Modelling Orebody Structures:
Block Merging Algorithms and Block Model Spatial Restructuring Strategies Given Mesh Surfaces of Geological Boundaries
Abstract
This paper describes a framework for capturing geological structures in a 3D block model and improving its spatial fidelity, including the correction of stratigraphic, mineralisation and other types of boundaries, given new mesh surfaces. Using surfaces that represent geological boundaries, the objectives are to identify areas where refinement is needed, increase spatial resolution to minimise surface approximation error, reduce redundancy to increase the compactness of the model and identify the geological domain on a block-by-block basis. These objectives are fulfilled by four system components which perform block-surface overlap detection, spatial structure decomposition, sub-blocks consolidation and block tagging, respectively. The main contributions are a coordinate-ascent merging algorithm and a flexible architecture for updating the spatial structure of a block model when given multiple surfaces, which emphasises the ability to selectively retain or modify previously assigned block labels. The techniques employed include block-surface intersection analysis based on the separable axis theorem and ray-tracing for establishing the location of blocks relative to surfaces. To demonstrate the robustness and applicability of the proposed block merging strategy in a more narrow setting, it is used to reduce block fragmentation in an existing model where surfaces are not given and the minimum block size is fixed. To obtain further insight, a systematic comparison with octree subblocking subsequently illustrates the inherent constraints of dyadic hierarchical decomposition and the importance of inter-scale merging. The results show the proposed method produces merged blocks with less extreme aspect ratios and is highly amenable to parallel processing. The overall framework is applicable to orebody modelling given geological boundaries, and 3D segmentation more generally, where there is a need to delineate spatial regions using mesh surfaces within a block model.
Keywords
Block merging algorithms
Block model structure
Spatial restructuring
Mesh surfaces
Subsurface modelling
Geological structures
Sub-blocking
Boundary correction
Domain identification
Iterative Refinement
Geospatial information system.
CCS Concepts:
Applied computing Earth and atmospheric sciences;
Computing methodologies Volumetric models;
Computing methodologies Mesh geometry models.
1 Introduction
This article considers the spatial interaction of triangle-mesh surfaces with a block model as defined by Poniewierski [1]. For this study, a block model may be conceptualised as a collection of rectangular prisms that span a modelled region in 3D space. Using a two-tier description, the block models of interest are formed initially by a set of non-overlapping ‘parent’ blocks; these blocks have identical dimensions and are evenly spaced so they form a regular 3D lattice. Furthermore, a subset of the parent blocks — particularly those that intersect with a surface — are decomposed into smaller cuboids (often referred as ‘children’ or sub-blocks) with the objective of preserving surface curvature subject to a minimum block size constraint. The sub-blocking problem represents a major theme in this paper. A distinguishing feature is that this problem is approached from a merging (bottom-up) perspective which offers opportunities for sub-block consolidation to minimise over-splitting, an issue often neglected in top-down approaches that focus exclusively on making block splitting decisions. The proposed framework allows new block models to be generated within a cell-based system using region partitioning surfaces. This comprises a spatial restructuring strategy that also allows iterative refinement of an existing block model given newer surfaces. At its core is a block merging algorithm that increases block model compaction and reduces spatial fragmentation due to subblocking. As motivation, we describe how this framework is deployed in a mine geology modelling system to illuminate key aspects of the proposal and illustrate what purpose they serve.
In mining, 3D geological models are used in resource assessment to characterise the spatial distribution of minerals in ore deposits [2]. A block model description of the geochemical composition is often created by fusing various sources of information from drilling campaigns, these include for instance: assay analysis, material or geophysical logging and alignment of stratigraphic units from geologic maps during the exploration phase. Due to the sparseness of these samples, the inherent resolution of these preliminary models are typically low. As the exploitation phase commences, denser samples may be taken strategically to develop a deeper understanding about the geology of viable ore deposits. This knowledge can assist miners with planning and various decision making processes [3], for instance, to prioritise areas of excavation, to develop a mining schedule [4], to optimise the quality of an ore blend in a production plant. Of particular relevance to spatial modelling is that wireframe surfaces can be generated by geo-modelling software [5] [6] [7], or via kriging [8], probabilistic boundary estimation [9], boundary propagation (differential geometry) [10] and other inference techniques [11] to minimise the uncertainty of interpolation at locations where data were previously unavailable. For instance, triangle meshes may be created by applying the marching cubes algorithm [12] to Gaussian process implicit surfaces [13]. These boundary updates provide an opportunity to refine existing block models and remove discrepancies with respect to verified boundaries. The objective is to maximise the model’s fidelity by increasing both accuracy and precision subject to some spatial constraints. The desired outcomes are improved localisation, reduced quantisation errors and less spatial fragmentation. In other words, the boundary blocks in the block model should accurately reflect the location of boundaries between geological domains; smaller blocks should be used to capture the curvature of regions near boundaries to minimise the surface approximation error; the model should provide a compact representation and have a low block count to limit spatial fragmentation.
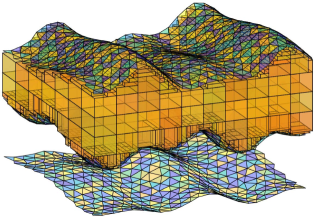
Figure 1 provides a visual summary of the primary objective. A key feature of spatial restructuring is that blocks are divided as necessary to adapt the block model to the curvature of the given surfaces. This process, known as sub-blocking, is commonly performed in a top-down recursive manner which prioritizes splitting ahead of block consolidation. In some implementations, block consolidation is omitted altogether; this usually results in a highly fragmented and inefficient block representation. In this paper, surface-intersecting blocks are decomposed down to some minimum block size, then hierarchical block merging is performed in a bottom-up manner to consolidate the sub-blocks. In the ensuing sections, a framework for modifying the spatial structure of a block model using triangular mesh surfaces is first presented, the techniques underpinning each subsystem are described. Subsequently, we devote our attention to the block merging component, the algorithm is extended to support different forms of merging constraint. The proposed methods are applicable to orebody modelling given surfaces of mineralisation or stratigraphic boundaries — see scenarios illustrated by [14], [15], [16], [17]; and general purpose 3D block-based modelling given other types of delineation.
1.1 Definition of a surface
In this paper, the term ‘surface’ encompasses both 2.5D and 3D surfaces. The former refers to open surfaces or warped 2D planes; these generally include mineralisation, hydration and stratigraphic surfaces in a mining context. The latter refers to closed surfaces that envelop a volume in 3D space. Examples include compact 2-manifolds that are topologically equivalent to a sphere. A simply-connected polyhedron surface would satisfy this requirement and have an Euler-Poincaré characteristic of 2. Closed surfaces may represent regions with local enrichment in an ore deposit or pockets with high level of contaminants.
1.2 Justification for a block-based approach
In our envisaged application, the resultant block structure facilitates volumetric estimation of geochemical or geometallurgical properties within a mine. A block-based representation provides spatial localisation while block labelling provides differentiation between geological domains. These properties are important for two reasons. First, it enables spatially varying signals and non-stationary geostatistics to be learned and captured at an appropriate granularity for mining. Individual blocks can be populated with local estimates of the geochemistry, material type composition or other physical attributes. Second, it prevents sample averaging from being applied across discontinuities (different domains) which can lead to incorrect probabilistic inferences and skewed predictions if applied unknowingly across a boundary with a steep attribute gradient. Although polyhedral, topological and surface-oriented models offer some interesting alternatives, block models have been well established and widely deployed within the resource industry. Introducing a radically different approach will likely cause significant disruption and require changes, acceptance and adaptation by various stakeholders. The proposed block model restructuring strategy is designed to work seamlessly with existing models. It makes changes which are transparent and compatible with subsequent processes such as mining exacavation which also operates on a block scale.
2 Framework for Block Model Spatial Restructuring
This section develops a framework for altering the spatial structure of a block model to reconcile with the shape of the supplied surfaces as depicted in Fig. 1. The input block model consists of non-overlapping blocks of varying sizes (with uniform 3D space partitioning being a special case) and the surfaces, typically produced by boundary modelling techniques, represent the interface between different geological domains. The triangular mesh surfaces, together with the initial block model and block tagging instructions constitute the entire input. The tagging instructions simply assign to each block a label which classifies its location relative to each surface. The framework may be described in terms of four components: block surface overlap detection, block structure decomposition, sub-blocks consolidation and block tagging (domain identification) as shown in Fig. 2.
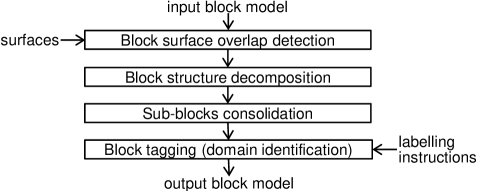
2.1 Block surface overlap detection
The goal is to identify blocks in the input model which intersect with the given surface(s). These represent areas where model refinement is needed in order to minimise the surface approximation error. To establish a sense of scale, the input blocks (also called “parent blocks”) typically measure m in an axis-aligned local frame, “axis-aligned” means the edges of each block are parallel to one of the (x, y or z) axes.
2.2 Block structure decomposition
Block decomposition is performed on surface-intersecting parent blocks to improve spatial localisation. This process divides each block into smaller blocks of some minimum size (e.g., m). These sub-blocks are disjoint and together, they span the whole parent block. Geometry tests are applied to determine which sub-block inside each surface-intersecting parent block actually intersects with a given surface. This process places blocks into one of three categories: (a) parent blocks that never intersect with any surface; or else sub-blocks inside surface-intersecting parent blocks that (b) intersect with a surface or (c) do not intersect with any surface.
2.3 Sub-blocks consolidation
This component coalesces sub-blocks to produce larger blocks in order to prevent over-segmentation. Recall that one of the objective is to minimise the total number of blocks in the output model. Therefore, if an array of sub-blocks could be merged into a perfect rectangular prism, it would be more efficient to represent them collectively by a single block with a new centroid and their combined dimensions.
In the event that the sub-blocks (within a surface-intersecting parent block) intersect with multiple different surfaces (say and ) then merging considerations will be applied separately to the sub-blocks intersecting with and . It is important to observe that block consolidation is applied to both category “b” and category “c” sub-blocks as defined above. Also, merging of sub-blocks across parent block boundaries is not permitted. In Sec. 3.3, we describe in detail the proposed block merging approach which draws inspiration from the coordinate-ascent algorithm.
2.4 Block tagging (domain identification)
As a general principle, block tagging assigns abstract block labels to differentiate blocks located above and below a given surface. The objective is to support tagging with respect to multiple surfaces and two labelling policies. The first policy distinguishes surface-intersecting blocks from non-intersecting blocks. The second policy forces a binary decision and labels surface-intersecting blocks as strictly above or below a surface. The scheme also offers the flexibility of using a surface to limit the scope of an update, thereby leaving previously assigned labels intact above / below a surface. The processes described throughout (Sec. 2.1 – Sec. 2.4) are deterministic and applicable in an iterative setting. This completes our brief overview of the system.
3 Techniques
The techniques used in each component will now be further described. For maximum efficiency, the general set up assumes the modelled region aligns with the xyz axes. If the modelled deposit follows the inclination of a slope, it is assumed that an appropriate 3D rotation is applied to all spatial coordinates before subsequent techniques are applied. This has the effect of producing axis-aligned blocks in the modelling space that ultimately align with the principal orientation of the deposit in real space once the inverse transformation is applied at the conclusion of the process.
3.1 Detecting block surface intersection
The method we employed for determining if an axis-aligned rectangular prism intersects with a triangular patch from a surface is described by Akenine-Möller in [18]. This approach applies the Separating Axis Theorem (SAT) which states that two convex polyhedra, A and B, are disjoint if they can be separated along either an axis parallel to a normal of a face of either A or B, or along an orthogonal axis computed from the cross product of an edge from A with an edge from B. The technical details can be found in Appendix A.
In essence, block-surface intersection assessment consists of a series of “block versus triangle” comparisons where the triangles considered for each block are selected based on spatial proximity. The block-triangle overlap assessment operates on one basic principle: a “no intersection” decision is reached as soon as one of the tests returns false. A block-triangle intersection is found only when all 13 tests return true, when it failed to find any separation. These tests are used to identify the surface triangles (if any) that intersect with each parent block.
To maximise computation efficiency, each block is tested against a subset of triangles on each mesh surface rather than the entire mesh surface. A kD-tree accelerator (a variation of binary space partitioning tree) [19] is constructed using the 3D bounding boxes of each triangle. The subset includes only triangles whose bounding box overlaps with the block; only these candidates can intersect with the block. This pruning step limits the number of comparisons and speeds up computation considerably. The indices harvested here can subsequently reduce the test effort in the block structure decomposition stage.
3.2 Block structure decomposition
The key premise is to decompose surface-intersecting blocks into smaller blocks to improve spatial localisation. The basic intuition is that the surface discretisation error decreases as spatial resolution increases. Precision increases when smaller blocks are used to approximate the surface curvature where the blocks meet the surface.
Block structure decomposition entails the following. For each block () that intersects with the surface, divide it volumetrically into multiple sub-blocks using the specified minimum block dimensions . The main constraints are that sub-blocks cannot overlap and they must be completely contained by the parent block whose volume is the union of all associated sub-blocks.111Although we typically require parent blocks to be divisible by the minimum block dimensions, the method works fine even if fractional blocks emerge during the division, i.e., the last block toward the end is smaller than the minimum size; the ratios in each dimension can be non-integers. This essentially means there is no fundamental limit on the minimum spatial resolution. Within each surface-intersecting parent block, we also identify all sub-blocks that intersect with a surface and which surface they intersect with. This is accomplished using the associative mapping [obtained during block-surface overlap detection] which limits the relevant surface triangles to a small subset for each surface-intersecting parent block. The relevant attributes captured in the output include a list of surface-intersecting parent blocks, and attributes for each sub-block: viz., its centroid, dimensions, parent block index, intersecting surface and position within the parent block.
3.3 Sub-blocks consolidation via coordinate-ascent
The consolidation component focuses on merging sub-blocks inside surface-intersecting parent blocks to reduce block fragmentation. Its basic objective is to minimise the block count, although other mining or geologically relevant criteria such as block aspect ratio can be optimised for. These options are considered later in Sec. 6.1 and Sec. 7.1. For now, these high resolution sub-blocks may themselves intersect or not intersect with any surface. This is indicated in the BlockStructureDecomposition result which serves as input. This component returns the SubBlockConsolidation result which describes the consolidated block structure. This encompasses all parent blocks processed, including those which do not intersect with any surface, as well as sub-blocks or super-blocks that constitute the surface-intersecting parent blocks.
The proposed merging algorithm is inspired by coordinate-ascent optimisation and may be summarised as follows.
-
•
The algorithm is inspired by “coordinate ascent” where the search proceeds along successive coordinate directions in each iteration. The goal is to grow each block (a rectangular prism) from a single cell and find the maximum extent of spatial expansion, , without infringing other blocks or cells that belong to a different class.
-
•
For merging purpose, each parent block is partitioned uniformly down to the minimum block size. The smallest unit (with minimum block size) is referred as a cell. Block dimensions are expressed in terms of the number of cells that span in the x, y and z directions. Accordingly, if a block with cell dimensions is anchored at position , its bounding box would stretch from to for .
-
•
Merging states are managed using a binary occupancy map (boolean 3D array) with cell dimensions identical to the parent block. Given a block anchor position with initialised to , expansion steps are considered in each direction which must alternate through the sequence , and .
-
•
A step in the direction is feasible if all of the cells within the bounding box (, ) are 1 (active). In this case, the spatial extent is updated via . Each iteration steps through , , in turn. This continues until no expansion is possible in any direction, at which point the centroid and dimensions of the merged block are computed and the corresponding cells in the occupancy map are set to 0 (marked as inactive).
-
•
Sub-block merging terminates for a parent block when all cells in the occupancy map are set to 0.
-
•
The volume of a consolidated block is effectively the outer product where , , each represents some integer multiple of the minimum block size, , with respect to x, y and z.
-
•
Different coordinate directions are used cyclically during the procedure. At all times, it must ensure the expansion does not include alien blocks in the encompassing cube, e.g., an L-shape block within a cube is not allowed.
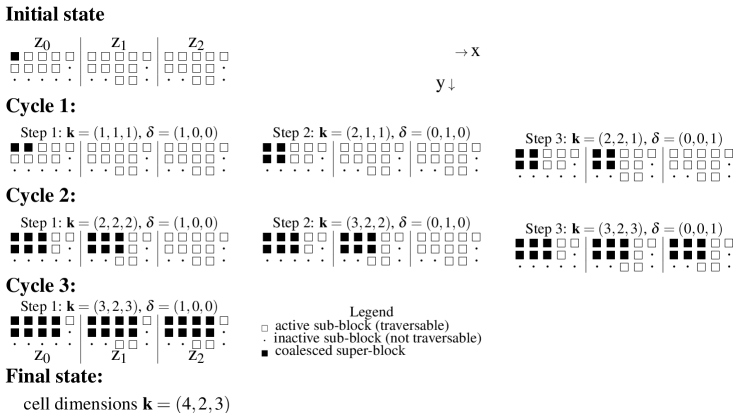
The algorithm is explained by way of an example in Fig. 3. To illustrate the algorithm, let us refer to blocks that belong to the class under consideration as the active cells. In the present context, this refers to either surface-intersecting sub-blocks, , or the non-intersecting sub-blocks, , inside a parent block. The inactive cells (labelled 0) refer to the complementary set to the active cells (labelled 1).
In Fig. 3, suppose the active sub-blocks (cells) refer to . The initial state shows the decomposition of a parent block in terms of three x/y cross-sections. There are sub-blocks (cells) within the parent block and 31 are considered “active”. The white square cells all intersect with the same surface. It so happens the first cell encountered (with index ) is the first active block. The algorithm considers expansion along each axis (x, y and z) in turn. In cycle 1, an expansion step in the x-direction is possible. The progressive expansion of the coalesced block is represented by black square cells. In cycle 2, further growth in the y-direction is not possible due to impediment by one or more “inactive” blocks (denoted by ), however, the x and z dimensions each allow one step expansion. In cycle 3, expansion continues in the x direction, resulting in the formation of a super-block. At this point, a coalesced block is extracted as no further growth in any direction is now possible. Subsequently, the cells which have just been merged are marked out-of-bounds. The process repeats itself, starting with the next active cell it encounters in the raster-scan order.
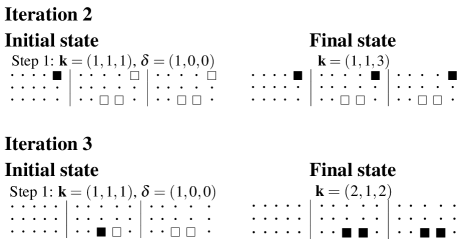
Once all the sub-blocks (cells) are coalesced within the surface-intersecting parent block, we are left with 3 merged blocks (coloured in different shades of red in Fig. 5). These have cell dimensions222These represent multiplying factors relative to the minimum block size. () of , and and relative centroids of , and , respectively, with respect to the parent block’s minimum vertex and parent block dimensions.
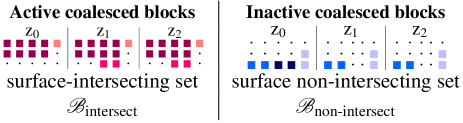
-
•
When multiple surfaces are considered, the coalesce function will next be applied to other sub-blocks (within the same parent block) that intersect with other surfaces. This seldom happens but it is possible if the surfaces are close.
-
•
Finally, the coalesce function is applied to inactive sub-blocks (within the same parent block) which do not intersect with any surface. The result for inactive blocks (coloured in different shades of blue) are shown in Fig. 5.
To summarise, coalescing is applied only to surface-intersecting parent blocks which are subject to decomposition. The sub-blocks contained within may intersect with one or more surfaces, or not intersect with any surface at all. After consolidation, the output contains both the original and merged blocks. Based on the sub-block and surface intersection status, the consolidated blocks may be arranged into two separate sets, and , as shown in Fig. 5. Surface intersecting merged blocks (within surface-intersecting parent blocks) are placed in . Non surface-intersecting merged blocks (within surface-intersecting parent blocks) are placed in . Non surface-intersecting parent blocks are also appended to this. The coordinate ascent algorithm provides a method for merging cells (sub-blocks of minimum size) within the confines of a parent block. Coalesced sub-blocks must share the same label and form a rectangular prism.
3.3.1 Practicalities
Since the cell division lines are identical for all parent blocks of the same size, to avoid having to compute the sub-block centroids and dimensions repeatedly, the cell dimensions and local coordinates of each sub-block’s centroid (relative to the parent block’s minimum vertex) are stored in a look-up table and indexed by parent block dimensions to speed up computation.
3.4 Block tagging: domain identification using surfaces
The primary objective is to label whether a block is located above or below a surface. A picture of this is shown in Fig. 6. More generally, the surface is not always horizontal, so it makes more sense referring to the space on one side of the surface as positive, the other as negative, however this is defined.
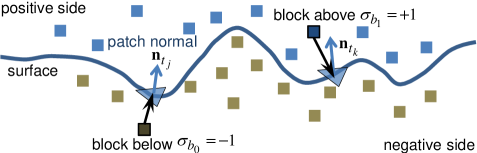
The main points to appreciate in Fig. 6 are that
-
•
Each triangular patch of the surface has a normal vector associated with it. For example, the normal associated with triangle points in the upward direction. This normal is computed by taking the cross product between two of its edges, for instance, . This arrow would point in the opposite direction (rotate by 180o) if the edge traversal direction is reversed; for instance, by swapping two vertices and in the triangle.
-
•
To determine “which side of the surface” a block is on, it suffices to consider the triangular patch located closest to the block. After establishing the positive side as the space ‘above’ the surface, one can say block is located above the surface and has a positive sign () because the inner product is negative. Here, and represent the normal and centroid of triangle , likewise represents the centroid of block . Conversely, block is below the surface and has a negative sign () because the inner product is positive. This ‘projection onto normal’ approach provides the first method for block tagging.
3.4.1 Discussion
For this method to work, the edges for each triangle in the mesh surface must be ordered consistently (e.g., in the anti-clockwise direction) and any ambiguity in regard to surface orientation must be resolved to ensure the assigned labels ultimately conform to user’s expectation — e.g., the positive direction points upward with respect to an open surface (see below) or outward in the case of a closed surface.
3.4.2 Labelling scheme: extension to multiple surfaces
This tagging logic may be extended to multiple surfaces. Fig. 7 depicts a multi-surface scenario and illustrates how abstract labels are assigned to multiple layers according to a logic table. Proceeding from left to right, blocks from seven distinct locations relative to the surfaces are shown. The mean surface orientation shows the direction obtained by averaging over all triangular patch normals. This arrow can point up or down provided the ordering of triangle vertices is consistent. Consistency can be enforced by ensuring triangle edges are traversed only in the anti-clockwise (or clockwise) direction.
The positive direction is a user-defined concept. By default, it points in the upward direction (+z axis). For a vertical surface (e.g., a geological feature such as a dyke) that runs across multiple layers, the positive direction may be defined as left (or right). Surface polarity indicates if there is agreement between the mean surface orientation (a property conferred by the mesh) and the positive direction (intention of the user). If they oppose, as is the case for the bottom surface in Fig. 7, the polarity is set to negative. The significance is that the interpretation of the projected distance between a block and relevant triangle, and subsequently what sign we assign to the block, depend on the surface polarity.
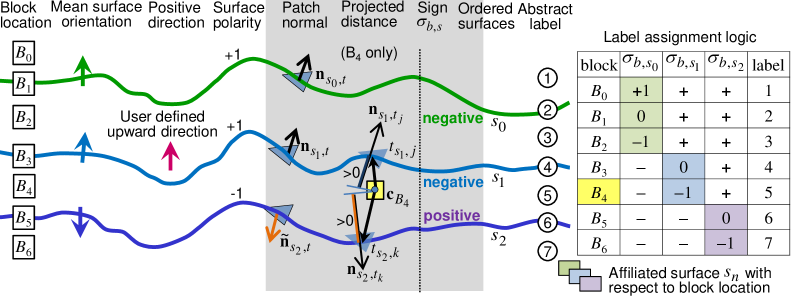
Focusing now on the shaded portion of Fig. 7, comparison of block with surface 1 yields , hence its sign is negative (it is below the surface). However, comparison with surface 2 yields a positive sign (it is above the surface) even though the projected distance ; this is correct since has negative surface polarity which negates the logic. This method is adequate for simple surfaces such as those depicted in Fig. 7; however it can fail in more complex situations. Therefore, the projection-onto-patch-normal approach is used here primarily as a vehicle for illustrating concepts and vulnerabilities. The pitfalls and robust solutions will be discussed in Sec. 5.
Abstract labels are assigned to merged blocks to distinguish between boundaries and embedded layers. In this example, layers are given odd-integer labels whereas boundaries (the interface between layers) are given even-integer labels, as indicated by the circles in Fig. 7. For the interleaved layers, given its sign and affiliated surface , the abstract label is given by for , where represent {below, across, above} the surface, respectively. The affiliated surface is deduced from the shaded column of the logic table in Fig. 7. For instance, at block locations and , the affiliated surface is . With and for , the label only depends on when .
3.4.3 Tagging instructions
With block tagging, there is tremendous scope for creativity. The scheme described below provides a flexible framework for domain specification given arbitrary surfaces. The diagram shown in Fig. 8 is similar to Fig. 7 for the most part. What is different is the emphasis on surface tagging instructions. Observe that there are three sets of tagging instructions: one for each surface. Each instruction specifies (1) a positive direction for each surface; (2) nominal labels for blocks located above, across and below each surface; (3) an override field (see “forced?”) which communicates an intent to either preserve the surface intersecting blocks (by assigning a label different to any other layers) or resolve whether these blocks are strictly above or below the surface, i.e., force a binary decision.
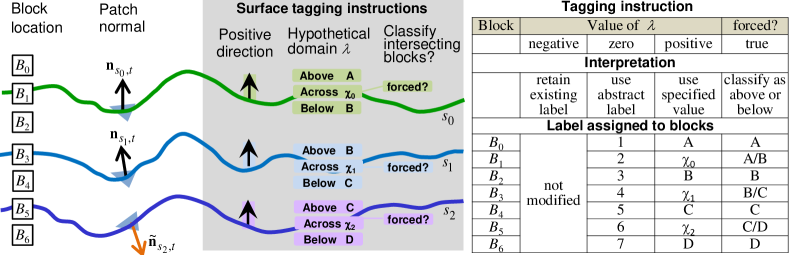
A trivalent logic is built into the nominal labels specified in item 2. In Fig. 8, this is denoted by . User-specified values are assigned to blocks when . In addition, there are two special cases worth mentioning. First, an input value of instructs the program to use abstract labels instead of specific domain values (see “zero” column in Fig. 8). Second, a negative input value instructs the program to leave current labels intact. This retains any prior label which has been assigned to that block (see “negative” column in Fig. 8). This ‘retain existing labels’ mode allows the spatial structure of a block model to be updated without invalidating previous domain assignments. For instance, a surface may be used as an upper bound. If , then all blocks located above this surface will not have their labels modified. Similarly, may be used as a lower bound. If , then all blocks located below this surface will not have their labels modified.
3.4.4 Retaining existing domain labels
As a motivating example, suppose we rotate the picture in Fig. 8 counter-clockwise by 45 degrees. Further, suppose the entire block model is currently labelled as domain A. Then, the space between the two tilted surfaces (below and above ) can be used to model a dolerite channel that runs diagonally across the layers. By using the following specification: , , , and forced() = true for both, blocks within the embedded layer will be tagged as domain B (dolerite) for some 0.
3.5 General interpretation
A volumetric block region (one comprising blocks of varying size) may be constructed in multiple passes and labelled sequentially by a single or a combination of surfaces using logical and/or operators based on the plane partitioning property of open surfaces, or expressed as the intersection/union of multiple closed surfaces. As an example, a fault surface may partition a space into two disjoint sets, say, blocks to the left (respectively, right) of the divide. Input blocks in contact with the fault line may be partitioned (subblocked) to conform to the shape of the fault surface. Subsequently, block tagging is applied independently to these two sets. The bounding surfaces that correspond across the discontinuity will provide similar block labelling instructions despite their physical separation. This ensures blocks within the same layer will receive the same label notwithstanding the vertical offset introduced by the fault.
4 Visualisation
This section illustrates some of the results produced by the proposed framework. Fig. 9(a) shows a regular block structure which covers the region with parent blocks measuring m. Three horizontal surfaces are also given as input, these are shown in Fig. 9(b). Surface-intersecting parent blocks identified in (c) are subject to block decomposition. Using block-triangle overlap detection, the surface-intersecting sub-blocks, each measuring m, are identified in Fig. 9(d). To reduce fragmentation, the decomposed sub-blocks in the surface-intersecting and non-intersecting sets are consolidated in Fig. 9(e)–(f). For the surface-intersecting set, the block-count decreases from 8497 to 2102 after sub-blocks are coalesced.
| (a) Regular block structure as input | (b) Multiple surfaces as input | (c) Surface intersecting parent blocks |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x9.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x10.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x11.png)
|
| (d) Surface intersecting sub-blocks | (e) Consolidated sub-blocks | (f) Consolidated sub-blocks from non- |
| from surface-intersecting set | intersecting (complementary) set | |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x12.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x13.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x14.png)
|
In regard to the forced option for block tagging, the differences between preserving the boundary and classifying the blocks at the interface as strictly above / below a surface are demonstrated in Fig. 10(g)–(h). For clarity, Fig. 10(i) shows only blocks labelled as A and C (belonging to two domains of interest) in isolation. Clearly, they conform to the shape of the relevant surfaces. In Fig. 10(j), only blocks that intersect with the top surface (labelled 2) have been extracted.
| (g) Resolving boundary blocks | (h) Preserving boundary blocks |
| forced=1 classifies as above/below | forced=0 maintains unique identity |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x15.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x16.png)
|
| (i) Isolated blocks from A and C | (j) Localised blocks extracted from |
| — two domains of interest | the A/B interface |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x17.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x18.png)
|
4.1 Iterative refinement: an application to tilted surfaces
The running example has thus far taken only a regular block structure as input. In this section, we demonstrate that the framework can also modify the spatial structure of a model with irregular (non-uniform) block dimensions. Of particular interest is that tilted surfaces are used to model a hypothetical dyke channel running through bedded layers. This highlights two significant features: (a) ability to iteratively improve the spatial structure of an existing block model whilst preserving the labels for horizontal strata which have been previously assigned; (b) ability to work with oblique surfaces and produce correct result when the surface orientation is ambiguous (positive may not point upward), thus user has to specify precisely what is meant by the positive direction in relation to the supplied tagging instructions. An example of this is shown in Fig. 11.
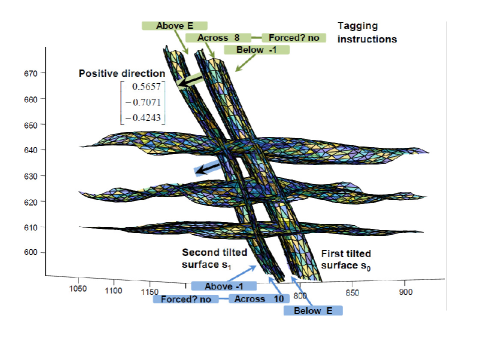
Fig. 12 shows the recut block model follows the curvature of the tilted surfaces. In (k), blocks within the dyke are removed for clarity. Pre-existing labels (outside the dyke) remain intact. The spatial structure is only modified around the tilted surfaces. In Fig. 12(l)–(m), blocks within the dyke and those located on the east / west interfaces are shown in isolation. Fig. 12(n)–(p) show the existing labels for blocks in A, B, C and D have been perfectly preserved. As expected, new labels — {8, 10} and E respectively — have only been assigned to blocks that intersect with and sandwiched between the tilted surfaces.
| (k) Recut block model | (l) Blocks within the dyke (E) | (m) Blocks intersecting with |
| east/west tilted surfaces | ||
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x20.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x21.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x22.png)
|
| (n) Blocks within the dyke | (o) Blocks in E, A and C | (p) Blocks in E, B and D |
| sandwiched in the middle. | ||
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x23.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x24.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x25.png)
|
5 Engineering perspectives and applications
Critical reflection and user feedback are both essential to designing robust and flexible systems [20]. Guided by the principle of reflective and iterative design [21], there was an early and continued focus in our approach on real usage scenarios [22], as well as successive evaluation, modification and scenario-based testing. In this section, we describe two improvements made to eliminate flaws identified through this process which made the system more robust.
5.1 Issue 1: Sign inversion due to sparse, jittery surface
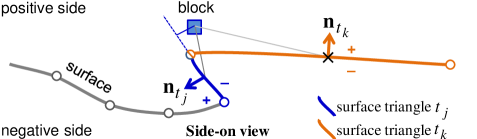
In regard to block tagging and ‘which-side-of-the-surface’ determination, the ‘projection-onto-normal’ method described in Section 2.4 works well when the surface is smooth and triangle mesh is dense and uniform. Potential issues arise when the surface exhibits local jitters and the triangles are sparse. For instance, the mesh resolution is low relative to the parent block size when triangle patches stretch over distances of up to one kilometer in certain areas. As an illustration, Fig. 13 shows a block associated with triangle (the nearest patch based on block-triangle centroid-to-centroid distance). This association yields the wrong result, a negative sign with respect to the normal is obtained (according to the plane partitioning test) even though it lies above the surface. We observe the projection of the block lies outside the support interval of the referenced triangle and the same comparison with which is further away would produce the right result (a positive sign). This problem can be remedied by upsampling the mesh surface to increase its density. Fig. 14 shows an example where triangles are recursively split along the longest edge until the maximum patch area and length of all edges fall below the thresholds of 1250m2 and 100m. A better solution, however, is ray-tracing [23]. In general terms, ray-tracing determines whether a block is above or below an open surface (resp., inside or outside a closed surface) by counting the number of intersections between the surface and a ray casted from the block. This recommended approach is described in Appendix B. The key advantage is that ray tracing is not susceptible to variation in surface mesh density (the sign inversion problem due to folding), furthermore, it does not require dense surfaces or consistent (e.g. clockwise) ordering of triangle vertices. Therefore, ray-tracing will be the method of choice for block tagging moving forward. It replaces the projection-onto-normal approach in our proposal.
| Before: non-uniform density | After: high density mesh |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x27.png)
|
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x28.png)
|
5.2 Issue 2: Boundary localisation accuracy
The block consolidation component, as it currently stands, considers the sub-blocks that belong to the surface-intersecting set () and non surface-intersecting set () independently. As Fig. 5 has shown, the sub-blocks (cells) within each respective set are merged separately to form larger rectangular prisms within the confines of the parent blocks. While this split is useful for extracting surface-intersecting sub-blocks, it has two drawbacks. In terms of boundary localisation accuracy, Fig. 15(a) shows that surface-intersecting sub-blocks — with centroids located on different sides of the surface — are merged together irrespective of whether it is predominantly above or below the surface. In terms of compaction, merging potential is limited because adjacent cells from and cannot be coalesced even if they lie on the same side of the surface.
To reinforce the first point, the two cells marked with “?” in Fig. 15(a) ought to be labelled as above the surface. However, under the current regime, they are considered jointly with the three cells immediately to the right that also intersect with the surface, thus they are treated collectively as a 1-by-5 merged block. Since the centroid (black dot) lies marginally below the surface, the merged block will also be labelled as such. This distorts the boundary as it introduces a vertical bias of around to the two left-most cells.
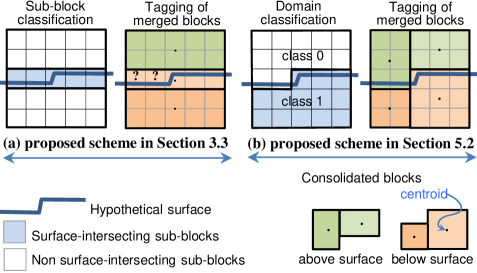
To accurately localise the boundary and achieve the result shown in Fig. 15(b), ray tracing is used to determine the location of cells with respect to each relevant surface that intersects the parent block. Given surfaces, the {0=above (or no intersection), 1=below} decisions naturally produce up to categories (or states) which would be treated separately during sub-blocks consolidation in lieu of and . In practice, however, we suggest encoding the location with respect to each surface using 3 bits , where the mutually exclusive bits are set to 1 to denote the outcomes of above, below and untested, respectively. The rationale is that when , domain identification needs not be attempted during block tagging with respect to surface , since the decision has already been made here prior to sub-blocks consolidation (either or ) and this information is passed on. In fact, applying ray-casting at the cellular-level (highest resolution) yields more accurate results near the surface than applying to merged blocks, especially for undulating surfaces with high local curvature.
To summarise, administering ray-casting before sub-blocks consolidation helps divide cells along surface boundaries; this increases boundary localisation accuracy and ensures merging is performed within the right domains with maximum potential. Table 1 provides a comparison of the techniques discussed.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x30.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x31.png) |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x32.png) |
5.3 Applications
The first application we preview relates to block modelling for a typical mine site located in Western Australia. The block model spatial restructuring results shown in Fig. 16 illustrate a block-wise partitioning of the mine site into different domains. This is achieved using surfaces which were created to separate geological domains (mineralised, hydrated and waste) within the Brockman Iron Formation which contains members of interbedded BIF and shale bands in the Hamersley Basin Iron Province [24]. Although ore-genesis theories vary depending on the minerals or commodity, the ability to model formations and features such as igneous intrusions in ore deposits is of general interest in areas not limited to mining, but also in further understanding the structural geology of mineral deposits. Using open and closed surfaces to represent structures of varying complexity — this may encompass volumes with exceptional geochemical or geophysical attributes — it is possible to extract waste pockets with high concentration of trace elements, or regions with magnetic / gravity anomaly [25]. Equally, if the surfaces represent the boundary of aquifers separated by clay and lignite seams [26], the process may serve as a basis for creating a structural hydrogeological model to study hydraulic and transport conditions in geotechnical or environmental risk assessment. The techniques developed for shaping a 3D block model can be used potentially in a variety of contexts, including surface buffer analysis (in GIS and structural modelling) for triangle mesh 3D boundary representation of localised objects [27]. In the next section, we focus on a specific application of block merging to reduce spatial fragmentation in a block model.
6 Block merging to reduce spatial fragmentation
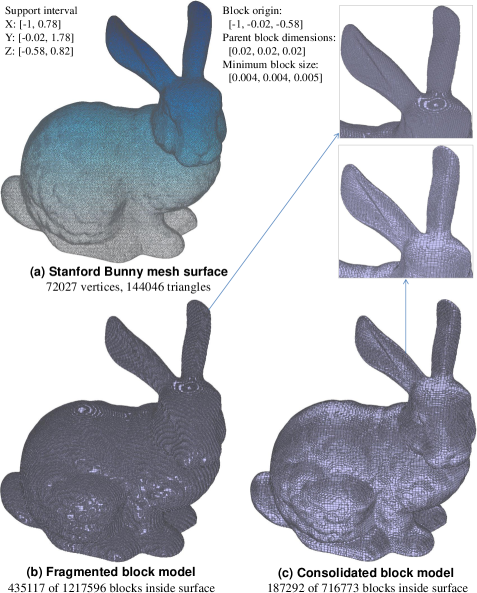
The proposed block merging algorithm can also be used to consolidate a fragmented block model that exists with or without reference to any mesh surface. Spatial fragmentation is used in this context to mean a highly redundant block model representation where blocks near the boundary are over-segmented or divided in an excessive manner to follow the curvature of a surface without regard for the compactness (total block count) of the model. As an illustration, Fig. 17(b) shows a highly fragmented block model for the Stanford Bunny created by block decomposition without consolidation. In an effort to closely approximate the surface, numerous blocks at the minimum block size were produced near the surface. Fig. 17(c) shows a clear reduction in block density as blocks are appropriately merged. This results in a more compact block representation (3D segmentation) of the object.
The block merging algorithms are formally described in the Supplementary Material wherein a number of technical issues are discussed in depth. At its core, a notable feature is that ‘feasibility of cell expansion’ is determined using a multi-valued (rather than boolean) 3D occupancy map, where the values correspond to the identity of the cells or sub-blocks. The spatial constraints governing cell expansion are somewhat different, in particular, the lateral dimensions orthogonal to the axis of expansion have to match for all the blocks involved in a merge. These, along with other relevant considerations and implementation details, are described in Appendix D.4–D.6.
6.1 Merging conventions and optimisation objectives
The block merging algorithms also recognise that merging can be performed under different conventions. For example, in Algorithm 2, the procedure preserves the input block boundaries, it does not introduce new partitions (sub-divisions) that are not already present in a parent block. This merging convention is referred as persistent block memory. It has the property that each input block is mapped uniquely to a single block in the merged model. In contrast, Algorithm 1 implicitly erases the sub-block boundaries before block consolidation begins. This merging convention is referred as dissolved sub-block boundaries, it generally achieves higher compaction because it makes no distinction between input blocks from the same class and parent. It is able to grow blocks more freely and produce fewer merged blocks since the size compatibility constraints between individual blocks no longer apply when internal sub-block boundaries are ignored. These differences are illustrated in Fig. 18.

The dissolved sub-block boundaries convention can be useful for healing a fractured block model, for instance, over a region where a false geological boundary was given in a previous surface update. Under the dissolved sub-block boundaries convention, coordinate-ascent can start from a clean slate and merge sub-blocks in a fragmented area back to the fullest extent in cases where individual sub-block dimensions or internal boundary alignments are otherwise incompatible. It is not bound by the consequences of prior model restructuring decisions. The technical details are given in Appendix D.7. For readers simply looking for a basic explanation, Fig. 19 reinforces these points and illustrates what healing really means in practice.
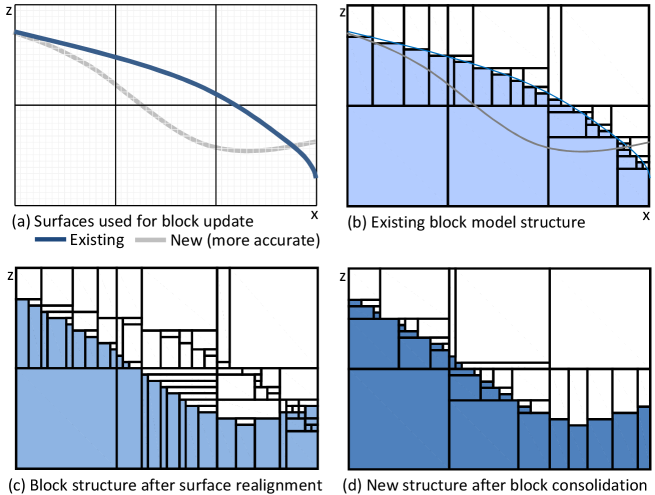
Fig. 19(a) shows an existing (poorly estimated) boundary created using limited data at an earlier point in time. Fig. 19(b) shows the existing block model structure created using this surface which unbeknown to the user is not faithful to the actual boundary shown in gray. At a later point in time (perhaps after several months have elapsed), more assay measurements have been taken at previously unsampled locations. These denser observations help improve the estimated boundary contact points and a new (more accurate) surface is produced as a result; see bottom curve in (a). A second iteration of the block model spatial restructuring process is applied using the new surface. This workflow significantly improves the boundary localisation property of the new block model in (c), however it leaves behind remnant sub-blocks from the previous iteration. By relaxing the internal constraints essentially by dissolving the sub-block boundaries, block merging under the dissolved sub-block boundaries convention helps promote healing in fractured areas. As evident in (d), fragmented blocks are coalesced into larger blocks in areas where the misplaced boundary (blue surface) once occupied.
The final block merging strategy (see Algorithm 3 in Appendix E) can optimise results with respect to different objectives. For instance, it can minimise the block count or avoid extremely elongated blocks by optimising for the block aspect ratio. It also exploits symmetry by following different scan patterns to alleviate ordering effects associated with using a fixed starting point. These issues are further discussed in Appendixes D.9 and D.10.
6.2 Pseudocode
The block merging algorithms are formally described in Appendix E which constitutes part of the Supplementary Material.
6.3 Evaluation
Two experiments were performed targeting two different usage scenarios. The first experiment described in Sec. 7 uses only the block merging algorithms to reduce block fragmentation in an existing block model where mesh surfaces are not available and the minimum block size has been fixed by the supplier of the model a priori. This restricted setting requires only the use of the sub-blocks consolidation component depicted in the system diagram (see Fig. 2). The main objective is to analyse its performance in terms of block compaction and multi-threaded execution.
The second experiment described in Sec. 8 provides an end-to-end evaluation of the entire system (from block model creation to block tagging) which applies sub-block consolidation and ray-tracing in an iterative setting. This involves over 80 surfaces and creates approximately 30 different domains. The goal is to compare the proposed strategies with two hierarchical subblocking techniques based on octrees, to highlight the constraints of dyadic decomposition and the importance of inter-scale block merging.
7 Experiment 1: Block merging efficacy on a mining resource block model
The proposed block merge strategy (Algorithm 3) was implemented in C++ (with boost python bindings) and evaluated using a real model developed for a Pilbara iron ore mine in Western Australia. The model contains 697,097 input blocks of varying sizes333There were 200 unique input block dimensions, these range from to with x and y varying in increments of 5. spanning 1342 parent blocks with dimensions . The input block model is given as is without associated surfaces. The minimum block dimensions are also fixed by the user at . A key requirement is that blocks smaller than , or being some fractional multiples of it, must not be introduced in the output. This is guaranteed by the proposed system.
The metrics of interest are the block aspect ratio, merged block count and execution times with multi-threading. The AspectRatio() obtained using method is defined by in (8). For comparison, a python implementation that uses a greedy merging strategy based on block edges connectivity is chosen to establish a baseline. Its sub-blocking approach is based on prime number factorisation. Given parent blocks with cell dimensions , it seeks to grow cells into subblocks with dimensions for or 5 and merge iteratively.444This heuristic is clearly suboptimal since 3 does not appear in the prime factorisation of the cell dimensions, it is not possible for sub-blocks with of 3 to emerge in the first pass.
7.1 Statistical perspective
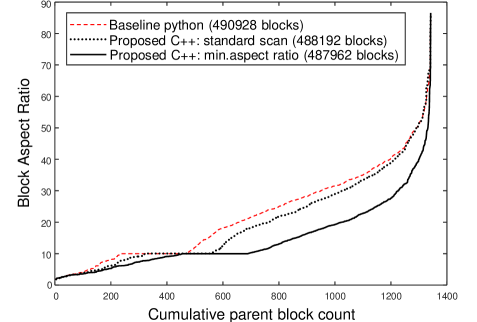
Fig. 20 illustrates the block merging performance of Algorithm 2 vs the baseline with emphasis on block aspect ratios. In this plot, performance is measured in terms of block aspect ratio. The volume-weighted aspect ratio is computed for each parent block and sorted in ascending order. Large aspect ratios correspond to long narrow blocks whereas small aspect ratios indicate more balanced, less extreme block dimensions which are more preferred in a mining context. In this plot, the lower the curve, the more desirable it is. The main observation is that the proposed block merge strategy is superior to the baseline. Even when the coordinate-ascent procedure follows only the standard scan pattern, it produces higher quality merged blocks (dotted line is below the dash line). The performance margin increases significantly when multiple scans are deployed in Algorithm 3 to minimise the aspect ratio explicitly (note: solid line is consistently below the dash line).
7.2 Spatial perspective
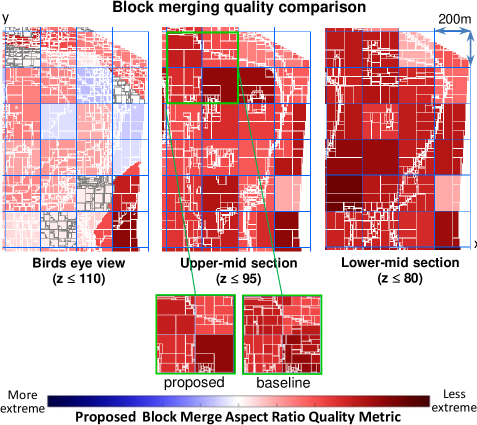
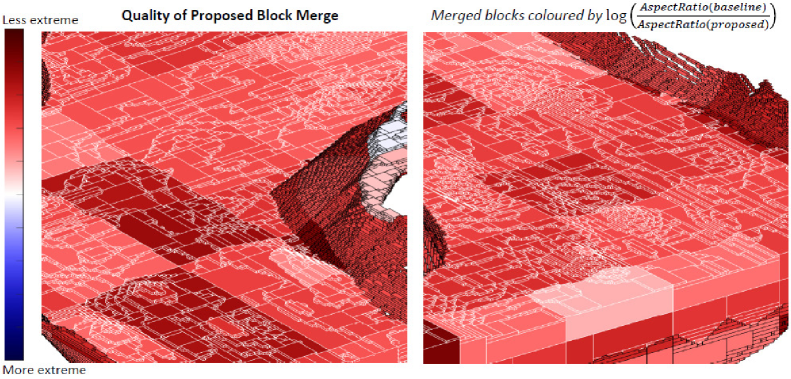
Fig. 21 provides an alternative view of the same result from a spatial perspective. A birds eye view and two cross-sections from the proposed method are shown. Blocks are coloured to highlight differences in aspect ratio between the baseline and proposed method. The darker the red, the more superior is the proposed method. Conversely, blue blocks show the proposed method is inferior. The dominance of the red blocks show the proposed block merge method is able to consistently produce blocks with less extreme aspect ratios across the site. A magnified view for two regions of interest are shown in Fig. 22.
7.3 Local perspective
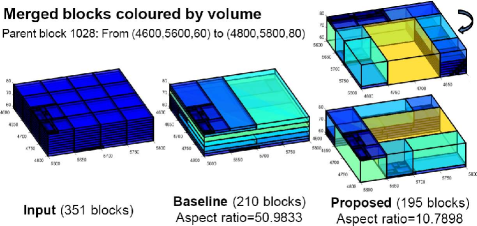
To verify these results, we compare the baseline and proposed method for parent blocks with a high contrast in . Fig. 23 shows the sub-block structure within a parent block of interest, it shows from left to right: the input blocks, and merge results from the baseline and proposed methods. The key observation is the presence of thin narrow blocks in the baseline result; these disappeared under the proposed method. Algorithm 3 discovers block merging opportunities missed by the baseline method. It is able to minimise the block aspect ratio by conducting multiple scans during coordinate-ascent.
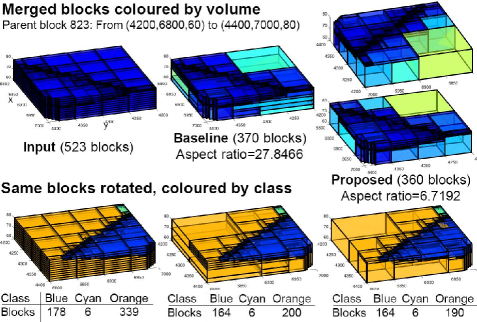
Fig. 24 shows a second example. In the top panel, blocks are coloured by block volume such that bigger blocks are coloured in warm colours (yellow, for instance). This shows the proposed method is more effective at consolidating smaller blocks into larger blocks. The bottom panel shows the merge result for the same parent block from a different vantage point. Here, blocks are coloured by domain labels. This illustrates an interesting case where there is a limit to how much merging can be achieved because input blocks from different classes are processed independently even when they share the same parent.
7.4 Block compaction
Table 2 reports the number of output blocks produced by the baseline and proposed methods. The block count column shows the proposed method is more efficient at coalescing blocks than the baseline method, as the block count under “persistent block memory” is lower. The block count reported for the proposed method under “dissolved sub-block boundaries” is lower still, this is consistent with our expectation and the reasoning given in Section D.7 based on constraint relaxation.
| merge method | convention | block count | relative % |
| Input | – | 697,097 | 100.0% |
| Baseline | – | 490,928 | 70.42% |
| Proposed | persistent | 487,962 | 70.00% |
| Proposed | dissolved | 447,412 | 64.18% |
| = persistent block memory = dissolved sub-block boundaries | |||
| both using multiple-scans, minimising block aspect ratio | |||
7.5 Execution times and memory
Table 3 reports the processing time for block merging and demonstrates the scalable nature of the proposed algorithm.555Experiments were conducted on a linux machine with 32 CPUs, 8 cores (Intel Xeon® CPU E5-2680 @ 2.70GHz), 64GB RAM and 2G swap memory The parallel nature of the algorithm is a consequence of processing all input blocks that belong to the same parent block together independent of other parent blocks. This allows processing to be compartmentalised. From the description in Sec. 3.3, it is clear that block consolidation and block tagging are applied locally to spatially disjoint regions; this is exploited in a multi-threaded implementation.
Merging under the “dissolved sub-block boundaries” convention given 697,097 blocks (of varying sizes) from the input model, is equivalent to merging 29,154,116 blocks (with single cell dimensions) directly under the “persistent block memory” convention. The problem size of “dissolved” grows by a factor of 41.8, however, the computation time increased sub-linearly by a factor of only 9.5, this is partly due to the removal of sub-block alignment / compatibility constraints when internal sub-block boundaries are dissolved. Of course, the run time still increases relative to “persistent”, ultimately this may be viewed as a trade-off between speed and compaction when Table 3 is viewed along side Table 2. The CPU utilisation and memory use columns are included for completeness, but these figures are otherwise unremarkable. Running 16 threads, the physical memory footprint amounts to of the RAM available.
| merge method | convention | threads | time (s) | relative | cpu% | mem (kB) |
| Baseline | – | – | 254.181 | 1.0000 | 94.1 | 365,344 |
| Proposed | persistent | 1 | 4.870 | 0.0192 | – | – |
| Proposed | persistent | 1 | 32.852 | 0.1292 | 100.0 | 285,076 |
| Proposed | persistent | 4 | 9.840 | 0.0387 | 400.0 | 380,884 |
| Proposed | persistent | 16 | 4.162 | 0.0164 | 1553.0 | 614,540 |
| Proposed | dissolved | 1 | 469.462 | 1.8470 | 100.0 | 293,988 |
| Proposed | dissolved | 4 | 125.111 | 0.4922 | 400.0 | 370,108 |
| Proposed | dissolved | 16 | 39.675 | 0.1561 | 1547.0 | 609,064 |
| = persistent block memory = dissolved sub-block boundaries | ||||||
| = single scan, coordinate-ascent follows the standard pattern | ||||||
| multiple scans, minimising block aspect ratio | ||||||
8 Experiment 2: The proposed coordinate-ascent block merging technique vs octree subblocking
Octree decomposition is a volumetric partitioning strategy that is well studied in the literature [28]. As this hierarchical structure has previously been considered as a potential representation for spatial information systems in geology [29], it provides an interesting reference point to measure our proposed method against. To obtain a fair comparison, the parent blocks () must be divisible by the minimum block size () by some vector where each element is a power of two. This dyadic constraint is necessary for compatibility since the standard octree has to split each dimension into half along the x, y and z axes at each spatial decomposition step. The analysis presented earlier in Table 2 pertains to a block model where its parameters (e.g. ) are already fixed and the cell dimensions are not divisible by 8; thus the maximum number of dyadic decomposition is limited to . To facilitate a more wide-ranging comparison, we have chosen another site for which the block structure is not fixed a priori and that geological surfaces are available. This enables all system components in Fig. 2 including block model creation (not just block merging) to be applied. The chosen parameters and satisfy the dyadic constraints and allow a maximum of levels of octree decomposition. Fig. 25 illustrates the complexity of the domain structure. This surface-induced structure provides spatial separation between significant geological units. A detailed explanation in terms of stratigraphy, material type or geochemical composition however is beyond the scope of this work. The main point is that deposits in the Hamersley Group typically contain interlayered Banded Iron Formations (BIF) and shale bands. Using multiple surfaces to express boundary constraints, it is possible to isolate, for instance, areas of localised iron enrichment within the BIFs where high grade iron ore deposits occur. Interested readers may refer to [30] for geological context.

The schemes being compared are the two proposed coordinate-ascent block merging algorithms performed under the persistent block memory and dissolved sub-block boundaries conventions (denoted ‘Proposed-P’ and ‘Proposed-D’ respectively) versus octree decomposition and a variant that permits intra-scale merging (denoted ‘Octree’ and ‘Octree+Merge’ respectively). In a standard octree decomposition, a heterogenous node (viz. a block with dimensions ) that contains smaller blocks with different labels is split into an octant with cells of size . This sub-division, similar to the approach implemented in the Surpac software [1], is applied recursively to all heterogenous nodes at each decomposition level . This process shatters a volume into many smaller blocks and thus vastly increases the block count in its pursuit of higher accuracy. The ‘Octree+Merge’ variant allows 2 and 4 edge-connected cells to be consolidated into a single (rectangular or square-like) block thus achieves higher compaction. This octree merging step applies only to cells at the same scale within an octant in the spatial hierarchy. For completeness, a full description and pictorial examples of these concepts are given in Appendix F.
8.1 Block count analysis
In Table 4, it can be seen that performing octree decomposition without merging produces a large number of blocks (4241289 for levels). With octree merging, the block count is reduced to 43.167%. The proposed strategies have a block count of about 25% relative to standard octree decomposition. It is worth mentioning that despite this block count disparity, each block model represents the modelled region with the same fidelity and the total block volume for each domain classification remains the same irrespective of and the block count. In one sense, the ‘Octree+Merge’ method provides an empirical bound on block model efficiency (as measured by block count) that other strategies can surpass. The impressive efficiency gains achieved by the proposed strategies may be attributed to inter-scale block merging without dyadic constraints. For instance, it is possible to combine two adjacent blocks and in neighbouring octants if their labels are the same and their cell-dimensions, say, and are compatible. This would not be possible using the naïve ‘Octree+Merge’ method as it involves blocks from different octants.
| Total block count, | ||||
| levels | Octree | Octree + Merge | Proposed-P | Proposed-D |
| 3 | 4241289 | 1830826 | 1094917 | 1100585 |
| 4 | 17414755 | 7455284 | 4053310 | 4007018 |
| 5 | 74065301 | 31052736 | 15608162 | 15204844 |
| Relative block count | ||||
| levels | Octree | Octree + Merge | Proposed-P | Proposed-D |
| 3 | 100% | 43.167% | 25.816% | 25.949% |
| 4 | 100% | 42.810% | 23.275% | 23.009% |
| 5 | 100% | 41.926% | 21.074% | 20.529% |
| The total block volume is approximately m3 | ||||
| A detailed breakdown of these figures is given in Appendix G | ||||
| Block count growth factor based on Table 4 | ||||
| Growth rate | Octree | Octree + Merge | Proposed-P | Proposed-D |
| 4.1060 | 4.0721 | 3.7019 | 3.6408 | |
| 4.2530 | 4.1652 | 3.8507 | 3.7946 | |
| 17.4629 | 16.9611 | 14.2551 | 13.8152 | |
From Table 4, it is evident the block count roughly grows by a factor of 4 with each additional decomposition level. This is made clear in Table 5 and expressed as a ratio between levels and . Intuitively, the growth rate relates to the surface contact area with the blocks which scales with where represents the number of cells measured in one dimension. Interestingly, the proposed coordinate-ascent block merging strategies have a lower growth rate compared to ‘Octree+Merge’ — moving from 3 to 4 levels, the block count increases by a factor of 3.6408 as opposed to 4.0721; from 3 to 5 levels, the growth rate is 13.8152 as opposed to 16.9611. In this respect, the proposed strategies scale better and they are more efficient at representing the same domain information. We caution however that block modelling is not ultimately about an endless pursuit for increasing precision. Block granularity (which may be specified in terms of the number of decompositions, ) is often limited by practical considerations. In our application, individual blocks in the model serve as containers for grade estimation. The blockwise spatial distribution of chemical attributes in turn informs what, where and how ore material are excavated. The heavy equipments used to extract and transport such material operate with physical or kinematic constraints (such as bucket size and turn radius), so the required spatial resolution in the case of mining is probably limited to 1.5m to 6m at best. This naturally imposes a lower bound on the spatial fidelity needed from a model. It informs the choice of in our evaluation, as and yield a resolution of 1.5625m and 6.25m, respectively, in a horizontal plane.
8.2 Block aspect ratio analysis
For grade estimation at a given level of spatial fidelity, a lower block count is desirable not so much for storage but from a computational perspective. A compact model contains fewer blocks that require the inference engine to estimate into, and by extension, it has fewer values to update when new information becomes available. For instance, the difference between ‘Octree+Merge’ and ‘Proposed’ can be as much as 50% (based on in Table 4). A secondary consideration is an optimisation preference for more uniform blocks (as opposed to thin, narrow blocks) that have lower aspect ratios. In a pure octree decomposition scheme, the blocks always maintain the same aspect ratio (in our experiment, this value is 50/20 or 2.5). However, this is obtained at significant cost, resulting in a substantial increase in block count. In Table 6, the main observation is that the weighted aspect ratios in the ‘Proposed-D’ column are a marked improvement over ‘Proposed-P’ when merging constraints are relaxed (when input block boundaries are no longer persistent in the sense defined in Sec. 6.1). It also increases slower than ‘Proposed-P’ as the resolution (number of levels ) increases, and tends toward the values in the ‘Octree+Merge’ column.
| weighted by block volume | ||||
|---|---|---|---|---|
| levels | Octree | Octree + Merge | Proposed-P | Proposed-D |
| 3 | 2.5 | 2.958828 | 3.668188 | 2.615373 |
| 4 | 2.5 | 2.968178 | 4.901418 | 2.941797 |
| 5 | 2.5 | 2.972378 | 7.395642 | 3.456381 |
8.3 Block fragmentation analysis
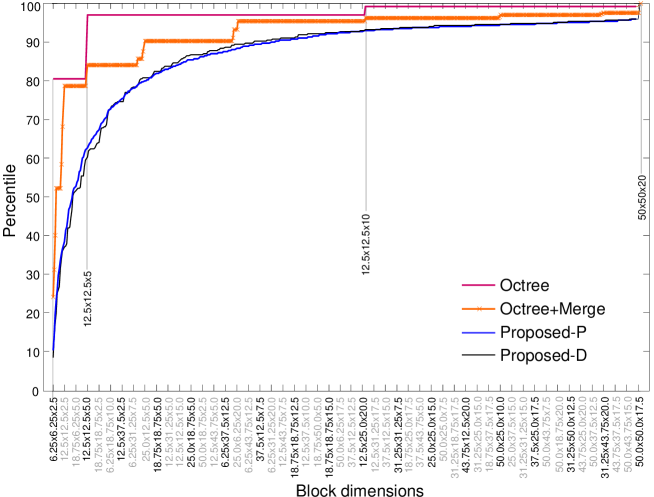
The diversity of blocks within each model is examined in Fig. 26. The graph shows the cumulative distribution of block dimensions for decomposition levels, with block volumes arranged in ascending order (from left to right) and sorted by aspect ratio in the event of a tie. The staircase nature of the orange curve for ‘Octree+Merge’ shows that there is a much smaller pool of possible block size permutations produced via octree decomposition with merging. To simplify the analysis, we measure blocks in multiples of , for instance, using to denote a block with real dimensions . Without merging, octree decomposition alone produces an overwhelming 80.44% of blocks with cell dimensions , while 96.86% and 98.93% of blocks have dimensions at/below and , respectively. The red curve demonstrates that the blocks in the ‘Octree’ model are indeed highly fragmented. With intra-scale merging, the orange curve shows there is a larger spread of blocks and the proportion occupied by the smallest blocks has substantially reduced. Blocks with cell dimensions , , and now occupy the 24.09th, 31.26st, 39.98th and 52.08nd pecentiles, respectively. Because this strategy does not permit inter-scale merging (outside of an octant), it cannot produce blocks with cell dimensions , or and indeed . These lost opportunities are capitalised by the proposed strategies. However, the ‘Octree+Merge’ strategy can still produce blocks of size , and ; the so called 4-connected cells occupy the 58.45th, 68.14th and 78.64th percentiles, respectively.
Moving up the spatial hierarchy, the , , and blocks correspond to the 84.01th, 85.50th, 87.36th and 90.13th percentiles; as opposed to 96.86% at the stage for octree decomposition without merging. With intra-scale merging, the , and blocks occupy the 91.07st, 92.99nd and 95.25th percentiles. Again, blocks with intermediate cell dimensions, such as and , can only be synthesized by the proposed techniques through inter-scale merging and relaxation of the dyadic constraints. Similar observations hold for more levels.
8.4 Discussion and insights
The octree comparisons with the proposed methods highlight the constraints imposed by hierarchical decomposition and the importance of block merging. In cases where the block structure is subsequently consumed by a block estimation process, minimising the block count (while maintaining the same level of spatial fidelity and domain classification granularity) can substantially reduce the computational effort associated with probabilistic inference of block attributes. The analysis has shown, for instance, when a minimum block size of and 5 decomposition levels are applied to the test site, the block count of the proposed model and ‘Octree+Merge’ model are 20.52% and 41.92% respectively relative to standard octree decomposition without block merging. The ‘Octree+Merge’ approach is probably more indicative of the flexible subblocking approach used in the Datamine software [1] which adjusts the split depending on the angle of intersection of a particular block with the surface controlling the sub-division. It is however unclear if a split extends all the way down within a parent block, whether different permutations and aspect ratio optimisation are considered in Datamine. Returning to the block count comparison, the factor of 2 reduction may be attributed to inter-scale merging and relaxation of dyadic constraints as illustrated in Sec. 8.3. The proposed coordinate-ascent block merging approach also scales better. For instance, the block count growth rate from 3 to 5 levels is kept at 13.8152 as opposed to 16.9611 (see Table 4). From the cumulative distribution in Fig. 26, we observed the block models obtained using the proposed methods are spatially less fragmented.
Although the performance metrics all point in favour of the proposed methods, the real strength of the proposal is its flexibility. First, the block merging algorithm was used on its own to consolidate and heal a spatially fragmented block model given only the parent block size and minimum block dimensions (see Sec. 7). Second, the same algorithm was used as part of a coherent block model spatial restructuring strategy to coalesce sub-blocks partitioned by intersecting surfaces (see Sec. 8). Finally, it provides a successive refinement framework for updating the spatial structure of a block model; this takes a dynamic (non-static) view and emphasizes the evolving nature of the model. In contrast, some commercial softwares [1] produce block models that cannot be altered or easily manipulated. The iterative setting implies the input blocks can have different dimensions. The standard octree paradigm is not equipped to deal with input blocks with varying sizes. As a case in point, given an input block with cell dimensions , a three level dyadic decomposition would need to be applied asymmetrically to each axis, via , to not violate the minimum block size (lower bound and integer multiple) conditions. Furthermore, an input block with cell dimensions would leave the octree approach with no viable sub-blocking options unless the block is divided non-uniformly which would set it on a similar path as the proposed strategy notwithstanding the hierarchical embedding (rigid subblock alignment) constraints.
A crucial part of ‘iterative refinement’ is that large portions of an existing model should remain intact, useful information in unaffected parts of the model are not invalidated through the update process, and changes affect only localised regions that interact with new surfaces. This allows creation of a new block model from scratch given a set of surfaces (representing geological boundaries or other types of delineation), as well as automatic correction for misplaced boundaries within an existing model. In [31], the current proposal is portrayed as a system within a system, where new information captured by sampled assay data are used to manipulate the shape of relevant surfaces to maximise agreement with the latest observations. These are used in turn to update the block model to improve the accuracy of its domain structure by maximising the resolution and positional integrity of the blocks near those surfaces. This has been shown in [31] to have a positive effect on processes downstream. In particular, grade estimation performance improves as boundary (smearing) artefacts are reduced during inferencing.
8.5 Summary of contributions
The overall contributions of this paper may be summarised as follows.
-
1.
Developing a flexible framework capable of altering the spatial structure of a block model given boundary constraints in the form of triangle mesh surfaces and a set of tagging instructions.
-
2.
Describing computational techniques for all system components
-
•
From block-surface intersection detection (identifying areas requiring an update), block structure decomposition (improving boundary localisation), block consolidation (increasing compactness of representation) to block tagging (encoding the location of blocks relative to the given surfaces).
-
•
-
3.
Devising a new algorithm (coordinate-ascent inspired block merging) that is amenable to multi-threading.
-
4.
Demonstrating real applications: The algorithm was used firstly to reduce block fragmentation in an existing mine resource estimation block model where parameters are fixed and no surfaces are given; secondly as an integrated component within the block model creation/augmentation workflow to coalesce subblocks partitioned by intersecting surfaces.
- 5.
The first point includes correcting the position of previously misplaced boundaries in an existing model (see Fig. 19). Philosophically, it challenges the perception that voxel-based models are hard to modify once they have been constructed. It demonstrates that local refinement (including consolidation of fragmented blocks from previous updates) is both possible and can be done efficiently in an iterative setting; with changes to the model confined to areas that interact with new surfaces. The second point is about greater transparency. In 3D geological modelling papers, models are often generated using commercial software where the fundamental techniques employed are unclear. This paper sheds light on this and discusses pit falls and robust solutions from an engineering perspective. The third point emphasizes flexibility. Depending on user requirement on whether internal subblock boundaries are to be respected, it can operate in two modes (see Fig. 18): with persistent block memory to ensure an input block always maps uniquely to a merged output block, or with dissolved subblock boundaries to achieve higher block compaction (a lower block count). The specific objective in the fourth point was to capture geological structures of an ore body in a block model at a specified resolution with a minimal block count. However, the method can potentially be applied elsewhere.
9 Conclusions
This paper described a framework for updating the spatial structure of a 3D geology block model given mesh surfaces. The system consists of four components which perform block-surface overlap detection, spatial structure decomposition, sub-blocks consolidation and block tagging, respectively. These processes are responsible for identifying areas where refinement is needed, increasing spatial resolution to minimise surface approximation error, reducing redundancy to increase the compactness of the model and establishing the domain of each block with respect to geological boundaries. A flexible architecture was presented which allows a model to be updated simultaneously, or iteratively, by multiple surfaces, to selectively retain or modify existing block domain labels. Robustness and accuracy of the system were considered during the design; one notable feature was using ray-tracing to establish the location of sub-blocks relative to surfaces, particularly those near boundaries, prior to block consolidation to minimise boundary distortion. Other techniques employed include block-surface intersection analysis based on the separable axis theorem.
The main contribution was a coordinate-ascent merging algorithm which is used during block consolidation in the proposed framework. This technique was extended to solve a related problem, viz., using block merging to reduce fragmentation in an existing block model where surfaces are not involved. Issues relating to scan pattern, merging conventions were discussed, differences between ‘persistent block memory’ and ‘dissolved sub-block boundaries’ were explained in terms of internal dimensions compatibility and sub-block alignment constraints imposed on the expansion feasibility test. Performance was evaluated with respect to block aspect ratio, output block count and processing time using a multi-threaded implementation. The results demonstrated the quality and scalability of the proposed technique. Systematic evaluation against octree subblocking futher highlights the limitations of hierarchical decomposition and the importance of inter-scale merging and relaxation of dyadic constraints. Algorithm 3 produced merged blocks with less extreme aspect ratios and the approach is well suited to parallel processing. The techniques described may apply to areas outside of geoscience (see Fig. 17) where 3D body localisation, also known as 3D region segmentation, is required inside a block model given some mesh surfaces.
References
- [1] Julian Poniewierski. Block model knowledge for mining engineers. https://www.deswik.com/wp-content/uploads/2019/07/Block-model-knowledge-for-mining-engineers-An-introduction.pdf, 2019. Accessed: 2020-08-08.
- [2] Zhou Quan Luo, Liu Xiao-ming, Su Jia-hong, Wu Ya-bin, and Liu Wang-ping. Deposit 3D modeling and application. Journal of Central South University of Technology, 14(2):225–229, 2007.
- [3] A Leite and R Dimitrakopoulos. Stochastic optimisation model for open pit mine planning: application and risk analysis at copper deposit. Mining Technology, 116(3):109–118, 2007.
- [4] R Dimitrakopoulos and S Ramazan. Stochastic integer programming for optimising long term production schedules of open pit mines: methods, application and value of stochastic solutions. Mining Technology, 117(4):155–160, 2008.
- [5] SRK Consulting. Block Modelling (“3D Modeling Project, Spout Lake, British Columbia, Canada”). http://webcache.googleusercontent.com/search?q=cache:https://www.srk.ru.com/en/block-modelling, 2018. Accessed: 2018-12-25.
- [6] Mira Geoscience. 3D Geological Modelling. http://webcache.googleusercontent.com/search?q=cache:http://www.mirageoscience.com/our-products/software-solutions/3d-geological-modelling, 2018. Accessed: 2018-12-23.
- [7] Leapfrog. Leapfrog Geo: Trainagulated Meshes. https://help.leapfrog3d.com/Geo/4.3/en-GB/Content/meshes/triangulated-meshes.htm, 2019. Accessed: 2019-10-25.
- [8] Xavier Emery. Simple and ordinary multigaussian kriging for estimating recoverable reserves. Mathematical Geology, 37(3):295–319, 2005.
- [9] Adrian Ball, Katherine Silversides, Anna Chlingaryan, and Arman Melkumyan. Creating large scale probabilistic boundaries using Gaussian Processes. In Proceedings of Geostats 2020, Toronto, Canada, 2021. International Geostatistics Congress.
- [10] Raymond Leung. Subsurface boundary geometry modeling: Applying computational physics, computer vision, and signal processing techniques to geoscience. IEEE Access, 7:161680–161696, 2019.
- [11] Shrihari Vasudevan, Fabio Ramos, Eric Nettleton, and Hugh Durrant-Whyte. Gaussian process modeling of large-scale terrain. Journal of Field Robotics, 26(10):812–840, 2009.
- [12] Timothy S Newman and Hong Yi. A survey of the marching cubes algorithm. Computers & Graphics, 30(5):854–879, 2006.
- [13] Stanimir Dragiev, Marc Toussaint, and Michael Gienger. Gaussian process implicit surfaces for shape estimation and grasping. In Robotics and Automation (ICRA), 2011 IEEE International Conference on, pages 2845–2850. IEEE, 2011.
- [14] Gongwen Wang, Shouting Zhang, Changhai Yan, Yaowu Song, Yue Sun, Dong Li, and Fengming Xu. Mineral potential targeting and resource assessment based on 3D geological modeling in Luanchuan region, China. Computers & Geosciences, 37(12):1976–1988, 2011.
- [15] L Feltrin, JG McLellan, and NHS Oliver. Modelling the giant, Zn–Pb–Ag Century deposit, Queensland, Australia. Computers & Geosciences, 35(1):108–133, 2009.
- [16] Stephen J Mathers, Holger Kessler, and Bruce Napier. British Geological Survey: A nationwide commitment to 3-D geological modeling. In Richard C Berg et al., editor, Synopsis of Current Three-dimensional Geological Mapping and Modeling in Geological Survey Organizations, volume 578, chapter 6, pages 25–30. 1Illinois State Geological Survey Circular, 2011.
- [17] Claire Castagnac, Catherine Truffert, Bernard Bourgine, and Gabriel Courrioux. French Geological Survey (Bureau de Recherches Géologiques et Minières): Multiple software packages for addressing geological complexities. In Richard C Berg et al., editor, Synopsis of Current Three-dimensional Geological Mapping and Modeling in Geological Survey Organizations, volume 578, chapter 8, pages 42–47. 1Illinois State Geological Survey Circular, 2011.
- [18] Tomas Akenine-Möller. Fast 3D triangle-box overlap testing. Journal of graphics tools, 6(1):29–33, 2001.
- [19] Matt Pharr, Wenzel Jakob, and Greg Humphreys. Physically based rendering: From theory to implementation. Morgan Kaufmann, 2016.
- [20] Martin Arvidsson and Ida Gremyr. Principles of robust design methodology. Quality and Reliability Engineering International, 24(1):23–35, 2008.
- [21] Michael Sedlmair, Miriah Meyer, and Tamara Munzner. Design study methodology: Reflections from the trenches and the stacks. IEEE Transactions on Visualization and Computer Graphics, 18(12):2431–2440, 2012.
- [22] Mary Beth Rosson and John M Carroll. Scenario based design. In J Jacko and A Sears, editors, The Human-Computer Interaction Handbook: Fundamentals, Evolving Technologies and Emerging Applications, chapter 53, pages 1032–1050. CRC Press, 2002.
- [23] Tomas Möller and Ben Trumbore. Fast, minimum storage ray/triangle intersection. In ACM SIGGRAPH 2005 Courses, page 7. ACM, 2005.
- [24] JMF Clout. Iron formation-hosted iron ores in the Hamersley Province of Western Australia. Applied Earth Science, 115(4):115–125, 2006.
- [25] Gongwen Wang, Ruixi Li, Emmanuel John M Carranza, Shouting Zhang, Changhai Yan, Yanyan Zhu, Jianan Qu, Dongming Hong, Yaowu Song, Jiangwei Han, et al. 3D geological modeling for prediction of subsurface Mo targets in the Luanchuan district, China. Ore Geology Reviews, 71:592–610, 2015.
- [26] P Wycisk, T Hubert, W Gossel, and Ch Neumann. High-resolution 3D spatial modelling of complex geological structures for an environmental risk assessment of abundant mining and industrial megasites. Computers & Geosciences, 35(1):165–182, 2009.
- [27] Nan Li, Leon Bagas, Mark Lindsay, Daniel Wedge, Lin Bai, and Xianglong Song. An irregular triangle mesh buffer analysis method for boundary representation geological object in three-dimension. Earth Science Informatics, 10(2):149–167, 2017.
- [28] Hanan Samet. An overview of quadtrees, octrees, and related hierarchical data structures. In Theoretical Foundations of Computer Graphics and CAD, pages 51–68. Springer, 1988.
- [29] Christopher B Jones. Data structures for three-dimensional spatial information systems in geology. International Journal of Geographical Information System, 3(1):15–31, 1989.
- [30] W Thorne, Steffen Hagemann, A Webb, and J Clout. Banded iron formation-related iron ore deposits of the Hamersley Province, Western Australia. In Banded Iron Formation-Related High-Grade Iron Ore, pages 197–221. Society of Economic Geologists, 2008.
- [31] Raymond Leung, Alexander Lowe, Anna Chlingaryan, Arman Melkumyan, and John Zigman. Bayesian surface warping approach for rectifying geological boundaries using displacement likelihood and evidence from geochemical assays. arXiv e-prints, page arXiv:2005.14427, May 2020.
- [32] Raymond Leung. Modelling orebody structures: Block merging algorithms and block model spatial restructuring strategies given mesh surfaces of geological boundaries. Journal of Spatial Information Science, 2020.
- [33] Andreas Dietrich, Enrico Gobbetti, and Sung-Eui Yoon. Massive-model rendering techniques: a tutorial. IEEE Computer Graphics and Applications, 27(6):1–18, 2007.
- [34] Morgan McGuire. Computer Graphics Archive, July 2017.
- [35] Greg Turk and Marc Levoy. The Stanford 3D Scanning Repository, August 2014.
- [36] Markku Tamminen and Hanan Samet. Efficient octree conversion by connectivity labeling. ACM SIGGRAPH Computer Graphics, 18(3):43–51, 1984.
10 Supplementary Material
This section elaborates on the computational aspects. In part A, a method is described for finding blocks in the model that intersect with triangular patches on a given surface. This is used to identify areas where model refinement is needed to accurately reflect the location of boundaries and more closely approximate the curvature of said surfaces. In part B, the concept of ray-tracing is described, this is used to establish the location of blocks relative to the surface(s) in the block tagging system component. Part D deals with the technical aspects of block merging and discusses various considerations fundamental to its design. This in-depth discussion explains the differences between two block merging conventions, the constraints, the block merging optimisation objective, and how different scanning sequences are implemented in practice. It should be noted that the overall block merging technique can be applied to areas outside of geoscience as shown in part C, to reduce redundancy / fragmentation in a parent-grid aligned block model, and in instances where 3D segmentation is desired given some triangle mesh surface for an object. Part E provides the pseudocode for the coordinate-ascent inspired block merging algorithms which is the main contribution of [32]. Finally, detailed commentary and results on octree subblocking are given in Part F and Part G.
Appendix A Akenine-Möller method for block triangle overlap detection
Assessment for “block-triangle” intersection involves at most 13 tests:
-
•
3 along the x, y, z axes, the orthonormal bases are denoted
-
•
9 for cross-products between edges of A and B, viz., cross() for
-
•
1 for the normal of the triangle based on cross() given vertices , edge vectors
Suppose a triangle has vertices , a block has centroid and dimensions , the SAT test for axes x, y, z asserts “no overlap” if or for any where and represent the minimum and maximum coordinates of the translated vertices, , after the block centroid is subtracted from the triangle vertices.
The SAT test for cross() exploits the properties of axis-aligned blocks. Its efficiency derives from terms cancellation in the cross-product expansion when the geometry of interest is limited to axis-aligned prisms and triangles. This uses only simple algebra; the relevant formulas may be found in [18].
The last SAT test for plane-block overlap requires and to be computed, where is the unit length plane normal, , is the plane distance from origin, assuming the plane passing through the triangle is described by the equation . The quantities and evaluate to . The test asserts “no overlap” if or .
Appendix B Side-of-surface determination via ray tracing
Ray tracing is a well known technique in the computer graphics community [33]. In the affiliated paper [32], it is used to establish where a block is located with respect to one or more triangle mesh surfaces, rather than for rendering purpose. A ray emanating from a block (specifically, its centroid) is casted in some specified direction.666For an open surface, this direction might be the upward (positive) direction specified in the tagging instructions. For a closed surface, the direction matters little, it is generally taken as the outward normal for the surface. The idea is to count the number of intersections between this ray and the relevant surface. An even number of intersections (including 0) result when the block is located above (respectively, outside) an open (respectively, closed) surface, and an odd number of interesections is interpreted as below (respectively, inside) the surface. The tests are based on the Möller–Trumbore algorithm [23] which is explained below.
B.1 Intersection between a ray and a plane
A ray extending from to intersects with a plane that passes through , with normal , at when where
| (1) |
A picture of this is shown in Fig. 27
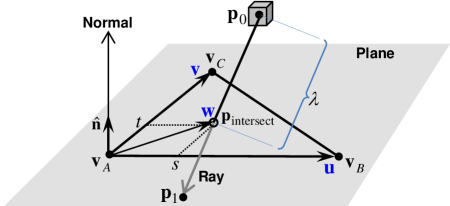
-
•
When , the ray does not intersect with the triangle described by vertices , , and plane .
-
•
When the denominator in (1) is zero, the ray is parallel to the triangle’s plane. If the numerator is also zero, the ray intersects with the face of the triangle along a line. Otherwise, there is no intersection.
B.2 Intersection between a ray and a triangle
When , the ray intersects with the triangle at if the barycentric coordinates and (see Fig. 27) satisfy and where
| (2) | |||
| (3) | |||
| (4) | |||
| (5) | |||
| (6) |
This involves only five distinct inner products, and the quantities ( and may be precomputed as they are independent of , unlike which is a function of the block centroid and ray direction.
B.3 Practicalities
Degenerate conditions must be handled to obtain proper results. First, when a ray intersects a surface at a common edge or vertex shared by multiple triangles, one needs to be careful that over-counting does not occur. In our implementation, a unique set of intersecting points is maintained for each ray to ensure the same intersecting point is not repeated. Second, when the denominator and numerator in (1) are both zero, is undefined, as the ray lies on the face of a triangle. This can be overcome by changing the direction slightly for the casted ray. Finally, triangles that collapse to a line segment or a single point need to be removed from the test surface since when either edge vector or in (2) and when and are parallel. Users may wish to perform surface integrity checks as a preprocessing step to eliminate these conditions.
Appendix C Demonstration on the Stanford Bunny
The block merging technique described in Algorithm 2 is applicable to more complex surfaces outside the geoscience domain. Fig. 28 (a) shows a triangular mesh surface [34] of the terracotta bunny obtained using multiple range scanners at the Stanford Computer Graphics Laboratory [35]. Fig. 28 (b) shows a highly fragmented block model created by block decomposition without consolidation. In an effort to closely approximate the surface, numerous blocks at the minimum block size were produced near the surface. Fig. 28 (c) shows a reduction in block density and increase in clarity as blocks are merged under the “dissolve sub-block boundaries” convention (see D.7). This resulted in a more efficient block representation (3D segmentation) of the object.
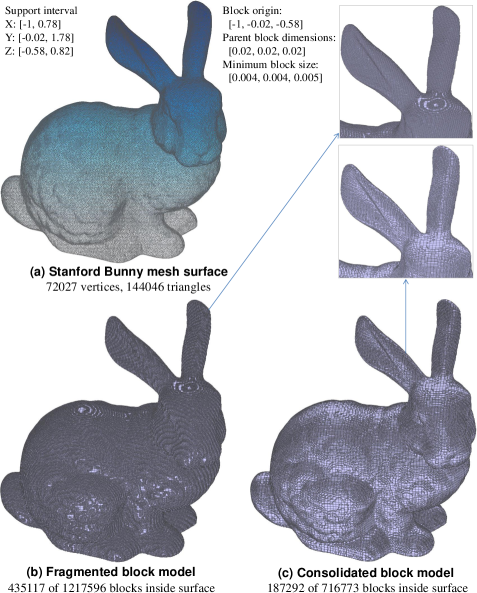
Appendix D Extended discussion about using block merging to reduce fragmentation
The adjustments foreshadowed in Section 5 of the paper [32] improve both the robustness and accuracy of the block model spatial restructuring system which utilises at least one surface. This section considers how the block consolidation component can be extended to serve the needs of a block merging application where the key objective is to coalesce blocks in a fragmented block model without any input surface. This extension builds upon the ideas described in Section 2.3. The characteristics and constraints of the problem will be described next. Henceforth, the established framework for block model spatial restructuring using surfaces from Section 5 and new block merge application will be abbreviated as SRUS and BM, respectively.
D.1 Problem description
In block model spatial restructuring using surfaces (SRUS), merging follows block-surface intersection detection and block decomposition, so we know precisely which input block (parent) a sub-block (cell) comes from. These input blocks may have different dimensions, particularly if the pipeline is repeated when individual surfaces are processed in cascade (see example in Section 4.1 where the output from the first iteration becomes the input in the second iteration). For the application envisaged in surface-free block merge (BM), the input contains only the labels, locations and dimensions of sub-blocks which are integer multiples of the minimum block size. Whilst the parent block and origin continues to provide a uniform grid structure that covers the 3D space, these parent-blocks have constant dimensions and only exist on a conceptual level for the purpose of grouping together the sub-blocks. Furthermore, ray-casting needs not be performed to determine which side of a surface a block is located, since the input provides domain labels for each block. The goal of BM is to consolidate the input blocks into larger rectangular prisms to minimise fragmentation.
D.2 Constraints
Before describing the constraints, it is instructive to first explain the spatial hierarchy and understand the assumptions. Fig. 29 illustrates the relationship between parent block, cells and input blocks (sub-blocks) of intermediate scale. Conceptually, the whole 3D space is spanned by parent blocks which represent uniform, non-overlapping tiles positioned with respect to the anchor point, block origin. Each parent block may be identified by an index obtained via uniform quantisation given the origin and parent block size, . Each parent has internal structure — each is divided by the minimum block size into cells in the same manner. A cell is the smallest spatial unit. The cell “walls” dictate what type of merges are possible within a parent block. All input blocks and merged blocks must adhere to this structure, i.e., each consisting of one or more whole cells.
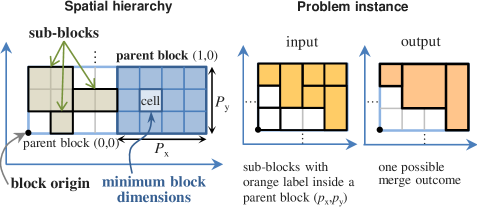
The assumptions are: 1) all input sub-blocks have dimensions which are integer-multiples of the minimum block; 2) all blocks must be rectangular prisms; 3) no sub-block straddles the boundary of any parent block; 4) edges of input and merged blocks must align perfectly with the internal grid lines of the parent block to which they belong; 5) only sub-blocks from the same class and parent may be merged.
D.3 Broad strategy
Beside some changes to the cell-expansion feasibility test, the block consolidation strategy based on coordinate-ascent merging is almost directly applicable to this problem. At a high level, the strategy comprises the following steps.
-
1.
Establish an input sub-block to parent block mapping.
-
2.
Divide and conquer (compartmental processing)
-
•
Each problem instance is restricted to a set of input blocks associated with (indexed by) a parent block. This is highly amendable to parallel processing.
-
•
-
3.
Within each parent block, process each category (collection of input blocks with the same class label) in turn.
-
•
The position / extent of sub-blocks undergoing consolidation are maintained by a 3D cell occupancy map and stateful objects.
-
•
-
4.
A modified coordinate-ascent merging algorithm is used to merge blocks from the same parent and class.
-
•
Feasibility of cell expansion is governed by specific rules which depend on the merging convention. However, the general goal remains the same, it still cycles through the x, y and z-coordinate one-by-one to consider if incremental expansion is possible.
-
•
D.4 Feasibility of cell expansion
For a parent block with cell dimensions , a 3D cell occupancy map with identical dimensions is used to manage merging states. To initialise this object, the cells occupied by each input block with the same label are set to 1 (active). A default value of 0 is set for the remaining (inactive) cells to signify a different domain classification. To advance this discussion, it is helpful to define a pooling function,
| (7) |
which counts the number of cells with label value over a support interval that extends from (the minimum cell coordinates) to (the maximum cell coordinates) where represents the provisional size of a block undergoing expansion. At any point during the coordinate-ascent algorithm, an incremental expansion — typically , , — is feasible if for a block with current cell dimensions .
D.5 Modifications
There are two key differences in the BlockMerge (BM) case. First, the boolean occupancy map now holds sub-block indices and becomes multi-valued, viz., . Second, when a block expansion step is feasible in one of the coordinate directions, the increment takes on the dimension of the block (or blocks) along the axis of expansion; this being typically larger than 1. Merging states are managed using an ordered777Objects of type are sorted in ascending order by the number of cells within each block, then by the minimum vertex coordinates to break ties. This priority gives smaller blocks the earliest opportunity to grow. list of structure similar to in Algorithm 1, where each structure initially contains the minimum vertex of an input block , its cell dimensions which can grow, the block label and a boolean flag, subsumed, which is set to false. The idea is to revise , the block dimensions expressed in terms of cells, as a block grows; blocks which have been swallowed are invalidated by setting subsumed to true and will be ignored in subsequent iterations. This effectively results in a shrinking set, the coalesced blocks are the surviving entries when the algorithm terminates. The algorithm continues as long as the cell count changes for any block between iterations. Details are given in Algorithm 2 on page 2.
D.6 Cell expansion feasibility test
For block merging, Algorithm 2 has essentially the same blueprint as Algorithm 1. The main difference is the acceptance criteria for each expansion step, see FeasibleCellExpansion in lines 25, 35 and 45 in Algorithm 2. This is explained with the aid of Fig. 30. When block merging is attempted, the expansion step proposes an elongation of the current block along one of the axes of expansion. The volumetric difference, before and after the proposed expansion, is referred as the delta region. Fig. 30 further illustrates 5 situations where a merge with adjacent block(s) are infeasible. A proposed expansion step is feasible when two conditions are satisfied: 1) the dimension along the axis of expansion is the same for all adjoining blocks in the delta region; 2) the lateral dimensions of these adjoining blocks are compatible with the current block; in other words, their cross-sections must join perfectly. The computation inside FeasibleCellExpansion is described in Subroutine 2.
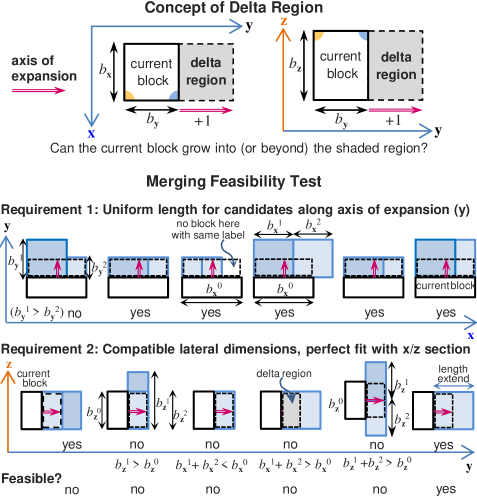
D.7 Merging conventions
In Algorithm 2, we have a block merging procedure that preserves the boundary of the input blocks, in the sense that it does not introduce new partitions (sub-divisions) that are not already present in a parent block. This is because when a sub-block is subsumed, it is swallowed whole by another block. This merging convention is referred as persistent block memory for future reference. A key property is that each input block is mapped uniquely to a single block in the merged model.
In contrast, Algorithm 1 implicitly erases sub-block boundaries before block consolidation begins. This merging convention is referred as dissolve sub-block boundaries, it generally achieves higher compaction because it makes no distinction between input blocks from the same class and parent. It is able to grow blocks more freely and produce fewer merged blocks since the size compatibility constraints between individual blocks no longer apply when they are treated as one. This can be useful for healing a fractured block model. It can consolidate sub-blocks introduced by a false boundary from a previous surface update. Under the “dissolve sub-block boundary” convention, coordinate-ascent can start from a clean slate. Sub-blocks in a fragmented area may grow back to the largest possible extent even if individual sub-block dimensions or internal boundary alignments are otherwise incompatible. It does not suffer the negative consequences of block structure decomposition from previous iterations. Some of these differences are shown in Fig. 31.
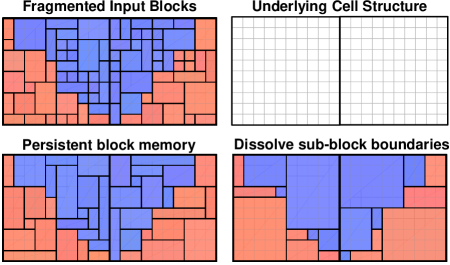
D.8 Fairness and regulating parameters
Both algorithms include optional parameters. The token life span, , limits the number of uninterrupted sequential merging steps a block can take during coordinate-ascent, to moderate aggressive merging behaviour. This token value is decremented by 1 after each x-y-z cycle. When it reaches zero, the current block must cease expansion and give other blocks the opportunity to grow. When every block in the queue has had its turn, this block may resume expansion. The token value is reset to each time a block takes possession. By default, is set to infinity so no progress is ever halted. An upper bound on merged block dimensions is given by . By default, this is set to the parent block size to remove any restriction.
D.9 Scan sequences to improve block aspect ratio
The final design consideration relates to the order in which input blocks are processed during coordinate-ascent. The main observation from Fig. 32 is that depending on the shape and direction of the class boundary, a sequential algorithm may generate a stair-case artefact, producing long narrow blocks which certain applications may find objectionable. The incremental block expansion may be obstructed by the boundary if it approaches from a certain direction as it cycles through each coordinate axis; this can lead to excessive growth in an unimpeded direction. In general, no single deterministic scanning sequence (e.g., increasing x, increasing y and increasing z as in the “standard” case) can be optimal in all situations. One way to overcome this is by introducing multiple scan patterns. For instance, instead of scanning (processing blocks) top-down, left-to-right, one can scan from bottom-up, from right-to-left. This is equivalent to flipping the x and y axes.
Accordingly, there are 8 distinct possibilities given we have 3 axes, these scan sequences may be abbreviated as , , and so forth, where a negative sign indicates reversal of the relevant axis. The algorithm will try all 8 scan patterns and select the result which minimises an objective function. In this work, the preferred solution minimises the volume-weighted block aspect ratio, the objective function may be expressed as
| (8) |
where merged block belongs to class in parent block , and represent the dimensions and volume of the merged block, obtained from scan sequence .
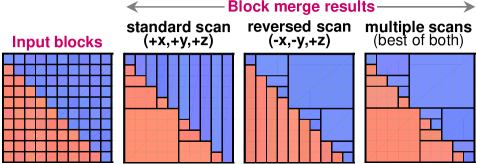
D.10 Scan sequence implementation
In practice, the eight individual scan patterns are not programmed explicitly. Instead, sub-blocks are rearranged within a parent block before coordinate-ascent, in such a way that a specific scan sequence is attained when the permuted data is subject to the standard scan. This is done to avoid code duplication and preserve the existing logic.888An explicit implementation for each scan pattern would involve nested for loops, this includes the standard / existing scan pattern — for (; ; ++) for (; ; ++) for (; ; ++) — and seven other combinations including, for instance, the (-x,-y,+z) scan pattern — for (; ; ++) for (; ; - -) for (; ; - -). This is not easy to maintain.
The approach is explained in Fig. 33. The key observation is that only the standard scan is necessary (we do not need to implement 8 different scans directly) provided the cells occupied by the input blocks are permuted to reflect a reversal of the relevant axes. For instance, a bottom–up, right–left scan sequence on the original block data may be implemented by mapping the white cells from the south-east corner to north-west corner (see Fig. 33 (top)), then applying the “standard” top-down, left-right scan. The two are equivalent. Fig. 33 (bottom) outlines the steps involved.
-
a)
(Forward permutation) For each input block labelled white in parent block , populate the occupancy map by sampling cells according to the direction of each axis specified in the scan instruction.999In reality, the occupancy map is a 3D array, but for simplicity, we only draw it in 2D.
-
b)
(Perform merging in rotated frame) Apply coordinate-ascent merging algorithm to permuted data using the standard scan pattern.
-
c)
(Inverse permutation) Register the location of merged blocks in the original frame using table-lookup.
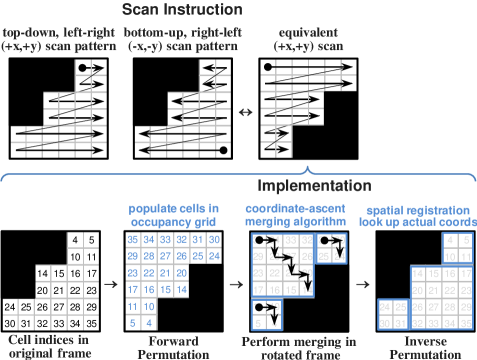
Synthesizing all the ideas, Algorithm 3 (page 3) describes the final block merging strategy which supports different merging conventions, multiple scan patterns and block aspect ratio optimisation. To elaborate on the the multi-threading aspect of the code, interleaved parent blocks are processed by individual threads within a region of interest. This choice, see interleaved parent indices in line 3 of Algorithm 3, is motivated by load balancing consideration. The intention is to spread the computation load evenly amongst the threads by decoupling spatial correlation, to avoid situations where too few (or too many) of the blocks processed by a thread actually intersect a surface.
Appendix E Pseudocode
This pseudocode comprises the following:
Algorithm 1:
Subroutine 1:
Compute sub-block properties
Algorithm 2:
Coordinate-ascent merging algorithm v2
(as used for model de-fragmentation in D)
Subroutine 2:
Feasibility tests and state updates during block expansion
Algorithm 3:
Block merging with multiple scans and optimised block aspect ratios
Appendix F Octree decomposition and merging
The two octree schemes considered in the paper are the standard octree decomposition, and octree with intra-scale merging. Starting at full resolution (), at each level of the spatial hierarchy, a rectangular block with dimensions may be split into eight sub-blocks (or cells) called an octant, where the dimensions of each sub-block are essentially halved along each axis, yielding . A split is performed when 2 or more of its sub-blocks at resolution carry different labels. This decomposition is performed recursively and stops only when the 3D block region becomes homogeneous (all 8 cells have the same label) or when the maximum decomposition level is reached. Such hierarchical structures are well studied in the literature, see [28] and [36] for instance. The purpose of this section is to clarify what intra-scale block merging means in this work, and how it relates to the standard octree.
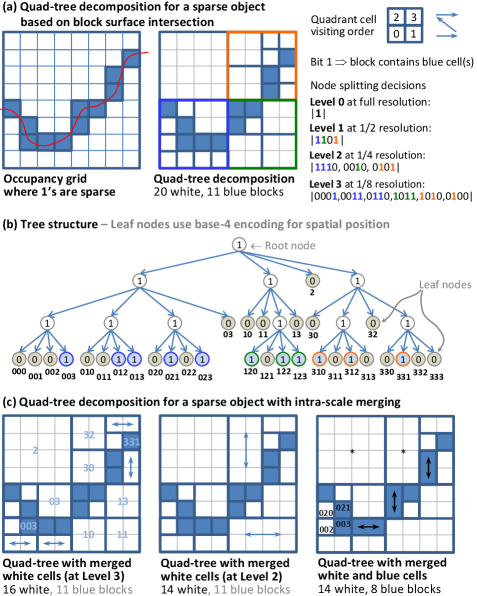
Octree decomposition is a popular technique for encoding sparse data such as edge pixels in an image array. Fig. 34 provides an example whereby block surface intersections are localised by blue cells in (a-left). A complete quad-tree decomposition of this region into sub-blocks at , and scale is shown in (a-middle). Following a particular quadrant cell scanning order, the 2D pattern may by represented by the tree-structure in (b). Intra-scale block merging has the specific meaning described in (c) where coalesced blocks are limited to adjacent cells within a quadrant; the arrows in (c-left) and (c-middle) show this happening at two spatial scales, and . The final result after octree decomposition and intra-scale merging is shown in (c-right). This picture illustrates that further merging is in fact possible — for instance between the white cells 002 and 020, or blue cells 003 and 021 — if inter-scale merging is permitted. We opted not to challenge these rules for the octree approach since these merging opportunities have already been exploited by the proposed methods, and intra-scale merging has its place in our performance comparison. For simplicity, the region is treated as a 2D block, however all aspects generalise to three-dimensions (from quadrant to octant) and all processes involved in the actual experiments operate in 3D.
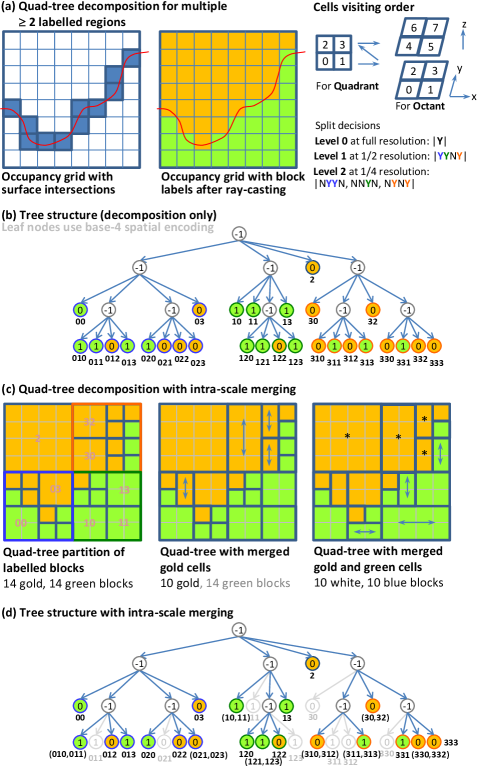
Extending these ideas to encode non-sparse regions, we observe that standard octree decomposition works in a top-down manner and has no innate ability for labelling cells at the minimum block size. Therefore, ray-tracing is used (since it forms part of the block model spatial restructuring workflow) to label cells as 0 or 1; colouring cells in gold or green in Fig. 35(a-middle) depending upon which side of the surface they are on.
Applying octree decomposition produces the tree-structure shown in Fig. 35(b) where split nodes are labelled -1, leaf nodes are labelled 0 or 1 (when there are two regions) and coloured gold or green accordingly. Result obtained with further intra-scale merging is shown in (c). As before, arrows indicate the blocks which have been merged within a quadrant at a given scale. The resultant tree-structure after intra-scale merging is depicted in (d). Comparing with (b), branches connecting with blocks which have been subsumed are evidently pruned with the corresponding nodes removed. Our earlier remarks on further inter-scale merging opportunities also exist here, for instance, blocks marked with asterisk in (c-right) can all potentially be combined into a single block. Although we focused our attention on two regions in this example, all relevant aspects generalise to three or more regions when multiple surfaces are involved.
F.1 Major difference between quadtree and octree
For an octree, the major difference with respect to quadtree are the candidates considered during intra-scale merging. Following the octant cell scanning order shown in Fig. 35 (a-right), prospective 2-cell merge candidates include basically 12 edges: viz., and from the top and bottom sides, and similarly from the north and south sides of an octant. Prospective 4-cell merge candidates include 6 square faces: {(0,1,2,3), (4,5,6,7), (0,1,4,5), (2,3,6,7), (0,2,4,6), (1,3,5,7)}.
Appendix G Detailed octree subblocking comparison
This section provides a more detailed breakdown of the model block count results presented in Sec. 8.1 of [32]. Henceforth, we use the word ‘Octree’ to denote standard octree decomposition. When the ‘+Merge’ suffix is added, intra-scale merging is attempted between compatible cells within each octant. This means, edge-connected cells within the same octant may be combined in groups of two or four to form a rectangular or squared block as described above (in Appendix F.1). However, inter-scale merging across different decomposition levels is not permitted. ‘Proposed-P’ refers to the proposed block merging algorithm performed under the persistent block memory convention. ‘Proposed-D’ refers to the same under the dissolved subblock boundary convention. ‘Domain’ means geological domain and ‘% volume’ means percentage of the total volume in the modelled region.
To promote spatial awareness, an animated sequence of the test site’s domain structure is shown layer-by-layer in Table 7 where the domain colour palette matches the colour labels used in the tables. A geology background is not required to understand this data. However, domain labels annotated by M, N and H may be interpreted as ‘mineralised’, ‘non-mineralised’ and ‘hydrated’ domains, respectively, by geologists.
| Domain | % volume | block count | volume-weighted block aspect ratio | ||||||
| Octree | Octree + Merge | Proposed-P | Proposed-D | Octree | Octree + Merge | Proposed-P | Proposed-D | ||
| 0.012340 | 2644 | 1154 | 772 | 704 | 2.5 | 3.954896 | 9.251789 | 3.685130 | |
| 0.012216 | 2422 | 1057 | 791 | 594 | 2.5 | 3.923701 | 6.925476 | 3.811883 | |
| 2.071587 | 326463 | 123708 | 59908 | 52925 | 2.5 | 2.435113 | 3.252310 | 2.386576 | |
| 0.571025 | 27523 | 11878 | 7256 | 7679 | 2.5 | 3.301445 | 4.297926 | 2.631313 | |
| 0.000045 | 17 | 12 | 12 | 12 | 2.5 | 3.529412 | 3.088235 | 3.088235 | |
| 0.247183 | 27769 | 12558 | 8132 | 8728 | 2.5 | 3.954645 | 6.093452 | 2.532378 | |
| 0.318811 | 34279 | 15510 | 10080 | 10732 | 2.5 | 3.954323 | 6.095554 | 2.586614 | |
| 1.036601 | 80587 | 35968 | 23032 | 23655 | 2.5 | 3.552698 | 5.208733 | 2.565268 | |
| 0.074106 | 13096 | 5958 | 3710 | 3788 | 2.5 | 3.723641 | 5.582627 | 3.214119 | |
| 1.996944 | 158170 | 70237 | 44619 | 45183 | 2.5 | 3.610081 | 5.044647 | 2.649020 | |
| 0.426214 | 53367 | 24250 | 15604 | 15490 | 2.5 | 3.638962 | 5.590088 | 2.862343 | |
| 1.058833 | 166835 | 75399 | 46713 | 47876 | 2.5 | 3.871672 | 5.621888 | 2.996686 | |
| 0.112265 | 23454 | 11036 | 7113 | 7121 | 2.5 | 3.780942 | 5.277800 | 3.288215 | |
| 0.332034 | 64151 | 29953 | 21128 | 19535 | 2.5 | 3.784879 | 7.178617 | 3.074582 | |
| 2.363637 | 241316 | 106972 | 67694 | 69211 | 2.5 | 3.942829 | 5.903363 | 2.878910 | |
| 0.035386 | 8595 | 4190 | 2824 | 2828 | 2.5 | 3.720205 | 6.229485 | 3.344340 | |
| 1.500652 | 249267 | 111807 | 67270 | 68843 | 2.5 | 3.928390 | 5.649683 | 3.162396 | |
| 0.005508 | 1579 | 811 | 576 | 568 | 2.5 | 3.527364 | 4.199520 | 3.340855 | |
| 0.052937 | 12489 | 6035 | 4357 | 4132 | 2.5 | 3.818116 | 6.895195 | 3.289241 | |
| 5.062708 | 394979 | 173877 | 108587 | 110817 | 2.5 | 3.756453 | 5.372227 | 2.753414 | |
| 0.230237 | 31048 | 13958 | 8972 | 8687 | 2.5 | 3.753732 | 4.868516 | 2.861059 | |
| 4.327004 | 450788 | 198725 | 123289 | 126389 | 2.5 | 3.966091 | 5.891937 | 2.966619 | |
| 0.119425 | 21038 | 9726 | 6387 | 6238 | 2.5 | 3.602132 | 5.310738 | 3.053729 | |
| 6.059302 | 517338 | 225301 | 138735 | 141283 | 2.5 | 3.893502 | 5.591457 | 2.858506 | |
| 0.092165 | 15999 | 7252 | 4671 | 4601 | 2.5 | 3.480721 | 5.185372 | 2.839088 | |
| 0.193627 | 42416 | 20254 | 14320 | 13380 | 2.5 | 3.691417 | 6.955868 | 3.105813 | |
| 3.049206 | 474133 | 208258 | 121712 | 124319 | 2.5 | 3.935326 | 5.502560 | 3.186988 | |
| 0.005196 | 1692 | 822 | 563 | 526 | 2.5 | 3.379135 | 5.267176 | 3.388906 | |
| 0.001007 | 339 | 180 | 138 | 133 | 2.5 | 3.366142 | 5.218110 | 3.547769 | |
| 68.631674 | 797448 | 323952 | 175932 | 174585 | 2.5 | 2.599801 | 2.867128 | 2.506040 | |
| 0.000127 | 48 | 28 | 20 | 23 | 2.5 | 3.645833 | 5.781250 | 3.564583 | |
| Total (avg. by volume) | 4241289 | 1830826 | 1094917 | 1100585 | 2.5 | 2.958828 | 3.668188 | 2.615373 | |
| Total (avg. by block count) | same | same | same | same | 2.5 | 3.535403 | 5.068056 | 2.839873 | |
| Ratio | 100.000 | 43.167 | 25.816 | 25.949 | |||||
| \animategraphics[autoplay,loop,trim=0 0 0 4cm,width=105mm]4fig30-0030 | |||||||||
| Animated sequence — birds eye view of Site 8’s spatial structure | |||||||||
| Geological domains are peeled back layer by layer in this animation | |||||||||
| Domain | % volume | block count | volume-weighted block aspect ratio | ||||||
| Octree | Octree + Merge | Proposed-P | Proposed-D | Octree | Octree + Merge | Proposed-P | Proposed-D | ||
| 0.012367 | 11742 | 5065 | 3317 | 2746 | 2.5 | 3.900329 | 15.549850 | 4.059046 | |
| 0.012224 | 10946 | 4650 | 3420 | 2201 | 2.5 | 3.909655 | 10.466585 | 4.674493 | |
| 2.071568 | 1429469 | 533237 | 223538 | 185677 | 2.5 | 2.438087 | 4.852193 | 3.363062 | |
| 0.571042 | 108496 | 47062 | 26560 | 28328 | 2.5 | 3.330618 | 6.133705 | 2.987043 | |
| 0.000039 | 112 | 62 | 45 | 44 | 2.5 | 3.592437 | 4.118487 | 3.170588 | |
| 0.247097 | 116150 | 52202 | 31105 | 33811 | 2.5 | 3.882805 | 9.738552 | 3.590038 | |
| 0.318835 | 143282 | 64352 | 38541 | 41093 | 2.5 | 3.928394 | 9.994956 | 3.620897 | |
| 1.036702 | 342263 | 150890 | 87578 | 89680 | 2.5 | 3.623427 | 8.200493 | 3.193486 | |
| 0.074196 | 60521 | 26754 | 14949 | 15198 | 2.5 | 3.768124 | 8.326254 | 3.820477 | |
| 1.996801 | 667620 | 292632 | 169023 | 170337 | 2.5 | 3.644469 | 7.759336 | 3.312802 | |
| 0.426296 | 235590 | 104610 | 60747 | 59749 | 2.5 | 3.610870 | 8.889136 | 3.776128 | |
| 1.058725 | 728816 | 324163 | 182289 | 186255 | 2.5 | 3.892632 | 8.553657 | 3.970692 | |
| 0.112501 | 110475 | 49990 | 28969 | 28582 | 2.5 | 3.779309 | 7.580900 | 4.003741 | |
| 0.331797 | 298282 | 135474 | 88804 | 78141 | 2.5 | 3.779701 | 11.899441 | 3.762755 | |
| 2.362666 | 1022988 | 450290 | 259668 | 261922 | 2.5 | 3.936937 | 9.418536 | 3.851701 | |
| 0.035805 | 45500 | 21242 | 12706 | 12578 | 2.5 | 3.677538 | 9.116177 | 3.699823 | |
| 1.501456 | 1098197 | 485024 | 264369 | 268390 | 2.5 | 3.963615 | 8.493589 | 4.080947 | |
| 0.005730 | 9258 | 4734 | 2985 | 2929 | 2.5 | 3.564548 | 5.640211 | 3.770489 | |
| 0.053013 | 62734 | 29214 | 19290 | 17460 | 2.5 | 3.701885 | 10.991420 | 3.706879 | |
| 5.064220 | 1663577 | 727924 | 410459 | 414897 | 2.5 | 3.794050 | 8.463884 | 3.543067 | |
| 0.228323 | 142484 | 61726 | 35310 | 33610 | 2.5 | 3.726269 | 7.352394 | 3.805164 | |
| 4.325235 | 1895420 | 828568 | 466319 | 473527 | 2.5 | 3.942704 | 9.354241 | 4.004534 | |
| 0.119550 | 99113 | 44273 | 25985 | 24900 | 2.5 | 3.579750 | 7.963333 | 3.817275 | |
| 6.059267 | 2143315 | 928956 | 519128 | 522118 | 2.5 | 3.921219 | 8.812658 | 3.766239 | |
| 0.092176 | 73872 | 32446 | 18975 | 18255 | 2.5 | 3.478816 | 8.269290 | 3.744605 | |
| 0.193962 | 201251 | 92622 | 60682 | 54519 | 2.5 | 3.722921 | 11.130710 | 3.710936 | |
| 3.050039 | 2038137 | 885891 | 469694 | 475684 | 2.5 | 3.970251 | 8.126027 | 4.180359 | |
| 0.005201 | 9332 | 4259 | 2611 | 2405 | 2.5 | 3.427114 | 7.226263 | 3.727820 | |
| 0.001046 | 2086 | 1004 | 647 | 610 | 2.5 | 3.463970 | 7.412168 | 3.983059 | |
| 68.632008 | 2643443 | 1065825 | 525508 | 501270 | 2.5 | 2.605537 | 3.283658 | 2.576202 | |
| 0.000115 | 284 | 143 | 89 | 102 | 2.5 | 3.832853 | 8.900865 | 2.621326 | |
| Total (avg. by volume) | 17414755 | 7455284 | 4053310 | 4007018 | 2.5 | 2.968178 | 4.901418 | 2.941797 | |
| Total (avg. by block count) | same | same | same | same | 2.5 | 3.585874 | 7.861600 | 3.650470 | |
| Ratio | 100.000 | 42.810 | 23.275 | 23.009 | |||||
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/747237e0-9df8-48c9-9048-0902fc785351/x52.png) |
|||||||||
| X cross-sections of the same geological domains | |||||||||
| Domain | % volume | block count | volume-weighted block aspect ratio | ||||||
| Octree | Octree + Merge | Proposed-P | Proposed-D | Octree | Octree + Merge | Proposed-P | Proposed-D | ||
| 0.012187 | 54650 | 22512 | 13500 | 10598 | 2.5 | 3.937759 | 28.207846 | 5.272790 | |
| 0.012225 | 47666 | 19995 | 14373 | 8581 | 2.5 | 3.880556 | 17.203926 | 6.303496 | |
| 2.069887 | 5966122 | 2206483 | 856985 | 691068 | 2.5 | 2.448336 | 8.103377 | 5.186617 | |
| 0.569810 | 465501 | 196686 | 101427 | 106403 | 2.5 | 3.341298 | 9.875999 | 3.403828 | |
| 0.000040 | 646 | 333 | 225 | 211 | 2.5 | 3.638946 | 7.322417 | 2.796074 | |
| 0.246775 | 482523 | 214397 | 120786 | 128908 | 2.5 | 3.872228 | 17.465091 | 5.425162 | |
| 0.318412 | 593948 | 264225 | 149991 | 157914 | 2.5 | 3.893686 | 18.004315 | 5.075332 | |
| 1.035730 | 1441073 | 626411 | 340497 | 345133 | 2.5 | 3.648167 | 14.088016 | 3.945783 | |
| 0.074129 | 266189 | 114990 | 59476 | 59692 | 2.5 | 3.725392 | 14.391746 | 5.381985 | |
| 1.994655 | 2809366 | 1215883 | 656664 | 653464 | 2.5 | 3.665340 | 13.196620 | 4.206202 | |
| 0.426116 | 994488 | 437691 | 238458 | 232800 | 2.5 | 3.634994 | 15.740771 | 5.344710 | |
| 1.057534 | 3076723 | 1352508 | 715135 | 728884 | 2.5 | 3.909520 | 14.793386 | 6.200759 | |
| 0.112500 | 484807 | 215842 | 116435 | 114125 | 2.5 | 3.801134 | 12.542677 | 5.895113 | |
| 0.331752 | 1295410 | 578825 | 360946 | 308160 | 2.5 | 3.779019 | 21.440046 | 5.554469 | |
| 2.361292 | 4261395 | 1856015 | 1009360 | 997440 | 2.5 | 3.932490 | 16.538731 | 5.283464 | |
| 0.035589 | 209842 | 94582 | 51685 | 50865 | 2.5 | 3.681174 | 15.741827 | 5.199280 | |
| 1.500113 | 4615285 | 2017890 | 1041881 | 1049804 | 2.5 | 3.979482 | 14.656347 | 6.338921 | |
| 0.005824 | 53198 | 25599 | 14448 | 14215 | 2.5 | 3.544744 | 8.629379 | 5.305402 | |
| 0.052644 | 302851 | 133967 | 79652 | 70437 | 2.5 | 3.725562 | 19.455017 | 5.425445 | |
| 5.059155 | 6903632 | 2989708 | 1582574 | 1573708 | 2.5 | 3.815540 | 14.647774 | 4.527278 | |
| 0.229129 | 615542 | 261940 | 139458 | 129839 | 2.5 | 3.719217 | 12.449978 | 5.553382 | |
| 4.322323 | 7841613 | 3398938 | 1800920 | 1801115 | 2.5 | 3.935243 | 16.360033 | 5.554397 | |
| 0.119576 | 434074 | 190030 | 104029 | 98436 | 2.5 | 3.584765 | 13.754793 | 5.630620 | |
| 6.055483 | 8847559 | 3800130 | 1995917 | 1975291 | 2.5 | 3.923066 | 15.285411 | 4.941555 | |
| 0.092180 | 322413 | 139347 | 76104 | 71667 | 2.5 | 3.464583 | 14.724576 | 5.738100 | |
| 0.193918 | 892552 | 402913 | 249416 | 217807 | 2.5 | 3.716055 | 19.805877 | 5.544980 | |
| 3.048503 | 8456955 | 3650182 | 1837766 | 1853527 | 2.5 | 3.977186 | 13.698514 | 6.438980 | |
| 0.005207 | 45786 | 20074 | 11478 | 10381 | 2.5 | 3.470138 | 11.670511 | 4.750513 | |
| 0.001024 | 10736 | 4770 | 2806 | 2567 | 2.5 | 3.561028 | 13.049818 | 4.983007 | |
| 68.656172 | 12271192 | 4599110 | 1865318 | 1741347 | 2.5 | 2.608728 | 4.109259 | 2.667184 | |
| 0.000117 | 1564 | 760 | 452 | 457 | 2.5 | 3.635483 | 12.809443 | 2.827696 | |
| Total (avg. by volume) | 74065301 | 31052736 | 15608162 | 15204844 | 2.5 | 2.972378 | 7.395642 | 3.456381 | |
| Total (avg. by block count) | same | same | same | same | 2.5 | 3.585541 | 13.523983 | 5.078064 | |
| Ratio | 100.000 | 41.926 | 21.074 | 20.529 | |||||