Model-Based Offline Reinforcement Learning with Pessimism-Modulated Dynamics Belief
Abstract
Model-based offline reinforcement learning (RL) aims to find highly rewarding policy, by leveraging a previously collected static dataset and a dynamics model. While the dynamics model learned through reuse of the static dataset, its generalization ability hopefully promotes policy learning if properly utilized. To that end, several works propose to quantify the uncertainty of predicted dynamics, and explicitly apply it to penalize reward. However, as the dynamics and the reward are intrinsically different factors in context of MDP, characterizing the impact of dynamics uncertainty through reward penalty may incur unexpected tradeoff between model utilization and risk avoidance. In this work, we instead maintain a belief distribution over dynamics, and evaluate/optimize policy through biased sampling from the belief. The sampling procedure, biased towards pessimism, is derived based on an alternating Markov game formulation of offline RL. We formally show that the biased sampling naturally induces an updated dynamics belief with policy-dependent reweighting factor, termed Pessimism-Modulated Dynamics Belief. To improve policy, we devise an iterative regularized policy optimization algorithm for the game, with guarantee of monotonous improvement under certain condition. To make practical, we further devise an offline RL algorithm to approximately find the solution. Empirical results show that the proposed approach achieves state-of-the-art performance on a wide range of benchmark tasks.
1 Introduction
In typical paradigm of RL, the agent actively interacts with environment and receives feedback to promote policy improvement. The essential trial-and-error procedure can be costly, unsafe or even prohibitory in practice (e.g. robotics robotic , autonomous driving driving , and healthcare health ), thus constituting a major impediment to actual deployment of RL. Meanwhile, for a number of applications, historical data records are available to reflect the system feedback under a predefined policy. This raises the opportunity to learn policy in purely offline setting.
In offline setting, as no further interaction with environment is permitted, the dataset provides a limited coverage in state-action space. Then, the policy that induces out-of-distribution (OOD) state-action pairs can not be well evaluated in offline learning phase, and deploying it online potentially attains terrible performance. Recent studies have reported that applying vanilla RL algorithms to offline dataset exacerbates such a distributional shift BCQ ; BEAR ; MOREL , making them unsuitable for offline setting.
To tackle the distributional shift issue, a number of offline RL approaches have been developed. Specifically, one category of them propose to directly constrain the policy close to the one collecting data BEAR ; BCQ ; BRAC ; EMaQ , or penalize Q-value towards conservatism for OOD state-action pairs CQL ; Fisher ; AlgaeDICE . While they achieve remarkable performance gains, the policy regularizer and the Q-value penalty tightly restricts the produced policy within the data manifold. Instead, more recent works consider to quantify the uncertainty of Q-value with neural network ensembles Ensemble , where the consistent Q-value estimates indicate high confidence and can be plausibly used during learning process, even for OOD state-action pairs EDAC ; PBRL . However, the uncertainty quantification over OOD region highly relies on how neural network generalizes BayesGenalization . As the prior knowledge of Q-function is hard to acquire and insert into the neural network, the generalization is unlikely reliable to facilitate meaningful uncertainty quantification SWAG . Notably, all these works are model-free.
Model-based offline RL optimizes policy based on a constructed dynamics model. Compared to the model-free approaches, one prominent advantage is that the prior knowledge of dynamics is easier to access. First, the generic prior like smoothness widely exists in various domains smooth . Second, the sufficiently learned dynamics models for relevant tasks can act as a data-driven prior for the concerned task blockMDP ; invariant ; zeroshot . With richer prior knowledge, the uncertainty quantification for dynamics is more trustworthy. Similar to the model-free approach, the dynamics uncertainty can be incorporated to find reliable policy beyond data coverage. However, an additional challenge is how to characterize the accumulative impact of dynamics uncertainty on the long-term reward, as the system dynamics is with entirely different meaning compared to the reward or Q-value.
Although existing model-based offline RL literature theoretically bounds the impact of dynamics uncertainty on final performance, their practical variants characterize the impact through reward penalty MOPO ; MOREL ; Revisit . Concretely, the reward function is penalized by the dynamics uncertainty for each state-action pair MOPO , or the agent is enforced to a low-reward absorbing state when the dynamics uncertainty exceeds a certain level MOREL . While optimizing policy in these constructed MDPs stimulates anti-uncertainty behavior, the final policy tends to be over-conservative. For example, even the transition dynamics for a state-action pair is ambiguous among several possible candidates, these candidates may generate the states from which the system evolves similarly.111Or from these states, the system evolves differently but generates similar rewards. Then, such a state-action pair should not be treated specially.
Motivated by the above intuition, we propose pessimism-modulated dynamics belief for model-based offline RL. In contrast with the previous approaches, the dynamics uncertainty is not explicitly quantified. To characterize its impact, we maintain a belief distribution over system dynamics, and the policy is evaluated/optimized through biased sampling from it. The sampling procedure, biased towards pessimism, is derived based on an alternating Markov game (AMG) formulation of offline RL. We formally show that the biased sampling naturally induces an updated dynamics belief with policy-dependent reweighting factor, termed Pessimism-Modulated Dynamics Belief. Besides, the degree of pessimism is monotonously determined by the hyperparameters in sampling procedure.
The considered AMG formulation can be regarded as a generalization of robust MDP, which is proposed as a surrogate to optimize the percentile performance in face of dynamics uncertainty RobustControl ; RMDP . However, robust MDP suffers from two significant shortcomings: 1) The percentile criterion is over-conservative since it fixates on a single pessimistic dynamics instance SRRL ; SRAC ; 2) Robust MDP is constructed based on an uncertainty set, and the improper choice of uncertainty set would further aggravate the degree of conservatism BCR ; Percentile . The AMG formulation is kept from these shortcomings. To solve the AMG, we devise an iterative regularized policy optimization algorithm, with guarantee of monotonous improvement under certain condition. To make practical, we further derive an offline RL algorithm to approximately find the solution, and empirically evaluate it on the offline RL benchmark D4RL. The results show that the proposed approach obviously outperforms previous state-of-the-art (SoTA) in 9 out of 18 environment-dataset configurations and performs competitively in the rest, without tuning hyperparameters for each task. The proof of theorems in this paper are presented in Appendix B.
2 Preliminaries
Markov Decision Process (MDP)
A MDP is depicted by the tuple , where are state and action spaces, is the transition probability, is the reward function, is the initial state distribution, and is the discount factor. The goal of RL is to find the policy that maximizes the cumulative discounted reward:
| (1) |
where denotes the probability simplex. In typical RL paradigm, this is done via actively interacting with environment.
Offline RL
In offline setting, the environment is unaccessible, and only a static dataset is provided, containing the previously logged data samples under an unknown behavior policy. Offline RL aims to optimize the policy by solely leveraging the offline dataset.
To simplify the presentation, we assume the reward function and initial state distribution are known. Then, the system dynamics is unknown only in terms of the transition probability . Note that the considered formulation and the proposed approach can be easily extend to the general case without additional technical modification.
Robust MDP
With the offline dataset, a straightforward strategy is first learning a dynamics model and then optimizing policy via simulation. However, due to the limitedness of available data, the learned model is inevitably imprecise. Robust MDP RobustControl is a surrogate to optimize policy with consideration of the ambiguity of dynamics. Concretely, robust MDP is constructed by introducing an uncertainty set to contain plausible transition probabilities. If the uncertainty set includes the true transition with probability of , the performance of any policy in true MDP can be lower bounded by with probability of at least . Thus, the percentile performance for the true MDP can be optimized by finding a solution to
| (2) |
Despite its popularity, Robust MDP suffers from two major shortcomings: First, the percentile criterion overly fixates on a single pessimistic transition instance, especially when there are multiple optimal policies for this transition but they lead to dramatically different performance for other transitions SRRL ; SRAC . This behavior results in unnecessarily conservative policy.
Second, the level of conservatism can be further aggravated when the uncertainty set is inappropriately constructed BCR . For a given policy , the ideal situation is that contains the proportion of transitions with which the policy achieves higher performance than with the other proportion. Then, is exactly the -quantile performance. This requires the uncertainty set to be policy-dependent, and during policy optimization the uncertainty set should change accordingly. Otherwise, if is predetermined and fixed, it is possible to have with non-zero probability and satisfying , where is the optimal policy for (2). Then, adding into does not affect the optimal solution of the problem (2). This indicates that we are essentially optimizing a -quantile performance, where can be much smaller than . In literature, the uncertainty sets are mostly predetermined before policy optimization RobustControl ; safe19 ; HCPE ; fastRMDP .
3 Pessimism-Modulated Dynamics Belief
In short, robust MDP is over-conservative due to the fixation on a single pessimistic transition instance and the predetermination of uncertainty set. In this work, we strive to take the entire spectrum of plausible transitions into account, and let the algorithm by itself determine which part deserves more attention. To this end, we consider an alternating Markov game formulation of offline RL, based on which the proposed offline RL approach is derived.
3.1 Formulation
Alternating Markov game (AMG)
The AMG is a specialization of two-player zero-sum game, depicted by . The game starts from a state sampled from , then two players alternatively choose actions and under states and , along with the game transition defined by and . At each round, the primary player receives reward and the secondary player receives its negative counterpart .
Offline RL as AMG
We formulate the offline RL problem as an AMG, where the primary player optimizes a reliable policy for our concerned MDP in face of stochastic disturbance from the secondary player. The AMG is constructed by augmenting the original MDP. As both have the transition probability, we use game transition and system transition to differentiate them.
For the primary player, its state space , action space and reward function are same with those in the original MDP. After the primary player acts, the game emits a -size set of system transition candidates , which later acts as the state of secondary player. Formally, is generated according to
| (3) |
where re-denotes the plausible system transition for short, and is a given belief distribution over . According to (3), the elements in are independent and identically distributed samples following . The major difference to uncertainty set in robust MDP is that the set introduced here is unfixed and stochastic for each step. To distinguish with uncertainty set, we call it candidate set. The belief distribution can be chosen arbitrarily to incorporate knowledge of system transition. Particularly, when the prior distribution of system transition is accessible, can be obtained as the posterior by integrating the prior and the evidence through Bayes’ rule.
The secondary player receives the candidate set as state. Thus, its state space can be denoted by , i.e., the n-fold Cartesian product of probability simplex over . Note that the state also takes the role of action space, i.e., , meaning that the action of secondary player is to choose a system transition from the candidate set. Given the chosen , the game evolves by sampling , i.e.,
| (4) |
and the primary player receives to continue the game. In the following, we use to compactly denote the game transition in (3), and omit the superscript in , and when it is clear from the context.
For the above AMG, we consider a specific policy (explained below) for the secondary player, such that the cumulative discounted reward of the primary player with policy can be written as:
| (5) |
where the subscripts of and denote time step, the expectation is over , and , and the operator denotes finding th minimum of over . The policy of secondary player is implicitly defined by the operator . When changing , the secondary player exhibits various degree of adversarial or aggressive disturbance to the future reward. From the view of original MDP, this behavior raises flexible tendency ranging from pessimism to optimism when evaluating policy .
The distinctions between the introduced AMG and the robust MDP are twofold: 1) With a belief distribution over transitions, robust MDP will select only part of its supports into uncertainty set, and the set elements are treated indiscriminatingly. It indicates that both the possibility of transitions out of the uncertainty set and the relative likelihood of transitions within the uncertainty set are discarded. However, in the AMG, the candidate set simply contains samples drawn from the belief distribution, implying no information drop in an average sense. Intuitively, by keeping richer knowledge of the system, the performance evaluation is more exact and away from excessive conservatism; 2) In robust MDP, the level of conservatism is expected to be controlled by its hyperparameter . However, as illustrated in Section 2, a smaller does not necessarily corresponds to a more conservative performance evaluation, due to the extra impact from uncertainty set construction. In contrast, for the AMG, the degree of conservatism is adjusted by the size of candidate size and the order of minimum . When changing values of or , the impact to performance evaluation is ascertained, as formalized in Theorem 3.
To evaluate , we define the following Bellman backup operator:
| (6) |
As the operator depends on , and we emphasize pessimism in offline RL, we call it -pessimistic Bellman backup operator. Compared to the standard Bellman backup operator in Q-learning, additionally includes the expectation over and the -minimum operator over . Despite these differences, we prove that is still a contraction mapping, based on which can be easily evaluated.
Theorem 1 (Policy Evaluation).
The -pessimistic Bellman backup operator is a contraction mapping. By starting from any function and repeatedly applying , the sequence converges to , with which we have .
3.2 Pessimism-Modulated Dynamics Belief
With the converged Q-value, we are ready to establish a more direct connection between the AMG and the original MDP. The connection appears as the answer to a natural question: the calculation of (6) encompasses biased samples from the dynamics belief distribution, can we treat these samples as the unbiased ones sampling from another belief distribution? We give positive answer in the following theorem.
Theorem 2 (Equivalent MDP with Pessimism-Modulated Dynamics Belief).
The alternating Markov game in (5) is equivalent to the MDP with tuple , where the transition probability is defined with the reweighted belief distribution :
| (7) | |||
| (8) |
and is cumulative density function. Furthermore, the value of first increases and then decreases with , and its maximum is obtained at the quantile, i.e., .
In right-hand side of (7), itself is random following the belief distribution, thus , as a functional of , is also a random variable, whose cumulative density function is determined by the belief distribution . Intuitively, we can treat as a pessimism indicator for transition , with larger value indicating less pessimism.
From Theorem 2, the maximum of is obtained at , i.e., the transition with -quantile pessimism indicator. Besides, when departs the quantile, the reweighting coefficient for its decreases. Considering the effect of to and the equivalence between the AMG and the refined MDP, we can say that is a soft percentile performance. Compared to the standard percentile criteria, is derived by reshaping belief distribution towards concentrating around a certain percentile, rather than fixating on a single percentile point. Due to this feature, we term Pessimism-Modulated Dynamics Belief (PMDB).
Lastly, recall that all the above derivations are with hyperparameters and , we present the monotonicity of over them in Theorem 3. Furthermore, by combining Theorem 1 with Theorem 3, we conclude that decreases with and increases with .
Theorem 3 (Monotonicity).
The converged Q-function are with the following properties:
-
•
Given any , the Q-function element-wisely decreases with .
-
•
Given any , the Q-function element-wisely increases with .
-
•
The Q-function element-wisely increases with .
Remark 1 (Special Cases). For , we have . Then, the performance is evaluated through sampling the initial belief distribution. This resembles the common methodology in model-based RL (MBRL), with dynamics belief defined by the uniform distribution over dynamics model ensembles. For and , asymptotically collapses to be a delta function. Then, degrades to fixate on a single transition instance. It is equivalent to the robust MDP with the uncertainty set constructed as . In this sense, the AMG is a successive interpolation between MBRL and robust MDP.
4 Policy Optimization with Pessimism-Modulated Dynamics Belief
In this section, we optimize policy by maximizing . The major consideration is that the methodology should adapt well for both discrete and continuous action spaces. In continuous setting of MDP, the policy can be updated by following stochastic/deterministic policy gradient SPG ; DPG . However, for the AMG, evaluating itself involves an inner dynamic programming procedure as in Theorem 1. As each evaluation of can only produce one exact gradient, it is inefficient to maximize via gradient-based method. In this section, we consider a series of sub-problems with Kullback–Leibler (KL) regularization. Solving each sub-problem makes prominent update to the policy, and the sequence of solutions for sub-problems monotonously improve regarding . Based on this idea, we further derive offline RL algorithm to approximately find the solution.
4.1 Iterative Regularized Policy Optimization
Define the KL-regularized return for the AMG by
| (9) |
where is the strength of regularization, and is a reference policy to keep close with.
KL-regularized MDP is considered in previous works to enhance exploration, improve robustness to noise or insert expert knowledge SQL ; SAC ; RegularizedMDP ; ISKL ; Prior . Here, the idea is to constrain the optimized policy in neighbour of a reference policy so that the inner problem is adequately evaluated for such a small policy region.
To optimize , we introduce the soft -pessimistic Bellman backup operator:
| (10) |
Theorem 4 (Regularized Policy Optimization).
The soft -pessimistic Bellman backup operator is a contraction mapping. By starting from any function and repeatedly applying , the sequence converges to , with which the optimal policy for is obtained as .
Apparently, the solved policy depends on the reference policy , and setting arbitrarily aforehand can result in suboptimal policy for . In fact, we can construct a sequence of sub-problems, with chosen as an improved policy from last sub-problem. By successively solving them, the impact from the initial reference policy is gradually eliminated.
Theorem 5 (Iterative Regularized Policy Optimization).
By starting from any stochastic policy and repeatedly finding , the sequence of monotonically improves regarding , i.e., . Especially, when and are obtained via regularized policy optimization in Theorem 4, we have for any such that .
Ideally, by combining Theorems 4 and 5, the policy for can be continuously improved by infinitely applying soft pessimistic Bellman backup operator for each of the sequential sub-problems.
Remark 2 (Iterative Regularized Policy Optimization as Expectation–Maximization with Structured Variational Posterior). According to Theorem 2, PMDB can be recovered with the converged Q-function . From an end-to-end view, we have an initial dynamics belief , then via the calculation based on the belief samples and the reward function, we obtain the updated dynamics belief . It is likely that we are doing some form of posterior inference, where the evidence comes from the reward function. In fact, the iterative regularized policy optimization can be formally recast as an Expectation-Maximization algorithm for offline policy optimization, where the Expectation step correponds to a structured variational inference procedure for dynamics. We elaborate it in Appendix C.
4.2 Offline Reinforcement Learning with Pessimism-Modulated Dynamics Belief
While solving each sub-problem makes prominent update to policy compared with the policy gradient method, we may need to construct several sub-problems before convergence, then exactly solving each of them incurs unnecessary computation. For practical consideration, next we introduce a smooth-evolving reference policy, with which the explicit boundary between sub-problems is blurred. Based on this reference policy, and by further adopting function approximator, we devise an offline RL algorithm to approximately maximize .
The idea of smooth-evolving reference policy is inspired by the soft-updated target network in deep RL literature DQN ; DDPG . That is setting the reference policy as a slowly tracked copy of the policy being optimized. Formally, consider a parameterized policy with the parameter . The reference policy is set as , where is the moving average of . With small enough , the Q-value of the state-action pairs induced by (or its slight variant) can be sufficiently evaluated, before being used to update the policy. Next, we detail the loss functions to learn Q-value and policy with neural network approximators.
Denote the parameterized Q-function by with the parameter . It is trained by minimizing the Bellman residual of both the AMG and the empirical MDP:
| (11) |
with
| (12) | |||
| (13) |
where represent the target Q-value softly updated for stability DDPG , i.e., , and is the on-policy data buffer for the AMG. Since the game transition is known, the game can be executed with multiple counterparts in parallel, and the buffer only collects the latest sample for each of them. To promote direct learning from , we also include the Bellman residual of the empirical MDP in (11).
As with policy update, Theorem 4 states that the optimal policy for is propotional to . Then, we update by supervisedly learning this policy, with and replaced by the smooth-evolving reference policy and the learned Q-value:
| (14) |
where and are constant terms. In general, (4.2) can be replaced by any tractable function that measures the similarity of distributions. For example, when is Gaussian, we can apply the recent proposed -NLL Pitfall , in which each data point’s contribution to the negative log-likelihood loss is weighted by the -exponentiated variance to improve learning heteroscedastic behavior.
To summarize, the algorithm alternates between collecting on-policy data samples in AMG and updating the function approximators. In detail, the latter procedure includes updating the Q-value with (11), updating the optimized policy with (4.2), and updating the target Q-value as well as the reference policy with the moving-average rule. The complete algorithm is listed in Appendix D.
5 Experiments
Through the experiments, we aim to answer the following questions: 1) How does the proposed approach compared to the previous SoTA offline RL algorithms on standard benchmark? 2) How does the learning process in the AMG connect with the performance change in the original MDP? 3) Section 3 presents the monotonicity of over and for any specified , and it is easy to verify that this statement also holds when considering optimal policy for each setting of . However, with neural network approximator, our proposed offline RL algorithm approximately solves the AMG. Then, how is the monotonicity satisfied in this case?
We consider the Gym domains in the D4RL benchmark D4RL to answer these questions. As PMDB relies on the initial dynamics belief, inserting additional knowledge into the initial dynamics belief will result in unfair comparison. To avoid that, we consider an uniform distribution over dynamics model ensembles as the initial belief. The dynamics model ensembles are trained in supervised manner with the offline dataset. This is similar to previous model-based works MOPO ; MOREL , where the dynamics model ensembles are considered for dynamics uncertainty quantification. Since hyperparameter tuning for offline RL algorithms requires extra online test for each task, we purposely keep the same hyperparameters for all tasks, except when answering the last question. Especially, the hyperparameters in sampling procedure are and . The more detailed setup for experiments and hyperparameters can be found in Appendix G. The code is available online222Code is released at https://github.com/huawei-noah/HEBO/tree/master/PMDB and https://gitee.com/mindspore/models/tree/master/research/rl/pmdb.
5.1 Performance Comparison
We compare the proposed offline RL algorithm with the baselines including: BEAR BEAR and BRAC BRAC , the model-free approaches based on policy constraint, CQL CQL , the model-free approach by penalizing Q-value, EDAC EDAC , the previous SoTA on the D4RL benchmark, MOReL MOREL , the model-based approach which terminates the trajectory if the dynamics uncertainty exceeds a certain degree, and BC, the behavior cloning method. These approaches are evaluated on a total of eighteen domains involving three environments (hopper, walker2d, halfcheetah) and six dataset types (random, medium, expert, medium-expert, medium-replay, full-replay) per environment. We use the v2 version of each dataset.
The results are summarized in Table LABEL:Table:D4RL. Our approach PMDB obviously improves over the previous SoTA on 9 tasks and performs competitively in the rest. Although EDAC achieves better performance in walker2d with several dataset types, its hyperparameters are tuned individually for each task. The later experiments on the impact of hyperparameters indicate that larger or smaller could generate better results for walker2d and halfcheetah. We also find that PMDB significantly outperforms MOReL, another model-based approach. It is encouraging that our model-based approach achieves competitive or better performance compared with the SoTA model-free approach, as model-based approach naturally has better support for multi-task learning and transfer learning, where the offline data from relevant tasks can be further leveraged.
| Task Name | BC | BEAR | BRAC | CQL | MOReL | EDAC | PMDB |
| hopper-random | 3.70.6 | 3.63.6 | 8.10.6 | 5.30.6 | 38.110.1 | 25.310.4 | 32.70.1 |
| hopper-medium | 54.13.8 | 55.33.2 | 77.86.1 | 61.96.4 | 84.017.0 | 101.60.6 | 106.80.2 |
| hopper-expert | 107.79.7 | 39.420.5 | 78.152.6 | 106.59.1 | 80.434.9 | 110.10.1 | 111.70.3 |
| hopper-medium-expert | 53.94.7 | 66.28.5 | 81.38.0 | 96.915.1 | 105.68.2 | 110.70.1 | 111.80.6 |
| hopper-medium-replay | 16.64.8 | 57.716.5 | 62.730.4 | 86.37.3 | 81.817.0 | 101.00.5 | 106.20.6 |
| hopper-full-replay | 19.912.9 | 54.024.0 | 107.40.5 | 101.90.6 | 94.420.5 | 105.40.7 | 109.10.2 |
| walker2d-random | 1.30.1 | 4.31.2 | 1.31.4 | 5.41.7 | 16.07.7 | 16.67.0 | 21.80.1 |
| walker2d-medium | 70.911.0 | 59.840.0 | 59.739.9 | 79.53.2 | 72.811.9 | 92.50.8 | 94.21.1 |
| walker2d-expert | 108.70.2 | 110.10.6 | 55.262.2 | 109.30.1 | 62.629.9 | 115.11.9 | 115.91.9 |
| walker2d-medium-expert | 90.113.2 | 107.02.9 | 9.318.9 | 109.10.2 | 107.55.6 | 114.70.9 | 111.90.2 |
| walker2d-medium-replay | 20.39.8 | 12.24.7 | 40.147.9 | 76.810.0 | 40.820.4 | 87.12.3 | 79.90.2 |
| walker2d-full-replay | 68.817.7 | 79.615.6 | 96.92.2 | 94.21.9 | 84.813.1 | 99.80.7 | 95.40.7 |
| halfcheetah-random | 2.20.0 | 12.61.0 | 24.30.7 | 31.33.5 | 38.91.8 | 28.41.0 | 37.8 0.2 |
| halfcheetah-medium | 43.20.6 | 42.80.1 | 51.90.3 | 46.90.4 | 60.74.4 | 65.90.6 | 75.6 1.3 |
| halfcheetah-expert | 91.81.5 | 92.60.6 | 39.013.8 | 97.31.1 | 8.411.8 | 106.83.4 | 105.7 1.0 |
| halfcheetah-medium-expert | 44.01.6 | 45.74.2 | 52.30.1 | 95.01.4 | 80.411.7 | 106.31.9 | 108.50.5 |
| halfcheetah-medium-replay | 37.62.1 | 39.40.8 | 48.60.4 | 45.30.3 | 44.55.6 | 61.31.9 | 71.71.1 |
| halfcheetah-full-replay | 62.90.8 | 60.13.2 | 78.00.7 | 76.90.9 | 70.15.1 | 84.60.9 | 90.00.8 |
| Average | 49.9 | 52.4 | 54.0 | 73.7 | 65.1 | 85.2 | 88.2 |
5.2 Learning in Alternating Markov Game
Figure 2 presents the learning curves in the AMG, as well as the received return when deploying the policy being learned in true MDP. The performance in the AMG closely tracks the true performance from the lower side, implying that it can act as a reasonable surrogate to evaluate/optimize performance for the true MDP. Besides, the performance in the AMG improves nearly monotonously, verifying the effectiveness of the proposed algorithm to approximately solve the game.
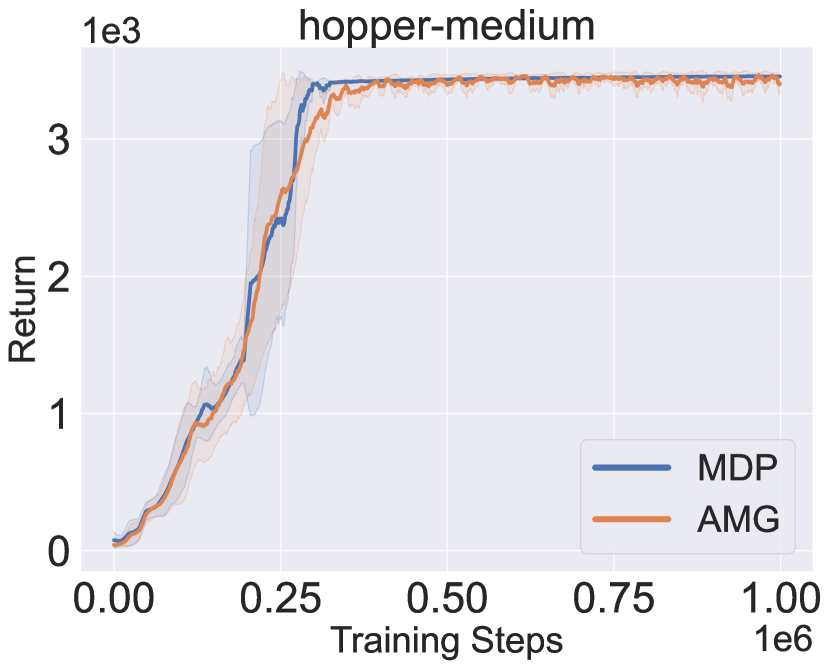
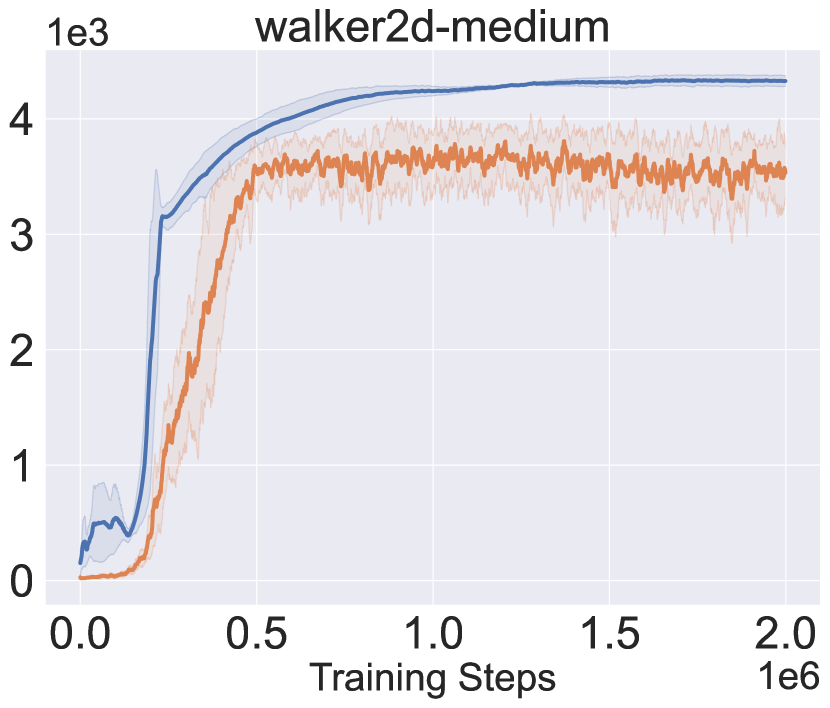
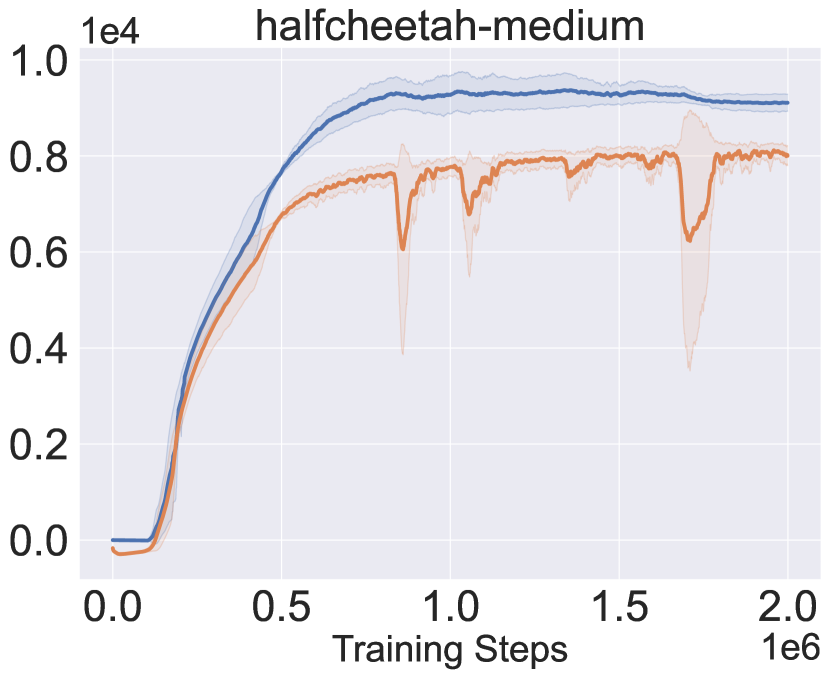
Recall that PMDB does not explicitly quantify dynamics uncertainty to penalize return, Figure 3 checks how the dynamics uncertainty and the Q-value of visited state-action pairs change during the learning process. The uncertainty is measured by the logarithm of standard deviation of the predicted means from the dynamics samples, i.e., . The policy being learned is periodically tested in the AMG for ten trials, and we collect the whole ten trajectories of state-action pairs. The solid curves in Figure 3 denote the mean uncertainty and Q-value over the collected pairs, and shaded regions denote the standard deviation. From the results, the dynamics uncertainty first sharply decreases and then keeps a slowly increasing trend. Besides, in the long-term view, the Q-value is correlated with the degree of uncertainty negatively in the first phase and positively in the second phase. This indicates that the policy first moves to the in-distribution region and then tries to get away by resorting to the generalization of dynamics model.
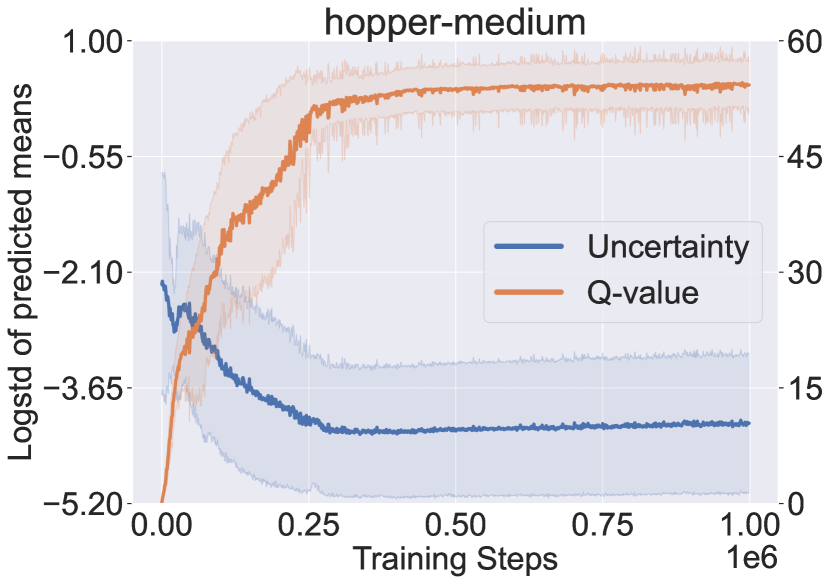
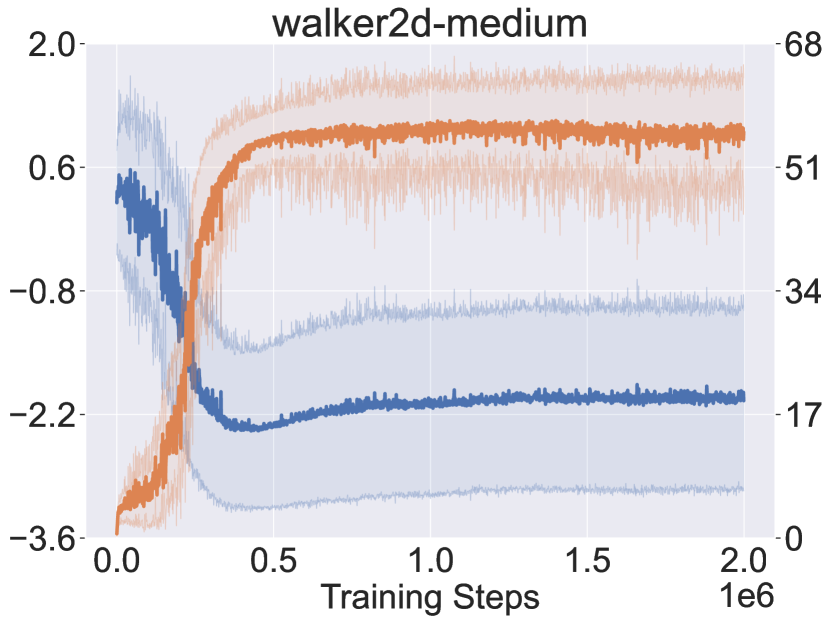
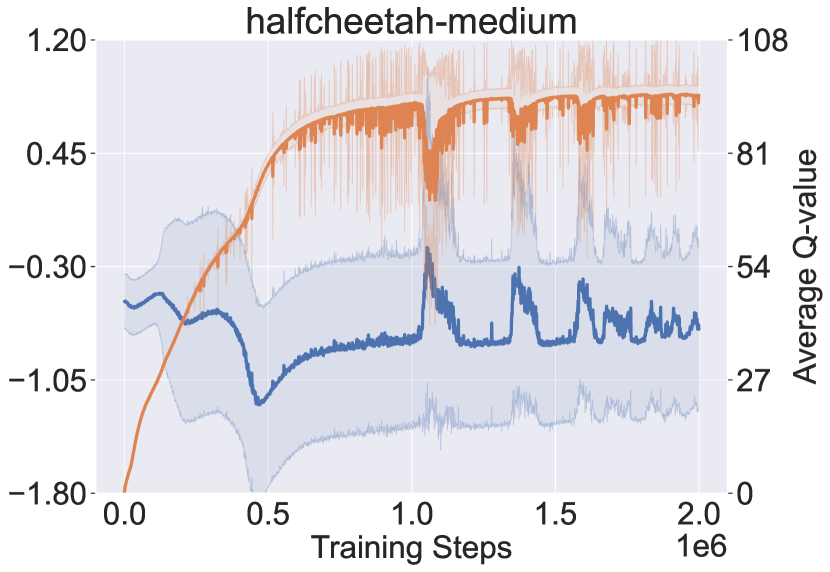
In Figure 3, we also notice that the large dip of Q-value is accompanied with the sudden raise of dynamics uncertainty. We suspect this is due to the optimized policy being far from the dataset. We try to verify by checking the maximal return covered by the offline dataset. It shows that the maximal normalized returns provided by offline datasets are 99.6, 92.0 and 45.0 respectively for hopper, walker2d and halfcheetah, while the proposed approach achieves 106.8, 94.2 and 75.6. The policy optimization is more significant for halfcheetah (where we observe the large dip), indicating the policy should move further from the dataset.
The above finding also explains why the AMG performance in Figure 2 runs into large dip only for halfcheetah: with the larger dynamics uncertainty, the secondary player can choose the more pessimistic transition. However, we want to highlight that it is normal behavior of the proposed algorithm and does not mean instability, as we are handling the alternating Markov game, a specialization of zero-sum game. Besides, we can see that even when the AMG performance goes down the MDP performance is still stable.
5.3 Practical Impact of Hyperparameters in Sampling Procedure
Table 2 lists the impact of . In each setting, we evaluate the learned policy in both the true MDP and the AMG. The performance in the AMGs improve when increasing . This is consistent with the theoretical result, even that we approximately solve the game. Regarding the performance in true MDPs, we notice that corresponds to the best performance for hopper, but for the others is better. This indicates that tuning hyperparameter online can further improve the performance. The impact of is presented in Appendix H, suggesting the opposite monotonicity.
| hopper-medium | walker2d-medium | halfcheetah-medium | ||||
|---|---|---|---|---|---|---|
| MDP | AMG | MDP | AMG | MDP | AMG | |
| 1 | 106.20.2 | 91.62.2 | 82.60.5 | 33.32.6 | 70.70.8 | 63.10.2 |
| 2 | 106.80.2 | 105.21.6 | 94.21.1 | 77.23.7 | 75.61.3 | 67.31.1 |
| 3 | 90.817.5 | 106.62.1 | 105.10.2 | 82.50.5 | 77.30.5 | 70.10.2 |
6 Related Works
Inadequate data coverage is the root of challenge in offline RL. Existing works differ in their methodology to reacting in face of limited system knowledge.
Model-free offline RL
The prevalent idea is to find policy within the data manifold through model-free learning. Analogous to online RL, both policy-based and value-based approaches are devised to this end. Policy-based approaches directly constrain the optimized policy close to the behavior policy that collects data, via various measurements such as KL divergence BRAC , MMD BEAR and action deviation BCQ ; EMaQ . Value-based approaches instead reflect the policy regularization through value function. For example, CQL enforces small Q-value for OOD state-action pairs CQL , AlgaeDICE penalizes return with the -divergence between optimized and offline state-action distributions AlgaeDICE , and Fisher-BRC proposes a novel parameterization of the Q-value to encourage the generated policy close to the data Fisher . Our proposed approach is more relevant to the value-based scope, and the key difference to existing works is that our Q-value is penalized through an adversarial choice of transition from plausible candidates.
Learning within the data manifold limits the degree to which the policy improves, and recent works attempt to relieve the restriction. Along the model-free line, EDAC EDAC and PBRL PBRL quantify uncertainty of Q-value via neural network ensemble, and assign penalty to Q-value depending on the uncertainty degree. In this way, the OOD state-action pairs are touchable if they pose low uncertainty on Q-value. However, the uncertainty quantification over OOD region highly relies on how neural network generalizes BayesGenalization . As the prior knowledge of Q-function is hard to acquire and insert into the neural network, the generalization is unlikely reliable to facilitate meaningful uncertainty quantification SWAG .
Model-based offline RL
Model-based approach is widely recognized due to its superior data efficiency. However, directly optimizing policy based on an offline learned model is vulnerable to model exploitation MBPO ; Revisit . A line of works improve the dynamics learning for seek of robustness PL or adaptation WME to distributional shift. In terms of policy learning, several works extend the idea from model-free approaches, and constrain the optimized policy close to the behavior policy when applying the dynamics model for planing MBOP or policy optimization BREMEN ; COMBO . There are also recent works incorporating uncertainty quantification of dynamics model to learn policy beyond data coverage. Especially, MOPO MOPO and MOReL MOREL perform policy improvement in states that may not directly occur in the static offline dataset, but can be predicted by leveraging the power of generalization. Compared to them, our approach does not explicitly characterize the dynamics uncertainty as reward penalty. There are also relevant works dealing with model ambiguity in light of Bayesian decision theory, which are discussed in Appendix A.
7 Discussion
We proposed model-based offline RL with Pessimism-Modulated Dynamics Belief (PMDB), a framework to reliably learn policy from offline dataset, with the ability of leveraging dynamics prior knowledge. Empirically, the proposed approach outperforms the previous SoTA in a wide range of D4RL tasks. Compared to the previous model-based approaches, we characterize the impact of dynamics uncertainty through biased sampling from the dynamics belief, which implicitly induces PMDB. As PMDB is with the form of reweighting an initial dynamics belief, it provides a principled way to insert prior knowledge via the belief to boost policy learning. However, posing a valuable dynamics belief for arbitrary task is challenging, as the expert knowledge is not always available. Besides, an over-aggressive belief may still incur high-risk behavior in reality. Encouragingly, recent works have done active research to learn data-driven prior from relevant tasks. We believe that integrating them as well as developing safe criterion to design/learn dynamics belief would further promote practical deployment of offline RL.
References
- [1] Shixiang Gu, Ethan Holly, Timothy Lillicrap, and Sergey Levine. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In IEEE ICRA, 2017.
- [2] B Ravi Kiran, Ibrahim Sobh, Victor Talpaert, Patrick Mannion, Ahmad A. Al Sallab, Senthil Yogamani, and Patrick Pérez. Deep reinforcement learning for autonomous driving: A survey. IEEE TITS, 2021.
- [3] Chao Yu, Jiming Liu, Shamim Nemati, and Guosheng Yin. Reinforcement learning in healthcare: A survey. ACM Computing Surveys, 2021.
- [4] Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. In ICML, 2019.
- [5] Aviral Kumar, Justin Fu, Matthew Soh, George Tucker, and Sergey Levine. Stabilizing off-policy Q-learning via bootstrapping error reduction. In NeurIPS, 2019.
- [6] Rahul Kidambi, Aravind Rajeswaran, Praneeth Netrapalli, and Thorsten Joachims. MOReL: Model-based offline reinforcement learning. In NeurIPS, 2020.
- [7] Yifan Wu, George Tucker, and Ofir Nachum. Behavior regularized offline reinforcement learning. arXiv preprint arXiv:1911.11361, 2019.
- [8] Seyed Kamyar Seyed Ghasemipour, Dale Schuurmans, and Shixiang Shane Gu. EMaQ: Expected-max Q-learning operator for simple yet effective offline and online RL. In ICML, 2021.
- [9] Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative Q-learning for offline reinforcement learning. In NeurIPS, 2020.
- [10] Ilya Kostrikov, Rob Fergus, Jonathan Tompson, and Ofir Nachum. Offline reinforcement learning with fisher divergence critic regularization. In ICML, 2021.
- [11] Ofir Nachum, Bo Dai, Ilya Kostrikov, Yinlam Chow, Lihong Li, and Dale Schuurmans. AlgaeDICE: Policy gradient from arbitrary experience. arXiv preprint arXiv:1912.02074, 2019.
- [12] Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In NeurIPS, 2017.
- [13] Gaon An, Seungyong Moon, Jang-Hyun Kim, and Hyun Oh Song. Uncertainty-based offline reinforcement learning with diversified Q-ensemble. In NeurIPS, 2021.
- [14] Chenjia Bai, Lingxiao Wang, Zhuoran Yang, Zhihong Deng, Animesh Garg, Peng Liu, and Zhaoran Wang. Pessimistic bootstrapping for uncertainty-driven offline reinforcement learning. arXiv preprint arXiv:2202.11566, 2022.
- [15] Andrew G Wilson and Pavel Izmailov. Bayesian deep learning and a probabilistic perspective of generalization. In NeurIPS, 2020.
- [16] Wesley J Maddox, Pavel Izmailov, Timur Garipov, Dmitry P Vetrov, and Andrew Gordon Wilson. A simple baseline for Bayesian uncertainty in deep learning. In NeurIPS, 2019.
- [17] Andy Zeng, Shuran Song, Johnny Lee, Alberto Rodriguez, and Thomas Funkhouser. Tossingbot: Learning to throw arbitrary objects with residual physics. IEEE T-RO, 2020.
- [18] Amy Zhang, Clare Lyle, Shagun Sodhani, Angelos Filos, Marta Kwiatkowska, Joelle Pineau, Yarin Gal, and Doina Precup. Invariant causal prediction for block MDPs. In ICML, 2020.
- [19] Amy Zhang, Rowan McAllister, Roberto Calandra, Yarin Gal, and Sergey Levine. Learning invariant representations for reinforcement learning without reconstruction. In ICLR, 2021.
- [20] Philip J Ball, Cong Lu, Jack Parker-Holder, and Stephen Roberts. Augmented world models facilitate zero-shot dynamics generalization from a single offline environment. In ICML, 2021.
- [21] Tianhe Yu, Garrett Thomas, Lantao Yu, Stefano Ermon, James Zou, Sergey Levine, Chelsea Finn, and Tengyu Ma. MOPO: Model-based offline policy optimization. In NeurIPS, 2020.
- [22] Cong Lu, Philip J. Ball, Jack Parker-Holder, Michael A. Osborne, and Stephen J. Roberts. Revisiting design choices in model-based offline reinforcement learning. In ICLR, 2022.
- [23] Arnab Nilim and Laurent El Ghaoui. Robust control of Markov decision processes with uncertain transition matrices. Operations Research, 2005.
- [24] Wolfram Wiesemann, Daniel Kuhn, and Berç Rustem. Robust Markov decision processes. Mathematics of Operations Research, 2013.
- [25] Elita A. Lobo, Mohammad Ghavamzadeh, and Marek Petrik. Soft-robust algorithms for batch reinforcement learning. arXiv preprint arXiv:2011.14495, 2020.
- [26] Esther Derman, Daniel J. Mankowitz, Timothy A. Mann, and Shie Mannor. Soft-robust actor-critic policy-gradient. In UAI, 2018.
- [27] Marek Petrik and Reazul Hasan Russel. Beyond confidence regions: Tight Bayesian ambiguity sets for robust MDPs. In NeurIPS, 2019.
- [28] Bahram Behzadian, Reazul Hasan Russel, Marek Petrik, and Chin Pang Ho. Optimizing percentile criterion using robust MDPs. In AISTATS, 2021.
- [29] Romain Laroche, Paul Trichelair, and Remi Tachet Des Combes. Safe policy improvement with baseline bootstrapping. In ICML, 2019.
- [30] Philip Thomas, Georgios Theocharous, and Mohammad Ghavamzadeh. High-confidence off-policy evaluation. In AAAI, 2015.
- [31] Chin Pang Ho, Marek Petrik, and Wolfram Wiesemann. Fast Bellman updates for robust MDPs. In ICML, 2018.
- [32] Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. In NeurIPS, 1999.
- [33] David Silver, Guy Lever, Nicolas Heess, Thomas Degris, Daan Wierstra, and Martin Riedmiller. Deterministic policy gradient algorithms. In ICML, 2014.
- [34] Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. In ICML, 2017.
- [35] Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In ICML, 2018.
- [36] Matthieu Geist, Bruno Scherrer, and Olivier Pietquin. A theory of regularized Markov decision processes. In ICML, 2019.
- [37] Alexandre Galashov, Siddhant M. Jayakumar, Leonard Hasenclever, Dhruva Tirumala, Jonathan Schwarz, Guillaume Desjardins, Wojciech M. Czarnecki, Yee Whye Teh, Razvan Pascanu, and Nicolas Heess. Information asymmetry in KL-regularized RL. In ICLR, 2019.
- [38] Noah Y. Siegel, Jost Tobias Springenberg, Felix Berkenkamp, Abbas Abdolmaleki, Michael Neunert, Thomas Lampe, Roland Hafner, Nicolas Heess, and Martin A. Riedmiller. Keep doing what worked: Behavioral modelling priors for offline reinforcement learning. In ICLR, 2020.
- [39] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature, 2015.
- [40] Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. In ICLR, 2016.
- [41] Maximilian Seitzer, Arash Tavakoli, Dimitrije Antic, and Georg Martius. On the pitfalls of heteroscedastic uncertainty estimation with probabilistic neural networks. arXiv preprint arXiv:2203.09168, 2022.
- [42] Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4RL: Datasets for deep data-driven reinforcement learning. arXiv preprint arXiv:2004.07219, 2020.
- [43] Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to trust your model: Model-based policy optimization. In NeurIPS, 2019.
- [44] Byung-Jun Lee, Jongmin Lee, and Kim Kee-Eung. Representation balancing offline model-based reinforcement learning. In ICLR, 2020.
- [45] Toru Hishinuma and Kei Senda. Weighted model estimation for offline model-based reinforcement learning. In NeurIPS, 2021.
- [46] Arthur Argenson and Gabriel Dulac-Arnold. Model-based offline planning. In ICLR, 2021.
- [47] Tatsuya Matsushima, Hiroki Furuta, Yutaka Matsuo, Ofir Nachum, and Shixiang Gu. Deployment-efficient reinforcement learning via model-based offline optimization. In ICLR, 2021.
- [48] Tianhe Yu, Aviral Kumar, Rafael Rafailov, Aravind Rajeswaran, Sergey Levine, and Chelsea Finn. COMBO: Conservative offline model-based policy optimization. In NeurIPS, 2021.
- [49] RT Rockafellar and Stanislav Uryasev. Optimization of conditional value-at-risk. Journal of Risk, 2000.
- [50] Aviv Tamar, Huan Xu, and Shie Mannor. Scaling up robust MDPs by reinforcement learning. arXiv preprint arXiv:1306.6189, 2013.
- [51] Romain Laroche, Paul Trichelair, and Remi Tachet Des Combes. Safe policy improvement with baseline bootstrapping. In ICML, 2019.
- [52] Daniel J. Mankowitz, Nir Levine, Rae Jeong, Abbas Abdolmaleki, Jost Tobias Springenberg, Timothy A. Mann, Todd Hester, and Martin A. Riedmiller. Robust reinforcement learning for continuous control with model misspecification. In ICLR, 2020.
- [53] Lerrel Pinto, James Davidson, Rahul Sukthankar, and Abhinav Gupta. Robust adversarial reinforcement learning. In ICML, 2017.
- [54] Chen Tessler, Yonathan Efroni, and Shie Mannor. Action robust reinforcement learning and applications in continuous control. In ICML, 2019.
- [55] Elena Smirnova, Elvis Dohmatob, and Jérémie Mary. Distributionally robust reinforcement learning. In ICML Workshop, 2019.
- [56] Marc Rigter, Paul Duckworth, Bruno Lacerda, and Nick Hawes. Planning for risk-aversion and expected value in MDPs. In ICAPS, 2022.
- [57] Esther Derman, Daniel Mankowitz, Timothy Mann, and Shie Mannor. A Bayesian approach to robust reinforcement learning. In Uncertainty in Artificial Intelligence Conference, pages 648–658, 2020.
- [58] Marc Rigter, Bruno Lacerda, and Nick Hawes. Risk-averse Bayes-adaptive reinforcement learning. In NeurIPS, 2021.
- [59] H.A. David and H.N. Nagaraja. Order Statistics. Wiley, 2004.
- [60] Sergey Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review. arXiv preprint arXiv:1805.00909, 2018.
- [61] Marc Rigter, Bruno Lacerda, and Nick Hawes. RAMBO-RL: Robust adversarial model-based offline reinforcement learning. arXiv preprint arXiv:2204.12581, 2022.
Appendix A Additional Related Works
Robust MDP and CVaR Criterion
Bayesian decision theory provides a principled formalism for decision making under uncertainty. Robust MDP [23, 24], Conditional Value at Risk (CVaR) [49] and our proposed criterion can be deemed as the specializations of Bayesian decision theory, but derived from different principles and with different properties.
Robust MDP is proposed as a surrogate to optimize the percentile performance. Early works mainly focus on the algorithmic design and theoretical analysis in the tabular case [23, 24] or under linear function approximation [50]. Recently, it has also been extended to continuous action spaces and nonlinear cases, by integrating the advances of deep RL [51, 52]. Meanwhile, a variety of works generalize the uncertainty in regard to system disturbance [53] and action disturbance [54, 55]. Although robust MDP produces robust policy, it purely focuses on the percentile performance, and ignoring the other possibilities is reported to be over-conservative [25, 26, 27].
CVaR instead considers the average performance of the worst -fraction possibilities. Despite involving more information about the stochasticity, CVaR is still solely from the pessimistic view. Recent works propose to improve by maximizing the convex combination of mean performance and CVaR [25], or maximizing mean performance under CVaR constraint [56]. However, they are intractable regarding policy optimization, i.e., proved as an NP-hard problem or relying on heuristic. As comparison, the proposed AMG formulation presents an alternative way to tackle the entire spectrum of plausible transitions while also give more attention on the pessimistic parts. Besides, the policy optimization is with theoretical guarantee.
Apart from offline RL, Bayesian decision theory is also applied in other RL settings. Particularly, Bayesian RL considers that new observations are continually received and utilized to make adaptive decision. The goal of Bayesian RL is to fast explore and adapt, while that of offline RL is to sufficiently exploit the offline dataset to generate the best-effort policy supported or surrounded by the dataset. Recently, Bayesian robust RL [57] integrates the idea of robust MDP in the setting of Bayesian RL, where the uncertainty set is constructed to produce robust policy, and will be updated upon new observations to alleviate the degree of conservativeness. Besides, CVaR criterion is also considered in Bayesian RL [58].
Appendix B Theorem Proof
We first present and prove the fundamental inequalities applied to prove the main theorem, and then present the proofs for Sections 3 and 4 respectively. For conciseness, the subscripts are omitted in Q-value and Bellman backup operator when clear from the context.
B.1 Preliminaries
Lemma 1.
Let denote the th minimum in , then
where is the size of both and .
Proof of Lemma 1.
Denote and . Next, we prove the first inequality. The proof is done by dividing into two cases.
Case 1:
It is easy to check
Case 2:
We prove by contradiction. Let . Assume
Since is the th minimum, the above assumption implies . Meanwhile, according to the condition of case 2, . Put these together, we have . According to the definition of , we know . This concludes that has at least elements, contradicting with its definition.
Thus,
By applying the above inequality and , we have
In summary, we have for both cases.
The second inequality can be proved by resorting to the first one. By respectively replacing and with and in first inequality, we obtain
which can be rewritten as
where the last equation is due to . As the above inequalities holds for any , we can replace by , and this is right the second inequality in Lemma 1. ∎
Corollary 1.
B.2 Proofs for Section 3
Proof of Theorem 1.
Let and be two arbitrary Q function, then
where the second inequality is due to Corollary 1. Thus, the pessimistic Bellman update operator is a contraction mapping.
After convergence, it is easy to check by recursively unfolding Q-function. ∎
Proof of Theorem 2.
For conciseness, in this proof we drop the superscript in and .
The proof is based on the definition and the probability density function of order statistic [59]. For any random variables , their th order statistic is defined as , which is another random variable. Particularly, when are independent and identically distributed following a probability density function , the order statistic is with the probability density function
where is the cumulative distribution corresponding to .
Let for short. As is random following the belief distribution, as the functional of is also a random variable. Its sample can be drawn by
As the elements in are independent and identically distributed samples from , the elements in are also independent and identically distributed. Thus, is their th order statistic, and we have
where is the reference measure based on which the belief distribution is defined, and the equation is obtained by exchanging the orders of integration. The above equation can rewritten as
Taking this into consideration, the pessimistic Bellman backup operator in (6) is exactly the vanilla Bellman backup operator for the MDP with transition probability . Then, evaluating/optimizing policy in the AMG is equivalent to evaluating/optimizing in this MDP.
To prove the property of , we treat it as a composite function with form of . Then, the derivative of over is
| (15) |
It is easy to check that for and for . Thus, reaches the maximum at . Besides, as is the PDF of , it monotonically increases with . Put the monotonicity of and together, we know first increases, then decreases with and achieves the maximimum at . ∎
Lemma 2 (Monotonicity of Pessimistic Bellman Backup Operator).
Assume that holds element-wisely, then element-wisely.
Proof of Theorem 3.
It is sufficient to prove and element-wisely. The idea is to first show and . Then, the proof can be finished by recursively applying Lemma 2, for example:
Next, we prove the three inequalities in sequence.
where we divide the -size set into and , contains the first elements and is the last element. The second equality is due to the independence among the set elements.
∎
B.3 Proofs for Section 4
Analogous to the policy evaluation for non-regularized case, we define the KL-regularized Bellman update operator for a given policy by
| (16) |
It is easy to check all proofs in last subsection adapt well for the KL-regularized case. We state the corresponding theorems and lemma as below, and apply them to prove the theorems in Section 4.
Theorem 6 (Policy Evaluation for KL-Regularized AMG).
The regularized -pessimistic Bellman backup operator is a contraction mapping. By starting from any function and repeatedly applying , the sequence converges to , with which we have .
Theorem 7 (Equivalent KL-Regularized MDP with Pessimism-Modulated Dynamics Belief).
The KL-regularized alternating Markov game in (4.1) is equivalent to the KL-regularized MDP with tuple , where the transition probability is defined with the reweighted belief distribution :
| (17) | |||
| (18) |
and is cumulative density function. Furthermore, the value of first increases and then decreases with , and its maximum is obtained at the quantile, i.e., . Similar to the non-regularized case, the reweighting factor reshapes the initial belief distribution towards being pessimistic in terms of .
Lemma 3 (Monotonicity of Regularized Pessimistic Bellman Backup Operator).
Assume that holds element-wisely, then element-wisely.
Theorem 8 (Monotonicity in Regularized Alternating Markov Game).
The converged Q-function are with the following properties:
-
•
Given any , the Q-function element-wisely decreases with .
-
•
Given any , the Q-function element-wisely increases with .
-
•
The Q-function element-wisely increases with .
Proof of Theorem 4.
The proof of contraction mapping basically follows the same steps in proof of Theorem 1 Let and be two arbitrary Q function.
where the second inequality is obtained with Corollary 1, and the last inequality is due to . We present its proof by following [34]:
Suppose , then
Similarly, . The desired inequality is proved by putting them together.
Next, we prove is the optimal policy for .
Besides,
By repeatedly applying to the above equation, we obtain
| (20) |
Proof of Theorem 5.
We first prove . As the iteration requires , it is sufficient to prove . We do that by showing element-wisely.
First,
| (22) |
where the first inequality is due to Lemma 1, the second inequality is due to the non-negativity of KL-divergence.
Then, by recursively applying Lemma 2 we obtain
| (23) |
By substituting into and , we have
| (24) |
To summarize, the proof is done via .
Next, we consider the special case where are obtained via regularized policy optimization in Theorem 4. For the th step, is the optimal solution for the sub-problem of maximizing . Thus, according to (21), . For , the KL term in Q-value vanishes and we have . By combining it with (23), we obtain
| (25) |
Then, the boundness of indicates the existence of and also .
For any satisfying , it satisfies . Thus,
| (26) |
According to Theorem 4, the updated policy is with form of333Strictly speaking, Theorem 4 shows . Besides, we have shown in (20). Thus, .
Then, the policy ratio can be rewritten and bounded as
| (27) |
With the prerequisite of and the form of policy update, we know , and further . Then, as approaches infinity in (27), we obtain . ∎
Appendix C Iterative Regularized Policy Optimization as Expectation–Maximization with Structured Variational Posterior
This section recasts the iterative regularized policy optimization as an Expectation-Maximization algorithm for policy optimization, where the Expectation step corresponds to a structured variational inference procedure for dynamics. To simplify the presentation, we consider the -length horizon and let (thus omitted in the derivation). For infinite horizon , the discounted factor can be readily recovered by modifying the transition dynamics, such that any action produces a transition into an terminal state with probability .
C.1 Review of RL as Probabilistic Inference
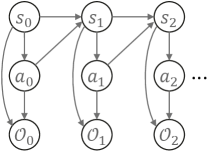
We first review the general framework of casting RL as probabilistic inference [60]. It starts by embedding the MDP into a probabilistic graphical model, as shown in Figure 4. Apart from the basic elements in MDP, an additional binary random variable is introduced, where denotes that the action at time step is optimal, and denotes the suboptimality. Its distribution is defined as444Assume the reward function is non-positive such that the probability is not larger than one. If the assumption is unsatisfied, we can subtract the reward function by its maximum, without changing the optimal policy.
| (28) |
where is the hyperparameter. As we focus on the optimality, in the following we drop and use to denote for conciseness. The remaining random variables in the probabilistic graphical model are and , whose distributions are defined by the system dynamics and as well as a reference policy . Then, the joint distribution over all random variables for can be written as
| (29) |
Regarding optimal control, a natural question to ask is what the trajectory should be like given the optimality over all time steps. This raises the posterior inference of . According to d-separation, the exact posterior follows the form of
| (30) |
Notice that the dynamics posterior and depends on , and in fact their concrete mathematical expressions are inconsistent with those of the system dynamics and [60]. This essentially poses the assumption that the dynamics itself can be controlled when referring to the optimality, unpractical in general.
Variational inference can be applied to correct this issue. Concretely, define the variational approximation to the exact posterior by
| (31) |
Its difference to (30) is enforcing the dynamics posterior to match the practical one. Under this structure, the variational posterior can be adjusted by optimizing to best approximate the exact posterior. The optimization is executed under measure of KL divergence, i.e.,
| (32) |
where the third equation is obtained by substituting (29) and (31). As the second term in (C.1) is constant, minimizing the above KL divergence is equivalent to maximize the cumulative reward with policy regularizer. Several fascinating online RL methods can be treated as algorithmic instances based on this framework [34, 35].
To summarize, the structured variational posterior with form (31) is vital to ensure the inferred policy meaningful in the actual environment.
C.2 Pessimism-Modulated Dynamics Belief as Structured Variational Posterior
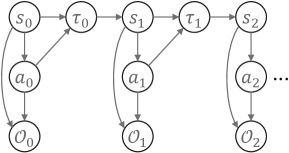
The probabilistic graphical model is previously devised for online RL. In offline setting, the environment can not be interacted to minimize (C.1). A straightforward modification to reflect this is to add the transition dynamics as a random variable in the graph, as shown in Figure 5. We assume the transition follows a predefined belief distribution, i.e., introduced in Subsection 3.1. To make its dependence on explicit, let redenote . For conciseness, we drop the superscript in in the remainder.
The joint distribution over all random variables in Figure 5 for can be written as
| (33) |
Similar to online setting, we wonder what the trajectory should be like given the optimality over all time steps. By examining the conditional independence in the probabilistic graphical model, the exact posterior follows the form of
| (34) |
Unsurprisingly, and again depend on , indicating that the system transition and its belief can be controlled when referring to optimality. In other words, it leads to over-optimistic inference.
To emphasize pessimism, we define a novel structured variational posterior:
| (35) |
with being the Pessimism-Modulated Dynamics Belief (PMDB) constructed via the KL-regularized AMG (see Theorem 7):
| (36) | |||
| (37) |
is cumulative density function and is the Q-value for the KL-regularized AMG. As discussed, reshapes the initial belief distribution towards being pessimistic in terms of .
It seems that we need to solve the AMG to obtain and further define . In fact, is also the Q-value for the MDP considered in (35). This can be verified by checking Theorem 7: the KL-regularized AMG is equivalent to the MDP with transition , which can be implemented by sampling first and then , right the procedure in (35).
To best approximate the exact posterior, we optimize the variational posterior by minimizing
| (38) |
where the equation is by unfolding the expectation sequentially over each step, is the normalization constant in (36), and is used to approximate . To clarify the approximation, recall Theorem 7 stating that a sample can be equivalently drawn by finding based on another sampling procedure . Then, given , we observe that is the empirical quantile of the random variable , i.e., . By substituting into , we obtain .
C.3 Full Expectation-Maximization Algorithm
In previous subsection, the reference policy is assumed as a prior, and the optimized policy would be constrained close to it through KL divergence. In practice, the prior of optimal policy can not easily obtained, and a popular methodology to handle this is to learn the prior itself in the data-driven way, i.e., the principle of empirical Bayes.
The prior learning is done by maximizing the log-marginal likelihood:
| (39) |
where is given in (C.2). As the log function includes a high-dimensional integration, evaluating incurs intensive computation. Expectation-Maximization algorithm instead considers a lower bound of to make the evaluation/optimization tractable:
| (40) |
where the inequality is due to the non-negativity of KL divergence, and is an approximation to the exact posterior . The lower bound is tighter with the more exact approximation for the posterior. In previous subsection, we introduce the structured variational approximation with form of (35) to emphasize pessimism on the transition dynamics. Although this variational posterior would lead to non-zero KL term, it promotes learning robust policy as we discussed in previous subsection. Since that the variational posterior is with an adjustable policy , we denote the lower bound by .
By substituting (35) into (C.3), it follows
| (41) |
where and includes the constant terms irrelevant to . According to the form of (C.3), given fixed , the optimal prior policy to maximize is obtained as . Maximizing the lower bound is known as Maximization step.
Recall in the variational posterior is adjustable, we can optimize it by minimizing to tighten the bound. The minimization procedure is known as Expectation step. In our case, the minimization problem is exactly the one discussed in previous subsection.
When repeatedly and alternately applying the Expectation and Maximization steps, the iterative regularized policy optimization algorithm is recovered. According to Theorem 5, both and continuously improve regarding the objective function.
Appendix D Algorithm and Implementation Details for Model-Based Offline RL with PMDB
The pseudocode for model-based offline RL with PMDB is presented in Algorithm 1. As is unknown in practice, we uniformly sample states from as the initial . In Step 4, the primary players act according to the non-parametric policy , rather than its approximated policy . This is because during learning process is not always trained adequately to approximate , then following will visit unexpected states. In Step 11, the reference policy is returned as the final policy, considering that it is more stable than .
Require: .
Computing expectation
Algorithm 1 involves the computation of expectation. In discrete domains, the expectation can be computed exactly. In continuous domains, we use Monte Carlo methods to approximate it. Concretely, for the expectation over states we apply vanilla Monte Carlo sampling, while for the expectation over actions we apply importance sampling. To elaborate, the expectation over actions can be written as
where is the proposal distribution.
In Algorithm 1, the above expectation is computed for both and . For , we choose
i.e., the samples are drawn close to the data points, and determines how much they keep close. For example, in Step 6 a batch of are sampled from to calculate (4.2), then we construct the proposal distribution as above for each in the batch. The motivation of drawing actions near the data samples is to enhance learning in the multi-modal scenario, where the offline dataset is collected by mixture of multiple policies. If is single-modal (say the widely adopted Gaussian policy) and we solely draw samples from it to approximate the expectation, these samples will be locally clustered. Then, applying them to update in (4.2) can be easily get stuck at local optimum.
For , we choose
The reason is that is an approximator to the improved policy with higher Q-value, and sampling from it hopefully reduces variance of the Monte Carlo estimator.
Although applying Monte Carlo methods to approximate the expectation incurs extra computation, all the operators can be executed in parallel. In the experiments, we use and samples respectively for the expectations over state and action, and the algorithm is run on a single machine with one Quadro RTX 6000 GPU. The results show that in average it takes 73.4 s to finish 1k training steps, and the GPU memory cost is 2.5 GB.
Several future directions regarding the Monte Carlo method are worthy to explore. For example, by reducing the sample size for the expectation over state, the optimized policy additionally tends to avoid the risk due to aleatoric uncertainty (while in this work we focus on epistemic uncertainty). Besides, the computational cost can be reduced by more aggressive Monte Carlo approximation, for example only using mean action to compute the expectation in terms of policy. We leave these as future work.
Appendix E Choice of Initial Dynamics Belief
In offline setting, extra knowledge is strongly desired to aggressively optimize policy. The initial dynamics belief provides an interface to absorb the aforehand knowledge of system transition. In what follows, we illustrate several potential usecases:
-
•
Consider the physical system where the dynamics can be described as mathematical expression but with uncertain parameter. If we have a narrow distribution over the parameter (according to expert knowledge or inferred from data), the system is almost known for certain. Here, both the mathematical expression and narrow distribution provide more information.
-
•
Consider the case where we know the dynamics is smooth with probability of 0.7 and periodic with probability of 0.3. Gaussian processes (GPs) with RBF kernel and periodic kernel can well encode these prior knowledge. Then, the 0.7-0.3 mixture of the two GPs trained with offline data can act as the dynamics belief to provide more information.
-
•
In the case where multi-task datasets are available, we can train dynamics models using each of the datasets and assign likelihood ratios to these models. If the likelihood ratio well reflects the similarity between the concerned task and the offline tasks, the multi-task datasets promote knowledge.
The performance gain is expected to monotonously increase with the amount of correct knowledge. As an impractical but intuitive example, with the exact knowledge of system transition (the initial belief is a delta function), the proposed approach is actually optimizing policy as in real system.
In practice, the expert knowledge is not available everywhere. When unavailable, the best we can hope for is that the final policy stays close to the dataset, but unnecessary to be fully covered (as we want to utilize the generalization ability of dynamics model at least around the data). To that end, the dynamics belief is desired to be certain at the region in distribution of dataset, and turns more and more uncertain when departing. It has been reported that the simple model ensemble leads to such a behavior [12]. In this sense, the uniform distribution over learned dynamics ensemble can act as a quite common belief. In the experiments, we apply it for fair comparison with baseline methods.
Appendix F Automatically Adjusting KL Coefficient
In Section 4, the KL regularizer is introduced to restrict in a small region near , such that the Q-value can be evaluated sufficiently before policy improvement. Apart from fixing the KL coefficient throughout, we provide a strategy to automatically adjust it.
Note that the optimal policy to minimize in (4.2) is . The criterion of choosing is to constrain the KL divergence between this policy and smaller than a specified constant, i.e.,
| (42) |
Finding to satisfy the above inequation is intractable, instead we consider a surrogate of the KL divergence:
where is a predefined lower bound of .
Then, (42) can be satisfied by setting
Combining with the predefined lower bound, we choose as
In practice, the expectation can be estimated over Monte Carlo samples. Note that the coefficient can be computed individually for each state, picking is hopefully easier than picking suitable for all states.
Appendix G Additional Experimental Setup
Task Domains
We evaluate the proposed methods and the baselines on eighteen domains involving three environments (hopper, walker2d, halfcheetah), each with six dataset types. The dataset types are collected by different policies, denoted by random: a randomly initialized policy, expert: a policy trained to completion with SAC, medium: a policy trained to approximately 1/3 the performance of the expert, medium-expert: 50-50 mixture of medium and expert data, medium-replay: the replay buffer of a policy trained up to the performance of the medium agent, full-replay: the replay buffer of a policy trained up to the performance of the expert agent.
Dynamics Belief
We adopt an uniform distribution over dynamics model ensemble as the initial belief. The ensemble contains neural networks, each is with hidden layers and hidden units per layer. All the neural networks are trained independently with the sample dataset and in parallel. The training process stops after the average training loss does not change obviously. Specifically, the number of epochs for hopper-random and walker2d-medium are , and those for other tasks are . Note that the level of pessimism depends on the candidate size by default), rather than the ensemble size.
Policy Network and Q Network
The policy network is with hidden layers and hidden units per layer. It outputs the mean and the diagonal variance for a Gaussian distribution, which is then transformed via tanh function to generate the policy. When evaluating our approach, we apply the deterministic policy, where the action is the tanh transformation of the Gaussian mean. The Q network is with the same architecture as the policy network except the output layer. Similar to existing RL approaches [35], we make use of two Q networks and apply the minimum of them for calculation in Algorithm 1, in order to mitigate over-estimation when learning in the AMG. The policy learning stops after the performance in AMG does not change obviously. Specifically, the gradient steps for walker2d-random, halfcheetah-random and hopper with all dataset types are million, and those for other tasks are millon.
Hyperparameters
We list the detailed hyperparameters in Table LABEL:Table:hyperparas.
| Parameter | Value |
| dynamics learning rate | |
| policy learning rate | |
| Q-value learning rate | |
| discounted factor () | |
| smoothing coefficient for policy () | |
| smoothing coefficient for Q-value () | |
| Exploration ratio for secondary player () | |
| KL coefficient () | |
| variance for important sampling () | 0.01 |
| Batch size for dynamics learning | |
| Batch size for AMG and MDP | |
| Maximal horizon of AMG |
Appendix H Practical Impact of
Table 4 lists the impact of . The performance in the AMGs improve when decreasing . Regarding the performance in true MDPs, we notice that corresponds to the best performance for hopper, but for the others is better.
| hopper-medium | walker2d-medium | halfcheetah-medium | ||||
|---|---|---|---|---|---|---|
| MDP | AMG | MDP | AMG | MDP | AMG | |
| 5 | 90.225.4 | 108.62.2 | 112.70.9 | 101.75.7 | 79.80.4 | 69.51.6 |
| 10 | 106.80.2 | 105.21.6 | 94.21.1 | 77.23.7 | 75.61.3 | 67.31.1 |
| 15 | 107.30.2 | 103.11.8 | 92.10.3 | 68.36.7 | 75.40.4 | 63.22.3 |
Appendix I Ablation of Randomness of
Compared to the standard Bellman backup operator in Q-learning, the proposed one additionally includes the expectation over and the -minimum operator over . We report the impact of choosing different in Table 2, and present the impact of the randomness of as below. Fixed denotes that after sampling once from the belief distribution we keep it fixed during policy optimization.
| Task Name | Stochastic | Fixed |
| hopper-medium | 106.8 0.2 | 106.2 0.3 |
| walker2d-medium | 94.2 1.1 | 90.1 4.3 |
| halfcheetah-medium | 75.6 1.3 | 73.1 2.8 |
We observe that the randomness of has a mild effect on the performance in average. The reason can be that we apply the uniform distribution over dynamics ensemble as initial belief (without additional knowledge to insert). The model ensemble is reported to produce low uncertainty estimation in distribution of data coverage and high estimation when departing the dataset [12]. This property makes the optimized policy keep close to the dataset, and it does not rely on the randomness of ensemble elements. However, involving the randomness can lead to more smooth variation of the estimated uncertainty, which benefits the training process and results in better performance. Apart from these empirical results, we highlight that in cases with more informative dynamics belief, only picking several fixed samples from the belief distribution as will result in the loss of knowledge.
Appendix J Weighting AMG Loss and MDP Loss in (11)
In (11), the Q-function is trained to minimize the Bellman residuals of both the AMG and the empirical MDP, equipped with the same weight (both are 1). In the following table, we show experiment results to check the impact of different weights.
| Task Name | 0.5:1.5 | 1.0:1.0 | 1.5:0.5 |
| hopper-medium | 106.6 0.3 | 106.8 0.2 | 106.5 0.3 |
| walker2d-medium | 93.8 1.5 | 94.2 1.1 | 93.1 1.3 |
| halfcheetah-medium | 75.2 0.8 | 75.6 1.3 | 76.1 1.0 |
The results suggests that the performance does not obviously depend on the weights. But in cases with available expert knowledge about dynamics, the weights can be adjusted to match our confidence on the knowledge, i.e., the less confidence, the smaller weight for AMG.
Appendix K Comparison with RAMBO
We additionally compared the proposed approach with RAMBO [61], a concurrent work that also formulates offline RL as a two-player zero-sum game. The results of RAMBO for random, medium, medium-expert and medium-replay are taken from [61]. For the other two dataset types, we run the official code and follow the hyperparameter search procedure reported in its paper.
| Task Name | BC | BEAR | BRAC | CQL | MOReL | EDAC | RAMBO | PMDB |
| hopper-random | 3.70.6 | 3.63.6 | 8.10.6 | 5.30.6 | 38.110.1 | 25.310.4 | 25.47.5 | 32.70.1 |
| hopper-medium | 54.13.8 | 55.33.2 | 77.86.1 | 61.96.4 | 84.017.0 | 101.60.6 | 87.015.4 | 106.80.2 |
| hopper-expert | 107.79.7 | 39.420.5 | 78.152.6 | 106.59.1 | 80.434.9 | 110.10.1 | 50.08.1 | 111.70.3 |
| hopper-medium-expert | 53.94.7 | 66.28.5 | 81.38.0 | 96.915.1 | 105.68.2 | 110.70.1 | 88.220.5 | 111.80.6 |
| hopper-medium-replay | 16.64.8 | 57.716.5 | 62.730.4 | 86.37.3 | 81.817.0 | 101.00.5 | 99.54.8 | 106.20.6 |
| hopper-full-replay | 19.912.9 | 54.024.0 | 107.40.5 | 101.90.6 | 94.420.5 | 105.40.7 | 105.2 2.1 | 109.10.2 |
| walker2d-random | 1.30.1 | 4.31.2 | 1.31.4 | 5.41.7 | 16.07.7 | 16.67.0 | 0.00.3 | 21.80.1 |
| walker2d-medium | 70.911.0 | 59.840.0 | 59.739.9 | 79.53.2 | 72.811.9 | 92.50.8 | 84.9 2.6 | 94.21.1 |
| walker2d-expert | 108.70.2 | 110.10.6 | 55.262.2 | 109.30.1 | 62.629.9 | 115.11.9 | 1.62.3 | 115.91.9 |
| walker2d-medium-expert | 90.113.2 | 107.02.9 | 9.318.9 | 109.10.2 | 107.55.6 | 114.70.9 | 56.739.0 | 111.90.2 |
| walker2d-medium-replay | 20.39.8 | 12.24.7 | 40.147.9 | 76.810.0 | 40.820.4 | 87.12.3 | 89.26.7 | 79.90.2 |
| walker2d-full-replay | 68.817.7 | 79.615.6 | 96.92.2 | 94.21.9 | 84.813.1 | 99.80.7 | 88.34.9 | 95.40.7 |
| halfcheetah-random | 2.20.0 | 12.61.0 | 24.30.7 | 31.33.5 | 38.91.8 | 28.41.0 | 39.53.5 | 37.8 0.2 |
| halfcheetah-medium | 43.20.6 | 42.80.1 | 51.90.3 | 46.90.4 | 60.74.4 | 65.90.6 | 77.9 4.0 | 75.6 1.3 |
| halfcheetah-expert | 91.81.5 | 92.60.6 | 39.013.8 | 97.31.1 | 8.411.8 | 106.83.4 | 79.315.1 | 105.7 1.0 |
| halfcheetah-medium-expert | 44.01.6 | 45.74.2 | 52.30.1 | 95.01.4 | 80.411.7 | 106.31.9 | 95.4 5.4 | 108.50.5 |
| halfcheetah-medium-replay | 37.62.1 | 39.40.8 | 48.60.4 | 45.30.3 | 44.55.6 | 61.31.9 | 68.7 5.3 | 71.71.1 |
| halfcheetah-full-replay | 62.90.8 | 60.13.2 | 78.00.7 | 76.90.9 | 70.15.1 | 84.60.9 | 87.03.2 | 90.00.8 |
| Average | 49.9 | 52.4 | 54.0 | 73.7 | 65.1 | 85.2 | 68.0 | 88.2 |