Model-based Adversarial
Meta-Reinforcement Learning
Abstract
Meta-reinforcement learning (meta-RL) aims to learn from multiple training tasks the ability to adapt efficiently to unseen test tasks. Despite the success, existing meta-RL algorithms are known to be sensitive to the task distribution shift. When the test task distribution is different from the training task distribution, the performance may degrade significantly. To address this issue, this paper proposes Model-based Adversarial Meta-Reinforcement Learning (AdMRL), where we aim to minimize the worst-case sub-optimality gap – the difference between the optimal return and the return that the algorithm achieves after adaptation – across all tasks in a family of tasks, with a model-based approach. We propose a minimax objective and optimize it by alternating between learning the dynamics model on a fixed task and finding the adversarial task for the current model – the task for which the policy induced by the model is maximally suboptimal. Assuming the family of tasks is parameterized, we derive a formula for the gradient of the suboptimality with respect to the task parameters via the implicit function theorem, and show how the gradient estimator can be efficiently implemented by the conjugate gradient method and a novel use of the REINFORCE estimator. We evaluate our approach on several continuous control benchmarks and demonstrate its efficacy in the worst-case performance over all tasks, the generalization power to out-of-distribution tasks, and in training and test time sample efficiency, over existing state-of-the-art meta-RL algorithms111Our code is available at https://github.com/LinZichuan/AdMRL.
1 Introduction
Deep reinforcement learning (Deep RL) methods can solve difficult tasks such as Go (Silver et al., 2016), Atari games (Mnih et al., 2013), robotic control (Levine et al., 2016) successfully, but often require sampling a large amount interactions with the environment. Meta-reinforcement learning and multi-task reinforcement learning aim to improve the sample efficiency by leveraging the shared structure within a family of tasks. For example, Model Agnostic Meta Learning (MAML) (Finn et al., 2017) learns in the training time a shared policy initialization across tasks, from which in the test time it can adapt to the new tasks quickly with a small amount of samples. The more recent work PEARL (Rakelly et al., 2019) learns latent representations of the tasks in the training time, and then infers the representations of test tasks and adapts to them.
The existing meta-RL formulation and methods are largely distributional. The training tasks and the testing tasks are assumed to be drawn from the same distribution of tasks. Consequently, the existing methods are prone to the distribution shift issue, as shown in (Mehta et al., 2020) — when the tasks in the test time are not drawn from the same distribution as in the training, the performance degrades significantly. Figure 1 also confirms this issue for PEARL (Rakelly et al., 2019), a recent state-of-the-art meta-RL method, on the Ant2D-velocity tasks. PEARL can adapt to tasks with smaller goal velocities much better than tasks with larger goal velocities, in terms of the relative difference, or the sub-optimality gap, from the optimal policy of the corresponding task.222The same conclusion is still true if we measure the raw performance on the tasks. But that could be misleading because the tasks have varying optimal returns. To address this issue, Mehta et al. (2020) propose an algorithm that iteratively re-define the task distribution to focus more on the hard task.
In this paper, we instead take a non-distributional perspective by formulating the adversarial meta-RL problem. Given a parametrized family of tasks, we aim to minimize the worst sub-optimality gap — the difference between the optimal return and the return the algorithm achieves after adaptation — across all tasks in the family in the test time. This can be naturally formulated mathematically as a minimax problem (or a two-player game) where the maximum is over all the tasks and the minimum is over the parameters of the algorithm (e.g., the shared policy initialization or the shared dynamics).
Our approach is model-based. We learn a shared dynamics model across the tasks in the training time, and during the test time, given a new reward function, we train a policy on the learned dynamics. The model-based methods can outperform significantly the model-free methods in sample-efficiency even in the standard single task setting (Luo et al., 2018; Dong et al., 2019; Janner et al., 2019; Wang and Ba, 2019; Chua et al., 2018; Buckman et al., 2018; Nagabandi et al., 2018c; Kurutach et al., 2018; Feinberg et al., 2018; Rajeswaran et al., 2016, 2020; Wang et al., 2019), and are particularly suitable for meta-RL settings where the optimal policies for tasks are very different, but the underlying dynamics is shared (Landolfi et al., 2019). We apply the natural adversarial training (Madry et al., 2017) on the level of tasks — we alternate between the minimizing the sub-optimality gap over the parameterized dynamics and maximizing it over the parameterized tasks.
The main technical challenge is to optimize over the task parameters in a sample-efficient way. The sub-optimality gap objective depends on the task parameters in a non-trivial way because the algorithm uses the task parameters iteratively in its adaptation phase during the test time. The naive attempt to back-propagate through the sequential updates of the adaptation algorithm is time costly, especially because the adaptation time in the model-based approach is computationally expensive (despite being sample-efficient). Inspired by a recent work on learning equilibrium models in supervised learning (Bai et al., 2019), we derive an efficient formula of the gradient w.r.t. the task parameters via the implicit function theorem. The gradient involves an inverse Hessian vector product, which can be efficiently computed by conjugate gradients and the REINFORCE estimator Williams (1992).
In summary, our contributions are:
-
1.
We propose a minimax formulation of model-based adversarial meta-reinforcement learning (AdMRL, pronounced like “admiral”) with an adversarial training algorithm to address the distribution shift problem.
-
2.
We derive an estimator of the gradient with respect to the task parameters, and show how it can be implemented efficiently in both samples and time.
-
3.
Our approach significantly outperforms the state-of-the-art meta-RL algorithms in the worst-case performance over all tasks, the generalization power to out-of-distribution tasks, and in training and test time sample efficiency on a set of continuous control benchmarks.
2 Related Work
The idea of learning to learn was established in a series of previous works (Utgoff, 1986; Schmidhuber, 1987; Thrun, 1996; Thrun and Pratt, 2012). These papers propose to build a base learner for each task and train a meta-learner that learns the shared structure of the base learners and outputs a base learner for a new task. Recent literature mainly instantiates this idea in two directions: (1) learning a meta-learner to predict the base learner (Wang et al., 2016; Snell et al., 2017); (2) learning to update the base learner (Hochreiter et al., 2001; Bengio et al., 1992; Finn et al., 2017). The goal of meta-reinforcement learning is to find a policy that can quickly adapt to new tasks by collecting only a few trajectories. In MAML (Finn et al., 2017), the shared structure learned at train time is a set of policy parameters. Some recent meta-RL algorithms propose to condition the policy on a latent representation of the task (Rakelly et al., 2019; Zintgraf et al., 2019; Wang et al., 2020; Humplik et al., 2019; Lan et al., 2019). Some prior work Duan et al. (2016); Wang et al. (2016) represent the reinforcement learning algorithm as a recurrent network. GMPS Mendonca et al. (2019) improves the sample efficiency during meta-training by consolidating the solutions of individual off-policy learners into a single meta-learner. VariBAD Schulze et al. meta-learns to perform approximate inference on an unknown task, and incorporate task uncertainty directly during action selection. ProMP Rothfuss et al. (2018) improves the sample-efficiency during meta-training by overcoming the issue of poor credit assignment. Some algorithms (Landolfi et al., 2019; Sæmundsson et al., 2018; Nagabandi et al., 2018a, b) also propose to share a dynamical model across tasks during meta-training and perform model-based adaptation in new tasks. These approaches are still distributional and suffers from distribution shift. We adversarially choose training tasks to address the distribution shift issue and show in the experiment section that we outperform the algorithm with randomly-chosen tasks. Unsupervised meta-RL Gupta et al. (2018) constructs a task proposal mechanism based on a mutual information objective to automatically acquire an environment-specific learning procedure. MetaGenRL Kirsch et al. (2019) proposes to meta-learn objective functions to generalize to different environments. MQL Fakoor et al. (2019) proposes ways to reuse data from the meta-training phase during meta-adaptation by employing propensity score estimation. Some recent works also attempt to mitigate the distribution shift issue. Meta-ADR Mehta et al. (2020) introduces a curriculum for meta-training tasks. MIER Mendonca et al. (2020) meta-learns a model representation and relabel meta-training experience during adaptation. Different from the method above, our method addresses the distribution shift issue in task level by taking a non-distributional perspective and meta-training on adversarial tasks.
Model-based approaches have long been recognized as a promising avenue for reducing sample complexity of RL algorithms. One popular branch in MBRL is Dyna-style algorithms (Sutton, 1990), which iterates between collecting samples for model update and improving the policy with virtual data generated by the learned model (Luo et al., 2018; Janner et al., 2019; Wang and Ba, 2019; Chua et al., 2018; Buckman et al., 2018; Kurutach et al., 2018; Feinberg et al., 2018; Rajeswaran et al., 2020). Another branch of MBRL produces policies based on model predictive control (MPC), where at each time step the model is used to perform planning over a short horizon to select actions (Chua et al., 2018; Nagabandi et al., 2018c; Dong et al., 2019; Wang and Ba, 2019).
Our approach is also related to active learning (Atlas et al., 1990; Lewis and Gale, 1994; Silberman, 1996; Settles, 2009). It aims to find the most useful or difficult data point whereas we are operating in the task space. Our method is also related to curiosity-driven learning (Pathak et al., 2017; Burda et al., 2018a, b), which defines intrinsic curiosity rewards to encourage the agent to explore in an environment. Instead of exploring in state space, our method are “exploring” in the task space. The work of Jin et al. (2020) aims to compute the near-optimal policies for any reward function by sufficient exploration, while we search for the reward function with the worst suboptimality gap.
3 Preliminaries
Reinforcement Learning. Consider a Markov Decision Process (MDP) with state space and action space . A policy specifies the conditional distribution over the action space given a state . The transition dynamics specifies the conditional distribution of the next state given the current state and . We will use to denote the unknown true transition dynamics in this paper. A reward function defines the reward at each step. We also consider a discount and an initial state distribution . We define the value function at state for a policy on dynamics : . The goal of RL is to seek a policy that maximizes the expected return .
Meta-Reinforcement Learning
In this paper, we consider a family of tasks parameterized by and a family of polices parameterized by . The family of tasks is a family of Markov decision process (MDP) which all share the same dynamics but differ in the reward function. We denote the value function of a policy on a task with reward and dynamics by , and denote the expected return for each task and dynamics by . For simplicity, we will use the shorthand .
Meta-reinforcement learning leverages a shared structure across tasks. (The precise nature of this structure is algorithm-dependent.) Let denote the set of all such structures. A meta-RL training algorithm seeks to find a shared structure , which is subsequently used by an adaptation algorithm to learn quickly in new tasks. In this paper, the shared structure is the learned dynamics (more below).
Model-based Reinforcement Learning
In model-based reinforcement learning (MBRL), we parameterize the transition dynamics of the model (as a neural network) and learn the parameters so that it approximates the true transition dynamics of . In this paper, we use Stochastic Lower Bound Optimization (SLBO) (Luo et al., 2018), which is an MBRL algorithm with theoretical guarantees of monotonic improvement. SLBO interleaves policy improvement and model fitting.
4 Model-based Adversarial Meta-Reinforcement Learning
4.1 Formulation
We consider a family of tasks whose reward functions are parameterized by some parameters , and assume that is differentiable w.r.t. for every . We assume the reward function parameterization is known throughout the paper.333It’s challenging to formulate the worst-case performance without knowing a reward family, e.g., when we only have access to randomly sampled tasks from a task distribution. Recall that the total return of policy on dynamics and tasks is denoted by Here is the return of the trajectory under reward function . As shorthand, we define as the return in the real environment on tasks and as the return on the virtual dynamics on task .
Given a learned dynamics and test task , we can perform a zero-shot model-based adaptation by computing the best policy for task under the dynamics , namely, . Let , formally defined in equation below, be the suboptimality gap of the -optimal policy on task , i.e. the difference between the performance of the best policy for task and the performance of the policy which is best for according to the model . Our overall aim is to find the best shared dynamics , such that the worst-case sub-optimality gap is minimized. This can be formally written as a minimax problem:
| (1) |
In the inner step (max over ), we search for the task which is hardest for our current model , in the sense that the policy which is optimal under dynamics is most suboptimal in the real MDP. In the outer step (min over ), we optimize for a model with low worst-case suboptimality. We remark that, in general, other definitions of sub-optimality gap, e.g., the ratio between the optimal return and achieved return may also be used to formulate the problem.
Algorithmically, by training on the hardest task found in the inner step, we hope to obtain data that is most informative for correcting the model’s inaccuracies.
4.2 Computing Derivatives with respect to Task Parameters
To optimize Eq. (1), we will alternate between the min and max using gradient descent and ascent respectively. Fixing the task , minimizing reduces to standard MBRL.
On the other hand, for a fixed model , the inner maximization over the task parameter is non-trivial, and is the focus of this subsection. To perform gradient-based optimization, we need to estimate . Let us define (the optimal policy under the true dynamics and task ) and (the optimal policy under the virtual dynamics and task ). We assume there is a unique for each . Then,
| (2) |
Note that the first term comes from the usual (sub)gradient rule for pointwise maxima, and the second term comes from the chain rule. Differentiation w.r.t. commutes with expectation over , so
| (3) |
Thus the first and last terms of the gradient of Eq. (2) can be estimated by simply rolling out and and differentiating the sampled rewards. Let be the advantage function. Then, the term in Eq. (2) can be computed by the standard policy gradient
| (4) |
The complicated part left in Eq. (2) is . We compute it using the implicit function theorem (Wikipedia contributors, 2020) (see Section A.1 for details):
| (5) |
The mixed-derivative term in equation above can be computed by differentiating the policy gradient:
| (6) |
An estimator for the Hessian term in Eq. (5) can be derived by the REINFORCE estimator (Sutton et al., 2000), or the log derivative trick (see Section A.2 for a detailed derivation),
| (7) |
By computing the gradient estimator using implicit function theorem, we do not need to back-propagate through the sequential updates of our adaptation algorithm, from which we can estimate the gradient w.r.t. task parameters in a sample-efficient and computationally tractable way.
4.3 AdMRL: a Practical Implementation
Algorithm 1 gives pseudo-code for our algorithm AdMRL, which alternates the updates of dynamics and tasks . Let be the shorthand for the procedure of learning a dynamics using data and then optimizing a policy from initialization on tasks under dynamics with virtual steps. Here parameterized arguments of the procedure are referred to by their parameters (so that the resulting policy, dynamics, are written in and ). For each training task parameterized by , we first initialize the policy randomly, and optimize a policy on the learned dynamics until convergence (Line 4), which we refer to as zero-shot adaptation. We then use the obtained policy to collect data from real environment and perform the MBRL algorithm SLBO (Luo et al., 2018) by interleaving collecting samples, updating models and optimizing policies (Line 5). After collecting samples and performing SLBO updates, we then get an nearly optimal policy .
Then we update the task parameter by gradient ascent. With the policy and , we compute each gradient component (Line 9, 10) and obtain the gradient w.r.t task parameters (Line 11) and perform gradient ascent for the task parameter (Line 12). Now we complete an outer-iteration. Note that for the first training task, we skip the zero-shot adaptation phase and only perform SLBO updates because our dynamical model is untrained. Moreover, because the zero-shot adaptation step is not done, we cannot technically perform our tasks update either because the tasks derivative depends on , the result of zero-shot adaption (Line 8).
Implementation Details. Computing Eq. (5) for each dimension of involves an inverse-Hessian-vector product. We note that we can compute Eq. (5) by approximately solving the equation , where is and is . However, in large-scale problems (e.g. has thousands of dimensions), it is costly (in computation and memory) to form the full matrix . Instead, the conjugate gradient method provides a way to approximately solve the equation without forming the full matrix of , provided we can compute the mapping . The corresponding Hessian-vector product can be computed as efficiently as evaluating the loss function (Pearlmutter, 1994) up to a universal multiplicative factor. Please refer to Appendix B to see how to implement it concretely. In practice, we found that the matrix of is always not positive-definite, which hinders the convergence of conjugate gradient method. Therefore, we turn to solve the equivalent equation .
In terms of time complexity, computing the gradient w.r.t task parameters is quite efficient compared to other steps. On one hand, in each task iteration, for the MBRL algorithm, we need to collect samples for dynamical model fitting, and then rollout virtual samples using the learned dynamical model for policy update to solve the task, which takes time complexity, where and denote the dimensionality of and . On the other hand, we only need to update the task parameter once in each task iteration, which takes time complexity by using conjugate gradient descent, where denotes the dimensionality of . In practice, for MBRL algorithm, we often need a large amount of virtual samples (e.g., millions of) to solve the tasks. In the meantime, the dimension of task parameter is a small constant and we have . Therefore, in our algorithm, the runtime of computing gradient w.r.t task parameters is negligible.
In terms of sample complexity, although computing the gradient estimator requires samples, in practice, however, we can reuse the samples that collected and used by the MBRL algorithm, which means we take almost no extra samples to compute the gradient w.r.t task parameters.
Relation to Meta-RL. Indeed, our method assumes the knowledge of the task parameters and is different from the standard meta-RL setting. However, we believe that our setting (a) is practically relevant and (b) provides new opportunities for more sample-efficient and robust algorithms. Handcrafted families of rewards functions are reasonable in practical applications, if not common. Moreover, if we don’t even know the family of test tasks, it’s challenging, if not impossible, to be robust to task shifts in the test time. Our more restricted setting makes it possible to be robust to worst-case task shifts. Some intermediate formulations may also be possible, e.g., it’s possible to adapt AdMRL to settings where the task family is known in the training time but the task parameters are unknown but inferred in the test time. We leave them as future work.
5 Experiments
In our experiments, we aim to study the following questions: (1) How does AdMRL perform on standard meta-RL benchmarks compared to prior state-of-the-art approaches? (2) Does AdMRL achieve better worst-case performance than distributional meta-RL methods? (3) How does AdMRL perform in environments where task parameters are high-dimensional? (4) Does AdMRL generalize better than distributional meta-RL on out-of-distribution tasks?
We evaluate our approach on a variety of continuous control tasks based on OpenAI gym (Brockman et al., 2016), which uses the MuJoCo physics simulator (Todorov et al., 2012).
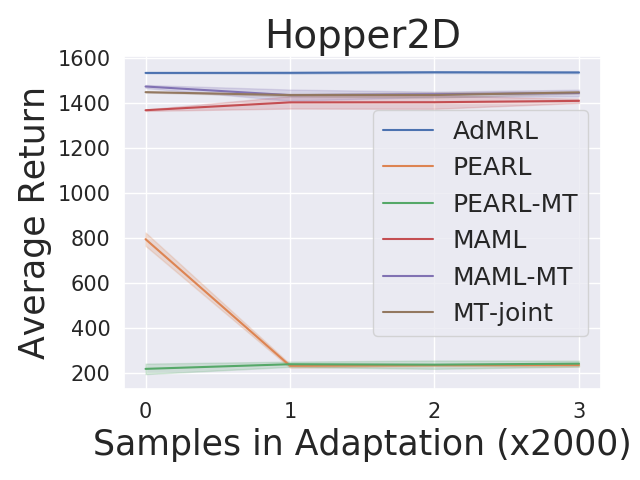
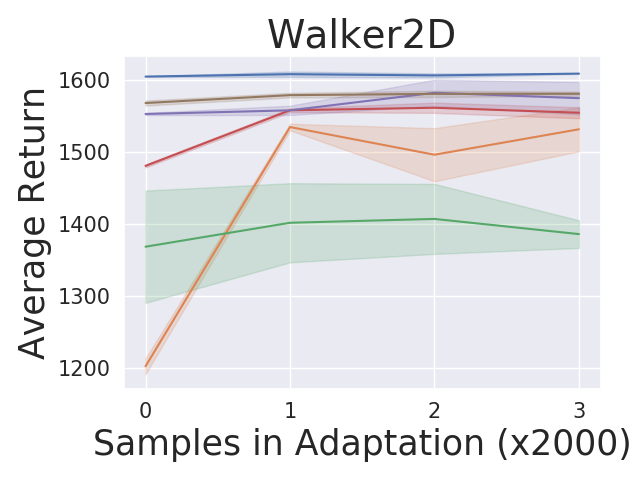
Low-dimensional velocity-control tasks
Following and extending the setup of (Finn et al., 2017; Rakelly et al., 2019), we first consider a family of environments and tasks relating to controlling 2-D or 3-D velocity control tasks. We consider three popular MuJoCo environments: Hopper, Walker and Ant. For the 3-D task families, we have three task parameters which corresponds to the target -velocity, -velocity, and -position. Given the task parameter, the agent’s goal is to match the target and velocities and position as much as possible. The reward is defined as: where and denotes and velocities and denotes height, and are handcrafted coefficients ensuring that each reward component contributes similarly. The set of task parameters is a 3-D box , which can depend on the particular environment. E.g., Ant3D has and here the range for -position is chosen so that the target can be mostly achievable. For a 2-D task, the setup is similar except only two of these three values are targeted. We experiment with Hopper2D, Walker2D and Ant2D. Details are given in Appendix C. We note that we extend the 2-D settings in (Finn et al., 2017; Rakelly et al., 2019) to 3-D because when the tasks parameters have more degrees of freedom, the task distribution shifts become more prominent.
High-dimensional tasks
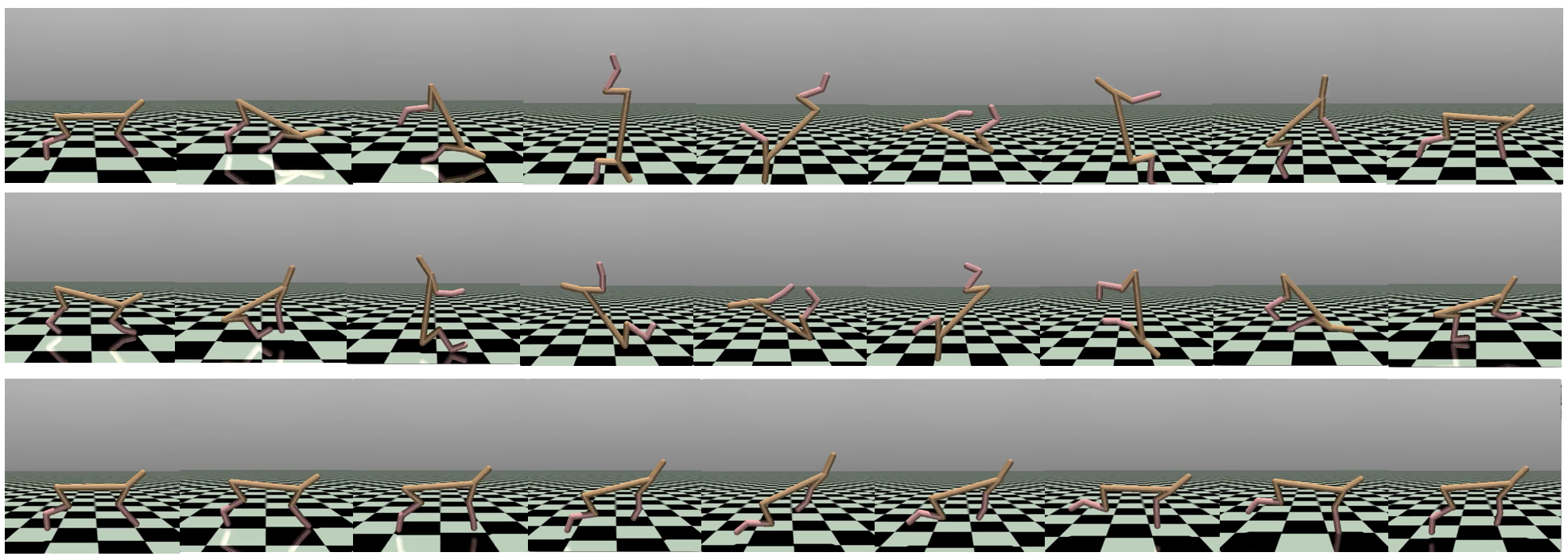
We also create a more complex family of high-dimensional tasks to test the strength of our algorithm in dealing with adversarial tasks among a large family of tasks with more degrees of freedom. Specifically, the reward function is linear in the post-transition state , parameterized by task parameter (where is the state dimension): Here the task parameter set is . In other words, the agent’s goal is to take action to make most linearly correlated with some target vector . We use HalfCheetah where . Note that to ensure that each state coordinate contributes similar to the total reward, we normalize the states by before computing the reward function, where are computed from all states collected by random policy from real environments. The high-dimensional task is called Cheetah-Highdim tasks. Tasks parameterized in this way are surprisingly often semantically meaningful, corresponding to rotations, jumping, etc. Appendix D shows some visualization of the trajectories.
Training
We compare our approach with previous meta-RL methods, including MAML (Finn et al., 2017) and PEARL (Rakelly et al., 2019). The training process for our algorithm is outlined in Algorithm 1. We build our algorithm based on the code that Luo et al. (2018) provides. We use the publicly available code for our baselines MAML, PEARL. Most hyper-parameters are taken directly from the supplied implementation. We list all the hyper-parameters used for all algorithms in the Appendix C. We note here that we only run our algorithm for or training tasks, whereas we allow MAML and PEARL to visit 150 tasks during the meta-training for generosity of comparison. The training process of MAML and PEARL requires 80 and 2.5 million samples respectively, while our method AdMRL only requires 0.4 or 0.8 million samples. Besides standard meta-RL methods, we also compare AdMRL with multi-task policy approaches which also leverage the task parameters explicitly. In detail, we experiment on three more baselines that use a multi-task policy that takes in the task parameters as inputs. (A) MT-joint: train multi-task policy jointly on all training tasks. (B) MAML-MT and (C) PEARL-MT: replace the policies in MAML and PEARL by a multi-task policy, respectively. We maintain the number of training samples and tasks.
Evaluation Metric
For low-dimensional tasks, we enumerate tasks in a grid. For each 2-D environment (Hopper2D, Walker2D, Ant2D) we evaluate at a grid of size . For the 3-D tasks (Ant3D), we evaluate at a box of size . For high-dimensional tasks, we randomly sample 20 testing tasks uniformly on the boundary. For each task , we compare different algorithms in: (zero-shot adaptation performance with no samples), (adaptation performance after collecting samples) and (suboptimality gap), and (worst-case suboptimality gap). In our experiments, we compare AdMRL with MAML and PEARL in all environments with . We also compare AdMRL with distributional variants (e.g., model-based methods with uniform or gaussian task sampling distribution) in worst-case tasks, high-dimensional tasks and out-of-distribution (OOD) tasks.
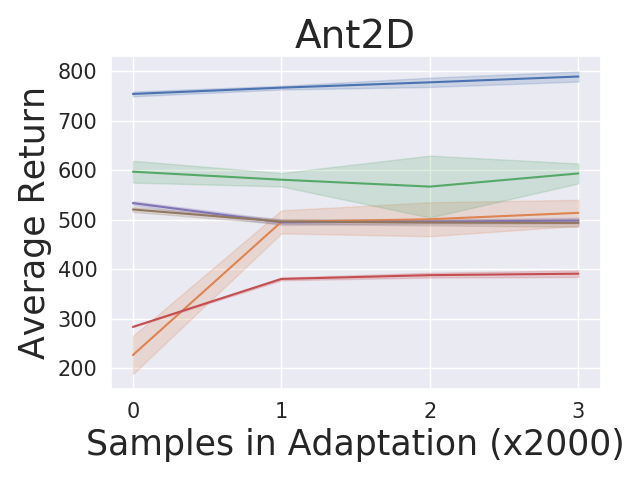
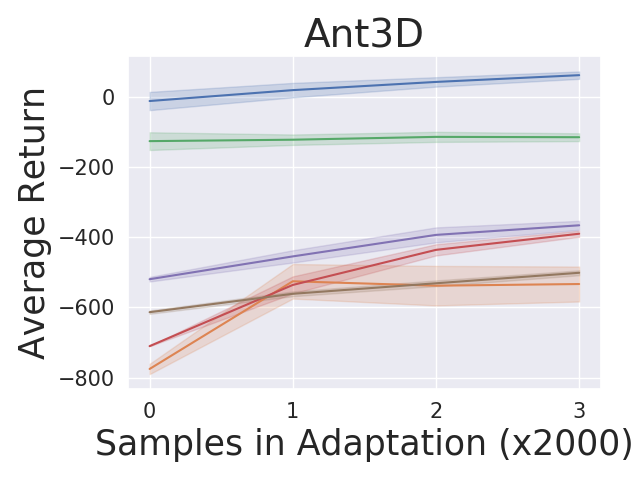
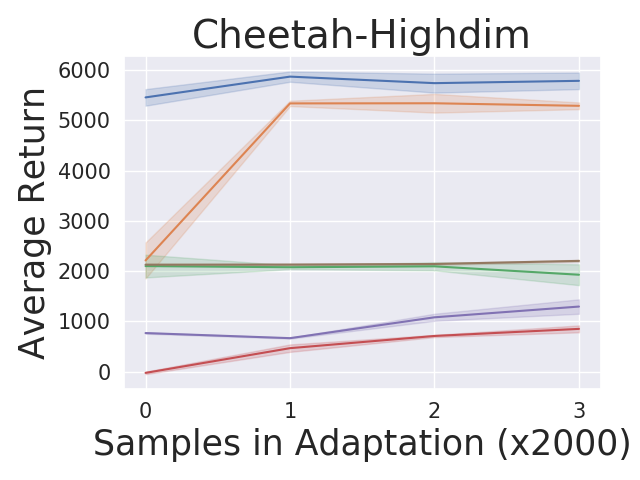
5.1 Adaptation Performance Compared to Baselines
For the tasks described in section 5, we compare our algorithm against MAML and PEARL. Figure 2 shows the adaptation results on the testing tasks set. We produce the curves by: (1) running our algorithm and baseline algorithms by training on adversarially chosen tasks and uniformly sampling random tasks respectively; (2) for each test task, we first do zero-shot adaptation for our algorithm and then run our algorithm and baseline algorithms by collecting samples; (3) estimating the averaged returns of the policies by sampling new roll-outs. The curves show the return averaged across all testing tasks with three random seeds in testing time. Our approach AdMRL outperforms MAML and PEARL across all test tasks, even though our method visits much fewer tasks (7/8) and samples (2/3) than baselines during meta-training. AdMRL outperforms MAML and PEARL with even zero-shot adaptation, namely, collecting no samples.444Note that the zero-shot model-based adaptation is taking advantage of additional information (the reward function) which MAML and PEARL have no mechanism for using. We also find that the zero-shot adaptation performance of AdMRL is often very close to the performance after collecting samples. This is the result of minimizing sub-optimality gap in our method. Our results also show that AdMRL outperforms the multi-task policy baselines consistently, although it is trained on 100X fewer samples than MT-joint and MAML-MT and 3X fewer than PEARL-MT. This implies that a multi-task policy does not necessarily help MAML and PEARL. We conjecture that this is because the optimal policy is a very complex function of the task parameters that cannot necessarily be expressed by neural nets.
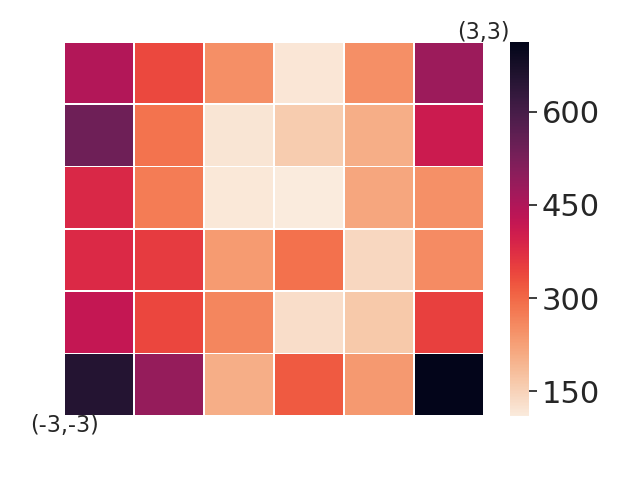
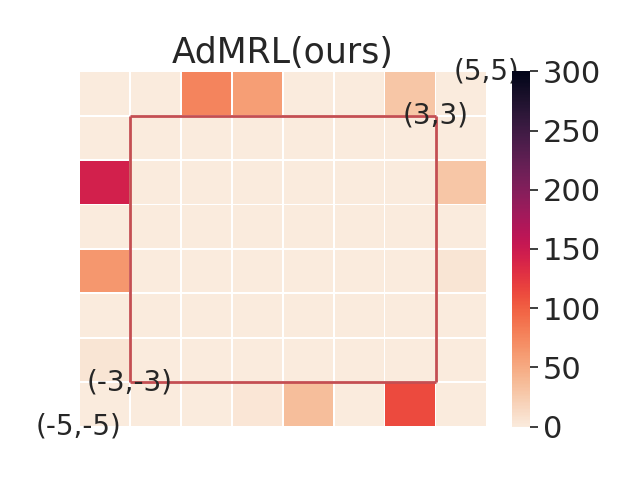
5.2 Comparing with Model-based Baselines in Worst-case Sub-optimality Gap
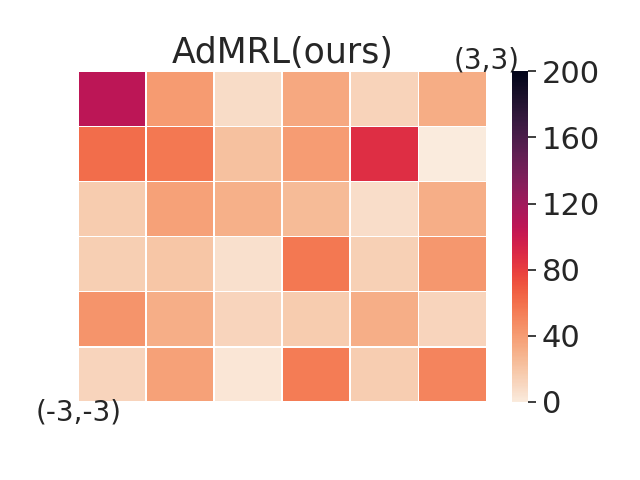
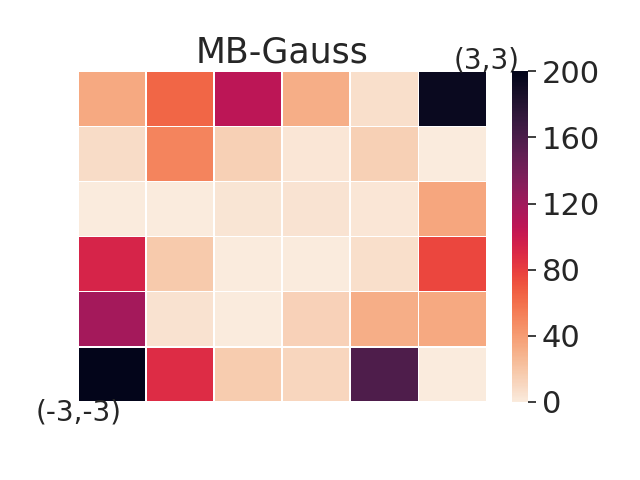
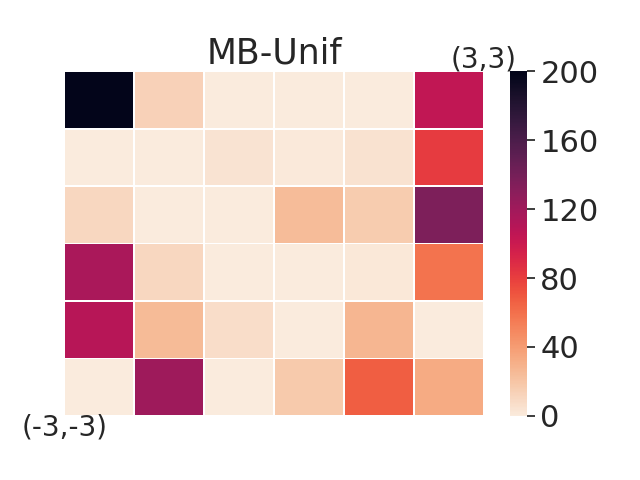
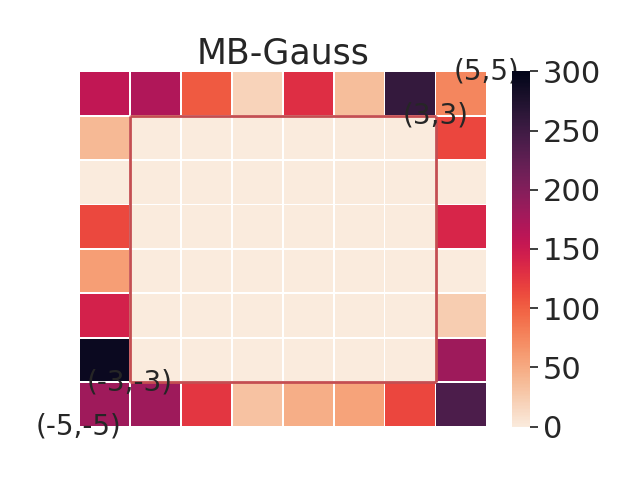
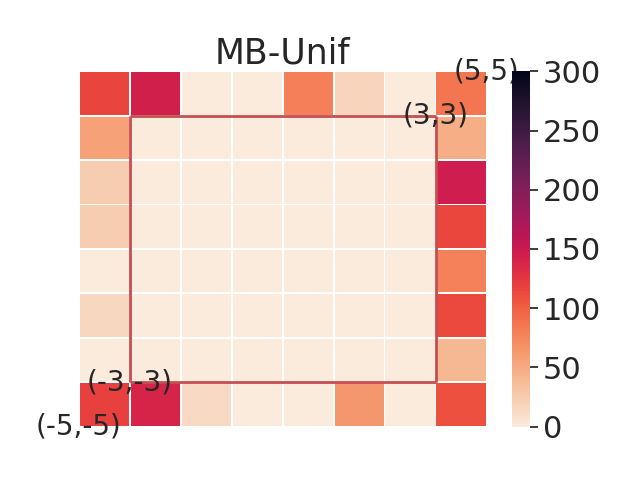
In this section, we aim to investigate the worst-case performance of our approach. We compare our adversarial selection method with distributional variants — using model-based training but sampling tasks with a uniform or gaussian distribution with variance 1, denoted by MB-Unif and MB-Gauss, respectively. All methods are trained on 20 tasks and then evaluated on a grid of test tasks. We plot heatmap figures by computing the sub-optimality gap for each test task in figure 3. We find that while both MB-Gauss and MB-Unif tend to over-fit on the tasks in the center, AdMRL can generalize much better to the tasks on the boundary. Figure 3 shows adapation performance on the tasks with worst sub-optimality gap. We find that AdMRL can achieve lower sub-optimality gap in the worst cases.
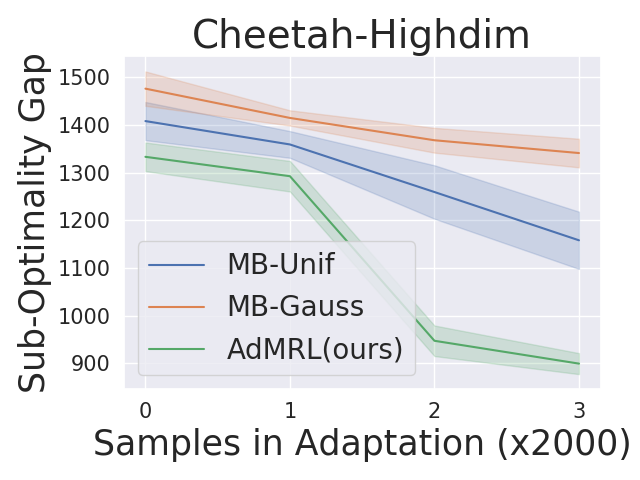
Performance on high-dimensional tasks
Figure 4 shows the suboptimality gap during adaptation on high-dimensional tasks. We highlight that AdMRL performs significantly better than MB-Unif and MB-Gauss when the task parameters are high-dimensional. In the high-dimensional tasks, we find that each task has diverse optimal behavior. Thus, sampling from a given distribution of tasks during meta-training becomes less efficient — it is hard to cover all tasks with worst suboptimality gap by randomly sampling from a given distribution. On the contrary, our non-distributional adversarial selection way can search for those hardest tasks efficiently and train a model that minimizes the worst suboptimality gap.
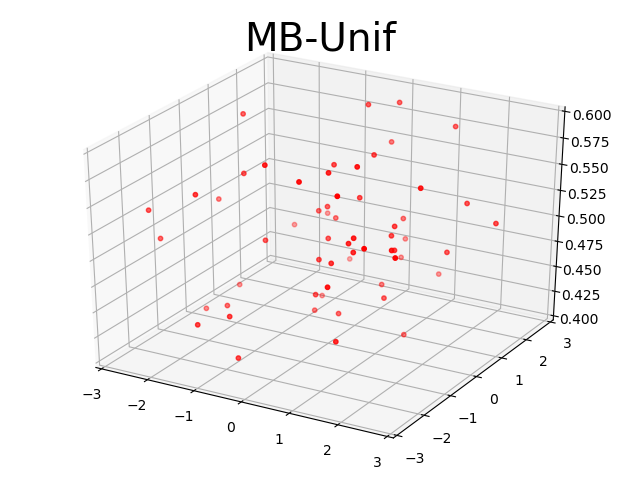
Visualization. To understand how our algorithm works, we visualize the task parameter that visited during meta-training in Ant3D environment. We compare our method with MB-Unif and MB-Gauss in figure 4. We find that our method can quickly visit the hard tasks on the boundary, in the sense that we can find the most informative tasks to train our model. On the contrary, sampling randomly from uniform or gaussian distribution has much less probability to visit the tasks on the boundary.
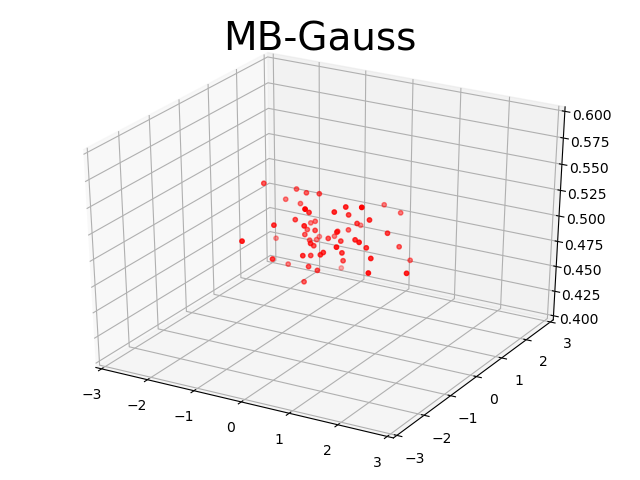
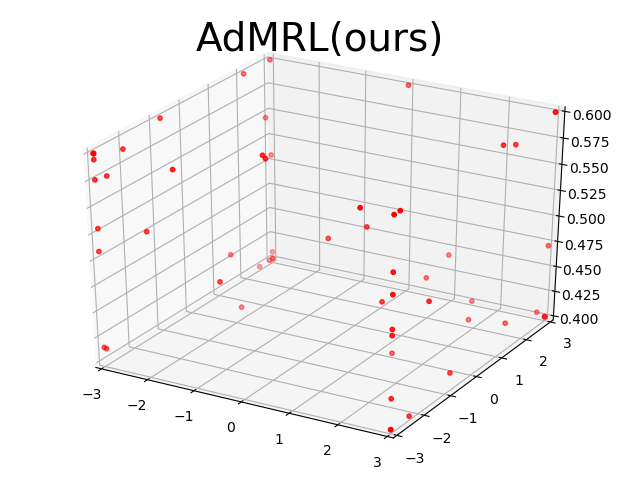
5.3 Out-of-distribution Performance
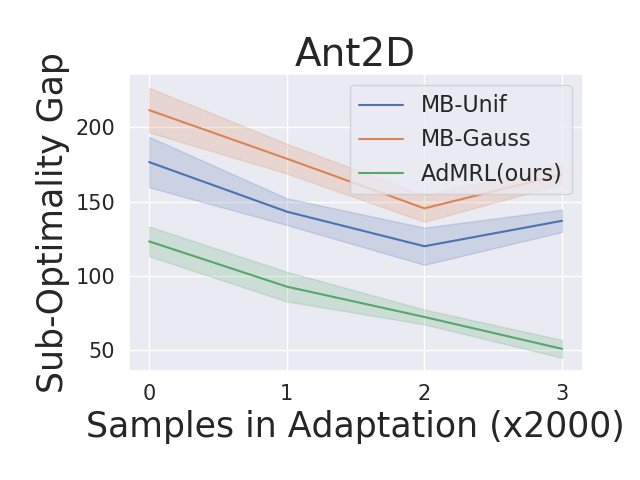
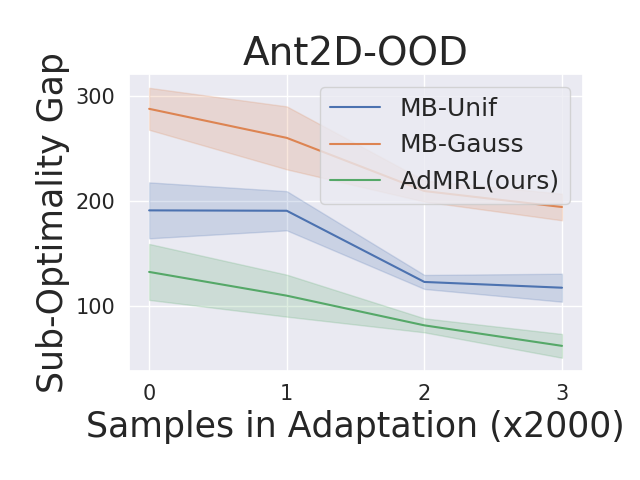
We evaluate our algorithm on out-of-distribution tasks in the Ant2D environment. We train agents with tasks drawn in while testing on OOD tasks from . Figure 5 shows the performance of AdMRL in comparison to MB-Unif and MB-Gauss. We find that AdMRL has much lower suboptimality gap than MB-Unif and MB-Gauss on OOD tasks, which shows the generalization power of AdMRL.
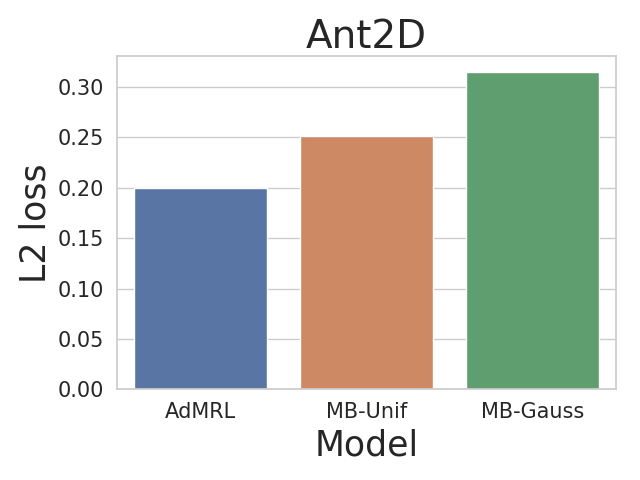
We also evaluate the quality of learned models. We first collect samples from true dynamics from OOD tasks in the Ant2D environment and then evaluate the prediction errors of learned models by L2 loss. As shown in Figure 6, the model learned by AdMRL is more accurate than those learned by MB-Unif and MB-Gauss.
6 Conclusion
In this paper, we propose Model-based Adversarial Meta-Reinforcement Learning (AdMRL), to address the distribution shift issue of meta-RL. We formulate the adversarial meta-RL problem and propose a minimax formulation to minimize the worst sub-optimality gap. To optimize efficiently, we derive an estimator of the gradient with respect to the task parameters, and implement the estimator efficiently using the conjugate gradient method. We provide extensive results on standard benchmark environments to show the efficacy of our approach over prior meta-RL algorithms. In the future, several interesting directions lie ahead. (1) Apply AdMRL to more difficult settings such as visual domain. (2) Replace SLBO by other MBRL algorithms. (3) Apply AdMRL to cases where the parameterization of reward function is unknown.
Acknowledgement
We thank Yuping Luo for helpful discussions about the implementation details of SLBO. Zichuan was supported in part by the Tsinghua Academic Fund Graduate Overseas Studies and in part by the National Key Research & Development Plan of China (grant no. 2016YFA0602200 and 2017YFA0604500). TM acknowledges support of Google Faculty Award and Lam Research. The work is also in part supported by SDSI and SAIL.
References
- Atlas et al. [1990] L. E. Atlas, D. A. Cohn, and R. E. Ladner. Training connectionist networks with queries and selective sampling. In Advances in neural information processing systems, pages 566–573, 1990.
- Bai et al. [2019] S. Bai, J. Z. Kolter, and V. Koltun. Deep equilibrium models. In Advances in Neural Information Processing Systems, pages 688–699, 2019.
- Bengio et al. [1992] S. Bengio, Y. Bengio, J. Cloutier, and J. Gecsei. On the optimization of a synaptic learning rule. In Preprints Conf. Optimality in Artificial and Biological Neural Networks, volume 2. Univ. of Texas, 1992.
- Brockman et al. [2016] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba. Openai gym. arXiv preprint arXiv:1606.01540, 2016.
- Buckman et al. [2018] J. Buckman, D. Hafner, G. Tucker, E. Brevdo, and H. Lee. Sample-efficient reinforcement learning with stochastic ensemble value expansion. In Advances in Neural Information Processing Systems, pages 8224–8234, 2018.
- Burda et al. [2018a] Y. Burda, H. Edwards, D. Pathak, A. Storkey, T. Darrell, and A. A. Efros. Large-scale study of curiosity-driven learning. arXiv preprint arXiv:1808.04355, 2018a.
- Burda et al. [2018b] Y. Burda, H. Edwards, A. Storkey, and O. Klimov. Exploration by random network distillation. arXiv preprint arXiv:1810.12894, 2018b.
- Chua et al. [2018] K. Chua, R. Calandra, R. McAllister, and S. Levine. Deep reinforcement learning in a handful of trials using probabilistic dynamics models. In Advances in Neural Information Processing Systems, pages 4754–4765, 2018.
- Dong et al. [2019] K. Dong, Y. Luo, and T. Ma. Bootstrapping the expressivity with model-based planning. arXiv preprint arXiv:1910.05927, 2019.
- Duan et al. [2016] Y. Duan, J. Schulman, X. Chen, P. L. Bartlett, I. Sutskever, and P. Abbeel. Rl2: Fast reinforcement learning via slow reinforcement learning. arXiv preprint arXiv:1611.02779, 2016.
- Fakoor et al. [2019] R. Fakoor, P. Chaudhari, S. Soatto, and A. J. Smola. Meta-q-learning. arXiv preprint arXiv:1910.00125, 2019.
- Feinberg et al. [2018] V. Feinberg, A. Wan, I. Stoica, M. I. Jordan, J. E. Gonzalez, and S. Levine. Model-based value estimation for efficient model-free reinforcement learning. arXiv preprint arXiv:1803.00101, 2018.
- Finn et al. [2017] C. Finn, P. Abbeel, and S. Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 1126–1135. JMLR. org, 2017.
- Gupta et al. [2018] A. Gupta, B. Eysenbach, C. Finn, and S. Levine. Unsupervised meta-learning for reinforcement learning. arXiv preprint arXiv:1806.04640, 2018.
- Hochreiter et al. [2001] S. Hochreiter, A. S. Younger, and P. R. Conwell. Learning to learn using gradient descent. In International Conference on Artificial Neural Networks, pages 87–94. Springer, 2001.
- Humplik et al. [2019] J. Humplik, A. Galashov, L. Hasenclever, P. A. Ortega, Y. W. Teh, and N. Heess. Meta reinforcement learning as task inference. arXiv preprint arXiv:1905.06424, 2019.
- Janner et al. [2019] M. Janner, J. Fu, M. Zhang, and S. Levine. When to trust your model: Model-based policy optimization. In Advances in Neural Information Processing Systems, pages 12498–12509, 2019.
- Jin et al. [2020] C. Jin, A. Krishnamurthy, M. Simchowitz, and T. Yu. Reward-free exploration for reinforcement learning. arXiv preprint arXiv:2002.02794, 2020.
- Kirsch et al. [2019] L. Kirsch, S. van Steenkiste, and J. Schmidhuber. Improving generalization in meta reinforcement learning using learned objectives. arXiv preprint arXiv:1910.04098, 2019.
- Kurutach et al. [2018] T. Kurutach, I. Clavera, Y. Duan, A. Tamar, and P. Abbeel. Model-ensemble trust-region policy optimization. arXiv preprint arXiv:1802.10592, 2018.
- Lan et al. [2019] L. Lan, Z. Li, X. Guan, and P. Wang. Meta reinforcement learning with task embedding and shared policy. arXiv preprint arXiv:1905.06527, 2019.
- Landolfi et al. [2019] N. C. Landolfi, G. Thomas, and T. Ma. A model-based approach for sample-efficient multi-task reinforcement learning. arXiv preprint arXiv:1907.04964, 2019.
- Levine et al. [2016] S. Levine, C. Finn, T. Darrell, and P. Abbeel. End-to-end training of deep visuomotor policies. The Journal of Machine Learning Research, 17(1):1334–1373, 2016.
- Lewis and Gale [1994] D. D. Lewis and W. A. Gale. A sequential algorithm for training text classifiers. In SIGIR’94, pages 3–12. Springer, 1994.
- Luo et al. [2018] Y. Luo, H. Xu, Y. Li, Y. Tian, T. Darrell, and T. Ma. Algorithmic framework for model-based deep reinforcement learning with theoretical guarantees. arXiv preprint arXiv:1807.03858, 2018.
- Madry et al. [2017] A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu. Towards deep learning models resistant to adversarial attacks. arXiv preprint arXiv:1706.06083, 2017.
- Mehta et al. [2020] B. Mehta, T. Deleu, S. C. Raparthy, C. J. Pal, and L. Paull. Curriculum in gradient-based meta-reinforcement learning. arXiv preprint arXiv:2002.07956, 2020.
- Mendonca et al. [2019] R. Mendonca, A. Gupta, R. Kralev, P. Abbeel, S. Levine, and C. Finn. Guided meta-policy search. In Advances in Neural Information Processing Systems, pages 9653–9664, 2019.
- Mendonca et al. [2020] R. Mendonca, X. Geng, C. Finn, and S. Levine. Meta-reinforcement learning robust to distributional shift via model identification and experience relabeling. arXiv preprint arXiv:2006.07178, 2020.
- Mnih et al. [2013] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
- Nagabandi et al. [2018a] A. Nagabandi, I. Clavera, S. Liu, R. S. Fearing, P. Abbeel, S. Levine, and C. Finn. Learning to adapt in dynamic, real-world environments through meta-reinforcement learning. arXiv preprint arXiv:1803.11347, 2018a.
- Nagabandi et al. [2018b] A. Nagabandi, C. Finn, and S. Levine. Deep online learning via meta-learning: Continual adaptation for model-based rl. arXiv preprint arXiv:1812.07671, 2018b.
- Nagabandi et al. [2018c] A. Nagabandi, G. Kahn, R. S. Fearing, and S. Levine. Neural network dynamics for model-based deep reinforcement learning with model-free fine-tuning. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 7559–7566. IEEE, 2018c.
- Pathak et al. [2017] D. Pathak, P. Agrawal, A. A. Efros, and T. Darrell. Curiosity-driven exploration by self-supervised prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 16–17, 2017.
- Pearlmutter [1994] B. A. Pearlmutter. Fast exact multiplication by the hessian. Neural computation, 6(1):147–160, 1994.
- Rajeswaran et al. [2016] A. Rajeswaran, S. Ghotra, B. Ravindran, and S. Levine. Epopt: Learning robust neural network policies using model ensembles. arXiv preprint arXiv:1610.01283, 2016.
- Rajeswaran et al. [2020] A. Rajeswaran, I. Mordatch, and V. Kumar. A game theoretic framework for model based reinforcement learning. arXiv preprint arXiv:2004.07804, 2020.
- Rakelly et al. [2019] K. Rakelly, A. Zhou, D. Quillen, C. Finn, and S. Levine. Efficient off-policy meta-reinforcement learning via probabilistic context variables. arXiv preprint arXiv:1903.08254, 2019.
- Rothfuss et al. [2018] J. Rothfuss, D. Lee, I. Clavera, T. Asfour, and P. Abbeel. Promp: Proximal meta-policy search. arXiv preprint arXiv:1810.06784, 2018.
- Sæmundsson et al. [2018] S. Sæmundsson, K. Hofmann, and M. P. Deisenroth. Meta reinforcement learning with latent variable gaussian processes. arXiv preprint arXiv:1803.07551, 2018.
- Schmidhuber [1987] J. Schmidhuber. Evolutionary principles in self-referential learning, or on learning how to learn: the meta-meta-… hook. PhD thesis, Technische Universität München, 1987.
- [42] S. Schulze, S. Whiteson, L. Zintgraf, M. Igl, Y. Gal, K. Shiarlis, and K. Hofmann. Varibad: a very good method for bayes-adaptive deep rl via meta-learning. International Conference on Learning Representations.
- Settles [2009] B. Settles. Active learning literature survey. Technical report, University of Wisconsin-Madison Department of Computer Sciences, 2009.
- Silberman [1996] M. Silberman. Active Learning: 101 Strategies To Teach Any Subject. ERIC, 1996.
- Silver et al. [2016] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, et al. Mastering the game of go with deep neural networks and tree search. nature, 529(7587):484, 2016.
- Snell et al. [2017] J. Snell, K. Swersky, and R. Zemel. Prototypical networks for few-shot learning. In Advances in neural information processing systems, pages 4077–4087, 2017.
- Sutton [1990] R. S. Sutton. Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. In Machine learning proceedings 1990, pages 216–224. Elsevier, 1990.
- Sutton et al. [2000] R. S. Sutton, D. A. McAllester, S. P. Singh, and Y. Mansour. Policy gradient methods for reinforcement learning with function approximation. In Advances in neural information processing systems, pages 1057–1063, 2000.
- Thrun [1996] S. Thrun. Is learning the n-th thing any easier than learning the first? In Advances in neural information processing systems, pages 640–646, 1996.
- Thrun and Pratt [2012] S. Thrun and L. Pratt. Learning to learn. Springer Science & Business Media, 2012.
- Todorov et al. [2012] E. Todorov, T. Erez, and Y. Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–5033. IEEE, 2012.
- Utgoff [1986] P. E. Utgoff. Shift of bias for inductive concept learning. Machine learning: An artificial intelligence approach, 2:107–148, 1986.
- Wang et al. [2020] H. Wang, J. Zhou, and X. He. Learning context-aware task reasoning for efficient meta-reinforcement learning. arXiv preprint arXiv:2003.01373, 2020.
- Wang et al. [2016] J. X. Wang, Z. Kurth-Nelson, D. Tirumala, H. Soyer, J. Z. Leibo, R. Munos, C. Blundell, D. Kumaran, and M. Botvinick. Learning to reinforcement learn. arXiv preprint arXiv:1611.05763, 2016.
- Wang and Ba [2019] T. Wang and J. Ba. Exploring model-based planning with policy networks. arXiv preprint arXiv:1906.08649, 2019.
- Wang et al. [2019] T. Wang, X. Bao, I. Clavera, J. Hoang, Y. Wen, E. Langlois, S. Zhang, G. Zhang, P. Abbeel, and J. Ba. Benchmarking model-based reinforcement learning. arXiv preprint arXiv:1907.02057, 2019.
- Wikipedia contributors [2020] Wikipedia contributors. Implicit function theorem — Wikipedia, the free encyclopedia, 2020. URL https://en.wikipedia.org/w/index.php?title=Implicit_function_theorem&oldid=953711659. [Online; accessed 2-June-2020].
- Williams [1992] R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8(3-4):229–256, 1992.
- Zintgraf et al. [2019] L. Zintgraf, M. Igl, K. Shiarlis, A. Mahajan, K. Hofmann, and S. Whiteson. Variational task embeddings for fast adapta-tion in deep reinforcement learning. In International Conference on Learning Representations Workshop on Structure & Priors in Reinforcement Learning, 2019.
Appendix A Omitted Derivations
A.1 Jacobian of with respect to
We begin with an observation: first-order optimality conditions for necessitate that
| (8) |
Then, the implicit function theorem tells us that for sufficiently small , there exists as a function of such that
| (9) |
To first order, we have
| (10) |
Thus, solving for as a function of and taking the limit as , we obtain
| (11) |
A.2 Policy Hessian
Fix dynamics , and let denote the probability density of trajectory under policy . Then we have
| (12) |
Thus we get the basic (REINFORCE) policy gradient
| (13) |
Differentiating our earlier expression for once more, and then reusing that same expression again, we have
| (14) | ||||
| (15) |
Thus
| (16) | ||||
| (17) | ||||
| (18) | ||||
| (19) |
Appendix B Implementation detail
The section discusses how to compute using standard automatic differentiation packages. We first define the following function:
| (20) |
where are parameter copies of . We then use Hessian-vector product to avoid directly computing the second derivatives. Specifically, we compute the two parts in Eq. (7) respectively by first differentiating w.r.t and
| (21) |
and then differentiate w.r.t for twice
| (22) |
and thus we have .
Appendix C Hyper-parameters
We experimented with the following task settings: Hopper-2D with velocity and height from , Walker-2D with velocity and height from , Ant-2D with velocity and velocity from , Ant-3D with velocity, velocity and height from , Cheetah-Highdim with . We also list the coefficient of the parameterized reward functions in Table 1.
| Hopper2D | Walker2D | Ant2D | Ant3D | |
|---|---|---|---|---|
| 1 | 1 | 1 | 1 | |
| 0 | 0 | 1 | 1 | |
| 5 | 5 | 0 | 30 |
The hyper-parameters of MAML and PEARL are mostly taken directly from the supplied implementation of [Finn et al., 2017] and [Rakelly et al., 2019]. We run MAML for 500 training iterations: for each iteration, MAML uses a meta-batch size of 40 (the number of tasks sampled at each iteration) and a batch size of 20 (the number of rollouts used to compute the policy gradient updates). Overall, MAML requires 80 million samples during meta training. For PEARL, we first collect a batch of training tasks (150) by uniformly sampling from . We run PEARL for 500 training iterations: for each iteration, PEARL randomly sample 5 tasks and collects 1000 samples for each task from both prior (400) and posterior (600) of the context variables; for each gradient update, PEARL uses a meta-batch size of 10 and optimizes the parameters of actor, critic and context encoder by 4000 steps of gradient descent. Overall, PEARL requires 2.5 million samples during meta training.
For AdMRL, we first do zero-shot adaptation for each task by 40 virtual steps (). We then perform SLBO [Luo et al., 2018] by interleaving data collection, dynamical model fitting and policy updates, where we use 3 outer iterations () and 20 inner iterations (). Algorithm 2 shows the pseudo code of the virtual training procedure. For each inner iteration, we update model for 100 steps (), and update policy for 20 steps (), each with 10000 virtual samples (). For the first task, we use (for Hopper2D, Walker2D) or (for Ant2D, Ant3D, Cheetah-Highdim). For all tasks, we sweep the learning rate in {1,2,4,8,16,32} and we use for Hopper2D, for Walker2D, for Ant2D and Ant3D, for Cheetah-Highdim. To compute the gradient w.r.t the task parameters, we do 200 iterations of conjugate gradient descent.
Appendix D Examples of high-dimensional tasks
Figure 7 shows some trajectories in the high-dimensional task Cheetah-Highdim.