[1]\fnmNaren \surDebnath
These authors contributed equally to this work.
These authors contributed equally to this work.
1,2]\orgdivDepartment of Computer Science and Engineering, \orgnameNational Institute of Technology Durgapur, \orgaddress\cityDurgapur, \postcode713209, \stateWest Bengal, \countryIndia
3]\orgdivDepartment of Computer Science, \orgnameUniversitat Politècnica de Catalunya, \orgaddress\cityBarcelona, \postcode08034, \stateCatalonia, \countrySpain
Mitigating Procrastination in Spatial Crowdsourcing Via Efficient Scheduling Algorithm
Abstract
Several works related to spatial crowdsourcing have been proposed in the direction where the task executers are to perform the tasks within the stipulated deadlines. Though the deadlines are set, it may be a practical scenario that majority of the task executers submit the tasks as late as possible. This situation where the task executers may delay their task submission is termed as procrastination in behavioural economics. In many applications, these late submission of tasks may be problematic for task providers. So here, the participating agents (both task providers and task executers) are articulated with the procrastination issue. In literature, how to prevent this procrastination within the deadline is not addressed in spatial crowdsourcing scenario. However, in a bipartite graph setting one procrastination aware scheduling is proposed but balanced job (task and job will synonymously be used) distribution in different slots (also termed as schedules) is not considered there. In this paper, a procrastination aware scheduling of jobs is proliferated by proposing an (randomized) algorithm in spatial crowdsourcing scenario. Our algorithm ensures that balancing of jobs in different schedules are maintained. Our scheme is compared with the existing algorithm through extensive simulation and in terms of balancing effect, our proposed algorithm outperforms the existing one. Analytically it is shown that our proposed algorithm maintains the balanced distribution.
keywords:
Spatial Crowdsourcing, Procrastination, Behavioural Economics, Balanced Task Distribution, Choice Reduction.1 Introduction
Consider a logo designing task of a multinational company which can be distributed to a set of current employees of the company or to obtain the best design, the company may float the task worldwide. Anyone possessing the design capacity can contribute her design to that company no matter which corner of the world she belongs to. This situation for asking contribution from unbounded bulk people around the world is generally termed as crowdsourcing as the task has been outsourced from the crowd without categorisation [1][2][3][4][5]. This concept has been utilized since 2006 and proliferated in various directions from disaster management [6] to atmospheric sciences [7], from agriculture to logistics [8], IoT to smart cities [9] and there are many to name.
Consider another scenario where an agency wants to measure the air moisture level in multiple agricultural areas in a city or in a district or so. In present time there are various sensory devices that can measure the moisture level. Also, with the increased usage of mobile devices (smartphones) [10], mobile users can easily read those sensory data using appropriate mobile application or through sensors in mobile phones [11]. To perform this kind of task from multiple locations, the agency could distribute the task to the general crowd who have smartphones. The extension of crowdsourcing, specifically crowdsensing through mobile devices (collecting sensor data) for a particular location, is termed as mobile crowdsourcing [12][13]. Mobile crowdsourcing (MCS) is emerging since 2009 with mobile applications like m-Clerke [14], a mobile (iPhone) application which utilizes sensors in iPhone to perform various crowdsourcing tasks, txteagle [15] through which agents (henceforth, task executers and task provider or requesters will also be termed as agents) can perform the task of translation, transcription and surveys. There are many other researches which has given MCS immense popularity and utmost importance [16].
When MCS tasks are to be executed at different geographic areas with spatiotemporal constraint, it is termed spatial crowdsourcing (SC), which is the boiling research topic and also the subset of MCS [17][18][19][20][21]. Some of the most customary examples of SC application are food delivery service[22], on-demand taxi[23] and bike service [18]. SC is also applied for collecting geospatial data [19], traffic information [24], pollution[25], disaster [26][27], journalism[28] and many more to name with requirement of spatial information. Though the demand and application of SC are increasing incrementally, some loopholes have been found, such as acquisition of inaccurate data, bounded capability of sensing devices, or untruthful data reporting from the worker end, etc., which has been notified and addressed in [29].
At an abstract level in SC111applicable in crowdsourcing in general sense, we have task provider(s) and task executers where the task provider(s) disseminate the tasks to the task executers. Many researches related to SC have been carried out in the direction where the task provider is constrained by deadlines [30][17][31][32][33][34][9][35]. Even if the deadlines are set, it may be a realistic situation that most of the agents submit the tasks at the penultimate day or at the last day of submission. This situation where the agents may delay their task submission is termed as procrastination [36][37][38][39][40] in behavioural economics[41][42][37][38]. In many applications, these late submissions of tasks may be problematic for task providers. In the SC literature (also in crowdsourcing), how to prevent this procrastination within the deadline is not addressed. However, in a bipartite graph setting, one procrastination aware scheduling is proposed in [43]. In [43], balanced job distribution in different slots (also termed as schedules) regarding procrastination perspective is not considered. In this paper, an algorithm named, Procrastination Preventive Scheduling of Jobs: A Balanced Perspective (PPSJBP) is proposed in SC scenario (also applicable in crowdsourcing), so that balancing of jobs in different schedules are maintained (The detailed objective of the paper is presented in Section 3.3). We have compared our scheme with [43] and have observed that in terms of balancing effect, our proposed algorithm outperforms [43]. Also we have shown analytically that our proposed algorithm maintains the balanced distribution.
2 Literature Review
In [36][37][41], an interesting story of the famous economist George Akerlof is presented, which goes like this. During his visit to India for one year, he had to return some of his friend’s luggage to USA. Every day Akerlof thought he would send off the luggage, but he delayed one more day due to the lengthy transportation process in India (he delayed as he thought that the loss of a whole day might be costly for him). This thought process of sending off the boxes on next day was continued for a few months before he finally managed to send the luggage. This story shows that procrastination could be a natural process, and we can build an efficient system taking procrastination into consideration. This viewpoint has been the prime motivation to write our paper.
Another concept of behavioral economics is loss aversion, where the participating agents perceive loss more seriously than the equivalent profit. Some works based on this aspect (loss aversion) of behavioral economics have been done in the Mobile Crowdsourcing and Spatial Crowdsourcing scenarios.
In spatial crowdsourcing, according to the agents’ participating location, there are two types of regions that are marked as higher participation and sparse participation regions. The task completion rate in sparse regions is much slower than in higher participation regions. Liu et al. in their paper [44] have addressed this issue by proposing two incentive mechanisms based on behavioral economics that would leverage to the selection and payment for participants (agents) for sparse regions. These two mechanisms are - Incentive mechanism based on Behavioral Economics for Participant Selection (IBE-PS) and Incentive mechanism based on Behavioral Economics for Payment Decisions (IBE-PD). The basis of the first mechanism is the reference effect and the second one is the loss aversion. They have shown that these two mechanisms have effectively enhanced the participation of agents at sparse regions by which the loss of utility is diminished and the task completion rate is enhanced.
In [45], we found another stress on behavioral economics where two problems are addressed. One is the fungibility of utility of various tasks and the other is the consistent behavioural preferences of the users (agents). According to the traditional economic theory, the utility of different tasks for agents is indistinguishable which refers to the term fungible. Mental Accounting in [46] first unveiled the fact that the utility of different tasks are different, non-fungible and users’ behavioral preferences are not consistent. Based on Mental Accounting, Deng et. al in [45] proposed an incentive mechanism called Mental Accounting Auction Incentive Mechanism (MAAIM). The proposed incentive mechanism is characterised by reference dependence, loss aversion, and sensitivity decline. Reference dependence and sensitivity decline have created an external reference environment and internal reference point which motivated the agents participating in the system. As a result, the utilisation of sensing platform and involvement of agents in task participation are improved. They have designed a payment mechanism based on loss aversion which also motivates the agents to collect better quality of data.
Li et al. in [47] have proposed a scalable payment algorithm for agents based on the parameter called loss aversion. In their work, the loss aversion is introduced as a coefficient (parameter) in the utility function (for calculation of agents’ utility) in order to modify the payment of agents to motivate their cooperative behaviour which leads to the enhancement of the crowdsensing platform.
Apart from crowdsourcing, there are other areas where the mechanisms are proposed considering the behavioral aspects of the agents who are participating in the system. One such work is presented in [48]. In their work, an incentive mechanism is proposed based on loss aversion called Loss Aversion Incentive Mechanism (LAIM) for Vehicular Ad-Hoc Networks (VANET). The incentive mechanisms for VANET until [48] are based on expected utility theory of traditional economics which assumes that participating in a system, the agents perceive the same effect by observing the same amount of gain or loss. However, the most realistic scenario would be to design mechanisms in VANET that will take the behavioral aspect of the agents where the agents perceive the profit and loss differently. In [48], a mechanism is proposed by assuming that the nodes will have this behavioral aspect in consideration and with that they have shown, their mechanism will improve the cooperation among the participating nodes.
As stated earlier, when the agents are executing the time bound jobs, it is quite realistic that they may submit the tasks as late as possible and these late submission of tasks may be problematic for task requester. The problem of the task provider aggravates if the task provider is also constrained by deadline. The above review
has not portrayed one very important step (often ignored), which is, the task provider is also constrained by deadline. The problem that arises, if the task provider is constrained by deadline, could be understood with the following example.
Consider a faculty member announces 3 assignments to the students be submitted within of a month and the marks of the submitted assignments which is to be given within of the same month by the faculty member. In worst case, all the assignments are submitted to her on . Thus, the evaluation quality will be compromised as the time left for evaluation is only days which is much less for evaluation in worst case scenario. So, the evaluation quality in this case is diminishing as the faculty member is getting less time to finish the stipulated work. This situation arises due to the fact that the deadline for submission of the assignments was not designed efficiently i.e., a single big deadline is given to the students to submit all the assignments. To mitigate this issue related to the deadline, a work is presented in [43] where they have proposed a Procrastination-aware-Scheduling algorithm (the algorithm is termed as OffPSP).
This algorithm has allocated all jobs into the schedules in some sorted order based on a threshold, set for each schedule. Accordingly, this algorithm has produced a set of unbalanced schedules in terms of cost and number of jobs allocated. With these unbalanced schedules, the agent may face the same problem (will not get ample time) as stated earlier. In our paper, the issue related to this unbalancing effect on the schedules is addressed.
3 System Models
3.1 Preliminaries:
Consider a 3-week short term course and the organiser of the course wants that a participant in the course, needs to submit two assignments at the end of the short term course. It may not be a good schedule, if we consider the fact that the bulk of the participants will procrastinate and submit the assignments as late as possible within the deadline (in our example, it is three weeks).
In this case, to prevent the procrastination, the organiser can reschedule the submission process to ensure a smooth and consistent submission from the participant. Here, the 3-week duration can be decomposed into 3 unit intervals - first week, second week, and third week and they can assure that one assignment to be completed by the end of first week or second week and the next assignment could be solved in the third week. In literature, this is called the choice reduction [37][36]. This viewpoint of choice reduction is considered while designing our proposed algorithm.
3.2 Notations and their Usage
Schedules: In this model, a time horizon is divided into a set of schedules and the time duration of each is . Here and is defined as . It is to be noted that, depends on the applications we are working in and thus our algorithm is flexible enough to be amenable to any such application. As is divided into several schedules and each schedule has a time duration , we can write . So, each schedule is a tuple denoted as , where .
Location and Task: An entire SC zone is divided into a set of locations . Each location is populated with a set of jobs (dispensed by an agent) which could be denoted as where . Each job is also associated with a cost . The cost of jobs may be considered as time span, amount of internet expenses, battery power, or distances to be travelled, etc. as per the SC system. As is associated with a cost and a location , we can redefine more formally as follows: , where the triplet denotes the job identifier, the cost associated with it and the location at which the job is to be executed respectively. These jobs are to be scheduled into each of (). Each is comprising of a set of jobs denoted as . As a ready reference, all symbols used so far in this paper are listed with their brief description in Table 1.
| Symbol | Definition |
|---|---|
| Set of jobs | |
| Set of locations | |
| Set of schedules | |
| job in set | |
| location in set | |
| schedule in set | |
| Number of jobs | |
| Number of schedules | |
| Total time horizon | |
| Time duration of each schedule | |
| Set of jobs allocated to | |
| Number of iterations | |
| An arbitrary iteration |
3.3 Objective
Given a set of jobs and the set of schedules , jobs are to be allocated into several schedules () in a balanced way for an agent (or for the set of agents who will perform the same set of jobs) such that the following constraint is satisfied.
where is the iterative index of iterations and is represented as the variance of the set of schedules () at iteration. By balancing we mean, the variance in will be least.
The objective of our mechanism is to prevent procrastination through allocation of jobs into a set of schedules in balanced manner. When all schedules are balanced, all jobs with higher cost will uniformly be distributed into different schedules. In such a way, the accumulation of higher cost jobs into one schedule will be prevented. Thus, delaying in execution of these higher cost jobs along with the other jobs allocated into the same schedule could be prevented. Another aspect we have considered here that as we have divided the large time horizon in several schedules (refer Section 3.2), the choices of procrastination are getting reduced. In the similar line we have stated earlier, we can argue that if all jobs are given weeks time , all the jobs can be completed any time within those weeks, chances of procrastination may be more. Instead, if the weeks time horizon is divided into different schedule with week time then the choices for submission of jobs are reduced. Here we have generalized the model by dividing the entire time horizon in number of divisions and thereby reducing the choices substantially.
We have developed our algorithm by considering an arbitrary () location so that it could be applicable to all locations under consideration in this SC model.

4 Proposed Mechanism
This section discusses the proposed algorithm (PPSJBP) in two different ways. First, a schematic diagram of the proposed mechanism is provided. Second, the step-wise algorithm is discussed. Finally, an example with an arbitrary set of data is furnished at the end of this section to illustrate the workflow of our algorithm.
4.1 Schematic Diagram of PPSJBP
Fig. 2 shows the flow of our proposed mechanism. A pool of jobs is available to the platform (block 1). Our mechanism randomly assigns those jobs into schedules (block 2). To achieve higher accuracy in balanced distribution of jobs into schedules, the random distribution of jobs is repeated for times (block 3). For each , the variance of is calculated (block 4). Let us denote the variance of by . For balancing purpose, we need to calculate (block 5). We obtain an almost balanced set of schedules as an outcome of block 5 (shown in block 6). Finally selected schedules are presented to the agents in non increasing order (block 7) of their cost. It is to be noted that our algorithm will also work for heterogeneous set of agents. By heterogeneous we mean that the set of jobs to be executed by them are different. In this case, we can apply our algorithm separately to each agent.

4.2 Procrastination Preventive Schedule of Jobs: A Balanced Perspective (PPSJBP)
The glimpse of the mechanism has already been discussed in Section 3. The detail method in the form of an algorithm is explained in this subsection. Our algorithm has four main sections.
-
•
Main Routine
-
•
Repeated Random Allocation (RRA)
-
•
Most Balanced Distribution Find (MBDF)
-
•
Largest Cost Schedule First (LCSF)
4.2.1 Main Routine
The main routine calls three subroutines, the first one is Repeated Random Allocation (RRA) which is framed in Algorithm 2, allocates jobs to the set of schedules and calculates the total cost of jobs in each schedule through repeated allocation strategy. The input to this subroutine is the set of jobs . The output of this subroutine is a cost matrix where every row represents the iteration and each column represents the total cost of a schedule at that iteration.
The second one is Most Balanced Distribution Find (MBDF) subroutine, given in Algorithm 3 which finds the most balanced set of schedules (in terms of total cost) using variance analysis. The input to this subroutine is the cost matrix returned by RRA subroutine.
The third subroutine is Largest Cost Schedule First (LCSF) which reorders the schedules according to their total costs and the corresponding algorithm is presented in Algorithm 4. The set of schedules (most balanced) returned by MBDF is used as the input to this subroutine. All three subroutines are explained in detail from the next subsection.
4.2.2 Repeated Random Allocation Algorithm
In Algorithm 2, all necessary initialization have been done from line 1 to line 4. The total time frame is initialized in line 1 by subtracting the start time by finish time. The number of schedules is determined by dividing the total time frame by time unit () in line 2. The time unit is same for all schedules and the value of which depends on the applications. A 2-D data structure is initialized in line 4 in which the total cost of each schedule obtained in each iteration will be stored. In line 6, the outer loop starts which repeats the random allocation of jobs into different schedules for times, where is defined as a large number (we have considered 8000 and more for our simulation) in line 5. In line 7, a temporary job set is initialized which will repeatedly be used in all iterations. The inner loop starts in line 8 and continues until all jobs are allocated into schedules for a single iteration of the outer loop. Every job from the job set and the schedule into which a particular job will be allocated are selected randomly in line 9 and line 10 respectively. The randomly selected job is then assigned to the randomly selected schedule in line 11. The temporary job set is updated by removing the allocated job from that set at line 12. After a job is allocated into a schedule (at line 11), the cost of the corresponding job is cumulatively added with the cost of other jobs in that schedule in line 13. Line 16 returns the total cost (of each schedule in each iteration) matrix to the main routine (line number 1 in Algorithm 1).
4.2.3 Most Balanced Distribution Find Algorithm
In this algorithm, the set of schedules with minimum variance is obtained (most balanced set of schedules) by calculating and comparing the variances of the total cost matrix obtained in Algorithm 2. In the beginning of the algorithm, a variable min_var is initialized with which represents a large value, in line number 1. Line number 2 starts the outer level iteration for calculation of the variances and the minimum of them. From line number 3 to line number 7, the variance of each row of total cost matrix is calculated using the formula given in (Eq. 1), where, (in the algorithm, it is ) is the number of samples and () is the sample mean of the sample set (set of costs of all schedules in a particular iteration). In the algorithm, is the . Line number 5 calculates the sum of squared difference between the cost of each schedule and the average cost in each iteration. Finally in line number 7, that sum is divided by to obtain the variance.
| (1) |
From line number 8 to line number 11, the minimum of all variances is determined using the comparison and replace method, , the temporary variable min_var is compared to each variance and the variance lesser than the content of min_var replaces the current content of min_var. In line number 13, the index of the minimum variance, over all iterations, is returned to the main routine. This index calculation is mathematically represented as: .
4.2.4 Largest Cost Schedule First Algorithm
From MBDF algorithm (Algorithm 3) we have obtained the most balanced set of schedules with minimum variance. We go further from here by taking that set of schedules to our last algorithm where schedules will be published according to the order of their costs. To achieve that, the schedule with the highest total cost is published first. Then the schedule with second highest total cost is published and so on. This method is aligned in Algorithm 4 (Merge Sort method is used here).
Purpose of variance analysis: The variance is a statistical method to observe the distance among the objects of similar type. In our proposed method, we are aiming to distribute jobs with various range of costs into different schedules so that all schedules get the jobs with balanced total cost. The variance analysis method is finding the set of schedules with minimum variance by calculating the variance of each set of schedules obtained in each iteration and then by comparing all the variances of all such sets. In Example 1, the entire algorithm is presented with more exposure to the core aspect of our method.
| Iteration# | Job Allocation() in Schedules | |||||
|---|---|---|---|---|---|---|
| 1 | ,, | , | 27 | 10 | 2 | |
| 2 | 12 | 10 | 17 | |||
| 3 | 13 | 15 | 11 | |||
| 4 | 12 | 12 | 15 | |||
| 5 | 14 | 10 | 15 | |||
Example 1.
An example in this subsection is presented to comprehend the algorithm using some arbitrary data. Let there be 6 jobs in . Let . Hence, . So, we have three schedules in which jobs will be assigned randomly for times. In this example, all five iterations of random job allocations into these three schedules are shown in Table 2. column to column shows all 6 random job allocation into 3 different schedules. from column 5 to column 7 the total cost of each schedule is shown. Column nos. 2, 3, and 4 forms the total cost matrix. Each row of the cost matrix is given as input to the variance analysis part of the algorithm in which the variance of each row is calculated and compared with the variance of the next row. The row with the lowest variance is returned as the most balanced distribution of jobs. In Table 3, the variance of each schedule after iterations is shown. Among all the variances found in each iteration shown in Table 3, the row with the minimum variance is selected. The corresponding row in Table 2 is then selected as the most balanced job distribution. The distribution of jobs of each schedule of that row is as follows: Now, in the last part of the algorithm we go a further step and select the schedule with the largest total cost first, second largest total cost next and so on.
5 Analysis of the Proposed Method
Lemma 1.
The probability of allocation of all higher cost jobs (suppose ) among jobs (where ) in a single schedule is , where is the number of schedules.
| Iteration# | Schedules | Variance | ||
| 1 | 27 | 10 | 2 | 163 |
| 2 | 12 | 10 | 17 | 13 |
| 3 | 13 | 15 | 11 | 4 |
| 4 | 12 | 12 | 15 | 3 |
| 5 | 14 | 10 | 15 | 7 |
Proof.
Let us fix any arbitrary schedule among schedules. Now, we define the event (where ) as any , is scheduled in an arbitrary schedule . Given the event , we are interested in finding . If this probability is calculated then we will find that for all , event will occur. So, we can write
| (2) |
Now, according to our method, any higher cost jobs () may be allocated into same schedule. But allocation of one higher cost job into one schedule has no impact on the other job which is yet to be allocated into the same schedule. Consider the probability , where event which has already occurred, the job is already been allocated into a schedule, has no impact on the event , event is independent of event . So we can write, . Similarly for probability where two events which has already occurred have no impact on the event . So, it can be written as, . In similar manner we can also write . Accordingly, we can rewrite Eq. 2 for the event that job is allocated into same schedule as follows: .
The probability of higher cost job to be allocated into schedule is: So, for two higher cost jobs Similarly, for higher cost jobs we have, .
Observation.
When is large, we can say that the probability of allocating all higher cost jobs in a single schedule is much less. For example, consider 50 jobs out of 200 jobs are of higher cost, and there are 6 schedules. So the probability of allocating higher cost jobs into any one schedule out of 6 schedules is which is very much less. It means that over repeated random allocation of jobs, the chances of accumulating higher cost jobs into any one schedule is almost 0.
Lemma 2.
The expected number of jobs to be assigned in a given schedule is considering an arbitrary iteration.
Proof.
We have here, number of trials of assigning jobs into the given schedule (as is the total number of jobs available in our setting). Among those trials, there are successes (the sampled job is landing in the given schedule) such that each success occurs with a probability of and some failure with a probability of . Every trial is independent and has the probability , as is the number of schedules available. Now, we take as a random variable to denote the successful assignment of jobs into the given schedule among trials range within . So the value of can be represented as , where . So, the probability of for i number of successes can be written as, .
This is true as there are ways to choose number of successes among trials and any one such successes occurs with the probability (as in that elementary event, successes will be there along with number of failures). Also, we can write;
| (3) |
Now, the expected number of successes, expected number of jobs in every schedule can be calculated as: observation Consider the synthetic dataset where , we have , and this value is the number of jobs allocated in each schedule. In Section 7.1.2, we have furnished the comparison between OffPSP and PPSJBP against the parameter number of jobs (Fig. 7a) where we can see that schedules are assigned with number of jobs as: which is almost balanced allocation of jobs in each of . The similar observations we have for our real life dataset (KDD Cup 2015 and Bus Driver Scheduling) in the simulation (given in Fig. 7b and Fig. 7c).
|
|
(4) |
From this proof, it is evident that our proposed PPSJBP distributes the jobs in each schedule in a balanced way.
observation Consider the synthetic dataset where , we have , and this value is the number of jobs allocated in each schedule. In Section 7.1.2, we have furnished the comparison between OffPSP and PPSJBP against the parameter number of jobs (Fig. 7a) where we can see that schedules are assigned with number of jobs as: which is almost balanced allocation of jobs in each of . The similar observations we have for our real life dataset (KDD Cup 2015 and Bus Driver Scheduling) in the simulation (given in Fig. 7b and Fig. 7c).
Lemma 3.
The expected number of jobs to be sampled so that every schedule is assigned with jobs is approximately , where is the number of assigned jobs in a schedule.
Proof.
Let us consider the number of jobs that have to be sampled before every schedule gets a job is and the allocation of a job into an empty schedule a ”success.” In this proof, we will apply the concept of geometric distribution as we know that the number of jobs to be sampled before every schedule gets atleast one job follows geometric distribution. We shall divide the sampling of jobs into partitions. Each partition will then boil down to the geometric distribution. The success requires sampling of jobs after the successes.
In the first partition, since all the schedules are initially empty, a schedule will get a job with probability . When one schedule has got one job, sampling of jobs in second partition may allocated an arbitrary job either into the non-empty schedule or into any one of the empty schedules. As there are empty schedules, while sampling in second partition, a job will be assigned in one of the empty schedules with the probability . In partition, there are number of empty schedules as schedules are allocated with atleast one job in partitions. Hence, the probability of getting a job into an empty schedule in partition is . In each partition the number of sampling of jobs can be represented with a random variable where lies within the range of . So, in order to get successes we need number of samplings. As in each partition, the random variable follows geometric distribution and probability of success is So the expected number of samples in partition is thus
Now the expected number of sampling of jobs required in all partitions can be obtained as:
Lemma 4.
The probability , for any schedule where .
Proof.
We can find the probability using Chernoff Bound as: .
We know that . So, plugging this in the above equation we get:
From the above discussion we can see that a little deviation of any schedule from balanced job assignment has the probability is upper bounded by . Now, as grows larger, will be decreasing exponentially.
Observation.
With and , the above said probability can be calculated as , which is much less. In terms of our dataset, namely, Bus Driver Scheduling dataset and KDD Cup 2015 dataset, and respectively. So the said probability will be much less than the case where .
Lemma 5.
The time complexity by PPSJBP is , where is the number of repetition of sampling of jobs, is the total number of jobs and is the number of schedules.
Proof.
Our algorithm PPSJBP consists of three subroutines - RRA, MBDF, and LCSF. In RRA number of jobs are allocated randomly in schedules and this random allocation is repeated for times. That means for each of the iterations, of jobs have been allocated into schedules. So the time complexity for RRA subroutine is . MBDF subroutine finds the most balanced set of schedules by calculating the variance of each set of schedule out of such sets. Variance calculation of each set takes time. This is for one iteration. So, variance calculation for such set of schedules take time. Now, in the last subroutine (LCSF), the minimum variant set of schedules i.e., most balanced set of schedules are arranged in descending order according to their costs. To achieve that arrangement, merge sort is used. The input for the sorting is number of costs (as each schedule will provide one cost). So the time complexity for LCSF subroutine is . Accordingly, the total time complexity for the three subroutine can be calculated as . If (which is most realistic scenario), the time complexity of PPSJBP is .
Now a connection will be established between finding our minimum variance with repetition and online hiring assistant problem for stating our next analytical result. In online hiring assistant problem, there are number of candidates who appear for the interview process in an online fashion we don’t know the list of the candidates apriori. In this problem we don’t want to interview all the number of candidates yet, we want to find the best candidate or a close to the best candidate (that is the target). The natural question that arises is that, how many samples we need to explore before we are sure that our target is achieved with a good probability. In literature [50][51][52][53][54][55][56], it is shown that we need to sample number of candidates to make sure that our target is achieved with a probabilistic lower bound of . In our problem, for each iteration, we calculate a variance. So, as a thought experiment, we can think the variances are appearing in an online fashion just like the candidates in the online hiring assistant problem. So the variances here are resembling the candidates and we need to find out the best (minimum) variance. So, the problem is boiling down to the fact that how many such variances to be sampled (to be calculated) before we achieve our target of finding the minimum variance.
Corollary 1.
number of variances to be calculated (per iteration we calculate one variance) to make sure that the minimum variance will be achieved with a probabilistic lower bound .
Proof.
The proof follows from the connection we have established above, we need number of samples for the probability to be atleast . Following this connection, we can say that number of variances to be calculated for making sure that we get a probabilistic lower bound of ( with probability atleast ).
Observation.
Consider the value of repeated random allocation of jobs. According to Corollary 1, we have to iterate the random allocation of jobs into schedules times times to get success with the probability of if we the repeat random allocation process for 1472 times, the chance to get best minimum variance is atleast 37%. Now, if we iterate our random allocation process for times, the lower bound of the probability will also increase. So, we can say that with larger value of , the lower bound of the probability of getting the best minimum variance is greater than .
6 Experiments and Results
6.1 Setup
Number of Schedules: It is stated earlier in Section 3.2 that in our model a time horizon is divided into a set of schedules and the time duration of each is with . So was defined as . It is to be noted that, depends on the applications we are working in and thus our algorithm is flexible enough to be amenable to any such application. In our algorithm, the number schedules () taken is 4 and the total duration () for all tasks is considered 4 weeks for simulation. So week .
Dataset: Another vital part of the setup is the dataset. First, a synthetic dataset was generated with random numbers as job cost for primary simulation of our algorithm. It was generated using Python Libraries. After the successful simulation with the synthetic dataset, we have used two real datasets, - i) Bus Driver Scheduling dataset [57] and ii) KDD Cup 2015 dataset [58]. All datasets are elaborated in Section 6.2.
System Specification: The simulation is carried out in personal computing environment with - generation microprocessor, 8 GB of RAM, Ubuntu as the operating system. Google Colab (with Python) is used for implementing the algorithm.
6.2 Dataset
Synthetic Dataset: The synthetic dataset, shown in Table 4 consists of the columns- () and (). This dataset has been generated randomly with 200 jobs. Once we have verified our algorithm with this synthetic dataset, we have employed two real datasets - Bus Driver Scheduling dataset [57] and KDD Cup 2015 dataset [58] in our algorithm.
| Sl # | Job () | Job Cost ( |
|---|---|---|
| 1 | 10 | |
| 2 | 40 | |
| 3 | 25 | |
| 4 | 100 | |
| 5 | 89 |
| Sl# | Bus_ID | Tot_Dur |
|---|---|---|
| 1 | 1 | 1145 |
| 2 | 2 | 1110 |
| 3 | 3 | 850 |
| 4 | 4 | 1090 |
| 5 | 5 | 840 |
Bus Driver Scheduling Dataset: Bus Driver Scheduling dataset has seven columns or attributes all of which are not required for the algorithm. As we are only concerned about the job_id and the job cost, we have extracted the values associated with rows ”Bus_Line_Id” and ”Duration”. In this dataset there are a total of 359 buses that run per day. The total running cost of every bus for the entire day is obtained by adding all the run time duration of that day. For example, total running time is 1145 minutes. The 5 samples of the dataset after summing up the run time cost of every bus is shown in Table 5.
| enroll_id | Date | Time | event | course_id |
|---|---|---|---|---|
| 76492 | 2013-12-12 | 03:46:04 | navigate | 81UZ |
| 115995 | 2013-11-28 | 12:00:10 | video | 3VkH |
| 124335 | 2014-05-13 | 09:37:03 | access | q6A6 |
| 81407 | 2014-01-01 | 08:03:01 | access | 5Gyp |
| 81407 | 2014-01-01 | 08:03:01 | video | 5Gyp |
| course_id | Job | Cost |
|---|---|---|
| 81UZ | navigate | 10 |
| access | 15 | |
| video | 4 | |
| G8EP | video | 1 |
| page_close | 1 | |
| discussion | 4 | |
| 3cnZ | access | 2 |
| video | 1 | |
| page_close | 1 | |
| discussion | 5 |
KDD Cup 2015 Dataset: KDD Cup 2015 dataset is a very large repository which contains online course enrollment and course log information of a large number of students. The interpretation of this dataset is as follows: a student can enroll in multiple courses, and every course has at most activities or events, which are - Access, Video, Discussion, Navigate, Problem, Wikipedia, Page Close. Each activity under every course in which a particular student has enrolled, is considered as a job in this paper. Each course log information entry has the information about a student’s - enrollment_id, entry time, activity name, and course_id. We have extracted the log information of 30 students who has enrolled for maximum courses. From course log information entry, the column is divided into and and put into a new entry (shown in Table 6). Then the total activity time for each event under each course is calculated by taking the difference between the of next event and the of that event. These differences of two different entry times are then summed up for each event under each course which is shown in Table Table 7. Again, for the course_id column, first four characters are shown. The total cost of an event under a course (considered as the job) is given in minutes. There are 3000 such jobs in our derived dataset, sample of which is presented in Table 7. The implementation of extraction of both the real datasets is done using Python with Pandas library.
6.3 Results of Simulation
In this section we have presented the outcome of simulation of our algorithm on various parameters.
6.3.1 Comparison Among the Set of Schedules with Minimum Variance and Randomly Chosen Sets of Schedules
This section shows the comparison between the most balanced set of schedules and the other randomly chosen sets of schedules which are unbalanced. Let us represent the most balanced set of schedules as and randomly chosen unbalanced set of schedules as . The setup for this simulation is given below.
In this setting, is the index position of the set of schedules with minimum variance. is the sets of schedules taken randomly and is the another sets of schedule taken randomly except the first sets. is the function which picks the set of schedules at random. For our case . This comparison is shown using synthetic dataset with , shown in Fig. 3a and then using the Bus Driver Scheduling dataset with , shown in Fig. 3b. In both the figures, first row of the figure contains five plots among which first four plots are from set of and the last plot is of . The second row is same but without replacement by the first four of and the fifth plot is of again. The purpose of this comparison is to show that set of schedules with minimum variance is most balanced one in comparison to any other sets of schedules obtained from repeated random allocation. When the number of jobs increases, the repetition of random allocation is also to be increased in order to lower the probability of concentration of higher cost jobs into one schedule (refer to Lemma 1).
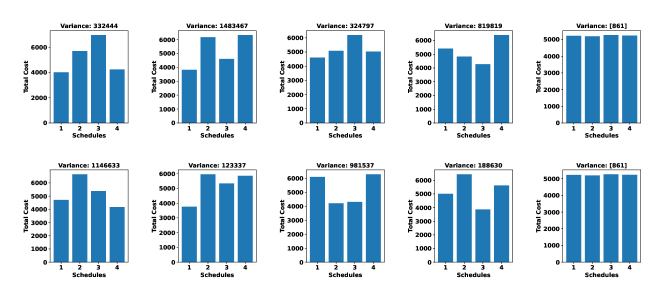

In Fig. 3a, it is to be noticed that the difference of variances of first four and is very large, first four schedules have variances of , , , and the most balanced one has the variance of (shown in first row of Fig. 3a). It is evident from the above simulation that our algorithm is able to allocate all jobs into schedules in most balanced manner according to their costs. This simulation follows Lemma 1 which states that the accumulation of all higher cost jobs into a single schedule is very less. We claim this because when the minimum variant schedules is found after iterations, we have seen that the cost of each schedule is almost equal.
The connection we have established in Section 5 reveals that the number of variances to be calculated to achieve the best minimum variance with a lower bound probability of 0.37, is approximately (when ). That means if we calculate number of variances ( the number of iterations), there is atleast chance to obtain the best minimum variance. When we take , to achieve the lower bound of 0.37 we need to find number of variances. In order to increase this lower bound, the value of is to be increased because this lower bound of is giving a benchmark. If we compute less number of variances, the scenario would not be realistic. So increasing value of will give higher accuracy. Accordingly, in our simulation we have considered and more number of iterations which is sufficiently larger than the value given in the benchmark.
From Lemma 3 we can say that the expected number of jobs to be sampled is . That means, if we sample jobs, all the schedule will be assigned with one or more jobs. From this simulation (in Fig. 3), we have seen that in the minimum variant set of schedules all the schedules have been assigned with jobs with almost balanced distribution. Also, in the randomly chosen sets, we have seen that all the schedules are assigned with one or more jobs and no schedule is left empty. Thus, the observation made from this simulation is plausible enough to justify Lemma 3.
6.3.2 Comparative Study Varying K
In this simulation we have shown a comparative study on the behaviour of every time when is varied. Here, we have varied the value of from to and in each case it has been observed that our algorithm is able to obtain the most balanced set of schedules. The comparison is given in Fig. 4. From this simulation, we can claim that the proposed mechanism will always produce the most balanced set of schedules which ensures the most uniform distribution of jobs in each set of schedules.
In each plot, axis denotes the schedule number and axis denotes the total cost of each schedule (Fig. 4).
Lemma 4 shows that our algorithm has a negligible chance for any schedule to deviate from getting the balanced job assignment. This simulation shows that in each of multiple iterations, the minimum variant set of schedules is achieved and it is balanced.

6.3.3 Comparative Study on Dispensing of Schedules with and without Ordering
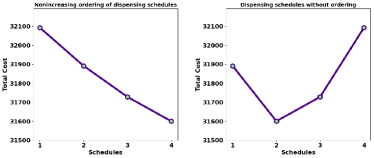
The last step of our proposed method is to dispense the schedules in nonincreasing order of their costs. This step is followed after we have found the minimum variant set of schedules. In the minimum variant set, the total cost of each is different but those costs are in close vicinity (refer Section 6.3.1 and Section 6.3.2). From that set, the schedule with the maximum cost is dispensed first, then the schedule with second maximum cost and so on. The representation of such ordering is given below.
where function rearranges the set of schedules with minimum variance in nonincreasing order of their cost. Through such ordering of dispensing of schedules, the agent will have maximum time to verify the jobs of heavier schedules after submission. In this method of dispensing of schedules, the submission and verification process are carried out simultaneously and the verification of all jobs could be performed efficiently. In Fig. 5a, the simulation in left hand side shows the dispensing of schedules with nonincreasing order of costs and right hand side shows without ordering. In the right hand side of Fig. 5a, we can see that if schedule 2 is dispensed before schedule 3, the verification time for schedule 3 would be less than schedule 2 even if schedule 3 is heavier than schedule 2. In the same figure, the left hand side shows that the schedule with largest cost, schedule 3 is dispensed first, then schedule 4 and so on which provides the maximum time for each schedule for verification after submission of jobs in those schedules.
In this simulation the minor difference among the cost of each schedule is amplified so that the dispense of schedules with and without ordering could clearly be understood.


7 Comparison with Existing Research
Our proposed scheduling mechanism that subvert the procrastinating nature of the agents is compared with the existing work in [43]. Through this comparison, we will discuss that our algorithm (PPSJBP) will generate a set of schedules which is much more balanced than the algorithm (OffPSP) mentioned in [43].
According to the algorithm OffPSP, a threshold regarding the cost of each schedule is fixed and all the jobs are allocated according to threshold to every schedule. In our algorithm PPSJBP, we have made a balanced allocation of all jobs into each schedule without taking any threshold (this gives a general flavour to our proposed algorithm as threshold based allocation is somewhat imposing extra restriction on the allocation of jobs to the schedule). In OffPSP the threshold based technique leads to a set of schedules where every schedule in that set is unbalanced (in terms of its costs).
Every schedule in OffPSP has a time period (T is the set of time periods). Each job ( is the set of jobs) that is assigned to a particular schedule has a start time and a deadline such that the job can be completed within the time period of that schedule. That means, the time period of a schedule is larger than the time period of a job assigned to that schedule. The job set and the time frame (of a schedule) in which a job can be completed, is mapped to a bipartite graph, from which each job is allocated to a schedule after satisfying a condition of maximum ratio of marginal utility to the cost. In this algorithm a threshold is maintained (already mentioned) which is violated once by the last allocated job of the current schedule and then for that schedule, the utility of the last job is checked with that of the other jobs in that schedule. Job with the higher utility is kept and the rest are discarded from the schedule.
We have implemented the OffPSP algorithm in our setting where we have considered that all jobs have uniform utility (this is taken as uniform to have the equivalence of the setting of OffPSP and our proposed algorithm PPSJBP). According to the OffPSP algorithm, a job is allocated to a schedule if the the ratio of marginal utility to the cost of that job is maximum compared to all other jobs left in that schedule. As we have considered the uniform utility for all jobs, the ratio is calculated as . Jobs are allocated into a particular schedule until the threshold (cost) of that schedule is violated once (the threshold is defined in Section 7.1). Let us understand the procedure with an example. Consider, the job set is , number of schedules are , and the threshold for each schedule is . The ratio of marginal utility and cost for each job is calculated as , as the marginal utility of the schedule after newly added job to that schedule and before adding it, is (definition of marginal utility is given in [43]). Now, after calculating the ratio, we found that the job with cost has the maximum ratio marginal utility to the cost. So it is allocated to schedule 1 as the total cost of schedule 1 is less than the threshold. The allocated job is them removed from the job pool. The total cost of that schedule becomes 4. In this way, the jobs are assigned to schedule 1. The total cost for schedule 1 becomes 86. Now the total cost is more than the threshold. As the condition is violated once the allocation process into schedule 1 is stopped. Now the only job left is which has the cost 45. This job is allocated to schedule 2 as it is empty. So, finally in schedule 1 and schedule 2, the total job cost is 86 and 45, and number of jobs are 5 and 1 respectively. From this example we can see that both the schedules produced, are not balanced in terms of the total cost and the number of jobs.


In OffPSP algorithm, it was also mentioned that after allocation of jobs into a schedule, if the utility of the last job allocated into a schedule is greater than the utility of the other jobs, the last job is kept and the other jobs are discarded. Wang. et. al. has not processed this discarded jobs further (as per the algorithm is presented in [43]). This creates a certain amount of disparity in the job allocation process. It is observed that the OffPSP may not perform efficiently in terms of balancing of the scheduled jobs as they are scheduling the jobs in a sorted order by using the concept of marginal utility and also, considering whether the utility of the of the last job allocated into a schedule is greater than the utility of the other jobs.
7.1 OffPSP Vs. PPSJBP
This comparative study will be done on the basis of various parameters which are: Average cost of each schedule, Total number of jobs allocated in each schedule. The set up for simulation of OffPSP algorithm in the perspective of our work is given as: (1) Number of schedules: , (2) Deadline for each schedule=1 week, (3) Threshold for each schedule: , and (4) Utility of .
7.1.1 OffPSP Vs. PPSJBP - On Average Cost per Schedule
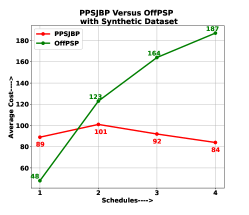
With the above settings, the OffPSP and PPSJBP algorithm is simulated with the synthetic dataset with 200 jobs, Bus Driver Scheduling dataset with 359 jobs and KDD Cup 2015 dataset with more than 3000 jobs. The schedules produced by the OffPSP is unbalanced in terms of average cost of jobs than PPSJBP. A comparison graph is shown from Fig. 6a to Fig. 6c using the Synthetic dataset, KDD Cup 2015 dataset, and Bus Driver Scheduling dataset respectively. It is pretty evident from the figure that PPSJBP is behaving in most balanced way, whereas OffPSP is varying (increasing) over average cost of each schedule.


7.1.2 OffPSP Vs. PPSJBP - On Number of Jobs per Schedule
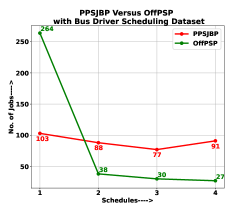
In this comparison, we will see that the number of jobs that are allocated into different schedules largely vary in OffPSP algorithm and are mostly balanced in PPSJBP algorithm. This is due to the fact that in OffPSP, all jobs are allocated into each schedule as per the decreasing order of the ratio of marginal utility and cost. In simple terms, all jobs are allocated into each schedule in sorted order. In our algorithm, all jobs are randomly allocated with large number of repetition. Accordingly, the schedules with minimum variance has produced the most balanced allocation. We have shown this comparison using Synthetic, Bus Driver Scheduling and KDD Cup 2015 datasets, from Fig. 7a to Fig. 7c respectively. As the number of jobs in each schedule is almost equal, the average cost of each schedule is almost uniform in our algorithm. It is due to the fact that higher cost jobs are distributed among all the schedules. According to OffPSP, the number of jobs in each schedule largely vary. As a result the higher cost jobs are accumulated into one schedule which enhances the chance of procrastination.
8 Conclusion and Future Works
In this paper we have proposed a novel procrastination preventive algorithm named PPSJBP which distributes jobs into different schedules (in most balanced manner) as per their costs to avoid procrastination in spatial crowdsourcing application. Every schedule is given equal time frame by subdividing the total time frame so that the on-time and efficient completion of jobs are guaranteed. Another aspect of PPSJBP is that, the schedules which are finally given to the agents are presented in non increasing order of their cost. The benefit of this is two fold: (1) the agents will have less burden as they will be going down the line to execute jobs in several schedules and (2) the task provider will have ample time to work on the little bit heavy schedule as it is submitted earlier. So the PPSJBP is relying on 3 facts: division of the time horizon into several schedules (choice reduction), aligning the jobs into the schedules by a randomized repetitive procedure (balancing), re-arrangement of the set of schedules (with minimum variance) in non increasing order of the cost of each schedule (benefiting task provider). We have compared our scheme with the existing algorithm with synthetic as well as real datasets through extensive simulation and it is observed that in terms of balancing effect, our proposed algorithm outperforms the existing one. Also we have shown analytically that our proposed algorithm maintains the balanced distribution.
As it is a new paradigm for spatial crowdsourcing, there are multiple future directions to address the prevention of procrastination. In a SC zone, the distance between two distinct locations might be very less. In such situation, these two locations coulde be merged to address as a single location. Platform-centric data about the agents may be used to avoid procrastination in a better way. Another direction could be to give incentives to the agents on the way of performing the task to avoid procrastination.
References
- \bibcommenthead
- Howe [2006] Howe, J.: The rise of crowdsourcing. Wired magazine 14(6), 1–4 (2006)
- Alam et al. [2020] Alam, M.Y., Nandi, A., Kumar, A., Saha, S., Saha, M., Nandi, S., Chakraborty, S.: Crowdsourcing from the true crowd: Device, vehicle, road-surface and driving independent road profiling from smartphone sensors. Pervasive and Mobile Computing 61, 101103 (2020)
- Cricelli et al. [2021] Cricelli, L., Grimaldi, M., Vermicelli, S.: Crowdsourcing and open innovation: a systematic literature review, an integrated framework and a research agenda. Review of Managerial Science, 1–42 (2021)
- Castillo et al. [2022] Castillo, H., Grijalvo, M., Martinez-Corral, A., Palacios, M.: Crowdsourcing ecosystem. the crowd pillars and their implementation process. In: Ensuring Sustainability, pp. 279–291. Springer, ??? (2022)
- Pan and Blevis [2011] Pan, Y., Blevis, E.: A survey of crowdsourcing as a means of collaboration and the implications of crowdsourcing for interaction design. In: 2011 International Conference on Collaboration Technologies and Systems (CTS), pp. 397–403 (2011). IEEE
- Besaleva and Weaver [2013] Besaleva, L.I., Weaver, A.C.: Crowdhelp: A crowdsourcing application for improving disaster management. In: 2013 IEEE Global Humanitarian Technology Conference (GHTC), pp. 185–190 (2013). IEEE
- Muller et al. [2015] Muller, C., Chapman, L., Johnston, S., Kidd, C., Illingworth, S., Foody, G., Overeem, A., Leigh, R.: Crowdsourcing for climate and atmospheric sciences: Current status and future potential. International Journal of Climatology 35(11), 3185–3203 (2015)
- Han and Cheng [2020] Han, C.-K., Cheng, S.-F.: An exact single-agent task selection algorithm for the crowdsourced logistics. In: Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI-20, pp. 4352–4358 (2020). IJCAI
- Singh et al. [2020] Singh, V.K., Mukhopadhyay, S., Xhafa, F., Sharma, A.: A budget feasible peer graded mechanism for iot-based crowdsourcing. Journal of Ambient Intelligence and Humanized Computing 11(4), 1531–1551 (2020)
- Wang et al. [2020] Wang, X., Tushar, W., Yuen, C., Zhang, X.: Promoting users’ participation in mobile crowdsourcing: A distributed truthful incentive mechanism (dtim) approach. IEEE Transactions on Vehicular Technology 69(5), 5570–5582 (2020)
- Yang et al. [2012] Yang, D., Xue, G., Fang, X., Tang, J.: Crowdsourcing to smartphones: Incentive mechanism design for mobile phone sensing. In: Proceedings of the 18th Annual International Conference on Mobile Computing and Networking, pp. 173–184 (2012)
- Fuchs-Kittowski and Faust [2014] Fuchs-Kittowski, F., Faust, D.: Architecture of mobile crowdsourcing systems. In: CYTED-RITOS International Workshop on Groupware, pp. 121–136 (2014). Springer
- Wang et al. [2016] Wang, Y., Jia, X., Jin, Q., Ma, J.: Quacentive: a quality-aware incentive mechanism in mobile crowdsourced sensing (mcs). The Journal of Supercomputing 72(8), 2924–2941 (2016)
- Yan et al. [2009] Yan, T., Marzilli, M., Holmes, R., Ganesan, D., Corner, M.: mcrowd: a platform for mobile crowdsourcing. In: Proceedings of the 7th ACM Conference on Embedded Networked Sensor Systems, pp. 347–348 (2009)
- Eagle [2009] Eagle, N.: txteagle: Mobile crowdsourcing. In: International Conference on Internationalization, Design and Global Development, pp. 447–456 (2009). Springer
- Phuttharak and Loke [2018] Phuttharak, J., Loke, S.W.: A review of mobile crowdsourcing architectures and challenges: Toward crowd-empowered internet-of-things. IEEE access 7, 304–324 (2018)
- Tong et al. [2020] Tong, Y., Zhou, Z., Zeng, Y., Chen, L., Shahabi, C.: Spatial crowdsourcing: a survey. The VLDB Journal 29(1), 217–250 (2020)
- Gummidi et al. [2019] Gummidi, S.R.B., Xie, X., Pedersen, T.B.: A survey of spatial crowdsourcing. ACM Transactions on Database Systems (TODS) 44(2), 1–46 (2019)
- Wang et al. [2021] Wang, Z., Li, Y., Zhao, K., Shi, W., Lin, L., Zhao, J.: Worker collaborative group estimation in spatial crowdsourcing. Neurocomputing 428, 385–391 (2021)
- Hamrouni et al. [2020] Hamrouni, A., Ghazzai, H., Frikha, M., Massoud, Y.: A spatial mobile crowdsourcing framework for event reporting. IEEE transactions on computational social systems 7(2), 477–491 (2020)
- Zhang et al. [2016] Zhang, X., Yang, Z., Gong, Y.-J., Liu, Y., Tang, S.: Spatialrecruiter: Maximizing sensing coverage in selecting workers for spatial crowdsourcing. IEEE Transactions on Vehicular Technology 66(6), 5229–5240 (2016)
- Liu et al. [2018] Liu, Y., Guo, B., Chen, C., Du, H., Yu, Z., Zhang, D., Ma, H.: Foodnet: Toward an optimized food delivery network based on spatial crowdsourcing. IEEE Transactions on Mobile Computing 18(6), 1288–1301 (2018)
- Guo et al. [2018] Guo, B., Liu, Y., Wang, L., Li, V.O., Lam, J.C., Yu, Z.: Task allocation in spatial crowdsourcing: Current state and future directions. IEEE Internet of Things Journal 5(3), 1749–1764 (2018)
- Wang et al. [2017] Wang, L., Liu, G., Sun, L.: A secure and privacy-preserving navigation scheme using spatial crowdsourcing in fog-based vanets. Sensors 17(4), 668 (2017)
- Zhang et al. [2016] Zhang, X., Yang, Z., Liu, Y., Tang, S.: On reliable task assignment for spatial crowdsourcing. IEEE Transactions on Emerging Topics in Computing 7(1), 174–186 (2016)
- Tehrani et al. [2018] Tehrani, P.F., Restel, H., Jendreck, M., Pfennigschmidt, S., Hardt, M., Meissen, U.: Toward privacy by design in spatial crowdsourcing in emergency and disaster response. In: 2018 5th International Conference on Information and Communication Technologies for Disaster Management (ICT-DM), pp. 1–9 (2018). IEEE
- Kong et al. [2019] Kong, X., Liu, X., Jedari, B., Li, M., Wan, L., Xia, F.: Mobile crowdsourcing in smart cities: Technologies, applications, and future challenges. IEEE Internet of Things Journal 6(5), 8095–8113 (2019)
- Li et al. [2021] Li, M., Wu, J., Wang, W., Zhang, J.: Toward privacy-preserving task assignment for fully distributed spatial crowdsourcing. IEEE Internet of Things Journal 8(18), 13991–14002 (2021)
- Zhang et al. [2019] Zhang, X., Wu, Y., Huang, L., Ji, H., Cao, G.: Expertise-aware truth analysis and task allocation in mobile crowdsourcing. IEEE Transactions on Mobile Computing (2019)
- Yadav et al. [2021] Yadav, A., Chandra, J., Sairam, A.S.: A budget and deadline aware task assignment scheme for crowdsourcing environment. IEEE Transactions on Emerging Topics in Computing (2021)
- Djigal et al. [2022] Djigal, H., Liu, L., Luo, J., Xu, J.: Buda: Budget and deadline aware scheduling algorithm for task graphs in heterogeneous systems. In: 2022 IEEE/ACM 30th International Symposium on Quality of Service (IWQoS), pp. 1–10 (2022). IEEE
- Fu and Liu [2021] Fu, D., Liu, Y.: Fairness of task allocation in crowdsourcing workflows. Mathematical Problems in Engineering 2021 (2021)
- Deng et al. [2013] Deng, D., Shahabi, C., Demiryurek, U.: Maximizing the number of worker’s self-selected tasks in spatial crowdsourcing. In: Proceedings of the 21st Acm Sigspatial International Conference on Advances in Geographic Information Systems, pp. 324–333 (2013)
- Mukhopadhyay et al. [2021] Mukhopadhyay, J., Singh, V.K., Mukhopadhyay, S., Dhananjaya, M.M., Pal, A.: An egalitarian approach of scheduling time restricted tasks in mobile crowdsourcing for double auction environment. International Journal of Web and Grid Services 17(3), 221–245 (2021)
- Ma et al. [2021] Ma, Y., Ni, R., Gao, X., Chen, G.: Mixed priority queue scheduling based on spectral clustering in spatial crowdsourcing. In: 2021 IEEE International Conference on Web Services (ICWS), pp. 293–302 (2021). IEEE
- Tim [2016] Tim, R.: CS269I: Incentives in Computer Science Lecture# 19: Time-Inconsistent Planning. Stanford Course, ??? (2016)
- Kleinberg and Oren [2014] Kleinberg, J., Oren, S.: Time-inconsistent planning: a computational problem in behavioral economics. In: Proceedings of the Fifteenth ACM Conference on Economics and Computation, pp. 547–564 (2014)
- Tang et al. [2017] Tang, P., Teng, Y., Wang, Z., Xiao, S., Xu, Y.: Computational issues in time-inconsistent planning. In: Thirty-First AAAI Conference on Artificial Intelligence (2017)
- Kleinberg et al. [2017] Kleinberg, J., Oren, S., Raghavan, M.: Planning with multiple biases. In: Proceedings of the 2017 ACM Conference on Economics and Computation, pp. 567–584 (2017)
- Gravin et al. [2016] Gravin, N., Immorlica, N., Lucier, B., Pountourakis, E.: Procrastination with variable present bias. arXiv preprint arXiv:1606.03062 (2016)
- Akerlof [1991] Akerlof, G.A.: Procrastination and obedience. The american economic review 81(2), 1–19 (1991)
- Kahneman and Tversky [2013] Kahneman, D., Tversky, A.: Prospect theory: An analysis of decision under risk. In: Handbook of the Fundamentals of Financial Decision Making: Part I, pp. 99–127. World Scientific, ??? (2013)
- Wang et al. [2019] Wang, L., Tong, Y., Hu, C., Chen, L., Li, Y.: Procrastination-aware scheduling: A bipartite graph perspective. In: 2019 IEEE 35th International Conference on Data Engineering (ICDE), pp. 1650–1653 (2019). IEEE
- Liu et al. [2020] Liu, J., Yang, Y., Li, D., Huang, S., Liu, H., et al.: An incentive mechanism based on behavioural economics in location-based crowdsensing considering an uneven distribution of participants. IEEE Transactions on Mobile Computing (2020)
- Li et al. [2019] Li, D., Wang, S., Liu, J., Liu, H., Wen, S.: Crowdsensing from the perspective of behavioral economics: An incentive mechanism based on mental accounting. IEEE Internet of Things Journal 6(5), 9123–9139 (2019)
- Thaler [1999] Thaler, R.H.: Mental accounting matters. Journal of Behavioral decision making 12(3), 183–206 (1999)
- Li et al. [2018] Li, D., Qiu, L., Liu, J., Xiao, C.: Analysis of behavioral economics in crowdsensing: A loss aversion cooperation model. Scientific Programming 2018 (2018)
- Liu et al. [2021] Liu, J., Huang, S., Xu, H., Li, D., Zhong, N., Liu, H.: Cooperation promotion from the perspective of behavioral economics: An incentive mechanism based on loss aversion in vehicular ad-hoc networks. Electronics 10(3), 225 (2021)
- Upfal Eli [2005] Upfal Eli, M.M.: Probability and Computing: Randomized Algorithms And. Cambridge University Press, ??? (2005)
- Cormen et al. [2010] Cormen, T.H., Leiserson, C.E., Rivest, R.L., Stein, C.: Introduction to Algorithms. PHI Learning (Originally MIT press), ??? (2010)
- Ajtai et al. [2001] Ajtai, M., Megiddo, N., Waarts, O.: Improved algorithms and analysis for secretary problems and generalizations. SIAM Journal on Discrete Mathematics 14(1), 1–27 (2001)
- Hajiaghayi et al. [2004] Hajiaghayi, M.T., Kleinberg, R., Parkes, D.C.: Adaptive limited-supply online auctions. In: Proceedings of the 5th ACM Conference on Electronic Commerce, pp. 71–80 (2004)
- Kleinberg [2005] Kleinberg, R.: A multiple-choice secretary algorithm with applications to online auctions. In: Proceedings of the Sixteenth Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 630–631 (2005). Citeseer
- Bateni et al. [2013] Bateni, M., Hajiaghayi, M., Zadimoghaddam, M.: Submodular secretary problem and extensions. ACM Transactions on Algorithms (TALG) 9(4), 1–23 (2013)
- Correa et al. [2020] Correa, J., Cristi, A., Epstein, B., Soto, J.: Sample-driven optimal stopping: From the secretary problem to the iid prophet inequality. arXiv preprint arXiv:2011.06516 (2020)
- Nuti [2022] Nuti, P.: The secretary problem with distributions. In: International Conference on Integer Programming and Combinatorial Optimization, pp. 429–439 (2022). Springer
- Constantino et al. [2017] Constantino, A.A., Mendonca, C.F., Araujo, S.A., Landa-Silva, D., Calvi, R., Santos, A.F.: Solving a large real-world bus driver scheduling problem with a multi-assignment based heuristic algorithm. Journal of Universal Computer Science 23(5) (2017)
- Feng et al. [2019] Feng, W., Tang, J., Liu, T.X.: Understanding dropouts in moocs. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 517–524 (2019)