Mode Connectivity and Data Heterogeneity of Federated Learning
Abstract
Federated learning (FL) enables multiple clients to train a model while keeping their data private collaboratively. Previous studies have shown that data heterogeneity between clients leads to drifts across client updates. However, there are few studies on the relationship between client and global modes, making it unclear where these updates end up drifting. We perform empirical and theoretical studies on this relationship by utilizing mode connectivity, which measures performance change (i.e., connectivity) along parametric paths between different modes. Empirically, reducing data heterogeneity makes the connectivity on different paths more similar, forming more low-error overlaps between client and global modes. We also find that a barrier to connectivity occurs when linearly connecting two global modes, while it disappears with considering non-linear mode connectivity. Theoretically, we establish a quantitative bound on the global-mode connectivity using mean-field theory or dropout stability. The bound demonstrates that the connectivity improves when reducing data heterogeneity and widening trained models. Numerical results further corroborate our analytical findings.
Index Terms:
Federated learning, mode connectivity, data heterogeneity, mean-field theory, loss landscape visualization.I Introduction
Federated Learning (FL) [1] is a collaborative paradigm that enables multiple clients to train a model while preserving data privacy. A primary challenge in FL is data heterogeneity across clients [2]. Previous works like [3] found that data heterogeneity induces a misalignment between clients’ local objectives and the FL’s global objective (hereinafter referred to as client objective and FL objective, respectively) and drifts client updates. Nevertheless, despite client-update drift, the FL objective can typically be optimized [4] effectively. This implies that the destinations of these drifting updates (i.e., the solutions to the client and FL objectives) may overlap. However, a systematic investigation of this relationship is currently lacking.
A straightforward method to examine this overlapping relationship is to investigate mode connectivity [5], where mode refers to a suit of solutions to a specific objective, i.e., a suit of neuron parameters, under permutation invariance. Mode connectivity measures the connectivity of two modes via a parametric path and reveals the geometric relationship in the solution space. Specifically, it evaluates the performance change (e.g., taking loss/error as metrics) along a given path with endpoints corresponding to two different modes. Maintaining a minor change along the path indicates better connectivity (i.e., the geometric landscape becomes increasingly connected between the two modes). Some works [5, 6] have discovered that two modes can be connected well in centralized training, but research on FL remains scarce.
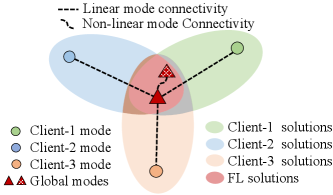
In this work, we conduct empirical and theoretical studies on mode connectivity in FL under data heterogeneity to unravel the relationship between client modes (i.e., the solutions to client objectives) and global modes (i.e., the solutions to the FL objective). Empirically, we consider linear and non-linear paths to evaluate the connectivity between client modes and global modes to show their overlap relationships, as illustrated in Figure 1. We also investigate the connectivity of global modes obtained under varying levels of data heterogeneity. Theoretically, we leverage mean-field theory [7] and dropout stability to establish a quantitative bound on the connectivity errors of global modes. In addition, we conduct a comprehensive numerical analysis to verify our analytical findings.
This study takes the first step to explore mode connectivity in FL. Our main contributions are summarized as follows:
-
•
Our empirical and theoretical investigations demonstrate that data heterogeneity deteriorates the connectivity between client and global modes, making it challenging to find solutions that meet both client and FL objectives.
-
•
It is revealed that FL solutions from different data heterogeneity belong to distinct global modes within a common region of the solution space. They can be connected on a polygonal chain while keeping error low but face an error barrier when considering a linear path.
-
•
We establish quantitative bounds on dropout and connectivity errors of global modes using mean-field theory, showing that both errors decrease with reduced data heterogeneity and widening trained models.
II Related Works
Data heterogeneity in FL. According to [3], data heterogeneity across clients significantly degrades the FL performance. Subsequent works have observed that data heterogeneity induces weight divergence and feature inconsistency. For weight divergence, studies such as [8, 9] show that client-update drift slows the FL convergence due to inconsistent client and FL objectives. Moreover, some studies, e.g., [10, 11], discover that the classifier divergence across clients is the main culprit of feature inconsistency, negatively affecting FL generalization. In contrast to previous works, we offer a novel perspective on data heterogeneity’s impact within the FL solution space.
Mode connectivity. The connectivity between neural network (NN) solutions due to the NN non-convexity, called mode connectivity, provides a new view into the geometric landscape of NNs in recent years. Despite the high dimension of NNs, the different solutions follow a clear connectivity pattern [12, 13, 6]. Specifically, it is possible to connect the local minima through specific paths that make it easier to find high-performance solutions when using gradient-based optimizers. The paths are often non-linear curves and are discovered by specific tasks. This suggests that the local minima are not isolated but rather interconnected within a manifold. Moreover, the geometric landscape of an NN becomes approximately linear-connected when considering the infinite neuron numbers as per [12]. Previous studies mainly focus on mode connectivity in centralized training with homogeneous data. Several pilot studies [14, 15] visualize the loss landscape of FL while not mode connectivity, and then our work tries to fill this gap of mode connectivity in FL under data heterogeneity.
Mean-field theory. A mean-field theory for the NN dynamics analysis is proposed by [7, 16] based on the gradient-flow approximation. The theory shows that when the neuron number is sufficiently large, the dynamics of stochastic gradient descent (SGD) to optimize NNs can be well approximated by a Wasserstein gradient flow. This approximation has been studied both in the two-layer case [7, 17] and the multi-layer case [18, 19]. In particular, the approximation is utilized to analyze the dropout stability of SGD solutions by [19], and the dropout stability implies mode connectivity of NNs according to [20]. However, these results are solely observed in centralized training. To the best of our knowledge, this paper is the first to expand upon the theoretical results into FL.
III Preliminaries

Mode connectivity. The forward function of an NN parameterized by is represented as , where denotes the parameter space of an NN architecture, and and are input and output spaces, respectively. When models and have the same neurons but different neuron permutations, they belong to the same mode. According to [20, 19], given an NN architecture , a dataset and a loss function , mode connectivity is defined as follows:
Definition 1.
(Mode connectivity). Two mode parameters and are -connected if there exists a continuous path in parameter space , such that and with , where is the connectivity error.
This definition measures the connectivity of two modes by comparing the loss change along a path to its endpoints. Moreover, we consider a path-finding task proposed by [5], which minimizes the expected loss over a uniform distribution on the path as:
| (1) |
where the path can be characterized by a Polygonal chain (PolyChain) with one or more bends [5]. We consider a PolyChain case with one bend as:
| (2) |
where is the model of the PolyChain-bend point and can be found by in (1). We refer to mode connectivity as linear (or non-linear) mode connectivity (LMC) when using linear interpolation (or PolyChain). Compared with the non-linear counterpart, LMC is a stronger constraint since LMC requires the two modes to stay in the same basin.
Federated leaning (FL). We consider an FL framework with clients, each with its own dataset , where data samples are indexed by . The global dataset is the union of all client datasets and denoted by on , which includes data samples. The FL objective is to minimize the expected global loss on , and is formulated as:
| (3) | ||||
where and denote the global and client loss functions, respectively. The -th client objective is . When , FedAvg [1] takes client models to solve (3) by minimizing client objectives locally and obtaining the global model round by round.
Experimental setups. We explore mode connectivity in FL on classification tasks, including MNIST [21], CIFAR-10 [22], and PACS [23]. The experimental setups used throughout this paper are as follows, unless stated otherwise. For NN architectures, we consider a two-layer NN, a shallow convolutional neural network (CNN) with two convolutional layers and a deep CNN, i.e., VGG architecture [24]. For the FL setup, we consider ten clients participating in FL with a total of 200 rounds. Client optimizers are SGD with a learning rate of 0.01 and momentum of 0.9, mini-batches of size 50, the local epoch of 1, and dropout of 0.5 for training VGG. For data heterogeneity, we follow [2] and examine label distribution skew by using Dirichlet distribution [25] to create client label datasets. A larger suggests more homogenous distributions across clients. On this basis, we also make use of the built-in domain shift of PACS to introduce feature distribution skew across clients.
IV Mode Connectivity of Client Modes
In this section, we explore mode connectivity among client modes trained on client datasets, where when . We first investigate the geometric landscape of client modes on their corresponding test sets. Specifically, we create a hyperplane by using the global mode and client modes , , which is represented as . We then use the test sets of clients and to evaluate the performance of all points on the hyperplane. Figure 2 displays the loss landscapes obtained on different test sets and distinguishes them by different colors. We also depict the loss landscape of the global mode (i.e., the initialization of client modes) on the global test set in Figure 2. For comparison, we set the legend scale of the client-mode landscape to be the same in each sub-figure of Figure 2 except the lowest value, and keep the scale of the global-mode landscape consistent among all the sub-figures.






Visualizing mode connectivity on client modes. As shown in Figure 2, the comparison between the cases of and indicates that when data heterogeneity increases, low-loss overlaps between client and global modes decrease, and the number of overlapping solutions to both client and FL objectives reduces. Similar results are also observed by comparing the cases of CIFAR-10 and PACS. Meanwhile, although client modes achieve a lower test loss than the global mode, they stray from the low-loss landscapes of the global mode. This indicates that client modes are prone to overfitting their own objectives when FedAvg solves (3) even if the global mode provides adequate initialization for them in the final round. On the other hand, we can linearly connect client models to the global model in all cases, as shown in the LMC of Figure 2. As the loss changes along these linear paths, it may eventually reach the low-loss landscapes of the global mode while still remaining in the low-loss landscapes of client modes. The above observations reveal that there exist some solutions that meet both client and FL objectives, but they may be overlooked by FedAvg.
Traversing loss along the paths connecting client modes. To delve deeper into the loss landscapes of Figure 2, we consider two paths to connect two client modes. One path is a linear connection between them (i.e., ), while the other is a PolyChain with the global mode as its bend (i.e., ) as per (2). We follow the paths to traverse the landscape from to on their test sets, and show the traversing losses along the paths in Figure 3. For the PolyChain in the case of , the intersection point of the two curves deviates from the global mode (i.e., ), where the intersection represents a solution that works effectively on both client datasets. Moreover, the traversing-loss gap between the two paths in the case of is greater than that of . This means that when heterogeneous data exist at clients, it becomes more difficult to find solutions that align with both the client and FL objectives.
Client-mode trajectory. The trajectory of client modes during optimization in the case of is depicted in Figure 4. This trajectory is based on t-SNE [26] and covers both training rounds and local iterations within each round. The figure illustrates that throughout the training process, the distance between client modes is controlled even under serious data heterogeneity, such that they closely surround the global mode. During the same round, data heterogeneity pushes client modes with the same initialization to be optimized locally along different directions. Therefore, the solutions found by client objectives vary when facing data heterogeneity even though they are close to each other in the parameter space. Figure 12 shows that the shallow CNN has similar results.
V Mode Connectivity of Global Modes
In this section, we explore the mode connectivity of global modes obtained by different data heterogeneity of the same training task. We consider two paths, linear interpolation and PolyChain, to investigate the mode connectivity among global modes on CIFAR-10 under and , as shown in Figure 5. Note that the initialization of global modes remains the same across these three cases.
Visualizing mode connectivity on global modes. In Figure 5, the linear-interpolation landscape reveals that global modes obtained from varying data heterogeneity are situated in distinct basins with an error barrier separating them. The landscape also shows that when sharing the same initialization, the global-mode basins are within a common region surrounded by high errors. With more heterogeneous data, like those involving , both training and test error barriers become higher, compared with that of . Furthermore, we also use a PolyChain found by (1) to connect the global modes of . Along the PolyChain, all the solutions keep no barrier in both training and test landscapes. The above results indicate that global modes can be connected without any barrier by some paths and they are situated within a manifold, as illustrated in Figure 1.


Barrier among global modes. To further quantify the mode connectivity of two global modes and , we define a barrier metric as:
| (4) |
where is equal to and (2) when considering linear interpolation and PolyChain, respectively. Here, measures the largest performance gap along comparing with its endpoints and . We say that and are well-connected if the barrier is close to .
We then use to explore mode connectivity during the whole training round. In Figure 6, the sub-figure on the left shows that more severe data heterogeneity causes greater barriers by comparing the cases of and , which persist throughout training. Meanwhile, as the rounds progress, the barrier shows an increasing trend after an initial oscillation. This causes various global modes to reach their own basins, as found in Figure 5. We also examine the difficulty of finding the global-mode PolyChain when facing varying data heterogeneity. Here, the difficulty is quantified by the relationship between barrier and data sample to optimize (1) and is depicted in the right sub-figure of Figure 6. The sub-figure illustrates that more samples are needed to find the specific PolyChain as data heterogeneity increases, resulting in more incredible difficulty in connecting global modes with no error barrier.
Function dissimilarity and distance of global modes. According to [27], permutation invariance may contribute to a linear-interpolation barrier between NN solutions in centralized training. When considering FL, data heterogeneity may disturb the permutation of FL solutions, leading to the barriers found in Figure 5. To verify whether the FL solutions obtained from different data heterogeneity belong to the same global mode, we measure their function dissimilarity on the left-hand side of Figure 7. The figure shows that function dissimilarity remains among these FL solutions even when the data heterogeneity is weakened. This means that the FL solutions belong to different global modes. Furthermore, Figure 7 presents that the distance between these FL solutions is smaller than the distance between them and their initial points. This means that different global modes with the same initialization are close to each other. Combined with the above results, it can be inferred that these FL solutions belonging to various global modes are adjacent and in a common region, but they cannot be linearly connected.


VI Mode Connectivity Analysis under Data Heterogeneity
As indicated by our experimental results, a sufficient condition to find the solutions meeting both client and FL objectives (3) is that the distributions represented by client modes are the same as the global mode . However, satisfying this condition is generally challenging since data heterogeneity induces client-gradient drifts [3] and then implicit output bias among client modes [15]. Building upon the drifts and bias, we consider client modes and formulate data heterogeneity as:
Definition 2.
(Data heterogeneity). Given a global mode and data samples , for , the global-mode output and its gradient differ from the client-mode output and its gradient , respectively, if the client distribution differs from the global distribution .
In this section, we will utilize dropout stability to analyze mode connectivity of global modes. First, let us define it as:
Definition 3.
(Dropout stability). Given a model with neurons and its dropout networks with , the model is -dropout stable if .
Then, we adopt the mean-field theory developed by [7] to analyze dropout stability under data heterogeneity. Mean-field theory shows that the trajectory of SGD can be approximated by a partial differential equation (PDE) called distributional dynamic (DD). Namely, under the assumption of enough neurons (i.e., is large enough) and one-pass data processing (i.e., for all , samples are independent and identically distributed), the SGD trajectory of neurons are close to the movement of i.i.d particles following the description of DD. Here, we consider a two-layer NN with hidden neurons, denoted as , where for all . The forward function of is represented as:
| (5) |
where is the activation function. For simplicity, we focus on the ReLU activation and the mean-square loss, i.e., and , which can be extended to other activation functions and losses in [7, 16].
Meanwhile, we consider FedAvg with each client undergoing local iterations in the -th round, and represent the global-mode update on the -th neuron as to get:
| (6) | ||||
where denotes the -th local iteration, denotes the step size at the -th iteration, denotes the weighted average of all the -th client neurons, denotes the output of the weighted-average model based on one-pass data , and denote the noise induced by data heterogeneity. Specifically, we follow Definition 2 and represent (the superscript is omitted for brevity) as:
| (7) | ||||
where the gradient drift and output bias depend on data heterogeneity, i.e., and , but .
Furthermore, the trajectory of in (6) subsumes the trajectory of the global model since FedAvg performs weighted averaging on the global model at each round. Therefore, we represent the global-mode trajectory as follows:
| (8) |
where when given a total round and when . See the appendix for detailed proof.
We make the following assumptions as per [7]:
Assumption 1.
The step size is denoted as , where is bounded by and -Lipschitz.
Assumption 2.
For , the label and the activation function with sub-Gaussian gradient are bounded by .
Assumption 3.
The functions and are differentiable, and their gradients are bounded by and -Lipschitz.
Assumption 4.
The initial condition is -sub-Gaussian. Let and , and is uniformly bounded for .
Assumption 5.
For and , the noise , where .
Assumptions 1-4 denote the requirements of mean-field theory on the learning rate , data distribution , activation function , and initialization . Assumption 5 indicates that the noise in (7) depends on data heterogeneity. Specifically, a generalized function is taken to measure the impact of data heterogeneity on , including the gradient drift and output bias, where and denotes the degree of data heterogeneity across clients (i.e., smaller , larger .
We take the mean-field theory to quantify the difference between the global-mode trajectory loss and the DD-solution loss and have:
Lemma 1.
(Mean field approximation.) Assume that conditions 1-5 hold, the solution of a PDE with initialization can approximate the update trajectory of the global mode as (8) with initialization and unchanged data heterogeneity throughout training. When , , and , there exists a constant (depending solely on the constants of assumptions 1-4) such that
with probability at least .
Lemma 1 shows when the number of neurons is sufficiently large and the step size is sufficiently small, the global-mode neurons obtained by running steps as (8) can be approximated as i.i.d. particles that evolve according to the DD at time . Then, we utilize Lemma 1 to show that the global mode remains dropout-stable even when faced with data heterogeneity.
Theorem 1.
(Dropout stability under data heterogeneity.) Assume that conditions 1-5 hold, and fix and . Let the global model be obtained by running steps as (8) with data and initialization . Then, the following results hold: Pick independent of . Then, with probability at least , for all is -dropout stable with equal to
where the constant depends only on the constants in the assumptions 1-4.
Following [20], we demonstrate that dropout-stable NNs in FL have mode connectivity as follows.
Theorem 2.
(Mode connectivity under data heterogeneity.) Under Theorem 1, fix and let and be the global models obtained by running running steps as (8) with data heterogeneity and and initialization and , respectively. Then, with probability at least , for all and and are -connected with equal to
where . Furthermore, the path connecting with consists of 7 line segments.
VII Numerical Results
To verify our analysis results, we undertake two classification tasks: i) using a two-layer NN on MNIST; ii) using a VGG11 network from scratch on CIFAR-10. The NNs take ReLU activations for both tasks and are optimized based on the cross-entropy loss. For the FL setup, we consider ten clients with training rounds for MNIST/CIFAR-10. Client optimizers are SGD with a learning rate of 0.02/0.01 for MNIST/CIFAR-10, where the mini-batch size is 50 and the number of local iterations is 10. Meanwhile, within the same task, the NN initialization is consistent under varying data heterogeneity and independent of neuron number , which aligns with the theoretical assumptions. We perform 20 independent trials to measure mean value and standard deviation in Figures 8 and 9.
Dropout stability under varying data heterogeneity.


Figure 8 compares the dropout error under varying data heterogeneity as per Definition 3 on the training dataset (blue curve) and test dataset (orange curve). For MNIST, the neuron number of the two-layer NN is , and for CIFAR-10, VGG11 follows the standard setup in [24]. As expected from Theorem 1, the dropout error shows a downward trend as client datasets become more homogeneous. For example, the case of has a more significant training/test dropout error than the i.i.d case at the different training stages of both tasks. When the same heterogeneity setting (e.g., ) is adopted, the effect of data heterogeneity on CIFAR-10 is stronger than that on MNIST. This leads to a larger dropout error in CIFAR-10, where the dropout error is for MNIST and for CIFAR-10. Moreover, we also consider two training stages in Figure 8, including the middle stage (dashed curve) and the ending stage (solid curve). For both tasks, the dropout-error gap between the two stages keeps small, i.e., for MNIST and for CIFAR-10. As expected, this indicates that the mean-field theory can view the dropout-out dynamics as long as the training time is sufficient.
Mode connectivity under varying neuron numbers and data heterogeneity.


Figure 9 takes dropout stability (left sub-figure) and linear-interpolation barrier (right sub-figure) to validate our analysis on mode connectivity of global modes in FL. Theorem 2 shows that dropout stability implies mode connectivity, and the connectivity error depends on the neuron number and data heterogeneity. For the MNIST under , we consider a two-layer NN and plot the relationship between its dropout error and neuron number . As expected, the training/test dropout error rapidly decreases as the width of the network grows. The dropout error for is less than , while for , it is up to . Then, we take the linear-interpolation barrier to explore the connectivity error , and connect the global mode obtained in the case to that of the cases (solid curve) and (dashed curve). With the expansion of the network, the barrier (i.e., connectivity error ) diminishes rapidly, which is consistent with dropout error v.s. neuron number . Furthermore, the barrier of to is higher than that of to when . This is expected because when is small, the connectivity error is amplified by the effect of data heterogeneity , i.e., the effect of data heterogeneity amortized to neurons would be even greater.
Neuron noise under varying data heterogeneity.


Figure 10 illustrates the L2 norm of the global-mode update noise under varying data heterogeneity in (7) along all iterations in the right sub-figure, where the mean, maximal, and minimal noise norms are reported in the left sub-figure. As shown in the left sub-figure, the noise norm decrease as data heterogeneity alleviates. Meanwhile, the maximal noise norm is limited, i.e., , but the noise norm does not decrease to zero even in the i.i.d case due to the randomness of SGD. Moreover, according to the right sub-figure, the noise is not strongly correlated with the iterations when the data heterogeneity is mild (i.e., ), and slightly decreases along the training iterations. This verifies Assumption 5, where the neuron noise arises from data heterogeneity and remains independent of the number of iterations.
VIII Discussion and Future Work
Through experimental and theoretical analysis, we unravel the relationship between client and global modes in FL under varying data heterogeneity. As data become more heterogeneous, finding solutions that optimize both the client and FL objectives becomes increasingly challenging due to the reduction of overlapping solutions between client and global modes. Meanwhile, the FL solutions obtained from different setups of data heterogeneity belong to distinct global modes, and are located in distinct basins of a joint region. These solutions can be connected by a specific PolyChain while showing an error barrier along the linear interpolation. This suggests that global modes in FL are not isolated but rather interconnected within a manifold. Our analysis demonstrates that the connectivity error between global modes decreases with weakened data heterogeneity and wider trained models.
The findings suggest potential directions for future work for the design of FL: i) exploring the solutions to the FL objective that maintain low error for both client and global test sets, i.e., the solutions to both client and FL objectives; ii) investigating the effect of model depth and architecture in FL based on mean-field theory; iii) understanding FL training dynamics by the gap between random and pre-trained initialization (see a preliminary investigation in Appendix).
References
- [1] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” in Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, vol. 54. PMLR, 20–22 Apr 2017, pp. 1273–1282. [Online]. Available: https://proceedings.mlr.press/v54/mcmahan17a.html
- [2] P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummings et al., “Advances and open problems in federated learning,” Foundations and Trends® in Machine Learning, vol. 14, no. 1–2, pp. 1–210, 2021.
- [3] Y. Zhao, M. Li, L. Lai, N. Suda, D. Civin, and V. Chandra, “Federated learning with non-iid data,” arXiv preprint arXiv:1806.00582, 2018.
- [4] J. Shao, Z. Li, W. Sun, T. Zhou, Y. Sun, L. Liu, Z. Lin, and J. Zhang, “A survey of what to share in federated learning: Perspectives on model utility, privacy leakage, and communication efficiency,” arXiv preprint arXiv:2307.10655, 2023.
- [5] T. Garipov, P. Izmailov, D. Podoprikhin, D. P. Vetrov, and A. G. Wilson, “Loss surfaces, mode connectivity, and fast ensembling of dnns,” in Advances in Neural Information Processing Systems, vol. 31. Curran Associates, Inc., 2018. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2018/file/be3087e74e9100d4bc4c6268cdbe8456-Paper.pdf
- [6] F. Draxler, K. Veschgini, M. Salmhofer, and F. Hamprecht, “Essentially no barriers in neural network energy landscape,” in Proceedings of the 35th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 80. PMLR, 10–15 Jul 2018, pp. 1309–1318. [Online]. Available: https://proceedings.mlr.press/v80/draxler18a.html
- [7] S. Mei, A. Montanari, and P.-M. Nguyen, “A mean field view of the landscape of two-layer neural networks,” Proceedings of the National Academy of Sciences, vol. 115, no. 33, pp. E7665–E7671, 2018. [Online]. Available: https://www.pnas.org/doi/abs/10.1073/pnas.1806579115
- [8] T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V. Smith, “Federated optimization in heterogeneous networks,” Proceedings of Machine Learning and Systems, vol. 2, pp. 429–450, 2020.
- [9] J. Wang, Q. Liu, H. Liang, G. Joshi, and H. V. Poor, “Tackling the objective inconsistency problem in heterogeneous federated optimization,” Advances in Neural Information Processing Systems, vol. 33, pp. 7611–7623, 2020.
- [10] M. Luo, F. Chen, D. Hu, Y. Zhang, J. Liang, and J. Feng, “No fear of heterogeneity: Classifier calibration for federated learning with non-iid data,” Advances in Neural Information Processing Systems, vol. 34, pp. 5972–5984, 2021.
- [11] T. Zhou, J. Zhang, and D. Tsang, “Fedfa: Federated learning with feature anchors to align feature and classifier for heterogeneous data,” arXiv preprint arXiv:2211.09299, 2022.
- [12] C. D. Freeman and J. Bruna, “Topology and geometry of half-rectified network optimization,” in International Conference on Learning Representations, 2017. [Online]. Available: https://openreview.net/forum?id=Bk0FWVcgx
- [13] T. Garipov, P. Izmailov, D. Podoprikhin, D. P. Vetrov, and A. G. Wilson, “Loss surfaces, mode connectivity, and fast ensembling of dnns,” Advances in Neural Information Processing Systems, vol. 31, 2018.
- [14] Z. Li, H.-Y. Chen, H. W. Shen, and W.-L. Chao, “Understanding federated learning through loss landscape visualizations: A pilot study,” in Workshop on Federated Learning: Recent Advances and New Challenges (in Conjunction with NeurIPS 2022), 2022.
- [15] T. Zhou, Z. Lin, J. Zhang, and D. H. Tsang, “Understanding model averaging in federated learning on heterogeneous data,” arXiv preprint arXiv:2305.07845, 2023.
- [16] S. Mei, T. Misiakiewicz, and A. Montanari, “Mean-field theory of two-layers neural networks: dimension-free bounds and kernel limit,” in Proceedings of the Thirty-Second Conference on Learning Theory, ser. Proceedings of Machine Learning Research, vol. 99. PMLR, 25–28 Jun 2019, pp. 2388–2464. [Online]. Available: https://proceedings.mlr.press/v99/mei19a.html
- [17] G. M. Rotskoff and E. Vanden-Eijnden, “Neural networks as interacting particle systems: Asymptotic convexity of the loss landscape and universal scaling of the approximation error,” Advances in neural information processing systems, p. 7146–7155, 2018.
- [18] P.-M. Nguyen and H. T. Pham, “A rigorous framework for the mean field limit of multilayer neural networks,” arXiv preprint arXiv:2001.11443, 2020.
- [19] A. Shevchenko and M. Mondelli, “Landscape connectivity and dropout stability of SGD solutions for over-parameterized neural networks,” in Proceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 119. PMLR, 13–18 Jul 2020, pp. 8773–8784. [Online]. Available: https://proceedings.mlr.press/v119/shevchenko20a.html
- [20] R. Kuditipudi, X. Wang, H. Lee, Y. Zhang, Z. Li, W. Hu, R. Ge, and S. Arora, “Explaining landscape connectivity of low-cost solutions for multilayer nets,” in Advances in Neural Information Processing Systems, vol. 32. Curran Associates, Inc., 2019. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2019/file/46a4378f835dc8040c8057beb6a2da52-Paper.pdf
- [21] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- [22] A. Krizhevsky, G. Hinton et al., “Learning multiple layers of features from tiny images,” 2009.
- [23] D. Li, Y. Yang, Y.-Z. Song, and T. M. Hospedales, “Deeper, broader and artier domain generalization,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 5542–5550.
- [24] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [25] M. Yurochkin, M. Agarwal, S. Ghosh, K. Greenewald, N. Hoang, and Y. Khazaeni, “Bayesian nonparametric federated learning of neural networks,” in Proceedings of the 36th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 97. Long Beach, California, USA: PMLR, 09–15 Jun 2019, pp. 7252–7261. [Online]. Available: http://proceedings.mlr.press/v97/yurochkin19a.html
- [26] L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.” Journal of machine learning research, vol. 9, no. 11, 2008.
- [27] R. Entezari, H. Sedghi, O. Saukh, and B. Neyshabur, “The role of permutation invariance in linear mode connectivity of neural networks,” in International Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=dNigytemkL
Appendix A Additional Experiments
A-A Additional Experiments in client-mode connectivity


Testing the models on the global test set along the paths connecting client models. Figure 11 considers the same paths as that of Figure 3 (i.e., the linear path and the PolyChain path) to connect two client models, and reports the loss of the models along both paths on the global test set. The left and right sub-figures display the results of the global model trained from scratch and pre-training, respectively. When data are more heterogeneous, the loss gap between the two paths becomes greater. For example, the gap of the case of is much larger than that of . Both sub-figures indicate that models along the PolyChain path exhibit good performance in the global test set when falls within the range of . The sub-figure in the right-hand side of Figure 3 also shows that the models in the range exhibit good performance in the client test sets. Upon comparing the left and right sub-figures, we observe a significant reduction in the loss gap between both paths due to the utilization of the pre-trained model. Therefore, it appears that there are certain solutions to the FL objective (3) that can maintain a low loss for both client test sets and the global test set, particularly when using a pre-trained model as the model initialization. It would be beneficial for future work to further explore how to find these solutions.


Optimization trajectory of shallow CNN. In Figure 12, we also visualize the optimization trajectory of client models to compare with the VGG11 trajectory illustrated in Figure 4. Similar to the observation of Figure 4, the solutions found by client objectives vary under data heterogeneity even though they are close to each other in the parameter space. Additionally, it is evident that during the training procedure, when utilizing shallow CNN, the distance between client solutions is regulated but is greater than that of VGG11. This implies that data heterogeneity affects models with various dimension sizes differently, which is in line with the results of Theorem 2 and Figure 14.
A-B Additional Experiments in global-mode connectivity
Connectivity landscape along the linear-interpolation path and the PolyChain path.


We take the classification accuracy as the metric and plot the connectivity landscape along the linear-interpolation path and the PolyChain path in Figure 13. As additional data to Figure 5, Figure 13 displays comprehensive accuracy fluctuations along both paths. As shown in the left sub-figure, when dealing with more heterogeneous data, such as in the case of , both training and test barriers become higher, compared with . Meanwhile, since all global models are not far away from each other and are located in a common region, the maximal accuracy drop induced by the barriers is around . The right sub-figure shows that the PolyChain with one bend easily connects the global models from to and from to , while all the models along the PolyChain keep no barrier.
Neuron noise insight into global-mode connectivity.


We resort to the noise norm in (7) to gain a better understanding of the relationship between the number of neurons () and the dropout error () and connectivity error (). As shown in Figure 14, the L2 norm of global-mode update noise is depicted under . This figure displays the noise norms for different neuron numbers and their visualization across all iterations. It also reports the mean, maximal, and minimal noise norms. The left sub-figure demonstrates that as the number of neurons increases, the noise norm decreases. When , the gap between maximal and minimal noise norms becomes much smaller than that of . As shown in the right sub-figure, the noise levels are distinguishable for different numbers of neurons. These results reveal that the wider models show smaller noise in their updates of FL, and then have lower dropout error () and connectivity error () in Figure 9.
Appendix B Proof
The approximation in Lemma 1 builds the connection from the nonlinear dynamics to the particle dynamics to the gradient descent to the SGD under the data-heterogeneity noise. The approximation relies on the following model update:
| (9) |
where denotes the -th neuron parameter, denotes the coefficient of regularizer in the objective (i.e., without regularizers), denotes the step size at the -th iteration, and denote the random noise at the -th iteration. By Proposition 33, 35, 37 and 38 in [16], when Assumptions 1 to 5 hold, we have the following proposition:
Proposition 1.
There exists a constant (depending solely on the constants of assumptions 1-5), such that with probability at least , we have:
where , and denote the solutions of the nonlinear dynamics, particle dynamics, gradient descent and SGD, respectively.
In Proposition 1, the main distinction from its counterpart in [16] is that it accounts for the impact of data heterogeneity in the model update, i.e., is not embraced into the constant . The proof for Proposition 1 aligns with the proof of its counterpart in [16], and see [16] for the details.
Lemma 2.
B-A Proof of Theorem 1
Proof.
In the following proof, we take to accommodate all constants that depend solely on the constants of assumptions 1-4. According to Definition 3, we have:
| (10) | ||||
where denotes the dropout model containing the first non-zero elements (i.e., non-dropout elements) of . Here, is the PDE solution of the distributional dynamic at time .
For the first term, we take Lemma 1 and directly obtain:
| (11) | ||||
For the second term, we compute its upper bound based on the maximal output gap between the -th neuron of and the -th neuron of , which can be represented as:
| (12) | ||||
where the second inequality follows that and the gradient of are bounded.
Furthermore, we take the sum of all inequalities in Proposition 1 and obtain:
| (13) | ||||
with probability at least . Consequently, we have: with probability at least ,
| (14) | ||||
For the third term, we follow the triangle inequality and have:
| (15) | ||||
where takes the expectation on . For the first term of (15), we consider the mean-square loss in this work and have:
| (16) |
where takes the expectation on . According to Lemma 1, we have under the PDE approximation, and rewrite the second term of (15) as:
| (17) | ||||
where the inequality is because the activation function is bounded by according to Assumption 2. That is, denoting by and be two parameters that differ only in the -th component, i.e., and , we have: .
With McDiarmid’s inequality, we have:
| (18) |
Furthermore, we have the following increment bound for time :
| (19) | ||||
Here, we take a union bound over and bound the variation inside the grid intervals. Then, with McDiarmid’s inequality, we get:
| (21) | ||||
We take and in (21) and combine it with (21), and get:
| (22) | ||||
with probability at least .
we summarize (11), (14) and (22) and have:
| (23) | ||||
with probability at least . Therefore, the global model obtained from the FL under data heterogeneity is -dropout stable with equal to .
∎
B-B Proof of Theorem 2
The proof of Theorem 2 is obtained by combining Theorem 1 with the following lemma, which is based on [20, 19].
Lemma 3.
(Dropout networks obtained from FL under varying data heterogeneity have connectivity). Consider a two-layer neural network with neurons, as in (5). Given , let and be solved under data heterogeneity and , which have dropout stability as in Definition 3. Then, and are -connected as in Definition 1. Furthermore, the path connecting with consists of 7 line segments.
Proof.
To consider the effect of the dropout stability on the given models, we represent the model parameters as:
where is the rescaling factor of dropout. That is, if the model components () perform dropout, and if the model components () do not perform dropout.
We consider the piecewise linear path in parameter space that connects to as one path of mode connectivity for over-parameterized neural networks. Namely, when is even, we can connect to with the following way:
Firstly, for the path between to , since is -dropout stable, we have that . Similarly, the loss along the path that connects to is also upper bounded by .
Then, for the path between to , only with the corresponding is changed to be . Thus, the loss along this path does not change; i.e., . Similarly, the loss does not change along the path between to and the path between to : and .
Next, for the path between to , the two subnetworks are equal, such that the loss of their interpolated models along this path does not change; i.e., .
Finally, based on the above analysis, we have and . For the path between to , since the loss is convex in the weights of the last layer, the loss along this path is upper bounded by .
When is odd, we can take a similar analysis to that of even . The differences are that (i) the -th parameter of and is and the -th parameter of and is , and (ii) the constant rescalling factor is replaced by .
Therefore, the loss along the above path between and is upper bounded by with equal to .
∎
B-C Proof of global-mode update (6)
Proof.
Here, we denote the client model as and its -th neuron as . Then, we represent the weighted average of all client models as and their -th neuron as . Meanwhile, for given a data sample , we formulate the model output as and , and the gradient deviation as .
With these notations, we formulate the update of the global model at the -th round as:
| (24) | ||||
| (25) | ||||
where the last equality hold because of the assumption of one-pass data processing and all client samples belong to the global distribution , i.e., . Here, we represent the noise as:
| (26) | ||||
Therefore, we obtain (6), i.e.,
| (27) | ||||
Furthermore, according to Definition 2, can be regarded as the noise induced by data heterogeneity in FL. Since , we take Assumption 5 and simplify (6) with when given a total training round as:
| (28) | ||||
Therefore, we obtain (8).
∎