MIPI 2022 Challenge on Under-Display Camera Image Restoration: Methods and Results
Abstract
Developing and integrating advanced image sensors with novel algorithms in camera systems are prevalent with the increasing demand for computational photography and imaging on mobile platforms. However, the lack of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). To bridge the gap, we introduce the first MIPI challenge including five tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Under-Display Camera (UDC) Image Restoration track on MIPI 2022. In total, 167 participants were successfully registered, and 19 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Under-Display Camera Image Restoration. A detailed description of all models developed in this challenge is provided in this paper. More details of this challenge and the link to the dataset can be found at https://github.com/mipi-challenge/MIPI2022.
Keywords:
Under-Display Camera, Image Restoration, MIPI challengeMIPI 2022 challenge website: http://mipi-challenge.org
1 Introduction
The demand for smartphones with full-screen displays has drawn interest from manufacturers in a newly-defined imaging system, Under-Display Camera (UDC). In addition, it also demonstrates practical applicability in other scenarios, e.g., for videoconferencing with a more natural gaze focus as cameras are placed at the center of the displays.
UDC is an imaging system whose camera is placed underneath a display. However, widespread commercial productions of UDC are prevented by poor imaging quality caused by diffraction artifacts. Such artifacts are unique to UDC, caused by the gaps between display pixels that act as an aperture and induce diffraction artifacts in the captured image. Typical diffraction artifacts include flare, saturated blobs, blur, haze, and noise. Therefore, while bringing a better user experience, UDC may sacrifice image quality, and affect other downstream vision tasks. The complex and diverse distortions make the reconstruction problem extremely challenging. Zhou et al.[42, 41] pioneered the attempt of the UDC image restoration and proposed a Monitor Camera Imaging System (MCIS) to capture paired data. However, their work only simulated incomplete degradation. To alleviate this problem, Feng et al.[9] reformulated the image formation model and synthesized the UDC image by considering the diffraction flare of the saturated region in the high-dynamic-range (HDR) images. This challenge is based on the dataset proposed in [9], and aims to restore UDC images with complicated degradations. More details will be discussed in the following sections.
We hold this image restoration challenge in conjunction with MIPI Challenge which will be held on ECCV 2022. We are seeking an efficient and high-performance image restoration algorithm to be used for recovering under-display camera images. MIPI 2022 consists of five competition tracks:
-
•
RGB+ToF Depth Completion uses sparse and noisy ToF depth measurements with RGB images to obtain a complete depth map.
-
•
Quad-Bayer Re-mosaic converts Quad-Bayer RAW data into Bayer format so that it can be processed by standard ISPs.
-
•
RGBW Sensor Re-mosaic converts RGBW RAW data into Bayer format so that it can be processed by standard ISPs.
-
•
RGBW Sensor Fusion fuses Bayer data and monochrome channel data into Bayer format to increase SNR and spatial resolution.
-
•
Under-Display Camera Image Restoration improves the visual quality of images captured by a new imaging system equipped with an under-display camera.
2 MIPI 2022 Under-Display Camera Image Restoration
To facilitate the development of efficient and high-performance UDC image restoration solutions, we provide a high-quality dataset to be used for training and testing and a set of evaluation metrics that can measure the performance of developed solutions. This challenge aims to advance research on UDC image restoration.
2.1 Datasets
The dataset is collected and synthesized using a model-based simulation pipeline as introduced in [9]. The training split contains 2016 pairs of images. Image values are ranging from [0, 500] and constructed in ‘.npy’ form. The validation set is a subset of the testing set in [9], and contains 40 pairs of images. The testing set consists of another 40 pairs of images. The input images from the validation set and testing set are provided and the Ground Truth data are not available to participants. Both input and Ground Truth data are high dynamic range. For evaluation, all measurements are computed in tone-mapped images (Modified Reinhard). The tone mapping operation can be expressed as .
2.2 Evaluation
The evaluation measures the objective fidelity and the perceptual quality of the UDC images with reference ground truth images. We use the standard Peak Signal To Noise Ratio (PSNR) and the Structural Similarity (SSIM) index as often employed in the literature. In addition, Learned Perceptual Image Patch Similarity (LPIPS) [37] will be used as a complement. All measurements are computed in tone-mapped images (Modified Reinhard [23]). For the final ranking, we choose PSNR as the main measure, yet the top-ranked solutions are expected to also achieve above-average performance on SSIM and LPIPS. For the dataset we report the average results over all the processed images.
2.3 Challenge Phase
The challenge consisted of the following phases:
-
1.
Development: The registered participants get access to the data and baseline code, and are able to train the models and evaluate their running time locally.
-
2.
Validation: The participants can upload their models to the remote server to check the fidelity scores on the validation dataset, and to compare their results on the validation leaderboard.
-
3.
Testing: The participants submit their final results, code, models, and factsheets.
3 Challenge Results
Among registered participants, teams successfully submitted their results, code, and factsheets in the final test phase. Table 1 reports the final test results and rankings of the teams. The methods evaluated in Table 1 are briefly described in Section 4 and the team members are listed in Appendix. We have the following observations. First, the USTC_WXYZ team is the first place winner of this challenge, while XPixel Group and SRC-B team win the second place and overall third place, respectively. Second, most methods achieve high PSNR performance (over 40 dB). This indicates most degradations, e.g., glare and haze, are easy to restore. Only three teams train their models with extra data, and several top-ranked teams apply ensemble strategies (self-ensemble [26], model ensemble, or both).
| Metric | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Team Name | User Name | PSNR | SSIM | LPIPS | Params (M) | Runtime (s) | Platform | Extra data | Ensemble |
| USTC_WXYZ | YuruiZhu | 16.85 | 0.27 | Nvidia A100 | Yes | model | |||
| XPixel Group | JFHu | 14.06 | 0.16 | Nvidia A6000 | - | - | |||
| SRC-B | xiaozhazha | 23.56 | 0.13 | RTX 3090 | - | self-ensemble + model | |||
| MIALGO | Xhjiang | 7.93 | 9 | Tesla V100 | - | - | |||
| LVGroup_HFUT | HuanZheng | 6.47 | 0.92 | GTX 2080Ti | - | - | |||
| GSM | Zhenxuan_Fang | 11.85 | 1.88 | RTX 3090 | - | - | |||
| Y2C | y2c | / | / | GTX 3090 | self-ensemble | ||||
| VIDAR | Null | 33.8 | 0.47 | RTX 3090Ti | - | model ensemble | |||
| IILLab | zhuhy | 82.2 | 2.07 | RTX A6000 | - | self-ensemble | |||
| jzsherlock | jzsherlock | 14.82 | 1.03 | Tesla A100 | - | self-ensemble | |||
| Namecantbenull | Namecantbenull | / | / | Tesla A100 | / | / | |||
| MeVision | Ziqi_Song | / | 0.08 | NVIDIA 3080ti | Yes | - | |||
| BIVLab | Hao-mk | 2.98 | 2.52 | Tesla V100 | - | self-ensemble | |||
| RushRushRush | stillwaters | 5.9 | 0.63 | RTX 2080Ti | / | ||||
| JMU-CVLab | nanashi | 2 | 0.48 | Tesla P100 | - | - | |||
| eye3 | SummerinSummer | 26.13 | 1.07 | Tesla V100 | - | - | |||
| FMS Lab | hrishikeshps94 | 4.40 | 0.04 | Tesla V100 | - | - | |||
| EDLC2004 | jiangbiao | 31 | 0.99 | RTX 2080Ti | Yes | - | |||
| SAU_LCFC | chm | 0.98 | 0.92 | Tesla V100 | - | - | |||
4 Challenge Methods and Teams
USTC_WXYZ Team.
Inspired by [6, 10, 34], this team designs an enhanced multi-inputs multi-outputs network, which mainly consists of dense residual blocks and the cross-scale gating fusion modules. The overall architecture of the network is depicted in Figure 1. The training phase could be divided into three stages: i) Adopt the Adam optimizer with a batch size of and the patch size of . The initial learning rate is and is adjusted with the Cosine Annealing scheme, including epochs in total. ii) Adopt the Adam optimizer with a batch size of and the patch size of . The initial learning rate is and is adjusted with the Cosine Annealing scheme, including epochs in total. iii) Adopt the Adam optimizer with a batch size of and the patch size of . The initial learning rate is and is adjusted with the Cosine Annealing scheme, including epochs in total. During inference, the team adopts model ensemble strategy averaging the parameters of multiple models trained with different hyperparameters, which brings around 0.09 dB increase on PSNR.


XPixel Group.
This team designs a UNet-like structure (see Figure 2), making full use of the hierarchical multi-scale information from low-level features to high-level features. To ease the training procedure and facilitate the information flow, several residual blocks are utilized in the base network, and the dynamic kernels in the skip connection bring better flexibility. Since UDC images have different holistic brightness and contrast information, the team applies the condition network with spatial feature transform (SFT) to deal with input images with location-specific and image-specific operations (mentioned in HDRUNet [4]), which could provide spatially variant manipulations. In addition, they incorporate the information of the point spread function (PSF) provided in DISCNet [9], which has demonstrated its effectiveness through extensive experiments on both synthetic and real UDC data. For training, the authors randomly cropped patches from the training images as inputs. The mini-batch size is set to and the whole network is trained for iterations. The learning rate is initialized as , decayed with a CosineAnnealing schedule, and restarted at iterations.

SRC-B Team.
This team proposes Multi-Refinement Network (MRNet) for Image Restoration on Under-Display Camera, as shown in Figure 3. In this challenge, the authors modify and improve the MRNet [1], which is mainly composed of 3 modules: shallow Feature Extraction, reconstruction module, and output module. The shallow Feature Extraction and output module only use one convolution layer. Multi-refinement is the main idea of the reconstruction module, which includes Multi-scale Residual Group Module (MSRGM) and progressively refines the features. MSRGM is also used to fuse information from three scales to improve the representation ability and robustness of the model, where each scale is composed of several residual group modules (RGM). RGM contains residual block module (RBM). In addition, the authors propose to remove Channel Attention (CA) module in RBM [38], since it brings limited improvement but increases the inference time.

MIALGO Team.
As shown in Figure 4, this team addresses the UDC image restoration problem with an Residual Dense Network (RDN) [39] as the backbone. The authors also adopt the strategy of multi-resolution feature fusion in HRNet [25] to improve the performance. In order to facilitate the recovery of high dynamic range images, the authors generate 6 non-HDR images with different exposure ranges from the given HDR images, where the value ranges of each split are: [0, 0.5], [0, 2], [0, 8], [0, 32], [0, 128], [0, 500], and normalize them and then stack into 18 channels of data for training. According to the dynamic range of the data, 2000 images in the training datasets (the remaining 16 are used as validation sets) are divided into two datasets: i) Easy sample dataset: 1318 images whose intensities lie in [0, 32]. ii) Hard sample dataset: easy samples plus doubled remaining hard samples. They use two datasets to train two models, each of which is first trained with 500k iterations. Then they fine-tune the easy sample model and the hard sample model by 200K iterations. In the validation/test phase, the 18-channel data is merged into 3-channel HDR images and fed to the network.



LVGroup_HFUT Team.
Considering the specificity of the UDC image restoration task (mobile deployment), this team designs a lightweight and real-time model for UDC image restoration using a simple UNet architecture with magic modifications as shown in Figure 5. Specifically, they combine the full-resolution network FRC-Net [40] and the classical UNet [24] to construct the model, which presents two following advantages: 1) directly stacking the residual blocks at the original resolution to ensure that the model learns sufficient spatial structure information, and 2) stacking the residual blocks at the downsampled resolution to ensure that the model learns sufficient semantic-level information.
During training, they first perform tone mapping, and then perform a series of data augmentation sequentially, including: 1) random crop to ; 2) vertical flip with probability ; 3): horizontal flip with probability . They train the model for epochs on provided training dataset with an initial learning rate and batch size 4.

GSM Team.
This team reformulates UDC image restoration as a Maximum Posteriori (MAP) estimation problem with the learned Gaussian Scale Mixture (GSM) models. Specifically, the can be solved by
| (1) |
where denotes the transposed version of A, denotes the step size, denotes the iteration for iteratively optimizing , denotes the regularization parameters, and denotes the mean of the GSM model. In [11], a UNet was used to estimated and and two sub-networks with 4 Resblocks and 2 Conv layers were used to learn A and , respectively. For UDC image restoration, they develop a network based on Swin Transformer to learn the GSM prior (i.e., and ) and use 4 Conv layers, respectively. As shown in Figure 6, the team constructs an end-to-end network for UDC image restoration. The transformer-based GSM prior network contains an embedding layer, Residual Swin Transformer Blocks (RSTB) [16], two downsampling layers, two upsampling layers, a -generator, and an -generator. The embedding layer, the -generator, and the -generator are a Conv layer. The RSTB [16] contains 6 Swin Transformer Layers, a Conv layer, and a skip connection. The features of the first two RSTBs are reused by two skip connections, respectively. For reducing the computational complexity, they implement the united framework Eq. 1 with only one iteration and use the input as the initial value .
The loss function is defined as
| (2) | ||||
where and denote the label and the output of the network, represents the Laplacian operator, and is the FFT operation.

Y2C Team.
This team takes model [6, 35] as a backbone network and introduces the multi-scale design. Besides, they reconstruct each color channel by a complete branch instead of processing them together. The overall architecture of the Multi-Scale and Separable Channels reconstruction Network (MSSCN) for UDC image restoration is shown in Figure 7. The network takes the multi-scale degraded images (1x, 0.5x, 0.25x) as inputs, and the initial feature maps of each color channel in each scale are extracted respectively. Before extracting feature maps, they use the discrete wavelet transform (DWT) [17] to reduce the resolution in each scale and improve the reconstruction efficiency. In the fusion module, this team fuses the feature maps in different scales in the same spatial resolution, concatenates the feature maps from each color channel and each scale, and processes them using a depth-wise convolution. In the feature extraction module, any efficient feature extraction block can be used to extract feature maps. Residual group (RG) with multiple residual channel attention blocks (RCAB) [38] is used as the feature extraction module. To improve the learning capacity of recovering images, they repeat the feature fusion module and feature extraction module times. Then the reconstructed images are generated by the inverse discrete wavelet transform (IWT).

VIDAR Team.
As shown in Figure 8, this team designs a dense U-Net for under-display camera image restoration. The architecture aggregates and fuses feature information with Dense RCAB [38]. During training, batch size is set to 4 with the patch of and the optimizer is ADAM [14] by setting , . The initial learning rate is . They use Charbonnier loss to train models and stop training when no notable decay of training loss is observed.
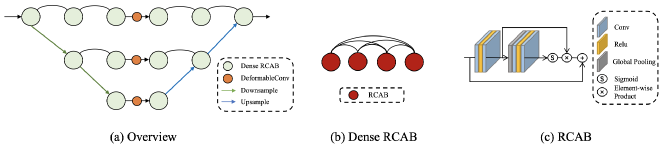
IILLab Team.
This team presents a Wiener Guided Coupled Dynamic Filter Network, which takes advantage of both DWDN [8] and BPN [31]. As shown in Figure 9, on top of the U-net-based backbone, they first used feature level wiener for global restoration with the estimated degradation kernel, then used the coupled dynamic filter network for local restoration. The network obtains the global and local information from the feature level wiener deconvolution and the coupled dynamic filter network, and thus achieves a better restoration result since the UDC degradation was modeled with higher accuracy. Wiener Guided Coupled Dynamic Filter Network was jointly trained under the supervision of L1 loss and perceptual loss [13].

jzsherlock Team.
This team proposes the U-RRDBNet for the task of UDC image restoration. UDC images suffer from the strong glare caused by the optical structure of OLED display, which usually occurs and degrades a large area around the light source (e.g.street lamp, sun) in the view. Therefore a larger receptive field is required to deal with this task. The proposed architecture and processing pipeline are illustrated in Figure 10. Though the original U-net and its variants have achieved promising results on segmentation tasks, the capability of representation learning of the U-net is still limited for dense prediction in low-level tasks. So the authors apply the Residual-in-Residual Dense Block (RRDB) [28] to substitute simple Conv layers in U-net after each down/up-sampling operation to increase the network capability. They first perform the modified Reinhard tone mapping, and then feed the tone-mapped image into the end-to-end U-RRDBNet for restoration, and produce the image in the tone-mapped domain with artifacts removed. The output of the network is then transformed back to the HDR domain using the inverse of Reinhard tone mapping. The model is first trained using loss and perceptual loss [13] in the tone-mapped domain, and then fine-tuned with MSE loss for higher PSNR performance.

Namecantbenull Team.
This team designs a deep learning model for the UDC image restoration based on the U-shaped network. In this network, they incorporate the convolution operation and attention mechanism into the transformer block architecture, which has been proved effective in image restoration tasks in [2]. Since there is no need to calculate the self-attention coefficient matrices, the memory cost and computation complexity can be reduced significantly. The overall network structure is shown in Figure 11. Specifically, they substitute the simplified channel attention module with the spatial and channel attention module [3] to additionally consider the correlation of the spatial pixels. They train the model with 1 and perceptual loss on the tone-mapped domain.

MeVision Team.
This team follows [15] and presents a two-branch network to restore UDC images. As shown in Figure 12, the input images are processed and fed to the restoration network. The original resolution image is processed in one branch while the blurred image with noise is processed in another one. Finally, the two branches are connected in series by the affine transformation connection. Then, they follow [20] and modify the high-frequency reconstruction branch with an encoder-decoder structure to reduce parameters. And they converted the smoothed diluted residual block into IMD block [12] so that the signals can propagate directly from skip connections to the bottom layers.


BIVLab Team.
This team develops a Self-Guided Coarse-to-Fine Network (SG-CFN) to progressively reconstruct the degraded under-display camera images. As shown in Figure 13, the proposed SG-CFN consists of two branches, the restoration branch and the condition branch. The restoration branch is constructed by Feature Extraction Module (FEM) based on improved RSTBs [16], which incorporates the paralleled Central Difference Convolution (CDC) with Swin Transformer Layer (STL) to extract rich features at multiple scales. The condition branch is constructed by Fast Fourier Convolution (FFC) blocks [5] that endowed with global receptive field to model the distribution of the large-scale point-spread function (PSF), which is indeed the culprit of the degradation. Furthermore, the multi-scale representations extracted from the restoration branch are processed via the Degradation Correction Module (DCM) to restore clean features, guided by the corresponding condition information. To fully exploit the restored multi-scale clean features, they enable the asymmetric feature fusion inspired by [6] to facilitate the flexible information flow. Images captured through under-display camera typically suffer from diffraction degradation caused by large-scale PSF, resulting in blurred and detail attenuated images. Thereby, (1) incorporating CDC into the restoration branch can greatly help to avoid over-smooth feature extraction and enrich the representation capability, (2) constructing the condition branch with FFC blocks endow the global receptive field to capture the degradation information, and (3) correcting the degraded features from both local adaptation and global modulation makes the process of restoration more effective. During the testing phase, they adopt self-ensemble strategy and it brings a 0.63 dB performance gain on PSNR.

RushRushRush Team.
This team reproduced the MIRNetV2 [36] on the UDC dataset. The network utilizes both spatially-precise high-resolution representations and contextual information from the low-resolution representations. The multi-scale residual block contains: (i) parallel multi-resolution convolution streams to extract multi-scale features, (ii) information exchange across streams, (iii) non-local attention mechanism to capture contextual information, and (iv) attention-based multi-scale feature aggregation. The approach learns an enriched set of features that combines contextual information from multiple scales, while simultaneously preserving the high-resolution spatial details.
JMU-CVLab Team.
This team proposes a dual-branch lightweight neural network. Inspired by recent camera modeling approaches [7], they design a dual-branch model, depending on the tradeoff between resources and performance. As shown in Figure 14, the method combines ideas from deblurring [21] and HDR [19] networks, and attention methods [18, 29]. This does not rely on metadata or extra information like the PSF. The main image restoration branch with a Dense Residual UNet architecture [39, 24]. They use an initial CoordConv [18] layer to encode positional information. Three Encoder blocks, each formed by 2 dense residual layers (DRL) [39] followed by the corresponding downsampling pooling. The decoder blocks D1 and D2 consist of a bilinear upsampling layer and 2 DRL The decoder block D3 does not have an upsampling layer, consists of 2 DRL and a series of convolutions with 7, 5, and 1 kernel sizes, the final convolution (cyan color) produces the residual using a tanh activation. Similar to [19], the additional attention branch aims to generate an attention map (per channel) to control the hallucination in overexposed areas. The attention map is generated after applying a CBAM block [29] on the features of the original image, and the final convolution is activated using a Sigmoid function.

eye3 Team.
This team implements the network architecture by Restormer [33]. Instead of exploring new architecture for under-display camera restoration, they attempt to mine the potential of the existing method to advance this field. Following the scheme of [33], they train an Restormer in a progressive fashion with loss for iterations, with , , , , , and iterations for patch size 128, 160, 192, 256, 320, and 384, respectively. Then they fix the patch size to and use a mask loss strategy [30] to train the model for another iterations, where saturated pixels are masked out. After that, inspired by self-training [32], they add Gaussian noise to the well-trained model and repeat the training process.
FMS Lab Team.
EDLC2004 Team.
This team adopted TransWeather [27] model to deal with the image restoration problem for UDC images. Specifically, they combine different loss functions including loss and loss. They train the model from scratch and it took approximately 17 hours with two 2080Ti GPUs.
SAU_LCFC Team.
The team proposes an Hourglass-Structured Fusion Network (HSF-Net) as shown in Figure 15. They start from a coarse-scale stream, and then gradually repeat top-down and bottom-up processing to form more coarse-to-fine scale streams one by one. In each stream, the residual dense attention modules (RDAMs) are introduced as the basic component to deeply learn the features of under-display camera images. Each RDAM contains dense residual blocks (RDBs) in series with channel-wise attention (CA). In each RDB, the first 4 convolutional layers are adopted to elevate the number of feature maps, while the last convolutional layer is employed to aggregate feature maps. The growth rate of RDB is set to 16.

5 Conclusions
In this report, we review and summarize the methods and results of MIPI 2022 challenge on Under-Display Camera Image Restoration. All the proposed methods are based on deep networks and most of them share a similar U-shape backbone to boost performance.
Acknowledgements. We thank Shanghai Artificial Intelligence Laboratory, Sony, and Nanyang Technological University to sponsor this MIPI 2022 challenge. We thank all the organizers and all the participants for their great work.
References
- [1] Abuolaim, A., Timofte, R., Brown, M.S.: Ntire 2021 challenge for defocus deblurring using dual-pixel images: Methods and results. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 578–587 (2021)
- [2] Chen, L., Chu, X., Zhang, X., Sun, J.: Simple baselines for image restoration. arXiv preprint arXiv:2204.04676 (2022)
- [3] Chen, L., Zhang, H., Xiao, J., Nie, L., Shao, J., Liu, W., Chua, T.S.: Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5659–5667 (2017)
- [4] Chen, X., Liu, Y., Zhang, Z., Qiao, Y., Dong, C.: Hdrunet: Single image hdr reconstruction with denoising and dequantization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 354–363 (2021)
- [5] Chi, L., Jiang, B., Mu, Y.: Fast fourier convolution. Advances in Neural Information Processing Systems 33, 4479–4488 (2020)
- [6] Cho, S.J., Ji, S.W., Hong, J.P., Jung, S.W., Ko, S.J.: Rethinking coarse-to-fine approach in single image deblurring. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4641–4650 (2021)
- [7] Conde, M.V., McDonagh, S., Maggioni, M., Leonardis, A., Pérez-Pellitero, E.: Model-based image signal processors via learnable dictionaries. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 36, pp. 481–489 (2022)
- [8] Dong, J., Roth, S., Schiele, B.: Deep wiener deconvolution: Wiener meets deep learning for image deblurring. Advances in Neural Information Processing Systems 33, 1048–1059 (2020)
- [9] Feng, R., Li, C., Chen, H., Li, S., Loy, C.C., Gu, J.: Removing diffraction image artifacts in under-display camera via dynamic skip connection networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021)
- [10] Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4700–4708 (2017)
- [11] Huang, T., Dong, W., Yuan, X., Wu, J., Shi, G.: Deep gaussian scale mixture prior for spectral compressive imaging. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16216–16225 (2021)
- [12] Hui, Z., Gao, X., Yang, Y., Wang, X.: Lightweight image super-resolution with information multi-distillation network. In: Proceedings of the 27th acm international conference on multimedia. pp. 2024–2032 (2019)
- [13] Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: European Conference on Computer Vision. pp. 694–711. Springer (2016)
- [14] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings (2015)
- [15] Koh, J., Lee, J., Yoon, S.: Bnudc: A two-branched deep neural network for restoring images from under-display cameras. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1950–1959 (2022)
- [16] Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., Timofte, R.: Swinir: Image restoration using swin transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 1833–1844 (2021)
- [17] Liu, P., Zhang, H., Zhang, K., Lin, L., Zuo, W.: Multi-level wavelet-cnn for image restoration. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops. pp. 773–782 (2018)
- [18] Liu, R., Lehman, J., Molino, P., Petroski Such, F., Frank, E., Sergeev, A., Yosinski, J.: An intriguing failing of convolutional neural networks and the coordconv solution. Advances in neural information processing systems 31 (2018)
- [19] Liu, Y.L., Lai, W.S., Chen, Y.S., Kao, Y.L., Yang, M.H., Chuang, Y.Y., Huang, J.B.: Single-image hdr reconstruction by learning to reverse the camera pipeline. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1651–1660 (2020)
- [20] Mao, X., Shen, C., Yang, Y.B.: Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. Advances in neural information processing systems 29 (2016)
- [21] Nah, S., Son, S., Lee, S., Timofte, R., Lee, K.M.: Ntire 2021 challenge on image deblurring. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 149–165 (2021)
- [22] Panikkasseril Sethumadhavan, H., Puthussery, D., Kuriakose, M., Charangatt Victor, J.: Transform domain pyramidal dilated convolution networks for restoration of under display camera images. In: European Conference on Computer Vision. pp. 364–378. Springer (2020)
- [23] Reinhard, E., Stark, M., Shirley, P., Ferwerda, J.: Photographic tone reproduction for digital images. In: Proceedings of the 29th annual conference on Computer graphics and interactive techniques. pp. 267–276 (2002)
- [24] Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 234–241. Springer (2015)
- [25] Sun, K., Xiao, B., Liu, D., Wang, J.: Deep high-resolution representation learning for human pose estimation. In: Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. pp. 5693–5703 (2019)
- [26] Timofte, R., Rothe, R., Van Gool, L.: Seven ways to improve example-based single image super resolution. In: Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. pp. 1865–1873 (2016)
- [27] Valanarasu, J.M.J., Yasarla, R., Patel, V.M.: Transweather: Transformer-based restoration of images degraded by adverse weather conditions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2353–2363 (2022)
- [28] Wang, X., Yu, K., Wu, S., Gu, J., Liu, Y., Dong, C., Qiao, Y., Change Loy, C.: Esrgan: Enhanced super-resolution generative adversarial networks. In: Proceedings of the European Conference on Computer Vision Workshops. pp. 63–79 (2018)
- [29] Woo, S., Park, J., Lee, J.Y., Kweon, I.S.: Cbam: Convolutional block attention module. In: Proceedings of the European Conference on Computer Vision. pp. 3–19 (2018)
- [30] Wu, Y., He, Q., Xue, T., Garg, R., Chen, J., Veeraraghavan, A., Barron, J.T.: How to train neural networks for flare removal. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2239–2247 (2021)
- [31] Xia, Z., Perazzi, F., Gharbi, M., Sunkavalli, K., Chakrabarti, A.: Basis prediction networks for effective burst denoising with large kernels. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11844–11853 (2020)
- [32] Xie, Q., Luong, M.T., Hovy, E., Le, Q.V.: Self-training with noisy student improves imagenet classification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10687–10698 (2020)
- [33] Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H.: Restormer: Efficient transformer for high-resolution image restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5728–5739 (2022)
- [34] Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H., Shao, L.: Multi-stage progressive image restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14821–14831 (2021)
- [35] Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H., Shao, L.: Learning enriched features for fast image restoration and enhancement. arXiv preprint arXiv:2205.01649 (2022)
- [36] Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H., Shao, L.: Learning enriched features for fast image restoration and enhancement. IEEE Transactions on Pattern Analysis and Machine Intelligence (2022)
- [37] Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 586–595 (2018)
- [38] Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., Fu, Y.: Image super-resolution using very deep residual channel attention networks. In: Proceedings of the European Conference on Computer Vision. pp. 286–301 (2018)
- [39] Zhang, Y., Tian, Y., Kong, Y., Zhong, B., Fu, Y.: Residual dense network for image super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2472–2481 (2018)
- [40] Zhang, Z., Zheng, H., Hong, R., Fan, J., Yang, Y., Yan, S.: FRC-Net: A Simple Yet Effective Architecture for Low-Light Image Enhancement (5 2022). https://doi.org/10.36227/techrxiv.19771120.v2
- [41] Zhou, Y., Kwan, M., Tolentino, K., Emerton, N., Lim, S., Large, T., Fu, L., Pan, Z., Li, B., Yang, Q., et al.: Udc 2020 challenge on image restoration of under-display camera: Methods and results. In: European Conference on Computer Vision. pp. 337–351. Springer (2020)
- [42] Zhou, Y., Ren, D., Emerton, N., Lim, S., Large, T.: Image restoration for under-display camera. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9179–9188 (2021)
Appendix 0.A Teams and Affiliations
USTC_WXYZ
Title: Enhanced Coarse-to-Fine Network for Restoring Images From Under-Display Cameras
Members:
Yurui Zhu1 ([email protected])
Xi Wang1 Xueyang Fu1 Xiaowei Hu2
Affiliations:
1 University of Science and Technology of China
2 Shanghai AI Laboratory
XPixel Group
Title: UDC-UNet: Under-Display Camera Image Reconstruction via U-shape Dynamic Network
Members:
Jinfan Hu1 ([email protected])
Xina Liu1 Xiangyu Chen1,2,3 Chao Dong1,2
Affiliations:
1 Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences
2 Shanghai AI Laboratory
3 University of Macau
SRC-B
Title: MRNet: Multi-Refinement Network for Images Restoration on Under-display Camera
Members:
Dafeng Zhang ([email protected])
Feiyu Huang Shizhuo Liu Xiaobing Wang Zhezhu Jin
Affiliations:
Samsung Research China, Beijing
MIALGO
Title: Residual Dense Network Based on Multi-Resolution Feature Fusion
Members:
Xuhao Jiang ([email protected])
Guangqi Shao Xiaotao Wang Lei lei
Affiliations:
Xiaomi, Beijing
LVGroup_HFUT
Title: Towards lightweight and real-time under-display camera image restoration
Members:
Zhao Zhang ([email protected])
Suiyi Zhao Huan Zheng Yangcheng Gao Yanyan Wei Jiahuan Ren
Affiliations:
Hefei University of Technology
GSM
Title: Deep Gaussian Scale Mixture Prior for UDC Image Restoration
Members:
Tao Huang ([email protected])
Zhenxuan Fang Mengluan Huang Junwei Xu
Affiliations:
School of Artificial Intelligence, Xidian University
Y2C
Title: N/A
Members:
Yong Zhang1 ([email protected])
Yuechi Yang1 Qidi Shu2 Zhiwen Yang1 Shaocong Li1
Affiliations:
1 School of Remote Sensing and Information Engineering, Wuhan University
2 State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University
VIDAR
Title: Deep Gaussian Scale Mixture Prior for UDC Image Restoration
Members:
Mingde Yao ([email protected])
Ruikang Xu Yuanshen Guan Jie Huang Zhiwei Xiong
Affiliations:
University of Science and Technology of China
IILLab
Title: Wiener Guided Coupled Dynamic Filter Network
Members:
Hangyan Zhu ([email protected])
Ming Liu Shaohui Liu Wangmeng Zuo
Affiliations:
Harbin Institute of Technology
jzsherlock
Title: U-RRDBNet for UDC Image Restoration
Members:
Zhuang Jia ([email protected])
Affiliations:
Xiaomi
Namecantbenull
Title: NAFNet
Members:
Binbin SONG ([email protected])
Affiliations:
University of Macau
MeVision
Title: Two-Branched Network for Image Restoration of Under-display Camera
Members:
Ziqi Song ([email protected])
Guiting Mao Ben Hou Zhimou Liu Yi Ke Dengpei Ouyang Dekui Han
Affiliations:
Changsha Research Institute of mining and metallurgy
BIVLab
Title: Self-Guided Coarse-to-Fine Network for Progressive Under-Display Camera Image Restoration
Members:
Jinghao Zhang ([email protected])
QiZhu Naishan Zheng Feng Zhao
Affiliations:
University of Science and Technology of China
RushRushRush
Title: N/A
Members:
Wu Jin ([email protected])
Affiliations:
Tianjin University
JMU-CVLab
Title: Lightweight Dual-branch UDC Blind Image Restoration
Members:
Marcos Conde1 ([email protected])
Sabari Nathan2 Radu Timofte1
Affiliations:
1 University of Wurzburg, Computer Vision Lab, Germany
2 Couger Inc., Japan
eye3
Title: N/A
Members:
Tianyi Xu ([email protected])
Jun Xu
Affiliations:
School of Statistics and Data Science, Nankai University
FMS Lab
Title: Dual Branch Wavelet Net (DBWN)
Members:
Hrishikesh P.S.1 ([email protected])
Densen Puthussery1 Jiji C.V.2
Affiliations:
1 Founding Minds Software
2 Department of Electronics and Communication SRM University
EDLC2004
Title: N/A
Members:
Jiang Biao ([email protected])
Ding Yuhan Li WanZhang Feng Xiaoyue Chen Sijing Zhong Tianheng
Affiliations:
Fudan University
SAU_LCFC
Title: Hourglass-Structured Fusion Network (HSF-Net)
Members:
Jiyang Lu1 ([email protected])
Hongming Chen1 Zhentao Fan1 Xiang Chen2
Affiliations:
1 Shenyang Aerospace University
2 Nanjing University of Science and Technology