Modular control of Boolean network models
Abstract
The concept of control is crucial for effectively understanding and applying biological network models. Key structural features relate to control functions through gene regulation, signaling, or metabolic mechanisms, and computational models need to encode these. Applications often focus on model-based control, such as in biomedicine or metabolic engineering. In a recent paper, the authors developed a theoretical framework of modularity in Boolean networks, which lead to a canonical semidirect product decomposition of these systems. In this paper, we present an approach to model-based control that exploits this modular structure, as well as the canalizing features of the regulatory mechanisms. We show how to identify control strategies from the individual modules, and we present a criterion based on canalizing features of the regulatory rules to identify modules that do not contribute to network control and can be excluded. For even moderately sized networks, finding global control inputs is computationally challenging. Our modular approach leads to an efficient approach to solving this problem. We apply it to a published Boolean network model of blood cancer large granular lymphocyte (T-LGL) leukemia to identify a minimal control set that achieves a desired control objective.
1Department of Mathematics, University of Kentucky, Lexington, KY 40506, USA
2Department of Mathematics, University of Dayton, Dayton, OH 45469, USA
3Mathematics Department, California Polytechnic State University, San Luis Obispo, CA 93407, USA
4Department of Mathematics, Iowa State University, Ames, IA 50011, USA
5Department of Medicine, University of Florida, Gainesville, FL 32610, USA
Keywords— Boolean networks, modularity, control, canalization, gene regulatory networks.
1 Introduction
With the availability of more experimental data and information about the structure of biological networks, computational modeling can capture increasingly complex features of biological networks [1, 2]. However, the increased size and complexity of dynamic network models also poses challenges in understanding and applying their structure as a tool for model-based control, important for a range of applications [3, 4]. This is our focus here. To narrow the scope of the problems we address we limit ourselves to intracellular networks represented by Boolean network (BN) models. BNs are widely used in molecular systems biology to capture the coarse-grained dynamics of a variety of regulatory networks [5]. They have been shown to provide a good approximation of the dynamics of continuous processes [6].
For the commonly-used modeling framework of ordinary differential equations, there is a well-developed theory of optimal control, which is largely absent from other modeling frameworks, such as Boolean networks or agent-based models, both frequently used in systems biology and biomedicine. Furthermore, control inputs, in many cases, are of a binary nature, such as gene knockouts or the blocking of mechanisms. Existing Boolean network control methods do not scale well. As networks get larger, with hundreds [7] or even thousands of nodes [8], only few computational tools can identify control inputs for achieving preselected objectives, such as moving a network from one phenotype (e.g., cancer) to another (e.g., normal). One approach is to reduce the system in a way that the reduced system maintains relevant dynamical properties such as its attractors [9, 10]. This allows the control methods to be applied to the reduced system, and the same controls can then be used for the original system.
Control targets in Boolean networks have been identified by a variety of approaches: using stable motifs [11, 12], feedback vertex sets [13, 14], trap spaces [15, 16], model checking [17], and other methods [18, 19]. A few further approaches have explicitly used strongly connected components (SCCs) for model analysis by decomposing the wiring diagram or the state space of the network [20, 21]. For example, stable motifs describe a set of network nodes and their corresponding states which are such that the nodes form a minimal SCC (e.g. a feedback loop) and their states form a partial fixed point of the Boolean network [22, 11]. An identification of the stable motifs yields not only an efficient way to derive the network attractors but also control targets. Trap spaces, defined in [23] and related to stable motifs, are subspaces of the entire state space of a Boolean network that the dynamics cannot escape. Trap spaces, which can often be efficiently computed for biological Boolean models, have recently been used to simplify the identification of both network attractors and controls [15, 16]. However, to our knowledge, none of the approaches developed thus far exploit the modular structure exhibited by many biological systems, in order to identify control strategies by focusing on one module at a time, which is the approach used in this paper. This approach can substantially simplify the problem of identifying suitable controls, specifically in networks that consist of multiple decently-sized modules. For example, we showed in [24] that our modular approach can efficiently solve the control identification problem for a 69-node pancreatic cancer model that consists of three modules of size greater than one, plus a number of single-node modules. Some of the existing control methods can often not handle reasonably large models of e.g. 70 nodes, as has been shown in [4, 25]. It is important to note, however, that our control approach does not guarantee finding a control of minimal size or all possible controls that achieve a given objective.
Modularity refers to the division of the system into separate units, or modules, that each have a specific function [26, 27]. Modularity is a fundamental property of biological systems that is essential for the evolution of new functions and the development of robustness [28, 29]. In [24], we developed a mathematical theory of modularity for Boolean network models and showed that one can identify network-level control inputs at the modular level. That is, we obtain global control inputs by identifying them at the local, modular level and assembling them to global control. This enables network control for much larger networks than would otherwise be computationally unfeasible. It is worth noting that, although the ideas and concepts behind our approach to modularity are intuitive and natural, to our knowledge, we developed the first rigorous mathematical theory of modular decomposition of Boolean networks, which we expand to questions related to the identification of biological network controls in this paper.
We further propose to use another property of biological networks, represented through Boolean network models. Almost all Boolean rules that describe the dynamics of over 120 published, expert-curated biological Boolean network models have the property that they exhibit some degree of canalization [30]. A Boolean function is canalizing if it has one or more variables that, when they take on a particular value, they determine the value of the function, irrespective of the values of all the other variables. As an example, any variable in a conjunctive rule (e.g., ) determines the value of the entire rule, when it takes on the value 0. We derive a criterion for Boolean network models whose Boolean functions are all canalizing, that can be used to exclude certain modules from needing to be considered for the identification of controls.
Our approach to control via modularity is summarized in Figure 1. We decompose the network into its constituent modules, then apply control methods to each module to identify a control target for the entire network. We show that by combining the controls of the modules, we can control the entire network. In the last part of the paper, we present theoretical results that exploit the canalizing properties of the regulatory functions to exclude certain modules from the control search. Finally, we demonstrate our approach by applying it to a published model of the blood cancer large granular lymphocyte (T-LGL) leukemia [31].

2 Background
We first describe Boolean networks and how to decompose a network into modules. In a BN, each gene is represented by a node that can be in one of two states: ON or OFF. Time is discretized as well, and the state of a gene at the next time step is determined by a Boolean function that takes as input the current states of a subset of the nodes in the BN. The dependence of a gene on the state of another gene can be graphically represented by a directed edge, and the wiring diagram contains all such dependencies.
2.1 Boolean Networks
Boolean networks can be seen as discrete dynamical systems. Specifically, consider variables each of which can take values in , where is the field with two elements, 0 and 1, where arithmetic is performed modulo 2. Then, a synchronously updated Boolean network is a function , where each coordinate function describes how the future value of variable depends on the present values of all variables. All variables are updated at the same time (synchronously).
Definition 2.1.
The wiring diagram of a Boolean network is the directed graph with vertices and an edge from to if depends on . That is, if there exists such that where is the th unit vector.
Definition 2.2.
The wiring diagram of a Boolean network is strongly connected if every pair of nodes is connected by a directed path. That is, for each pair of nodes in the wiring diagram with there exists a directed path from to (and vice versa). In particular, a one-node wiring diagram is strongly connected by definition.
Remark 2.3.
The wiring diagram of any Boolean network is either strongly connected or it is composed of a collection of strongly connected components where connections between different components move in only one direction.
Example 2.4.

2.2 Dynamics of Boolean networks
Another directed graph associated with a BN is the state transition graph, also referred to as the state space. It describes all possible transitions of the BN from one time step to the next. The attractors of a BN are minimal sets of states from which there is no escape as the system evolves. An attractor with a single state is also called a steady state (or fixed point). In mathematical models of intracellular regulatory networks, the attractors of the model are often associated with the possible phenotypes of the cell. This idea can be traced back to Waddington [32] and Kauffman [33]. For example, in a model of cancer cells, the steady states of the model correspond to proliferative, apoptotic, or growth-arrest phenotypes [34]. Mathematically, a phenotype is associated with a group of attractors where a subset of the system’s variables have the same states. These shared states are then used as biomarkers that indicate diverse hallmarks of the system.
There are two ways to describe the dynamics of a Boolean network , (i) as trajectories for all possible initial conditions, or (ii) as a directed graph with nodes in . Although the first description is less compact, it will allow us to formalize the dynamics of coupled networks.
Definition 2.5.
A trajectory of a Boolean network is a sequence of elements of such that for all .
Example 2.6.
For the network in the example above, , there are possible initial states giving rise to the following trajectories (commas and parenthesis for states are omitted for brevity).
We can see that and are periodic trajectories with period 2. Similarly, and are periodic with period 1. All other trajectories eventually reach one of these 4 states.
When seen as trajectories, and are different, but they can both be encoded by the fact that and . Similarly, and can be encoded by the equalities and . This alternative, more compact way of encoding the dynamics of a Boolean network is the standard approach, which we formalize next.
Definition 2.7.
The state space of a (synchronously updated) Boolean network is a directed graph with vertices in and an edge from to if .
Example 2.8.
From the state space, one can easily obtain all periodic points, which form the attractors of the network.
Definition 2.9.
The set of attractors for a Boolean network is the set of all minimal nonempty subsets satisfying .
-
1.
The subset of sets of exact size 1 consists of all steady states (also known as fixed points) of .
-
2.
The subset of sets of exact size consists of all cycles of length of .
Equivalently, an attractor of length is an ordered set with elements, , such that .
Remark 2.10.
In the case of steady states, the attractor may be denoted simply by .
2.3 Modules
In [24], a concept of modularity was introduced for Boolean networks. The decomposition into modules occurs on structural (wiring diagram) level but induces an analogous decomposition of the network dynamics, in the sense that one can recover the dynamics of the entire network from the dynamics of the modules. For this decomposition, a module of a BN is defined as a subnetwork that is itself a BN with external parameters in the subset of variables that specifies a strongly connected component (SCC) in the wiring diagram (see Example 2.12). More precisely, for a Boolean network and subset of its variables , we define the restriction of to to be the BN , where for . We note that might contain inputs that are not part of (e.g., when is regulated by some variables that are not in ). Therefore, the BN may contain external parameters (which are themselves fixed and do not possess an update rule). Given a with wiring diagram , let be the SCCs of with pairwise disjoint sets of variables . The modules of are then the restrictions to these sets of variables, . Further, the modular structure of can be described by a directed acyclic graph with vertex set (where we contracted each SCC into a single vertex) and edge set by setting whenever there exists a node from to (we show a modular decomposition of a small BN in Example 2.12).
Example 2.12.
Consider the Boolean network
with wiring diagram in Figure 3a. The restriction of this network to is the 2-variable network , which forms the first module (indicated by the amber box in Figure 3a), while the restriction of to is the 2-variable network with external parameters and , which forms the second module (indicated by the green module in Figure 3a). Note that the module , i.e., the restriction of to , is simply the projection of onto the variables because does not receive feedback from the other component.
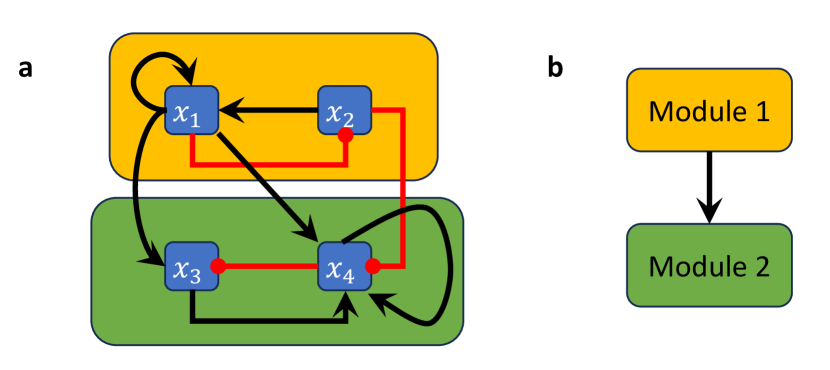
3 Control via Modularity
In this section, we apply the modular decomposition theory described in the previous section and in [24] to make the control problem of Boolean networks more tractable. We show how the decomposition into modules can be used to obtain controls for each module, which can then be combined to obtain a control for the entire network. In this context, two types of control actions are generally considered: edge controls and node controls. For each type of control, one can consider deletions or constant expressions as defined below. The motivation for considering these control actions is that they represent the common interventions that can be implemented in practice. For instance, edge deletions can be achieved by the use of therapeutic drugs that target specific gene interactions, whereas node deletions represent the blocking of effects of products of genes associated to these nodes; see [35, 36].
Once the modules have been identified, different methods for phenotype control (that is, control of the attractor space) can be used to identify controls in these networks. Some of these methods employ stable motifs [11], feedback vertex sets [13], as well as algebraic approaches [37, 38, 39]. For our examples below, we will use the methods defined in [11, 37, 13] to find controls for the modules.
A Boolean network with control is a Boolean network , where is a set that denotes all possible controls, defined below. The case of no control coincides with the original Boolean network, that is, . Given a control , the dynamics are given by . See [37] for additional details and examples of how to encode control edges and nodes in a Boolean network.
Definition 3.1 (Edge Control).
Consider the edge in the wiring diagram . The function
| (1) |
where is a constant in , encodes the control of the edge , since for each possible value of we have the following control settings:
-
•
If , . That is, the control is not active.
-
•
If , . In this case, the control is active, and the action represents the removal of the edge when , and the constant expression of the edge if . We use to denote that the control is active.
This definition can be easily extended for the control of many edges, so that we obtain , where is the number of edges in the wiring diagram. Each coordinate, , of in encodes the control of an edge .
Definition 3.2 (Node Control).
Consider the node in the wiring diagram . The function
| (2) |
encodes the control (knock-out or constant expression) of the node , since for each possible value of we have the following control settings:
-
•
For , . That is, the control is not active.
-
•
For , . This action represents the knock-out of the node .
-
•
For , . This action represents the constant expression of the node .
-
•
For , . This action changes the Boolean function to its negative value. This case is usually not considered in the control search since it is biologically impractical to implement.
We note that the algebraic framework is versatile enough that we can encode any type of control, such as a combination of node and edge control at the same time.
Definition 3.3.
For a Boolean network , we let denote the set of its attractors. Whenever a Boolean network has more than one module we say that it is decomposable into its constituent modules (), and write where the semi-product operation indicates the coupling of the subnetworks, as described in [24] (see Example 3.4 for an example of coupling). Furthermore, from the decomposition theory described in [24], the attractors of are of the form where is an attractor of the subnetwork, for (one can think of this direct sum operation as concatenating the attractors from the different modules, see Example 3.6 where we show an example of this operation).
Example 3.4.
Consider the Boolean network in Example 2.12,
with wiring diagram in Figure 3a. Let be the restriction of to which forms the first module (indicated by the amber box in Figure 3a) and let be the restriction of to , which forms the second module (indicated by the green box in Figure 3a). Here, and are external parameters of that take the place of and , which is indicated by the coupling . is thus decomposable into and and we have .
The following theorem takes advantage of the modular structure of the network to find controls one module at a time.
Theorem 3.5.
Given a decomposable network , if is a control that stabilizes in (whether is an existing attractor of or a new one, after applying control ) and is a control that stabilizes in (whether is an existing attractor of or a new one, after applying control ), then is a control that stabilizes in provided that at least one of or is a steady state.
Proof.
Let be the resulting network after applying the control . Thus, the dynamics of is , that is . Similarly, the dynamics of is . Let be the network that results after setting all external parameters of to the states of and applying the control . Then, . Thus,
Therefore,
For the last equality we used the fact that the product of a steady state and a cycle (or vice versa) will result in only one attractor for the combined network. Notice, however, that multiplying two attractors (of length greater than 1) might result in several attractors for the composed network due to the attractors starting at different states.
It follows that there is only one attractor of and that attractor is . Thus, is stabilized by and we have .
Example 3.6.
Consider the network whose wiring diagram and state space are given in Figure 4, which can be decomposed into , with where and where and is an external parameter. Here the coupling is given by . Suppose we want to stabilize in 0110, which is not an attractor of (see Figure 4(c)). The set of attractors of is given by .
-
•
Consider the control . That is, the control is the combined action of setting the input from to to 1 and the input from to to 0. The control stabilizes at , which is not an original attractor of . Let . Let be the network that results after setting all external parameters of to the states of . Note that the space of attractors for is .
-
•
Now consider the control . That is, the control is the combined action of setting the input from to to 1 and the input from to to 0. This control stabilizes at , which is not an original attractor of .
-
•
Finally, the control stabilizes at by Theorem 3.5.
Theorem 3.5 shows how the modular structure can be used to identify controls that stabilize the network in any desired state. In particular, we can use the modular structure of a network to find controls that stabilize a network at an existing attractor, which is often the case in biological control applications. We state this fact in the following corollary.
Corollary 3.7.
Given a decomposable network , let be an attractor of , where and and at least or is a steady state. If is a control that stabilizes in and is a control that stabilizes in , then is a control that stabilizes in .
Theorem 3.5 uses the modular structure of a Boolean network to identify controls that stabilize the network in any desired attractor. In biological applications, the attractors typically correspond to distinct biological phenotypes (defined more rigorously in the next section) and a common question is how to force a network to always transition to only one of these phenotypes. For example, cancer biologists may use an appropriate Boolean network model with the two phenotypes proliferation and apoptosis to identify drug targets (i.e., edge or node controls), which force the system to always undergo apoptosis. In [24], we applied the approach described in Corollary 3.7 to find an efficient intervention that solves the control problem for the pancreatic cancer model with 69 nodes. In the following example, we illustrate the approach described in Corollary 3.7 using a toy model.
Example 3.8.
Consider again the network from Example 3.6 with where and where and is an external parameter. Here the coupling is given by . Suppose we want to stabilize in 1111, which is one of the attractors of (see Figure 4(c)). The set of attractors of is . Let .
-
•
The edge control (that is, the control that constantly expresses the edge from to ) stabilizes at . Let be the network that results after setting all external parameters of to the states of . The space of attractors for is then . Note that would be an alternative control.
-
•
The edge control (that is, the control that constantly expresses the edge from to ) stabilizes at . Again, note that would be an alternative control.
-
•
Now, the control stabilizes at by Corollary 3.7.
Remark 3.9.
In Theorem 3.5, we required one of the stabilized attractors to be a steady state in order to be able to combine the controls from the modules. We can remove this requirement by using the following definition of stabilization for non-autonomous networks (defined in [24]), which will guarantee that and can be combined in a unique way, resulting in a unique attractor of the whole network.
Definition 3.10.
[24] A non-autonomous Boolean network is defined by
where and is a sequence with elements in . We call this type of network non-autonomous because its dynamics will depend on . We use to denote this non-autonomous network.
A state is a steady state of if for all . Similarly, an ordered set with elements, , is an attractor of length of if , , , . Note that in general is not necessarily of period and may even not be periodic.
If for some network (that is, it does not depend on ) for all , then and this definition of attractors coincides with the classical definition of attractors for (autonomous) Boolean networks (Definition 2.9).
Definition 3.11.
Consider a controlled non-autonomous network given by , where is a trajectory representation of an attractor of an upstream network. We say that a control stabilizes this network, (as in Definition 3.10), at an attractor when the resulting network after applying (denoted here as ) has as its unique attractor. For non-autonomous networks the definition of unique attractor requires that has a unique periodic trajectory up to shifting of (which is automatically satisfied if or is a steady state).

4 Control via Modularity and Canalization
In addition to using the modular structure of the network, we can take advantage of the canalizing structure of the regulatory functions to identify control targets.
We first review some concepts and definitions, and introduce the concept of canalization.
Definition 4.1.
A Boolean function is essential in the variable if there exists an such that
where is the th unit vector. In that case, we also say depends on .
Definition 4.2.
A Boolean function is canalizing if there exists a variable , a Boolean function and such that
In that case, we say that canalizes (to ) and call the canalizing input (of ) and the canalized output.
Definition 4.3.
A Boolean function is a nested canalizing function (NCF) with respect to the permutation , inputs and outputs , if
The last line ensures that actually depends on all variables.
To account for partial canalization, we also define -canalizing functions, which were first introduced in [41].
Definition 4.4.
A Boolean function is -canalizing, where , with respect to the permutation , inputs , and outputs if
where is the core function, a Boolean function on variables. When is not canalizing, then the integer is the canalizing depth of [42]. Note that an -canalizing function (i.e., a function where all variables become eventually canalizing) is an NCF.
We restate the following stratification theorem for reference.
Theorem 4.5 ([41]).
Every Boolean function can be uniquely written as
| (3) |
where each is a nonconstant function, called an extended monomial, is the core polynomial of , and is the canalizing depth. Each appears in exactly one of , and the only restrictions are the following “exceptional cases”:
-
1.
If and , then ;
-
2.
If and and , then .
When is not canalizing (i.e., when ), we simply have .
Definition 4.6.
Given a Boolean function represented as in Equation 3, we call the extended monomials the layers of and if , we say that and its variables are more dominant and and its variables are less dominant. We also define, as in [43], the layer structure as the vector , which describes the number of variables in each layer.
Note that is nested canalizing if and only if .
Remark 4.7.
Here we note the following important properties of layers of canalization.
-
(a)
Theorem 4.5 shows that any Boolean function has a unique extended monomial form given by Equation 3, in which the variables are partitioned into different layers based on their dominance. Any variable that is canalizing (independent of the values of other variables) is in the first layer. Any variable that “becomes” canalizing when excluding all variables from the first layer is in the second layer, etc. All remaining variables that never become canalizing are part of the core polynomial. The number of variables that eventually become canalizing is the canalizing depth of the function. NCFs are exactly those functions where all variables become eventually canalizing (note not all variables of an NCF must be in the first layer).
-
(b)
While variables in the same layer may have different canalizing input values, they all share the same canalized output value, i.e., they all canalize a function to the same output. On the other hand, the outputs of two consecutive layers are distinct. Therefore, the number of layers of a -canalizing function, expressed as in Definition 4.4, is simply one plus the number of changes in the vector of canalized outputs, .
Example 4.8.
The Boolean functions
are nested canalizing. The function has layer structure because
-
•
canalizes to if it receives its canalizing input ;
-
•
if this is not the case, canalizes to ;
-
•
or canalizes to .
On the other hand, has layer structure . As for , canalizes to . If this does not happen, any of the following, , canalizes to .
While finding the layer structure of a Boolean function is an NP-hard problem, there exist several algorithmic implementations [44].
Next we will define phenotypes. In meaningful biological networks, the attractors correspond to phenotypes. Typically a small subset of all Boolean variables is used to define phenotypes.
Definition 4.9.
Given a Boolean network with attractor space and phenotype-defining variables , we associate the same phenotype to all attractors that are identical in . The states in will be called markers of the phenotype.
Suppose is a decomposable network, and that there is a phenotype that depends on variables in only (that is, all markers of the phenotype are part of ), and that we wish to control the phenotype through . The most straightforward approach is to set the variables that the phenotype depends on to the appropriate values that result in the desired phenotype. However, such intervention may not be experimentally possible. Instead, we can exploit the canalizing properties of the functions corresponding to the nodes connecting the modules and to identify control targets.
By Theorem 4.5, the variables of any Boolean update function can be ordered by importance/dominance, based on which layer they appear in, which is why in Definition 4.6 we called variables in lower/upper layers “more/less dominant,” respectively. Thus, once we control a variable in a certain layer (by setting it to its canalizing input value), any further control of variables in less dominant layers will have no effect on the function (and thus on the network). We state this fact in the following lemma.
Lemma 4.10.
Suppose is a decomposable network. Suppose further that only one node with update function is regulated by nodes in . If is canalizing with layers, let be the most dominant layer of which contains nodes from . If all regulators of from appear in the core polynomial, we set . Then, setting to its canalizing value decouples the systems and , as long as appears in a layer of that is more dominant than .
Proof.
The lemma is a direct consequence of Theorem 4.5. If receives its canalizing input and is in a more dominant layer of than all variables in , then none of these variables can affect anymore. Thus, controlling to receive its canalizing input eliminates the link between and .
The modularity approach in [24] yields an acyclic directed graph after one collapses each module into a single node. This endows a natural partial ordering on the collection modules of a network where one module precedes the next if there is a path for every node in the first module which ends in the second module. While not all modules are comparable, we can speak of chains of modules which consist of subsets of the partial ordering which are totally ordered. Furthermore, one can rank the modules based on the percentile scores (i.e., rank module out of modules). This type of ranking has been studied in [45], where it was shown that the importance of the modules is strongly correlated with the aggressiveness of mutations occurring within those modules and the effectiveness of interventions.
Theorem 4.11.
Suppose is a decomposable network. If for some ,
-
(i)
only one node with update function is regulated by nodes in , and
-
(ii)
is a canalizing function, which possesses none of the variables from in its most dominant layer, and
-
(iii)
the phenotype of interest only depends on variables in as well as modules , for which any chain containing and also contains
then the module can be excluded from the control search by setting any node to its canalizing input, as long as this node appears in a more dominant layer of than all inputs of that are part of .
Proof.
By Lemma 4.10, setting to its canalizing value results in decoupling and . will no longer have any effect on , and thus, due to condition (iii), on the phenotype of interest. Therefore, can be removed from the control search.

The third condition of this theorem is illustrated in Figure 5.
Remark 4.12.
The method in Theorem 4.11 can be extended to the case when and are connected via multiple nodes. In that case, decoupling is achieved through the same procedure presented above, applied to each node in that is regulated by nodes in .

Theorem 4.11 is illustrated in Figure 6. Note that node can be in or some other module as in the figure. In this theorem, we assumed that none of the variables of are in the most dominant layer in the update rules of variables in . If some variables of are in the most dominant layer, we can still remove module from the control search using an edge control, as shown in the following theorem.
Theorem 4.13.
Suppose is a decomposable network. If for some ,
-
(i)
only one node with update function is regulated by nodes in , and
-
(ii)
is a canalizing function with some variables from in its most dominant layer, and
-
(iii)
the phenotype of interest only depends on variables in as well as modules , for which any chain containing and also contains
then the module can be excluded from the control search by applying an edge control to any input in the most dominant layer of .
Proof.
Let such that appears as a variable in , and that is located in the most dominant layer . Then, setting to its canalizing value results in decoupling the subnetworks and . Thus, will no longer have any effect on and thus it can be removed from the control search.
Remark 4.14.
The method can be extended to the case when and are connected via multiple nodes (that is, condition (i) in Theorem 4.11 and Theorem 4.13 can be relaxed. In that case decoupling is achieved through the same procedure presented above, applied to each node in with regulators from .
We further note that condition (ii) in the theorems above is generally very restrictive as only a small proportion of Boolean functions in variables are canalizing, let alone nested canalizing. However, as shown in [30], most biological Boolean network models are almost entirely governed by nested canalizing functions.
5 An application: Control of a Blood Cancer Boolean Model
To showcase these methods, we will now decompose a published Boolean network model into its modules, and then identify the minimal set of controls for the entire network by exploiting the canalizing structure of the regulatory functions within the modules. The identified set of controls will force the entire system into a desired attractor.

We consider a Boolean network model for the blood cancer large granular lymphocyte (T-LGL) leukemia, which was published in [31]. T-LGL leukemia is a clonal hematological disorder characterized by persistent increases of large granular lymphocytes in the absence of reactive cause [46]. The wiring diagram of this model is depicted in Figure 7a. This network has 16 nodes and three non-trivial modules (i.e., modules containing more than one node, highlighted by the amber, green, and gray boxes in Figure 7a). The control objective here is to identify control targets that lead the system to programmed cell death. In other words, we aim to direct the system into an attractor that has the marker apoptosis ON.
Since the model has three non-trivial modules, the approach described in Section 3 would require us to identify control targets for three modules. However, an exploitation of the canalizing structure and common sense reveals that we do not need to control every module to ensure apoptosis, the desired control objective. First, irrespective of canalization, the module highlighted in gray in Figure 7a does not affect the phenotype apoptosis. Therefore, we can focus on the modules “upstream” of apoptosis (i.e., the amber and green modules in Figure 7a).
In this case, we will apply Theorem 4.13 to identify control targets for this model. We note that the edges from the upstream module (amber box in Figure 7a) to the downstream module (green box in Figure 7a) all end in the node DISC. Therefore, we will investigate the canalizing properties of the regulatory function of DISC (see Figure 7b),
Using the approach described in [44], we find that has two canalizing layers, and , and extended monomial form (Theorem 4.5) given in Figure 7c).
We note that the only variable in the most dominant canalizing layer, , is in the upstream module. Thus, we can decouple the modules via an edge control on the connection between the upstream and downstream modules. That is, the constant expression of the edge from Ceramide to DISC will decouple the two modules and will lead to constant expression of DISC. We can check that this control is effective at stabilizing the system in the desired attractor and the control set obviously has minimal size.
In summary, in this example we used an edge control to decouple the upstream and downstream modules and then identified a control target in the downstream module which contains the markers of the phenotype of interest.
6 Conclusion
Model-based control is a mainstay of industrial engineering, and there is a well-developed mathematical theory of optimal control that can be applied to models consisting of systems of ordinary differential equations. While this model type is also commonly used in biology, for instance in biochemical network modeling or epidemiology and ecology, there are many biological systems that are more suitably modeled in other ways. Boolean network models provide a way to encode regulatory rules in networks that can be used to capture qualitative properties of biological networks, when it is unfeasible or unnecessary to determine kinetic information. While they are intuitive to build, they have the drawback that there is very little mathematical theory available that can be used for model analysis, beyond simulation approaches. And for large networks, simulation quickly becomes ineffective.
The results in this paper, building on those in [24], can be considered as a contribution to a mathematical control theory for Boolean networks, incorporating key features of biological networks. There are many open problems that remain, and we hope that this work will inspire additional developments.
Our concrete contributions here are as follows. The modularization method makes the control search far more efficient and allows us to combine controls at the module level obtained with different control methods. For example, methods based on computational algebra [37, 39] can identify controllers that can create new (desired) steady states, which other methods cannot. Feedback vertex set [14, 13] is a structure-based method that identifies a subset of nodes whose removal makes the graph acyclic. Stable motifs [11] are based on identifying strongly connected subgraphs in the extended graph representation of the Boolean network. Other control methods include [47, 48, 25]. We can use any combination of these methods to identify the controls in each module.
7 Acknowledgments
Author Matthew Wheeler was supported by The American Association of Immunologists through an Intersect Fellowship for Computational Scientists and Immunologists. This work was further supported by the Simons foundation [grant numbers 712537 (to C.K.), 850896 (to D.M.), 516088 (to A.V.)]; the American Mathematical Society and the Simons Foundation [Enhancement Grant for PUI faculty (to A.V.)]; the National Institute of Health [grant number 1 R01 HL169974-01 (to R.L.)]; and the Defense Advanced Research Projects Agency [grant number HR00112220038 (to R.L.)]. The authors also thank the Banff International Research Station for support through its Focused Research Group program during the week of May 29, 2022 (22frg001), which was of great help in framing initial ideas of this paper.
References
- [1] Boris Aguilar, David L Gibbs, David J Reiss, Mark McConnell, Samuel A Danziger, Andrew Dervan, Matthew Trotter, Douglas Bassett, Robert Hershberg, Alexander V Ratushny, et al. A generalizable data-driven multicellular model of pancreatic ductal adenocarcinoma. GigaScience, 9(7):giaa075, 2020.
- [2] Daniel Plaugher and David Murrugarra. Modeling the pancreatic cancer microenvironment in search of control targets. Bulletin of Mathematical Biology, 83(11):1–26, 2021.
- [3] Jordan Rozum and Réka Albert. Leveraging network structure in nonlinear control. NPJ systems biology and applications, 8(1):36, 2022.
- [4] Daniel Plaugher and David Murrugarra. Phenotype control techniques for boolean gene regulatory networks. Bulletin of Mathematical Biology, 85(10):1–36, 2023.
- [5] Julian D Schwab, Silke D Kühlwein, Nensi Ikonomi, Michael Kühl, and Hans A Kestler. Concepts in boolean network modeling: What do they all mean? Computational and structural biotechnology journal, 18:571–582, 2020.
- [6] Alan Veliz-Cuba, Joseph Arthur, Laura Hochstetler, Victoria Klomps, and Erikka Korpi. On the relationship of steady states of continuous and discrete models arising from biology. Bulletin of mathematical biology, 74:2779–2792, 2012.
- [7] Vidisha Singh, Aurelien Naldi, Sylvain Soliman, and Anna Niarakis. A large-scale boolean model of the rheumatoid arthritis fibroblast-like synoviocytes predicts drug synergies in the arthritic joint. NPJ systems biology and applications, 9, 2023.
- [8] Sara Sadat Aghamiri, Vidisha Singh, Aurélien Naldi, Tomáš Helikar, Sylvain Soliman, and Anna Niarakis. Automated inference of boolean models from molecular interaction maps using casq. Bioinformatics, 36(16):4473–4482, 2020.
- [9] A. Veliz-Cuba. Reduction of Boolean network models. Journal of Theoretical Biology, 289:167–172, 2011.
- [10] Assieh Saadatpour, Réka Albert, and Timothy Reluga. A reduction method for boolean network models proven to conserve attractors. SIAM Journal on Applied Dynamical Systems, 12:1997–2011, 01 2013.
- [11] Jorge GT Zanudo and Réka Albert. Cell fate reprogramming by control of intracellular network dynamics. PLoS computational biology, 11(4):e1004193, 2015.
- [12] Jordan C Rozum, Dávid Deritei, Kyu Hyong Park, Jorge Gómez Tejeda Zañudo, and Réka Albert. pystablemotifs: Python library for attractor identification and control in boolean networks. Bioinformatics, 38(5):1465–1466, 2022.
- [13] Jorge Gomez Tejeda Zañudo, Gang Yang, and Réka Albert. Structure-based control of complex networks with nonlinear dynamics. Proceedings of the National Academy of Sciences, 114(28):7234–7239, 2017.
- [14] Atsushi Mochizuki, Bernold Fiedler, Gen Kurosawa, and Daisuke Saito. Dynamics and control at feedback vertex sets. ii: A faithful monitor to determine the diversity of molecular activities in regulatory networks. Journal of theoretical biology, 335:130–146, 2013.
- [15] Laura Cifuentes Fontanals, Elisa Tonello, and Heike Siebert. Control strategy identification via trap spaces in boolean networks. In Computational Methods in Systems Biology: 18th International Conference, CMSB 2020, Konstanz, Germany, September 23–25, 2020, Proceedings 18, pages 159–175. Springer, 2020.
- [16] Van-Giang Trinh, Kunihiko Hiraishi, and Belaid Benhamou. Computing attractors of large-scale asynchronous boolean networks using minimal trap spaces. In Proceedings of the 13th ACM International conference on bioinformatics, computational biology and health informatics, pages 1–10, 2022.
- [17] Laura Cifuentes-Fontanals, Elisa Tonello, and Heike Siebert. Control in boolean networks with model checking. Frontiers in Applied Mathematics and Statistics, 8:838546, 2022.
- [18] Roland Kaminski, Torsten Schaub, Anne Siegel, and Santiago Videla. Minimal intervention strategies in logical signaling networks with asp. Theory and Practice of Logic Programming, 13(4-5):675–690, 2013.
- [19] Regina Samaga, Axel Von Kamp, and Steffen Klamt. Computing combinatorial intervention strategies and failure modes in signaling networks. Journal of Computational Biology, 17(1):39–53, 2010.
- [20] Gang Wu, Lisha Zhu, Jennifer E Dent, and Christine Nardini. A comprehensive molecular interaction map for rheumatoid arthritis. PLoS One, 5(4):e10137, 2010.
- [21] Abdul Salam Jarrah, Reinhard Laubenbacher, and Alan Veliz-Cuba. The dynamics of conjunctive and disjunctive boolean network models. Bulletin of mathematical biology, 72:1425–1447, 2010.
- [22] Jorge GT Zañudo and Réka Albert. An effective network reduction approach to find the dynamical repertoire of discrete dynamic networks. Chaos: An Interdisciplinary Journal of Nonlinear Science, 23(2), 2013.
- [23] Hannes Klarner, Alexander Bockmayr, and Heike Siebert. Computing maximal and minimal trap spaces of boolean networks. Natural Computing, 14:535–544, 2015.
- [24] Claus Kadelka, Matthew Wheeler, Alan Veliz-Cuba, David Murrugarra, and Reinhard Laubenbacher. Modularity of biological systems: a link between structure and function. Journal of the Royal Society Interface, 20(207):20230505, 2023.
- [25] Enrico Borriello and Bryan C Daniels. The basis of easy controllability in boolean networks. Nature communications, 12(1):1–15, 2021.
- [26] Nadav Kashtan and Uri Alon. Spontaneous evolution of modularity and network motifs. Proceedings of the National Academy of Sciences, 102(39):13773–13778, 2005.
- [27] Leland H Hartwell, John J Hopfield, Stanislas Leibler, and Andrew W Murray. From molecular to modular cell biology. Nature, 402(Suppl 6761):C47–C52, 1999.
- [28] Hiroaki Kitano. Biological robustness. Nature Reviews Genetics, 5(11):826–837, 2004.
- [29] Dirk M Lorenz, Alice Jeng, and Michael W Deem. The emergence of modularity in biological systems. Physics of life reviews, 8(2):129–160, 2011.
- [30] Claus Kadelka, Taras-Michael Butrie, Evan Hilton, Jack Kinseth, Addison Schmidt, and Haris Serdarevic. A meta-analysis of boolean network models reveals design principles of gene regulatory networks. Science Advances, 10(2):eadj0822, 2024.
- [31] Assieh Saadatpour, Rui-Sheng Wang, Aijun Liao, Xin Liu, Thomas P Loughran, István Albert, and Réka Albert. Dynamical and structural analysis of a t cell survival network identifies novel candidate therapeutic targets for large granular lymphocyte leukemia. PLoS Comput Biol, 7(11):e1002267, Nov 2011.
- [32] Conrad Hal Waddington. The strategy of the genes. Routledge, 2014.
- [33] S A Kauffman. Metabolic stability and epigenesis in randomly constructed genetic nets. J Theor Biol, 22(3):437–67, Mar 1969.
- [34] Daniel Plaugher, Boris Aguilar, and David Murrugarra. Uncovering potential interventions for pancreatic cancer patients via mathematical modeling. Journal of theoretical biology, 548:111197, 2022.
- [35] Minsoo Choi, Jue Shi, Sung Hoon Jung, Xi Chen, and Kwang-Hyun Cho. Attractor landscape analysis reveals feedback loops in the p53 network that control the cellular response to dna damage. Science signaling, 5(251):ra83–ra83, 2012.
- [36] David J Wooten, Jorge Gómez Tejeda Zañudo, David Murrugarra, Austin M Perry, Anna Dongari-Bagtzoglou, Reinhard Laubenbacher, Clarissa J Nobile, and Réka Albert. Mathematical modeling of the candida albicans yeast to hyphal transition reveals novel control strategies. PLoS computational biology, 17(3):e1008690, 2021.
- [37] David Murrugarra, Alan Veliz-Cuba, Boris Aguilar, and Reinhard Laubenbacher. Identification of control targets in boolean molecular network models via computational algebra. BMC systems biology, 10:1–11, 2016.
- [38] D Murrugarra and ES Dimitrova. Molecular network control through boolean canalization. eurasip j. Bioinformatics Syst. Biol, 9, 2015.
- [39] Luis Sordo Vieira, Reinhard C Laubenbacher, and David Murrugarra. Control of intracellular molecular networks using algebraic methods. Bulletin of mathematical biology, 82(1):2, 2020.
- [40] Elena S Dimitrova, Adam C Knapp, Brandilyn Stigler, and Michael E Stillman. Cyclone: open-source package for simulation and analysis of finite dynamical systems. Bioinformatics, 39(11):btad634, 10 2023.
- [41] Qijun He and Matthew Macauley. Stratification and enumeration of boolean functions by canalizing depth. Physica D: Nonlinear Phenomena, 314:1–8, 2016.
- [42] Lori Layne, Elena S Dimitrova, and Matthew Macauley. Nested canalyzing depth and network stability. Bulletin of Mathematical Biology, 74(2):422–433, 2012.
- [43] Claus Kadelka, Jack Kuipers, and Reinhard Laubenbacher. The influence of canalization on the robustness of boolean networks. Physica D: Nonlinear Phenomena, 353:39–47, 2017.
- [44] Elena Dimitrova, Brandilyn Stigler, Claus Kadelka, and David Murrugarra. Revealing the canalizing structure of boolean functions: Algorithms and applications. Automatica, 146:110630, 2022.
- [45] Daniel Plaugher and David Murrugarra. Pancreatic cancer mutationscape: revealing the link between modular restructuring and intervention efficacy amidst common mutations. bioRxiv, 2024.
- [46] Anila Rashid, Mohammad Khurshid, and Arsalan Ahmed. T-cell large granular lymphocytic leukemia: 4 cases. Blood research, 49(3):203–205, 2014.
- [47] Sang-Mok Choo, Byunghyun Ban, Jae Il Joo, and Kwang-Hyun Cho. The phenotype control kernel of a biomolecular regulatory network. BMC systems biology, 12(1):1–15, 2018.
- [48] Laura Cifuentes-Fontanals, Elisa Tonello, and Heike Siebert. Control in boolean networks with model checking. Frontiers in Applied Mathematics and Statistics, 8, 2022.