Minimization Problems on Strictly Convex Divergences
Abstract
The divergence minimization problem plays an important role in various fields. In this note, we focus on differentiable and strictly convex divergences. For some minimization problems, we show the minimizer conditions and the uniqueness of the minimizer without assuming a specific form of divergences. Furthermore, we show geometric properties related to the minimization problems.
Keywords: convex, minimization problem, projection, centroid, Bregman divergence, f-divergence, Rényi-divergence, Lagrange multiplier.
I Introduction
The divergences are quantities that measure discrepancy between probability measures.
For two probability measures and , divergences satisfy the following properties.
with equality if and only if .
In particular, the -divergence [15, 7], the Bregman divergence [3] and the Rényi divergence [16, 14] are often used in various fields such as machine learning, image processing, statistical physics, finance and so on.
In order to find the probability measures closest (in the meaning of divergence) to the target probability measure subject to some constraints, it is necessary to solve divergence minimization problems and there are many works about them [8, 4, 2]. Divergence minimization problems are also deeply related to the geometric properties of divergences such as the projection from a probability measure to a set.
The main purpose of this note is to study minimization problems and geometric properties of differentiable and strictly convex divergences in the first or the second argument [13]. For example, the squared Euclidean distance is differentiable and strictly convex. The most important result is that we can derive the minimizer conditions and the uniqueness of the minimizer from only these assumptions without specifying the form of divergences if there exist the solutions that satisfy the minimizer conditions. The minimizer conditions are consistent with the results of the method of Lagrange multipliers.
First, We introduce divergence lines, balls, inner products and orthogonal subsets that are the generalization of line segments, spheres, inner products and orthogonal planes perpendicular to lines in the Euclidean space, respectively. Furthermore, we show the three-point inequality as a basic geometric property and show some properties of the divergence inner product.
Next, we discuss the minimization problem of the weighted average of divergences from some probability measures, which is important in clustering algorithms such as k-means clustering [10]. We show that the minimizer of the weighted average of divergences is the generalized centroid as in the case of the Euclidean space.
Finally, we discuss the minimization problems between a probability measure and a set . These are interpreted as a projection from the probability measure to the set . In the Euclidean space, the minimum distance from a point to a plane is given by the perpendicular foot, and the minimum distance to the sphere is given by the intersection of the sphere and a line connecting and the center of the sphere. We show that the minimizer of divergence between a probability measure and the divergence ball or the orthogonal subset have the similar properties as in the case of the Euclidean space.
II Preliminaries
This section provides definitions and notations which are used in this note. Let denotes the set of probability measures. For , denotes . Let be a dominating measure of () and be the density of .
Divergences are defined as functions that satisfy the following properties.
Let . For any ,
Definition 1 (Strictly convex divergence).
Let and . Let and let be a divergence. The divergence is strictly convex in the second argument if
| (1) |
Definition 2 (Differentiable divergence).
Let and let be a divergence. The divergence is differentiable with respect to the second argument if is the functional of and the functional derivative exists with respect to . Let be a functional with respect to . The functional derivative of with respect to is defined by
| (2) |
where is an arbitrary function.
The strictly convex or differentiable divergence in the first argument, we can define in the same way as the second argument. We show some examples of the functional derivative.
Example 1 (Squared Euclidean distance).
Let . The functional derivative is
| (3) |
Example 2 (Bregman divergence).
Let be a differentiable and strictly convex function. The Bregman divergence is defined by
| (4) |
where denotes the derivative of . The Bregman divergence is strictly convex in the first argument. The functional derivative is
| (5) |
Example 3 (-divergence).
Let be a strictly convex function and . The -divergence is defined by
| (6) |
The -divergence is strictly convex in the first and the second argument. If is differentiable, the functional derivatives are
| (7) |
where and
| (8) |
Example 4 (Rényi-divergence).
For , the Rényi-divergence is defined by
| (9) | |||
The Rényi divergence is strictly convex in the second argument for (see [16]). The functional derivative is
| (10) |
If a divergence is differentiable or strictly convex in the first argument, by putting , is differentiable or strictly convex in the second argument. Hence, in the following, we only consider the differentiable or strictly convex divergences in the second argument.
Definition 3 (Divergence line).
Let be a differentiable divergence and let . The “divergence line” is defined by
| (11) |
We also define probability measures on the divergence line at by
| (12) |
We show some examples of the divergence lines.
Example 5 (Squared Euclidean distance).
| (13) |
These are mixture distributions and a line segment in Euclidean space.
Example 6 (Kullback-Leibler divergence).
Definition 4 (Divergence inner product).
Let be a differentiable divergence. Let . We define “divergence inner product” by
| (17) |
For the squared Euclidean distance , and this is the inner product of functions and .
Definition 5 (Orthogonal subspace).
Let . We define the orthogonal subspace at by
| (18) |
Since the divergence inner product is linear with respect to , the orthogonal subspace is a convex set.
Definition 6 (Divergence ball).
Let and be a divergence. We define the divergence ball by
| (19) |
and the surface of the divergence ball by
| (20) |
If the divergence is convex, the divergence ball is a convex set from the definition.
III Main results
In this section, we focus on the differentiable and strictly convex divergences and show some properties of them. We first show the three-point inequality and some properties of the divergence inner product. Next, we discuss some minimization problems and we show that the minimizer conditions and the uniqueness of the minimizer if there exist the solutions that satisfy the minimizer conditions.
We prove the following lemma that we use in various proofs.
Lemma 1.
Let be a strictly convex divergence and . Let and . Then, is strictly convex with respect to .
Proof.
When , holds since . From the assumption of strictly convexity of the divergence, for ,
| (21) |
From the definition of , we have . By combining this equality and (21), the result follows. ∎
III-A Three-point inequality
In this subsection, we show some geometric properties of differentiable and strictly convex divergences.
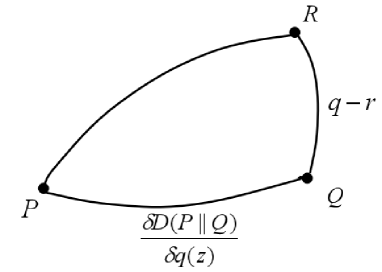
Theorem 1 (Three-point inequality).
Let be a differentiable and strictly convex divergence. Let .
Then,
| (22) |
where the equality holds if and only if .
Proof.
For the Bregman divergence, three-point identity holds [11].
| (26) |
By using and the result of Example 2, we have the same inequality as (22) by putting
We show the figure of three-point inequality.
Proposition 1.
Let be a differentiable and strictly convex divergence. Let and for .
Then,
| (27) |
Proof.
From the assumption, satisfies
| (28) |
By multiplying both sides by and integrating with respect to and using , the result follows. ∎
Corollary 1.
Let be a differentiable and strictly convex divergence and .
Then,
| (29) |
Proof.
By substituting into (22), the result follows. ∎
Proposition 2.
Let be a differentiable and strictly convex divergence. Let , and .
For all ,
| (30) |
Proof.
Let and . From the assumption, is the minimum value for . Hence, and we have
| (31) |
From this inequality, the result follows. ∎
This is the same approach to show the Pythagorean inequality for the KL-divergence [6].
Corollary 2.
Let and let for . Then,
| (32) |
Proof.
The result follows from Proposition 1. ∎
III-B Centroids
We consider the minimization problem of the weighted average of differentiable and strictly convex divergences. This problem is important for the clustering algorithm and we show that the minimizer is a generalized centroid and the uniqueness of the minimizer if there exists the solution that satisfies the generalized centroid condition.
Theorem 2 (Minimization of the weighted average of divergences).
Let be a differentiable and strictly convex divergence. Let and be parameters that satisfy and . Suppose that there exists that satisfies
| (33) |
where is the Lagrange multiplier.
Then, the minimizer of the weighted average of divergences
| (34) |
is unique and is the unique solution of (33).
Proof.
We first prove (34). Let be an arbitrary probability measure. Let and . By differentiating with respect to and substituting , it follows that
| (35) |
where we use (33), and the definition of the functional derivative. From Lemma 1 and , is strictly convex with respect to . Hence, we have . Since is an arbitrary probability measure, from and , it follows that is the unique minimizer. If there exists an another probability measure that is the solution of (33), is also a minimizer of (34). This contradicts that is the unique minimizer. Hence, the result follows. ∎
The equality (33) is the generalized centroid condition.
Proposition 3.
Let and suppose that for . Then, and .
Proof.
By applying Theorem 2 for and putting , it follows that is the unique solution of
| (36) |
where is the Lagrange multiplier. From the definition of , the result follows.
Next, we show that . From Theorem 2, it follows that . Since and is unique, we have . We also have the result in the same way. ∎
We can show the same theorem for the real-valued vector of .
Proposition 4.
Let and be parameters that satisfy and . Let be a differentiable and strictly convex divergence. Suppose that there exists that satisfies
| (37) |
where and are components of the vector .
Then, the minimizer of the weighted average of divergences
| (38) |
is unique and and is the unique solution of (37).
The proof is the same as Theorem 2.
For the Bregman divergence, holds [12], where is a differentiable and strictly convex function, denotes the Legendre convex conjugate [5] and . Since for , is also strictly convex. Hence, is a differentiable and strictly convex divergence with respect to . By combining and (37), it follows that
| (39) |
Hence, is the unique minimizer.
III-C Projection from a probability measure to a set
In this subsection, we discuss the minimization problems of divergence between a probability measure and a set such as a orthogonal subset, a divergence ball or a set subject to linear moment-like constraint, we show the minimizer conditions and the uniqueness of the minimizer if there exist the solutions that satisfy the minimizer conditions.
Corollary 3 (Minimization of the divergence between a probability measure and a orthogonal subspace).
Let be a differentiable and strictly convex divergence and let .
Then, the minimizer of divergence between a probability measure and the orthogonal subspace
| (40) |
is unique.
Proof.
Since for , the result follows from Theorem 1. ∎
Theorem 3 (Minimization of the divergence between a probability measure and a divergence ball).
Let be a differentiable and strictly convex divergence. Let and suppose that .
Then, the minimizer of divergence between a probability measure and a divergence ball
| (41) |
is unique.
Proof.
Since the case is trivial, we consider the case . By combining Proposition 3 and , it follows that . Consider an arbitrary probability measure . From the assumption and Proposition 3, there exists and . Let and .
By differentiating with respect to and substituting , it follows that
| (42) |
where we use , and the definition of the functional derivative. From Lemma 1 and , is strictly convex with respect to . Hence, we have . From and , it follows that
| (43) |
From , and , it follows that
| (44) |
Since is an arbitrary probability measure in , the result follows. ∎
The next corollary follows from Theorem 3.
Corollary 4.
Let and . Then, .

Theorem 4 (Minimization of the divergence subject to linear moment-like constraint).
Let be a differentiable and strictly convex divergence and let . Let be functions of a random variable (vector) and , where denotes the expected value and are constants.
Suppose that there exists that satisfies
| (45) |
where and are the Lagrange multipliers.
Then, the minimizer of divergence between a probability measure and the set
| (46) |
is unique and is the unique solution of (45).
Proof.
We use the same technique in Theorem 2. Consider an arbitrary . Let and .
By differentiating with respect to and substituting , it follows that
| (47) |
where we use (45), and the definition of the functional derivative. From Lemma 1 and the linearity of with respect to , is strictly convex with respect to . Hence, we have . From , , it follows that
| (48) |
From , it follows that
| (49) |
IV Summary
We have discussed the minimization problems and geometric properties for the differentiable and strictly convex divergences. We have derived the three-point inequality and introduced the divergence lines, inner products, balls and orthogonal subsets that are the generalization of lines, inner product, spheres and planes perpendicular to a line in the Euclidean space.
Furthermore, we have shown the minimizer conditions and the uniqueness of the minimizer if there exist the solutions that satisfy the minimizer conditions in the following cases,
1) Minimization of weighted average of divergences from multiple probability measures.
2) Minimization of divergence between a probability measure and the orthogonal subsets, divergence balls, or the set subject to linear moment-like constraints.
References
- [1] Shun-ichi Amari and Andrzej Cichocki. Information geometry of divergence functions. Bulletin of the Polish Academy of Sciences: Technical Sciences, 58(1):183–195, 2010.
- [2] Arindam Banerjee, Srujana Merugu, Inderjit S Dhillon, and Joydeep Ghosh. Clustering with bregman divergences. Journal of machine learning research, 6(Oct):1705–1749, 2005.
- [3] Lev M Bregman. The relaxation method of finding the common point of convex sets and its application to the solution of problems in convex programming. USSR computational mathematics and mathematical physics, 7(3):200–217, 1967.
- [4] Thomas Breuer and Imre Csiszár. Measuring distribution model risk. Mathematical Finance, 26(2):395–411, 2016.
- [5] Yair Censor, Stavros Andrea Zenios, et al. Parallel optimization: Theory, algorithms, and applications. Oxford University Press on Demand, 1997.
- [6] Thomas M Cover and Joy A Thomas. Elements of information theory. John Wiley & Sons, 2012.
- [7] Imre Csiszár. Information-type measures of difference of probability distributions and indirect observation. studia scientiarum Mathematicarum Hungarica, 2:229–318, 1967.
- [8] Imre Csiszár and Frantisek Matus. Information projections revisited. IEEE Transactions on Information Theory, 49(6):1474–1490, 2003.
- [9] Solomon Kullback and Richard A Leibler. On information and sufficiency. The annals of mathematical statistics, 22(1):79–86, 1951.
- [10] Stuart Lloyd. Least squares quantization in pcm. IEEE transactions on information theory, 28(2):129–137, 1982.
- [11] Frank Nielsen, Jean-Daniel Boissonnat, and Richard Nock. On bregman voronoi diagrams. In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms, pages 746–755. Society for Industrial and Applied Mathematics, 2007.
- [12] Frank Nielsen and Sylvain Boltz. The burbea-rao and bhattacharyya centroids. IEEE Transactions on Information Theory, 57(8):5455–5466, 2011.
- [13] Tomohiro Nishiyama. Monotonically decreasing sequence of divergences. arXiv preprint arXiv:1910.00402, 2019.
- [14] Alfréd Rényi et al. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics. The Regents of the University of California, 1961.
- [15] Igal Sason and Sergio Verdu. -divergence inequalities. IEEE Transactions on Information Theory, 62(11):5973–6006, 2016.
- [16] Tim Van Erven and Peter Harremos. Rényi divergence and kullback-leibler divergence. IEEE Transactions on Information Theory, 60(7):3797–3820, 2014.