Modeling Users’ Behavior Sequences with Hierarchical Explainable Network for Cross-domain Fraud Detection
Abstract.
With the explosive growth of the e-commerce industry, detecting online transaction fraud in real-world applications has become increasingly important to the development of e-commerce platforms. The sequential behavior history of users provides useful information in differentiating fraudulent payments from regular ones. Recently, some approaches have been proposed to solve this sequence-based fraud detection problem. However, these methods usually suffer from two problems: the prediction results are difficult to explain and the exploitation of the internal information of behaviors is insufficient. To tackle the above two problems, we propose a Hierarchical Explainable Network (HEN) to model users’ behavior sequences, which could not only improve the performance of fraud detection but also make the inference process interpretable.
Meanwhile, as e-commerce business expands to new domains, e.g., new countries or new markets, one major problem for modeling user behavior in fraud detection systems is the limitation of data collection, e.g., very few data/labels available. Thus, in this paper, we further propose a transfer framework to tackle the cross-domain fraud detection problem, which aims to transfer knowledge from existing domains (source domains) with enough and mature data to improve the performance in the new domain (target domain). Our proposed method is a general transfer framework that could not only be applied upon HEN but also various existing models in the Embedding & MLP paradigm.
By utilizing data from a world-leading cross-border e-commerce platform, we conduct extensive experiments in detecting card-stolen transaction frauds in different countries to demonstrate the superior performance of HEN. Besides, based on 90 transfer task experiments, we also demonstrate that our transfer framework could not only contribute to the cross-domain fraud detection task with HEN, but also be universal and expandable for various existing models. Moreover, HEN and the transfer framework form three-level attention which greatly increases the explainability of the detection results.
1. Introduction
With the rapid growth of information technologies, e-commerce has become prevalent nowadays. A large online e-commerce website serves millions of users with numerous products and services everyday, providing them a convenient, fast, and reliable manner of shopping, service acquisition, reviewing, comment feedback, etc. Unfortunately, the problem of online transaction fraud has become increasingly prominent, putting the finance of e-commerce at risk (Fastoso et al., 2012). Online fraud activities have caused a loss in billions of dollars 111https://www.signifyd.com/blog/2017/10/26/ecommerce-fraud-eight-industries/.

Detection of real-time online fraud is critical to the development of e-commerce platforms. To solve the fraud detection problem, many approaches have been proposed (Phua et al., 2010; Cohen, 1995; Baulier et al., 2000; Brause et al., 1999; Fu et al., 2016; Zakaryazad and Duman, 2016). However, these approaches did not consider the sequential behavior history of users, which has been utilized in many studies (Wang et al., 2017c; Jurgovsky et al., 2018) to improve the performance of the fraud detection system. Such sequence prediction task exploits the users’ historical behavior sequences to help differentiate fraudulent payments from regular ones, as shown in Figure 1. For the sequence prediction task, some effective models have been proposed to capture the sequential information in user’s behavior history, such as Markov Chains based methods (Zhang et al., 2018), convolutional neural networks based methods (Tang and Wang, 2018), and recurrent neural networks based methods (Wang et al., 2017c; Jurgovsky et al., 2018). These methods utilize sequential information to further improve performance. However, (1) The prediction results are difficult to explain for these methods. (2) They focus more on the sequential information of the behaviors, but fail to thoroughly exploit the internal information of each behavior, e.g., only the first-order information of fields’ embeddings is used to represent events (Wang et al., 2017c; Zhang et al., 2018; Jurgovsky et al., 2018).
In order to tackle the above two problems, we propose a Hierarchical Explainable Network (HEN) to model users’ behavior sequences, which could not only improve the performance of fraud detection but also help answer this “why”. HEN contains two-level extractors: 1) Field-level extractor extracts the representations of behavior events that contain both first- and second-order information from the embedding of fields, and it learns to choose informative fields, e.g., the card-related fields would be more important than the time-related fields. 2) Event-level extractor extracts the representations of users’ historical behavior sequences from the representations of behavior events and could score the event importance. Besides, the wide layer of HEN could help to identify the specific value of fields with high-risk/low-risk, which could be used as whitelist/blacklist.
In this paper, the fraud detection dataset is collected from one of the world-leading cross-border e-commerce companies. As its e-commerce business expands to new domains, e.g., new countries or new markets, one major problem for modeling users’ behavior in fraud detection systems is the limitation of data collection, e.g., very few data/labels available.
Hence, we introduce cross-domain fraud detection, which aims to transfer knowledge from existing domains (source domains) with enough and mature data to improve the performance in the new domain (target domain). The main challenges of the cross-domain fraud detection problem are elaborated as follows: (1) In our problem, the source and target domains share some knowledge but also have some specific characteristics, e.g., the IP address of different countries are different, while the card type is shared. (2) For the prediction of different samples, the weight of the shared and specific knowledge would be different. (3) Due to the domain-specific knowledge, the distributions of source and target samples can differ in many ways.
Due to these challenges, modeling users’ behavior sequences with a single structure, as shown in most previous cross-domain works (Long et al., 2015; Ganin et al., 2016; Sun and Saenko, 2016; Xie et al., 2018), could not meet the demand of our fraud detection task, because it only learns shared representations without paying attention to domain-specific knowledge. To tackle the cross-domain fraud detection problem, we propose three important aspects: (1) The network should be divided into two parts to capture domain-shared and domain-specific knowledge, respectively. (2) Domain attention is useful to automatically learn the weights of domain-shared and domain-specific representations for each sample. (3) Existing marginal (Long et al., 2015; Ganin et al., 2016; Sun and Saenko, 2016) and conditional (Long et al., 2013; Xie et al., 2018) alignment methods are not suitable for the cross-domain fraud detection tasks which suffer extremely unbalanced categories problem. To this end, we propose Class-aware Euclidean Distance which considers both intra- and inter-class information. Along this line, we propose a general transfer framework that can be applied upon various existing models in the Embedding & MLP paradigm.
The main contributions of this work are summarized into three folds:
-
•
To solve the sequence-based fraud detection problem, we propose hierarchical explainable network (HEN) to model users’ behavior sequences, which could not only improve the performance of fraud detection but also give reasonable explanations for the prediction results.
-
•
For cross-domain fraud detection, we propose a general transfer framework that can be applied upon various existing models in the Embedding & MLP paradigm.
-
•
We perform experiments on real-world datasets of four countries to demonstrate the effectiveness of HEN. In addition, we demonstrate our transfer framework is general for various existing models on 90 transfer tasks. Finally, we conduct case study to prove the explainability of HEN and the transfer framework.
2. Related Work
In this section, we will introduce the related work from three aspects: Fraud Detection, Sequence Prediction, Transfer Learning.
Fraud Detection: Researchers have investigated in fraud detection problems for a long time. Early explorations of fraud detection focus on rule-based methods. Quinlan (Quinlan, 1990) and Cohen (Cohen, 1995) introduced assertion statement of IF {conditions} and THEN {a consequent} to recognize fraud records. Association rules have been applied to detect credit card fraud (Brause et al., 1999). Rosset et al. (Rosset et al., 1999) presented a two-stage rules-based fraud detection system to detect telephone fraud.
However, fraudulent behaviors change over time, which greatly deteriorates the effectiveness of rules summarized by expert experience. Recently, with millions of transaction data available, more and more data-driven and learning-based methods are applied for the fraud detection problem. SVM-based ensemble strategy was utilized for detecting telecommunication subscription fraud and credit fraud (Wang and Ma, 2012). Some fraud detection works focused on using graphs for spotting frauds (Tian et al., 2015; Tseng et al., 2015). Convolutional neural network (CNN) has been applied for credit card fraud detection (Fu et al., 2016). Some works used recurrent neural networks for sequence-based fraud detection (Wang et al., 2017c; Zhang et al., 2018; Jurgovsky et al., 2018). In this paper, we also focus on sequence-based fraud detection, and compare our HEN with the RNN based methods in experiments.
Sequence Prediction: Sequence prediction (Li et al., 2018; Huang et al., 2019) is a kind of prediction problem which exploits the users’ historical behavior sequences to help prediction. He et al. (He and McAuley, 2016) combined similarity-based models with high-order Markov chains to make personalized sequential recommendations. Tang et al. (Tang and Wang, 2018) proposed to apply the convolutional neural network (CNN) on the embedding sequence, where the short-term contexts can be captured by the convolutional operations. Some works (Wang et al., 2017c; Zhang et al., 2018; Jurgovsky et al., 2018) exploited recurrent neural networks for sequence-based fraud detection. Zhou et al. (Zhou et al., 2018) exploited an attention module for sequence recommendation. Besides, a method called Multi-temporal-range Mixture Model (M3) (Tang et al., 2019) has been proposed to apply a dense layer to extract behavior representation from the embedding of fields, and then employ a mixture of models to deal with both short-term and long-term dependencies. Nevertheless, these studies focus on the sequential information without effectively exploiting the internal information of each behavior. In addition, most of these methods ignore the importance of explainability while our HEN is able to give reasonable explanations for the prediction results.
Transfer Learning: Transfer learning aims to leverage knowledge from a source domain to improve the learning performance or minimize the number of labeled examples required in a target domain (Pan and Yang, 2009; Zhuang et al., 2019). Some transfer methods have been widely adopted for many problems, such as pre-training a model on a large dataset and then fine-tuning on the target task (Hinton et al., 2006). However, the improvement of such general transfer methods is limited. Recently, transfer learning on computer vision and natural language process has attracted the attention of amounts of researchers (Long et al., 2015; Zhuang et al., 2015; Ganin et al., 2016; Sun and Saenko, 2016; Wang et al., 2017a). These approaches largely improve performance, but most of them have not been used for practical industrial problems. There are some transfer approaches for practical industrial problems, such as cross-domain recommendation (Hu et al., 2019), adaptively handwritten Chinese character recognition (Zhu et al., 2019c), passenger demand forecasting (Bai et al., 2019). However, to the best of our knowledge, this is the first work to propose cross-domain fraud detection.

3. Hierarchical Explainable Network
3.1. Problem Statement
Given a user’s behavior event sequence , where is the the length of the sequence. Each behavior event has fields, such as IP_address, Event_category, Issuer, etc. The behavior event is denoted as , where denotes the value of the -th field. The task is to predict whether the target payment event is fraud ( denotes is fraud) with the user’s historical behavior event sequence and available information of the target event . In such setting, the task can be formulated as a binary prediction task.
3.2. Look-up Embedding
Look-up embedding has been widely adopted to learn dense representations from raw data for prediction (He and Chua, 2017; Tang and Wang, 2018). In practice, we have two types of fields, categorical fields that have a limited number of distinct values (such as Issuer, Event_category) and numerical fields which are continuous values (such as Balance_amount). For the two types of fields, the methods of look-up embedding are different. We formulate the embedding matrix or the look-up table of the -th field as:
| (1) |
where denotes the dimension of the embedding vectors, and denotes the number of distinct values in a categorical field . Then, we obtain the embedding vector of by:
| (2) |
where denotes the -th row of .
3.3. Field-level Extractor
The field-level extractor aims to extract the event representations from the embedding vectors of fields. However, some existing methods (Zhang et al., 2018; Wang et al., 2017c; Tang et al., 2019) only use a simple dense layer and the embedding concatenation as the field-level extractor, which could not effectively extract the internal information of each behavior event. In addition, the results of the above methods are hard to interpret. We aim to design a novel field-level extractor that could not only extract the internal information of each behavior event more effective but also score the importance of different fields.
Recent studies (Rendle, 2010; Wang et al., 2017b; He and Chua, 2017; Lian et al., 2018) find that the high-order feature interaction is very useful. Inspired by the success of factorization machines (Rendle, 2010) which captures the second-order feature interaction, we design a novel field-level extractor that captures both the first- and second-order feature interaction, and the event representations could be fed into the event-level extractor and MLP to capture higher-order feature interaction. The field-level extractor is formulated as:
| (3) |
denotes the event embedding of the -th event , and denotes the -th field embedding of the -th event. represents Hadamard product. is the attention weight for which is computed as:
| (4) |
where is a learnable parameter for the embedding of of the -th field. In other words, for each value of each categorical field and each numerical field, the model learns a learnable parameter. Note that for all values of a numerical field, the is the same parameter (not related to the values of ). Due to all pairwise interactions need to be computed, the complexity of straight forward computation of Equation 3 is in . Actually, it can be reformulated to linear runtime (Rendle, 2010):
| (5) |
Our field-level extractor is able to choose informative fields. indicates the attention distribution of field embeddings that could explain which field embedding is more important to represent event embedding.
3.4. Event-level Extractor
The event-level extractor aims to extract the sequence embedding from the historical event embedding vectors . Some existing approaches (He and McAuley, 2016; Tang and Wang, 2018; Wang et al., 2017c; Zhang et al., 2018) use such as Markov chains, CNN, RNN as the event-level extractor. These methods only capture the sequential information, however, they suffer from the problem of lacking explainability. With the attention mechanism, we design an explainable event-level extractor as:
| (6) |
where is the attention weight which is formulated as:
| (7) |
where denotes the inner product. , and represent the feed-forward networks to project the input event vector to one new vector representation. Actually, there are lots of ways to design , and . In this paper, we use one simple dense layer as , and .
With the attention mechanism, our event-level extractor is able to score the event importance, and from the score, we could find which event is more important to represent the sequence embedding. To analyze the score of fraud samples, we could find some high-risk behavior sequences.
3.5. Prediction and Learning
We concatenate the sequence embedding and the target event embedding as . And then, we feed into a multi-layer perceptron (MLP) to get the final prediction :
| (8) |
where is the linear part just like the “wide” part in Wide & Deep (Cheng et al., 2016) to capture the first-order information:
| (9) |
where indicates the mapping function of the -th field which could denote the importance of the feature. Actually, is a look-up embedding layer as Section 3.2 with the dimension . With the fraud sample , it is easy to understand that the value of should be big. Hence, the wide layer of HEN could help to identify specific value of fields with high-risk/low-risk, which could be used as whitelist/blacklist. For example, the -th categorical field has two distinct values , and indicates is higher-risk than .
For binary prediction tasks, we need to minimize the negative log-likelihood:
| (10) |
where is the number of samples, is the label of sample , is the parameters set and is the dataset. The overall structure of HEN is shown in Figure 2.
4. General Transfer Framework
4.1. Definition of Cross-domain Fraud Detection
In cross-domain fraud detection problem, we are given a source domain of labeled samples ( has the same definition as Section 3.1 and denotes the label of in ). Similarly, we have a target domain . Note that which is also called semi-supervised transfer problem (Tzeng et al., 2015). The transfer task aims to improve the model performance on the unlabeled test set with the help of .
4.2. The Strategy of Embedding
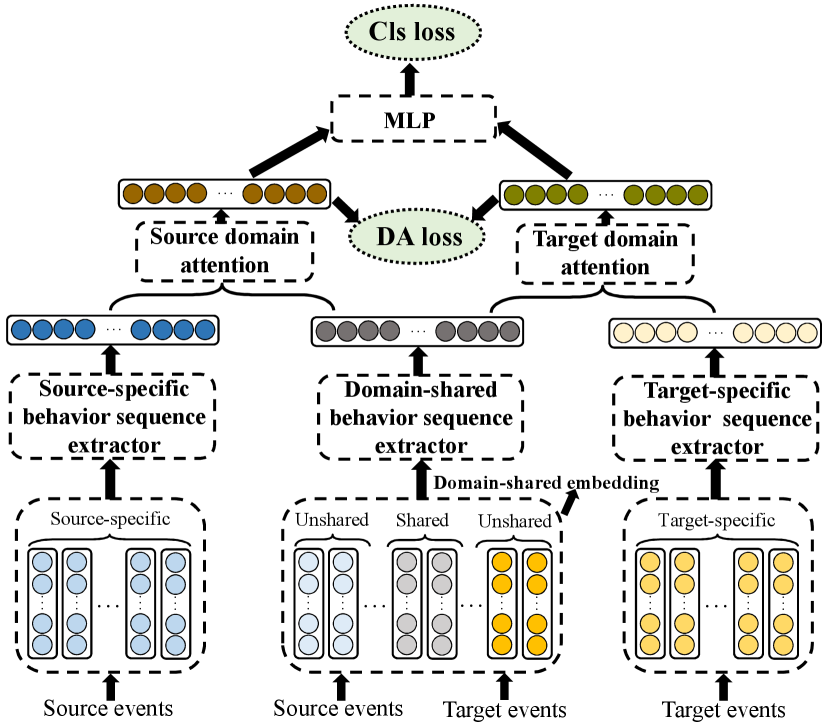
We find that some fields of different domains have unshared values, such as IP_address, City, while some fields share the same values, such as Event_category, Card_type. In addition, we conduct experiments to train a model on , and the performance of the model on is unsatisfying. The main reason for the unsatisfying performance is that models trained on source samples could not learn the embedding of the unshared fields. Hence, we consider to share the embedding of the fields’ shared values and learn the embedding of the unshared values respectively (named domain-shared embedding layer as shown in Figure 3).
With more samples, the domain-shared embedding layer could learn the shared embedding better. However, it has some negative influence. For example, even though the Issuer bank information is shared by both domains, the Issuer distribution of the fraudsters may differ a lot in the two domains. Since the source samples are much more than the target samples, the domain-shared embedding would more focus on Issuer1 which would lose the domain-specific information. Hence, we also design a source- and target-specific embedding layer to capture the domain-specific information.
4.3. Shared and Specific behavior sequence extractor
The behavior sequence extractor aims to extract the sequence feature from the embedding of fields for prediction. It is easy to consider sharing the behavior sequence extractor for all domain-shared, source- and target-specific embedding. However, there are two bottlenecks with single shared behavior sequence extractor: (1) The distributions of the domain-shared, source- and target-specific embedding are completely different, which may affect the performance of the network. (2) The shared behavior sequence extractor could not capture all sequential information of both domains, and it misses some domain-specific sequential information.
Hence, we propose domain-shared and domain-specific behavior sequence extractors as shown in Figure 3. There are three main advantages of the structure: (1) The domain-shared behavior sequence extractor focuses on common sequential information. (2) The target-specific extractor can make up for the disadvantages of the domain-shared extractor which ignores the target-specific knowledge, and it could capture sufficient target-specific sequential information. (3) The source-specific extractor could capture sufficient source-specific sequential information. Here, we formulate the representations extracted by domain-shared, target-specific and source-specific extractors as , respectively.
4.4. Domain Attention
The shared behavior sequence extractor could extract sequence representations that contain domain-shared sequential information. In addition, the domain-specific behavior sequence extractor could extract more specific sequential information which could make up for the disadvantages of the domain-shared extractor. By combining the two representations , it could contain more useful knowledge. The simplest methods to combine the two representations are such as average and concatenation. However, for different samples, the weights of the shared and specific knowledge would be different. Meanwhile, they could not explain from which part the knowledge is more important for target prediction. Hence, we also propose a domain attention mechanism to combine the two representations:
| (11) |
where denotes the domain of the representations , and is the attention weight which is formulated as:
| (12) |
where , , and are the feed-forward networks to project the input representations to new representations. Domain attention module is capable of learning the importance of domain-shared and domain-specific representations.
4.5. Aligning Distributions
Note that the distributions of representations and are different. We could feed them into a source MLP and a target MLP, respectively. However, we find the performance is unsatisfying, and the reason would be the limitation of target samples which lead to the target MLP overfitting. Thus we consider aligning the distributions of representations and , and feeding them into the same MLP to avoid overfitting. Most existing transfer approaches (Long et al., 2015; Tzeng et al., 2015; Sun and Saenko, 2016; Ganin et al., 2016; Xie et al., 2018) aim to align the marginal and conditional distributions. However, in our scenario, the class distribution is extremely unbalanced that the number of non-fraud samples is about 100 times more than fraud samples. Hence, aligning the marginal and conditional distributions would lead to unsatisfying performance. For our scene, we propose Class-aware Euclidean Distance which explicitly takes the class information into account and measures the intra-class and inter-class discrepancy across domains. First, we formulate Euclidean Distance between two classes as:
| (13) |
where and denote the class label (fraud and non-fraud), and represent the numbers of samples of classes in and domains, respectively. The denotes the Euclidean Distance between the embeddings of class in domain and class in domain. Note that and could denote the same domain. Then, we formulate Class-aware Euclidean Distance as:
| (14) |
where the numerator represents the sum of intra-class distance and the denominator denotes the sum of inter-class distance. Existing transfer methods that align marginal distributions ignore the class information (Long et al., 2015; Tzeng et al., 2015; Sun and Saenko, 2016). The transfer methods which match conditional distributions consider the intra-class information without considering the inter-class information (Xie et al., 2018). By minimizing the left part of Equation (14), the intra-class domain discrepancy is minimized to compact the feature representations of samples within a class, whereas the inter-class domain discrepancy is maximized to push the representations of each other further away from the decision boundary. Hence, Class-aware Euclidean Distance could achieve better performance in our scene.
4.6. Apply The General Transfer Framework upon Various Models
The general transfer framework as shown in Figure 3 could be applied upon various existing models in the Embedding & MLP paradigm. The most important thing to apply the transfer framework is to define the behavior sequence extractor. For our HEN, the behavior sequence extractor contains a field-level extractor and an event-level extractor as shown in Figure 2. For neural factorization machines (NFM) (He and Chua, 2017), we use the FM module as the behavior sequence extractor. For wide & deep (Cheng et al., 2016), we use a dense layer as the behavior sequence extractor. For all models, we feed the output of the behavior sequence extractor into an MLP to get the final prediction. Other details are easy to understand as shown in Figure 3.
The training mainly follows the back-propagation algorithm. The target loss is formulated as:
| (15) |
where is a trade-off parameter, denotes the classification loss and denotes the domain adaptation loss. In this paper, we choose the Class-aware Euclidean Distance in Equation (14) as . can choose most classification loss, such as negative log-likelihood, Least Square loss, Pair-wise loss. In this paper, we adopt negative log-likelihood for training as Equation (10).
5. Experiment
5.1. Datasets
| Dataset | #pos | #neg | #pos ratio | #fields | #events | #avglen |
|---|---|---|---|---|---|---|
| C1 | 10K | 1.93M | 5.2‰ | 56 | 3.57M | 4.94 |
| C2 | 4.2K | 1.48M | 2.8‰ | 56 | 3.91M | 4.73 |
| C3 | 15K | 1.37M | 10.8‰ | 56 | 4.28M | 14.97 |
| C4 | 5.7K | 174K | 31.7‰ | 56 | 353K | 4.91 |

The fraud detection dataset 222In order to comply with the data protection regulation in each country, multiple approaches have been taken in the data processing step, which include but are not limited to: personally identifiable information (PII) encrypted with salted MD5, data abstraction, data sampling, etc. By doing so, no original data could be restored and the statistics in this manuscript does not represent any the real business status. Meanwhile the dataset is generated only for research purpose in our study and will be destroyed after the experiments. is collected from one of the world-leading cross-border e-commerce company, which utilizes the risk management system to detect the transaction frauds. The dataset contains the card transaction samples from four countries (C1, C2, C3, C4), across a timespan of 10 weeks in 2019. For samples in each country, we utilize users’ historical behavior sequences of the last month. The task is to detect whether the current payment event is a card-stolen case, with knowing users’ historical sequential information. The fraud labels are collected from the chargeback reports from card issuer banks (e.g., the card issuer receives claims on unauthorized charges from the cardholders and report related transaction frauds to the merchants) and label propagation (e.g., the device and card information are also utilized to mark similar transactions). The details of the dataset are listed in Table 1.
5.2. Base Models
To show the effectiveness of HEN, we choose 4 prediction models as baselines.
-
•
W & D (Cheng et al., 2016): In real industrial applications, Wide & Deep model has been widely accepted. It consists of two parts: i) wide model, which handles the manually designed cross-field features, ii) deep model, which automatically extracts nonlinear relations among features.
-
•
NFM (He and Chua, 2017): It is a recent state-of-the-art simple and efficient neural factorization machine model. It feeds dense embedding into FM, and the output of FM is fed to MLP for capturing higher-order feature interactions.
- •
-
•
M3R (Tang et al., 2019): It is a most recent hierarchical sequence-based model (M3R and M3C) which deals with both short-term and long-term dependencies with mixture models. We choose the better hierarchical model M3R as the baseline.
Note that our transfer framework is a general framework that can be applied upon various existing models in the Embedding & MLP paradigm. To show the compatibility of our transfer framework, we apply our transfer framework upon both non-hierarchical models (W & D, NFM) and hierarchical models (LSTM4FD, M3R, HEN). For W & D, we add a dense layer as the behavior sequence extractor before MLP. For NFM, we use the FM as the extractor before MLP. For hierarchical models, we use the combination of event-level and field-level extractor as the behavior sequence extractor.

5.3. Experimental Set-Up
5.3.1. Dataset splits
The dataset contains the card transaction samples from four countries across the same time span of 10 weeks in 2019. Then, for each country, we sort all users’ prediction events according to timestamp order, taking the first 5 weeks as the training set, the following 2 weeks as the validation set and the remaining 3 weeks as the test set. To demonstrate the effectiveness of HEN, we run standard supervised prediction experiments on the dataset of four countries.
The e-commerce of the company expands to C4 recently, and it is easy to find that the size of the C4 dataset is much smaller than the other three countries. Hence, we use C4 as the target domain and the other three countries (C1, C2, C3) as source domains. To prove our transfer framework is widely applicable, we use [0.5, 1, 2, 3, 4, 5] weeks of the training set of each country as new training sets (six divisions) with the validation and test sets unchanged. For transfer experiments, we use the same divisions of source and target training sets to train the model and then evaluate the performance on the target domain.
5.3.2. Evaluation metric.
In binary prediction tasks, AUC (Area Under ROC) is a widely used metric (Fawcett, 2006). However, in our real card-stolen fraud detection scenario, we should increase the recall rate, while avoid disturbing the normal users as few as possible. In other words, the task is improving the True Positive Rate (TPR) on the basis of low False Positive Rate (FPR). In our scenario, we should pay attention to partial AUC (AUCFPR≤maxfpr) which denotes the area of the head of the ROC curve when the . While the is very low, AUCFPR≤maxfpr has a small range of variation which makes it difficult to compare the performance of the model. Therefore, we adopt the standardized partial AUC (SPAUCFPR≤maxfpr) (McClish, 1989):
| (16) |
It is easy to understand the range of SPAUCFPR≤maxfpr is 0.5 to 1 (we assume the prediction by models is better than stochastic prediction). In practice, we require FPR to be less than 1%. Hence, in this paper, we use for all experiments.

5.3.3. Implementation Details
For a fair comparison, we use the same setting for all methods. The MLP in these models use the same structure with two dense layers (hidden units 64), and the LSTM in both LSTM4FD and M3R is the Bi-LSTM (Graves et al., 2013) with a single layer. The dimensionality of embedding vectors of each input field is fixed to 16 for all our experiments. In addition, we set: learning rate of 0.005, maximum number of events , dropout (keep probability 0.8). Besides, there is a clear class imbalance in the dataset as shown in Table 1, so we upsample the positive sample to 5 times. For non-hierarchical models, we combine all the features of user’s events (history events and the current payment event) as the input. Following (Ganin et al., 2016; Long et al., 2015), instead of fixing the adaptation factor , we gradually change it from to by a progressive schedule: , and denotes the training step. We do not perform any datasets-specific tuning except early stopping on validation sets. Training is done through stochastic gradient descent over shuffled mini-batches with the Adam (Kingma and Ba, 2015) update rule. For each task, we report the SPAUCFPR≤maxfpr and 95% confidence intervals on ten random trials.
5.4. Results
5.4.1. Standard supervised prediction tasks
We demonstrate the effectiveness of our HEN on standard supervised prediction tasks of two parts. (1) We run experiments on the four countries with 5 weeks of data as training sets, and the results are shown in Figure 4. (2) We conduct experiments on the C4 with training sets of six different divisions, and the results are shown in Figure 5 (the results are the baseline of transfer tasks). The experimental results further reveal several insightful observations.
-
•
With different countries or different divisions, HEN outperforms all compared methods which demonstrates the effectiveness of HEN. The improvement mainly comes from the hierarchical structure and higher-order feature interactions.
-
•
Hierarchical models could achieve better performance on sequence-based fraud detection tasks. For the models with higher-order feature interactions, HEN which is a hierarchical model outperforms the non-hierarchical models NFM. For the models only considering the first-order feature, hierarchical LSTM4FD and M3R outperform non-hierarchical W & D on most tasks.
-
•
Considering higher-order feature interactions could improve the performance. Comparing non-hierarchical models W & D and NFM, NFM which considers higher-order feature interactions achieves a better result. The comparison results among HEN and LSTM4FD, M3R could draw the same conclusion.
-
•
On the tasks of C1, C2, C3, M3R achieves better results except for HEN. However, on most tasks of C4, the performance of M3R is worse than NFM, LSTM4FD. We conjecture that the field-level of M3R is a dense layer that would be overfitting on small datasets.
5.4.2. Transfer tasks
Our transfer framework is a general framework that can be applied upon various existing models in the Embedding & MLP paradigm. Thus we apply the transfer framework on HEN, M3R, LSTM4FD, NFM, W & D. Besides, we use three counties (C1, C2, C3) as the source domains while the country C4 which has much fewer samples as the target domain. In order to prove that our transfer framework is applicable to different sizes of training sets, we use the six divisions of training sets ({0.5, 1, 2, 3, 4, 5} weeks). Note that the training sets of source and target domains should be in the same time period, e.g., both C1 and C4 use 3 weeks training samples as the training set. We conduct transfer experiments on 90 tasks (, 3 source countries, 5 base models, 6 divisions). The results of the transfer experiments are shown in Figure 6, and the red lines are the baselines which only use the target training set to train model, also shown in Figure 5. From the results, we have the following findings:
| Methods | 3days | 1week | 2weeks | 3weeks | 4weeks | 5weeks | avg |
| target | 0.85340.0173 | 0.88110.0232 | 0.89710.0111 | 0.90090.0117 | 0.91050.0099 | 0.90500.0171 | 0.8913 |
| source | 0.57240.0230 | 0.57320.0272 | 0.59090.0576 | 0.58770.0334 | 0.54740.0393 | 0.57050.0419 | 0.5737 |
| pretrain | 0.86390.0047 | 0.89200.0066 | 0.89830.0115 | 0.91200.0051 | 0.91720.0064 | 0.91910.0054 | 0.9004 |
| domain-shared | 0.88110.0110 | 0.89950.0119 | 0.90250.0153 | 0.91570.0109 | 0.92040.0068 | 0.91940.0067 | 0.9065 |
| our structure | 0.88010.0101 | 0.90710.0042 | 0.90380.0085 | 0.91520.0094 | 0.92260.0081 | 0.92330.0113 | 0.9087 |
| Coral | 0.85660.0156 | 0.89380.0096 | 0.90280.0112 | 0.91630.0128 | 0.92360.0080 | 0.92210.0081 | 0.9025 |
| Adversarial | 0.87630.0113 | 0.89630.0135 | 0.89510.0109 | 0.91160.0099 | 0.92890.0053 | 0.92600.0069 | 0.9057 |
| MMD | 0.87440.0107 | 0.89640.0105 | 0.90490.0091 | 0.91850.0058 | 0.92490.0075 | 0.92130.0057 | 0.9067 |
| CMMD | 0.87970.0136 | 0.88970.0132 | 0.89630.0145 | 0.91210.0135 | 0.92190.0069 | 0.91460.0122 | 0.9024 |
| ED | 0.87670.0148 | 0.90100.0088 | 0.91800.0063 | 0.91860.0073 | 0.92580.0076 | 0.92510.0046 | 0.9109 |
| CED | 0.88660.0091 | 0.90760.0073 | 0.91400.0059 | 0.92200.0070 | 0.93050.0076 | 0.92980.0059 | 0.9151 |
| ours | 0.90380.0052 | 0.91880.0052 | 0.92420.0063 | 0.92830.0039 | 0.93670.0041 | 0.93400.0059 | 0.9243 |
-
•
On most tasks, our transfer framework is effective to improve the performance of the base models which also demonstrates the transfer framework can be applied upon various existing models in the Embedding & MLP paradigm.
-
•
Comparing with C1 and C2 as source domains, the performance of the transfer framework with C3 as the source domain is unsatisfying. The reason would be that C1 and C2 are more similar to the target country C4, while C3 is more different from C4. As shown in Table 1, the average length of the historical behavior sequences of C3 is 14.97, while the other three countries are about 4.8.
-
•
On the tasks with C3 as source domain, the transfer framework is effective for HEN, M3R, W & D, while it is unsatisfying for LSTM4FD, NFM. We think that the behavior extractors of HEN, M3R, W & D contain dense layers that have a stronger fitting ability to fit the dissimilar source domain.
-
•
The improvement on NFM is smaller than the other four base models. The main reason would be that the user behavior extractor of NFM is a non-parametric FM that is hard to fit the various distributions of different domains. On the contrary, the user behavior extractors of HEN, M3R, LSTM4FD, W & D are more complex parametric layers that are easy to adapt to the different distributions.
Overall, we observe that the transfer framework is able to improve the performance of base models with different sizes of training sets, which proves that the transfer framework is compatible with many models in the Embedding & MLP paradigm.
5.5. Ablation Study
To demonstrate how each component contributes to the overall performance, we now present an ablation test on our transfer framework. To prove the effectiveness of the transfer framework, we not only compare each component but also compare it with some baselines. We divide the ablation study into three parts: (1) Only use samples of single domain: target (only use data of target domain), source (only use data of source domain). (2) Considering the design of structure: pretrain (Hinton et al., 2006) (first train a model on source domain and then fine-tune on target domain), domain-shared (combine source and target dataset into single dataset, and share the common embedding and network), our structure (the structure designed by us contains domain-shared, domain-specific parts and the domain attention without domain adaptation loss). (3) Based on our structure, compare different domain adaptation loss: Coral (Sun and Saenko, 2016) (align the second-order statistics of the source and target distributions), Adversarial (Ganin et al., 2016) (adversarial training), MMD (Long et al., 2015; Zhu et al., 2019a) (a kernel two-sample test), CMMD (Long et al., 2013; Wang et al., 2017a; Zhu et al., 2019b) (conditional MMD), ED (Euclidean Distance), CED (Xie et al., 2018) (Conditional Euclidean Distance), ours (use the Class-aware Euclidean Distance to align the distributions, which also denotes the overall transfer framework).
| Email_suffix | Card_bin | Issuer | |
|---|---|---|---|
| High- Risk | email1(123/131) | card1(33/33) | issuer1(602/607) |
| email2(27/27) | card2(42/54) | issuer2(76/108) | |
| email3(54/59) | card3(77/78) | issuer3(77/90) | |
| Low- Risk | email4(0/382) | card4(0/2365) | issuer4(27/12491) |
| email5(0/298) | card5(0/245) | issuer5(0/789) | |
| email6(0/471) | card6(0/5972) | issuer6(1/725) |

We conduct experiments for ablation study with dataset C1 as the source domain and dataset C4 as the target domain. Besides, all experiments are based on HEN, and the results are shown in Table 2. From the results, we can make interesting observations:
-
•
The performance of ‘our structure’ is better than ‘target’, which proves the domain-shared and domain-specific structure is useful. ‘ours’ outperforms ‘our structure’ that proves the aligning distributions with Class-aware Euclidean Distance is effective. Hence, each component of the transfer framework is useful and effective.
-
•
In the first part, the performance of ‘source’ is largely worse than ‘target’ which proves the domain shift between source and target domains could seriously destroy the performance. Thus it is necessary to use effective transfer methods.
-
•
Comparing ‘our structure’ with ‘pretrain’ and ‘domain-shared’, we could find ‘our structure’ is more effective. ‘pretrain’ and ‘domain-shared’ are simple and generally adopted transfer methods. The results show ‘ours’ outperforms the general transfer methods which demonstrate our transfer framework is more suitable for cross-domain fraud detection.
-
•
Comparing different domain adaptation loss, we could find ‘ours’ outperforms both marginal and conditional methods which prove the effectiveness of Class-aware Euclidean Distance in this scene. Besides, the performance of ‘Coral’, ‘Adversarial’, ‘MMD’, ‘CMMD’ is worse than ‘our structure’ without domain adaptation loss, which reveals that the inappropriate aligning methods could lead to negative transfer.
Overall, we observe each component of the transfer framework is effective, and the Class-aware Euclidean Distance is more suitable than previous marginal and conditional aligning methods for our scenario.
5.6. Case Study
5.6.1. Explanation of Wide Layer
Firstly, we extract some high-risk and low-risk features according to the learned weights of the wide layer in Equation (8). The corresponding features are listed in Table 3. Since the email_suffix, card_bin and issuer name need to be kept private, we only use such as email1, card1, issuer1 to denote the ID and name. For each field, we select the three highest-risk and lowest-risk samples with specific values and present the ratio of each feature (black number / total number) which is helpful to understand the reason for risks. From Table 3, we find the wide layer could learn the blacklist and whitelist.
5.6.2. Three-level Attention
HEN with the general transfer framework has three-level attention and each level has its own explanation settings. Field-level attention could help us understand which field is important for the target prediction. Event-level attention could find the important events, and from the important events, we could find the high-risk sequences. The domain-level attention could show the importance of domain-shared and domain-specific knowledge. We present one case with explanations of positive (fraud) samples in Figure 7 on task (C1 C4). To focus on showing the capability of the three-level explanation, we only present the case about the historical behavior sequences. In addition, we use 56 fields in our experiments, but only show the representative fields in Figure 7.
The case in Figure 7 is a typical fraud case and the prediction of the sample is 0.97. The five history events are 1 register event and 4 payment events. (left) The domain-shared attention is 0.56. Besides, the domain-shared extractor more focuses on event1,2,4 and card-related fields. Then we analyze the history events: after registration, the fraudster immediately used a high-risk card_bin which had been used to fraud 5 times. For the event4, the fraudster tried to change the card expiration time to make the system recognize it as a new card. (right) The target-specific attention is 0.44. The target-specific extractor more focuses on event2-5 and item- and result-related fields. Then we analyze the history events: the fraudster tried to buy the same item 4 times. All of the four payment events triggered 3D verification and failed. From the case, we could find domain-shared and target-specific extractors would focus on different fields and different behavior sequences.
6. Conclusion
In this paper, we studied the online transaction fraud detection problem from the perspective of modeling users’ behavior sequences. Along this line, to effectively capture the sequential information and explore the explainability for fraud detection, we proposed a Hierarchical Explainable Network (HEN). HEN can extract both representations of the target behavior events and users’ historical behavior sequences to significantly improve prediction performance. Furthermore, to handle the real-world scenarios when there are only limited labeled data in the target domain with hardly model reused, we proposed a general transfer framework that can not only be applied upon HEN but also various existing models in the Embedding & MLP paradigm. Finally, we conducted extensive experiments on real-world data sets collected from a world-leading cross-border e-commerce platform to validate the effectiveness of our proposed models, and the case study further approves the explainability of our models.
Acknowledgements.
The research work is supported by the National Key Research and Development Program of China under Grant No. 2018YFB1004300, the National Natural Science Foundation of China under Grant No. U1836206, U1811461, 61773361, the Project of Youth Innovation Promotion Association CAS under Grant No. 2017146. This work is funded in part by Ant Financial through the Ant Financial Science Funds for Security Research. We also thank Minhui Wang, Zhiyao Chen, Changjiang Zhang, Dan Hong for their valuable suggestions.References
- (1)
- Bai et al. (2019) Lei Bai, Lina Yao, Salil S Kanhere, Zheng Yang, Jing Chu, and Xianzhi Wang. 2019. Passenger demand forecasting with multi-task convolutional recurrent neural networks. In PAKDD. Springer, 29–42.
- Baulier et al. (2000) Gerald Donald Baulier, Michael H Cahill, Virginia Kay Ferrara, and Diane Lambert. 2000. Automated fraud management in transaction-based networks. US Patent 6,163,604.
- Brause et al. (1999) R Brause, T Langsdorf, and Michael Hepp. 1999. Neural data mining for credit card fraud detection. In ICTAI. IEEE, 103–106.
- Cheng et al. (2016) Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. In RS. ACM, 7–10.
- Cohen (1995) William W Cohen. 1995. Fast effective rule induction. In Machine learning proceedings 1995. Elsevier, 115–123.
- Fastoso et al. (2012) Fernando Fastoso, Jeryl Whitelock, Constanza Bianchi, and Lynda Andrews. 2012. Risk, trust, and consumer online purchasing behaviour: a Chilean perspective. International Marketing Review (2012).
- Fawcett (2006) Tom Fawcett. 2006. An introduction to ROC analysis. Pattern recognition letters 27, 8 (2006), 861–874.
- Fu et al. (2016) Kang Fu, Dawei Cheng, Yi Tu, and Liqing Zhang. 2016. Credit card fraud detection using convolutional neural networks. In ICONIP. Springer, 483–490.
- Ganin et al. (2016) Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. 2016. Domain-adversarial training of neural networks. JMLR 17, 1 (2016), 2096–2030.
- Graves et al. (2013) Alex Graves, Abdel-rahman Mohamed, and Geoffrey Hinton. 2013. Speech recognition with deep recurrent neural networks. In ICASSP. IEEE, 6645–6649.
- He and McAuley (2016) Ruining He and Julian McAuley. 2016. Fusing similarity models with markov chains for sparse sequential recommendation. In ICDM. IEEE, 191–200.
- He and Chua (2017) Xiangnan He and Tat-Seng Chua. 2017. Neural factorization machines for sparse predictive analytics. In SIGIR. ACM, 355–364.
- Hinton et al. (2006) Geoffrey E Hinton, Simon Osindero, and Yee-Whye Teh. 2006. A fast learning algorithm for deep belief nets. Neural computation 18, 7 (2006), 1527–1554.
- Hu et al. (2019) Guangneng Hu, Yu Zhang, and Qiang Yang. 2019. Transfer Meets Hybrid: A Synthetic Approach for Cross-Domain Collaborative Filtering with Text. In WWW. ACM, 2822–2829.
- Huang et al. (2019) Zhenya Huang, Yu Yin, Enhong Chen, Hui Xiong, Yu Su, Guoping Hu, et al. 2019. EKT: Exercise-aware Knowledge Tracing for Student Performance Prediction. IEEE Transactions on Knowledge and Data Engineering (2019).
- Jurgovsky et al. (2018) Johannes Jurgovsky, Michael Granitzer, Konstantin Ziegler, Sylvie Calabretto, Pierre-Edouard Portier, Liyun He-Guelton, and Olivier Caelen. 2018. Sequence classification for credit-card fraud detection. Expert Systems with Applications 100 (2018), 234–245.
- Kingma and Ba (2015) Diederik P Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In ICLR, Vol. 5.
- Li et al. (2018) Zhi Li, Hongke Zhao, Qi Liu, Zhenya Huang, Tao Mei, and Enhong Chen. 2018. Learning from history and present: Next-item recommendation via discriminatively exploiting user behaviors. In KDD. ACM, 1734–1743.
- Lian et al. (2018) Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. In KDD. ACM, 1754–1763.
- Long et al. (2015) Mingsheng Long, Yue Cao, Jianmin Wang, and Michael I Jordan. 2015. Learning transferable features with deep adaptation networks. In ICML. JMLR. org, 97–105.
- Long et al. (2013) Mingsheng Long, Jianmin Wang, Guiguang Ding, Jiaguang Sun, and Philip S Yu. 2013. Transfer feature learning with joint distribution adaptation. In ICCV. 2200–2207.
- McClish (1989) Donna Katzman McClish. 1989. Analyzing a portion of the ROC curve. Medical Decision Making 9, 3 (1989), 190–195.
- Pan and Yang (2009) Sinno Jialin Pan and Qiang Yang. 2009. A survey on transfer learning. IEEE TKDE 22, 10 (2009), 1345–1359.
- Phua et al. (2010) Clifton Phua, Vincent Lee, Kate Smith, and Ross Gayler. 2010. A comprehensive survey of data mining-based fraud detection research. arXiv preprint arXiv:1009.6119 (2010).
- Quinlan (1990) J. Ross Quinlan. 1990. Learning logical definitions from relations. Machine learning 5, 3 (1990), 239–266.
- Rendle (2010) Steffen Rendle. 2010. Factorization machines. In ICDM. IEEE, 995–1000.
- Rosset et al. (1999) Saharon Rosset, Uzi Murad, Einat Neumann, Yizhak Idan, and Gadi Pinkas. 1999. Discovery of fraud rules for telecommunications-challenges and solutions. In KDD. ACM, 409–413.
- Sun and Saenko (2016) Baochen Sun and Kate Saenko. 2016. Deep coral: Correlation alignment for deep domain adaptation. In ECCV. Springer, 443–450.
- Tang et al. (2019) Jiaxi Tang, Francois Belletti, Sagar Jain, Minmin Chen, Alex Beutel, Can Xu, and Ed H Chi. 2019. Towards neural mixture recommender for long range dependent user sequences. In WWW. ACM, 1782–1793.
- Tang and Wang (2018) Jiaxi Tang and Ke Wang. 2018. Personalized top-n sequential recommendation via convolutional sequence embedding. In WSDM. ACM, 565–573.
- Tian et al. (2015) Tian Tian, Jun Zhu, Fen Xia, Xin Zhuang, and Tong Zhang. 2015. Crowd fraud detection in internet advertising. In WWW. International World Wide Web Conferences Steering Committee, 1100–1110.
- Tseng et al. (2015) Vincent S Tseng, Jia-Ching Ying, Che-Wei Huang, Yimin Kao, and Kuan-Ta Chen. 2015. Fraudetector: A graph-mining-based framework for fraudulent phone call detection. In KDD. ACM, 2157–2166.
- Tzeng et al. (2015) Eric Tzeng, Judy Hoffman, Trevor Darrell, and Kate Saenko. 2015. Simultaneous deep transfer across domains and tasks. In ICCV. 4068–4076.
- Wang and Ma (2012) Gang Wang and Jian Ma. 2012. A hybrid ensemble approach for enterprise credit risk assessment based on Support Vector Machine. Expert Systems with Applications 39, 5 (2012), 5325–5331.
- Wang et al. (2017a) Jindong Wang, Yiqiang Chen, Shuji Hao, Wenjie Feng, and Zhiqi Shen. 2017a. Balanced distribution adaptation for transfer learning. In ICDM. IEEE, 1129–1134.
- Wang et al. (2017b) Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017b. Deep & cross network for ad click predictions. In ADKDD. ACM, 12.
- Wang et al. (2017c) Shuhao Wang, Cancheng Liu, Xiang Gao, Hongtao Qu, and Wei Xu. 2017c. Session-based fraud detection in online e-commerce transactions using recurrent neural networks. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 241–252.
- Xie et al. (2018) Shaoan Xie, Zibin Zheng, Liang Chen, and Chuan Chen. 2018. Learning semantic representations for unsupervised domain adaptation. In ICML. 5419–5428.
- Zakaryazad and Duman (2016) Ashkan Zakaryazad and Ekrem Duman. 2016. A profit-driven Artificial Neural Network (ANN) with applications to fraud detection and direct marketing. Neurocomputing 175 (2016), 121–131.
- Zhang et al. (2018) Ruinan Zhang, Fanglan Zheng, and Wei Min. 2018. Sequential Behavioral Data Processing Using Deep Learning and the Markov Transition Field in Online Fraud Detection. arXiv preprint arXiv:1808.05329 (2018).
- Zhou et al. (2018) Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. In KDD. ACM, 1059–1068.
- Zhu et al. (2019a) Yongchun Zhu, Fuzhen Zhuang, and Deqing Wang. 2019a. Aligning domain-specific distribution and classifier for cross-domain classification from multiple sources. In AAAI, Vol. 33. 5989–5996.
- Zhu et al. (2019b) Yongchun Zhu, Fuzhen Zhuang, Jindong Wang, Jingwu Chen, Zhiping Shi, Wenjuan Wu, and Qing He. 2019b. Multi-representation adaptation network for cross-domain image classification. Neural Networks 119 (2019), 214–221.
- Zhu et al. (2019c) Yongchun Zhu, Fuzhen Zhuang, Jingyuan Yang, Xi Yang, and Qing He. 2019c. Adaptively Transfer Category-Classifier for Handwritten Chinese Character Recognition. In PAKDD. Springer, 110–122.
- Zhuang et al. (2015) Fuzhen Zhuang, Xiaohu Cheng, Ping Luo, Sinno Jialin Pan, and Qing He. 2015. Supervised representation learning: Transfer learning with deep autoencoders. In IJCAI.
- Zhuang et al. (2019) Fuzhen Zhuang, Zhiyuan Qi, Keyu Duan, Dongbo Xi, Yongchun Zhu, Hengshu Zhu, Hui Xiong, and Qing He. 2019. A Comprehensive Survey on Transfer Learning. arXiv preprint arXiv:1911.02685 (2019).