP, followed by residual connection and LayerNorm.
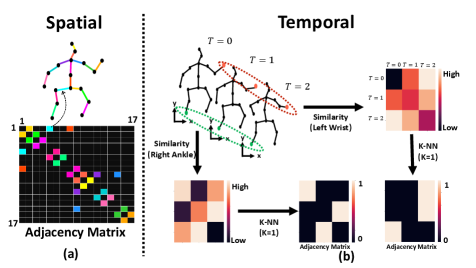
The difference between the Spatial GCNFormer and the Temporal GCNFormer lies in their adjacency matrices and input features. The input features resemble that of the Transformer stream. In the Spatial GCNFormer, the adjacency matrix represents the human topology (Figure 3a). For Temporal GCNFormer, on the other hand, we calculate the similarity between a single joint at different time frames using and choose the nearest neighbors as the connected nodes in the graph (Figure 3b). Hence, the graph topology in Temporal GCNFormer is determined by the learned node features.
Adaptive Fusion. Similar to MotionBERT [53], we use adaptive fusion to aggregate extracted features of the Transformer and GCNFormer streams. This is defined as:
| (8) |
where represents the feature embedding extracted at depth , the element-wise multiplication denoted by , and , refer to the extracted Transformer stream and GCNFormer stream features at depth , respectively. The adaptive fusion weights and are defined as
| (9) |
where is a learnable linear transformation.
4 Experiments
We evaluate the performance of our proposed MotionAGFormer on two large-scale 3D human pose estimation datasets, i.e., Human3.6M [14] and MPI-INF-3DHP [25].
4.1 Datasets and Evaluation Metrics
Human3.6M is a widely used indoor dataset for 3D human pose estimation. It contains 3.6 million video frames of 11 subjects performing 15 different daily activities. To ensure fair evaluation, we follow the standard approach and train the model using data from subjects 1, 5, 6, 7, and 8, and then test it on data from subjects 9 and 11. Following previous works [50, 40], we use two protocols for evaluation. The first protocol (referred to as P1) uses Mean Per Joint Position Error (MPJPE) in millimeters between the estimated pose and the actual pose, after aligning their root joints (sacrum). The second protocol (referred to as P2) measures Procrustes-MPJPE, where the actual pose and the estimated pose are aligned through a rigid transformation.
MPI-INF-3DHP is another large-scale dataset gathered in three different settings: green screen, non-green screen, and outdoor environments. Following previous works [50, 40], MPJPE, Percentage of Correct Keypoint (PC) within 150 mm range, and Area Under the Curve (AUC) are reported as evaluation metrics.
4.2 Implementation Details
Model Variants. We build four different configurations of our model, as summarized in Table 1. Our base model, known as MotionAGFormer-B, strikes a balance between accurate estimation and computational cost. The remaining variants are named according to their parameter size and computational demands and selection of each variant can be based on an application’s requirements, such as choosing between real-time processing or more precise estimations. The motion semantic dimension is , the expansion layer of each MLP is , the number of attention heads is , and the number of temporal neighbours in GCNformer stream is , for all experiments.
| Method | Params | MACs | |||
|---|---|---|---|---|---|
| MotionAGFormer-XS | 12 | 64 | 27 | 2.2 M | 1.0 G |
| MotionAGFormer-S | 26 | 64 | 81 | 4.8 M | 6.6 G |
| MotionAGFormer-B | 16 | 128 | 243 | 11.7 M | 48.3 G |
| MotionAGFormer-L | 26 | 128 | 243 | 19.0 M | 78.3 G |
Experimental settings. Our model is implemented using PyTorch [30] and executed on a setup with two NVIDIA A40 GPUs. We apply horizontal flipping augmentation for both training and testing following [53, 50]. For model training, we set each mini-batch as 16 sequences. The network parameters are optimized using AdamW [23] optimizer over 90 epochs with a weight decay of 0.01. The initial learning rate is set to 5e-4 with an exponential learning rate decay schedule and the decay factor is 0.99. We use the Stacked Hourglass [29] 2D pose detection results and 2D ground truths on Human3.6M, following [53]. For MPI-INF-3DHP, ground truth 2D detection is used following a similar approach used in comparison baselines [50, 40].
| Method | CE | Param | MACs | MACs/frame | P1 /P2 | ||
|---|---|---|---|---|---|---|---|
| *MHFormer [20] CVPR’22 | 351 | ✓ | 30.9 M | 7.0 G | 7,096 M | 43.0/34.4 | 30.5 |
| MixSTE [47] CVPR’22 | 243 | 33.6 M | 139.0 G | 572 M | 40.9/32.6 | 21.6 | |
| P-STMO [36] ECCV’22 | 243 | ✓ | 6.2 M | 0.7 G | 740 M | 42.8/34.4 | 29.3 |
| Stridedformer [19] TMM’22 | 351 | ✓ | 4.0 M | 0.8 G | 801 M | 43.7/35.2 | 28.5 |
| Einfalt et al. [11] WACV’23 | 351 | ✓ | 10.4 M | 0.5 G | 498 M | 44.2/35.7 | - |
| STCFormer [40] CVPR’23 | 243 | 4.7 M | 19.6 G | 80 M | 41.0/32.0 | 21.3 | |
| STCFormer-L [40] CVPR’23 | 243 | 18.9 M | 78.2 G | 321 M | 40.5/31.8 | - | |
| PoseFormerV2 [50] CVPR’23 | 243 | ✓ | 14.3 M | 0.5 G | 528 M | 45.2/35.6 | - |
| UPS [12] CVPR’23 | 243 | ✓ | - | - | - | 40.8/32.5 | - |
| GLA-GCN [44] ICCV’23 | 243 | ✓ | 1.3 M | 1.5 G | 1,556 M | 44.4/34.8 | 21.0 |
| MotionBERT [53] ICCV’23 | 243 | 42.5 M | 174.7 G | 719 M | 39.2/32.9 | 17.8 | |
| HDFormer [3] IJCAI’23 | 96 | 3.7 M | 0.6 G | 6 M | 42.6/33.1 | 21.6 | |
| HSTFormer [33] arXiv’23 | 81 | 22.7 M | 1.0 G | 13 M | 42.7/33.7 | 27.8 | |
| DC-GCT [16] arXiv’23 | 81 | ✓ | 3.1 M | 41 M | 41 M | 44.7/- | - |
| MotionAGFormer-XS | 27 | 2.2 M | 1.0 G | 37 M | 45.1/36.9 | 28.1 | |
| MotionAGFormer-S | 81 | 4.8 M | 6.6 G | 81 M | 42.5/35.3 | 26.5 | |
| MotionAGFormer-B | 243 | 11.7 M | 48.3 G | 198 M | 38.4/32.6 | 19.4 | |
| MotionAGFormer-L | 243 | 19.0 M | 78.3 G | 322 M | 38.4/32.5 | 17.3 |
4.3 Performance comparison on Human3.6M
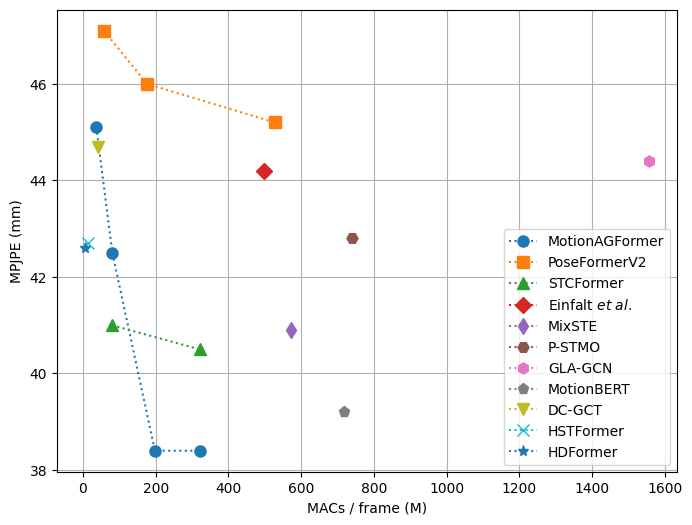
We compare our MotionAGFormer with other models on Human3.6M. For a fair comparison, only results of models without extra pre-training on additional data is included. The results, outlined in Table 2, demonstrate that MotionAGFormer-L attains a P1 error of 38.4 mm for estimated 2D pose and 17.3 mm for ground truth 2D pose. Remarkably, this is achieved with approximately half the computational requirements and parameters compared to the previous SOTA (MotionBERT [53]), while being 0.8 mm and 0.5 mm more accurate, respectively. When comparing the Base and Large variants, MotionAGFormer-L shares the same P1 error as MotionAGFormer-B in the presence of noisy data, while exhibiting a 2.1 mm reduction in error when using ground truth 2D data. Furthermore, MotionAGFormer-S takes in only a third of the frames compared to the baselines, yet it manages to attain a superior P1 error compared to a majority of them. Similarly, MotionAGFormer-XS delivers comparable performance to PoseTransformerV2, even though it receives only a ninth of the input information (27 vs. 243 frames) and operates with approximately seven times fewer parameters.
4.4 Performance comparison on MPI-INF-3DHP
In evaluating our method on the MPI-INF-3DHP dataset, we modified our base and large variants to use 81 frames due to shorter video sequences. Across all variants, our method consistently outperforms others in terms MPJPE. Notably, our large variant achieves remarkable results with an 85.3% AUC and a 16.2 mm P1 error. This outperforms the best models by a significant margin of 1.4% in AUC and 6.9 mm in P1 error. However, it achieves 98.2% PCK, which is 0.5% lower than the PCK performance of the compared models (Table 3).
| Method | PCK | AUC | MPJPE | |
|---|---|---|---|---|
| MHFormer [20] | 9 | 93.8 | 63.3 | 58.0 |
| MixSTE [47] | 27 | 94.4 | 66.5 | 54.9 |
| P-STMO [36] | 81 | 97.9 | 75.8 | 32.2 |
| Einfalt et al. [11] | 81 | 95.4 | 67.6 | 46.9 |
| STCFormer [40] | 81 | 98.7 | 83.9 | 23.1 |
| PoseFormerV2 [50] | 81 | 97.9 | 78.8 | 27.8 |
| GLA-GCN [44] | 81 | 98.5 | 79.1 | 27.7 |
| HSTFormer [33] | 81 | 97.3 | 71.5 | 41.4 |
| HDFormer [3] | 96 | 98.7 | 72.9 | 37.2 |
| MotionAGFormer-XS | 27 | 98.2 | 83.5 | 19.2 |
| MotionAGFormer-S | 81 | 98.3 | 84.5 | 17.1 |
| MotionAGFormer-B | 81 | 98.3 | 84.2 | 18.2 |
| MotionAGFormer-L | 81 | 98.2 | 85.3 | 16.2 |
4.5 Ablation Studies
A series of ablation studies were conducted on the Human3.6M dataset to explore different design choices for the AGFormer block.
The initial ablation study investigates the influence of favoring the number of AGFormer blocks and the width of our model on the P1 error. As shown in Table 4, the trend generally leans towards favoring a model that is deeper but narrower. Interestingly, a model with 16 AGFormer blocks and a width of 128 exhibits similar performance to a model featuring 12 AGFormer blocks with a width of 256, while the first configuration uses approximately three times less memory and computational resources.
The second part of the ablation study explores alternative modules for the graph stream within the AGFormer block. The results are presented in Table 5. Shifting from GCNFormer to GCN blocks degrades the P1 error by 0.7 mm. Similarly, substituting the Temporal GCNFormer with TCN degrades the P1 error by 0.2 mm when using GCN and 0.9 mm when using GCNFormer. Lastly, replacing the GCN with a CTR-GCN [5] increases the P1 error by 2.5 mm. We hypothesize that is because of the continuous refinement of topology for each channel in CTR-GCN during training. As a result, every joint not only obtains information from its immediate neighbors but also from all other joints. This prevents the generation of complementary information for the transformer stream.
To explore the impact of positional embedding on the the final performance, we conducted a series of experiments outlined in Table 6. Surprisingly, including temporal positional embedding in addition to spatial positional embedding leads to a 0.6 mm increase in P1 error. As mentioned in Section 3.2, this result stems from the non-permutation equivariant nature of the GCNFormer stream. Unlike transformers, our network inherently maintains the temporal sequence of frames. However, as shown in Figure 5, adding temporal positional embedding leads to a better acceleration error (0.88 mm) compared to using spatial positional embedding (0.94 mm).
Finally, to verify the efficiency of the proposed AGFormer block, Table 7 shows alternative blocks. When using GCNFormer, a P1 error of 57.5 mm is observed, indicating its limited capability to accurately capture the underlying 3D sequence structure. Nevertheless, a hybrid approach involving both GCNFormer and Transformer yields a noteworthy improvement, reducing the P1 error by 5.2 mm compared to using Transformer alone. Furthermore, the sequential fusion of these two modules is not as effective as their parallel integration.
| Layers | Param | MACs | P1 | ||
|---|---|---|---|---|---|
| 5 | 512 | 512 | 58 M | 252.8 G | 39.2 |
| 4 | 256 | 512 | 11.7 M | 54.G G | 40.2 |
| 6 | 256 | 512 | 17.5 M | 81.64 G | 39.6 |
| 8 | 256 | 512 | 23.3 M | 108.6 G | 39.5 |
| 10 | 256 | 512 | 29.1 M | 135.7 G | 38.6 |
| 12 | 256 | 512 | 34.9 M | 162.7 G | 38.4 |
| 14 | 256 | 512 | 40.7 M | 189.7 G | 38.6 |
| 16 | 128 | 512 | 11.7 M | 64.7 G | 38.4 |
| 16 | 128 | 256 | 11.7 M | 64.5 G | 38.7 |
| 16 | 128 | 1024 | 11.7 M | 64.9 G | 39.2 |
| 26 | 64 | 512 | 4.8 M | 39.5 G | 39.5 |
| GCN | TCN | GCNFormer | CTR-GCNFormer | P1 |
|---|---|---|---|---|
| ✓ | - | - | - | 39.1 |
| ✓ | ✓ | - | - | 39.3 |
| - | ✓ | ✓ | - | 39.7 |
| - | - | - | ✓ | 40.9 |
| - | - | ✓ | - | 38.4 |
4.6 Qualitative Analysis
Validation of MotionAGFormer-B is conducted using the adjacency matrix of temporal GCNFormer and visualization of 3D human pose estimation. The instances for validation are randomly chosen from the evaluation set of Human3.6M.
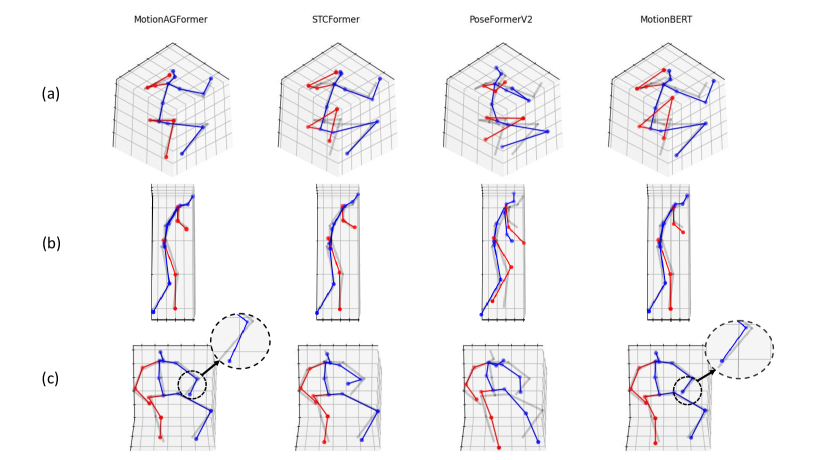
Qualitative Comparisons. Figure 4 compares MotionAGFormer-B with recent approaches including STCFormer [40], PoseFormerV2 [50], and MotionBERT [53]. By design, confidence scores of the 2D detector are only included into MotionBERT and MotionAGFormer-B. Overall, MotionAGFormer-B shows better reconstruction results across all three samples than PoseFormerV2 and STCFormer, while maintaining competitive performance with MotionBERT. Specifically, in Figure 4a, MotionAGFormer exhibits improved alignment with the ground truth in comparison to alternative approaches. In Figure 4b, it displays a slightly superior alignment, whereas in Figure 4c, its alignment is marginally less optimal than that of MotionBERT.
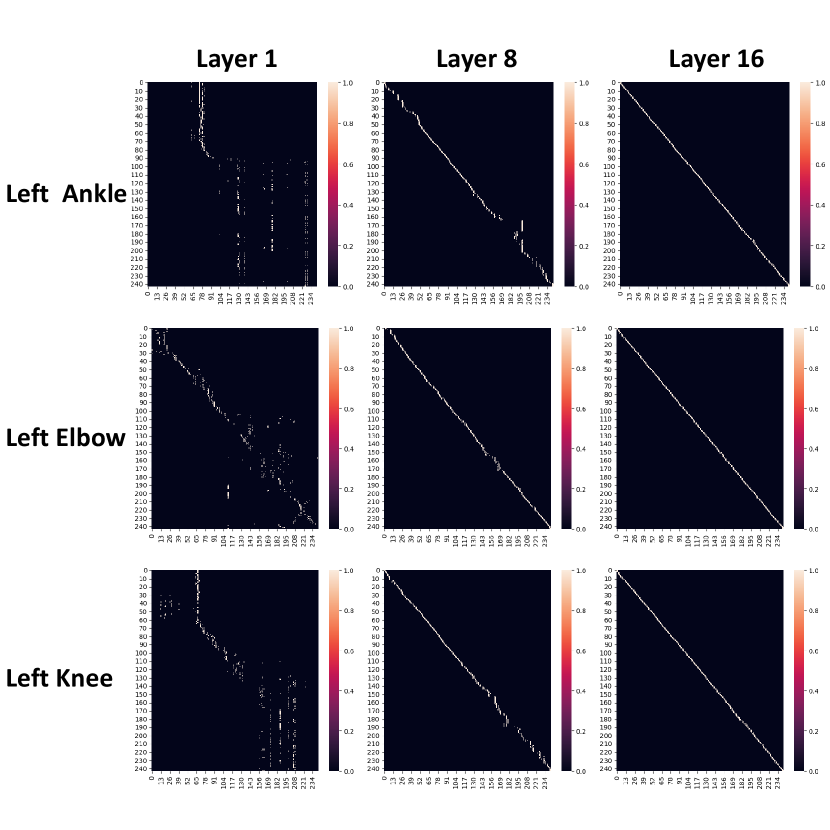
Temporal adjacency visualization. The adjacency matrix of temporal GCNFormer is visualized in Figure 6. In the initial layers, individual joints exhibit distinct adjacency matrices, which should vary across different sequences due to the changing joint positions over time. Nevertheless, as we progress through the model’s depth, it appears to learn a representation where each joint is most akin to its own state in neighboring frames. Consequently, this leads to connections being formed with adjacent frames.
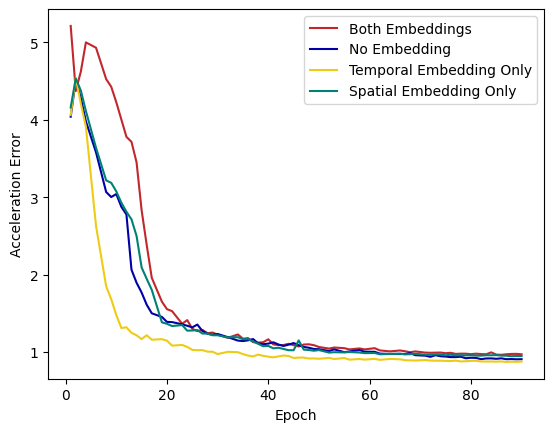
| Temporal Embedding | Spatial Embedding | P1 |
| - | - | 39.3 |
| - | ✓ | 38.4 |
| ✓ | - | 38.9 |
| ✓ | ✓ | 40.5 |
| Method | P1 |
|---|---|
| GCNFormer only | 57.5 |
| Transformer only | 43.6 |
| GCNFormer Transformer (Sequential) | 39.1 |
| Transformer GCNFormer (Sequential) | 38.9 |
| Transformer - GCNFormer (Parallel) | 38.4 |
5 Conclusion
We introduced MotionAGFormer, a novel approach that leverages GCNFormer to capture intricate local joint relationships, and combines it with Transformer that effectively captures global joint interdependencies. This fusion enhances the model’s ability to comprehend the inherent 3D structure within input 2D sequences. Additionally, MotionAGFormer offers various adaptable variants, allowing the selection of an optimal balance between speed and accuracy. Empirical evaluations show that our method surpasses alternative methods on Human3.6M and MPI-INF-3DHP.
References
- [1] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- [2] Peter Bauer, Arij Bouazizi, Ulrich Kressel, and Fabian B Flohr. Weakly supervised multi-modal 3d human body pose estimation for autonomous driving. In 2023 IEEE Intelligent Vehicles Symposium (IV), pages 1–7. IEEE, 2023.
- [3] Hanyuan Chen, Jun-Yan He, Wangmeng Xiang, Wei Liu, Zhi-Qi Cheng, Hanbing Liu, Bin Luo, Yifeng Geng, and Xuansong Xie. HDFormer: High-order directed transformer for 3d human pose estimation. arXiv preprint arXiv:2302.01825, 2023.
- [4] Yilun Chen, Zhicheng Wang, Yuxiang Peng, Zhiqiang Zhang, Gang Yu, and Jian Sun. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7103–7112, 2018.
- [5] Yuxin Chen, Ziqi Zhang, Chunfeng Yuan, Bing Li, Ying Deng, and Weiming Hu. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF international conference on computer vision, pages 13359–13368, 2021.
- [6] Hongsuk Choi, Gyeongsik Moon, and Kyoung Mu Lee. Pose2Mesh: Graph convolutional network for 3d human pose and mesh recovery from a 2d human pose. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VII 16, pages 769–787. Springer, 2020.
- [7] Sungho Chun, Sungbum Park, and Ju Yong Chang. Learnable human mesh triangulation for 3d human pose and shape estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2850–2859, 2023.
- [8] Hai Ci, Chunyu Wang, Xiaoxuan Ma, and Yizhou Wang. Optimizing network structure for 3d human pose estimation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2262–2271, 2019.
- [9] Phillip Czech, Markus Braun, Ulrich Kreßel, and Bin Yang. On-board pedestrian trajectory prediction using behavioral features. In 2022 21st IEEE International Conference on Machine Learning and Applications (ICMLA), pages 437–443. IEEE, 2022.
- [10] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- [11] Moritz Einfalt, Katja Ludwig, and Rainer Lienhart. Uplift and upsample: Efficient 3d human pose estimation with uplifting transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), January 2023.
- [12] Lin Geng Foo, Tianjiao Li, Hossein Rahmani, Qiuhong Ke, and Jun Liu. Unified pose sequence modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13019–13030, 2023.
- [13] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pages 448–456. pmlr, 2015.
- [14] Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE transactions on pattern analysis and machine intelligence, 36(7):1325–1339, 2013.
- [15] Karim Iskakov, Egor Burkov, Victor Lempitsky, and Yury Malkov. Learnable triangulation of human pose. In Proceedings of the IEEE/CVF international conference on computer vision, pages 7718–7727, 2019.
- [16] Hongbo Kang, Yong Wang, Mengyuan Liu, Doudou Wu, Peng Liu, and Wenming Yang. Double-chain constraints for 3d human pose estimation in images and videos. arXiv preprint arXiv:2308.05298, 2023.
- [17] Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
- [18] Jungho Lee, Minhyeok Lee, Dogyoon Lee, and Sangyoun Lee. Hierarchically decomposed graph convolutional networks for skeleton-based action recognition. arXiv preprint arXiv:2208.10741, 2022.
- [19] Wenhao Li, Hong Liu, Runwei Ding, Mengyuan Liu, Pichao Wang, and Wenming Yang. Exploiting temporal contexts with strided transformer for 3d human pose estimation. IEEE Transactions on Multimedia, 25:1282–1293, 2022.
- [20] Wenhao Li, Hong Liu, Hao Tang, Pichao Wang, and Luc Van Gool. MHFormer: Multi-hypothesis transformer for 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13147–13156, 2022.
- [21] Huei-Yung Lin and Ting-Wen Chen. Augmented reality with human body interaction based on monocular 3d pose estimation. In International Conference on Advanced Concepts for Intelligent Vision Systems, pages 321–331. Springer, 2010.
- [22] Ziyu Liu, Hongwen Zhang, Zhenghao Chen, Zhiyong Wang, and Wanli Ouyang. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 143–152, 2020.
- [23] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- [24] Cheng Luo, Siyang Song, Weicheng Xie, Linlin Shen, and Hatice Gunes. Learning multi-dimensional edge feature-based au relation graph for facial action unit recognition. arXiv preprint arXiv:2205.01782, 2022.
- [25] Dushyant Mehta, Helge Rhodin, Dan Casas, Pascal Fua, Oleksandr Sotnychenko, Weipeng Xu, and Christian Theobalt. Monocular 3d human pose estimation in the wild using improved cnn supervision. In 2017 international conference on 3D vision (3DV), pages 506–516. IEEE, 2017.
- [26] Dushyant Mehta, Srinath Sridhar, Oleksandr Sotnychenko, Helge Rhodin, Mohammad Shafiei, Hans-Peter Seidel, Weipeng Xu, Dan Casas, and Christian Theobalt. VNect: Real-time 3d human pose estimation with a single rgb camera. Acm transactions on graphics (tog), 36(4):1–14, 2017.
- [27] Tewodros Legesse Munea, Yalew Zelalem Jembre, Halefom Tekle Weldegebriel, Longbiao Chen, Chenxi Huang, and Chenhui Yang. The progress of human pose estimation: A survey and taxonomy of models applied in 2d human pose estimation. IEEE Access, 8:133330–133348, 2020.
- [28] Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part VIII 14, pages 483–499. Springer, 2016.
- [29] Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part VIII 14, pages 483–499. Springer, 2016.
- [30] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. 2017.
- [31] Georgios Pavlakos, Xiaowei Zhou, and Kostas Daniilidis. Ordinal depth supervision for 3d human pose estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7307–7316, 2018.
- [32] Georgios Pavlakos, Xiaowei Zhou, Konstantinos G Derpanis, and Kostas Daniilidis. Coarse-to-fine volumetric prediction for single-image 3d human pose. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7025–7034, 2017.
- [33] Xiaoye Qian, Youbao Tang, Ning Zhang, Mei Han, Jing Xiao, Ming-Chun Huang, and Ruei-Sung Lin. HSTFormer: Hierarchical spatial-temporal transformers for 3d human pose estimation. arXiv preprint arXiv:2301.07322, 2023.
- [34] N Dinesh Reddy, Laurent Guigues, Leonid Pishchulin, Jayan Eledath, and Srinivasa G Narasimhan. TesseTrack: End-to-end learnable multi-person articulated 3d pose tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15190–15200, 2021.
- [35] Edoardo Remelli, Shangchen Han, Sina Honari, Pascal Fua, and Robert Wang. Lightweight multi-view 3d pose estimation through camera-disentangled representation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6040–6049, 2020.
- [36] Wenkang Shan, Zhenhua Liu, Xinfeng Zhang, Shanshe Wang, Siwei Ma, and Wen Gao. P-STMO: Pre-trained spatial temporal many-to-one model for 3d human pose estimation. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part V, pages 461–478. Springer, 2022.
- [37] Weijie Su, Xizhou Zhu, Chenxin Tao, Lewei Lu, Bin Li, Gao Huang, Yu Qiao, Xiaogang Wang, Jie Zhou, and Jifeng Dai. Towards all-in-one pre-training via maximizing multi-modal mutual information. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15888–15899, 2023.
- [38] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5693–5703, 2019.
- [39] Xiao Sun, Bin Xiao, Fangyin Wei, Shuang Liang, and Yichen Wei. Integral human pose regression. In Proceedings of the European conference on computer vision (ECCV), pages 529–545, 2018.
- [40] Zhenhua Tang, Zhaofan Qiu, Yanbin Hao, Richang Hong, and Ting Yao. 3D human pose estimation with spatio-temporal criss-cross attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4790–4799, 2023.
- [41] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [42] Jingbo Wang, Sijie Yan, Yuanjun Xiong, and Dahua Lin. Motion guided 3d pose estimation from videos. In European Conference on Computer Vision, pages 764–780. Springer, 2020.
- [43] Julian Wiederer, Arij Bouazizi, Ulrich Kressel, and Vasileios Belagiannis. Traffic control gesture recognition for autonomous vehicles. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10676–10683. IEEE, 2020.
- [44] Bruce X. B. Yu, Zhi Zhang, Yongxu Liu, Sheng hua Zhong, Yan Liu, and Chang Wen Chen. GLA-GCN: Global-local adaptive graph convolutional network for 3d human pose estimation from monocular video, 2023.
- [45] Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. CoCa: Contrastive captioners are image-text foundation models. arXiv preprint arXiv:2205.01917, 2022.
- [46] Weihao Yu, Mi Luo, Pan Zhou, Chenyang Si, Yichen Zhou, Xinchao Wang, Jiashi Feng, and Shuicheng Yan. MetaFormer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10819–10829, 2022.
- [47] Jinlu Zhang, Zhigang Tu, Jianyu Yang, Yujin Chen, and Junsong Yuan. MixSTE: Seq2seq mixed spatio-temporal encoder for 3d human pose estimation in video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13232–13242, June 2022.
- [48] Zhe Zhang, Chunyu Wang, Weichao Qiu, Wenhu Qin, and Wenjun Zeng. Adafuse: Adaptive multiview fusion for accurate human pose estimation in the wild. International Journal of Computer Vision, 129:703–718, 2021.
- [49] Long Zhao, Xi Peng, Yu Tian, Mubbasir Kapadia, and Dimitris N Metaxas. Semantic graph convolutional networks for 3d human pose regression. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3425–3435, 2019.
- [50] Qitao Zhao, Ce Zheng, Mengyuan Liu, Pichao Wang, and Chen Chen. PoseFormerV2: Exploring frequency domain for efficient and robust 3d human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8877–8886, June 2023.
- [51] Ce Zheng, Sijie Zhu, Matias Mendieta, Taojiannan Yang, Chen Chen, and Zhengming Ding. 3d human pose estimation with spatial and temporal transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11656–11665, 2021.
- [52] Kun Zhou, Xiaoguang Han, Nianjuan Jiang, Kui Jia, and Jiangbo Lu. HEMlets pose: Learning part-centric heatmap triplets for accurate 3d human pose estimation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2344–2353, 2019.
- [53] Wentao Zhu, Xiaoxuan Ma, Zhaoyang Liu, Libin Liu, Wayne Wu, and Yizhou Wang. MotionBERT: A unified perspective on learning human motion representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023.
- [54] Zhuofan Zong, Guanglu Song, and Yu Liu. DETRs with collaborative hybrid assignments training. arXiv preprint arXiv:2211.12860, 2022.
Appendix
Appendix A Additional Results on Human3.6M
A.1 Per-action Result
| MPJPE | Dire. | Disc. | Eat | Greet | Phone | Photo | Pose | Purch. | Sit | SitD | Smoke | Wait | WalkD | Walk | WalkT | Avg | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| *MHFormer [20] | 351 | 39.2 | 43.1 | 40.1 | 40.9 | 44.9 | 51.2 | 40.6 | 41.3 | 53.5 | 60.3 | 43.7 | 41.1 | 43.8 | 29.8 | 30.6 | 43.0 |
| MixSTE [47] | 243 | 37.6 | 40.9 | 37.3 | 39.7 | 42.3 | 49.9 | 40.1 | 39.8 | 51.7 | 55.0 | 42.1 | 39.8 | 41.0 | 27.9 | 27.9 | 40.9 |
| P-STMO [36] | 243 | 38.9 | 42.7 | 40.4 | 41.1 | 45.6 | 49.7 | 40.9 | 39.9 | 55.5 | 59.4 | 44.9 | 42.2 | 42.7 | 29.4 | 29.4 | 42.8 |
| StridedFormer [19] | 351 | 40.3 | 43.3 | 40.2 | 42.3 | 45.6 | 52.3 | 41.8 | 40.5 | 55.9 | 60.6 | 44.2 | 43.0 | 44.2 | 30.0 | 30.2 | 43.7 |
| Einfalt et al. [11] | 351 | 39.6 | 43.8 | 40.2 | 42.4 | 46.5 | 53.9 | 42.3 | 42.5 | 55.7 | 62.3 | 45.1 | 43.0 | 44.7 | 30.1 | 30.8 | 44.2 |
| STCFormer [40] | 243 | 39.6 | 41.6 | 37.4 | 38.8 | 43.1 | 51.1 | 39.1 | 39.7 | 51.4 | 57.4 | 41.8 | 38.5 | 40.7 | 27.1 | 28.6 | 41.0 |
| STCFormer-L [40] | 243 | 38.4 | 41.2 | 36.8 | 38.0 | 42.7 | 50.5 | 38.7 | 38.2 | 52.5 | 56.8 | 41.8 | 38.4 | 40.2 | 26.2 | 27.7 | 40.5 |
| UPS [12] | 243 | 37.5 | 39.2 | 36.9 | 40.6 | 39.3 | 46.8 | 39.0 | 41.7 | 50.6 | 63.5 | 40.4 | 37.8 | 44.2 | 26.7 | 29.1 | 40.8 |
| GLA-GCN [44] | 243 | 41.3 | 44.3 | 40.8 | 41.8 | 45.9 | 54.1 | 42.1 | 41.5 | 57.8 | 62.9 | 45.0 | 42.8 | 45.9 | 29.4 | 29.9 | 44.4 |
| † MotionBERT [53] | 243 | 36.6 | 39.3 | 37.8 | 33.5 | 41.4 | 49.9 | 37.0 | 35.5 | 50.4 | 56.5 | 41.4 | 38.2 | 37.3 | 26.2 | 26.9 | 39.2 |
| HDFormer [3] | 96 | 38.1 | 43.1 | 39.3 | 39.4 | 44.3 | 49.1 | 41.3 | 40.8 | 53.1 | 62.1 | 43.3 | 41.8 | 43.1 | 31.0 | 29.7 | 42.6 |
| HSTFormer [33] | 81 | 39.5 | 42.0 | 39.9 | 40.8 | 44.4 | 50.9 | 40.9 | 41.3 | 54.7 | 58.8 | 43.6 | 40.7 | 43.4 | 30.1 | 30.4 | 42.7 |
| MotionAGFormer-XS | 27 | 42.7 | 46.7 | 41.1 | 39.4 | 47.0 | 56.3 | 44.4 | 41.0 | 52.4 | 66.3 | 46.7 | 43.2 | 43.4 | 32.4 | 34.0 | 45.1 |
| MotionAGFormer-S | 81 | 41.9 | 42.7 | 40.4 | 37.6 | 45.6 | 51.3 | 41.0 | 38.0 | 54.1 | 58.8 | 45.5 | 40.4 | 39.8 | 29.4 | 31.0 | 42.5 |
| MotionAGFormer-B | 243 | 36.4 | 38.4 | 36.8 | 32.9 | 40.9 | 48.5 | 36.6 | 34.6 | 51.7 | 52.8 | 41.0 | 36.4 | 36.5 | 26.7 | 27.0 | 38.4 |
| MotionAGFormer-L | 243 | 36.8 | 38.5 | 35.9 | 33.0 | 41.1 | 48.6 | 38.0 | 34.8 | 49.0 | 51.4 | 40.3 | 37.4 | 36.3 | 27.2 | 27.2 | 38.4 |
| P-MPJPE | Dire. | Disc. | Eat | Greet | Phone | Photo | Pose | Purch. | Sit | SitD | Smoke | Wait | WalkD | Walk | WalkT | Avg | |
| MHFormer [20] | 351 | 31.5 | 34.9 | 32.8 | 33.6 | 35.3 | 39.6 | 32.0 | 32.2 | 43.5 | 48.7 | 36.4 | 32.6 | 34.3 | 23.9 | 25.1 | 34.4 |
| MixSTE [47] | 243 | 30.8 | 33.1 | 30.3 | 31.8 | 33.1 | 39.1 | 31.1 | 30.5 | 42.5 | 44.5 | 34.0 | 30.8 | 32.7 | 22.1 | 22.9 | 32.6 |
| P-STMO [36] | 243 | 31.3 | 35.2 | 32.9 | 33.9 | 35.4 | 39.3 | 32.5 | 31.5 | 44.6 | 48.2 | 36.3 | 32.9 | 34.4 | 23.8 | 23.9 | 34.4 |
| StridedFormer [19] | 351 | 32.7 | 35.5 | 32.5 | 35.4 | 35.9 | 41.6 | 33.0 | 31.9 | 45.1 | 50.1 | 36.3 | 33.5 | 35.1 | 23.9 | 25.0 | 35.2 |
| Einfalt et al. [11] | 351 | 32.7 | 36.1 | 33.4 | 36.0 | 36.1 | 42.0 | 33.3 | 33.1 | 45.4 | 50.7 | 37.0 | 34.1 | 35.9 | 24.4 | 25.4 | 35.7 |
| STCFormer [40] | 243 | 29.5 | 33.2 | 30.6 | 31.0 | 33.0 | 38.0 | 30.4 | 29.4 | 41.8 | 45.2 | 33.6 | 29.5 | 31.6 | 21.3 | 22.6 | 32.0 |
| STCFormer-L [40] | 243 | 29.3 | 33.0 | 30.7 | 30.6 | 32.7 | 38.2 | 29.7 | 28.8 | 42.2 | 45.0 | 33.3 | 29.4 | 31.5 | 20.9 | 22.3 | 31.8 |
| UPS [12] | 243 | 30.3 | 32.2 | 30.8 | 33.1 | 31.1 | 35.2 | 30.3 | 32.1 | 39.4 | 49.6 | 32.9 | 29.2 | 33.9 | 21.6 | 24.5 | 32.5 |
| GLA-GCN [44] | 243 | 32.4 | 35.3 | 32.6 | 34.2 | 35.0 | 42.1 | 32.1 | 31.9 | 45.5 | 49.5 | 36.1 | 32.4 | 35.6 | 23.5 | 24.7 | 34.8 |
| † MotionBERT [53] | 243 | 30.8 | 32.8 | 32.4 | 28.7 | 34.3 | 38.9 | 30.1 | 30.0 | 42.5 | 49.7 | 36.0 | 30.8 | 22.0 | 31.7 | 23.0 | 32.9 |
| HDFormer [3] | 96 | 29.6 | 33.8 | 31.7 | 31.3 | 33.7 | 37.7 | 30.6 | 31.0 | 41.4 | 47.6 | 35.0 | 30.9 | 33.7 | 25.3 | 23.6 | 33.1 |
| HSTFormer [33] | 81 | 31.1 | 33.7 | 33.0 | 33.2 | 33.6 | 38.8 | 31.9 | 31.5 | 43.7 | 46.3 | 35.7 | 31.5 | 33.1 | 24.2 | 24.5 | 33.7 |
| MotionAGFormer-XS | 27 | 34.4 | 37.6 | 34.7 | 33.0 | 38.4 | 43.4 | 34.7 | 33.8 | 44.6 | 53.6 | 39.4 | 34.5 | 36.2 | 26.4 | 28.5 | 36.9 |
| MotionAGFormer-S | 81 | 33.7 | 35.0 | 34.8 | 31.2 | 37.9 | 40.8 | 33.2 | 32.6 | 45.3 | 50.5 | 38.7 | 32.7 | 33.4 | 24.1 | 25.7 | 35.3 |
| MotionAGFormer-B | 243 | 30.6 | 32.6 | 32.2 | 28.2 | 33.8 | 38.6 | 30.5 | 29.9 | 43.3 | 47.0 | 35.2 | 29.8 | 31.4 | 22.7 | 23.5 | 32.6 |
| MotionAGFormer-L | 243 | 31.0 | 32.6 | 31.0 | 27.9 | 34.0 | 38.7 | 31.5 | 30.0 | 41.4 | 45.4 | 34.8 | 30.8 | 31.3 | 22.8 | 23.2 | 32.5 |
To assess the effectiveness of our proposed methods for each action, Table 8 provides a comparison of P1 and P2 errors between our method and alternative methods on the Human3.6M dataset. Our proposed methods demonstrate superior performance in terms of P1 error across various actions such as Direction, Discuss, Eating, Greet, Purchase, Sitting, Sitting Down, Smoke, Wait, and Walk Dog, when compared to other existing methods. For the remaining actions, our methods deliver the second-best results.
A.2 Per-joint Error Comparison
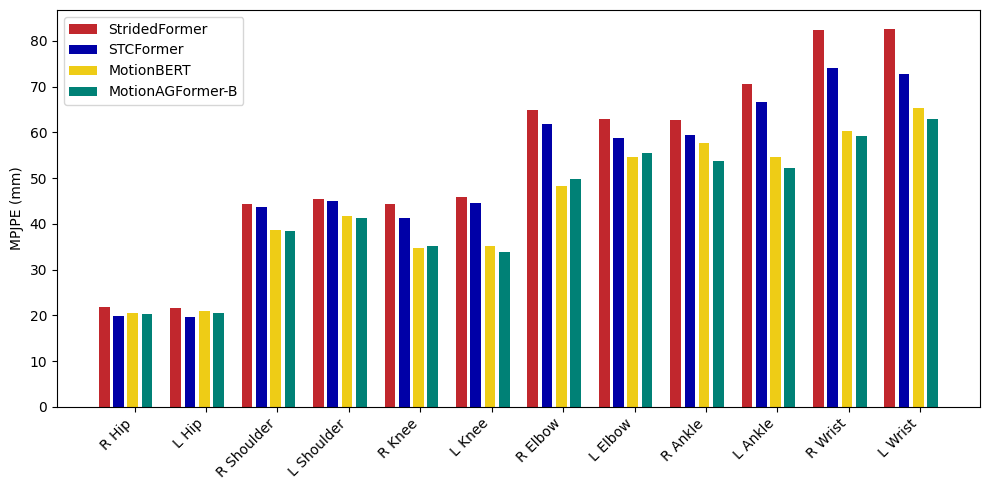
Figure 7 shows per-joint comparisons of MotionAGFormer-B, MotionBERT, STCFormer, and StridedFormer on Human3.6M benchmark dataset. STCFormer demonstrates a slight performance advantage on hips, whereas for shoulders, MotionAGFormer exhibits a slight superiority over MotionBERT and significantly outperforms other models. MotionBERT generally outperforms MotionAGFormer on joints with a degree of freedom (DoF) of 2, including knees and elbows, with a notable gap between them and other models. However, for joints with a DoF of 3, such as ankles and wrists, MotionAGFormer consistently outperforms all other models, which is particularly important due to their greater contribution to overall error and their significance in applications like hand/object interaction and gait analysis.
Appendix B Ablation on Temporal GCNFormer
In the main manuscript, we examined various alternatives for the temporal GCNFormer and reported their corresponding P1 errors. Nevertheless, we have yet to investigate the acceleration error associated with each of these alternatives. The acceleration error is defined as follows:
| (10) | ||||
where and denote the ground truth 3D pose and estimated 3D pose, respectively.
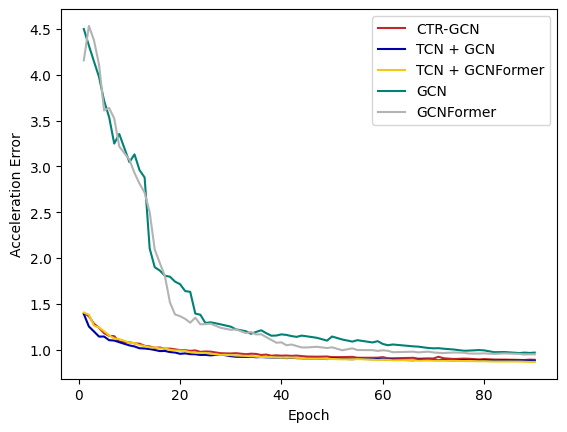
Figure 8 illustrates the acceleration error of different models when used to capture temporal local dependencies. Interestingly, despite CTR-GCN and TCN resulting in higher P1 error (as mentioned in the main manuscript), their acceleration error convergence during training is faster. In addition, it leads to an eventual acceleration error improvement of approximately 0.1 mm.
Appendix C Qualitative comparison for a sequence
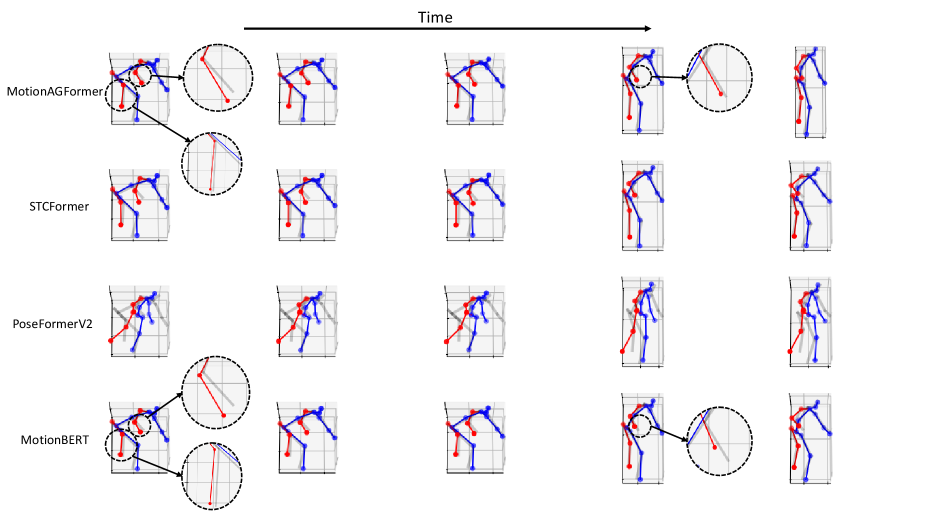
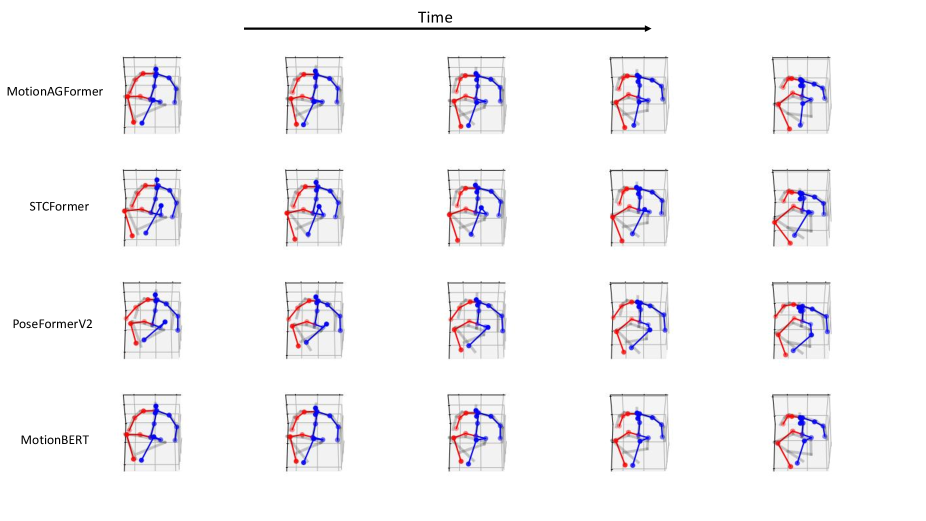
Apart from making qualitative comparisons using a random frame from the Human3.6M dataset, we also analyzed consecutive frames within a single sequence. This allows us to observe the behavior of the compared models over a sequence, rather than qualitatively evaluating them solely based on a single frame. Figure 9 compares MotionAGFormer-B with STCFormer, PoseFormerV2, and MotionBERT. Overall, MotionAGFormer and MotionBERT demonstrate superior alignment with the ground truth compared to the other two models. When comparing MotionAGFormer and MotionBERT, MotionAGFormer exhibits slightly better performance on joints with a DoF, such as wrists and ankles, as opposed to MotionBERT. There are also challenging sequences (see Figure 10) that all models fail to accurately estimate the joints.
Appendix D In-the-wild Evaluation
To verify the generalization of the proposed MotionAGFormer, we tested our base variant on some unseen in-the-wild videos. Our estimations show that even in scenarios where the inferred 2D poses exhibit some noise (as observed in the final frame of the second example shown in Figure 11), the corresponding 3D pose estimations remain reasonable and resilient against sudden noisy movements in the 2D sequence. Moreover, when the subject is positioned at a distance from the camera, the 3D pose estimates exhibit a high degree of accuracy (as demonstrated in the last example of Figure 11).
