\model: Progressively Refined View Synthesis
from 3D Lifting with Volume-Triplane Representations
Abstract
We propose a new view synthesis method via synthesizing a 3D neural field from both single or few-view input images. To address the ill-posed nature of the image-to-3D generation problem, we devise a two-stage method that involves a reconstruction model and a diffusion model for view synthesis. Our reconstruction model first lifts one or more input images to the 3D space from a volume as the coarse-scale 3D representation followed by a tri-plane as the fine-scale 3D representation. To mitigate the ambiguity in occluded regions, our diffusion model then hallucinates missing details in the rendered images from tri-planes. We then introduce a new progressive refinement technique that iteratively applies the reconstruction and diffusion model to gradually synthesize novel views, boosting the overall quality of the 3D representations and their rendering. Empirical evaluation demonstrates the superiority of our method over state-of-the-art methods on the synthetic SRN-Car dataset, the in-the-wild CO3D dataset, and large-scale Objaverse dataset while achieving both sampling efficacy and multi-view consistency.
Abstract
In this supplementary document, we first provide more details about our architecture design in Sec. 6, and then discuss training and inference details in Sec. 7. We then present additional experiments in Sec. 8 with more qualitative results in Sec. 9. Readers are encouraged to view the supplementary videos for more visual results of our method.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/3e895849-a457-4695-8c65-cf096d2e7db4/x1.png)
1 Introduction
View synthesis is a traditional task in computer vision and graphics with typical applications to enhance audience experience in entertainment and telepresence. At its core, view synthesis can be solved via image-based rendering and 3D reconstruction methods. The recent introduction of diffusion models (Ho, Jain, and Abbeel 2020) and neural radiance field (NeRF) (Mildenhall et al. 2020) have enabled high-quality image-based rendering and 3D reconstruction, renewing interest in effective and efficient view synthesis.
State-of-the-art view synthesis methods based on neural representations (Tucker and Snavely 2020; Yu et al. 2021; Wang et al. 2021; Chen et al. 2021; Mildenhall et al. 2020; Sitzmann, Zollhöfer, and Wetzstein 2019; Lin et al. 2023) tend to exhibit a mean-seeking behavior that often results in blurriness in unseen regions. Inspired by the advance of generative modeling, to address this limitation, several methods incorporate a generative model to synthesize details for the occluded regions. This approach can be tracked with two notable directions: image-based and 3D-based synthesis.
Particularly, image-based synthesis approach involves training an image diffusion model on the 2D view distribution. This method offers numerous advantages, such as directly leveraging prior knowledge from existing large pretrained diffusion models (e.g., Zero123 (Liu et al. 2023a) finetuned on Stable Diffusion (Rombach et al. 2021)). However, a notable challenge is that these methods cannot guarantee multi-view consistency among the generated images. Typically, they are coupled with auto-regressive sampling techniques or resort to test-time optimization (Poole et al. 2022; Wang et al. 2023), incurring a significant time cost.
In contrast to image-based models, 3D-based synthesis involves training a 3D diffusion model that ensures multi-view consistency as it directly predicts a 3D representation from the input views. However, training a 3D diffusion model requires substantial memory and the availability of 3D datasets remains limited in scale and diversity compared to massive 2D datasets such as LAION-5B (Schuhmann et al. 2022). These challenges hinder the scalability of this approach.
In this paper, we introduce a two-stage method that takes advantage of both 3D reconstruction and image synthesis for realistic novel view synthesis. In the first stage, we propose a novel reconstruction model that integrates both volume and tri-plane features. The motivation behind our fusion comes from two key considerations. Firstly, volumetric representation has demonstrated impressive results in various reconstruction models (Chan et al. 2023; Szymanowicz, Rupprecht, and Vedaldi 2023b; Karnewar et al. 2023), but its memory-intensive nature limits scalability. Conversely, tri-plane representation offers a more compact alternative that supports higher resolutions. However, existing approaches (Hong et al. 2024; Anciukevicius et al. 2022) face challenges in transforming 2D images into 3D tri-planes. Utilizing simplistic methods such as 2D-UNet or transformer-based architectures without geometry guidance often leads to mixed-up features within each tri-plane and an inability to capture high-frequency details of 3D objects. By combining volumetric and tri-plane representations, our approach effectively leverages the geometric interpretation provided by volumetric representation while enjoying the compactness of triplane representation. This integration enables us to overcome the limitations of each individual representation and enhance the reconstruction capability of our model. In the second stage, our method focuses on the image-based diffusion paradigm, leveraging its efficiency and access to extensive literature and massive datasets. Inspired by Latent Diffusion (Rombach et al. 2021), our diffusion model operates in latent space to capture the distribution of novel views. More importantly, we devise a progressive inference procedure that iteratively applies both stages to gradually boost the quality of the 3D representation and rendered novel views across the initial and target view angles.
In summary, our contributions can be given as follows:
-
•
We introduce a novel view synthesis method that employs a 3D reconstruction stage using both volumetric and tri-plane representations, along with an image synthesis stage based on image diffusion to predict novel views. We devise a training strategy to learn both the reconstruction model and the image diffusion model.
-
•
We present a progressive inference procedure designed to systematically enhance the image quality of unseen regions by iteratively generating intermediate views from the input view toward the target view.
-
•
We extensively conduct experiments on several datasets to validate our approach’s effectiveness, consistently showing substantial improvements over previous state-of-the-art methods, as shown in Fig.1.
2 Related work
Novel view synthesis has recently gained renewed attention thanks to the introduction of neural radiance fields (NeRFs) (Mildenhall et al. 2020). NeRF-based novel view synthesis is based on the concept of regressing a neural field from the input images (Tucker and Snavely 2020; Yu et al. 2021; Wang et al. 2021; Chen et al. 2021; Mildenhall et al. 2020; Sitzmann, Zollhöfer, and Wetzstein 2019; Lin et al. 2023) so that novel views at any camera pose can be rendered from this radiance field. A common issue of these methods is that when rendering occluded parts of the scene, these models tend to generate blurry images, primarily because they are mean estimators (Chan et al. 2023). A long series of work (Chan et al. 2023; Karnewar et al. 2023; Liu et al. 2023a; Tewari et al. 2023; Szymanowicz, Rupprecht, and Vedaldi 2023b; Chen et al. 2023; Rombach, Esser, and Ommer 2021; Ren and Wang 2022; Liu et al. 2021; Kim et al. 2023) focus on the use of generative models to capture the underlying distribution of the data in order to generate plausible content for unseen regions. For example, diffusion models (Liu et al. 2023a; Tseng et al. 2023; Zhou and Tulsiani 2023; Watson et al. 2022; Tewari et al. 2023; Szymanowicz, Rupprecht, and Vedaldi 2023b; Chen et al. 2023; Kim et al. 2023) have demonstrated the ability to synthesize realistic novel views when conditioned on an input image. (Kim et al. 2023) uses a two-stage design by first learning a 3D reconstruction model on a 2D dataset and then training a 3D diffusion model. (Chan et al. 2023; Zhou and Tulsiani 2023; Tseng et al. 2023) focus on a 3D-aware diffusion model to refine the deterministic 2D feature map into novel-view images. In the context of the diffusion-based novel view synthesis model, learning from the 2D distribution of novel view images is favored over the 3D distribution of the dataset due to the use of massive pretrained 2D diffusion models and datasets.
2D Novel View Diffusion. Early research efforts (Chan et al. 2023; Gu et al. 2023; Tseng et al. 2023; Zhou and Tulsiani 2023; Watson et al. 2022) have been dedicated to capture the distribution of 3D objects by analyzing 2D novel image distributions. Notably, Tewari et al. (Tewari et al. 2023), despite only generating 2D images, have managed to synthesize outputs that closely mimic the 3D distribution, resulting in consistent and high-fidelity visuals. In a similar vein, GeNVS (Chan et al. 2023) leverages a volumetric representation of the input camera’s frustum to create a novel view feature map through volume rendering, which then is used as the condition for the diffusion model. Additionally, certain studies (Tseng et al. 2023; Zhou and Tulsiani 2023) employ epipolar lines to better guide the diffusion process. Whereas, another line of work (Watson et al. 2022; Liu et al. 2023a) omits explicit 3D geometrical modeling, relying solely on the capabilities of the diffusion model to generate novel 2D views. Despite these advancements, image-based diffusion models still encounter view inconsistency. To mitigate this issue, one ought to to utilize auto-regressive sampling techniques to gradually generate the complete image sequences (Chan et al. 2023) or to employ test-time optimization with score distillation sampling (Gu et al. 2023; Zhou and Tulsiani 2023; Liu et al. 2023a), aiming for more accurate and consistent 3D representations.
3D Reconstruction Model. Multi-plane representation (Tucker and Snavely 2020) and the epipolar line constraint (Tseng et al. 2023; Zhou and Tulsiani 2023) are favored methods for novel-view synthesis due to their lightweight nature. However, these methods encounter difficulties when the target novel views are significantly different from the original input views. On the other hand, volumetric representation (Chan et al. 2023; Szymanowicz, Rupprecht, and Vedaldi 2023b; Karnewar et al. 2023) offers impressive accuracy without the above-mentioned limitation, although they suffers from a high memory footprint. To address such a problem, various methods (Hong et al. 2024; Anciukevicius et al. 2022; Chen et al. 2023) utilize a compact form of 3D volume called tri-plane. However, RenderDiffusion (Anciukevicius et al. 2022) adopts a 2D-UNet to encode 2D images and decode them into tri-planes, resulting in mixed-up features within the tri-plane due to the lack of geometry guidance. While LRM (Hong et al. 2024) demonstrates impressive performance on large-scale datasets, it still exhibits poor quality on smaller datasets such as SRN-Car.
In our work, LiftRefine leverages the synergy between a 3D fusion representation and 2D image diffusion to set new standards in novel view synthesis. By addressing the limitations of existing methods in handling 3D scenes, ensuring spatial consistency, and reconstructing fine details in occluded region, our work marks a significant advancement in 3D generation for both single-view and few-view settings.
3 Proposed Method

We take a two-stage approach for novel view synthesis. Stage 1 involves a reconstruction model that lifts input from a single view or few views to a neural 3D representation, and Stage 2 involves a diffusion model that refines the rendering from the neural representation by hallucinating details for occluded regions. The reconstruction model (Section 3.1) combines a volumetric radiance field and a tri-plane radiance field for both coarse- and fine-scale 3D representations. Like previous NeRF-based view synthesis methods (Mildenhall et al. 2020; Yu et al. 2021; Lin et al. 2023), our reconstruction model may produce blurry results in occluded regions due to the inherent ambiguity in unseen views. We propose a latent diffusion model conditioned on the novel view feature maps (Section 3.2) to refine view rendering. We propose progressive inference (Section 3.3) that exploits the view consistency of our reconstruction model and the hallucination ability of our diffusion model to effectively enhance the fidelity and completeness of the final reconstructed 3D scene.
3.1 Lift: 3D Reconstruction
In the first stage, our reconstruction model transforms the input view(s) into a 3D representation, utilizing both volumetric and tri-plane approaches to generate coarse- and fine-scale representation. An overview of our proposed reconstruction model is shown in Fig. 2.
Coarse-scale Volumetric Radiance Field. Given an input image and its corresponding camera pose , we begin by extracting a feature map using a pretrained feature extractor (e.g., ResNet34, Dino-v2). Next, every voxel coordinate of a unit volume where the center is the world origin, is projected onto the image screen, and bilinear interpolation is applied to obtain the feature for each voxel. This process results in a coarse single-view volume feature. This coarse feature is then processed by a 3D convolutional encoder, the output of which is then aggregated via a cross-attention mechanism in the volume decoder to output a unified multi-view feature volume, similar to the approach in (Szymanowicz, Rupprecht, and Vedaldi 2023b). The final output of this stage is a coarse-scale multi-view feature volume , where , , are the coarse-scale volume dimension, respectively.
While the volumetric radiance field can be used to predict a 3D scene, the resulting images or features often suffer from low resolution, leading to visual artifacts such as blurriness and grid-like patterns. Although increasing the resolution of the feature volume could improve image quality, the memory requirements grow cubically with the volume dimension , quickly leading to out-of-memory issue. To address this problem, we gradually enhance the quality of the reconstructed images by progressively upsampling the low-resolution feature volume into high-resolution tri-plane . Leveraging tri-plane features allows us to achieve significantly higher resolution rendering compared to volumetric methods, thereby improving the quality of novel views.
Fine-scale Tri-plane Radiance Field. To reconstruct the tri-plane representation from a low-resolution feature volume , we first project the feature volume onto three orthogonal planes to form depth-aware feature planes , and . Each depth-aware feature plane is then fed to Triplane Decoder which consist of multiple upsampling blocks. Each block include a convolutional network with upsampling layers to refine details and increase the resolution. The final output of three feature planes is reshaped to construct the high-resolution tri-plane radiance field , where , represent the fine-scale image dimensions. This tri-plane representation can then be rendered to generate color images and feature maps:
| (1) |
where is the function that renders the triplane to image and feature map at the target camera pose . The feature map will be used as a condition for rendering diffusion in the following stage. To train the reconstruction model, we combine the standard L2 loss and LPIPS loss:
| (2) |
We discover that our reconstructor excels at generating detailed 3D objects from just a few views. In fact, it performs well in rendering novel views with minimal ambiguity, even without the assistance of a diffusion model. However, when information on occluded regions is lacking, the reconstructor tends to produce blurry results. To overcome this issue, we incorporate a diffusion model, as detailed below.

3.2 Refine: Conditional Rendering Diffusion
In the second stage, our method refines blurry novel view images in the previous step using a diffusion model conditioned on the feature map rendered from the first stage. This second stage is depicted in Fig. 3. Our diffusion model, based on latent diffusion (Rombach et al. 2021), can be trained as follows. We first precompute a conditional rendering dataset, where each sample contains a pair of input view and a ground truth novel view . We perform Stage 1 (Lift) to predict the feature map of the novel view using Eq. 1. The denoising process of our latent diffusion model then follows. The key idea is to make the diffusion model learn to refine the novel view conditioned by the input view. Therefore, for each data sample and time step , we add Gaussian noise to the novel view , which is then concatenated with the predicted feature map to form the input for the denoising U-Net. We further extract the CLIP embedding of the input view and use this embedding to condition the U-Net via cross attentions. The diffusion model predicts the added noise, which is trained by the following diffusion loss:
| (3) |
where is the denoising U-Net parameterized by .
3.3 Progressive Inference
In scenarios with significant ambiguities, the reconstruction model tends to produce blurry images in occluded regions, but albeit with strong view-to-view consistency. Conversely, the diffusion model generates high-quality results but may introduce inconsistencies across views. To leverage the strengths of both models, we introduce a progressive inference procedure that integrates the high-fidelity outputs from the diffusion model into the consistent 3D reconstructor, gradually filling in unseen regions and enhancing the overall reconstruction quality. This technique is demonstrated in Fig. 4.
Our inference process begins by initializing an image buffer to store all input views. In each iteration of the inference, we render a feature map using the reconstructor, conditioned on all images currently in the buffer. This feature map is then fed to the diffusion model, which generates an intermediate novel view image. The newly generated image is subsequently added to the buffer. All images in the buffer are then used for the next iteration to generate the next intermediate novel view image. At the final iteration, we applied the reconstructor to generate the final novel view image. In our experiments, for clarity, we refer to the novel views rendered by the reconstructor without using progressive inference as deterministic novel views , and novel views from progressive inference as , respectively.

4 Experiments
Training. We first train our reconstruction model, followed by precomputing the conditional renderings to train the diffusion model. Our training is conducted on three different datasets: CO3D (Reizenstein et al. 2021), Objaverse (Deitke et al. 2022), and Shapenet-SRN Cars (Sitzmann, Zollhöfer, and Wetzstein 2019). The CO3D dataset, an in-the-wild collection, is utilized to assess the robustness of our method in real-world conditions where imperfections are present. The Objaverse dataset demonstrates the scalability of our model on a large-scale dataset. Finally, Shapenet-SRN Cars, a synthetic dataset focused on single-category objects, is employed in our ablation study. More details on ShapeNet-SRN Cars are provided in the supplementary material.
Inference. We evaluate our method with two different settings: deterministic and a diffusion-based. In the deterministic setting, we utilize the reconstruction model to synthesize a tri-plane from the input view, and then render the novel view images without progressive refinement. In the diffusion-based setting, we employ progressive inference as outlined in Sec. 3.3, and use the final tri-plane to render the refined novel view. Please prefer to supplementary material for video qualitative results.
Dataset and Evaluation Protocol. Some methods are trained for a specific setting, such as single-view or few-views reconstruction. Therefore, we divide our evaluation protocol into these two settings. Notably, our method is effective in both scenarios.
We conduct both single-view and few-views evaluations on the CO3D dataset (Reizenstein et al. 2021) and the Google Scanned Object (GSO) dataset (Francis et al. 2022). We assess our method at a resolution of 128x128 for in-the-wild CO3D dataset (Reizenstein et al. 2021) and 256x256 for the GSO dataset (Francis et al. 2022).
4.1 CO3D
On the CO3D dataset, we conduct a comparative analysis on four classes (Hydrant, Teddybear, Vase and Plant) on two state-of-the-art methods: ViewsetDiffusion (Szymanowicz, Rupprecht, and Vedaldi 2023b) and SparseFusion (Zhou and Tulsiani 2023). The quantitative results are summarized in Tab. 1. In both single-view and few-views reconstruction tasks, our model consistently surpasses previous methods across key metrics, including PSNR, SSIM, and LPIPS, highlighting its effectiveness in capturing fine details and preserving image quality. In the diffusion setting, while there is a decrease in pixel-wise metrics, our approach shows improvements in object quality, evidenced by better SSIM and LPIPS scores. Additionally, for the distribution-based metric FID, our diffusion-based setting demonstrates significant gains over the deterministic setting, indicating the efficacy of progressive inference in enhancing the overall quality of the generated images. It is important to note that SpareFusion generates images, while ViewsetDiffusion and our method reconstruct 3D representations. Consequently, SpareFusion exhibits a higher FID but lower consistency compared to our method.
In Fig. 5, for a deterministic setting with a single input view, we observe high-quality synthesis in visible regions but encounter blurriness in occluded areas. Upon employing progressive inference, the final object fidelity is significantly improved, approaching the performance achieved in the deterministic setting with three input views. For results on multi-view consistency, please refer to the supplementary material, where a video presentation is provided.
4.2 Google Scanned Object
On the GSO dataset, we compare our method under the single-view setting with OpenLRM (He and Wang 2023), an open-source version of the LRM model (Hong et al. 2024), and Splatter Image (Szymanowicz, Rupprecht, and Vedaldi 2023a), as these methods are designed for single-view reconstruction. Results are shown in Tab. 2 and Fig. 1. Our model outperforms previous methods for more than 1 db in PSNR while having competitive performance on SSIM and LPIPS. Compared to LRM which is purely transformer-based, our method effectively leverages inductive bias from the volume and triplane representations, leading to more robust models with reduced training time. Our method requires 4 NVIDIA A100 GPUs for training in 7 days while LRM needs 128 A100 GPUs for training in 3 days.
In the few-view reconstruction task, we compare our model with the current SOTA method LaRa (Chen et al. 2024). The results is shown in Tab. 2. Our model outperforms LaRa significantly when using 2 or 3 input views and remains competitive with 4 input views. This advantage arises from our volume-based representation, which excels at reconstructing unseen regions. In contrast, LaRa’s Gaussian splatting method struggles to render occluded areas when input views are limited.

| 1-view | ||||
|---|---|---|---|---|
| PSNR | SSIM | LPIPS | FID | |
| SparseFusion | 16.45 | 0.652 | 0.278 | 46.5 |
| ViewsetDiffusion | 18.41 | 0.684 | 0.280 | 99.6 |
| Ours (Det) | 20.38 | 0.747 | 0.204 | 73.4 |
| Ours (Diff) | 20.10 | 0.744 | 0.195 | 39.6 |
| 3-view | ||||
| PSNR | SSIM | LPIPS | FID | |
| SparseFusion | 21.48 | 0.773 | 0.175 | 29.3 |
| ViewsetDiffusion | 21.86 | 0.752 | 0.241 | 91.7 |
| Ours (Det) | 22.82 | 0.800 | 0.166 | 59.5 |
| Ours (Diff) | 22.66 | 0.797 | 0.161 | 43.3 |
| # Views | Method | PSNR | SSIM | LPIPS |
|---|---|---|---|---|
| OpenLRM | 18.06 | 0.840 | 0.129 | |
| 1 | Splatter Image | 21.06 | 0.880 | 0.111 |
| Ours (Det) | 22.23 | 0.880 | 0.113 | |
| Ours (Diff) | 22.55 | 0.895 | 0.116 | |
| LaRa | 19.59 | 0.877 | 0.151 | |
| 2 | Ours (Det) | 23.82 | 0.908 | 0.092 |
| Ours (Diff) | 23.91 | 0.909 | 0.090 | |
| LaRa | 23.92 | 0.915 | 0.112 | |
| 3 | Ours (Det) | 24.99 | 0.916 | 0.085 |
| Ours (Diff) | 25.11 | 0.917 | 0.083 | |
| LaRa | 26.03 | 0.930 | 0.098 | |
| 4 | Ours (Det) | 25.64 | 0.920 | 0.082 |
| Ours (Diff) | 25.79 | 0.922 | 0.080 |
4.3 Ablation Study
In this section, we validate the impact of our design choices. Unless otherwise mentioned, we drop the 2D conditional diffusion model and perform the ablation studies with the deterministic setting.
Analysis of 3D Representations. To demonstrate the efficacy of incorporating low-resolution volume and high-resolution tri-plane representations, we conducted several experiments on CO3D-Hydrant, as shown in Tab. 3. Our method is denoted as the default setting. Firstly, by replacing our upsampler layers with bicubic interpolation (setting C), we observed a significant drop in the performance of the reconstructor, nearly 1dB. This indicates the importance of our upsampler in preserving image quality and details during reconstruction. Additionally, we replaced the low-resolution volume features with low-resolution tri-plane representations (setting B). We achieved this by projecting the volume features, obtained after lifting from the input view, onto a tri-plane, and then replacing every 3D layer in the 3D encoder and decoder with 2D convolutional layers to operate on tri-plane features. However, the results showed that the performance of setting B is inferior to using volume features as the low-resolution representation. We hypothesize that this is because working on volume at low-resolution allows for more informative 3D features rather than its compact tri-plane version.
| Method | PSNR | SSIM | LPIPS |
|---|---|---|---|
| Default | 24.56 | 0.868 | 0.100 |
| B | 24.06 | 0.860 | 0.113 |
| C | 23.66 | 0.853 | 0.111 |
| Method | PSNR | SSIM | LPIPS |
|---|---|---|---|
| OpenLRM | 22.88 | 0.910 | 0.082 |
| Triplane | 21.83 | 0.898 | 0.087 |
| Volume | 22.78 | 0.908 | 0.087 |
| Ours | 23.76 | 0.921 | 0.067 |
Analysis of Image-to-Triplane Backbone. To study the importance of the low-resolution volume, we conducted a series of experiments with different image-to-triplane backbones. The quantitative results are presented in Tab. 4. Firstly, we utilized LRM (Hong et al. 2024), a transformer-based reconstruction model renowned for its ability to output tri-plane representations from single images. While LRM demonstrated remarkable performance when applied to large datasets, its efficacy diminishes when working on smaller datasets such as ShapeNet-SRN Cars. This is because the transformers are unaware of 3D inductive bias, and instead are tasked to implicitly learn spatial relationship, which deteriorates its performance when training on a small dataset like ShapeNet. Notably in Fig. 6, the tri-plane features from LRM exhibited pixelated noise, thereby impairing its overall performance. Subsequently, following (Anciukevicius et al. 2022), we leveraged a 2D UNet to encode and decode 2D images into 3D tri-planes without volume representation. However, we encountered a significant challenge as the output tri-plane appears mixed up due to the absence of channel decoupling during the encoding and decoding stages of the 2D UNet. Consequently, this led to a notable drop in the PSNR metric, indicating a degradation in the quality of reconstruction. Lastly, we modify our backbone to use only the volume representation. The results were blurry due to the low volume resolution, resulting in high PSNR but low LPIPS scores.

Study on Progressive Inference. We investigated the effects of increasing the number of iterations during progressive inference. In Tab. 5, while we observed a decline in pixel-wise metrics such as PSNR and SSIM, there was a clear improvement in the semantic quality of the generated images, reflected by metrics like FID. We found that using 4 iterations leads to the best balanced result across metrics. Therefore, we used 4 iterations for progressive refinement in our experiments.
Comparision with Multi-view Generation. To position our method against SOTA methods in multi-view generation (Shi et al. 2024; Wang and Shi 2023; Long et al. 2024; Liu et al. 2023b; Xu et al. 2024), we compare our method with SyncDreamer (Liu et al. 2023b), a multi-view diffusion model that generates 16 views from input images. We found that although SyncDreamer demonstrates impressive view consistency, their method only works well for input views at frontal angles. Their performance significantly deteriorates when synthesizing from side or rear views of objects. In contrast, our method consistently maintains high-fidelity images across all perspectives as shown in Fig. 7. For a quantitative comparison with SyncDreamer on novel view synthesis, please refer to the supplementary material.

| # iters | PSNR | SSIM | LPIPS | FID |
|---|---|---|---|---|
| 0 | 22.64 | 0.834 | 0.118 | 42.7 |
| 1 | 22.61 | 0.845 | 0.105 | 37.0 |
| 2 | 22.43 | 0.843 | 0.107 | 35.4 |
| 4 | 22.12 | 0.840 | 0.108 | 34.7 |
| 6 | 21.89 | 0.836 | 0.111 | 34.0 |
| 8 | 21.73 | 0.834 | 0.113 | 34.7 |
5 Discussion and Conclusion
In conclusion, this paper introduces LiftRefine, a new method for novel view synthesis combining 3D reconstruction with image-based diffusion empowerd by a progressive refinement procedure. Our two-stage method achieves SOTA results, delivering realistic and consistent novel views. Extensive testing on diverse datasets validates its effectiveness.
While our method produces plausible results across datasets, we found that our method struggles in some cases such as the Plant category in CO3D, where the synthesized novel views tend to be blurry. This could be because of the high-resolution details in the plant images that are not well captured by the current resolution of our representations. Improving the high-frequency rendering of this category would be our future work.
References
- Anciukevicius et al. (2022) Anciukevicius, T.; Xu, Z.; Fisher, M.; Henderson, P.; Bilen, H.; Mitra, N. J.; and Guerrero, P. 2022. RenderDiffusion: Image Diffusion for 3D Reconstruction, Inpainting and Generation. arXiv.
- Chan et al. (2023) Chan, E. R.; Nagano, K.; Chan, M. A.; Bergman, A. W.; Park, J. J.; Levy, A.; Aittala, M.; Mello, S. D.; Karras, T.; and Wetzstein, G. 2023. GeNVS: Generative Novel View Synthesis with 3D-Aware Diffusion Models. In arXiv.
- Chen et al. (2024) Chen, A.; Xu, H.; Esposito, S.; Tang, S.; and Geiger, A. 2024. LaRa: Efficient Large-Baseline Radiance Fields. In European Conference on Computer Vision (ECCV).
- Chen et al. (2021) Chen, A.; Xu, Z.; Zhao, F.; Zhang, X.; Xiang, F.; Yu, J.; and Su, H. 2021. Mvsnerf: Fast generalizable radiance field reconstruction from multi-view stereo. In ICCV.
- Chen et al. (2023) Chen, H.; Gu, J.; Chen, A.; Tian, W.; Tu, Z.; Liu, L.; and Su, H. 2023. Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction. In ICCV.
- Deitke et al. (2022) Deitke, M.; Schwenk, D.; Salvador, J.; Weihs, L.; Michel, O.; VanderBilt, E.; Schmidt, L.; Ehsani, K.; Kembhavi, A.; and Farhadi, A. 2022. Objaverse: A Universe of Annotated 3D Objects. arXiv preprint arXiv:2212.08051.
- Francis et al. (2022) Francis, A. G.; Kinman, B.; Reymann, K. A.; Downs, L.; Koenig, N.; Hickman, R. M.; McHugh, T. B.; and Vanhoucke, V. O., eds. 2022. Google Scanned Objects: A High-Quality Dataset of 3D Scanned Household Items.
- Gu et al. (2023) Gu, J.; Trevithick, A.; Lin, K.-E.; Susskind, J.; Theobalt, C.; Liu, L.; and Ramamoorthi, R. 2023. NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion. In ICML.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep Residual Learning for Image Recognition. CVPR.
- He and Wang (2023) He, Z.; and Wang, T. 2023. OpenLRM: Open-Source Large Reconstruction Models. https://github.com/3DTopia/OpenLRM.
- Ho, Jain, and Abbeel (2020) Ho, J.; Jain, A.; and Abbeel, P. 2020. Denoising Diffusion Probabilistic Models. CVPR.
- Hong et al. (2024) Hong, Y.; Zhang, K.; Gu, J.; Bi, S.; Zhou, Y.; Liu, D.; Liu, F.; Sunkavalli, K.; Bui, T.; and Tan, H. 2024. LRM: Large Reconstruction Model for Single Image to 3D.
- Karnewar et al. (2023) Karnewar, A.; Vedaldi, A.; Novotny, D.; and Mitra, N. 2023. HoloDiffusion: Training a 3D Diffusion Model using 2D Images. In CVPR.
- Kim et al. (2023) Kim, S. W.; Brown, B.; Yin, K.; Kreis, K.; Schwarz, K.; Li, D.; Rombach, R.; Torralba, A.; and Fidler, S. 2023. NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models. In CVPR.
- Kingma and Ba (2017) Kingma, D. P.; and Ba, J. 2017. Adam: A Method for Stochastic Optimization. arXiv:1412.6980.
- Lin et al. (2023) Lin, K.-E.; Yen-Chen, L.; Lai, W.-S.; Lin, T.-Y.; Shih, Y.-C.; and Ramamoorthi, R. 2023. Vision Transformer for NeRF-Based View Synthesis from a Single Input Image. In WACV.
- Liu et al. (2021) Liu, A.; Tucker, R.; Jampani, V.; Makadia, A.; Snavely, N.; and Kanazawa, A. 2021. Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image. In ICCV.
- Liu et al. (2023a) Liu, R.; Wu, R.; Hoorick, B. V.; Tokmakov, P.; Zakharov, S.; and Vondrick, C. 2023a. Zero-1-to-3: Zero-shot One Image to 3D Object. arXiv:2303.11328.
- Liu et al. (2023b) Liu, Y.; Lin, C.; Zeng, Z.; Long, X.; Liu, L.; Komura, T.; and Wang, W. 2023b. SyncDreamer: Learning to Generate Multiview-consistent Images from a Single-view Image. arXiv preprint arXiv:2309.03453.
- Long et al. (2024) Long, X.; Guo, Y.-C.; Lin, C.; Liu, Y.; Dou, Z.; Liu, L.; Ma, Y.; Zhang, S.-H.; Habermann, M.; Theobalt, C.; et al. 2024. Wonder3D: Single Image to 3D using Cross-Domain Diffusion. In CVPR.
- Mildenhall et al. (2020) Mildenhall, B.; Srinivasan, P. P.; Tancik, M.; Barron, J. T.; Ramamoorthi, R.; and Ng, R. 2020. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In ECCV.
- Poole et al. (2022) Poole, B.; Jain, A.; Barron, J. T.; and Mildenhall, B. 2022. DreamFusion: Text-to-3D using 2D Diffusion. arXiv.
- Reizenstein et al. (2021) Reizenstein, J.; Shapovalov, R.; Henzler, P.; Sbordone, L.; Labatut, P.; and Novotny, D. 2021. Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction. In ICCV.
- Ren and Wang (2022) Ren, X.; and Wang, X. 2022. Look Outside the Room: Synthesizing A Consistent Long-Term 3D Scene Video from A Single Image. In CVPR.
- Rombach et al. (2021) Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; and Ommer, B. 2021. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv:2112.10752.
- Rombach, Esser, and Ommer (2021) Rombach, R.; Esser, P.; and Ommer, B. 2021. Geometry-Free View Synthesis: Transformers and no 3D Priors. arXiv:2104.07652.
- Schuhmann et al. (2022) Schuhmann, C.; Beaumont, R.; Vencu, R.; Gordon, C.; Wightman, R.; Cherti, M.; Coombes, T.; Katta, A.; Mullis, C.; Wortsman, M.; Schramowski, P.; Kundurthy, S.; Crowson, K.; Schmidt, L.; Kaczmarczyk, R.; and Jitsev, J. 2022. LAION-5B: An open large-scale dataset for training next generation image-text models. arXiv:2210.08402.
- Shi et al. (2024) Shi, Y.; Wang, P.; Ye, J.; Mai, L.; Li, K.; and Yang, X. 2024. MVDream: Multi-view Diffusion for 3D Generation. In ICLR.
- Sitzmann, Zollhöfer, and Wetzstein (2019) Sitzmann, V.; Zollhöfer, M.; and Wetzstein, G. 2019. Scene Representation Networks: Continuous 3D-Structure-Aware Neural Scene Representations. In NeurIPS.
- Song, Meng, and Ermon (2022) Song, J.; Meng, C.; and Ermon, S. 2022. Denoising Diffusion Implicit Models. arXiv:2010.02502.
- Szymanowicz, Rupprecht, and Vedaldi (2023a) Szymanowicz, S.; Rupprecht, C.; and Vedaldi, A. 2023a. Splatter Image: Ultra-Fast Single-View 3D Reconstruction. In arXiv.
- Szymanowicz, Rupprecht, and Vedaldi (2023b) Szymanowicz, S.; Rupprecht, C.; and Vedaldi, A. 2023b. Viewset Diffusion: (0-)Image-Conditioned 3D Generative Models from 2D data. In ICCV.
- Tewari et al. (2023) Tewari, A.; Yin, T.; Cazenavette, G.; Rezchikov, S.; Tenenbaum, J. B.; Durand, F.; Freeman, W. T.; and Sitzmann, V. 2023. Diffusion with Forward Models: Solving Stochastic Inverse Problems Without Direct Supervision. In arXiv.
- Tseng et al. (2023) Tseng, H.-Y.; Li, Q.; Kim, C.; Alsisan, S.; Huang, J.-B.; and Kopf, J. 2023. Consistent View Synthesis with Pose-Guided Diffusion Models. In CVPR.
- Tucker and Snavely (2020) Tucker, R.; and Snavely, N. 2020. Single-view View Synthesis with Multiplane Images. In CVPR.
- Wang and Shi (2023) Wang, P.; and Shi, Y. 2023. ImageDream: Image-Prompt Multi-view Diffusion for 3D Generation. arXiv preprint arXiv:2312.02201.
- Wang et al. (2021) Wang, Q.; Wang, Z.; Genova, K.; Srinivasan, P.; Zhou, H.; Barron, J. T.; Martin-Brualla, R.; Snavely, N.; and Funkhouser, T. 2021. IBRNet: Learning Multi-View Image-Based Rendering. In CVPR.
- Wang et al. (2023) Wang, Z.; Lu, C.; Wang, Y.; Bao, F.; Li, C.; Su, H.; and Zhu, J. 2023. ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation. arXiv preprint arXiv:2305.16213.
- Watson et al. (2022) Watson, D.; Chan, W.; Martin-Brualla, R.; Ho, J.; Tagliasacchi, A.; and Norouzi, M. 2022. Novel View Synthesis with Diffusion Models. arXiv:2210.04628.
- Xu et al. (2024) Xu, Y.; Tan, H.; Luan, F.; Bi, S.; Wang, P.; Li, J.; Shi, Z.; Sunkavalli, K.; Wetzstein, G.; Xu, Z.; and Zhang, K. 2024. DMV3D: Denoising Multi-View Diffusion using 3D Large Reconstruction Model. In ICLR.
- Yu et al. (2021) Yu, A.; Ye, V.; Tancik, M.; and Kanazawa, A. 2021. pixelNeRF: Neural Radiance Fields from One or Few Images. In CVPR.
- Zhou and Tulsiani (2023) Zhou, Z.; and Tulsiani, S. 2023. SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction. In CVPR.
Supplementary Material
6 Architecture
6.1 Reconstructor
Our reconstructor takes in input frames and outputs a single feature tri-plane representation that can be used to render arbitrary novel views.
Encoder. Our encoder is based on ViewsetDiffusion (Szymanowicz, Rupprecht, and Vedaldi 2023b) but we replace the feature extractor with a pretrained ResNet34 (He et al. 2016) or Dino-V2 for enhanced feature extraction capabilities. We adjust the output of the reconstructor, changing from a radiance field volume to a feature volume by increasing the channel dimension from 4 to 32.
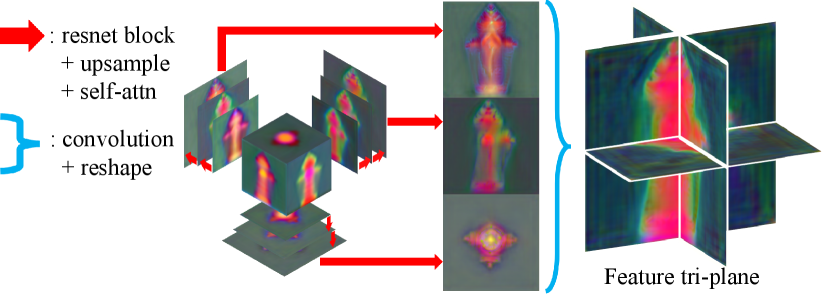
Decoder. Our tri-plane decoder architecture is based on a 2D UNet decoder (Ho, Jain, and Abbeel 2020), comprising multiple upsampler blocks. Each upsampler block consists of a ResNet block, an upsample layer, and a self-attention layer at the end. Further details on our tri-plane decoder are illustrated in Fig. 8. In our experiments, we upscale the resolution of the feature volume, initially sized at 32, to a feature tri-plane with resolution of 256.
6.2 Diffusion model
Our diffusion operates in the latent space, where we use a VAE model to map an input image to a latent representation . We use the UNet architecture from Zero123 (Liu et al. 2023a) for our 2D conditional diffusion model and increase the condition channel of the original Zero123 model from 4 to 32 to match our conditional feature map. Additionally, we leverage their pretrained model as an initialization for our training process.
7 Implementation Details
Training. In the first stage, we train the reconstructor until the validation accuracy stall. For data sampling strategy, we randomly sample 1 to 3 image(s) as input and 1 image as . After that, we precompute the conditional renderings and follow the same data sampling strategy as training reconstructor to train the diffusion model.
Inference. We use progressive inference (Fig. 4 in our main paper) to combine our 3D reconstructor and our 2D diffusion model. For CO3D dataset, we interpolate camera poses between the input and target camera pose. For GSO dataset, we calculate the azimuth and elevation of input view and interpolate camera poses on the spherical trajectory. In our main experiment, we employ 200-steps DDIM sampling (Song, Meng, and Ermon 2022) with classifier free guidance to sample the images.
Optimization. We employ the Adam optimizer (Kingma and Ba 2017) and cosine scheduler with a learning rate of for our reconstructor and for our diffusion model. We set the maximum 300k training steps and but stop the training if there is no improvement. The total batch size is 128 and 256 across 4 A100 GPUs for reconstructor and diffusion model respectively. In , we set to 0.1 for all experiments.
8 Additional Experiments

Results on ShapeNet-SRN Cars. We evaluate our method at a resolution of 128x128 for the single-view reconstruction on ShapeNet-SRN Cars dataset (Sitzmann, Zollhöfer, and Wetzstein 2019). Following the evaluation protocol from PixelNerf (Yu et al. 2021), we adopt their train/val/test split and utilize the view as input, while the remaining 250 views serve as unseen target views. For Shapenet SRN-Car, we employ the pretrained models from the baselines for inference whenever available. Otherwise, we utilize their reported results for our quantitative analysis.
In Tab. 6, we provide a comprehensive evaluation of our method in comparison to SOTA methods. In the deterministic setting, our model demonstrates superior quantitative performance, notably surpassing regression-based models such as PixelNeRF (Yu et al. 2021) and VisionNeRF (Lin et al. 2023) across pixel-wise metrics like PSNR and SSIM, as well as perceptual metric LPIPS. Additionally, our approach outperforms probabilistic-based methods such as GeNVS (Chan et al. 2023) and ViewSet Diffusion (Szymanowicz, Rupprecht, and Vedaldi 2023b) in FID. Our deterministic setting generates plausible output in occluded regions, whereas ViewsetDiffusion with diffusion still yields blurry results or hallucinates implausible outcomes. For instance, the trunk of the car appears blurry and grey instead of maintaining a similar color to the front, as illustrated in Fig. 10.
In the diffusion setting, with the incorporation of progressive inference, our model achieves even better results in distribution-based metrics (FID). However, it is worth noting that there is a slight decrease in pixel-wise metrics, namely PSNR and SSIM, due to the fact that these metrics are more favorable for mean-seeking models, as discussed in (Chan et al. 2023). The incorporation of a 2D diffusion model significantly reduces blurriness in the final output of the generative setting. Notably, the output of the car remains interpretable, even when considering only the input view (the last two columns in Fig. 10).
| Method | PSNR | SSIM | LPIPS | FID |
| PixelNerf | 23.17 | 0.90 | 0.111 | 64.08 |
| VisionNerf | 22.87 | 0.90 | 0.084 | 24.24 |
| SSDNeRF | 23.52 | 0.91 | 0.078 | 16.39 |
| GeNVS | 20.07 | 0.89 | 0.104 | 6.47 |
| Viewset Diffusion | 23.29 | 0.91 | 0.094 | 39.54 |
| Splatter Image | 24.00 | 0.92 | 0.078 | - |
| Ours (deterministic) | 24.20 | 0.92 | 0.057 | 6.44 |
| Ours (diffusion) | 23.67 | 0.92 | 0.061 | 6.08 |

Study on Tri-plane Resolution. We investigate the impact of varying tri-plane resolution on reconstruction quality. We start from volumetric representation (volume dimensions equal to ) and then add a tri-plane decoder which gradually increases the tri-plane resolution. The results in Tab. 7 demonstrate a clear trend: as the tri-plane resolution increases, the quality of novel view images improves noticeably. As shown in Fig. 11, the rendered images indicate enhanced sharpness as the tri-plane resolution grows higher.

| Triplane resolution | PSNR | SSIM | LPIPS |
|---|---|---|---|
| None | 22.78 | 0.908 | 0.087 |
| 16 | 23.07 | 0.912 | 0.081 |
| 32 | 23.53 | 0.918 | 0.069 |
| 64 | 23.70 | 0.920 | 0.078 |
| 128 | 23.76 | 0.921 | 0.067 |
| 256 | 23.79 | 0.92 | 0.066 |
9 Qualitative Results
Qualitative results on Shapenet SRN-Car. We present additional qualitative results on Shapenet SRN-Car in Table 13. While our deterministic setting achieves good quality in the reconstruction view, it tends to produce blurry results in high ambiguity regions, like the back of the car. However, after progressive inference, our diffusion setting generates a plausible result with significantly reduced blurriness.

We include small and non-centric samples for Shapenet SRN-Car in Fig. 12. Despite ViewsetDiffusion (Szymanowicz, Rupprecht, and Vedaldi 2023b) being a probabilistic model, it still generates blurry results and saturated colors, as seen in the first row. PixelNerf (Yu et al. 2021) and our deterministic setting are regressive models, yet our method produces significantly improved results. Moreover, with progressive inference, our diffusion setting generates realistic, sharper outcomes in all samples.

Qualitative results on CO3D. We present additional qualitative results for each category of the CO3D dataset in Fig. 9, with Hydrant in Fig. 15, Teddybear in Fig. 16, Vase in Fig. 17, and Plant in Fig. 18. Our deterministic setting can reconstruct with mild ambiguity but tends to be blurry in high ambiguity regions, while our diffusion setting has the capability to hallucinate the unseen regions with plausible results.
While our method produces plausible results for most categories in CO3D, we found that examples in the Plant category are the most challenging, where the synthesized novel views tend to be blurry. This could be because of the high-frequency details in the plant images that are not well captured by the current resolution of our representations. Improving the high-frequency rendering of this category would be future work.
Diversity of generated images. We demonstrate the diversity of the diffusion model by sampling a novel view multiple times on CO3D dataset. As shown in Fig. 14, each sample exhibits a distinct appearance while being consistent with the input view.
Qualitative results on GSO. We provide additional qualitative results for single-view and two-view reconstructions in Fig.19 and Fig.20. The images generated by the diffusion model, shown in the Fig.21, exhibit minor inconsistencies across views, but their fidelity is significantly higher compared to the renderings produced by our 3D representation.
Comparision with SyncDreamer on GSO dataset. We compare our deterministic model with the multi-view diffusion method, SyncDreamer (Liu et al. 2023b), in Table 8. While our approach demonstrates competitive performance against SyncDreamer, it also offers greater flexibility. Unlike SyncDreamer, which generates only 16 views at a fixed elevation of 0 degrees, our method can accept arbitrary input view(s) and render at any desired pose(s).
| Method | PSNR | SSIM | LPIPS |
|---|---|---|---|
| SyncDreamer | 19.46 | 0.83 | 0.142 |
| Ours | 19.49 | 0.82 | 0.180 |







