M&M3D: Multi-Dataset Training and Efficient Network for Multi-view 3D Object Detection
Abstract
In this research, I proposed a network structure for multi-view 3D object detection using camera-only data and a Bird’s-Eye-View (BEV) map. My work is based on a current key challenge - domain adaptation and visual data transfer. Although many excellent camera-only 3D object detection has been continuously proposed, many research work risk dramatic performance drop when the networks are trained on the source domain but tested on a different target domain. Then I found it is very surprising that predictions on bounding boxes (bbox) and classes are still replied to on 2D networks. Based on the domain gap assumption on various 3D datasets, I found they still shared a similar data extraction on the same BEV map size and camera data transfer. Therefore, to analyze the domain gap influence on the current method and to make good use of 3D space information among the dataset and the real world, I proposed a transfer learning method and Transformer construction to study the 3D object detection on NuScenes-mini and Lyft. Through multi-dataset training and a detection head from the Transformer, the network demonstrated good data migration performance and efficient detection performance by using 3D anchor query and 3D positional information. Relying on only a small amount of source data and the existing large model pre-training weights, the efficient network manages to achieve competitive results on the new target domain. Moreover, my study utilizes 3D information as available semantic information and 2D multi-view image features blending into the visual-language transfer design. In the final 3D anchor box prediction and object classification, my network achieved good results on standard metrics of 3D object detection, which differs from dataset-specific models on each training domain without any fine-tuning. The work is available at GitHub.
1 Introduction
In recent years, the research and application of large-scale vision and language models have shown a rapidly growing trend, and some outstanding representatives include OpenAI’s Contrastive Language-Image Pre-training (CLIP) [1] model and stable fusion model. This trend reflects the profound development in the fields of natural language processing (NLP) and computer vision (CV), and shows the ability of visual-language models to achieve major breakthroughs in 2D vision tasks, derived from combining image features and sequence context New concept of combination. The CLIP model, proposed by OpenAI in 2021, is a classic pioneer visual-language model. It has excellent multi-modal understanding capabilities and can process 2D images and text simultaneously to achieve cross-modal retrieval and classification tasks. The core idea is to align the embedding spaces of images and text with each other so that image and text descriptions can be compared in a common embedding space, thus achieving impressive cross-modal performance.
My work, M&M3D, ’Multi-Dataset Training and Efficient Network for Multi-view 3D Object Detection’, also borrows this idea to align the camera’s multi-view images and the 3D space of the scene with each other, so that the network can use 2D image features and 3D spatial information to bring about a turnaround in the challenge of 3D object detection tasks. One of the key focuses of the project is to achieve efficient general feature extraction and application in the face of data constraints and limited computing resources, such as very limited labeled or unlabeled training data, to fully exploit the visual-language model structure potential. This requires me to design and develop new domain adaptation and 3D feature transfer technologies to fit the application of autonomous driving in actual scenarios, which means an unlimited target domain. Transferring 2D object detection to 3D or real scenes is currently a big challenge and research potential. This is a very promising practical project in the field of unsupervised or semi-supervised 3D visual recognition research.
2 Related Work
2.1 Bird’s-Eye-View
Bird’s-Eye-View, or BEV in short, is a critical perspective in computer vision using a top-down view or overhead view, particularly in applications such as 3D object detection, and widely applied in autonomous driving. This section provides an in-depth exploration of the foundational research areas and influential works that have contributed to the advancement of BEV-based vision tasks. BEV-based methods tend to introduce the Z-axis error, resulting in poor performance for other 3D-aware tasks. This is a line of practical work of converting 2D image features into 3D predictions, using a 3D space transformer on BEV information. From CaDDN [2], BEVDet [3] and BEVDet4D [4], it shows a solid proof for image-based 3D object detection explicitly predicts depth distribution to explore the new method in 3D space, from 2D attributes to real-world scenes. By performing successful visual attention, BEVFormer [5] inspired a 2D-to-3D transformer with local attention in BEV grid and a parameter query. Taking ideas from 2D object detection, DETR3D [6] using 3D position presentations from a 2D work DETR [7].
2.2 Vision-based 3D object detection
Vision-based 3D object detection, generally for monocular or multi-view camera-only detection methods, has received increasing attention from researchers due to its rich semantics and low deployment cost and has seen rapid development in recent years. As another key perception task in autonomous driving, early approaches to 3D object detection are similar to 2D detection methods. These methods usually predict 3D bounding boxes based on 2D bounding boxes from camera images. The earl method started as RGB image detection from Mono3D [8] in 2016, using scene and other priors to collect semantic or shape proposals. Then [9] shared the first idea of using BEV views and leveraging 2D detection work to minimize the 2D-3D visual gap. This work on 2D visual detectors as a starter and inspiration for following 3D visual recognition recently has become a trending approach to lower the training cost. Ssd-6d [10] and monocular-3D work like shape reconstructions [11], adding geometric reasoning part[12] and SMOKE [13] for one-stage network are continuing on monocular 3D object detection. Later, FCOS3D [14] extends this paradigm to 3D object detection and achieves great performance, inspiring many future multi-view 3D tasks.
Many researchers have worked on predicting objects directly from a single image view. However, limited data and a single viewpoint make it impossible to develop more complex tasks. Meanwhile, as some large benchmarks with more data and multiple viewpoints have been released together with multi-view datasets collected from autonomous driving industrial motivations, new perspectives are provided for the development of paradigms for multi-view 3D images. Thus, vision-based 3D object detection is gaining more attention [15]. Due to rich semantic information and low cost for deployment in multi-view images, in the last few years, many efforts have been made to predict objects from multi-view image sets. LSS [16] pioneered to proposal the multi-view features to BEV space. Based on these benchmarks, some multi-camera 3D object detection paradigms have been developed with good performance. A number of recent papers have already found that using Transformer and 2D target recognition frameworks can perform well on a single 3D dataset such as FCOS3D [14], BEVFormer[5], BEVFusion [17], DERT3D [6], or supervised method such as BEVDet [3] and BEVDepth [18] to enhance the depth information. Then 3D convolutions and domain-specific heads are used to detect objects in both indoor and outdoor scenes. to transform 2D multi-view features into BEV representation. Transformer-based methods can gain benefits from 2D well-developing modeling tricks with additional training augmentations in 3D information. DETR3D [6] and PETR [19] propose 3D position-aware encoding, which greatly improves the performance of DET3D.
3 Method
3.1 3D Multi-Datasets Training
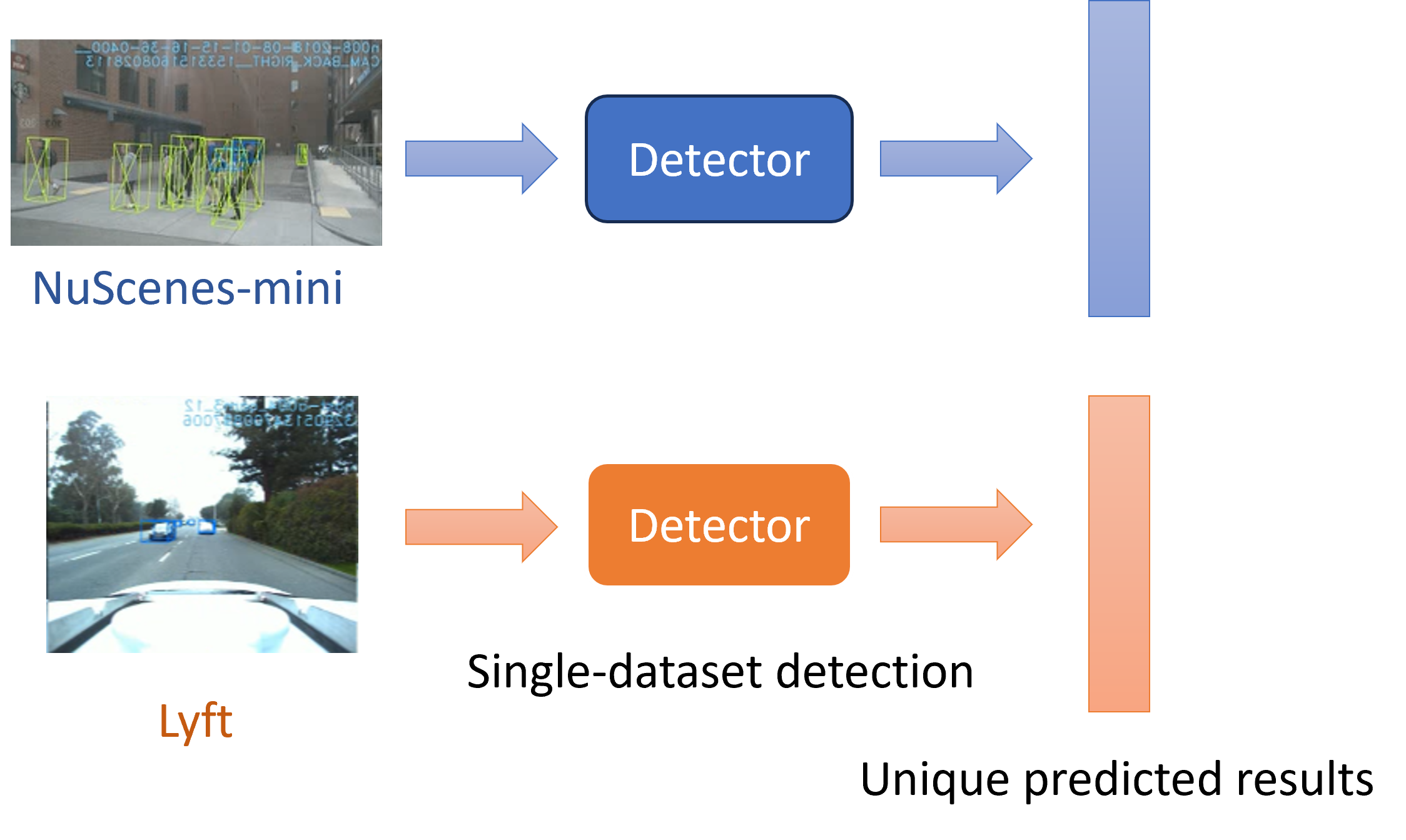
In this section, we will briefly introduce and analyze two important types of 3D datasets: NuScenes [20] and Lyft [21]. Our main research goal is to analyze the domain gap between them. Both datasets are designed to represent real-world road scenes and provide rich sensor data. Here we only take camera data to the table, the multi-view data, to simulate the automatic driving scenes. However, although they are all oriented towards similar 3D visual tasks, there is a domain gap between them, which has an important impact on the generalization ability and performance of the networks. T
3.1.1 Domain Gap between NuScenes-mini and Lyft
The domain gap that exists between different data sets is an indisputable fact. Different cameras can produce different domains in a 3D dataset, mainly because of differences in the way they capture and represent visual information. Different cameras use different sensors that have unique characteristics and technologies, including sensitivity to light, noise levels, and color representation, which may lead to differences in the visual data they capture. A camera also has a variety of shooting settings, and different settings can cause that camera to capture more and different details, such as variations in lighting, resolution, and other specialized parameters. The level of detail affects the way objects and scenes are presented in the image. Even more, the camera may have different color profiles or color calibrations during data production, which can affect the way colors are rendered in the image. This may result in variations in color accuracy and saturation.
3.1.2 Multi-dataset Training in 3D Object Detection
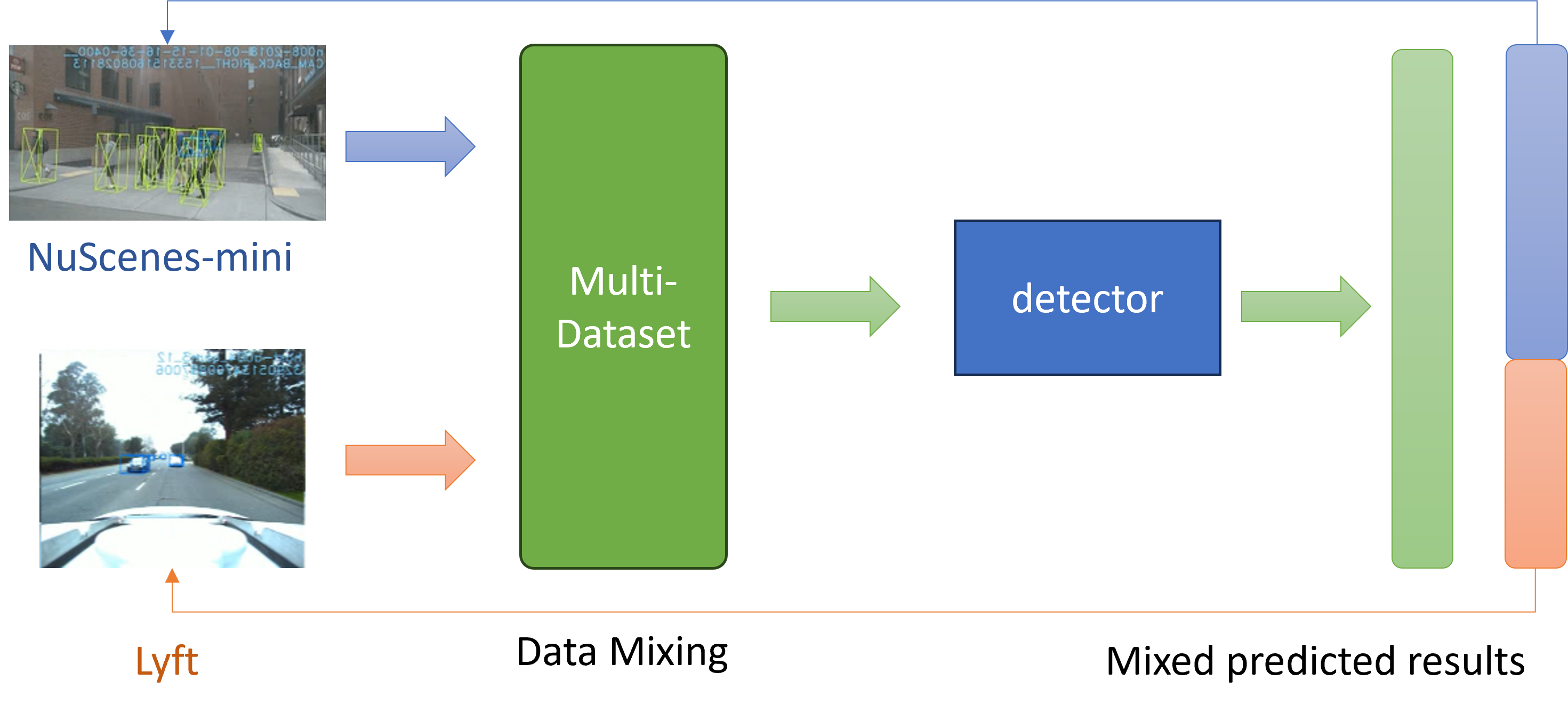
This approach has been successful in 2D visual recognition. Then we expect to borrow this form and hope that it is also a practical approach in scenarios where 3D object detection tasks are challenging. As we mentioned above and in the related work section, some of the best 3D models or network designs, such as BEVFormer [5], have shown very strong performance on the NuScenes dataset alone. But it is very challenging to improve upon the existing results with the limited computational resources I have and it is very challenging to improve on the existing results. That’s why we mention the use of ’Multi-dataset Training’ to improve the network’s performance because I want the network to be able to efficiently learn more information about the 3D image from a new perspective while leveraging the properties of these excellent models, and it can transfer to a new target domain. It is important to note that this approach is currently a very promising direction in 3D, and any theoretically feasible way of pre-data is architecture-independent.
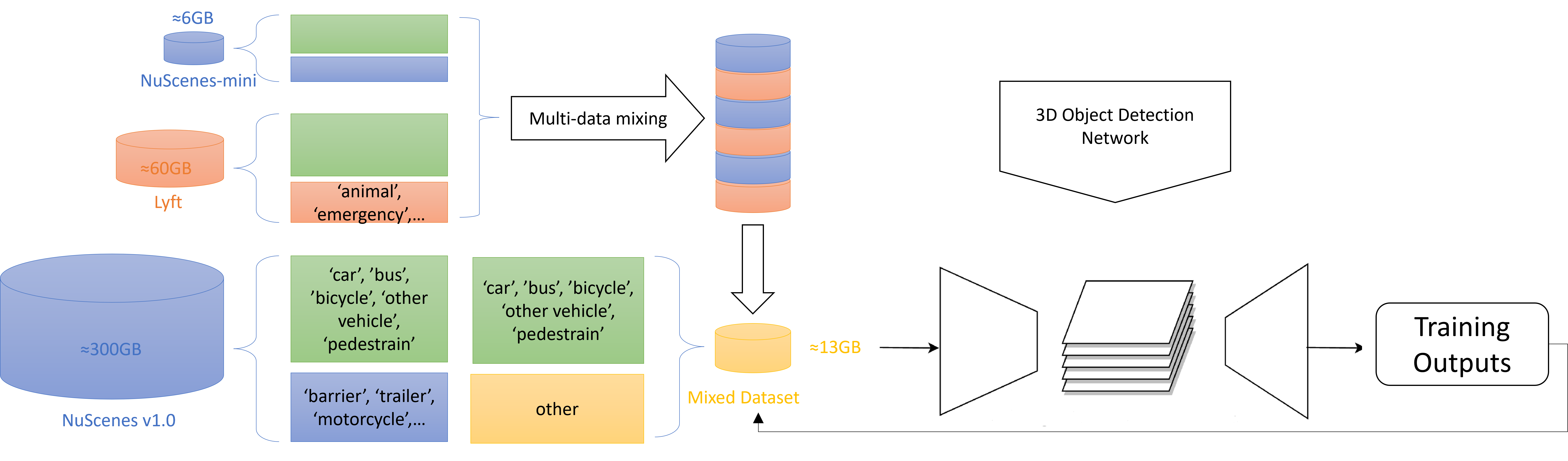
Mixing Data from Different Dataset is a key part of our domain adaptation method. In multi-dataset training, the model can train multiple datasets simultaneously, some of which may be relevant to the target task. In this case, the model can improve its performance on the target task by learning on multiple data sets, thereby achieving the effect of transfer learning. Instead of using a single 3D dataset, I aim to take advantage of the adaptation to the unseen scenes or a new type of camera. Here for my NuScenes-mini and Lyft, and also for possible future research, I named the multi-dataset , where represents one of the pure 3D datasets I used to mix in with various data distriution. With , the key data distributions of each class and objects are represented by annotations with a bounding box set with with 3D coordinates, and with related labels . Also, is used to represent other fixed 3D information such as BEV map size, and camera instincts information that every dataset uses for data format transfer. It is very obvious that NuScenes-mini and Lyft hold different dataset sizes and formats, this imbalance number of the camera images in each dataset needs an aligned simple mixing method. Therefore, as shown in Fig 3, I shuffled and regrouped the images, keeping the 3D position relationship, and a mixed dataset with six positions images set with the diversity of NuScenes-mini and Lyft, will be used for further training and experiments. Various scenes will be included in each epoch that the network would be forced out of overfit and could be used in the data transfer learning.
Labels for Mixed Dataset is a practical challenge I met trying to solve the domain gap of datasets. Each self-driving dataset uses its own set of labels, corresponding to objects with different semantic hierarchies. For example, the NuScenes dataset combines a collection of object classes, including human, vehicle, etc., with potential subclasses represented in the form human.pedestrain.adult. Lyft’s open dataset annotations will contain simple object classifications, but not more refined classifications. After a brief consideration, the label differences shown in Fig LABEL: only contain object labels, while the hidden subclasses continue to follow the structure of the source dataset. As analyzed before, the unreconciled parts of several datasets will more or less destabilize the training because the datasets do not have the same class nomenclature. Additionally, I would like to have a more unified set of statistical methods.
3.2 M&M-3D
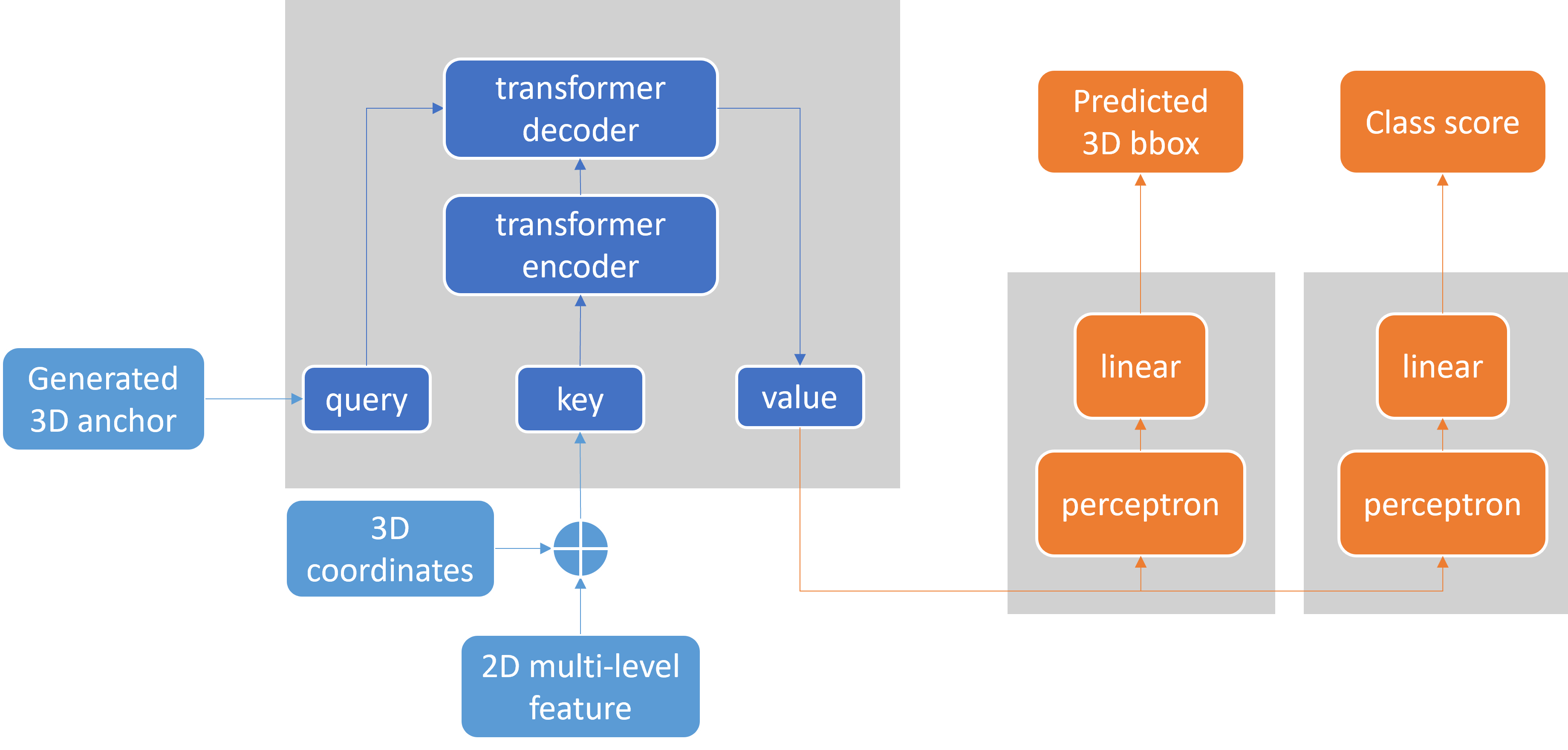
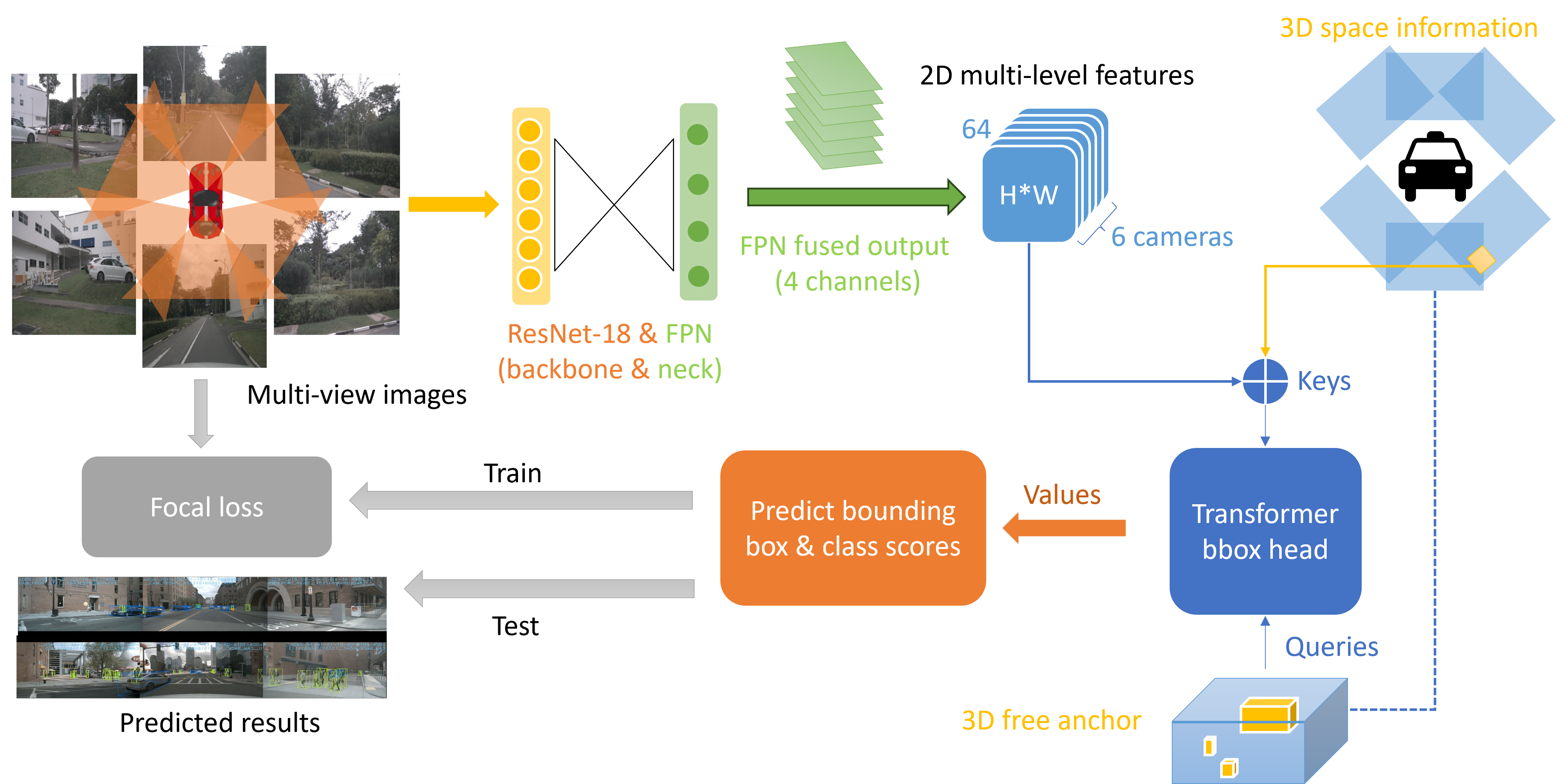
The entire transformer network involved in Fig 13 can be taken a brief look at. Although transformers have been widely used in the language and vision domains in recent years because of their powerful visual-language transfer, their actual deployment for 3D object detection still requires additional modifications. In addition, the 2D image features output from the FPN also needs to be further modified to 2D multi-level features.
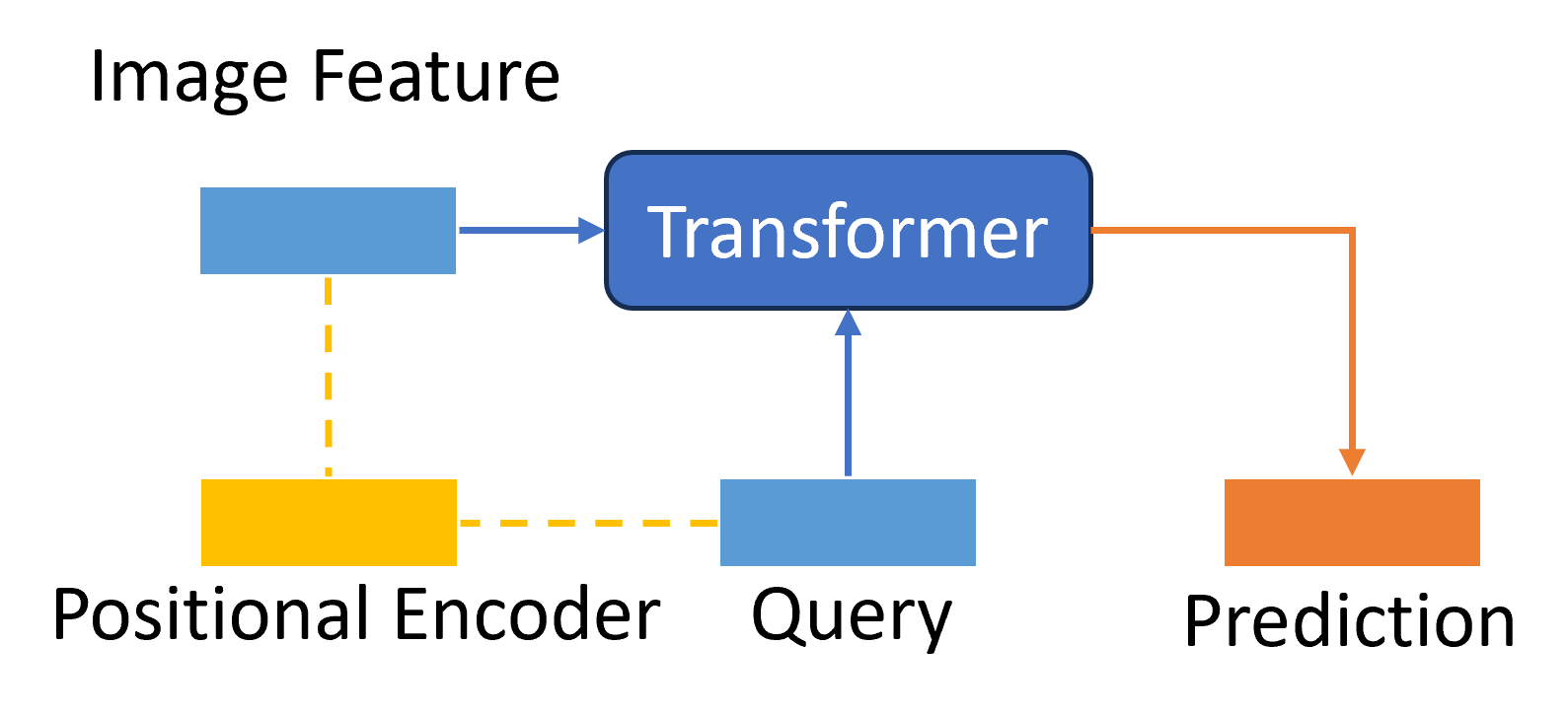
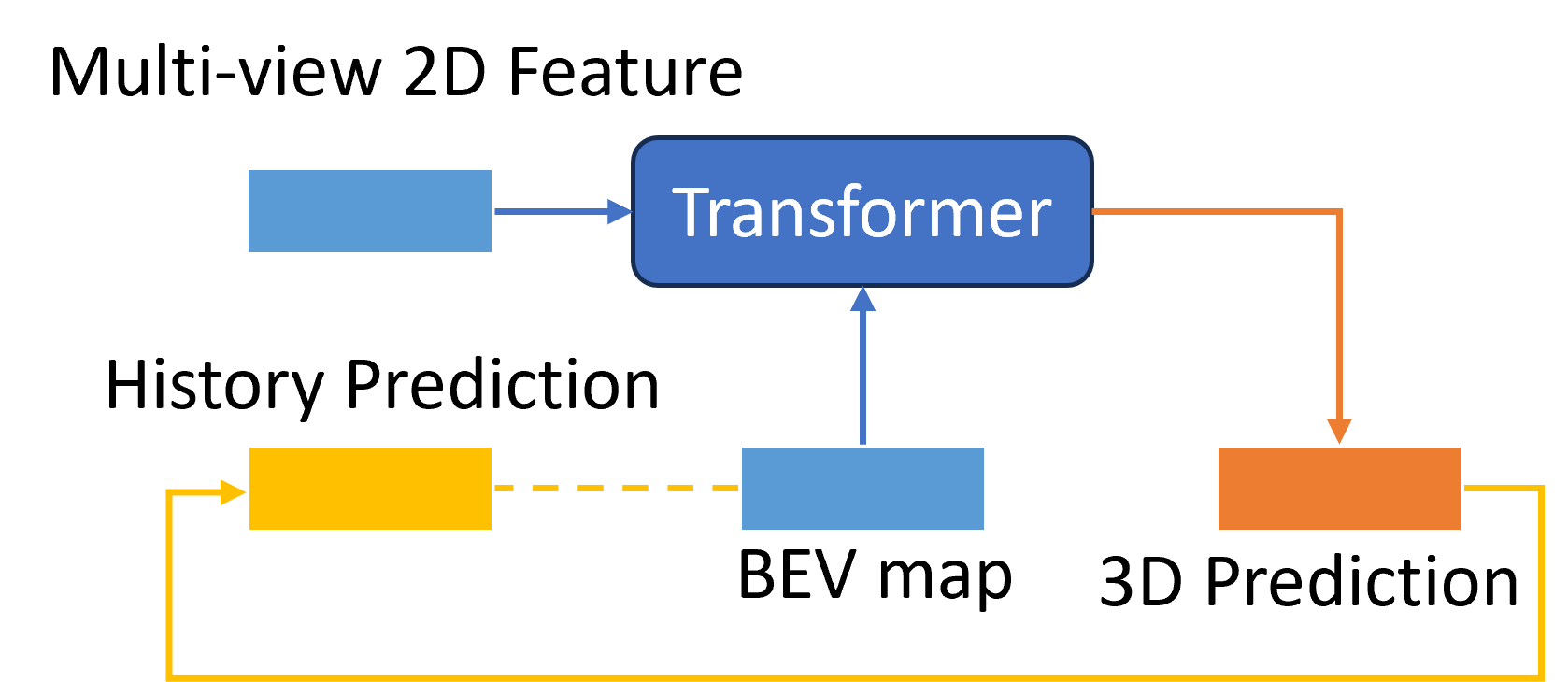
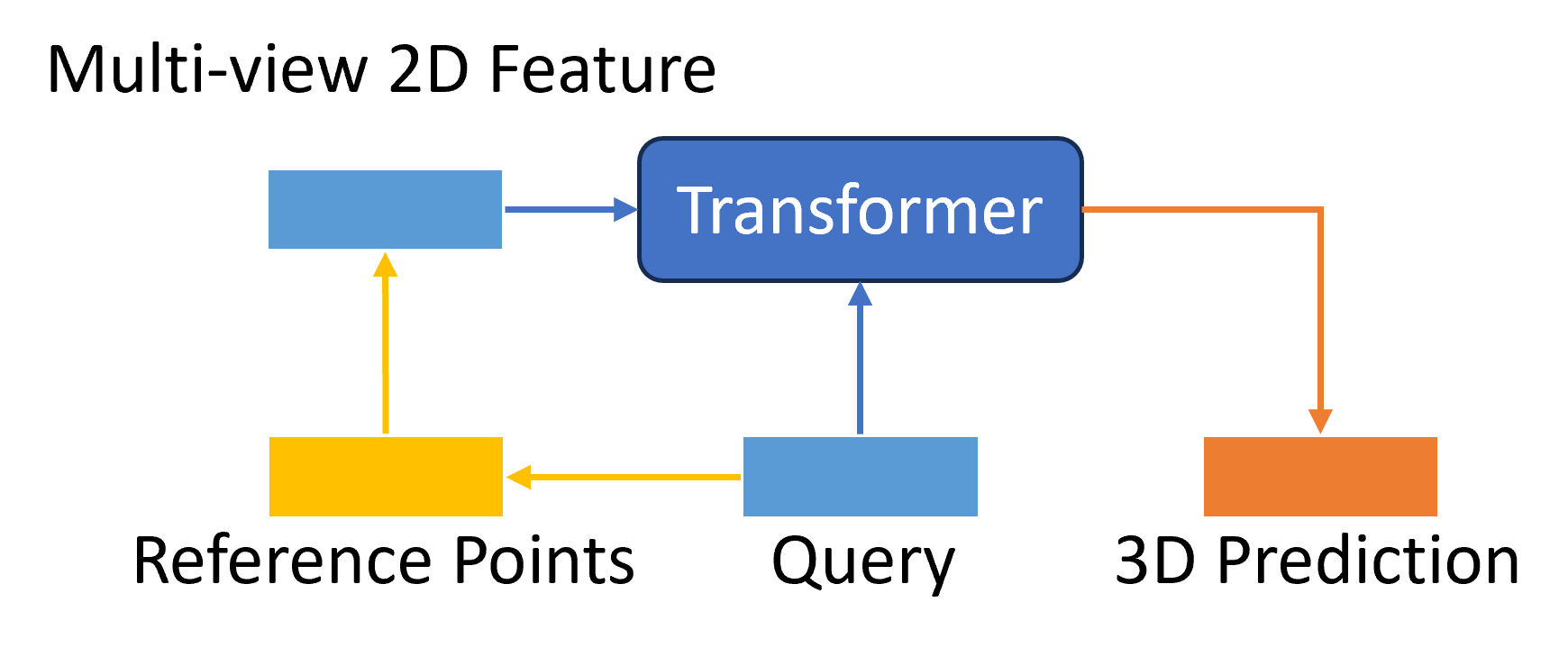
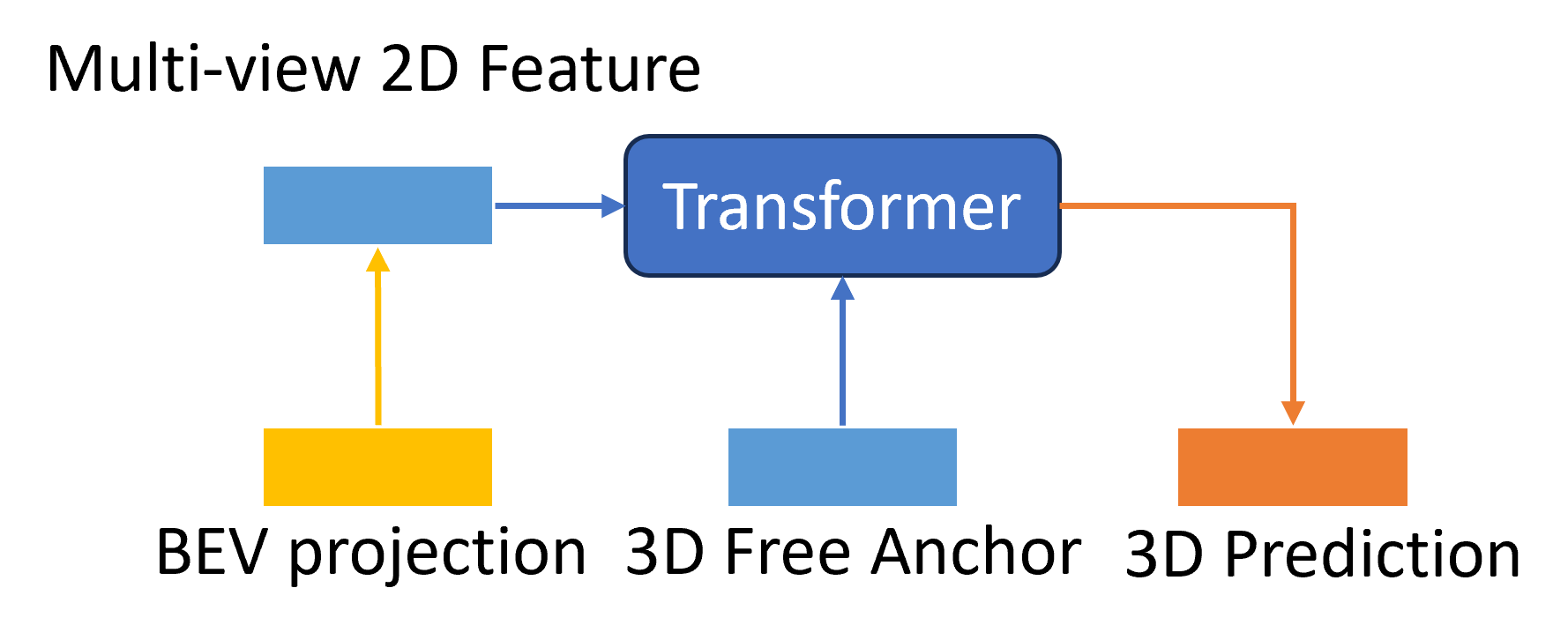
I don’t mean the 3D attention is brought out here as the first time for 3D object detection. However, as shown in Fig.9 existing 2D-to-3D transformer works remain many future challenges. The query was represented by BEV grid-size parameters (BEVFormer) or reference points in camera images (DETR3D). The initiated inaccurate coordinates may lead the network to perform weirdly from the training features. Also, BEVFormer used the space-cross part of the BEV map but didn’t connect the global location; DETR3D introduced the related points but repeatedly projected them, which is less effective if the attention is enough. Combining their advantages is a tryout and the main idea of this new design. So in my new design, I use related 3D coordinates among the 3D space to imply the possible real-world objects and also give a global space region to improve the positional information quality in 2D images.
3.2.1 Multi-level feature process
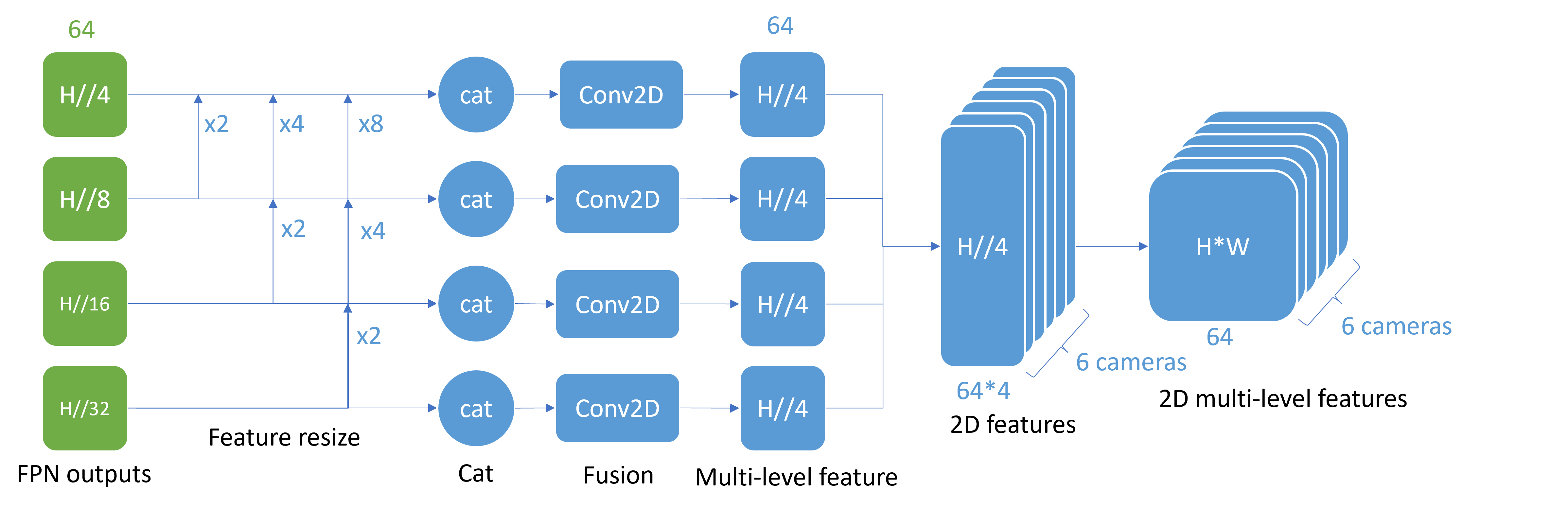
The FPN outputs are 4 channel with size for the channel, where . Then for each channel, the network upscales every other channel with smaller feature sizes and uses a cat function to add them together. Next, as four features with same feature size but different channels, I introduced four fusion Conv2D with different in channels but same 64 out channels. Until now, the network converts the FPN outputs of different sizes of features to a multi-level feature with size . To fit the following Transformer and the related 3D information, a final reshape is needed to output the 2D multi-level feature in size . Noted that there are 6 camera images fed to the network at the same batch, forming the 3D scenes.
3.2.2 3D Anchor as Customized Query
As mentioned before, the Transformer structure will be used for the bbox prediction work. As the integral query in my Transformer network, I chose to customize the 3D anchor box as the query for the task of 3D object detection. The functions and the class I used here to generate the promoted anchors are from the class ’Anchor3DRangeGenerator’ [22] provided by MMDet3D [mmengine2022].
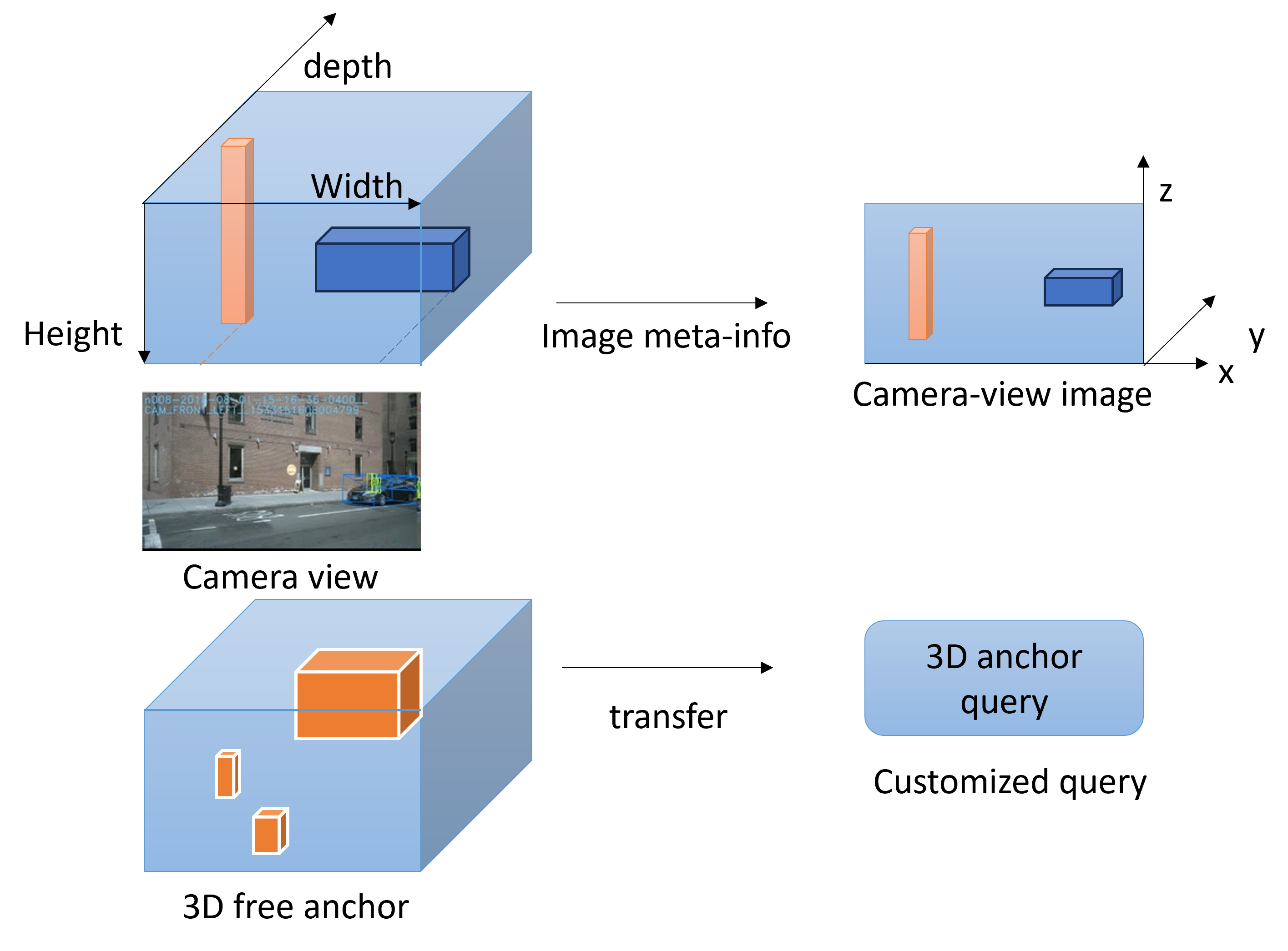
As shown in Fig 11, it generates the center by evenly distributing the predefined size of anchor frames in the minimum and maximum range according to the size of the image. If we give the pre-provided 3D anchor type in camera format, then the function I named will give information about all possible 3D anchors in a known camera-aware field of view , which is subsequently passed through the meta info of the datasets (also the camera intrinsic and extrinsic information to know the camera view range and twisted angle ) into our common visual bbox .
3.2.3 3D Coordinates as Positional Encoder
Two points worth noting, however, are that first, we can only obtain 3D coordinates from 2D images. Secondly, the 3D position will only be added to the 2D multi-level feature (Transformer input), not to the anchor as Query, because the 3D anchor already has a 3D position, so there is no need to add the same content again. This means that we need to do some processing on the initial to get the final , and my expression for the 3D position needs to end up in the same format as the 2D multi-level feature, but with the same content as the anchor.
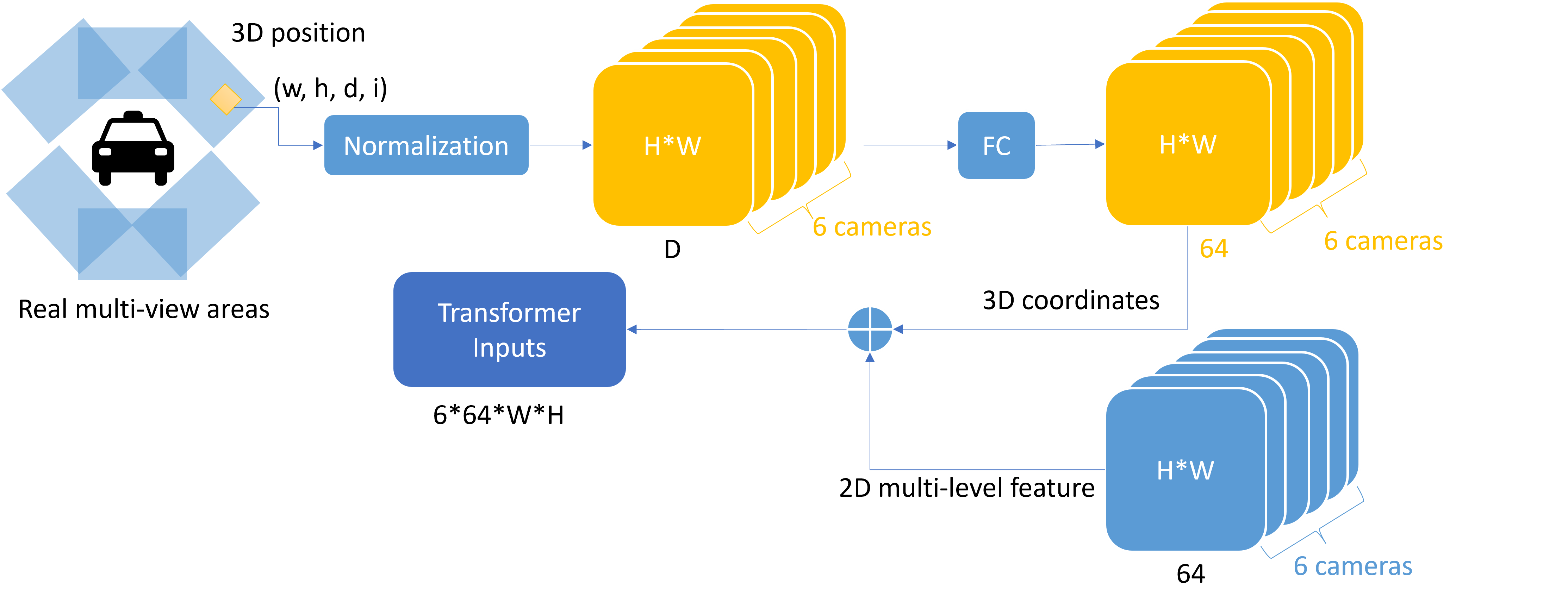
As shown in Fig 12, I decided to start with the pixel points of the 2D image, as the picture pixel points directly represent its position in our ’multi-view images’. Firstly, a rough representation of the position of pixel point in a set of 6 camera images can be written as , where means the th of the 6 views from ’FRONT LEFT’, ’FRONT’, ’FRONT RIGHT’, ’BACK LEFT’, ’BACK’, ’BACK RIGHT’. Obviously, this representation is not feasible, because there is no way to represent the 3D information in here, and it is not consistent with the previous anchor. Then, referring to the previous anchor frame generation, we express any point in a set of 6 images like this: , where . Then I further normalize the pixel coordinates in order to make sure that such 3D information also works for different and to reduce the amount of computation. Then a pixel point in the view can be represented as
, where
So now, we get 3D coordinates of size . In order to be consistent with the 2D multi-level feature format, we add a fully connected layer to make the final 3D coordinates .
3.2.4 Transformer Bounding Box Head
Although the performance of conv2d has been confirmed by a lot of excellent work, it has spatial invariance when processing features at different locations. This means that Conv2D network cannot directly consider the 3D information of a specific location, which has a very large negative impact on our 3D target detection and 3Dbbox prediction. In addition, Conv2D cannot explicitly express the conversion from image features to bbox.

Now, let me explain how some of the data I customized earlier will enter this Transformer network.
Transformer network contains the input and output that will processed by it including 2D image multi-level features , 3D coordinates , anchor box query , , and the final result . The self-attention mechanism in Transformer allows the network to automatically learn the relationship between features and notice features at different locations. Specifically, the network combines the input with sequence with the query to obtain each feature and each anchor attentional correlation between boxes. In other words, the network will automatically learn the relationship between features, notice features at different locations, and calculate the attention score between them. When predicting the task, we combine the attention score and the input to get the final prediction result . The grey networks in Fig 13 are introduced separately in the input and output parts below.
Inputs are 3D features combining the 2D multi-level features and 3D coordinates. The 3D features could be extend as where . Also, the 2D multi-level features are where and 3D coordinates where . However, as in position part 3.2.3, the original where is the depth in known 3D information, which transposed into a FC layer then we have . For the combination of features and positional encoder, I cat them of the same size together to be the 3D features.
Outputs from the network will be sent to another network to predict bbox and class results. In the structural sense of Transformer, Output is actually Query at the next moment. But in my simple Transformer, the output is direct, containing the corresponding 3D features. But for a single predicted data , after the Transformer outputs the output, further processing is required to obtain the predicted bbox and class information from the same set of outputs. As shown in Fig 4, here I have designed two identical ‘Perception + Linear’. Because here the 3D output is converted to 3D bbox and category, so only simple regression and classification functions are needed.
4 Results
4.1 Experiments Setup
Implementation Details followed the standard as others methods and work. The network structure follows the BEVFromer settings. The initial image size is the smallest considering the network’s efficiency, with data augmentations including random scaling, random flipping, and random rotation. For the 2D image feature extraction, I used ResNet-18 with PyTorch pre-trained checkpoint, FPN for multi-scale features with sizes of 1/4, 1/8, 1/16, 1/32, and the channel dimension of 64. For the 3D information on datasets, the BEV map size is the default , where the 3D space ranges from to for and and to for . For the training, I used one 12GB GTX2080Ti with 100GB disk space to train the model. The configuration contains 10 epochs(2x schedule in MMDet3D) training in 16 hours with a base learning rate and the AdamW optimizer with a weight decay of 0.01. No data augmentation methods are used for the test.
Dataset & Evaluation Metrics for the 3D detection task are same with others. I used nuScenes Detection Score (NDS), mean Average Precision(mAP), mean Average Translation Error (mATE), mean Average Scale Error (mASE), mean Average Orientation Error(mAOE), mean Average Velocity Error (mAVE), mean Average Attribute Error (mAAE) as the result scores shown in result tables for NuScenes-mini, Lyft and the mixed dataset.
4.2 Results
4.2.1 Benchmark Results
This is a part summarizing other pioneer and excellent work that also uses camera data. Comparing their adjustments on the backbone, and image size, their results show more information beyond my limited research.
| Method | Modality | Backbone | Image Size | Epochs | 3D Object Detection | |
|---|---|---|---|---|---|---|
| Camera Only | NDS () | mAP () | ||||
| FCOS3D [14] | yes | ResNet-101 | 1600x900 | 48 | 0.372 | 0.295 |
| BEVFormer-S | no | ResNet-50 | - | 48 | 0.448 | 0.375 |
| BEVFormer [5] | no | ResNet-101 | 1600x900 | 48 | 0.517 | 0.416 |
| BEVDet [3] | yes | ResNet-50 | 704x256 | 48 | 0.372 | 0.286 |
| BEVDet | yes | ResNet-50 | 704x256 | 48 | 0.379 | 0.298 |
| BEVDet | yes | ResNet-101 | 704x256 | 48 | 0.381 | 0.302 |
| BEVDet | yes | Swin-Tiny | 704x256 | 48 | 0.392 | 0.312 |
| BEVDet | yes | ResNet-50 | 1056x384 | 48 | 0.389 | 0.318 |
| BEVDet | yes | ResNet-101 | 1056x384 | 48 | 0.396 | 0.330 |
| BEVDet | yes | Swin-Tiny | 1056x384 | 48 | 0.410 | 0.333 |
| BEVDet | yes | Swin-Tiny | 1408x512 | 48 | 0.417 | 0.349 |
| DETR3D [6] | yes | Swin-Small | 1600x900 | 48 | 0.374 | 0.303 |
| DETR3D-CBGS | yes | Swin-Small | 1600x900 | 48 | 0.434 | 0.349 |
| PETR [19] | yes | ResNet-50-DCN | 1056x384 | 48 | 0.381 | 0.313 |
| PETR | yes | ResNet-101-DCN | 1408X512 | 48 | 0.421 | 0.357 |
| PETR | yes | Swin-Tiny | 1408X512 | 48 | 0.431 | 0.361 |
| BEVDepth [18] | no | ResNet-50 | 704x256 | 48 | 0.475 | 0.351 |
| BEVDepth | no | ResNet-101 | 1408X512 | 48 | 0.535 | 0.421 |
| BEVDepth | no | ResNet-101-DCN | 1408X512 | 48 | 0.538 | 0.418 |
| Network | Camera Only | Backbone | Image Size | 10 | NuScenes-mini | |
| My Design | yes | ResNet-18 | 704x256 | 10 | 0.4637 | 0.3767 |
Through comparison, it is found that existing work confirms that even on a large-scale data set such as NuScenes v1.0, just replacing a larger backbone and inputting a larger image size has a significant impact on the final 3D object detection score. My work is inspired by it. First, these works proved the feasibility of transferring 2D visual recognition to 3D visual recognition, and then some work confirmed the importance of 3D spatial features such as BEV for 3D object recognition, especially models trained using only multi-view camera data. This is also the main reason why my network can process efficiently using only multi-view camera 2D images and BEV maps, combined with the modified Transformer structure.
4.2.2 My Results on NuScenes-mini and Lyft
Table 2 and Table 3 show my network prediction results with multi-dataset training. Although Lyft is not a popular research dataset, I still want to use the predictions on Lyft to show the impacts form my new network design.
| NuSenes-mini Results | ||||||
| Object Class | AP () | ATE () | ASE () | AOE () | AVE () | AAE () |
| Car | 0.609 | 0.467 | 0.136 | 0.205 | 0.692 | 0.240 |
| Bicycle | 0.338 | 0.584 | 0.228 | 0.413 | 0.345 | 0.053 |
| Motorcycle | 0.384 | 0.635 | 0.188 | 1.014 | 0.957 | 0.214 |
| Truck | 0.399 | 0.553 | 0.198 | 0.242 | 0.662 | 0.238 |
| Bus | 0.431 | 0.611 | 0.176 | 0.221 | 0.945 | 0.283 |
| Pedestrian | 0.441 | 0.672 | 0.232 | 0.944 | 0.665 | 0.293 |
| mAP for Common 6 | 0.4370 | |||||
| Construction Vehicle | 0.147 | 0.962 | 0.408 | 0.896 | 0.122 | 0.383 |
| Trailer | 0.153 | 0.903 | 0.214 | 0.571 | 0.469 | 0.131 |
| Traffic Cone | 0.477 | 0.492 | 0.344 | nan | nan | nan |
| Barrier | 0.436 | 0.712 | 0.241 | 0.119 | nan | nan |
| NDS () | mAP () | mATE () | mASE () | mAOE () | mAVE () | mAAE () |
| 0.4637 | 0.3767 | 0.6590 | 0.2364 | 0.5139 | 0.6071 | 0.2300 |
| Lyft Results | ||||||
| Object Class | AP | ATE | ASE | AOE | AVE | AAE |
| Car | 0.389 | 0.476 | 0.217 | 0.253 | 0.703 | 0.246 |
| Bicycle | 0.127 | 0.733 | 0.252 | 0.951 | 0.326 | 0.231 |
| Motorcycle | 0.201 | 0.785 | 0.294 | 1.056 | 0.956 | 0.249 |
| Truck | 0.246 | 0.781 | 0.198 | 0.342 | 0.468 | 0.228 |
| Bus | 0.297 | 0.622 | 0.264 | 0.311 | 1.146 | 0.235 |
| Pedestrian | 0.274 | 0.749 | 0.305 | 0.947 | 0.563 | 0.344 |
| mAP for Common 6 | 0.2557 | |||||
| Emergency Vehicle | 0.108 | 0.262 | 0.437 | 1.177 | 1.098 | 0.050 |
| Other Vehicle | 0.300 | 0.857 | 0.634 | 0.569 | 0.729 | 0.194 |
| Animal | 0.104 | 0.304 | 0.433 | 1.089 | 0.267 | 0.399 |
| NDS () | mAP () | mATE () | mASE () | mAOE () | mAVE () | mAAE () |
| 0.3677 | 0.2046 | 0.5569 | 0.2763 | 0.670 | 0.6250 | 0.2176 |
4.3 Ablation Studies and Analysis
In Table 4 below, three experiment results are shown. And I will focus on the performance of NDS, mAP for 6 shared classes and mAP for both datasets NuScenes-mini and Lyft.
| Target Domain | NuScenes-mini | |||||||
| Method | NDS() | mAP-6() | mAP() | mATE() | mASE() | mAOE() | mAVE() | mAAE() |
| NuScenes-mini Only | 0.3638 | 0.3560 | 0.3248 | 0.7729 | 0.3232 | 0.8915 | 0.6644 | 0.3332 |
| MdT | 0.3605 | 0.3620 | 0.3284 | 0.8948 | 0.3203 | 0.8422 | 0.6532 | 0.3256 |
| MdT+Transformer | 0.4637 | 0.4370 | 0.3767 | 0.6590 | 0.2364 | 0.5139 | 0.6071 | 0.2300 |
| Target Domain | Lyft | |||||||
| Method | NDS() | mAP-6() | mAP() | mATE() | mASE() | mAOE() | mAVE() | mAAE() |
| NuScenes-mini Only | 0.0012 | 0.004 | 0.0024 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| MdT | 0.2541 | 0.1658 | 0.1044 | 0.5460 | 0.3647 | 0.4496 | 0.3914 | 0.2670 |
| MdT+Transformer | 0.3677 | 0.2557 | 0.2046 | 0.5569 | 0.2763 | 0.670 | 0.6250 | 0.2176 |
4.3.1 Multi-source Domain Adaptation
In Tabel 4, we can see that for the two test results of the NuScenes-mini part, the changes in NuScenes-mini training and multi-dataset training are very weak. This is because my multi-dataset itself is Contains all NuScenes-mini. This small change is not surprising, because this part is mainly used for the transfer capability of training models, facing data and domains like Lyft that are several times larger than NuScenes-mini. Looking at it this way, the improvement brought by multi-dataset training technology is considerable. The test data on Lyft shows that NDS increased by 0.25 (0.00120.2541), and mAP-6 increased by 0.16 (0.040.1658). mAP increased by 0.10 (0.0240.1044). The main increase comes from mAP-6.
4.3.2 Transformer for 3D Object Detection Tasks
For the Transformer structure I designed, the performance improvement it provides is very significant, even NuScenes-mini’s NDS (0.36050.4637), mAP-6 (0.36200.4370) and mAP (0.32840.3767) exceeds the impact of multi-dataste training. Lyft’s improvement here is also amazing. However, there is no way to further verify whether the changes in Lyft’s NDS (0.25410.3677), mAP-6 (0.26580.2577) and mAP (0.10440.2046) come from changes in the network structure or the training data Increase and diversify.
4.3.3 Network Effectiveness
My lightweight model has demonstrated high efficiency, and I think it has the potential to become a cornerstone choice for handling 3D object detection tasks in the future. The computational efficiency of the model is a key feature. By adopting the network architecture of multi-layer feature and Transformer models and efficient algorithms, my model can be trained and inferred with only one GTX2080Ti (12GB). This not only reduces hardware requirements but also shortens training time, which will not exceed 8 hours at a time. This facilitates rapid iteration and model improvement. Second, we have made significant progress in resource efficiency. The entire training and testing requires no more than 100GB of memory, which means it can run in constrained hardware environments and does not put unnecessary pressure on system resources.
5 Conclusion
I proposed a network structure for multi-view 3D object detection. Through multi-dataset training and anchor frame detection head based on the Transformer structure, the network demonstrated good domain transfer performance and efficient detection performance by image features and 3D information combined. The purpose of the network is to use a small amount of data in a limited source domain and use the existing large model pre-training backbone weights to achieve competitive index data in the new target domain. My main techniques include a diverse 3D dataset that fuses different datasets across domains, 2D multi-level image feature fusion, new anchor box object query, utilizing 3D information as available semantic information, and 2D multi-view image feature blending with 3D free anchor box. In conclusion, my network achieved good results on standard metrics of 3D object detection by using data transfer, and it shows promising potential in ’2D features-3D space’ for 3D visual recognition by using 2D visual recognition techniques.
References
- [1] A. Radford and et al, “Learning transferable visual models from natural language supervision,” in International conference on machine learning, pp. 8748–8763, PMLR, 2021.
- [2] C. Reading, A. Harakeh, J. Chae, and S. L. Waslander, “Categorical depth distributionnetwork for monocular 3d object detection,” CVPR, 2021.
- [3] J. Huang, G. Huang, Z. Zhu, Y. Ye, and D. Du, “Bevdet: High-performance multi-camera 3d object detection in bird-eye-view,” arXiv preprint arXiv:2112.11790, 2021.
- [4] J. Huang and G. Huang, “Bevdet4d: Exploit temporal cues in multi-camera 3d object detection,” arXiv preprint arXiv:2203.17054, 2022.
- [5] Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y. Qiao, and J. Dai, “Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,” in European conference on computer vision, pp. 1–18, Springer, 2022.
- [6] Y. Wang, V. C. Guizilini, T. Zhang, Y. Wang, H. Zhao, and J. Solomon, “Detr3d: 3d object detection from multi-view images via 3d-to-2d queries,” in Conference on Robot Learning, pp. 180–191, PMLR, 2022.
- [7] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” Lecture Notes in Computer Science, p. 213–229, 2020.
- [8] X. Chen, K. Kundu, Z. Zhang, H. Ma, S. Fidler, and R. Urtasun, “Monocular 3d object detection for autonomous driving,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2147–2156, 2016.
- [9] T. Roddick, A. Kendall, and R. Cipolla, “Orthographic feature transform for monocular 3d object detection,” 2018.
- [10] W. Kehl, F. Manhardt, F. Tombari, S. Ilic, and N. Navab, “Ssd-6d: Making rgb-based 3d detection and 6d pose estimation great again,” 2017 IEEE International Conference on Computer Vision (ICCV), Oct 2017.
- [11] J. Ku, A. D. Pon, and S. L. Waslander, “Monocular 3d object detection leveraging accurate proposals and shape reconstruction,” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2019.
- [12] D. Beker, H. Kato, M. A. Morariu, T. Ando, T. Matsuoka, W. Kehl, and A. Gaidon, “Monocular differentiable rendering for self-supervised 3d object detection,” Lecture Notes in Computer Science, pp. 514––529, 2020.
- [13] Z. Liu, Z. Wu, and R. Toth, “Smoke: Single-stage monocular 3d object detection via keypoint estimation,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Jun 2020.
- [14] T. Wang, X. Zhu, J. Pang, and D. Lin, “Fcos3d: Fully convolutional one-stage monocular 3d object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 913–922, 2021.
- [15] Y. Ma, T. Wang, X. Bai, H. Yang, Y. Hou, Y. Wang, Y. Qiao, R. Yang, D. Manocha, and X. Zhu, “Vision-centric bev perception: A survey,” 2022.
- [16] J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” Lecture Notes in Computer Science, pp. 194––210, 2020.
- [17] Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. L. Rus, and S. Han, “Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,” in 2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 2774–2781, IEEE, 2023.
- [18] Y. Li, Z. Ge, G. Yu, J. Yang, Z. Wang, Y. Shi, J. Sun, and Z. Li, “Bevdepth: Acquisition of reliable depth for multi-view 3d object detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, pp. 1477–1485, 2023.
- [19] Y. Liu, T. Wang, X. Zhang, and J. Sun, “Petr: Position embedding transformation for multi-view 3d object detection,” in European Conference on Computer Vision, pp. 531–548, Springer, 2022.
- [20] H. Caesar and et al, “nuscenes: A multimodal dataset for autonomous driving,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11621–11631, 2020.
- [21] J. Houston and et al, “One thousand and one hours: Self-driving motion prediction dataset,” in Conference on Robot Learning, pp. 409–418, PMLR, 2021.
- [22] X. Zhang, F. Wan, C. Liu, R. Ji, and Q. Ye, “Freeanchor: Learning to match anchors for visual object detection,” Advances in neural information processing systems, vol. 32, 2019.