Mining of Switching Sparse Networks for Missing Value Imputation in Multivariate Time Series
Abstract.
Multivariate time series data suffer from the problem of missing values, which hinders the application of many analytical methods. To achieve the accurate imputation of these missing values, exploiting inter-correlation by employing the relationships between sequences (i.e., a network) is as important as the use of temporal dependency, since a sequence normally correlates with other sequences. Moreover, exploiting an adequate network depending on time is also necessary since the network varies over time. However, in real-world scenarios, we normally know neither the network structure nor when the network changes beforehand. Here, we propose a missing value imputation method for multivariate time series, namely MissNet, that is designed to exploit temporal dependency with a state-space model and inter-correlation by switching sparse networks. The network encodes conditional independence between features, which helps us understand the important relationships for imputation visually. Our algorithm, which scales linearly with reference to the length of the data, alternatively infers networks and fills in missing values using the networks while discovering the switching of the networks. Extensive experiments demonstrate that MissNet outperforms the state-of-the-art algorithms for multivariate time series imputation and provides interpretable results.
1. Introduction

With the development of the Internet of Things (IoT), multivariate time series are generated in many real-world applications, such as motion capture (Qin et al., 2020), and health monitoring (Chambon et al., 2018). However, there are inevitably many values missing from these data, and this has many possible causes (e.g., sensor malfunction). As most algorithms assume an intact input when building models, missing value imputation is indispensable for real-world applications (Shadbahr et al., 2023; Berrevoets et al., 2023).
In time series data, missing values often occur consecutively, leading to a missing block in a sequence, and can happen simultaneously to multiple sequences (Liu et al., 2020). To effectively reconstruct missing values from such partially observed data, we must exploit both temporal dependency, by taking account of past and future values in the sequence, and inter-correlation, by using the relationship between different sequences (i.e., a network) (Cini et al., 2021; Yi et al., 2016). Here, a network does not necessarily mean the spatial proximity of sensors but rather underlying connectivity (e.g., Pearson correlation or partial correlation). Moreover, as time series data are normally non-stationary, so is the network; an adequate network must be exploited depending on time (Tomasi et al., 2018, 2021). We collectively refer to a group of time points with the same network as a “regime”. Fig. 1 shows an illustrative example where missing blocks randomly exist in a multivariate time series consisting of three features (i.e., A, B, and C). Each time point belongs to either of two regimes with different networks (i.e., and ), where the thickness of the edge indicates the strength of the interplay between features. It is appropriate to use the values of feature C to impute the block missing from feature B in regime since the network has an edge between B and C. On the other hand, in regime , it is preferable to use feature A, as the network suggests. Nevertheless, in real-world scenarios, we often have no information about the data; that is, we do not know the structure of the network, let alone when the network changes. Thus, given a partially observed multivariate time series, how can we infer networks and allocate each time point to the correct regime? How can we achieve an accurate imputation exploiting both temporal dependency and inter-correlation?
There have been many studies on time series missing value imputation with machine learning and deep learning models (Khayati et al., 2020). Many of them employ time-variant latent/hidden states, as used in a State-Space Model (SSM) or a Recurrent Neural Network (RNN), to learn the dynamic patterns of time series (Li et al., 2009; Chen and Sun, 2021; Cao et al., 2018; Yoon et al., 2018b). However, they do not make full use of inter-correlation, while the sequences of a multivariate time series usually interact. Although they implicitly capture inter-correlation in latent space, they potentially capture spurious correlations under the presence of missing values, leading to inaccurate imputation. To tackle this problem, several studies explicitly utilize the network (Cai et al., 2015a, b; Hairi et al., 2019; Jing et al., 2021; Cini et al., 2021; Wang et al., 2023a). However, they require a predefined network, even though we rarely know it in advance.
In this work, we propose MissNet 111Our source code and datasets are publicly available:
https://github.com/KoheiObata/MissNet.
, Mining of switching sparse Networks for multivariate time series imputation, which repeatedly infers sparse networks from imputed data and fills in missing values using the networks while allocating each time point to regimes.
Specifically, our model has three components:
(1) a regime-switching model based on a discrete Markov process for detecting the change point of the network.
(2) An imputation model based on an SSM for exploiting temporal dependency and inter-correlation by latent space and the networks.
(3) A network inference model for inferring sparse networks via graphical lasso, where each network encodes pairwise conditional independencies among features, and the lasso penalty helps avoid capturing spurious correlations.
Our proposed algorithm maximizes the joint probability distribution over the above components.
Our method has the following desired properties:
-
•
Effective: MissNet, which exploits both temporal dependency and inter-correlation by inferring switching sparse networks, outperforms the state-of-the-art algorithms for missing value imputation for multivariate time series.
-
•
Scalable: Our proposed algorithm scales linear with regard to the length of the time series and is thus applicable to a long-range time series.
-
•
Interpretable: MissNet discovers regimes with distinct sparse networks, which help us interpret data, e.g., what is the key relationship in the data, and why does a particular regime distinguish itself from others?
2. Related work
We review previous studies closely related to our work. Table 1 shows the relative advantages of MissNet. Current approaches fall short with respect to at least one of these desired characteristics.
Time series missing value imputation. Missing value imputation for time series is a very rich topic (Khayati et al., 2020). We roughly classify missing value imputation methods as Matrix Factorization (MF)-based, SSM-based, and Deep Learning (DL)-based approaches.
MF-based methods, such as SoftImpute (Mazumder et al., 2010) based on Singular Value Decomposition (SVD), recover missing values from low-dimensional embedding matrices of partially observed data (Papadimitriou et al., 2005; Khayati et al., 2014; Zhang and Balzano, 2016; Yi et al., 2016). For example, SoRec (Ma et al., 2008), proposed as a recommendation system, constrains MF with a predefined network to exploit inter-correlation. Since MF is limited in capturing temporal dependency, TRMF (Yu et al., 2016) uses an Auto-Regressive (AR) model and imposes temporal smoothness on MF.
SSMs, such as Linear Dynamical Systems (LDS) (Ghahramani, 1998), use latent space to capture temporal dependency, where the data point depends on all past data points (Rogers et al., 2013; Dabrowski et al., 2018; Chen and Sun, 2021; Hairi et al., 2019). To fit more complex time series, Switching LDS (SLDS) (Pavlovic et al., 1999; Fox et al., 2008) switches multiple LDS models. SSM-based methods, such as DynaMMo (Li et al., 2009), focus on capturing the dynamic patterns in time series rather than inter-correlation implicitly captured through the latent space. To use the underlying connectivity in multivariate time series, DCMF (Cai et al., 2015a), and its tensor extension Facets (Cai et al., 2015b) use SSM constrained with a predefined network, which is effective, especially when the missing rate is high. However, they assume that the network is accurately known and fixed, while it is usually unknown and may change over time in real-world scenarios.
Recently, extensive research has focused on DL-based methods, employing techniques including graph neural networks (Jing et al., 2021; Cini et al., 2021; Fan et al., 2023; Ren et al., 2023), self-attention (Shukla and Marlin, 2021; Du et al., 2023), and, most recently, diffusion models (Alcaraz and Strodthoff, 2022; Tashiro et al., 2021; Wang et al., 2023b), to harness their high model capacity (Yoon et al., 2018a; Bansal et al., 2021). For example, BRITS (Cao et al., 2018) and M-RNN (Yoon et al., 2018b) impute missing values according to hidden states from bidirectional RNN. To utilize dynamic inter-correlation in time series, POGEVON (Wang et al., 2023a) requires a sequence of networks and imputes missing values in time series and missing edges in the networks, assuming that the network varies over time. Although DL-based methods can handle complex data, the imputation quality depends heavily on the size and the selection of the training dataset.
| MF | SSM | DL | GL | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
SoftImpute (Mazumder et al., 2010) |
SoRec (Ma et al., 2008) |
TRMF (Yu et al., 2016) |
SLDS (Pavlovic et al., 1999) |
DynaMMo (Li et al., 2009) |
DCMF (Cai et al., 2015a) |
BRITS (Cao et al., 2018) |
POGEVON (Wang et al., 2023a) |
TICC (Hallac et al., 2017b) |
MMGL (Tozzo et al., 2020) |
MissNet |
|
| Temporal dependency | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | - | - | ✓ |
| Inter-correlation | - | ✓ | - | - | - | ✓ | - | ✓ | - | ✓ | ✓ |
| Time-varying inter-correlation | - | - | - | - | - | - | - | ✓ | - | ✓ | ✓ |
| Missing value imputation | ✓ | ✓ | ✓ | - | ✓ | ✓ | ✓ | ✓ | - | ✓ | ✓ |
| Segmentation | - | - | - | ✓ | - | - | - | - | ✓ | - | ✓ |
| Sparse network inference | - | - | - | - | - | - | - | - | ✓ | ✓ | ✓ |
Sparse network inference. From another perspective, our method infers sparse networks from time series containing missing values and discovers regimes (i.e., clusters) based on networks. Inferring a sparse inverse covariance matrix (i.e., network) from data helps us to understand feature dependency in a statistical way. Graphical lasso (Friedman et al., 2008), which maximizes the Gaussian log-likelihood imposing an -norm penalty, is one of the most commonly used techniques for estimating a sparse network from static data. Städler and Bühlmann (Städler and Bühlmann, 2012a) have tackled inferring a sparse network from partially observed data according to conditional probability. However, the network varies over time (Namaki et al., 2011; Monti et al., 2014; Malte Londschien and Bühlmann, 2021); thus, TVGL (Hallac et al., 2017a) infers time-varying networks by considering the time similarity with a network belonging to neighboring segments. To infer time-varying networks in the presence of missing values, MMGL (Tozzo et al., 2020), which employs TVGL, uses the expectation-maximization (EM) algorithm to repeat the inference of time-varying networks and missing value imputation based on conditional probability under the condition that each segment has the same observed features. Discovering clusters based on networks (Obata et al., 2024), such as TICC (Hallac et al., 2017b) and TAGM (Tozzo et al., 2021), provides interpretable results that other traditional clustering methods cannot find. However, they cannot handle missing values.
As a consequence, none of the previous studies have addressed missing value imputation for multivariate time series by employing sparse network inference and segmentation based on the network.
3. Preliminaries
3.1. Problem definition
In this paper, we focus on the task of multivariate time series missing value imputation. We use a multivariate time series with features and timesteps . To represent the missing values in , we introduce the indicator matrix , where indicates the availability of feature at timestep : being or indicates whether is missing or observed. Thus, the observed entries can be described as , where is a Hadamard product. Our problem is formally written as follows:
Problem 1 (Multivariate Time Series Missing Value Imputation).
Given: a partially observed multivariate time series ; Recover: its missing parts indicated by .
3.2. Graphical lasso
We use graphical lasso (Friedman et al., 2008) to infer the network for each regime. Given , graphical lasso estimates the sparse Gaussian inverse covariance matrix (i.e., network) , also known as the precision matrix. The network encodes pairwise conditional independencies among features, e.g., if , then features and are conditionally independent given the values of all the other features. The optimization problem is expressed as follows:
| (1) | ||||
| (2) |
where must be symmetric positive definite (). is the log-likelihood and is the empirical mean of . is a hyperparameter for determining the sparsity level of the network, and indicates the off-diagonal -norm. This is a convex optimization problem that can be solved via the alternating direction method of multipliers (ADMM) (Boyd et al., 2011).
4. Proposed MissNet
In this section, we present our proposed MissNet for missing value imputation. We give the formal formulation of the model and then provide the detailed algorithm to learn the model.
4.1. Optimization model
MissNet infers sparse networks and fills in missing values using the networks while discovering regimes. We first introduce three interacting components of our model: a regime-switching model, an imputation model, and a network inference model. Then, we define the optimization formulation.
Regime-switching model. MissNet describes the change of networks by regime-switching. Let be the number of regimes, be regime assignments, and be a one-hot vector 222We use it interchangeably with the index of the regime (i.e., -regime). that indicates belongs to -regime. We assume regime-switching to be a discrete first-order Markov process:
| (3) |
where is the Markov transition matrix and is the initial state distribution.
Imputation model. MissNet imputes missing values exploiting temporal dependency and inter-correlation indicated by the networks. We assume that the temporal dependency is consistent throughout all regimes and captured in the latent space of an SSM, which allows us to consider long-term dependency. We define the latent states corresponding to , where is the number of latent dimensions, and is linear to through the transition matrix with the covariance , shown in Eq. (5). As defined in Eq. (4), the first timestep of latent state is defined by the initial state and the covariance .
| (4) | ||||
| (5) |
We define the observation assigned to -regime as being linear to the latent state through the observation matrix of -regime with the covariance :
| (6) |
MissNet captures inter-correlation by adding a constraint on . Let it be assumed that the contextual matrix of the -regime encodes the inter-correlation of belonging to the -regime (). We define the contextual latent factor of the -regime , and the -th column () of the contextual matrix as linear to through the observation matrix with the covariance , formulated in Eq. (7). In Eq. (8), we place zero-mean spherical Gaussian priors on under the assumption that .
| (7) | ||||
| (8) |
To avoid our model overfitting the observed entries since many entries are missing, we simplify the covariances by assuming that all noises are independent and identically distributed (i.i.d.). Thus, the parameters are reduced to , respectively (i.e., , , , and ).
With the above imputation model, the imputed time series at timestep is recovered as follows:
| (9) |
Network inference model. MissNet infers the network for each regime to exploit inter-correlation. We define a Gaussian distribution and -norm for the imputed data belonging to each regime to allow us to estimate networks accurately:
| (10) |
where is any constant value for convenience, and is a hyperparameter that controls the sparsity of the network (i.e., inverse covariance matrix) with -norm, which helps avoid capturing spurious correlations.
Optimazation formulation. Our goal is to estimate the model parameters and find the latent factors , where the letters with a dot indicate a set of vectors/matrices/scalers (e.g., ), that maximizes the following joint probability distribution:
4.2. Algorithm
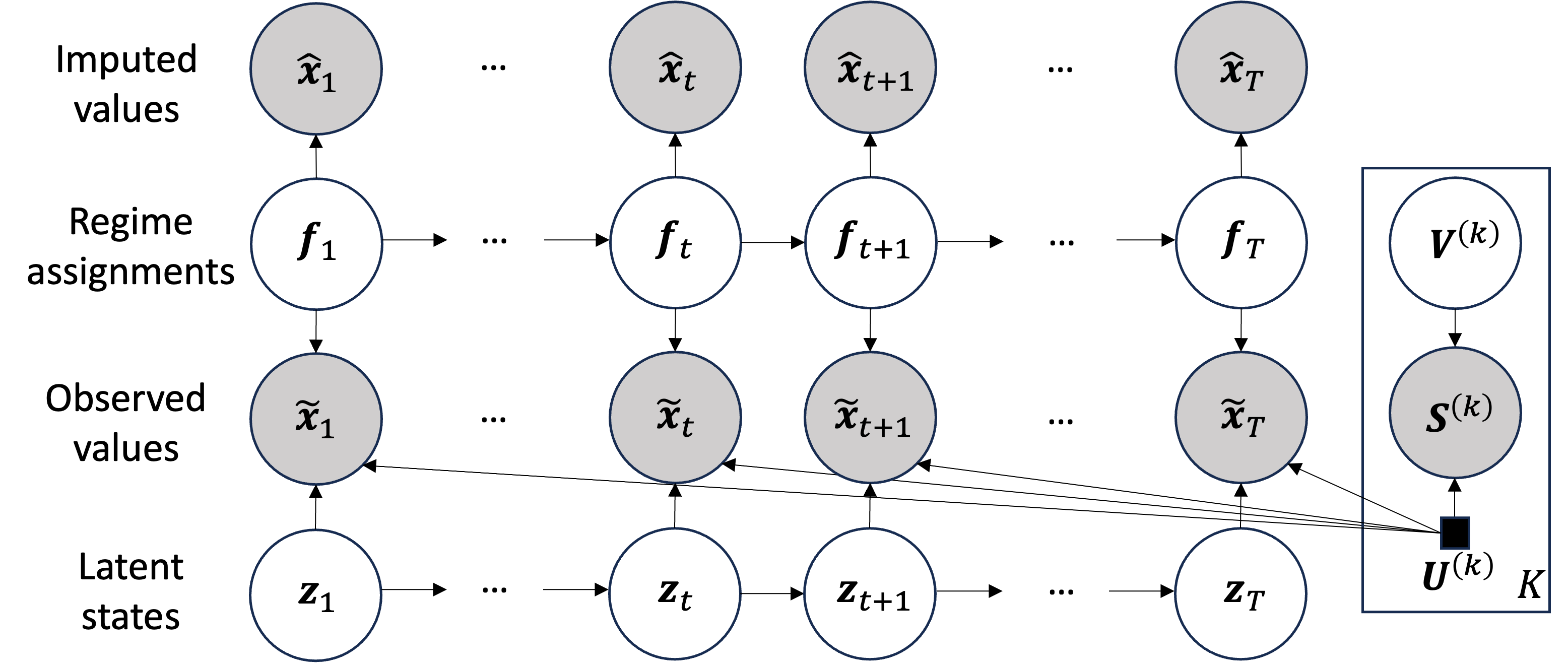
It is difficult to find the global optimal solution of Eq. (4.1), for the following reasons: As a constraint for , has to be fixed and encode inter-correlation; , and jointly determine , and and jointly determine ; Calculating the correct is NP-hard. Hence, we aim to find its local optimum instead, following the EM algorithm, where the graphical model for each iteration is shown in Fig. 2. Specifically, to address the aforementioned difficulties, we employ the following steps: we consider is observed in each iteration, and we update it at the end of the iteration using ; we regard as a model parameter, thus are independent with . We alternate the inference of and and the update of the model parameters; we employ a Viterbi approximation and infer the most likely .
4.2.1. E-step
Given , we can infer and independently.
Let denote the indices of the observed entries of . The observed-only data and the corresponding observed-only observation matrix are defined as follows:
| (12) |
Inferring and . and are coupled, and so must be jointly determined. We first use a Viterbi approximation to find the most likely regime assignments that maximize the log-likelihood Eq. (4.1). The likelihood term obtained during the calculation of also acts as a Kalman Filter (forward algorithm). Then, we infer with a Rauch-Tung-Streibel (RTS) smoother (backward algorithm).
In a Viterbi approximation, finding requires the partial cost when the switch is to regime at time from regime at time . To calculate the partial cost, we define the following LDS state and variance terms:
| (13) |
with the initial state:
| (14) |
where and are the one-step predicted LDS state and the best-filtered state estimates at , respectively, given the switch is in regime at time and in regime at time and only the measurements are known. Similar definitions are used for and .
The partial cost is obtained by calculating the logarithm of Eq. (4.1) related to :
| (15) | ||||
Once all partial costs are obtained, it is well-known how to apply a Viterbi inference to a discrete Markov process to obtain the most likely regime assignments (Viterbi, 1967).
Then, we infer . Let the posteriors of be as follows:
| (16) |
We now obtain using ; thus, in practice, we have conducted a Kalman Filter. We apply the RTS smoother to infer .
| (17) | ||||
| (18) |
4.2.2. M-step
After obtaining and , we update the model parameters to maximize the expectation of the log-likelihood:
| (20) | ||||
where we incorporate the -norm constraint.
Parameters for the imputation model, and , can be obtained by taking the derivative of . For , we update each row individually:
| (21) | ||||
where is a hyperparameter employed as a trade-off for the contributions of inter-correlation and temporal dependency. The details of updating are presented in Appendix A.3.
For the network inference model, we calculate with Eq. (22) and then update by calculating the empirical mean of belonging to the -regime and by solving the graphical lasso problem shown in Eq. (23) via ADMM.
| (22) | |||
| (23) |
For the regime-switching model, the initial state distribution and the Markov transition matrix are updated as follows:
| (24) |
4.2.3. Update
We update at the end of each iteration. As shown in Eq. (25), we define the off-diagonal elements of as partial correlations calculated from the network to encode the inter-correlation.
| (25) |
4.2.4. Overall algorithm
We have the overall algorithm shown as Alg. 1 to obtain a local optimal solution of Eq. (4.1). Given a partially observed multivariate time series , an indicator matrix , the dimension of latent state , the number of regimes , the network parameter , and the sparse parameter , our algorithm aims to find the latent factors , other model parameters in , and imputed time series .
The MissNet algorithm starts by initializing with a linear interpolation, and by randomly initializing , and (Line 3). Then, it alternately updates the latent factors and parameters until they converge. In each iteration, we consider to be given and to be a model parameter. In an iteration, we first conduct a Viterbi approximation to calculate the most likely regime assignments (Line 5-12). Then, we infer the expectations of and (Line 13-15 and Line 16-18), and we update and model parameters (Line 20), and at the end of the iteration, we update (Line 21).
4.3. Complexity analysis
Lemma 0.
The time complexity of MissNet is
.
Proof.
See Appendix A.2. ∎
represents the number of observed features of . Note that is upper bounded by . In practice, the length of the time series () is often orders of magnitude greater than the number of features (). Hence, the actual running time of MissNet is dominated by the term related to , which is linear in .
Lemma 0.
The space complexity of MissNet is
.
Proof.
See Appendix A.2. ∎
5. Experiments
 (a) PatternA
()
(a) PatternA
()
|
 (b) PatternB
()
(b) PatternB
()
|
 (c) Run
()
(c) Run
()
|
 (d) Bouncy walk
()
(d) Bouncy walk
()
|
 (e) Swing shoulder
()
(e) Swing shoulder
()
|
 (f) Walk slow
()
(f) Walk slow
()
|
 (g) Mawashigeri
()
(g) Mawashigeri
()
|
 (h) Jump distance
()
(h) Jump distance
()
|
 (i) Wave hello
()
(i) Wave hello
()
|
 (j) Football throw
()
(j) Football throw
()
|
 (k) Boxing
()
(k) Boxing
()
|
 (l) Motes
()
(l) Motes
()
|
In this section, we empirically evaluate our approach against state-of-the-art baselines on 12 datasets.
We present experimental results for the following questions:
Q1. Effectiveness: How accurate is the proposed MissNet for recovering missing values?
Q2. Scalability: How does the proposed algorithm scale?
Q3. Interpretability: How can MissNet help us understand the data?
5.1. Experimental setup
5.1.1. Datasets
We use the following datasets.
Synthetic. We generate two types of synthetic data, PatternA and PatternB, five times each, by defining and . We set and (Appendix B.1). PatternA has one regime (), and in PatternB (), two regimes switch at every timesteps.
MotionCapture. This dataset contains nine types of full body motions of MotionCapture database 333http://mocap.cs.cmu.edu. Each motion measures the positions of bones in the human body, resulting in a total of features (X, Y, and Z coordinates).
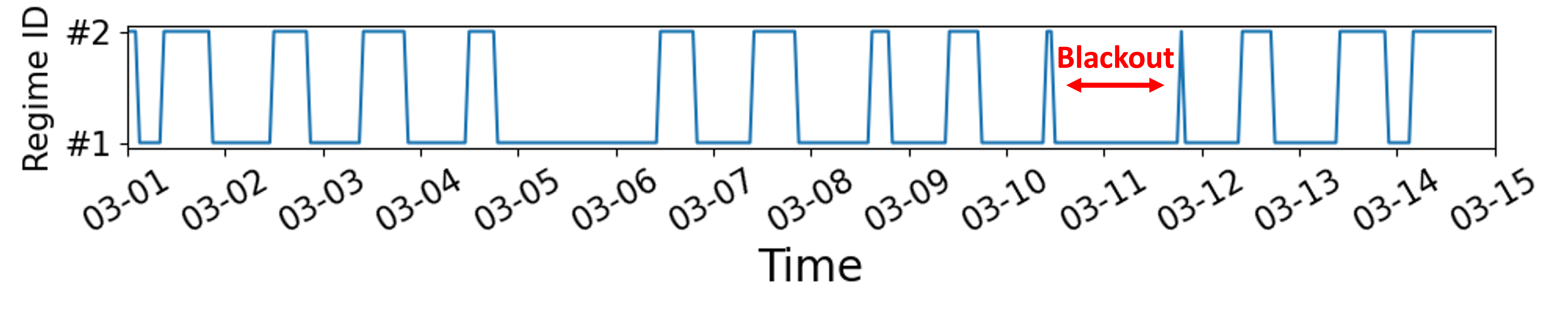
Motes. This dataset consists of temperature measurements from the sensors deployed in the Intel Berkeley Research Lab 444https://db.csail.mit.edu/labdata/labdata.html. We use hourly data for the first two weeks (03-01 03-14). Originally, of the data is missing, including a blackout from 03-10 to 03-11 where all the values are missing.
5.1.2. Data preprocessing
We generate a synthetic missing block at a length of of the data length and place it randomly until the total missing rate reaches . Thus, a missing block can be longer than when it overlaps. An additional of missing values are added for hyperparameter tuning. Each dataset feature is normalized independently using a z-score so that each dataset has a zero mean and a unit variance.
5.1.3. Comparison methods
We compare our method with state-of-the-art imputation methods ranging from classical baselines (Linear and Quadratic), MF-based methods (SoftImpute, CDRec and TRMF), SSM-based methods (DynaMMo and DCMF), to DL-based methods (BRITS, SAITS and TIDER).
-
•
Linear/Quadratic 555https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.interpolate.html use linear/quadratic equations to interpolate missing values.
-
•
SoftImpute (Mazumder et al., 2010) first fills in missing values with zero, then alternates between recovering the missing values and updating the SVD using the recovered matrix.
-
•
CDRec (Khayati et al., 2014) is a memory-efficient algorithm that iterates centroid decomposition (CD) and missing value imputation until they converge.
-
•
TRMF (Yu et al., 2016) is based on MF that imposes temporal dependency among the data points with the AR model.
-
•
DynaMMo (Li et al., 2009) first fills in missing values using linear interpolation and then uses the EM algorithm to iteratively recover missing values and update the LDS model.
-
•
DCMF (Cai et al., 2015a) adds a contextual constraint to SSM and captures inter-correlation by a predefined network. As suggested in the original paper, we give the cosine similarity between each pair of time series calculated after linear interpolation as a predefined network. This method is similar to MissNet if we set , employ a predefined network that is fixed throughout the algorithm, and eliminate the effect of regime-switching and network inference models from MissNet.
-
•
BRITS (Cao et al., 2018) imputes missing values according to hidden states from bidirectional RNN.
-
•
SAITS (Du et al., 2023) is a self-attention-based model that jointly optimizes imputation and reconstruction to perform the missing value imputation of multivariate time series.
-
•
TIDER (LIU et al., 2022) learns disentangled seasonal and trend representations by employing a neural network combined with MF.
5.1.4. Hyperparameter setting
For MissNet, we use the latent dimensions of and for Synthetic, MotionCapture and Motes, respectively, and we set for all datasets. We set the correct number of regimes on Synthetic datasets; we vary for other datasets. We list the detailed hyperparameter settings for the baselines in Appendix B.2.
5.1.5. Evaluation metric
To evaluate the effectiveness, we use Root Mean Square Error (RMSE) of the observed time series (Cai et al., 2015a).
5.2. Results
5.2.1. Q1. Effectiveness
We show the effectiveness of MissNet over baselines in missing value imputation.
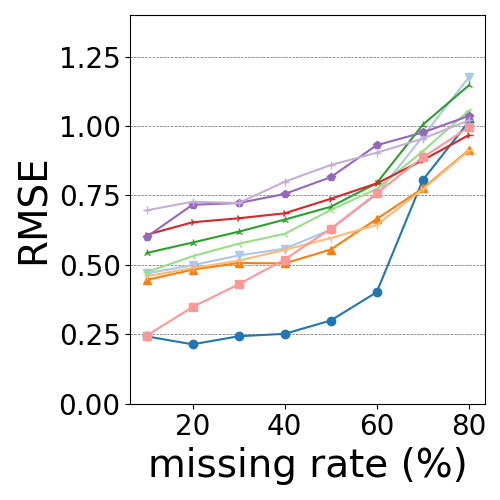
Synthetic. Fig. 3 (a) and (b) show the results obtained with Synthetic datasets. SSM and MF-based methods perform worse with PatternB than with PatternA due to the increased complexity of data. DL-based methods, especially BRITS, are less affected thanks to their high modeling power. MissNet significantly outperforms DCMF for PatternB although it produces similar results for PatternA. This is because DCMF fails to capture inter-correlation with PatternB since it can only use one predefined network and cannot afford a change of network. Meanwhile, MissNet can capture the inter-correlation for two different regimes thanks to our regime-switching model. However, MissNet fails to discover the correct transition when the missing rate exceeds , and RMSE becomes similar to DCMF.
MotionCapture and Motes. The results for MotionCapture and Motes datasets are shown in Fig. 3 (c) (l). We can see that MissNet and DCMF constantly outperform other baselines thanks to their ability to exploit inter-correlation explicitly.
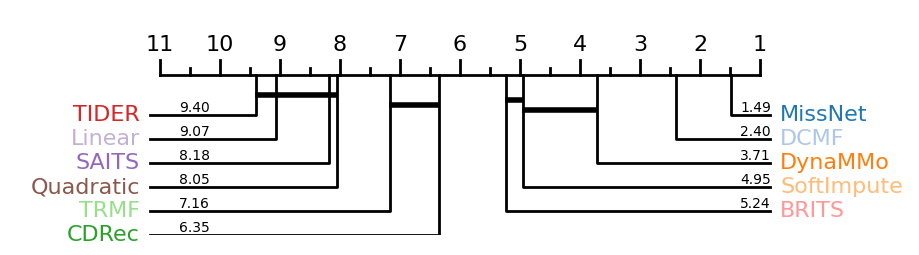
Fig. 4 shows the corresponding critical difference diagram for all missing rates based on the Wilcoxon-Holm method (Ismail Fawaz et al., 2019), where methods that are not connected by a bold line are significantly different in average rank. This confirms that MissNet significantly outperforms other methods, including DCMF, in average rank. Our algorithm for repeatedly inferring networks and the use of -norm enables the inference of adequate networks for imputation, contributing to better results than DCMF, which uses cosine similarity as a predefined network that may contain spurious correlations in the presence of missing values. Note that MissNet and DCMF exhibit only minor differences when the missing rate is low () because a plausible predefined network can be calculated from observed data.
Classical Linear and Quadratic baselines are unsuitable for imputing missing blocks since they impute missing values mostly from neighboring observed points and cannot capture temporal patterns when there are large gaps. DL-based methods lack sufficient training data and are not suitable for the data we use here, making them perform particularly poorly at a high missing rate, as also noted in (Khayati et al., 2020). MF-based methods, SoftImpute and CDRec, have a higher RMSE than SSM-based methods since they do not model the temporal dynamics of the data. TRMF utilizes temporal dependency with the AR model, however, it can only capture certain lags specified on the hyperparameter of the AR model. SSM-based methods are superior in imputation to other groups owing to their ability to capture temporal dependency in latent space. DynaMMo implicitly captures inter-correlation in latent space. Therefore, it is no match for MissNet or DCMF.
Fig. 5 demonstrates the results for the MotionCapture Run dataset (missing rate ). We compare the imputation result for the sensor at RKNE provided by the top five methods in terms of average rank, including MissNet, in Fig. 5 (a). BRITS and SoftImpute fail to capture the dynamics of time series while providing a good fit to observed values. The imputation of DynaMMo is smooth, but some parts are imprecise since it cannot explicitly exploit inter-correlation. MissNet and DCMF can effectively exploit other observed features associated with RKNE, thereby accurately imputing missing values where other methods fail (e.g., ). Fig. 5 (b) shows the sensor network of Y-coordinate values obtained by MissNet plotted on the human body, where a green/yellow dot (node) indicates a sensor placed on the front/back of the body and the thickness and color (blue/red) of the edges are the value and sign (positive/negative) of partial correlations, respectively. We can see that the sensors located close together have edges, meaning they are conditionally dependent given all other sensor values. For example, the sensor at RKNE has edges between RTHI, RSHN, LKNE, and LTHI. They are located to RKNE nearby and show similar dynamics, thus it is reasonable to consider that they are connected. Since MissNet can infer such a meaningful network from partially observed data, the imputation of MissNet is more accurate than that of DCMF.
 (a) Imputation results at RKNE
(a) Imputation results at RKNE
|
 (b) Y-network of MissNet
(b) Y-network of MissNet
|
 (a) Impact of
(a) Impact of
|
 (b) Impact of
(b) Impact of
|
 (c) Impact of
(c) Impact of
|
5.2.2. Hyperparameter sensitivity
We take the Motes dataset and show the impact of hyperparameters: the latent dimension , the network parameter , and the sparse parameter . We show the mean RMSE of all missing rates.
Latent dimension. Fig. 6 (a) shows the impact of . As becomes larger, the model’s fitting against the observed data increases. As we can see, the RMSE is constantly decreasing as increases and stabilizes after . This shows that MissNet does not overfit the observed data even for a large .
Network parameter. determines the contributions of inter-correlation and temporal dependency to learning . If , the contextual matrix is ignored. If , only is considered for learning . Fig. 6 (b) shows the results of varying and they are robust except when (RMSE ). We can see that shows the best result, indicating that both temporal dependency and inter-correlation are important for precise imputation.
Sparse parameter. controls the sparsity of the networks through -norm. The bigger becomes, the more sparse the networks become, resulting in MissNet considering only strong interplay. By contrast, when is small, MissNet considers insignificant interplays. Fig. 6 (c) shows the impact of . We can see that the sparsity of the networks affects the accuracy, and the best exists between and . Thus, the -norm constraint helps MissNet to exploit important relationships.
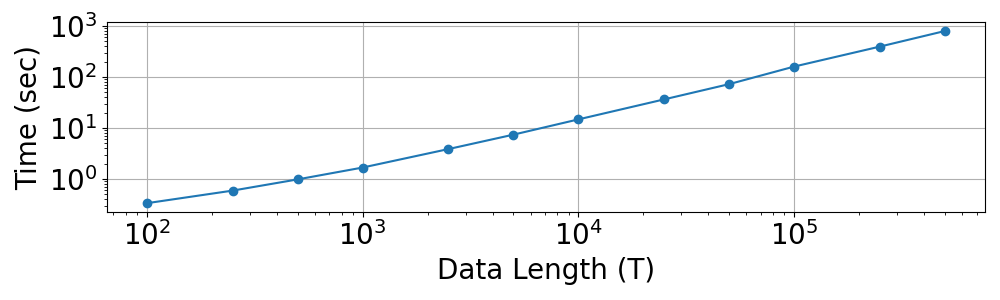
5.2.3. Q2. Scalability
We test the scalability of the MissNet algorithm by changing the number of the data length () in PatternA. Fig. 7 shows the computation time for one iteration plotted with the data length. As it shows, our proposed MissNet algorithm scales linearly with regard to the data length .
(a) Results of regime assignments
 (b) Regime , of edges: 116
(b) Regime , of edges: 116
|
 (c) Regime , of edges: 134
(c) Regime , of edges: 134
|
5.2.4. Q3. Interpretability
We demonstrate how MissNet helps us understand data. We have shown an example with the MotionCapture Run dataset in Fig. 5 (b) where MissNet provides an interpretable network. Here, we demonstrate the results on the Motes dataset (missing rate ) of MissNet (). Fig. 8 (a) shows the regime assignments , and MissNet mostly assigns night hours to regime and working hours (about am. to pm.) to regime , suggesting that they have different networks. Fig. 8 (b) and (c) show the networks for regimes and obtained by MissNet plotted on the building layout. The sensor numbers in the figure are plotted on the actual sensor deployments. As we can see, the two regimes have different networks, and a common feature is that the neighboring sensors tend to form edges, which aligns with our expectations, considering that the sensors measure temperature and, thus, neighboring sensors correlate. The network of regime has more edges than that of , and the edges are times longer on average, which might be caused by air convection due to the movement of people during working hours. Consequently, MissNet provides regime assignments and sparse networks, which help us understand how data can be separated and important relationships for imputation.
6. Conclusion
In this paper, we proposed an effective missing value imputation method for multivariate time series, namely MissNet, which captures temporal dependency based on latent space and inter-correlation by the inferred networks while discovering regimes. Our proposed method has the following properties: (a) Effective: it outperforms the state-of-the-art algorithms for multivariate time series imputation. (b) Scalable: the computation time of MissNet scales linearly with regard to the length of the data. (c) Interpretable: it provides sparse networks and regime assignments, which help us understand the important relationships for imputation visually. Our extensive experiments demonstrated the above properties of MissNet.
Acknowledgements.
The authors would like to thank the anonymous referees for their valuable comments and helpful suggestions. This work was supported by JSPS KAKENHI Grant-in-Aid for Scientific Research Number JP21H03446, JP22K17896, NICT JPJ012368C03501, JST-AIP JPMJCR21U4, JST CREST JPMJCR23M3.References
- (1)
- Alcaraz and Strodthoff (2022) Juan Miguel Lopez Alcaraz and Nils Strodthoff. 2022. Diffusion-based time series imputation and forecasting with structured state space models. arXiv preprint arXiv:2208.09399 (2022).
- Bansal et al. (2021) Parikshit Bansal, Prathamesh Deshpande, and Sunita Sarawagi. 2021. Missing Value Imputation on Multidimensional Time Series. Proc. VLDB Endow. 14, 11 (jul 2021), 2533–2545.
- Berrevoets et al. (2023) Jeroen Berrevoets, Fergus Imrie, Trent Kyono, James Jordon, and Mihaela van der Schaar. 2023. To impute or not to impute? missing data in treatment effect estimation. In International Conference on Artificial Intelligence and Statistics. PMLR, 3568–3590.
- Boyd et al. (2011) Stephen P. Boyd, Neal Parikh, Eric Chu, Borja Peleato, and Jonathan Eckstein. 2011. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Found. Trends Mach. Learn. 3, 1 (2011), 1–122.
- Cai et al. (2015a) Yongjie Cai, Hanghang Tong, Wei Fan, and Ping Ji. 2015a. Fast mining of a network of coevolving time series. In Proceedings of the 2015 SIAM International Conference on Data Mining. SIAM, 298–306.
- Cai et al. (2015b) Yongjie Cai, Hanghang Tong, Wei Fan, Ping Ji, and Qing He. 2015b. Facets: Fast comprehensive mining of coevolving high-order time series. In KDD. 79–88.
- Cao et al. (2018) Wei Cao, Dong Wang, Jian Li, Hao Zhou, Lei Li, and Yitan Li. 2018. Brits: Bidirectional recurrent imputation for time series. Advances in neural information processing systems 31 (2018).
- Chambon et al. (2018) Stanislas Chambon, Mathieu N Galtier, Pierrick J Arnal, Gilles Wainrib, and Alexandre Gramfort. 2018. A deep learning architecture for temporal sleep stage classification using multivariate and multimodal time series. IEEE Transactions on Neural Systems and Rehabilitation Engineering 26, 4 (2018), 758–769.
- Chen and Sun (2021) Xinyu Chen and Lijun Sun. 2021. Bayesian temporal factorization for multidimensional time series prediction. IEEE Transactions on Pattern Analysis and Machine Intelligence 44, 9 (2021), 4659–4673.
- Cini et al. (2021) Andrea Cini, Ivan Marisca, and Cesare Alippi. 2021. Filling the g_ap_s: Multivariate time series imputation by graph neural networks. arXiv preprint arXiv:2108.00298 (2021).
- Dabrowski et al. (2018) Joel Janek Dabrowski, Ashfaqur Rahman, Andrew George, Stuart Arnold, and John McCulloch. 2018. State Space Models for Forecasting Water Quality Variables: An Application in Aquaculture Prawn Farming (KDD ’18). Association for Computing Machinery, New York, NY, USA, 177–185.
- Du et al. (2023) Wenjie Du, David Côté, and Yan Liu. 2023. Saits: Self-attention-based imputation for time series. Expert Systems with Applications 219 (2023), 119619.
- Fan et al. (2023) Yangxin Fan, Xuanji Yu, Raymond Wieser, David Meakin, Avishai Shaton, Jean-Nicolas Jaubert, Robert Flottemesch, Michael Howell, Jennifer Braid, Laura Bruckman, Roger French, and Yinghui Wu. 2023. Spatio-Temporal Denoising Graph Autoencoders with Data Augmentation for Photovoltaic Data Imputation. Proc. ACM Manag. Data 1, 1, Article 50 (may 2023), 19 pages. https://doi.org/10.1145/3588730
- Fox et al. (2008) Emily Fox, Erik Sudderth, Michael Jordan, and Alan Willsky. 2008. Nonparametric Bayesian learning of switching linear dynamical systems. Advances in neural information processing systems 21 (2008).
- Friedman et al. (2008) Jerome Friedman, Trevor Hastie, and Robert Tibshirani. 2008. Sparse inverse covariance estimation with the graphical lasso. Biostatistics 9, 3 (2008), 432–441.
- Ghahramani (1998) Zoubin Ghahramani. 1998. Learning dynamic Bayesian networks. Springer Berlin Heidelberg, Berlin, Heidelberg, 168–197.
- Hairi et al. (2019) N Hairi, Hanghang Tong, and Lei Ying. 2019. NetDyna: mining networked coevolving time series with missing values. In 2019 IEEE International Conference on Big Data (Big Data). IEEE, 503–512.
- Hallac et al. (2017a) David Hallac, Youngsuk Park, Stephen P. Boyd, and Jure Leskovec. 2017a. Network Inference via the Time-Varying Graphical Lasso. In KDD. 205–213.
- Hallac et al. (2017b) David Hallac, Sagar Vare, Stephen P. Boyd, and Jure Leskovec. 2017b. Toeplitz Inverse Covariance-Based Clustering of Multivariate Time Series Data. In KDD. 215–223.
- Ismail Fawaz et al. (2019) Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, Lhassane Idoumghar, and Pierre-Alain Muller. 2019. Deep learning for time series classification: a review. Data mining and knowledge discovery 33, 4 (2019), 917–963.
- Jing et al. (2021) Baoyu Jing, Hanghang Tong, and Yada Zhu. 2021. Network of tensor time series. In Proceedings of the Web Conference 2021. 2425–2437.
- Khayati et al. (2014) Mourad Khayati, Michael Böhlen, and Johann Gamper. 2014. Memory-efficient centroid decomposition for long time series. In 2014 IEEE 30th International Conference on Data Engineering. IEEE, 100–111.
- Khayati et al. (2020) Mourad Khayati, Alberto Lerner, Zakhar Tymchenko, and Philippe Cudré-Mauroux. 2020. Mind the gap: an experimental evaluation of imputation of missing values techniques in time series. In Proceedings of the VLDB Endowment, Vol. 13. 768–782.
- Kolar and Xing (2012) Mladen Kolar and Eric P Xing. 2012. Estimating sparse precision matrices from data with missing values. In International Conference on Machine Learning. 635–642.
- Li et al. (2009) Lei Li, James McCann, Nancy S Pollard, and Christos Faloutsos. 2009. Dynammo: Mining and summarization of coevolving sequences with missing values. In KDD. 507–516.
- LIU et al. (2022) SHUAI LIU, Xiucheng Li, Gao Cong, Yile Chen, and YUE JIANG. 2022. Multivariate Time-series Imputation with Disentangled Temporal Representations. In The Eleventh International Conference on Learning Representations.
- Liu et al. (2020) Yuehua Liu, Tharam Dillon, Wenjin Yu, Wenny Rahayu, and Fahed Mostafa. 2020. Missing value imputation for industrial IoT sensor data with large gaps. IEEE Internet of Things Journal 7, 8 (2020), 6855–6867.
- Ma et al. (2008) Hao Ma, Haixuan Yang, Michael R Lyu, and Irwin King. 2008. Sorec: social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM conference on Information and knowledge management. 931–940.
- Malte Londschien and Bühlmann (2021) Solt Kovács Malte Londschien and Peter Bühlmann. 2021. Change-Point Detection for Graphical Models in the Presence of Missing Values. Journal of Computational and Graphical Statistics 30, 3 (2021), 768–779.
- Mazumder et al. (2010) Rahul Mazumder, Trevor Hastie, and Robert Tibshirani. 2010. Spectral regularization algorithms for learning large incomplete matrices. The Journal of Machine Learning Research 11 (2010), 2287–2322.
- Mohan et al. (2014) Karthik Mohan, Palma London, Maryam Fazel, Daniela Witten, and Su-In Lee. 2014. Node-Based Learning of Multiple Gaussian Graphical Models. J. Mach. Learn. Res. 15, 1 (jan 2014), 445–488.
- Monti et al. (2014) Ricardo Pio Monti, Peter Hellyer, David Sharp, Robert Leech, Christoforos Anagnostopoulos, and Giovanni Montana. 2014. Estimating time-varying brain connectivity networks from functional MRI time series. NeuroImage 103 (2014), 427–443.
- Namaki et al. (2011) A. Namaki, A.H. Shirazi, R. Raei, and G.R. Jafari. 2011. Network analysis of a financial market based on genuine correlation and threshold method. Physica A: Statistical Mechanics and its Applications 390, 21 (2011), 3835–3841.
- Obata et al. (2024) Kohei Obata, Koki Kawabata, Yasuko Matsubara, and Yasushi Sakurai. 2024. Dynamic Multi-Network Mining of Tensor Time Series. In Proceedings of the ACM on Web Conference 2024 (WWW ’24). 4117–4127.
- Papadimitriou et al. (2005) Spiros Papadimitriou, Jimeng Sun, and Christos Faloutsos. 2005. Streaming pattern discovery in multiple time-series. (2005).
- Pavlovic et al. (1999) Vladimir Pavlovic, James M Rehg, Tat-Jen Cham, and Kevin P Murphy. 1999. A dynamic Bayesian network approach to figure tracking using learned dynamic models. In Proceedings of the seventh IEEE international conference on computer vision, Vol. 1. IEEE, 94–101.
- Qin et al. (2020) Zhen Qin, Yibo Zhang, Shuyu Meng, Zhiguang Qin, and Kim-Kwang Raymond Choo. 2020. Imaging and fusing time series for wearable sensor-based human activity recognition. Information Fusion 53 (2020), 80–87.
- Ren et al. (2023) Xiaobin Ren, Kaiqi Zhao, Patricia Riddle, Katerina Taškova, Lianyan Li, and Qingyi Pan. 2023. DAMR: Dynamic Adjacency Matrix Representation Learning for Multivariate Time Series Imputation. SIGMOD (2023). https://doi.org/10.1145/3589333
- Rogers et al. (2013) Mark Rogers, Lei Li, and Stuart J Russell. 2013. Multilinear dynamical systems for tensor time series. Advances in Neural Information Processing Systems 26 (2013).
- Shadbahr et al. (2023) Tolou Shadbahr, Michael Roberts, Jan Stanczuk, Julian Gilbey, Philip Teare, Sören Dittmer, Matthew Thorpe, Ramon Viñas Torné, Evis Sala, Pietro Lió, Mishal Patel, Jacobus Preller, Ian Selby, Anna Breger, Jonathan R. Weir-McCall, Effrossyni Gkrania-Klotsas, Anna Korhonen, Emily Jefferson, Georg Langs, Guang Yang, Helmut Prosch, Judith Babar, Lorena Escudero Sánchez, Marcel Wassin, Markus Holzer, Nicholas Walton, Pietro Lió, James H. F. Rudd, Tuomas Mirtti, Antti Sakari Rannikko, John A. D. Aston, Jing Tang, and Carola-Bibiane Schönlieb. 2023. The impact of imputation quality on machine learning classifiers for datasets with missing values. Communications Medicine 3, 1 (2023).
- Shukla and Marlin (2021) Satya Narayan Shukla and Benjamin M Marlin. 2021. Multi-time attention networks for irregularly sampled time series. arXiv preprint arXiv:2101.10318 (2021).
- Städler and Bühlmann (2012a) Nicolas Städler and Peter Bühlmann. 2012a. Missing values: sparse inverse covariance estimation and an extension to sparse regression. Statistics and Computing 22 (2012), 219–235.
- Städler and Bühlmann (2012b) Nicolas Städler and Peter Bühlmann. 2012b. Missing values: sparse inverse covariance estimation and an extension to sparse regression. Statistics and Computing 22 (2012), 219–235.
- Tashiro et al. (2021) Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. 2021. Csdi: Conditional score-based diffusion models for probabilistic time series imputation. Advances in Neural Information Processing Systems 34 (2021), 24804–24816.
- Tomasi et al. (2021) Federico Tomasi, Veronica Tozzo, and Annalisa Barla. 2021. Temporal Pattern Detection in Time-Varying Graphical Models. In ICPR. 4481–4488.
- Tomasi et al. (2018) Federico Tomasi, Veronica Tozzo, Saverio Salzo, and Alessandro Verri. 2018. Latent Variable Time-varying Network Inference. In KDD. 2338–2346. https://doi.org/10.1145/3219819.3220121
- Tozzo et al. (2021) Veronica Tozzo, Federico Ciech, Davide Garbarino, and Alessandro Verri. 2021. Statistical Models Coupling Allows for Complex Local Multivariate Time Series Analysis. In KDD. 1593–1603.
- Tozzo et al. (2020) Veronica Tozzo, Davide Garbarino, and Annalisa Barla. 2020. Missing Values in Multiple Joint Inference of Gaussian Graphical Models. In Proceedings of the 10th International Conference on Probabilistic Graphical Models (Proceedings of Machine Learning Research, Vol. 138), Manfred Jaeger and Thomas Dyhre Nielsen (Eds.). PMLR, 497–508.
- Viterbi (1967) Andrew Viterbi. 1967. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE transactions on Information Theory 13, 2 (1967), 260–269.
- Wang et al. (2023a) Dingsu Wang, Yuchen Yan, Ruizhong Qiu, Yada Zhu, Kaiyu Guan, Andrew Margenot, and Hanghang Tong. 2023a. Networked time series imputation via position-aware graph enhanced variational autoencoders. In KDD. 2256–2268.
- Wang et al. (2023b) Xu Wang, Hongbo Zhang, Pengkun Wang, Yudong Zhang, Binwu Wang, Zhengyang Zhou, and Yang Wang. 2023b. An Observed Value Consistent Diffusion Model for Imputing Missing Values in Multivariate Time Series. In KDD. 2409–2418.
- Yi et al. (2016) Xiuwen Yi, Yu Zheng, Junbo Zhang, and Tianrui Li. 2016. ST-MVL: filling missing values in geo-sensory time series data. In Proceedings of the 25th International Joint Conference on Artificial Intelligence.
- Yoon et al. (2018a) Jinsung Yoon, James Jordon, and Mihaela Schaar. 2018a. Gain: Missing data imputation using generative adversarial nets. In International conference on machine learning. PMLR, 5689–5698.
- Yoon et al. (2018b) Jinsung Yoon, William R Zame, and Mihaela van der Schaar. 2018b. Estimating missing data in temporal data streams using multi-directional recurrent neural networks. IEEE Transactions on Biomedical Engineering 66, 5 (2018), 1477–1490.
- Yu et al. (2016) Hsiang-Fu Yu, Nikhil Rao, and Inderjit S. Dhillon. 2016. Temporal Regularized Matrix Factoriztion for High-dimensional Time Series Prediction. In Advances in Neural Information Processing Systems 28.
- Zhang and Balzano (2016) Dejiao Zhang and Laura Balzano. 2016. Global convergence of a grassmannian gradient descent algorithm for subspace estimation. In Artificial Intelligence and Statistics. PMLR, 1460–1468.
Appendix A Proposed model
A.1. Symbols
Table 2 lists the main symbols we use throughout this paper.
A.2. Complexity analysis
Proof of Lemma 1.
Proof.
The overall time complexity is composed of four parts by taking the most time-consuming part of equations for each iteration considering : the complexity for the inference of and is related to Eq. (13) and Eq. (15); the inference of is (Eq. (19)); M step is related to the calculation of (Eq. (21)); and the update of is (Eq. (23)). Thus, the overall time complexity is . ∎
Proof of Lemma 2.
Proof.
The space complexity is composed of three parts: storing input dataset is ; intermediate values in E step are ; and storing parameter set is . Thus, the overall space complexity is . ∎
| Symbol | Definition |
|---|---|
| Multivariate time series | |
| Indicator matrix | |
| Partially observed multivariate time series | |
| Inputed multivariate time series | |
| Time series latent states | |
| Contextual latent factor of -regime | |
| Contextual matrix of -regime | |
| Transition matrix | |
| Observation matrix of -regime | |
| Regime assignments | |
| Mean vector of -regime | |
| Inverse covariance matrix (i.e., network) of -regime | |
| Number of features | |
| Number of timesteps | |
| Number of latent dimensions | |
| Number of regimes | |
| Trade-off between temporal dependency and inter-correlation | |
| Parameter for -norm that regulates network sparsity |
A.3. Updating parameters
The parameters are updated as follows:
| (26) |
Appendix B Experiments
B.1. Synthetic data generation
We first generate a latent factor containing a linear trend, a sinusoidal seasonal pattern, and a noise, , s.t. , where . We then project the latent factor with object matrix , where , and is a random graph created as follows (Mohan et al., 2014):
-
(1)
Set equal to the adjacency matrix of an Erdős-Rényi directed random graph, where every edge has a chance of being selected.
-
(2)
Set selected edge Uniform, where denotes the weight between variables and .
We set . We generate two types of synthetic data, PatternA and PatternB, five times each, where , respectively. In PatternB, the regime switches every timesteps.
B.2. Hyperparameters
We describe the hyperparameters of the baselines. For Synthetic datasets, we give a latent dimension of for all baselines. For a fair comparison, we set the latent dimension of the SSM-based methods at the same value as MissNet. For the MF-based methods, we vary the latent dimension . We vary the AR parameter for TRMF . To learn the DL-based methods, we add of the data as missing values for training the model. We vary the window size . Other hyperparameters are the same as the original codes.
Appendix C Discussion
While MissNet achieved superior performance against state-of-the-art baselines in missing value imputation, here, we mention two limitations of MissNet in terms of sparse network inference and data size.
As mentioned in Section 5.2.1, MissNet fails to discover the correct transition when the missing rate exceeds . However, we claim that MissNet failing to discover the correct transition when the missing rate exceeds is reasonable; rather, correctly discovering transition up to is valuable. Several studies (Tozzo et al., 2020; Kolar and Xing, 2012; Städler and Bühlmann, 2012b) tackled the sparse network inference under the existence of missing values. They aim to infer the correct network and, thus, only utilize the observed value for the network inference. Since observing a complete pair at a high missing rate is rare, it is difficult to infer the correct network. Therefore, the maximum missing rate in their experiments is . Although the experimental settings are different from ours, we can say that the task of sparse network inference in the presence of missing values itself is challenging.
As shown in the experiments, MissNet performs well even when a relatively small number of samples () and a large number of features () since MissNet is a parametric model and we assume the sparse networks to capture inter-correlation. This cannot be achieved by DL models, which contain a massive number of parameters that require a large amount of , especially when is large since all the relationships between features need to be learned. However, unlike DL models, the increased number of samples may not greatly improve MissNet’s performance as it has a much smaller number of parameters than DL models, even though switching sparse networks increases the model’s flexibility.