Mitigating the Impact of False Negatives in Dense Retrieval
with Contrastive Confidence Regularization
Abstract
In open-domain Question Answering (QA), dense retrieval is crucial for finding relevant passages for answer generation. Typically, contrastive learning is used to train a retrieval model that maps passages and queries to the same semantic space. The objective is to make similar ones closer and dissimilar ones further apart. However, training such a system is challenging due to the false negative issue, where relevant passages may be missed during data annotation. Hard negative sampling, which is commonly used to improve contrastive learning, can introduce more noise in training. This is because hard negatives are those closer to a given query, and thus more likely to be false negatives. To address this issue, we propose a novel contrastive confidence regularizer for Noise Contrastive Estimation (NCE) loss, a commonly used loss for dense retrieval. Our analysis shows that the regularizer helps dense retrieval models be more robust against false negatives with a theoretical guarantee. Additionally, we propose a model-agnostic method to filter out noisy negative passages in the dataset, improving any downstream dense retrieval models. Through experiments on three datasets, we demonstrate that our method achieves better retrieval performance in comparison to existing state-of-the-art dense retrieval systems.
1 Introduction
Text retrieval involves searching for relevant information in vast text collections based on user queries. Efficient and effective methods for this task have revolutionized how we interact with information systems. Recently, there has been growing interest in augmenting large language models (LLMs) with text retrieval for question answering (QA) (Lewis et al. 2020a; Guu et al. 2020; Glass et al. 2022; Borgeaud et al. 2022; Fu et al. 2022; Zhang et al. 2023). These approaches harness retrieval models to obtain external knowledge and ground LLM outputs, reducing hallucinations and the need for frequent LLM updates. Interestingly, augmenting an LM with a retrieval helps reduce the number of parameters required to achieve similar performance as larger LMs (Mialon et al. 2023).
Text retrieval methods can be broadly categorized into two main approaches: sparse and dense retrievals. Sparse methods, such as BM25, exploit the frequency of words to measure the relevance between a passage and a query. While efficient, these methods often fall short of capturing intricate relationships and contextual nuances of language. In contrast, dense retrieval methods aim to learn meaningful representations from the semantic content of passages and queries effectively. These models can be trained based on a pretraining model (e.g. BERT, RoBERTa) as well as fine-tuned for downstream QA tasks (Lewis et al. 2020b), offering easy integration. In addition, it is possible to apply approximate nearest neighbors (ANN) with dense retrieval (Xiong et al. 2021) for efficient retrieval.
This paper focuses on dense retrieval, where contrastive learning is often employed to train passage and query encoders. The core principle of contrastive learning is to encode passages and queries such that relevant passages are closer to their corresponding query in the embedding space, while irrelevant passages are farther away. To train such encoders, we need a labeled dataset with queries annotated with relevant passages (positive samples). However, due to the vast number of candidate passages and the complexity of questions, it is common for annotators to miss relevant information (texts) during data preparation, leading to unlabeled positive examples (false negatives) in the training set. Recent studies support this assumption. For instance, Ni, Gardner, and Dasigi (2021) found that over half of 50 answerable questions from the IIRC dataset (Ferguson et al. 2020) had at least one missing piece of evidence. Similarly, Qu et al. (2021) manually reviewed top-retrieved passages not labeled as positives in MSMARCO (Nguyen et al. 2016) and detected a 70% false negative rate. On the other hand, it is essential to sample hard negatives for effective contrastive learning. Here, hard negatives refer to passages obtained from the top results of a pre-trained dense retrieval model or BM25. Unfortunately, hard negative sampling is susceptible to higher false negative rates in noisy datasets because such negative samples are more likely to be mislabeled ones. Therefore, mitigating the impact of false negatives can potentially improve the performance of dense retrieval.
Several strategies have recently emerged to address the problem of false negatives. Qu et al. (2021) use a highly effective but inefficient reranker based on a cross-encoder to identify high-confidence negatives as true negatives, which were then used to train the retrieval model. Ni, Gardner, and Dasigi (2021) leverage answers in the downstream QA task and design several heuristics to detect valid contexts such as lexical overlapping (between a gold answer and a candidate passage). Recently, Zhou et al. (2022) suggests selecting samples that are highly similar to positive samples but not too close to the query. These samples are considered informative negatives and unlikely to be false negatives. Despite the recent progress, these current methods are primarily based on heuristics and lack a theoretical guarantee.
This paper formalizes the problem of training dense retrieval with false negatives into the peer loss framework (Liu and Guo 2020; Cheng et al. 2021), a theoretical sound approach to learning with label noise. We extend this framework by developing a confidence regularizer for NCE, a commonly used loss for training dense retrieval models. Our regularized loss function increases the model’s confidence and proves to be robust against false negatives. By encouraging confident scoring, we prevent the model from overfitting to noise, resulting in a more robust retrieval model. We then propose a new passage sieve algorithm, that makes use of a confidence regularized retrieval model to select true hard negatives. The clean dataset after the passage sieve is then used to train a stronger retrieval model. We prove that our method can successfully filter out false negatives from hard negatives under mild assumptions. Through experiments on three datasets, we demonstrate that our method achieves better retrieval performance compared to existing state-of-the-art dense retrieval systems that rely on heuristic false negative filtering. Supplementary materials (the appendix, codes) can be found in our GitHub111https://github.com/wangskyGit/passage-sieve.
2 Related Works
2.1 Dense Retrieval
The dual-encoder (two-towers or biencoder) architecture (Huang et al. 2013; Reimers and Gurevych 2019) is the common choice for dense retrieval thanks to its high efficiency. However, vanilla dual encoders have several challenges such as the limited expressiveness compared to cross-encoders, and the suboptimal performance due to non-informative negative samples. As a result, various solutions have been introduced to improve vanilla dual encoders from different perspectives such as knowledge distillation (Ren et al. 2021b; Lu et al. 2022), lightweight interaction models (Khattab and Zaharia 2020; Humeau et al. 2019), sophisticated training procedure (Zhang et al. 2021; Qu et al. 2021; Ren et al. 2021b), negative sampling strategies (Karpukhin et al. 2020; Xiong et al. 2021; Qu et al. 2021; Zhou et al. 2022). In this paper, we focus mostly on negative sampling strategies, particularly targeting the false negative issue. Unlike the closely related works (Qu et al. 2021; Zhou et al. 2022; Ni, Gardner, and Dasigi 2021), which exploit heuristic strategies, our method leverages the peer-loss approach (Liu and Guo 2020), effectively combining practical application with a theoretically-informed perspective.
2.2 Label-Noise Robust Machine Learning
Developing machine learning models that are robust against label noise is important for supervised learning. Existing methods tackle label noise based on the type of noise, such as random noise (Natarajan et al. 2013; Manwani and Sastry 2013), class-dependent noise (Liu and Tao 2015; Patrini et al. 2017; Yao et al. 2020), or instance-dependent noise (Zhu, Liu, and Liu 2021; Cheng et al. 2021; Xia et al. 2020; Yang et al. 2022; Hao et al. 2022). Unfortunately, these methods are mainly designed for multi-class classification, and thus cannot be directly applied to our task.
Also relevant to our work are (Chuang et al. 2020; Robinson et al. 2020) which consider the issue of bias in contrastive learning for multi-class classification. These studies rely on the assumption of a fixed uniform noise probability across different classes (i.e. queries in our case) to approximate the positive and negative distributions. In contrast, our work concerns noise in supervised contrastive learning for query-dependent ranking, where the distributions of positives and negatives are not the same for different queries. For example, it is more likely for queries with high recall to be associated with false negatives. In other words, the noise probability is not uniform across queries.
3 Preliminaries
3.1 Problem Formalization
Let be a collection of textual passages, and indicates the noisy set of tuples, each consists of a query , an annotated positive , and a set of sampled negatives with possible false negatives. Our objective is to mitigate the impacts of such false negatives and learn a robust retrieval model that can closely match the model trained on the clean dataset without false negatives.
3.2 Dual-Encoders for Dense Retrieval
A question or a passage is encoded as dense vectors separately, and the similarity is determined as the dot product of the encoder outputs.
| (1) |
where , represent distinct encoders that map the query and the passage into dense vectors, and is the similarity function such as dot product, cosine or Euclidean distance. The encoders are often built based on a pre-trained language model such as BERT-based (Karpukhin et al. 2020; Luan et al. 2021; Xiong et al. 2021; Oguz et al. 2022; Zhang et al. 2022), ERNIE-based (Qu et al. 2021; Ren et al. 2021b; Zhang et al. 2021) or RoBERTa-based (Oguz et al. 2022) etc. Since passages and queries are encoded separately, passage embeddings can be precomputed and indexed using Faiss (Johnson, Douze, and Jégou 2021) for efficient search.
Contrastive learning is commonly used to train dual encoders (Karpukhin et al. 2020; Xiong et al. 2021; Qu et al. 2021; Zhou et al. 2022). Typically, it is assumed that we have access to the clean training set . Using this training set, we measure the NCE (Noise-Contrastive Estimation) loss for a given query as follows:
| (2) | ||||
The total loss function can be calculated as follows:
| (3) |
where is the total number of queries in the dataset, and .
Negative sampling aims to select samples for and plays an important role in learning effective representations with contrastive learning. In the context of dense retrieval, two common strategies for negative sampling are in-batch negatives and hard negatives (Karpukhin et al. 2020; Xiong et al. 2021; Qu et al. 2021). In-batch negatives involve selecting positive passages from other queries in the same batch as negative samples. Generally, increasing the number of in-batch negatives improves dense retrieval performance. On the other hand, hard negatives are usually informative samples that receive a high similarity score from another retrieval model (e.g., BM25, a pre-trained DPR) (Karpukhin et al. 2020). Hard negatives can result in more effective training for DPR, yet including such samples may exaggerate the issue of false negatives.
3.3 Peer Loss and Confidence Regularization
The problem of learning with label noise has been extensively researched in the context of classification tasks (Liu and Guo 2020; Xia et al. 2020; Zhu, Liu, and Liu 2021; Cheng et al. 2021; Yang et al. 2022; Hao et al. 2022). Recently, two effective methods called Peer Loss (Liu and Guo 2020) and its inspired Confidence Regularizer (Cheng et al. 2021; Zhu, Liu, and Liu 2021) have been introduced to train robust machine learning models. One advantage of these methods is that they can work without requiring knowledge of the noise transition matrix or the probability of labels being flipped between classes.
The concept of peer loss is initially introduced for the binary classification problem. In this setting, we use to indicate an instance (a feature vector), and to represent the clean label and noisy labels, respectively. For each sample , the peer loss is then defined for cross-entropy loss as follows:
| (4) |
where indicates the classification function, and are derived from different, randomly selected peer sample for . Here, the first term measures the loss of the classifier prediction, whereas the second term penalizes the model when it excessively agrees with the incorrect or noisy labels (Liu and Guo 2020).
Inspired by peer loss, Cheng et al. (2021) develops , which extends the framework for multi-class classification and uses the first-order statistic instead of randomly selecting peer samples. Specifically, the new loss in is defined as follows:
| (5) |
where is a hyper-parameter, denotes the random variable corresponding to the noisy label and indicates the marginal distribution of . It has been shown that learning with an appropriate will make the loss function robust to instance-dependent label noise with theoretical guarantee (Cheng et al. 2021).
4 Contrastive Confidence Regularizer
We can adopt the above confidence regularization by introducing a binary label associated with each pair of queries and passages, where indicates the positive pair and vice versa. Subsequently, can be used with pairwise cross-entropy to mitigate the impacts of false negatives on training the retrieval model. Unfortunately, the cross-entropy loss is not as effective as the NCE loss (Eq. 3) for dense retrieval since the latter can learn a good ranking function by contrasting a positive sample over a list of negatives (Karpukhin et al. 2020). As a result, we aim to extend the framework of peer loss and tailor the confidence regularization to the NCE loss.
To adopt the peer-loss framework, we extend NCE loss to measure loss values associated with negative pairs besides positive ones. It is noteworthy that the original NCE loss (Eq. 3) incorporates all positive and negative pairs as normalization factors but only calculates loss values for positive pairs while disregarding the negative pairs. Formally, we use without superscript as a generic term for positive passage and negative passage , and define a general NCE loss as follows:
| (6) | ||||
where p could be either positive or negative passages for query . By this convention, the peer-loss framework can be applied by introducing randomly selected pairs , () as peer samples to regularize the NCE loss. We then obtain the contrastive peer loss as follows:
| (7) |
While our regularized loss appears similar to the original peer-loss outlined in Eq. 4, the major difference lies in the structure of the loss functions. Specifically, the first term of Eq. 7 is calculated only for positive pairs whereas the first term of Eq. 4 involves both positive () and negative () samples.
Similar to , we introduce and as the random variables corresponding to the peer passage and the peer query , respectively. Let be the distribution of given distribution . Note that is a uniform random variable, or , the contrastive peer loss has the following form in expectation:
The last approximation equation is obtained because when considering the batch training in dense retrieval, is drawn from in-batch passages. In addition, all the passages in batch form the conditional passage distribution of query . From this derivation, we can get the new noise robust contrastive loss function (i.e. ) with contrastive confidence regularizer denoted by as follows:
| (8) | ||||
In the following, we first empirically prove that our regularized loss function makes the retrieval model more confident, hence being more robust against false negatives. We then present the main theories that guarantee the robustness of our regularized NCE loss.
4.1 Analysis on Simulated Data
The RCL loss (eq. 8) is minimized by making the first term smaller and the expectation term bigger. In other words, we pull the loss associated with positive passages further from the average (the expectation) loss, subsequently making the model more confident in predicting positive passages. Intuitively, as label noise distorts the learning signal in clean data, the model trained on noisy datasets often fits noises, hence becoming less confident (Cheng et al. 2021). By making the model more confident, we can partially reverse it and obtain a more robust retrieval model. We verify this intuition by conducting a simulation on the Natural Question (NQ) dataset (Kwiatkowski et al. 2019). Specifically, we randomly convert some positive passages to false negatives and observe the effects of contrastive confidence regularizer on the distributions of the similarity scores in different groups of passages including false negatives, hard negatives and in-batch negatives. The experimental results in Figure 1 indicate that if we do not include the term (i.e., ), the distributions are close to each other. On the other hand, incorporating the term makes it easier to separate these distributions. It should be noted that a small overlapping between the false negative and hard negative distributions is expected. This is because while all samples in the simulated “false negatives” category are certainly positive passages, there exist (unknown) false negatives in the “hard negatives” category.




4.2 Theoretical Analysis
Theoretical analysis shows that our RCL loss enjoys similar properties with . The detailed proof can be found in the Appendix, where the main idea is that we introduce pseudo-labels to bridge NCE loss and cross-entropy loss and follow a similar proof sketch with (Cheng et al. 2021). The main result is summarized in the following theorem.
Theorem 1.
With the assumption that the possibility of a noisy pair is smaller than a clean pair and a suitable selection of , we have: minimizing is equivalent to minimizing
Theorem 1 indicates that the contrastive confidence regularizer effectively addresses the adverse effect of false negatives on the loss function. Specifically, we can decompose the regularized loss so that the impact of false negatives is mostly captured by the product of and a scaling factor (the last term in Eq.14, Appendix). Here, the scaling factor is intuitively related to the difference between the relative clean rate of a sample (compared to the average clean rate) and . When is large enough, this scaling factor is negative, thus reversing the (term) gradient associated with instances with labeled noise. Note that should not be too large, otherwise it will affect learning from clean data. This raises a crucial question regarding the existence of parameter . Analyzing the existence of becomes challenging when the nature of the noise is uncertain. Fortunately, in the context of false negatives in dense passage retrieval, we can derive the following theorem.
Theorem 2.
When the assumption in Theorem 1 holds, the similarity function is bounded (e.g. cosine similarity) and there is no false positive in the dataset , the that satisfies Theorem 1 must exist and in the interval [0,1].
Theorem 2 shows that under the setting of dense passage retrieval with false negatives, one can select a suitable between the interval [0,1]. However, this theorem only applies when the similarity function is bounded and there is no other source of noise besides false negatives. In practical scenarios, many dense passage retrieval algorithms employ dot-product similarity instead of cosine similarity. When the loss function is not bounded, and there is an excessive number of negative passages, the confidence regularizer can cause the model to overly optimize the loss associated with negative cases. Our experiments indicate that in such situations, the contrastive confidence regularizer still helps as long as a sufficiently small value for is selected. In general, as the batch size increases and in-batch negative sampling is utilized, we should decrease the value of .
5 Passage Sieve Method
Input: Noisy dataset with false negatives
Parameter: Hyper-parameter , learning rate , training epochs
Output: Sieved dataset
The previously proposed regularization is helpful towards dense retrieval models based on contrastive NCE loss, but not applicable to sophisticated methods such as AR2 (Zhang et al. 2021), which do not make use of NCE loss. As a result, we design a novel passage sieve algorithm, which can be used as pre-processing for the noisy datasets to obtain relatively clean datasets for training.
Our method is presented in Algorithm 1. We first train DPR (Karpukhin et al. 2020), a dual-encoder based retrieval model on the noisy dataset. We then refine the retrieval model using the contrastive confidence regularizer. Afterward, we identify the hard negative passages with a loss function value higher than the average loss value , and set them as confident negatives. Finally, we discard all other passages except for the confident negatives to obtain a “clean” dataset. It is noteworthy that we employ cosine similarity to satisfy the assumptions outlined in Theorem 2.
Lemma 1.
Lemma 1 provides the sufficient condition for accurately selecting true negatives in Algorithm 1. In this algorithm, the DPR model is trained with robust contrastive loss and cosine similarity. According to Theorems 1 and 2, by selecting a suitable value of , minimizing is equivalent to minimizing . This implies that false negatives are gradually given scores closer to the positive passage, and higher compared to hard negatives and in-batch negatives. Considering the abundance of true negatives, the scores assigned to false negatives will exceed random guesses at some point. Consequently, false negatives will be excluded from the sieved dataset in Algorithm 1, resulting in a clean dataset .
Compared to vanilla DPR, DPR with CCR introduces additional computation associated with the expectation calculation, the second term in Eq. 8. Fortunately, this can be approximated by taking the mean value of the NCE losses of all passages given the query. In addition, the calculation of NCE losses is dominated by the calculation of the similarity matrix (Eq. 2), which is also needed in vanilla DPR. Consequently, the contrastive confidence regularizer only slightly increases the time complexity when implemented appropriately. It is worth noting that when using retrieval models like DPR, ANCE, or RocketQA that employ NCE loss, using the robust contrastive loss in section 4 should be sufficient.
6 Experiment
| Method | NQ | TQ | MS-pas | ||||||
|---|---|---|---|---|---|---|---|---|---|
| R@5 | R@20 | R@100 | R@5 | R@20 | R@100 | MRR@10 | R@50 | R@1k | |
| DPR (Karpukhin et al. 2020) | - | 78.4 | 85.3 | - | 79.3 | 84.9 | - | - | - |
| ANCE (Xiong et al. 2021) | 71.8 | 81.9 | 87.5 | - | 80.3 | 85.3 | 33.0 | 81.1 | 95.9 |
| COIL (Gao, Dai, and Callan 2021) | - | - | - | - | - | - | 35.5 | - | 96.3 |
| ME-BERT (Luan et al. 2021) | - | - | - | - | - | - | 33.8 | - | - |
| Individual top-k (Sachan et al. 2021) | 75.0 | 84.0 | 89.2 | 76.8 | 83.1 | 87.0 | - | - | - |
| RocketQA (Qu et al. 2021) | 74.0 | 82.7 | 88.5 | - | - | - | 37.0 | 85.5 | 97.9 |
| RDR (Yang and Seo 2020) | - | 82.8 | 88.2 | - | 82.5 | 87.3 | - | - | - |
| RocketQAv2 (Ren et al. 2021b) | 75.1 | 83.7 | 89.0 | - | - | - | 38.8 | 86.2 | 98.1 |
| PAIR (Ren et al. 2021a) | 74.9 | 83.5 | 89.1 | - | - | - | 37.9 | 86.4 | 98.2 |
| DPR-PAQ (Oguz et al. 2022) | 74.2 | 84.0 | 89.2 | - | - | - | 31.1 | - | - |
| Condenser (Gao and Callan 2021) | - | 83.2 | 88.4 | - | 81.9 | 86.2 | 36.6 | - | 97.4 |
| coCondenser (Gao and Callan 2022) | 75.8 | 84.3 | 89.0 | 76.8 | 83.2 | 87.3 | 38.2 | - | 98.4 |
| ERNIE-Search (Lu et al. 2022) | 77.0 | 85.3 | 89.7 | - | - | - | 40.1 | 87.7 | 98.2 |
| MVR (Zhang et al. 2022) | 76.2 | 84.8 | 89.3 | 77.1 | 83.4 | 87.4 | - | - | - |
| PROD (Lin et al. 2023) | 75.6 | 84.7 | 89.6 | - | - | - | 39.3 | 87.0 | 98.4 |
| COT-MAE (Wu et al. 2023) | 75.5 | 84.3 | 89.3 | - | - | - | 39.4 | 87.0 | 98.7 |
| AR2 (Zhang et al. 2021) | 77.9 | 86.0 | 90.1 | 78.2 | 84.4 | 87.9 | 39.5 | 87.8 | 98.6 |
| AR2+passage sieve | 79.2 | 86.4 | 90.7 | 78.7 | 84.7 | 88.2 | 39.8 | 88.3 | 98.6 |
| Method | B | R@5 | R@20 | R@100 | |
|---|---|---|---|---|---|
| NQ | AR2 | 64 | 77.9 | 86.0 | 90.1 |
| AR2+SimANS | 64 | 78.6 | 86.2 | 90.3 | |
| AR2+passage sieve | 32 | 78.6 | 86.1 | 90.5 | |
| AR2+passage sieve | 64 | 79.2 | 86.4 | 90.6 | |
| TQ | AR2 | 64 | 78.2 | 84.4 | 87.9 |
| AR2+SimANS | 64 | 78.6 | 84.6 | 88.1 | |
| AR2+passage sieve | 32 | 78.6 | 84.8 | 88.3 | |
| AR2+passage sieve | 64 | 78.7 | 84.7 | 88.2 |
6.1 Experimental Setup
Datasets
Evaluation Metrics
Following previous works, we report R@k (k=5, 20, 100) for NQ and TQ, and MRR@10, R@k (k=50, 1K) for MS-pas. Here, MRR refers to the Mean Reciprocal Rank that calculates the reciprocal rank where the first relevant passage is achieved, and R@k measures the proportion of relevant passages (recall) in top-k results.
6.2 Effects of Passage Sieve Method
Experimental Design
We implement our passage sieve method on top of AR2 (Zhang et al. 2021), which is referred to as AR2+passage sieve. To evaluate the effectiveness of our passage sieve method, we compare it with the original AR2 along with other contemporary baselines. The details on the baselines are given in the supplementary material.
During the passage sieve procedure in AR2+passage sieve, we set and epochs , learning rate . Additionally, we leverage the cosine similarity function and set the initial number of hard negative passages to be two times the number of hard negatives to be used in the downstream AR2 model. As for AR2 training, all settings are set the same way as in (Zhang et al. 2021). Specifically, the batch size is set to 64 and the number of hard negatives is 15.
Overall Results
| Method | # hn | NQ | ||
|---|---|---|---|---|
| R@5 | R@20 | R@100 | ||
| AR2 | 1 | 76.4 | 85.3 | 89.7 |
| AR2+passage sieve | 1 | 77.6 | 86.1 | 90.3 |
| AR2 | 5 | 76.9 | 85.3 | 89.7 |
| AR2+passage sieve | 5 | 78.0 | 85.9 | 90.6 |
| AR2 | 15 | 77.9 | 86.0 | 90.1 |
| AR2+passage sieve | 15 | 78.6 | 86.1 | 90.5 |
Table 1 presents the results of AR2+passage sieve on NQ and TQ test sets, as well as MS-pas development set. It can be observed that AR2 outperforms most of the baseline models on all three datasets across different evaluation metrics. Furthermore, the proposed passage sieve approach enhances the performance of AR2 on all three datasets and evaluation metrics. The findings suggest that the sieve algorithm significantly contributes to improving the quality of hard negative samples in the dataset, enabling better results even with less GPU memory requirement. It is worth mentioning that our passage sieve procedure only accounts for one-tenth of the training time compared to AR2, the downstream retrieval model.
SimANS (Zhou et al. 2022) is the recently proposed method to address the issue of false negatives based on some useful heuristic assumptions. When combined with AR2, AR2+SimANS achieves state-of-the-art results in dense retrieval. In contrast, we start from theory in noise-robust machine learning algorithms and develop a new loss function. The results in Table 2 show that both SimANS and our method enhance the performance of AR2. However, compared to AR2+SimANS, the passage sieve achieves better results in all terms of TQ and NQ datasets. The advantage is more clearly seen on NQ dataset. It should be noted that we do not include the result on the MS-pas dataset of SimANS because they leverage a 4 times larger batch size than AR2 which makes the comparison unfair.

6.3 Detailed Analysis
Influence of limited batch size
We investigate the impact of smaller batch size on the performance of AR2+passage sieve. Table 2 shows that AR2+passage sieve achieves better results in terms of R@5, R@20, and R@100 on TQ dataset, even with a smaller batch size. On NQ dataset, our method achieves comparable results with AR2+SimANS while having only a slight decrease in R@20.
Influence of the number of hard negatives
To evaluate the impact of hard negatives, we experiment with varying numbers of hard negatives during training. To speed up the experiment, the batch size is set to 32 and we only work on NQ dataset. The results in Table 3 demonstrate that the passage sieve approach consistently enhances the performance of AR2 across all settings. Particularly, with only 5 hard negatives, our method can reach a performance near that of 15 hard negatives. Intuitively, when the quality of hard negative samples is higher, we do not need many negative samples, thus reducing computing resources for training.
Influence of hyper-parameter
To study the influence of the hyper-parameter on the passage sieve algorithm, we conduct experiments on NQ dataset with different and all other settings remain the same. Specifically, we vary the values of to be 0, 0.25, 0.5. Figure 2 indicates the passage sieve method is not sensitive to . This is because DPR in the passage sieve method is trained with cosine similarity, which satisfies our assumptions in Theorem 2.
| Method | Batch size | R@5 | R@20 | R@100 | |
|---|---|---|---|---|---|
| NQ | DPR | 128 | - | 78.4 | 85.4 |
| DPR+CCR | 64 | 65.9 | 77.6 | 85.4 | |
| DPR+CCR | 128 | 68.4 | 79.5 | 86.1 | |
| TQ | DPR | 128 | - | 79.3 | 84.9 |
| DPR+CCR | 64 | 70.5 | 78.7 | 84.9 | |
| DPR+CCR | 128 | 71.5 | 79.8 | 85.1 |
6.4 Effects of Contrastive Confidence Regularizer
Exterimental Design
We evaluate the performance of the Contrastive Confidence Regularizer on the DPR model (Karpukhin et al. 2020). We incorporate the regularizer into the existing NCE loss function during the final 5 epochs of training. Other parameters and configurations are kept consistent with those in the original DPR paper. Since the DPR model utilizes a dot-product similarity function, we select the values of from the range of 0.001 to 0.0001. The selection of is based on the performance observed on the validation set.
Experiment Results
Table 4 shows results on NQ and TQ datasets. It is observable that the proposed contrastive confidence regularizer helps DPR get a better performance across all metrics on NQ and TQ datasets. The experimental results also show that the reduction of batch size has a greater impact on R@20 and R@5, but a smaller impact on R@100. On both datasets, the proposed CCR helps achieve the same R@100 value as DPR with only half the batch size.
7 Conclusion
This paper aims to mitigate the impact of false negatives on dense passage retrieval. Toward such a goal, we extend the peer-loss framework and develop a confidence regularization for training robust retrieval models. The proposed regularization is compatible with any base retrieval model that uses NCE loss, a widely used contrastive loss function in dense retrieval. Through empirical and theoretical analysis, it is demonstrated that contrastive confidence regularization leads to more robust retrieval models. Building on this regularization, a passage sieve algorithm is proposed. The algorithm leverages a dense retrieval model trained with confidence regularized NCE loss to filter out false negatives, thereby improving any downstream retrieval model including those that do not exploit NCE loss. The effectiveness of both the passage sieve algorithm and the confidence regularization method is validated through extensive experiments on three commonly used QA datasets. The results show that these methods can enhance base retrieval models, even when fewer negative samples are used.
Acknowledgments
We thank all the reviewers for their helpful comments. This work is supported by the National Key R&D Program of China (2022ZD0116600).
References
- Borgeaud et al. (2022) Borgeaud, S.; Mensch, A.; Hoffmann, J.; Cai, T.; Rutherford, E.; et al. 2022. Improving Language Models by Retrieving from Trillions of Tokens. In International Conference on Machine Learning.
- Cheng et al. (2021) Cheng, H.; Zhu, Z.; Li, X.; Gong, Y.; Sun, X.; and Liu, Y. 2021. Learning with Instance-Dependent Label Noise: A Sample Sieve Approach. In International Conference on Learning Representations.
- Chuang et al. (2020) Chuang, C.-Y.; Robinson, J.; Lin, Y.-C.; Torralba, A.; and Jegelka, S. 2020. Debiased contrastive learning. Advances in Neural Information Processing Systems.
- Ferguson et al. (2020) Ferguson, J.; Gardner, M.; Hajishirzi, H.; Khot, T.; and Dasigi, P. 2020. IIRC: A Dataset of Incomplete Information Reading Comprehension Questions. In Proceedings of the 2020 Conference on EMNLP. Association for Computational Linguistics.
- Fu et al. (2022) Fu, H.; Zhang, Y.; Yu, H.; Sun, J.; Huang, F.; Si, L.; Li, Y.; and Nguyen, C.-T. 2022. Doc2Bot: Accessing Heterogeneous Documents via Conversational Bots. In Findings of the Association for Computational Linguistics: EMNLP.
- Gao and Callan (2021) Gao, L.; and Callan, J. 2021. Is your language model ready for dense representation fine-tuning. arXiv preprint arXiv:2104.08253.
- Gao and Callan (2022) Gao, L.; and Callan, J. 2022. Unsupervised Corpus Aware Language Model Pre-training for Dense Passage Retrieval. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics.
- Gao, Dai, and Callan (2021) Gao, L.; Dai, Z.; and Callan, J. 2021. COIL: Revisit Exact Lexical Match in Information Retrieval with Contextualized Inverted List. In Proceedings of the 2021 Conference of NAACL: Human Language Technologies.
- Glass et al. (2022) Glass, M. R.; Rossiello, G.; Chowdhury, M. F. M.; Naik, A.; Cai, P.; and Gliozzo, A. 2022. Re2G: Retrieve, Rerank, Generate. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
- Guu et al. (2020) Guu, K.; Lee, K.; Tung, Z.; Pasupat, P.; and Chang, M. 2020. Retrieval Augmented Language Model Pre-Training. In Proceedings of the 37th International Conference on Machine Learning.
- Hao et al. (2022) Hao, S.; Li, P.; Wu, R.; and Chu, X. 2022. A Model-Agnostic approach for learning with noisy labels of arbitrary distributions. In International Conference on Data Engineering. IEEE.
- Huang et al. (2013) Huang, P.-S.; He, X.; Gao, J.; et al. 2013. Learning Deep Structured Semantic Models for Web Search Using Clickthrough Data. In CIKM.
- Humeau et al. (2019) Humeau, S.; Shuster, K.; Lachaux, M.-A.; and Weston, J. 2019. Poly-encoders: Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring. In International Conference on Learning Representations.
- Johnson, Douze, and Jégou (2021) Johnson, J.; Douze, M.; and Jégou, H. 2021. Billion-Scale Similarity Search with GPUs. IEEE Trans. Big Data, 535–547.
- Joshi et al. (2017) Joshi, M.; Choi, E.; Weld, D. S.; and Zettlemoyer, L. 2017. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics.
- Karpukhin et al. (2020) Karpukhin, V.; Oguz, B.; Min, S.; Lewis, P.; Wu, L.; Edunov, S.; Chen, D.; and Yih, W.-t. 2020. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on EMNLP. Association for Computational Linguistics.
- Khattab and Zaharia (2020) Khattab, O.; and Zaharia, M. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval.
- Kwiatkowski et al. (2019) Kwiatkowski, T.; Palomaki, J.; Redfield, O.; Collins, M.; Parikh, A.; Alberti, C.; Epstein, D.; Polosukhin, I.; Devlin, J.; Lee, K.; et al. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics.
- Lewis et al. (2020a) Lewis, P. S. H.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.; Rocktäschel, T.; Riedel, S.; and Kiela, D. 2020a. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020.
- Lewis et al. (2020b) Lewis, P. S. H.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.; Rocktäschel, T.; Riedel, S.; and Kiela, D. 2020b. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Advances in Neural Information Processing Systems.
- Lin et al. (2023) Lin, Z.; Gong, Y.; Liu, X.; Zhang, H.; Lin, C.; Dong, A.; Jiao, J.; Lu, J.; Jiang, D.; Majumder, R.; et al. 2023. Prod: Progressive distillation for dense retrieval. In Proceedings of the ACM Web Conference.
- Liu and Tao (2015) Liu, T.; and Tao, D. 2015. Classification with noisy labels by importance reweighting. IEEE Transactions on Pattern Analysis and Machine Intelligence.
- Liu and Guo (2020) Liu, Y.; and Guo, H. 2020. Peer loss functions: Learning from noisy labels without knowing noise rates. In International Conference on Machine Learning. PMLR.
- Lu et al. (2022) Lu, Y.; Liu, Y.; Liu, J.; Shi, Y.; Huang, Z.; Sun, S. F. Y.; Tian, H.; Wu, H.; Wang, S.; Yin, D.; et al. 2022. Ernie-search: Bridging cross-encoder with dual-encoder via self on-the-fly distillation for dense passage retrieval. arXiv preprint arXiv:2205.09153.
- Luan et al. (2021) Luan, Y.; Eisenstein, J.; Toutanova, K.; and Collins, M. 2021. Sparse, dense, and attentional representations for text retrieval. Transactions of the Association for Computational Linguistics.
- Manwani and Sastry (2013) Manwani, N.; and Sastry, P. 2013. Noise tolerance under risk minimization. IEEE Transactions on Cybernetics.
- Mialon et al. (2023) Mialon, G.; Dessì, R.; Lomeli, M.; Nalmpantis, C.; Pasunuru, R.; Raileanu, R.; Rozière, B.; Schick, T.; Dwivedi-Yu, J.; Celikyilmaz, A.; et al. 2023. Augmented language models: a survey. arXiv preprint arXiv:2302.07842.
- Natarajan et al. (2013) Natarajan, N.; Dhillon, I. S.; Ravikumar, P. K.; and Tewari, A. 2013. Learning with noisy labels. Advances in Neural Information Processing Systems.
- Nguyen et al. (2016) Nguyen, T.; Rosenberg, M.; Song, X.; Gao, J.; Tiwary, S.; Majumder, R.; and Deng, L. 2016. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. choice.
- Ni, Gardner, and Dasigi (2021) Ni, A.; Gardner, M.; and Dasigi, P. 2021. Mitigating False-Negative Contexts in Multi-document Question Answering with Retrieval Marginalization. In Proceedings of the 2021 Conference on EMNLP. Association for Computational Linguistics.
- Oguz et al. (2022) Oguz, B.; Lakhotia, K.; Gupta, A.; Lewis, P.; Karpukhin, V.; Piktus, A.; Chen, X.; Riedel, S.; Yih, W.; Gupta, S.; et al. 2022. Domain-matched Pre-training Tasks for Dense Retrieval. In Findings of the Association for Computational Linguistics: NAACL 2022-Findings. Association for Computational Linguistics.
- Patrini et al. (2017) Patrini, G.; Rozza, A.; Krishna Menon, A.; Nock, R.; and Qu, L. 2017. Making deep neural networks robust to label noise: A loss correction approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Qu et al. (2021) Qu, Y.; Ding, Y.; Liu, J.; Liu, K.; Ren, R.; Zhao, W. X.; Dong, D.; Wu, H.; and Wang, H. 2021. RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2021 Conference of the NAACL: Human Language Technologies.
- Reimers and Gurevych (2019) Reimers, N.; and Gurevych, I. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on EMNLP-IJCNLP. Association for Computational Linguistics.
- Ren et al. (2021a) Ren, R.; Lv, S.; Qu, Y.; Liu, J.; Zhao, W. X.; She, Q.; Wu, H.; Wang, H.; and Wen, J.-R. 2021a. PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021.
- Ren et al. (2021b) Ren, R.; Qu, Y.; Liu, J.; Zhao, W. X.; She, Q.; Wu, H.; Wang, H.; and Wen, J.-R. 2021b. RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking. In Proceedings of the 2021 Conference on EMNLP.
- Robinson et al. (2020) Robinson, J. D.; Chuang, C.-Y.; Sra, S.; and Jegelka, S. 2020. Contrastive Learning with Hard Negative Samples. In International Conference on Learning Representations.
- Sachan et al. (2021) Sachan, D.; Patwary, M.; Shoeybi, M.; Kant, N.; Ping, W.; Hamilton, W. L.; and Catanzaro, B. 2021. End-to-End Training of Neural Retrievers for Open-Domain Question Answering. In Proceddings of the Association for Computational Linguistics: ACL-IJCNLP 2021.
- Wu et al. (2023) Wu, X.; Ma, G.; Lin, M.; Lin, Z.; Wang, Z.; and Hu, S. 2023. Contextual masked auto-encoder for dense passage retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence.
- Xia et al. (2020) Xia, X.; Liu, T.; Han, B.; Wang, N.; Gong, M.; Liu, H.; Niu, G.; Tao, D.; and Sugiyama, M. 2020. Part-dependent label noise: Towards instance-dependent label noise. Advances in Neural Information Processing Systems.
- Xiong et al. (2021) Xiong, L.; Xiong, C.; Li, Y.; Tang, K.; Liu, J.; Bennett, P. N.; Ahmed, J.; and Overwijk, A. 2021. Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval. In 9th International Conference on Learning Representations.
- Yang and Seo (2020) Yang, S.; and Seo, M. 2020. Is retriever merely an approximator of reader? arXiv preprint arXiv:2010.10999.
- Yang et al. (2022) Yang, S.; Yang, E.; Han, B.; Liu, Y.; Xu, M.; Niu, G.; and Liu, T. 2022. Estimating instance-dependent Bayes-label transition matrix using a deep neural network. In International Conference on Machine Learning. PMLR.
- Yao et al. (2020) Yao, Y.; Liu, T.; Han, B.; Gong, M.; Deng, J.; Niu, G.; and Sugiyama, M. 2020. Dual t: Reducing estimation error for transition matrix in label-noise learning. Advances in Neural Information Processing Systems.
- Zhang et al. (2021) Zhang, H.; Gong, Y.; Shen, Y.; Lv, J.; Duan, N.; and Chen, W. 2021. Adversarial Retriever-Ranker for Dense Text Retrieval. In International Conference on Learning Representations.
- Zhang et al. (2022) Zhang, S.; Liang, Y.; Gong, M.; Jiang, D.; and Duan, N. 2022. Multi-View Document Representation Learning for Open-Domain Dense Retrieval. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics.
- Zhang et al. (2023) Zhang, Y.; Fu, H.; Fu, C.; Yu, H.; Li, Y.; and Nguyen, C.-T. 2023. Coarse-To-Fine Knowledge Selection for Document Grounded Dialogs. In 2023 IEEE International Conference on Acoustics, Speech and Signal Processing.
- Zhou et al. (2022) Zhou, K.; Gong, Y.; Liu, X.; Zhao, W. X.; Shen, Y.; Dong, A.; Lu, J.; Majumder, R.; Wen, J.-R.; and Duan, N. 2022. SimANS: Simple Ambiguous Negatives Sampling for Dense Text Retrieval. In Proceedings of the 2022 Conference on EMNLP: Industry Track.
- Zhu, Liu, and Liu (2021) Zhu, Z.; Liu, T.; and Liu, Y. 2021. A second-order approach to learning with instance-dependent label noise. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
Appendix
Appendix A Missing Details
A.1 Limitations and future work
This paper proposed a novel contrastive confidence regularizer and a passage sieve algorithm to handle the false negative problem in dense retrieval training. The theory analysis and experimental results have shown the effectiveness of our methods, however, there are still several limitations of our work:
- 1.
-
2.
Theorem 1 only assumes the loss function to be NCE loss and does not require the task to be dense retrieval. Thus, the proposed contrastive confidence regularizer has the same power on any other self-supervised tasks using NCE loss, e.g. self-supervised image classification, sentence embedding, etc. More experiments on these benchmarks should be conducted in future work.
-
3.
The proposed methods are built upon (Cheng et al. 2021), which consider the first-order statistic(estimation) of peer loss. However, Zhu, Liu, and Liu (2021) has extended this into considering the second-order statistics and achieving better performance in CV benchmarks. More work is needed to extend the contrastive confidence regularizer into second-order statistics as well.
A.2 Details about baselines
Details about the baselines in Table 1 in the main content are shown in this subsection.
DPR (Karpukhin et al. 2020) employs a dual-encoder architecture, leveraging BM25 for the identification of hard negatives and utilizing the in-batch negatives for efficiency.
ANCE (Xiong et al. 2021) constructs hard negatives from an Approximate Nearest Neighbor (ANN) index.
COIL (Gao, Dai, and Callan 2021) integrates semantic with lexical matching, storing contextualized token representations in inverted lists.
ME-BERT (Luan et al. 2021) merges the efficiency of dual encoders with the expressiveness of attentional architectures, further venturing into sparse-dense hybrids.
Individual top-k (Sachan et al. 2021) utilizes unsupervised pre-training, focusing on the inverse cloze task and masked salient spans within question-context pairs.
RocketQA (Qu et al. 2021) explores the ability of the cross-encoder model to denoise hard negatives.
RDR (Yang and Seo 2020) seeks to distill knowledge from the reader into the retriever, aiming for the retriever to gain reader strengths without loss of inherent advantages.
RocketQAv2 (Ren et al. 2021b) distills knowledge from the cross-encoder model by narrowing the relevance distribution between the retrieval model and the cross-encoder model.
PAIR (Ren et al. 2021a) considers both query-centric similarity relations and passage-centric similarity relations.
DPR-PAQ (Oguz et al. 2022) introduces the PAQ dataset, concentrating on the question-answering pretraining task.
Condenser (Gao and Callan 2021) boosts optimization readiness by performing mask language model predictions actively condition on dense representation.
coCondenser (Gao and Callan 2022) adds a corpus-level contrastive learning goal to the existing Condenser pre-training architecture.
ERNIE-Search (Lu et al. 2022) refines the distillation process by sharing the encoding layers with the dual-encoder and conducting a cascaded approach.
MVR (Zhang et al. 2022) offers multiple representations for candidate passages and proposes a global-local loss to prevent multiple embeddings from collapsing to the same.
PROD (Lin et al. 2023) enhances the cross-encoder distillation by cyclically improving teacher models and tailoring sample selections to student needs.
COT-MAE (Wu et al. 2023) utilizes an asymmetric encoder-decoder architecture with self-supervised and context-supervised masked auto-encoding tasks.
AR2 (Zhang et al. 2021) jointly optimizes the retrieval and re-ranker model according to a minimax adversarial objective.
A.3 Example implementation of contrastive confidence regularizer
In section 5, we mentioned that CCR (eq.8 in the main content) only slightly increases the time complexity when implemented properly. In this subsection, we will demonstrate the implementation to prove this claim.
The example code is shown in listing 1. The dimension of is the number of queries in the batch times the number of passages (including positive, in-batch negatives, and hard negatives) of each query. In order to calculate the NCE loss, a log softmax function on the passage dimension is required. And after that, an NLL loss with only positive passages labeled as 1 is calculated with the after-softmax matrix . The only additional code for CCR is to calculate the NLL loss for all elements in the and get the mean value of each row of it.
A.4 Efficiency analysis of passage sieve algorithm
Overall speaking, The time taken to integrate the passage sieve (algorithm 1) into AR2 is equivalent to that of training a vanilla DPR(Karpukhin et al. 2020) model. Compared with the time consumption of AR2 training itself, the additional training time is relatively small. We record the time consumption of one epoch training on the TQ dataset and show it in table 5.
It should be noted that the passage sieve has nothing to do with the inference time consumption. Adding the passage sieve only requires an additional data preprocessing time during training.
| AR2 | AR2+passage sieve | |
| Batch size | 32 | 32 |
| Number of hard negatives | 15 | 15 |
| Data preprocessing | 10min | 2h 10min |
| Retrieval & Reranker training | 2h 5min | 2h 5min |
| Corpus and query encoding | 6h 6min | 6h 6min |
| ANN index build and Retrieval | 30min | 30min |
| Overall | 9h | 11h |
A.5 Intermediate experiment result
Sieve out rate of passage sieve
In the passage sieve algorithm, we perform passage sieves according to their loss value and the average loss value (i.e. threshold). And we prove that those who get a score more than the average value will be sieved out for sure, however, it remains unknown what percentage of all negative passages will be sieved out (we called it sieve out rate). The sieve out rate directly affects how many passages we need to examine during the passage sieve in order to meet the hard negatives requirement of the downstream retrieval model.
In the main content, we mentioned that we choose two times the number of hard negatives that the downstream retrieval model (AR2 in this case) will use. This ratio is actually chosen by some preliminary experiments, in which we observed that the passage sieve algorithm usually sieves out examples less than half. We show the sieve-out rate during training on the NQ dataset in figure 3. The figure shows that the sieve rate is usually smaller than but close to 0.5 and usually when one epoch achieves a sieve-out rate near 0.5, the rate of the next epoch will drop immediately. It should be noted that this rate has nothing to do with the estimated noise pair possibility. The strategy adopted by the passage sieve algorithm is to filter aggressively and only retain confident ones, in which only the sufficient conditions for filtering are specified (see Lemma 1).

Learning curves
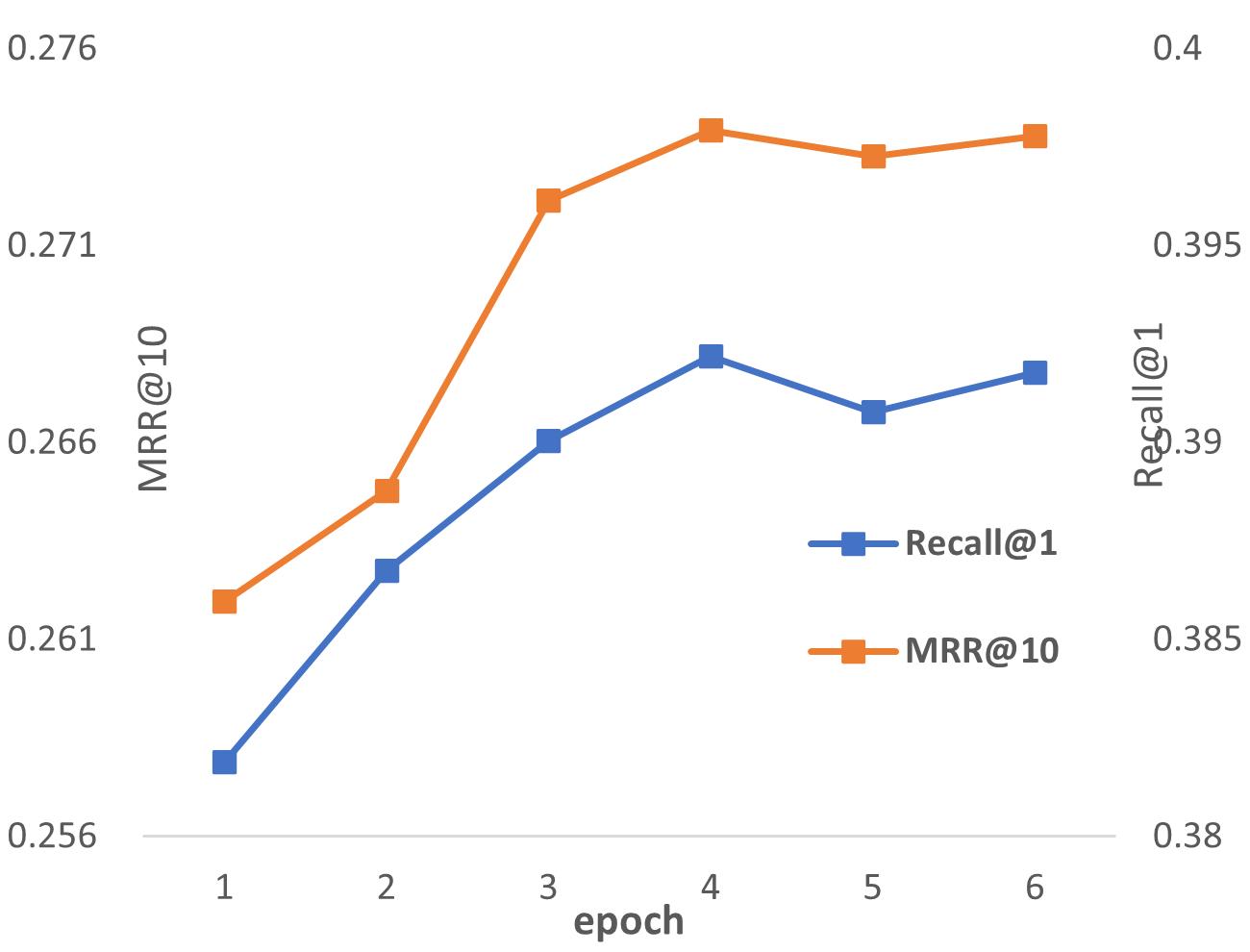
We also show the visualization of the training procedure. Specifically, the Recall@1 Recall@5 of the TQ test set and Recall@1 MRR@10 of the MS-Pas dataset are shown in the figure. And we can see from fig.4 that the metrics on both TQ and MS-pas datasets gradually increase until convergence.

A.6 Annotation Table
We conclude the annotation we used in the main content of the paper and show them in table 6 to help read our paper.
| passage | clean distribution | ||
| query | distribution of P given q | ||
| negatives passage | contrastive confidence regularizer | ||
| positive passage | robust contrastive loss | ||
| negative set for query q | sieved dataset | ||
| Noisy distribution | confident negative list | ||
| NCE loss | similarity score of p,q after softmax |
Appendix B Important Proofs
Before we start the proof, we will first introduce the pseudo-label and corresponding loss function we used during the proof. Let’s consider a positive pair as label and negative pair as label . Remind that means passages and stands for queries. In the following context, instead of using superscript, we will leverage this label to indicate the relation between passages and queries. And similar to the context in the label-noise robust machine learning papers, represents the real label and for the noisy label in the dataset. Thus we can represent the false negatives in the dataset as . We then re-define the contrastive loss function as :
| (9) |
where
| (10) | ||||
Here, is the model that gives the score between queries and passages. is the broadened NCE loss as we discussed in the preliminary part. This newly defined pseudo loss is for proof purposes only which helps better analyze the performance of the proposed methods during proof. Pay attention that such a definition will not affect the original contrastive learning in dense retrieval as the loss for negative pairs is always equal to 0. And there is only a coefficient difference between them:
|
|
In the following context, unless otherwise specified, stands for this defined loss, and stands for the original NCE loss.
B.1 Proof for theorem 1 and theorem 2
To make the reading more natural and smooth, we simultaneously prove Theorems 1 and 2 in this section.
Theorem 1.
With the assumption that the possibility of a noisy pair is smaller than a clean pair and a suitable selection of , we have: minimizing is equivalent to minimizing
Theorem 2.
When the assumption in Theorem 1 holds, the similarity function is bounded (e.g. cosine similarity) and there is no false positive in the dataset , the that satisfies Theorem 1 must exist and in the interval [0,1].
Proof.
We first prove that with the new regularizer, the Main Theorem of (Cheng et al. 2021), which decouples the expected regularized loss, still holds. For simplicity, considering
We define the new pseudo loss as in eq.9, and this loss is aligned with the basic form of the classification loss function with feature x and label y which is used by (Cheng et al. 2021). And we first get those that do NOT require the specific form of the loss function and thus remain unchanged in our case as the original confidence regularizer paper as the eq.11 follows:
| (11) | ||||
where
and follow the same definition in , and we don’t list them here as it’s not required in our proof. Furthermore, as in the pseudo loss (eq. 9) we defined, we can further get the new decoupled NCE loss in our problem:
| (12) | ||||
We use a novel contrastive confidence regularizer which is different from the original regularizer in . And the expected form of the new is
| (13) | ||||
The first equation in eq.13 is true because the clean distribution and the noisy distribution differ from labels instead of distributions of and . It helps bridge the clean distribution and the noisy distribution. And with the final equivalent transformation in eq.13, we are able to merge the third term of the decoupled NCE loss eq.12 and the expectation of CCR together. Thus the expectation of regularized loss is:
| (14) | ||||
After we get eq.14, the next key problem is to examine the influence of each term in it during training on noisy datasets. Optimizing the first term represents the optimization of the clean distribution and so we don’t need to consider it. The second term represents expectation on a shifted distribution . Lemma 2 in indicates that as long as the dataset is informative and the clean label equals the Bayes optimal label , the second term won’t change the Bayes optimal label. In our case, the second assumption is naturally satisfied as one sample (p,q) only belongs to one class (positive or negative) in the clean dataset. So, with the assumption that the noisy distribution is informative, i.e. “Possibility of any pair to be noisy is smaller than clean (Assumption I)”, the second term in eq.14 does NOT change the Bayes optimal classifier during training.
Considering the third term in eq.14, the ideal condition is and so the third term will always be equal to zero. However, this condition is nearly impossible to meet and violates the assumption of instance-dependent noise. In the original confidence regularizer paper (Cheng et al. 2021), they succeed in proving an interval of in which the regularized loss will produce the same Bayes optimal classifier as in the clean distribution. Nevertheless, with a complex interval expression, there is still a risk of nonexistence for beta due to the unclear relationship between the starting and ending points of the interval.
In contrast, the third term in eq.14 is significantly different from the original one. And we have a more concrete problem setting. So with new assumptions associated with the problem, we can re-prove a new must-exist bound for to make the estimation unbiased for the clean datasets. Intuitively, the proof can be concluded as follows: Firstly, is related to the relative clean rate of X compared to the average clean rate and so when is large enough, the scaling factor of the third term will be negative, thus reversing the loss associated with instances with labeled noise. Secondly, should not be too large, otherwise, it will affect the learning from clean data.
On the one hand, when , all the scaling factor would be negative, minimizing the third term equals to minimize the regularization term. It should be noted that, given the assumption that “The NCE loss has an infimum, i.e. similarity function is bounded with a minimal value (Assumption II)”, Theorem 1 in (Cheng et al. 2021) still holds even when we use a different form of the loss function. According to this theorem, minimizing the regularization term will induce confidence prediction no matter whether the distribution is noisy or clean.
Pay attention that, given the assumption that “There is no false positive problem in the distribution (Assumption III)”, we have in our problem and so the lower bound become:
| (15) | ||||
On the other hand, we still need to determine an upper bound on the beta to prevent the loss function from being biased against the clean data set. Consider a sample whose clean label is , and the model does not fit it well so that its loss . To make the regularized loss unbiased in this case, it should also be bigger than 0:
| (16) | ||||
And with the assumption that the noise rate is bounded as , we will get that and so
| (17) |
And
| (18) |
so there must be feasible which satisfies the two bounds at the same time and thus reduces unbiased confidence prediction of the clean dataset. And more concretely, is a safe choice all the time.
In conclusion, with Assumptions I, II, and III, when
minimizing is equivalent to minimizing in the dense retrieval problem and such must exist in [0,1]. ∎
B.2 Proof for Lemma 1
lemma 1. The passage sieve algorithm (1) ensures that a negative sample in hard negatives will NOT be selected into the sieved dataset if its score given by the model f is more than a random guess, i.e. its similarity score after softmax is bigger than the average value
Proof.
Considering the sieving process in (1). for a negative pair , NOT being selected into the confident negative set equals the following inequality, for simplicity, define :
| (2-1) | ||||
By Jensen’s inequality, we have:
Given that:
, we can further get:
And so, we will have the:
| (2-2) | ||||
Together with (2-1) and (2-2), we will get:
Therefore, one sufficient condition of to be not selected is that the model give the higher score than random guess, i.e. ∎